Abstract
To address the high complexity and low accuracy issues of traditional methods in mixed coal vitrinite identification, this paper proposes a method based on an improved DeepLabv3+ network. First, MobileNetV2 is used as the backbone network to reduce the number of parameters. Second, an atrous convolution layer with a dilation rate of 24 is added to the ASPP (atrous spatial pyramid pooling) module to further increase the receptive field. Meanwhile, a CBAM (convolutional block attention module) attention mechanism with a channel multiplier of 8 is introduced at the output part of the ASPP module to better filter out important semantic features. Then, a corrective convolution module is added to the network’s output to ensure the consistency of each channel’s output feature map for each type of vitrinite. Finally, images of 14 single vitrinite components are used as training samples for network training, and a validation set is used for identification testing. The results show that the improved DeepLabv3+ achieves 6.14% and 3.68% improvements in MIOU (mean intersection over union) and MPA (mean pixel accuracy), respectively, compared to the original DeepLabv3+; 12% and 5.3% improvements compared to U-Net; 9.26% and 4.73% improvements compared to PSPNet with ResNet as the backbone; 5.4% and 9.34% improvements compared to PSPNet with MobileNetV2 as the backbone; and 6.46% and 9.05% improvements compared to HRNet. Additionally, the improved ASPP module increases MIOU and MPA by 3.23% and 1.93%, respectively, compared to the original module. The CBAM attention mechanism with a channel multiplier of 8 improves MIOU and MPA by 1.97% and 1.72%, respectively, compared to the original channel multiplier of 16. The data indicate that the proposed identification method significantly improves recognition accuracy and can be effectively applied to mixed coal vitrinite identification.
1. Introduction
Coal is an important fossil fuel in China, where power generation accounts for approximately 45% of coal consumption [1]. The microcomponent composition of coal determines its physical and chemical properties, technological characteristics, and industrial applications. Petrographic analysis of coal has been widely applied in commercial coal quality testing and industrial fields such as coal coking, gasification, liquefaction, and oil and gas exploration [2].
Petrographic analysis of coal currently still relies primarily on manual identification and measurement, which involves high labor intensity and time consumption. Additionally, the subjective differences in observation among personnel lead to poor comparability of identification data between laboratories, etc. At home and abroad, automatic vitrinite reflectance measurement of coal has been realized through automatic coal–rock measurement technology, but there are some problems, such as inaccurate vitrinite identification and low vitrinite identification rate, especially the low content of the vitrinite or small particles in mixed coal. The existing identification technologies cannot accurately and efficiently identify vitrinite, and there are problems of data omission and misdetection [3]. Identifying the vitrinite in mixed coal efficiently, accurately, and completely is the premise and basis of vitrinite reflectance measurement of coal.
Sun Tao et al. [4] developed a CA_Poly_DeepLab v3+ network tailored for coal–rock image segmentation. This network integrates a channel attention module into the DeepLab v3+ network and employs an adaptive learning strategy to adjust the network’s learning rate. This approach improves the accuracy of target segmentation and edge processing, resulting in contours that are closer to reality. However, this method still has issues with robustness, making its practical application less than ideal. Shi Guangliang et al. [5] proposed a coal–rock identification method based on the Kalman optimal estimation of load data from the shearer arm pin. They used the Kalman optimal estimation algorithm for noise reduction and then determined the interval of real-time load values to identify the coal–rock interface on the cutting face. Experiments verified that this improvement reduced data fluctuation and effectively increased data discernibility. However, the overall algorithm is complex, and its generalization reliability is unclear. Jiang Song et al. [6] proposed a refined segmentation method for blast heap blocks based on the DeepLabV3+ network. They first introduced a multi-branch separable attention mechanism into the backbone network to fuse features from different channels. Then, they used a point rendering module to reduce the loss of semantic information and finally employed a dynamic learning rate adjustment strategy to accelerate the model’s convergence speed. This method has better overall performance, particularly in improving edge and small object segmentation. However, due to the difficulty and high risk of collecting images in mining areas, as well as the challenges in semantic segmentation annotation, the dataset remains limited. Qinpeng Guo et al. [7] proposed a segmentation method for blast rock images based on an improved watershed algorithm. They first obtained a preprocessed binary image then performed distance transformation and selected an appropriate grayscale threshold to obtain contours. Finally, they applied the watershed algorithm for segmentation. This algorithm can accurately mark seed points and perform watershed segmentation on blast rock images, effectively reducing the likelihood of incorrect segmentation. However, this method still cannot meet real-time requirements. Zhiwei Li et al. [8] proposed a coal–rock fracture segmentation method based on contour evolution and gradient direction consistency. They first established a fracture contour evolution model to obtain preliminary segmentation results. Then, they used adaptive median filtering to remove high-density noise from the image and employed 3D bilateral filtering to enhance fracture boundaries. Finally, they optimized the preliminary segmentation results with a gradient direction consistency model. This method can accurately capture the boundaries of fractures with weak edges, offering high segmentation efficiency and strong adaptability. However, it does not fully utilize the scene, affecting its detection accuracy. Xiao Dong et al. [9] combined spectroscopy with deep learning algorithms to propose a rapid field identification method for coal types. They first preprocessed the spectral data of various coal and rock types then used a convolutional neural network to extract 2D spectral features and an extreme learning machine to classify these features. Finally, they optimized the model parameters using the whale optimization algorithm. This method can quickly and accurately identify coal types, but the complexity of the algorithm design leads to relatively low efficiency.
