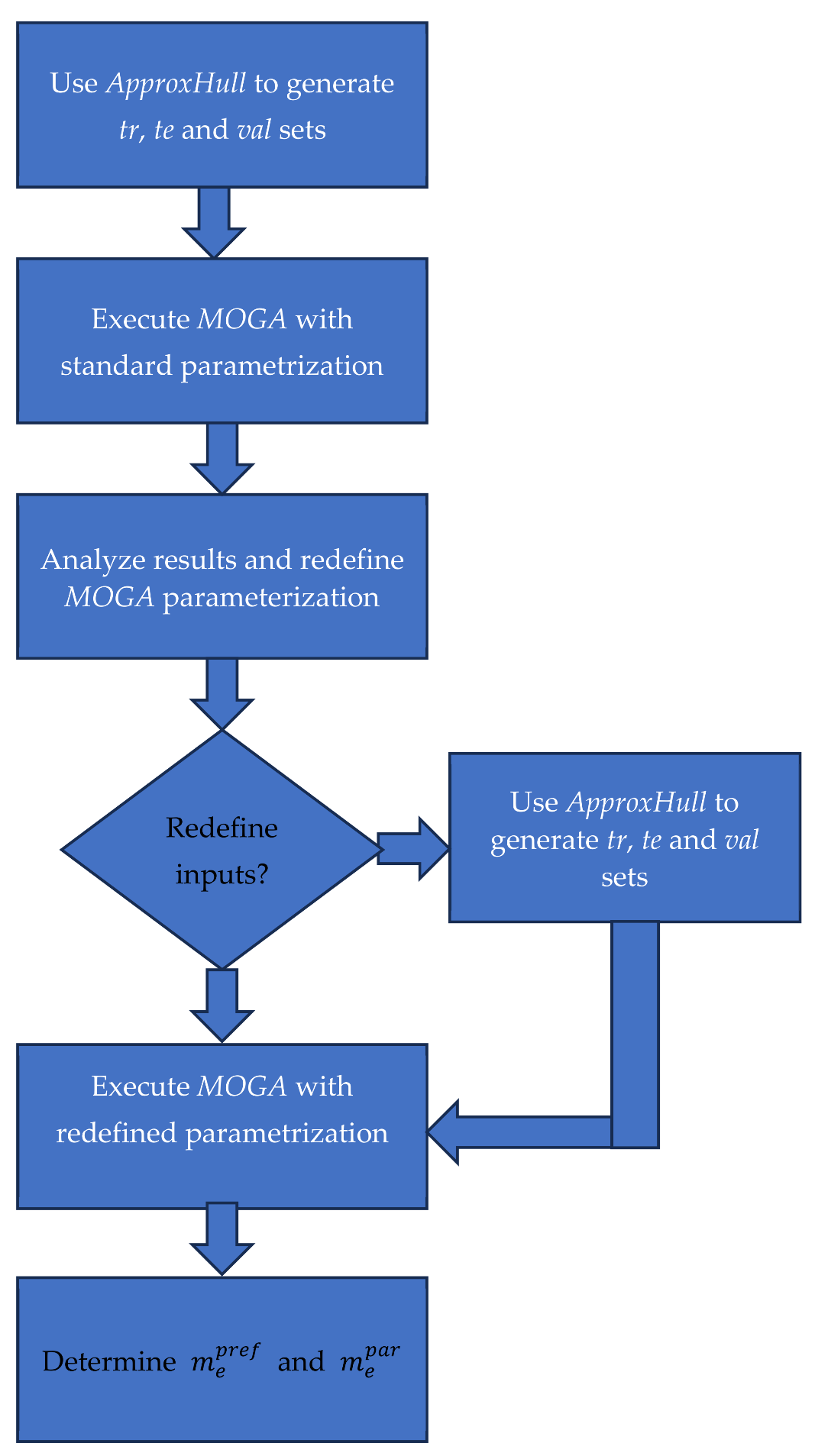
Figure 1.
Model design fluxogram.
Figure 1.
Model design fluxogram.
Figure 2.
Solar Radiation. Left: 1st period; Right: 2nd period.
Figure 2.
Solar Radiation. Left: 1st period; Right: 2nd period.
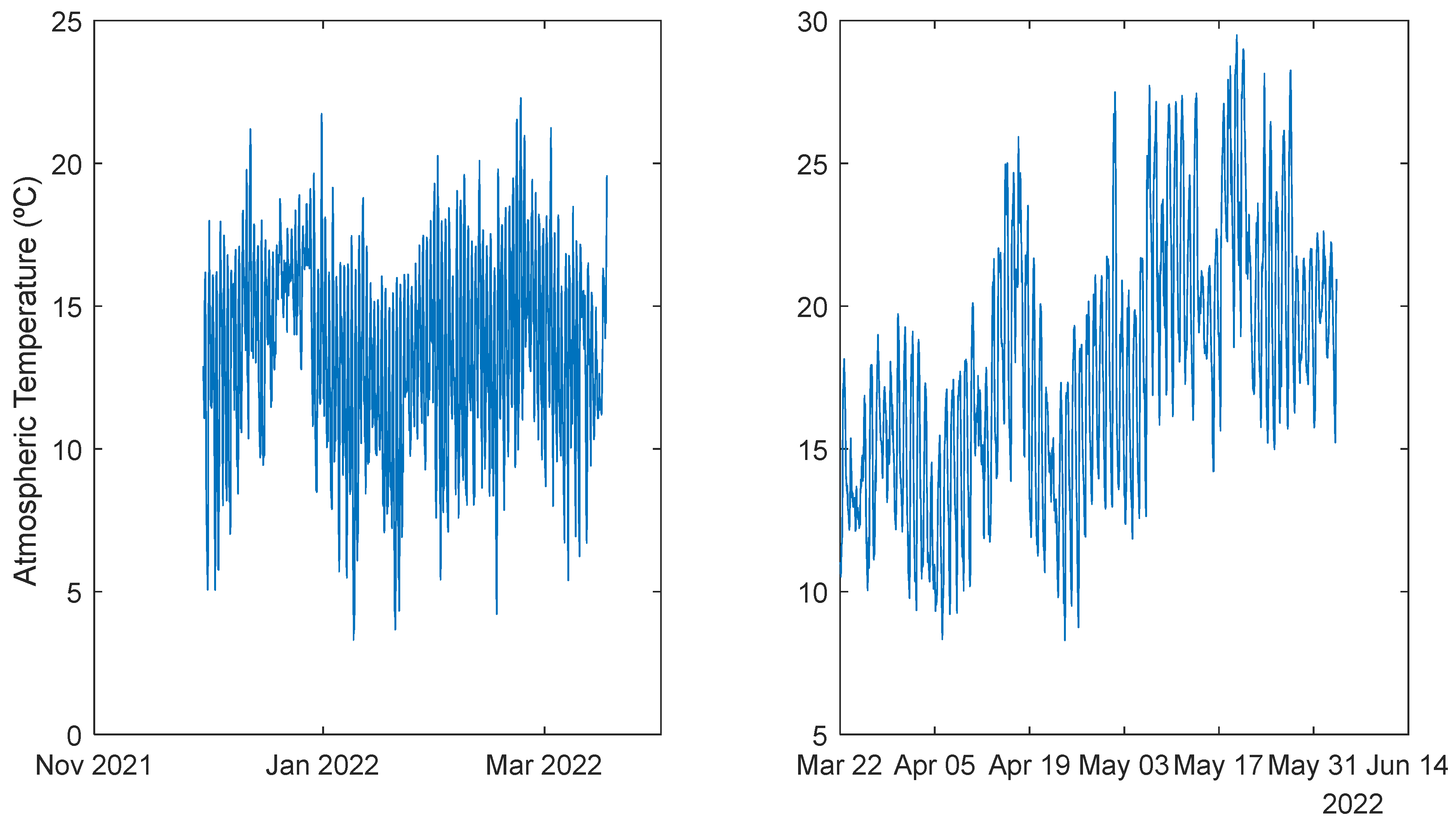
Figure 3.
Atmospheric Temperature. Left: 1st period; Right: 2nd period.
Figure 3.
Atmospheric Temperature. Left: 1st period; Right: 2nd period.
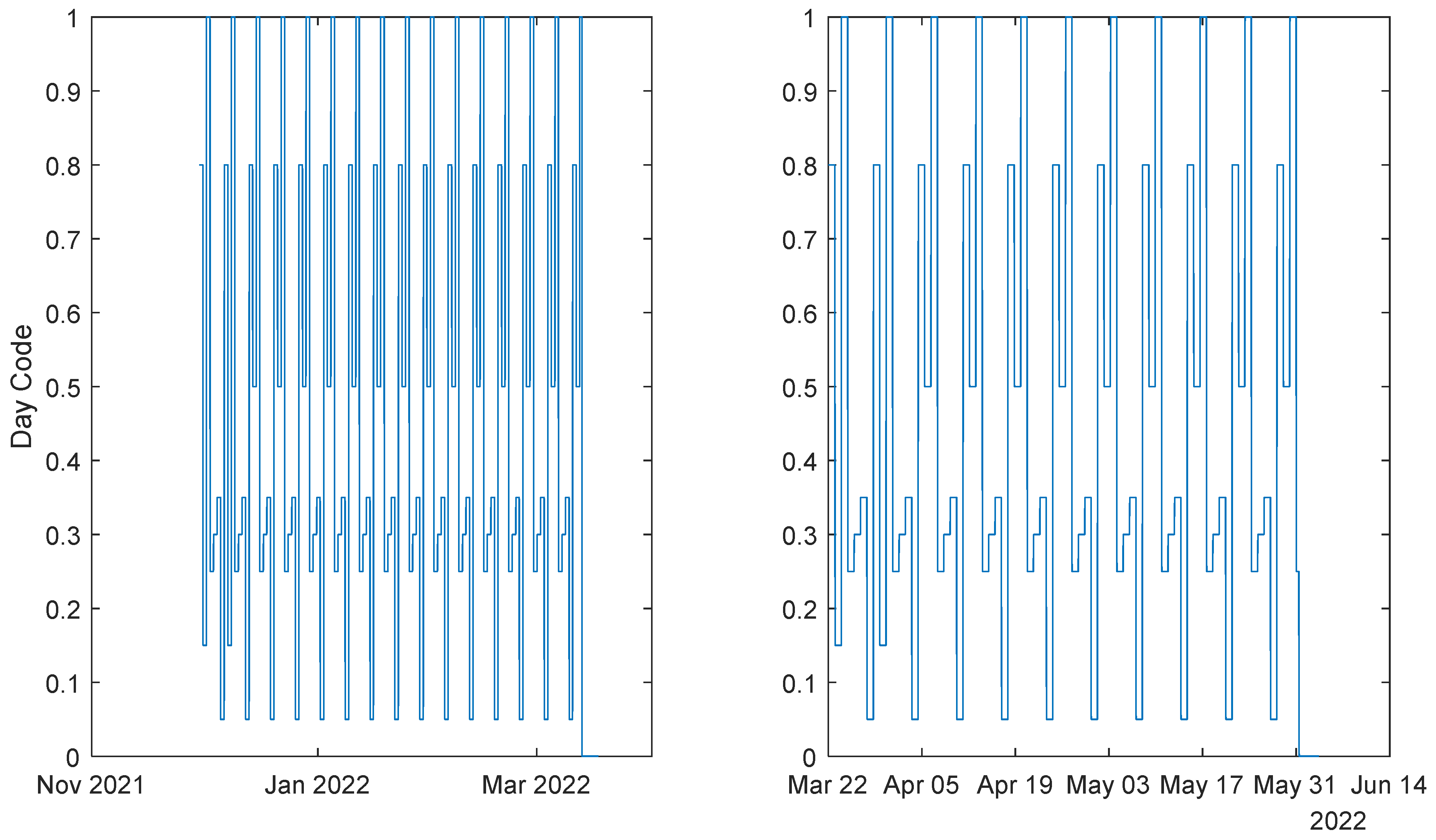
Figure 4.
Day Code. Left: 1st period; Right: 2nd period.
Figure 4.
Day Code. Left: 1st period; Right: 2nd period.
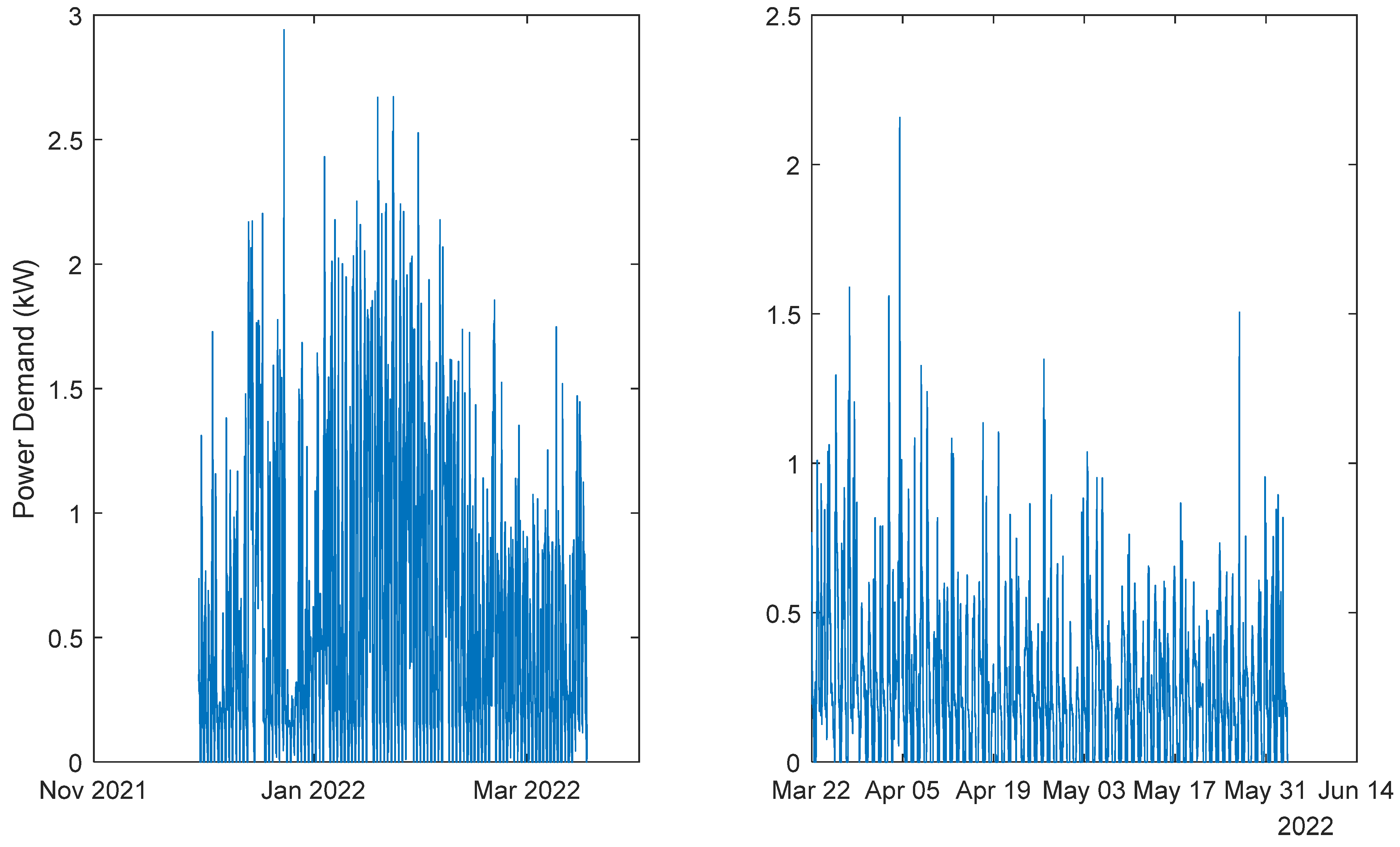
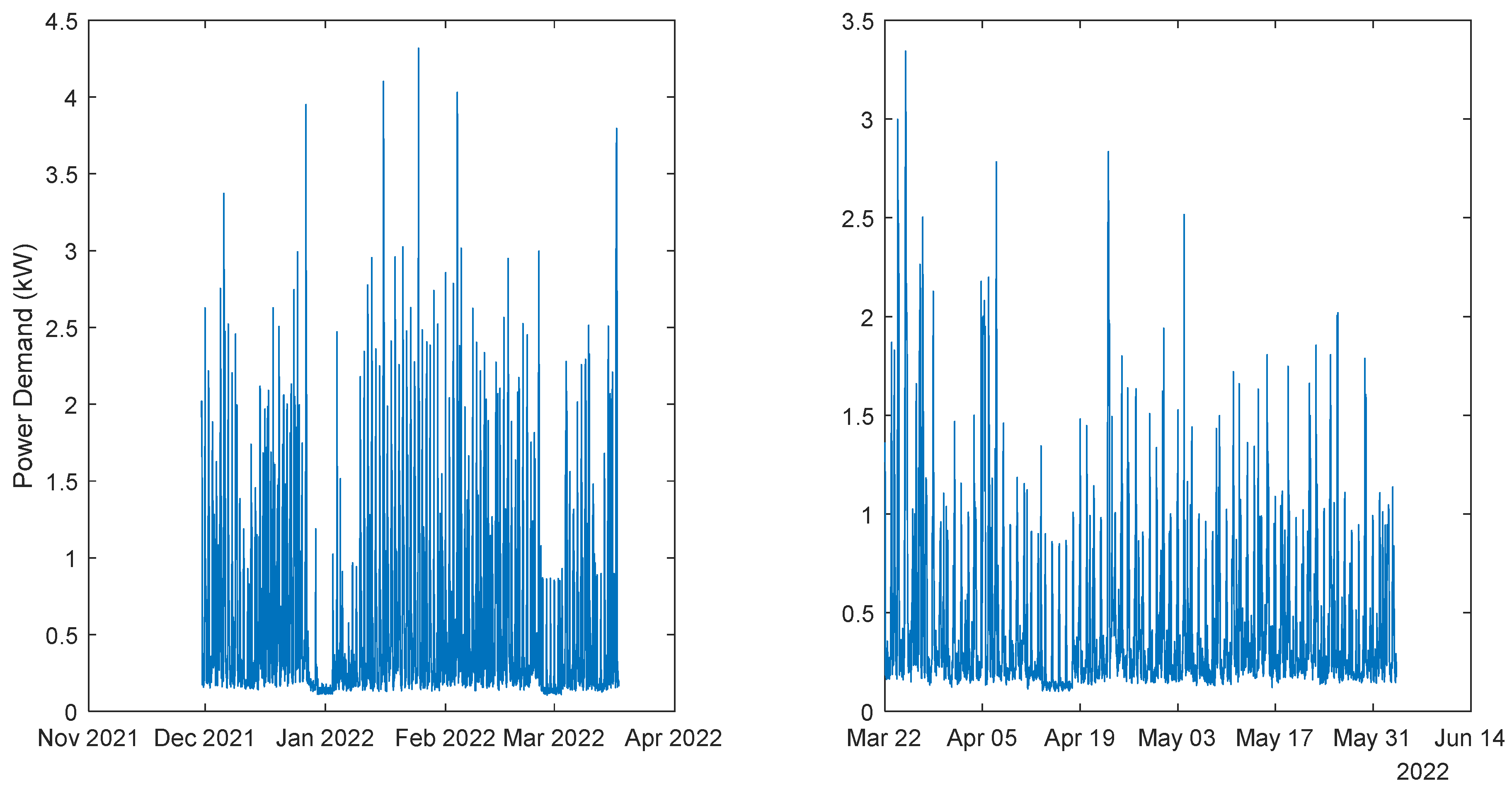
Figure 5.
Power Demand: House 1 (monophasic). Left: 1st period; Right: 2nd period.
Figure 5.
Power Demand: House 1 (monophasic). Left: 1st period; Right: 2nd period.
Figure 6.
Power Demand: House 2 (monophasic). Left: 1st period; Right: 2nd period.
Figure 6.
Power Demand: House 2 (monophasic). Left: 1st period; Right: 2nd period.
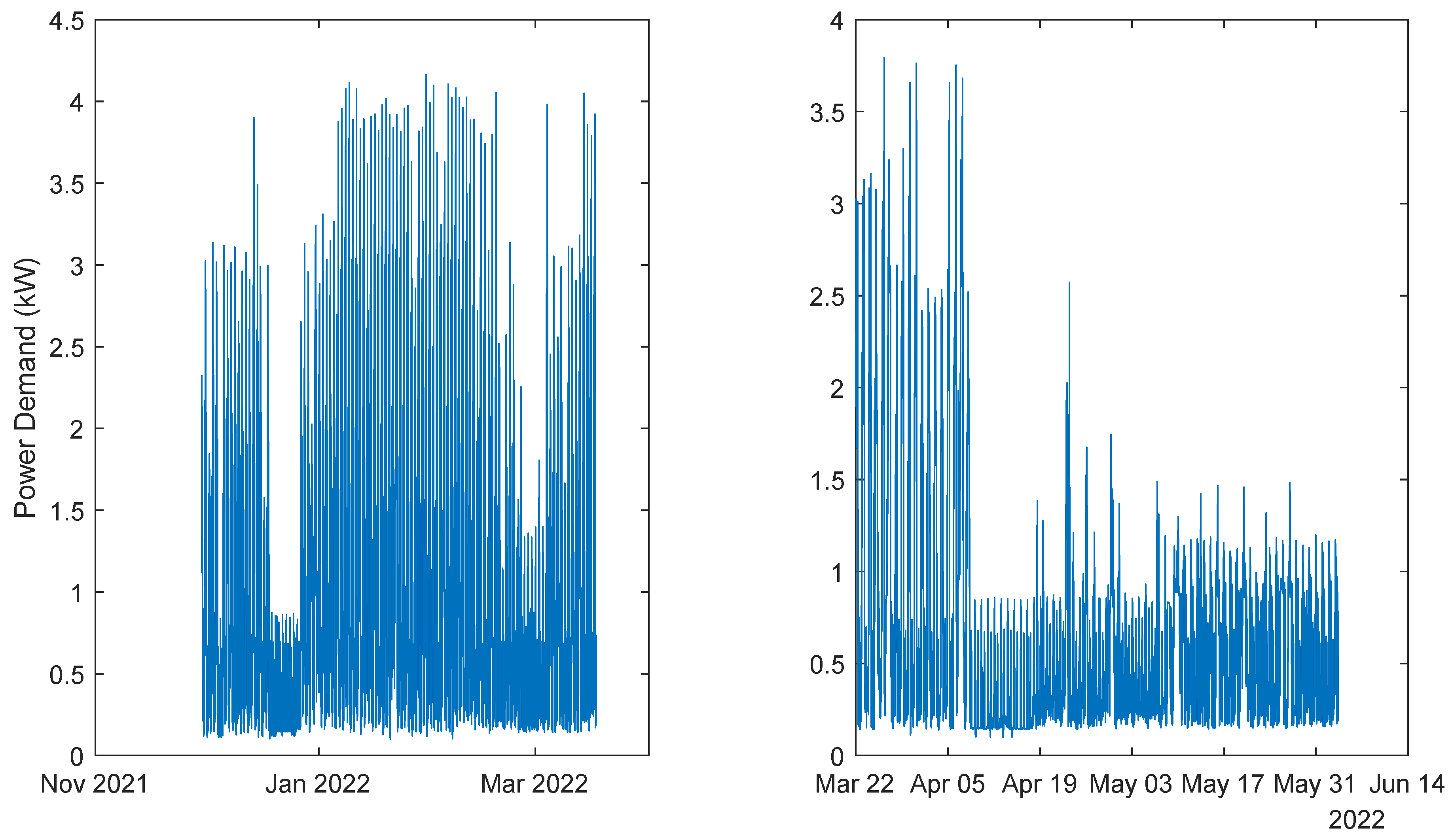
Figure 7.
Power Demand: House 3 (triphasic). Left: 1st period; Right: 2nd period.
Figure 7.
Power Demand: House 3 (triphasic). Left: 1st period; Right: 2nd period.
Figure 8.
Power Demand: House 4 (triphasic). Left: 1st period; Right: 2nd period.
Figure 8.
Power Demand: House 4 (triphasic). Left: 1st period; Right: 2nd period.
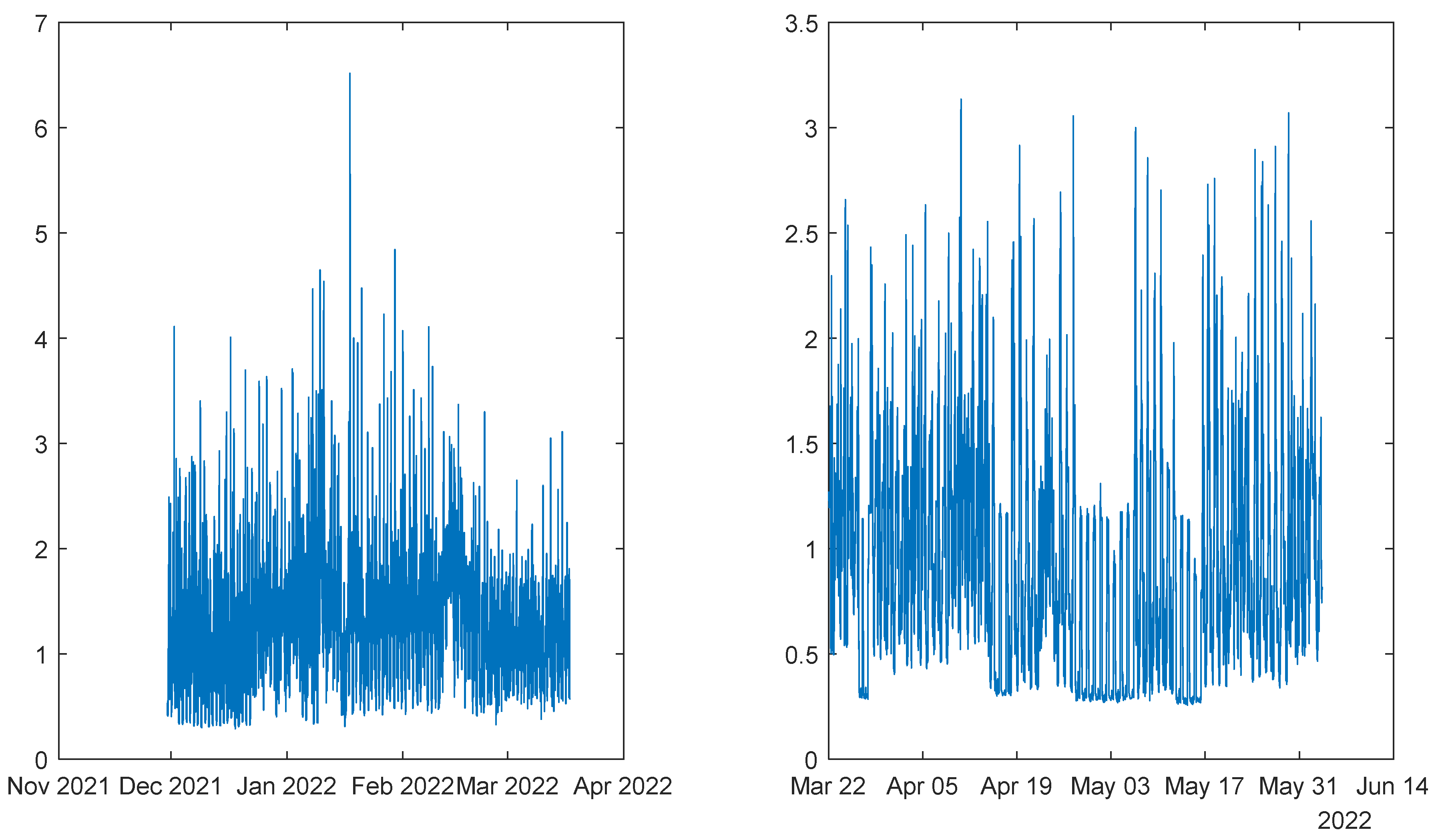
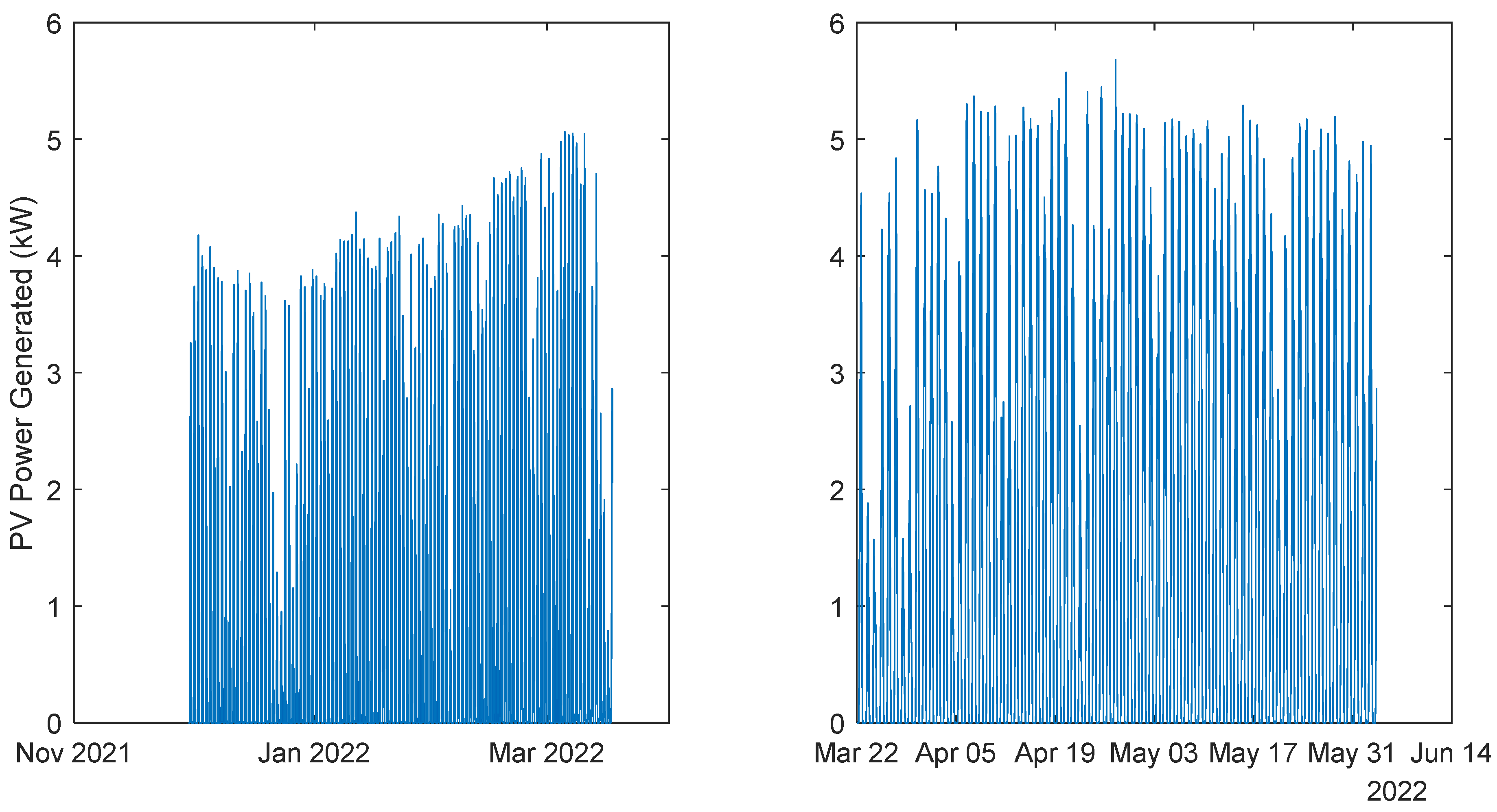
Figure 9.
