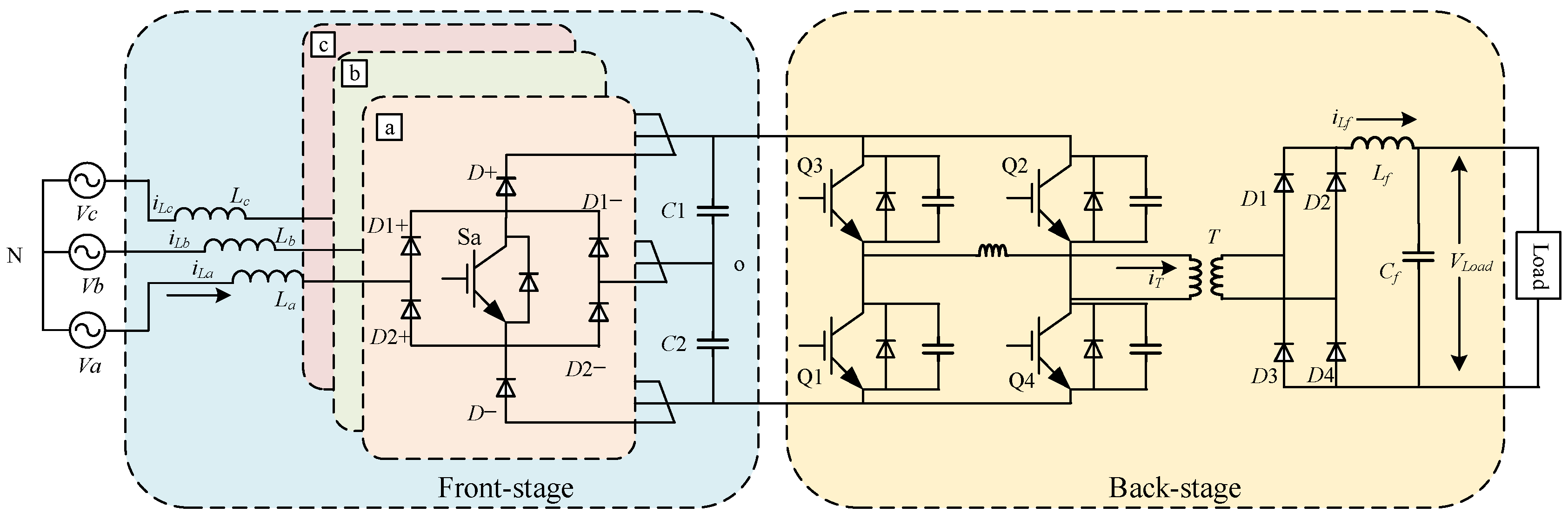
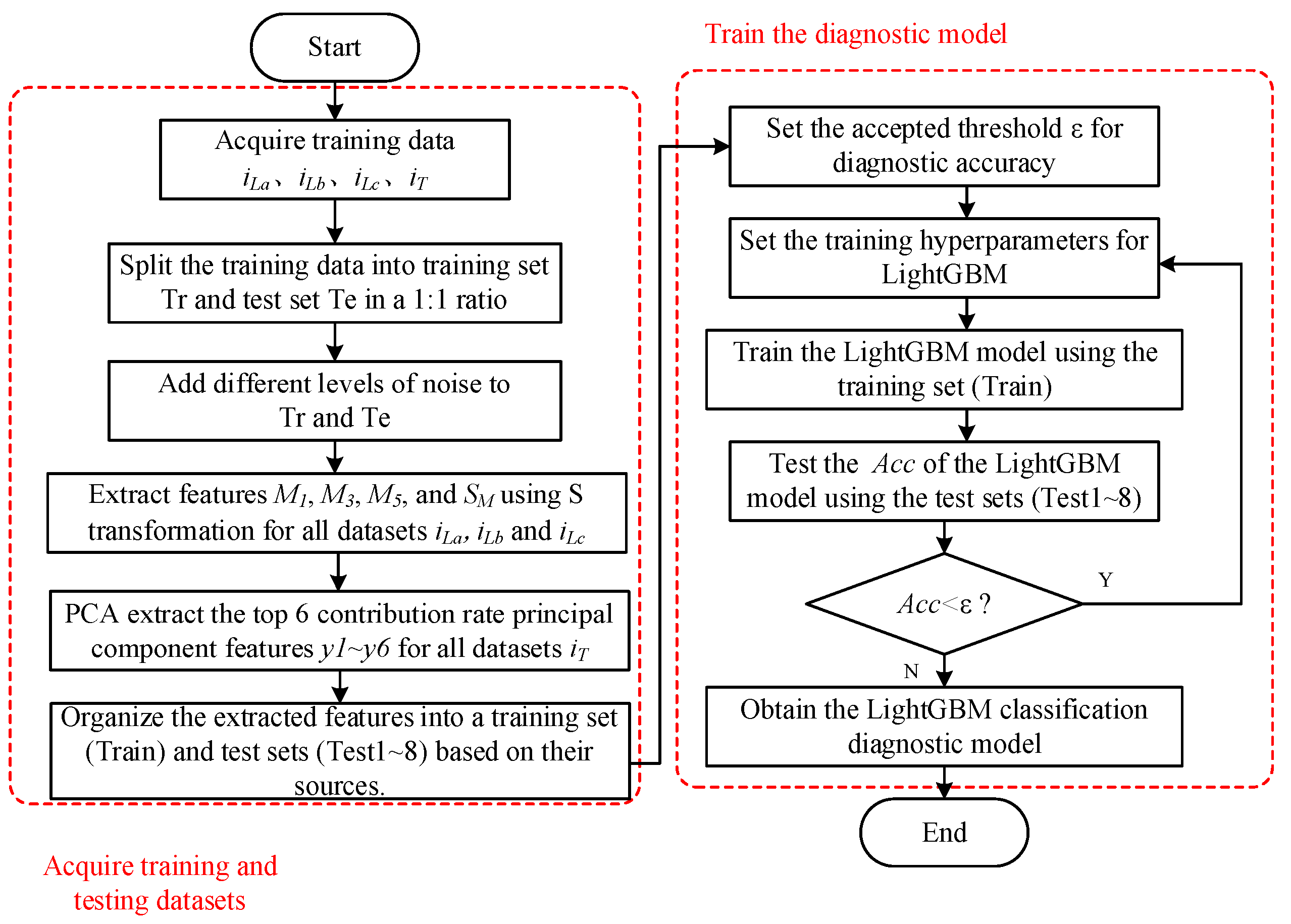
In this section, we’ll delve into the diagnostic methodology for electric vehicle DC charging pile openings, outlining a framework intricately woven with advancements in S-transform and LightGBM. First, we enhance the S-transform algorithm by tailoring it to the distinct characteristics of charging pile fault signals. The optimization process focuses on refining the window width, addressing incompleteness for an optimal outcome. Subsequently, we employ LightGBM to adeptly classify and extract features, culminating in a robust system for diagnosing charging pile failures.
3.1. Feature Extraction of Preliminary Faults Based on Improved S-Transform
S-transform is a proposed signal time-frequency analysis method. The principle involves a one-dimensional signal
x(
t), undergoing windowing operations and Fourier transformation to obtain a two-dimensional matrix
ST(
τ,
f). The formula is as follows:
where
w(
τ −
t,
f) is the window function. The traditional S-transform uses the Gaussian window function. The expression is as follows:
where
τ represents the central position of the window, and the variation of
τ controls the sliding of the window along the time axis.
σ(
f) denotes the standard deviation of the Gaussian function and simultaneously serves as the window function adjustment factor.
