








Using Deep Neural Network Methods for Forecasting Energy Productivity Based on Comparison of Simulation and DNN Results for Central Poland—Swietokrzyskie Voivodeship

Abstract
:1. Introduction
2. Materials and Methods
2.1. Simulation-Based Techniques
- Precision: Simulation models can offer precise predictions when properly calibrated and grounded in real-world data.
- Flexibility: They can be tailored to accommodate diverse scenarios and configurations.
- Understanding: Simulations facilitate comprehension of the intricate interactions between different components within the energy system.
- Computational Intensity: Developing and executing simulations can be computationally demanding, particularly for large-scale systems.
- Data Requirements: High-quality data pertaining to weather, energy demand, and system parameters are crucial for ensuring accurate simulations.
- Complexity: Constructing a reliable simulation model necessitates expertise and domain knowledge.
2.2. AI Predictions for Electricity Generation
- Speed: AI models can rapidly process vast datasets and provide real-time predictions.
- Adaptability: They possess the ability to adapt to changing conditions and learn from newly acquired data.
- Scalability: AI models demonstrate efficacy in handling large-scale systems.
- Data Quality: The accuracy of AI predictions heavily relies on the quality and sensitive character of the training data.
- Black-Box Nature: Neural networks can be challenging to interpret, making it difficult to comprehend the underlying reasoning behind predictions.
- Limited Generalization: AI models may encounter difficulties when dealing with unseen situations or data that significantly deviate from the training set.
2.3. ML Methods for Predictions of Electricity Generation
2.3.1. Random Forest (RF)
2.3.2. XGBoost
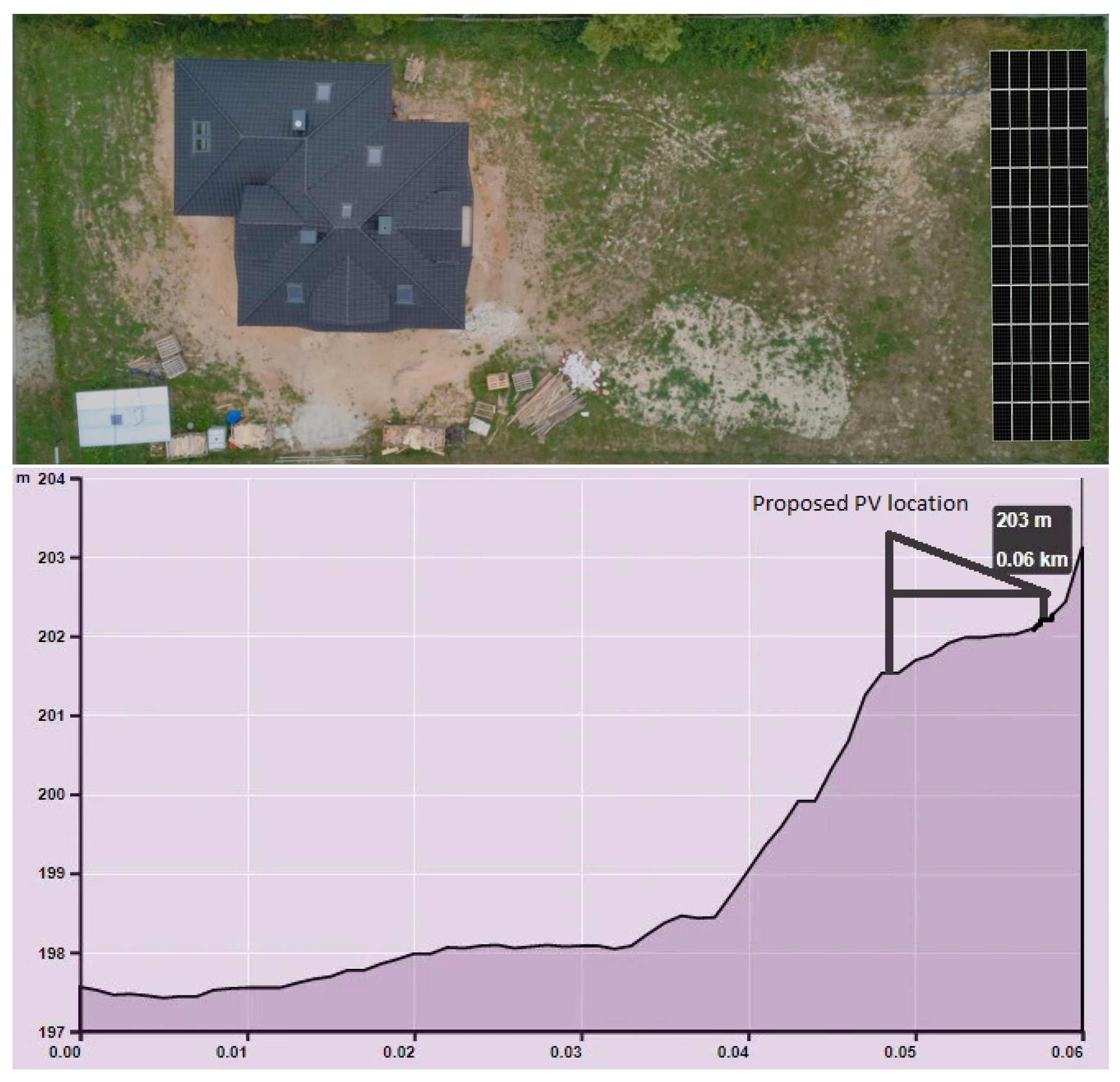
2.4. Analyzed Designed PV Farm
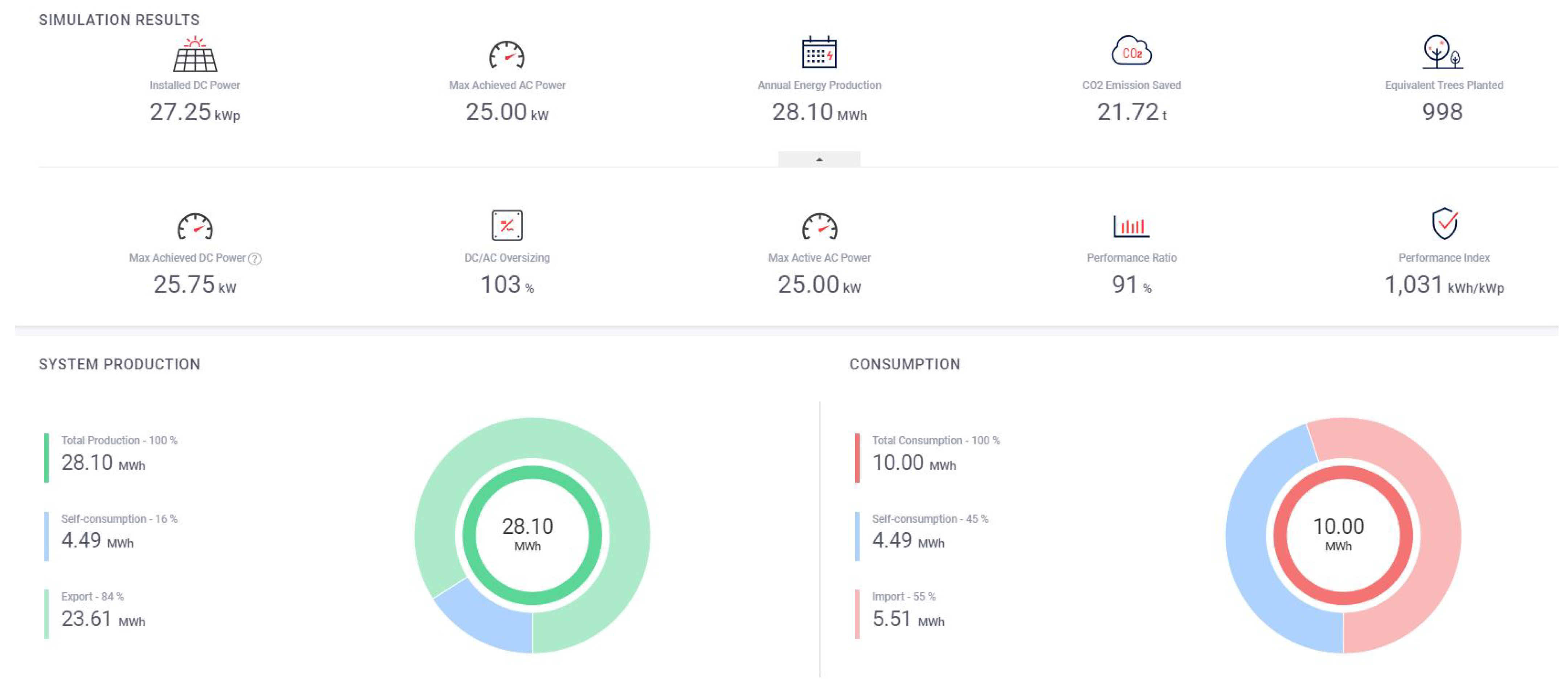
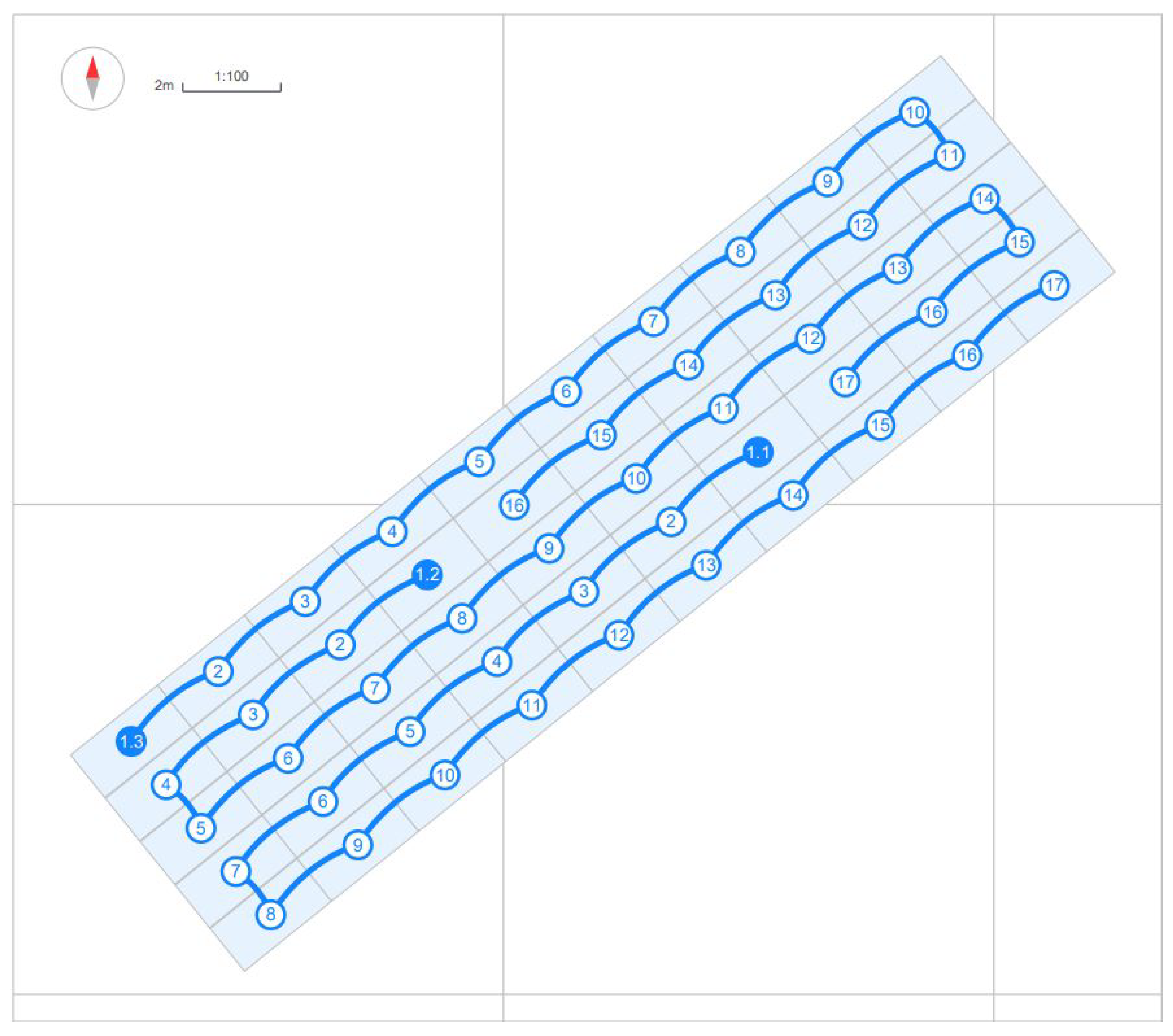
- The PV farm has a total installed DC power capacity of 27.25 kilowatts peak (KWp). This is achieved through the use of 50 JAM72D30-545/MB solar panels (Figure 1).
- The PV system utilizes a Solar Edge SE25K inverter, which has a capacity of 25,000 watts. The inverter converts the DC power generated by the solar panels into AC power, suitable for use in homes and businesses (Figure 2).
- To maximize energy production and improve efficiency, the PV farm is equipped with 50 Solar Edge S650B optimizers. These optimizers individually track and optimize the performance of each solar panel, ensuring that the entire system operates at its highest potential (Figure 3).
- The maximum AC power output of the PV farm is 25 kilowatts (KW). This represents the highest amount of electricity that the system can produce and supply to the grid or connected loads at any given moment.
