1. Introduction
The global energy consumption scenario is dominated by non-renewable sources such as coal, oil and natural gas. In 2022, according to the Energy Information Administration (EIA) [
1], the consumption was: oil (29.5%), coal (26.8%), natural gas (23.7%), biomass (9.8%), nuclear energy (5.0%), hydroelectric energy (2.7%) and other sources (2.5%). In the coming years, oil and natural gas are expected to remain prominent, driven by the development of nations such as China, the largest importer and second largest consumer of oil [
2].
Oil, a raw material with high industrial value, has its price influenced by global economic and geopolitical aspects [
3,
4,
5,
6,
7,
8,
9]. This price is determined by a complex, non-linear system with many uncertainties [
10].
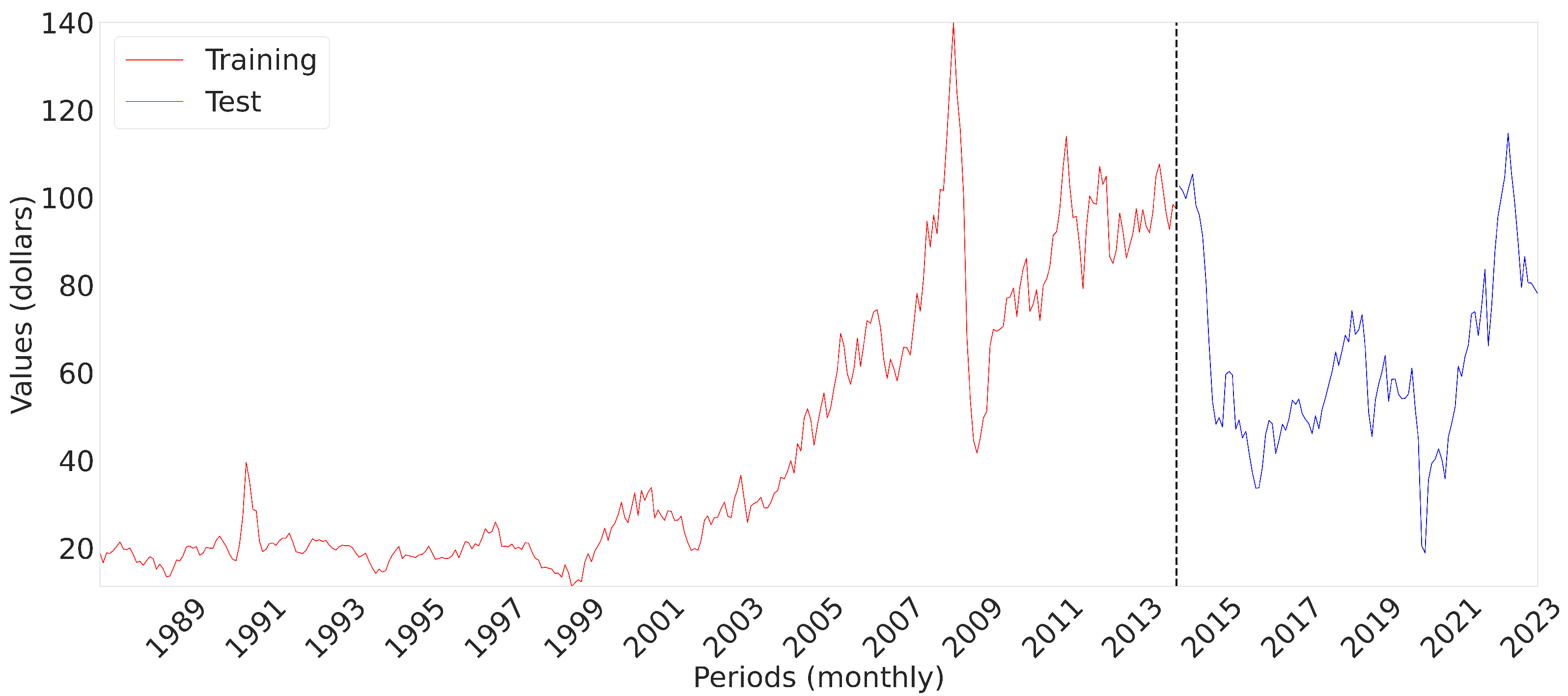
Since 2008, the fall in oil prices has been influenced by the global economic slowdown and geopolitical instability, as well as the crisis between China and the US. The COVID-19 pandemic and the war between Russia and Ukraine have added new uncertainties, affecting price formation [
6,
11,
12]. These events have caused fluctuations in prices, challenging market and political decisions, but also offering opportunities to explore forecasting methods.
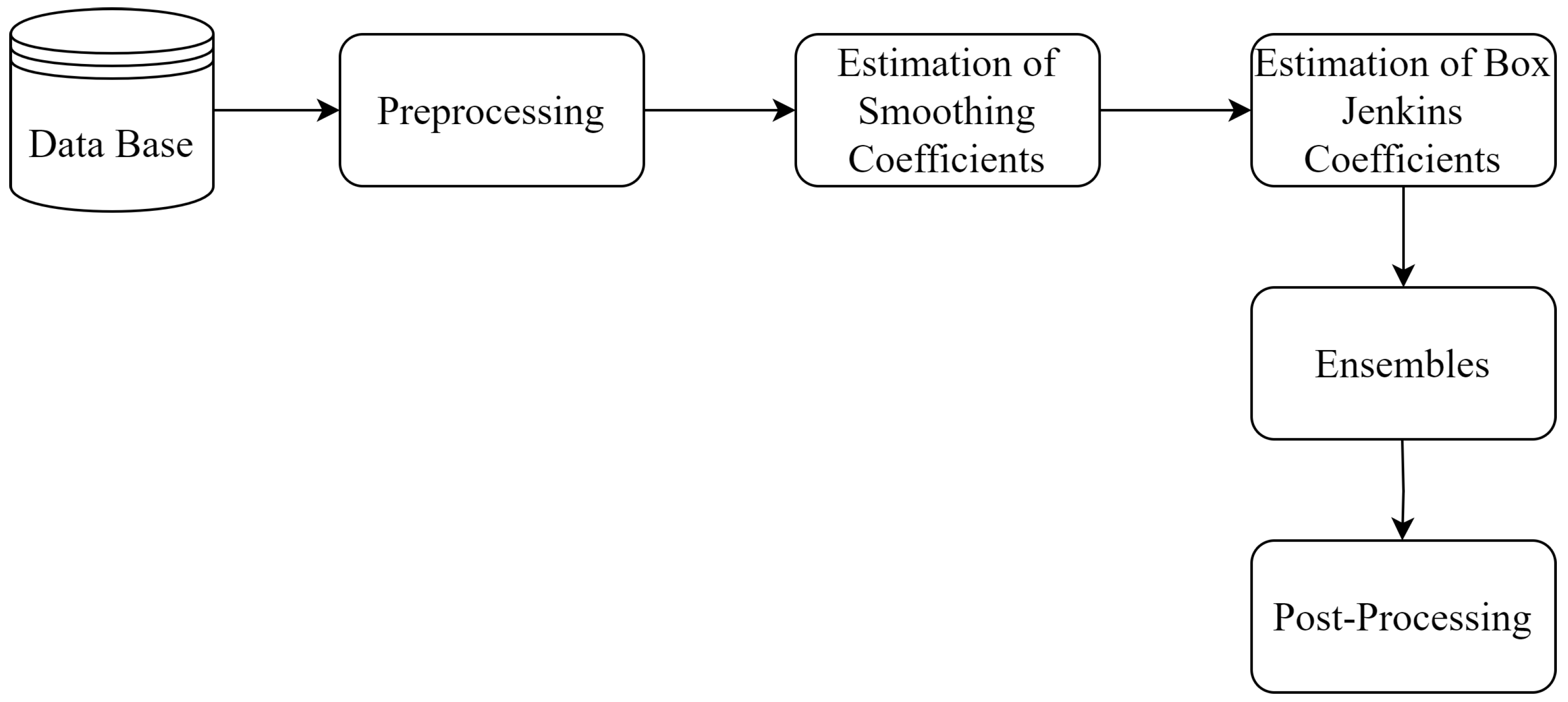
Forecasting models include linear and non-linear approaches and combination strategies such as hybrids and ensemble. Linear models, such as exponential smoothing, are used to capture patterns in time series by adjusting for trends and seasonality. For example, Simple Exponential Smoothing (SES) is suitable for series with no trend or seasonality, while the Holt-Winters model deals with series that have these characteristics.
