1. Introduction
Transmission lines are a critical component of the power grid, and their secure operation is vital for ensuring reliable power supply [
1,
2,
3]. However, external damage hazards caused by unauthorized construction activities, such as those involving excavators and cranes, frequently occur within transmission line corridors. These hazards can severely damage the transmission facilities, leading to grid trips, power outages, and even serious safety incidents such as electric shocks [
4,
5]. Therefore, promptly identifying these external damage hazards is essential for maintaining the safe operation of transmission lines, and research aimed at preventing such external damage is of significant importance.
To ensure the stable operation of transmission lines, it is necessary to conduct safety inspections of the corridors [
6]. Current inspection methods mainly include manual inspections, drone inspections, and video-based online monitoring systems [
7]. Manual inspections are costly, inefficient, and susceptible to weather and terrain conditions. While drone inspections offer higher efficiency, they have limited endurance and complex operation, and pose significant risks in adverse weather conditions. In contrast, installing fixed cameras to monitor transmission line corridors and using computer vision technology to process real-time data to accurately identify potential hazards has become a key technical approach in preventing external damage to transmission lines. With the continuous development of computer vision technology, object detection techniques have been widely applied in detecting hazards in transmission lines. For instance, the literature [
8] proposed a re-parameterized YOLOv5-based edge intelligence detection method for transmission line defect hazards, utilizing R-D modules and re-parameterized spatial pyramid pooling (SPP) to improve the accuracy of recognizing insulator self-explosion, pin missing, and bird nest hazards. The literature [
9] introduced a YOLOv4-based bird-related fault detection method for transmission lines, employing multi-stage transfer learning for model training and integrating mosaic data augmentation, cosine annealing decay, and label smoothing to enhance training effects, effectively detecting bird targets and identifying bird species in transmission lines. The literature [
10] proposed a low false negative defect detection method using a combined target detection framework, adaptively fusing feature extraction results from YOLOv3 and faster RCNN networks, thereby effectively reducing the false negative rate in inspection image defect detection. The literature [
11] presented an instance segmentation neural network algorithm using partial bounding box annotation, transferring detection branch features to the mask branch to achieve recognition and segmentation of common external damage categories. The literature [
12] proposed an insulator fault detection method for transmission lines based on USRNet and an improved YOLOv5x algorithm. Firstly, USRNet was used for super-resolution reconstruction of inspection images to reduce complex background interference, and then the YOLOv5x algorithm was improved to enhance the detection accuracy of small targets. However, this method, which involves super-resolution reconstruction before detection, increases accuracy but has significant shortcomings in processing speed and lacks generalization capability in complex environments. The literature [
13] introduced a YOLOv4-based external damage hazard detection algorithm for transmission lines, improving the K-means algorithm for clustering the target sizes in the image sample set to select anchor boxes that match the target detection characteristics. The CSPDarknet-53 residual network was then used to extract deep network feature data from images, followed by processing the feature maps using the SPP algorithm. Although this improved detection accuracy to some extent, the complex network structure resulted in slower detection speeds, failing to meet real-time hazard detection requirements. The literature [
14] proposed a YOLOv5-based fault detection algorithm for transmission lines, incorporating attention mechanisms and cross-scale feature fusion. Firstly, attention mechanisms were introduced to suppress complex background interference, and then the BiFPN feature fusion structure was used to enhance the detection accuracy of multi-scale fault targets. However, this approach did not effectively address the loss of small target information during downsampling, potentially leading to inaccurate positioning and safety hazards.
In summary, current research on detecting external damage hazards has made some progress, but the actual transmission line scenarios are complex. High-rise buildings, forests, and slopes often present in transmission line corridors can interfere with detection. When the characteristics of external damage hazard targets are similar to those of the background or when occlusion occurs, misdetections and missed detections are still prevalent. Additionally, since cameras are usually installed on transmission towers, distant construction machinery appears very small in the field of view, posing a greater challenge for small target detection. Considering these issues and the fact that object detection algorithms will be deployed on edge devices close to cameras outdoors, which have limited computing resources [
15,
16], this paper selects the YOLOv8s algorithm to meet the real-time and accuracy requirements of hazard detection while keeping the parameter count low for ease of deployment. Based on this, we optimized the model and proposed a detection method for external damage hazards in transmission line corridors based on YOLO-LSDW. The main contributions of this paper are as follows:
1. The combination of LSKA [
17] with the SPPF module in the baseline model led to the proposal of the SPPF-LSKA module, which reduces complex background interference on construction machinery by capturing long-range dependencies and adaptivity, thereby improving the model’s accuracy in complex environments.
