
Energy Management in Hybrid Electric Vehicles: A Q-Learning Solution for Enhanced Drivability and Energy Efficiency

 ,
,  ,
,  and
and 
Abstract
:1. Introduction
1.1. Related Works
1.2. Contribution
- Integration of comfort and ride quality indicators, such as ICE de/activation frequency and torque rate variation constraints, into the energy management control problem using an off-policy RL approach.
- Testing the approach in diverse driving scenarios to validate its applicability and reliability.
- Comparison against a benchmark solution to demonstrate the proposed approach’s performance in fuel and energy efficiency, as well as overall system performance.
- Development of a concise, real-time map for use in automotive control units or similar decision-making systems across different domains.
2. Vehicle Model
3. Problem Formulation
3.1. Control Problem
3.2. Benchmark Algorithm
- A classical approach where fuel economy and charge sustainability are considered;
- A trade-off between fuel economy and drivability/comfort requirements ensuring charge sustaining operation [19].
| Algorithm 1 Dynamic programming with terminal constraint |
|
3.3. Proposed Solution
| Algorithm 2 Tabular Q-learning |
|
Simulation Setup and Q-Learning Based Controller Design
4. Results
4.1. Evaluation Metrics
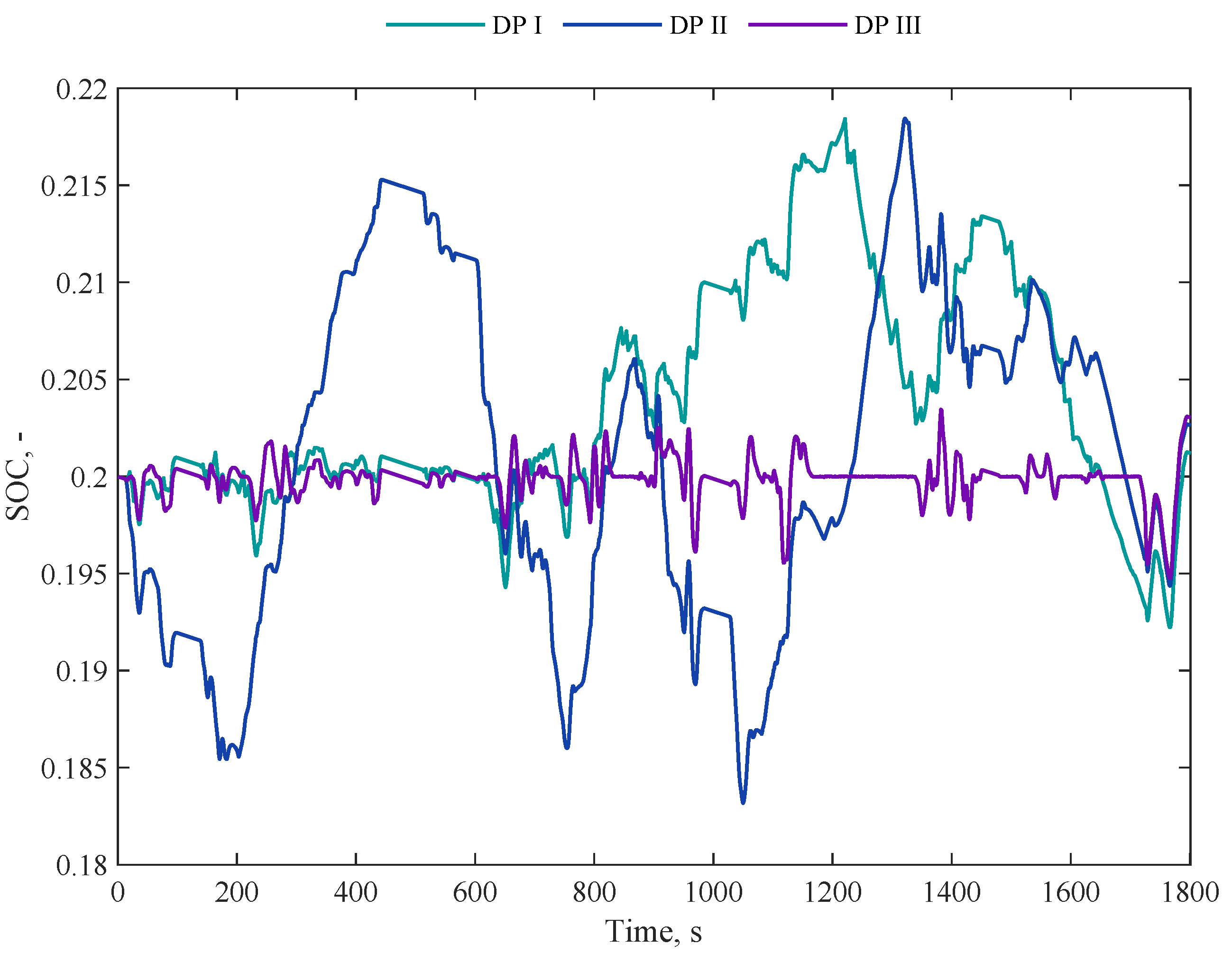
4.2. DP Results
4.3. Comparison Assumptions
4.4. Correction of Fuel Consumption to Account for SOC Variation with Respect to the Target Value
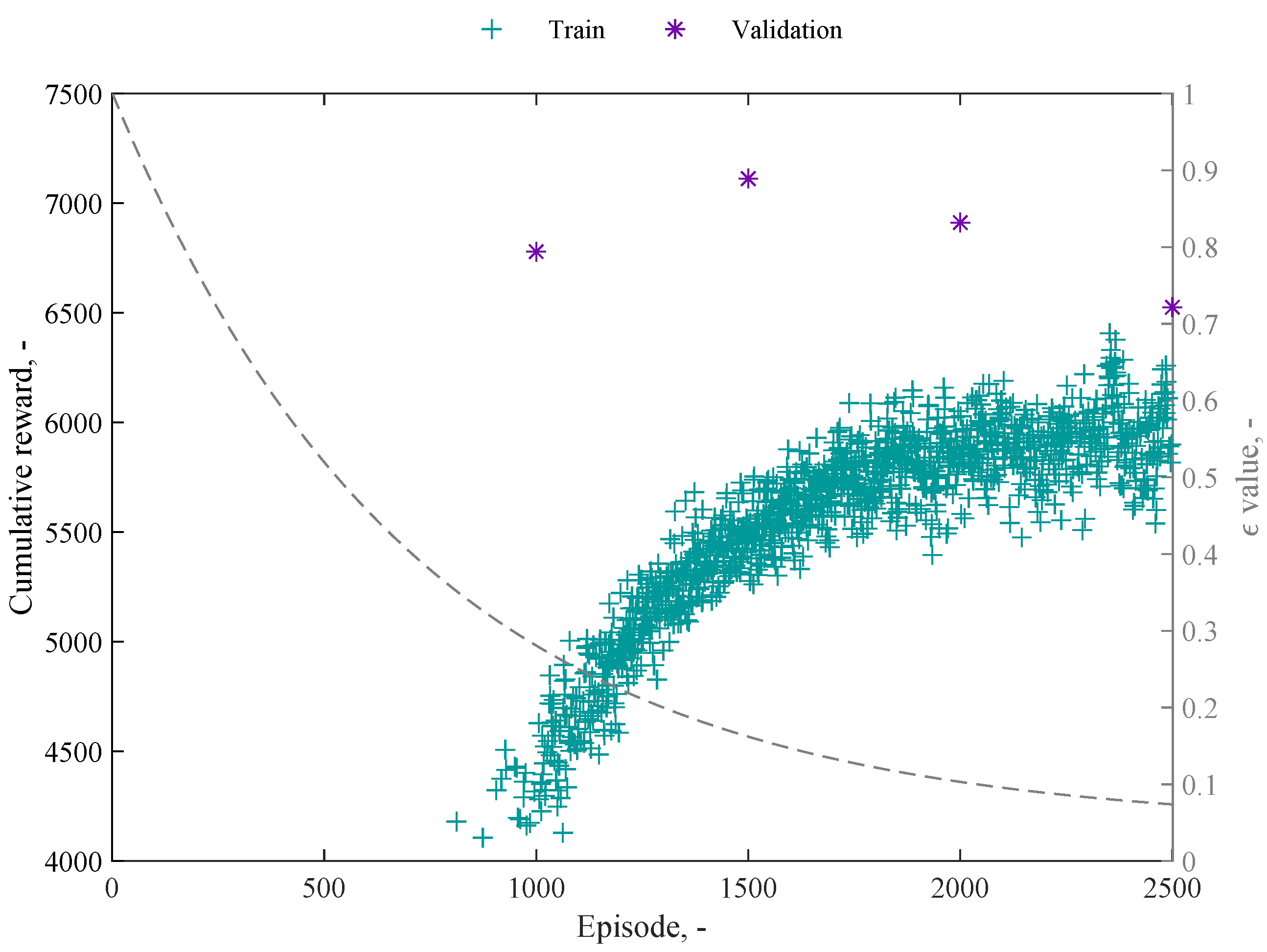
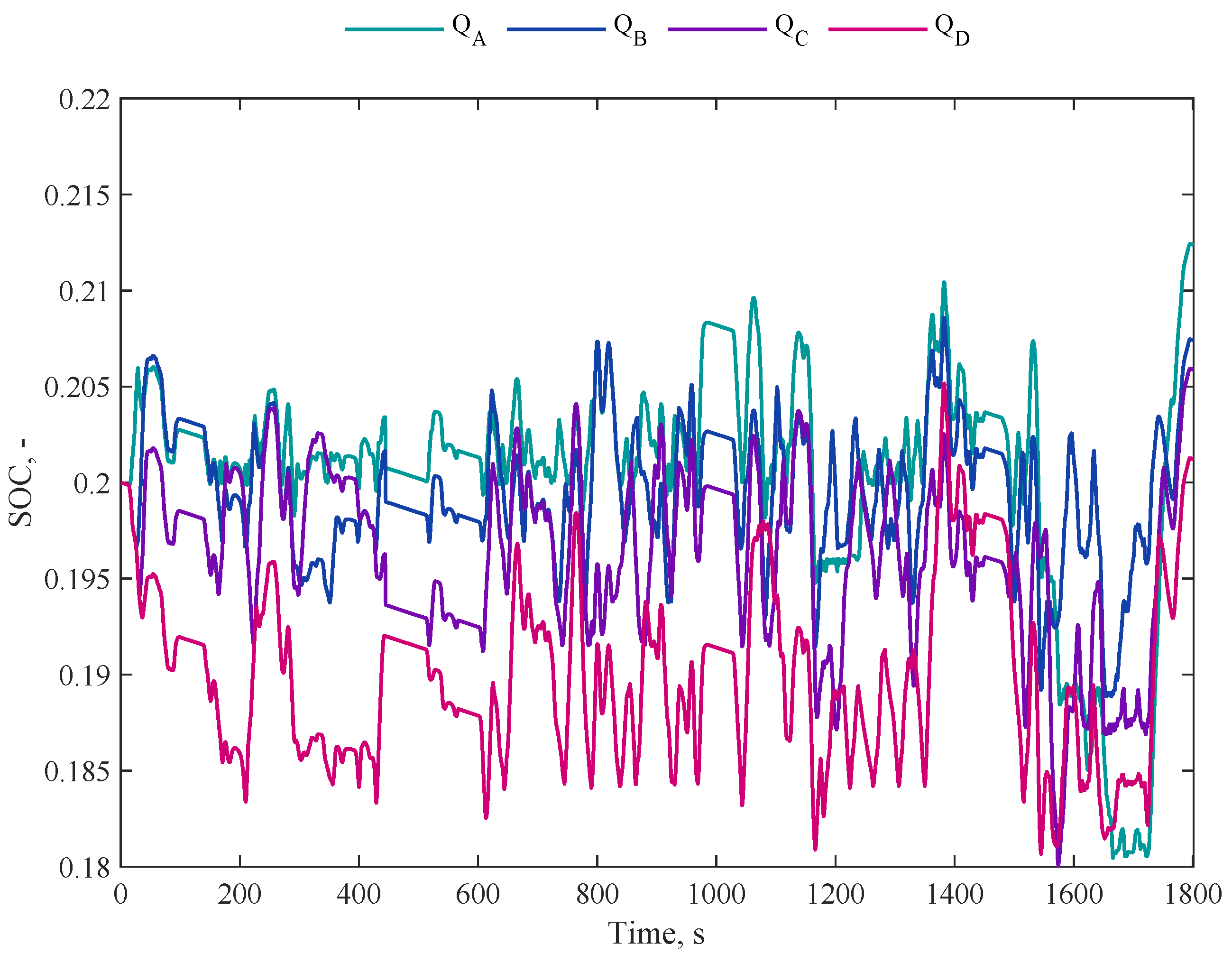
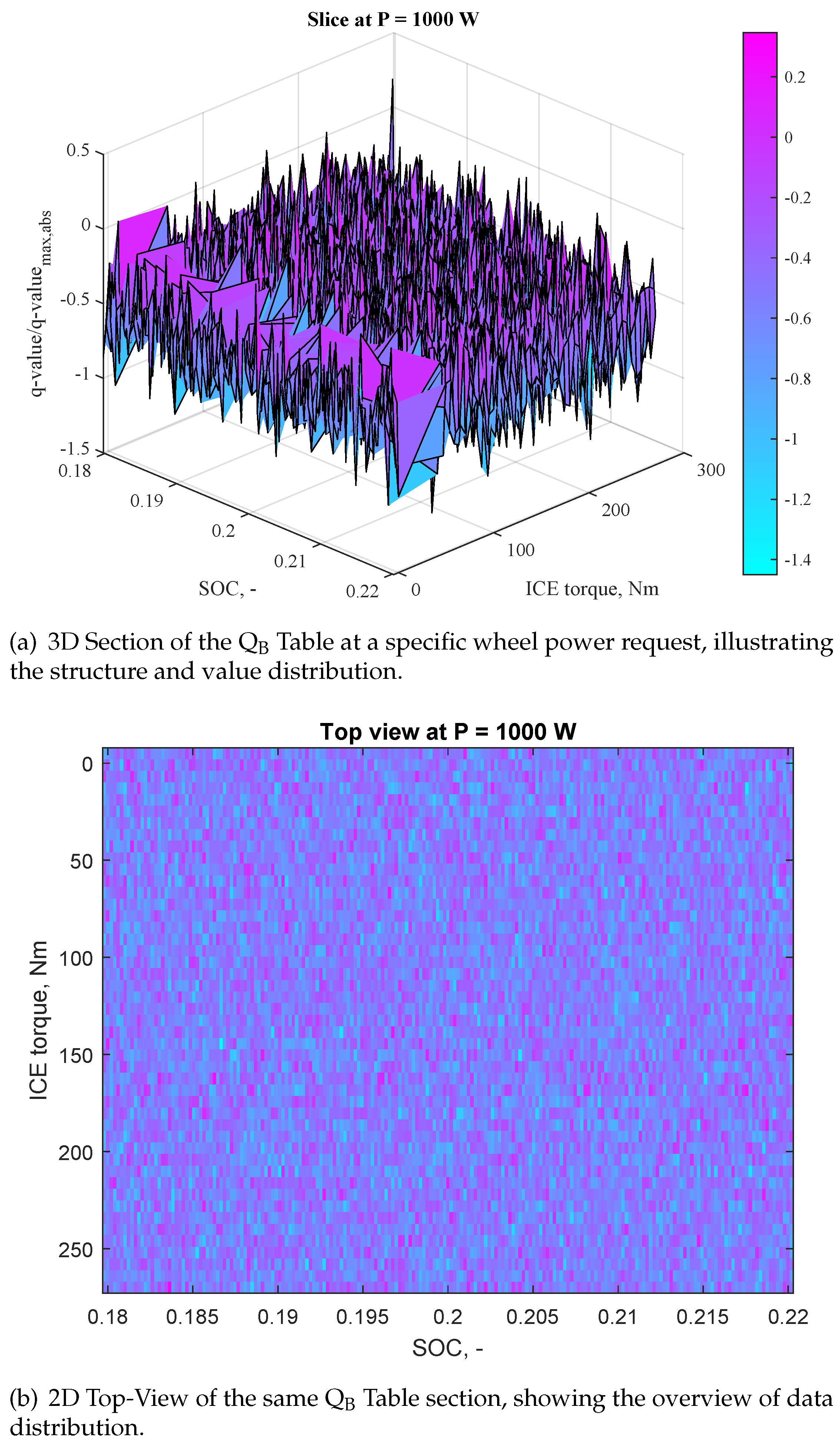
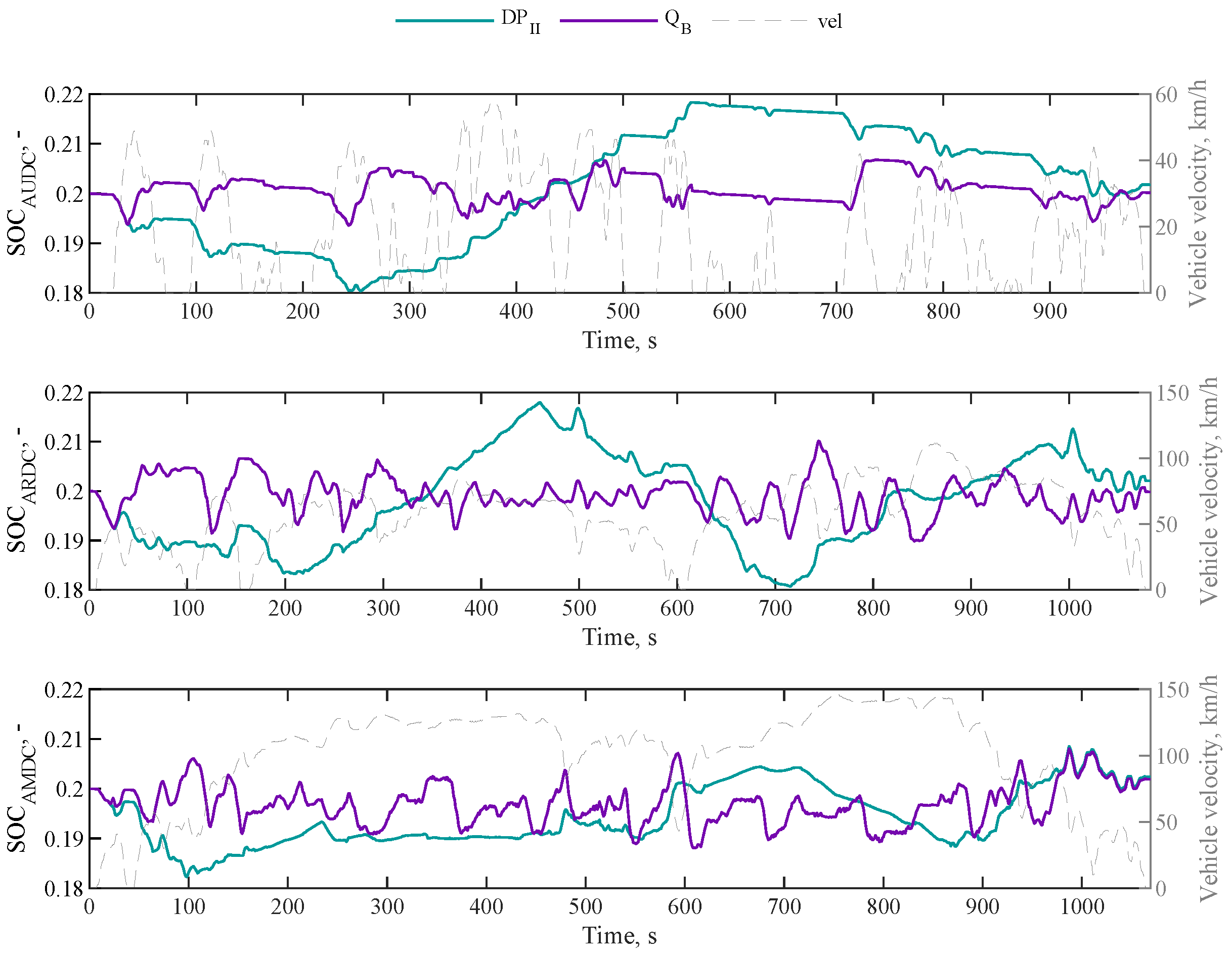
4.5. Q-Learning Results and Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| AMDC | Artemis motorway driving cycle |
| ARDC | Artemis rural driving cycle |
| AUDC | Artemis urban driving cycle |
| DP | Dynamic programming |
| HEV | Hybrid electric vehicle |
| ICE | Internal combustion engine |
| PHEV | Plug-in hybrid electric vehicle |
| RL | Reinforcement leaning |
| SOC | State of charge |
| WLTP | Worldwide harmonised light vehicle test procedure |
References
- MordorIntelligence. Hybrid Vehicle Market Analysis—Industry Report—Trends, Size & Share. Available online: https://www.mordorintelligence.com/industry-reports/hybrid-vehicle-market (accessed on 30 October 2022).
