
Decentralized Smart Grid Stability Modeling with Machine Learning





Abstract
:1. Introduction
- Is it possible to estimate the stability of the DSGC system with high performance using AI-based models?
- What are the hyperparameters of the AI algorithms used that provide satisfactory results or otherwise the best-achieved results within the scope of this research?
- Is it possible to use a stacking ensemble made up of previously used algorithms to achieve a higher performance in obtaining regression and classification models for addressing the problem of stability prediction?
2. Materials and Methods
2.1. Dataset Description
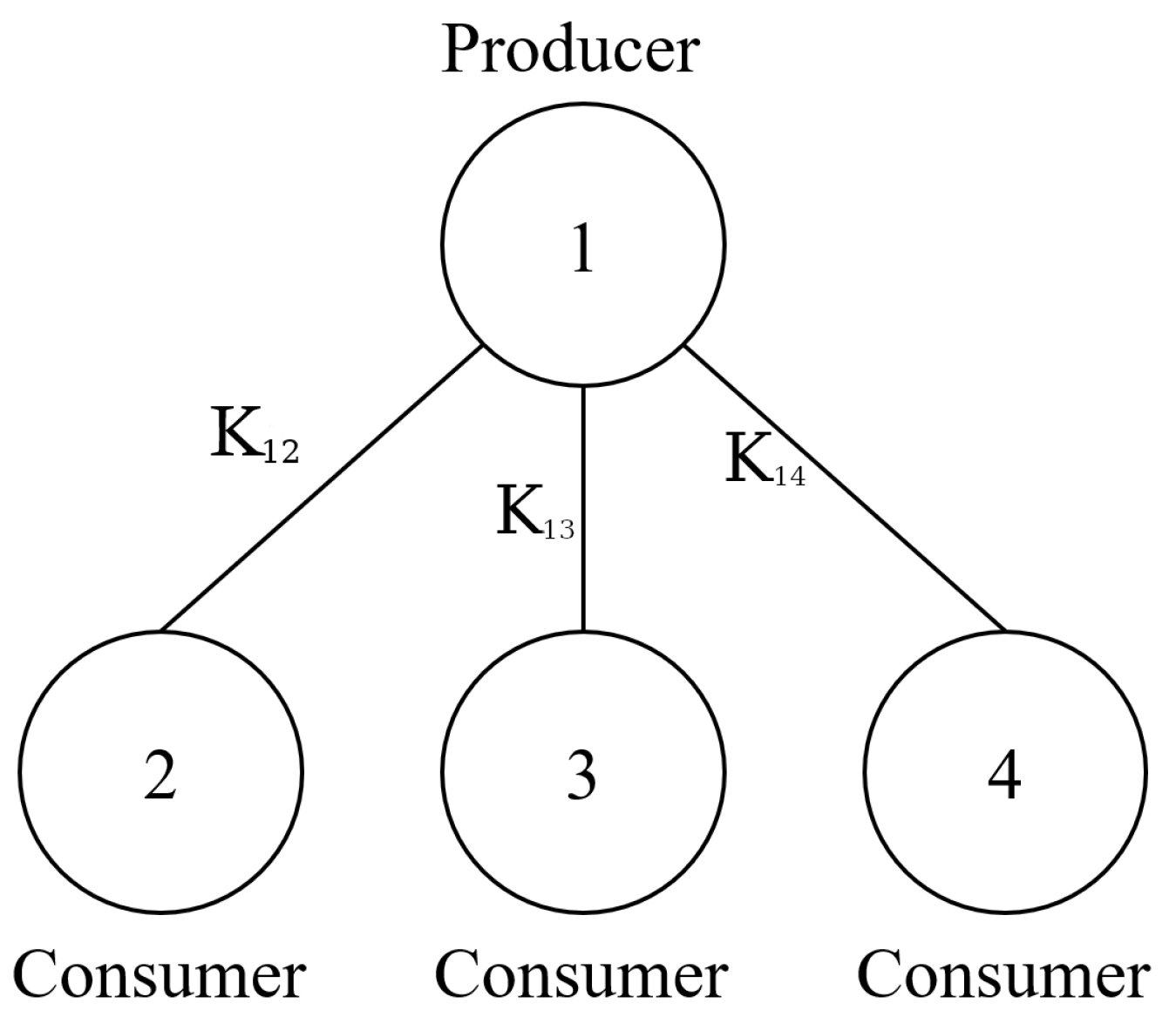
2.1.1. The Mathematical Model of the DSGC System
