
A Review on the Application of Artificial Intelligence in Anomaly Analysis Detection and Fault Location in Grid Indicator Calculation Data

Abstract
1. Introduction
2. Traditional Methods
2.1. The Application of Traditional Methods in Power Grid Data Anomaly Analysis and Detection
2.2. The Application of Traditional Methods in Power Grid Fault Location
2.3. The Limitations of Traditional Methods
- Difficulty in handling massive data:
- Weak nonlinear relationship handling:
- Lack of self-learning capability
3. Deep Learning Methods
3.1. The Application of Deep Learning in Power Grid Data Anomaly Analysis and Detection
3.1.1. Convolutional Neural Network
3.1.2. Deep Neural Network
3.1.3. Long Short-Term Memory Network
3.1.4. Recurrent Neural Network
3.2. The Application of Deep Learning in Power Grid Fault Localization
3.2.1. Convolutional Neural Network
3.2.2. Deep Neural Network
3.2.3. Artificial Neural Network
3.2.4. Graph Convolutional Network
4. Advantages and Limitations
4.1. Advantages
4.1.1. Automated Feature Extraction
4.1.2. Efficient Handling of Massive Data
4.1.3. Self-Learning and Adaptability
4.2. Limitations
4.2.1. Data Quality Dependency
4.2.2. Model Generalization Ability
4.2.3. Lack of Interpretability
5. Future Research Directions
5.1. Advanced Models
5.2. Transfer Learning and Few-Shot Learning
5.3. Federated Learning
5.4. Multi-Source Data Integration
6. Conclusions
Funding
Conflicts of Interest
References
- Li, Y.; Chen, H.; Shi, J.; Chen, L.; Hu, Z.; Wu, X. Rapid Detection Method for Short-Circuit Faults Based on the Sum of Squares of Three-Phase Currents Ratio. Power Syst. Prot. Control 2020, 48, 111–119. [Google Scholar]
- Ban, X.; Ning, S.; Xu, Z. Novel method for the evaluation of data quality based on fuzzy control. J. Syst. Eng. Electron. 2008, 19, 606–610. [Google Scholar]
- Huang, Y.; Cheng, F. Automatic Data Quality Evaluation for the AVM System. IEEE Trans. Semicond. Manuf. 2011, 24, 445–454. [Google Scholar] [CrossRef]
- Rezapour, H.; Jamali, S.; Bahmanyar, A. Review on artificial intelligence-based fault location methods in power distribution networks. Energies 2023, 16, 4636. [Google Scholar] [CrossRef]