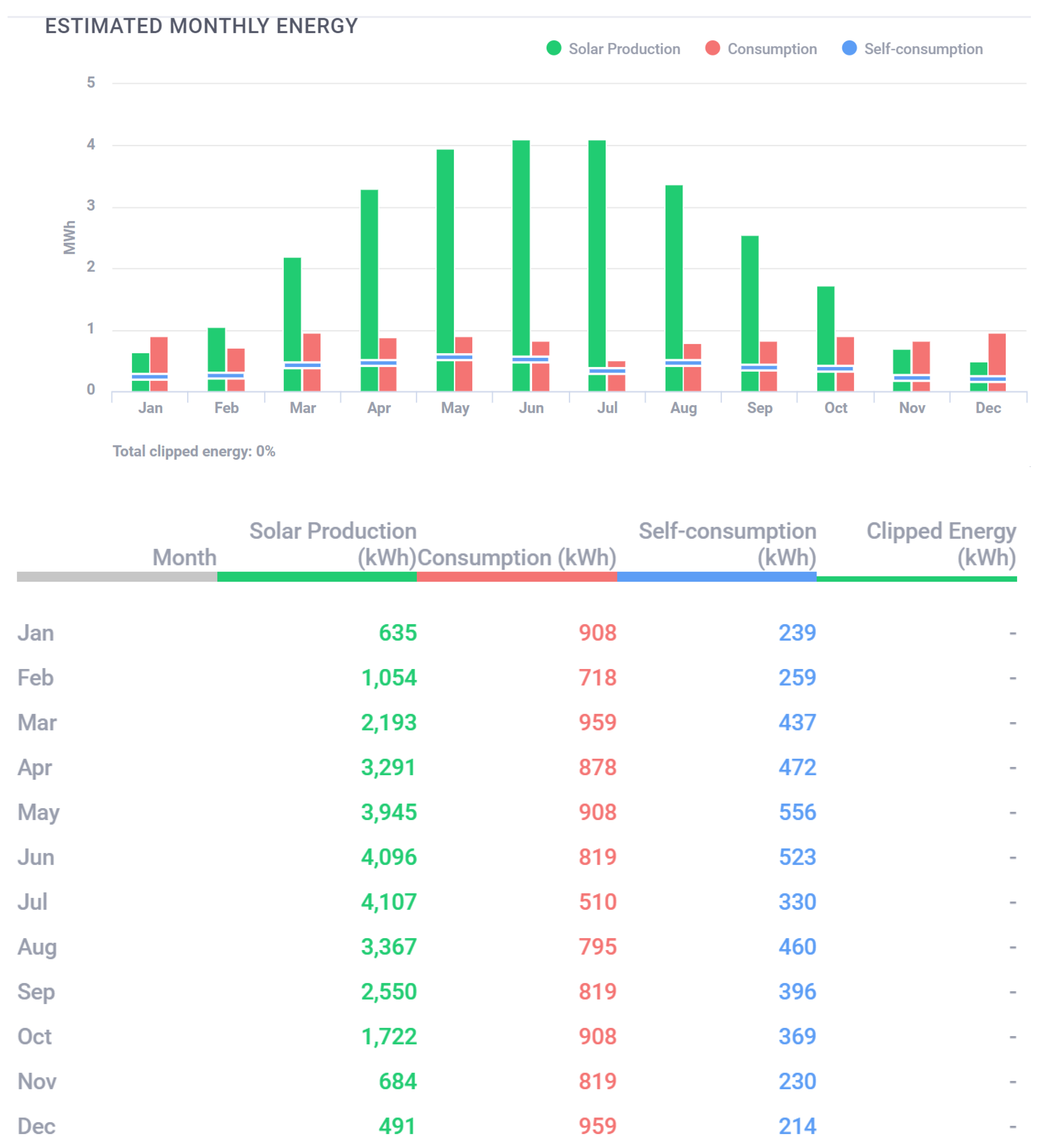
- The PV farm’s estimated annual energy production is 28.10 megawatt-hours (MWh). This figure indicates the total amount of electricity the system is expected to generate over the course of a year under average sunlight conditions (Figure 4).
- The performance index of the PV farm is 91%. This metric represents the efficiency of the system in converting sunlight into electricity. An index of 91 suggests that the PV farm is performing at a high level