Community Power Generated. Left: 1st period; Right: 2nd period.
Figure 9.
Community Power Generated. Left: 1st period; Right: 2nd period.
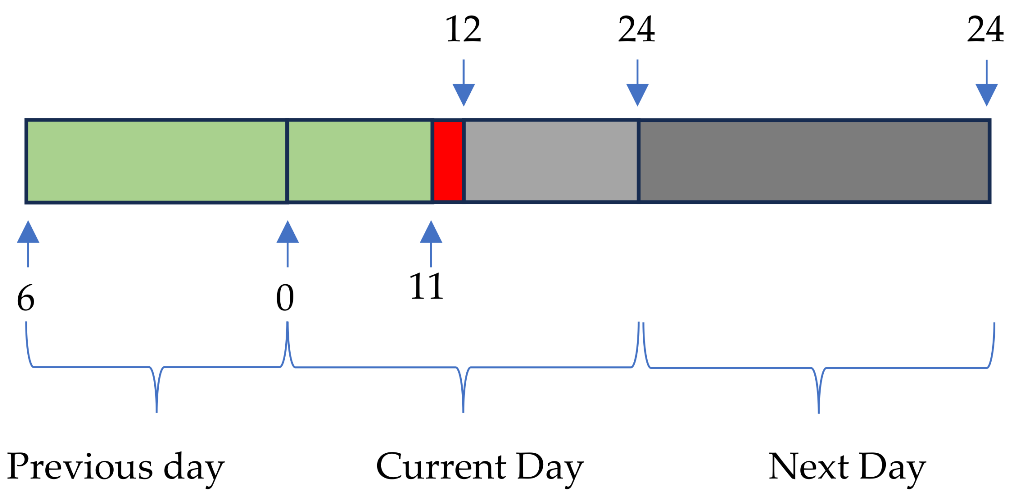
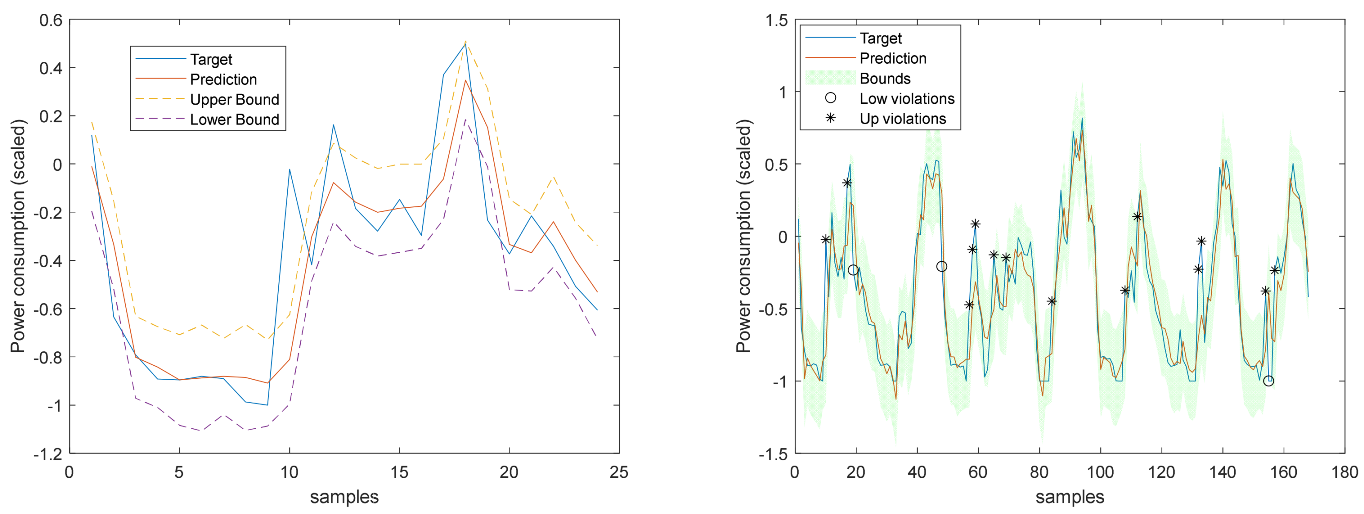
Figure 10.
Power delays and forecasts.
Figure 10.
Power delays and forecasts.
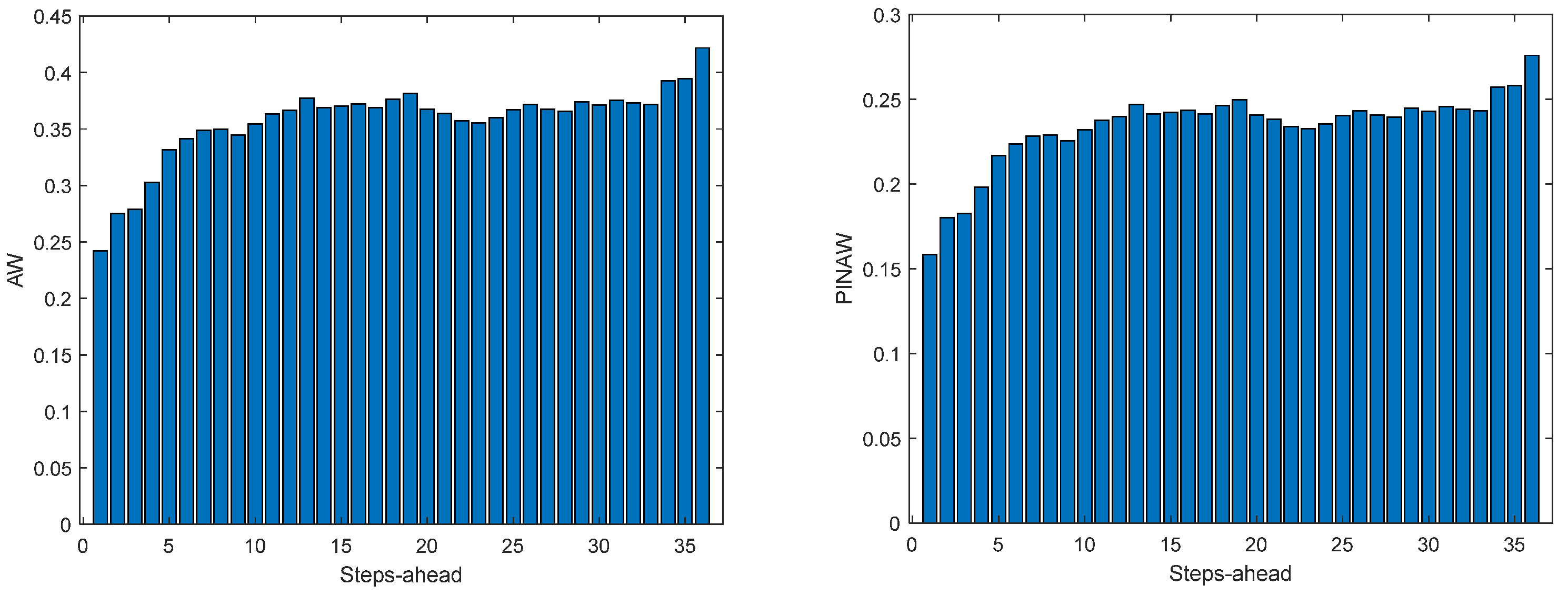
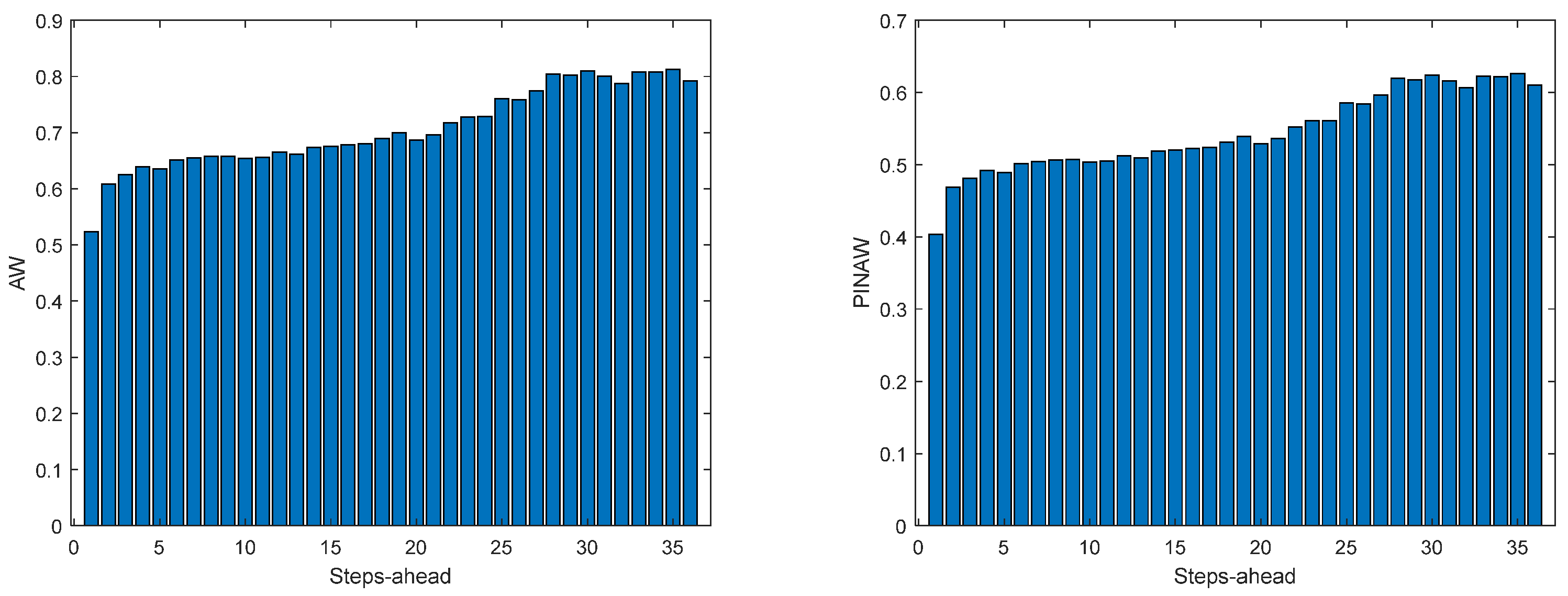
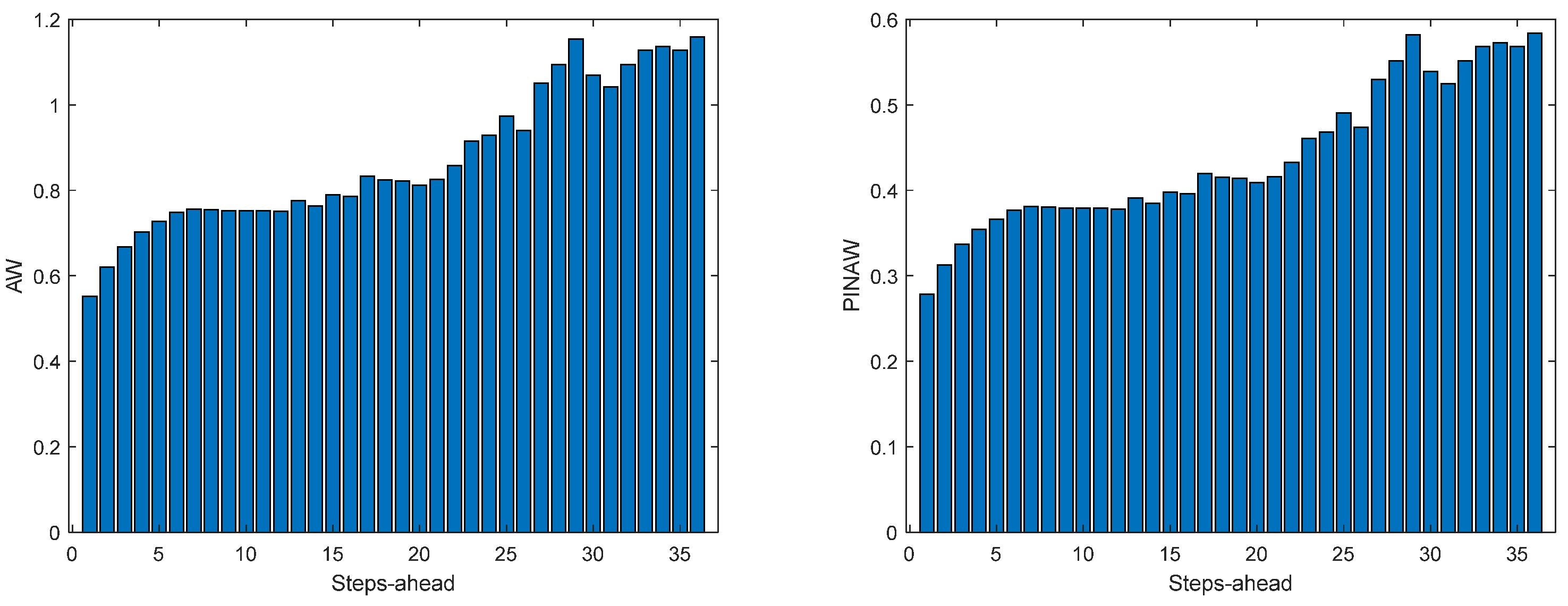
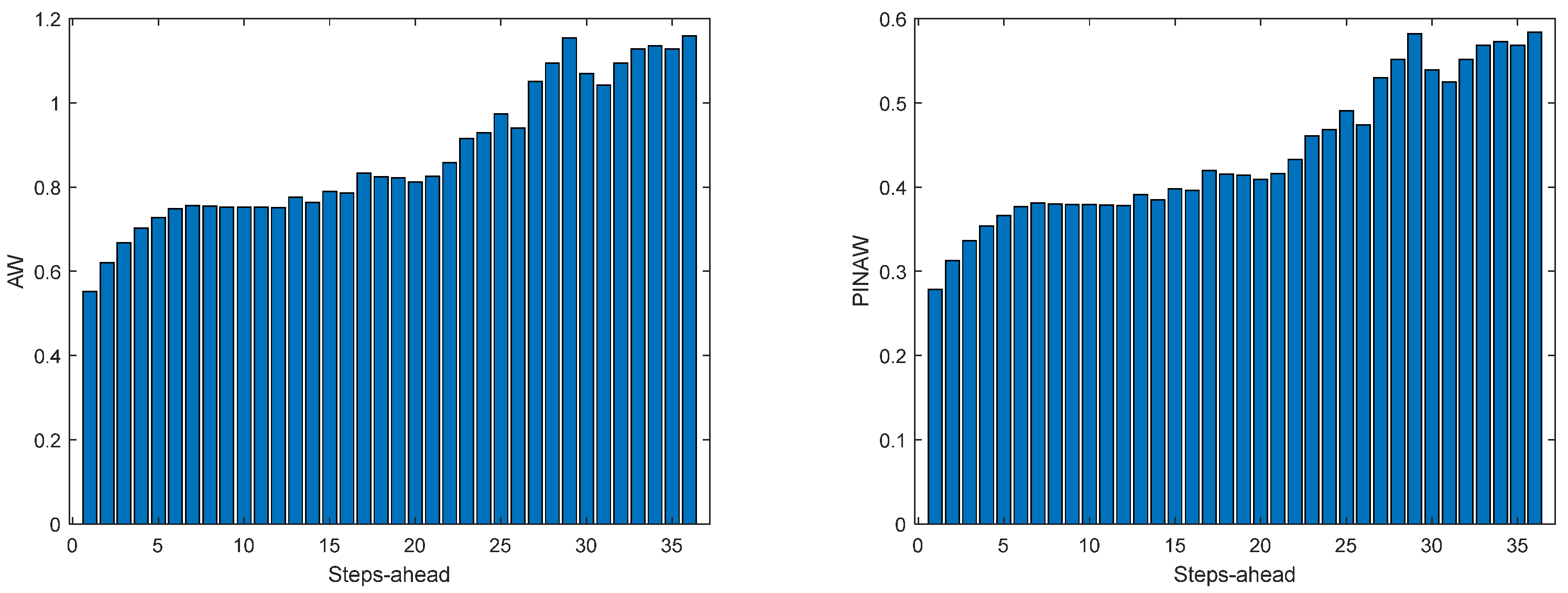
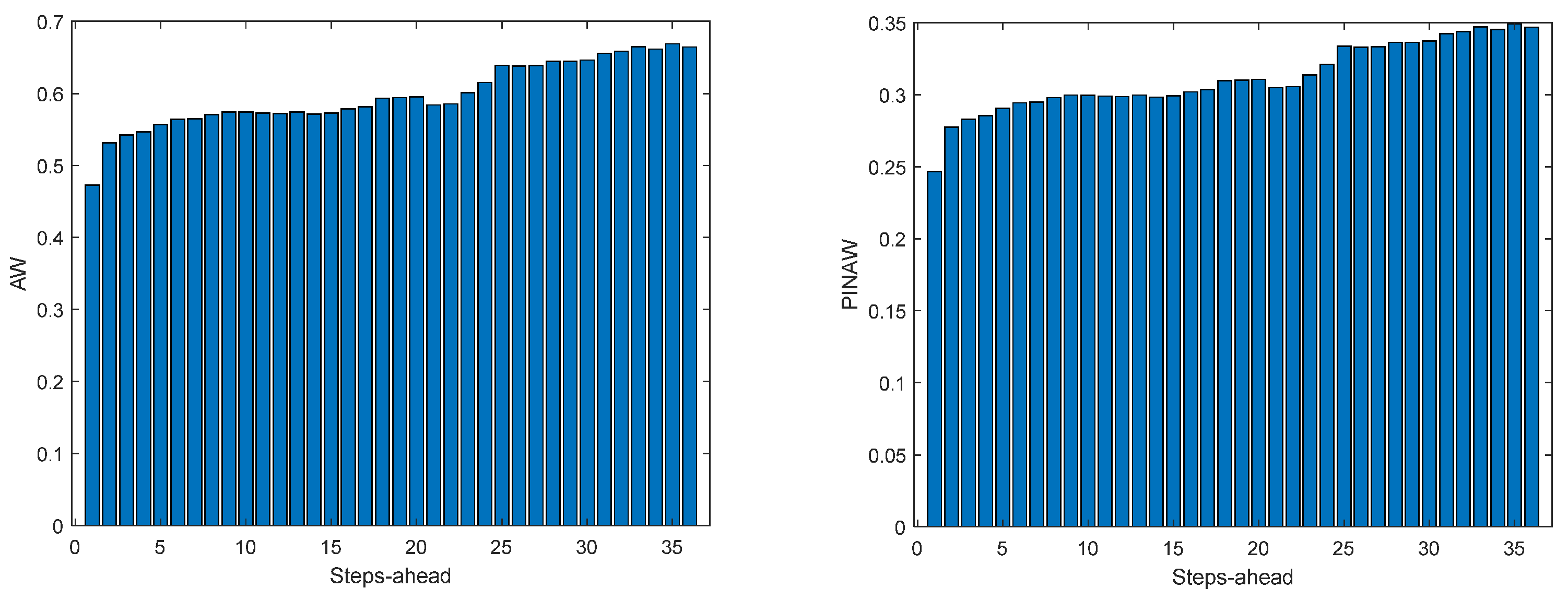
Figure 11.
Solar Radiation AW (left) and PINAW (right) forecasts.
Figure 11.
Solar Radiation AW (left) and PINAW (right) forecasts.