- Hinton, G.E.; Osindero, S.; The, Y.W. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef] [PubMed]
- Qin, H.; Gong, R.; Liu, X.; Shen, M.; Wei, Z.; Yu, F.; Song, J. Forward and Backward Information Retention for Accurate Binary Neural Networks. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 2247–2256. [Google Scholar]
- Amodei, D.; Ananthanarayanan, S.; Anubhai, R.; Bai, J.; Battenberg, E.; Case, C.; Casper, J.; Catanzaro, B.; Cheng, Q.; Chen, G.; et al. Deep speech 2: End-to-end speech recognition in english and mandarin. In Proceedings of the International Conference on Machine Learning, PMLR, New York, NY, USA, 19–24 June 2016; pp. 173–182. [Google Scholar]
- Tom, Y.; Devamanyu, H.; Soujanya, P.; Erik, C. Recent trends in deep learning based natural language processing. IEEE Comput. Intell. Mag. 2018, 13, 55–75. [Google Scholar]
- Rodriguez, A.; Laio, A. Clustering by fast search and find of density peaks. Science 2014, 344, 1492–1496. [Google Scholar] [CrossRef] [PubMed]
- Wang, M.; Min, F.; Zhang, Z.; Wu, Y. Active learning through density clustering. Expert Syst. Appl. 2017, 85, 305–317. [Google Scholar] [CrossRef]
- Lu, C.; Ye, F.; Zhao, L. Power Big Data Anomaly Detection Algorithm Based on Density Peak Clustering. Sci. Technol. Eng. 2020, 20, 654–658. [Google Scholar]
- Wu, R.; Zhang, A.; Tian, X.; Zhang, T. Power Data Anomaly Detection Algorithm Based on Improved K-means. J. East China Norm. Univ. (Nat. Sci. Ed.) 2020, 04, 79–87. [Google Scholar]
- Wang, P.; Xie, X. Power Data Anomaly Detection Method Based on Improved FCM Algorithm. Electron. Des. Eng. 2023, 31, 33–37. [Google Scholar]
- Li, Q. Power Big Data Anomaly Detection Method Based on Improved PSO-PFCM Clustering Algorithm. Power Syst. Prot. Control 2021, 49, 161–166. [Google Scholar]
- Gao, S.; Li, C. An Improved Spectral Clustering Algorithm for Power Data Anomaly Detection. Comput. Simul. 2019, 36, 239–242+304. [Google Scholar]
- Niu, G.; Wang, L.; Tan, L.; Mao, T.; Gao, Y. Design of Power Data Anomaly Detection Method Based on Isolation Forest Algorithm. Autom. Instrum. 2023, 08, 52–55. [Google Scholar]
- Li, X.; Gao, X.; Yan, B.; Chen, C.; Chen, B.; Li, J.; Xu, J. Anomaly Detection Method for Power Dispatch Flow Data Based on Isolation Forest Algorithm. Power Grid Technol. 2019, 43, 1447–1456. [Google Scholar]
