1. Introduction
In recent years, global ecological and environmental issues have gained growing prominence on the international stage, prompting discussions about implementing energy conservation, emission reduction measures, and goals for ecological preservation. The severity of climate conditions has emerged as one of the major challenges facing the world today, largely driven by the worsening environmental issues caused by the greenhouse effect, which poses a significant threat to human living conditions and safety. The building sector is responsible for more than 33% of global energy consumption [
1] and, in China, energy consumption in the construction industry accounts for approximately 36% of the total consumption [
2]. As a result, the construction industry must prioritize energy-efficient and emission-reducing designs. Zero energy buildings are defined as structures that achieve high-performance standards while significantly reducing energy consumption [
3]. Compared to traditional buildings, they offer substantial advantages in terms of energy efficiency and the use of renewable energy sources, leading to energy savings ranging from 60% to 75% [
4,
5]. Zero energy building projects are not only suitable for research on energy conservation and emission reduction in various climate zones but also for a range of building types, including residential, public, and community structures. Moreover, zero energy buildings not only improve building performance but also place a strong emphasis on continuous research and the optimization of comfort for living. Thanks to the benefits of energy conservation and emission reduction, coupled with advancements in construction and renovation techniques and the support of zero energy building research from policies in various countries, these buildings are rapidly gaining global acceptance, resulting in a significant increase in the number of projects. The advantages of zero energy buildings, in the realms of energy conservation and emission reduction, present both opportunities and challenges for building design.
The design strategy for zero energy buildings has evolved into a hybrid approach that combines passive and active techniques [
6,
7]. Specifically, in the realm of passive design, numerous researchers have conducted comprehensive studies, addressing applications under various climate conditions [
8], quantifying the energy implications of passive design [
9,
10], and exploring economic [
11] aspects.
Researchers have extensively explored various passive design methods aimed at reducing the energy consumption of buildings. To begin, the feedback design method based on regulatory standards represents the most conventional approach in traditional design thinking. This method entails designing within established energy efficiency frameworks, with the goal of meeting the design’s adaptable requirements while ensuring compliance with the energy-saving standards specified in regulations [
12]. However, regulation-based design primarily addresses basic requirements and, as a result, has limitations in fostering innovation in building design and enhancing energy efficiency. It often falls short in fully considering the unique characteristics of the building and specific climate conditions. Secondly, the feedback design method based on performance simulation leverages software simulations to gather feedback information related to building performance, including energy consumption and comfort [
13,
14]. Designers can make adjustments to design plans and related data based on simulation results, thereby achieving improved performance. Thirdly, the optimization design method based on intelligent algorithms [
15], while holding significant potential for application, places high demands on model establishment and requires the use of various tools. This is particularly notable when dealing with more detailed and multi-objective designs, as it leads to extended computation and feedback times.
In contrast to the methods mentioned earlier, supervised learning aims to build a concise model that generates class label distributions based on predictor features [
16,
17]. This approach depends on data for modeling and training, enabling the swift creation of multiple design concepts in the initial stages of architectural design, with subsequent ranking based on performance metrics. Supervised learning methods are grounded in real observed data rather than theoretical specifications, allowing for early predictions of building performance and enhancing the efficiency of design decisions [
18]. Furthermore, these methods exhibit significant flexibility, adapting to evolving design requirements and performance criteria. They can accommodate new objectives and constraints to meet the constantly changing demands of design.
Decision trees represent a supervised learning method and, as a data-driven modeling technique, have found extensive use in fields such as artificial intelligence, gaming, and finance for classification and prediction [
19,
20,
21]. In the realm of architecture, decision trees prove effective in addressing complex issues related to architectural design and management, with a particular strength in predicting building energy usage to enhance intelligent building performance. Khosravi and colleagues employed decision trees and other regression models to forecast the primary fuel consumption, electricity usage, and cost savings of buildings by scrutinizing the factors influencing building costs and energy consumption. Furthermore, they optimized the decision tree algorithm through metaheuristic methods, thereby improving its predictive accuracy and identifying the most practical features for specific building objectives [
22]. Decision trees automatically generate a tree-like structure based on the features and conditions of input data. Each node in this structure represents a decision point, while each branch signifies different decision options. This structure offers a high level of interpretability, enabling architects, engineers, and decision-makers to gain a clear understanding of the decision-making process and the underlying rationales for each decision [
23].
In comparison to performance simulation methods, decision trees demonstrate superior computational efficiency. Traditional performance simulations typically involve running numerical models to simulate a building’s energy usage and indoor environment, consuming significant computational resources and time. Conversely, decision tree models are constructed and trained based on existing data, enabling the rapid generation of building performance predictions and resulting in substantial savings of computational resources and time. Mariano-Hernandez and other researchers analyzed a range of methods designed to help decision tree models better accommodate variations in building behavior, serving as tools for enhancing building energy efficiency. Research findings indicate that the continuous retraining of decision tree models and the integration of change detection methods contribute to improving the model’s capacity to adapt to variations in overall building electricity consumption [
24]. In their efforts to enhance the sustainability of renovations, Vytautas Martinaitis and his team chose energy efficiency assessment criteria that align with a sustainable approach. They defined and analyzed five key standards, encompassing energy efficiency, environmental impact, economic feasibility, comfort, and sustainability over the lifecycle. To allocate energy efficiency measures into basic and additional energy-efficient measures, they developed a sequential priority and allocation decision tree. The outcomes showed that all data packages generated through this distribution decision tree had higher overall sustainability standard values and smaller value spreads (with only a 12% difference), thereby enhancing decision efficiency [
25]. Hosseini and his team utilized a univariate regression algorithm to forecast the factors that impact building energy consumption and determine the most influential factors. This algorithm pinpointed the factors with the greatest impact on building energy consumption and quantified their effects. The research results indicated that a building’s overall height, roof area, surface area, and relative compactness have the most pronounced impact on its energy consumption. The prediction errors for cooling load and heating load were 1.128% and 0.404%, respectively [
26]. Smarra and his team introduced a novel predictive control method based on machine learning algorithms, including decision trees and random forests. They named this approach Data-Based Predictive Control (DPC) and applied it in three distinct case studies. The results from these case studies revealed that the DPC method had an average error of just 3% and could improve energy efficiency by as much as 49.2%, clearly demonstrating the effectiveness and efficiency of the DPC method [
27].