In order to accurately identify each type of vitrinite and reduce the complexity of identification, this paper analyzes and researches the improved methods mentioned above, proposing a new improvement strategy based on the DeepLabv3+ network [10]. First, addressing the issues of slow prediction speed and low prediction accuracy, this paper employs the lightweight MobileNetV2 network as the backbone network. Additionally, to obtain multi-scale features with a larger receptive field, the ASPP module is improved by adding an atrous convolution layer with a dilation rate of 24, thereby reducing feature loss and increasing identification accuracy. Then, to avoid the amplification of erroneous or unimportant features, different mainstream attention mechanisms are compared when added to various parts of the DeepLabv3+ network to determine the impact on identification results, thus selecting an appropriate attention mechanism module. Meanwhile, experiments are conducted with channel multipliers of 5, 8, 12, and 16 in the channel module of the CBAM attention mechanism to choose the suitable channel multiplier. Finally, to ensure the consistency of each channel’s output feature map for each type of coal vitrinite, a corrective convolution module is added to the network’s output, further enhancing the model’s identification accuracy.
2. Theories and Methods
2.1. Theories
2.1.1. Semantic Segmentation Related Evaluation Indicators
With the rapid development of deep learning, semantic segmentation has gradually become an important branch of deep learning. When designing a network model with good effect for a specific problem, it is particularly important to select an index that can objectively evaluate the network model. At present, widely used indicators include F1 score, MIOU, MPA, etc.
F1 score [11] is an evaluation index that integrates the precision rate and the recall rate. It is redefined on the basis of a confusion matrix to improve the precision rate as much as possible on the premise of ensuring the recall rate [12]. Its mathematical expression is as follows:
where precision indicates the precision rate, and recall indicates the recall rate.
Precision rate refers to the proportion of true positive samples among all the samples predicted as positive.
Recall rate refers to the proportion of true positive samples among all the actual positive samples.
MIOU [13] is the arithmetic mean of the intersection over union (IoU) [14] of each coal–rock vitrinite, which can directly reflect the image recognition effect of coal–rock vitrinite. The mathematical expression is shown as follows:
where A and B represent the real region and the predicted region, respectively; Pij is the total number of pixels of class j vitrinite predicted to be class i; and k is the total number of vitrinite categories, which is 14 in this paper.
MPA [15] is the mean of pixel accuracy of all vitrinite categories. Its mathematical expression is as follows:
To sum up, MIOU and MPA are selected as the basis of the evaluation model in this paper. Compared with the accuracy rate and recall rate alone, the model recognition effect can be better reflected.
2.1.2. Semantic Segmentation Related Network Models
Different from object detection, semantic segmentation is pixel level classification. Currently, the mainstream semantic segmentation models include U-net, PSPnet, HRNet and DeepLabv3+ network.
U-net uses an architecture called encoder–decoder, in which the encoder is used to extract the features of the image and the decoder is used to generate the final segmentation result based on the extracted features [16]. The advantage of U-net network lies in its simple structure and high accuracy, which is often used in the field of medical image segmentation.
PSPnet (pyramid scene parsing network) uses atrous convolution and multi-scale fusion to improve the accuracy and precision of image semantic segmentation [17]. Atrous convolution is a special kind of convolution, which is more detailed than ordinary convolution and can capture more details so as to improve the accuracy of semantic segmentation. Multi-scale fusion is a multi-scale feature extraction technology, which can effectively extract multi-scale features and improve the accuracy of semantic segmentation. The characteristic quality of PSPnet is that it can achieve high accuracy and precision with low computational complexity, so it has attracted a wide range of attention.
The main idea of HRNet (high-resolution network) is to adopt constant resolution multi-scale feature representation to improve the accuracy and precision of multi-scale feature representation [18]. HRNet’s structure is particularly suitable for processing complex images, and it can effectively extract high-resolution features to improve the performance for tasks such as image classification, instance segmentation, and key point detection. It is often used in the field of human posture estimation.
The DeepLabv3+ is an improvement on DeeplabV3. The network structure is shown in the Figure 1 with the addition of spatial pyramid pooling (SPP) layers and atrous spatial pyramid pooling layers, as well as more pooling layers to improve the accuracy of the model [19]. It uses the improved Xception model, which is a kind of residual network based on the architecture, and it adds a depth-separable convolutional layer in order to improve the efficiency of the model. It can effectively identify objects in an image and divide them into different categories. Its network structure is shown in Figure 1, which is divided into two parts: coding layer and decoding layer. In the coding layer, parallel atrous convolution is used to extract the features extracted from the backbone extraction network, and then the full convolutional layer is used to compress the features. In the decoding layer, the number of channels is adjusted for shallow features in the backbone network using full convolution, which is then stacked with the results after sampling on the effective features after atrous convolution. Then, the final effective feature layer is obtained using the depth-separable convolutional layer, and the number of channels is adjusted to be consistent with the number of segmentation categories by using the full convolutional layer. Finally, the width and height of the feature map are consistent with the input size of the original image via the above sampling.