- Luo, S.; Luan, L.; Cui, Y.; Chai, X.; Wang, Z.; Kong, Y. An attribute associated isolation forest algorithm for detecting anomalous electro-data. In Proceedings of the 2019 Chinese Control Conference (CCC), Guangzhou, China, 27–30 July 2019; pp. 3788–3792. [Google Scholar]
- Mao, W.; Cao, X.; Zhou, Q.; Yan, T.; Zhang, Y. Anomaly detection for power consumption data based on isolated forest. In Proceedings of the 2018 International Conference on Power System Technology (POWERCON), Guangzhou, China, 6–8 November 2018; pp. 4169–4174. [Google Scholar]
- Li, H. Research on User-Side Data Anomaly Detection Method Based on Power Big Data. Microcomput. Appl. 2023, 39, 229–231. [Google Scholar]
- Liu, Z. Power System Dispatch Data Anomaly Detection Method Based on Support Vector Machine. Autom. Technol. Appl. 2023, 42, 24–27+37. [Google Scholar]
- Yu, J.; Liu, W.; Li, Y.; Zhang, B.; Yao, W. Anomaly Detection of Power Big Data Based on Improved Support Vector Machine. In Proceedings of the 2022 4th International Academic Exchange Conference on Science and Technology Innovation (IAECST), Guangzhou, China, 9–11 December 2022; pp. 102–105. [Google Scholar]
- Sunyaev, A.; Sunyaev, A. Cloud computing. In Internet Computing: Principles of Distributed Systems and Emerging Internet-Based Technologies; Springer: Cham, Switzerland, 2020; Volume 8, pp. 195–236. [Google Scholar]
- Shi, Y.; Luo, Z.; Hu, J.; Wei, T. Rapid Detection Algorithm for Power Operation Big Data Anomalies Based on Cloud Computing. Electron. Des. Eng. 2020, 28, 43–46+51. [Google Scholar]
- Lu, J.; Liu, X.; Li, H. Anomaly detection method of power dispatching data based on cloud computing platform. In Proceedings of the 2020 International Conference on Big Data & Artificial Intelligence & Software Engineering (ICBASE), Bangkok, Thailand, 30 October 2020–1 November 2020; pp. 23–26. [Google Scholar]
- Shafiullah, M.; Abido, M.A.; Abdel-Fattah, T. Distribution Grids Fault Location Employing ST Based Optimized Machine Learning Approach. Energies 2018, 11, 2328. [Google Scholar] [CrossRef]