In the realm of traditional S-transform, its limited control over the Gaussian window function width impedes the attainment of ideal time-frequency resolution at both low and high frequencies, resulting in suboptimal recognition accuracy. To address this challenge, researchers have introduced an enhanced version of S-transform. By refining the window function expression, this modified S-transform achieves superior time-frequency resolution. An example of such improvement is evident in the adjusted formulation of
σ(
f), as depicted in the following equation.
where
a,
b,
c, and
d are adjustment factors that can be customized based on the actual signal. The generalized S-transform with adjustable window width offers better time-frequency resolution. However, such methods often rely on empirically enhanced window function expressions without clear theoretical foundations. Moreover, parameter tuning is intricate, and these approaches may not perform optimally when faced with changes in parameters such as sampling frequency. Hence, this paper introduces an incomplete S-transform algorithm based on effective window width improvement.
The two-dimensional matrix obtained through traditional S-transform encompasses temporal information for various frequency points. However, a substantial portion of these frequency point details constitute redundant values that are unnecessary for transformation. Hence, the principle of the incomplete S-transform is as follows:
S-transformation expression (1) can be transformed to the following expression:
where
U(
α) represents the Fourier transform result of the signal
x(
t). Equation (4) indicates that the Fourier transform results
U and
W of the signal and the window function, respectively, can be used to transform specific frequency points
f, yielding the temporal information for that frequency point. When the transformation is applied only to certain frequency points within
U(
α), it is referred to as incomplete S-transform. When analyzing fault characteristics, one can initially employ complete S-transformation. After selecting the characteristic frequency points, utilizing incomplete S-transform for signal processing eliminates a significant number of redundant calculations, thereby enhancing the real-time performance of the diagnostic algorithm.
Before performing the S-transform on specific frequency points, it is advisable to calculate the optimal window width for that frequency to achieve the best time-frequency resolution. The effective window width
D for each frequency point with a Gaussian window function can be computed based on the frequency domain expansion
σf and the 3
σ energy coverage criterion of the window function. The process is outlined as follows:
In accordance with the 3
σ criterion, the effective window width
D is defined as the length of the horizontal axis interval covering 99.73% of the window function’s area. When
, the Gaussian window function is as follows:
According to the normal curve nature, the horizontal axis interval
contains the area of 99.73% of the Gaussian window function shown in Formula (7), so the Gaussian window function effective window width
D is:
After performing the FFT transformation on the one-dimensional signal
x(
t), the spectrum
U(
fk) is obtained. When the S-transform applies windowing to the spectrum, the effective window width
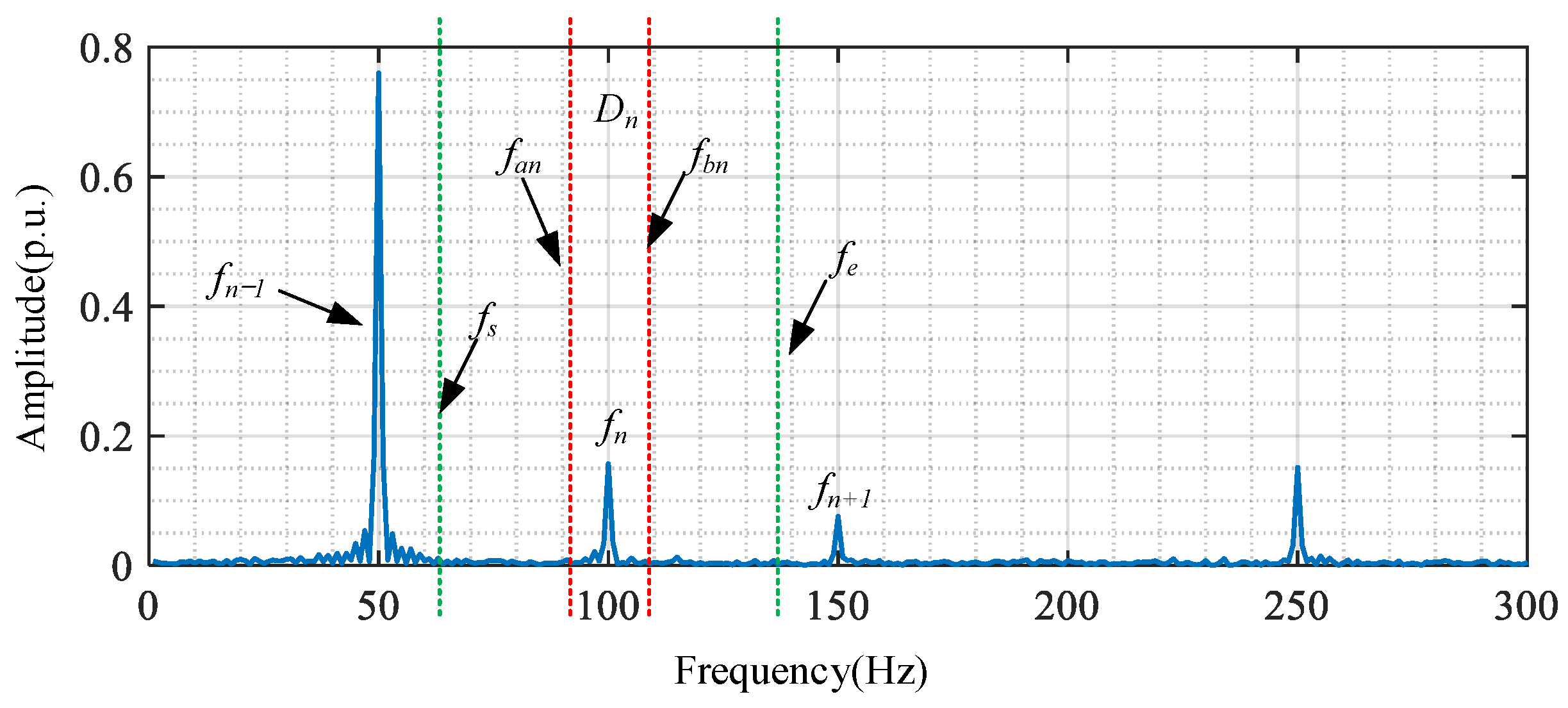
Dn of the window function at the main frequency point
fn should cover the main value interval of
fn, as illustrated in
Figure 4.
The main value interval corresponding to the main frequency point
fn can be calculated using the frequency point energy
En, as follows:
where
fs and
fe represent three-fourths between the main frequency point
fn and the preceding main frequency point
fn−1, and the succeeding main frequency point
fn+1. This can be expressed as follows:
Taking into account noise interference, when the energy
ED within the interval [
fan,
fbn] covered by the effective window width
Dn accounts for 95% or more of
En, it can be considered that the Gaussian window corresponding to this
σ value has covered the main value interval of the frequency point
fn. The expression is as follows:
With the interval [
fan,
fbn] being symmetric about the
fn axis, obtaining [
fan,
fbn], the calculation for
σ is as follows:
In summary, this method calculates the optimal window width corresponding to each frequency point’s σ value through the effective window width D of the Gaussian window and the energy distribution characteristics of the test signal. It enables the selection of the optimal window width for each frequency point in the test signal, thereby conducting the S-transform. This approach mitigates issues arising from excessively narrow window widths, such as low-frequency domain resolution problems, or overly broad window widths leading to frequency aliasing and low time-domain resolution problems. The resulting improved S-transform achieves commendable time-frequency resolution.
