2.1. Data Processing and Analysis
Boiler operational data frequently exhibit anomalies due to various sources of interference, such as noise, sensor malfunctions, abnormal operational conditions, system instability, and other factors. It is necessary to assess the reliability of the measurement data [
10].
(1) Data cleaning
The threshold of 3
-based PauTa [
11] criterion is used as the outlier detection method. The standard deviation is calculated with Equation (1):
where
is the number of observations,
is the mean of the observations, and
is the standard deviation.
The residual error is calculated with Equation (2):
where
is the residual, and
is the estimated value of the observation.
When the residual error surpasses 3, it is categorized as a gross error and the data are screened out; otherwise, it is deemed a random error and the data are kept. Thus, the dataset is refined, reducing its size from 22,900 to 22,477 groups.
(2) Data classification
The operational status of the biomass boiler tends to vary with unit load. It is difficult for a single model to accurately predict parameters for all operational scenarios. Therefore, the k-means algorithm is employed to classify the pre-cleaning data and carried out as follows [
12,
13,
14]:
(1) Normalized raw data;
(2) Initialize k center points;
(3) Data partitioning.
Calculate the distance between each sample
in the dataset
and
k center points
:
Divide each data sample into clusters corresponding to the shortest distance from the center point.
(4) Update center point
Recalculate the center points of samples
within each cluster:
Repeat Steps (3) and (4) until the iteration ends or the partitioning results remain unchanged for each iteration.
