

Short-Term Wind Power Prediction Based on a Variational Mode Decomposition–BiTCN–Psformer Hybrid Model
Abstract
1. Introduction
- Through VMD, the original signal is decomposed as a whole into other component signals. The decomposition process is carried out on the features of specific significance and can yield a greater amount of comprehensive information and structure within the signal.
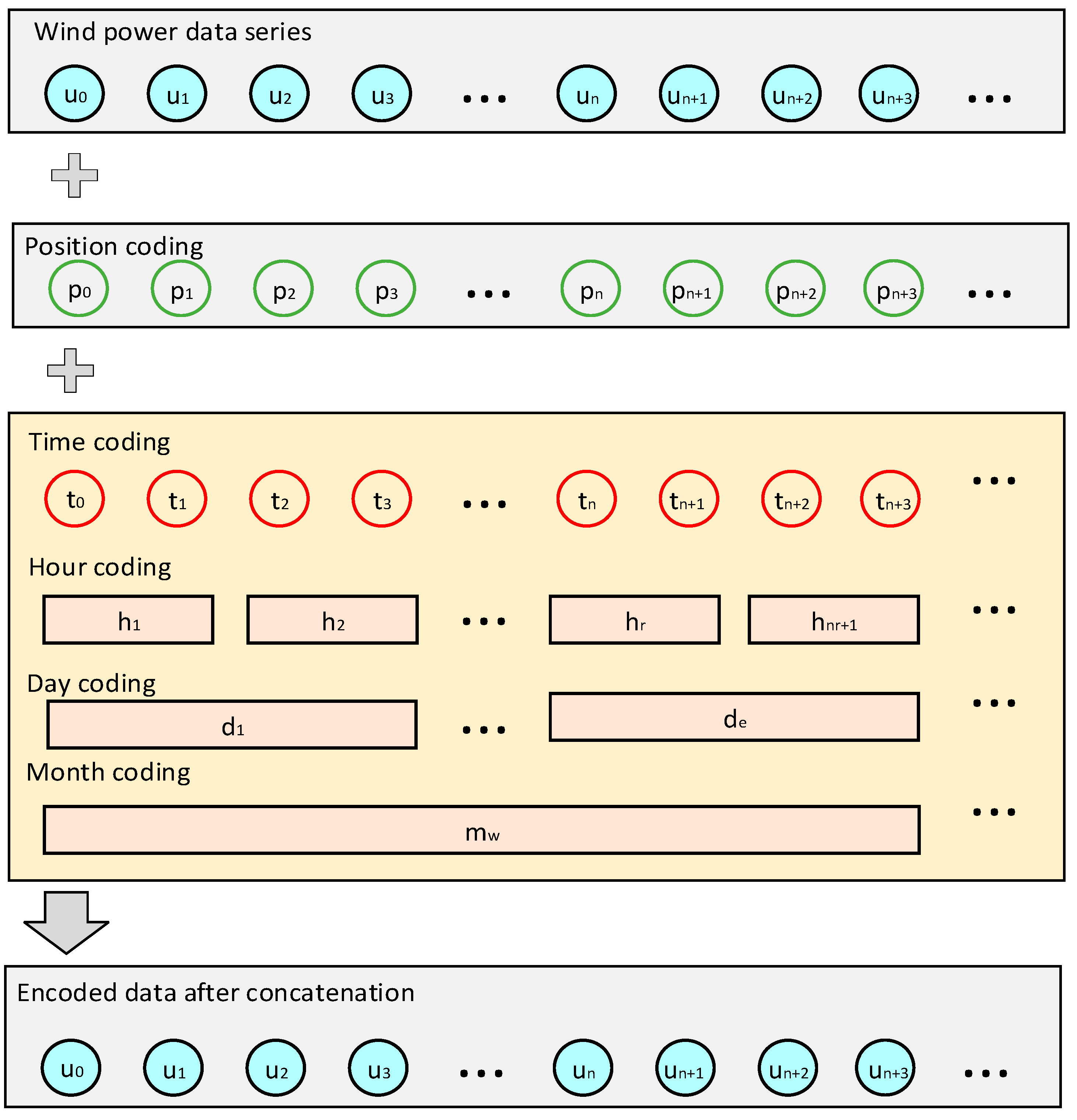
- The concept of position encoding is utilized to extract the hidden aspects of multi-scale temporal seasonal information, which are then merged with position encoding.
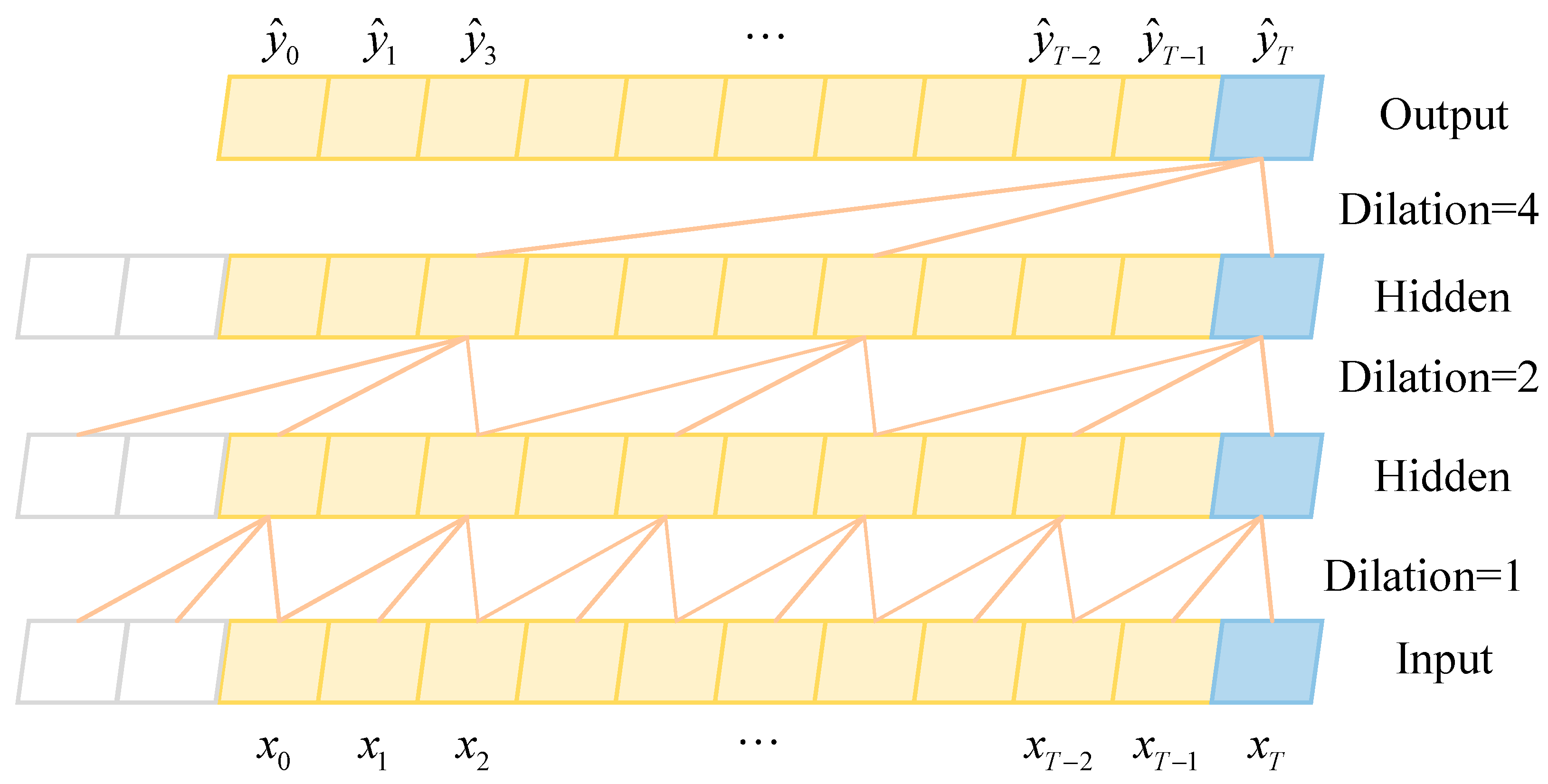
- BiTCN was introduced to extract features of near-time segments of observation points, expand the scope from which the model may acquire information and generate predictions, and adjust the connection structure of the self-attention mechanism and BiTCN output data.
