
Wave Power Prediction Based on Seasonal and Trend Decomposition Using Locally Weighted Scatterplot Smoothing and Dual-Channel Seq2Seq Model
 ,
, 
Abstract
:1. Introduction
1.1. Recent Investigations
1.2. Objective of This Study
- To mitigate the issue of component redundancy in the current forecasting decomposition step, this paper employs STL and leverages the principle of minimal residual correlation to extract trend and seasonal sequences.
- To address the shortcomings in current forecasting models that directly concatenate multiple features, this paper strengthens the extraction of trend and periodic features using the dual-channel Seq2Seq model, thereby augmenting the model’s ability to mine historical features effectively.
- The proposed model is compared with baseline models and other ‘decomposition-prediction’ models. The results demonstrate that the proposed model surpasses the performance of other models, with both STL and the dual-channel Seq2Seq model contributing to enhanced predictive accuracy.
2. Basic Theoretical Foundation
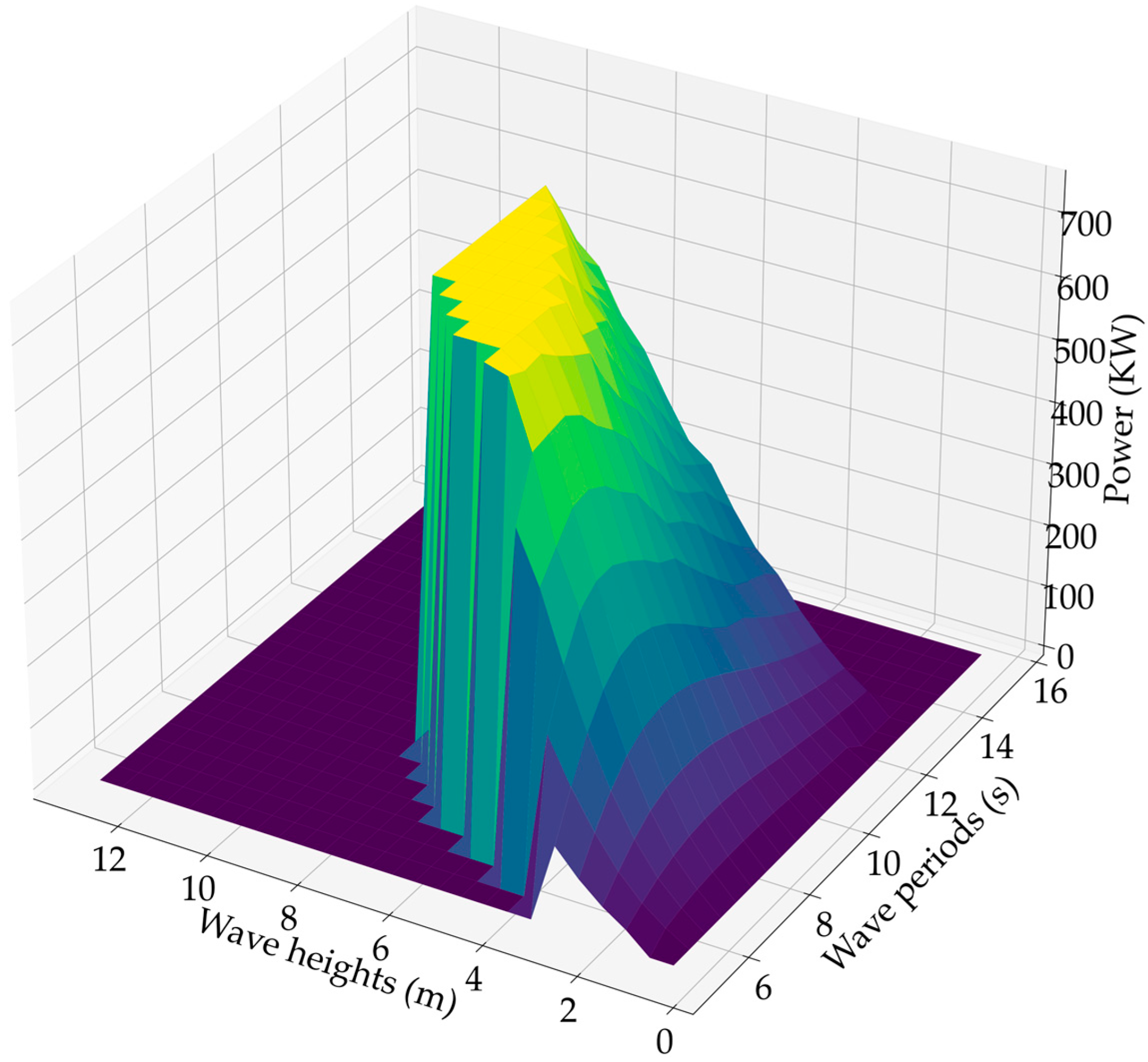
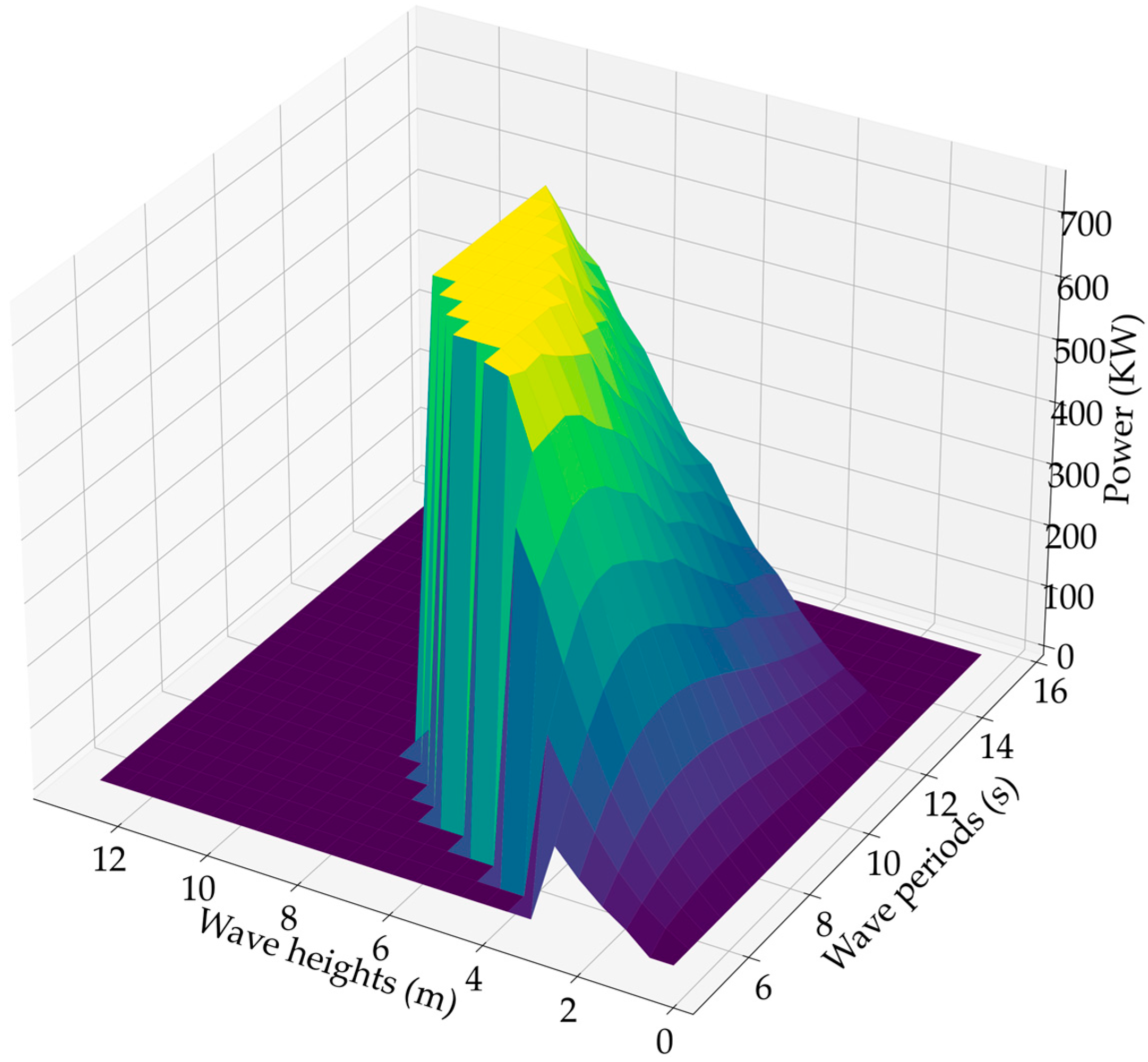
2.1. Wave Power Modelling
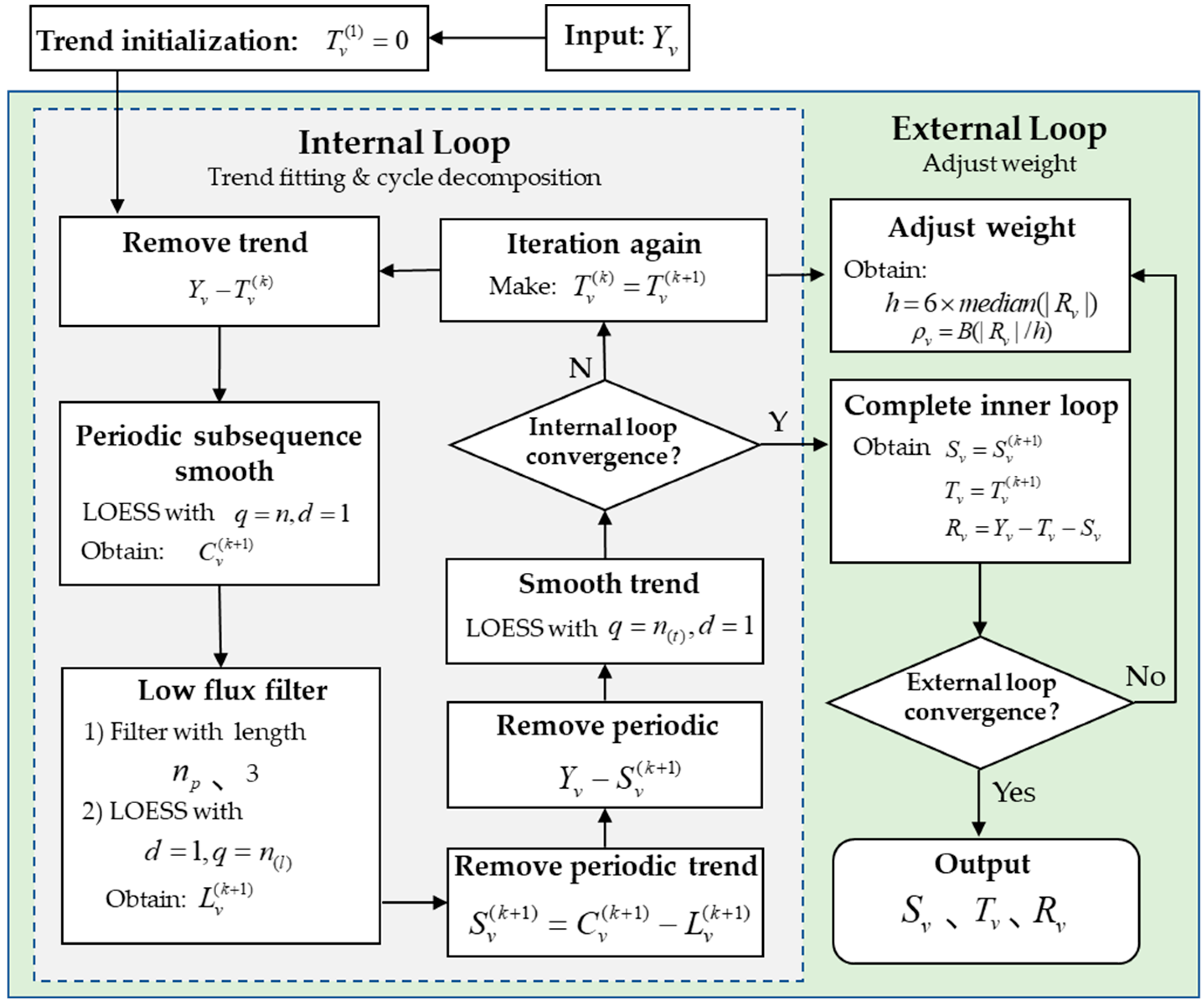
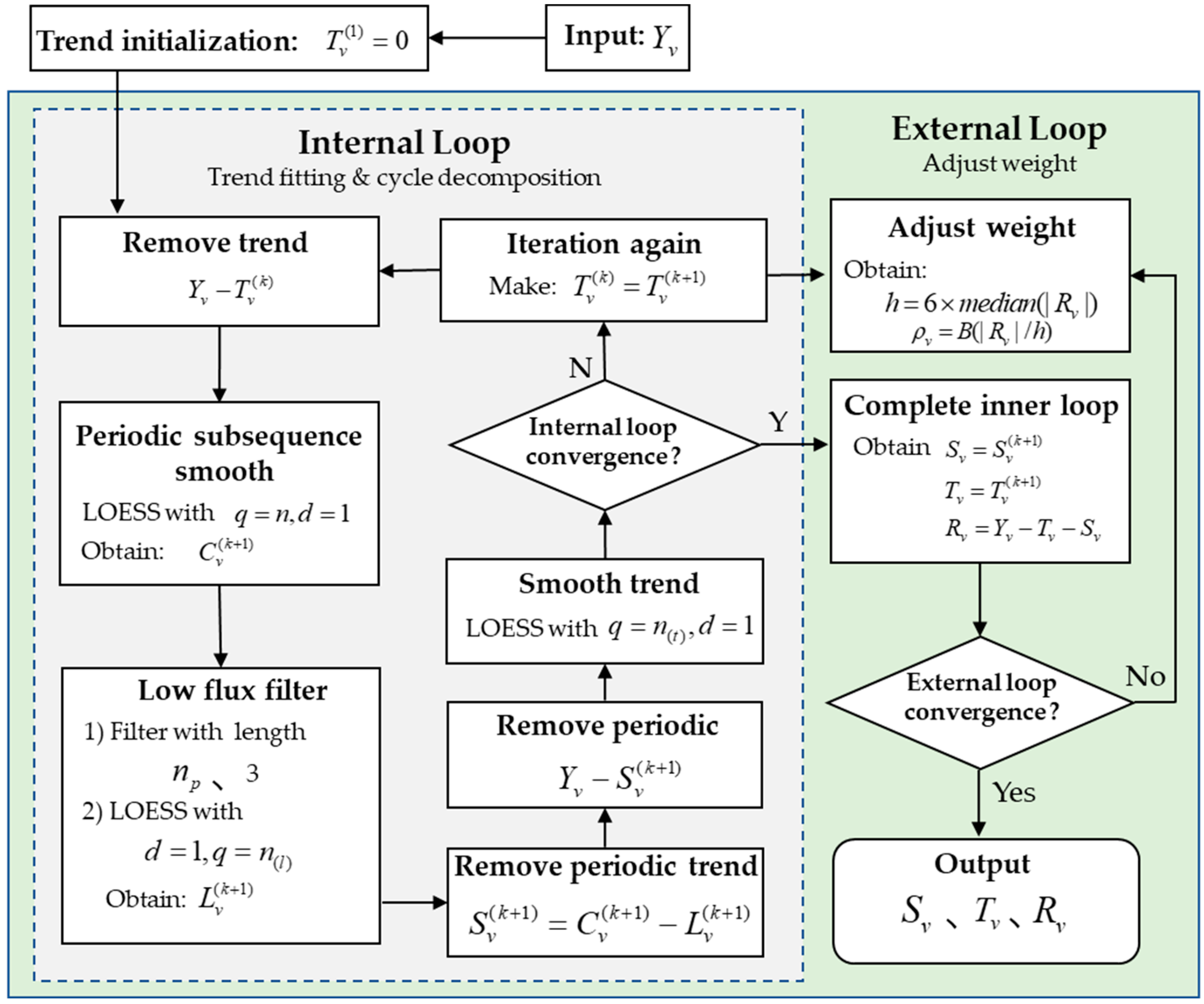
2.2. Seasonal–Trend Decomposition Using LOESS
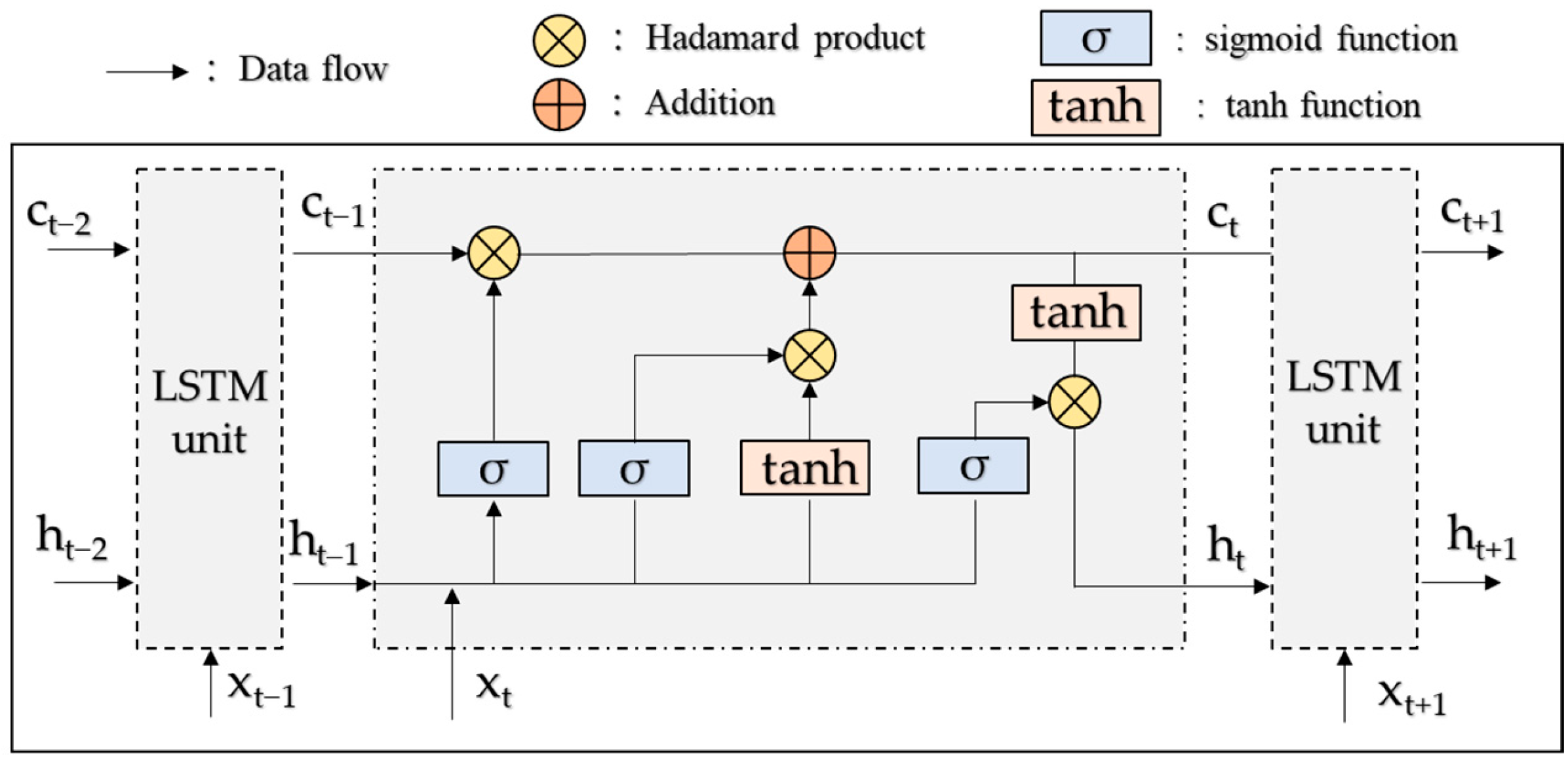
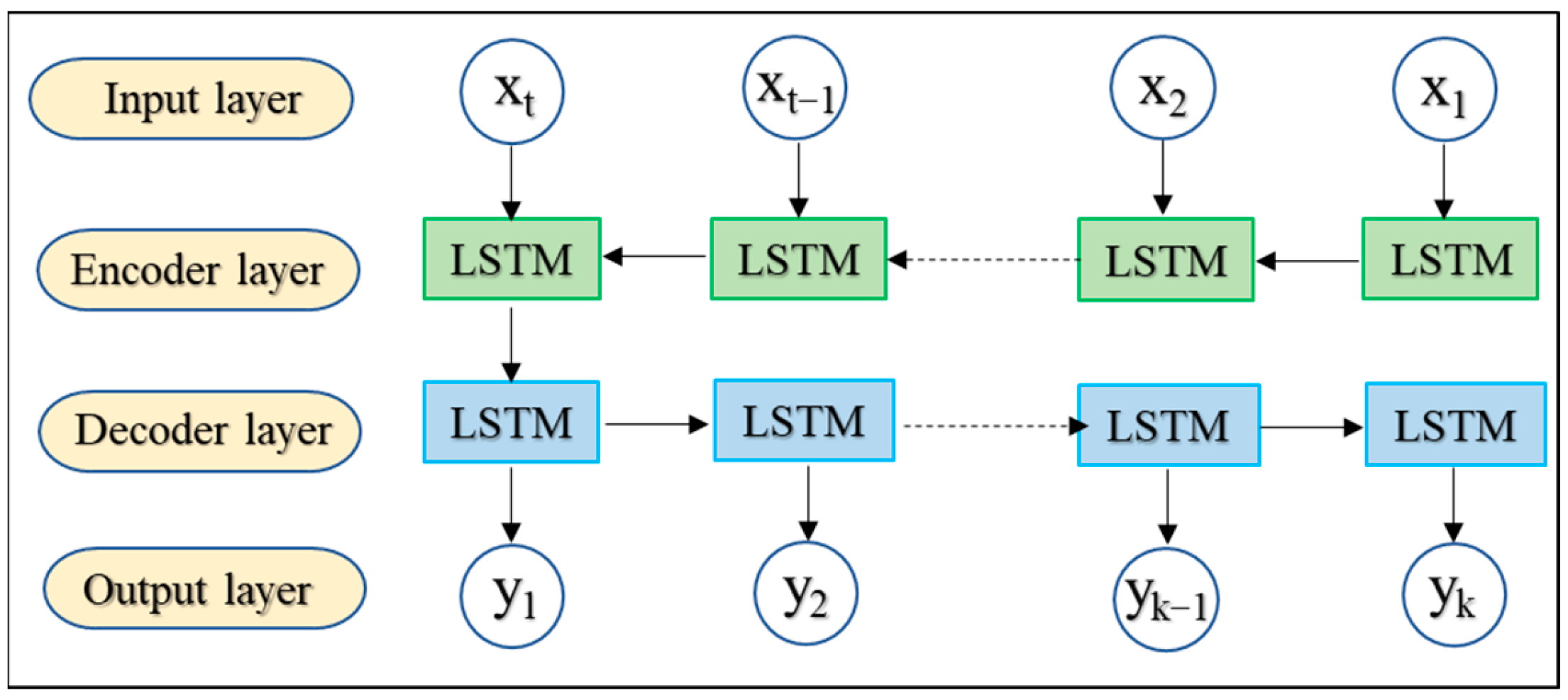
2.3. Seq2Seq Based on LSTM
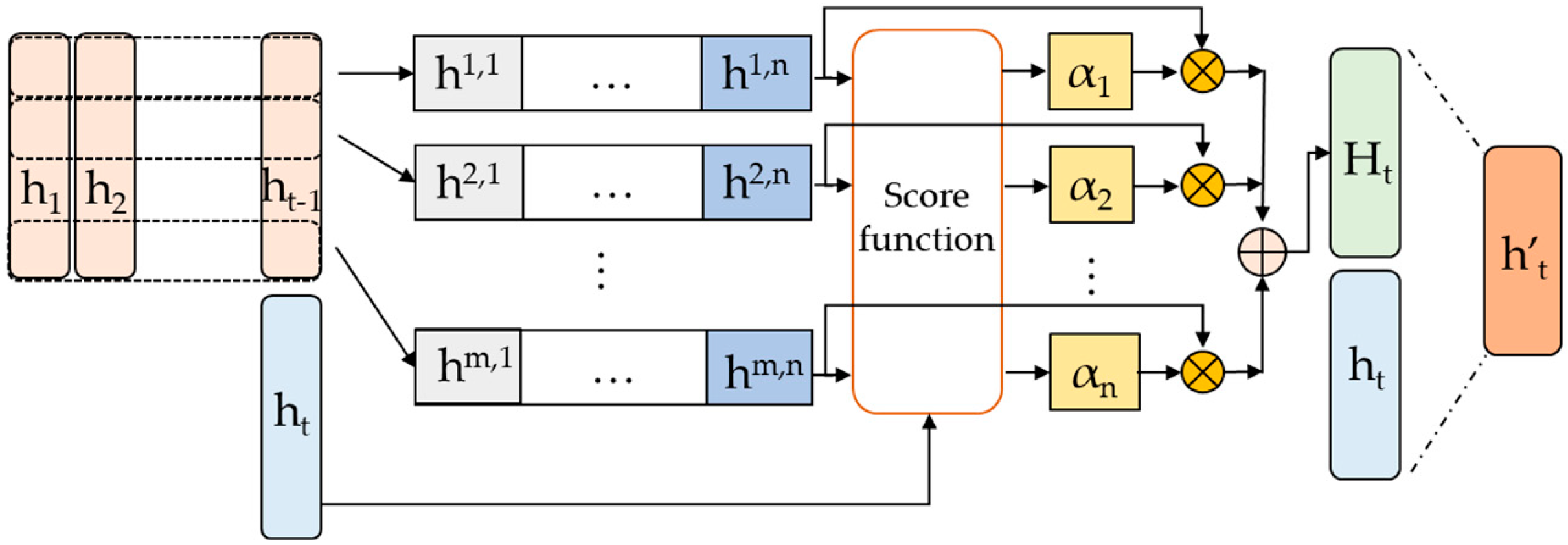
2.4. Temporal Pattern Attention
2.5. Multi-Head Self-Attention
2.6. Performance Evaluation
3. Composition of the Proposed Model
3.1. Determination of STL Decomposition Parameters
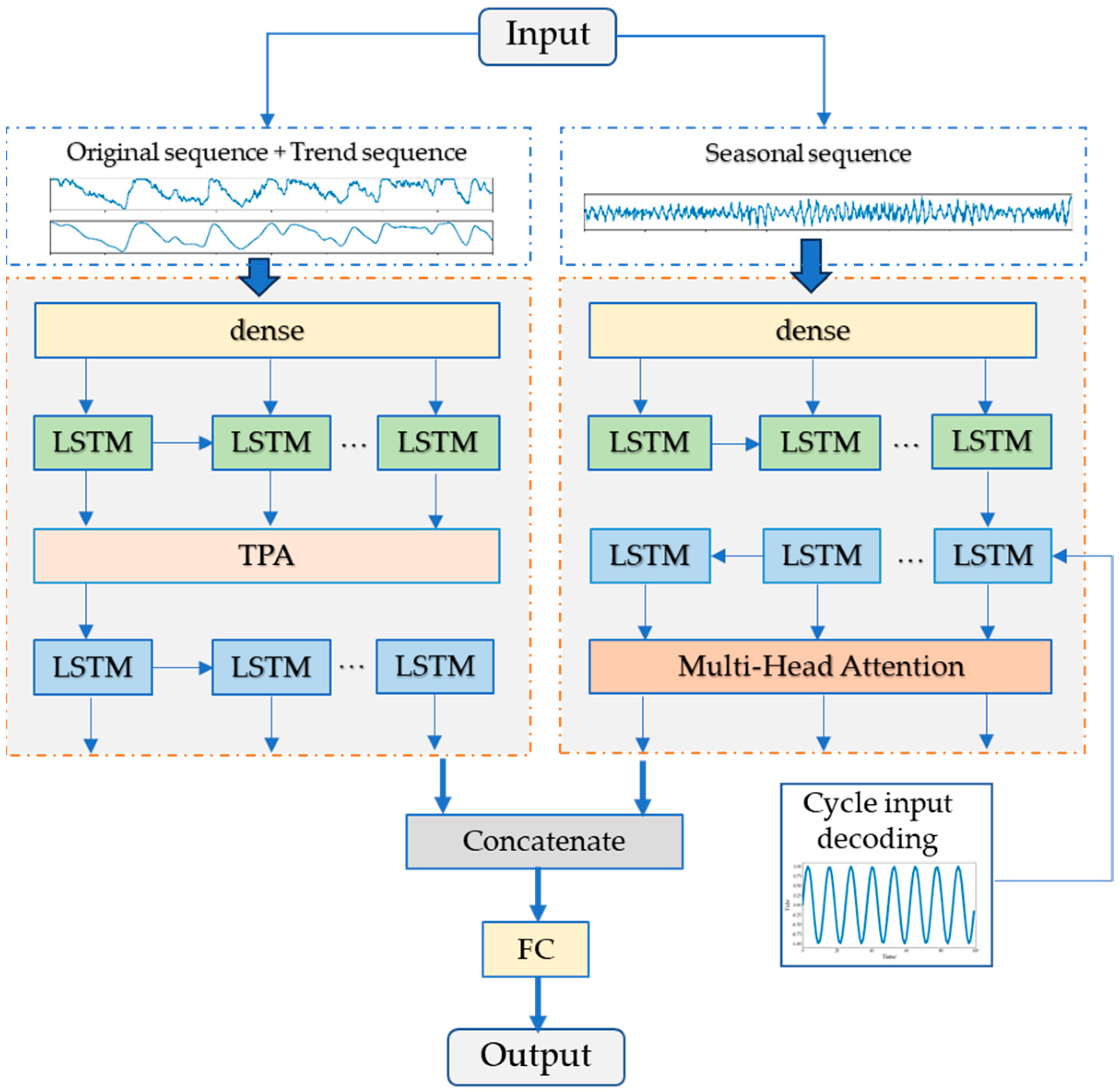
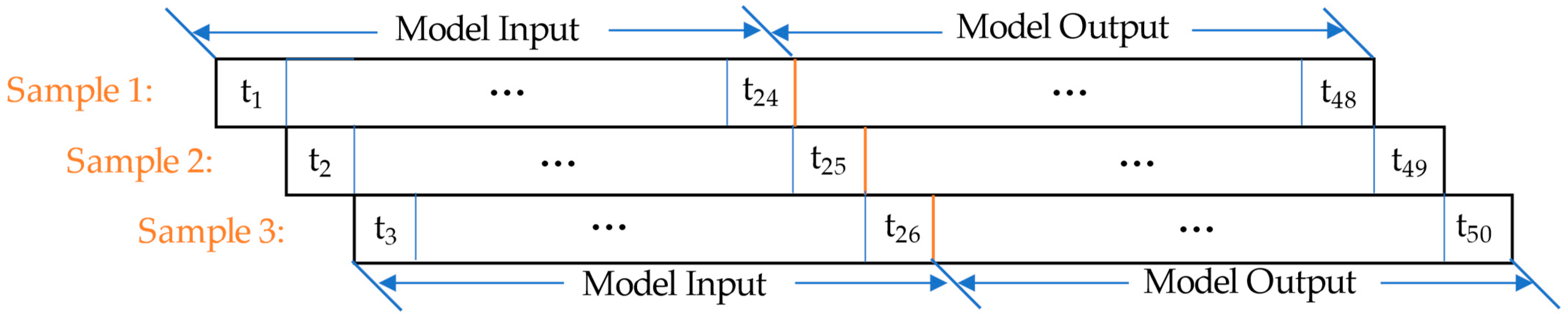
3.2. The Dual-Channel Seq2Seq Prediction Model
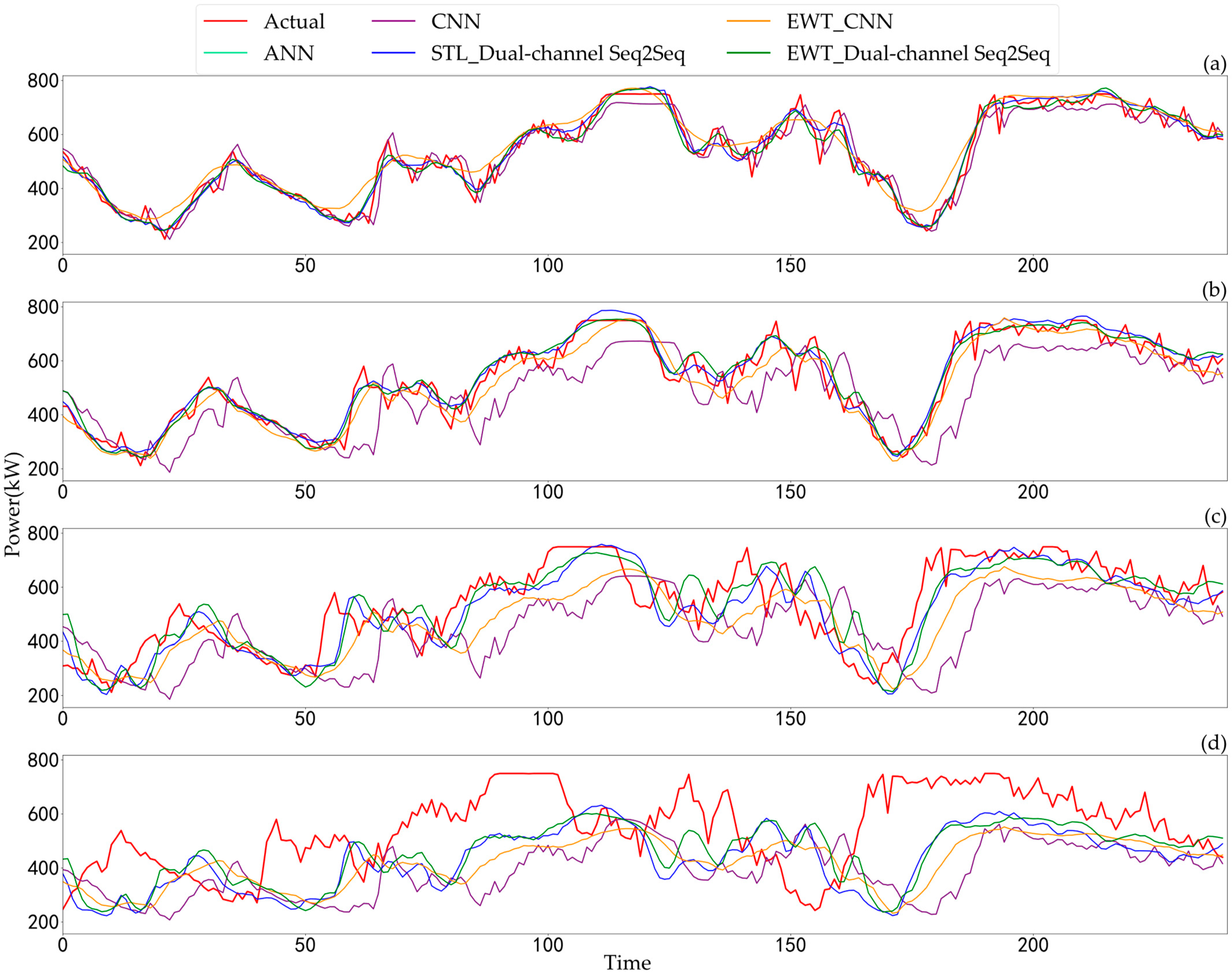
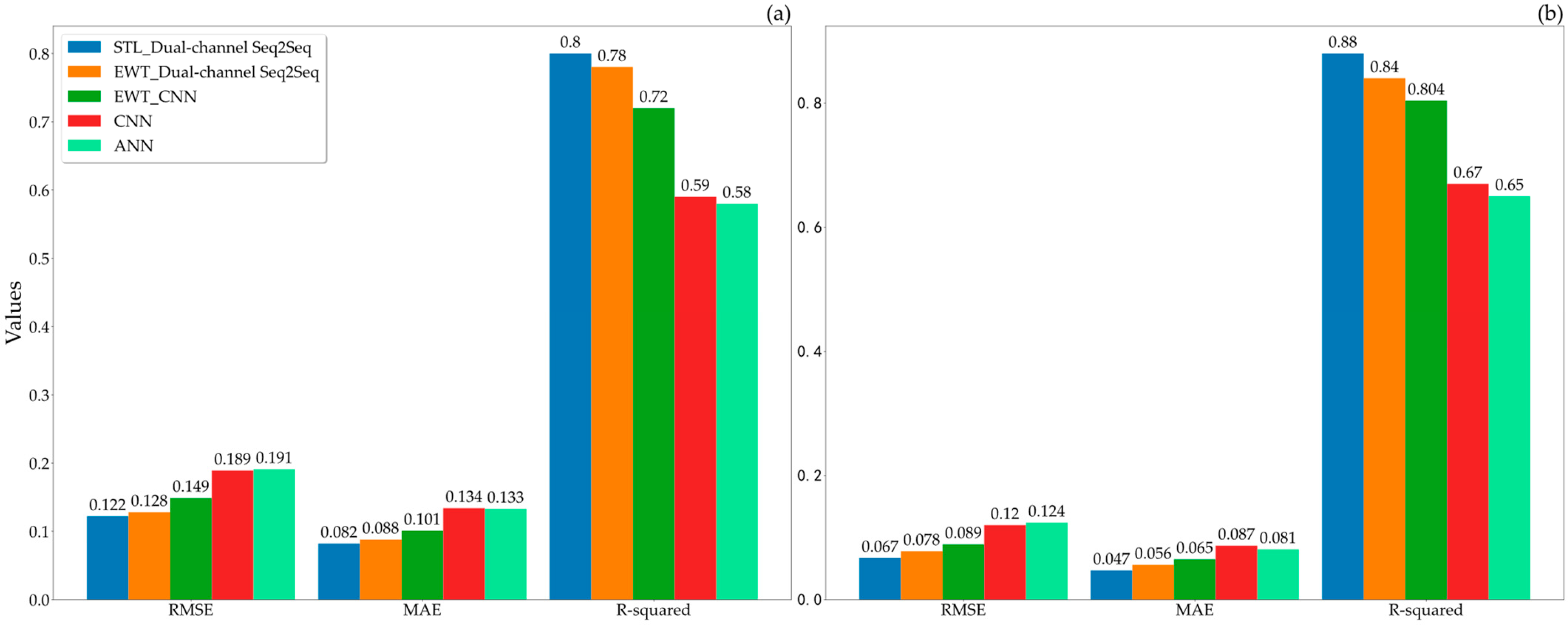
4. Results and Discussion
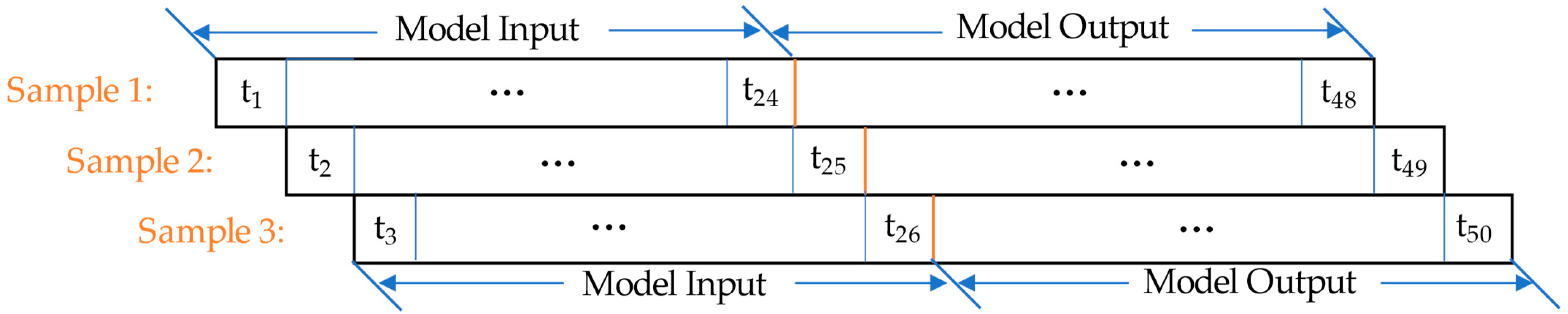
4.1. Data Preparation
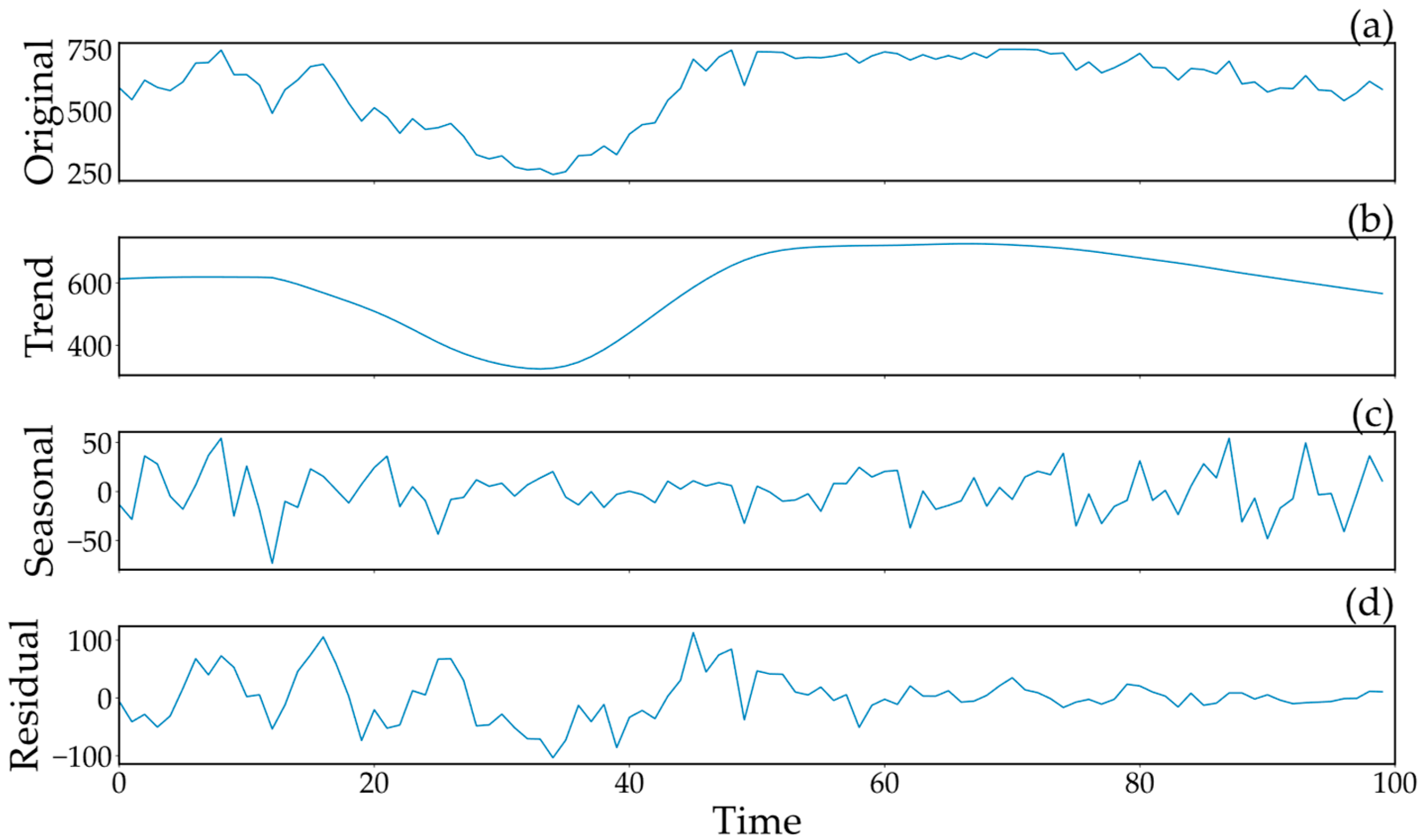
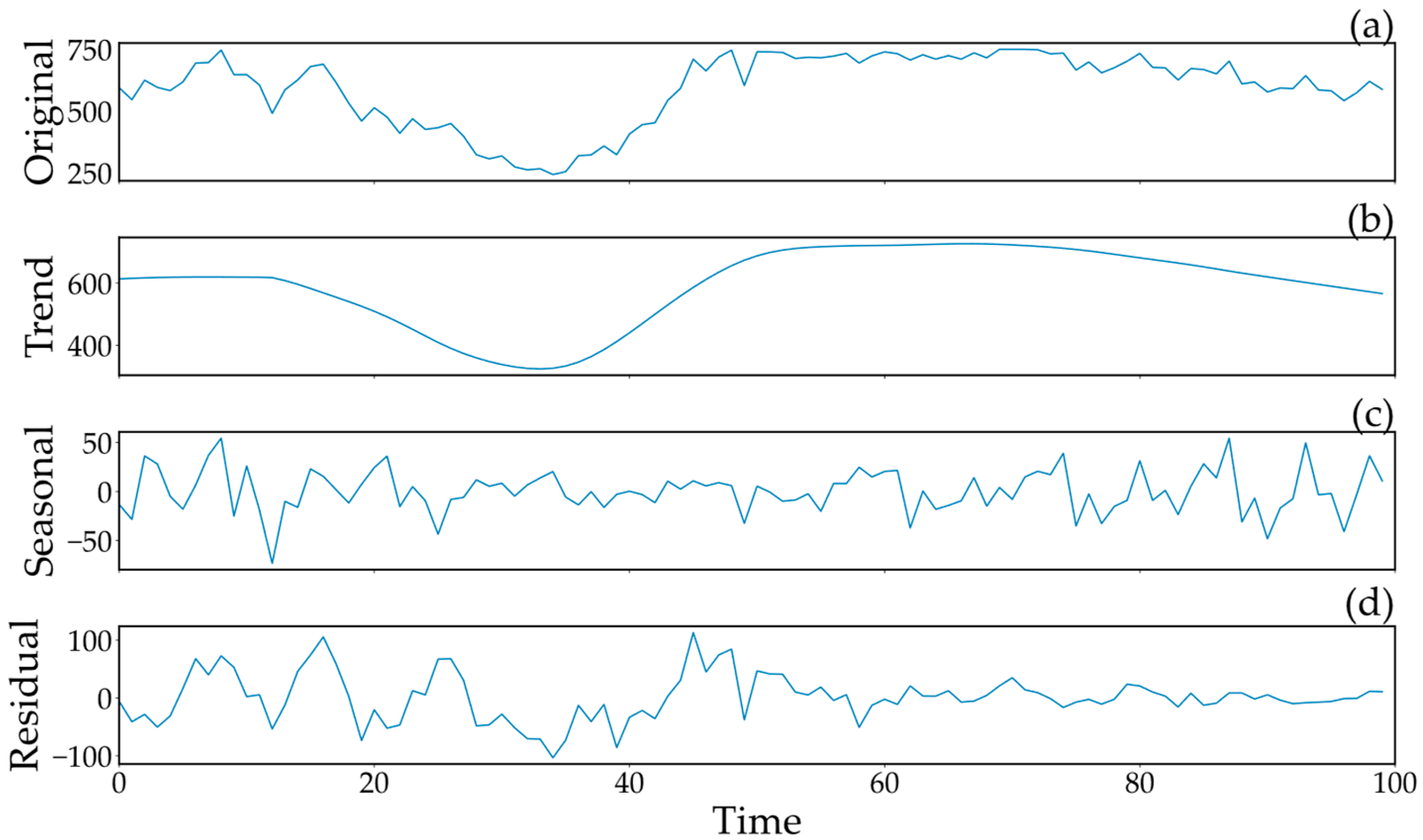
4.2. STL Results