Box & Jenkins models, such as AR, ARMA and ARIMA, are essential for analyzing time dependencies, where AR captures the linear relationship between an observation and several past lags, MA models the forecast error as a linear combination of past errors and ARIMA handles non-stationary series by incorporating differentiation [
13].
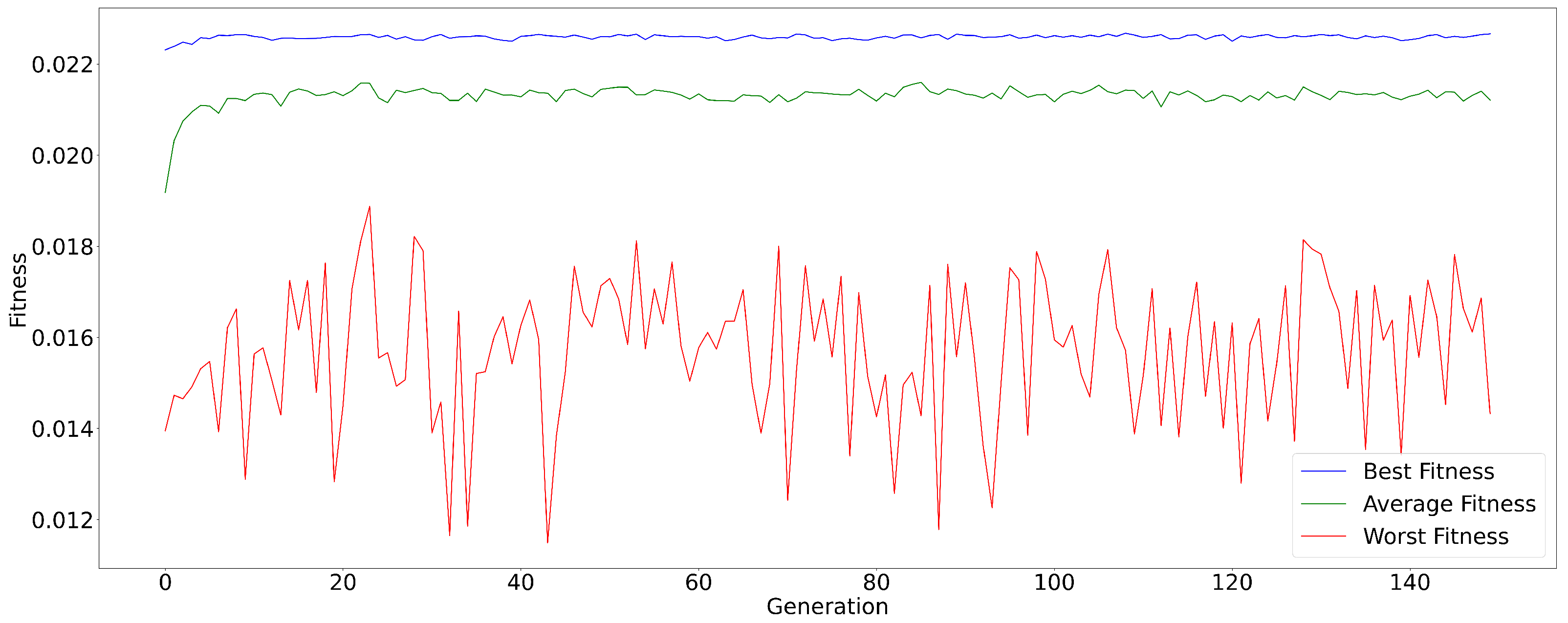
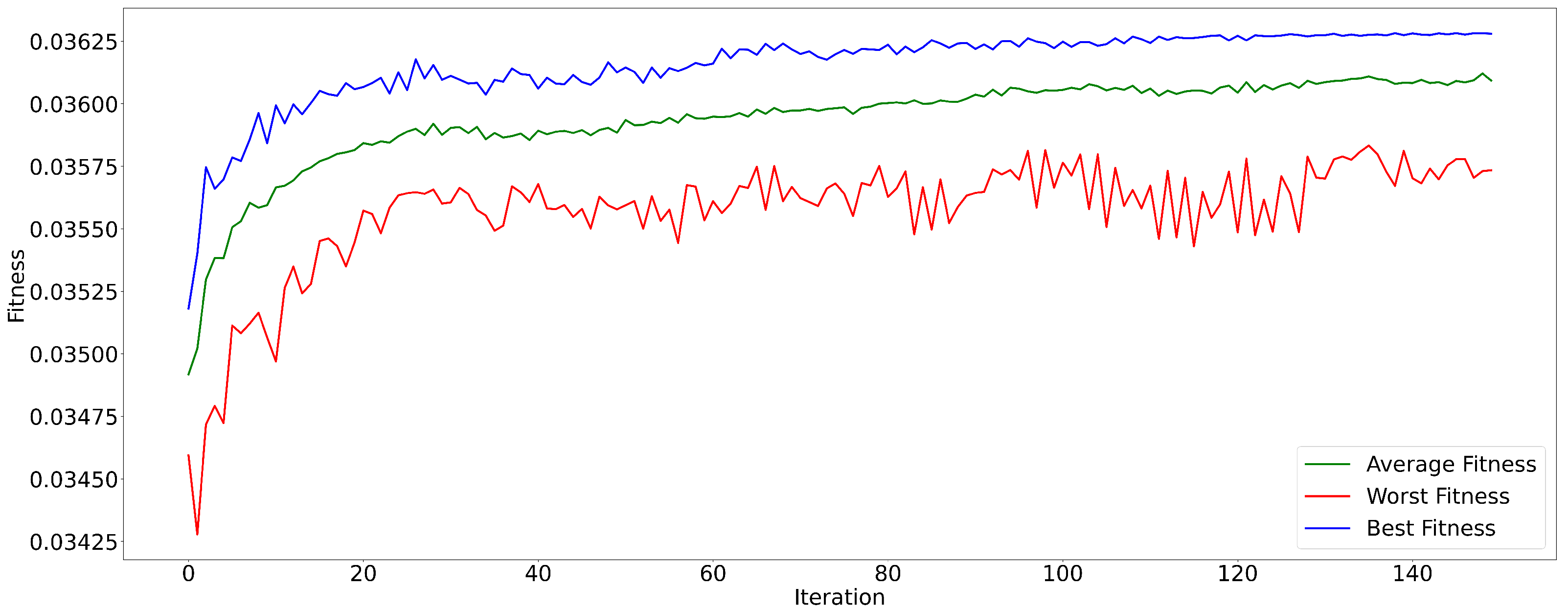
Variants of the ARMA model optimized by Genetic Algorithm (GA) and Particle Swarm Optimization (PSO) improve forecast accuracy by automatically adjusting parameters, allowing for more effective modeling of complex dynamics [
14]. These optimization techniques provide an enhanced ability to capture subtle patterns and deal with the inherent complexity of time series.