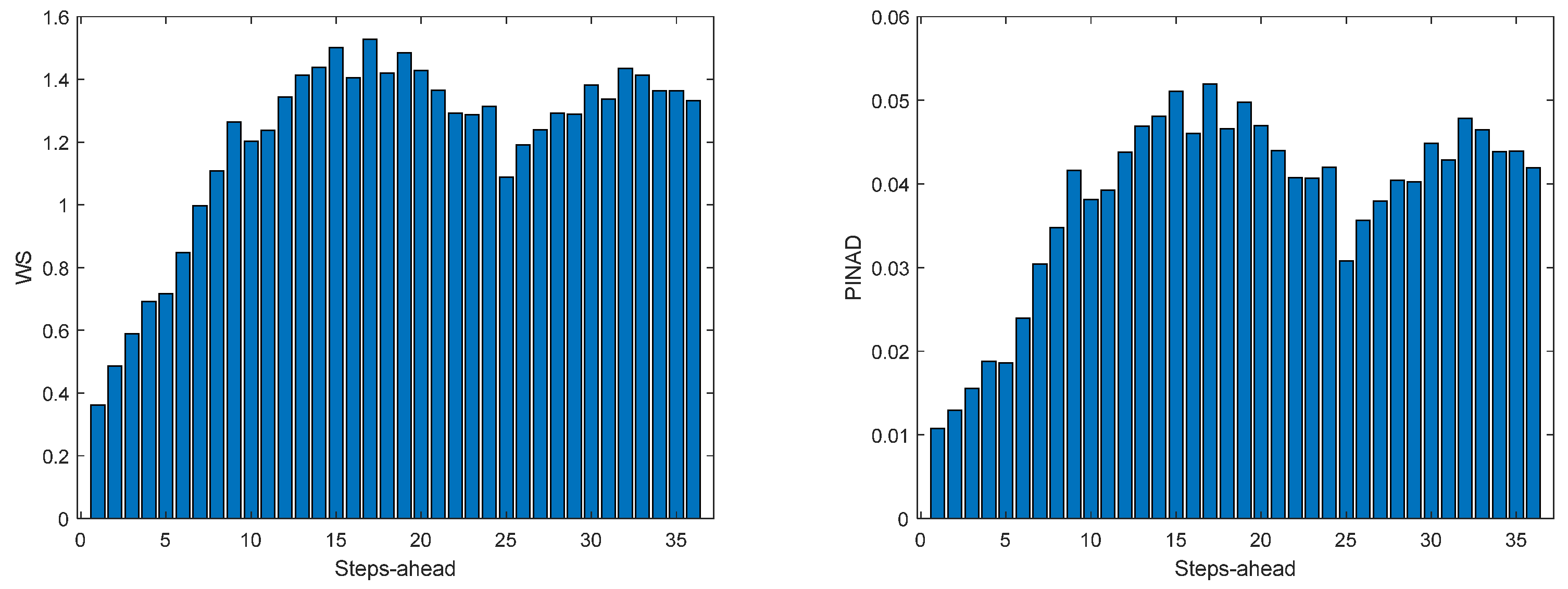
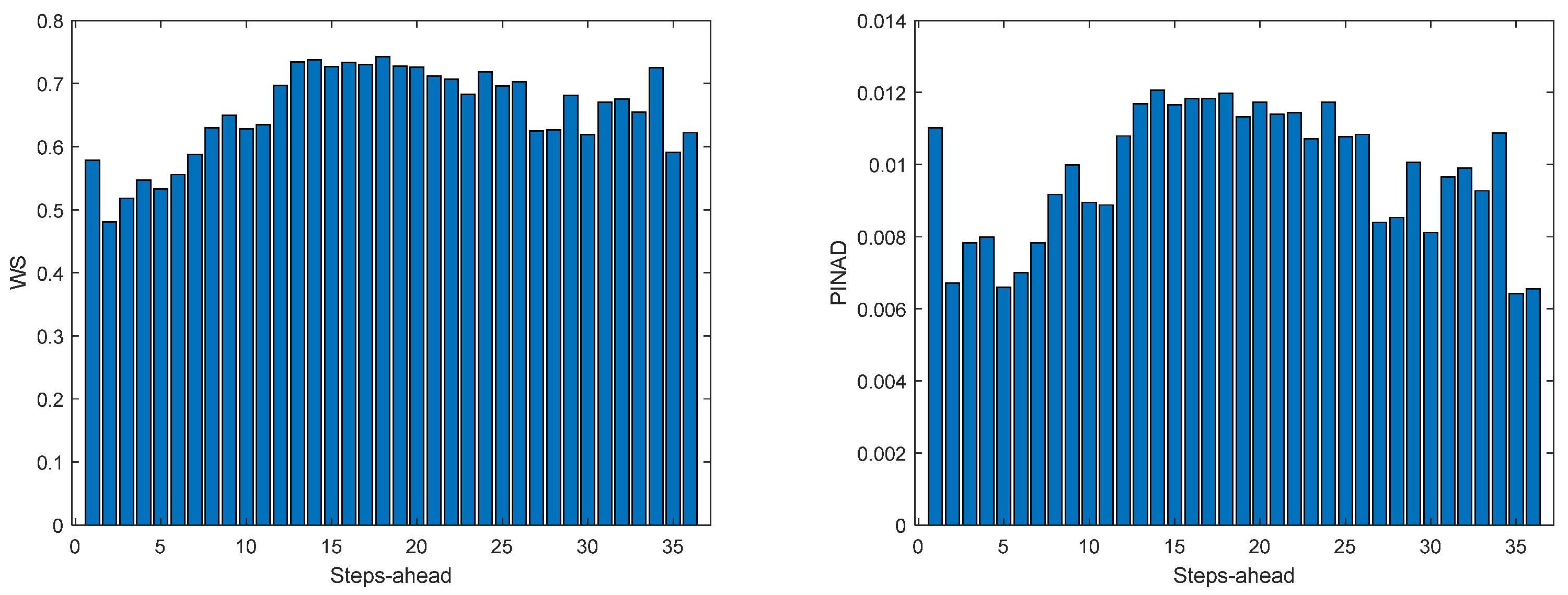
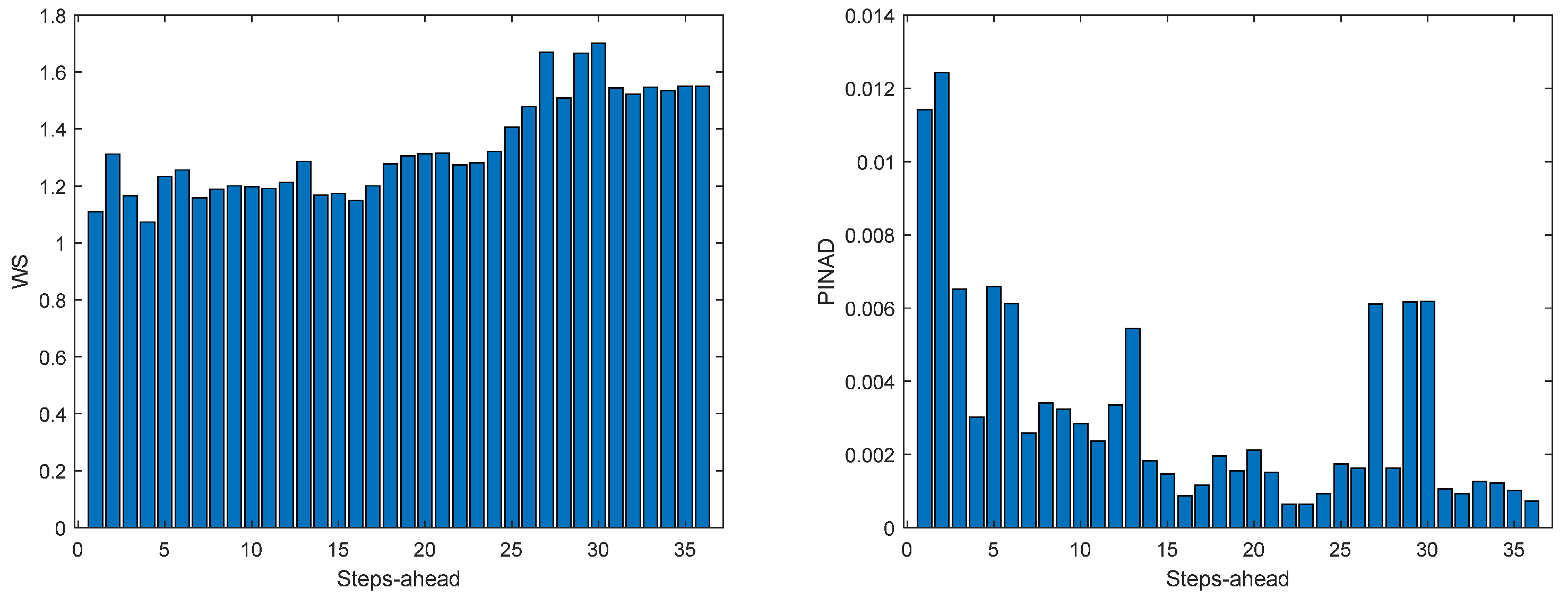
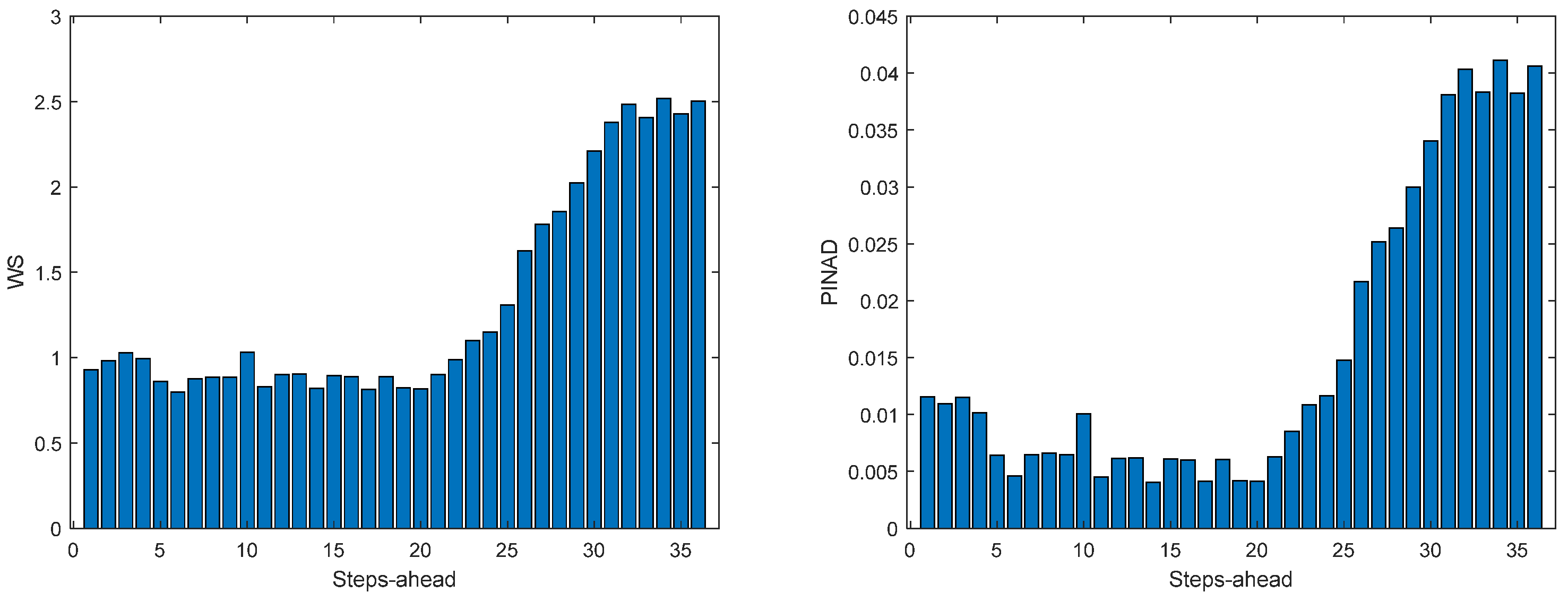
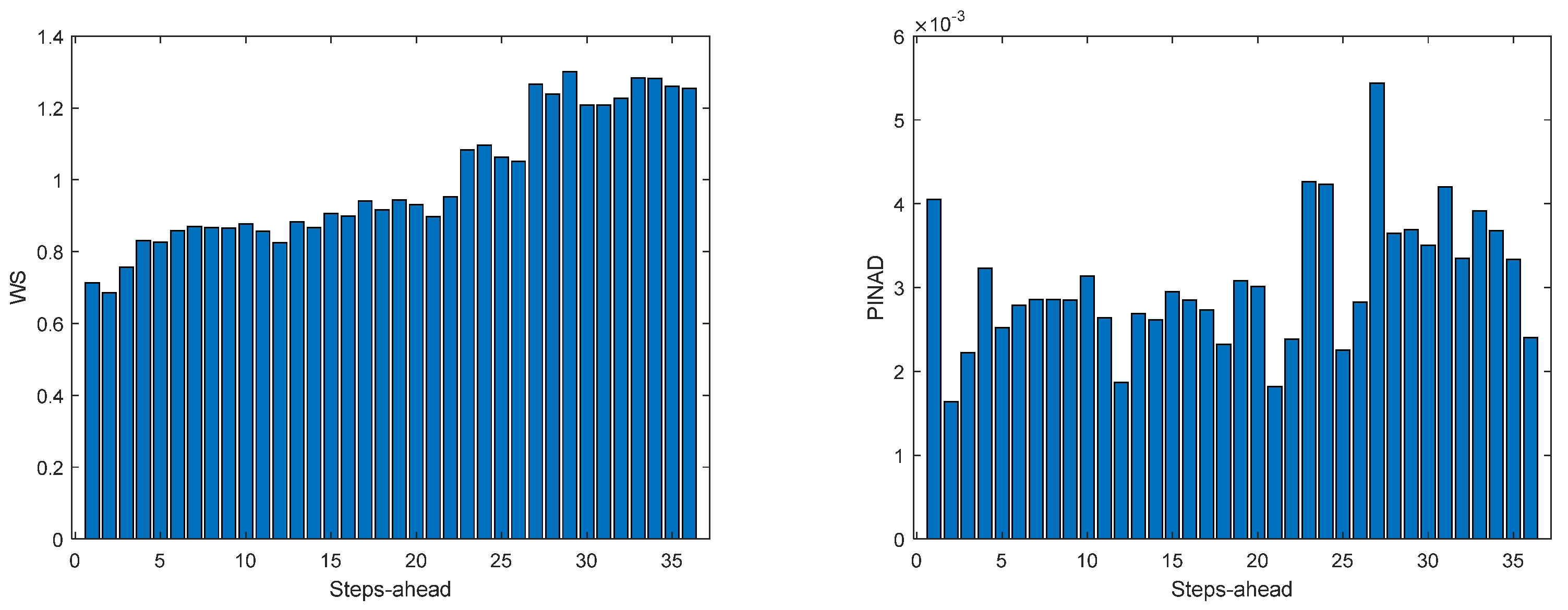
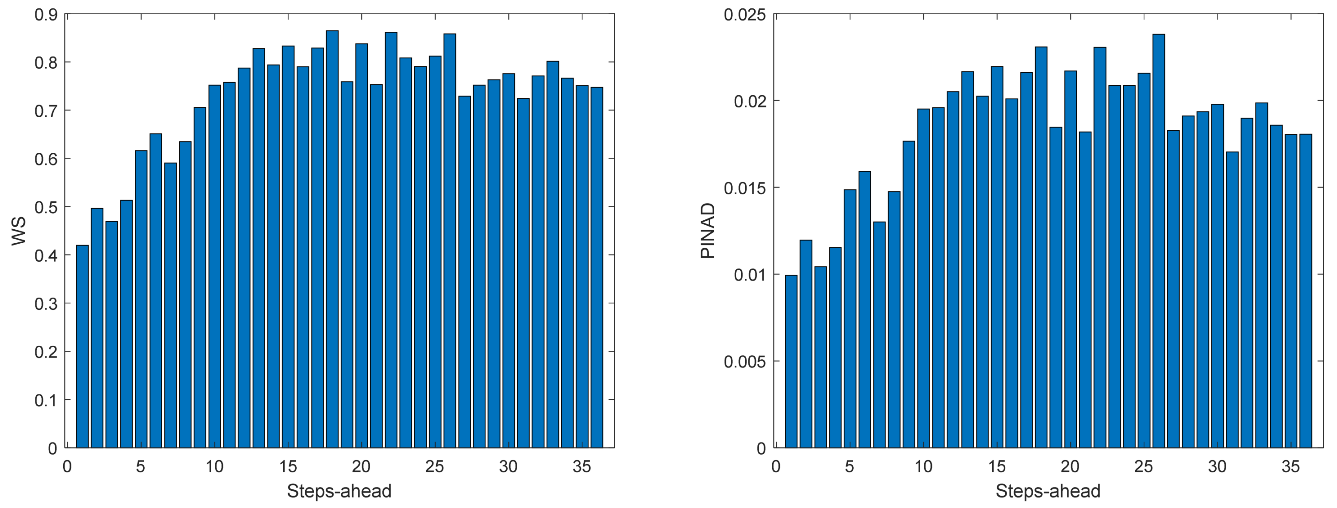
Figure 12.
Solar Radiation WS (left) and PINAD (right) forecasts.
Figure 12.
Solar Radiation WS (left) and PINAD (right) forecasts.
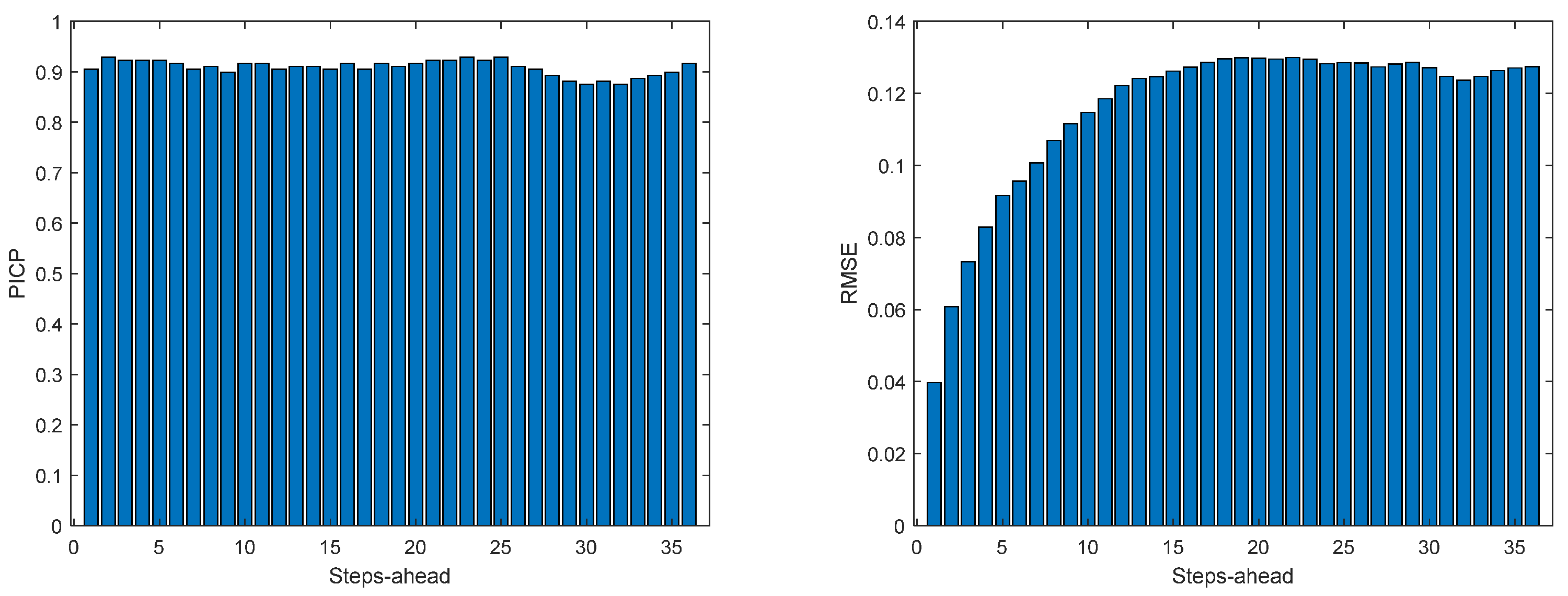
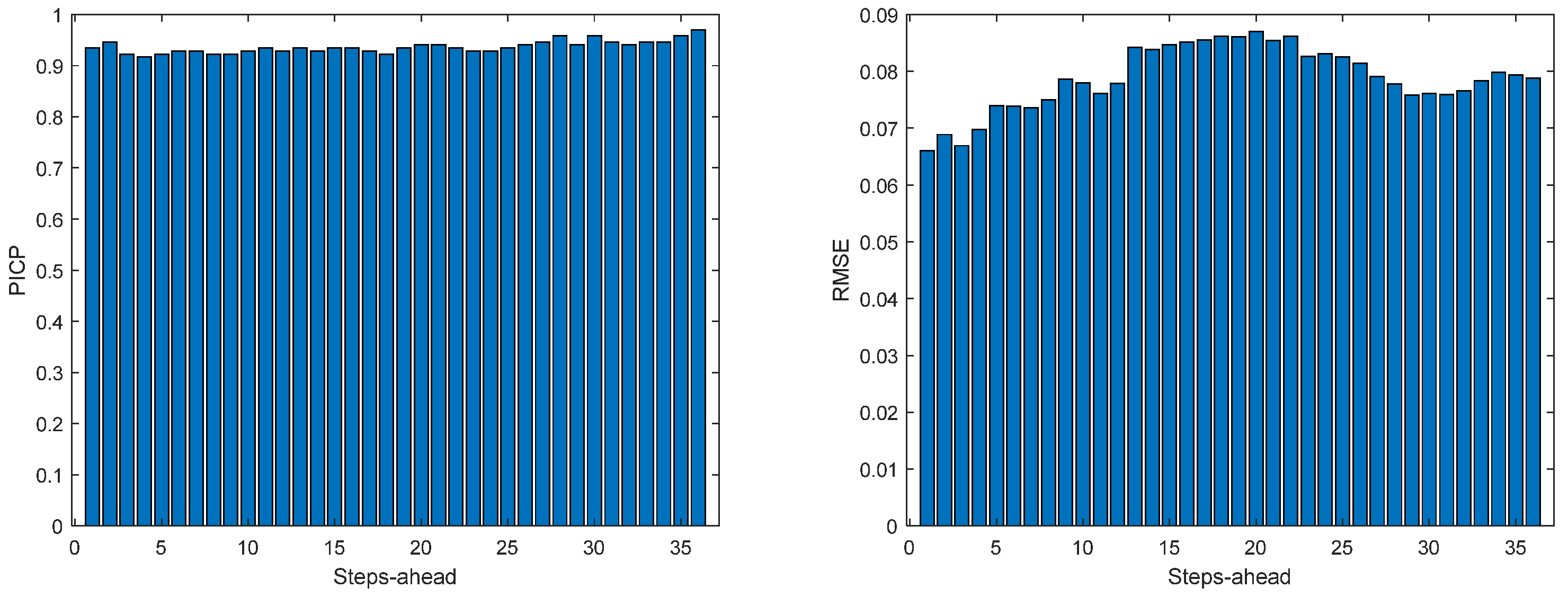
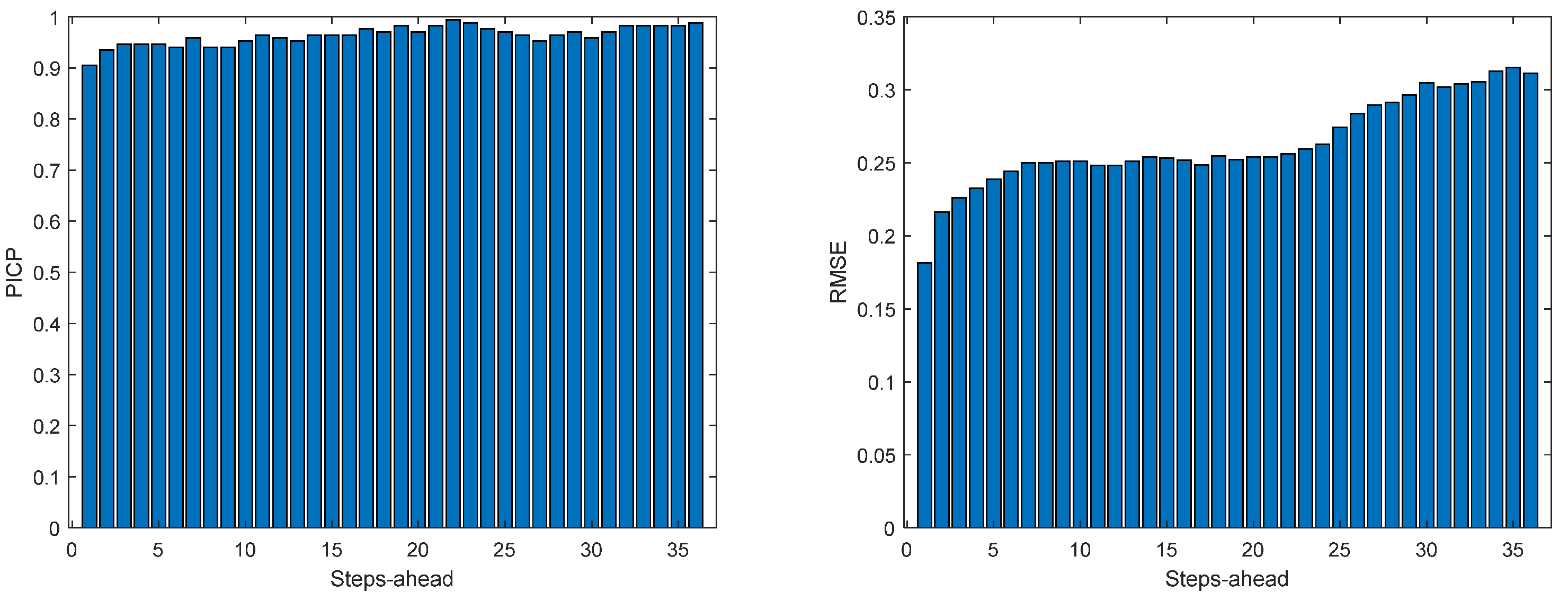
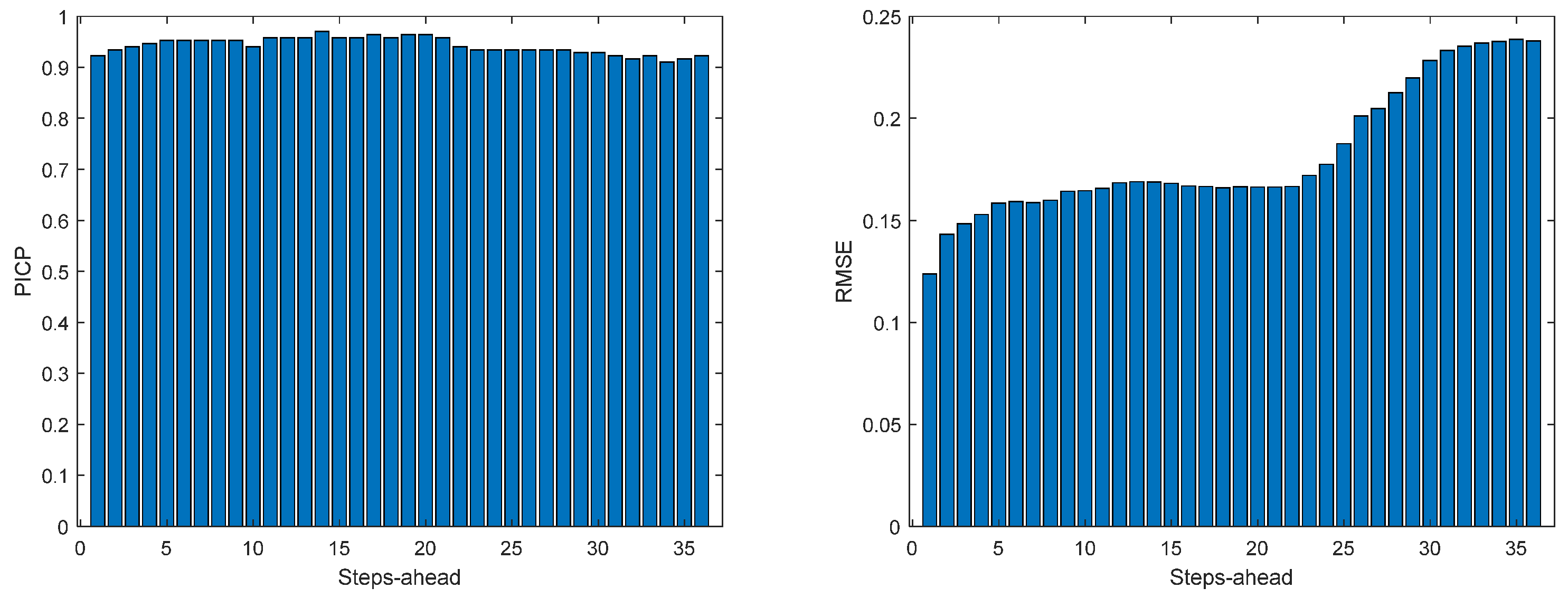
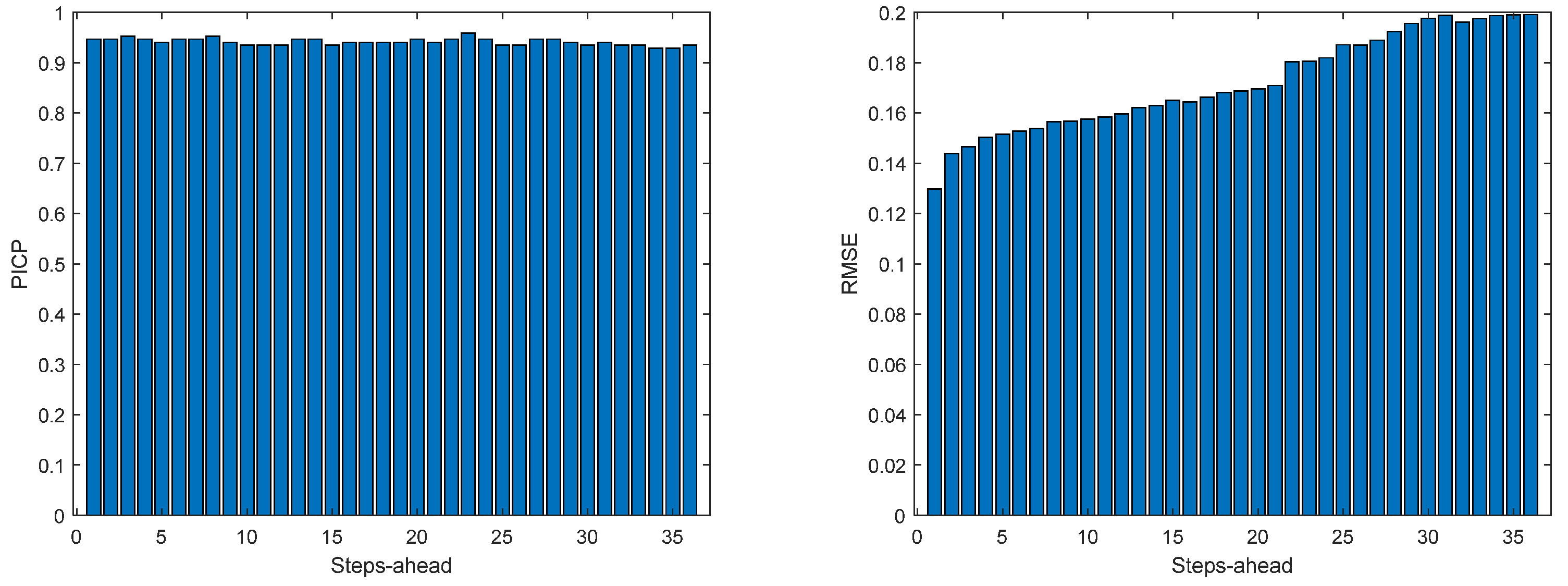
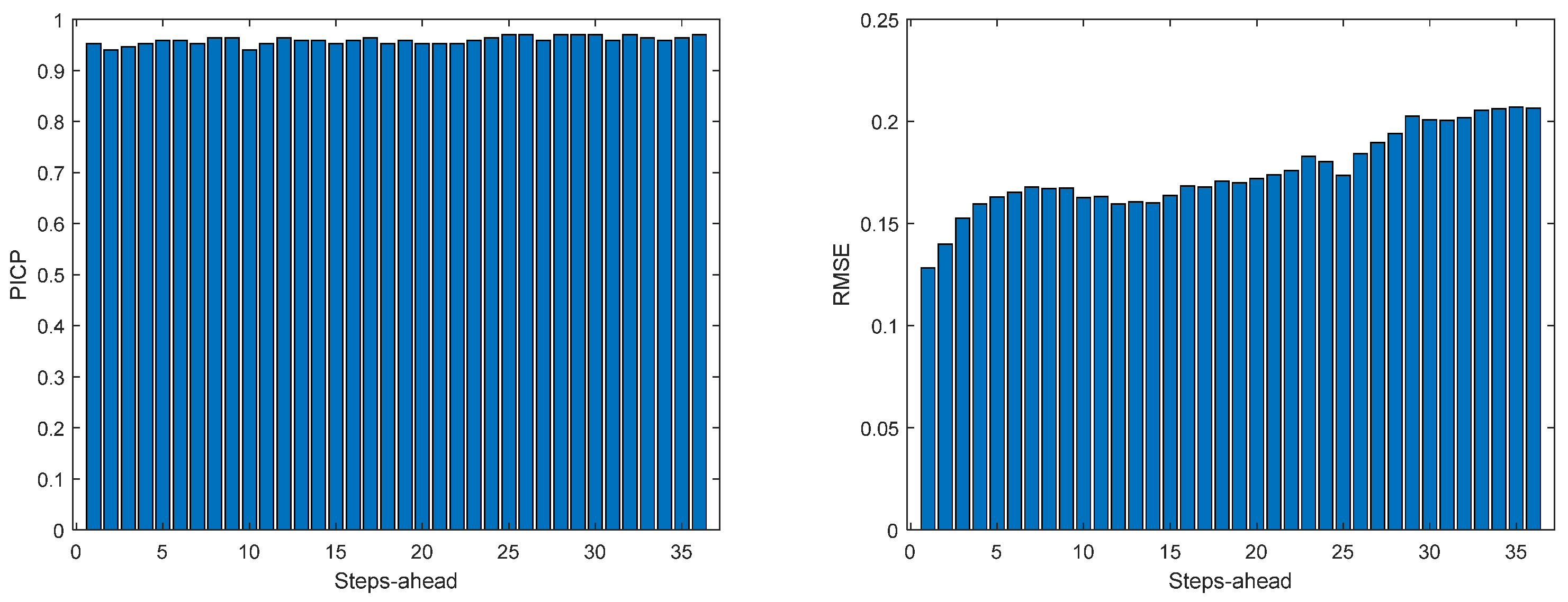
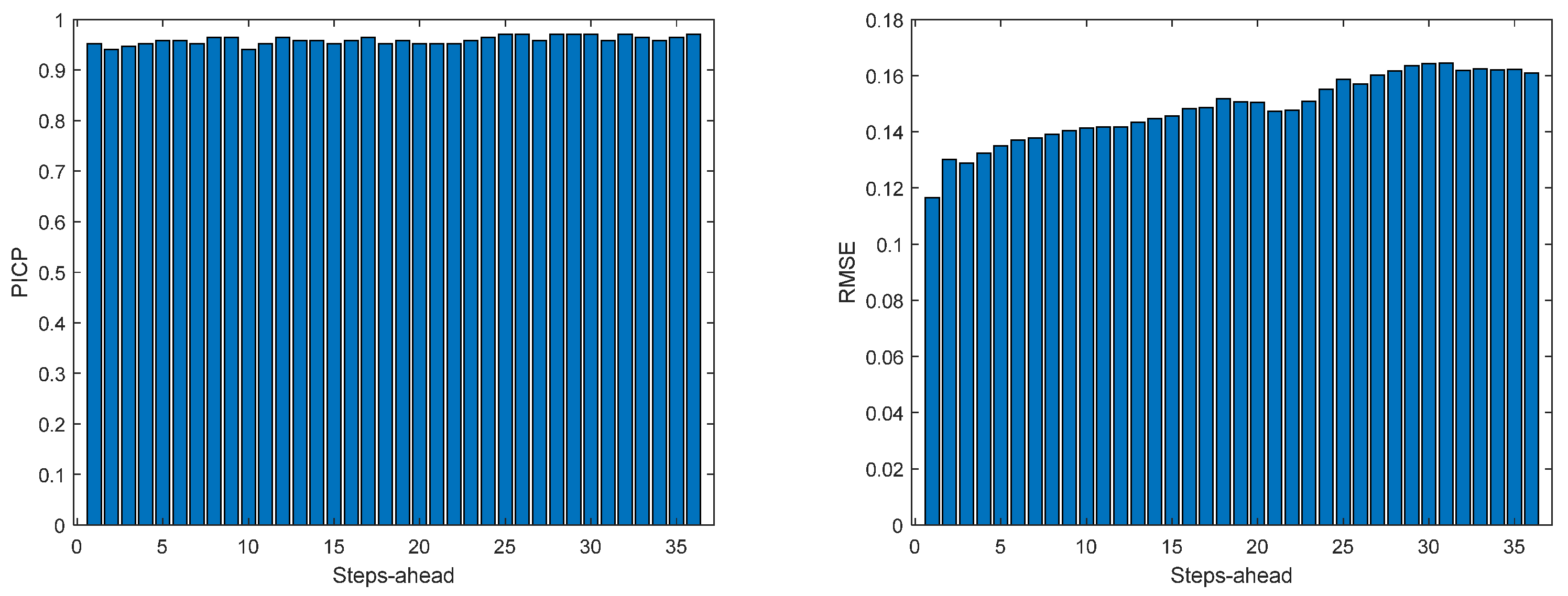
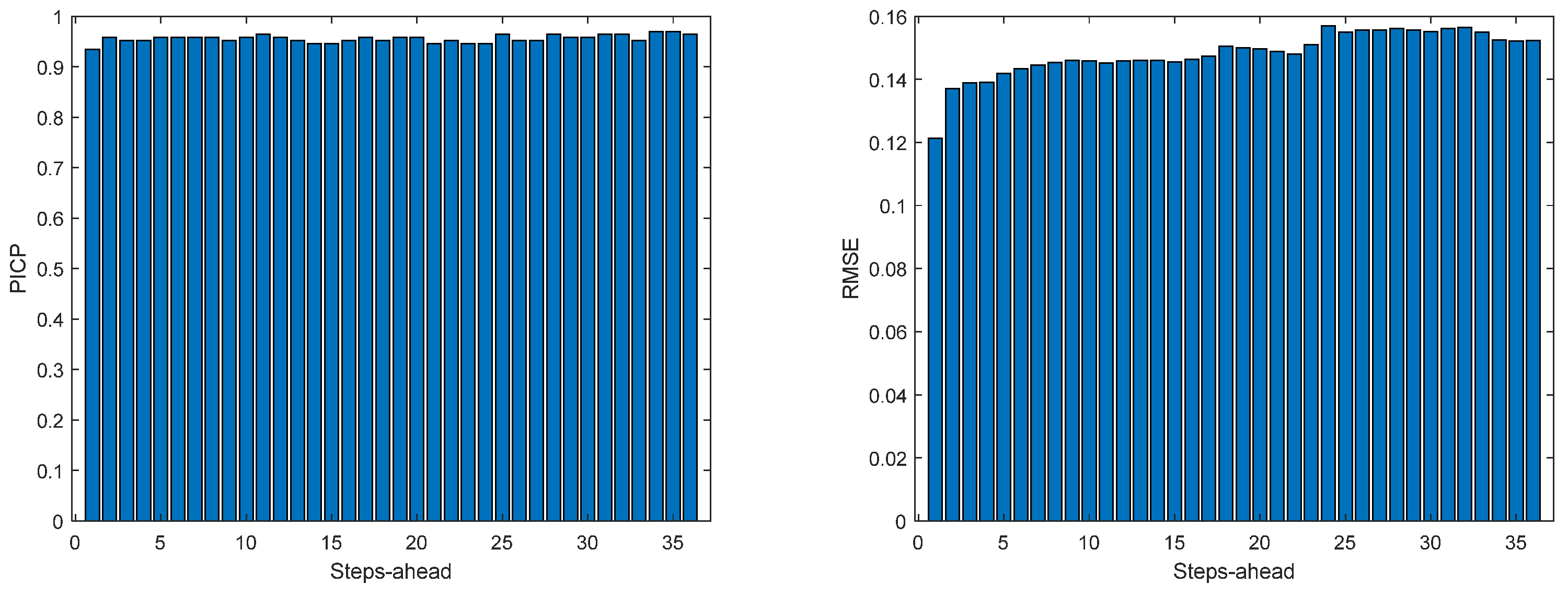
Figure 13.