- Lelli, E.; Musa, A.; Batista, E.; Misul, D.A.; Belingardi, G. On-Road Experimental Campaign for Machine Learning Based State of Health Estimation of High-Voltage Batteries in Electric Vehicles. Energies 2023, 16, 4639. [Google Scholar] [CrossRef]
- Guzzella, L.; Sciarretta, A. Vehicle Propulsion Systems: Introduction to Modeling and Optimization; Springer: Berlin/Heidelberg, Germany, 2007. [Google Scholar] [CrossRef]
- Onori, S.; Serrao, L.; Rizzoni, G. Hybrid Electric Vehicles: Energy Management Strategies; Springer: London, UK, 2016. [Google Scholar]
- Wirasingha, S.G.; Emadi, A. Classification and Review of Control Strategies for Plug-In Hybrid Electric Vehicles. IEEE Trans. Veh. Technol. 2011, 60, 111–122. [Google Scholar] [CrossRef]
- Pisu, P.; Rizzoni, G. A Comparative Study Of Supervisory Control Strategies for Hybrid Electric Vehicles. IEEE Trans. Control. Syst. Technol. 2007, 15, 506–518. [Google Scholar] [CrossRef]
- Jalil, N.; Kheir, N.; Salman, M. A rule-based energy management strategy for a series hybrid vehicle. In Proceedings of the 1997 American Control Conference (Cat. No.97CH36041), Albuquerque, NM, USA, 6 June 1997; Volume 1, pp. 689–693. [Google Scholar] [CrossRef]
- Hofman, T.; Steinbuch, M.; Druten, R.; Serrarens, A. A Rule-based energy management strategies for hybrid vehicles. Int. J. Electr. Hybrid Veh. 2007, 1, 71–94. [Google Scholar] [CrossRef]
- Banvait, H.; Anwar, S.; Chen, Y. A rule-based energy management strategy for Plug-in Hybrid Electric Vehicle (PHEV). In Proceedings of the 2009 American Control Conference, St. Louis, MO, USA, 10–12 June 2009; pp. 3938–3943. [Google Scholar] [CrossRef]
- Hofman, T.; Steinbuch, M.; van Druten, R.; Serrarens, A. Rule-Based Energy Management Strategies for Hybrid Vehicle Drivetrains: A Fundamental Approach in Reducing Computation Time. IFAC Proc. Vol. 2006, 39, 740–745. [Google Scholar] [CrossRef]
- Goerke, D.; Bargende, M.; Keller, U.; Ruzicka, N.; Schmiedler, S. Optimal Control based Calibration of Rule-Based Energy Management for Parallel Hybrid Electric Vehicles. SAE Int. J. Altern. Powertrains 2015, 4, 178–189. [Google Scholar] [CrossRef]
- Peng, J.; He, H.; Xiong, R. Rule based energy management strategy for a series–parallel plug-in hybrid electric bus optimized by dynamic programming. Appl. Energy 2017, 185, 1633–1643. [Google Scholar] [CrossRef]
- Sciarretta, A.; Guzzella, L. Control of hybrid electric vehicles. IEEE Control. Syst. Mag. 2007, 27, 60–70. [Google Scholar] [CrossRef]
- Xie, S.; Hu, X.; Xin, Z.; Brighton, J. Pontryagin’s Minimum Principle based model predictive control of energy management for a plug-in hybrid electric bus. Appl. Energy 2019, 236, 893–905. [Google Scholar] [CrossRef]
- Kim, N.; Cha, S.; Peng, H. Optimal Control of Hybrid Electric Vehicles Based on Pontryagin’s Minimum Principle. IEEE Trans. Control. Syst. Technol. 2011, 19, 1279–1287. [Google Scholar] [CrossRef]
- Musardo, C.; Rizzoni, G.; Guezennec, Y.; Staccia, B. A-ECMS: An Adaptive Algorithm for Hybrid Electric Vehicle Energy Management. Eur. J. Control. 2005, 11, 509–524. [Google Scholar] [CrossRef]
- Onori, S.; Serrao, L.; Rizzoni, G. Adaptive equivalent consumption minimization strategy for hybrid electric vehicles. In Proceedings of the Dynamic Systems and Control Conference, Cambridge, MA, USA, 12–15 September 2010; Volume 44175, pp. 499–505. [Google Scholar]
- Delprat, S.; Lauber, J.; Guerra, T.; Rimaux, J. Control of a parallel hybrid powertrain: Optimal control. IEEE Trans. Veh. Technol. 2004, 53, 872–881. [Google Scholar] [CrossRef]