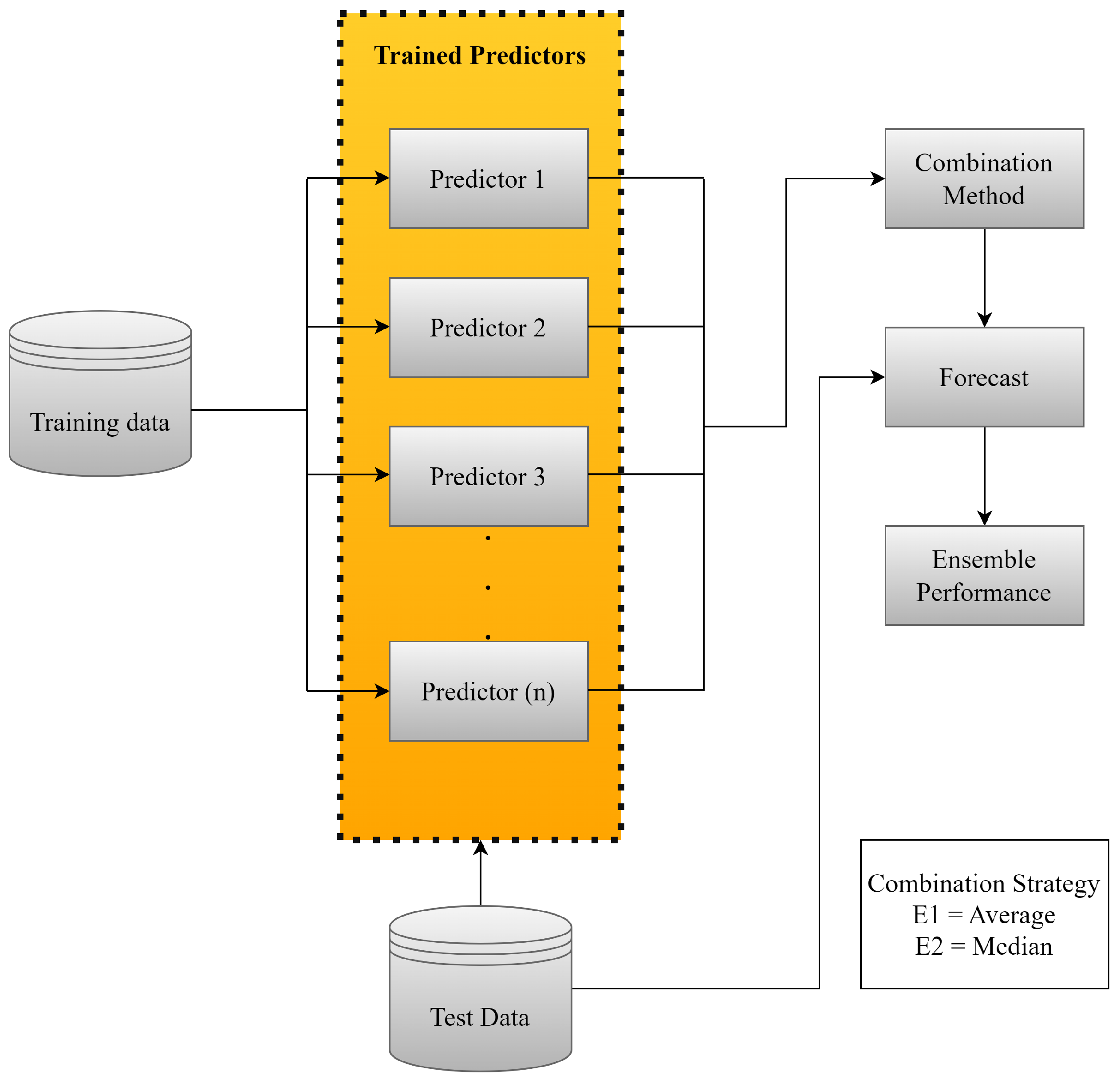
In addition to hybrid models, combination strategies such as ensemble combine outputs from individual predictors [
15]. These strategies include averages, medians, weighted averages and other combinations [
16,
17]. ensemble techniques optimize the accuracy of forecasts by combining results from multiple models, reducing the variance of errors and increasing the consistency of estimates in volatile markets.
The literature has evolved regarding forecasting models for monthly crude oil (WTI) futures prices [
18,
19,
20]. Although new techniques are emerging, linear models are still widely used, from simple comparisons to hybrid models [
21].ensemble models have the potential to improve forecast accuracy, but are still little explored [
15,
16,
17].