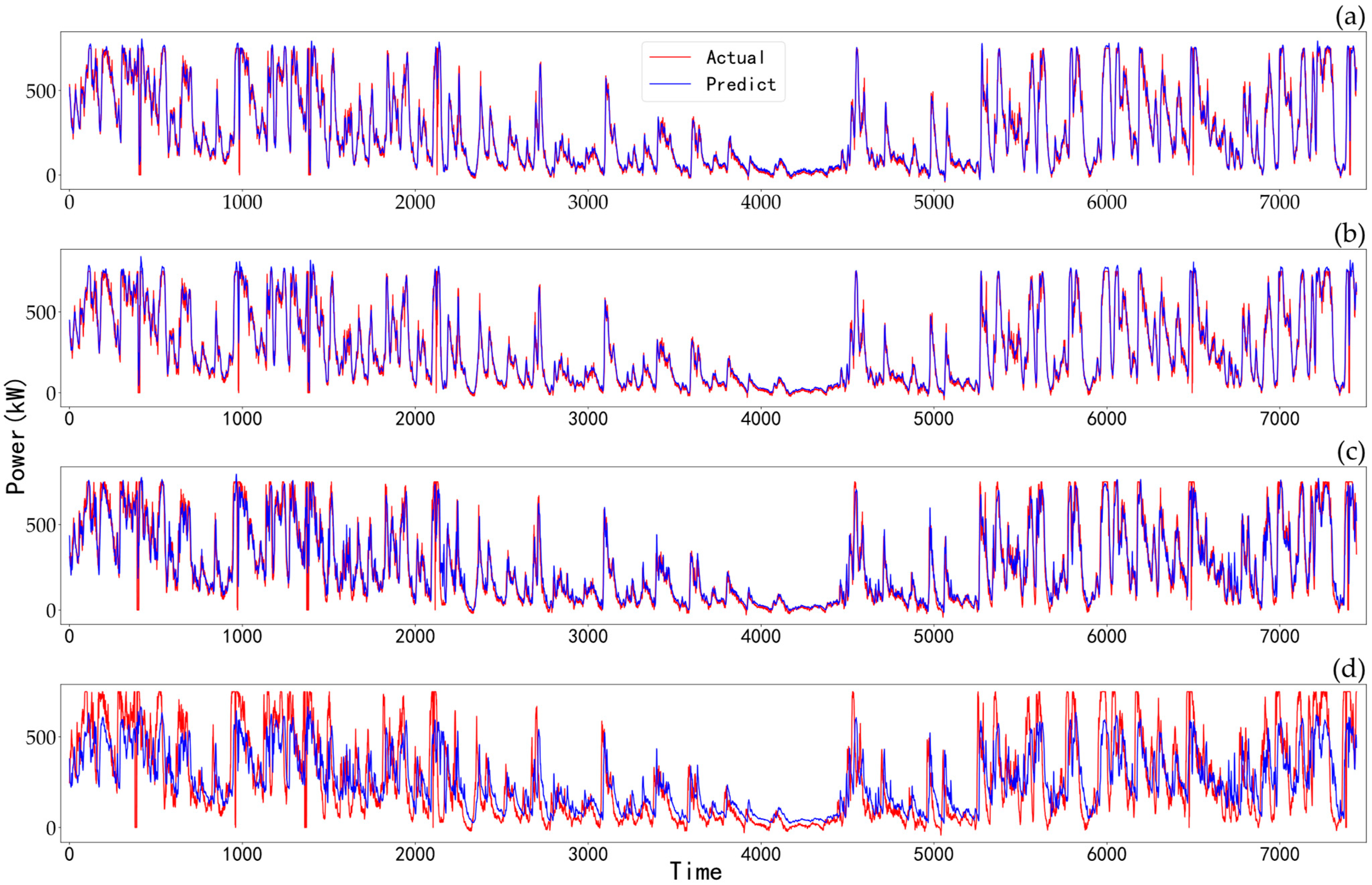
4.3. Dual-Channel Seq2Seq Prediction
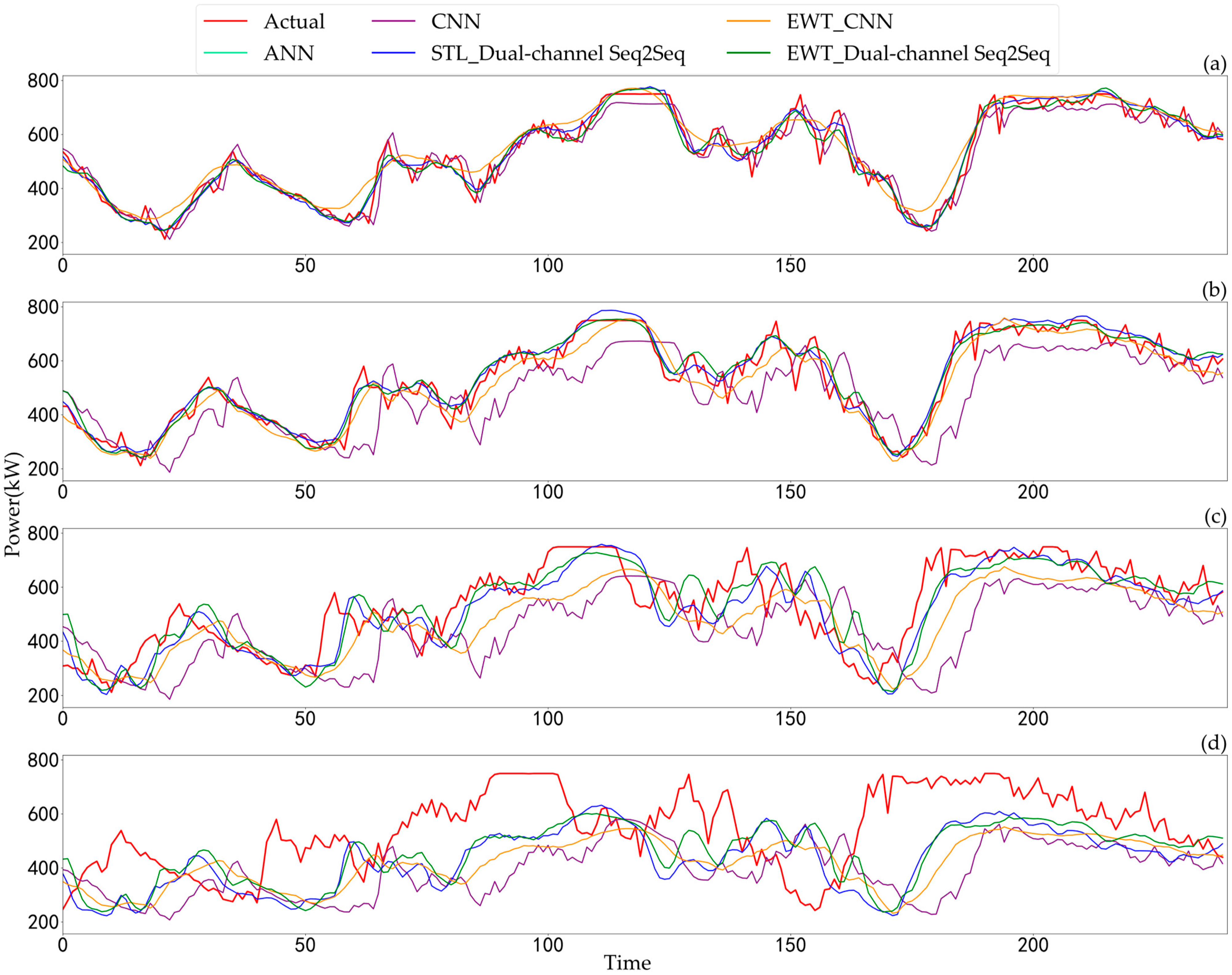
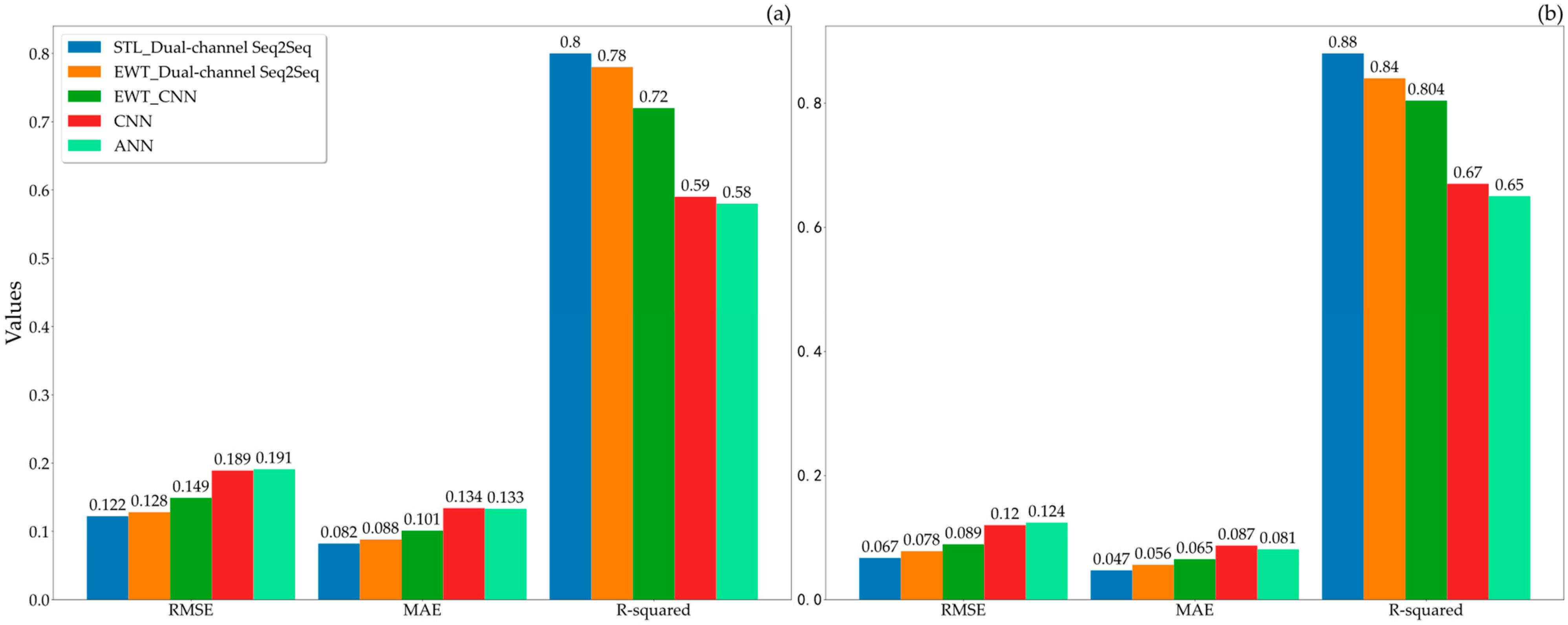
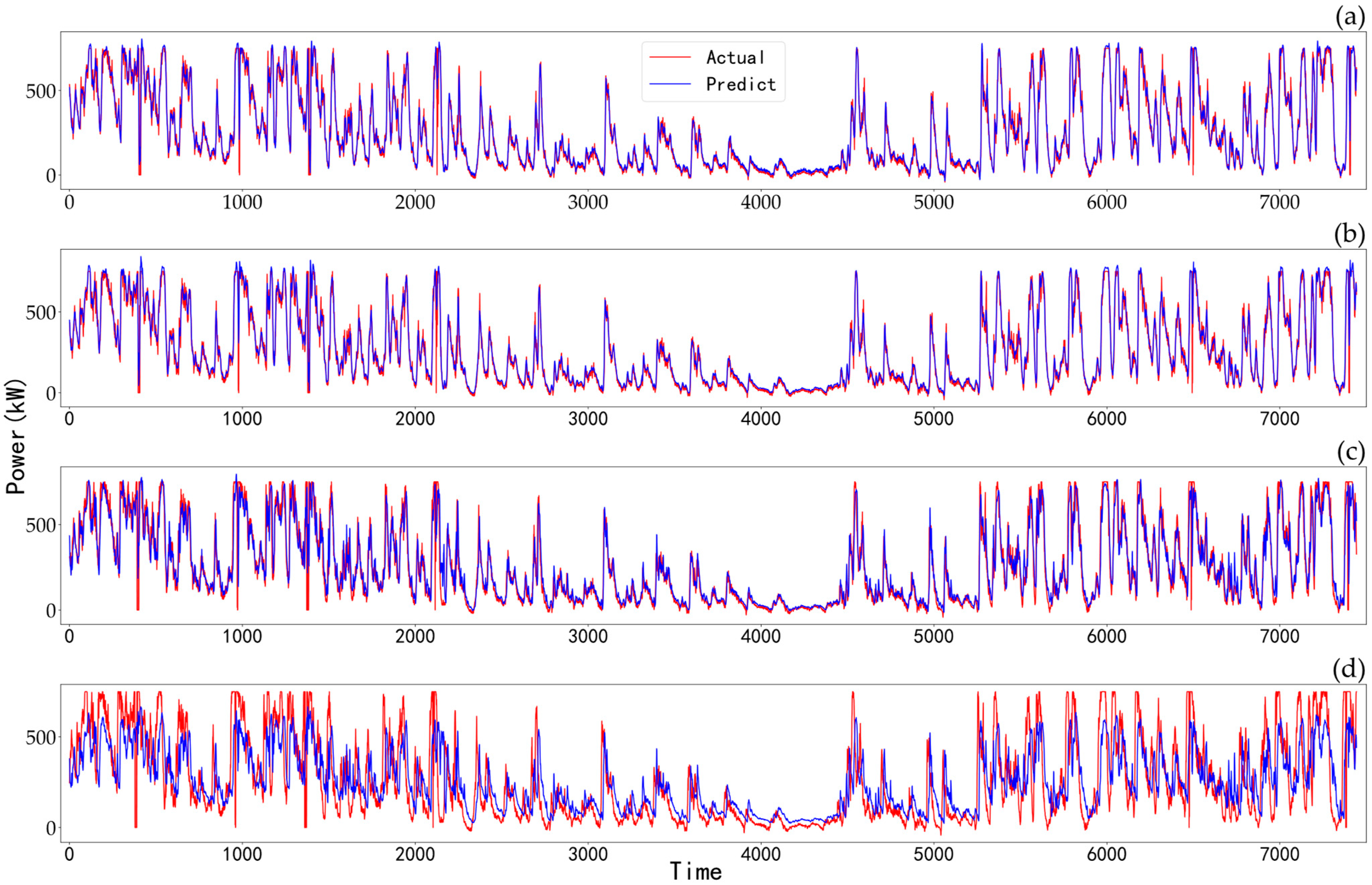
4.4. Comparison of Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Time Step | STL_Dual-Channel Seq2Seq | EWT_Dual-Channel Seq2Seq | EWT_CNN | CNN | ANN | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RMSE (%) | MAE (%) | R2 | RMSE (%) | MAE (%) | R2 | RMSE (%) | MAE (%) | R2 | RMSE (%) | MAE (%) | R2 | RMSE (%) | MAE (%) | R2 | |
| 1 | 2.82 | 1.91 | 0.98 | 2.90 | 2.12 | 0.98 | 6.82 | 2.35 | 0.97 | 3.96 | 2.77 | 0.97 | 4.41 | 4.05 | 0.96 |
| 2 | 2.84 | 2.01 | 0.98 | 3.01 | 2.31 | 0.98 | 6.61 | 2.55 | 0.97 | 4.97 | 3.49 | 0.95 | 5.35 | 5.00 | 0.94 |
| 3 | 2.79 | 1.97 | 0.98 | 3.06 | 2.35 | 0.98 | 6.16 | 2.69 | 0.97 | 6.12 | 4.31 | 0.92 | 6.44 | 6.02 | 0.91 |
| 4 | 2.78 | 1.97 | 0.98 | 3.14 | 2.41 | 0.98 | 5.70 | 2.78 | 0.97 | 7.17 | 5.00 | 0.89 | 7.53 | 6.98 | 0.88 |
| 5 | 2.80 | 1.98 | 0.98 | 3.17 | 2.42 | 0.98 | 5.50 | 2.89 | 0.97 | 8.12 | 5.62 | 0.86 | 8.52 | 8.61 | 0.85 |
| 6 | 2.84 | 2.00 | 0.98 | 3.07 | 2.35 | 0.98 | 6.11 | 3.12 | 0.96 | 8.95 | 6.17 | 0.83 | 9.37 | 9.33 | 0.82 |
| 7 | 2.92 | 2.04 | 0.98 | 2.97 | 2.28 | 0.98 | 7.42 | 3.53 | 0.95 | 9.70 | 6.69 | 0.81 | 10.12 | 10.00 | 0.79 |
| 8 | 3.17 | 2.21 | 0.98 | 3.33 | 2.53 | 0.98 | 9.07 | 4.06 | 0.93 | 10.37 | 7.21 | 0.78 | 10.78 | 10.88 | 0.76 |
| 9 | 3.41 | 2.41 | 0.98 | 4.24 | 3.16 | 0.96 | 10.78 | 4.65 | 0.91 | 10.96 | 7.67 | 0.75 | 11.35 | 11.52 | 0.73 |
| 10 | 3.68 | 2.61 | 0.97 | 5.31 | 3.86 | 0.94 | 12.36 | 5.24 | 0.89 | 11.51 | 8.10 | 0.73 | 11.88 | 12.70 | 0.71 |
| 11 | 4.41 | 3.12 | 0.96 | 6.33 | 4.53 | 0.92 | 13.79 | 5.80 | 0.86 | 12.03 | 8.53 | 0.70 | 12.38 | 13.78 | 0.68 |
| 12 | 5.22 | 3.72 | 0.94 | 7.30 | 5.16 | 0.89 | 15.11 | 6.32 | 0.83 | 12.51 | 8.95 | 0.68 | 12.86 | 14.18 | 0.66 |
| 13 | 6.09 | 4.38 | 0.92 | 8.18 | 5.78 | 0.86 | 16.33 | 6.83 | 0.81 | 12.96 | 9.36 | 0.65 | 13.31 | 14.43 | 0.63 |