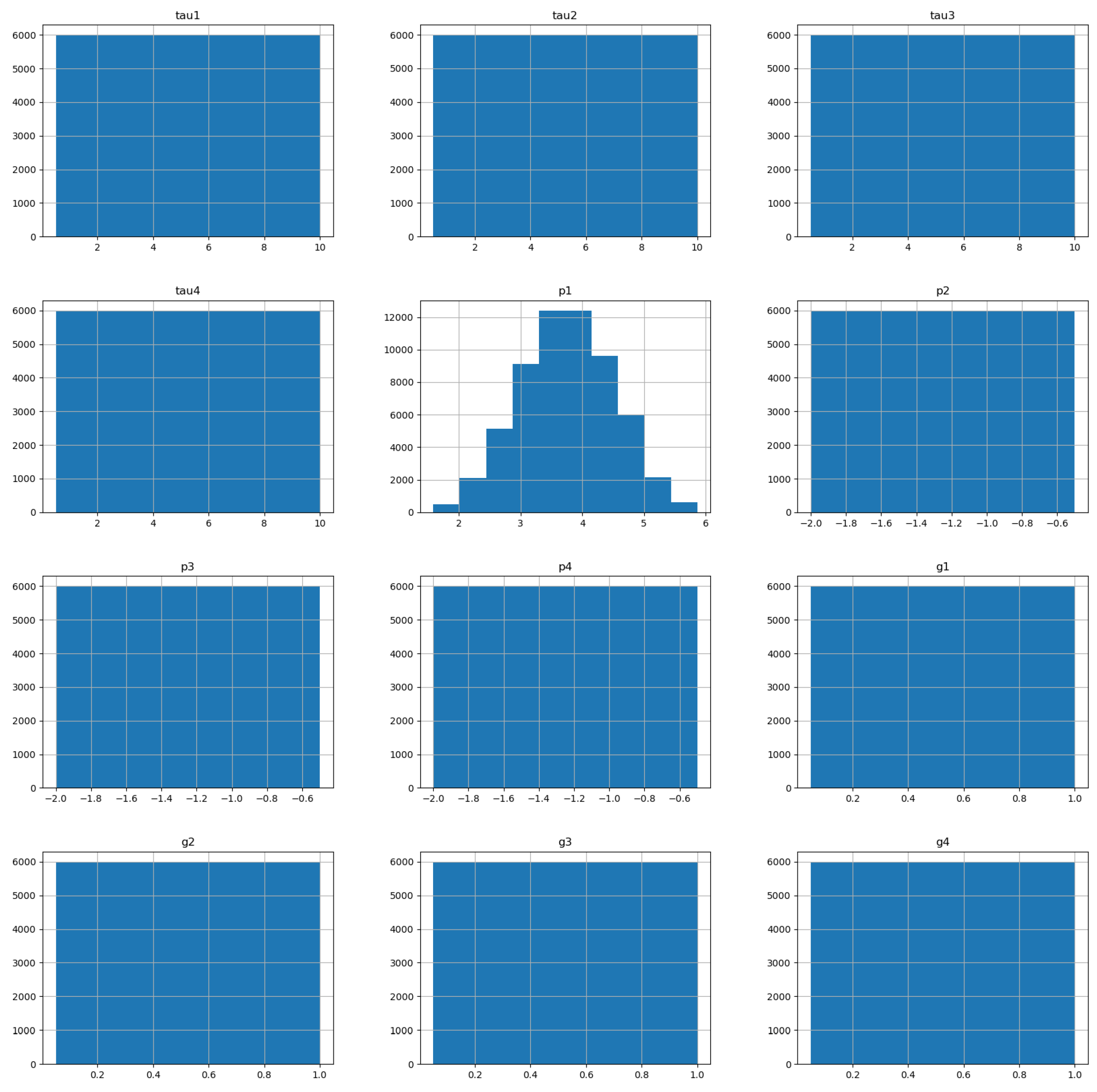
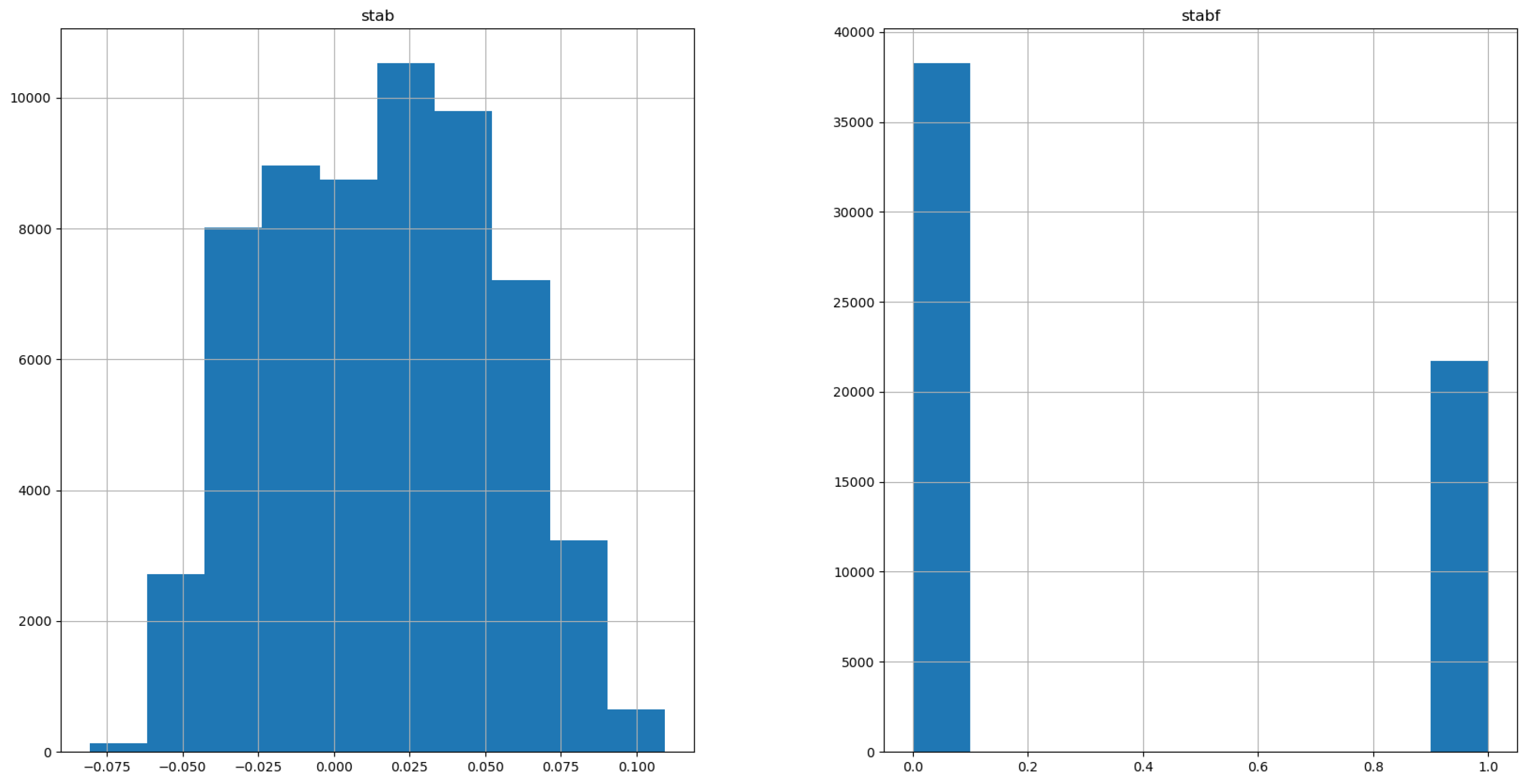
2.1.2. Description and Analysis of the Dataset Used
- —the stability of the systems, represented as an eigenvalue of the Equation (9) for that set of input values, as a numerical value,
- —the stability of the system as a categorical value divided between two states, ‘stable’ and ‘unstable’.