The decision tree model exhibits a broad range of applicability, making it suitable for diverse building projects, ranging from residential to commercial, and from small individual structures to large building complexes. In order to uncover hidden factors, a novel approach that combines linear and nonlinear models, specifically Multiple Linear Regression (MLR) and Decision Trees (DT), has been introduced. You-Jeong Kim and a team of researchers utilized energy consumption and feature data from 71 apartment units in Seoul, South Korea. They applied MLR and DT models to identify building, system, and occupant characteristics that significantly influence energy consumption for various end uses. The research findings indicate that both models share common determinants, while specific factors, such as the year of the building permit and the performance coefficient of air conditioners, are unique to the decision tree model. These results suggest that, when conducting a comprehensive analysis of relationships and interactions between variables, it is advisable to employ a nonlinear model, such as DT, rather than relying solely on linear models [
28]. Another study proposed by Rasiulis and others aimed to select the optimal combination of modernization measures for public buildings, using a decision tree model as an effective tool to facilitate big data analysis. The research findings indicate that the proposed algorithm is highly suitable for evaluating modernization decisions for buildings, assisting decision-makers in choosing alternative solutions with the best performance in terms of energy consumption, installation costs, and other relevant criteria [
29]. Furthermore, there is also related research concerning building energy consumption and carbon emissions. In one study, they introduced a novel benchmarking approach to evaluate emissions and cost performance across an entire portfolio, enabling building managers to identify underperforming locations. This research, which considered multi-level and detailed variable selection, including weather characteristics and various regression techniques like MLR, Artificial Neural Networks (ANN), and DT, successfully categorized building cases with varying carbon emission scenarios, demonstrating both high precision and discrimination [
30]. Another study proposed a decision support model for selecting one-way slab design parameters. This study aimed to find environmentally friendly and cost-effective solutions while considering the regulatory standards, materials, and manufacturing processes commonly used in Spain. To achieve this, they established decision criteria based on the implicit carbon dioxide emissions and the overall cost of one-way slabs. Three decision trees were developed in the study to formulate practical guidelines for making design decisions for one-way slabs. The final Spanish case study demonstrated the feasibility of reducing implicit carbon dioxide emissions by nearly 2% with an increase in cost of less than 2% [
31].
Furthermore, in comparison to other machine learning methods more widely used in the field of zero-energy building research, decision tree methods offer certain advantages. In contrast to artificial neural network methods [
32,
33], decision tree methods possess high interpretability, and the visual model is simple, intuitive, and easy to understand. Compared to the K-nearest neighbors algorithm [
34], the training and prediction processes of decision trees are typically efficient, especially for small to medium-sized datasets. When compared to support vector machine methods [
