
Enhancing LOCA Breach Size Diagnosis with Fundamental Deep Learning Models and Optimized Dataset Construction



Abstract
:1. Introduction
2. Related Work
3. Methodology
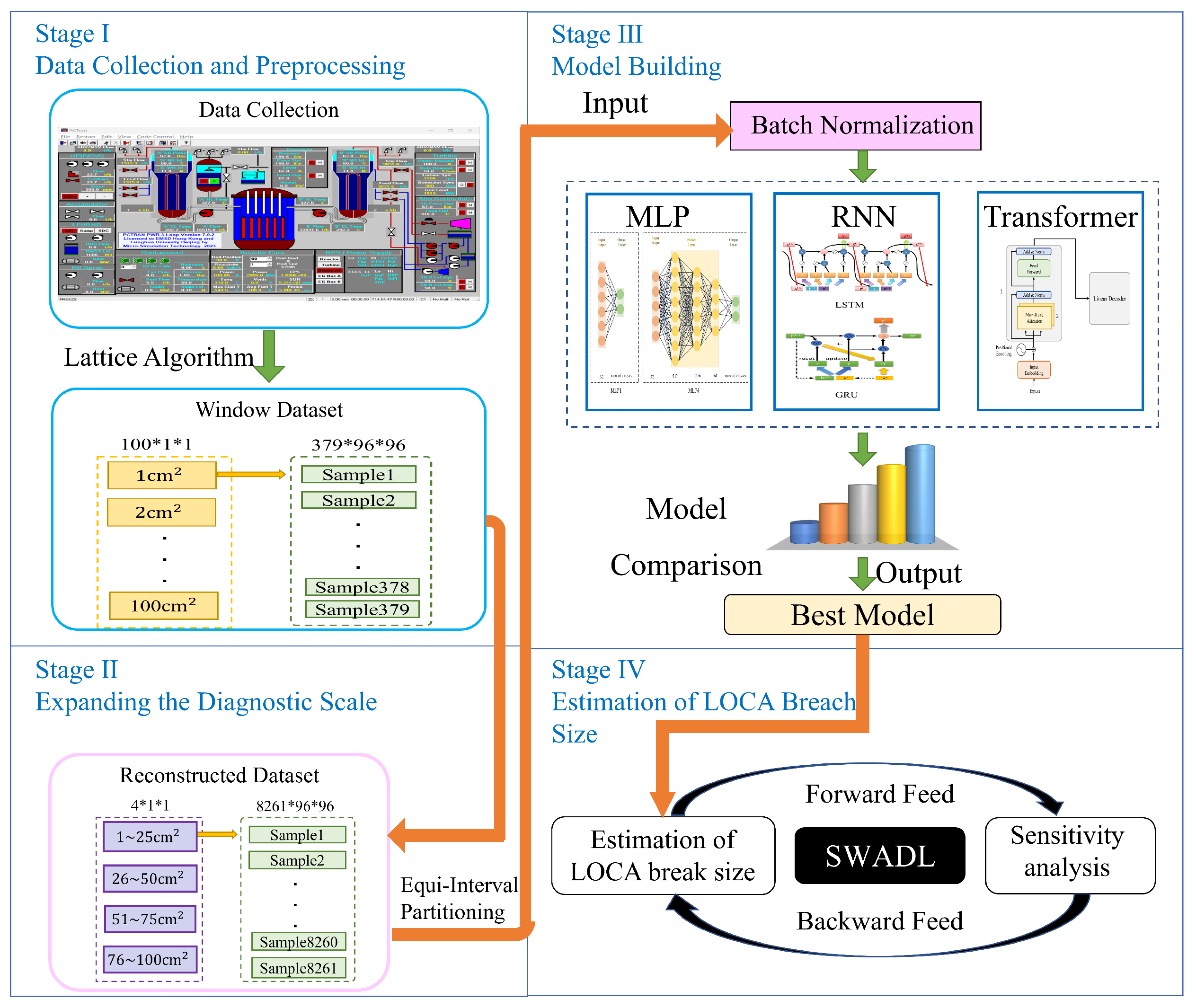
3.1. Structure of Proposed DeepLOCA-Lattice Framework
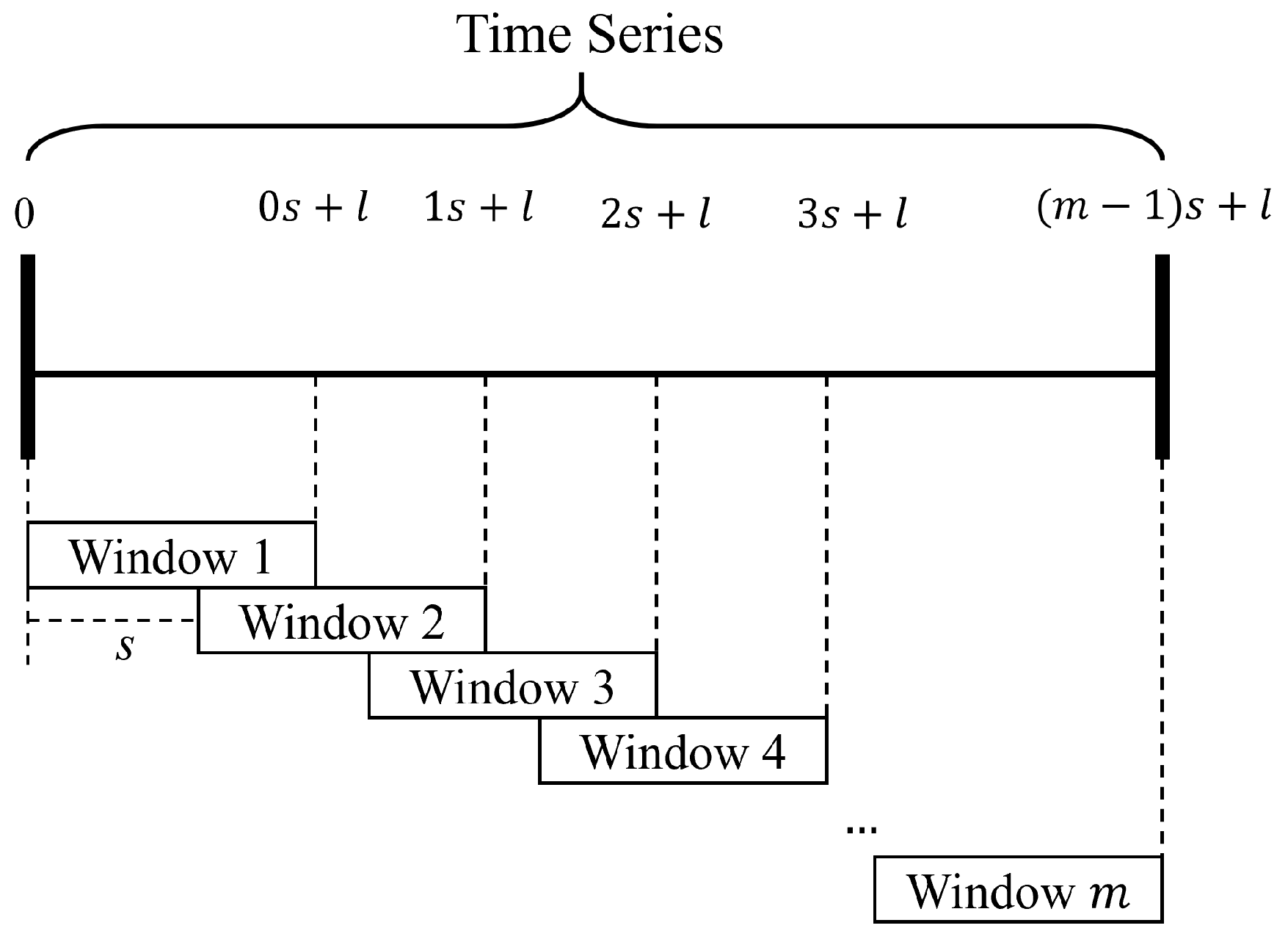
3.2. Lattice Algorithm
3.3. DL Architectures
4. DeepLOCA-Lattice Construction
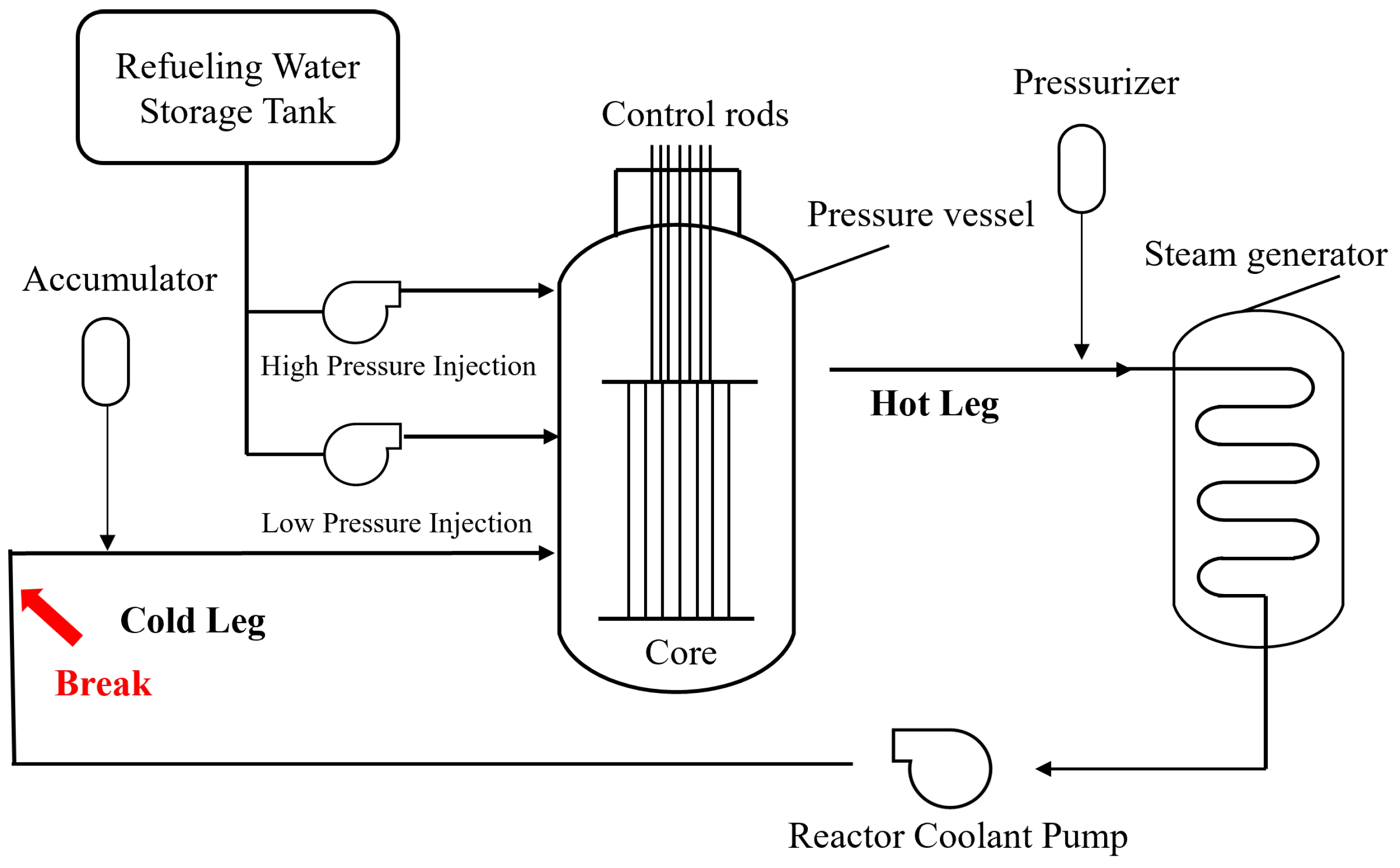
4.1. Data Description and Preprocessing