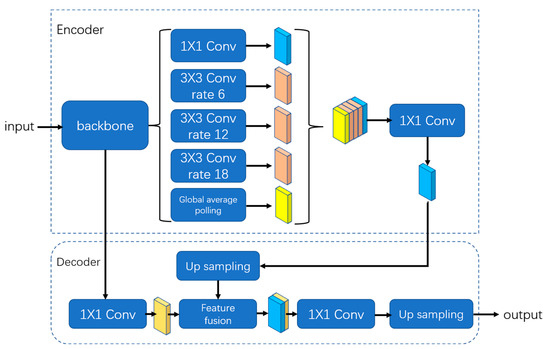
Figure 1.
Structure of DeepLabv3+ model.
2.2. Methods
2.2.1. Improved DeepLabv3+ Network Model
In this paper, we propose an improved DeepLabv3+ network, as shown in Figure 2. In the encoder part, first, the lightweight MobileNetV2 is used as the backbone network; then, an atrous convolution layer with a dilation rate of 24 is added to the ASPP feature fusion module; next, an attention mechanism module is introduced; finally, in the decoder part, a corrective convolution module is added.
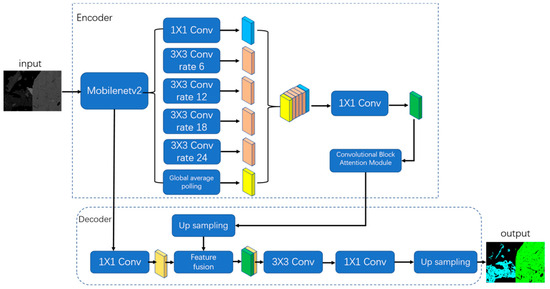
Figure 2.
Structure of improved DeepLabv3+ model.
2.2.2. MobileNetV2 Network Model
In industrial environments, there are certain requirements for detection speed. The existing Xception network is relatively complex and has a large number of parameters, making it difficult to deploy on mobile devices and unable to meet detection needs [20]. Therefore, in the encoder part, this paper uses the MobileNetV2 network, which can significantly reduce the number of model parameters, speed up detection, and improve the real-time performance of mixed coal vitrinite identification.
MobileNetV2 is a lightweight deep neural network designed for computer vision tasks such as image classification, object detection, and semantic segmentation. It improves upon MobileNetV1 by using depthwise separable convolutions, reducing the number of parameters by 50%, and providing higher accuracy with lower computational complexity. As shown in Figure 3, it employs an inverted residual structure, which is narrow at the ends and wide in the middle, outputting low-dimensional features. By using linear activation functions, it avoids feature loss.
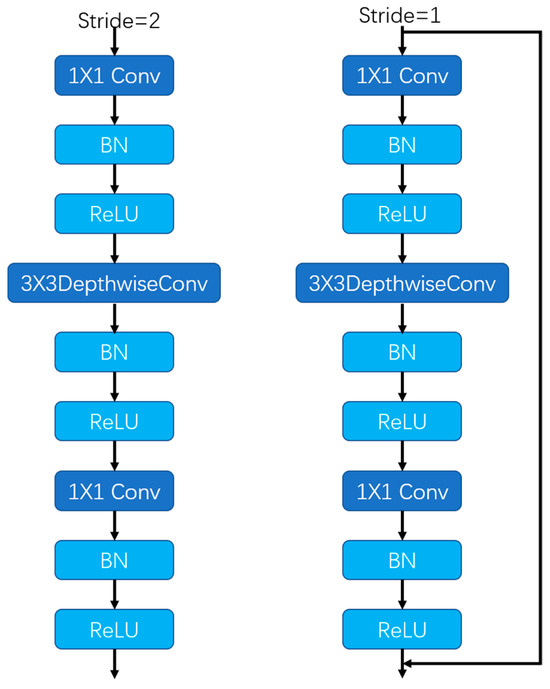
Figure 3.
Inverted residual structure.
2.2.3. ASPP Feature Extraction Module
ASPP, also known as the spatial atrous convolution pooling pyramid [21], is illustrated in Figure 4. It utilizes atrous convolution layers with different dilation rates to capture multi-scale image features and integrate them. In the DeepLabv3+ network, the ASPP employs dilation rates of 6, 12, and 18. The larger the dilation rate, the larger the receptive field. In this paper, an additional atrous convolution layer with a dilation rate of 24 is introduced to the existing ASPP structure to obtain an even larger receptive field. This allows for the extraction of more feature information and increases detection accuracy.