| 14 | 6.82 | 4.95 | 0.90 | 8.98 | 6.33 | 0.83 | 17.44 | 7.30 | 0.78 | 13.42 | 9.74 | 0.63 | 13.77 | 15.11 | 0.61 |
| 15 | 7.57 | 5.52 | 0.88 | 9.71 | 6.84 | 0.81 | 18.45 | 7.76 | 0.76 | 13.85 | 10.09 | 0.60 | 14.20 | 15.62 | 0.58 |
| 16 | 8.39 | 6.07 | 0.85 | 10.39 | 7.33 | 0.78 | 19.37 | 8.18 | 0.73 | 14.27 | 10.43 | 0.58 | 14.62 | 16.12 | 0.56 |
| 17 | 9.27 | 6.64 | 0.82 | 11.04 | 7.81 | 0.75 | 20.22 | 8.60 | 0.71 | 14.67 | 10.77 | 0.56 | 15.04 | 16.51 | 0.53 |
| 18 | 10.14 | 7.19 | 0.79 | 11.63 | 8.27 | 0.72 | 20.99 | 9.00 | 0.68 | 15.05 | 11.10 | 0.53 | 15.43 | 17.06 | 0.51 |
| 19 | 10.89 | 7.64 | 0.76 | 12.19 | 8.70 | 0.69 | 21.68 | 9.36 | 0.66 | 15.42 | 11.40 | 0.51 | 15.80 | 17.37 | 0.48 |
| 20 | 11.48 | 7.99 | 0.73 | 12.66 | 9.08 | 0.67 | 22.30 | 9.70 | 0.64 | 15.76 | 11.69 | 0.49 | 16.16 | 18.23 | 0.46 |
| 21 | 11.89 | 8.24 | 0.71 | 13.07 | 9.42 | 0.65 | 22.87 | 10.04 | 0.62 | 16.09 | 11.96 | 0.47 | 16.49 | 18.23 | 0.44 |
| 22 | 12.19 | 8.45 | 0.69 | 21.90 | 9.74 | 0.63 | 23.39 | 10.36 | 0.60 | 16.39 | 12.22 | 0.45 | 16.81 | 3.14 | 0.42 |
| 23 | 12.54 | 8.74 | 0.68 | 22.45 | 10.04 | 0.61 | 23.86 | 10.70 | 0.57 | 16.68 | 12.46 | 0.43 | 17.11 | 3.63 | 0.40 |
| 24 | 12.87 | 9.05 | 0.66 | 22.95 | 10.34 | 0.59 | 24.29 | 11.03 | 0.55 | 16.94 | 12.69 | 0.41 | 17.38 | 4.26 | 0.38 |
References
- Shadman, M.; Roldan-Carvajal, M.; Pierart, F.G.; Haim, P.A.; Alonso, R.; Silva, C.; Osorio, A.F.; Almonacid, N.; Carreras, G.; Maali Amiri, M.; et al. A Review of Offshore Renewable Energy in South America: Current Status and Future Perspectives. Sustainability 2023, 15, 1740. [Google Scholar] [CrossRef]
- Yan, J.; Mei, N.; Zhang, D.; Zhong, Y.; Wang, C. Review of Wave Power System Development and Research on Triboelectric Nano Power Systems. Front. Energy Res. 2022, 10, 966567. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhao, Y.; Sun, W.; Li, J. Ocean Wave Energy Converters: Technical Principle, Device Realization, and Performance Evaluation. Renew. Sustain. Energy Rev. 2021, 141, 110764. [Google Scholar] [CrossRef]