2. Introduction of the slim-neck [
18] structure in the neck network of the original model for feature fusion, enhancing the detection capability of small targets by integrating contextual information while reducing the model’s parameter count and computational load.
3. Replacing the head network of the baseline model with the dynamic head (DyHead) [
19] module for prediction output, further enhancing the model’s performance in recognizing construction machinery of different scales, complex backgrounds, and small targets.
4. Introduction of the WIoU [
20] loss function to enhance the convergence capability of the network’s classification loss, optimizing the training process to improve the model’s bounding box prediction and regression performance.
The structure of this paper is as follows:
Section 2 introduces the YOLO-LSDW model and its enhancements, including the SPPF-LSKA module, slim-neck feature fusion, DyHead module, and WIoU loss function.
Section 3 describes the experimental setup, datasets, and evaluation metrics, and validates the model’s effectiveness through ablation and comparison experiments.
Section 4 analyzes the experimental results, discussing the model’s performance and limitations.
Section 5 concludes with a summary of the research contributions and future directions.
2. YOLO-LSDW Network Model
2.1. Method Overview
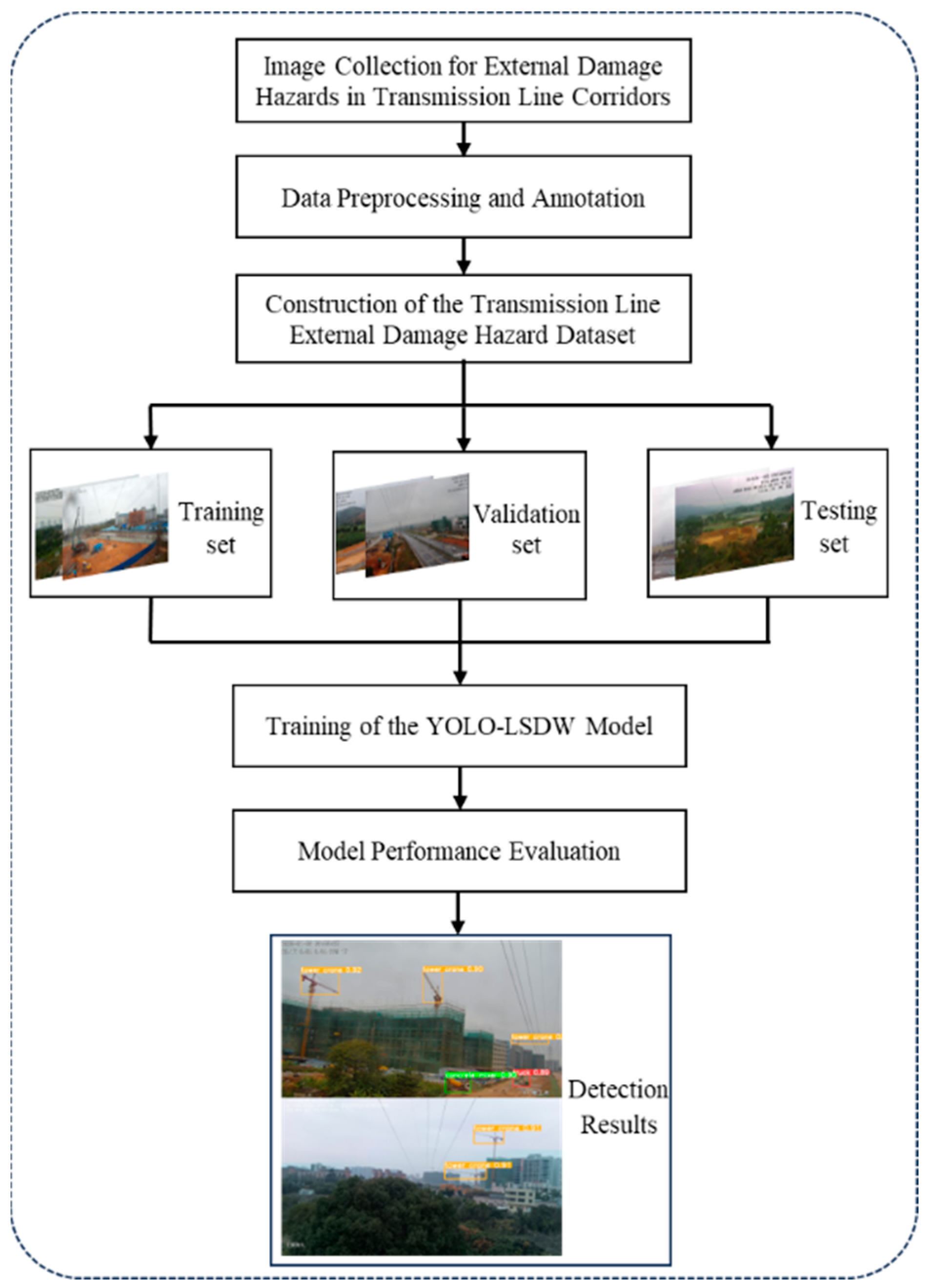
The process of the proposed detection method for external damage hazards in transmission line corridors is illustrated in
Figure 1. The method begins by collecting raw image data from monitoring equipment, which is then preprocessed and annotated to construct a dataset containing six categories of construction machinery. The dataset is subsequently divided into training, validation, and testing sets, which are used for the development of the YOLO-LSDW model. This model incorporates several improvements based on the YOLOv8s framework, enhancing detection performance through a process of training and optimization. As depicted in
Figure 1, after comprehensive testing and performance evaluation, the model is capable of real-time processing of input images of transmission lines, outputting information such as the location, category, and confidence level of external damage hazards, thereby providing robust support for the safety monitoring of transmission lines.
2.2. YOLOv8 Network Model
YOLOv8 [
21] is a CNN-based object detection network implemented on the PyTorch framework. It is available in different versions based on network width and depth, ranked from smallest to largest as YOLOv8n, YOLOv8s, YOLOv8m, YOLOv8l, and YOLOv8x. The YOLOv8 algorithm model primarily comprises four modules: the input end, the backbone network, the neck end, and the output end.
At the input end, the images fed into the network are preprocessed using techniques such as mosaic data augmentation [