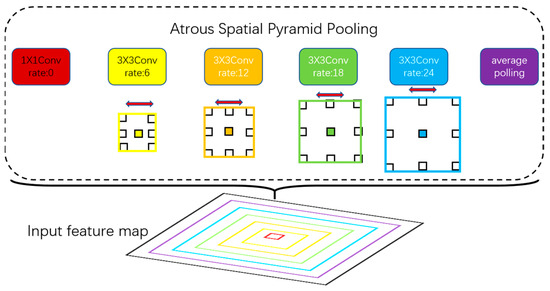
Figure 4.
Atrous spatial pyramid pooling.
2.2.4. Attention Mechanisms Module
The attention mechanism is a machine learning technique used to simulate human attention patterns [22]. It enables models to automatically learn which information is most important from the input, thereby improving the accuracy and performance of the model. The purpose of attention mechanism is to make models more efficient by focusing only on the most relevant parts of the input data while ignoring the rest. It can be applied in fields such as natural language processing (NLP), computer vision (CV), and reinforcement learning (RL). It helps models better understand the input and can enhance the performance of the model. Commonly used attention mechanisms include SE (squeeze-and-excitation), CA (channel attention), and CBAM.
The SE attention mechanism is a novel natural language processing technique that utilizes neural network models to capture relationships between each word in a sentence, thereby better understanding the meaning of the sentence. It can more accurately identify important keywords in the sentence and better handle complex structures within the sentence, aiding machines in understanding the meaning of the sentence and thus better accomplishing natural language processing tasks [23].
The CA attention mechanism can correlate features in input images with target objects, simulating human visual attention. By calculating the similarity between features in the input image, it mimics human attention, enabling more accurate identification of target objects. It enhances the performance of computer vision systems and can be used for handling complex image tasks such as object detection and image segmentation [24].
CBAM is an attention mechanism based on convolutional neural networks, which automatically learns important features of input images and combines them to enhance model performance [25]. As shown in Figure 5, it consists of two sub-modules: the channel attention submodule and the spatial attention submodule. In the channel attention module, input features are separately processed through max-pooling and average-pooling, then fed into a shared multi-layer perceptron (MLP), and finally aggregated and passed through an activation function to obtain channel attention features. In the spatial attention module, input features are processed through channel-wise global max-pooling and global average-pooling then concatenated and convolved to reduce to a single channel, followed by an activation function to obtain spatial attention features [26].
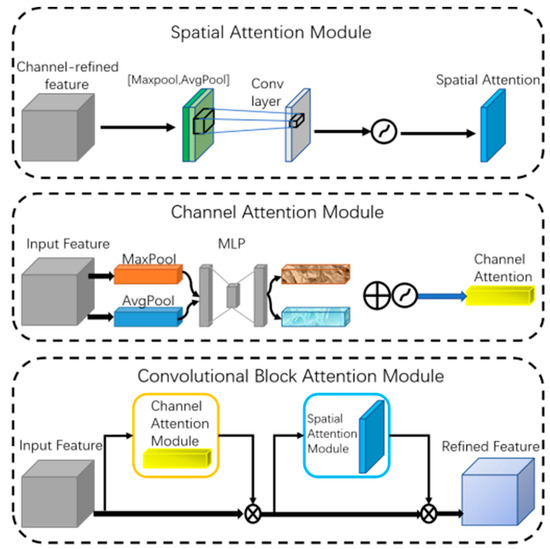
Figure 5.
CBAM attention mechanism module.
2.2.5. Corrective Convolution Module
In this study, the proposed coal vitrinite identification task covers a total of 15 categories, including 14 types of coal vitrinite and background impurities. As shown in the Figure 6, at the network output, shallow features from MobileNetV2+ are fused with the output features of the ASPP module to generate a feature map with 304 channels. This feature map then undergoes a 3 × 3 convolution to reduce the channel number to 256. Subsequently, in the decoder section, a corrective convolution module is added, and the corrective convolution adjusts the number of channels to 300. Finally, a fully convolutional layer reduces the number of channels to 15, with each set of 20 channels corresponding to one category. The output is then resized to the original input image dimensions.
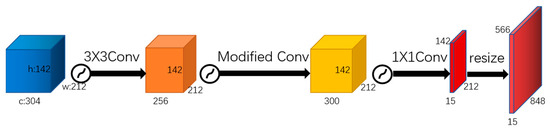
Figure 6.
Corrective convolution module.
3. Experimentation and Pre-Processing
3.1. Data Acquisition and Pre-Processing
This paper prepared samples of coal rocks containing 14 types of single vitrinite components. Under a microscope, for each sample, images were collected from 20 × 20 different areas to statistically analyze the distribution of components within the same sample. These images were preprocessed to extract vitrinite component images, which were used as a learning database for subsequent type recognition.
3.1.1. Removal of Colloids
First, spatial domain denoising is applied, including median filtering and mean filtering; then, frequency domain denoising is performed, including high-pass filtering, low-pass filtering, mid-pass filtering, and Gaussian filtering. In in Figure 7, Figure 7a is the image before preprocessing, containing colloids and Figure 7b is the image after preprocessing, with colloids removed.