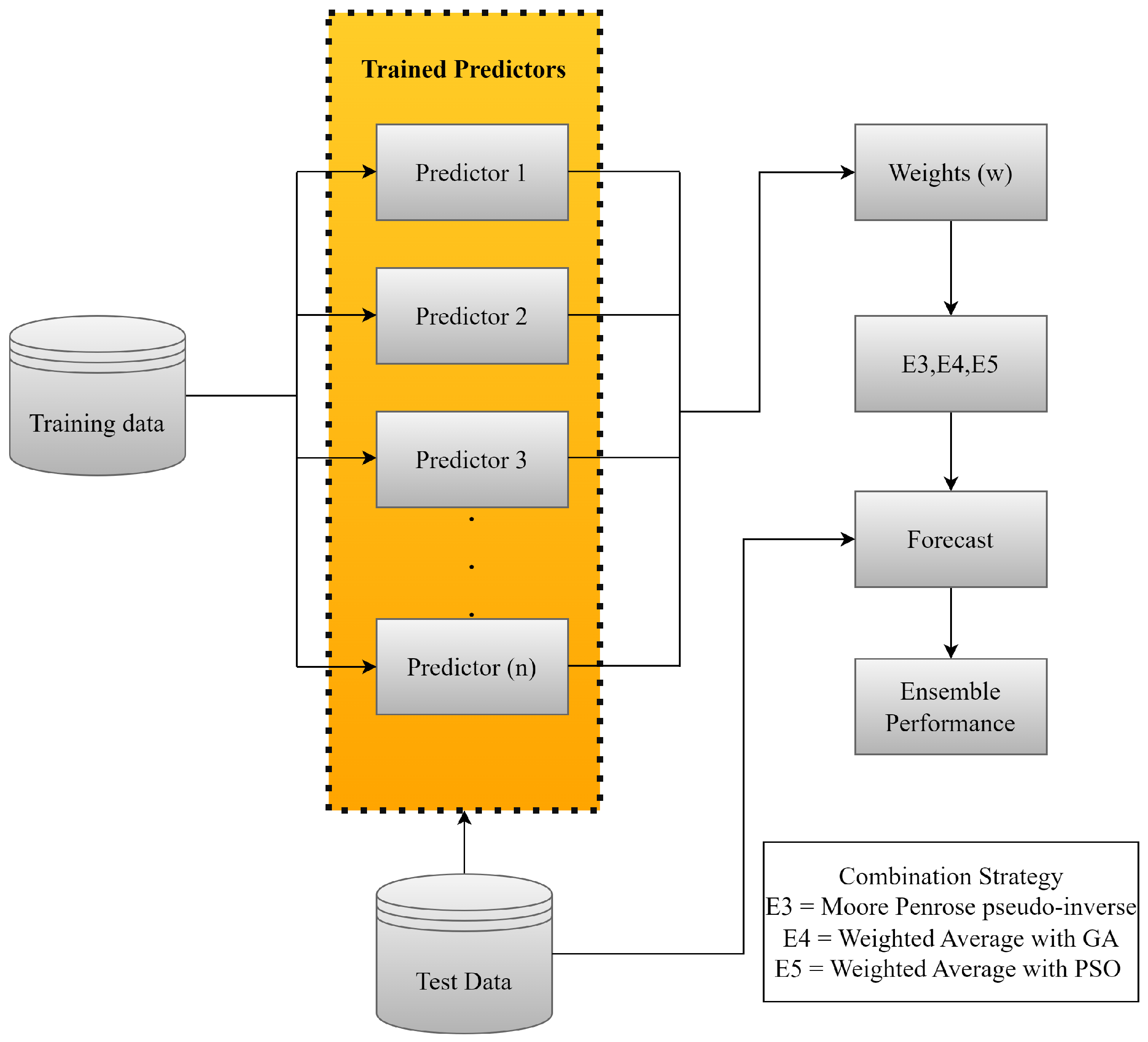
The aim of this article is to explore linear models, specifically smoothing and Box & Jenkins models, and apply incremental adjustments to the ARMA model using GA and PSO. Combination strategies ensemble considered include mean, median, pseudo-inverse of Moore-Penrose and dynamic adjustments of weights with GA and PSO, significantly improving the performance of the results.
4. Results
This section presents the results of the models evaluated for each forecast horizon, based on the
MSE,
MAE and
MAPE errors, followed by a ranking of the models (