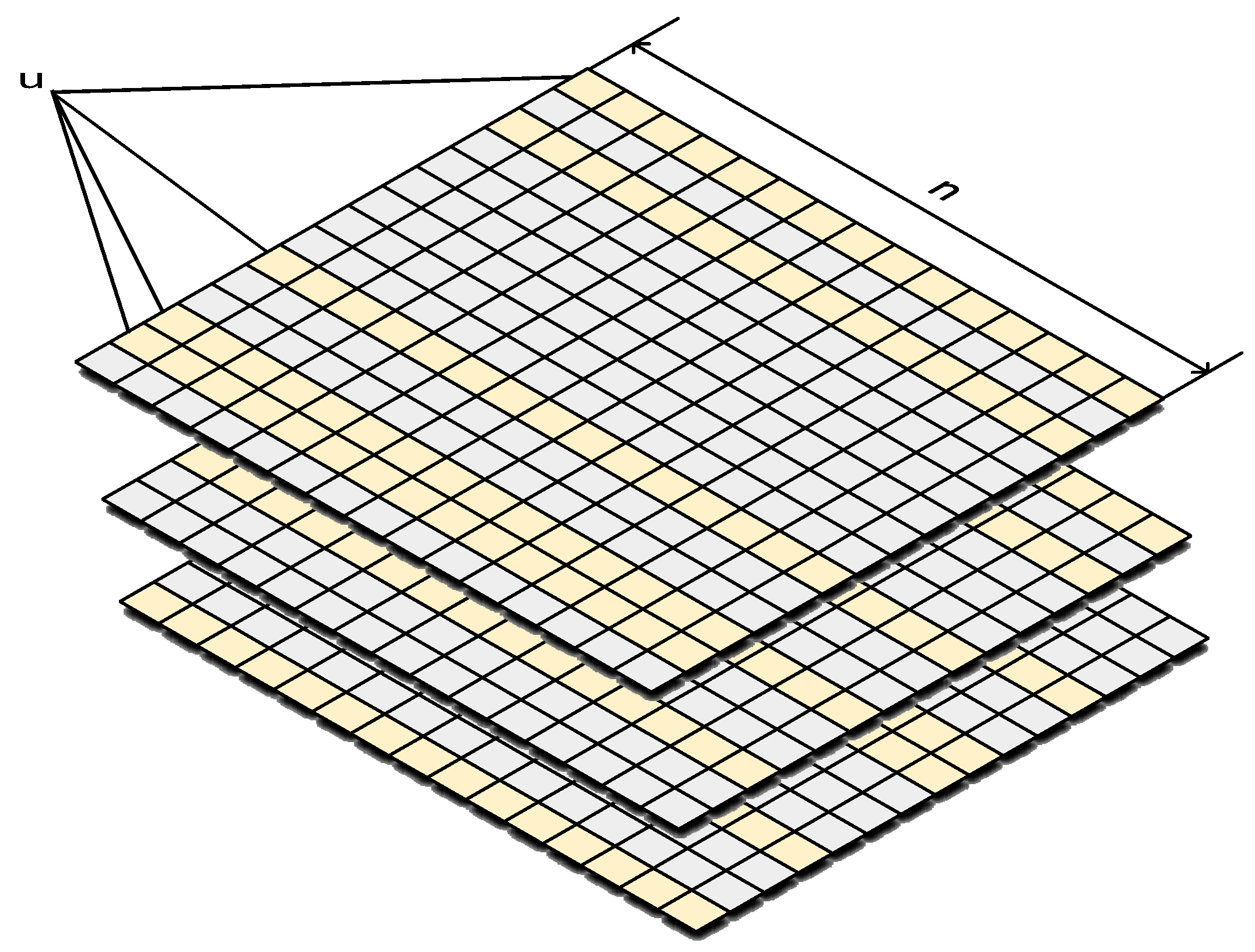
- The ProbSparse self-attention is introduced, and the Psformer model is designed to integrate the characteristics of significant time points into the self-attention mechanism, resulting in enhanced forecast accuracy of wind power and reduced computational complexity.