Figure 7.
Comparison of images before and after colloid removal: (a) with containing colloids; (b) without containing colloids.
3.1.2. Removal of Small Interference Areas
The boundaries obtained after image thresholding are usually not very smooth, with object regions containing some noise holes and background regions scattered with small noise objects. Sequential opening and closing operations can effectively improve this situation. Sometimes, it is necessary to perform multiple erosions followed by the same number of dilations to achieve better results. The effect is shown in Figure 8, where Figure 8a is the image containing interference regions and Figure 8b is the image after preprocessing, without interference regions.
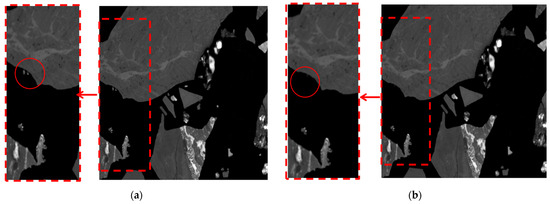
Figure 8.
Comparison of images before and after interference areas removal: (a) with containing interference areas; (b) without containing interference areas.
3.1.3. Creating Labels for Pre-Processed Images
A total of 5600 images were labeled using the Labelme annotation software (4.5.13). In Figure 9, Figure 9a is the image after preprocessing and Figure 9b is the labeled image. There are 14 types of coal–rock vitrinite, each represented by a different color as detailed in Table 1. Different types of coal–rock vitrinite are denoted by code words, and when such vitrinite are identified, they are displayed in their corresponding colors.

Figure 9.
The original and labeled image: (a) the original image; (b) the labeled image.

Table 1.
Display of BGR values and colors for different types of vitrinite.
3.2. Experimental Environment Configuration
This experiment uses a computer configured with Intel(R) Core(TM) i9-12900k, operating system Windows 10, graphics card NVIDIA GeForce RTX 3090Ti, an experimental network model based on Pytorch framework, python3.7.12 and cuda11.7, and a migration learning approach. The parameters of the experiment are shown in Table 2.
Table 2.
Experimental parameters.
3.3. Experimental Methods
This paper conducted extensive comparative experiments to obtain the optimal model for mixed coal vitrinite recognition. These experiments included assessing the impact of different attention mechanisms added at various parts of the model, evaluating the influence of channel multiplier in the CBAM attention mechanism, examining the effects of dilation rates in the ASPP module on recognition performance, and comparing the model against other mainstream models. Subsequently, ablation experiments were conducted to analyze the impacts of each optimization component on model recognition performance.
4. Results and Discussion
4.1. The Impact of Attention Mechanisms on Recognition Performance
Different attention mechanisms have varying impacts on model recognition performance. To select the most suitable attention mechanism, this paper conducted comparative experiments using CA, SE, and CBAM mechanisms at different positions within the DeepLabv3+ network. As shown in Table 3, the results indicate that CBAM achieves the highest MIOU and MPA scores longitudinally. Horizontally, applying each attention mechanism at the output of the ASPP module shows the best recognition performance for the model. Therefore, using the CBAM attention mechanism at the output of the ASPP module in the DeepLabv3+ network yields the best recognition performance. The training loss variation with epochs is depicted in Figure 10. Before epoch 60, the loss on the validation dataset fluctuates violently, while the loss on the training dataset smoothly and steadily decreases, indicating that the model is in an overfitting state. This is due to the high learning rate at the beginning, which leads to significant updates to the model parameters in an effort to minimize the loss, causing the model to fall into a local optimum. However, under the optimization of the stochastic gradient descent algorithm, along with the gradual reduction of the learning rate, the range of the optimal parameters for the model gradually narrows. After 60 epochs, the loss values for both the validation and training datasets gradually level off, indicating that the model has converged. The absence of severe fluctuations implies that the model is not overfitting and has good robustness.
Table 3.
The impact of attention mechanisms on recognition.
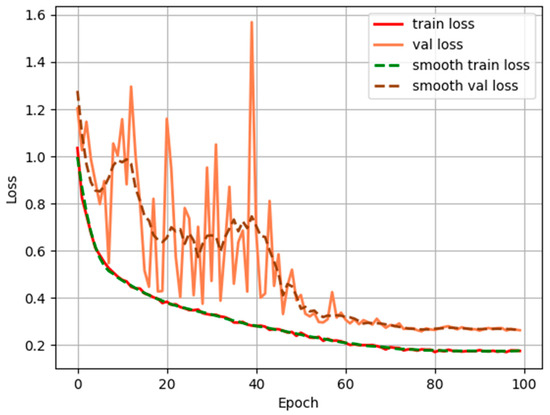
Figure 10.
The change of loss value during training with respect to epoch.