22], adaptive image scaling, and grayscale padding. In the backbone network, features are extracted using Conv, C2f, and SPPF structures, employing convolution and pooling to capture deep image features. The neck end utilizes the feature pyramid network (FPN) [
23] and path aggregation network (PAN) [
24] structures for design, merging features from different scales through upsampling, downsampling, and feature concatenation. The output end employs a decoupled head structure, which separates the classification and regression processes and includes positive-negative sample matching and loss calculation. YOLOv8 also incorporates the TaskAlignedAssigner [
25] method, which weights the classification and regression scores and matches positive samples based on the weighted result. The loss function calculation consists of two parts: the classification branch, which uses binary cross entropy loss (BCE Loss), and the regression branch, which employs the integral representation form in distribution focal loss (DFL) [
26] combined with the complete intersection over union (CIoU) loss function to enhance the accuracy of bounding box predictions.
To meet the needs of edge devices in detecting external damage hazards in transmission line corridors, which require high detection speed and deployment efficiency, this paper selects the YOLOv8s network as the foundation due to its lower parameter count and computational load, yet high detection accuracy. Various improvements have been made, resulting in a detection method named YOLO-LSDW for external damage hazards in transmission line corridors. The structure of the YOLO-LSDW model is shown in
Figure 2.
2.3. SPPF-LSKA Module
Transmission line corridors often feature complex environments such as high-rise buildings, forests, and slopes, which pose significant challenges for detection due to interference, occlusion, and multi-scale external damage hazard targets. To enhance the model’s ability to extract key features of construction machinery, the LSKA attention mechanism is introduced into the SPPF module of the YOLOv8 backbone network. This integration helps the network ignore irrelevant background information and focus on more effective hazard target features.
LSKA is an innovative attention module that captures long-range dependencies and adaptivity by decomposing large kernel convolution operations. It splits a k × k convolution kernel into separable 1 × k and k × 1 kernels, processing input features in a cascading manner to reduce computational complexity and memory usage.
The improved SPPF-LSKA structure, illustrated in
Figure 3, modifies the original SPPF, which passes the input through three 5 × 5 max-pooling layers sequentially, concatenates the outputs from each layer, and then uses a regular convolution for feature fusion to obtain multi-scale features. In the enhanced SPPF-LSKA structure, the concatenated results after the three pooling layers are fed into an 11 × 11 LSKA convolution module. This modification strategy enriches the receptive field information in multi-scale features, thereby improving the model’s robustness in complex environments.
