1. Introduction
MCDA (Multi-Criteria Decision Analysis) methods are a useful and expanding tool to assist in the decision-making process in various disciplines [
1], such as health care [
2], environmental sciences [
3], energy and environmental modeling [
4], natural resource management [
5], or finances [
6]. In MCDA problems, a given set of alternatives is present and subject to evaluation. These alternatives are described by multiple criteria that often conflict with each other [
7]. The requirement for sustainable solutions, particularly in the realm of electric vehicles, is increasing, making it necessary to have reliable and adjustable decision-making tools such as TOPSIS with interval numbers.
An example of such a problem is the evaluation of electric vehicles (EVs). The topic of EVs is important and relevant as it relates to environmental protection and sustainability [
8,
9,
10]. EVs are mentioned as a technology that offers the opportunity to reduce CO
2 emissions and noise [
11]. In the literature, there are examples of applications of MCDA methods to EV evaluation and selection problems [
10,
12,
13]. Although studies also occur for other types of vehicles, such as electric cargo bikes [
14] and aircraft [
15], electric cars remain the most popular subject. Frequently mentioned metrics when evaluating EVs are driving range, price, and charging speed [
9,
16,
17]. Battery-related concerns also arise, which is an important factor not only from the consumer’s point of view [
18], but also an influential variable from a development point of view [
19,
20]. Electric vehicles can also be examined from the angle of energy consumption. However, research suggests that this characteristic is influenced by various factors and there are ways to optimize it [
21,
22,
23]. Some of the EV features can easily be used as criteria for the application of MCDA methods [
24]. Quantitative criteria often discussed in relation to EVs, in addition to those mentioned, include maximum power [
17,
25], cargo volume [
26], top speed [
13,
17,
27], and acceleration [
17,
28]. There are also qualitative attributes, such as reliability [
9], safety [
29], comfort [
20], or prestige [
29]. The use of these, however, might bring uncertainty into the problem as they often cannot be straightforwardly expressed in numerical units.
One of the most popular MCDA methods is TOPSIS (Technique for Order Preference by Similarity to Ideal Solution) proposed in 1981 by Hwang and Yoon [
30]. At the basis of the TOPSIS method is the identification of what are called ideal solutions; namely, a positive ideal solution (PIS) and a negative ideal solution (NIS). The alternatives are evaluated based on their distance from the aforementioned ideal solutions. Essentially, they obtain a better score the shorter their distance from PIS and the greater their distance from NIS. The TOPSIS method has many advantages that contribute to its popularity. Among the most apparent are its simplicity and efficiency [
31], ability to be adapted to deal with both quantitative and qualitative data [
32], and the fact that no advanced tools or knowledge are required to implement it [
33].
The popularity of the TOPSIS method is reflected in its large presence in the literature. Behzadian et al. [
34] created a well-known literature review in which they described and categorized 266 papers from 2000 to 2012 that employ the TOPSIS method. TOPSIS is also commonly used in the present day [
35]. Areas of its application include sustainability [
36,
37,
38,
39], finances [
40,
41,
42], energy planning and management [
43,
44,
45], and transportation [
46,
47,
48]. Among the applications listed, not only the original TOPSIS method is used, but also combinations with other methodologies and different extensions adapted to the addressed issue.
An important advantage of the TOPSIS method is its susceptibility to creating extensions. Many extensions of the TOPSIS method are based on fuzzy numbers [
49] or interval numbers [
50]. However, new types of uncertainty data, such as basic uncertain information and others, are still being developed [
51]. Such approaches are associated with uncertainty in the data, as in some problems, the attribute values of alternatives to criteria cannot be unambiguously determined. This is a common concern in MCDA methods in general [
52,
53]. Many other MCDA methods have also been adapted to deal with uncertain data; for example, PROMETHEE (Preference Ranking Organization Method of Enrichment Evaluation) [
54], VIKOR (VlseKriterijumska Optimizacija I Kompromisno Resenje) [
55], and COMET (Characteristic Objects METhod) [
56]. Moreover, Jin et al. introduce in [
57] two novel concepts in handling uncertainty: interval extensions of cognitive interval information and cognitive uncertain information, which replace real-numbered values with intervals. These extensions exhibit enhanced algorithmic versatility and applicability, particularly in group decision-making scenarios. This provides the opportunity to employ the interval-valued operator as a means of combining interval-valued functions [
58].