2. Materials and Methods
2.1. Decomposition of Wind Power Using VMD
2.2. Original Transformer’s Multi-Head Self-Attention
2.3. Original Transformer’s Positional Encoding
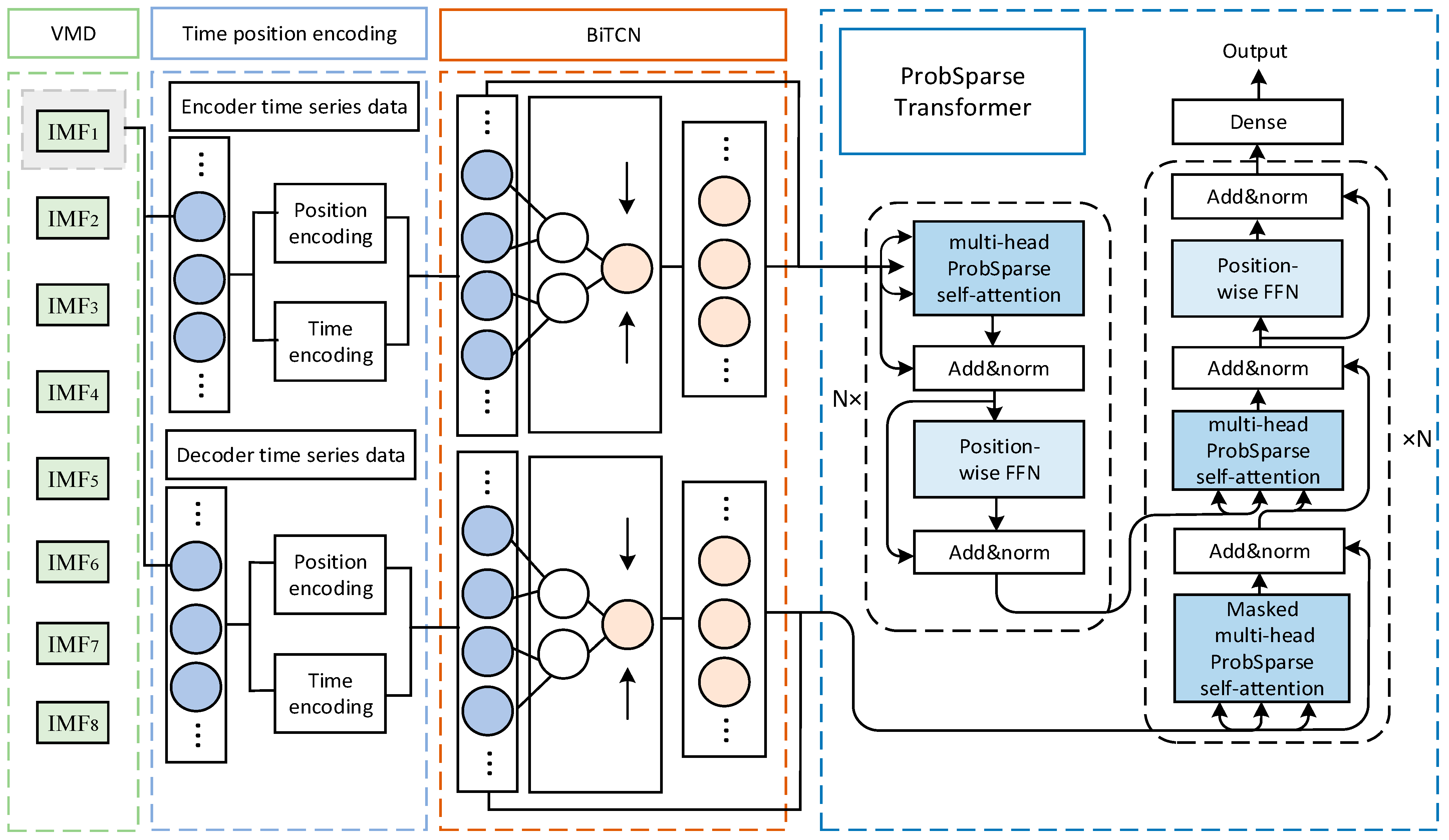
3. Model of VMD-BiTCN-Psformer
3.1. Improvement of Transformer’s Positional Encoding
3.2. BiTCN
3.3. Improvement of Multi-Head Self-Attention Mechanism
| Algorithm 1. ProbSparse Self-Attention Calculation Process |
| Initialize: hyperparameter c, u = clnm, U = mlnn |
| 1. Choose dot product pairs randomly from to |