- Clemente, D.; Rosa-Santos, P.; Taveira-Pinto, F. On the Potential Synergies and Applications of Wave Energy Converters: A Review. Renew. Sustain. Energy Rev. 2021, 135, 110162. [Google Scholar] [CrossRef]
- Gao, Q.; Khan, S.S.; Sergiienko, N.; Ertugrul, N.; Hemer, M.; Negnevitsky, M.; Ding, B. Assessment of Wind and Wave Power Characteristic and Potential for Hybrid Exploration in Australia. Renew. Sustain. Energy Rev. 2022, 168, 112747. [Google Scholar] [CrossRef]
- Sun, R.; Cobb, A.; Villas Bôas, A.B.; Langodan, S.; Subramanian, A.C.; Mazloff, M.R.; Cornuelle, B.D.; Miller, A.J.; Pathak, R.; Hoteit, I. Waves in SKRIPS: WAVEWATCH III Coupling Implementation and a Case Study of Tropical Cyclone Mekunu. Geosci. Model Dev. 2023, 16, 3435–3458. [Google Scholar] [CrossRef]
- Amarouche, K.; Akpınar, A.; Rybalko, A.; Myslenkov, S. Assessment of SWAN and WAVEWATCH-III Models Regarding the Directional Wave Spectra Estimates Based on Eastern Black Sea Measurements. Ocean. Eng. 2023, 272, 113944. [Google Scholar] [CrossRef]
- Wu, F.; Jing, R.; Zhang, X.-P.; Wang, F.; Bao, Y. A Combined Method of Improved Grey BP Neural Network and MEEMD-ARIMA for Day-Ahead Wave Energy Forecast. IEEE Trans. Sustain. Energy 2021, 12, 2404–2412. [Google Scholar] [CrossRef]
- Guillou, N. Estimating Wave Energy Flux from Significant Wave Height and Peak Period. Renew. Energy 2020, 155, 1383–1393. [Google Scholar] [CrossRef]
- Ni, C. Data-driven Models for Short-term Ocean Wave Power Forecasting. IET Renew. Power Gen 2021, 15, 2228–2236. [Google Scholar] [CrossRef]
- Ni, C.; Ma, X. Prediction of Wave Power Generation Using a Convolutional Neural Network with Multiple Inputs. Energies 2018, 11, 2097. [Google Scholar] [CrossRef]
- Lu, H.; Xi, D.; Ma, X.; Zheng, S.; Huang, C.; Wei, N. Hybrid Machine Learning Models for Predicting Short-Term Wave Energy Flux. Ocean. Eng. 2022, 264, 112258. [Google Scholar] [CrossRef]