of efficiency, considering various factors such as shading, temperature, and soiling losses.
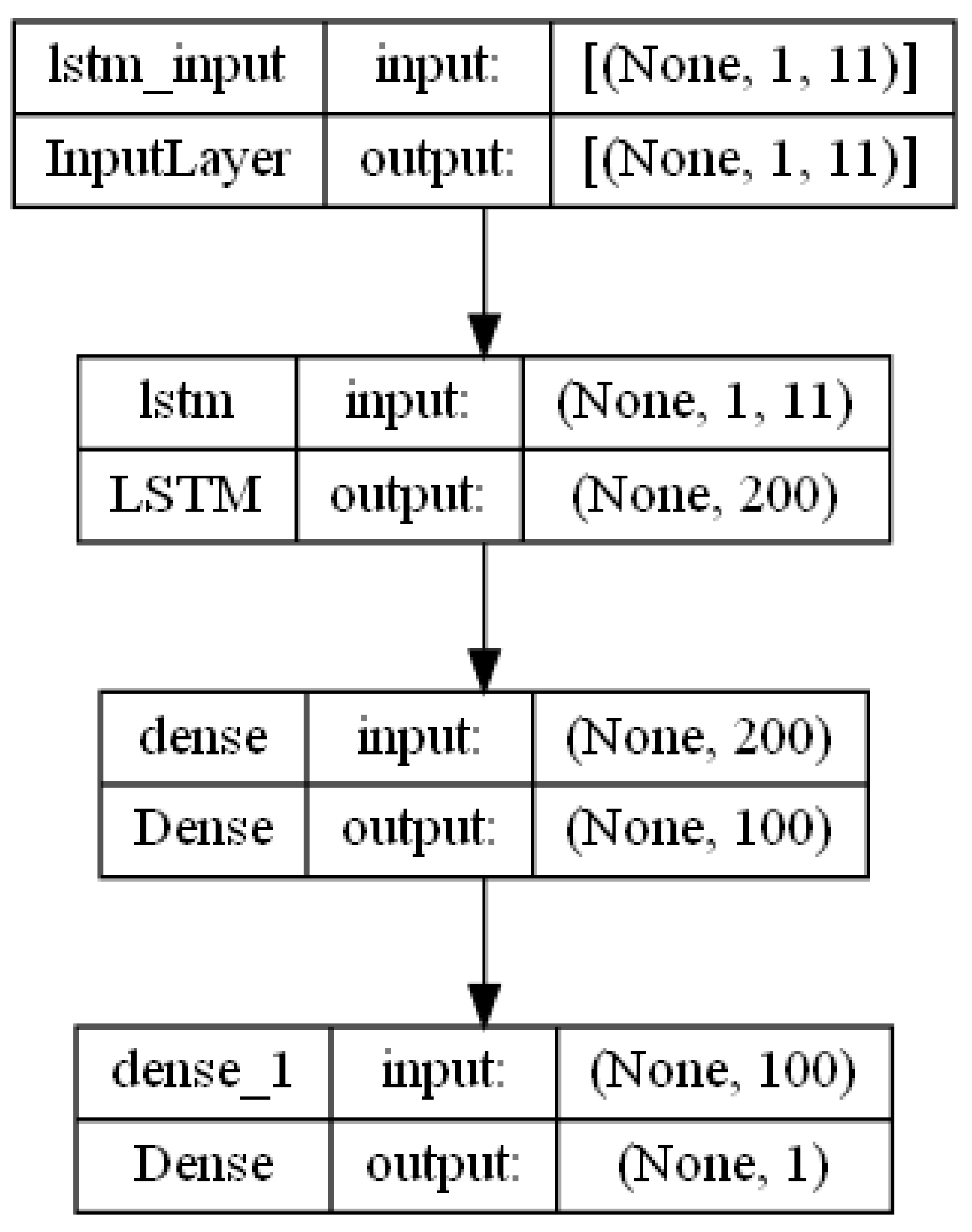
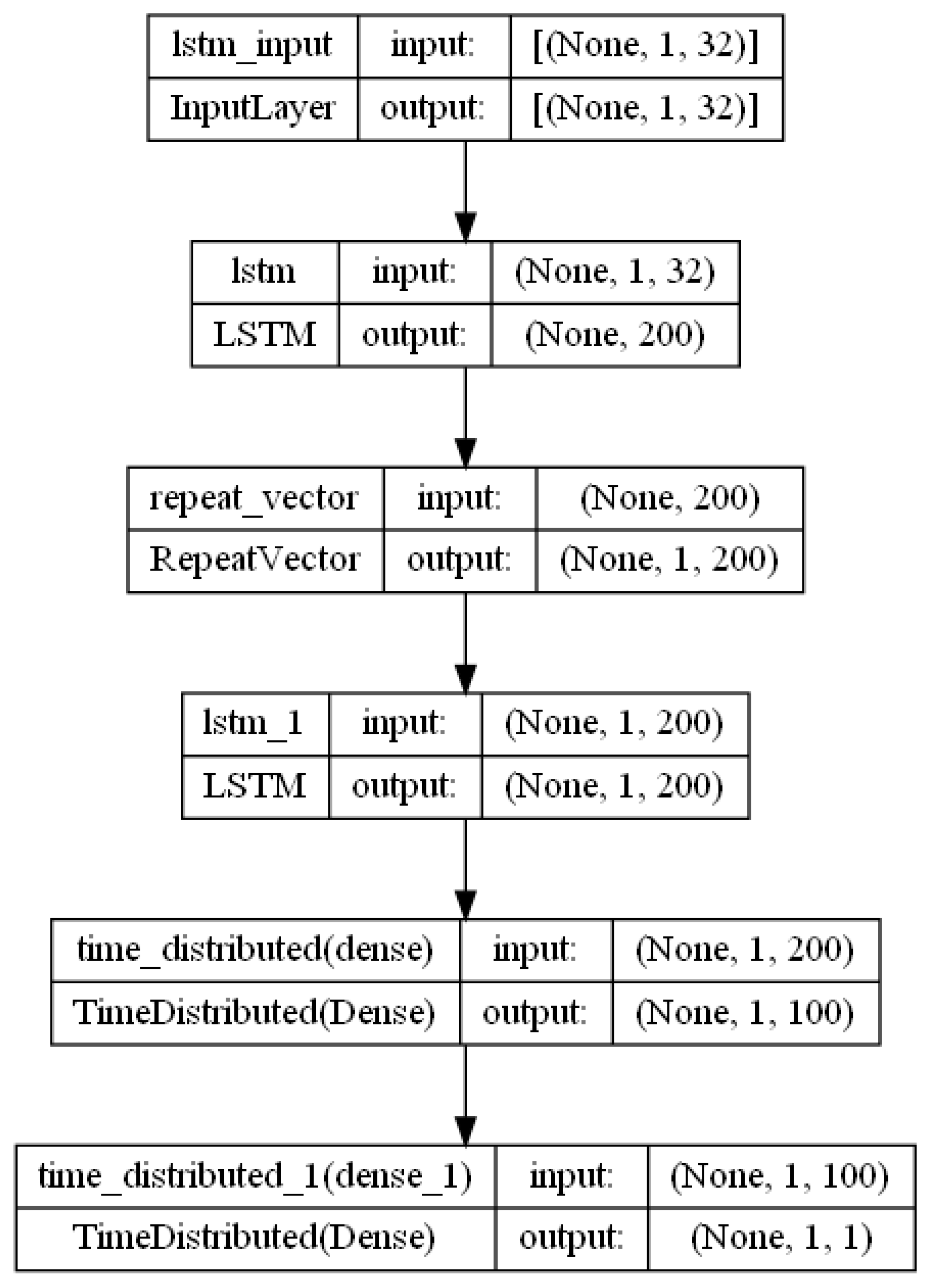
2.5. MultiLSTM DNN Model Architecture
MultiLSTMDNN Hyperparameters
- LSTM units in the encoder and decoder layers: 200 units each.
- Activation function used in the LSTM and dense layers: ReLU (rectified linear unit).
- First dense unit (fully dense connected layer) with number of 100 units
- Output layer: 1 unit.