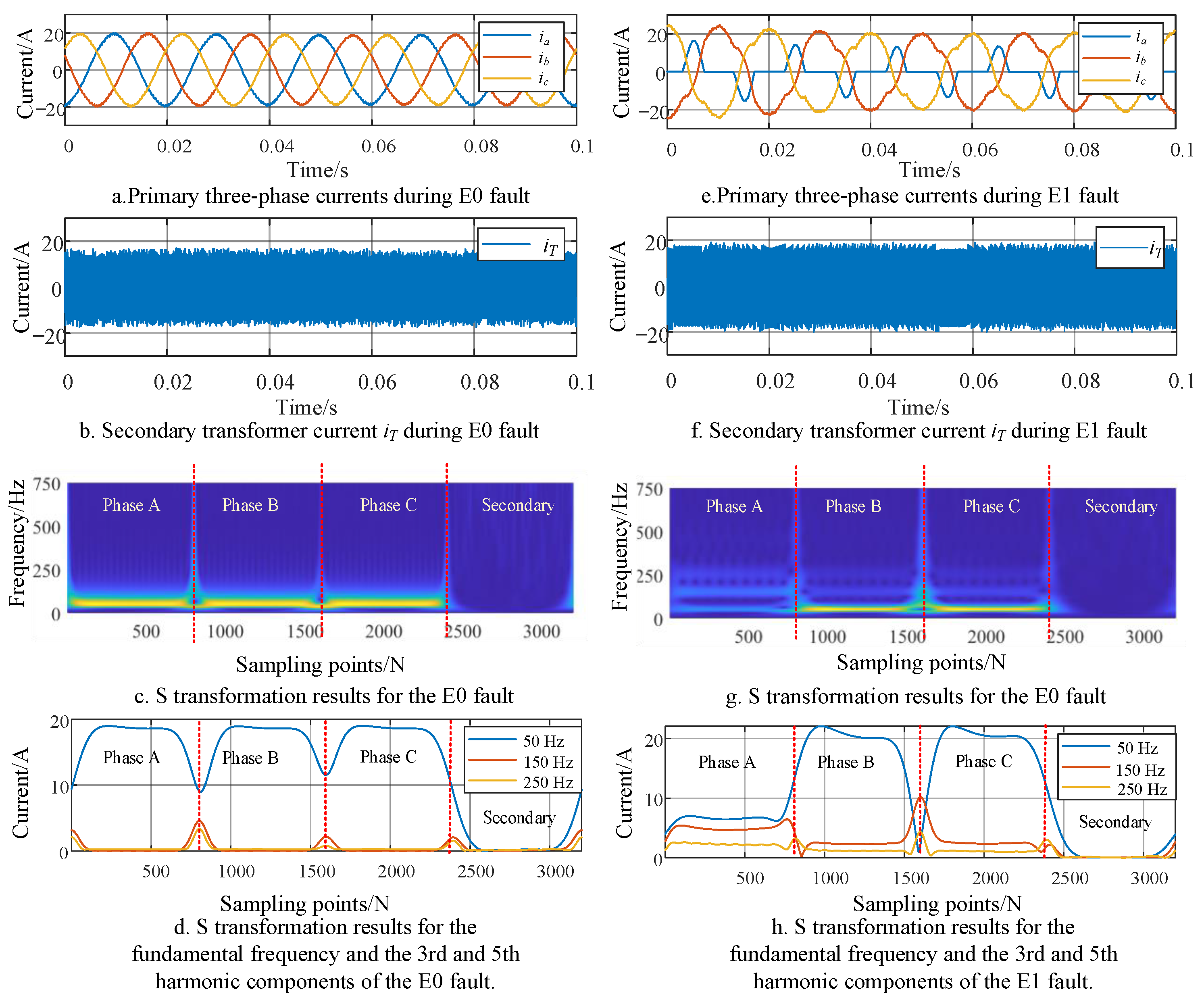
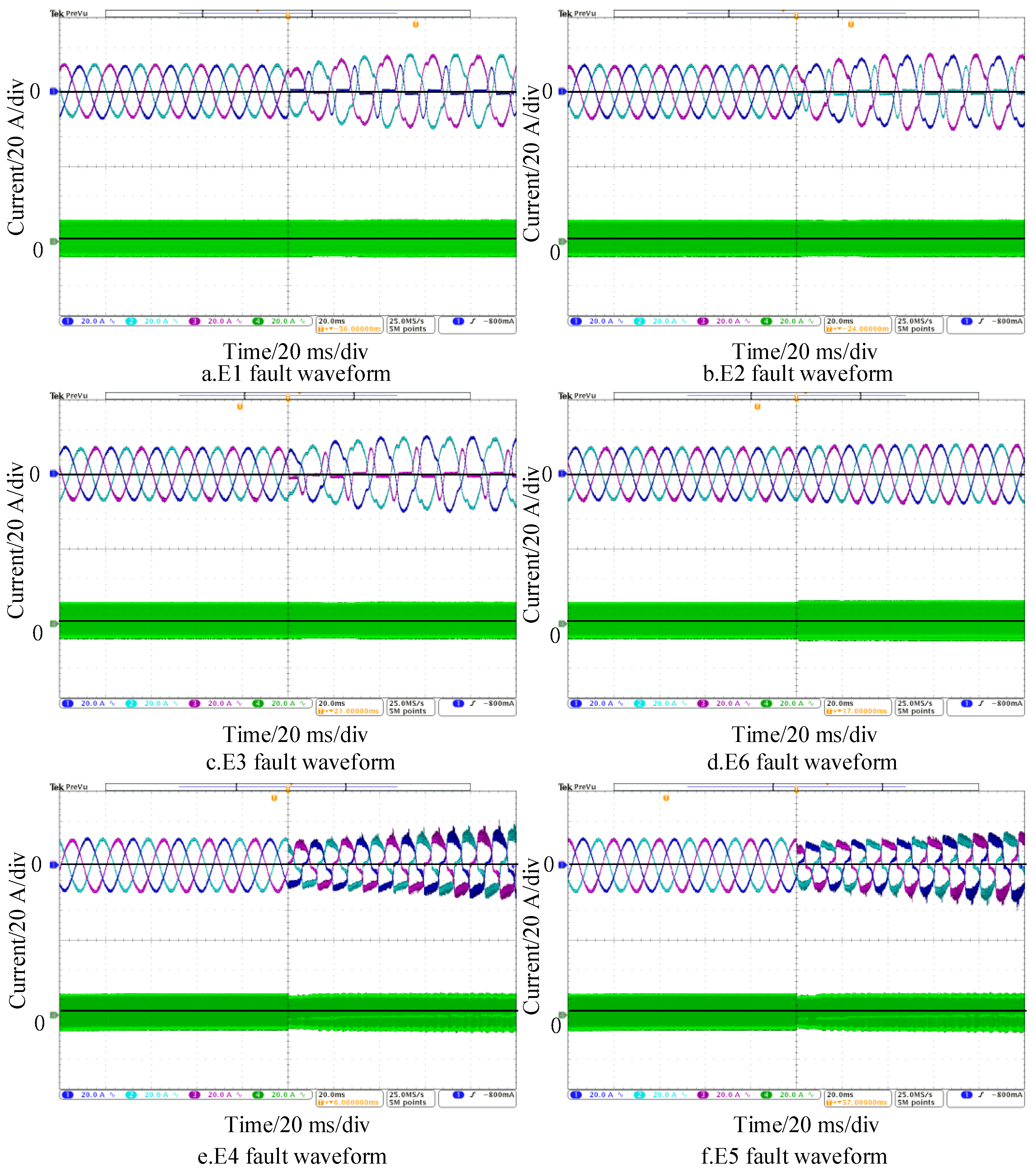
Based on the analysis in the previous section, the signal used for identifying primary faults is the three-phase sinusoidal waveform of the power frequency, suitable for feature extraction using the improved S-transform. The collected signal results with the improved S-transform for faults E0 and E1 are shown in
Figure 5. In this case, the fused data
x processed by the improved S-transform are formed by concatenating the three-phase currents (
ia,
ib,
ic) of the primary inductance A, B, and C, and the high-frequency transformer current
iT of the secondary stage. The data processing is described by the following equation:
Therefore, the results of the complete S-transform in
Figure 5c,g can be divided into four parts based on the sampling points. These parts represent the complete S-transform results of the primary inductance currents
ia,
ib, and
ic for phases A, B, and C, and the high-frequency transformer current
iT of the secondary stage.