2.2. Methods
2.2.1. Multilayer Perceptron
2.2.2. Support Vector Machine
2.2.3. Gradient Boosting Machine
2.2.4. Genetic Programming
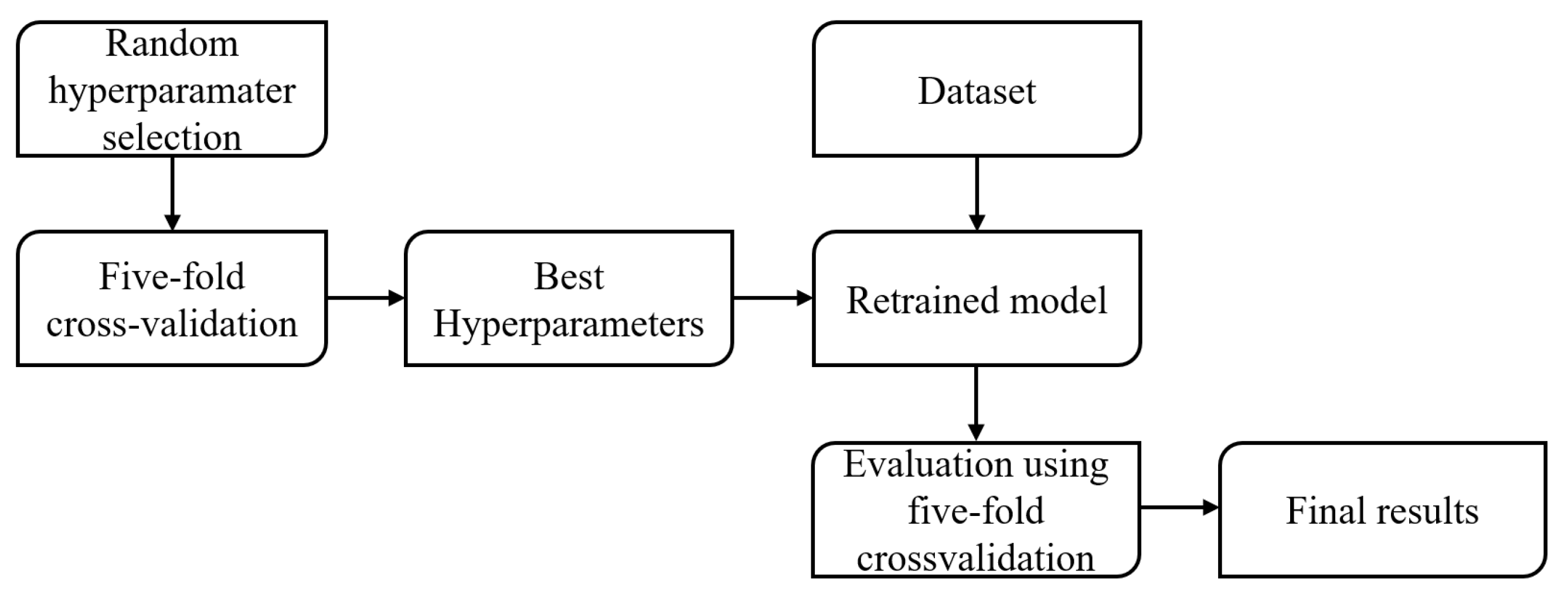
2.3. Model Evaluation
2.3.1. Regression Evaluation Metrics
2.3.2. Classification Evaluation Metrics
3. Results and Discussion
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kundur, P.S.; Malik, O.P. Power System Stability and Control; McGraw-Hill Education: New York, NY, USA, 2022. [Google Scholar]
- Weedy, B.; Cory, B.; Jenkins, N.; Ekanayake, J.; Strbac, G. Electric Power Systems; Wiley: Hoboken, NJ, USA, 2012. [Google Scholar]
- Plötz, P.; Wachsmuth, J.; Gnann, T.; Neuner, F.; Speth, D.; Link, S. Net-Zero-Carbon Transport in Europe until 2050—Targets, Technologies and Policies for a Long-Term EU Strategy; Fraunhofer Institute for Systems and Innovation Research ISI: Karlsruhe, Germany, 2021; Available online: https://www.isi.fraunhofer.de/en.html (accessed on 25 July 2021).