An overview of the applications of fuzzy TOPSIS variants is provided by Palczewski and Sałabun [
59]. This study focuses on extensions of the TOPSIS method that operate on interval numbers. There are many extensions of this kind that approach the use of intervals in different ways [
60,
61,
62,
63]. A popular extension is the interval TOPSIS proposed by Jahanshahloo [
60], in which the PIS and NIS, as well as the final evaluation of alternatives, are crisp numbers. Another existing extension is the direct interval extension by Dymova [
63]. Here, PIS and NIS are expressed in interval form, but the evaluation of alternatives is a crisp number. It is noticeable that in such cases some nuances are disregarded. Since the alternatives are given in the form of interval values, it seems logical that a crisp result could result in a loss of accuracy.
This paper aims to investigate a comprehensive analysis of the comparative performance between two innovative extensions of the TOPSIS method, which are tailored to operate specifically within the domain of intervals. The conventional interval TOPSIS approach, as proposed by Jahanshahloo, derives preference values for alternatives as precise real numbers [
60]. On the contrary, the novel methodology introduced in this study generates preference values as intervals [
64]. Through this investigation, our primary objective is to evaluate the robustness and consistency of the results produced by these two distinct approaches and, furthermore, to elucidate how such a fundamental difference in methodology can potentially impact the decision-making process. To enable a meaningful comparison between these two methods, we propose a simple approach to represent the intervals obtained in our extension as crisp values (left bound, right bound, or midpoint). It is important to highlight that in our extension, each preference is explicitly expressed as an interval with defined minimum and maximum possible values. The use of midpoints is primarily for the purpose of comparison with the Jahanshahloo approach, where preference values are presented as single, noninterval numbers. In the Jahanshahloo approach, the use of single crisp values may impose limitations in capturing the inherent variability and uncertainty inherent in the decision-making process.
The rest of the paper is structured as follows.
Section 2 provides a detailed description of how the TOPSIS method and its discussed interval extensions operate.
Section 3 contains a numerical example involving data on EVs.
Section 4 contains the analysis of the results and discussion. Finally,
Section 5 provides a summary and direction for further research.
2. Materials and Methods
This section presents the algorithms of TOPSIS and its considered extensions. Next, the coefficients used to determine the similarity of the rankings are presented. Finally, the method for obtaining interval numbers used in this study is explained.
2.1. The TOPSIS Method
In the classic TOPSIS method, the problem is given in the form of a decision matrix
M with
m alternatives and
n criteria, as well as a vector of weights
[
65].
In the decision matrix, is the attribute of the j-th alternative () to the i-th criterion (). The vector is a vector of weights associated with each criterion—one weight is assigned to every criterion .
- Step 1.
Normalize the decision matrix, where
is the normalized attribute of the alternative
against the criterion
:
- Step 2.
Calculate the weighted normalized decision matrix, where
is the weighted normalized attribute of the alternative
against the criterion
:
- Step 3.
Determine the positive ideal solution
PIS (
) and the negative ideal solution
NIS (
):
where
I stands for profit-type criteria, and
J stands for cost-type criteria.
- Step 4.
Calculate the separation (as Euclidean distance) of each alternative
from the positive ideal solution
and from the negative ideal solution
, respectively:
- Step 5.
Determine the relative closeness
of each alternative
to the positive ideal solution
:
- Step 6.
Rank each alternative by the values of their obtained relative closeness . The higher the relative closeness , the better the position of alternative in the final ranking.
2.2. The Interval TOPSIS Method
In 2006, Jahanshahloo proposed an extension to the TOPSIS method that operates on interval numbers [
60]. It provides a way to incorporate uncertain data into the decision-making process. In this approach, the algorithm is similar to the classic approach, but some operations have been adapted for the purpose of applying interval numbers. The problem is given in a similar form:
In the decision matrix, instead of crisp values, intervals [] are given. The value stands for the lower limit of the interval, whereas stands for the upper limit of the interval. To distinguish between the approaches, some of the symbols concerning the interval TOPSIS method feature a bar (e.g., as opposed to ).
In the interval TOPSIS method proposed by Jahanshahloo, the procedure is as follows.
- Step 1.
Normalize the decision matrix, where
i
are, respectively, the lower and upper limit of the normalized interval attribute of the alternative
to the criterion
:
- Step 2.
Calculate the weighted normalized decision matrix, where
and
are, respectively, the lower and upper limit of the weighted normalized interval attribute of the alternative
to the criterion
:
- Step 3.