| 2. |
| 3. |
| 4. Choose the first u-th as |
| 5. |
| 6. |
| 7. |
| Output: feature |
3.4. VMD-BiTCN-Psformer Wind Power Prediction Model
4. Results and Discussion
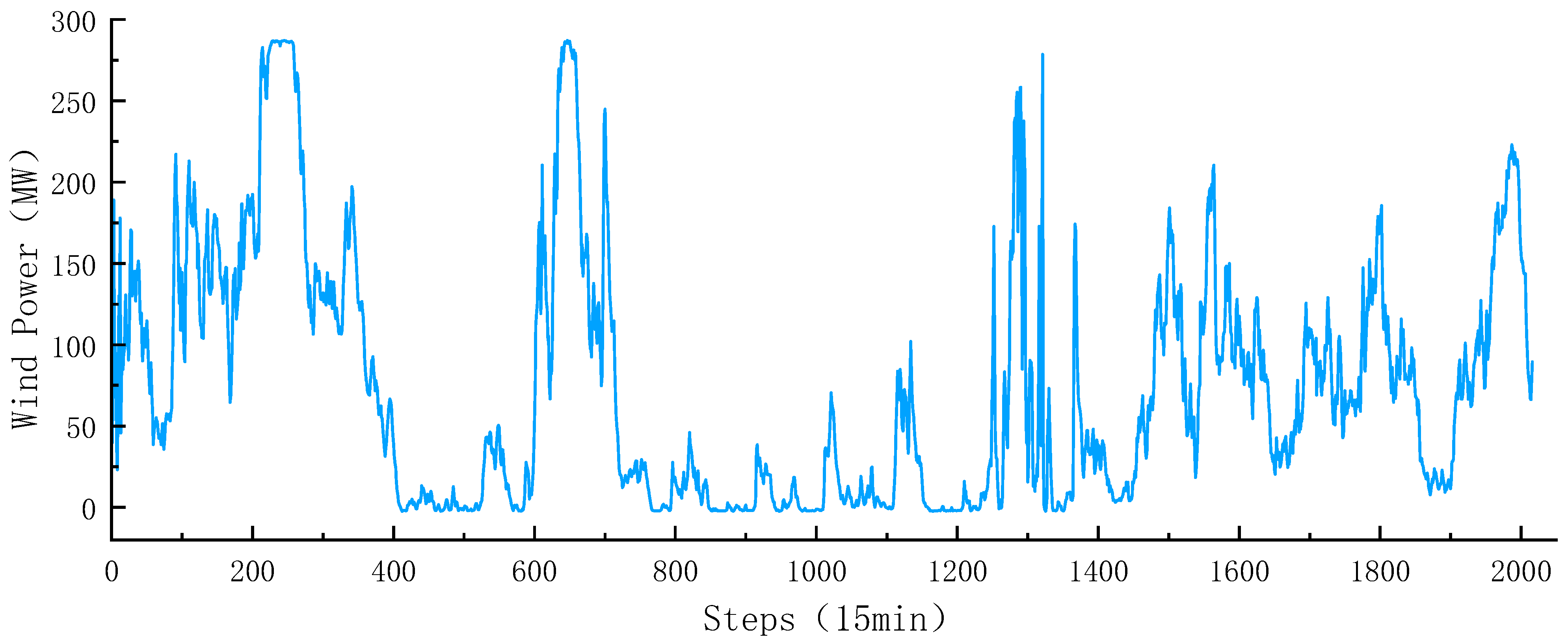
4.1. Data and Evaluation Metrics
4.2. Model Parameter Setting
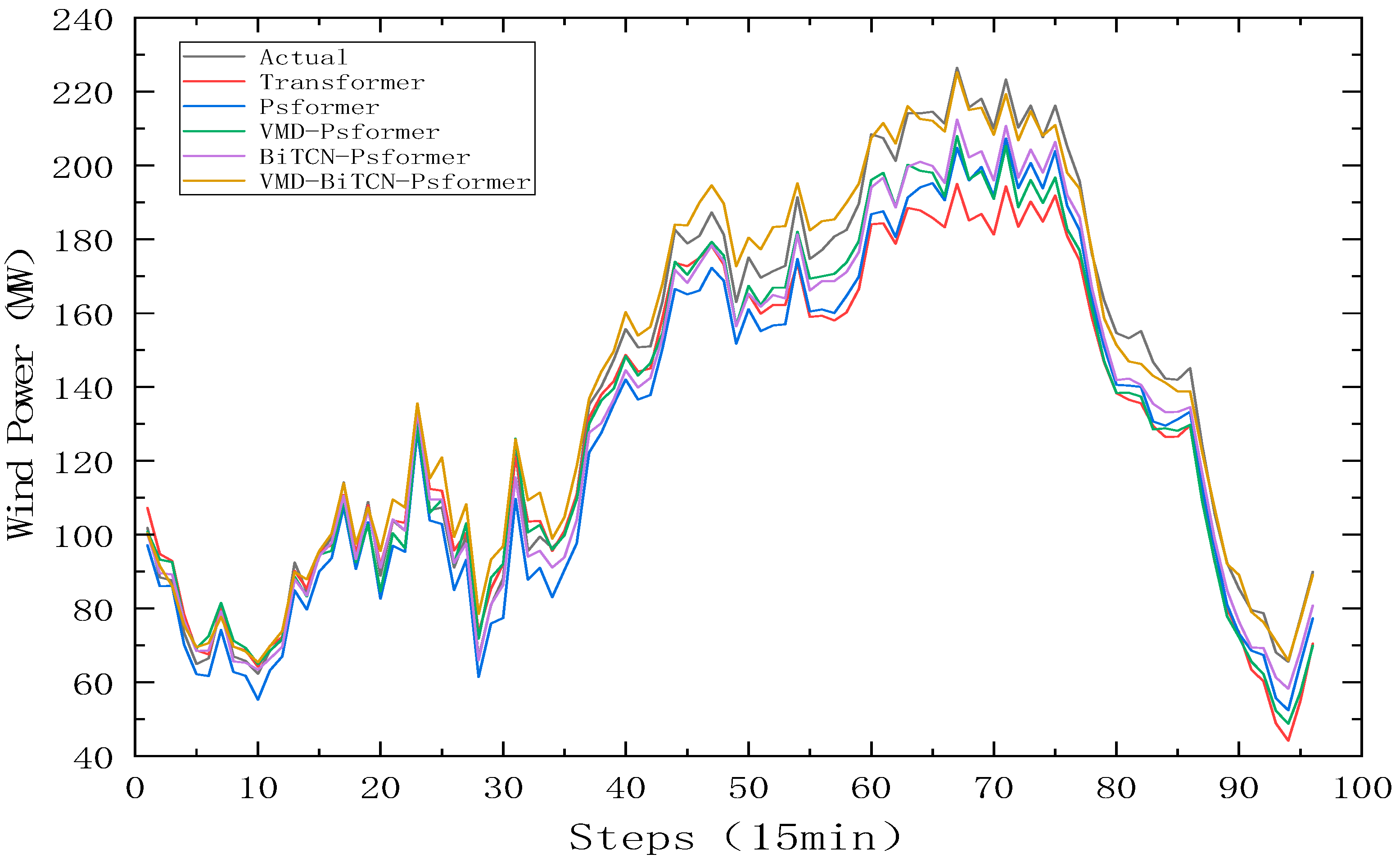
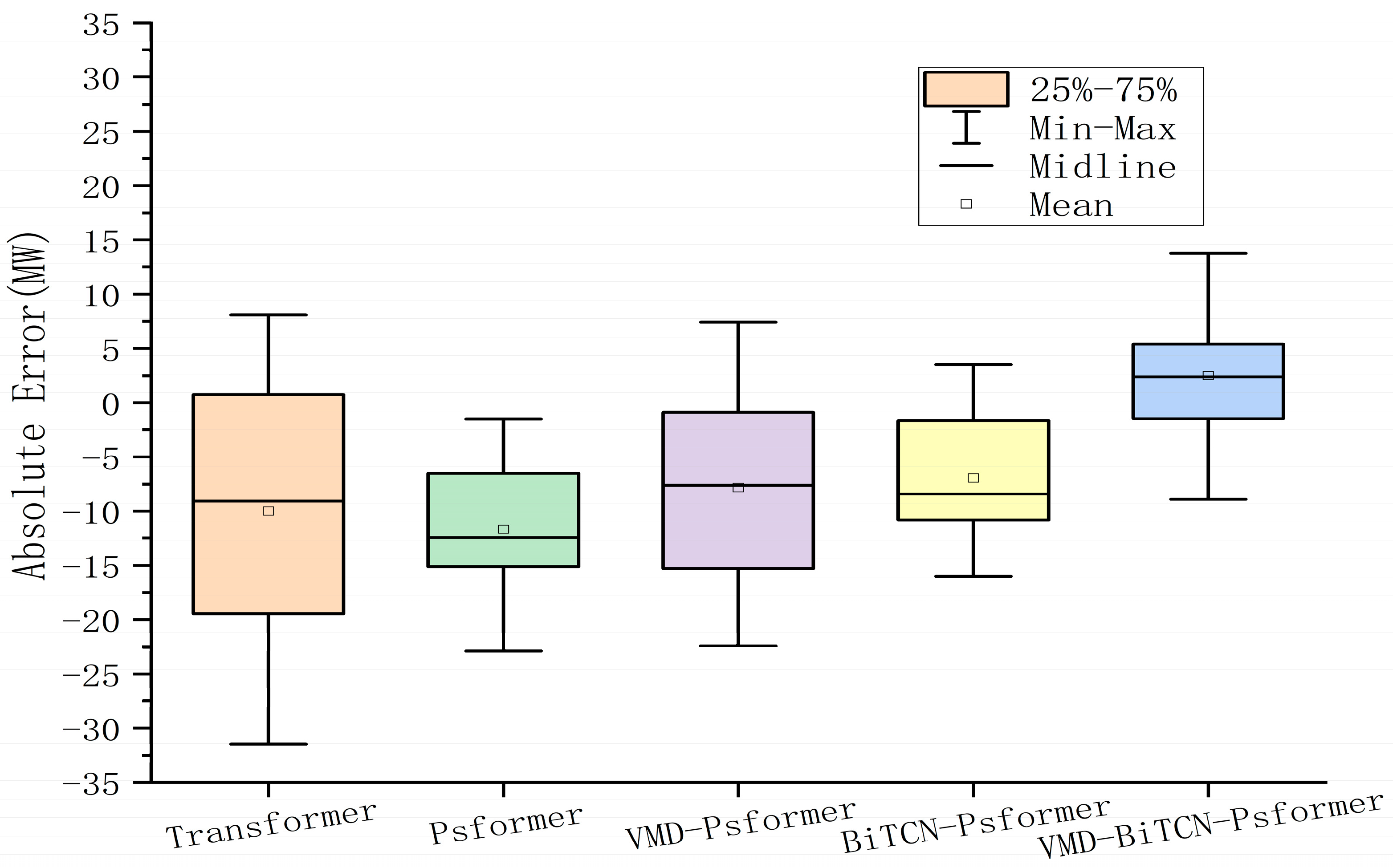
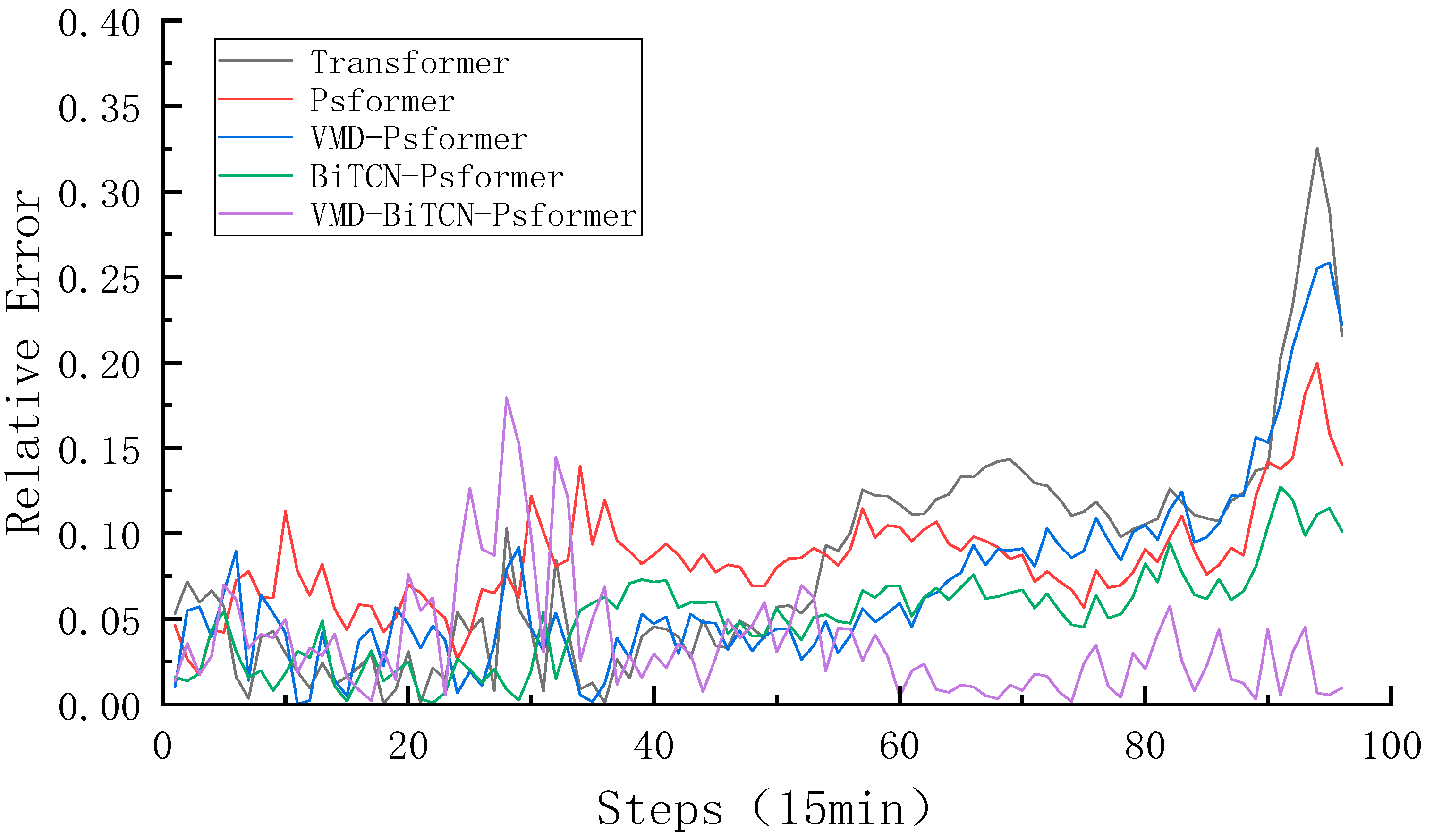
4.3. Validation of Model Effectiveness
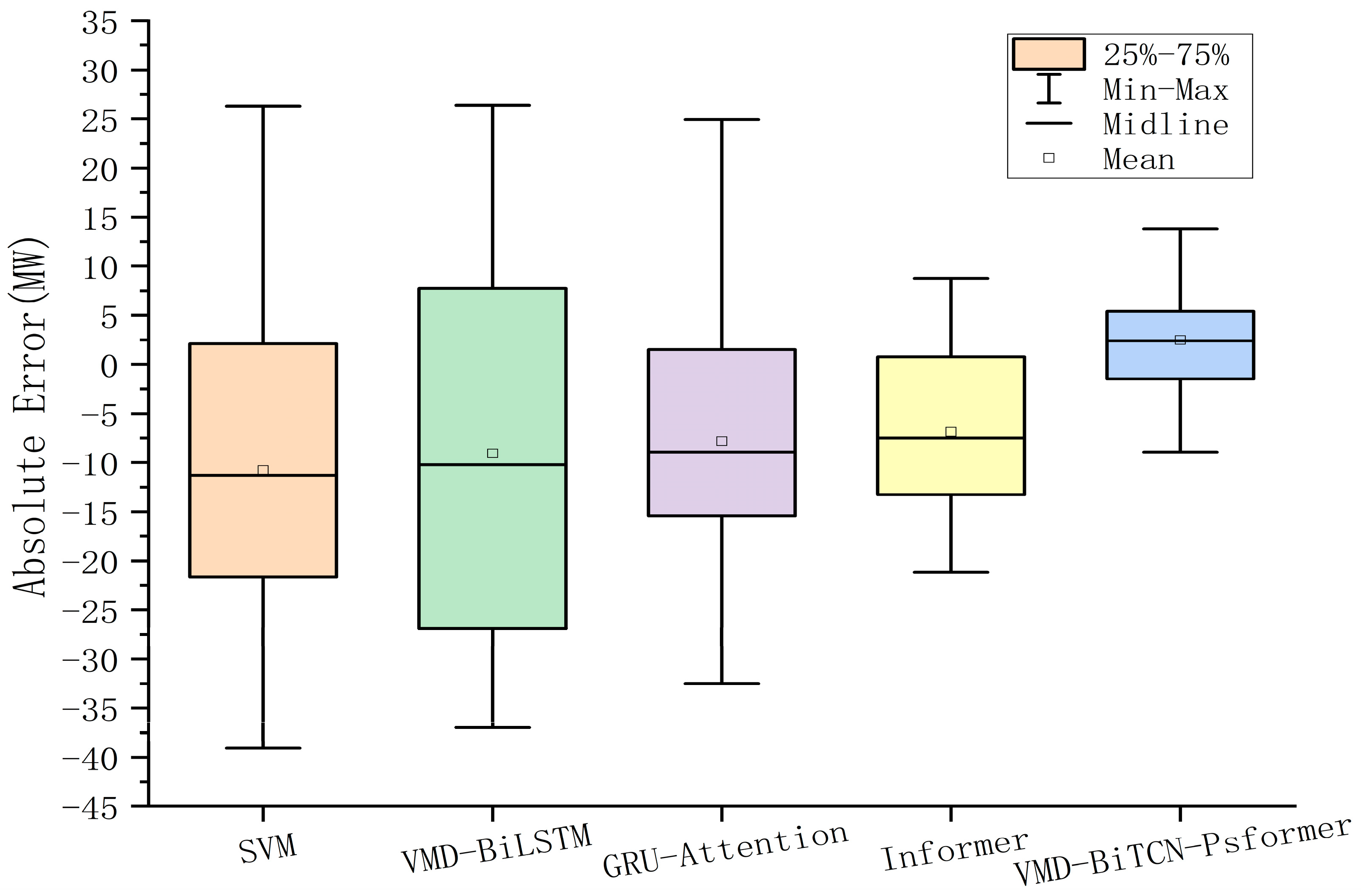
4.3.1. Comparative Analysis of the Forecasting
- (1)
- Comparing VMD-Psformer with Psformer, and VMD-BITCN-Psformer with BiTCN-Psformer, the MAE of each model decreased by 25.58% and 32.08%, respectively, and the R2 of each model increased by 1.52% and 1.23%, respectively. We found that the prediction effect of the model with VMD is better than that of the model without VMD. The VMD is able to decompose the unstable and highly fluctuating wind power signal into more stable sub-sequences, which greatly improves the accuracy of the model prediction.