- Golombek, R.; Lind, A.; Ringkjøb, H.K.; Seljom, P. The role of transmission and energy storage in European decarbonization towards 2050. Energy 2022, 239, 122159. [Google Scholar] [CrossRef]
- Verde, S.F. The impact of the EU emissions trading system on competitiveness and carbon leakage: The econometric evidence. J. Econ. Surv. 2020, 34, 320–343. [Google Scholar] [CrossRef]
- Sioshansi, F.P. Evolution of Global Electricity Markets: New Paradigms, New Challenges, New Approaches; Academic Press: Cambridge, MA, USA, 2013. [Google Scholar]
- Wang, J.; Zhong, H.; Wu, C.; Du, E.; Xia, Q.; Kang, C. Incentivizing distributed energy resource aggregation in energy and capacity markets: An energy sharing scheme and mechanism design. Appl. Energy 2019, 252, 113471. [Google Scholar] [CrossRef]
- Tuballa, M.L.; Abundo, M.L. A review of the development of Smart Grid technologies. Renew. Sustain. Energy Rev. 2016, 59, 710–725. [Google Scholar] [CrossRef]
- Tu, C.; He, X.; Shuai, Z.; Jiang, F. Big data issues in smart grid—A review. Renew. Sustain. Energy Rev. 2017, 79, 1099–1107. [Google Scholar] [CrossRef]
- El Mrabet, Z.; Kaabouch, N.; El Ghazi, H.; El Ghazi, H. Cyber-security in smart grid: Survey and challenges. Comput. Electr. Eng. 2018, 67, 469–482. [Google Scholar] [CrossRef]
- Colak, I.; Sagiroglu, S.; Fulli, G.; Yesilbudak, M.; Covrig, C.F. A survey on the critical issues in smart grid technologies. Renew. Sustain. Energy Rev. 2016, 54, 396–405. [Google Scholar] [CrossRef]
- Schäfer, B.; Matthiae, M.; Timme, M.; Witthaut, D. Decentral smart grid control. New J. Phys. 2015, 17, 015002. [Google Scholar] [CrossRef]
- Schäfer, B.; Grabow, C.; Auer, S.; Kurths, J.; Witthaut, D.; Timme, M. Taming instabilities in power grid networks by decentralized control. Eur. Phys. J. Spec. Top. 2016, 225, 569–582. [Google Scholar] [CrossRef]
- Arzamasov, V.; Böhm, K.; Jochem, P. Towards concise models of grid stability. In Proceedings of the 2018 IEEE International Conference on Communications, Control, and Computing Technologies for Smart Grids (SmartGridComm), Aalborg, Denmark, 29–31 October 2018; pp. 1–6. [Google Scholar]
- Kruse, J.; Schäfer, B.; Witthaut, D. Revealing drivers and risks for power grid frequency stability with explainable AI. Patterns 2021, 2, 100365. [Google Scholar] [CrossRef]
- Solyali, D. A comparative analysis of machine learning approaches for short-/long-term electricity load forecasting in Cyprus. Sustainability 2020, 12, 3612. [Google Scholar] [CrossRef]
- Liu, S.; Shi, R.; Huang, Y.; Li, X.; Li, Z.; Wang, L.; Mao, D.; Liu, L.; Liao, S.; Zhang, M.; et al. A data-driven and data-based framework for online voltage stability assessment using partial mutual information and iterated random forest. Energies 2021, 14, 715. [Google Scholar] [CrossRef]
- Shi, Z.; Yao, W.; Zeng, L.; Wen, J.; Fang, J.; Ai, X.; Wen, J. Convolutional neural network-based power system transient stability assessment and instability mode prediction. Appl. Energy 2020, 263, 114586. [Google Scholar] [CrossRef]
- Wang, Q.; Li, F.; Tang, Y.; Xu, Y. Integrating model-driven and data-driven methods for power system frequency stability assessment and control. IEEE Trans. Power Syst. 2019, 34, 4557–4568. [Google Scholar] [CrossRef]