35], decision trees can handle nonlinear relationships, whereas support vector machines often require the use of kernel functions for mapping when dealing with nonlinear problems, adding complexity to the model.
Decision trees offer unique advantages in solving multi-objective optimization problems. They have the capacity to simultaneously consider multiple decision variables and objective functions, thereby assisting decision makers in striking a balance among various objectives. Decision trees can provide comprehensive recommendations for optimizing multi-objective building designs. However, the application of decision trees in the field of architecture is primarily focused on areas such as building energy management [
36], operations and maintenance [
37], building code assessments [
38], sociological analyses of buildings [
39], and government recommendations [
40]. Researchers in these areas typically play a primary role in building management and operations rather than in building design. Moreover, in specific studies related to buildings, most researchers tend to concentrate on exploring the influence of HVAC systems on building energy performance [
41], with only a limited number delving into passive design methods for buildings.
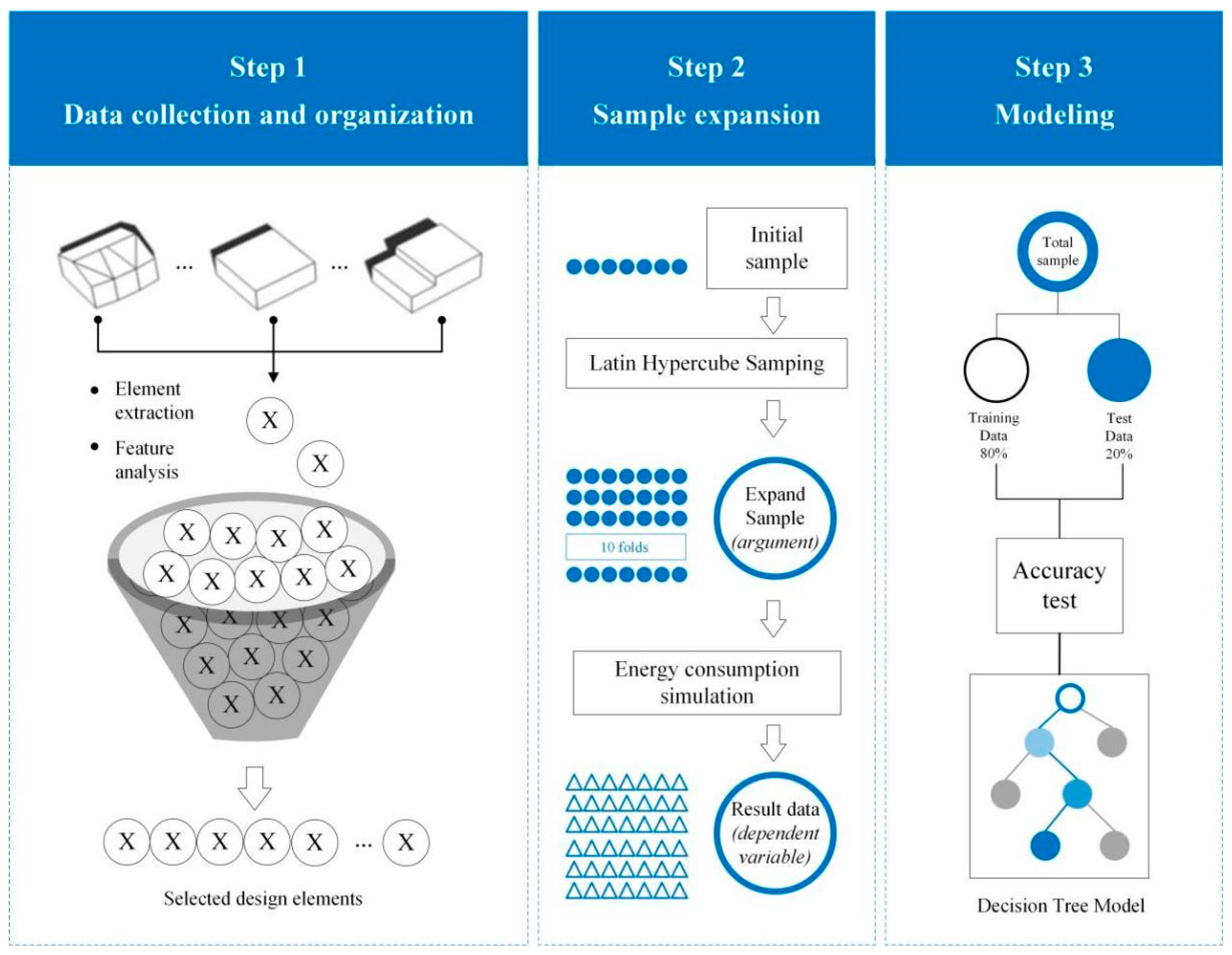
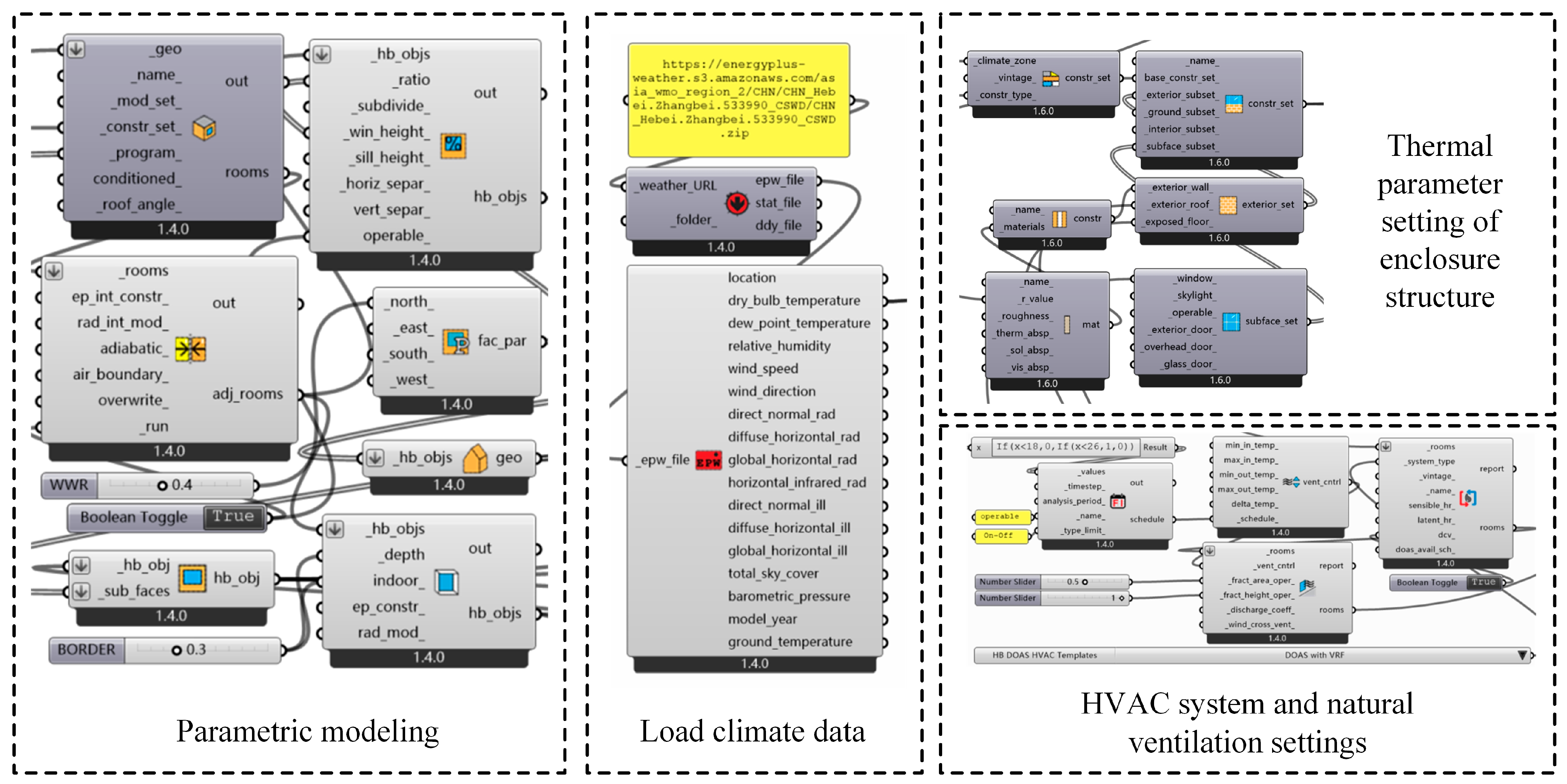
Therefore, considering the knowledge gap in the field of passive design for zero energy houses, and the deficiencies in data quantification and preliminary results prediction, this study introduces a novel framework termed “Case Induction—Sample Expansion—Performance Simulation—Decision Tree Model”. Within this framework, the initial step involves the preliminary induction of collected building cases through data analysis techniques to clarify relevant parameters and data features associated with passive design. Subsequently, sample expansion, based on data features and energy simulations, is conducted using the Latin Hypercube sampling method. To enhance the interpretability and predictability of passive design parameters, the Classification and Regression Trees (CART) model is employed as the predictive model to identify the relationship between building energy flexibility and design parameters. This, in turn, contributes to a better understanding of how buildings respond to changes in operational conditions when energy consumption is the objective, such as alterations in energy-efficient design strategies. The objective of this framework is to select more reliable ranges of passive design parameters and design combinations, thereby guiding the optimization of parameters for zero energy house design.
Furthermore, it is worth mentioning that this study serves as a method framework study. In the subsequent stages, we will consider extensively applying this framework in designs and expanding the research using the analysis of variance method [
42].
The innovation in this study can be summarized as follows: (1) it introduces an effective reference framework for the passive design of zero energy houses, providing guidance for designs in the region; (2) it combines performance simulation and decision tree methods to investigate the interactions between building energy consumption and three-dimensional building parameters, as well as variables related to the thermal transmission coefficient of the building envelope, thus enhancing the interpretability of the framework.