4.2. Equal-Interval Partitioning and Data Reconstruction
4.3. Estimation of LOCA Breach Size
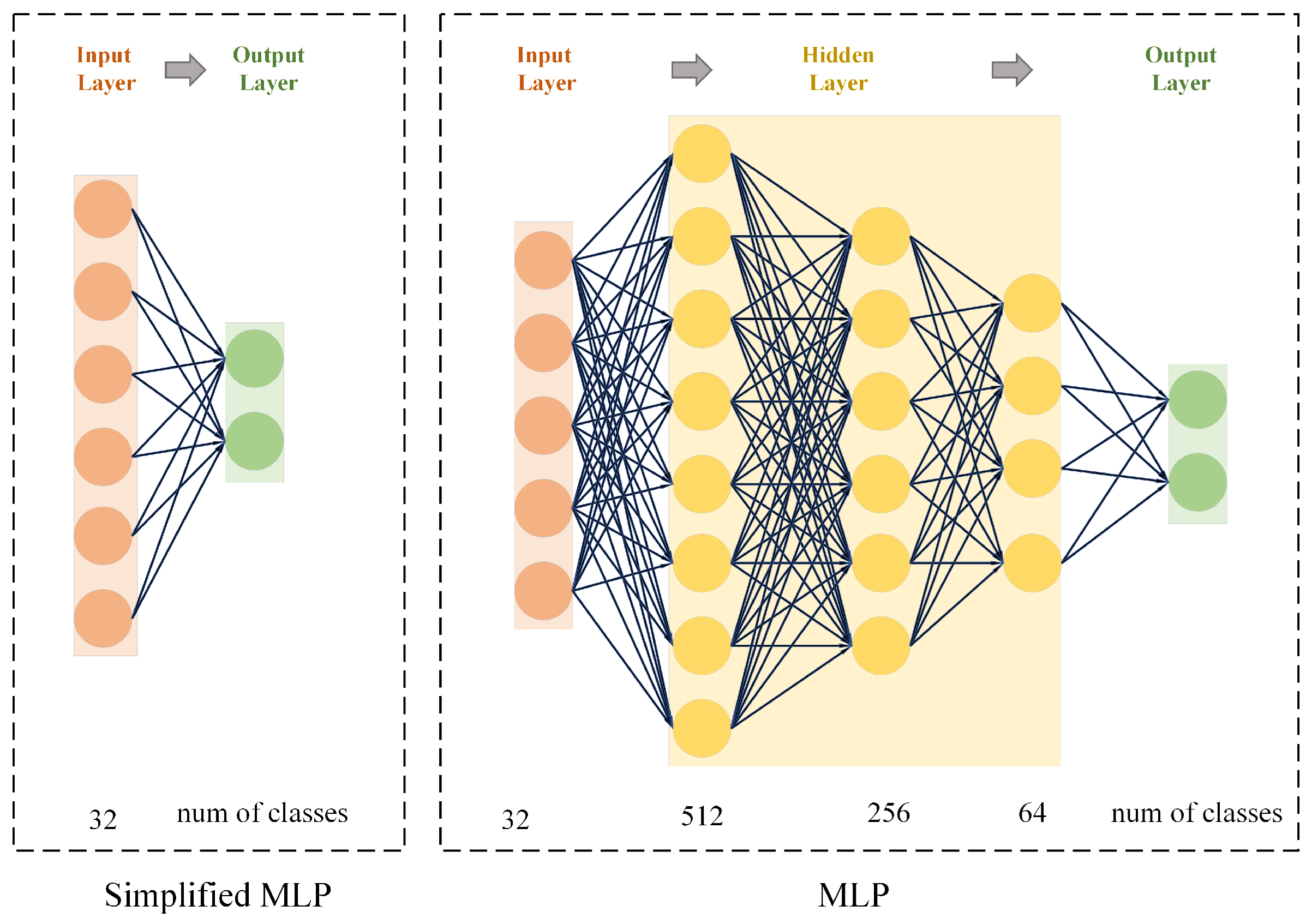
4.3.1. Multi-Layer Perceptron (MLP)
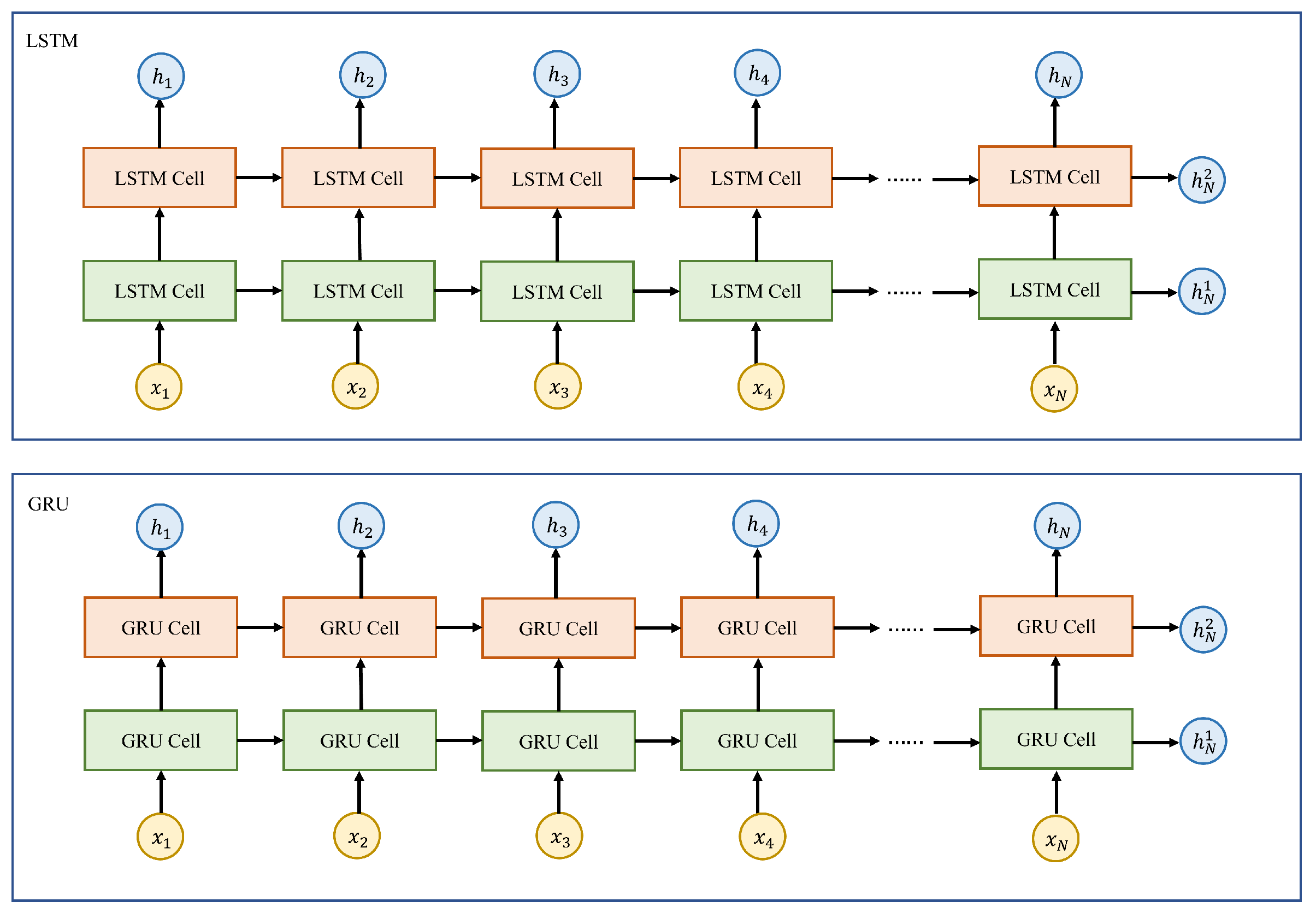
4.3.2. Recurrent Neural Networks (RNNs)
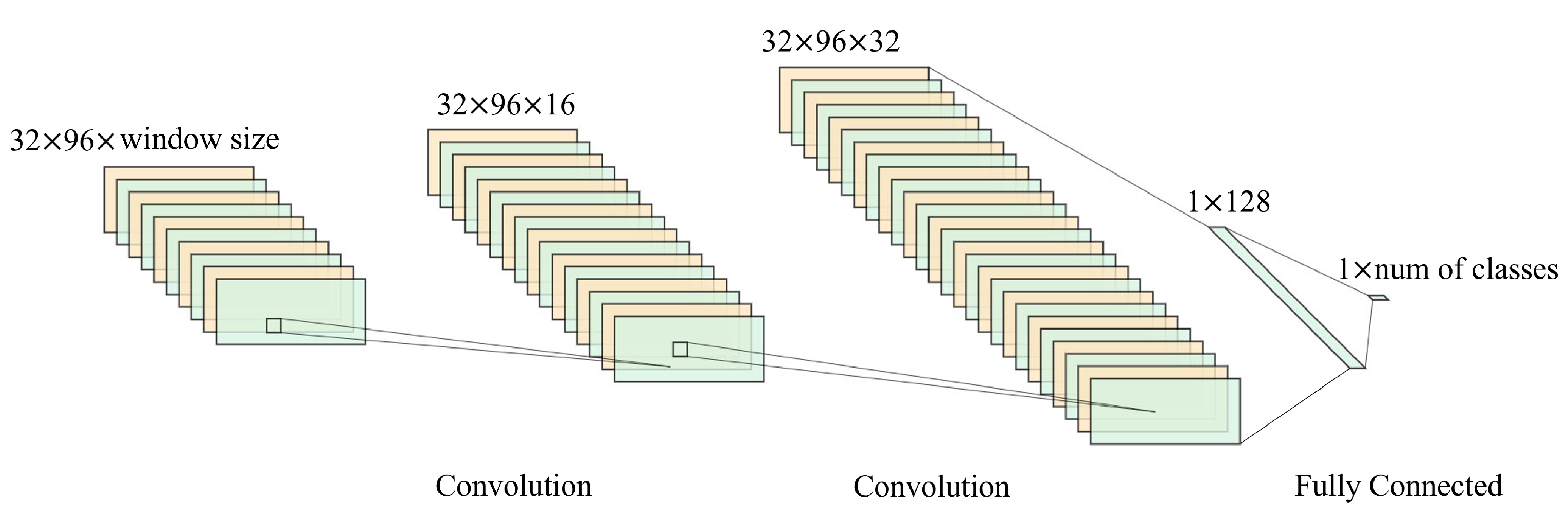
4.3.3. Convolutional Neural Networks (CNNs)
4.3.4. Transformer Model
5. Results and Discussion
5.1. Scenario Deduction
5.2. Sensitivity Analysis