- Gómez-Orellana, A.M.; Guijo-Rubio, D.; Gutiérrez, P.A.; Hervás-Martínez, C. Simultaneous Short-Term Significant Wave Height and Energy Flux Prediction Using Zonal Multi-Task Evolutionary Artificial Neural Networks. Renew. Energy 2022, 184, 975–989. [Google Scholar] [CrossRef]
- Ni, C.; Peng, W. An Integrated Approach Using Empirical Wavelet Transform and a Convolutional Neural Network for Wave Power Prediction. Ocean. Eng. 2023, 276, 114231. [Google Scholar] [CrossRef]
- Rasool, S.; Muttaqi, K.M.; Sutanto, D.; Hemer, M. Quantifying the Reduction in Power Variability of Co-Located Offshore Wind-Wave Farms. Renew. Energy 2022, 185, 1018–1033. [Google Scholar] [CrossRef]
- Babarit, A.; Hals, J.; Muliawan, M.J.; Kurniawan, A.; Moan, T.; Krokstad, J. Numerical Benchmarking Study of a Selection of Wave Energy Converters. Renew. Energy 2012, 41, 44–63. [Google Scholar] [CrossRef]
- Cleveland, R.B.; Cleveland, W.S. STL: A Seasonal-Trend Decomposition Procedure Based on Loess. J. Off. Stat. 1990, 6, 3–33. [Google Scholar]
- Li, W.; Jiang, X. Prediction of Air Pollutant Concentrations Based on TCN-BiLSTM-DMAttention with STL Decomposition. Sci. Rep. 2023, 13, 4665. [Google Scholar] [CrossRef]
- Stefenon, S.F.; Seman, L.O.; Mariani, V.C.; Coelho, L.D.S. Aggregating Prophet and Seasonal Trend Decomposition for Time Series Forecasting of Italian Electricity Spot Prices. Energies 2023, 16, 1371. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Wei, W.; Li, X.; Zhang, B.; Li, L.; Damaševičius, R.; Scherer, R. LSTM-SN: Complex Text Classifying with LSTM Fusion Social Network. J. Supercomput. 2023, 79, 9558–9583. [Google Scholar] [CrossRef]
- Chen, H.; Lu, T.; Huang, J.; He, X.; Yu, K.; Sun, X.; Ma, X.; Huang, Z. An Improved VMD-LSTM Model for Time-Varying GNSS Time Series Prediction with Temporally Correlated Noise. Remote Sens. 2023, 15, 3694. [Google Scholar] [CrossRef]
- Harie, Y.; Gautam, B.P.; Wasaki, K. Computer Vision Techniques for Growth Prediction: A Prisma-Based Systematic Literature Review. Appl. Sci. 2023, 13, 5335. [Google Scholar] [CrossRef]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to Sequence Learning with Neural Networks. Adv. Neural Inf. Process. Syst. 2014, 27, 3104–3112. [Google Scholar]