- Xi, L.; Wu, J.; Xu, Y.; Sun, H. Automatic generation control based on multiple neural networks with actor-critic strategy. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 2483–2493. [Google Scholar] [CrossRef]
- Meng, X.; Zhang, P.; Xu, Y.; Xie, H. Construction of decision tree based on C4.5 algorithm for online voltage stability assessment. Int. J. Electr. Power Energy Syst. 2020, 118, 105793. [Google Scholar] [CrossRef]
- Amroune, M.; Bouktir, T.; Musirin, I. Power system voltage stability assessment using a hybrid approach combining dragonfly optimization algorithm and support vector regression. Arab. J. Sci. Eng. 2018, 43, 3023–3036. [Google Scholar] [CrossRef]
- An, L.; Yang, G.H. Secure state estimation against sparse sensor attacks with adaptive switching mechanism. IEEE Trans. Autom. Control 2017, 63, 2596–2603. [Google Scholar] [CrossRef]
- Bergen, A.R.; Hill, D.J. A structure preserving model for power system stability analysis. IEEE Trans. Power Appar. Syst. 1981, PAS-100, 25–35. [Google Scholar] [CrossRef]
- Nimalsiri, N.I.; Mediwaththe, C.P.; Ratnam, E.L.; Shaw, M.; Smith, D.B.; Halgamuge, S.K. A survey of algorithms for distributed charging control of electric vehicles in smart grid. IEEE Trans. Intell. Transp. Syst. 2019, 21, 4497–4515. [Google Scholar] [CrossRef]
- Gangale, F.; Mengolini, A.; Onyeji, I. Consumer engagement: An insight from smart grid projects in Europe. Energy Policy 2013, 60, 621–628. [Google Scholar] [CrossRef]
- Stein, M. Large sample properties of simulations using Latin hypercube sampling. Technometrics 1987, 29, 143–151. [Google Scholar] [CrossRef]
- Breviglieri, P. Smart Grid Stability. 2020. Available online: https://www.kaggle.com/datasets/pcbreviglieri/smart-grid-stability (accessed on 25 January 2023).
- Arzamasov, V. Electrical Grid Stability Simulated Data Data Set. 2018. Available online: https://www.kaggle.com/datasets/ishadss/electrical-grid-stability-simulated-data-data-set (accessed on 11 November 2023).
- Akoglu, H. User’s guide to correlation coefficients. Turk. J. Emerg. Med. 2018, 18, 91–93. [Google Scholar] [CrossRef] [PubMed]
- Car, Z.; Baressi Šegota, S.; Anđelić, N.; Lorencin, I.; Mrzljak, V. Modeling the spread of COVID-19 infection using a multilayer perceptron. Comput. Math. Methods Med. 2020, 2020, 5714714. [Google Scholar] [CrossRef]
- Bishop, C.M. Pattern recognition and feed-forward networks. In The MIT Encyclopedia of the Cognitive Sciences; MIT Press: Cambridge, MA, USA, 1999; Volume 13. [Google Scholar]
- Suthaharan, S.; Suthaharan, S. Support vector machine. In Machine Learning Models and Algorithms for Big Data Classification: Thinking with Examples for Effective Learning; Springer: New York, NY, USA, 2016; pp. 207–235. [Google Scholar]
- Burkov, A. The Hundred-Page Machine Learning Book; Andriy Burkov: Quebec City, QC, Canada, 2019; Volume 1. [Google Scholar]
- Nguyen-Sy, T.; Wakim, J.; To, Q.D.; Vu, M.N.; Nguyen, T.D.; Nguyen, T.T. Predicting the compressive strength of concrete from its compositions and age using the extreme gradient boosting method. Constr. Build. Mater. 2020, 260, 119757. [Google Scholar] [CrossRef]
- Poli, R.; Langdon, W.B.; McPhee, N.F.; Koza, J.R. A Field Guide to Genetic Programming. With Contributions by JR Koza. 2008. Available online: https://www.zemris.fer.hr/~yeti/studenti/izvori/A_Field_Guide_to_Genetic_Programming.pdf (accessed on 4 October 2023).