Figure 5d,h depicts the improved incomplete S-transform results for the fundamental frequency and the 3rd and 5th harmonic components of the E0 and E1 fault data, respectively.
From the complete S-transform results in
Figure 5, specifically c and g, it can be observed that after the occurrence of the E1 fault, the fundamental frequency amplitude of phase A decreases. Additionally, the waveforms of the three-phase currents A, B, and C contain 3rd and 5th harmonic components. However, the S-transform results of the secondary transformer current do not show a clear distinction within 700 Hz. As shown in
Figure 5, specifically d and h, during the E1 fault occurrence, compared with phases B and C, the fundamental frequency amplitude of phase A is lower, the amplitude of the 3rd harmonic is higher, and the amplitude of the 5th harmonic is slightly higher.
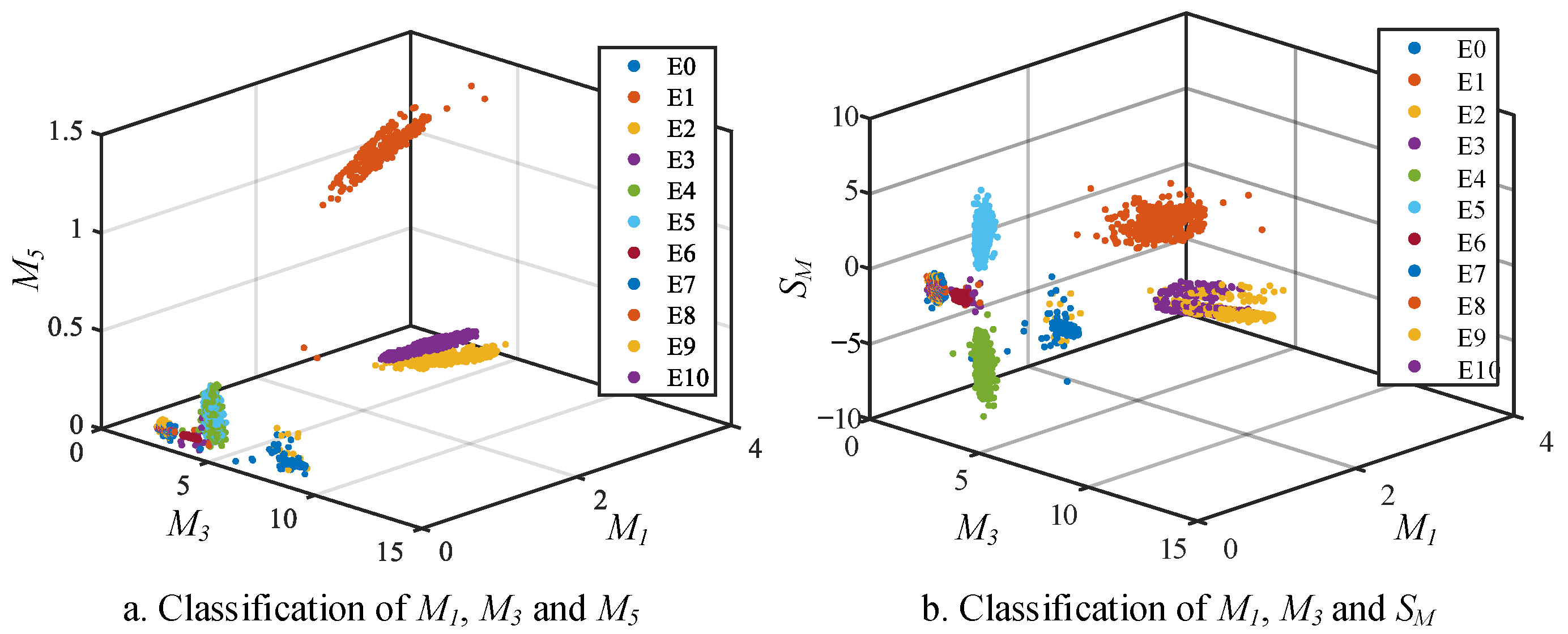
Due to the three-phase symmetry of faults E2 and E3 with E1, fault characteristics for the primary faults E1, E2, and E3 can be extracted based on the results of the improved incomplete S-transform. The designated feature values for primary faults are set as follows.
The average values of the fundamental frequency in the incomplete S-transform results within each interval:
where
N represents the number of sampled data points for each phase.
The average values of the 3rd and 5th harmonic incomplete S-transform results within each interval are expressed as the following equations:
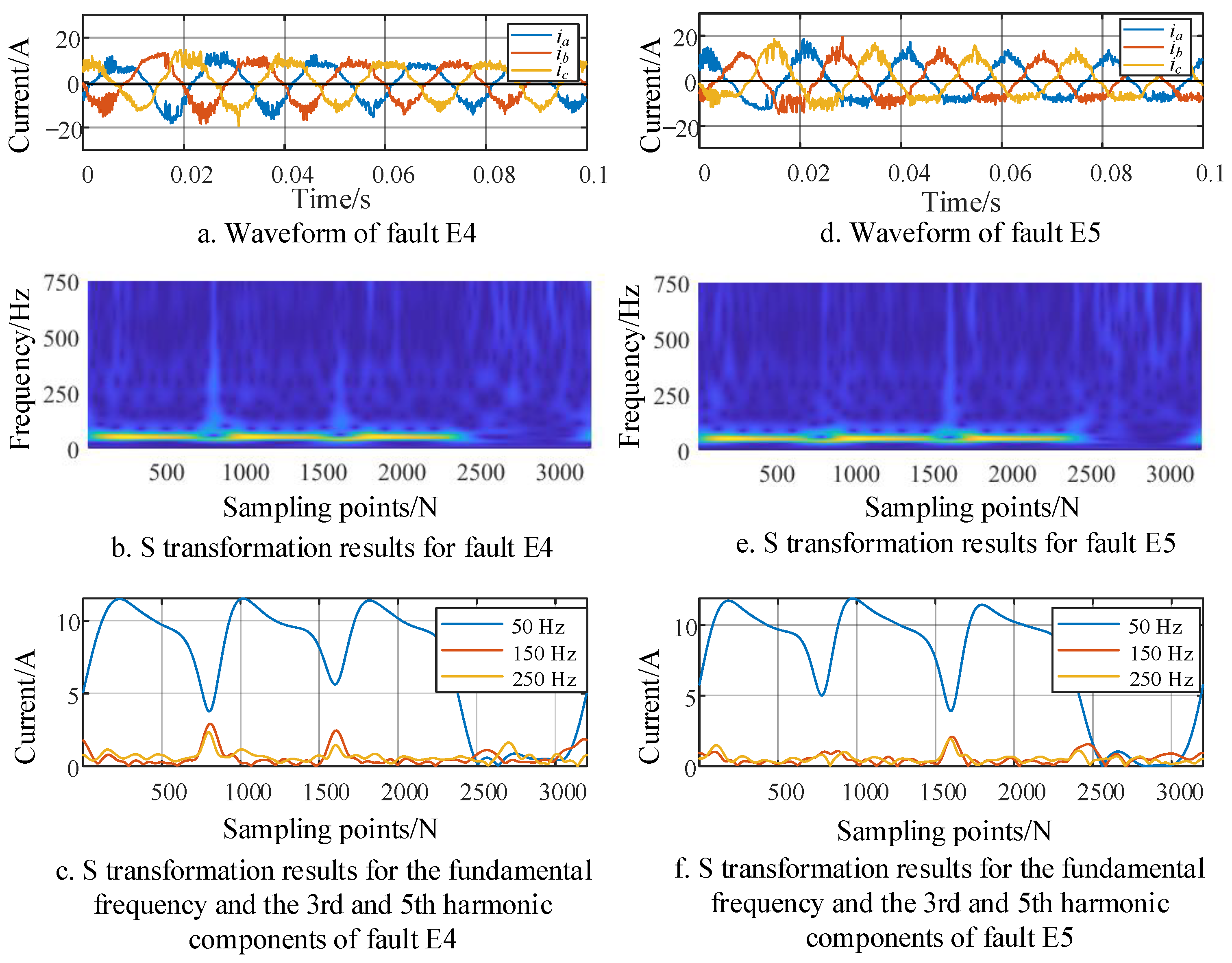
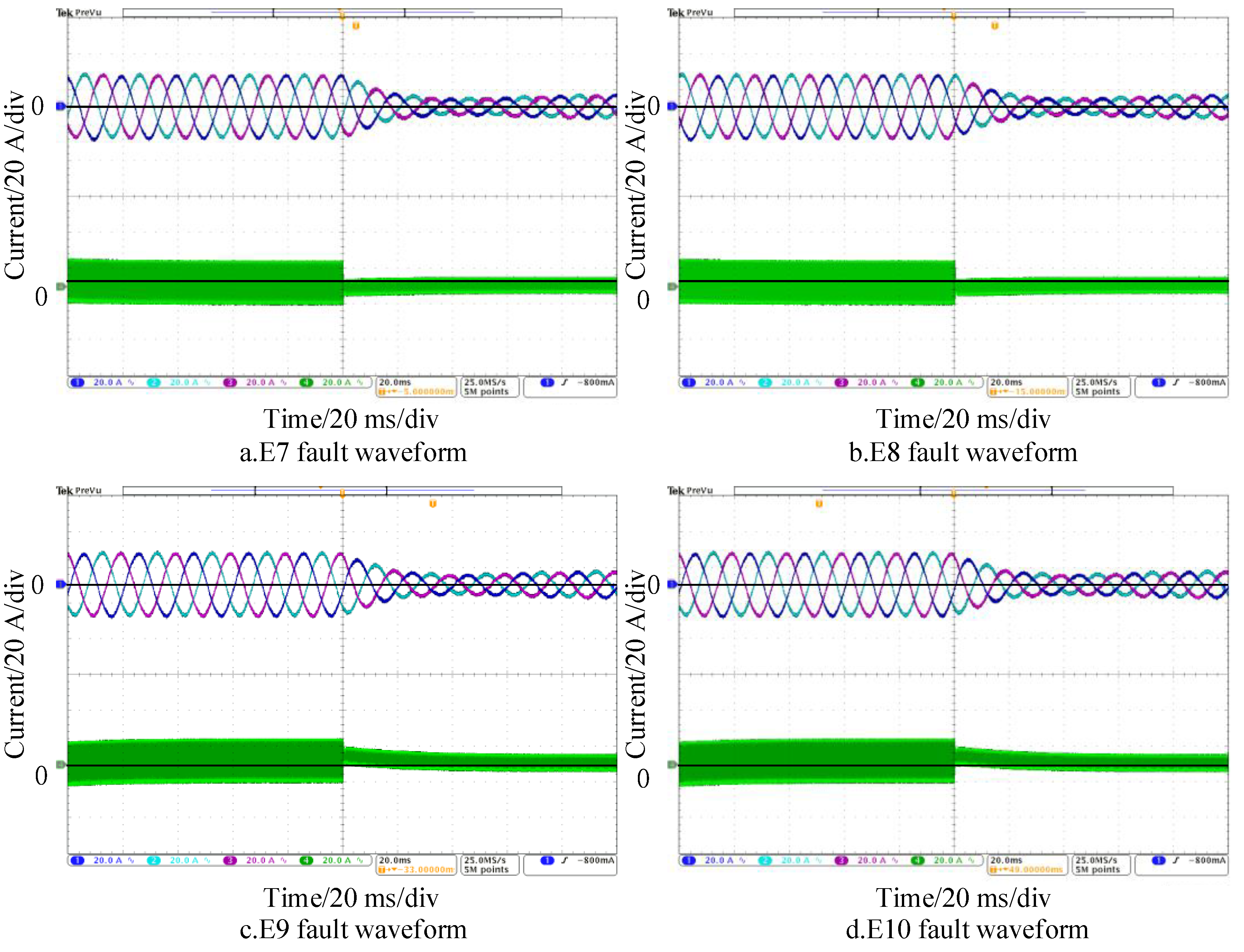
For the imbalance capacitor faults E4 and E5 in the VIENNA rectifier front stage, the fault waveforms and S-transform results are illustrated in
Figure 6.
From the complete S-transform results in
Figure 6, it can be observed that for faults E4 and E5, there is no distinct feature differentiation in the S-transform results. However, as shown in