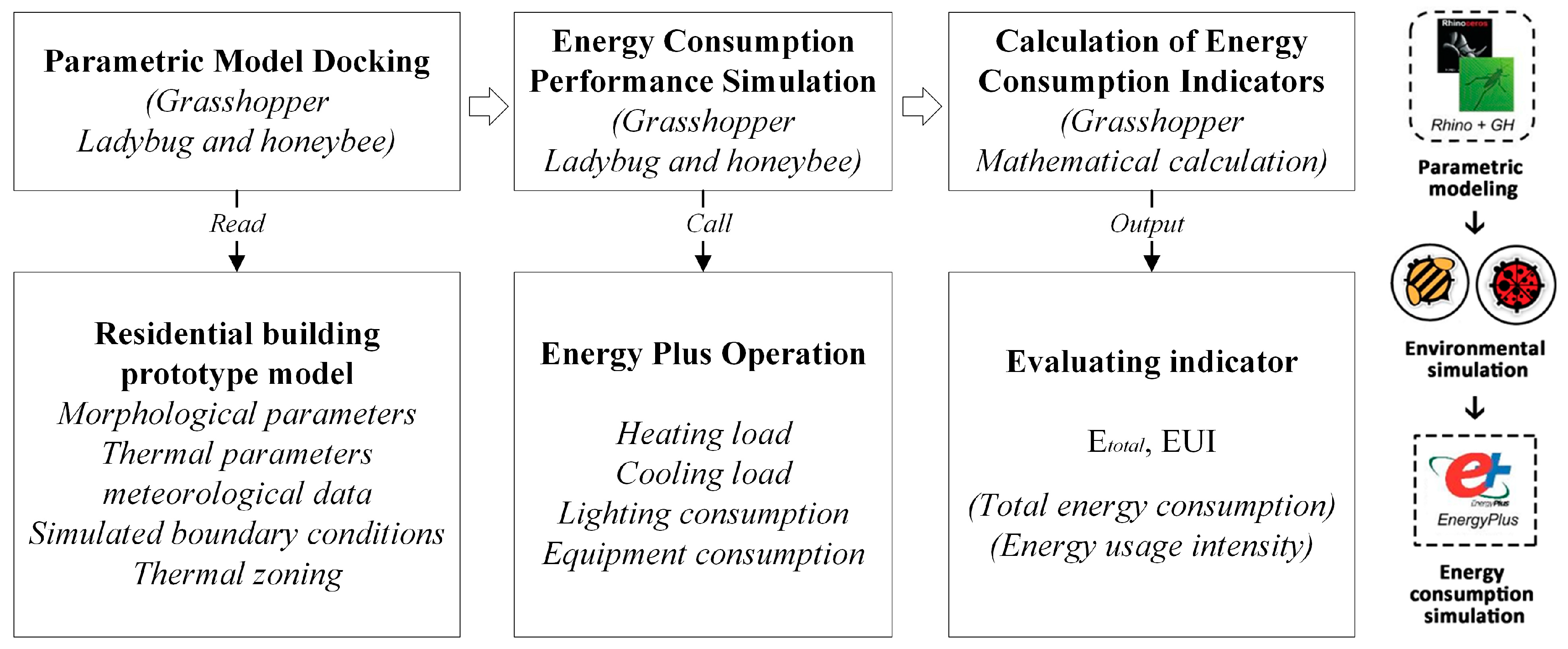
4. Analysis and Results
4.1. Target Variable
To demonstrate the energy performance of the buildings, the model’s target variable is represented as Energy Use Intensity (EUI), defined as the ratio of annual total energy consumption to the total building area. Therefore, before classification and prediction, a hierarchical structure for constructing EUI is established. Due to the relatively small size of the database, two descending levels, namely high-level and low-level, corresponding to low energy consumption and high energy consumption, are considered suitable and meaningful. Based on the performance simulation statistics of the expanded samples, building EUI falls within the range of 45–55 kWh/m2 for low and 55–65 kWh/m2 for high.
The energy consumption formula and EUI formula are as follows:
where
ETOTAL represents the annual total energy consumption of the building, measured in kWh;
EHEAT stands for heating energy consumption, measured in kWh;
ECOOL represents cooling energy consumption, measured in kWh;
ELIGHT indicates lighting energy consumption, measured in kWh; and
EQUIP denotes equipment energy consumption, measured in kWh.
where EUI represents the building energy use intensity (kWh/m
2); The
ETOTAL represents the total building energy consumption (kWh); and
A stands for the building area (m
2).
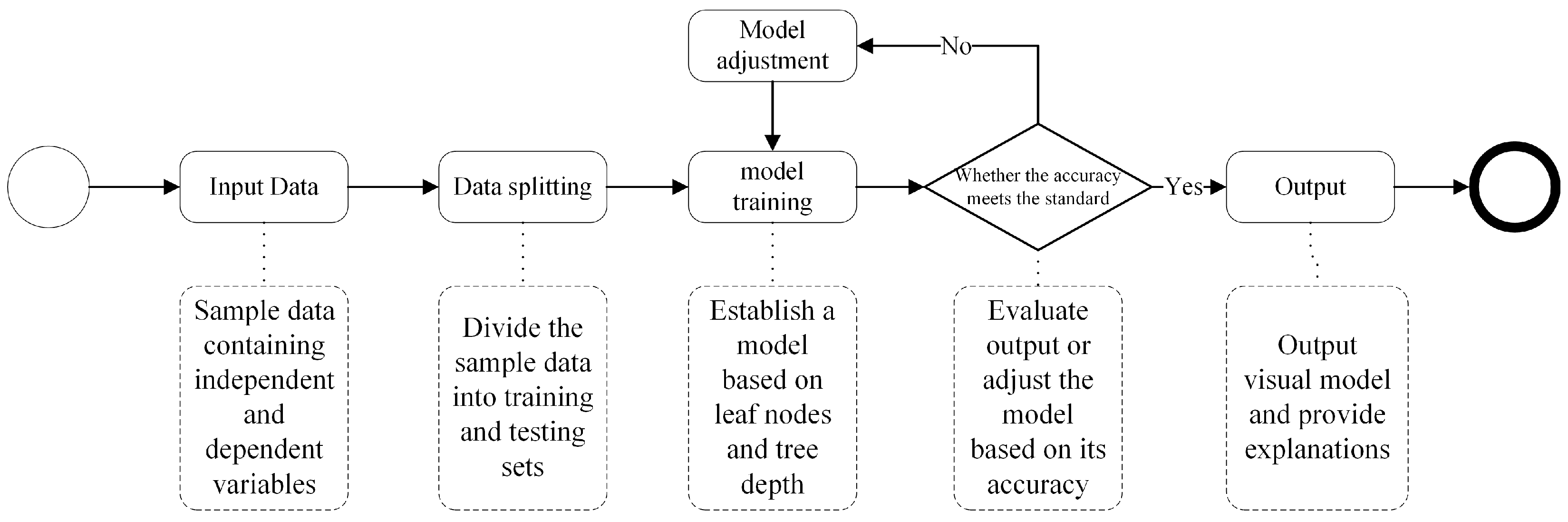
4.2. Development of Decision Tree Model
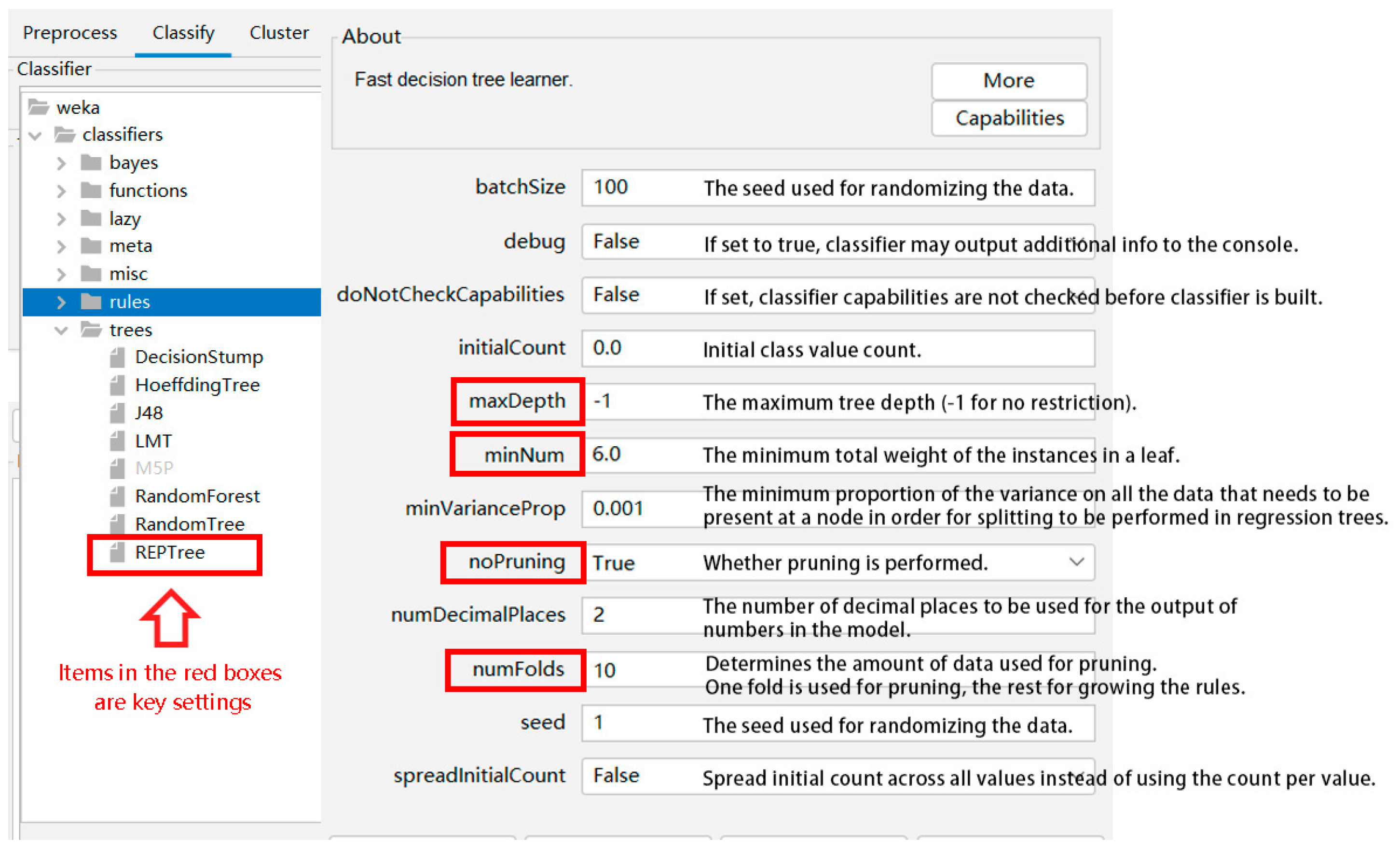
During the development of the decision tree model, two crucial aspects are the division of the training set ratio and the setting of decision tree parameters. The division of the training set ratio applied the most common proportion, with 80% assigned to the training set and 20% to the testing set. REPtree is chosen as the classifier, and four key parameters are set:
- (1)
maxDepth: This determines the maximum depth of the decision tree. By default, it is −1, meaning the algorithm will automatically control the depth.
- (2)
noPruning: Pruning automatically trims leaf nodes that do not contain much information, making the decision tree simpler and more understandable.
- (3)