- Anđelić, N.; Baressi Šegota, S.; Glučina, M.; Lorencin, I. Classification of Wall Following Robot Movements Using Genetic Programming Symbolic Classifier. Machines 2023, 11, 105. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input | Description | Type | Chosen Value |
|---|---|---|---|
| Damping constant | Control input | 0.1 s | |
| Coupling strengths | Control input | 8 s | |
| Averaging time | Control input | 2 s | |
| Price elasticity | Environmental input | [0.05, 1.00] | |
| Reaction time | Environmental input | [0.5, 10] | |
| Mechanical power | Environmental input | [−0.5, −2] |
| Mean | Std | Min | Max | Unique Values | ||
|---|---|---|---|---|---|---|
| Input values | 1 | 5.25 | 2.74 | 0.50 | 10.00 | 10,000 |
| 2 | 5.25 | 2.74 | 0.50 | 10.00 | 30,000 | |
| 3 | 5.25 | 2.74 | 0.50 | 10.00 | 30,000 | |
| 4 | 5.25 | 2.74 | 0.50 | 10.00 | 30,000 | |
| p1 | 3.75 | 0.75 | 1.58 | 5.86 | 10,000 | |
| p2 | −1.25 | 0.34 | −2.00 | −0.50 | 30,000 | |
| p3 | −1.25 | 0.34 | −2.00 | −0.50 | 30,000 | |
| p4 | −1.25 | 0.34 | −2.00 | −0.50 | 30,000 | |
| g1 | 0.52 | 0.27 | 0.05 | 1.00 | 10,000 | |
| g2 | 0.53 | 0.27 | 0.05 | 1.00 | 30,000 | |
| g3 | 0.53 | 0.27 | 0.05 | 1.00 | 30,000 | |
| g4 | 0.53 | 0.27 | 0.05 | 0.11 | 30,000 | |
| Output values | 0.02 | 0.04 | −0.08 | 0.11 | 10,000 | |
| stable 36% | unstable 64% | 2 | ||||
| Hyperparameter | Range of Values |
|---|---|
| ‘hidden_layer_sizes’ | (50,50,50,50,50,50,50,50,50,50), (75,75,75,75,75,75,75,75,75), (80,80,80,80,80,80,80,80), (90,90,90,90,90,90,90), (100,100,100,100,100,100), (200,200,200,200,200) |
| ‘activation’ | ‘identity’, ‘logistic’, ‘tanh’, ‘relu’ |
| ‘solver’ | ‘lbfgs’, ‘adam’ |
| ‘alpha’ | [0.0001–0.001] |
| ‘beta_1’ | [0–0.9] |
| ‘beta_2’ | [0.9–0.999] |
| ‘learning_rate_init’ | [0.0001–0.001] |
| ‘epsilon’ | – |
| Hyperparameter | Range of Values |
|---|---|
| ‘kernel’ | ‘linear’, ‘poly’, ‘rbf’, ‘sigmond’ |
| ‘C’ | [0–100] |
| ‘degree’ | [2, 3, 4, 5] |
| ‘gamma’ | [0.001, 10] |
| ‘coef0’ | [0, 1] |
| ‘epsilon’ | [0.001–1] |
| Hyperparameter | Range of Values |
|---|---|
| ‘eta’ | [0–1] |
| ‘max_depth’ | [4–10] |
| ‘min_child_weight’ | [0–1] |
| ‘max_delta_step’ | [1–10] |
| ‘colsample_bytree’ | [0–1] |
| ‘colsample_bylevel’ | [0–1] |
| ‘colsample_bynode’ | [0–1] |
| ‘num_parallel_tree’ | [1–5] |
| Hyperparameter | Range of Values |
|---|---|
| population_size | [1000–2000] |
| generations | [200–1000] |
| tournament_size | [50–500] |
| init_depth | [2-3]–[5-7] |
| init_method | ‘grow’, ‘full’, ‘half and half’ |
| parsimony_coefficient | [0.001–0.01] |
| Regression | |||
|---|---|---|---|
| Algorithm | Average Score | Deviation | Chosen Hyperparameters |
| MLP | 0.9772 | 0.0025 | learning_rate_init = 0.0001, hidden_layer_sizes = (200, 200, 200, 200, 200), epsilon = 1.8 × 10, beta_2 = 0.936, beta_1 = 0.3, alpha = 0.0001, activation = relu |
| SVM | 0.8709 | 0.0015 | kernel = poly, gamma = 0.219, epsilon = 0.042, degree = 3, coef0 = 2.2, C = 46 |
| XGB | 0.9820 | 0.0007 | subsample = 0.9, num_parallel_tree = 4, min_child_weight = 0.5, max_depth = 9, max_delta_step = 9, eta = 0.4, colsample_bytree = 0.9, colsample_bynode = 0.7, colsample_bylevel = 1.0 |