Figure 6a,d, due to the fault occurring at the balancing capacitor of the primary rectifier, causing the output voltage of the converter to be 0 during either the positive or negative half-cycle, the three-phase input currents will be clamped at a fixed value with a 120° phase difference during the positive and negative half-cycles due to the influence of inductance and other factors after the capacitor fault occurs. Based on this, specific feature values can be determined as follows, with the sum of the maximum and minimum values of the primary input current denoted as
SM:
3.2. Feature Extraction for Back-Stage Faults Based on PCA
PCA is a data dimensionality reduction method based on the concept of maximizing separability. It achieves this by linearly projecting data from high-dimensional space to a lower-dimensional one, generating principal component data. The principal component data encapsulates the primary features of the original data while eliminating certain inherent correlations. The process of extracting principal components in this data dimensionality reduction primarily relies on the theory of maximizing variance, as outlined below.
Assume that there are
N groups of data
to be processed, and the length of each group of data is
p, then there is a sample matrix
X.
Calculate the covariance matrix
C of the sample matrix
X and obtain the correlation coefficient between each sample.
Then, perform eigenvalue decomposition on the covariance matrix
C to obtain its eigenvalue
λ and eigenvector
w.
The eigenvalues of the covariance matrix represent the contribution of each principal component. The ordering of them is as follows:
. The eigenvectors corresponding to the largest
d eigenvalues can be taken to form a reduced-dimensional projection matrix
. The process of reducing the sample matrix
X from
N dimensions to
d dimensions through principal component analysis is as follows.