- (2)
- To verify the effectiveness of the improved ProbSparse module, the Psformer model is compared with the Transformer model. We found that Psformer, which discards key values of relatively low importance, performs better in terms of prediction accuracy. The MAE, RMSE, and RRMSE of Psformer are reduced by 1.28%, 18.13%, and 18.12%, respectively, and R2 is increased by 2.73%.
- (3)
- Compared with Psformer and BiTCN-Psformer, the MAE, RMSE, and RRMSE decreased by 57.92%, 47.60%, and 47.55%, respectively, while R2 increased by 3.64%. BiTCN-Psformer uses BiTCN to adequately capture bi-directional information in time series data, improving the model’s modeling and forecasting performance on sequence data. This means that BiTCN provides a better performance in complex time series tasks.
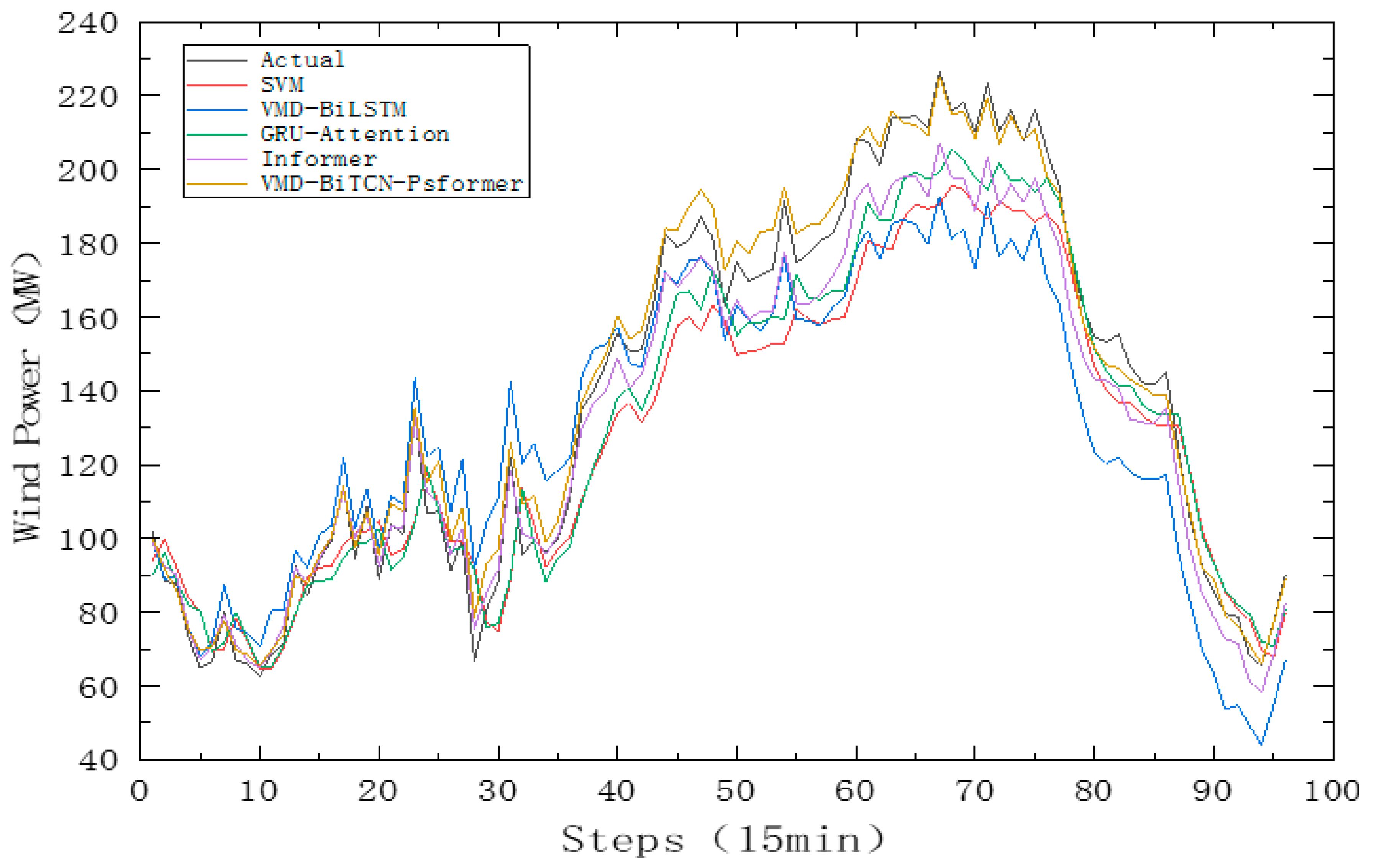
4.3.2. Comparative Analysis with Other Models
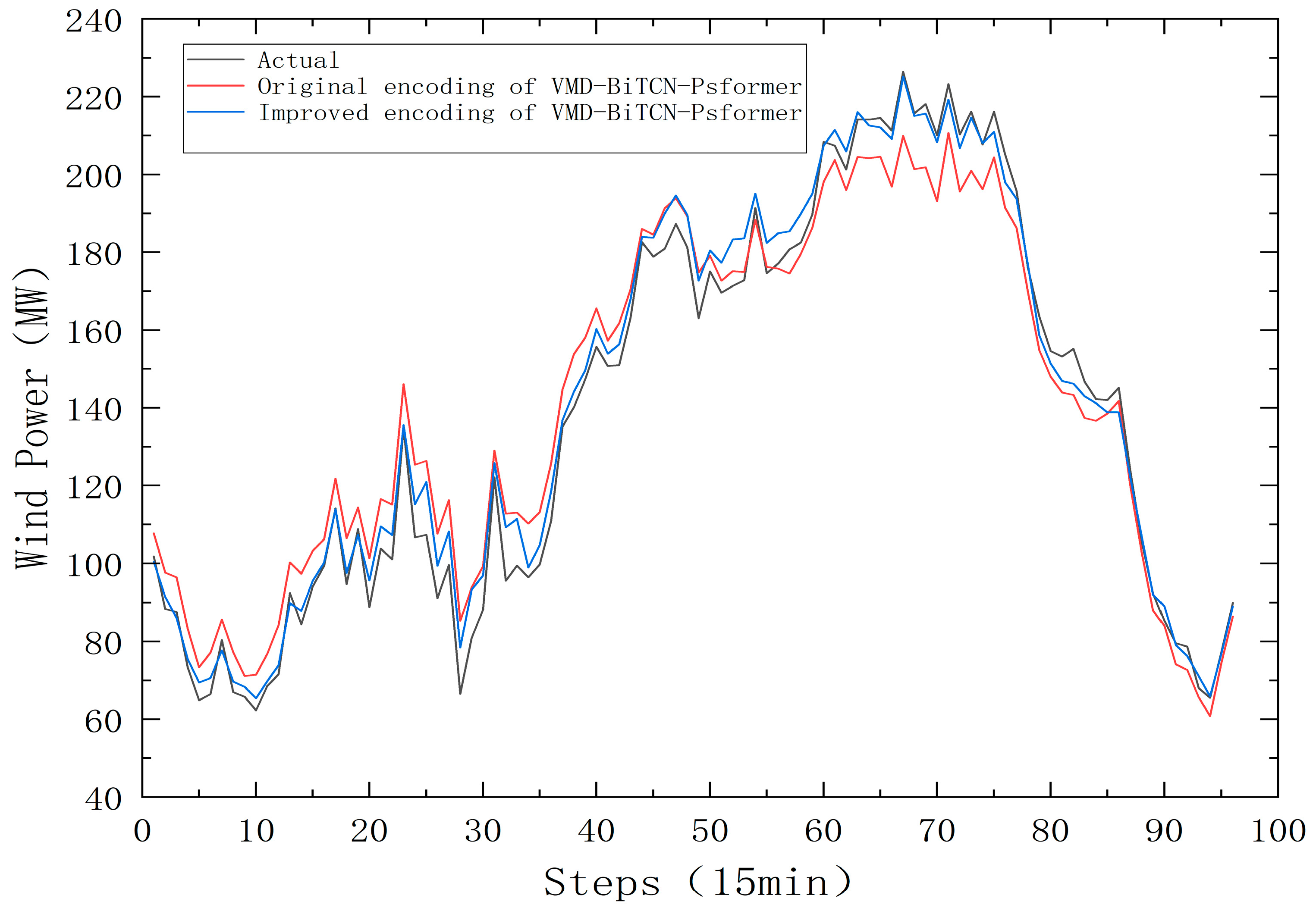
4.3.3. Forecasting Performance of Improved Positional Encoding
5. Conclusions
- (1)
- The combination model of VMD-BiTCN-Psformer is superior to relatively single combination models, and the application of VMD, BiTCN, and Transformer all contributes to improving the accuracy of predictions.
- (2)
- Table 4 shows that the MAE, RMSE, RRMSE, and R2 of the wind power prediction results of the proposed model are better than those of other models. The prediction of the designed model is closest to the actual values, so it has a more accurate prediction effect.
- (3)
- We compared the models before and after improving the positional encoding and found that the prediction accuracy improved after the improvement, demonstrating the effectiveness of the improved encoding.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Foley, A.M.; Leahy, P.G.; Marvuglia, A.; McKeogh, E.J. Current methods and advances in forecasting of wind power generation. Renew. Energy 2012, 37, 1–8. [Google Scholar] [CrossRef]
- Ye, L.; Li, Y.; Pei, M.; Zhao, Y.; Li, Z.; Lu, P. A novel integrated method for short-term wind power forecasting based on fluctuation clustering and history matching. Appl. Energy 2022, 327, 120131. [Google Scholar] [CrossRef]
- Liu, H.; Yang, L.; Zhang, B.; Zhang, Z. A two-channel deep network based model for improving ultra-short-term prediction of wind power via utilizing multi-source data. Energy 2023, 283, 128510. [Google Scholar] [CrossRef]
- Sun, H.; Cui, Q.; Wen, J.; Kou, L.; Ke, W. Short-term wind power prediction method based on CEEMDAN-GWO-Bi-LSTM. Energy Rep. 2024, 11, 1487–1502. [Google Scholar] [CrossRef]
- Zhu, L. Review of Wind Power Prediction Methods Based on Artificial Intelligence Technology. In Proceedings of the 2024 IEEE 7th Advanced Information Technology, Electronic and Automation Control Conference (IAEAC), Chongqing, China, 15–17 March 2024; Volume 7, pp. 1454–1457. [Google Scholar]
- Ahmad, T.; Chen, H. A review on machine learning forecasting growth trends and their real-time applications in different energy systems. Sustain. Cities Soc. 2020, 54, 102010. [Google Scholar] [CrossRef]
- Shahid, F.; Zameer, A.; Mehmood, A.; Raja, M.A.Z. A novel wavenets long short term memory paradigm for wind power prediction. Appl. Energy 2020, 269, 115098. [Google Scholar] [CrossRef]
- Hossain, M.A.; Gray, E.; Lu, J.; Islam, M.R.; Alam, M.S.; Chakrabortty, R.; Pota, H.R. Optimized forecasting model to improve the accuracy of very short-term wind power prediction. IEEE Trans. Ind. Inform. 2023, 19, 10145–10159. [Google Scholar] [CrossRef]