- Mu, L.; Han, H.; Jiang, B.; Guo, W. Microgrid protection based on principle of fault location. IEEE Trans. Electr. Electron. Eng. 2016, 11, 30–35. [Google Scholar] [CrossRef]
- Mrabet, Z.E.; Sugunaraj, N.; Ranganathan, P.; Abhyankar, S. Random forest regressor-based approach for detecting fault location and duration in power systems. Sensors 2022, 22, 458. [Google Scholar] [CrossRef] [PubMed]
- Guo, N.; Yang, F.; Qin, J.; Chen, X. Power Grid Fault Location Method Based on Genetic Algorithm and Signal Spectrum Analysis. Power Syst. Autom. 2016, 40, 79–85. [Google Scholar]
- Galvez, C.; Abur, A. Fault location in power networks using a sparse set of digital fault recorders. IEEE Trans. Smart Grid 2022, 13, 3468–3480. [Google Scholar] [CrossRef]
- Caporuscio, M.; Dupuis, A.; Löwe, W. Data-Driven Ground-Fault Location Method in Distribution Power System With Distributed Generation. arXiv 2024, arXiv:2402.14894. [Google Scholar]
- Mohammadi, R.; Ghotbi-Maleki, M.; Ghaffarzadeh, A. Wide-Area Fault Location in Transmission Power System Considering Measurement Uncertainty. IEEE Access 2024, 33, 56–67. [Google Scholar] [CrossRef]
- Hassani, H.; Razavi-Far, R.; Saif, M.; Zarei, J.; Blaabjerg, F. Intelligent decision support and fusion models for fault detection and location in power grids. IEEE Trans. Emerg. Top. Comput. Intell. 2021, 6, 530–543. [Google Scholar] [CrossRef]
- Yang, H.; Guo, Y.; Liu, X. Fault Section Location of Active Distribution Network based on Wolf Pack and Differential Evolution Algorithms. Int. J. Perform. Eng. 2020, 16, 143–151. [Google Scholar] [CrossRef]
- Zou, J. Power System Fault Location Method Based on Weighted Least Squares Estimation. Wirel. Internet Technol. 2023, 20, 120–122. [Google Scholar]
- Li, Z.; Liu, F.; Yang, W.; Peng, S.; Zhou, J. A survey of convolutional neural networks: Analysis, applications, and prospects. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 6999–7019. [Google Scholar] [CrossRef]
- Zhou, F.; Jin, L.; Dong, J. A Comprehensive Review of Convolutional Neural Networks. Chin. J. Comput. 2017, 40, 1229–1251. [Google Scholar]
- Danilczyk, W.; Sun, Y.L.; He, H. Smart grid anomaly detection using a deep learning digital twin. In Proceedings of the 2020 52nd North American Power Symposium (NAPS), Tempe, AZ, USA, 11–13 April 2021; pp. 1–6. [Google Scholar]