- Optimizer: Adam
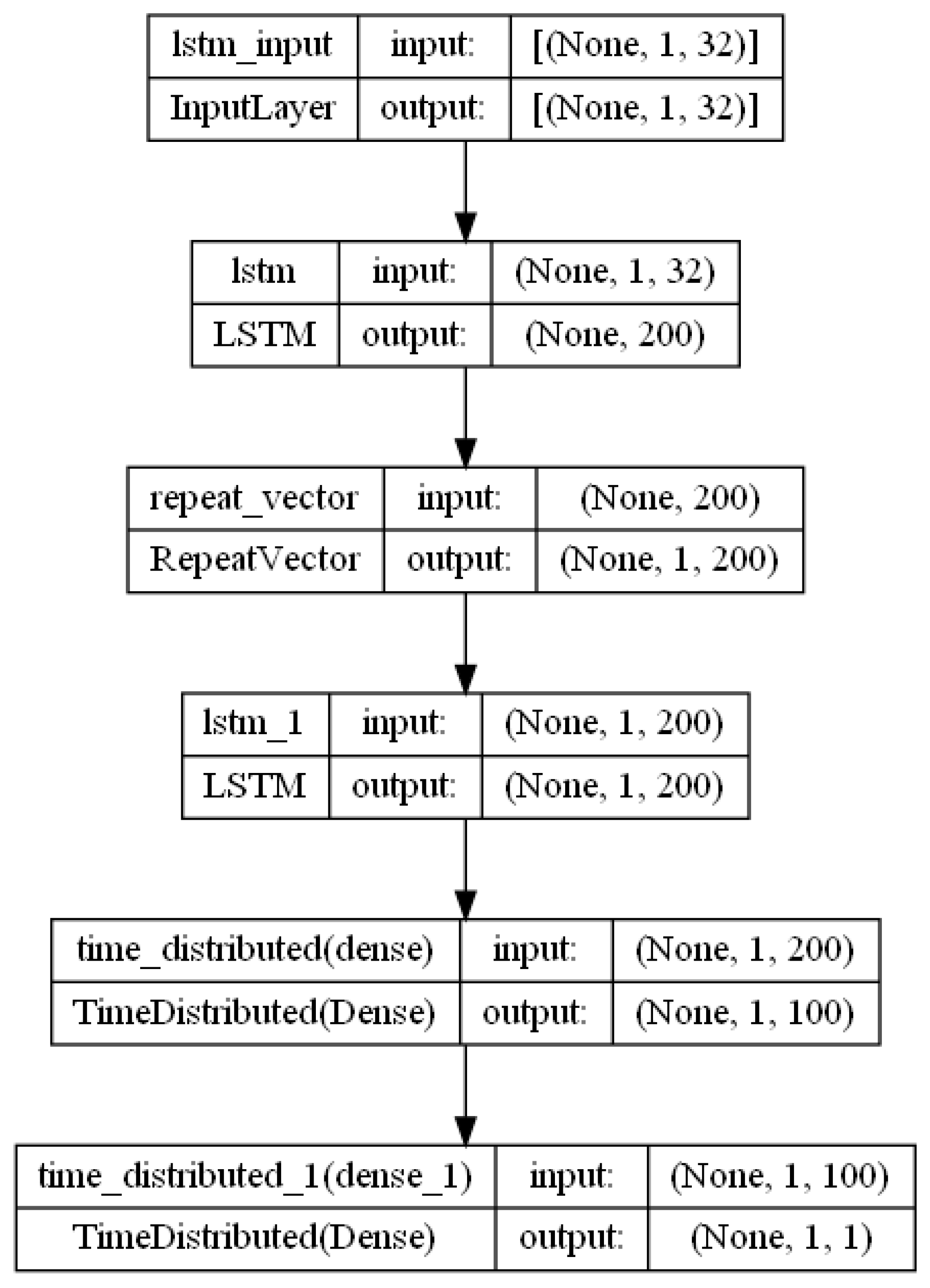
2.6. EncoderDecoder DNN Model Archiecture
2.6.1. EncoderDecoderDNN Hyperparameters
- LSTM units in the encoder and decoder layers: 200 units each.
- Activation function used in the LSTM and dense layers: ReLU (rectified linear unit).
- First dense unit (TimeDistributed layer) with number of 100 units
- Second dense unit TimeDistributed dense layer: 1 unit.
- Optimizer: Adam
2.6.2. Avoiding Overfitting for LSTM-Based Architectures
- Keeping LSTM units relatively simple.
- Stopping training when validation loss stalls.
- Monitoring model on separate validation data.
- Incorporating L2 regularization into weights.
- Exploring ensemble techniques for combined predictions.
2.7. Data Preparation EDA
2.8. Parameters Used as Input for DNN
- Timestamp: The date and time at which the data is recorded, providing a temporal context for the other parameters.
- Global Horizontal Irradiance: The total solar irradiance received on a horizontal surface, including direct and diffuse sunlight.
- Diffuse Horizontal Irradiance: The solar irradiance from the sky’s scattered radiation received on a horizontal surface.
- Diffused Normal Irradiance: The solar irradiance received on a surface perpendicular to the sun’s rays, after scattering in the atmosphere.
- Global Tilted Irradiance: The total solar irradiance received on a tilted surface, which is typically the PV panel’s orientation.
- Temperature: The ambient temperature of the solar PV panels or system.
- GTI Loss: Loss in global tilted irradiance, potentially due to shading or orientation issues.
- Irradiance Shading Loss: Loss in irradiance due to shading on the PV panels.
- Array Incidence Loss: Loss caused by the angle at which sunlight strikes the PV panels.
- Soiling and Snow Loss: Loss due to the accumulation of dirt, dust, or snow on the PV panels, reducing their efficiency.
- Nominal Energy: The expected energy output from the PV system under ideal conditions.
- Irradiance Level Loss: Loss related to variations in solar irradiance levels.
- Shading Electrical Loss: Electrical losses occurring in the system due to shading.
- Temperature Loss: Electrical losses caused by temperature variations in the PV panels.
- Optimizer Loss: Losses associated with power optimizers used in the PV system.
- Yield Factor Loss: Losses due to factors impacting the system’s overall yield.
- Module Quality Loss: Losses caused by the quality of PV modules used in the system.
- LID Loss: Light-Induced Degradation losses in PV modules.
- Ohmic Loss: Electrical losses caused by the resistance of materials in the system.
- String Clipping Loss: Losses due to limiting the output of strings of PV panels.
- Array Energy: The total energy output from the PV array.
- Inverter Efficiency Loss: Losses due to inefficiencies in the inverter.
- Clipping Loss: Losses due to limiting the system’s output to protect the inverter.
- System Unavailability Loss: Losses due to system downtime or unavailability.
- Export Limitation Loss: Losses caused by limitations on exporting excess energy to the grid.
- Battery Charge: The amount of energy being charged into the battery storage system.
- Battery Discharge: The amount of energy being discharged from the battery storage system.
- Battery State of Energy: The current energy level or state of charge of the battery.
- Inverter Output: The energy output from the inverter.
- Consumption: The amount of energy consumed by the user or load.
- Self-consumption: The energy consumed from the PV system by the user.
- Imported Energy: The amount of energy imported from the grid.
- Exported Energy: The amount of excess energy exported to the grid.