- Anselma, P.G. Rule-based Control and Equivalent Consumption Minimization Strategies for Hybrid Electric Vehicle Powertrains: A Hardware-in-the-loop Assessment. In Proceedings of the 2022 IEEE 31st International Symposium on Industrial Electronics (ISIE), Anchorage, AK, USA, 1–3 June 2022; pp. 680–685. [Google Scholar] [CrossRef]
- Millo, F.; Rolando, L.; Tresca, L.; Pulvirenti, L. Development of a neural network-based energy management system for a plug-in hybrid electric vehicle. Transp. Eng. 2023, 11, 100156. [Google Scholar] [CrossRef]
- Finesso, R.; Spessa, E.; Venditti, M. An Unsupervised Machine-Learning Technique for the Definition of a Rule-Based Control Strategy in a Complex HEV. SAE Int. J. Altern. Powertrains 2016, 5. [Google Scholar] [CrossRef]
- Zhang, Y.; Chen, Z.; Li, G.; Liu, Y.; Chen, H.; Cunningham, G.; Early, J. Machine Learning-Based Vehicle Model Construction and Validation—Toward Optimal Control Strategy Development for Plug-In Hybrid Electric Vehicles. IEEE Trans. Transp. Electrif. 2022, 8, 1590–1603. [Google Scholar] [CrossRef]
- Chen, Z.; Yang, C.; Fang, S. A Convolutional Neural Network-Based Driving Cycle Prediction Method for Plug-in Hybrid Electric Vehicles With Bus Route. IEEE Access 2020, 8, 3255–3264. [Google Scholar] [CrossRef]
- Lin, X.; Bogdan, P.; Chang, N.; Pedram, M. Machine learning-based energy management in a hybrid electric vehicle to minimize total operating cost. In Proceedings of the 2015 IEEE/ACM International Conference on Computer-Aided Design (ICCAD), Austin, TX, USA, 2–6 November 2015; pp. 627–634. [Google Scholar] [CrossRef]
- Sabri, M.M.; Danapalasingam, K.; Rahmat, M. A review on hybrid electric vehicles architecture and energy management strategies. Renew. Sustain. Energy Rev. 2016, 53, 1433–1442. [Google Scholar] [CrossRef]
- Huang, X.; Tan, Y.; He, X. An Intelligent Multifeature Statistical Approach for the Discrimination of Driving Conditions of a Hybrid Electric Vehicle. IEEE Trans. Intell. Transp. Syst. 2011, 12, 453–465. [Google Scholar] [CrossRef]
- Murphey, Y.L.; Park, J.; Kiliaris, L.; Kuang, M.L.; Masrur, M.A.; Phillips, A.M.; Wang, Q. Intelligent Hybrid Vehicle Power Control—Part II: Misc Intelligent Energy Management. IEEE Trans. Veh. Technol. 2013, 62, 69–79. [Google Scholar] [CrossRef]
- Liu, K.; Asher, Z.; Gong, X.; Huang, M.; Kolmanovsky, I. Vehicle Velocity Prediction and Energy Management Strategy Part 1: Deterministic and Stochastic Vehicle Velocity Prediction Using Machine Learning. In Proceedings of the WCX SAE World Congress Experience, Detroit, MI, USA, 9–11 April 2019; SAE International: Warrendale, PA, USA, 2019. [Google Scholar] [CrossRef]
- Han, L.; Jiao, X.; Zhang, Z. Recurrent neural network-based adaptive energy management control strategy of plug-in hybrid electric vehicles considering battery aging. Energies 2020, 13, 202. [Google Scholar] [CrossRef]
- Maroto Estrada, P.; de Lima, D.; Bauer, P.H.; Mammetti, M.; Bruno, J.C. Deep learning in the development of energy Management strategies of hybrid electric Vehicles: A hybrid modeling approach. Appl. Energy 2023, 329, 120231. [Google Scholar] [CrossRef]
- Zhang, T.; Zhao, C.; Sun, X.; Lin, M.; Chen, Q. Uncertainty-Aware Energy Management Strategy for Hybrid Electric Vehicle Using Hybrid Deep Learning Method. IEEE Access 2022, 10, 63152–63162. [Google Scholar] [CrossRef]
- Liu, T.; Tang, X.; Wang, H.; Yu, H.; Hu, X. Adaptive Hierarchical Energy Management Design for a Plug-In Hybrid Electric Vehicle. IEEE Trans. Veh. Technol. 2019, 68, 11513–11522. [Google Scholar] [CrossRef]
- Liu, T.; Hu, X.; Li, S.E.; Cao, D. Reinforcement Learning Optimized Look-Ahead Energy Management of a Parallel Hybrid Electric Vehicle. IEEE/ASME Trans. Mechatronics 2017, 22, 1497–1507. [Google Scholar] [CrossRef]