- Huang, W.; Liang, L.; Zhao, X.; Zhang, H.; Lin, Q.; Feng, Q.; Li, H.; Cao, S. Electricity Anomaly Detection with Self-Supervised Time Convolutional Networks. In Proceedings of the 2023 3rd International Conference on Electrical Engineering and Mechatronics Technology (ICEEMT), Nanjing, China, 21–23 July 2023; pp. 733–736. [Google Scholar]
- Sze, V.; Chen, Y.H.; Yang, T.J.; Emer, J.S. Efficient processing of deep neural networks: A tutorial and survey. Proc. IEEE 2017, 105, 2295–2329. [Google Scholar] [CrossRef]
- Chang, R.; Xu, M. Power Data Anomaly Detection Based on Improved K-Means and DNN Algorithms. J. Nanjing Univ. Sci. Technol. 2023, 47, 790–796+858. [Google Scholar]
- Siniosoglou, I.; Efstathopoulos, G.; Pliatsios, D.; Moscholios, I.D.; Sarigiannidis, A.; Sakellari, G.; Loukas, G.; Sarigiannidis, P. An industrial honeypot implementation based on deep neural networks. In Proceedings of the 2020 IEEE Symposium on Computers and Communications (ISCC), Rennes, France, 7–10 July 2020; pp. 1–7. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Zhang, B.; Wang, G.; Xie, F.; Sun, D.; Yang, Q. Research on Power Data Anomaly Detection Based on Deep Neural Networks. Microcontroller Embed. Syst. Appl. 2023, 23, 36–39. [Google Scholar]
- Wu, G. Research on Electricity Data Anomaly Detection Algorithm Based on Data Intrinsic Characteristics and LSTM. Wirel. Internet Technol. 2019, 16, 96–99+112. [Google Scholar]
- Guha, D.; Chatterjee, R.; Sikdar, B. Anomaly Detection Using LSTM-Based Variational Autoencoder in Unsupervised Data in Power Grid. IEEE Syst. J. 2023, 10, 120–131. [Google Scholar] [CrossRef]
- Parsai, S.; Mahajan, S. Anomaly detection using long short-term memory. In Proceedings of the 2020 International Conference on Electronics and Sustainable Communication Systems (ICESC), Coimbatore, India, 2–4 July; 2020; pp. 333–337. [Google Scholar]
- Zhou, M.; Musilek, P. Real-time anomaly detection in distribution grids using long short term memory network. In Proceedings of the 2021 IEEE Electrical Power and Energy Conference (EPEC), Toronto, ON, Canada, 22–31 October 2021; pp. 208–213. [Google Scholar]