Solar Radiation PICP (left) and RMSE (right) forecasts.
Figure 13.
Solar Radiation PICP (left) and RMSE (right) forecasts.
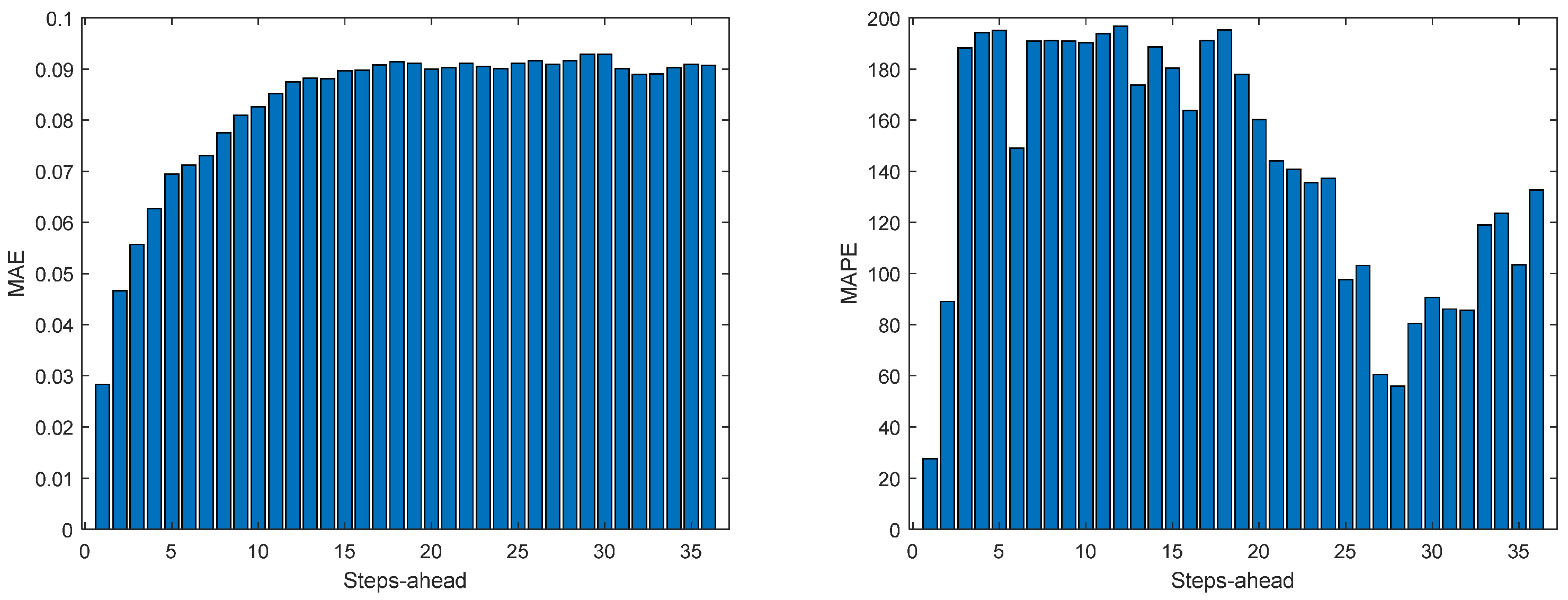
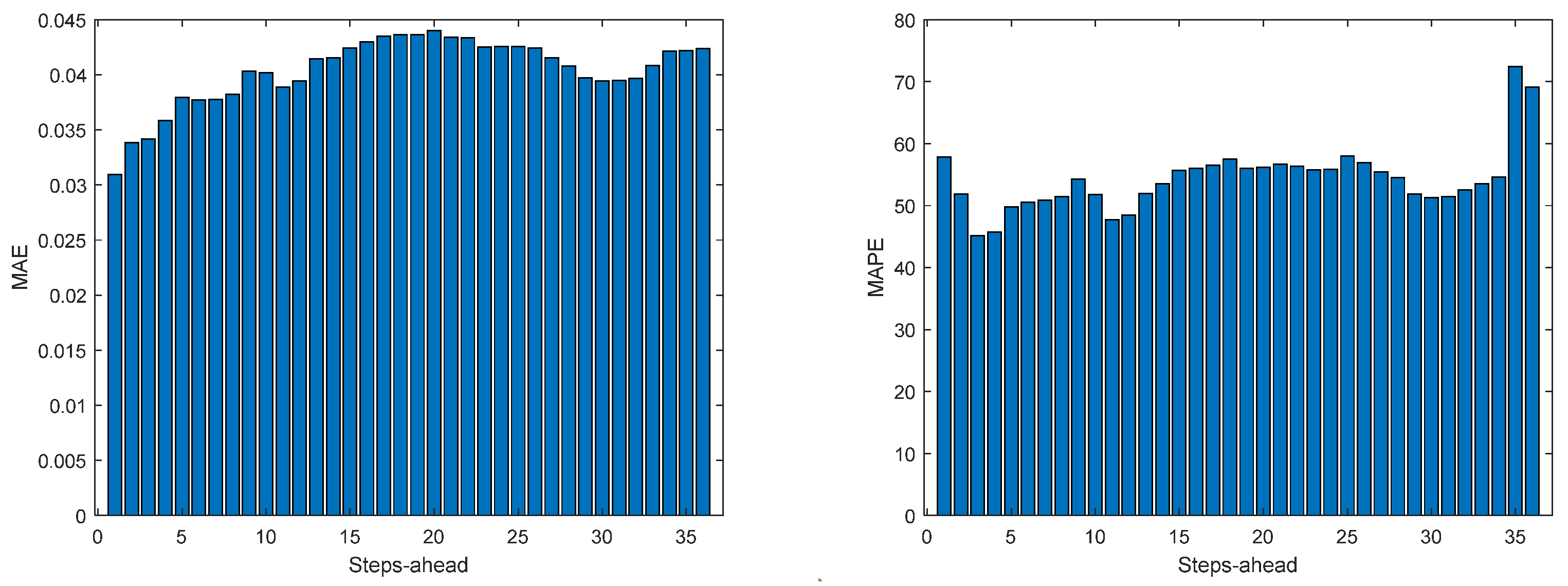
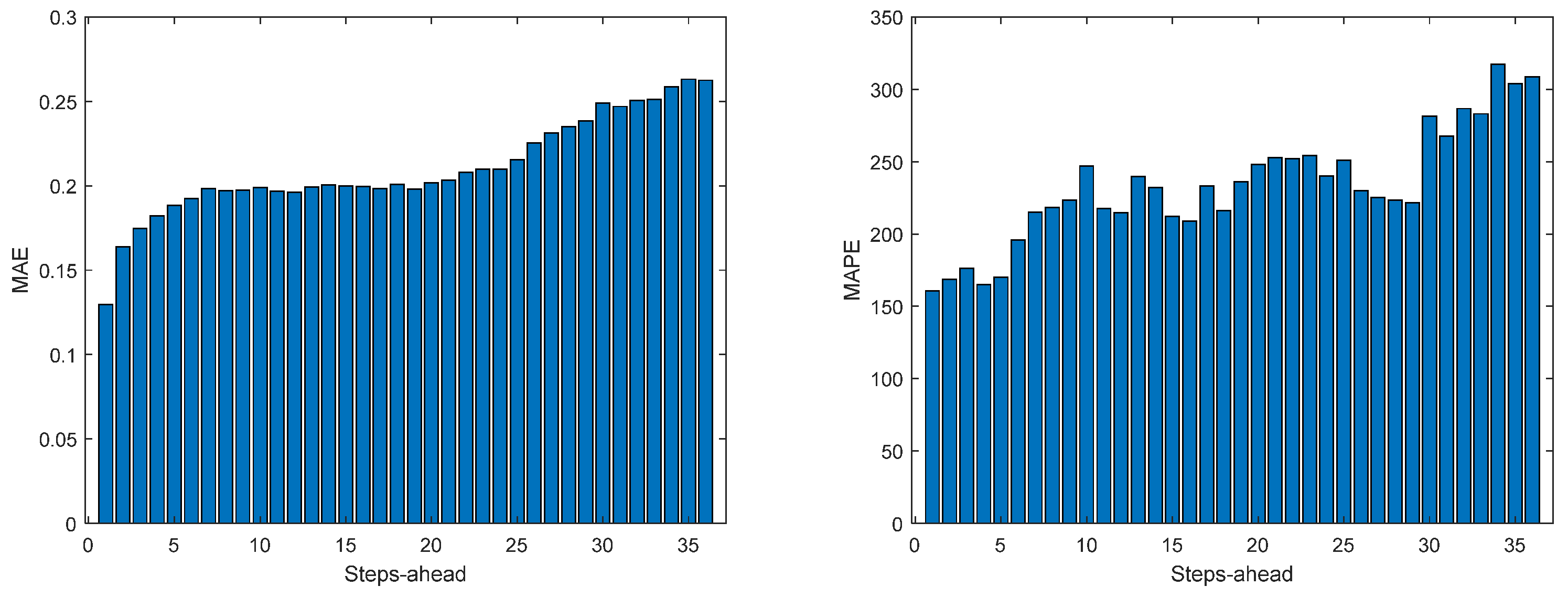
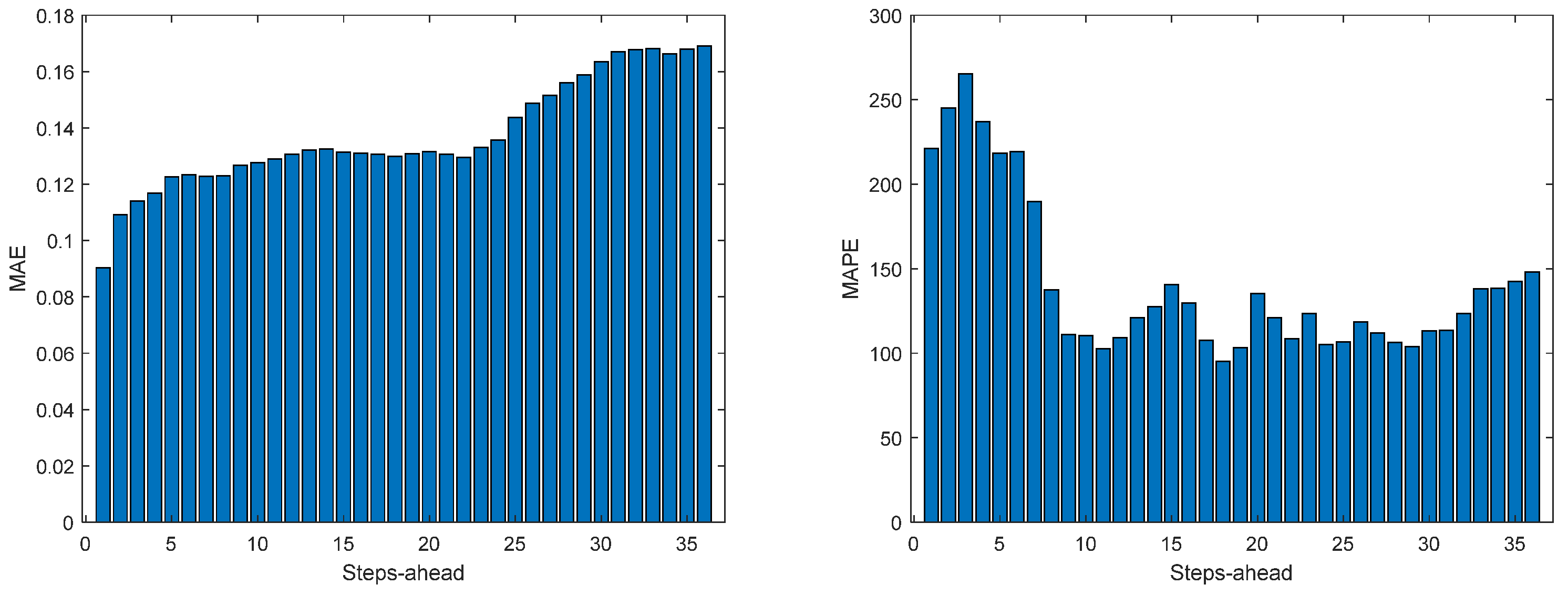
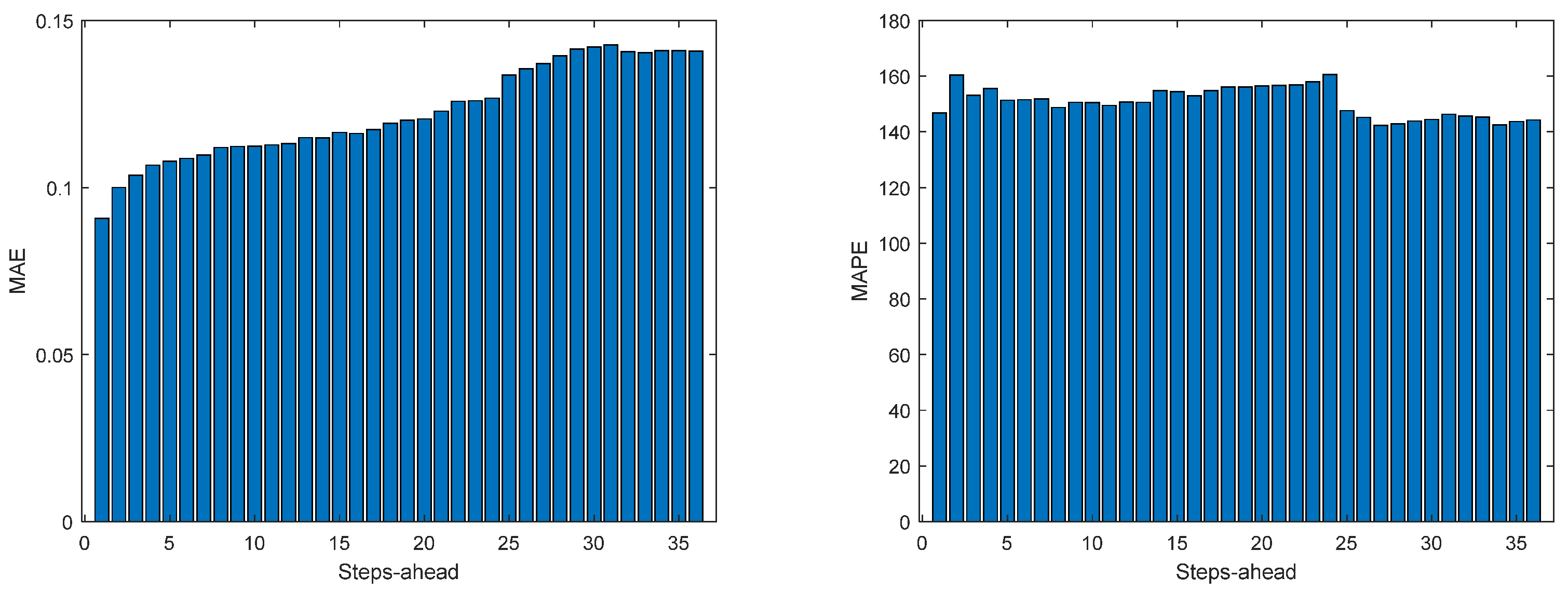
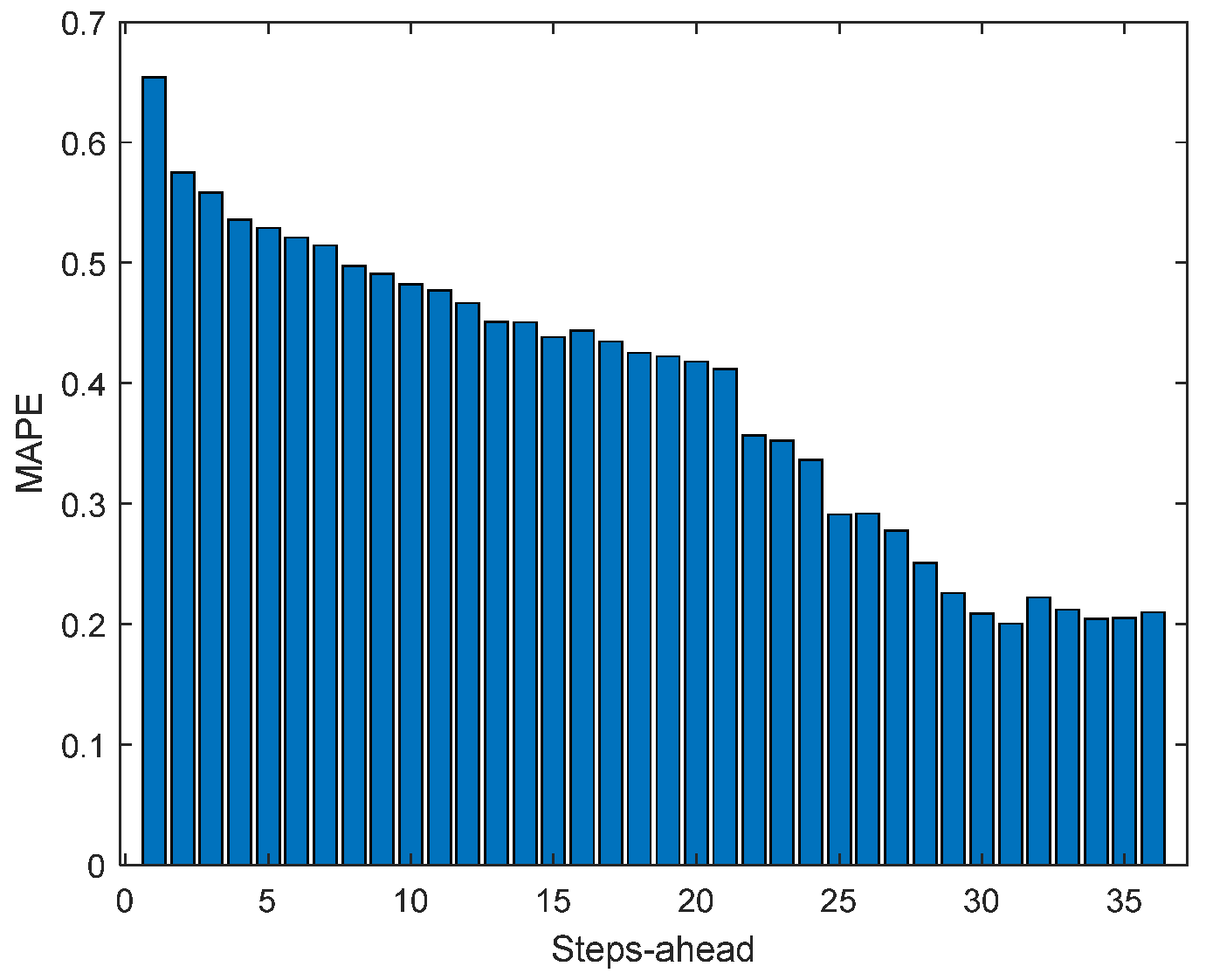
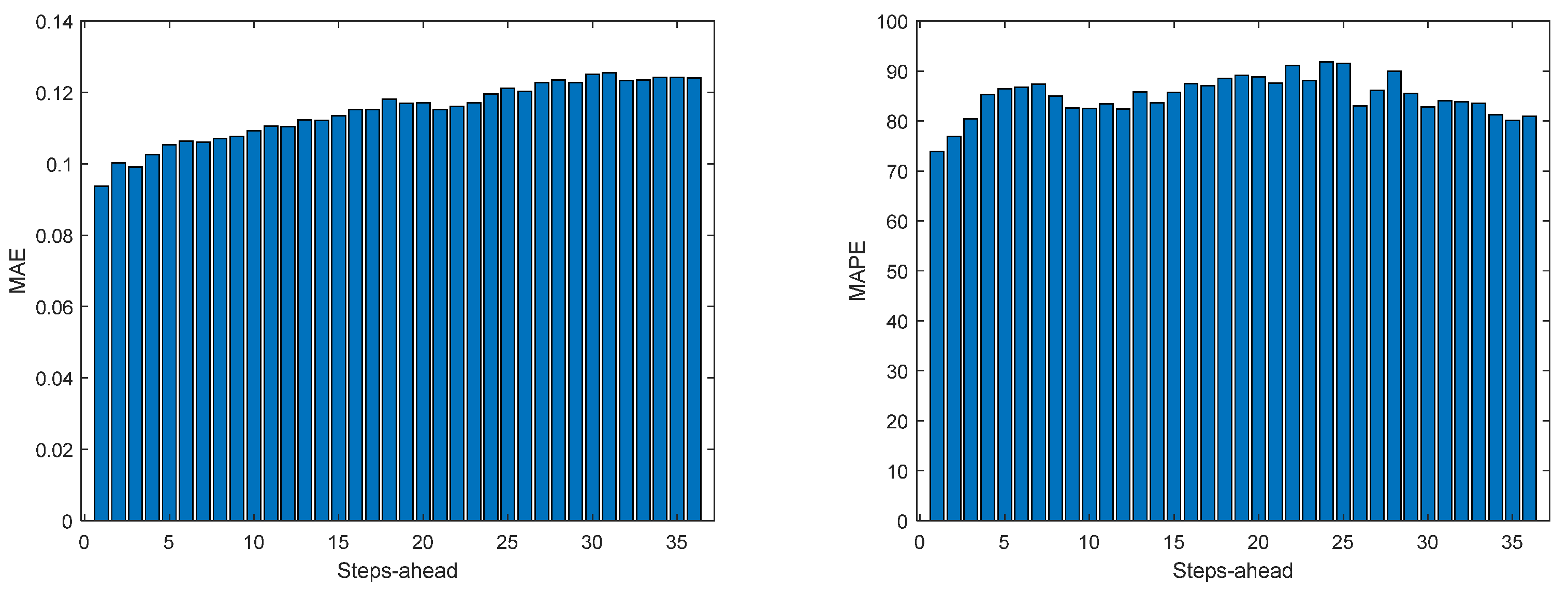
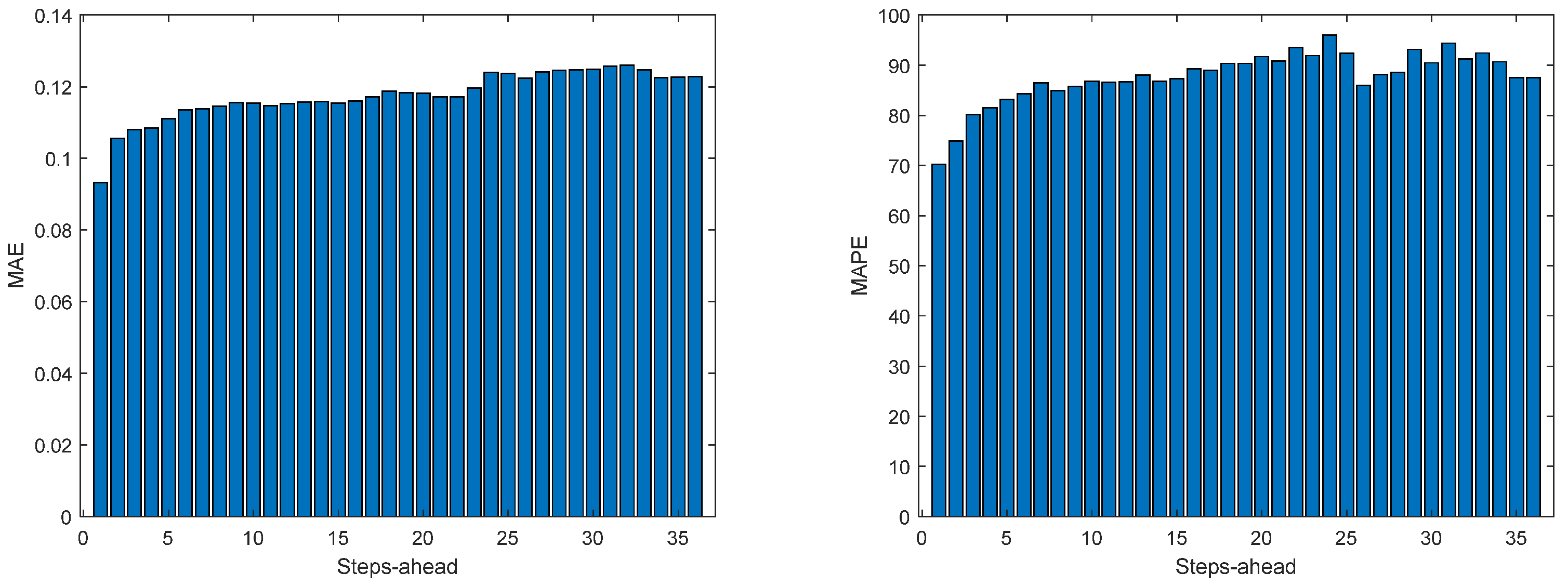
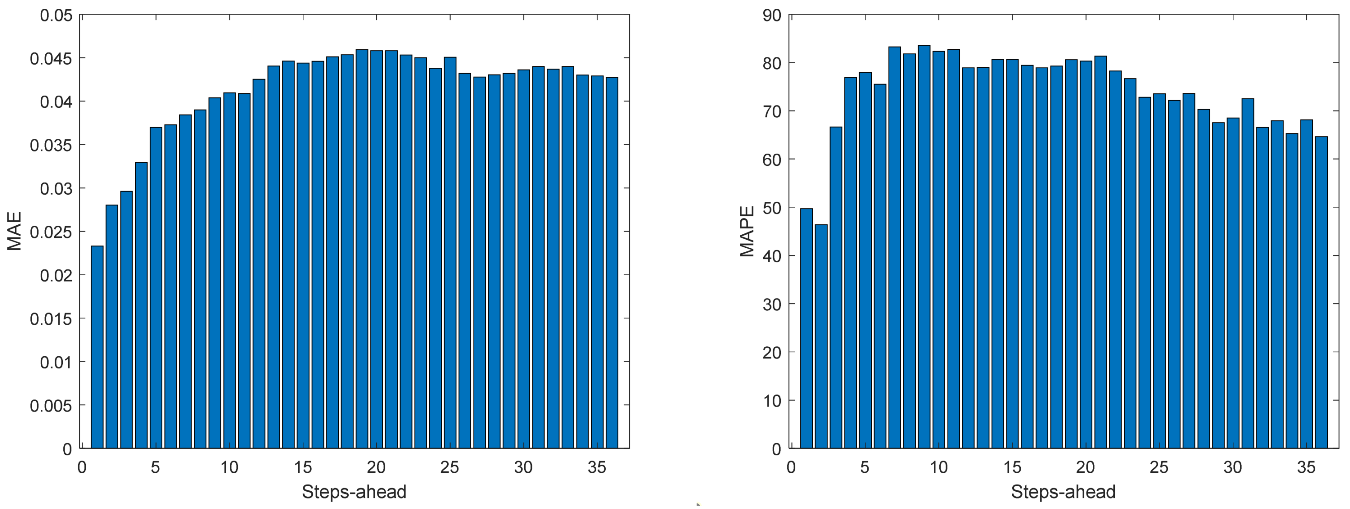
Figure 14.