2.4. Slim-Neck Feature Fusion Structure
When capturing image data of transmission lines, cameras are typically installed at the location of transmission towers to obtain a broader field of view. However, construction machinery that is further away from the camera tends to appear smaller, making the detection of these small targets more challenging. To address the difficulty of detecting small targets among external damage hazards and achieve real-time detection, the design of the feature fusion network needs to balance accuracy and speed. Standard convolution (SC) can directly obtain convolution results since the convolution kernel channels are the same as the image channels, preserving the hidden connections between channels. In contrast, depth-wise separable convolution (DSC) [
27] processes the input channels in layers, performing separate convolutions for each channel and then recombining them according to their input channels. DSC reduces the computational load associated with multi-channel processing, enhancing prediction speed, but it loses inter-channel correlation information, which directly reduces accuracy.
Figure 4a,b illustrate the calculation processes of SC and DSC, respectively. To enhance prediction speed while approaching the performance of SC, this paper adopts GSConv to replace a portion of the Conv convolutions. GSConv combines DSC with SC.
As shown in
Figure 5, the input features first undergo SC, then are concatenated with the features processed by DWC, followed by a Shuffle operation to gradually integrate them. However, using GSConv at all stages of the model would deepen the network layers, increasing data flow resistance and significantly extending inference time. By the time these feature maps reach the neck, they have become elongated (maximum channel dimension, minimal width-height dimension). Therefore, this paper introduces GSConv modules only in the neck layer, replacing standard convolution to reduce model parameters and computation while ensuring maximum sampling effectiveness. The lightweight convolution of GSConv combined with the one-shot aggregation method to design the cross-stage partial network module [
28], VoV-GSCSP. The original C2f module is replaced by the VoV-GSCSP module, as shown in
Figure 6. The slim-neck structure, formed after improving the neck with GSConv and VoV-GSCSP modules, enhances the fusion of feature layers extracted by the backbone network, allowing each feature layer to balance deep semantic information and shallow detail features. This improvement helps increase the feature recognition ability for small targets, and, while maintaining high accuracy, reduces computational complexity and inference time. The specific slim-neck structure is shown in
Figure 2. Finally, the processed features enter the DyHead module for detection, further enhancing model performance.
2.5. DyHead Module
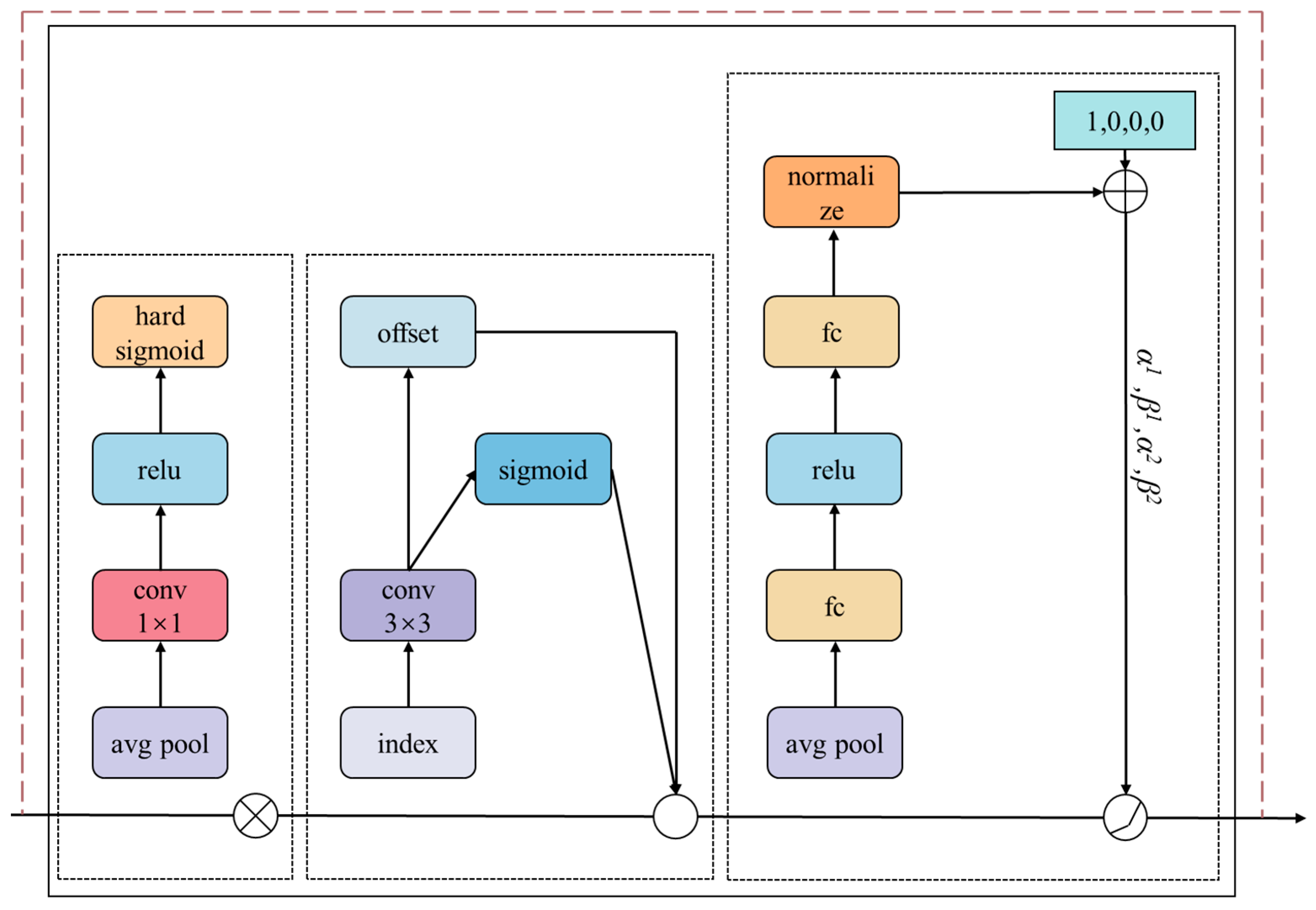