- Dong, H.; Zhu, J.; Li, S.; Wu, W.; Zhu, H.; Fan, J. Short-Term Residential Household Reactive Power Forecasting Considering Active Power Demand via Deep Transformer Sequence-to-Sequence Networks. Appl. Energy 2023, 329, 120281. [Google Scholar] [CrossRef]
- Yang, M.; Wang, D.; Zhang, W. A Short-Term Wind Power Prediction Method Based on Dynamic and Static Feature Fusion Mining. Energy 2023, 280, 128226. [Google Scholar] [CrossRef]
- Qian, C.; Xu, B.; Xia, Q.; Ren, Y.; Sun, B.; Wang, Z. SOH Prediction for Lithium-Ion Batteries by Using Historical State and Future Load Information with an AM-Seq2seq Model. Appl. Energy 2023, 336, 120793. [Google Scholar] [CrossRef]
- Shih, S.-Y.; Sun, F.-K.; Lee, H. Temporal Pattern Attention for Multivariate Time Series Forecasting. Mach. Learn. 2019, 108, 1421–1441. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Wang, X.; Li, Y.; Xu, Y.; Liu, X.; Zheng, T.; Zheng, B. Remaining Useful Life Prediction for Aero-Engines Using a Time-Enhanced Multi-Head Self-Attention Model. Aerospace 2023, 10, 80. [Google Scholar] [CrossRef]
- Phan, H.M.; Ye, Q.; Reniers, A.J.H.M.; Stive, M.J.F. Tidal Wave Propagation along The Mekong Deltaic Coast. Estuar. Coast. Shelf Sci. 2019, 220, 73–98. [Google Scholar] [CrossRef]
- Ray, R.D. First Global Observations of Third-Degree Ocean Tides. Sci. Adv. 2020, 6, eabd4744. [Google Scholar] [CrossRef] [PubMed]
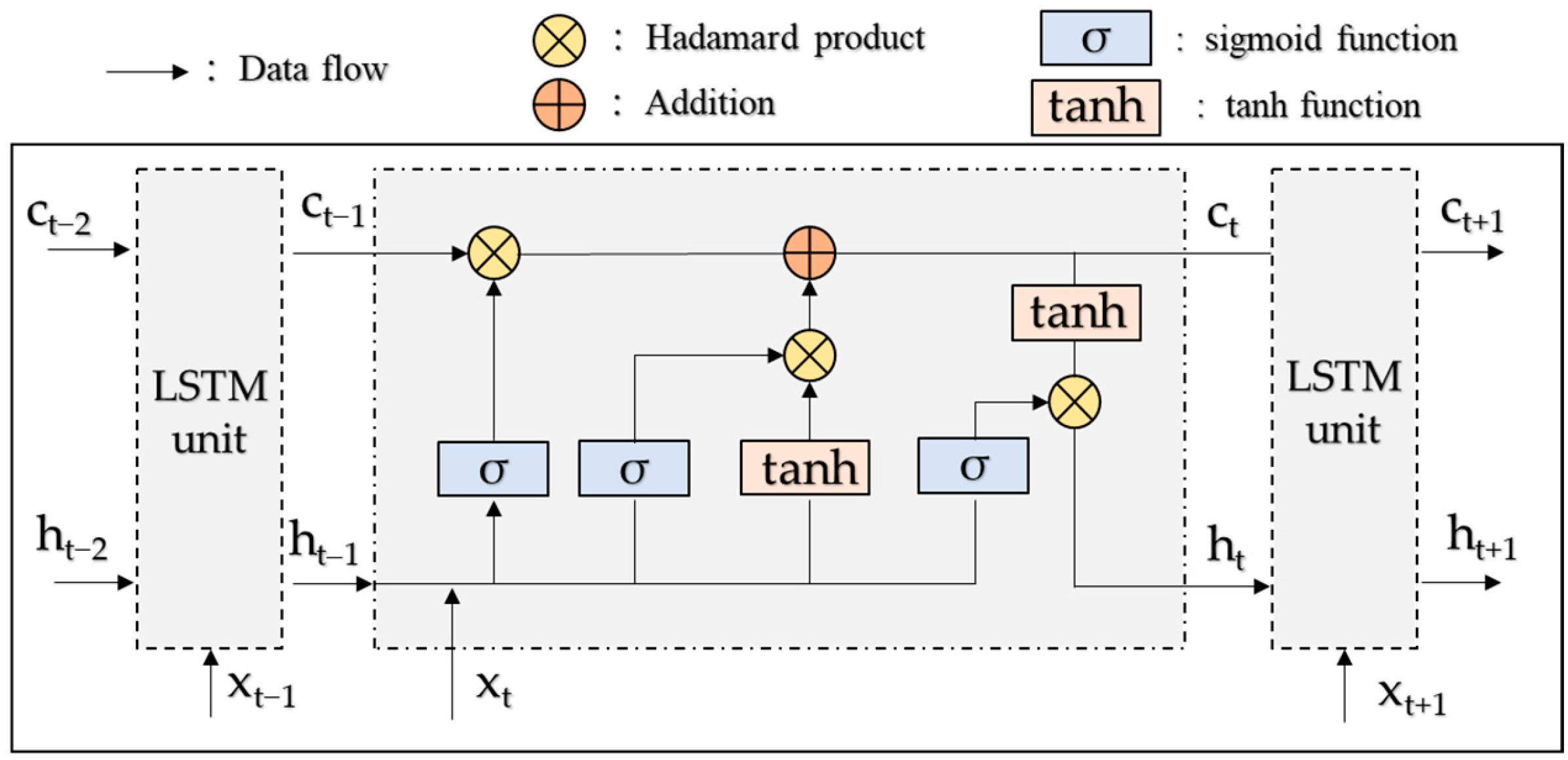

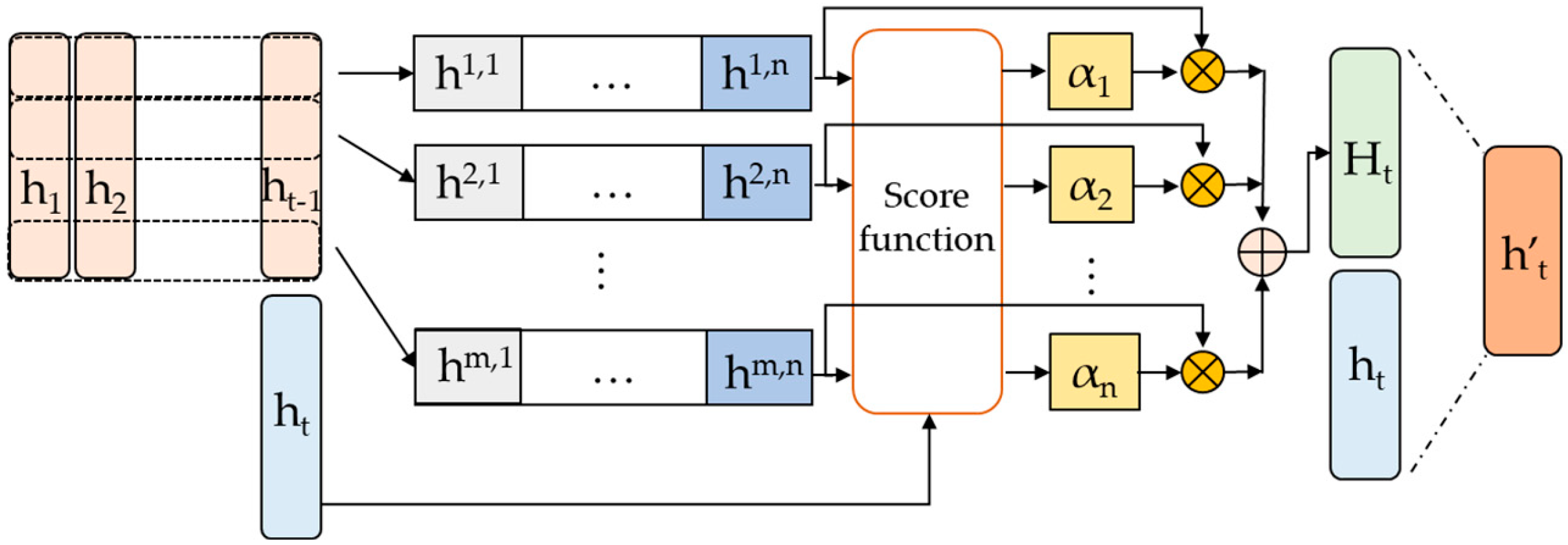
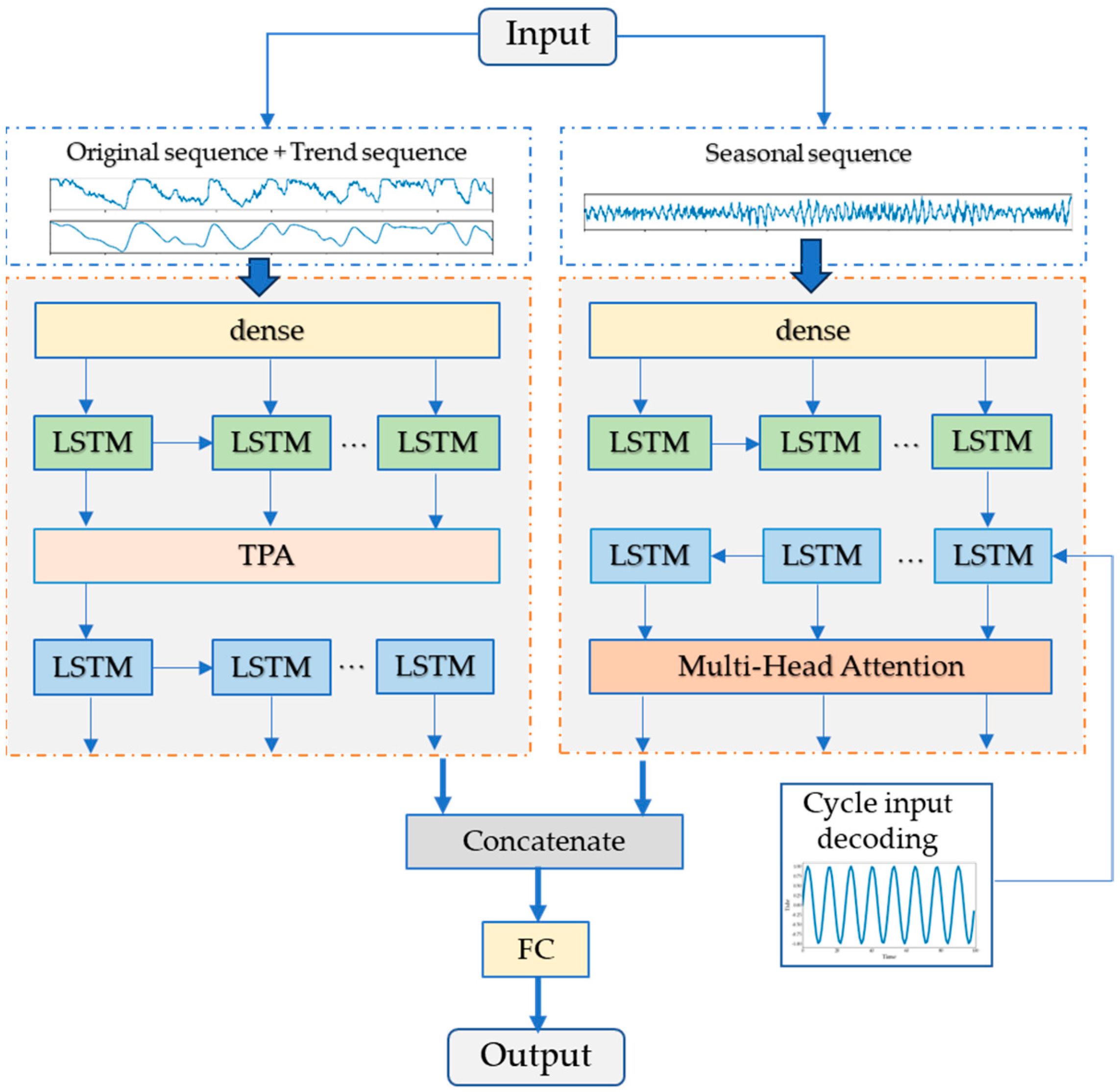
| LSTM Structure | Expression Formula |
|---|---|
| Input gate | |
| Forget gate | |
| Cell gate | |
| Output gate | |
| Cell state | |
| Hidden state |
| Time Step | STL_Dual-Channel Seq2Seq | EWT_Dual-Channel Seq2Seq | EWT_CNN | CNN | ANN | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RMSE (%) | MAE (%) | R2 | RMSE (%) | MAE (%) | R2 | RMSE (%) | MAE (%) | R2 | RMSE (%) | MAE (%) | R2 | RMSE (%) | MAE (%) | R2 | |