- Scholar, R. Optimizing Anomaly Detection in Smart Grids with Modified FDA and Dilated GRU-Based Adaptive Residual RNN. 2024. Available online: https://assets-eu.researchsquare.com/files/rs-3869400/v1_covered_a35420f4-c40d-49b6-86bc-255b083a2f97.pdf (accessed on 25 January 2024).
- Zheng, F.; Li, S.; Guo, Z.; Wu, B.; Tian, S.; Pan, M. Anomaly detection in smart grid based on encoder-decoder framework with recurrent neural network. J. China Univ. Posts Telecommun. 2017, 24, 67–73. [Google Scholar]
- Patel, V.; Ghosh, S.; Chakrabarti, S.; Sharma, A.; Pannala, S. Neural Network Based Fault Location in Power Distribution System. In Proceedings of the 2023 IEEE PES Innovative Smart Grid Technologies-Asia (ISGT Asia), Auckland, New Zealand, 21–24 November 2023; pp. 1–6. [Google Scholar]
- Shi, X.; Xu, Y. A Fault Location Method for Distribution System Based on One-Dimensional Convolutional Neural Network. In Proceedings of the 2021 IEEE International Conference on Power, Intelligent Computing and Systems (ICPICS), Shenyang, China, 29–31 July 2021; pp. 333–337. [Google Scholar]
- Yu, Y.; Li, M.; Ji, T.; Wu, Q.H. Fault Location in Distribution System Using Convolutional Neural Network Based on Domain Transformation. CSEE J. Power Energy Syst. 2021, 7, 472–484. [Google Scholar]
- Ghorbani, A.; Mehrjerdi, H. Negative-sequence network based fault location scheme for double-circuit multi-terminal transmission lines. IEEE Trans. Power Deliv. 2019, 34, 1109–1117. [Google Scholar] [CrossRef]
- Sapountzoglou, N.; Lago, J.; De Schutter, B.; Raison, B. A Generalizable and Sensor-Independent Deep Learning Method for Fault Detection and Location in Low-Voltage Distribution Grids. Appl. Energy 2020, 276, 115299–115320. [Google Scholar] [CrossRef]
- Luo, G.; Tan, Y.; Yao, C.; Liu, Y.; He, J. Deep learning-based fault location of DC distribution networks. J. Eng. 2019, 2019, 3301–3305. [Google Scholar]
- Zhang, C.; Guo, Y.; Li, M. Overview of the Development and Application of Artificial Neural Network Models. Comput. Eng. Appl. 2021, 57, 57–69. [Google Scholar]
- Dashtdar, M.; Dashti, R.; Shaker, H.R. Distribution Network Fault Section Identification and Fault Location Using Artificial Neural Network. In Proceedings of the 2018 5th International Conference on Electrical and Electronic Engineering (ICEEE), Istanbul, Turkey, 3–5 May 2018; pp. 273–278. [Google Scholar]