Finally, a
d-dimensional sample matrix
Y is obtained, and the contribution rate
ri of each principal component is:
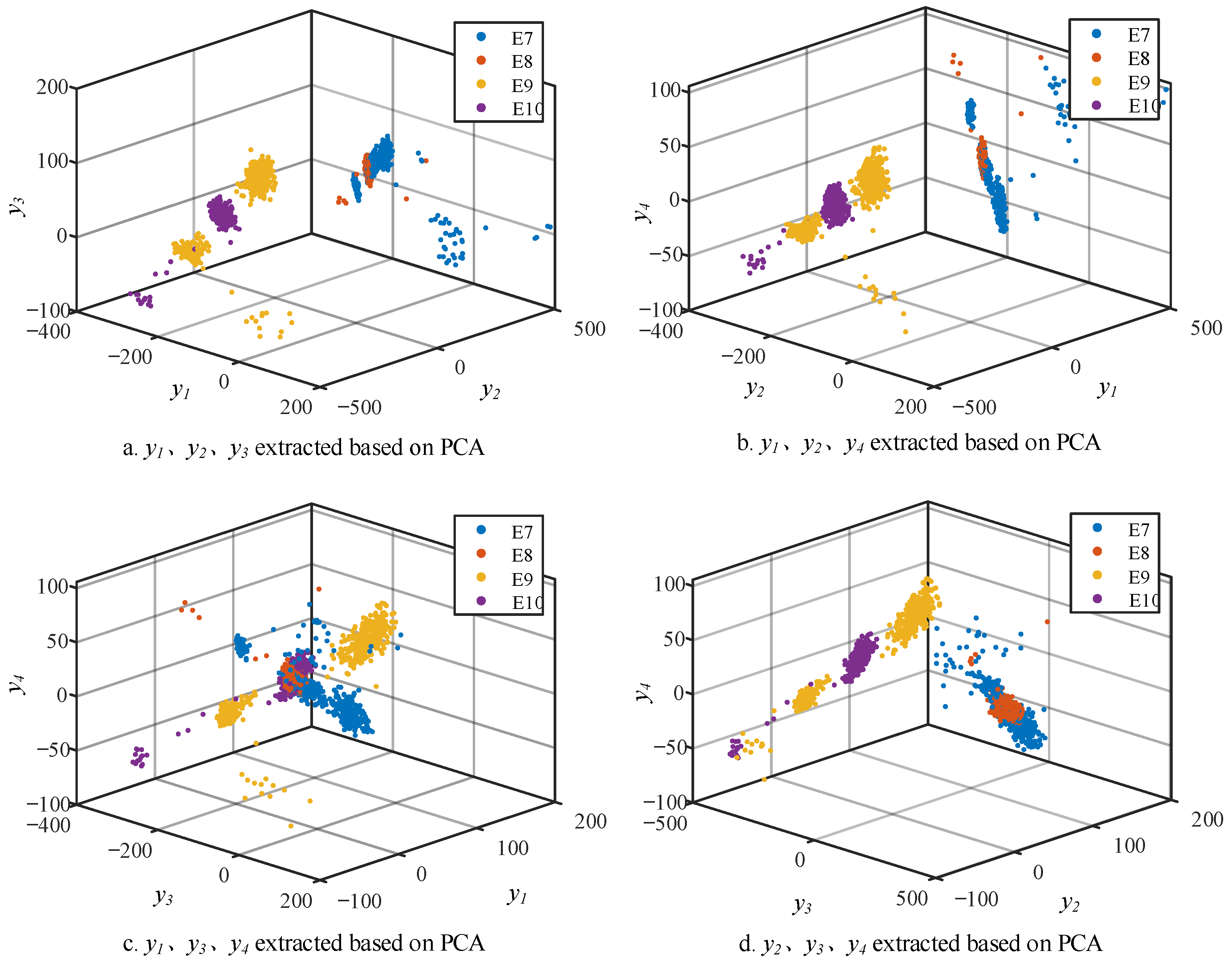
Perform PCA processing on the collected downstream transformer current
iT data. The processed data are set to be
iT data 0.02s after the fault. The data length is 160 points. The top 10 contribution rates of the extracted principal components are shown in the
Table 2.
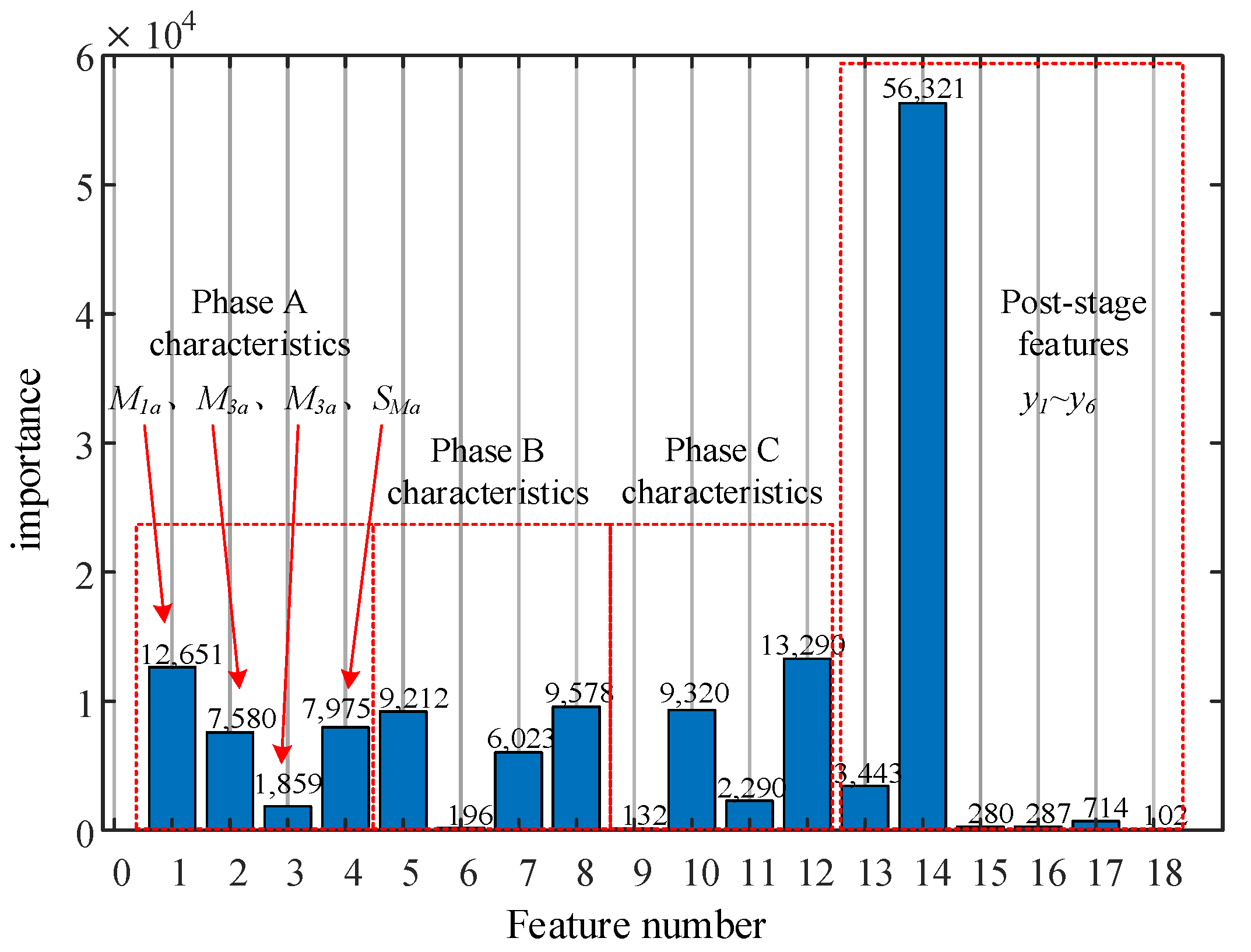
As can be seen in
Table 2, the contribution rate of the top 10 features accounted for 85.62%, and the contribution rate of the top six principal components accounted for 85.32%. Therefore, the first six principal components with contribution rates are selected as the subsequent stage fault characteristic values.