Determine the positive ideal solution
PIS (
) and the negative ideal solution
NIS (
):
where
I stands for profit-type criteria, whereas
J stands for cost-type criteria.
- Step 4.
Calculate the separation of each alternative
from the positive ideal solution
and from the negative ideal solution
, respectively:
- Step 5.
Determine the relative closeness
of each alternative
to the positive ideal solution
:
- Step 6.
Rank each alternative as in the classical approach.
2.3. The New Approach
A significant difference between the interval TOPSIS and the new approach is the way the score is evaluated since in the new approach, the assessment of alternatives is given as an interval [
64].
In the new approach, the first steps (1–3) are identical to those in the interval TOPSIS method. The decision matrix and the vector of weights are given in the same format. The positive and negative ideal solutions also remain the same. However, the method of determining the evaluation of each alternative is different. For each alternative (), the following steps are required:
- Step 4.1.
Generate an auxiliary decision matrix
, for which the classical TOPSIS method can be used. The individual alternatives are expressed as follows:
where
stands for the
j-th of the
m considered alternatives. Then, the generation of the auxiliary decision matrix for this alternative involves determining the Cartesian product of the lower and upper limits of the value of each criterion:
The auxiliary decision matrix is then expressed as:
where
(
) is the
j-th of the
auxiliary alternatives.
- Step 4.2.
Apply the classic TOPSIS method to the generated auxiliary decision matrix. Substitute the and determined in step 3 for PIS and NIS. Then calculate:
- (a)
The Euclidean distance of each auxiliary alternative
from the positive ideal solution
and from the negative ideal solution
—using Formula (
6);
- (b)
The relative closeness of each auxiliary alternatives
to
—using Formula (
7).
- Step 4.3.
The result for alternative
is an interval:
2.4. Correlation Coefficients
Correlation coefficients and similarity coefficients are used to provide a numerical expression of the similarity of two rankings. In this study, two coefficients described below were chosen to evaluate the rankings obtained from extensions of the TOPSIS method.
2.4.1. Weighted Spearman’s Rank Correlation Coefficient
In this approach, it is not only the occurrence of differences that affects the result, but also at which ranking position they occur. Differences in the top ranking positions are more significant than those in the bottom ranking positions [
65,
66]. This coefficient is defined as (
19):
where
N is the size sample,
are the rank values of the first ranking, and
are the rank values of the second ranking.
2.4.2. Rank Similarity Coefficient
This coefficient is asymmetric, with the first ranking being the reference ranking. The score is closely related to the ranking positions on which differences occur, with the top ranking positions being the most significant [
65,
66]. The coefficient is defined as (
20):
where
N is the size sample,
are the rank values of the first ranking, and
are the rank values of the second ranking.
2.5. Extending Crisp Numbers to Interval Numbers
In order to compare the performance of the extensions in question, it is necessary to provide data in interval form. In this paper, we propose the following method of extending crisp data to interval form (
21):
where
is an arbitrarily selected factor.
3. Study Case
The data in the example come from Dviwedi and Sharma [
67], in which a comparison of 15 models of EVs is conducted. The authors take into consideration the following criteria:
—total power, expressed in horsepower (hp);
—electric range, expressed in kilometers (km);
—battery capacity, expressed in kilowatt-hours (kWh);
—top speed, expressed in kilometers per hour (km/h);
—cargo volume, expressed in liters (l);
—acceleration as the acceleration time from 0 to 100 km/h, expressed in seconds (s);
—base price, expressed in British pound sterling (£);
—fast charge time as the time of charging from to , expressed in minutes (min);
—full charge time, expressed in hours (h);
—unladen weight, expressed in kilograms (kg).
The data in the original paper are crisp data. For the purposes of this paper, they have been converted to interval data using Formula (
21) with
. This means that from each value an interval is derived with the lower limit reduced and the upper limit increased by
of that value.
The original data can be found in
Table 1. In addition to the attribute values for each criterion, the names of the EV models being evaluated are also included. The vector of weights
is taken from the original paper without changes.