| 1 | 4.96 | 3.01 | 0.97 | 5.10 | 3.03 | 0.97 | 6.82 | 4.12 | 0.95 | 6.75 | 4.05 | 0.95 | 6.79 | 4.05 | 0.95 |
| 2 | 4.88 | 2.99 | 0.97 | 5.15 | 3.16 | 0.97 | 6.61 | 3.91 | 0.95 | 8.29 | 5.03 | 0.93 | 8.31 | 5.00 | 0.92 |
| 3 | 4.86 | 3.05 | 0.98 | 5.05 | 3.12 | 0.97 | 6.16 | 3.75 | 0.96 | 10.03 | 6.22 | 0.89 | 10.06 | 6.02 | 0.88 |
| 4 | 5.00 | 3.10 | 0.97 | 5.08 | 3.15 | 0.97 | 5.70 | 3.54 | 0.97 | 11.63 | 7.38 | 0.86 | 11.68 | 6.98 | 0.86 |
| 5 | 5.05 | 3.19 | 0.97 | 5.11 | 3.19 | 0.97 | 5.50 | 3.37 | 0.97 | 13.15 | 8.51 | 0.82 | 13.25 | 8.61 | 0.81 |
| 6 | 5.05 | 3.19 | 0.97 | 5.10 | 3.21 | 0.97 | 6.11 | 3.62 | 0.96 | 14.47 | 9.53 | 0.78 | 14.47 | 9.33 | 0.77 |
| 7 | 4.88 | 3.01 | 0.97 | 5.22 | 3.17 | 0.97 | 7.42 | 4.43 | 0.94 | 15.65 | 10.46 | 0.74 | 15.72 | 10.00 | 0.73 |
| 8 | 5.25 | 3.12 | 0.97 | 6.00 | 3.60 | 0.96 | 9.07 | 5.49 | 0.91 | 16.68 | 11.29 | 0.71 | 16.69 | 10.88 | 0.70 |
| 9 | 6.63 | 3.94 | 0.95 | 7.49 | 4.52 | 0.94 | 10.78 | 6.64 | 0.88 | 17.61 | 12.02 | 0.67 | 17.59 | 11.52 | 0.67 |
| 10 | 8.26 | 5.00 | 0.93 | 9.12 | 5.61 | 0.91 | 12.36 | 7.74 | 0.84 | 18.49 | 12.70 | 0.64 | 18.45 | 12.70 | 0.63 |
| 11 | 9.80 | 6.06 | 0.90 | 10.63 | 6.67 | 0.88 | 13.79 | 8.78 | 0.80 | 19.30 | 13.36 | 0.61 | 19.37 | 13.78 | 0.59 |
| 12 | 11.29 | 7.10 | 0.87 | 12.03 | 7.74 | 0.85 | 15.11 | 9.77 | 0.76 | 20.06 | 14.03 | 0.58 | 20.05 | 14.18 | 0.57 |
| 13 | 12.66 | 8.12 | 0.83 | 13.32 | 8.76 | 0.81 | 16.33 | 10.73 | 0.72 | 20.76 | 14.60 | 0.55 | 20.80 | 14.43 | 0.54 |
| 14 | 13.88 | 9.07 | 0.80 | 14.49 | 9.73 | 0.78 | 17.44 | 11.63 | 0.68 | 21.44 | 15.19 | 0.52 | 21.52 | 15.11 | 0.51 |
| 15 | 15.00 | 9.97 | 0.76 | 15.60 | 10.64 | 0.74 | 18.45 | 12.48 | 0.64 | 22.07 | 15.77 | 0.49 | 22.18 | 15.62 | 0.48 |
| 16 | 16.03 | 10.80 | 0.73 | 16.68 | 11.54 | 0.71 | 19.37 | 13.27 | 0.61 | 22.66 | 16.32 | 0.46 | 22.54 | 16.12 | 0.45 |
| 17 | 17.01 | 11.59 | 0.70 | 17.77 | 12.43 | 0.67 | 20.22 | 14.00 | 0.57 | 23.17 | 16.81 | 0.44 | 23.15 | 16.51 | 0.44 |