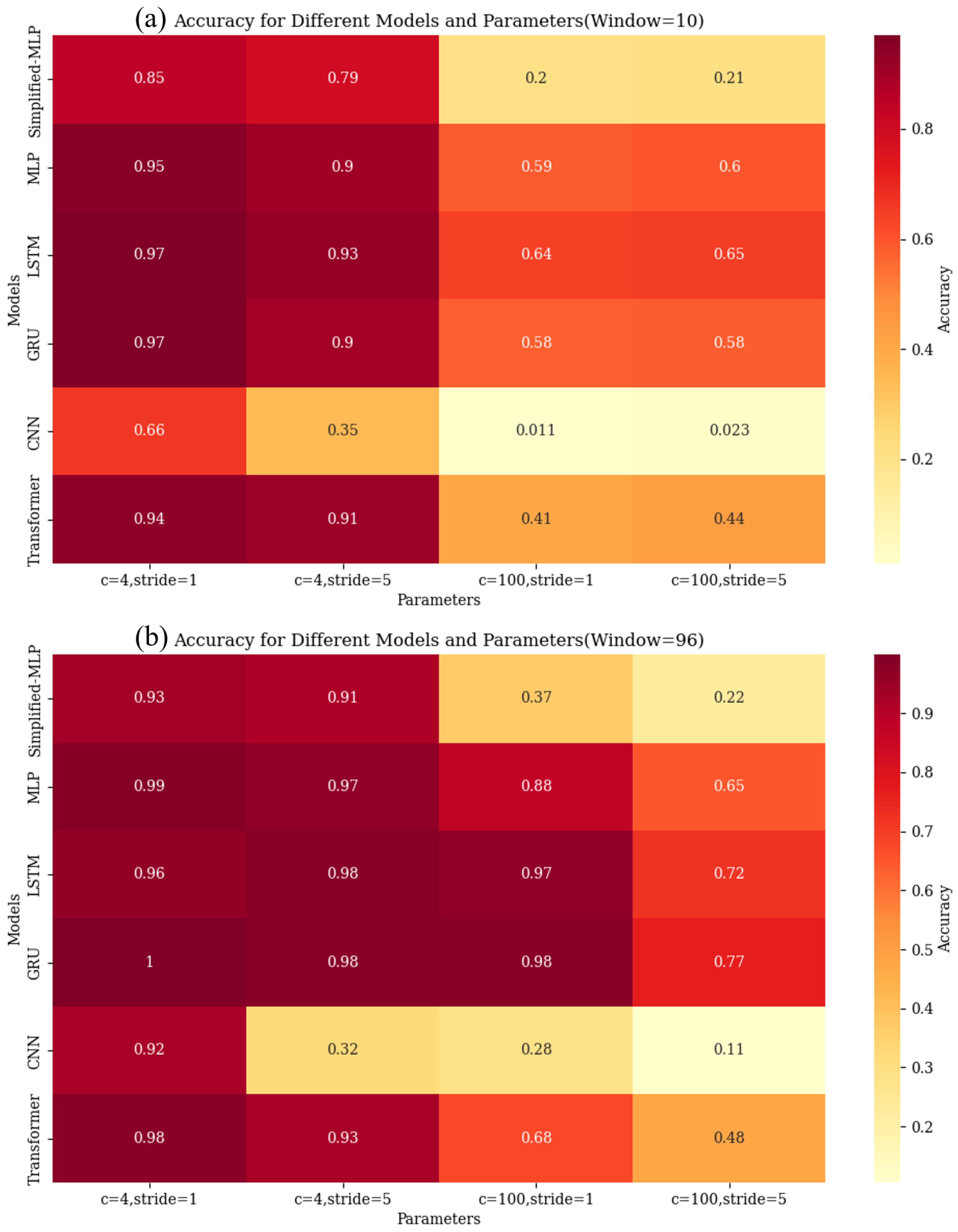
5.2.1. Window Size and Sliding Stride
5.2.2. Diagnostic Scales
6. Conclusions
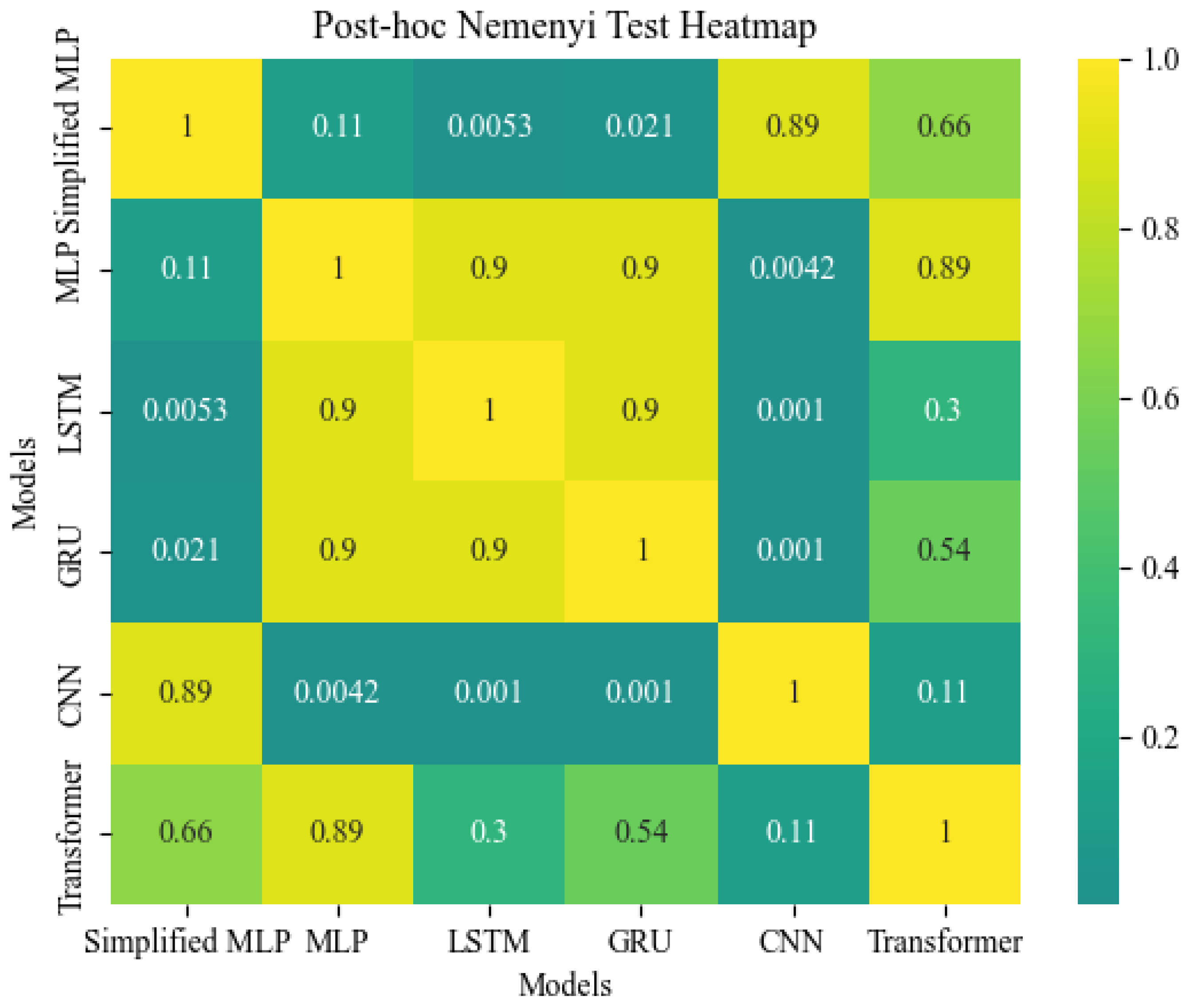
- The complexity of a model does not necessarily equate to its performance. In this study, even the simplest deep learning models can achieve accuracy rates that exceed 90% in LOCA breach size diagnoses, while the accuracy of the complex CFNN and NARX models is less than 40%. On the other hand, the high accuracy of 