The derived interval decision matrix can be found in
Table 2. For criterion
, the alternatives take values in the range
, with an average of
. For criterion
, the range of values is
and the mean is
, for criterion
there is a range of values of
and a mean of
, the range of values for criterion
is
and the mean is
, and criterion
has a range of values of
and a mean of
. The lowest mean value occurs for criterion
; it is
with a range of values
. Meanwhile, the highest average value occurs for criterion
; it is 83,334.67 whereas the range of values is [38,380.5, 153,208]. For the other criteria, the values are as follows: range
and mean
for
, range
and mean
for
, and range
and mean
for
. Thus, it can be seen that the values within the criteria vary, and this indicates the need for normalization.
The normalized interval decision matrix can be found in
Table 3. All values are scaled to interval
. The results of the next stage of the calculation, which is weighting, can be found in
Table 4. The ideal solutions identified are in
Table 5. At this point, the common part of the calculations for interval TOPSIS and the new approach ends.
The results obtained by applying the interval TOPSIS method are shown in
Table 6. The best three alternatives suggested by this extension are
(Tesla Model S Plaid),
(Lucid Air Touring), and
(Porsche Taycan Turbo) with relative closeness of
,
, and
, respectively. In comparison,
(Mercedes EQV 300) with relative closeness of
was identified to be the least attractive alternative.
The results obtained from the application of the new approach can be found in
Table 7. Since, with 10 criteria, the auxiliary decision matrices mentioned in
Section 2.3 have
rows, they are not presented here.
For readability, the following designations of the final rankings are used in the remainder of the paper:
—ranking obtained from interval TOPSIS;
—ranking obtained from only the lower limits of the intervals resulting from the new approach;
—ranking obtained from the mean of the interval limits resulting from the new approach;
—ranking obtained from only the upper limits of the intervals resulting from the new approach.
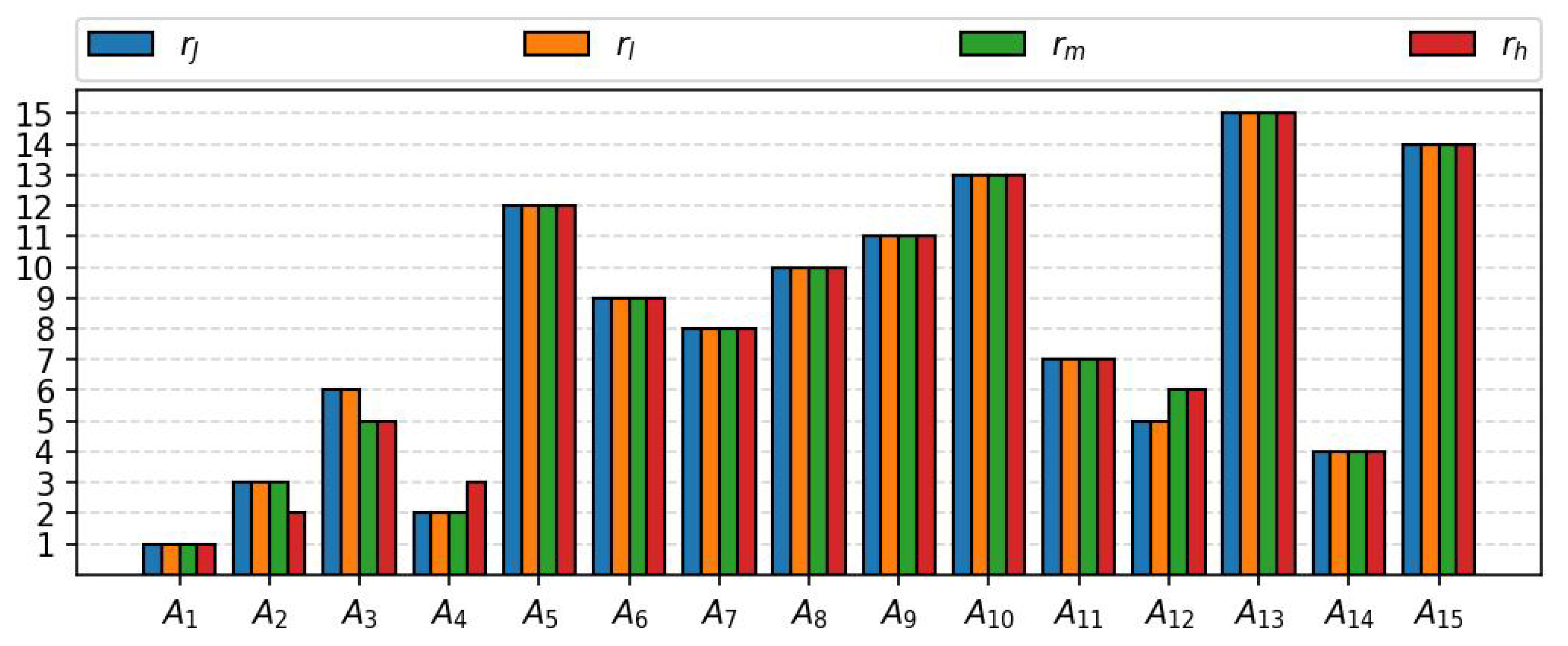
Not all of the aforementioned rankings are consistent with each other. Most of the alternatives (
–
,
–
) are ranked the same in each case. This is particularly important regarding alternative
, which holds the most significant first position in the ranking. However, there are differences for the remaining alternatives.