To further improve the model’s performance in recognizing construction machinery across different scales, complex backgrounds, and small targets, this paper introduces the DyHead module in the YOLOv8 head network. The original detection head does not consider contextual information, making predictions at each location independently and lacking a global perspective. Moreover, it predicts from only one scale of the feature map, ignoring the contributions of other scale features, thus inadequately handling multi-scale targets. The DyHead module employs a dynamic routing mechanism to better fuse contextual information and recognize multi-scale targets. It can dynamically adjust the weights of different feature layers, aiding in the extraction of multi-scale features.
The DyHead module leverages a self-attention mechanism to unify scale-aware attention, spatial-aware attention, and task-aware attention, enhancing the representation capability and accuracy of target detection. Given a three-dimensional feature tensor
at the detection layer, the attention calculation formula is as follows:
where
F represents an input three-dimensional tensor
L ×
S ×
C, with
L denoting the feature map’s levels,
S representing the spatial dimensions (height and width product), and
C indicating the number of channels.
,
, and
correspond to the scale-aware attention module, spatial-aware attention module, and task-aware attention module, respectively, and are applied to the
L,
S, and
C dimensions of the three-dimensional tensor
F. As shown in
Figure 7, the internal structure of the three attention modules,
,
, and
, and the single DyHead structure they form in series are depicted. These attention modules are embedded within a target detection head and can be stacked multiple times. Based on experimental comparisons and considering computational cost and model performance, this paper employs only one DyHead module.
2.6. Loss Function
YOLOv8 adopts CIoU as the loss function for the bounding box. While CIoU considers overlap area, center point distance, and aspect ratio, it has a certain degree of ambiguity in the relative value description of the aspect ratio and does not address the issue of sample balance. When the training data contains many low-quality samples, geometric factors such as distance and aspect ratio aggravate the penalty on low-quality samples, reducing the algorithm’s generalization ability and leading to unstable training. Therefore, this paper employs the WIoU loss function instead of the CIoU loss function to better address the sample imbalance issue and improve the model’s convergence speed. The visualization of each parameter in the loss function is shown in
Figure 8. WIoU is defined by Formulas (2)–(4):
where
represents the high-quality anchor box loss,
and
are the coordinates of the center points of the anchor box and target box, respectively, while
and
are the height and width of the minimum enclosing box formed by the target box and prediction box, respectively. The
denotes separating
and
of the minimum enclosing box from the gradient calculation, reducing the adverse impact on model training. The intersection over union (IoU) is an indicator to measure the degree of overlap between the predicted bounding box and the ground truth bounding box.