90% also underscores the idealized nature of the PCTRAN simulated data, emphasizing the necessity of considering the disparity between simulated and real data in genuine research endeavors.
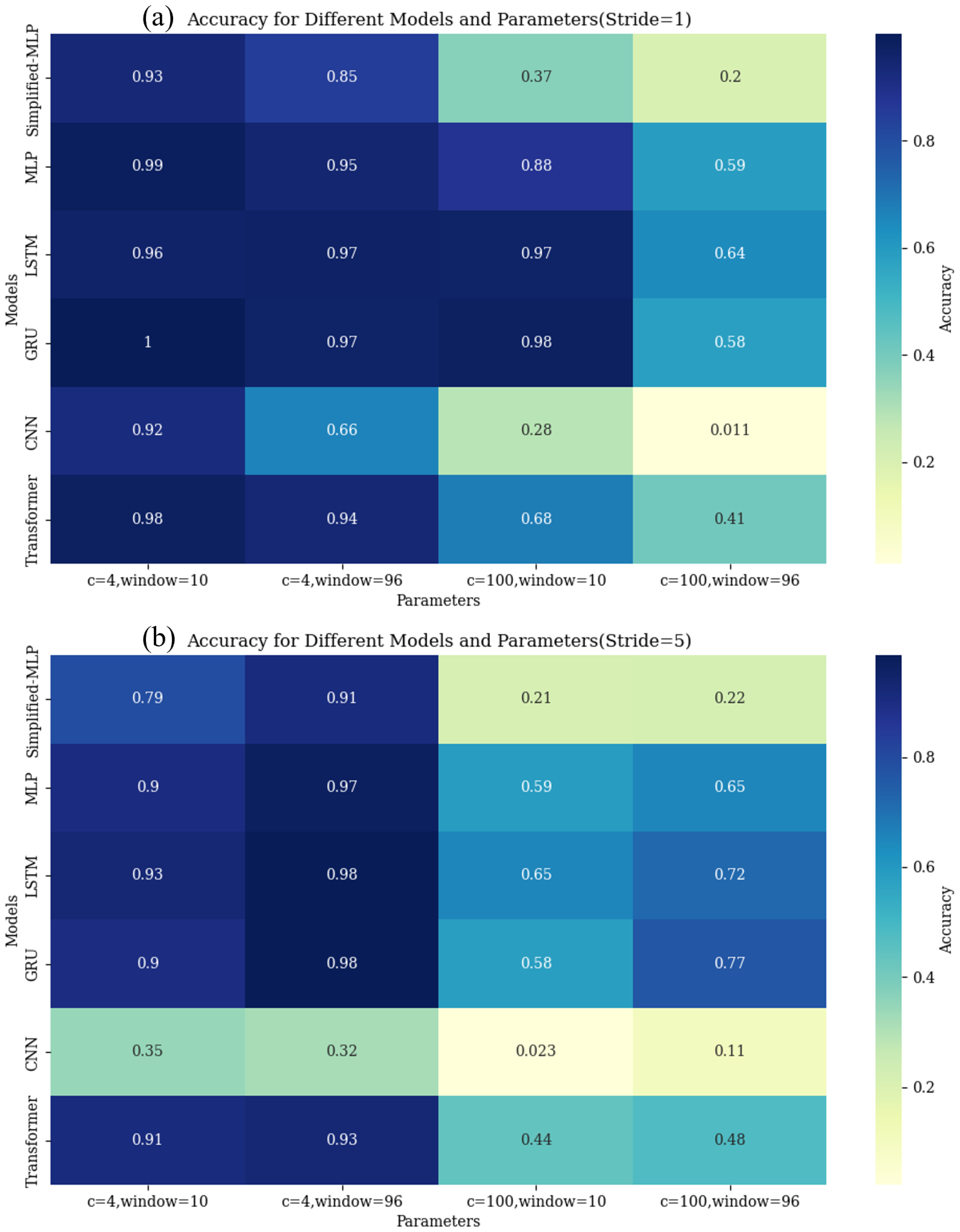
- The findings reveal the existence of an intricate relationship among diagnostic scales, sliding window size, and sliding stride. It is not the case that larger sliding windows and smaller stride lengths consistently yield higher model accuracy. Specific outcomes are also influenced by factors such as the number of categories and the precise architecture of the model. For instance, as discussed in Section 5.2.1, in the scenario where the number of categories is four and the stride is 5, increasing the window size results in a decrease in the model accuracy. In contrast, with a window size of 10 and 100 categories, reducing the stride leads to an increase in the accuracy of the model.