Figure 1 provides a visual summary of all the rankings in question in the form of a bar chart.
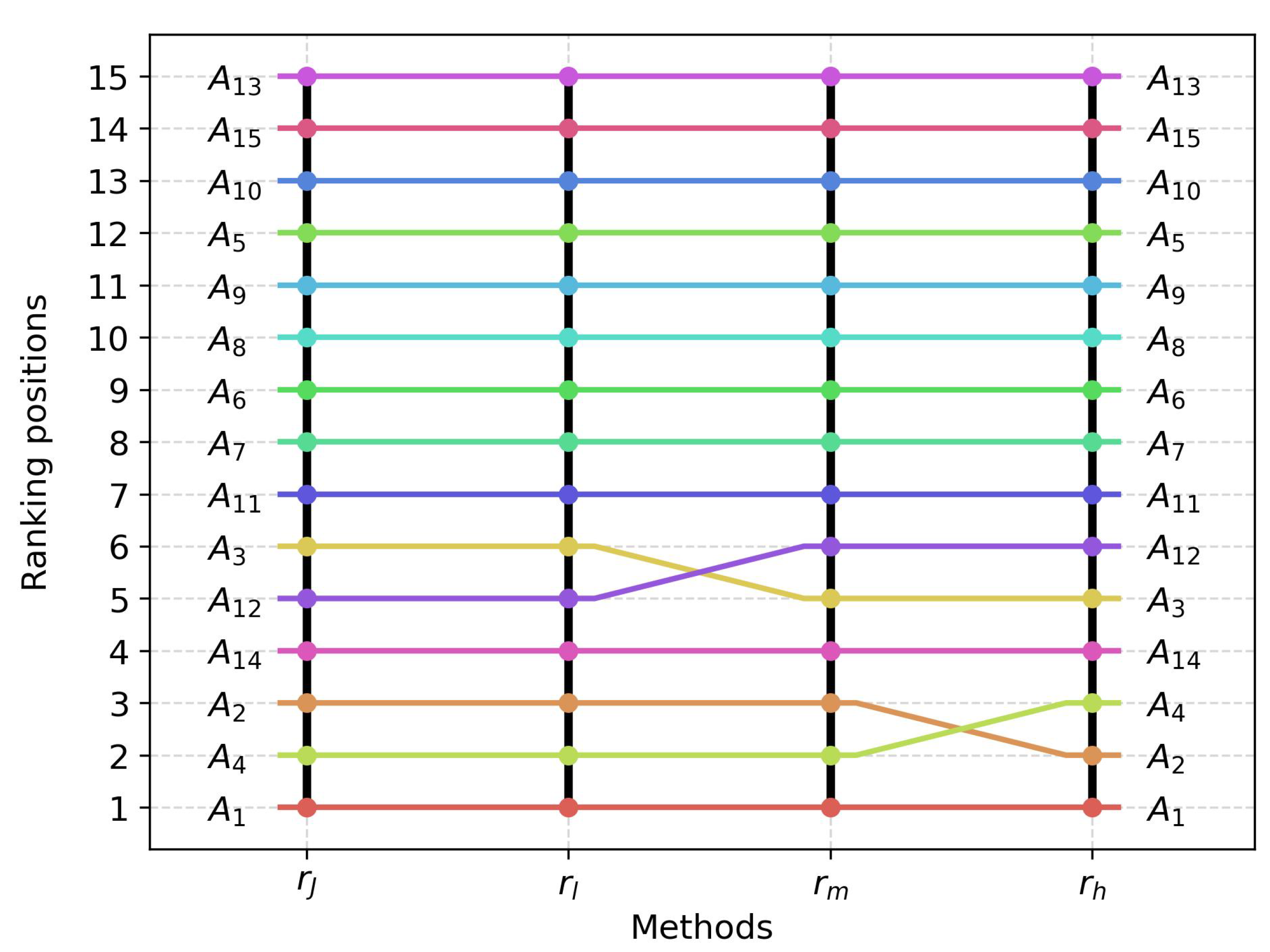
Figure 2 shows the differences between the ranking obtained from the interval TOPSIS and the individual rankings obtained from the new approach. The rankings of
and
appear first. In this case, both rankings turned out to be identical.