numFolds: This specifies the data multiplier to be used for pruning the decision tree. The remainder will be used to formulate rules.
- (4)
minNum: The minimum number of instances for each leaf. If not specified, the tree will continue to split until all leaf nodes have only one associated class.
By setting and adjusting the above parameters, the decision tree model is pruned and standardized until satisfactory results are achieved. In this study, the final settings, after multiple adjustments, are presented in
Figure 10.
4.3. Decision Tree Results and Model Interpretation
Through pruning and adjustments, each decision tree model for EUI associated with the secondary elements exhibits an accuracy level of approximately 70%, signifying a suboptimal model performance (
Table 3,
Table 4,
Table 5 and
Table 6). This outcome implies that the consideration scope for each secondary element is not comprehensive enough to establish a more precise model. Nevertheless, these models still offer some valuable reference and can aid in local element design decisions.
Based on the analysis, if design decisions solely revolve around form elements within passive design, it is advisable, in this region, to prioritize the impact of roof form, plan form, functional structure, and frame form on building energy consumption in order of their significance. Concerning the geometric parameters, adjustments should be made in the sequence of length, height, and width. Given the high-latitude location of the area, modifying a building’s length and height proves beneficial in reducing the impact of its shape on energy consumption and maximizing solar radiation utilization. Interestingly, concerning building envelope parameters, the external wall garners the lowest score in the importance ranking. Moreover, in the context of window-to-wall ratio parameters, the south-facing window-to-wall ratio is less significant than its west-facing counterpart. This result may be attributed to regional characteristics.
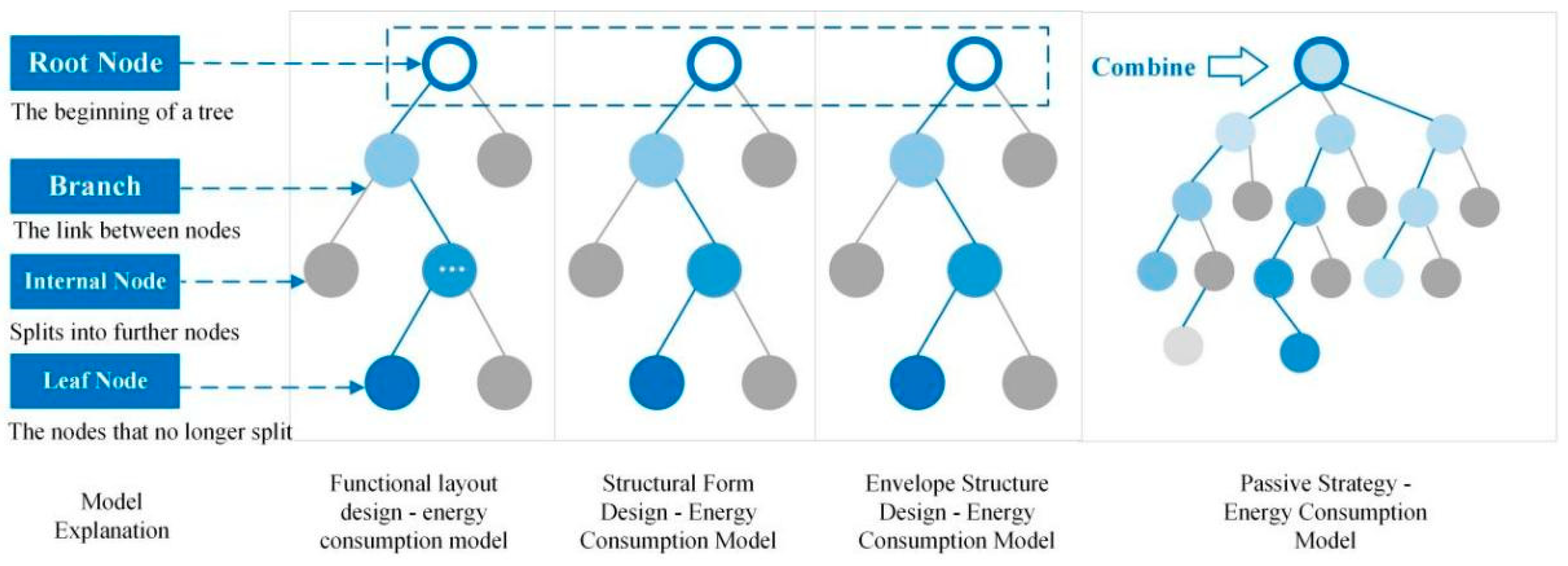
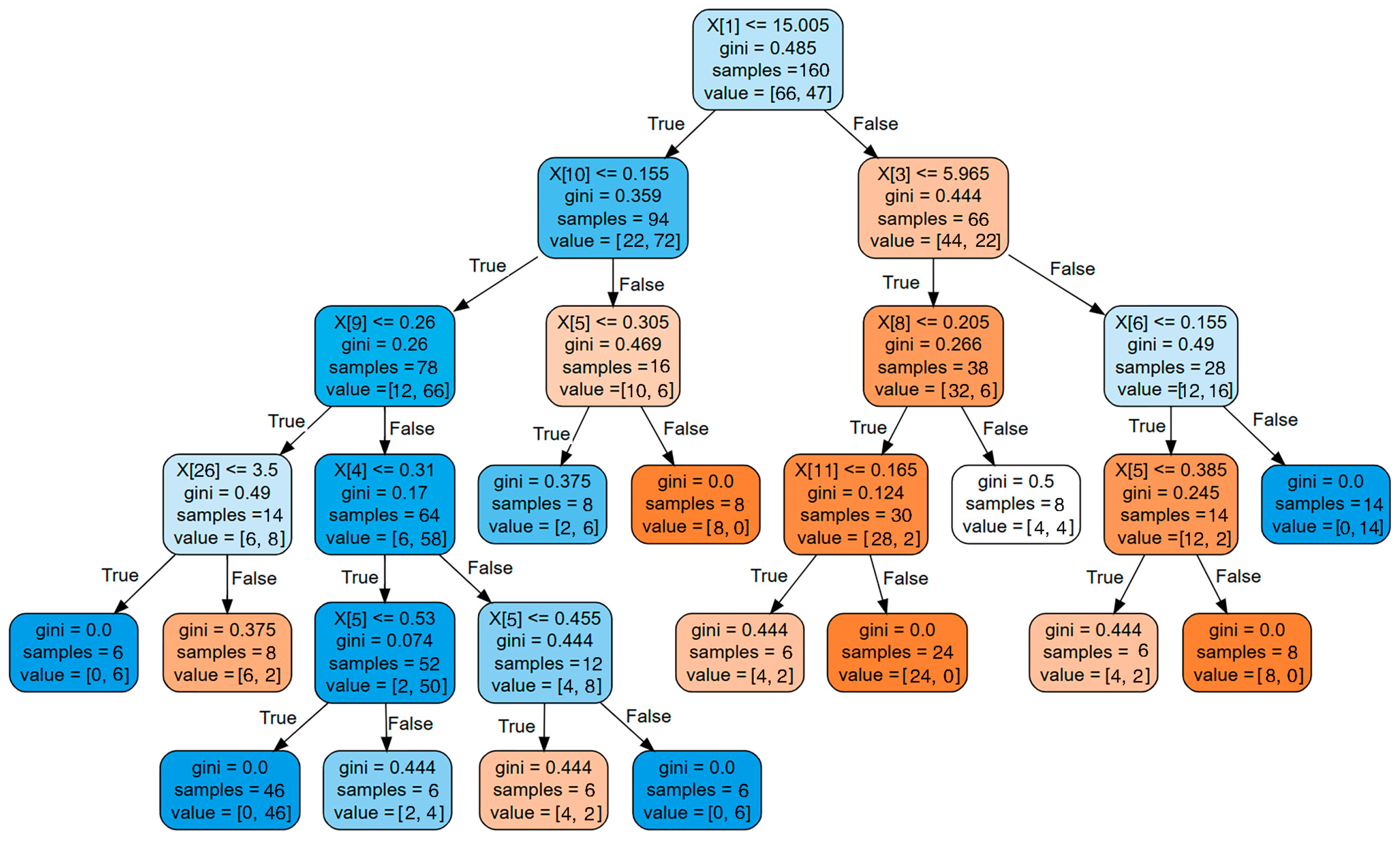
The decision tree for classifying building EUI levels is presented in
Figure 11. This decision tree was constructed based on a training dataset that includes 200 data records, incorporating the 15 attributes from