- Hu, Y.; Li, W.; Xu, K.; Zahid, T.; Qin, F.; Li, C. Energy Management Strategy for a Hybrid Electric Vehicle Based on Deep Reinforcement Learning. Appl. Sci. 2018, 8, 187. [Google Scholar] [CrossRef]
- Zou, Y.; Liu, T.; Liu, D.; Sun, F. Reinforcement learning-based real-time energy management for a hybrid tracked vehicle. Appl. Energy 2016, 171, 372–382. [Google Scholar] [CrossRef]
- Wu, Y.; Tan, H.; Peng, J.; Zhang, H.; He, H. Deep reinforcement learning of energy management with continuous control strategy and traffic information for a series-parallel plug-in hybrid electric bus. Appl. Energy 2019, 247, 454–466. [Google Scholar] [CrossRef]
- Hu, X.; Liu, T.; Qi, X.; Barth, M. Reinforcement Learning for Hybrid and Plug-In Hybrid Electric Vehicle Energy Management: Recent Advances and Prospects. IEEE Ind. Electron. Mag. 2019, 13, 16–25. [Google Scholar] [CrossRef]
- Xu, B.; Rathod, D.; Zhang, D.; Yebi, A.; Zhang, X.; Li, X.; Filipi, Z. Parametric study on reinforcement learning optimized energy management strategy for a hybrid electric vehicle. Appl. Energy 2020, 259, 114200. [Google Scholar] [CrossRef]
- Wu, J.; He, H.; Peng, J.; Li, Y.; Li, Z. Continuous reinforcement learning of energy management with deep Q network for a power split hybrid electric bus. Appl. Energy 2018, 222, 799–811. [Google Scholar] [CrossRef]
- Biswas, A.; Anselma, P.G.; Emadi, A. Real-Time Optimal Energy Management of Multimode Hybrid Electric Powertrain with misc Trainable Asynchronous Advantage Actor–Critic Algorithm. IEEE Trans. Transp. Electrif. 2022, 8, 2676–2694. [Google Scholar] [CrossRef]
- Wang, Z.; He, H.; Peng, J.; Chen, W.; Wu, C.; Fan, Y.; Zhou, J. A comparative study of deep reinforcement learning based energy management strategy for hybrid electric vehicle. Energy Convers. Manag. 2023, 293, 117442. [Google Scholar] [CrossRef]
- Han, X.; He, H.; Wu, J.; Peng, J.; Li, Y. Energy management based on reinforcement learning with double deep Q-learning for a hybrid electric tracked vehicle. Appl. Energy 2019, 254, 113708. [Google Scholar] [CrossRef]
- Xu, B.; Tang, X.; Hu, X.; Lin, X.; Li, H.; Rathod, D.; Wang, Z. Q-Learning-Based Supervisory Control Adaptability Investigation for Hybrid Electric Vehicles. IEEE Trans. Intell. Transp. Syst. 2022, 23, 6797–6806. [Google Scholar] [CrossRef]
- Chen, Z.; Gu, H.; Shen, S.; Shen, J. Energy management strategy for power-split plug-in hybrid electric vehicle based on MPC and double Q-learning. Energy 2022, 245, 123182. [Google Scholar] [CrossRef]
- Miretti, F.; Misul, D.; Spessa, E. DynaProg: Deterministic Dynamic Programming solver for finite horizon multi-stage decision problems. SoftwareX 2021, 14, 100690. [Google Scholar] [CrossRef]
- Miretti, F.; Misul, D. Driveability Constrained Models for Optimal Control of Hybrid Electric Vehicles. In Proceedings of the International Workshop IFToMM for Sustainable Development Goals, Bilbao, Spain, 22–23 June 2023. [Google Scholar] [CrossRef]
- Du, G.; Zou, Y.; Zhang, X.; Liu, T.; Wu, J.; He, D. Deep reinforcement learning based energy management for a hybrid electric vehicle. Energy 2020, 201, 117591. [Google Scholar] [CrossRef]
- Richard, S.S.; Andrew, G.B. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- openAI. Part 2: Kinds of RL Algorithms. Available online: https://spinningup.openai.com/en/latest/spinningup/rl_intro2.html (accessed on 18 June 2023).
- TowardsDataScience. Value-Based Methods in Deep Reinforcement Learning. Available online: https://towardsdatascience.com/value-based-methods-in-deep-reinforcement-learning-d40ca1086e1 (accessed on 18 June 2023).
- The MathWorks Inc. MATLAB Version: 9.12.0 (R2022a); The MathWorks Inc.: Natick, MA, USA, 2022; Available online: https://www.mathworks.com (accessed on 18 June 2023).