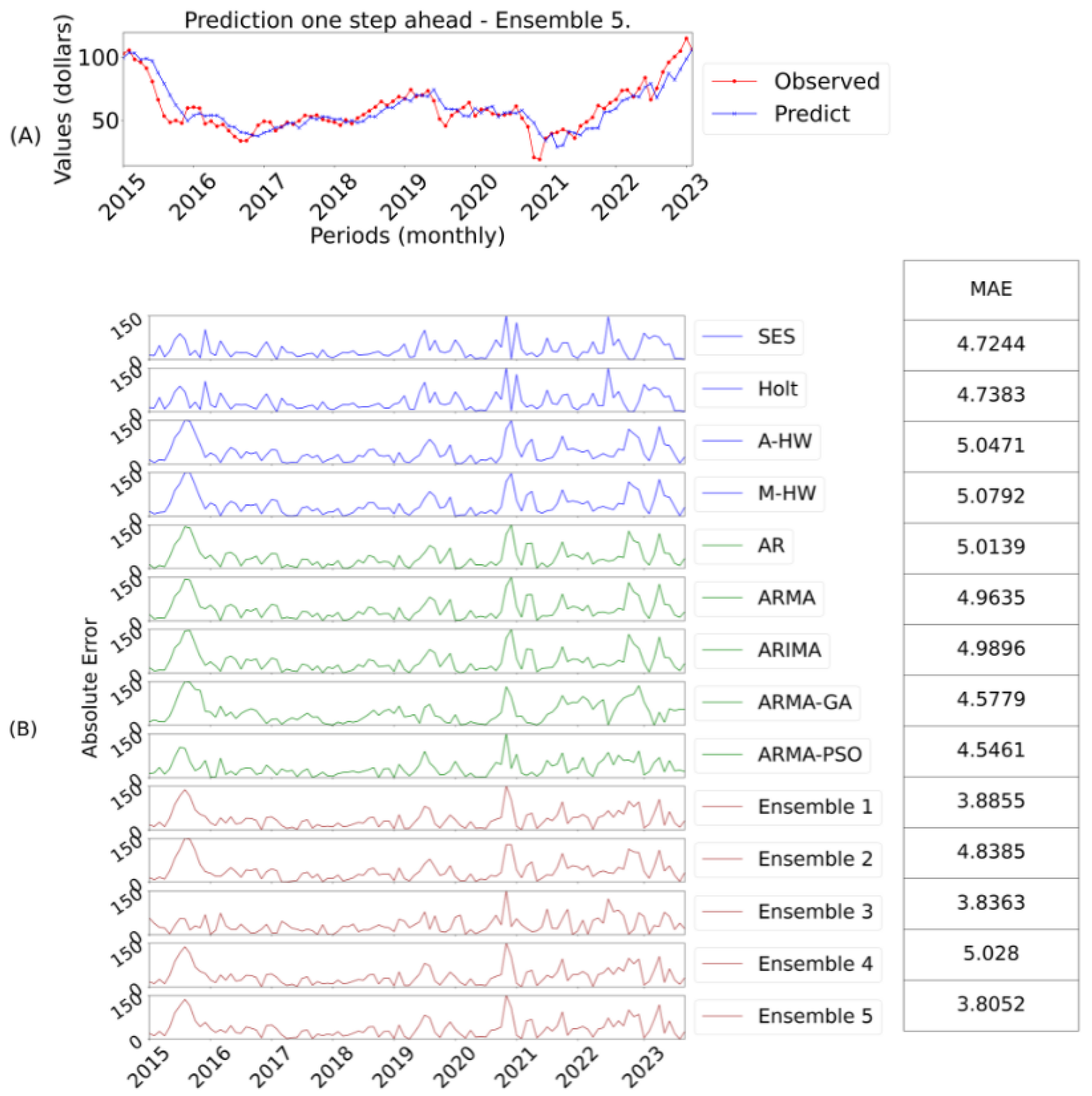
Table 8). For each horizon, the best result is illustrated next to the actual data, as well as the Absolute Error
AE curves over time for the 14 models evaluated.The graphs are organized as follows:
Figure 6:
A corresponds to the prediction of the best model and
B o the evaluation of the
AE for one-step ahead;
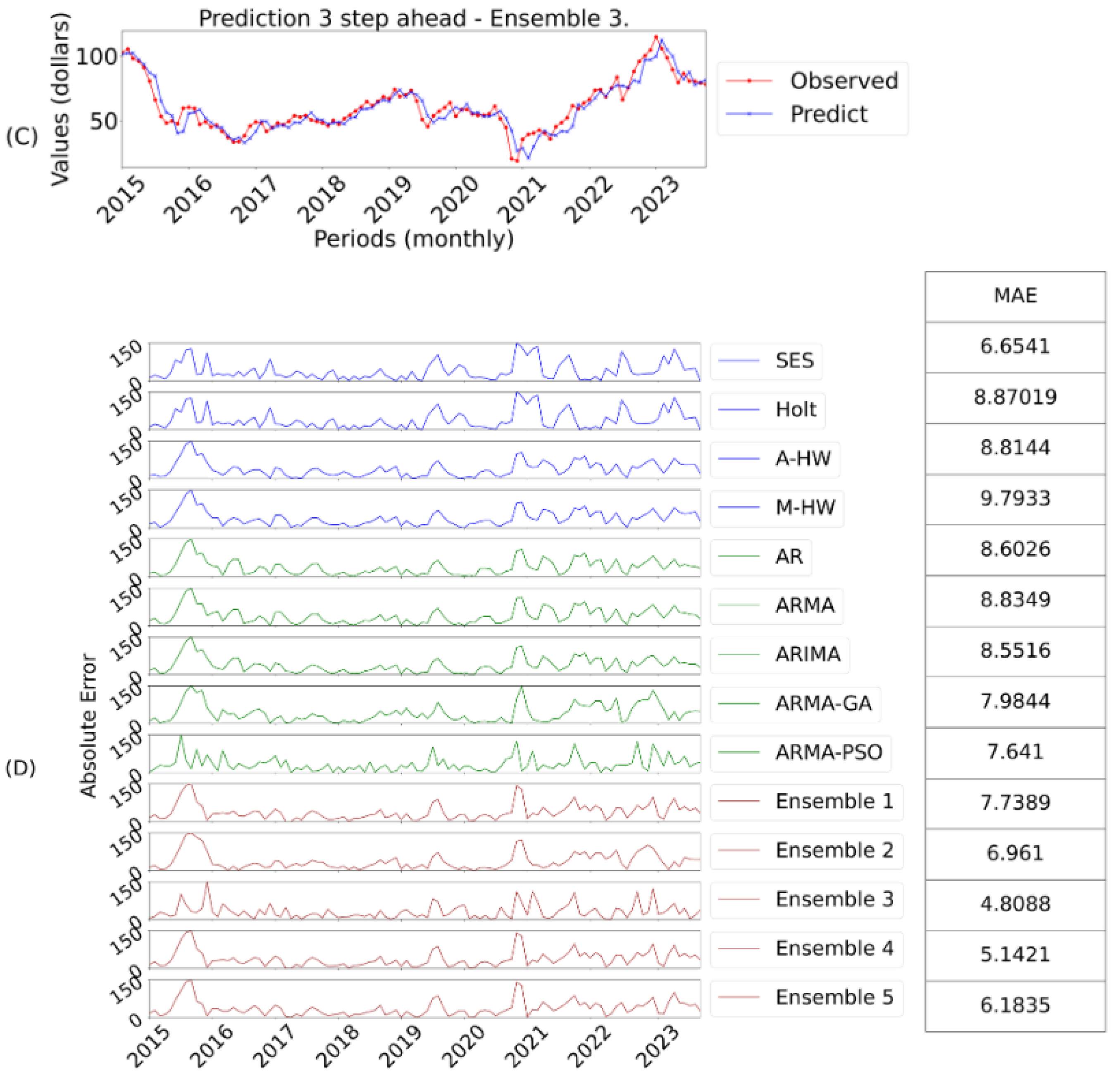
Figure 7:
C represents the prediction of the best model and
D the
AE evaluation for three-steps ahead;
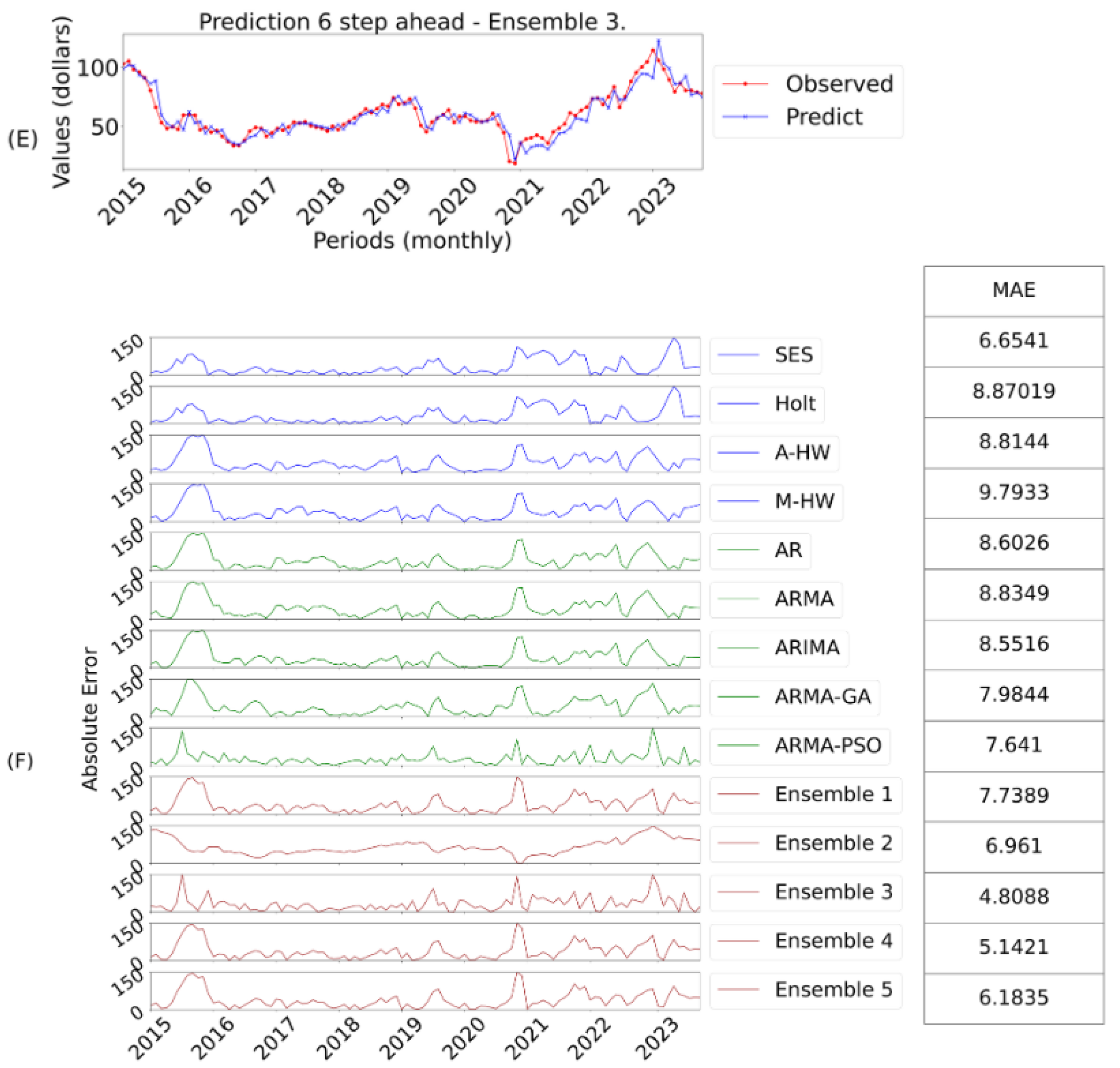
Figure 8:
E shows the prediction of the best model and
F the
AE evaluation corresponding to six-steps ahead;
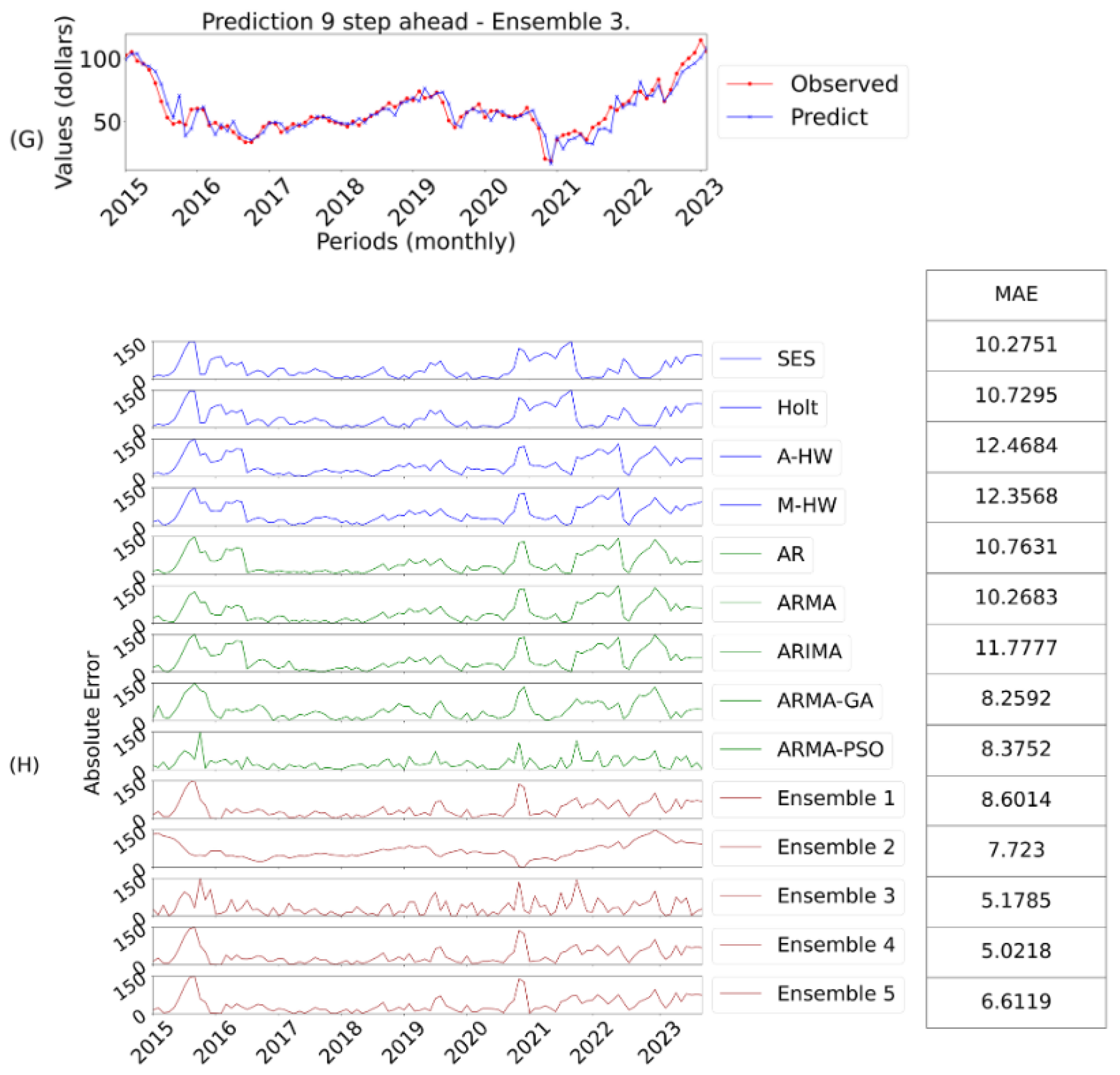
Figure 9:
G shows the best model prediction and
H the
AE evaluation for nine-steps ahead;
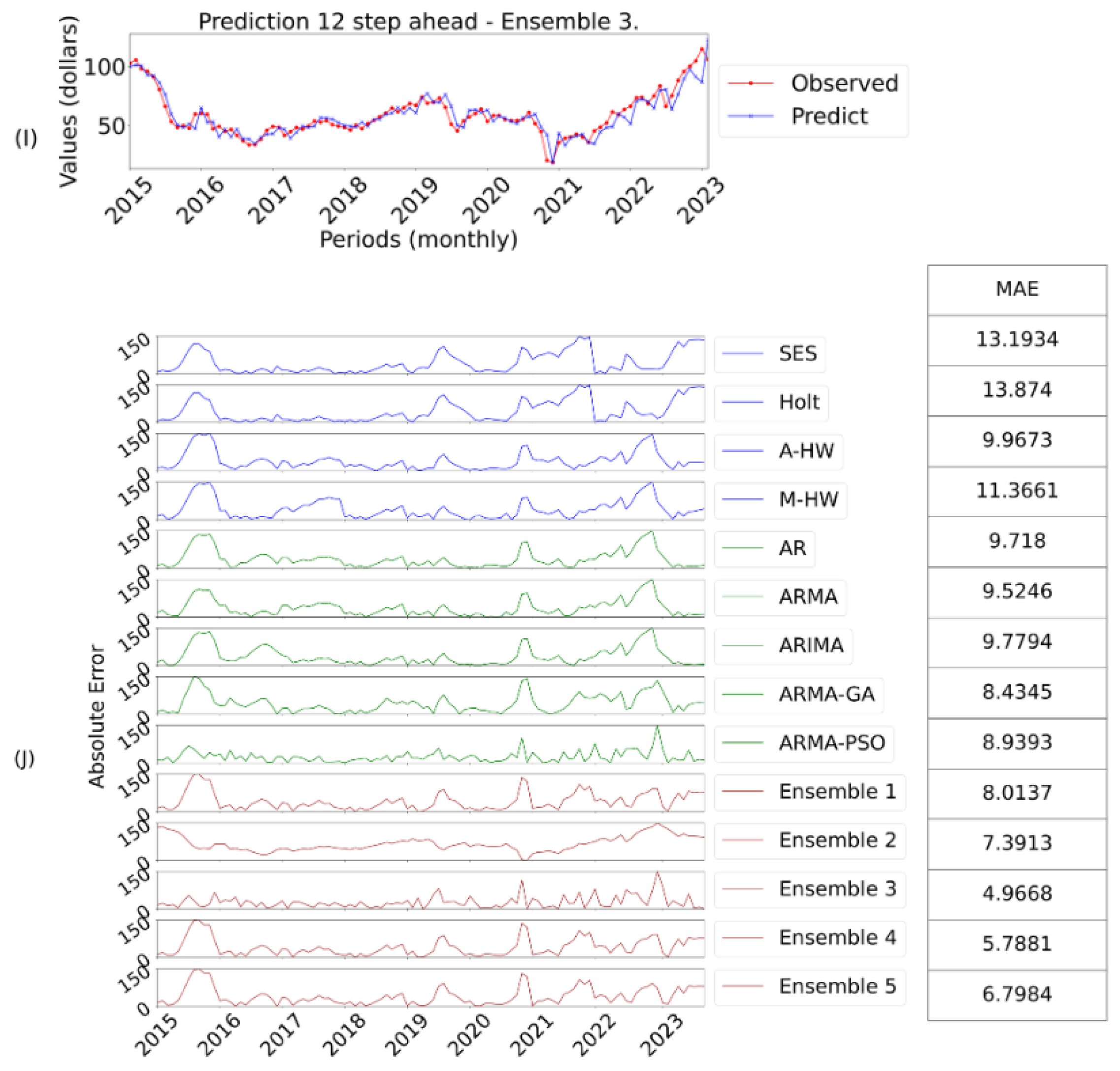
Figure 10:
I contains the prediction of the best model and
J the
AE evaluation of the absolute error considering twelve-steps ahead.
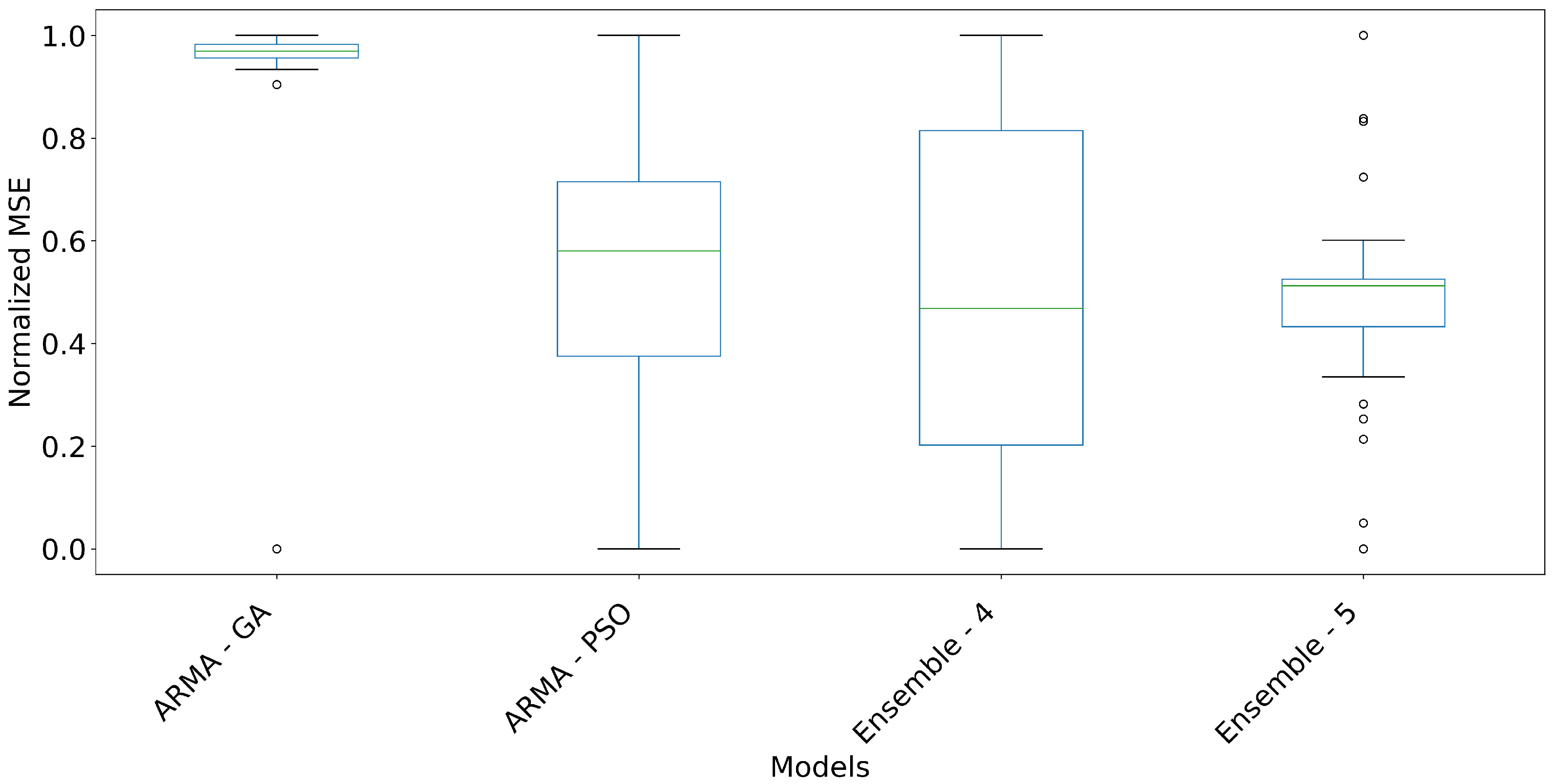
As shown in
Table 8, ensemble 5, using the weighted average with PSO, stood out by dynamically adjusting the weights of the models in the Ensemble based on historical performance, maximizing overall accuracy. This flexibility justifies its superior performance compared to ensembles 1 and 2, which assign equal weights to each model, according to Equations (
17) and (
18). By looking at the scores assigned to each model according to its performance per evaluation metric, it is possible to construct a score with the sum of all the scores. It can be seen that although ensemble 5 had the best overall performance, ensemble 3 stood out with the best position in relation to
MAPE error.