Table 2. The decision tree comprises a total of 27 nodes, including 14 leaf nodes. Each node provides information such as its node number, the number of samples it contains, and details regarding the classification outcome (EUI = HIGH or EUI = LOW). In the figure, blue nodes represent EUI = LOW, while orange nodes represent EUI = HIGH. The shade of the node color indicates the purity of the classification outcomes for the samples within that node, reflecting the confidence in its classification strategy. Therefore, this decision tree model includes 14 leaf nodes, with 7 nodes considered as reliable decision criteria.
The primary advantage of decision trees lies in their interpretability and ease of use, particularly in creating decision rules. By utilizing decision trees, decision rules can be easily generated by following the path from the root node to the leaf node. Since each leaf node corresponds to a decision rule, considering all leaf nodes allows us to obtain a complete set of decision rules equivalent to the rules of the entire decision tree. Therefore, we transform the decision tree with the high-purity nodes mentioned above into a set of decision rules, as shown in
Table 7. By employing these rules in passive design, it becomes possible to rapidly predict the initial EUI levels, thereby enhancing design efficiency.
In the actual design process, these seven decision rules can serve as a reference for combining and selecting various passive design strategies. Given the relatively large sample sizes and high data purity associated with these rules, the optimal decision rules for EUI = HIGH and EUI = LOW scenarios are Rule 5 (EUI = HIGH) and Rule 2 (EUI = LOW), respectively. Specifically, for achieving low energy consumption, design decisions should consider the following features: building length less than 15 m, west-facing window-to-wall ratio below 0.155, south-facing window-to-wall ratio above 0.26, external wall heat transfer coefficient below 0.31, and ground heat transfer coefficient above 0.455. Adhering to these design criteria will result in a building falling within the EUI range of 45–55 kWh/m2.