- Xiong, B.; Lou, L.; Meng, X.; Wang, X.; Ma, H.; Wang, Z. Short-term wind power forecasting based on Attention Mechanism and Deep Learning. Electr. Power Syst. Res. 2022, 206, 107776. [Google Scholar] [CrossRef]
- Niksa-Rynkiewicz, T.; Stomma, P.; Witkowska, A.; Rutkowska, D.; Słowik, A.; Cpałka, K.; Jaworek-Korjakowska, J.; Kolendo, P. An intelligent approach to short-term wind power prediction using deep neural networks. J. Artif. Intell. Soft Comput. Res. 2023, 13, 197–210. [Google Scholar] [CrossRef]
- Li, Z.; Ye, L.; Zhao, Y.; Pei, M.; Lu, P.; Li, Y.; Dai, B. A spatiotemporal directed graph convolution network for ultra-short-term wind power prediction. IEEE Trans. Sustain. Energy 2022, 14, 39–54. [Google Scholar] [CrossRef]
- Yu, G.Z.; Lu, L.; Tang, B.; Wang, S.Y.; Chung, C.Y. Ultra-short-term wind power subsection forecasting method based on extreme weather. IEEE Trans. Power Syst. 2022, 38, 5045–5056. [Google Scholar] [CrossRef]
- Sun, S.; Liu, Y.; Li, Q.; Wang, T.; Chu, F. Short-term multi-step wind power forecasting based on spatio-temporal correlations and transformer neural networks. Energy Convers. Manag. 2023, 283, 116916. [Google Scholar] [CrossRef]
- Bentsen, L.Ø.; Warakagoda, N.D.; Stenbro, R.; Engelstad, P. Spatio-temporal wind speed forecasting using graph networks and novel Transformer architectures. Appl. Energy 2023, 333, 120565. [Google Scholar] [CrossRef]
- Nascimento, E.G.S.; de Melo, T.A.C.; Moreira, D.M. A transformer-based deep neural network with wavelet transform for forecasting wind speed and wind energy. Energy 2023, 278, 127678. [Google Scholar] [CrossRef]
- Xiang, L.; Fu, X.; Yao, Q.; Zhu, G.; Hu, A. A novel model for ultra-short term wind power prediction based on Vision Transformer. Energy 2024, 294, 130854. [Google Scholar] [CrossRef]
- Zhou, H.; Zhang, S.; Peng, J.; Zhang, S.; Li, J.; Xiong, H.; Zhang, W. Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting. Proc. AAAI Conf. Artif. Intell. 2020, 35, 11106–11115. [Google Scholar] [CrossRef]
- Sheng, Y.; Wang, H.; Yan, J.; Liu, Y.; Han, S. Short-term wind power prediction method based on deep clustering-improved Temporal Convolutional Network. Energy Rep. 2023, 9, 2118–2129. [Google Scholar] [CrossRef]
- Chen, Y.; He, Y.; Xiao, J.W.; Wang, Y.W.; Li, Y. Hybrid model based on similar power extraction and improved temporal convolutional network for probabilistic wind power forecasting. Energy 2024, 304, 131966. [Google Scholar] [CrossRef]
- Xie, P.; Liu, Y.; Yang, Y.; Lin, X.; Chen, Y.; Hu, X.; Li, L. Offshore wind power output prediction based on convolutional attention mechanism. Energy Sources 2023, 45, 13041–13056. [Google Scholar] [CrossRef]
- Kari, T.; Guoliang, S.; Kesong, L.; Xiaojing, M.; Xian, W. Short-Term Wind Power Prediction Based on Combinatorial Neural Networks. Intell. Autom. Soft Comput. 2023, 37, 1437–1452. [Google Scholar] [CrossRef]
- Guan, S.; Wang, Y.; Liu, L.; Gao, J.; Xu, Z.; Kan, S. Ultra-short-term wind power prediction method based on FTI-VACA-XGB model. Expert Syst. Appl. 2024, 235, 121185. [Google Scholar] [CrossRef]
- Mujeeb, S.; Alghamdi, T.A.; Ullah, S.; Fatima, A.; Javaid, N.; Saba, T. Exploiting deep learning for wind power forecasting based on big data analytics. Appl. Sci. 2019, 9, 4417. [Google Scholar] [CrossRef]