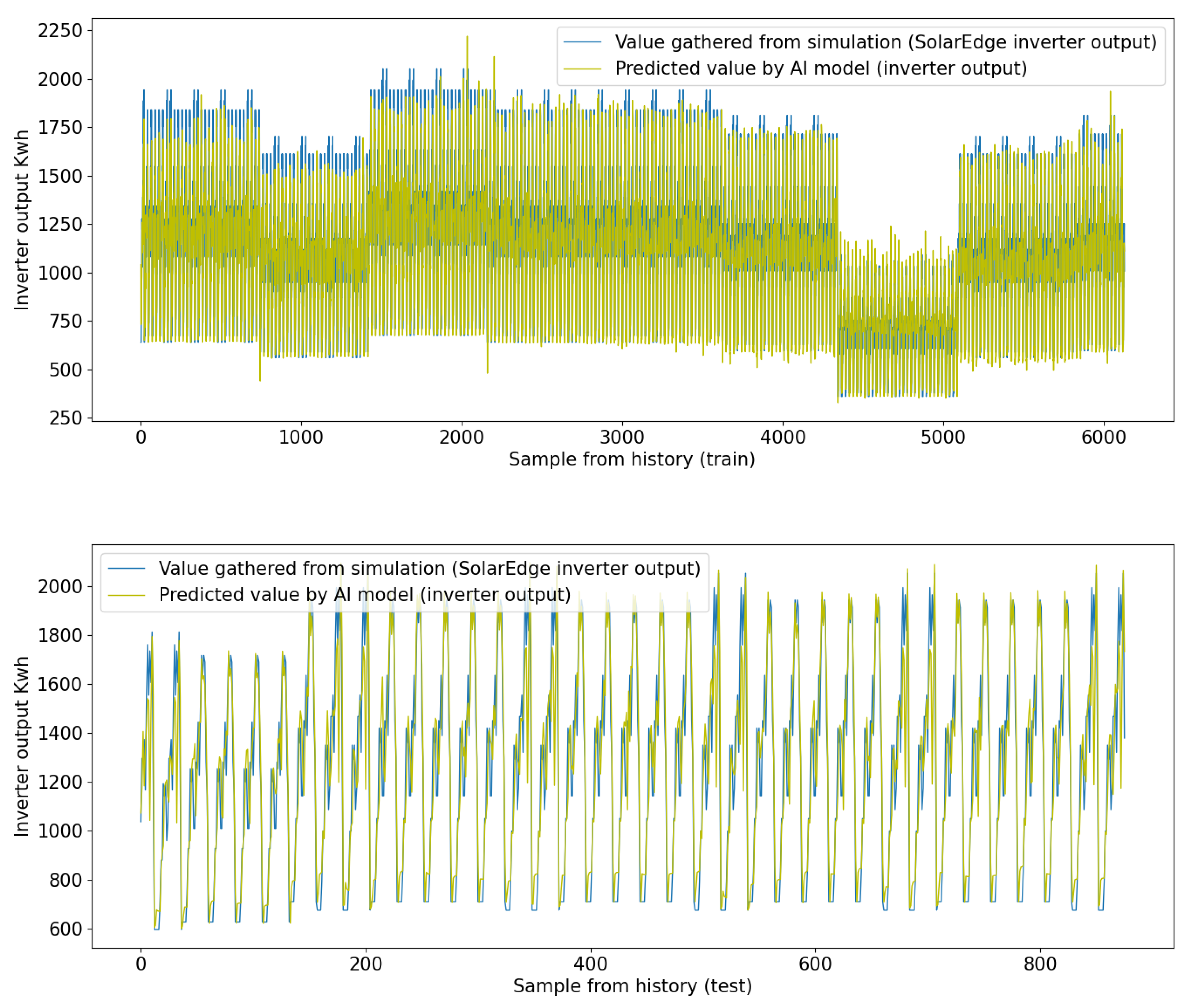
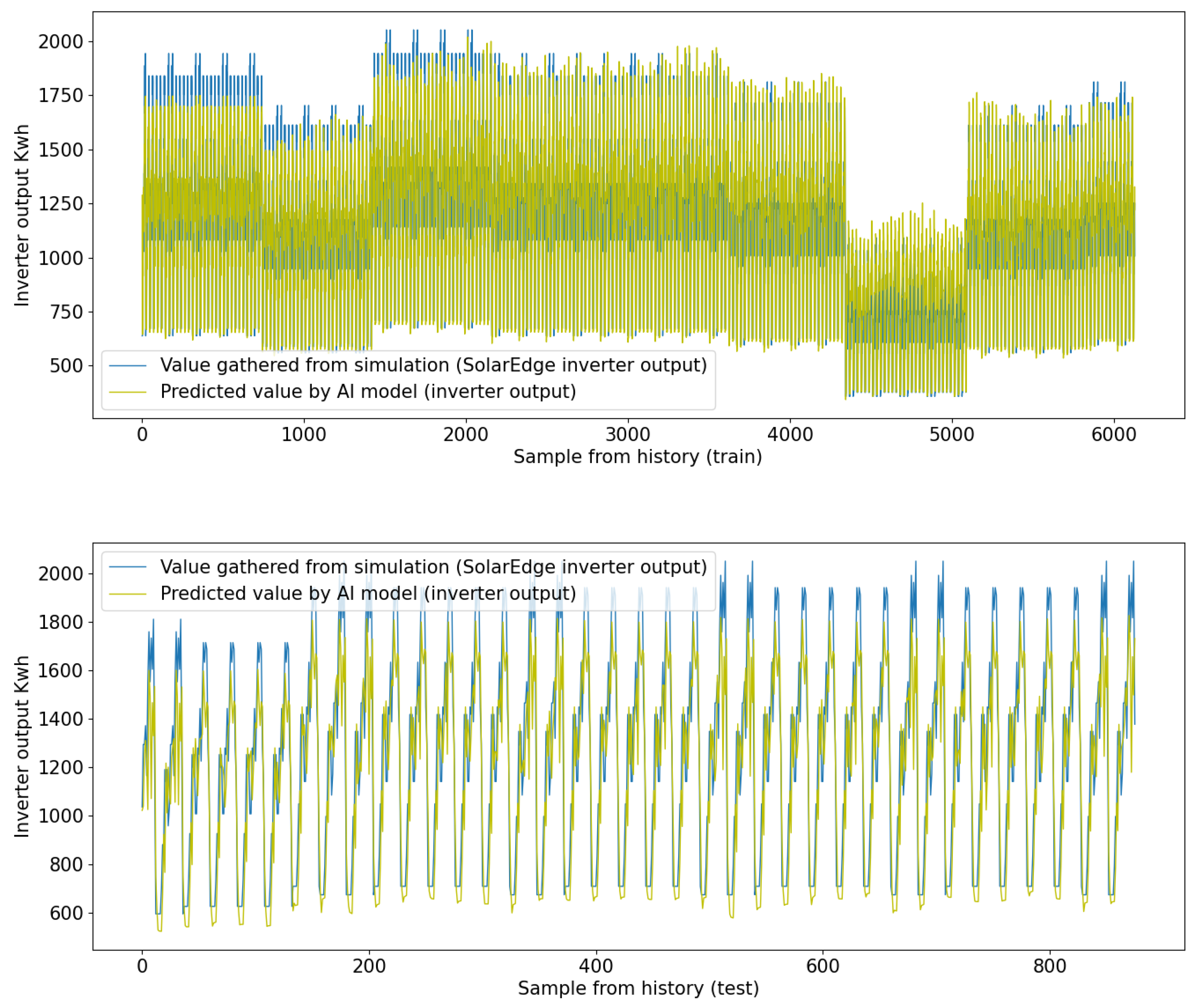
3. Results
- MAE (mean absolute error): 102.09 (train), 112.179 (test). The MAE represents the average absolute difference between the predicted values and the actual values. In this case, the average absolute error is 102.09, which means, on average, the predictions made by the DNN are off by approximately 102.09 Kwh.