4.2. The Impact of Channel Multiplier of the CBAM Attention Mechanism on Recognition Performance
In the channel attention module of CBAM, there is a channel multiplier parameter, also known as the dimension reduction coefficient. This parameter first reduces the total number of feature channels and then enlarges them back to the initial number of channels. This process helps reduce computational parameters but can also affect the final recognition performance. Therefore, this paper conducted comparative experiments with channel multipliers of 5, 8, 12, and 16. As shown in the Table 4, when the CBAM channel multiplier is 8, the MIOU and MPA reach 71.22% and 85.72%, respectively, which is an improvement of 1.97% and 1.72% compared to the original multiplier of 16. Overall, the CBAM attention mechanism performs best when the channel multiplier is set to 8 for model recognition performance. The training loss variation with epochs is depicted in Figure 11, showing gradual convergence after 70 epochs.
Table 4.
The impact of different channel multipliers of CBAM on recognition.
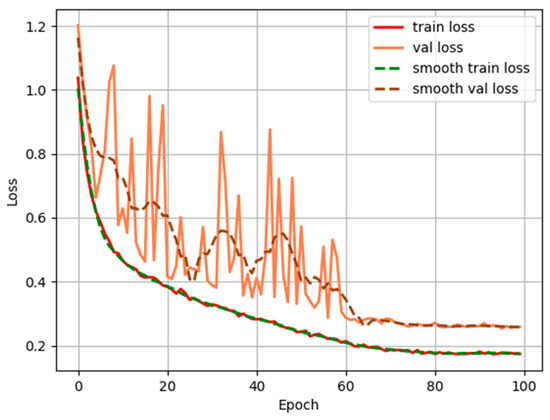
Figure 11.
The change of loss value during training with respect to epoch.
4.3. The Impact of the ASPP Module on Recognition Performance
In the DeepLabv3+ network, the ASPP module plays a crucial role in extracting multi-scale features. The choice of dilation rate and the number of atrous convolution layers directly impact the model’s ability to extract effective features, as atrous convolution helps reduce redundant feature information between adjacent pixels. Therefore, this paper conducted comparative experiments with different dilation rates, as shown in Table 5. The first column in the table represents the dilation rates in the atrous spatial pyramid pooling. By adding an atrous convolution layer with a dilation rate of 24 to the original setup, the MIOU and MPA reach 69.36% and 83.71%, respectively, which is an improvement of 3.23% and 1.93% compared to the original ASPP module. Overall, adding an atrous convolution layer with a dilation rate of 24 to the original ASPP module yields the best recognition performance for the model. The training loss variation with epochs is depicted in Figure 12, showing gradual convergence after 65 epochs.
Table 5.
The impact of ASPP with different dilation rates on recognition.
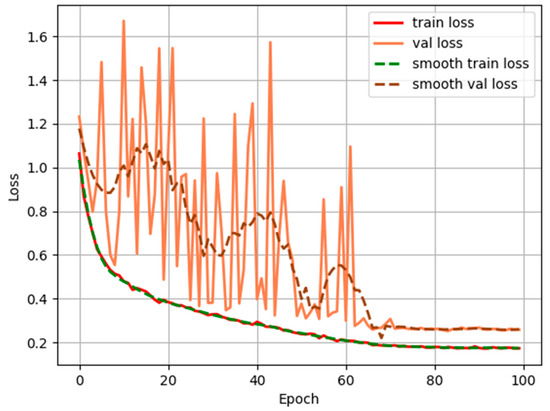
Figure 12.
The change of loss value during training with respect to epoch.
4.4. Comparison of the Improved Model with Mainstream Models
To validate the effectiveness of the proposed network model in this paper, comparative experiments were conducted with current mainstream models including U-net, PSPnet with ResNet and MobileNet backbones, HRNet, and DeepLabv3+. The experimental results are shown in Table 6.
Table 6.
Comparison of the improved model with mainstream models.
As shown in Table 6 and Figure 13, the network architecture proposed in this paper outperforms other networks in terms of MIOU and MPA. After 100 epochs, the model tends to converge with MIOU and MPA, reaching 71.53% and 85.46%, respectively. Compared to U-net, PSPnet (ResNet), PSPnet (MobileNet), HRNet, and DeepLabV3+, the proposed network architecture achieves improvements of 12%, 5.3%, 9.26%, 4.73%, and 5.4% and 9.34%, 6.46%, 9.05%, 6.14%, and 3.68% in terms of MIOU and MPA, respectively. Moreover, the proposed model has relatively fewer parameters and can be easily deployed on mobile devices. The effectiveness is demonstrated in Figure 14, which includes 28 small images arranged in pairs. Each pair shows the original image followed by the recognition result image, representing the recognition performance comparison for each type of vitrinite. Different colors indicate different types of vitrinite. It can be observed that the identification performance is quite good.