The choice of the k value in k-means significantly impacts condition classification accuracy. The elbow method helps determine the optimal k value as follows:
(a) Calculate the sum of squared errors (SSE) value:
Assume there are
data samples in
k clusters. The
SSE is the sum of squared distances from each data point to its cluster center, calculated using Equation (5):
(b) Plot SSE values against different k values.
(c) The SSE vs. k graph typically resembles an elbow, and the k value at the “elbow point” indicates the optimal cluster count for classification.
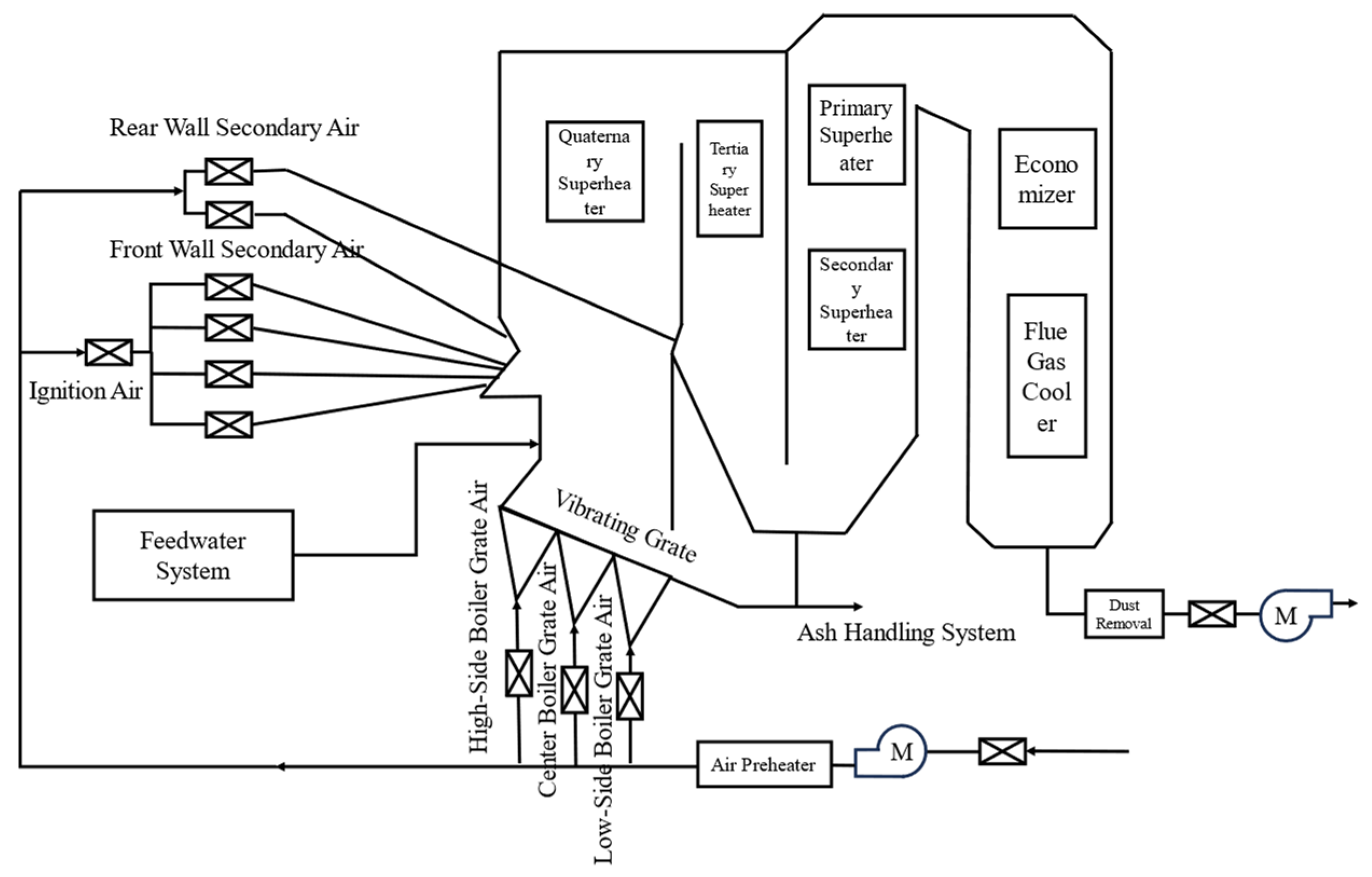
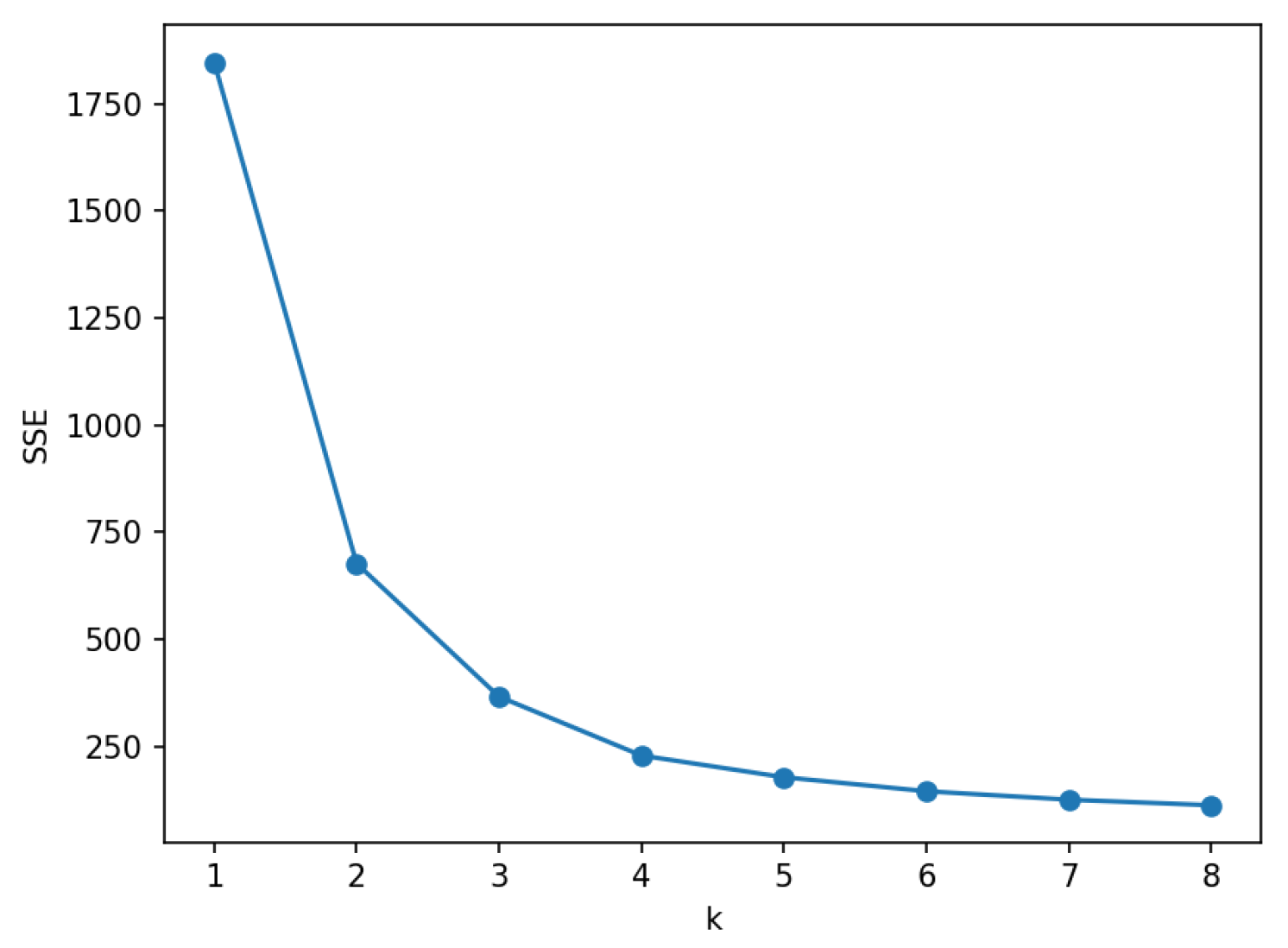
Three parameters (steam drum pressure, feedwater flow rate, and unit load) which are strongly correlated with the boiler operational state are used as sample co-ordinates for k-means classification. As shown in
Figure 3, the
k value corresponding to the elbow point is 2. Then, the experimental dataset is partitioned into two categories (condition 1 and condition 2), delineated by the boundaries of steam drum pressure, feedwater flow rate, and unit load. The parameter ranges for each type of operating condition, along with the quantity of data encompassed within each operational group, are itemized in
Table 1, respectively.
2.2. Parameter Extraction
To improve model accuracy and reduce modeling time, tens of thousands of measurement points in the distributed control system (DCS) are screened. The average influence value method based on the BP neural network is used to screen the characteristic parameters of two output parameters, respectively:
Convert the initialization dataset into an independent variable matrix with l rows and m columns and a dependent variable matrix with m rows and 1 column, where l represents the number of data samples and m is the number of feature parameters.
- (2)
Normalization processing
Normalized input parameters:
Normalized output parameters:
Using the normalized data from the previous step as input and output parameters, combined with the BP neural network algorithm, establish a prediction model for the target parameters.
- (4)
Average impact value (AIV) analysis
Enlarge and shrink each column of the input parameter matrix to 1.1 and 0.9 times the original data to obtain the scaling matrices, as shown in Equations (8) and (9):
Place the scaled matrices
and
into the BP neural network model established in step (3) for prediction, and obtain the prediction results
and
. The difference between two squares of
and
is calculated to obtain the influence value IV of the corresponding characteristic variable on the output parameter.
- (5)
Calculate the average of each IV value to obtain the AIV:
- (6)
Calculate contribution rate:
If the cumulative contribution rate of the set of feature variables reaches 80%, it is considered that there is a significant connection between the set of feature parameters and the output parameters, which are used as input parameters for the optimizing model.
2.3. Algorithm Optimization
In this study, the backpropagation neural network [
9,
15,
16] with an input layer, a single hidden layer, and an output layer is selected as the core algorithm. The activation function for the hidden layer is set to sigmoid. At the same time, the random forest algorithm [
17,
18] is employed for comparison.