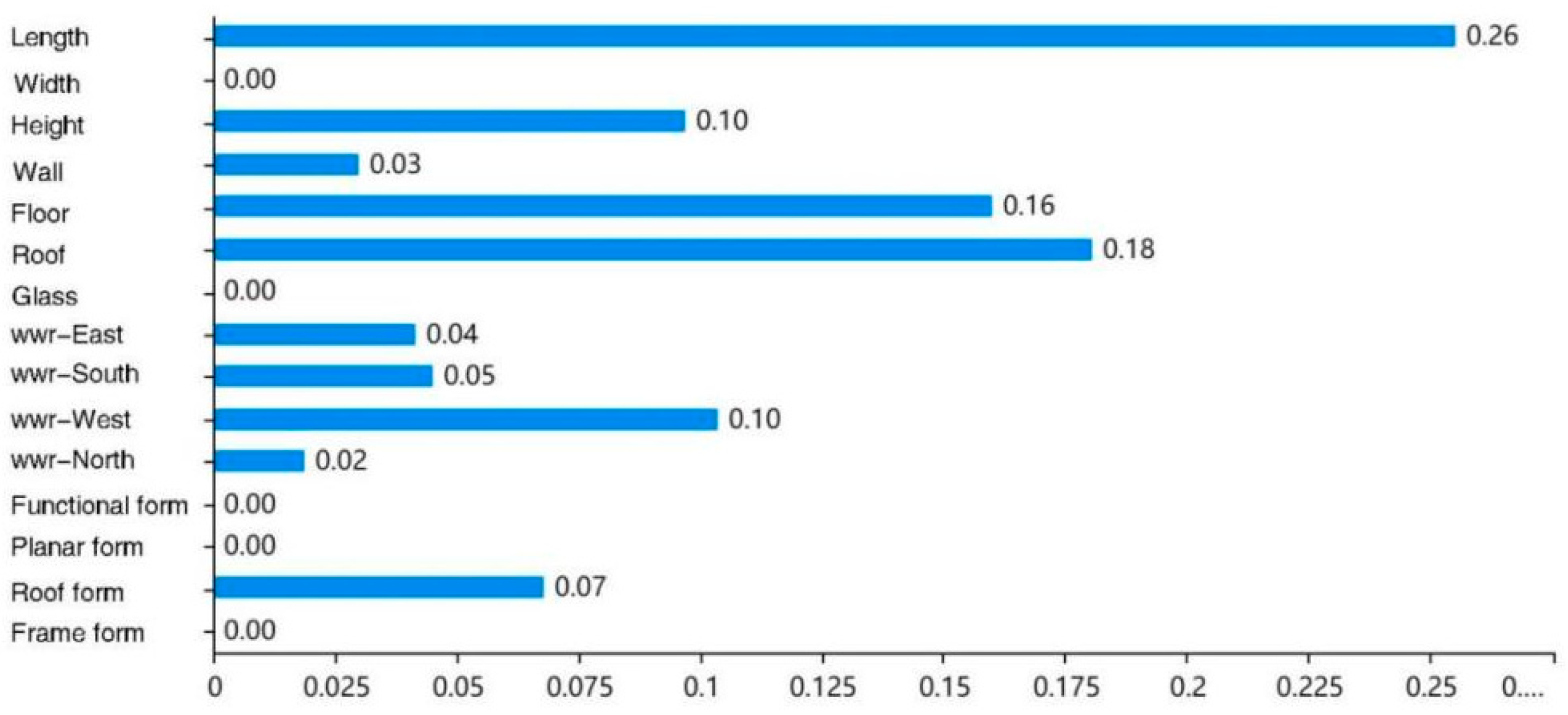
Additionally, this study provides feature importance weights for the global decision tree model (see
Figure 12). Upon analyzing the decision tree model and the weight data, it becomes evident that the feature importance weight chart of the global decision tree model exhibits some differences compared to the feature weight chart obtained from the local decision tree. In the global decision tree model, building length, roof, and ground elements carry the highest weight proportions among all the features, while the weights for building width, glass doors and windows, functional plan, and frames are nearly negligible. This suggests that the data results obtained through supervised learning display variances compared to empirical features. These variances do not diminish the importance of low-weight features but arise from the decision tree analysis, which makes their significance relatively less prominent when combined. Conversely, due to distinct feature combinations, variations exist between local and global analysis results. In practical applications of passive design strategies, energy-efficient design can be guided based on the following weight ranking.
In guiding the design process, it is essential to recognize that architectural design involves a comprehensive regulatory process. This implies that a change in one element may have a cascading effect on other elements. When addressing such influences, decision-making can follow the priority sequence outlined above. Thus, decisions can be made step by step, or alternative solutions can be determined based on the established priorities. For instance, increasing the length of the building footprint, which alters the building’s spatial volume, may necessitate changes in the heat transfer coefficient of the building roof. Material and construction conditions may impose specific requirements on the heat transfer coefficient of the building roof. In such cases, if the design prioritizes energy efficiency, the adjustment of building length should take precedence in decision-making.
According to
Table 8, within the entire sample dataset, the proportion of accurate classifications reaches as high as 93.5%. To visualize the classification performance, a confusion matrix is employed, where the number of correctly classified records is presented along the main diagonal, running from the top-left to the bottom-right. Any incorrect classifications are located outside the main diagonal. Notably, records categorized as “LOW EUI” were misclassified as “HIGH EUI” only seven times, while records belonging to the “HIGH EUI” category were misclassified as “LOW EUI” just six times. These results indicate a higher susceptibility to misclassification for “LOW EUI” compared to “HIGH EUI”. This tendency may be influenced by the predominance of “LOW EUI” samples in the data records, making the decision tree more sensitive to them.
According to the description provided earlier, the accuracy, precision, recall, and
F-Score will be used for assessing the decision tree model, and the evaluation results are presented in
Table 9. Based on the data, it is evident that the evaluation values of the decision tree model consistently exceed 80%, indicating that the model is highly reliable.
The framework proposed in this study, based on decision trees for passive design parameter decisions in zero-energy residences in cold regions, demonstrates more regional specificity compared to feedback design methods based on design specifications. However, due to its focus on only a subset of passive design strategies, the content covered by this method is not comprehensive enough. Additionally, our research framework can optimize the stages of feedback design methods based on performance simulation, enabling rapid preliminary predictions. However, these predictions are limited to simple models, making it relatively challenging to address complex models and intricate issues. In comparison to optimization design methods based on intelligent algorithms, our framework can provide design solutions with guidance more quickly, but its precision is not as high as that achieved by intelligent algorithm optimization. In summary, the method proposed in this study is suitable for making fundamental decisions and designs rapidly in the early stages of scenario design and optimization. However, when dealing with complex models and multi-objective problems, it is still necessary to consider other methods.
5. Conclusions
This study presents an innovative framework that, based on real-world cases, utilizes sample expansion and performance simulation. It employs a CART model for the quantitative analysis of passive design parameters for rural residential buildings in Zhangbei, Zhangjiakou region. The aim is to guide energy-efficient design. This framework can provide effective guidance for architectural design and optimization.