- Zhang, D.; Chen, B.; Zhu, H.; Goh, H.H.; Dong, Y.; Wu, T. Short-term wind power prediction based on two-layer decomposition and BiTCN-BiLSTM-attention model. Energy 2023, 285, 128762. [Google Scholar] [CrossRef]
- Li, Z.; Luo, X.; Liu, M.; Cao, X.; Du, S.; Sun, H. Wind power prediction based on EEMD-Tent-SSA-LS-SVM. Energy Rep. 2022, 8, 3234–3243. [Google Scholar] [CrossRef]
- Yang, M.; Chen, X.; Du, J.; Cui, Y. Ultra-short-term multistep wind power prediction based on improved EMD and reconstruction method using run-length analysis. IEEE Access 2018, 6, 31908–31917. [Google Scholar] [CrossRef]
- Liu, H.; Han, H.; Sun, Y.; Shi, G.; Su, M.; Liu, Z.; Wang, H.; Deng, X. Short-term wind power interval prediction method using VMD-RFG and Att-GRU. Energy 2022, 251, 123807. [Google Scholar] [CrossRef]
- Xie, T.; Zhang, G.; Liu, H.; Liu, F.; Du, P. A hybrid forecasting method for solar output power based on variational mode decomposition, deep belief networks and auto-regressive moving average. Appl. Sci. 2018, 8, 1901. [Google Scholar] [CrossRef]
- Dragomiretskiy, K.; Zosso, D. Variational Mode Decomposition. IEEE Trans. Signal Process. 2013, 62, 531–544. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Set Value | Parameter | Set Value |
|---|---|---|---|
| seq_len | 192 | batch_size | 64 |
| enc_in | 6 | train_epochs | 50 |
| dec_in | 6 | dropout | 0.05 |
| sampling factor u | 5 | learning_rate | 0.001 |
| n_head | 8 | activation | Gelu |
| Model | VMD | BiTCN | Psformer |
|---|---|---|---|
| Transformer | × | × | × |
| Psformer | × | × | √ |
| VMD-Psformer | √ | × | √ |
| BiTCN-Psformer | × | √ | √ |
| VMD-BiTCN-Psformer | √ | √ | √ |
| Model | Evaluation Metrics | |||
|---|---|---|---|---|
| MAE | RMSE | RRMSE | ||
| Transformer | 11.8262 | 15.1559 | 0.9120 | 0.1030 |
| Psformer | 11.6762 | 12.8298 | 0.9369 | 0.0872 |
| VMD-Psformer | 9.2985 | 11.3005 | 0.9511 | 0.0768 |
| BiTCN-Psformer | 7.3939 | 8.6925 | 0.9710 | 0.0591 |
| VMD-BiTCN-Psformer | 5.5979 | 6.6849 | 0.9829 | 0.0454 |
| Model | Evaluation Metrics | |||
|---|---|---|---|---|
| MAE | RMSE | RRMSE | ||
| SVM | 15.0076 | 17.7801 | 0.8039 | 0.1333 |
| VMD-BiLSTM | 15.6544 | 18.0880 | 0.8746 | 0.1230 |
| GRU-Attention | 11.7395 | 13.7568 | 0.9023 | 0.1001 |
| Informer | 8.6425 | 10.4532 | 0.9581 | 0.0711 |
| VMD-BiTCN-Psformer | 5.5979 | 6.6849 | 0.9829 | 0.0454 |
| Model | Evaluation Metrics | |||
|---|---|---|---|---|
| MAE | RMSE | R2 | RRMSE | |
| Original encoding of VMD-BiTCN-Psformer | 9.0976 | 10.1782 | 0.9603 | 0.0692 |
| Improved encoding of VMD-BiTCN-Psformer | 5.5979 | 6.6849 | 0.9829 | 0.0454 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, W.; Dai, W.; Li, D.; Wu, Q. Short-Term Wind Power Prediction Based on a Variational Mode Decomposition–BiTCN–Psformer Hybrid Model. Energies 2024, 17, 4089. https://doi.org/10.3390/en17164089
Xu W, Dai W, Li D, Wu Q. Short-Term Wind Power Prediction Based on a Variational Mode Decomposition–BiTCN–Psformer Hybrid Model. Energies. 2024; 17(16):4089. https://doi.org/10.3390/en17164089
Chicago/Turabian StyleXu, Wu, Wenjing Dai, Dongyang Li, and Qingchang Wu. 2024. "Short-Term Wind Power Prediction Based on a Variational Mode Decomposition–BiTCN–Psformer Hybrid Model" Energies 17, no. 16: 4089. https://doi.org/10.3390/en17164089
APA StyleXu, W., Dai, W., Li, D., & Wu, Q. (2024). Short-Term Wind Power Prediction Based on a Variational Mode Decomposition–BiTCN–Psformer Hybrid Model. Energies, 17(16), 4089. https://doi.org/10.3390/en17164089