- Our analysis reveals that when using a window size of 96 and a stride of 1, all models demonstrated optimal performance in terms of accuracy. This can serve as a reference for the construction of datasets for subsequent LOCA breach size estimation models. Researchers can attempt to use smaller window sizes with larger stride sizes for LOCA breach size diagnosis.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Qi, B.; Zhang, L.; Liang, J.; Tong, J. Combinatorial techniques for fault diagnosis in nuclear power plants based on Bayesian neural network and simplified Bayesian network-artificial neural network. Front. Energy Res. 2022, 10, 920194. [Google Scholar] [CrossRef]
- Lee, S.; Kim, J.; Arigi, A.M.; Kim, J. Identification of Contributing Factors to Organizational Resilience in the Emergency Response Organization for Nuclear Power Plants. Energies 2022, 15, 7732. [Google Scholar] [CrossRef]
- Lin, Y.; Zhang, W.J. Towards a novel interface design framework: Function–behavior–state paradigm. Int. J. Hum.–Comput. Stud. 2004, 61, 259–297. [Google Scholar] [CrossRef]
- Lin, Y.; Zhang, W.J. A function-behavior-state approach to designing human–machine interface for nuclear power plant operators. IEEE Trans. Nucl. Sci. 2005, 52, 430–439. [Google Scholar] [CrossRef]
- Yamanouchi, A. Effect of core spray cooling in transient state after loss of coolant accident. J. Nucl. Sci. Technol. 1968, 5, 547–558. [Google Scholar] [CrossRef]
- Zhang, C.; Chen, P.; Jiang, F.; Xie, J.; Yu, T. Fault Diagnosis of Nuclear Power Plant Based on Sparrow Search Algorithm Optimized CNN-LSTM Neural Network. Energies 2023, 16, 2934. [Google Scholar] [CrossRef]
- Qi, B.; Liang, J.; Tong, J. Fault Diagnosis Techniques for Nuclear Power Plants: A Review from the Artificial Intelligence Perspective. Energies 2023, 16, 1850. [Google Scholar] [CrossRef]
- She, J.; Shi, T.; Xue, S.; Zhu, Y.; Lu, S.; Sun, P.; Cao, H. Diagnosis and prediction for loss of coolant accidents in nuclear power plants using deep learning methods. Front. Energy Res. 2021, 9, 665262. [Google Scholar] [CrossRef]
- Choi, G.P.; Yoo, K.H.; Back, J.H.; Na, M.G. Estimation of LOCA breach Size Using Cascaded Fuzzy Neural Networks. Nucl. Eng. Technol. 2017, 49, 495–503. [Google Scholar] [CrossRef]
- Wang, Y.; Liu, R.; Lin, D.; Chen, D.; Li, P.; Hu, Q.; Chen, C.L.P. Coarse-to-fine: Progressive knowledge transfer-based multitask convolutional neural network for intelligent large-scale fault diagnosis. IEEE Trans. Neural Netw. Learn. Syst. 2021, 34, 761–774. [Google Scholar] [CrossRef]
- Mandal, S.; Santhi, B.; Sridhar, S.; Vinolia, K.; Swaminathan, P. Nuclear power plant thermocouple sensor-fault detection and classification using deep learning and generalized likelihood ratio test. IEEE Trans. Nucl. Sci. 2017, 64, 1526–1534. [Google Scholar] [CrossRef]
- Yao, Y.; Wang, J.; Long, P.; Xie, M.; Wang, J. Small-batch-size convolutional neural network based fault diagnosis system for nuclear energy production safety with big-data environment. Int. J. Energy Res. 2020, 44, 5841–5855. [Google Scholar] [CrossRef]
- Wang, H.; Peng, M.; Ayodeji, A.; Xia, H.; Wang, X.; Li, Z. Advanced fault diagnosis method for nuclear power plant based on convolutional gated recurrent network and enhanced particle swarm optimization. Ann. Nucl. Energy 2021, 151, 107934. [Google Scholar] [CrossRef]
- Saghafi, M.; Ghofrani, M. Real-time estimation of break sizes during LOCA in nuclear power plants using NARX neural network. Nucl. Eng. Technol. 2019, 51, 702–708. [Google Scholar] [CrossRef]
- Xu, Y.; Lin, K.; Hu, C.; Wang, S.; Wu, Q.; Zhang, L.; Ran, G. Deep transfer learning based on transformer for flood forecasting in data-sparse basins. J. Hydrol. 2023, 625, 129956. [Google Scholar] [CrossRef]
- El-Shafeiy, E.; Alsabaan, M.; Ibrahem, M.; Elwahsh, H. Real-Time Anomaly Detection for Water Quality Sensor Monitoring Based on Multivariate Deep Learning Technique. Sensors 2023, 23, 8613. [Google Scholar] [CrossRef]
- Liapis, C.M.; Kotsiantis, S. Temporal Convolutional Networks and BERT-Based Multi-Label Emotion Analysis for Financial Forecasting. Information 2023, 14, 596. [Google Scholar] [CrossRef]