Solar Radiation MAE (left) and MAPE (right) forecasts.
Figure 14.
Solar Radiation MAE (left) and MAPE (right) forecasts.
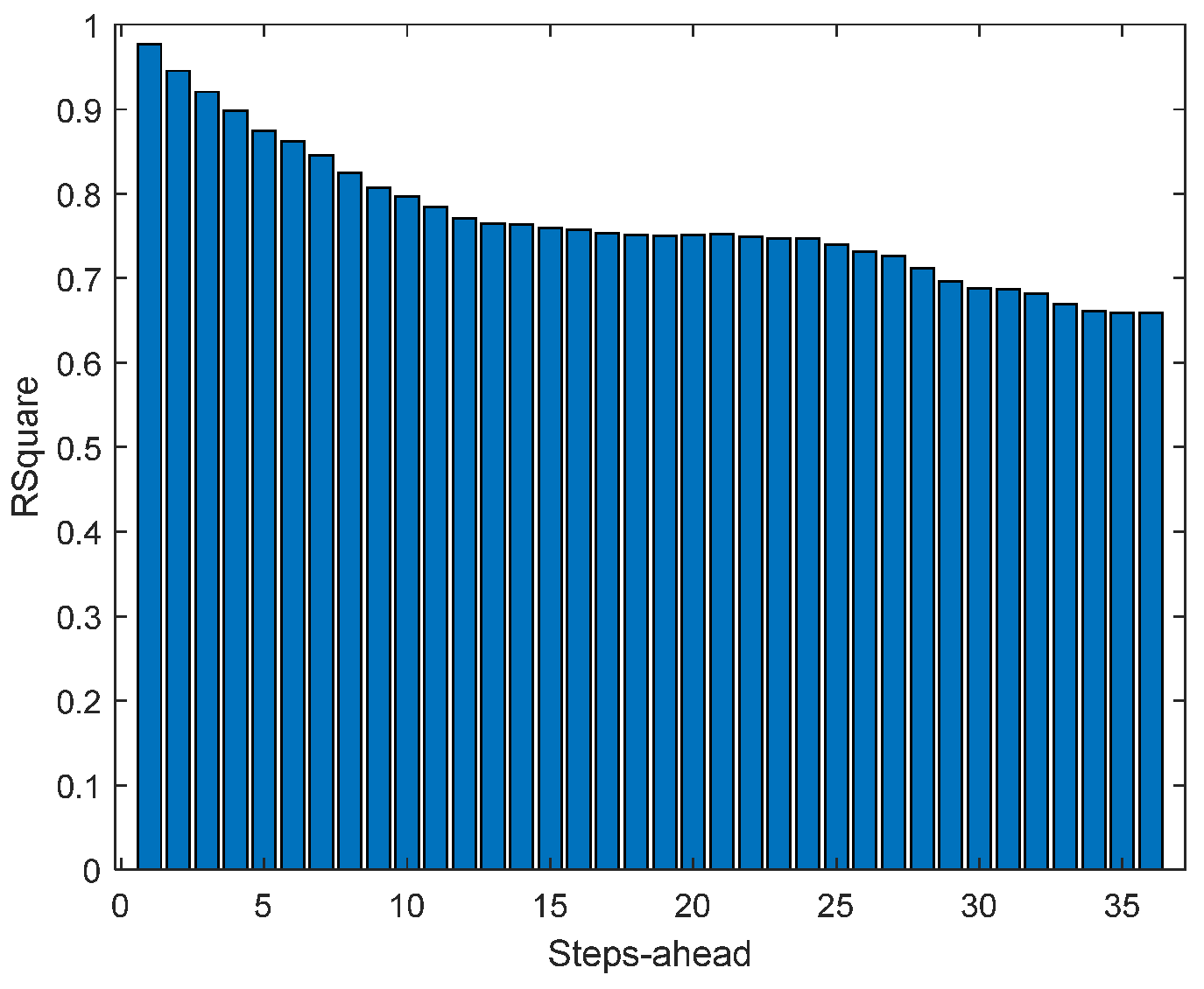
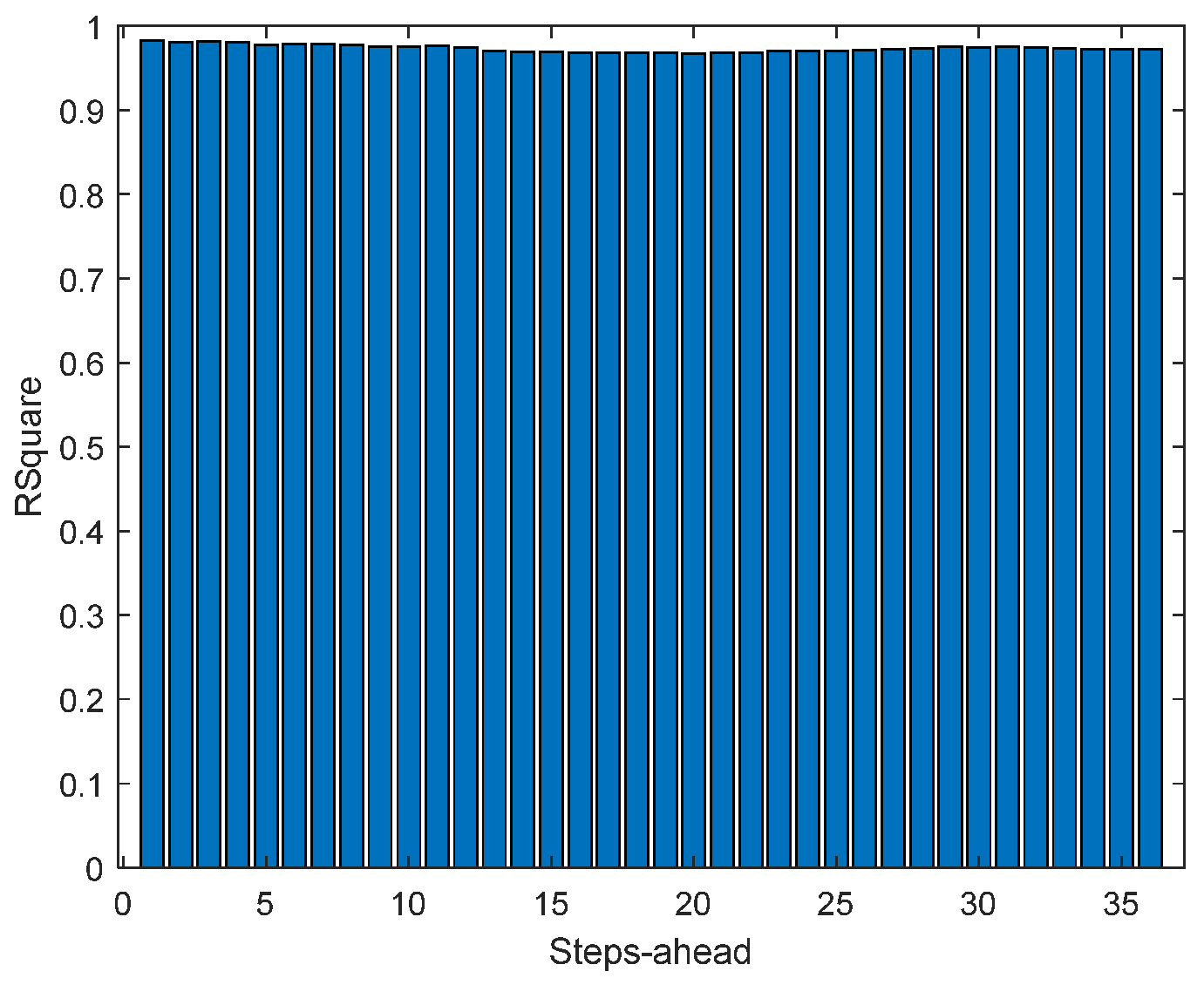
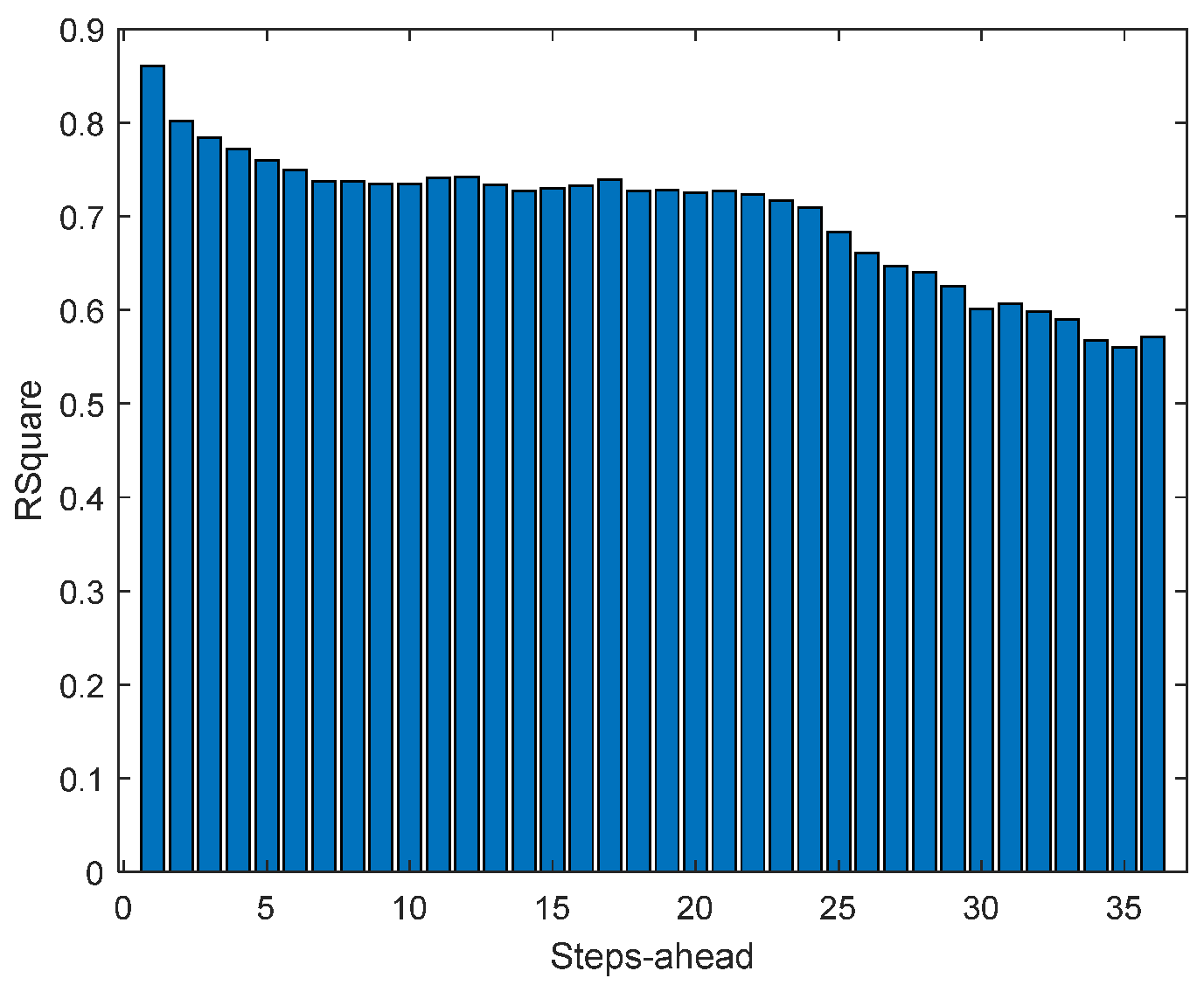
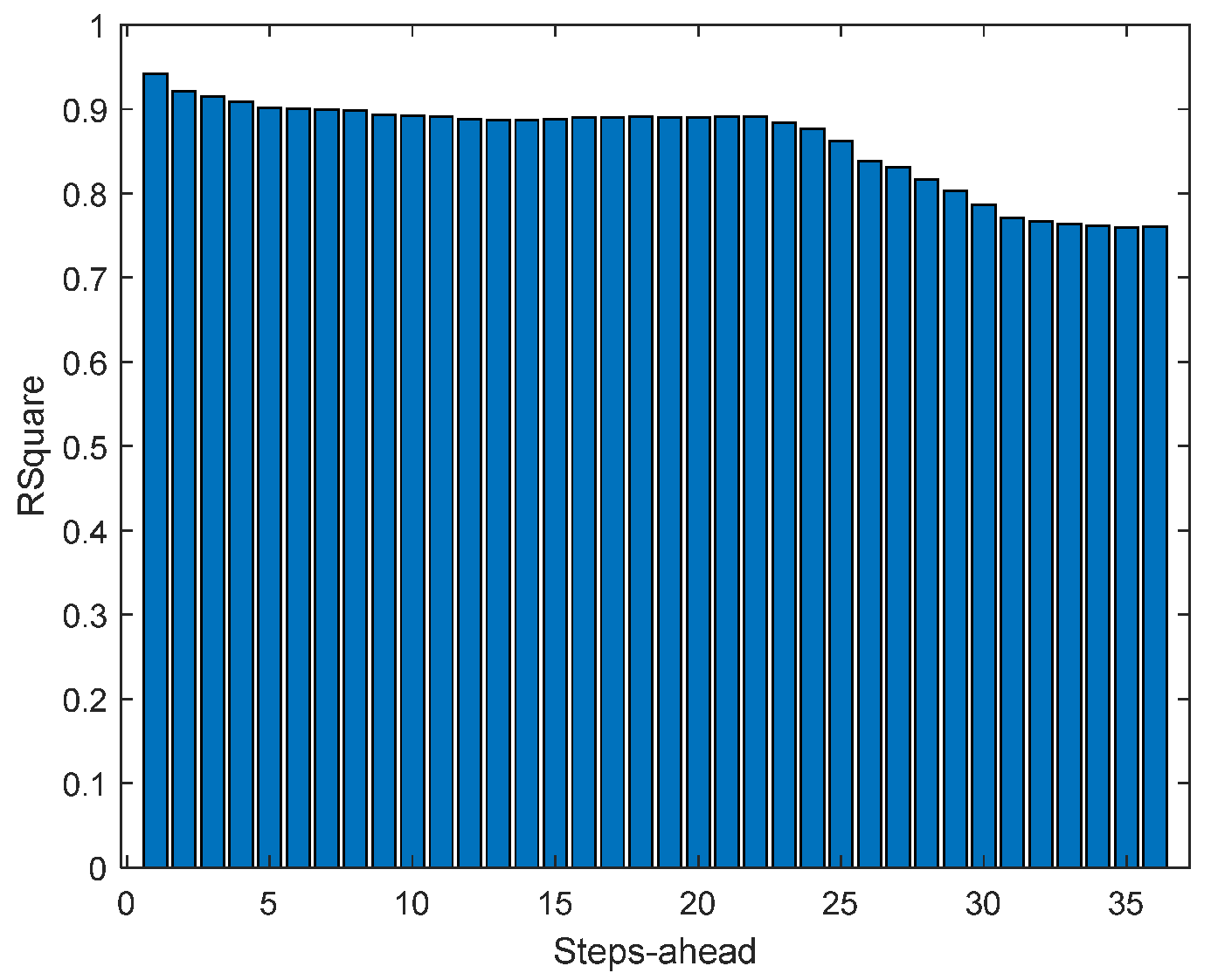
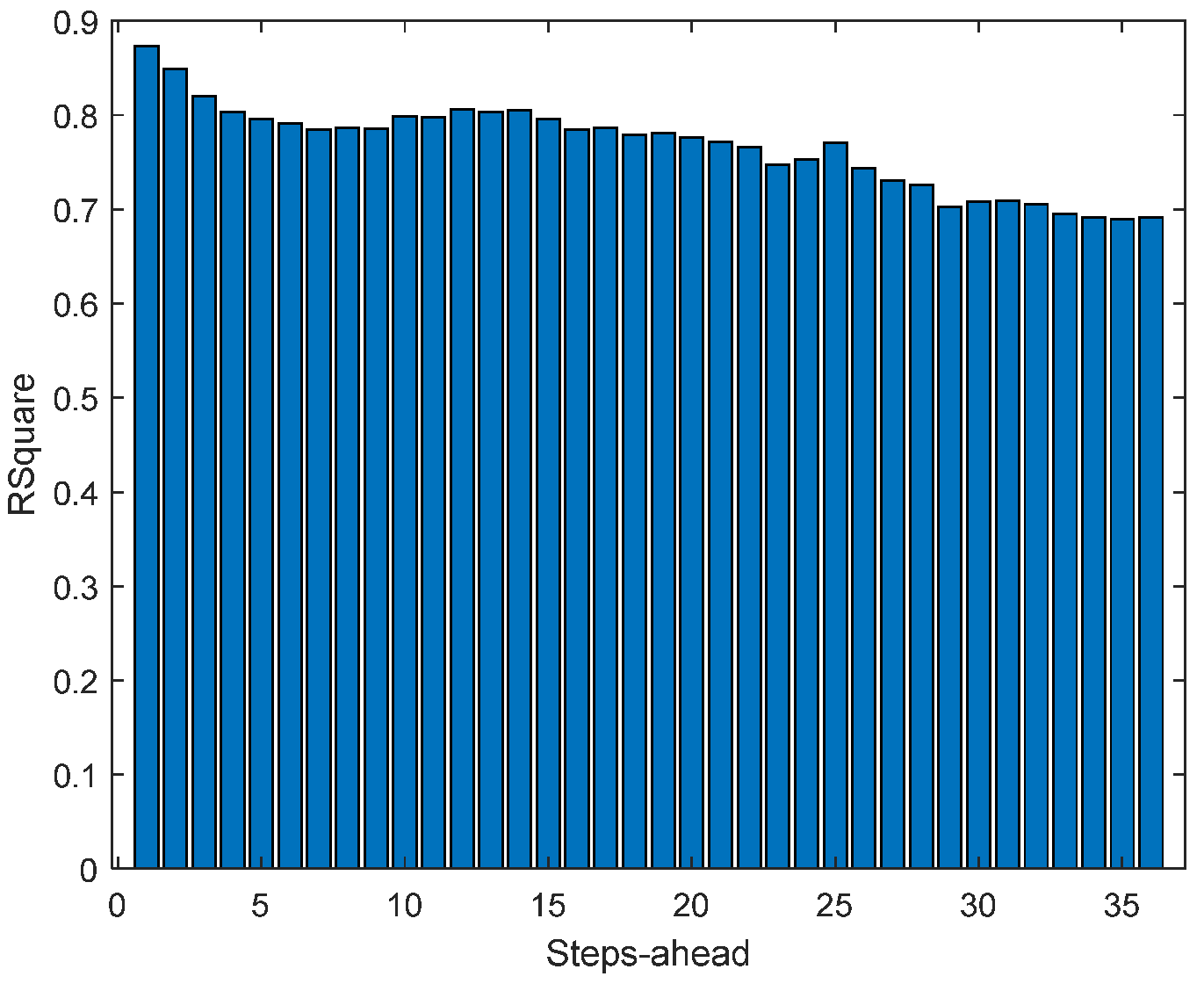
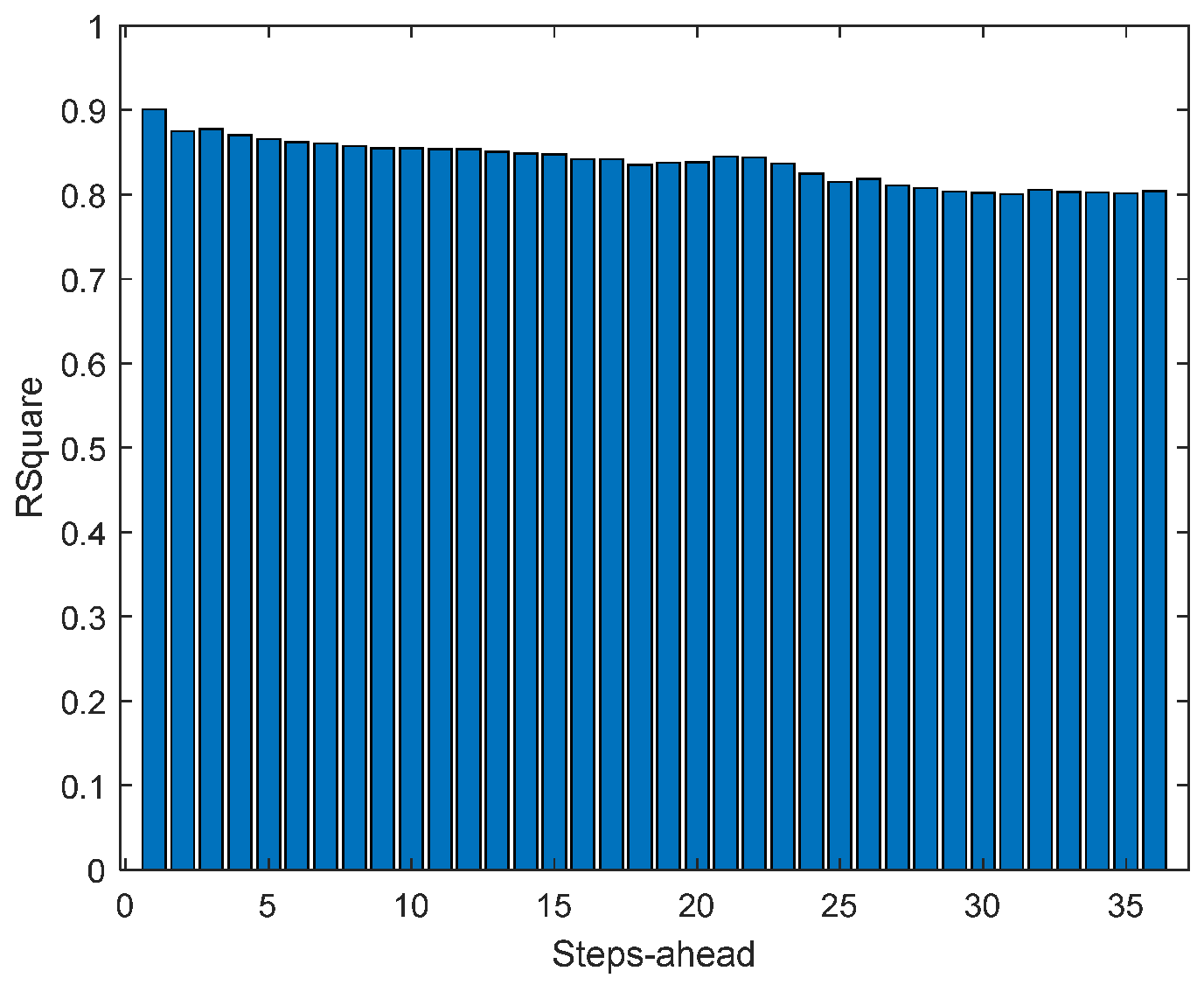
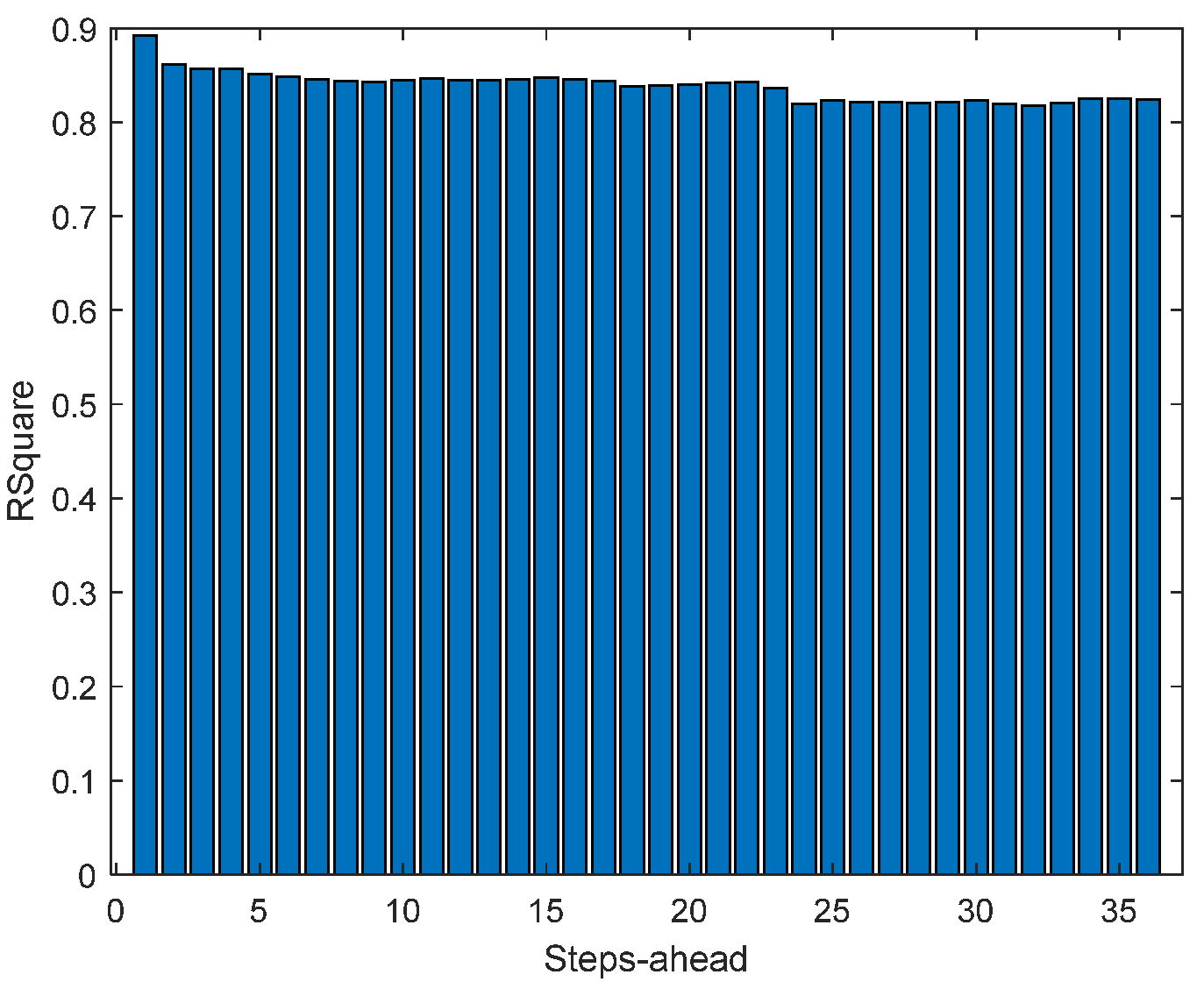
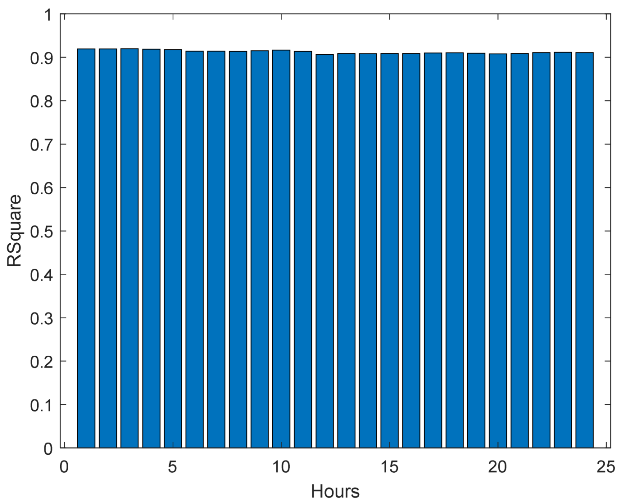
Figure 15.
Solar Radiation R2 forecasts.
Figure 15.
Solar Radiation R2 forecasts.