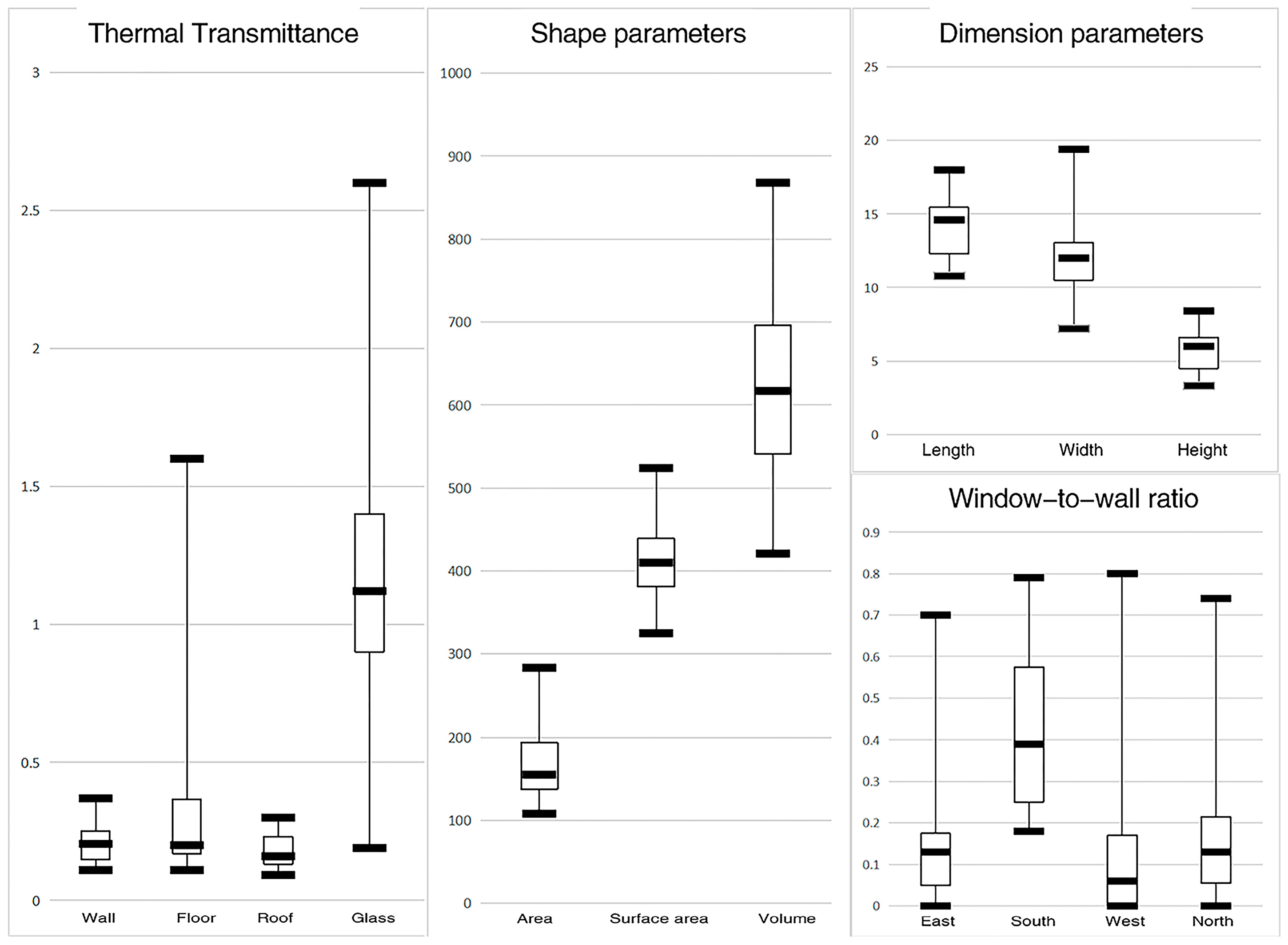
Through a comprehensive analysis, this paper summarizes 15 key passive design elements, encompassing typological and design factors. The study reveals that architectural designs in the Zhangbei area of Zhangjiakou exhibit relatively consistent characteristics. Concerning architectural forms, there is a predominant use of centralized square plans and regular shapes. Roof forms primarily consist of flat roofs and gable roofs, with slopes concentrated around 14–20 degrees and approximately 45 degrees. In terms of the building envelope, materials with relatively high thermal transmittance values are utilized, with values ranging from 0.25 to 0.5. As for window-to-wall ratios, the south-facing window-to-wall ratio is relatively high, falling within the range of 0.3–0.6, while the window-to-wall ratios on the other three facades range from 0.1 to 0.3.
Through the construction of the CART model, this study successfully established a decision tree model with building energy efficiency as the dependent variable, achieving an accuracy rate of 93% and demonstrating excellent interpretability. CART analysis results reveal that building height is the most significant influencing factor for the energy efficiency of rural residential buildings in the Zhangbei area of Zhangjiakou. Therefore, when designing with energy efficiency as the objective, building length, roof and ground heat transfer coefficients, and the west-facing window-to-wall ratio should be prioritized as design parameters.
Furthermore, the decision tree model provides specific numerical recommendations for these design elements. For instance, by incorporating design elements such as a building length of less than 15 m, a west-facing window-to-wall ratio below 0.155, a south-facing window-to-wall ratio above 0.26, an external wall heat transfer coefficient below 0.31, and a ground heat transfer coefficient above 0.455, buildings within the range of 45–55 kWh/m2 for EUI can be achieved. Therefore, the decision tree model not only assists in determining the importance ranking of design strategies but also offers precise numerical recommendations for designing strategies based on specific objectives, thus enhancing architectural design efficiency.
The contribution of the decision tree model encompasses aspects of design orientation, the design process, and design solutions.
Firstly, in terms of design orientation—taking energy consumption as an example—the decision tree model offers a concise checklist for reference. For instance, if the design conditions align with those in
Table 7, the decision tree model facilitates an estimation of whether the building’s energy consumption falls within the high or low energy consumption range. This significantly enhances the design efficiency compared to energy consumption results obtained through simulation.
Secondly, in the design process, the direct application of relevant strategy data from the decision tree model can position the energy consumption of the designed building within a specified range. This approach, as opposed to the iterative process of “design–simulation–optimize design–simulation”, can streamline certain steps, thereby enhancing the efficiency of energy-efficient design.
Thirdly, in terms of design solutions, the decision tree model furnishes an empirical model for zero-energy houses in cold regions. Designers can gain initial insights into the region and directly reference and apply the model, saving time on research, data retrieval, and independent deconstruction. This facilitates the efficient design of zero-energy houses in cold regions.
In addition, this study has limitations in the following aspects:
- (1)
The sample size and model complexity have certain limitations. The original sample size of 15 cases is relatively small, and, as a methodological study, the 15 passive design elements chosen in this article are limited. It may be relatively challenging when dealing with complex models involving in-depth design.
- (2)
The decision tree model established in this method is oriented towards energy efficiency goals. More targeted decision tree models can be established based on different design objectives.
- (3)
This study primarily serves as a methodological investigation, emphasizing the explanation of the method framework and process research. Subsequently, we will expand and refine this research through applied research in design to explore the practical application of the method.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}