The two rankings and agree on most positions. Only the alternatives and are interchanged with each other in these rankings. The interchange occurs in the 5th and 6th positions in the ranking, so the difference is not as significant as it would be if there were differences in the upper ranking positions.
The most differences occur between the rankings of and . They are also the most significant. In addition to the same interchange in ranking positions 5 and 6 as in comparison of and , there is also an interchange in positions 2 and 3 (alternatives and ). These are among the top-ranked positions, so they play a greater role in, for example, calculating selected correlation coefficients.
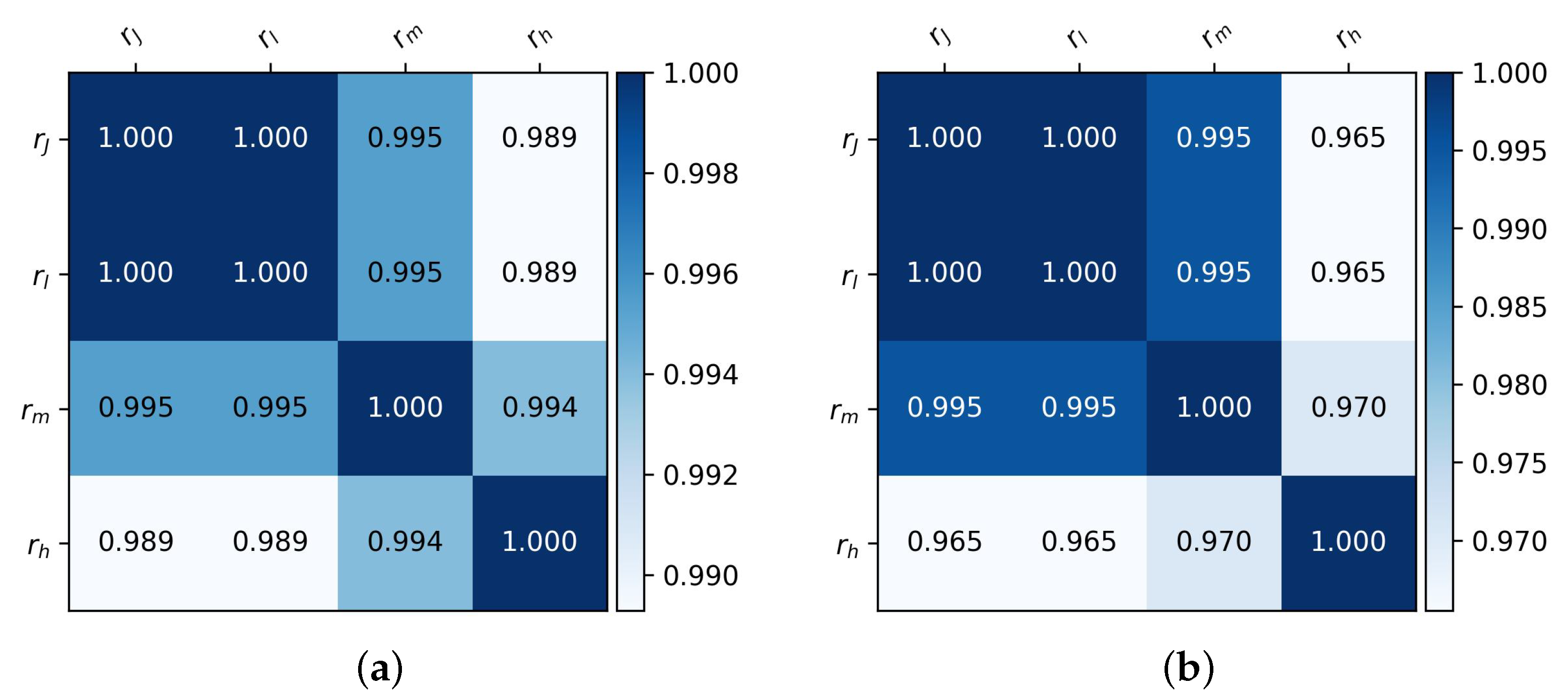
The calculated correlation coefficients between the rankings in the form of a correlation matrix can be found in
Figure 3. As could be deduced from previous visualizations, the rankings
and
are the least similar to each other, scoring
for the
coefficient and
for the
coefficient. Even though this is the lowest of the results obtained, it still indicates that the two rankings are similar. Better results (
for both
and
) are achieved by the
and
rankings, as differences in them occur less frequently and further down the ranking.