- Barra, P.H.A.; Pessoa, A.L.D.S.; Menezes, T.S.; Santos, G.G.; Coury, D.V.; Oleskovicz, M. Fault Location in Radial Distribution Networks Using ANN and Superimposed Components. In Proceedings of the 2019 IEEE PES Innovative Smart Grid Technologies Conference-Latin America (ISGT Latin America), Gramado, Brazil, 15–18 September 2019; pp. 1–6. [Google Scholar]
- Usman, M.U.; Ospina, J.; Faruque, M.O. Fault Classification and Location Identification in a Smart Distribution Network Using ANN. In Proceedings of the 2018 IEEE Power & Energy Society General Meeting (PESGM), Portland, OR, USA, 5–10 August 2018; pp. 1–6. [Google Scholar]
- Han, N.; Zou, H.; Yu, S. Research on Distribution Network Fault Location Based on Traditional BP Neural Network and Cloud Genetic Optimization Neural Network. J. Electr. Power 2018, 33, 116–122+133. [Google Scholar]
- Li, K.; He, J.; Cao, L.; Yang, F.; Zhou, S. Application of Optimized BP Neural Network in Distribution Network Fault Location. Electr. Eng. 2019, 11, 1–13. [Google Scholar]
- Xu, B.; Cen, K.; Huang, J.; Shen, H.; Cheng, X. A Survey of Graph Convolutional Neural Networks. J. Comput. Sci. 2020, 43, 755–780. [Google Scholar]
- Chen, K.; Hu, J.; Zhang, Y.; Yu, Z.; He, J. Fault location in power distribution systems via deep graph convolutional networks. IEEE J. Sel. Areas Commun. 2019, 38, 119–131. [Google Scholar] [CrossRef]
- Wu, D.; Wang, B.; Precup, D.; Boulet, B. Boosting based multiple kernel learning2 and transfer regression for electricity load forecasting. In Proceedings of the Machine Learning and Knowledge Discovery in Databases: European Conference, ECML PKDD 2017, Skopje, Macedonia, 18–22 September 2017; pp. 39–51. [Google Scholar]
- Wu, D.; Wang, B.; Precup, D.; Boulet, B. Multiple kernel learning-based transfer regression for electric load forecasting. IEEE Trans. Smart Grid 2019, 11, 1183–1192. [Google Scholar] [CrossRef]
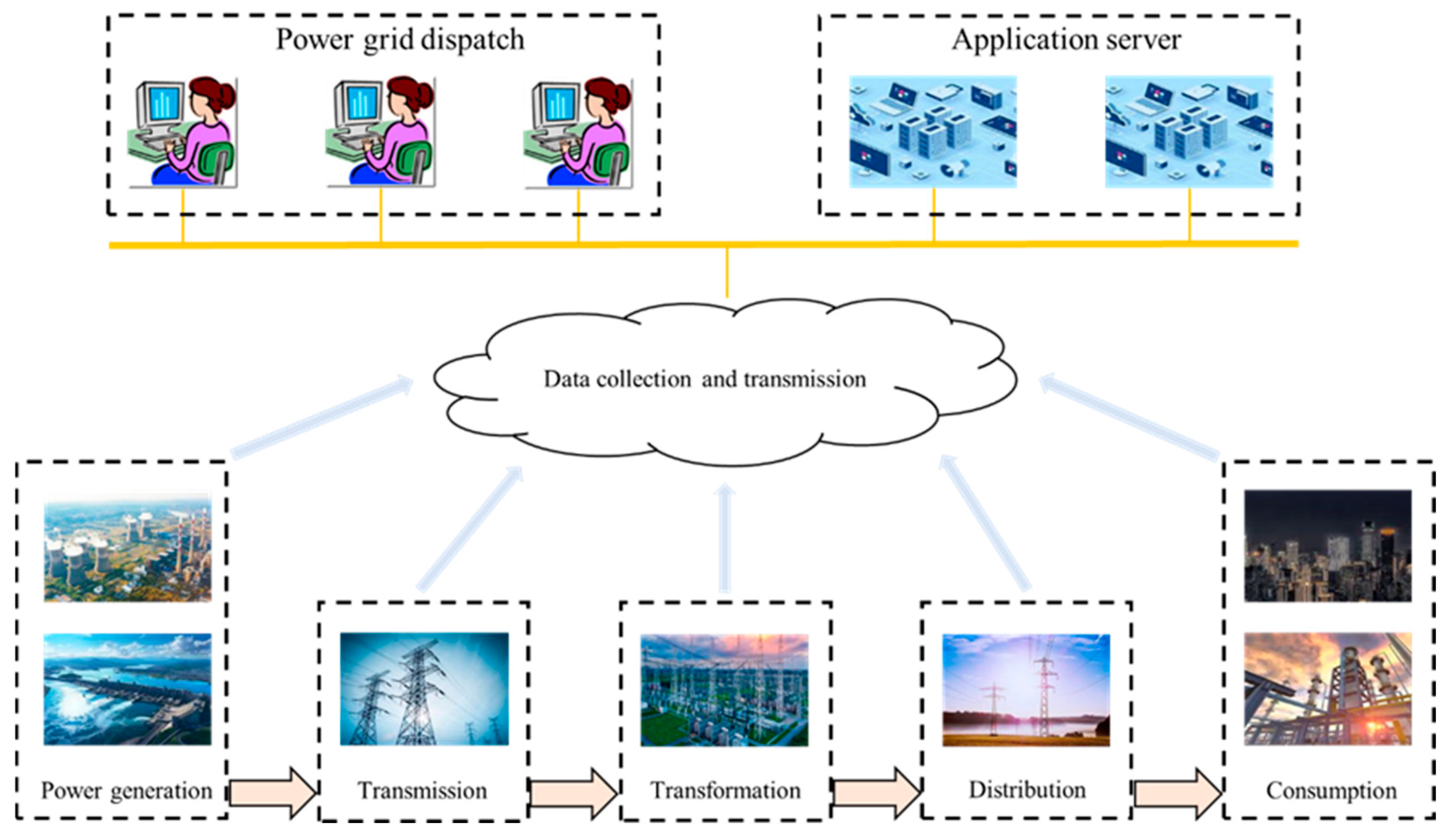
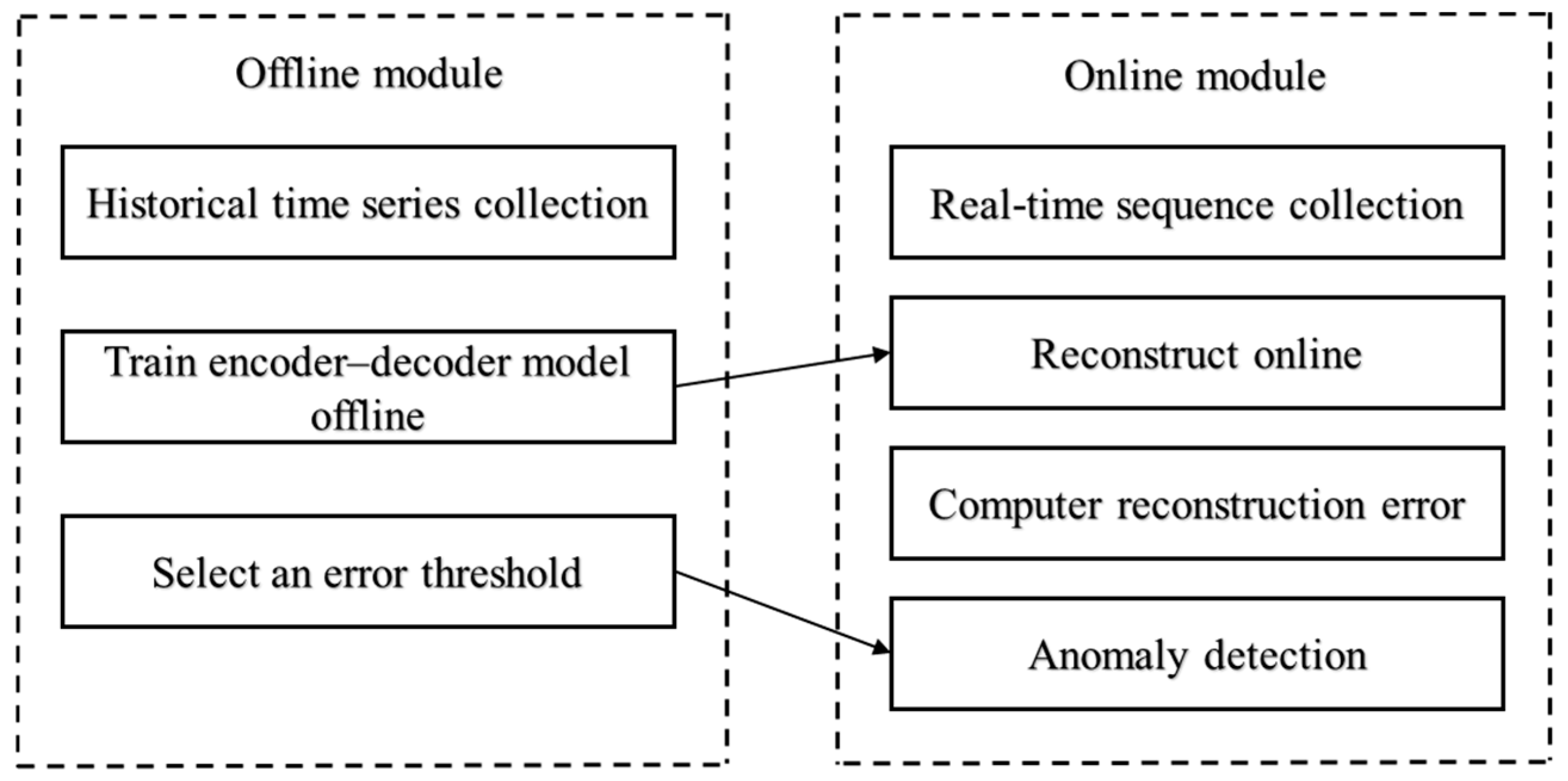
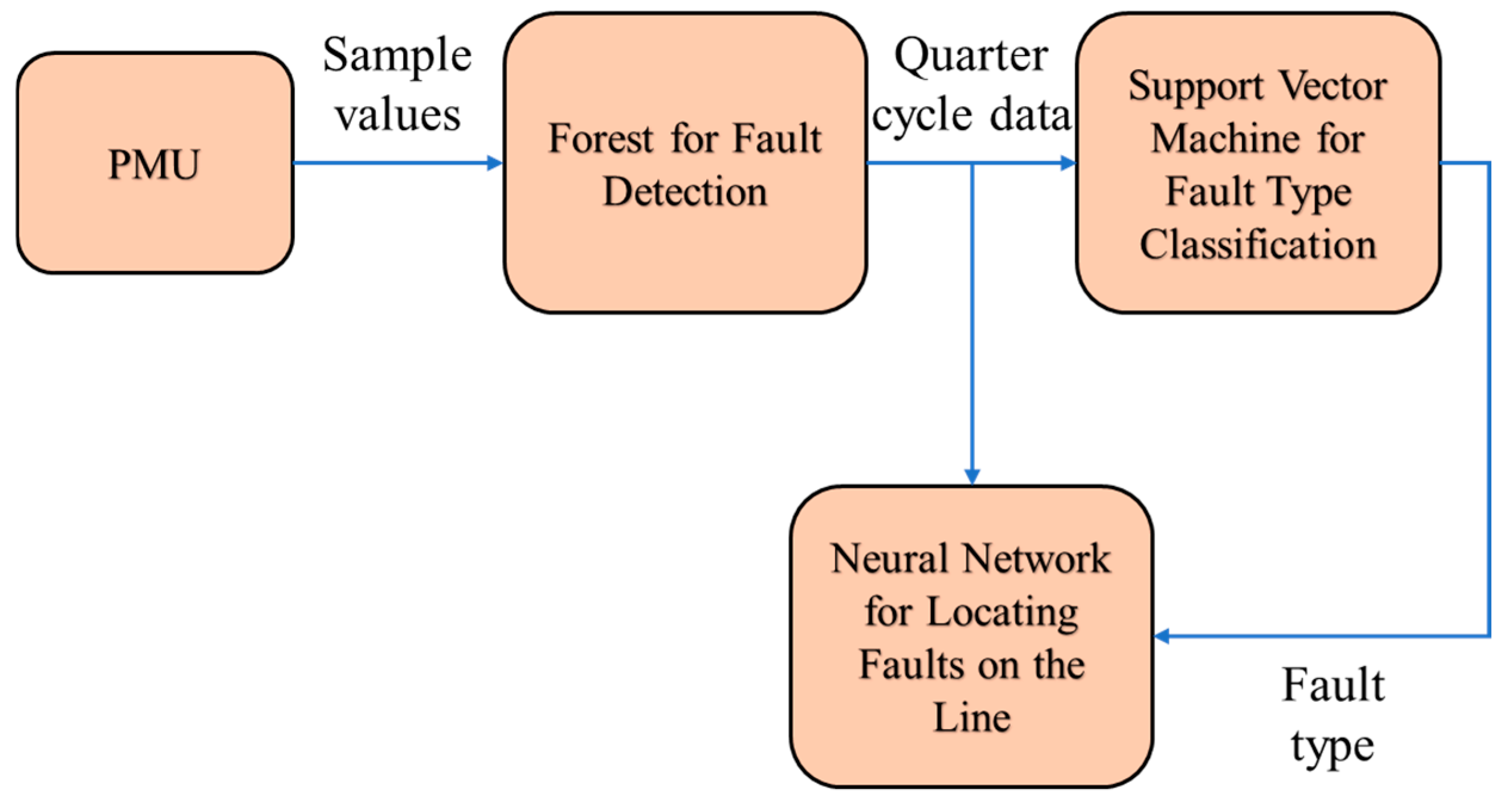

{kind=link}
{kind=link}
{kind=link}