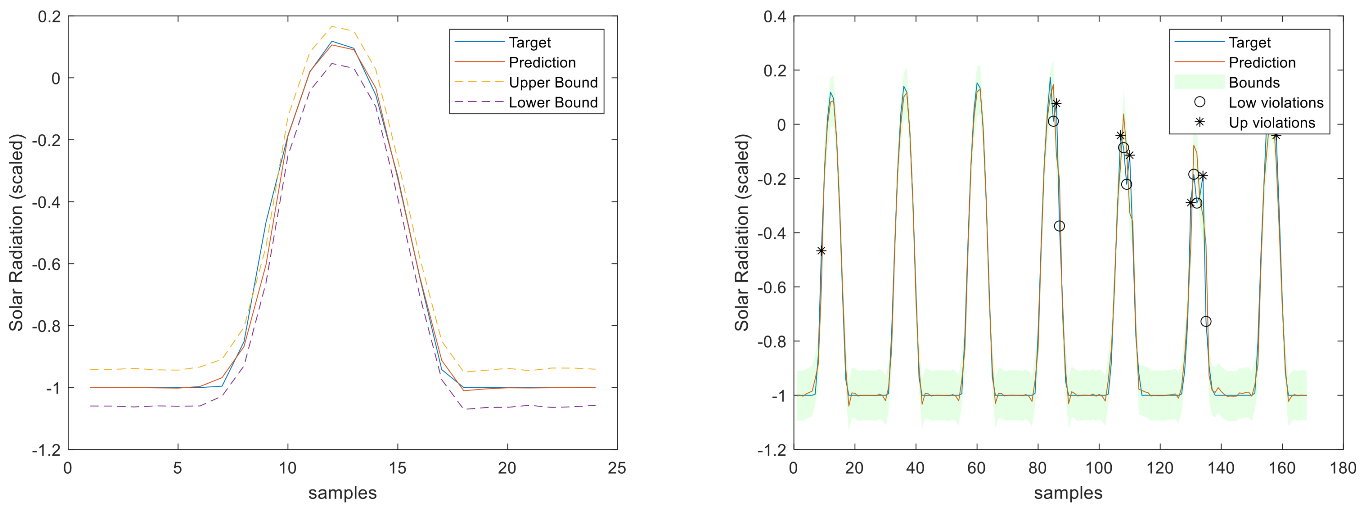
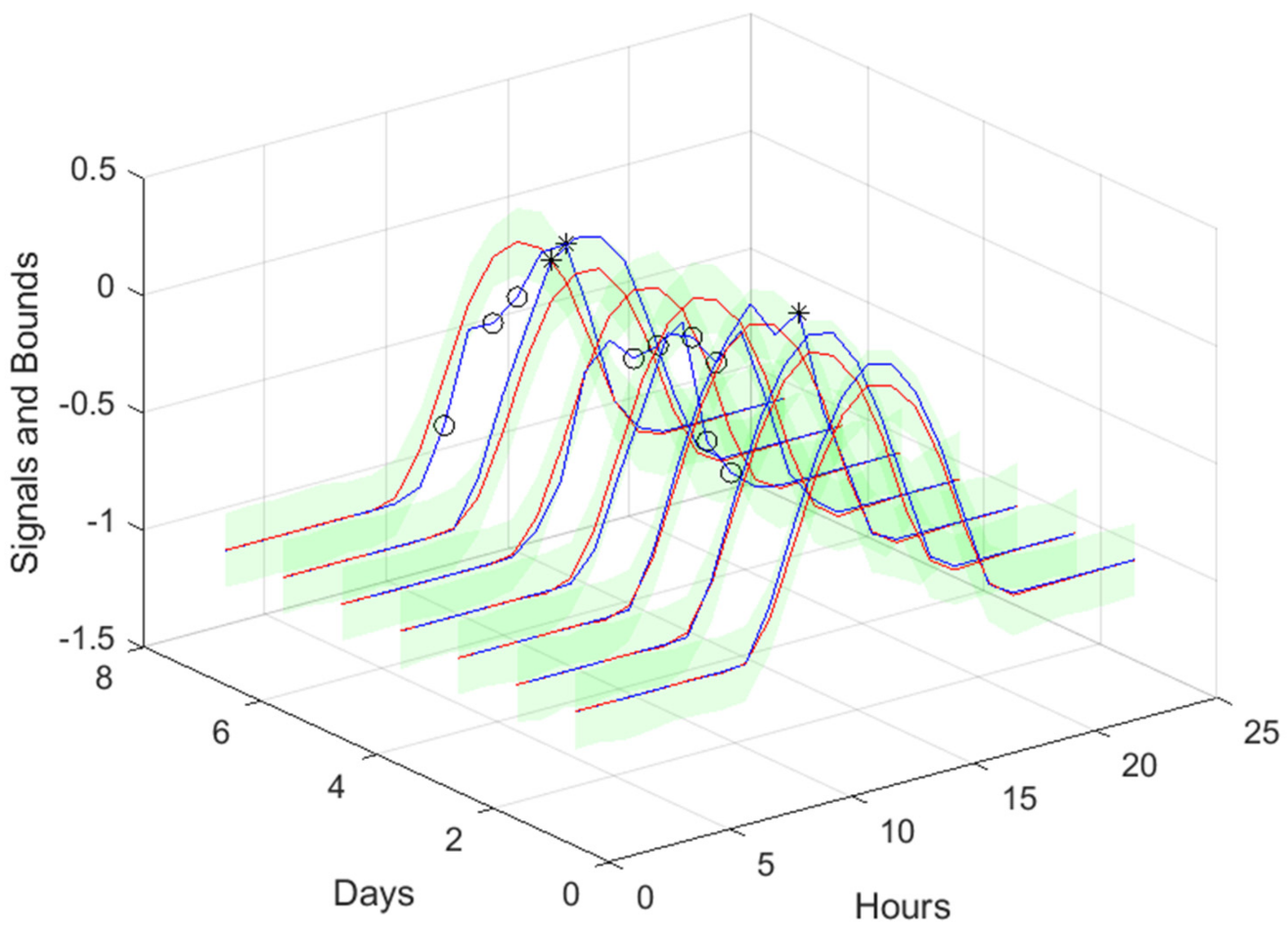
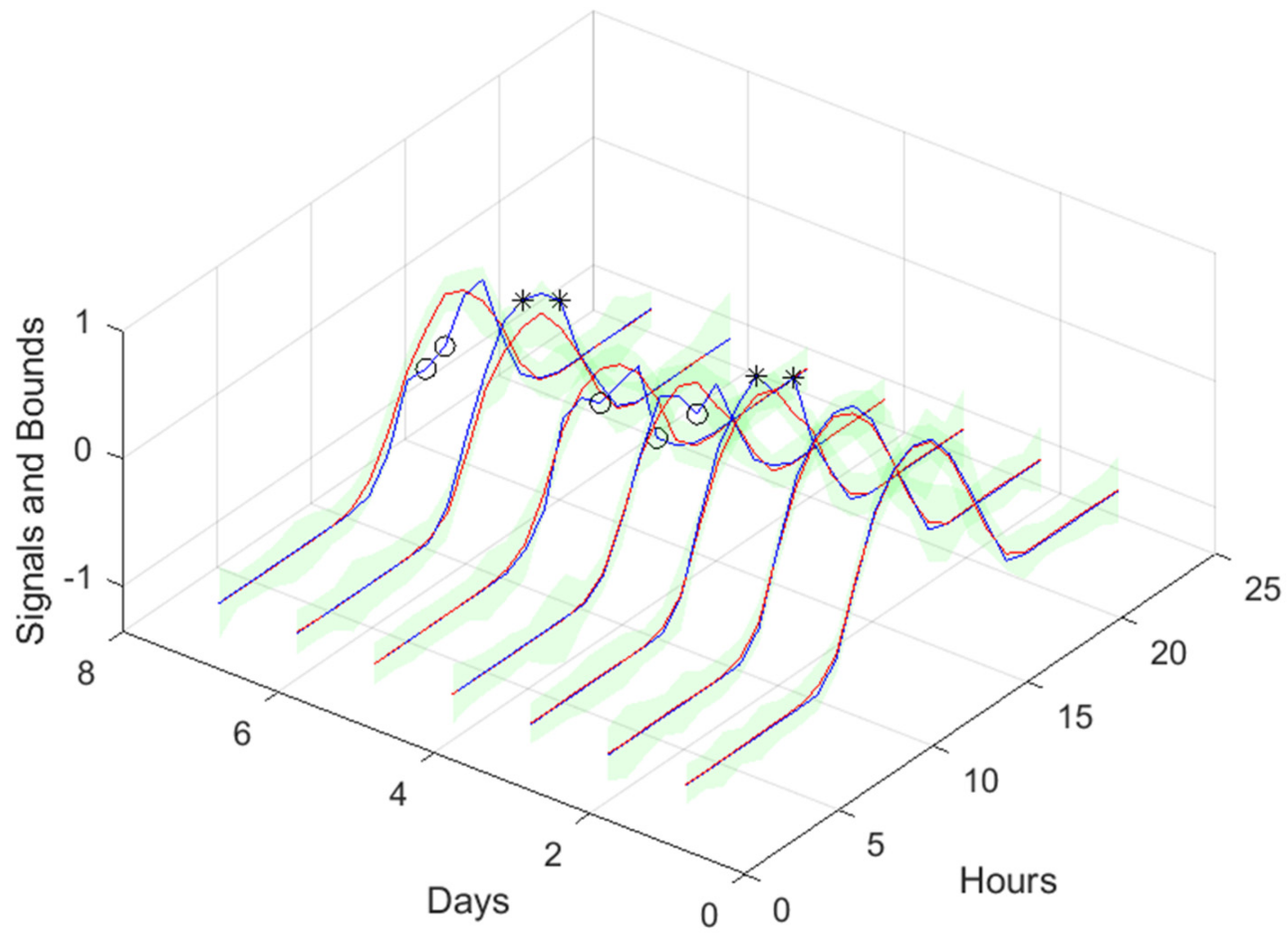
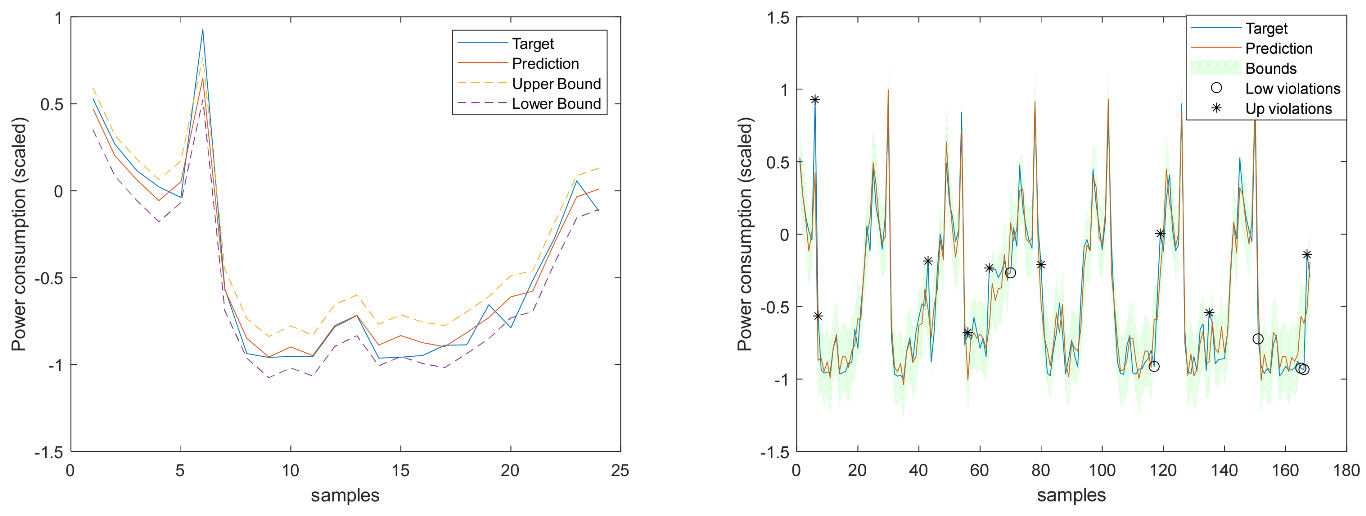
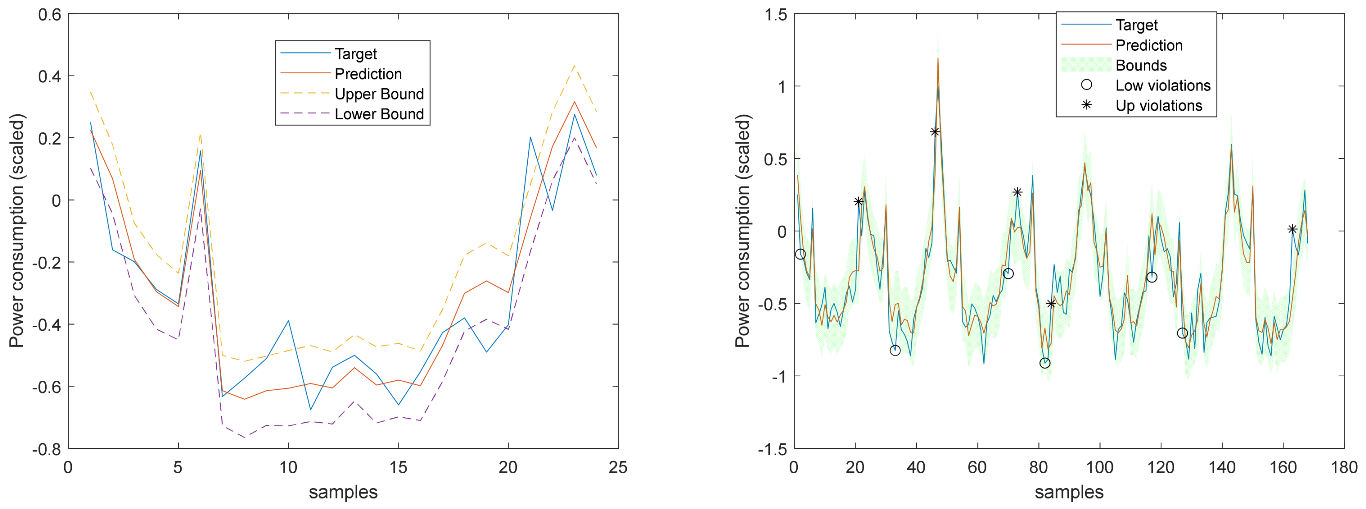
Figure 16.
Solar Radiation 1-step-ahead. Left: One Day; Right: All days in the prediction time series. The ‘o’ symbols denote the target upper bound violations, and the symbols ‘*’ are the lower bound violations by the target. The x-axis label denotes the samples of the prediction time series.
Figure 16.
Solar Radiation 1-step-ahead. Left: One Day; Right: All days in the prediction time series. The ‘o’ symbols denote the target upper bound violations, and the symbols ‘*’ are the lower bound violations by the target. The x-axis label denotes the samples of the prediction time series.
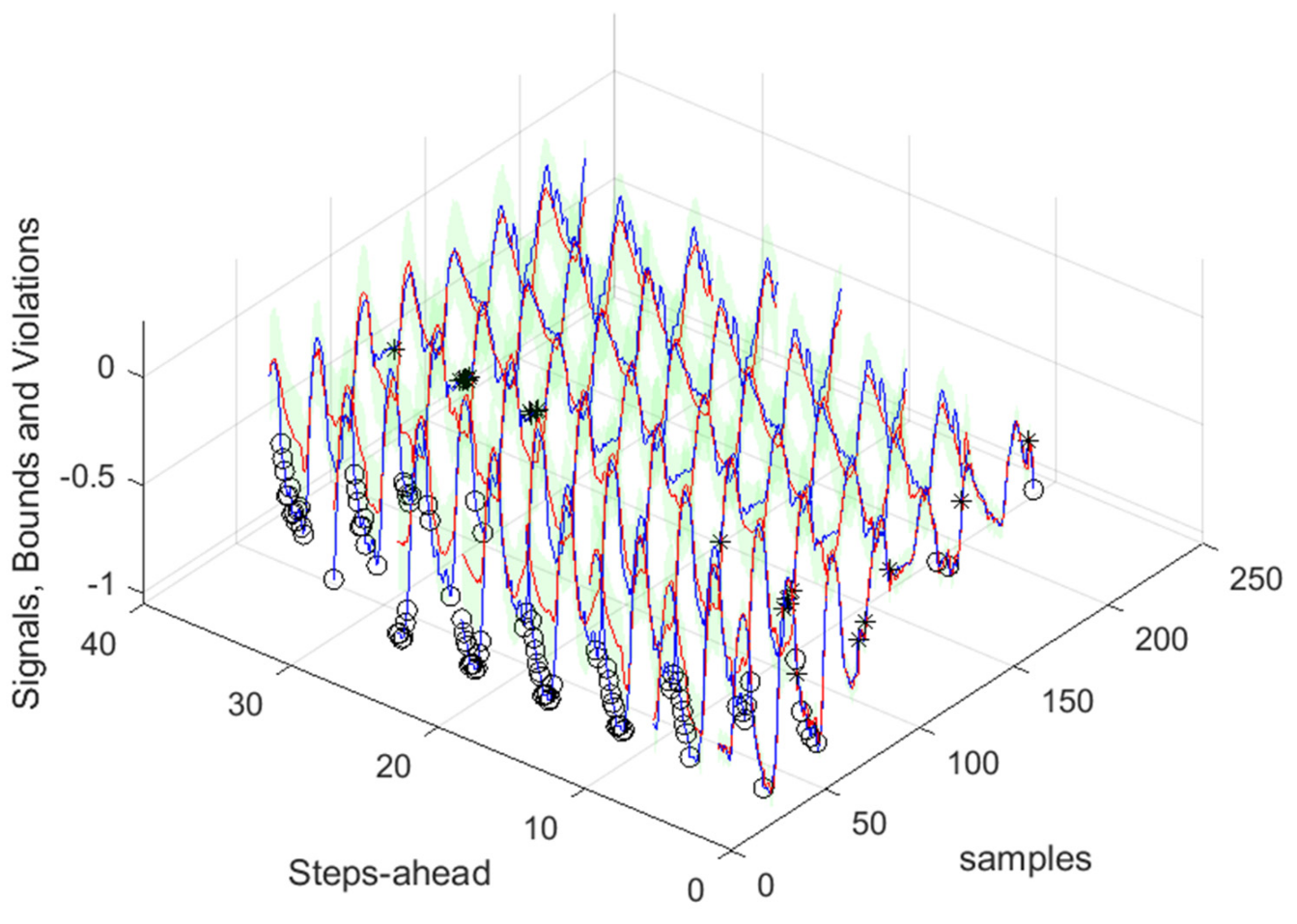
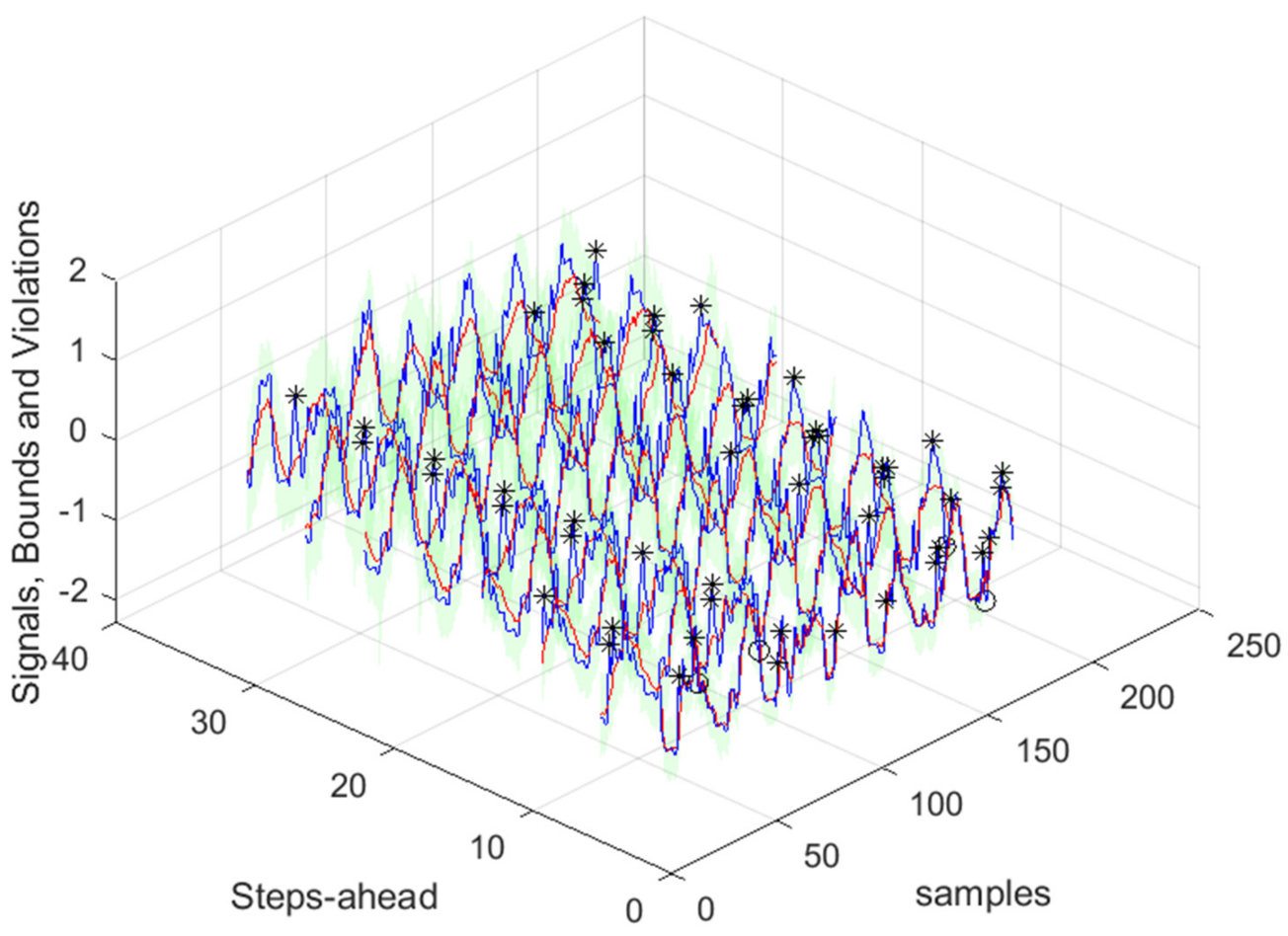
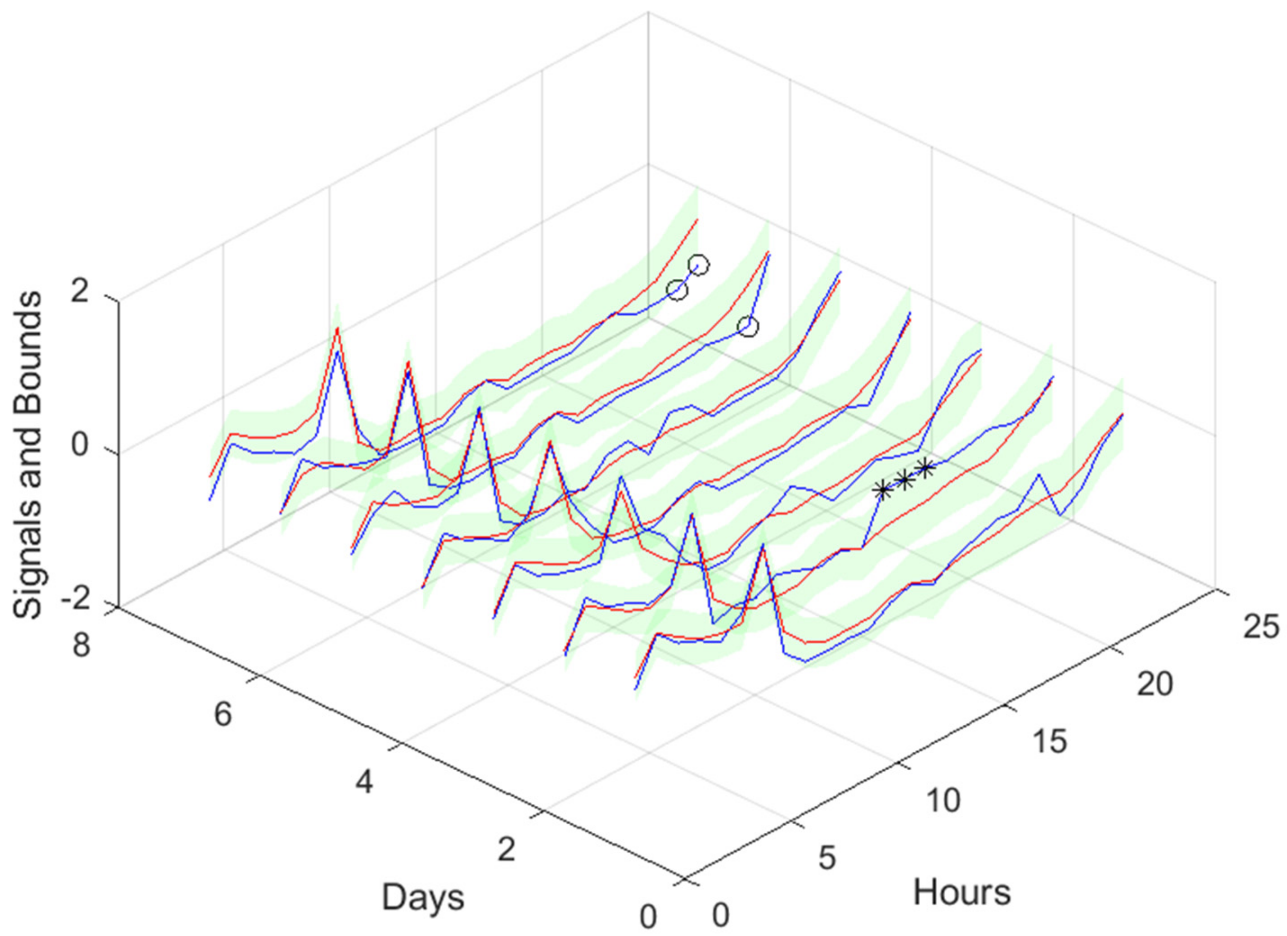
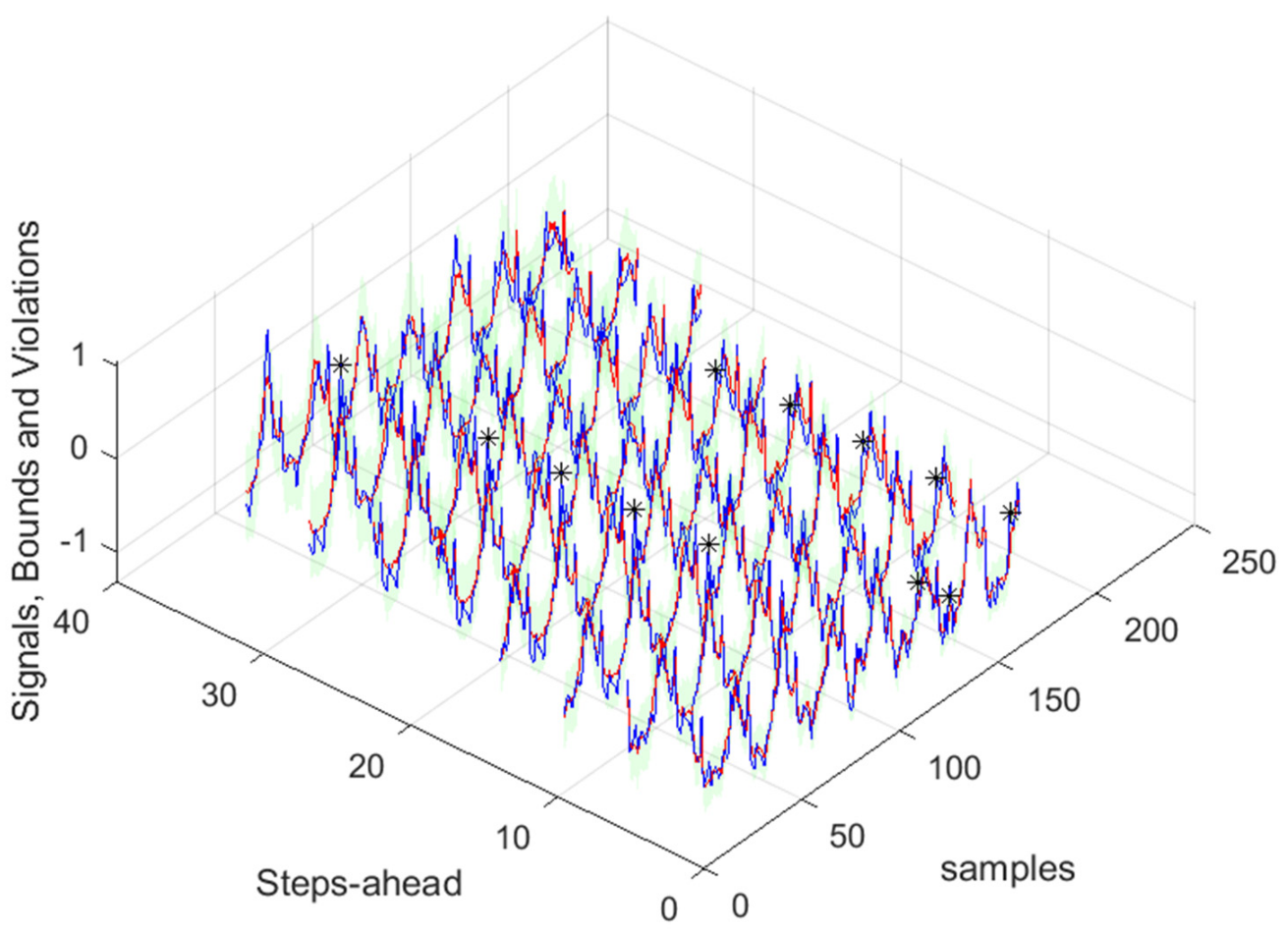
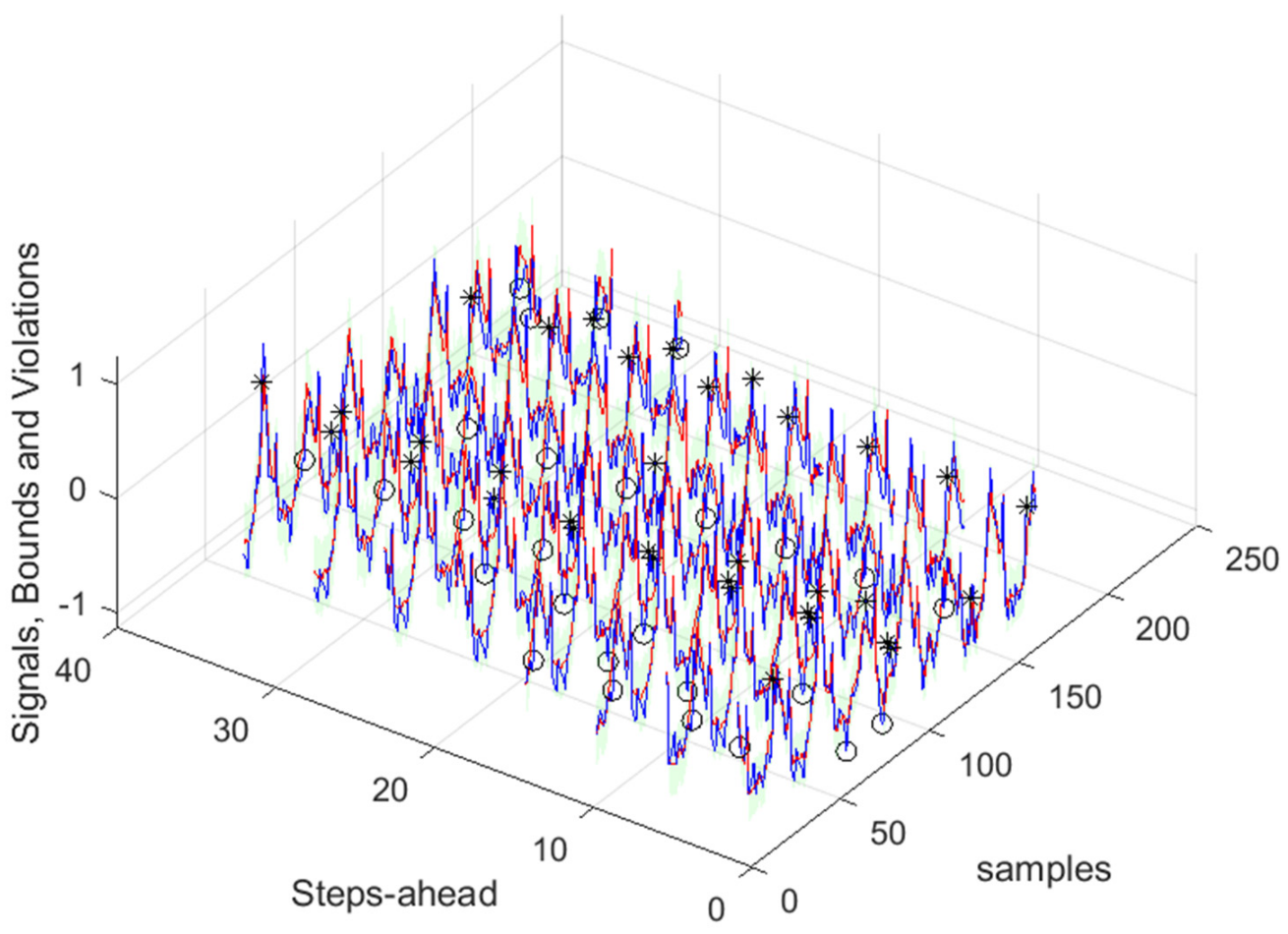
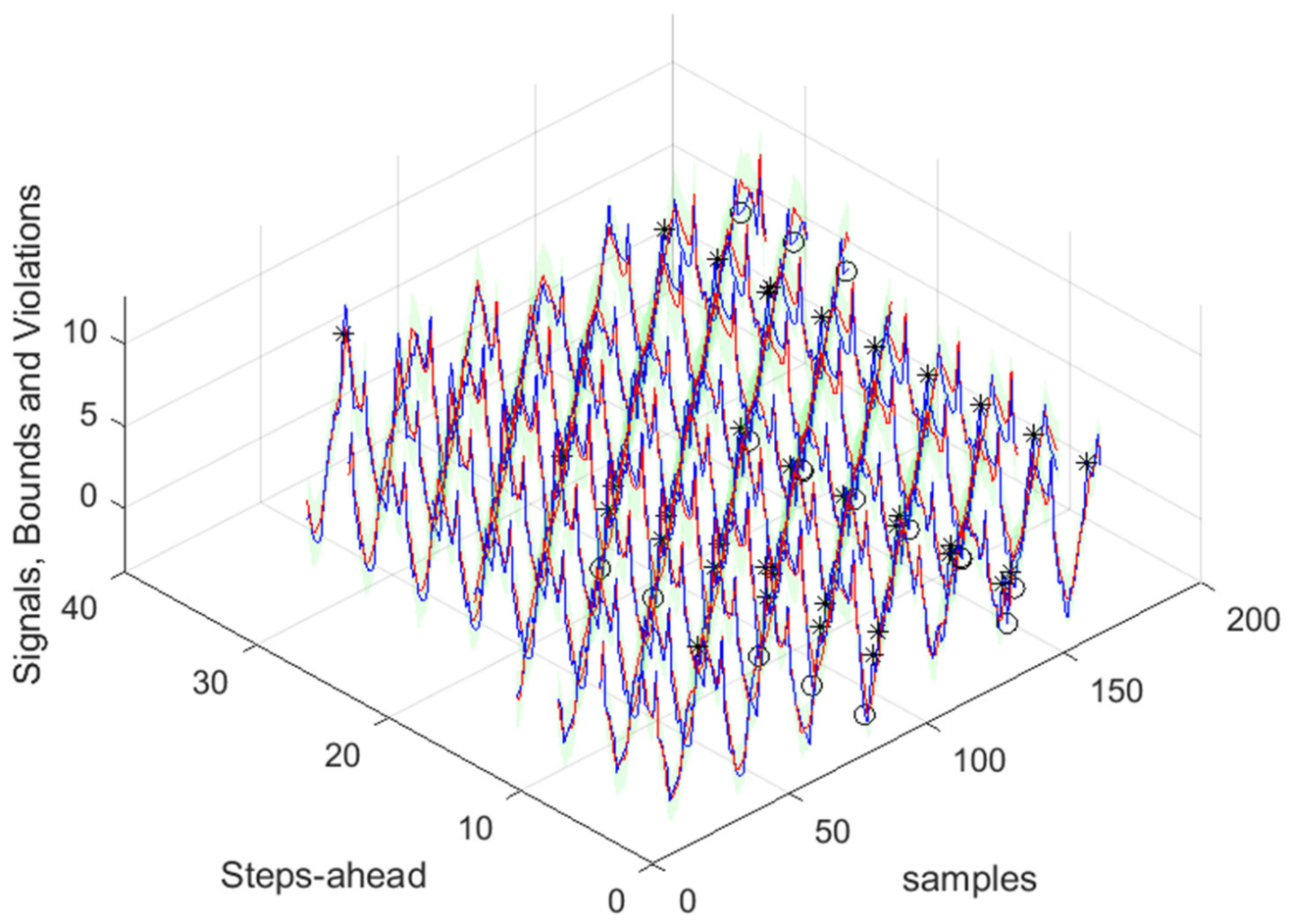
Figure 17.