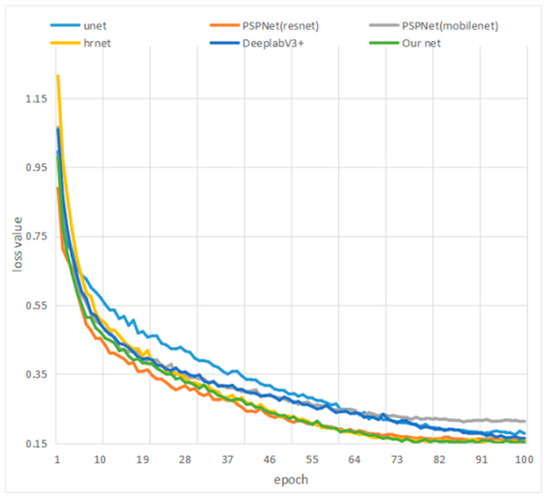
Figure 13.
The change in loss values with epochs for different network models.

Figure 14.
The display of recognition effect.
4.5. Results and Discussion of Ablation Experiments
To validate the optimization effect of the proposed improvements on vitrinite component recognition, a series of ablation experiments were conducted. As shown in Table 7, to address issues related to excessive model parameters leading to potential overfitting and reduced real-time capability in mixed coal vitrinite recognition, a lightweight MobileNetV2 network was used as the backbone, achieving an MIOU of 66.13% and an MPA of 81.78%. Due to the slightly inferior deep feature extraction capability of lightweight networks compared to original deep neural networks, the enhanced ASPP module was introduced to enlarge the receptive field, ignore redundant feature information between adjacent pixels, and further extract effective features, resulting in an improvement of 3.23% in MIOU and 1.93% in MPA. After integrating a corrective convolution module at the network output, MIOU and MPA increased by 1.24% and 1.21%, respectively. Finally, incorporating the CBAM attention mechanism with a channel multiplier of 8 further boosted MIOU by 0.93% and MPA by 0.54%. Ultimately, the proposed improved DeepLabv3+ network achieved an MIOU of 71.53% and MPA of 85.46% for mixed coal vitrinite component recognition. Compared to the best-performing HRNet network, this represents improvements of 4.73% and 6.14% in MIOU and MPA, respectively.
Table 7.
Results of ablation experiments.
5. Conclusions
In this paper, we address the problem of the difficult identification of mixed coal vitrinite and propose an improved method based on Deeplabv3+ for mixed coal vitrinite recognition. Extensive comparative experiments were conducted to achieve the optimal mixed coal vitrinite recognition model. These experiments included evaluating the effects of different attention mechanisms applied to different parts of the model on recognition performance, the impact of the channel multiplier on the CBAM attention mechanism, and the influence of ASPP module dilation rates on recognition performance. The proposed method was also compared with other mainstream models to validate its improvements. Furthermore, ablation experiments were performed to analyze the impact of each optimization component on model recognition performance and verify the effectiveness of the proposed method. Experimental results demonstrate that the proposed improved DeepLabv3+ network achieves an MIOU of 71.53% and MPA of 85.46%. Additionally, compared with other mainstream models, the improved DeepLabv3+ demonstrates favorable performance in mixed coal vitrinite recognition. In conclusion, the proposed improvements effectively address the challenges of high complexity and low accuracy in vitrinite recognition, providing significant guidance for mixed coal vitrinite recognition.
Author Contributions
Conceptualization, F.W. and F.L.; methodology, F.L.; software, F.L.; investigation, X.S.; resources, X.S.; data curation, F.W.; writing—original draft preparation, F.L. and W.S.; writing—review and editing, W.S.; supervision, H.L.; project administration, F.W.; funding acquisition, F.W. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Fundamental Research Program of Shanxi Province (No. 20210302123054).
Data Availability Statement
Data can be made available upon request from the authors.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Yuan, J.H.; Na, C.N.; Lei, Q.; Xiong, M.P.; Guo, J.S.; Zheng, H. Coal use for power generation in China. Resour. Conserv. Recycl. 2018, 129, 443–453. [Google Scholar] [CrossRef]
- Yang, N.; Fu, H.; Ma, K.F.; Yang, H.Y. Proficiency testing and application assessment of random reflectance and maceral detection of vitrinite in coal. Coal Qual. Technol. 2023, 38, 78–83. [Google Scholar]
- Yang, L.; Jia, H.; Wu, A.; Jiao, H.; Chen, X.; Kou, Y.; Dong, M. Particle Aggregation and Breakage Kinetics in Cemented Paste Backfill. Int. J. Miner. Metall. Mater. 2023, 220, 172–186. [Google Scholar]
- Sun, T.; Wang, H.W.; Yan, Z.R. Research on Coal-rock Recognition System Based on Convolutional Neural Network and Semantic Segmentation Hybrid Model. Min. Res. Dev. 2022, 42, 179–187. [Google Scholar]