| Algorithm | Accuracy (%)↑ |
|---|---|
| Spectral clustering [15] | 86.50 |
| K-means [15] | 87.55 |
| Mini-batch K-means [15] | 88.50 |
| Improved algorithm [15] | 92.50 |
| Method | Traditional Multi-Domain Feature Extraction [22] | Traditional Clustering Algorithm [22] | Improved SVM [22] |
|---|---|---|---|
| Abnormal difference value↓ | 1.25 | 1.03 | 0.67 |
| Location response time(s)↓ | 2.12 | 2.35 | 1.03 |
| Dynamic precision ratio↓ | 4.30 | 5.20 | 2.10 |
| Missing report rate (%)↓ | 7.15 | 10.31 | 2.04 |
| Method | Advantages | Disadvantages |
|---|---|---|
| Traditional methods | Strong interpretability, relatively low computational cost | Difficult to handle large-scale data |
| Deep learning methods | Strong learning ability, capable of handling large-scale data | High data and computational resource requirements with lower interpretability |
| Algorithm | SVM [39] | CNN [39] | RNN [39] | Ours-Sup [39] |
|---|---|---|---|---|
| Recall↑ | 0.633 | 0.838 | 0.836 | 0.908 |
| AUC↑ | 0.633 | 0.803 | 0.811 | 0.889 |
| F1-Score↑ | 0.663 | 0.781 | 0.829 | 0.901 |
| Accuracy (%)↑ | 69.80 | 73.30 | 82.40 | 89.60 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, S.; Tang, Y.; Tai, T.; Wei, X.; Fang, W. A Review on the Application of Artificial Intelligence in Anomaly Analysis Detection and Fault Location in Grid Indicator Calculation Data. Energies 2024, 17, 3747. https://doi.org/10.3390/en17153747
Sun S, Tang Y, Tai T, Wei X, Fang W. A Review on the Application of Artificial Intelligence in Anomaly Analysis Detection and Fault Location in Grid Indicator Calculation Data. Energies. 2024; 17(15):3747. https://doi.org/10.3390/en17153747
Chicago/Turabian StyleSun, Shiming, Yuanhe Tang, Tong Tai, Xueyun Wei, and Wei Fang. 2024. "A Review on the Application of Artificial Intelligence in Anomaly Analysis Detection and Fault Location in Grid Indicator Calculation Data" Energies 17, no. 15: 3747. https://doi.org/10.3390/en17153747
APA StyleSun, S., Tang, Y., Tai, T., Wei, X., & Fang, W. (2024). A Review on the Application of Artificial Intelligence in Anomaly Analysis Detection and Fault Location in Grid Indicator Calculation Data. Energies, 17(15), 3747. https://doi.org/10.3390/en17153747