Solar Radiation [1, 5, 11, …, 36]-steps-ahead. The same notation of
Figure 16 right is used.
Figure 17.
Solar Radiation [1, 5, 11, …, 36]-steps-ahead. The same notation of
Figure 16 right is used.
Figure 18.
Solar Radiation next-day forecast is computed with data measured up to 12 h the day before. The same notation of
Figure 15 right is used.
Figure 18.
Solar Radiation next-day forecast is computed with data measured up to 12 h the day before. The same notation of
Figure 15 right is used.
Figure 19.
Air temperature snapshot.
Figure 19.
Air temperature snapshot.
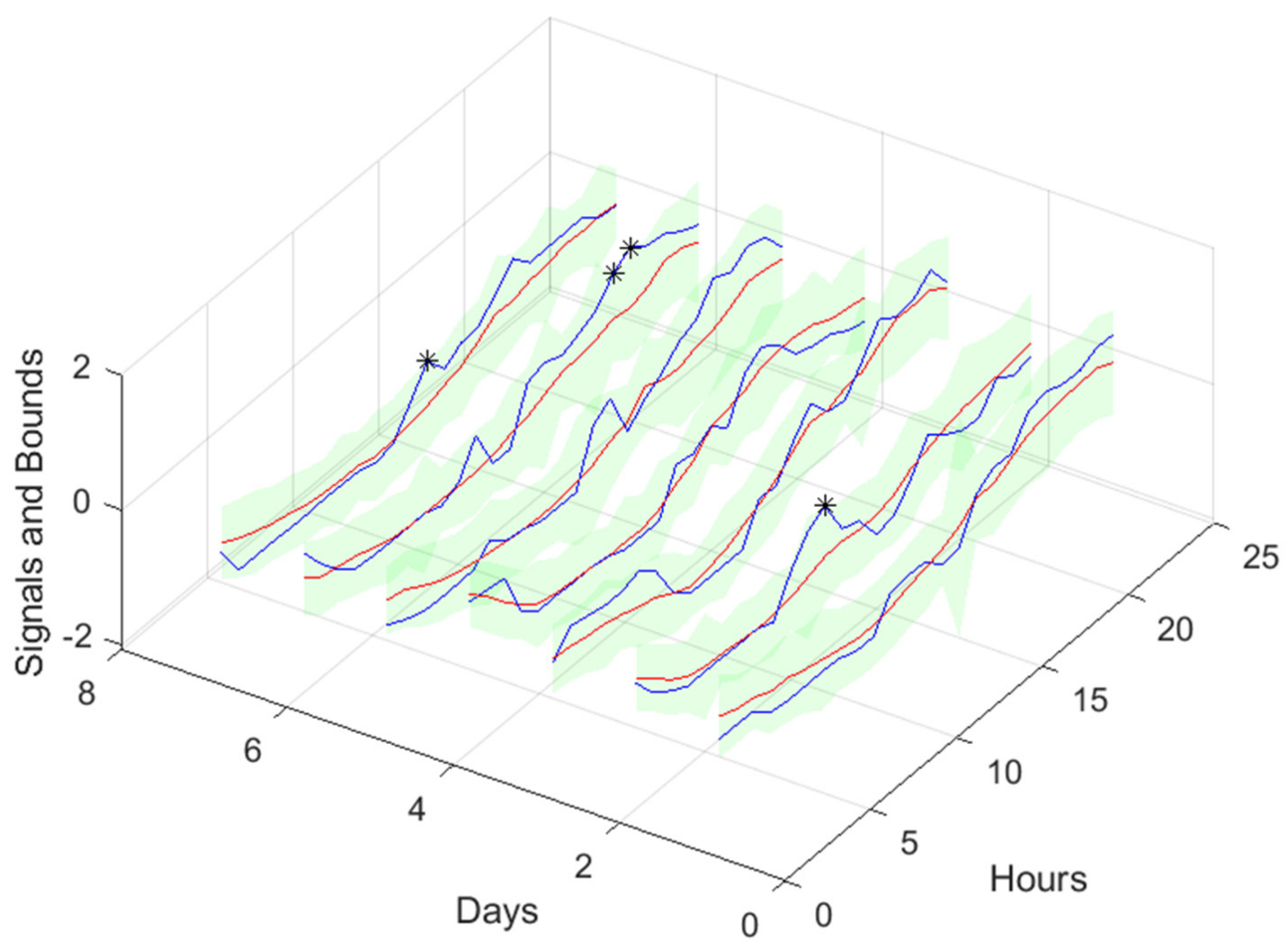
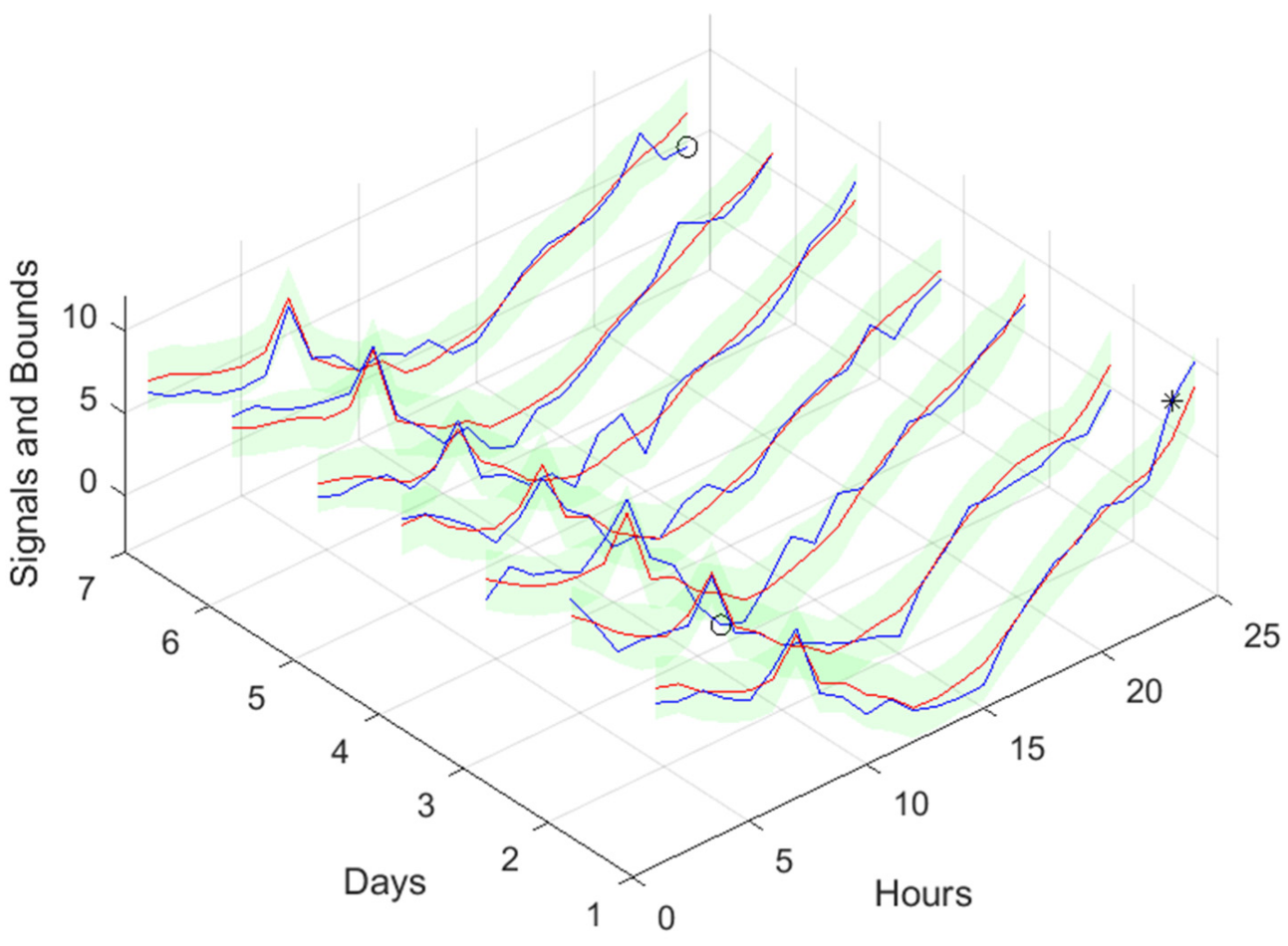
Figure 20.
Atmospheric Temperature 1-step-ahead. Left: One Day; Right: All days in the prediction time series.
Figure 20.
Atmospheric Temperature 1-step-ahead. Left: One Day; Right: All days in the prediction time series.
Figure 21.
Atmospheric Temperature [1, 5, 11, …, 36]-steps-ahead.
Figure 21.
Atmospheric Temperature [1, 5, 11, …, 36]-steps-ahead.
Figure 22.
Atmospheric Temperature next-day forecast, with measured data until 12 h the day before.
Figure 22.
Atmospheric Temperature next-day forecast, with measured data until 12 h the day before.
Figure 23.
Power Generation 1-step-ahead. Left: One Day; Right: All days in the prediction time series.
Figure 23.
Power Generation 1-step-ahead. Left: One Day; Right: All days in the prediction time series.
Figure 24.
Power Generation [1, 5, 11, …, 36]-steps-ahead.
Figure 24.
Power Generation [1, 5, 11, …, 36]-steps-ahead.
Figure 25.
Power Generation next-day forecast, with measured data until 12 h the day before.
Figure 25.
Power Generation next-day forecast, with measured data until 12 h the day before.
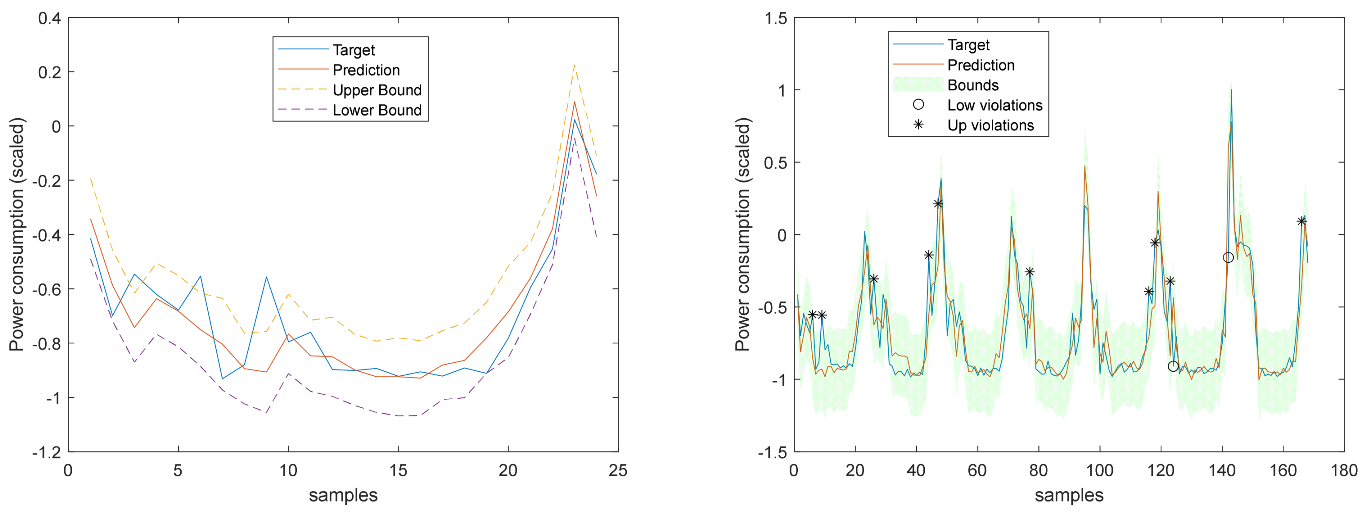
Figure 26.
MP1 Load Demand 1-step-ahead. Left: One Day; Right: All days in the prediction time series.
Figure 26.
MP1 Load Demand 1-step-ahead. Left: One Day; Right: All days in the prediction time series.
Figure 27.
MP1 Load Demand [1, 5, 11, …, 36]-steps-ahead.
Figure 27.
MP1 Load Demand [1, 5, 11, …, 36]-steps-ahead.
Figure 28.
MP1 Load Demand next-day forecast, with measured data until 12 h the day before.
Figure 28.
MP1 Load Demand next-day forecast, with measured data until 12 h the day before.
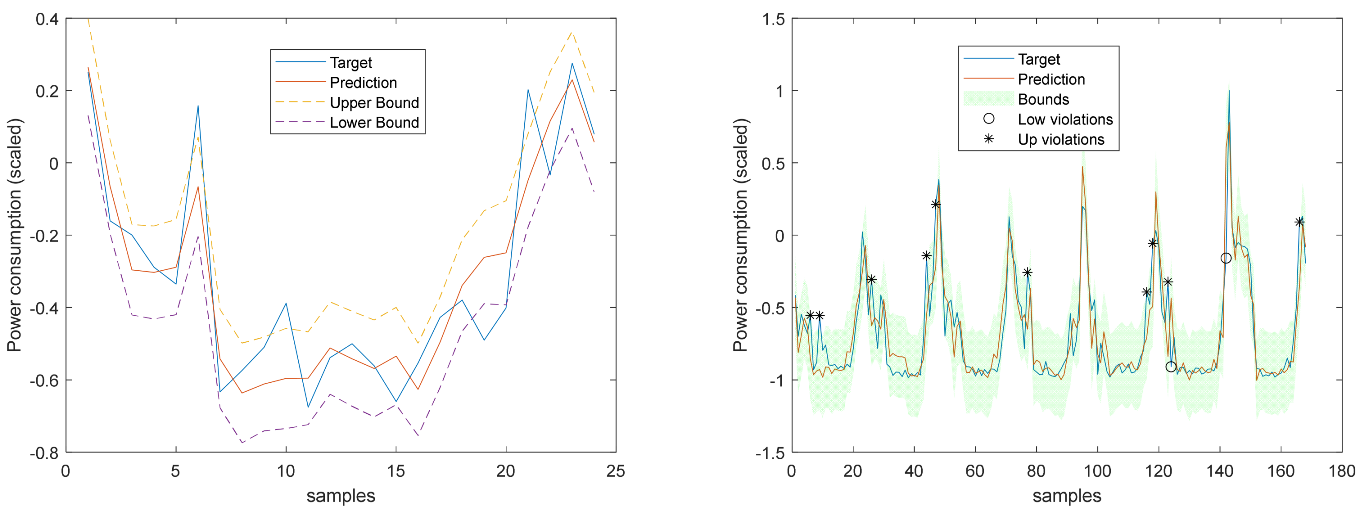
Figure 29.
MP2 Load Demand 1-step-ahead. Left: One Day; Right: All days in the prediction time series.
Figure 29.
MP2 Load Demand 1-step-ahead. Left: One Day; Right: All days in the prediction time series.
Figure 30.
MP2 Load Demand [1, 5, 11, …, 36]-steps-ahead.
Figure 30.
MP2 Load Demand [1, 5, 11, …, 36]-steps-ahead.
Figure 31.
MP2 Load Demand next-day forecast, with measured data until 12 h the day before.
Figure 31.
MP2 Load Demand next-day forecast, with measured data until 12 h the day before.
Figure 32.
TP1 Load Demand 1-step-ahead. Left: One Day; Right: All days in the prediction time series.
Figure 32.
TP1 Load Demand 1-step-ahead. Left: One Day; Right: All days in the prediction time series.
Figure 33.
TP1 Load Demand [1, 5, 11, …, 36]-steps-ahead.
Figure 33.
TP1 Load Demand [1, 5, 11, …, 36]-steps-ahead.
Figure 34.
TP1 Load Demand next-day forecast, with measured data until 12 h the day before.
Figure 34.
TP1 Load Demand next-day forecast, with measured data until 12 h the day before.
Figure 35.
TP2 Load Demand 1-step-ahead. Left: One Day; Right: All days in the prediction time series.
Figure 35.
TP2 Load Demand 1-step-ahead. Left: One Day; Right: All days in the prediction time series.
Figure 36.
TP2 Load Demand [1, 5, 11, …, 36]-steps-ahead.
Figure 36.
TP2 Load Demand [1, 5, 11, …, 36]-steps-ahead.
Figure 37.
TP2 Load Demand next-day forecast, with measured data until 12 h the day before.
Figure 37.
TP2 Load Demand next-day forecast, with measured data until 12 h the day before.
Figure 38.
Community Load Demand 1-step-ahead. Left: One Day; Right: All days in the prediction time series.
Figure 38.
Community Load Demand 1-step-ahead. Left: One Day; Right: All days in the prediction time series.
Figure 39.
Community Load Demand [1, 5, 11, …, 36]-steps-ahead.
Figure 39.
Community Load Demand [1, 5, 11, …, 36]-steps-ahead.
Figure 40.
Community Load Demand next-day forecast, with measured data until 12 h the day before.
Figure 40.
Community Load Demand next-day forecast, with measured data until 12 h the day before.
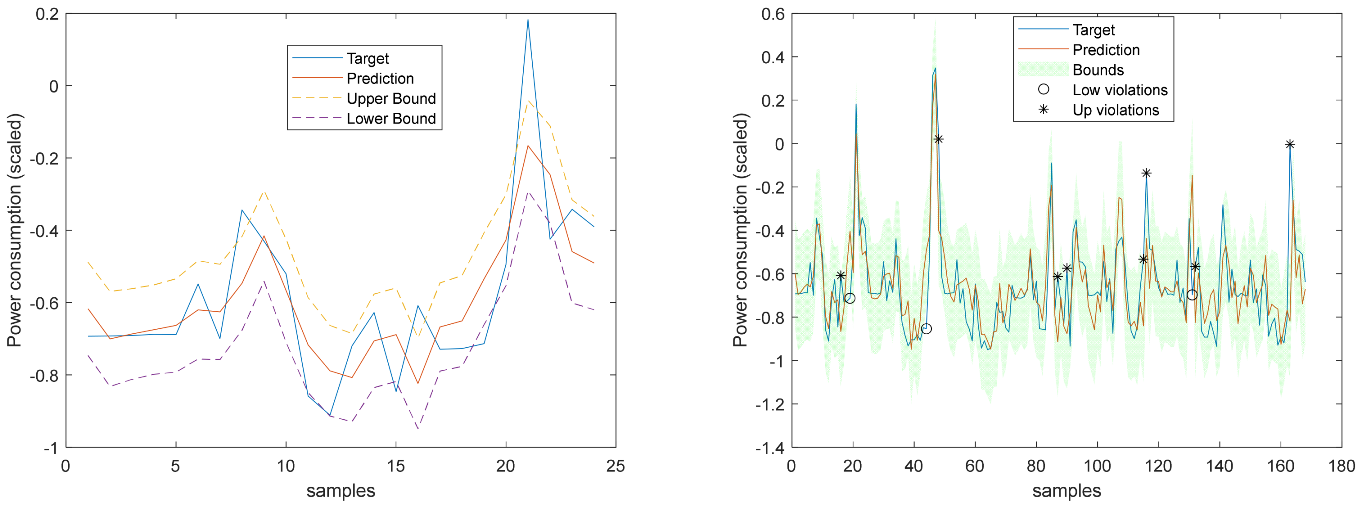
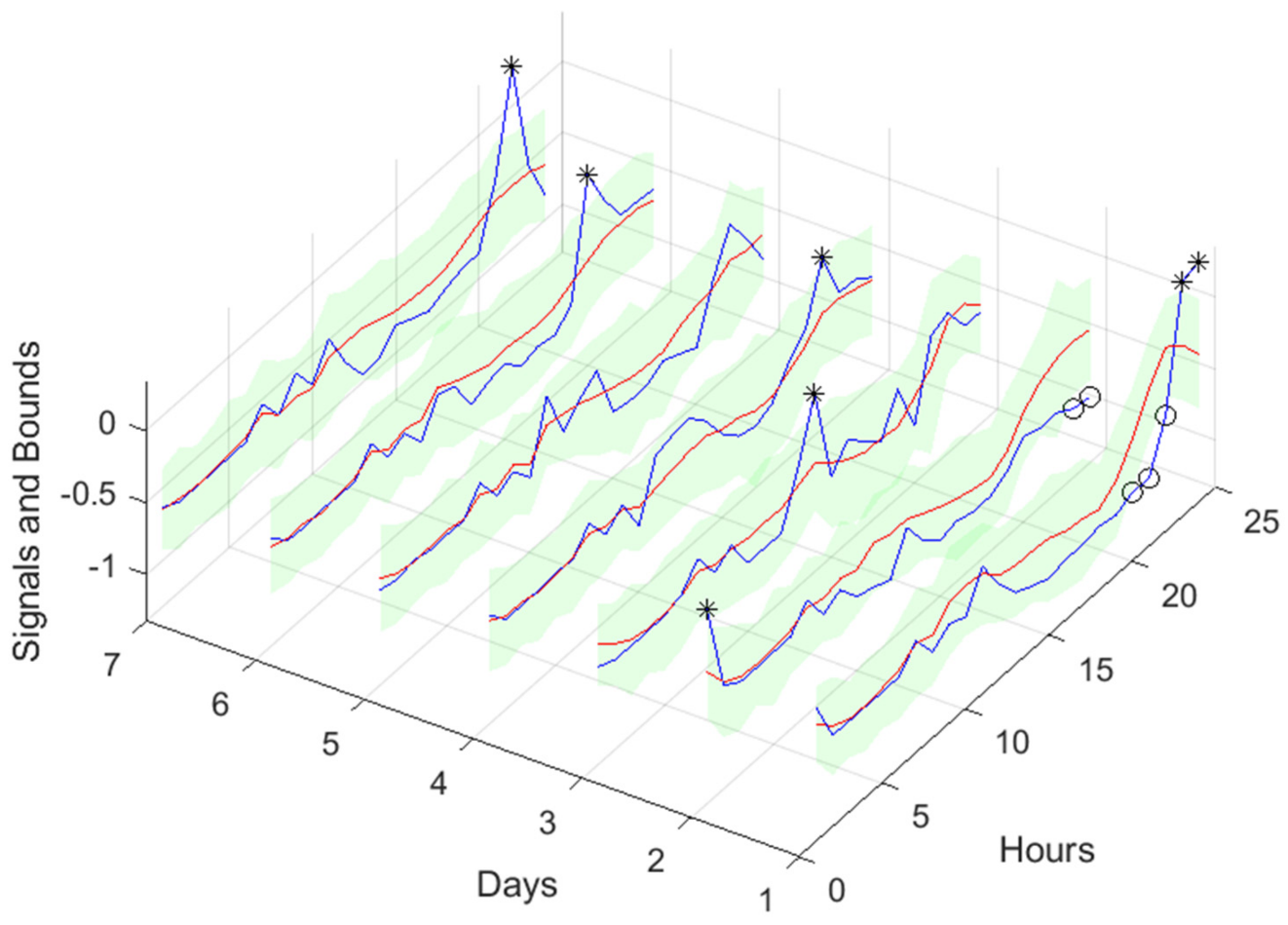
Figure 41.
Community Load Demand 1-step-ahead. Left: One Day; Right: All days in the prediction time series.
Figure 41.
Community Load Demand 1-step-ahead. Left: One Day; Right: All days in the prediction time series.