| GP | 0.062 | 0.0526 | tournament_size = 300, population_size = 1300, parsimony_coefficient = 0.001, init_method = ‘full’, init_depth = (2, 6), generations = 900 |
| Classification | |||
| AI Algorithm | Average Score | Standard Deviation | Chosen Hyperparameters |
| MLP | 0.9930 | 0.0026 | solver = lbfgs, hidden_layer_sizes = (50,50,50,50,50), activation = logistic |
| SVM | 0.9599 | 0.0007 | kernel = poly, gamma = 0.007, degree = 3, coef0 = 0, C = 28 |
| XGB | 0.9934 | 0.0022 | subsample = 0.9, num_parralel_tree = 4, min_child_weight = 0.9, max_depth = 10, max_delta_step = 5, eta = 0.9, colsample_bytee = 0.2, colsample_bylevel = 0.6, colsample_bynode = 0.9 |
| GP | 0.8414 | 0.0208 | tournament_size = 50, population_size = 800, parsimony_coefficient = 0.001, init_method = full, init_depth = (3, 7), generation = 300 |
| Regression | |||
|---|---|---|---|
| AI Algorithm | Average Score | Standard Deviation | Chosen Hyperparameters |
| MLP | 0.9794 | 0.0008 | solver = adam, learning_rate_init = 0.0001, hidden_layer_sizes = (200, 200, 200, 200, 200), epsilon = 1.7 × 10, beta_2 = 0.9, beta_1 = 0.7, alpha = 0.00018, activation = relu |
| SVM | 0.8502 | 0.0080 | kernel = poly, gamma = 1.082, epsilon = 0.039, degree = 4, coef0 = 7.0, C = 49 |
| XGB | 0.9815 | 0.0007 | subsample = 0.6, num_parallel_tree = 4, min_child_weight = 0.8, max_depth = 9, max_delta_step = 8, eta = 0.4, colsample_bytree = 0.8, colsample_bynode = 0.2, colsample_bylevel = 1.0 |
| GP | 0.068 | 0.0565 | tournament_size = 300, population_size = 1300, parsimony_coefficient = 0.001, init_method = ‘full’, init_depth = (2, 6), generations = 900 |
| Classification | |||
| AI Algorithm | Average Score | Standard Deviation | Chosen Hyperparameters |
| MLP | 0.9933 | 0.0006 | hidden_layer_sizes = (50, 50, 50, 50, 50, 50, 50, 50, 50, 50), activation = identity, solver = lbfgs |
| SVM | 0.9865 | 0.0005 | kernel = rbf, gamma = 0.062, C = 100 |
| XGB | 0.9970 | 0.0015 | subsample = 0.9, num_parralel_tree = 4, min_child_weight = 0.0, max_depth = 10, max_delta_step = 9, eta = 0.9, colsample_bytee = 0.3, colsample_bylevel = 0.8, colsample_bynode = 0.5 |
| GP | 0.8422 | 0.0198 | tournament_size = 50, population_size = 800, parsimony_coefficient = 0.001, init_method = full, init_depth = (3, 7), generation = 300 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Franović, B.; Baressi Šegota, S.; Anđelić, N.; Car, Z. Decentralized Smart Grid Stability Modeling with Machine Learning. Energies 2023, 16, 7562. https://doi.org/10.3390/en16227562
Franović B, Baressi Šegota S, Anđelić N, Car Z. Decentralized Smart Grid Stability Modeling with Machine Learning. Energies. 2023; 16(22):7562. https://doi.org/10.3390/en16227562
Chicago/Turabian StyleFranović, Borna, Sandi Baressi Šegota, Nikola Anđelić, and Zlatan Car. 2023. "Decentralized Smart Grid Stability Modeling with Machine Learning" Energies 16, no. 22: 7562. https://doi.org/10.3390/en16227562
APA StyleFranović, B., Baressi Šegota, S., Anđelić, N., & Car, Z. (2023). Decentralized Smart Grid Stability Modeling with Machine Learning. Energies, 16(22), 7562. https://doi.org/10.3390/en16227562