It is worth noting the similarity between the rankings of
and
. In
Table 7 and
Figure 2, one can see that they differ at positions 2 and 3. With this insight, it is possible to observe that it is indeed not only the occurrence of differences in rankings itself that matters, but also the position at which the differences occur. The results of
for
and
for
are worse than for the rankings of
and
, where there was also only one interchange, but at positions 5 and 6.
The rankings and are identical, so the value of both coefficients and for them equals 1.
4. Discussion
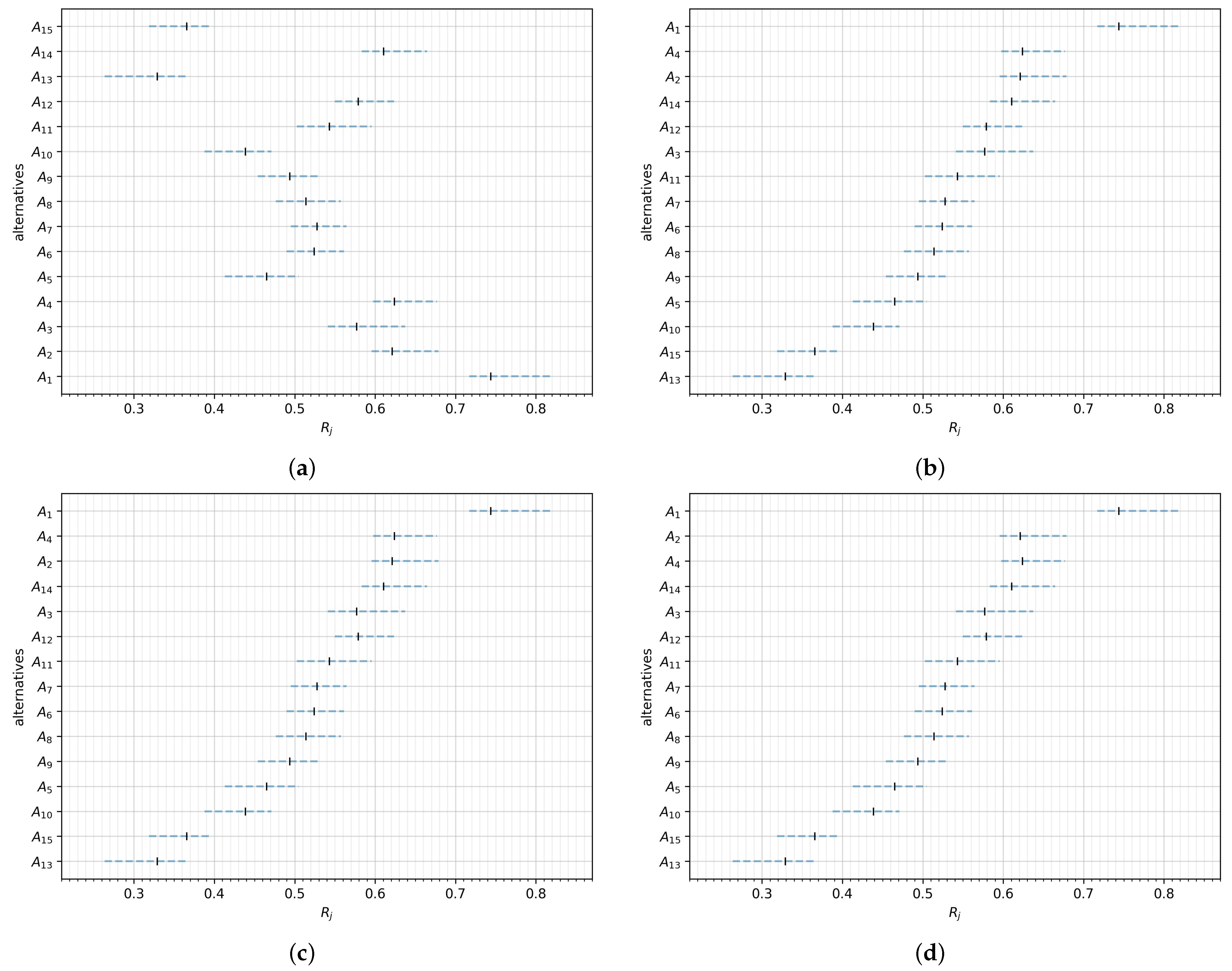
The results obtained from all the considered approaches consistently display a high degree of reliability and conformity. This is vividly depicted in
Figure 4, where we visualize the relative closeness achieved through the new approach (depicted as intervals in blue) in comparison to the results obtained using the interval TOPSIS method (represented as points in black within the intervals). Two specific cases within the visualization warrant special attention.