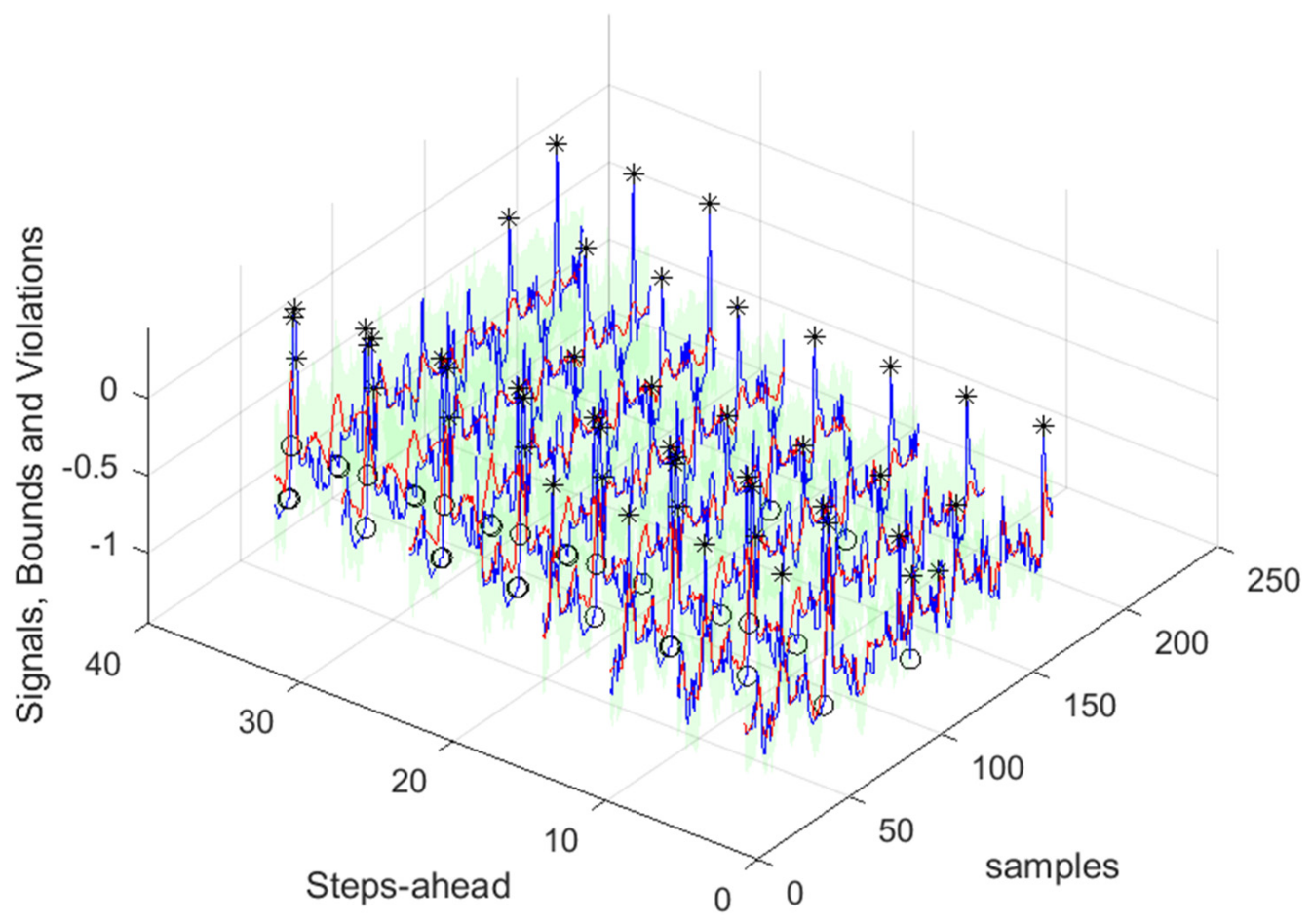
Figure 42.
Community Load Demand [1, 5, 11, …, 36]-steps-ahead.
Figure 42.
Community Load Demand [1, 5, 11, …, 36]-steps-ahead.
Figure 43.
Community Load Demand next-day forecast, with measured data until 12 h the day before.
Figure 43.
Community Load Demand next-day forecast, with measured data until 12 h the day before.
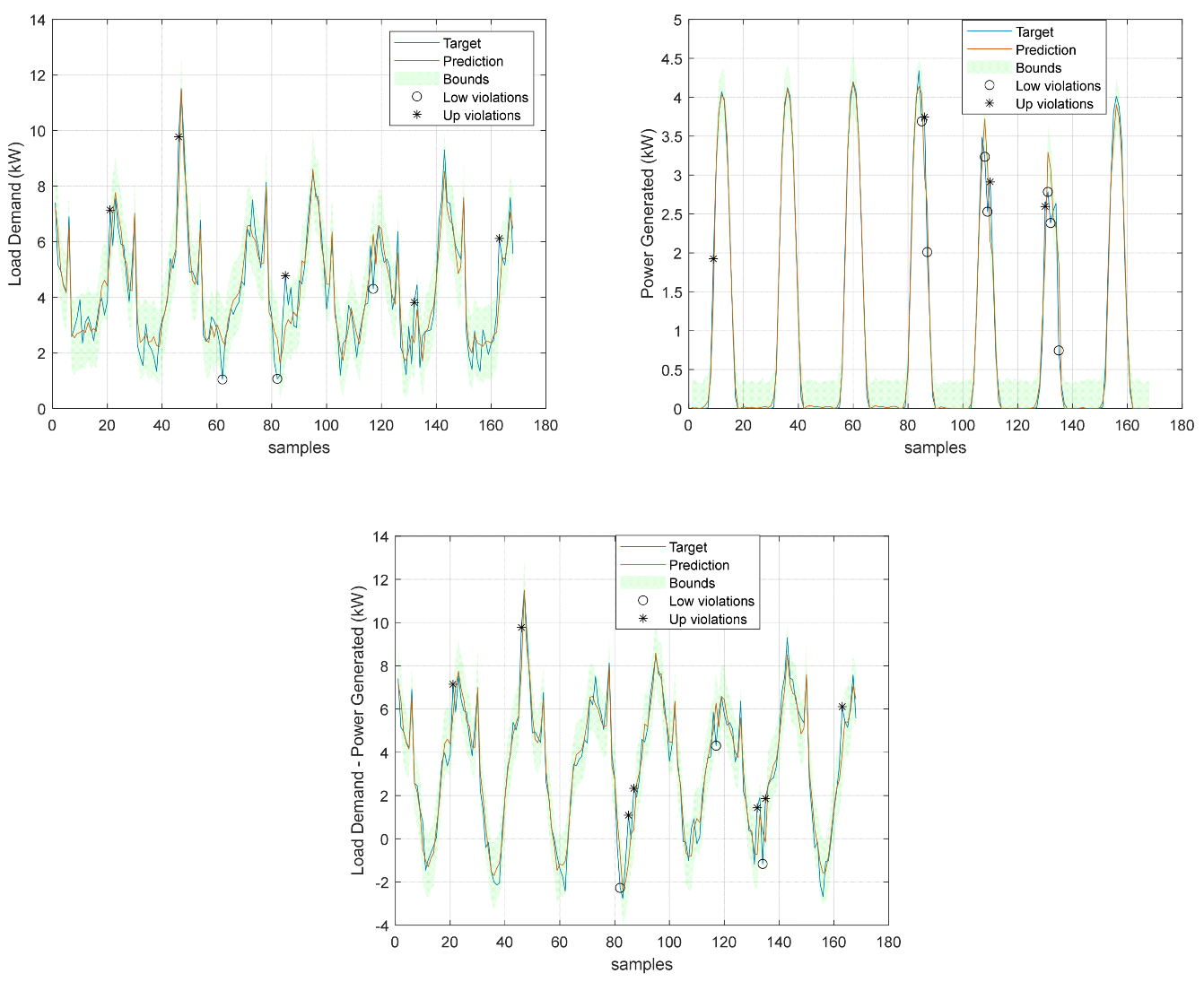
Figure 44.
Community Load Demand, Power Generated, and Net Load Demand 1 step ahead of forecast.
Figure 44.
Community Load Demand, Power Generated, and Net Load Demand 1 step ahead of forecast.
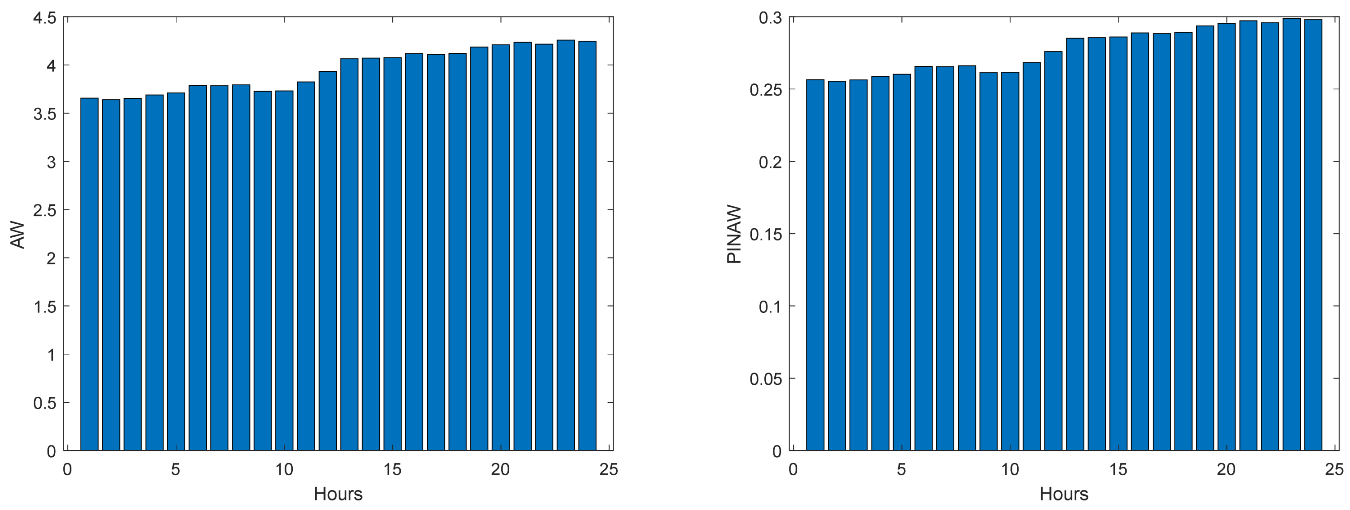
Figure 45.
Community Net Demand AW (left) and PINAW (right) evolutions.
Figure 45.
Community Net Demand AW (left) and PINAW (right) evolutions.
Figure 46.
Community Net Demand PINRW (left) and PINAD (right) evolutions.
Figure 46.
Community Net Demand PINRW (left) and PINAD (right) evolutions.
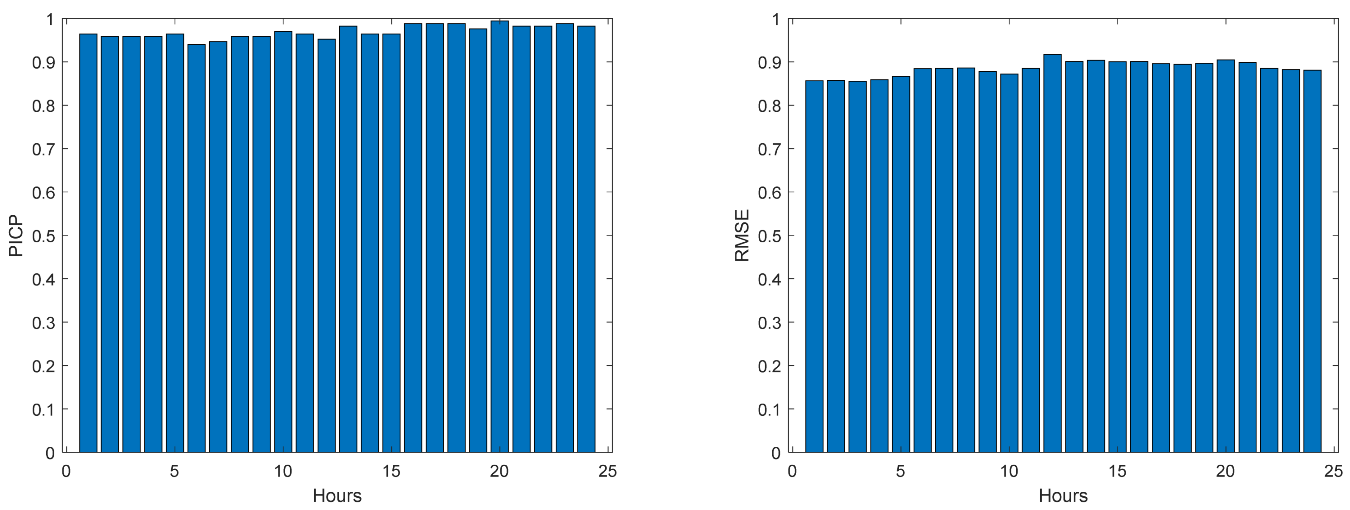
Figure 47.
Community Net Demand PICP (left) and RMSE (right) evolutions.
Figure 47.
Community Net Demand PICP (left) and RMSE (right) evolutions.
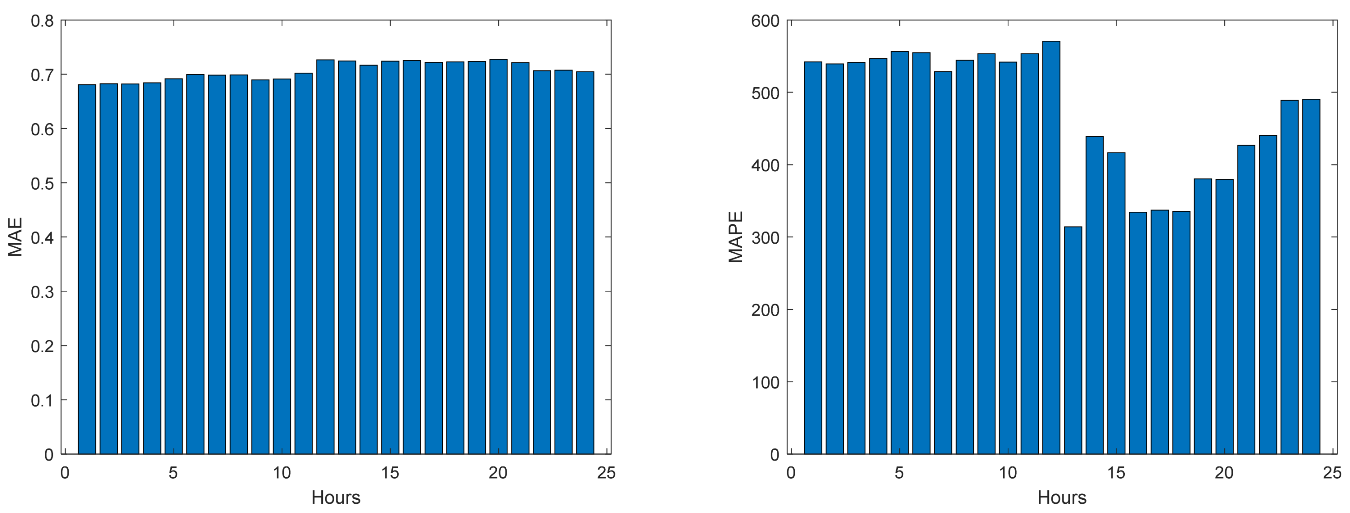
Figure 48.
Community Net Demand MAE (left) and MAPE (right) evolutions.
Figure 48.
Community Net Demand MAE (left) and MAPE (right) evolutions.
Figure 49.
Community Net Demand R2 evolution.
Figure 49.
Community Net Demand R2 evolution.
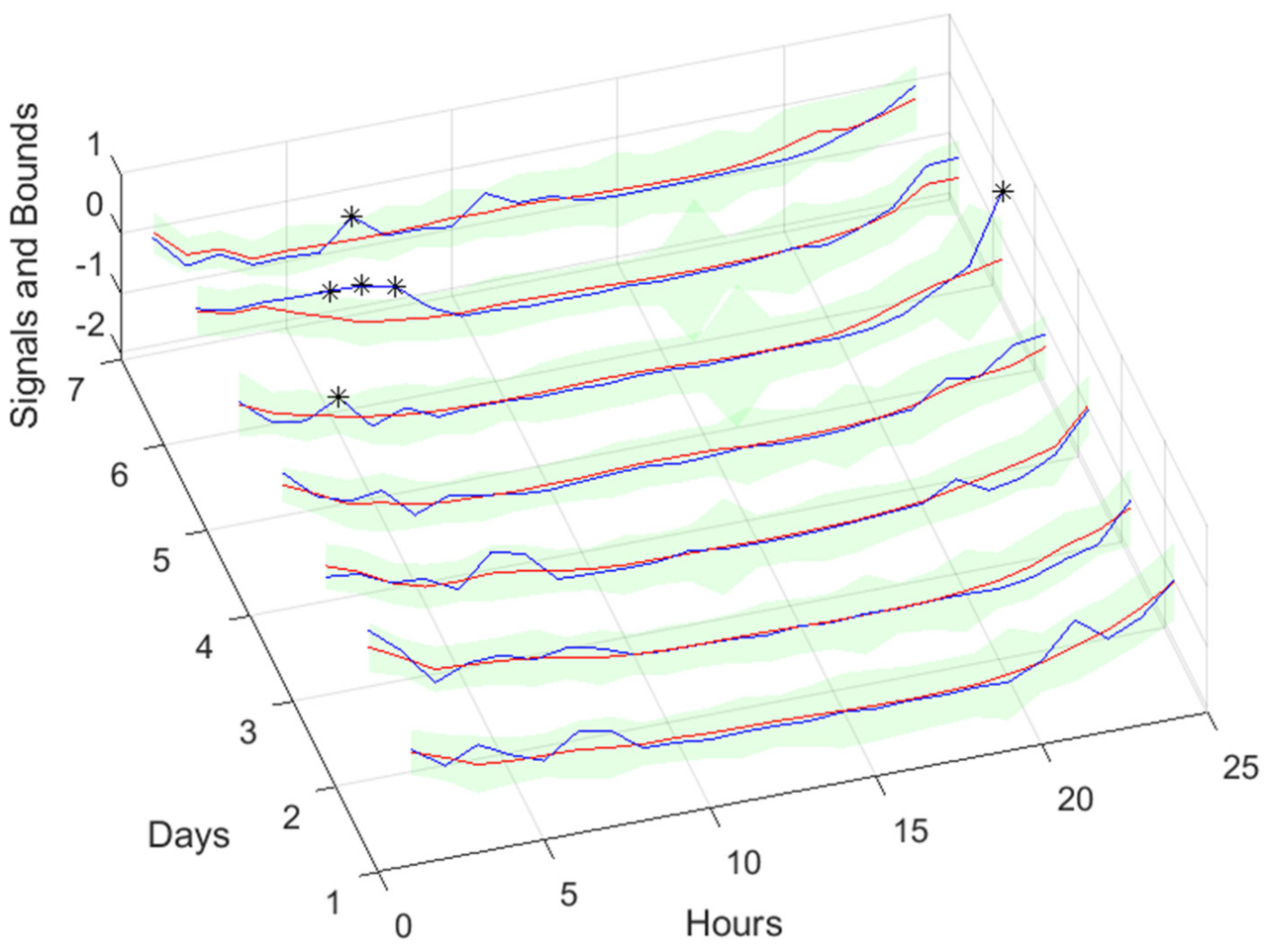
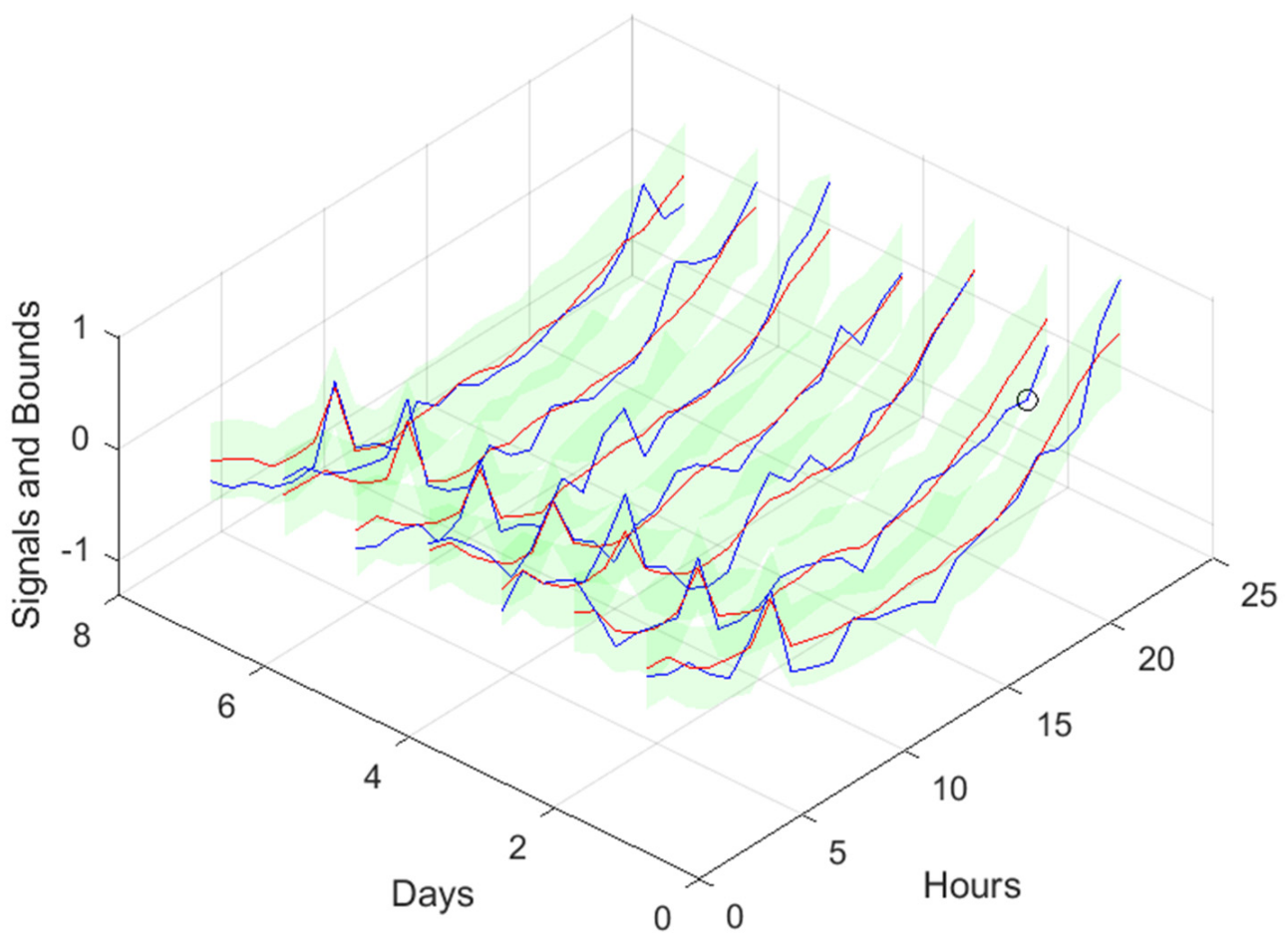
Figure 50.
Community Net Demand [1, 4, 8, …, 24] hours in the day-ahead.
Figure 50.
Community Net Demand [1, 4, 8, …, 24] hours in the day-ahead.
Figure 51.
Community Net Demand next-day forecast, with measured data until 12 h the day before.
Figure 51.
Community Net Demand next-day forecast, with measured data until 12 h the day before.
Table 1.
Solar Radiation Ensemble Model statistics.
Table 1.
Solar Radiation Ensemble Model statistics.
| | | | | | | | |
|---|
| 0.30 | 0.26 | 0.73 | 0.02 | 0.92 | 0.08 | 0.04 | 74 | 0.96 |
Table 2.
Atmospheric Air Temperature Ensemble Model statistics.
Table 2.
Atmospheric Air Temperature Ensemble Model statistics.
| | | | | | | | |
|---|
| 0.42 | 0.41 | 1.21 | 0.04 | 0.91 | 0.12 | 0.08 | 142.36 | 0.77 |
Table 3.
Power Generation Ensemble Model statistics.
Table 3.
Power Generation Ensemble Model statistics.
| | | | | | | | | |
|---|
| 0.36 | 0.23 | 0.66 | 0.01 | 0.94 | 0.08 | 0.04 | 2.64 | 54.32 | 0.97 |
Table 4.
Monophasic House 1 Load Demand Ensemble Model statistics.
Table 4.
Monophasic House 1 Load Demand Ensemble Model statistics.
| | | | | | | | |
|---|
| 1.22 | 0.67 | 1.33 | 0.003 | 0.96 | 0.26 | 0.21 | 233.30 | 0.70 |
Table 5.
Monophasic House 2 Load Demand Ensemble Model statistics.
Table 5.
Monophasic House 2 Load Demand Ensemble Model statistics.
| | | | | | | | |
|---|
| 0.72 | 0.37 | 1.32 | 0.02 | 0.94 | 0.18 | 0.14 | 140.26 | 0.86 |
Table 6.
Triphasic House 1 Load Demand Ensemble Model statistics.
Table 6.
Triphasic House 1 Load Demand Ensemble Model statistics.
| | | | | | | | |
|---|
| 0.71 | 0.54 | 1.17 | 0.02 | 0.94 | 0.17 | 0.12 | 150.62 | 0.39 |
Table 7.
Triphasic House 2 Load Demand Ensemble Model statistics.
Table 7.
Triphasic House 2 Load Demand Ensemble Model statistics.
| | | | | | | | |
|---|
| 0.87 | 0.44 | 0.99 | 0.003 | 0.96 | 0.17 | 0.12 | 99.95 | 0.77 |
Table 8.
Community Load Demand Ensemble Model statistics.
Table 8.
Community Load Demand Ensemble Model statistics.
| | | | | | | | |
|---|
| 0.87 | 0.44 | 0.99 | 0.003 | 0.96 | 0.15 | 0.11 | 85.01 | 0.84 |
Table 9.
Community Load Demand Ensemble Model statistics.
Table 9.
Community Load Demand Ensemble Model statistics.
| | | | | | | | |
|---|
| 0.60 | 0.31 | 0.86 | 0.01 | 0.96 | 0.15 | 0.12 | 87.77 | 0.84 |
Table 10.
Net Load Demand Ensemble Model statistics (original scale, 13–36 steps ahead).
Table 10.
Net Load Demand Ensemble Model statistics (original scale, 13–36 steps ahead).
| | | | | | | | |
|---|
| 3.95 | 0.28 | 4.07 | 0.0004 | 0.97 | 0.89 | 0.71 | 473.17 | 0.91 |










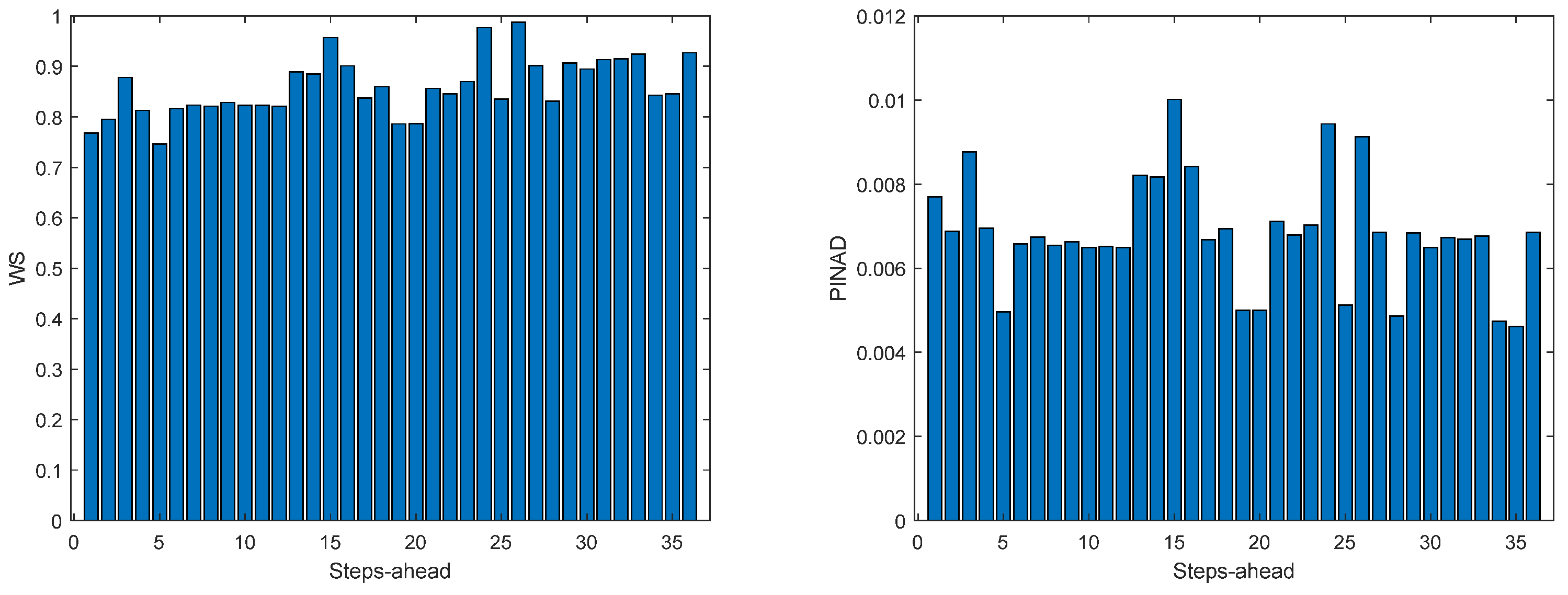















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}