Figure 6 illustrates the best model for predicting a step forward on the test set (Observed).
Subfigure A contains the predicted values with the best model. While subfigure B presents the absolute error for each predicted value of all models. Next to it are the values with the MAE errors per model. This analogy is used for the other predicted steps.
After evaluating the one-step ahead forecasts, we moved on to analyze the three-steps ahead horizons.
Table 9 shows the results of all the models based on the
MSE,
MAE and
MAPE error metrics.
For this horizon, ensemble 3 stood out, using the pseudo-inverse of Moore-Penrose to combine the models, taking better advantage of their individual characteristics. The ensembles 4 and 5 also outperformed the individual models, indicating the effectiveness of the GA and PSO approaches. Individual models such as AR, ARMA and ARIMA showed relatively high errors, with the multiplicative Holt Winters model obtaining the highest MSE.
In the three-steps horizon, the ARMA-GA model outperformed ARMA-PSO, possibly due to uncertainties in the parameter selection process. The smoothing models behaved similarly to the one-step horizon, with larger errors in multi-step forecasts. Ensemble 3 again stood out in this horizon.
As mentioned above and illustrated in
Table 9, ensemble 3 obtained better results than all the predictive models. This is because ensemble 3 is more precise when adjusting the weights, directly minimizing the prediction error. In this case, it provides more sensitive and accurate responses to fluctuations, which are more evident in forecasts with longer horizons. Its performance is also evident when evaluating the final ranking, thus obtaining a better score in all error metrics. It is worth noting, however, that as in the previous step, ensembles 4 and 5 obtained good results compared to the other ensembles, again highlighting the efficiency of using GA and PSO. In this sense,
Figure 7 shows the best prediction model, obtained by ensemble 3.
Similarly, we went on to evaluate other forecast horizons, in this case for six-steps ahead, as shown in
Table 10.
Ensemble 3 was again superior, reinforcing its ability to determine the best weightings for longer forecasts. The ensemble 5 also stood out, showing the efficiency of the optimization algorithms. Its performance is also evident when evaluating the final ranking, thus obtaining a better score in all the error metrics. Ensemble 2, which uses the median, performed reasonably well, being robust against outliers as the steps increase.
Figure 8 shows the best result for this horizon, obtained by ensemble 3.
After these considerations, the forecasts for the models considering nine-steps ahead were evaluated, as illustrated in
Table 11.
Ensemble 3 stood out again, as shown in
Table 11. As the horizons increase, the errors of the individual models increase significantly, which does not occur in the ensembles. Ensemble 3 was the best for forecasts nine-steps ahead, as illustrated in
Figure 9. Its performance is also evident when evaluating the final ranking, thus obtaining a better score in all the error metrics. The
Box & Jenkins models maintained their performance, highlighting the efficiency of the GA and PSO algorithms. Although ensemble 2 was not the best, it obtained considerable results, demonstrating its robustness for longer horizon forecasts, due to the reduction in variability when using central values.
Finally, with regard to the last forecast horizon, considering twelve-steps ahead,
Table 12 shows the results of all the models.
The Box & Jenkins models maintained the same results as the previous cases. In the Smoothing models, there was a change, with the additive and multiplicative models, previously the worst, becoming the best. The ensemble 3 remains the most effective.
The exponential smoothing models showed variations in results, with the Additive Holt Winters being the most effective, especially in long-term forecasts, due to its stability and predictability. The SES model also benefited from stationarity in shorter horizon forecasts.
Finally, the results reinforce that ensemble 3 significantly outperformed the individual models, and the ensembles in general proved superior at other forecast horizons.
After the aforementioned considerations for a forecast horizon of twelve-steps ahead,
Figure 10 shows the best answer, in this case ensemble 3.
Several were analyzed and MSE, MAE and MAPE were used to evaluate them. These metrics illustrate average values (the best overall approximation in the analysis). Abrupt changes in the direction of the time series make it difficult for models to predict, but some models have the ability to adapt better than others. By analyzing AE, it is possible to see which models have the smallest outliers, which is additional behavioral information that the usual averages do not provide.
The results presented in this section confirm the concepts discussed in the
Section 2.4, demonstrating the robustness of the ensemble models over different forecast horizons. Specifically, ensemble 5 proved to be superior in the forecast horizon of one-step ahead, while for forecasts of 3, 6, 9 and 12 steps ahead, ensemble 3 was superior to all models.
In general, ensemble models have different advantages and disadvantages. The mean is simple, but can be influenced by outliers. The median is robust against outliers, but can ignore variability. The Moore-Penrose inverse optimizes weights based on historical performance, and is accurate but computationally complex. Weighted averaging with PSO and GA dynamically adjusts the weights, improving accuracy, but requires more computing power. For short-term forecasts, the mean and median are effective; for the long term, the inverse of Moore-Penrose and the weighted mean offer better optimization, provided there is sufficient data.
5. Conclusions
The main contribution of this work is related to the use of the pseudo-inverse of Moore-Penrose to determine the weights of the models to be used in the formation of the Ensemble, in addition to the use of metaheuristics.
It is known that GA and PSO algorithms are widely used in the literature, although not so much for application in ensemble. In this sense, as an initial work, it was decided to use these techniques.
The results show that the ensemble models, especially those that used metaheuristics and the pseudo-inverse of Moore-Penrose, significantly improved the individual results of the predictive models at all forecast horizons.
After pre-processing the data, the model parameters were determined in various ways: for the smoothing models, a numerical model that minimizes the cost function was used; for the Box & Jenkins models, the Yule-Walker equations and maximum likelihood estimators were used, with delays tested exhaustively. Specifically for the ARMA model, two coefficient optimization techniques were used: GA and PSO. For the ensemble, several strategies were tested, including arithmetic mean, median, pseudo-inverse of Moore-Penrose and weighted mean with GA and PSO. The results showed that the ensemble approaches outperformed the individual models, with the weighted average with PSO (ensemble 5) standing out in step 1, and the pseudo-inverse of Moore-Penrose (ensemble 3) in the other steps.
The results indicate the feasibility of using ensembles in time series forecasting, allowing it to be applied to forecasting models other than linear ones.
In this sense, the research can be further developed with the insertion of other approaches aimed at technological development, such as the creation of other Ensembles. Mention could be made of the use of artificial neural networks to form a non-linear ensemble.


 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}