Firstly, the relative closeness of the interval attributed to the alternative stands out as it does not overlap with any other interval. Consequently, there is unequivocal certainty regarding its ranking position, with no room for dispute or contention with other alternatives.
Secondly, the pairs of alternatives, namely and , along with and , merit a close examination. Here, the relative closeness of the interval for alternative is fully encompassed within the interval of alternative . An analogous situation occurs with the alternatives and . Such pairs of alternatives are the only ones in which there have been changes within the rankings available using the new approach.
It is also worth noting that although each value was symmetrically expanded by the same value, the results in comparison to the interval TOPSIS method are not symmetrical. With some alternatives, for example and generally the highest-rated alternatives, crisp relative closeness is closer to the lower limit of interval relative closeness. In contrast, with the lowest-rated alternatives, such as , the value moves closer to the upper limit.
Based on the results, it can be concluded that the new approach substantially matches the interval TOPSIS. Relative closeness obtained from the interval TOPSIS never, in fact, exceeds the intervals established by the new approach. Therefore, the use of the new approach is not expected to cause inconsistencies in the results. Instead, it presents other opportunities and brings into discussion the adequacy of the original interval extension.
The results returned as intervals are in a form consistent with the input data. This provides an alternative, more relevant way to model uncertainty. It also leaves more possibilities for interpretation for the decision-maker. For example, for the data used, most alternatives are unambiguously evaluated, such as the first ranking being the same regardless of which interval limit is considered. In some other cases, the decision-maker can decide how to interpret overlapping intervals of relative closeness in the decision-making process. Thus, if the TOPSIS method is chosen to deal with interval data, the new approach may provide additional insight into the results compared to the interval TOPSIS proposed by Jahanshahloo.
5. Conclusions
Through this investigation, our primary objective is to evaluate the robustness and consistency of the results produced by these two distinct approaches and, furthermore, to elucidate how such a fundamental difference in methodology can potentially impact the decision-making process. To enable a meaningful comparison between these two methods, we propose a simple approach to represent the intervals obtained in our extension as crisp values (left bound, right bound, or midpoint). It is important to note that in our extension, each preference is explicitly expressed as an interval with defined minimum and maximum possible values. The use of crisp values is primarily for the purpose of comparison with the Jahanshahloo approach, where preference values are presented as single, noninterval numbers. In the Jahanshahloo approach, the use of single crisp values may impose limitations in capturing the inherent variability and uncertainty inherent in the decision-making process.
The paper compares two interval-based extensions of the TOPSIS method. An electric vehicle evaluation challenge was used as an example due to the relevance of the topic and possible straightforward adaptation to an MCDA problem. The two approaches are found to have high mutual compatibility. The most popular approach proposed by Jahanshahloo returns results that fall within the limits defined by the results obtained from the new approach. This suggests that the new approach could be used interchangeably with the original interval extension. However, it does not neglect the uncertain nature of the problem. In Jahanshahloo’s extension, evaluating an alternative with interval attributes by a crisp number poses the risk of eliminating other potential evaluations for that alternative. In the new approach, there is no such risk, because the interval evaluation of an alternative by definition represents the range of all possible evaluations for that alternative.
Further research directions could be to continue investigating the adequacy of the results returned by the new approach, to examine how the new approach performs on data from other domains, and to study the behavior of the new approach under different levels of uncertainty.






{kind=link}
{kind=link}
{kind=link}
{kind=link}