- Daniel, L. Calculus of Variations and Optimal Control Theory; Princeton University Press: Princeton, NJ, USA, 2012. [Google Scholar] [CrossRef]
- Bertsekas, D.P. Dynamic Programming and Optimal Control, 3rd ed.; Athena Scientific: Belmont, MA, USA, 2005; Volume I. [Google Scholar]
- Brahma, A.; Guezennec, Y.; Rizzoni, G. Optimal energy management in series hybrid electric vehicles. In Proceedings of the 2000 American Control Conference, ACC (IEEE Cat. No.00CH36334), Chicago, IL, USA, 28–30 June 2000; Volume 1, pp. 60–64. [Google Scholar] [CrossRef]
- Song, Z.; Hofmann, H.; Li, J.; Han, X.; Ouyang, M. Optimization for a hybrid energy storage system in electric vehicles using dynamic programing approach. Appl. Energy 2015, 139, 151–162. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Component | Parameter | Value |
|---|---|---|
| Vehicle | Mass, | 1850 |
| , | 125.22 | |
| , | 1.95 | |
| , | 0.59 | |
| Tyre radius, m | 0.29 | |
| Engine | Displacement, | 1.4 |
| Rated Power, | 133 | |
| Maximum torque, | 270 | |
| EM | Rated Power, | 44 |
| Maximum torque, | 250 | |
| Battery | Type | NMC |
| Nominal capacity, | 28.4 | |
| Nominal voltage, | 400 |
| Parameter | Value |
|---|---|
| Learning Rate | 0.9 |
| Discount Factor | 0.99 |
| greedy law | Exponential decay |
| Action(s) | {} |
| State(s) | {SOC, , } |
| Reward Function |
| Label 1 - | FC 2 L/100 km | 2 1/min | - | 2,3 L/100 km |
|---|---|---|---|---|
| I | 6.69 | 2.1 | 0.201 | 6.71 |
| II | 7.08 | 0.13 | 0.203 | 7.18 |
| III | 7.6 | 0.07 | 0.203 | 7.74 |
| 1 - | Episode - | FC 2 L/100 km | 2 1/min | 2,3 L/100 km | |
|---|---|---|---|---|---|
| 1000 | 7.62 | 1.63 | 0.212 | 9.89 | |
| 1500 | 7.59 | 1 | 0.207 | 8.39 | |
| 2000 | 7.56 | 1.17 | 0.206 | 8.07 | |
| 2500 | 7.53 | 0.8 | 0.201 | 7.55 |
| Fuel Consumption % Difference | |||
|---|---|---|---|
| 1 | w.r.t. 2 | w.r.t. | |
| +13.9 | +7.6 | +0.2 | |
| +13.45 | +7.2 | −0.13 | |
| +13 | +6.78 | −0.53 | |
| +12.56 | +6.35 | −0.92 | |
| Corrected Fuel Consumption % Difference | |||
| w.r.t. | w.r.t. | w.r.t. | |
| +46 | +37.7 | +27.8 | |
| +25 | +16.85 | +8.4 | |
| +20.27 | +12.39 | +4.26 | |
| +12.52 | +5.15 | −2.45 | |
| Frequency of ICE de/Activations Compared to DP | |||
| w.r.t. | w.r.t. | w.r.t. | |
| −0.47 | +1.5 | +1.56 | |
| −1.1 | +0.87 | +0.93 | |
| −0.93 | +1.04 | +1.1 | |
| −1.3 | +0.67 | +0.73 | |
| 1 - | Cycle - | FC 2 L/100 km | 2 1/min | - | 2,3 L/100 km |
|---|---|---|---|---|---|
| AUDC | 5.77 | 0.66 | 0.2 | 5.77 | |
| ARDC | 6.74 | 1.72 | 0.2 | 6.74 | |
| AMDC | 10.87 | 1.24 | 0.202 | 10.91 | |
| AUDC | 4.96 | 0.483 | 0.187 | 16.26 | |
| ARDC | 6.38 | 1.22 | 0.192 | 7.75 | |
| AMDC | 10.42 | 0.67 | 0.192 | 11.15 |
| Cycle - | FC 1 L/100 km | 1 1/min | - | 1,2 L/100 km |
|---|---|---|---|---|
| AUDC | 5.75 | 0.121 | 0.2018 | 5.97 |
| ARDC | 6.27 | 0.167 | 0.202 | 6.36 |
| AMDC | 10.1 | 0.06 | 0.202 | 10.17 |
| Cycle - | FC 1 L/100 km | 1 1/min | 1,2 L/100 km | - |
|---|---|---|---|---|
| AUDC | 5.77 | 0.66 | 5.77 | 0.201 |
| w.r.t. 3 | +0.34% | +0.54 | −3.35 | - |
| ARDC | 6.74 | 1.72 | 6.74 | 0.1998 |
| w.r.t. | +7.49% | +1.55 | +5.97 | - |
| AMDC | 10.87 | 1.23 | 10.91 | 0.2019 |
| w.r.t. | +7.62% | +1.17 | + 7.27 | - |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Musa, A.; Anselma, P.G.; Belingardi, G.; Misul, D.A. Energy Management in Hybrid Electric Vehicles: A Q-Learning Solution for Enhanced Drivability and Energy Efficiency. Energies 2024, 17, 62. https://doi.org/10.3390/en17010062
Musa A, Anselma PG, Belingardi G, Misul DA. Energy Management in Hybrid Electric Vehicles: A Q-Learning Solution for Enhanced Drivability and Energy Efficiency. Energies. 2024; 17(1):62. https://doi.org/10.3390/en17010062
Chicago/Turabian StyleMusa, Alessia, Pier Giuseppe Anselma, Giovanni Belingardi, and Daniela Anna Misul. 2024. "Energy Management in Hybrid Electric Vehicles: A Q-Learning Solution for Enhanced Drivability and Energy Efficiency" Energies 17, no. 1: 62. https://doi.org/10.3390/en17010062
APA StyleMusa, A., Anselma, P. G., Belingardi, G., & Misul, D. A. (2024). Energy Management in Hybrid Electric Vehicles: A Q-Learning Solution for Enhanced Drivability and Energy Efficiency. Energies, 17(1), 62. https://doi.org/10.3390/en17010062