3.3. Feature Classification Diagnosis Based on LightGBM
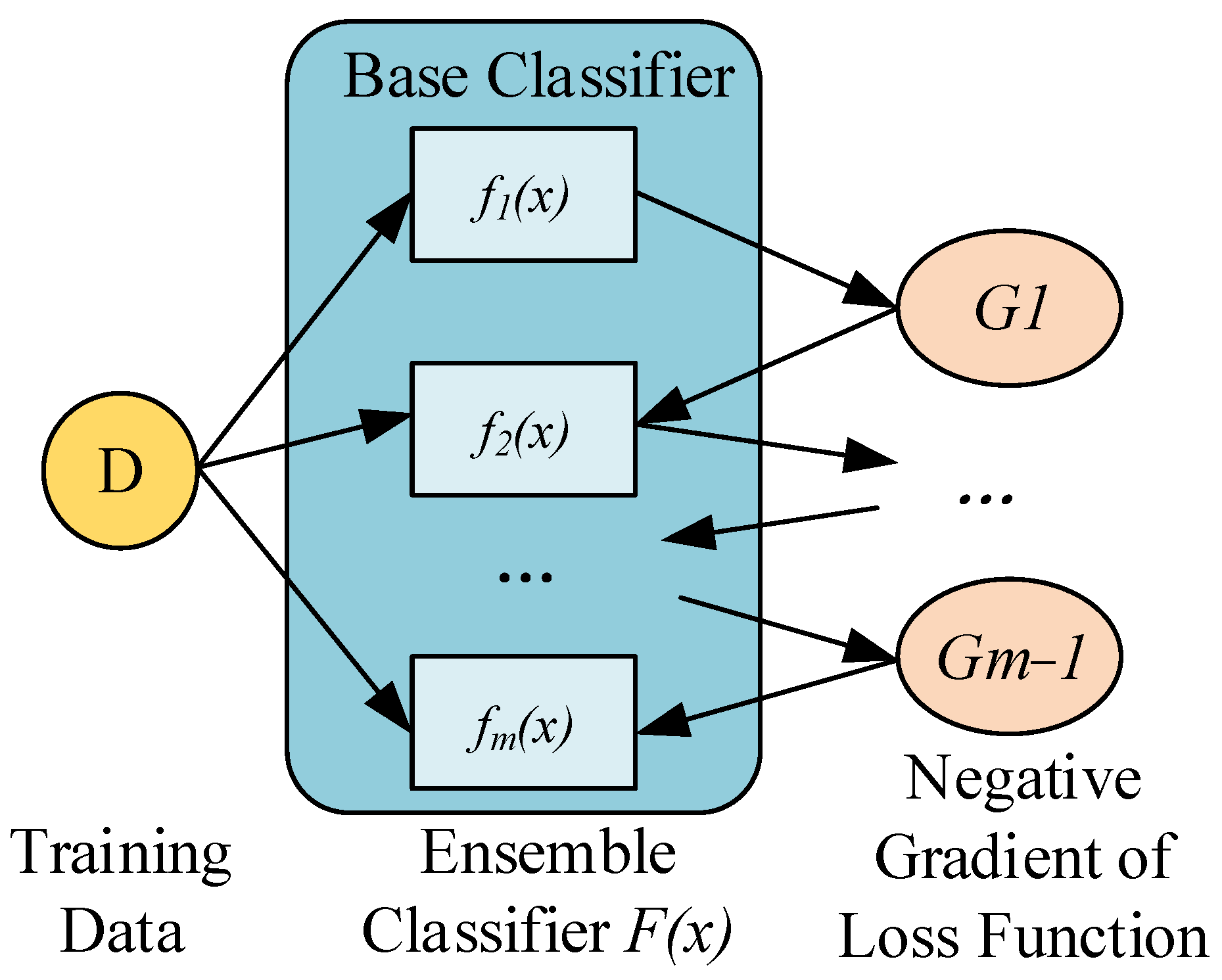
The LightGBM algorithm is an ensemble learning model based on a decision tree (DT), with the DT serving as its foundational classifier model. LightGBM utilizes gradient boosting technology. Boosting is an ensemble learning algorithm that involves linearly combining multiple sequentially generated base classifiers to integrate training and obtain a more powerful model. Its framework can be described as follows:
where
F(
x) represents the ensemble classification model obtained through training,
m denotes the number of base classifiers
fi(
x), and
αi represents the weight of the base classifier.
Each time a new base classifier is generated, gradient boosting follows the direction of gradient descent based on the loss function of the previous base classifier. Assuming the loss function of the ensemble classification model is
L(
F(
x),
y) for gradient boosting, the framework would be as follows:
In other words, each newly generated base classifier
fi(
x) fits the negative gradient of the loss function of the previous ensemble classifier
Fi−1(
x). Through continuous iterations, the ensemble classifier
F(
x) systematically reduces errors, ultimately resulting in a classifier with higher accuracy. Its fundamental principle is depicted in
Figure 7.
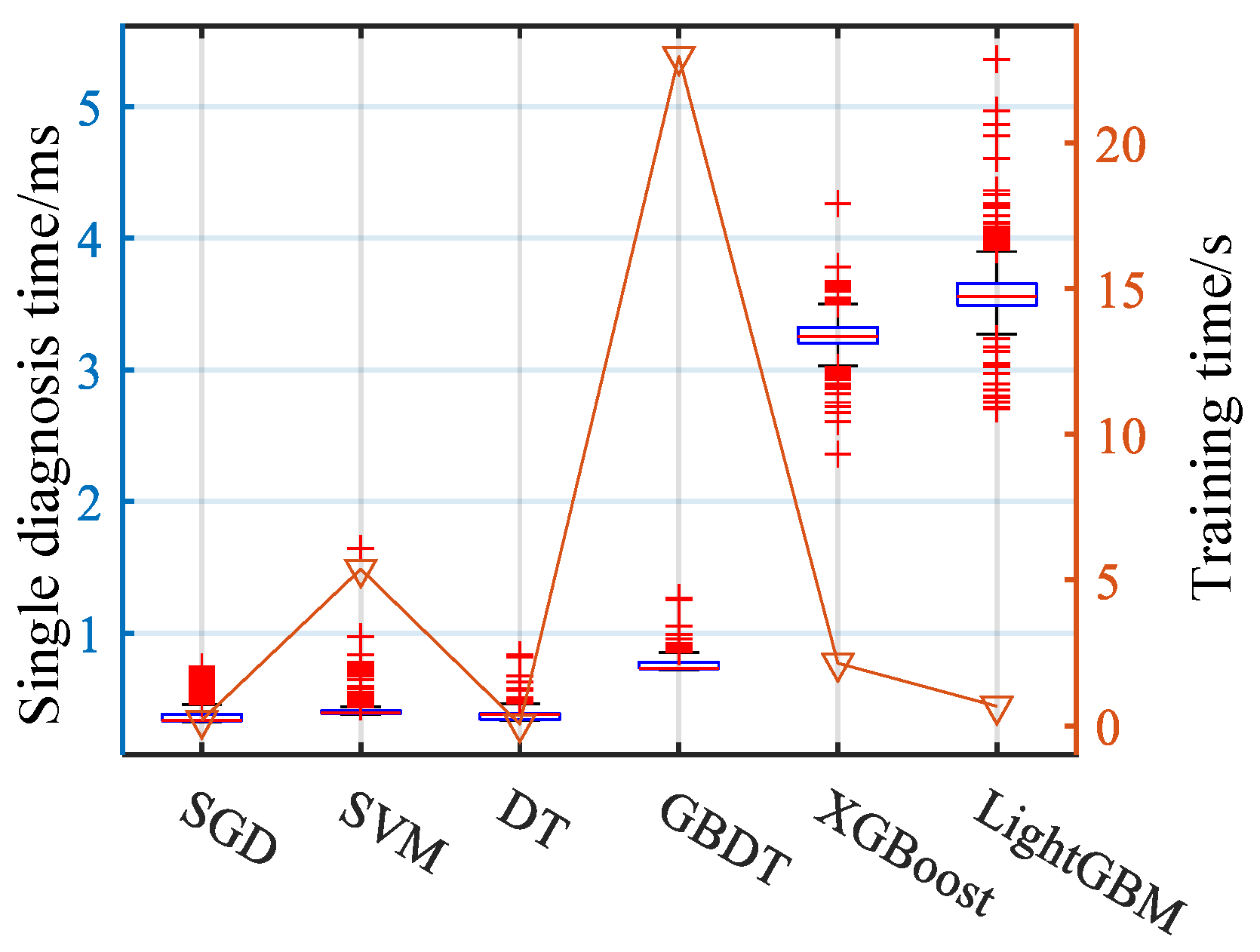
LightGBM is a lightweight gradient boosting model developed to cater to the needs of handling massive datasets, building upon the foundation of XGBoost. Addressing the challenges posed by XGBoost, such as high memory requirements and computational time, LightGBM optimizes various aspects. This includes reducing the computational load of splitting points, minimizing the quantity of training data, managing the number of feature values, and optimizing decision tree construction strategies.
With these enhancements and optimizations, LightGBM achieves faster data processing speed and lower memory usage without compromising accuracy. It demonstrates the capability to swiftly handle massive datasets.