The non-monotonic focus convergence efficiency
is defined as:
where
is defined as the outlier degree, introduced to measure the quality of the anchor box, which is negatively correlated with the anchor box quality.
is the gradient gain for the monotonic focusing coefficient, defined similarly to
. Here,
indicates that during training, the quality of the anchor box is continually calculated and updated based on each target detection. When
is smaller, the anchor box quality is higher; when
is larger, the anchor box quality is lower. To make the bounding box focus more on ordinary-quality anchor boxes, a smaller gradient gain is assigned for both larger and smaller
, constructing a non-monotonic focusing coefficient
through a dynamic focusing mechanism, used to control the importance weights between different positions. During model training, the gradient gain decreases as
decreases, causing the training speed to slow down in the later stages. Therefore, the mean value of
, denoted as
, is introduced as a normalization factor to alleviate the problem of slow convergence speed in the later stages.
and
are two hyperparameters set to 1.9 and 3.
WIoU balances the penalty strength between low-quality and high-quality anchor boxes, employing a dynamic non-monotonic focus mechanism to mask the impact of low-quality examples, allowing the model to focus more on ordinary-quality anchor boxes and improving the overall performance of the model.
4. Discussion
The proposed YOLO-LSDW model has demonstrated superior performance in the task of detecting external damage hazards in transmission line corridors. Through an in-depth analysis of the experimental results, the following points can be discussed.
4.1. Model Performance Analysis
The YOLO-LSDW model outperforms the comparison models in both mAP@0.5 and mAP@0.5:0.95 metrics, especially excelling in complex backgrounds and small object detection. By introducing the SPPF-LSKA module, this model effectively mitigates the interference of complex backgrounds on the features of construction machinery, significantly improving detection accuracy in challenging environments. Additionally, the lightweight slim-neck feature fusion structure not only enhances the detection capability for small objects but also reduces the model’s parameter count and computational load. The integration of the DyHead detection head, which incorporates scale, spatial, and task-specific attention mechanisms, further boosts the model’s performance in the head network. Moreover, the use of the WIoU loss function optimizes the model’s generalization ability, enhancing stability and convergence speed during training. However, the model still exhibits certain false positives and false negatives in specific scenarios, which may be related to the diversity and representativeness of the training data.
4.2. Computational Efficiency and Real-Time Performance
Although the YOLO-LSDW model shows a significant improvement in detection accuracy, its computational complexity and parameter count are reduced compared to the original YOLOv8s model. This “lightweight” design makes the model more suitable for deployment on edge computing devices, enhancing its feasibility in practical applications. However, during actual deployment, hardware conditions and environmental factors must be considered to ensure the model’s stability and real-time performance across different scenarios.
4.3. Limitations and Future Directions
Despite the achievements of this study, there are still some limitations. Firstly, although the dataset includes a variety of construction machinery, it may not fully represent all possible external damage hazards. Secondly, the model’s performance under extreme weather conditions has not been thoroughly validated. Future research could focus on the following improvements:
1. Expanding the dataset to include more diverse scenarios and target types.
2. Exploring more effective feature fusion methods to further enhance the model’s adaptability to complex scenes.
3. Investigating optimized deployment strategies for the model across different hardware platforms to meet practical application requirements.
5. Conclusions
This paper proposes a detection method for external damage hazards in transmission line corridors based on the YOLO-LSDW model and develops a corresponding dataset. By incorporating the SPPF-LSKA module, slim-neck feature fusion structure, DyHead detection head, and WIoU loss function, the model significantly improves its performance in detecting complex backgrounds and small objects. Experimental results demonstrate that the YOLO-LSDW model outperforms existing mainstream object detection models in both mAP@0.5 and mAP@0.5:0.95 metrics, while maintaining low computational complexity and fast detection speed, showcasing strong potential for practical applications.
However, as noted in the discussion section, there are still some limitations to this study, such as the insufficient diversity of the dataset and the need for further validation of the model’s adaptability under extreme conditions. Future research should focus on expanding and diversifying the dataset, further optimizing feature fusion methods, and enhancing the model’s deployment and performance in real-world application environments.
In summary, the YOLO-LSDW model offers an effective solution for the real-time and efficient detection of external damage hazards in transmission line corridors, contributing significantly to the safety and reliability of power systems. With further optimization and improvements, this method is expected to play a crucial role in the broader field of transmission line safety monitoring, providing essential technical support for the development of smart grids.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}