- NMAE (normalized mean absolute error): 0.049 (train), 0.054 (test). NMAE is the MAE normalized by the mean of the actual values. It is a relative measure of the MAE and is useful for comparing performance across different datasets. In this case, the NMAE is 0.049, indicating that the DNN’s predictions have an average absolute error of 4.9% relative to the mean of the actual values.
- MPL (mean percentage loss): 56.089 (train/test). The MPL represents the average percentage difference between the predicted values and the actual values. In this case, the average percentage loss is 56.089, which means, on average, the predictions made by the DNN deviate from the actual values by approximately 56.089%.
- MAPE (mean absolute percentage error): 0.0918 (train/test). MAPE is a common metric for measuring the accuracy of predictions as a percentage. It represents the average absolute percentage difference between the predicted values and the actual values. In this case, the average absolute percentage error is 0.0918, meaning that the DNN’s predictions have an average error of 9.1% relative to the actual values.
- MSE (mean squared error): 18869.570 (train), 27767.949 (test). The MSE represents the average of the squared differences between the predicted values and the actual values. It gives higher weights to larger errors. In this case, the MSE is 18869.570, providing an insight into the average squared error of the DNN’s predictions.
- EVS (explained variance score): 0.890 (train), 0.839 (test). EVS measures the proportion of variance in the target variable that is explained by the model. It ranges from 0 to 1, where 1 indicates a perfect fit. An EVS of 0.889 means that the DNN explains about 89% of the variance in the data, which is considered a good result.
- R2 (R-squared): 0.885 (train), 0.839 (test). R-squared is another measure of how well the model fits the data. It represents the proportion of variance in the target variable that can be predicted from the input features. R-squared also ranges from 0 to 1, with 1 indicating a perfect fit. An R2 value of 0.885 indicates that the DNN explains about 86.7% of the variance in the data.
- RMSE (root mean squared error): 166.637 (train/test). RMSE is the square root of the MSE and is a common metric for evaluating the accuracy of predictions. It represents the average magnitude of the errors made by the DNN. In this case, the RMSE is 166.637, providing an insight into the average magnitude of the errors made by the DNN’s predictions.
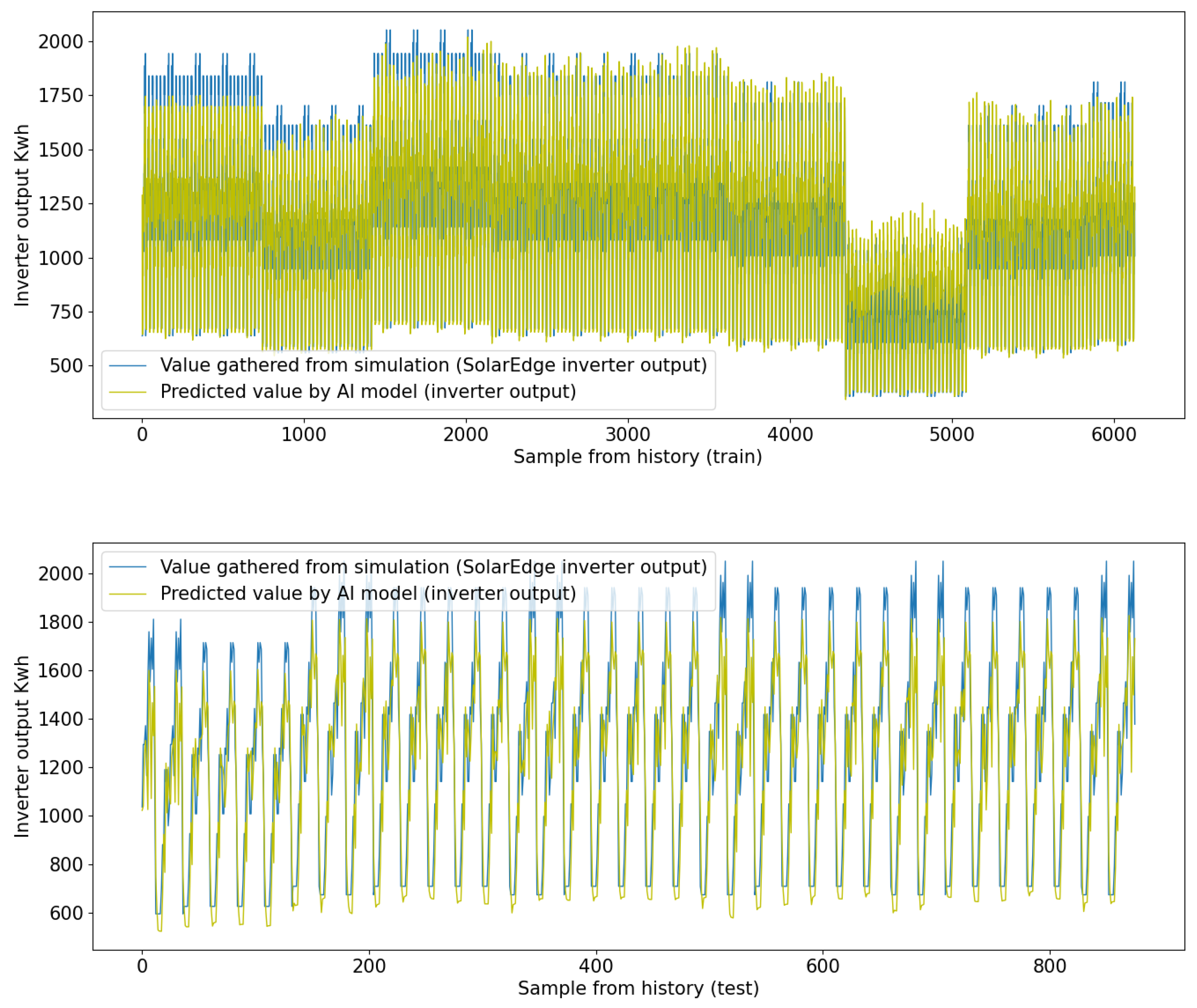
- Mean Absolute Error (MAE): The MAE is measured at approximately 131.257 Kwh (test), 178.811 KWh (train), indicating the average discrepancy between predicted and actual values.
- Normalized Mean Absolute Error (NMAE): The NMAE stands at around 0.063 (train), 0.087 (test) representing the relative average absolute error.
- Mean Absolute Percentage Error (MAPE): The MAPE is about 0.124% (train), 0.139% (test), signifying the average error as a percentage of the actual values.
- Mean Squared Error (MSE): The MSE is approximately 31018.050 (train), 50300.413 (test), reflecting the average squared difference between predicted and actual values.