 ,
, 

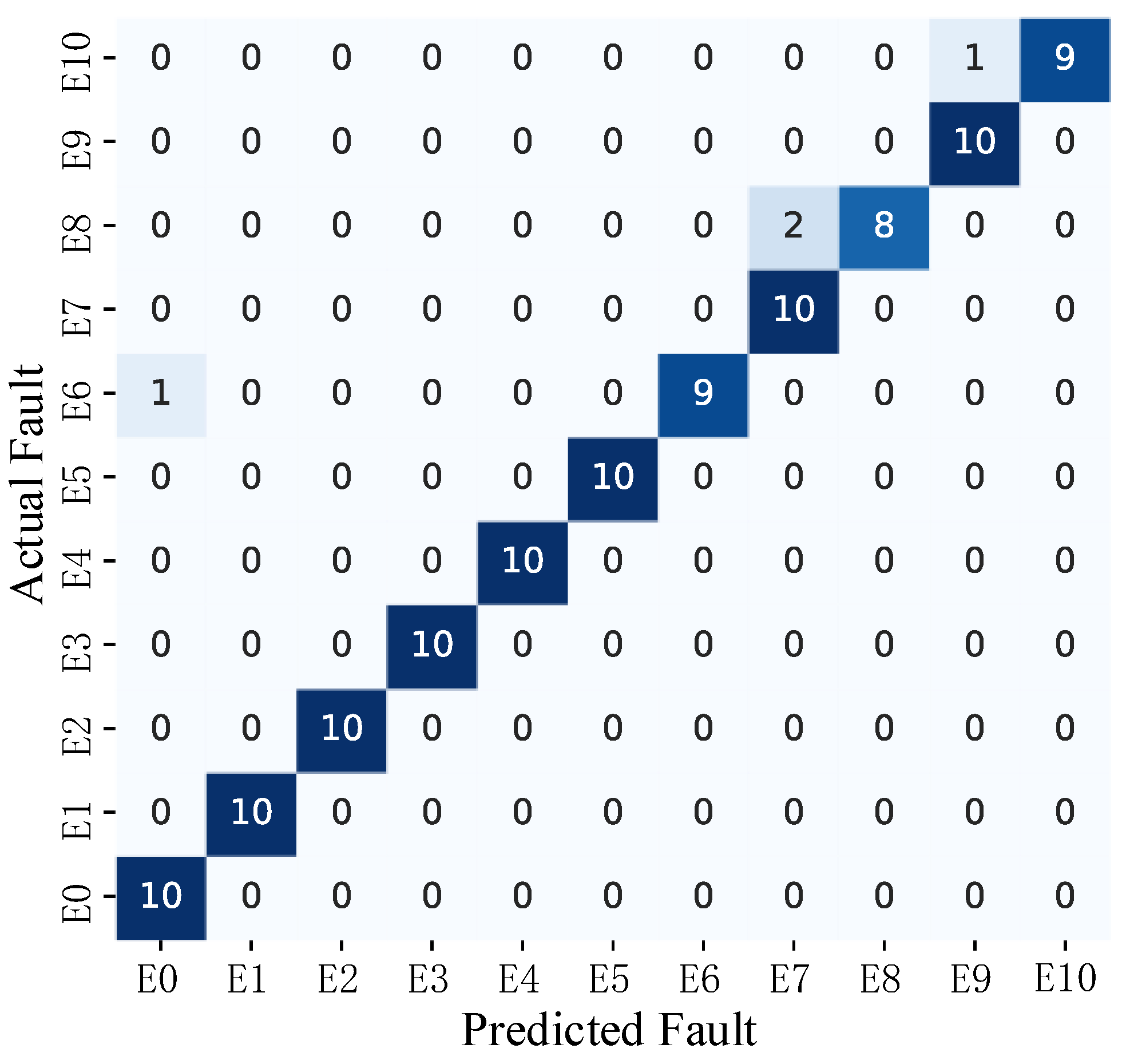
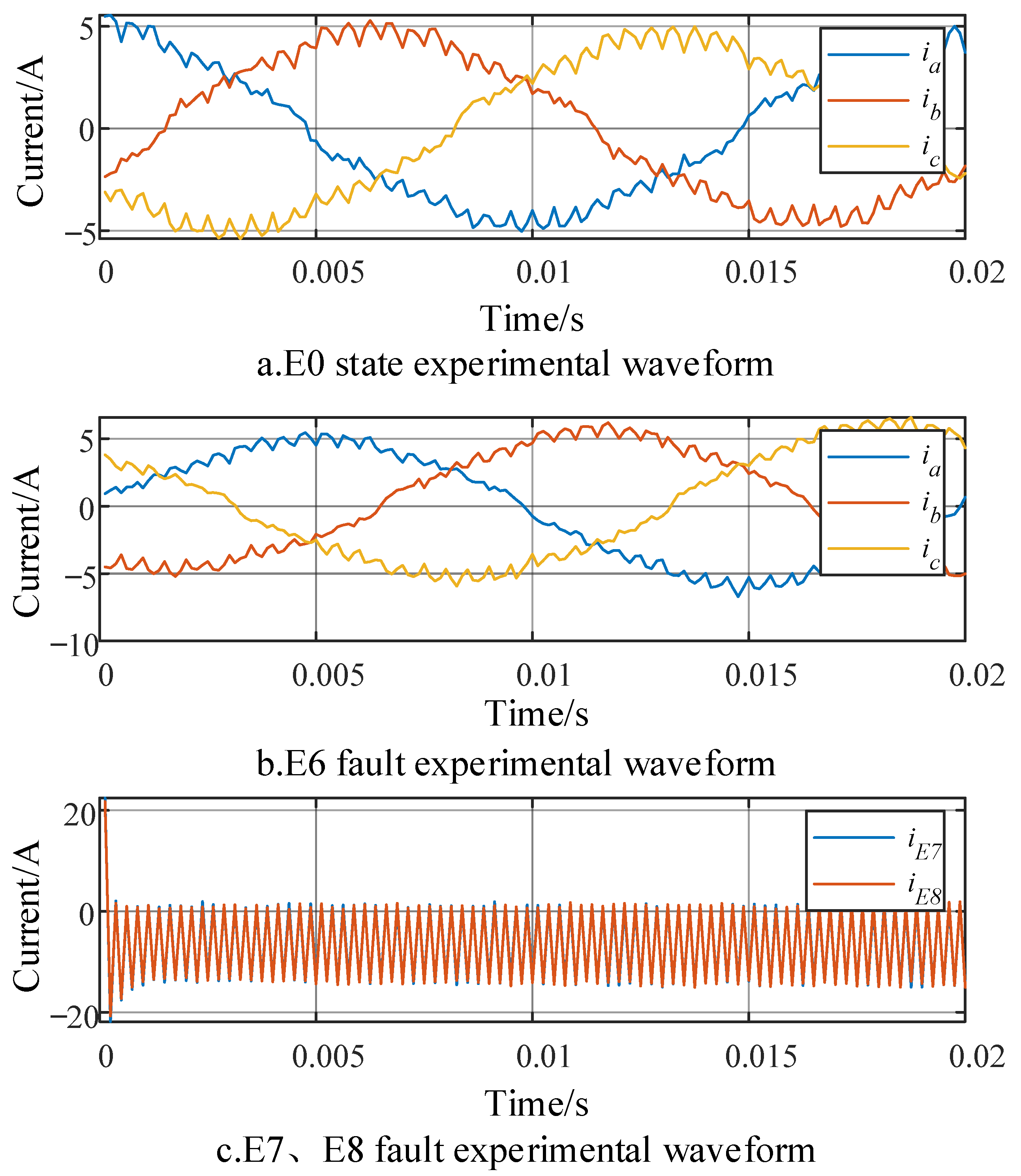

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}