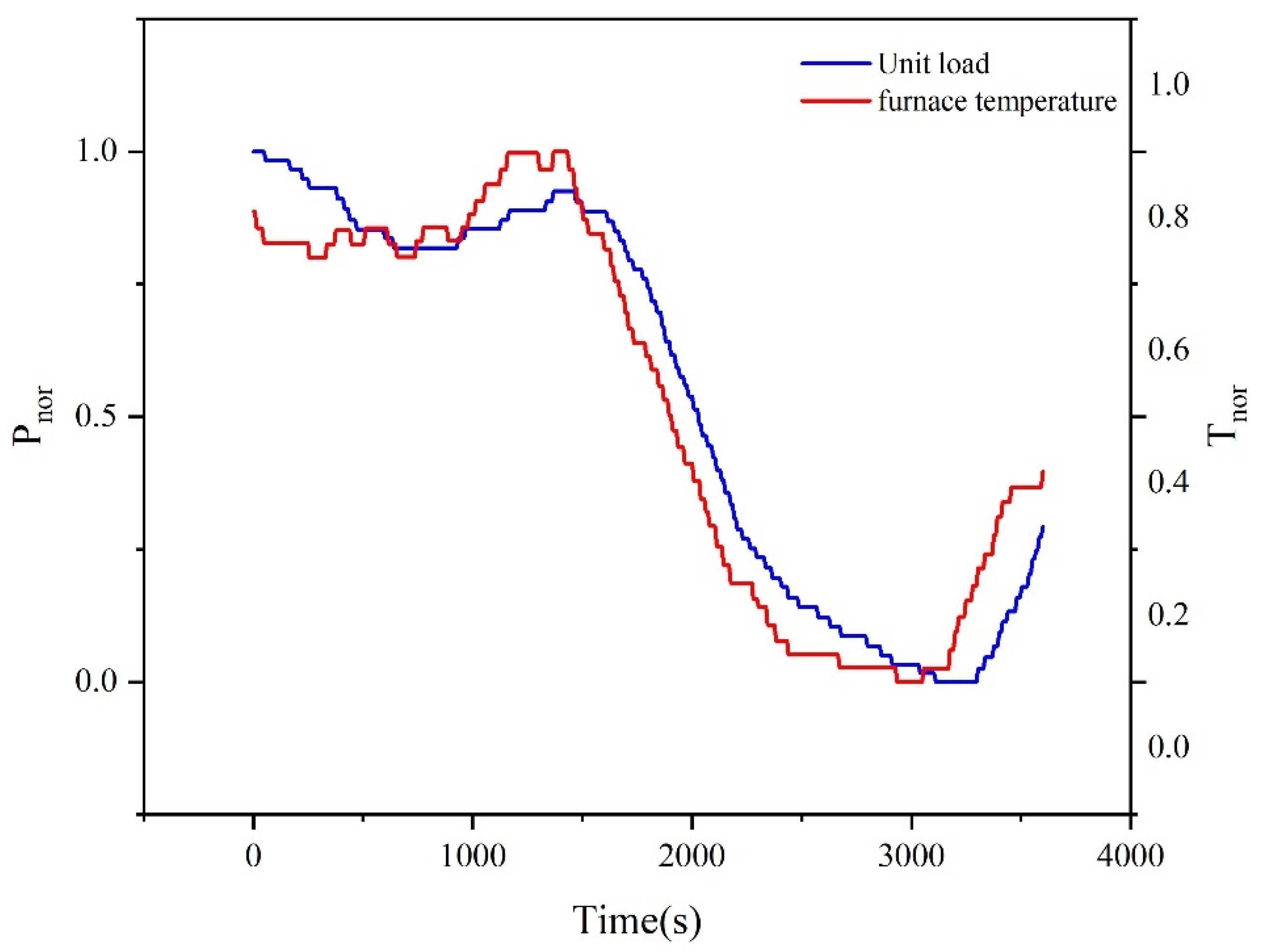
In practical applications, using only the BP algorithm poses challenges due to the asynchronous changes between input parameters, influenced by the control system and the inertia of combustion within the furnace, and the corresponding output parameters. The sampling process, indexed at the same time point, may compromise the model’s accuracy, especially when dealing with terminal output parameters like unit load in DCS systems, directly impacting the predictive model’s precision. Therefore, this study innovatively combines first-order derivative (FOD) with the BP algorithm. Additionally, a search mechanism based on ant colony optimization (ACO) is incorporated [
19,
20,
21], enabling the FOD-BP-ACO model to effectively enhance boiler thermal efficiency.
Assume that the probability of ant
k (
k = 1, 2, …,
m) transitioning from location i to location j at a certain moment is
. The calculation formula is as follows:
In the equation,
represents the amount of pheromone between location
i and location
j on the path at a certain moment,
represents the expected level of ant transitioning from
i to
j,
is the set of accessible locations for the ant in the next step,
is the importance factor of pheromone, and
is the importance factor of heuristics. The operation of ant colony optimization is shown in
Figure 4.
When
m ants complete one iteration of path traversal, typically, the ACO model is used to update the pheromone. The following formula can be used to update the pheromone concentration:
In this formula, is the evaporation rate (a value between 0 and 1), and represents the amount of pheromone deposited by the ants on the path from i to j during the iteration.