- Explained Variance Score (EVS): With a value of approximately 0.814 (train), 0.745 (test), the EVS suggests a reasonably good fit of the model to the data. An EVS close to 1 indicates a stronger fit.
- Coefficient of Determination (R2): The R2 value is estimated at around 0.812 (train), 0.709 (test), which serves as a measure of the model’s accuracy in explaining the variance in the dependent variable.
- Root Mean Squared Error (RMSE): The RMSE is evaluated at approximately 176.119 KWh (train), 224.277 (test), signifying the square root of the average squared error.
4. Discussion
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Demirkiran, M.; Karakaya, A. Efficiency analysis of photovoltaic systems installed in different geographical locations. Open Chem. 2022, 20, 748–758. [Google Scholar] [CrossRef]
- Bochenek, B.; Jurasz, J.; Jaczewski, A.; Stachura, G.; Sekuła, P.; Strzyżewski, T.; Wdowikowski, M.; Figurski, M. Day-Ahead Wind Power Forecasting in Poland Based on Numerical Weather Prediction. Energies 2021, 14, 2164. [Google Scholar] [CrossRef]
- Gołȩbiewski, D.; Barszcz, T.; Skrodzka, W.; Wojnicki, I.; Bielecki, A. A New Approach to Risk Management in the Power Industry Based on Systems Theory. Energies 2022, 15, 9003. [Google Scholar] [CrossRef]
- Roberts, J.; Cassula, A.; Freire, J.; Prado, P. Simulation and Validation Of Photovoltaic System Performance Models. In Proceedings of the XI Latin-American Congress on Electricity Generation and Transmission–CLAGTEE 2015, Sao Paulo, Brazil, 8–11 November 2015. [Google Scholar]
- Milosavljević, D.D.; Kevkić, T.S.; Jovanović, S.J. Review and validation of photovoltaic solar simulation tools/software based on case study. Open Phys. 2022, 20, 431–451. [Google Scholar] [CrossRef]
- Shao, X.; Kim, C.-S.; Sontakke, P. Accurate Deep Model for Electricity Consumption Forecasting Using Multi-Channel and Multi-Scale Feature Fusion CNN–LSTM. Energies 2020, 13, 1881. [Google Scholar] [CrossRef]
- Ma, H.; Xu, L.; Javaheri, Z.; Moghadamnejad, N.; Abedi, M. Reducing the consumption of household systems using hybrid deep learning techniques. Sustain. Comput. Inform. Syst. 2023, 38, 100874. [Google Scholar] [CrossRef]
- Wang, B.; Wang, X.; Wang, N.; Javaheri, Z.; Moghadamnejad, N.; Abedi, M. Machine learning optimization model for reducing the electricity loads in residential energy forecasting. Sustain. Comput. Inform. Syst. 2023, 38, 100876. [Google Scholar] [CrossRef]
- Bilski, J.; Rutkowski, L.; Smolag, J.; Tao, D. A novel method for speed training acceleration of recurrent neural networks. Inf. Sci. 2021, 553, 266–279. [Google Scholar] [CrossRef]
- Wąs, K.; Radoń, J.; Sadłowska-Sałęga, A. Thermal Comfort—Case Study in a Lightweight Passive House. Energies 2022, 15, 4687. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| MAE: 102.09 | NMAE: 0.049 | MPL: 51.0468 |
| MAPE: 0.091 | MSE: 18869.570 | MAXERROR: 771.923 |
| EVS: 0.890 | R2: 0.885 | RMSE: 137.366 |
| MEAN TWEEDIE DEVIANCE: 18869.570 | MEAN POISSON DEVIANCE: 16.032 | |
| MEAN GAMMA DEVIANCE 0.0147 | D2 TWEEDIE SCORE: 0.885 | |
| D2 PINBALL SCORE: 0.703 | D2 ABSOLUTE ERROR SCORE 0.703 |
| MAE: 112.179 | NMAE: 0.0546 | MPL: 56.089 |
| MAPE: 0.091 | MSE: 27767.949 | MAXERROR: 803.295 |
| EVS: 0.839 | R2: 0.839 | RMSE: 166.637 |
| MEAN TWEEDIE DEVIANCE: 27767.949 | MEAN POISSON DEVIANCE: 21.329 | |
| MEAN GAMMA DEVIANCE 0.0172 | D2 TWEEDIE SCORE: 0.839 | |
| D2 PINBALL SCORE: 0.676 | D2 ABSOLUTE ERROR SCORE 0.676 |
| MAE: 131.257 | NMAE: 0.063 | MPL: 65.628 |
| MAPE: 0.124 | MSE: 31018.050 | MAXERROR: 649.162 |
| EVS: 0.814 | R2: 0.812 | RMSE: 176.119 |
| MEAN TWEEDIE DEVIANCE: 31018.050 | MEAN POISSON DEVIANCE: 26.525 | |
| MEAN GAMMA DEVIANCE 0.0246 | D2 TWEEDIE SCORE: 0.812 | |
| D2 PINBALL SCORE: 0.618 | D2 ABSOLUTE ERROR SCORE 0.618 |
| MAE: 178.811 | NMAE: 0.087 | MPL: 89.405 |
| MAPE: 0.139 | MSE: 50300.413 | MAXERROR: 801.092 |
| EVS: 0.745 | R2: 0.709 | RMSE: 224.277 |
| MEAN TWEEDIE DEVIANCE: 50300.413 | MEAN POISSON DEVIANCE: 39.998 | |
| MEAN GAMMA DEVIANCE 0.034 | D2 TWEEDIE SCORE: 0.709 | |
| D2 PINBALL SCORE: 0.484 | D2 ABSOLUTE ERROR SCORE 0.484 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pikus, M.; Wąs, J. Using Deep Neural Network Methods for Forecasting Energy Productivity Based on Comparison of Simulation and DNN Results for Central Poland—Swietokrzyskie Voivodeship. Energies 2023, 16, 6632. https://doi.org/10.3390/en16186632
Pikus M, Wąs J. Using Deep Neural Network Methods for Forecasting Energy Productivity Based on Comparison of Simulation and DNN Results for Central Poland—Swietokrzyskie Voivodeship. Energies. 2023; 16(18):6632. https://doi.org/10.3390/en16186632
Chicago/Turabian StylePikus, Michal, and Jarosław Wąs. 2023. "Using Deep Neural Network Methods for Forecasting Energy Productivity Based on Comparison of Simulation and DNN Results for Central Poland—Swietokrzyskie Voivodeship" Energies 16, no. 18: 6632. https://doi.org/10.3390/en16186632
APA StylePikus, M., & Wąs, J. (2023). Using Deep Neural Network Methods for Forecasting Energy Productivity Based on Comparison of Simulation and DNN Results for Central Poland—Swietokrzyskie Voivodeship. Energies, 16(18), 6632. https://doi.org/10.3390/en16186632