- Islam, M.M.; Islam, M.Z.; Asraf, A.; Al-Rakhami, M.S.; Ding, W.P.; Sodhro, A.H. Diagnosis of COVID-19 from X-rays using combined CNN-RNN architecture with transfer learning. Benchcouncil Trans. Benchmarks Stand. Eval. 2022, 2, 100088. [Google Scholar] [CrossRef]
- Zaki, M.J.; Hsiao, C.J. Efficient algorithms for mining closed itemsets and their lattice structure. IEEE Trans. Knowl. Data Eng. 2005, 17, 462–478. [Google Scholar] [CrossRef]
- Yang, Z.; Yang, H.; Chang, C.-C.; Huang, Y.; Chang, C.-C. Real-time steganalysis for streaming media based on multi-channel convolutional sliding windows. Knowl.-Based Syst. 2022, 237, 107561. [Google Scholar] [CrossRef]
- Yaroslavsky, L.P.; Egiazarian, K.O.; Astola, J.T. Transform domain image restoration methods: Review, comparison, and interpretation. Nonlinear Image Process. Pattern Anal. XII 2001, 4304, 155–169. [Google Scholar]
- Chang, C.-I.; Wang, Y.; Chen, S.-Y. Anomaly detection using causal sliding windows. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 3260–3270. [Google Scholar] [CrossRef]
- Rubinger, B. Performance of a sliding window detector in a high interference air traffic environment. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Kłosowski, P. Deep learning for natural language processing and language modelling. In Proceedings of the 2018 Signal Processing: Algorithms, Architectures, Arrangements, and Applications (SPA), Poznań, Poland, 19–21 September 2018. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Baker, B.; Gupta, O.; Naik, N.; Raskar, R. Designing neural network architectures using reinforcement learning. arXiv 2016, arXiv:1611.02167. [Google Scholar]
- Rosenblatt, F. The perceptron: A probabilistic model for information storage and organization in the brain. Psychol. Rev. 1958, 65, 386. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 1–11. [Google Scholar]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Qi, B.; Xiao, X.; Liang, J.; Po, L.; Zhang, L.; Tong, J. An open time-series simulated dataset covering various accidents for nuclear power plants. Sci. Data 2022, 9, 766. [Google Scholar] [CrossRef]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef]
- Ostrand, T.J.; Balcer, M.J. The category-partition method for specifying and generating fuctional tests. Commun. ACM 1988, 31, 676–686. [Google Scholar] [CrossRef]
- McClell, J.L.; Rumelhart, D.E.; PDP Research Group. Parallel Distributed Processing, Volume 2: Explorations in the Microstructure of Cognition: Psychological and Biological Models; MIT Press: Cambridge, MA, USA, 1987. [Google Scholar]
- Ackley, D.H.; Hinton, G.E.; Sejnowski, T.J. A learning algorithm for Boltzmann machines. Cogn. Sci. 1985, 9, 147–169. [Google Scholar]
- Bao, Y.; Wang, B.; Guo, P.; Wang, J. Chemical process fault diagnosis based on a combined deep learning method. Can. J. Chem. Eng. 2022, 100, 54–66. [Google Scholar] [CrossRef]
- Arena, P.; Basile, A.; Bucolo, M.; Fortuna, L. Image processing for medical diagnosis using CNN. Nucl. Instruments Methods Phys. Res. Sect. Accel. Spectrometers Detect. Assoc. Equip. 2003, 497, 174–178. [Google Scholar] [CrossRef]
- Saponara, S.; Elhanashi, A.; Gagliardi, A. Real-time video fire/smoke detection based on CNN in antifire surveillance systems. J. Real-Time Image Process. 2021, 18, 889–900. [Google Scholar] [CrossRef]
- Beane, S.R.; Bedaque, P.F.; Parreno, A.; Savage, M.J. Two nucleons on a lattice. Phys. Lett. B 2004, 585, 106–114. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Index | Parameter Name | Parameter Abbreviation |
|---|---|---|
| 1 | Loss-of-coolant accident | LOCA |
| 2 | Simplified multi-layer perceptron | Simplified MLP |
| 3 | Multi-layer perceptron | MLP |
| 4 | Long short-term memory | LSTM |
| 5 | Gated recurrent unit | GRU |
| 6 | Convolutional neural network | CNN |
| 7 | Deep learning | DL |
| 8 | Nuclear power plants | NPPs |
| 9 | Deep learning framework for LOCA breach size diagnosis based on the lattice algorithm | DeepLOCA-Lattice |
| 10 | Pressurized water reactor | PWR |
| Author | Main Work |
|---|---|