This study does not aim to solve a path problem. Therefore, the two equations mentioned above will be rewritten to solve the maximization of a specified function:
In this formula,
,
represents the initialization of pheromone values for the data.
represents the specified objective function and the optimization problem is transformed into a maximization problem; the formula for updating the pheromone concentration can be modified as follows:
represents the total pheromone concentration released by the ants after completing one iteration or cycle. As increases, it indicates a higher value of the objective function, which, in turn, leads to a larger overall pheromone concentration at the location where the ants are located.
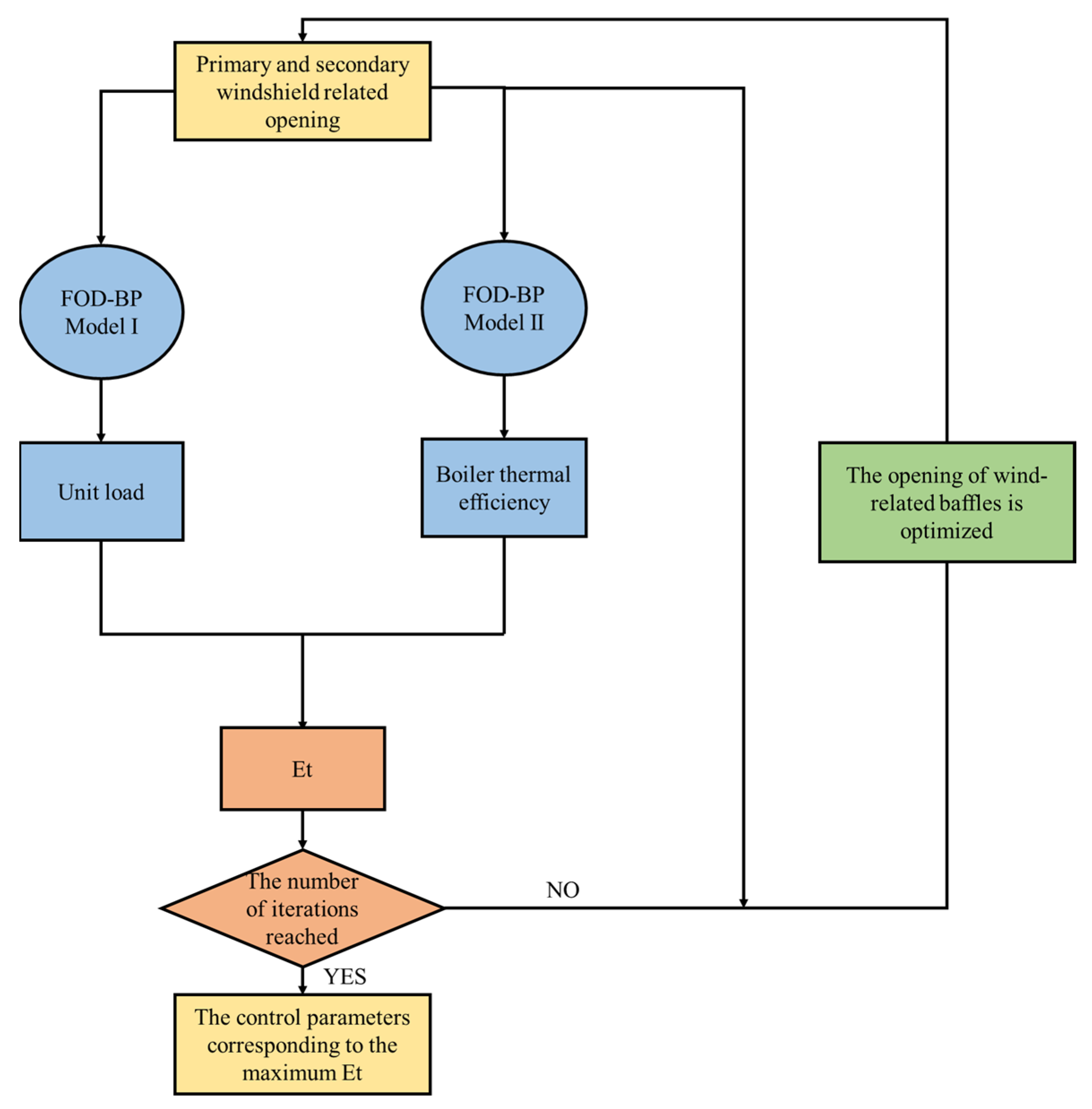
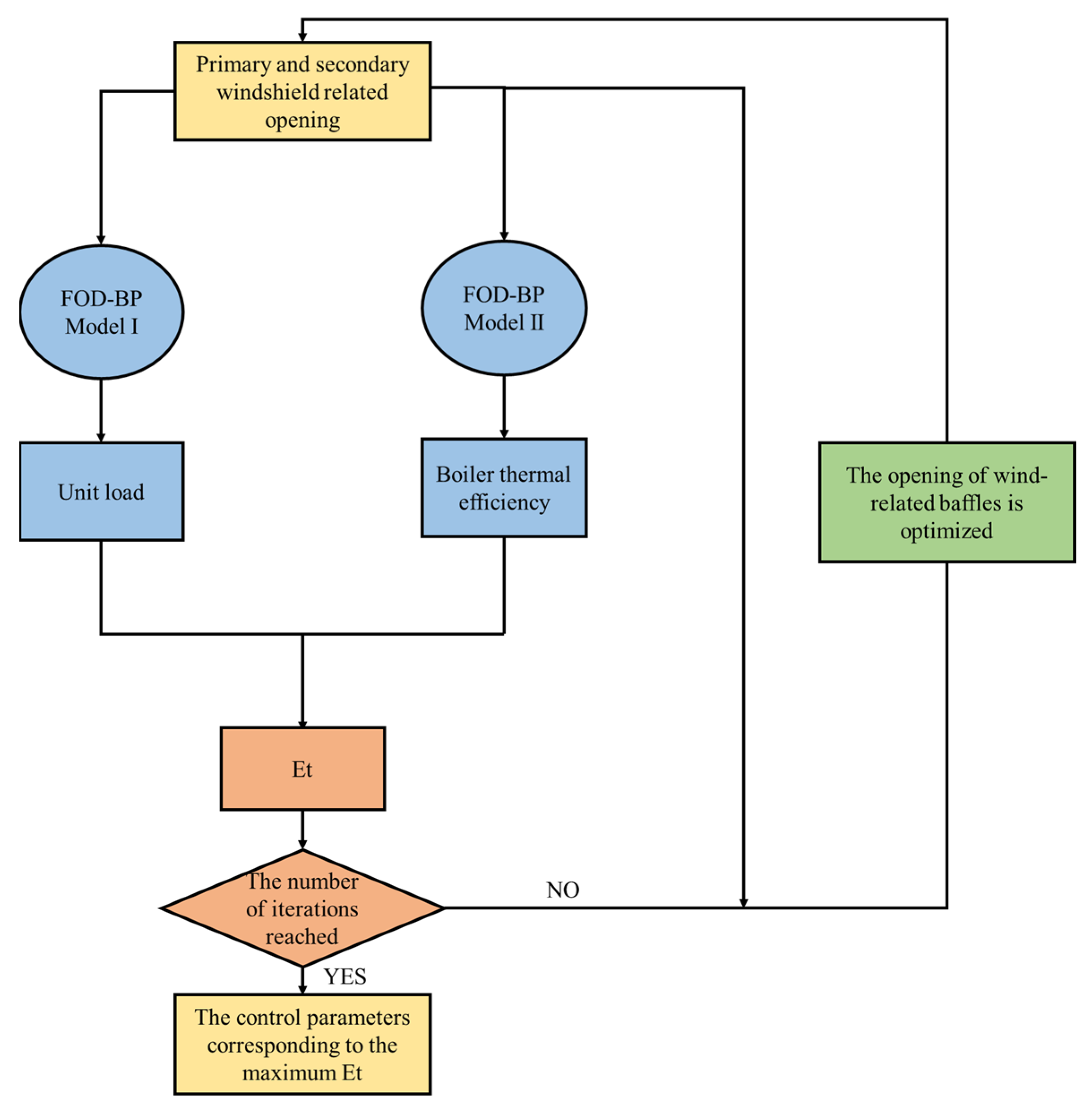
The introduction of the ACO algorithm significantly enhances the local search capability of the BP algorithm. Additionally, to improve the precision of the predictive model, this study proposes the optimization of BP through the introduction of FOD. The FOD is used to estimate the delay time of a particular parameter relative to another output parameter within a given system or process, and the specific process is as follows:
Firstly, calculate the Pearson correlation coefficient of the unit load characteristic parameters with Equation (17):
Next, conduct a lag analysis by selecting representative parameters with a correlation coefficient greater than 0.5 relative to the unit load from the input parameters. Subsequently, the interpolation function is fitted to the scattered data points over a complete period, the FOD of the fitted function is performed, and the estimation of the parameter relative to the output parameter is obtained by comparing the time difference between adjacent extreme points delay.