- Shi, G.L.; Yu, R.; Wang, H.Y.; Ge, J.M.; Zhang, S.T. Coal and rock identification method based on Kalman optimal estimation of load data of rocker arm pin axle of shearer. J. Mine Autom. 2023, 49, 109–115+122. [Google Scholar]
- Jiang, S.; Rao, B.J.; Lu, C.W.; Gu, Q.H.; Ruan, S.L.; Yang, H. Fine segmentation method of blast heap block in open pit mine based on point rendering and multi-branch fusion. J. China Coal Soc. 2023, 48, 542–552. [Google Scholar]
- Guo, Q.P.; Wang, Y.C.; Yang, S.J.; Xiang, Z.B. A method of blasted rock image segmentation based on improved watershed algorithm. Sci. Rep. 2022, 12, 7143. [Google Scholar] [CrossRef] [PubMed]
- Li, Z.W.; Zhang, G.Y. Fracture Segmentation Method Based on Contour Evolution and Gradient Direction Consistency in Sequence of Coal Rock CT Images. Math. Probl. Eng. 2019, 2019, 2980747. [Google Scholar] [CrossRef]
- Dong, X.; Giang, T.T.L.; Thanh, T.D.; Tuan, B.L. Coal identification based on a deep network and reflectance spectroscopy. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2022, 270, 120859. [Google Scholar]
- Wang, J.D.; Sun, K.; Cheng, T.H.; Jiang, B.R.; Deng, C.R.; Zhao, Y. Deep High-Resolution Representation Learning for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 3349–3364. [Google Scholar] [CrossRef]
- Kang, J.H.; Liu, C.Z.; Yang, H.Q. Research on wheat rust detection method based on attention ResNet model. Intell. Comput. Appl. 2023, 13, 124–128. [Google Scholar]
- Yu, Y.; Yang, T.T.; Yang, B.X. Confusion Matrix Classification Performance Evaluation and Python Implementation. Mod. Comput. 2021, 20, 70–73+79. [Google Scholar]
- Gu, W.J.; Wei, J.; Yin, Y.C.; Liu, X.B.; Ding, C. Multi-category Segmentation Method of Tomato Image Based on Improved DeepLabv3+. Trans. Chin. Soc. Agric. Mach. 2023, 54, 261–271. [Google Scholar]
- Xu, Z.C.; Xue, J.P.; Sun, P.F.; Song, Z.Y.; Yu, C.Z. Robot Grasp Detection Method Based on Stable Lightweight Network. Chin. J. Lasers 2023, 50, 71–80. [Google Scholar]
- Yu, Y.; Wang, C.P.; Fu, Q.; Kou, R.K.; Wu, W.Y.; Liu, T.Y. Survey of Evaluation Metrics and Methods for Semantic Segmentation. Comput. Eng. Appl. 2023, 59, 57–69. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. arXiv 2015, arXiv:1505.04597. [Google Scholar]
- Cai, Q.L.; Wang, Q. Research on application of improved deep learning algorithm PSPnet in water obstacle detection. Hoisting Conveying Mach. 2023, 13, 43–53. [Google Scholar]
- Ye, S.J.; Wei, Y.; Du, H.Y.; Deng, J.Z. HRNet lmage Semantic Segmentation Algorithm Combined with Attention Mechanism. Comput. Mod. 2023, 59, 65–69. [Google Scholar]
- Qu, F.H.; Li, J.Z.; Yang, Y.; Kang, Z.N.; Yan, X.W. Lightweight crop and weed recognition method based on imporved DeepLabv3+. J. Shihezi Univ. 2024, 42, 117–125. [Google Scholar]
- Tong, S.B.; Sun, P.; Lang, Y.B.; Xie, M.D.; Liu, T.Y. Tamper lmage Detection Method Based on Xception Siamese Structure Network. Comput. Simul. 2023, 1–8. Available online: https://link.cnki.net/urlid/11.3724.TP.20231108.1106.002 (accessed on 1 June 2024).
- AboElenein, N.M.; Piao, S.H.; Zhang, Z.H. Encoder–Decoder Network with Depthwise Atrous Spatial Pyramid Pooling for Automatic Brain Tumor Segmentation. Neural Process. Lett. 2022, 55, 1697–1713. [Google Scholar] [CrossRef]
- Ren, H.; Wang, X.G. Review of attention mechanism. J. Comput. Appl. 2021, 41, 1–6. [Google Scholar]
- Xiao, P.C.; Xu, W.G.; Zhang, Y.; Zhu, L.G.; Zhu, R.; Xu, Y.F. Research on scrap classification and rating method based on SE attention mechanism. Chin. J. Eng. 2023, 45, 1342–1352. [Google Scholar]
- Guo, K.Y.; Wang, P.S.; Shi, P.P.; He, C.B.; Wei, C.L. A New Partitioned Spatial–Temporal Graph Attention Convolution Network for Human Motion Recognition. Appl. Sci. 2023, 13, 1647. [Google Scholar] [CrossRef]
- Liu, N. Semantic segmentation algorithm of transmission lines based on Cbam attention mechanism. Chang. Inf. Commun. 2023, 36, 60–62. [Google Scholar]
- Yang, L.; Gao, Y.; Chen, H.; Jiao, H.; Dong, M.; Bier, T.A.; Kim, M. Three-dimensional concrete printing technology from a rheology perspective: A review. Adv. Cem. Res. 2024, 126, 72–86. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).