| She et al. [8] | Integrated CNN, LSTM, and ConvLSTM for diagnosing and predicting LOCAs. Demonstrated functionality, accuracy, and divisibility. |
| Choi et al. [9] | Employed a cascaded fuzzy neural network (CFNN) for estimating LOCA breach sizes. |
| Wang et al. [10] | Proposed a PKT algorithm for extracting more generalized fault information in NPP fault diagnosis and intelligent construction of a coarse-to-fine knowledge structure. |
| Mandal et al. [11] | Utilized a deep belief network (DBN) for classifying fault data in NPPs. |
| Yao et al. [12] | Optimized CNNs with small-batch-size processing for assembly in NPP diagnostic systems. |
| Wang et al. [13] | Developed a highly accurate and adaptable fault diagnosis technique using CGRU and improved particle swarm optimization (EPSO). |
| Saghafi et al. [14] | Defined a nonlinear auto-regressive model with exogenous input (NARX) for diagnosing LOCA breach sizes. |
| Time | P | TAVG | THA | … | RRCO | WFLB |
|---|---|---|---|---|---|---|
| 0 | 155.5000 | 310.0000 | 327.8240 | … | 1.0000 | 0 |
| 10 | 155.4682 | 309.9801 | 327.8055 | … | 1.0000 | 0 |
| 20 | 155.4674 | 309.9777 | 327.8105 | … | 1.0000 | 0 |
| 30 | 155.4719 | 309.9802 | 327.8112 | … | 1.0000 | 0 |
| 40 | 155.4711 | 309.9779 | 327.8114 | … | 1.0000 | 0 |
| … | … | … | … | … | … | … |
| … | … | … | … | … | … | … |
| … | … | … | … | … | … | … |
| 4710 | 157.0756 | 292.0552 | 292.2995 | … | 1.0621 | 0 |
| 4720 | 157.0776 | 292.0528 | 292.2970 | … | 1.0621 | 0 |
| 4730 | 157.1084 | 292.0511 | 292.2944 | … | 1.0621 | 0 |
| 4740 | 157.0882 | 292.0486 | 292.2919 | … | 1.0621 | 0 |
| Hyperparameter | Number |
|---|---|
| Learning rate | 0.0001 |
| Number of iterations | 250 |
| Batch size | 32 |
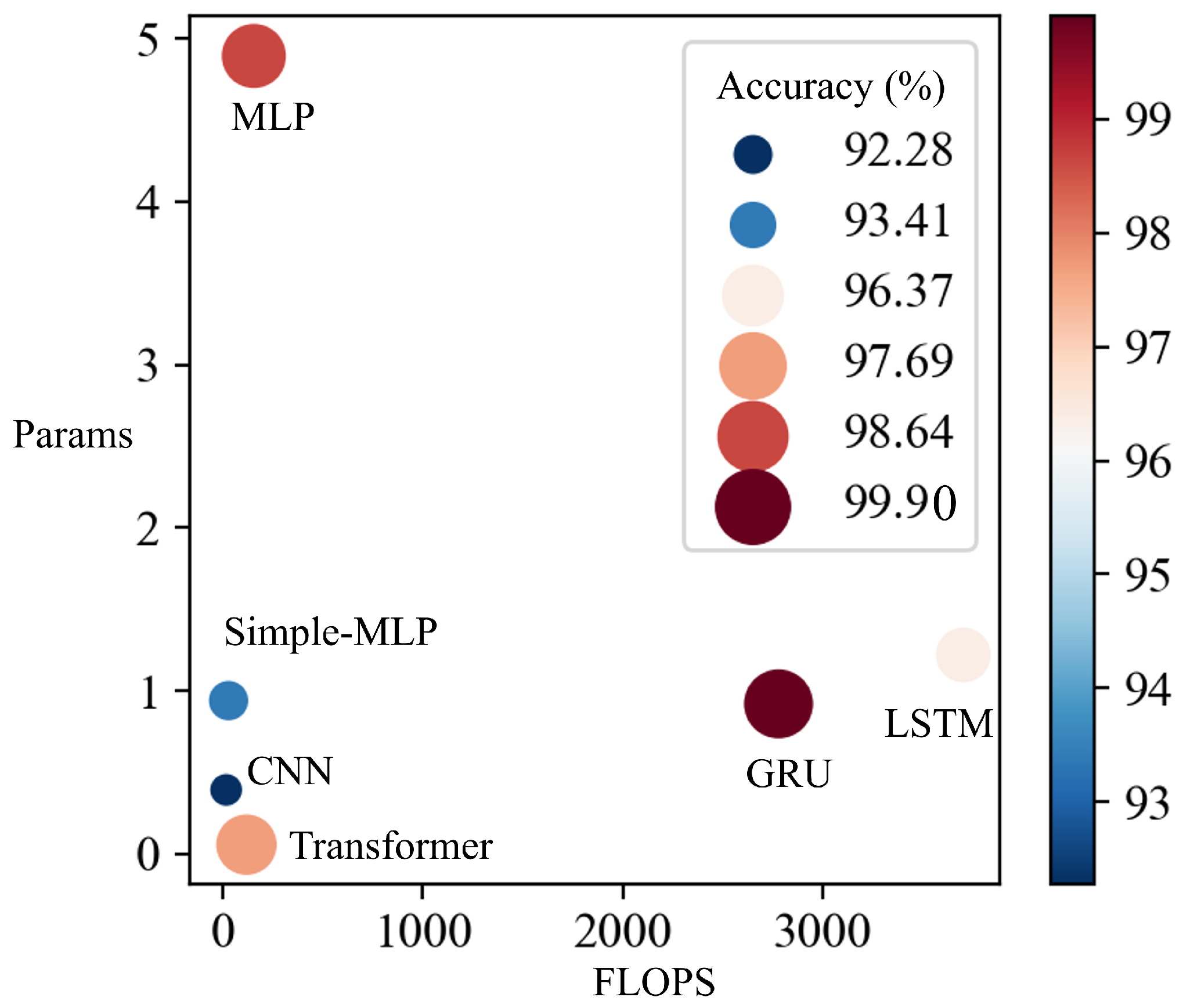
| Model | FLOPs | Params (MB) | FLOPs/Params | Accuracy (%) |
|---|---|---|---|---|
| Simplified MLP | 30.6708 | 0.9401 | 32.65 | 93.41 |
| MLP | 157.2045 | 4.8935 | 32.11 | 98.64 |
| LSTM | 3702.402 | 1.2202 | 3031.23 | 96.37 |
| GRU | 2778.9588 | 0.9202 | 3019.45 | 99.90 |
| CNN | 18.9153 | 0.3929 | 48.18 | 92.28 |
| Transformer | 120.3241 | 0.0568 | 2119.29 | 97.69 |
| NARX | 0.0461 | 0.0015 | 31.05 | 36.46 |
| CFNN | / | 0.0066 | / | 35.48 |
| Index | Window | Stride |
|---|---|---|
| 1 | 10 | 1 |
| 2 | 10 | 5 |
| 3 | 96 | 1 |
| 4 | 96 | 5 |
| 5 | none | |
| Model | Number of Categories | Stride = 5 Window = 10 | Stride = 5 Window = 96 | Stride = 1 Window = 96 | Stride = 1 Window = 10 | Average Factor |
|---|---|---|---|---|---|---|
| Simplified MLP | 4 | 79.08% | 91.23% | 93.41% | 84.59% | 3.63 |
| 100 | 21.33% | 22.09% | 36.90% | 20.38% | ||
| MLP | 4 | 90.46% | 96.63% | 98.64% | 95.17% | 1.46 |
| 100 | 59.70% | 64.92% | 87.67% | 58.64% | ||
| LSTM | 4 | 92.81% | 98.48% | 96.37% | 96.95% | 1.33 |
| 100 | 64.83% | 72.01% | 96.70% | 64.34% | ||
| GRU | 4 | 89.90% | 98.48% | 99.90% | 96.63% | 1.38 |
| 100 | 58.21% | 76.56% | 97.86% | 57.98% | ||
| CNN | 4 | 34.55% | 31.98% | 92.28% | 66.04% | 19.92 |
| 100 | 2.31% | 10.56% | 28.22% | 1.13% | ||
| Transformer | 4 | 90.97% | 92.55% | 97.69% | 93.79% | 1.94 |
| 100 | 43.66% | 47.55% | 67.66% | 40.59% |
| Friedman Test Statistic | p-Value |
|---|---|
| 33.5663 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiao, X.; Qi, B.; Liang, J.; Tong, J.; Deng, Q.; Chen, P. Enhancing LOCA Breach Size Diagnosis with Fundamental Deep Learning Models and Optimized Dataset Construction. Energies 2024, 17, 159. https://doi.org/10.3390/en17010159
Xiao X, Qi B, Liang J, Tong J, Deng Q, Chen P. Enhancing LOCA Breach Size Diagnosis with Fundamental Deep Learning Models and Optimized Dataset Construction. Energies. 2024; 17(1):159. https://doi.org/10.3390/en17010159
Chicago/Turabian StyleXiao, Xingyu, Ben Qi, Jingang Liang, Jiejuan Tong, Qing Deng, and Peng Chen. 2024. "Enhancing LOCA Breach Size Diagnosis with Fundamental Deep Learning Models and Optimized Dataset Construction" Energies 17, no. 1: 159. https://doi.org/10.3390/en17010159
APA StyleXiao, X., Qi, B., Liang, J., Tong, J., Deng, Q., & Chen, P. (2024). Enhancing LOCA Breach Size Diagnosis with Fundamental Deep Learning Models and Optimized Dataset Construction. Energies, 17(1), 159. https://doi.org/10.3390/en17010159