Assuming there are n hysteresis-compensated operating state parameters, for
, define the latency
as shown in the following Equation (18):
where
is for unit load,
is the ith hysteresis-compensated operating state parameter,
is for the unit load interpolation function corresponding to the extreme value point,
represents the ith running parameter interpolating the extremum point corresponding to the time,
represents DCS sampling interval,
represents the latency for running parameter
, and
is for maximum lag time of biomass boiler unit load.
The FOD-BP algorithm corrects the weights and thresholds of hidden layer nodes by propagating the error values generated after forward propagation back to the hidden layer, distributing them across the nodes. This process is iteratively repeated until the iteration reaches the minimum error value and concludes.
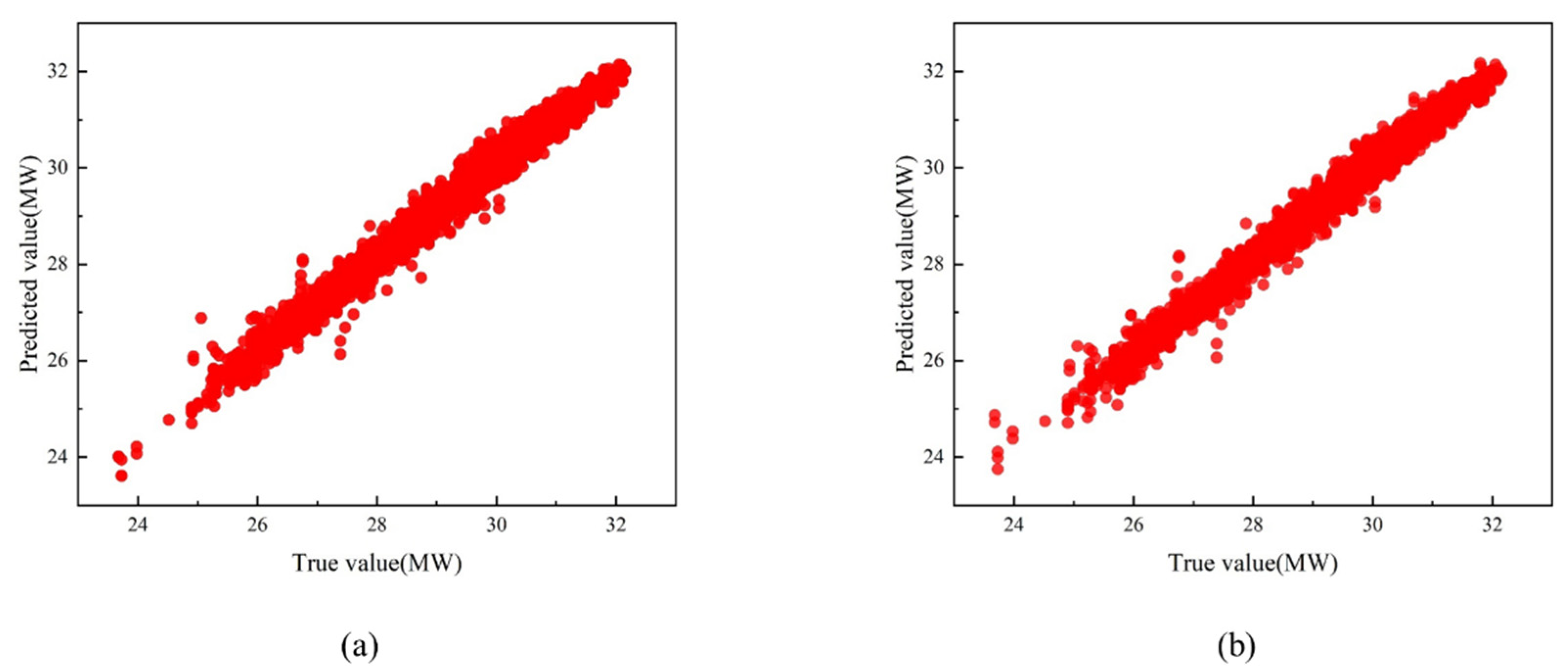
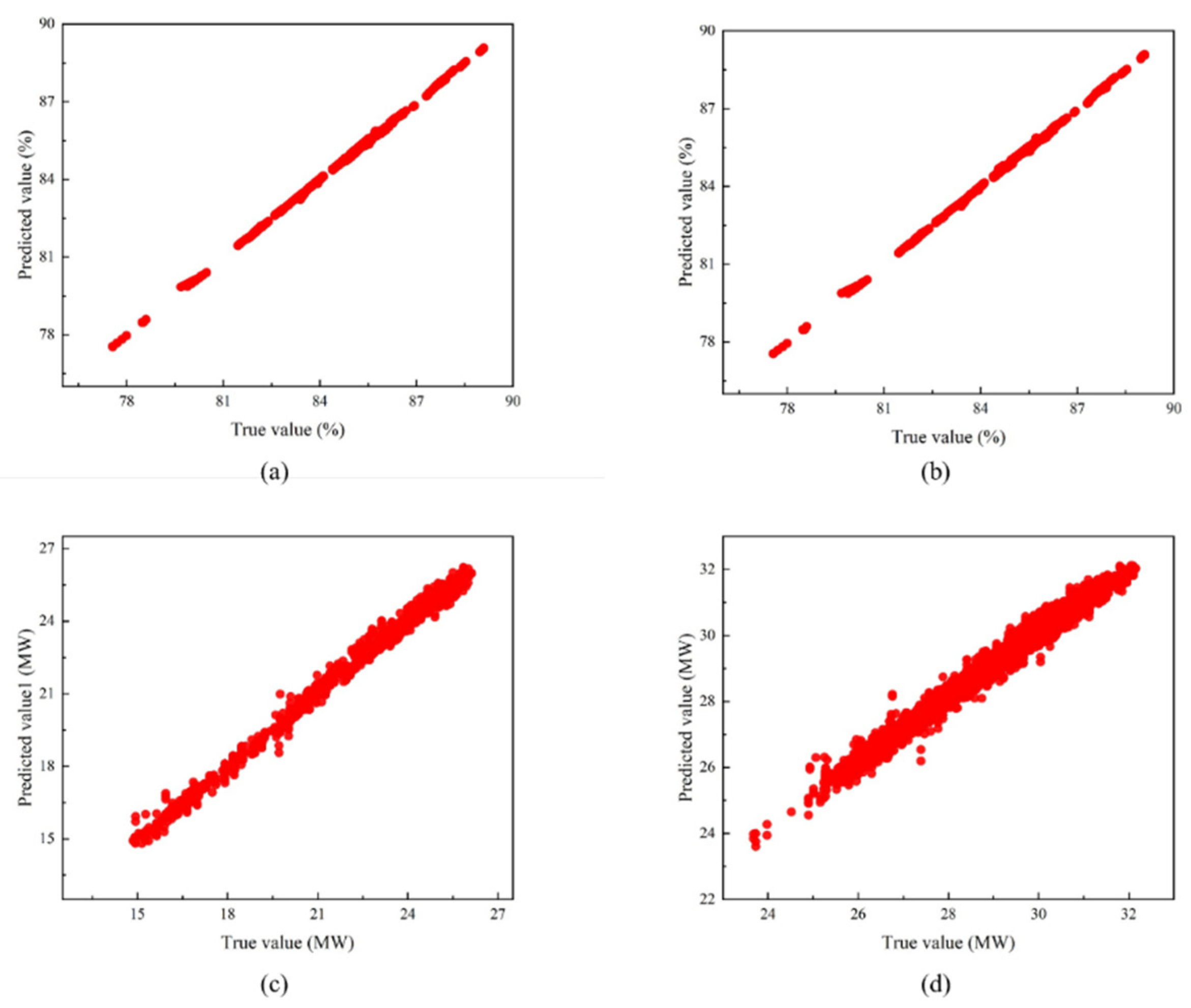
The FOD-BP model is a hybrid neural network based on the traditional BP algorithm. To enhance the local search capability of the BP algorithm, the ACO algorithm is introduced into the network’s weight-updating mechanism. The FOD algorithm adjusts the delay time difference to provide accurate input parameters for the BP algorithm, improving the model accuracy. By combining the FOD and ACO algorithms, it effectively obtains more accurate input parameters, thereby enhancing the precision of the BP model and maximizing thermal efficiency through control parameter adjustments.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}