| 18 | 17.98 | 12.39 | 0.66 | 18.80 | 13.28 | 0.63 | 20.99 | 14.67 | 0.54 | 23.62 | 17.26 | 0.41 | 23.73 | 17.06 | 0.41 |
| 19 | 18.95 | 13.18 | 0.62 | 19.75 | 14.09 | 0.59 | 21.68 | 15.31 | 0.51 | 24.03 | 17.67 | 0.39 | 24.33 | 17.37 | 0.39 |
| 20 | 19.81 | 13.89 | 0.59 | 20.58 | 14.84 | 0.56 | 22.30 | 15.90 | 0.48 | 24.39 | 18.03 | 0.38 | 24.53 | 18.23 | 0.36 |
| 21 | 20.52 | 14.49 | 0.56 | 21.28 | 15.50 | 0.52 | 22.87 | 16.45 | 0.45 | 24.69 | 18.33 | 0.36 | 24.92 | 18.23 | 0.35 |
| 22 | 21.14 | 15.05 | 0.53 | 21.90 | 16.13 | 0.50 | 23.39 | 16.96 | 0.43 | 24.95 | 18.61 | 0.35 | 25.36 | 18.21 | 0.33 |
| 23 | 21.70 | 15.57 | 0.51 | 22.45 | 16.72 | 0.47 | 23.86 | 17.43 | 0.40 | 25.18 | 18.83 | 0.34 | 25.91 | 19.13 | 0.32 |
| 24 | 22.22 | 16.09 | 0.48 | 22.95 | 17.29 | 0.45 | 24.29 | 17.86 | 0.38 | 25.42 | 19.07 | 0.32 | 26.22 | 19.24 | 0.30 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Z.; Wang, J.; Tao, T.; Zhang, Z.; Chen, S.; Yi, Y.; Han, S.; Liu, Y. Wave Power Prediction Based on Seasonal and Trend Decomposition Using Locally Weighted Scatterplot Smoothing and Dual-Channel Seq2Seq Model. Energies 2023, 16, 7515. https://doi.org/10.3390/en16227515
Liu Z, Wang J, Tao T, Zhang Z, Chen S, Yi Y, Han S, Liu Y. Wave Power Prediction Based on Seasonal and Trend Decomposition Using Locally Weighted Scatterplot Smoothing and Dual-Channel Seq2Seq Model. Energies. 2023; 16(22):7515. https://doi.org/10.3390/en16227515
Chicago/Turabian StyleLiu, Zhigang, Jin Wang, Tao Tao, Ziyun Zhang, Siyi Chen, Yang Yi, Shuang Han, and Yongqian Liu. 2023. "Wave Power Prediction Based on Seasonal and Trend Decomposition Using Locally Weighted Scatterplot Smoothing and Dual-Channel Seq2Seq Model" Energies 16, no. 22: 7515. https://doi.org/10.3390/en16227515
APA StyleLiu, Z., Wang, J., Tao, T., Zhang, Z., Chen, S., Yi, Y., Han, S., & Liu, Y. (2023). Wave Power Prediction Based on Seasonal and Trend Decomposition Using Locally Weighted Scatterplot Smoothing and Dual-Channel Seq2Seq Model. Energies, 16(22), 7515. https://doi.org/10.3390/en16227515