Abstract
The new power system is an energy interconnection network based on renewable energy generation. Information interconnection, data security, and reliability are the basis for the digital transformation of the power grid. Data sharing, lifecycle management, security, and user information privacy are issues that need to be addressed urgently. This paper analyzes the characteristics of the multi-combination of power grid data across services and introduces smart contract, cross-chain, and security encryption-related technologies. Based on the effective combination of smart contract and CP-ABE, data sharing schemes, including data sharing mechanism and data access control model are designed. Given this scheme, the blockchain system’s overall architecture is proposed, including the main chain, side chain, data sharing, and cross-chain information interaction. Finally, the underlying blockchain service platform is built using the Hyperledger open-source framework. We deploy the platform to verify the feasibility of the scheme according to the requirements of the data center, trust center, and blockchain-distributed nodes.
1. Introduction
The energy internet is an Internet-style smart grid. The new power system is an energy interconnection network based on renewable energy power generation. Through the intelligent energy management system, real-time, high-speed, two-way power data reading and renewable energy access are realized. Information interconnection, data security, and reliability are the basis for the digital transformation of the power grid. As the production, marketing, and management data of the power grid belong to different physical partitions, there is a problem of “data island” due to the connection and sharing of information. The user authentication information in the process of business handling must be manually audited. The process is cumbersome, the efficiency is low, and the service experience is difficult to improve. In addition, for the rich data resources collected by power grid enterprises, effective sharing and management mechanisms need further research and exploration. The construction of new data storage methods, such as power grid data centers and data lakes, to some extent, solves the problem of digital asset sharing and commercialization. However, data sharing, data lifecycle management, data security, and privacy of user information are problems that need to be solved urgently. With the development demand for new power systems, grid integration information fusion is an important technical guarantee for low-carbon systems with stable operation, safety and reliability, balance of energy supply and demand, improvement of grid quality, and effective consumption of renewable energy.
Some scholars carried out research on related issues [1,2], and others use the advantages of blockchain decentralization, autonomy, leak prevention, and openness to apply to data management. Considering the unstable characteristics of new energy power generation, ref. [3] proposed that 51% attack, internal attack, modification attack, and other measures in micro-grid data security sharing should be guaranteed by a systematic model. The State Grid Corporation of China (SGCC) has a large number of cloud applications on the system, and puts forward high requirements for data security. In terms of data sharing difficulties and privacy leakage risks of grid cloud server data, ref. [4] proposes a smart grid data sharing model (DSDCB) of dual alliance chain. In terms of the application of high-value data, ref. [5,6] proposed a high-value data sharing model of data center based on blockchain and game theory. In view of the security problem of edge power data in the smart grid, ref. [7] proposed the method of alliance chain. The data storage alliance chain system can realize safe and effective data storage and sharing. Through the compressed private data sharing framework, it provides efficient private data management for product data stored on the blockchain [8,9,10].
For the current data middle platform construction [11,12], data governance uses blockchain technology to provide a technical basis for the industry’s metadata management, data standard sharing and application [13]. Using blockchain to provide access control [14], promoted data search and retrieval for efficient distributed data storage and sharing. For frequent information sharing, users’ data are subject to security threats, such as data theft and tampering. Ref. [15] proposed a distributed ciphertext data security sharing scheme based on blockchain and outsourcing decryption CP-ABE. Ref. [16] investigated a secure data-sharing method based on CP-ABE and blockchain, and [17,18] investigate CP-ABE with efficient keys.
In view of the unreasonable data management mode, unreliable data sharing scheme, difficult repair of smart contract vulnerabilities, incomplete privacy protection of various types of data and other problems existing in the current blockchain security, ref. [19] analyzed and summarized the research on data security management and privacy protection technology at home and abroad. Combining traditional data storage (RDBMS), distributed data storage, and blockchain technology, ref. [20] explored three different models to build the security of the data storage system. Other fields, such as the government, have made good application exploration in data sharing and process unification of “All in One Network” [21].
The storage, positioning, redundancy, synchronization, and security of real-time data of power grid dispatching automation system put forward significant requirements and application prospects [22]. In the existing data sharing models, the security of data circulation transactions needs to be considered [23,24], such as low transparency of data transactions [25], lack of security guarantees for data, and lack of effective data tracking methods. Ref. [26] proposed a multi-group data sharing scheme with anonymity and traceability.
The above studies mainly focus on data management from the aspects of data storage, sharing, security, etc., and propose solutions for blockchain data storage, data transaction, etc. However, there is no systematic discussion on the whole life cycle of cross-business and cross-industry data capitalization, and there are no systematic technical means for data sharing and collaboration strategies in the transmission, transformation, distribution, and use of the energy Internet system. Scholars at home and abroad have carried out a lot of research on blockchain multi-chain data-sharing technology, and the problems of information interaction and value transfer between different blockchains need to be solved urgently.
According to the characteristics of large data volume, many data types, high data rate, and high-security requirements of power grid data, this work focuses on data service sharing, data storage involved in applications, security and privacy inclusion of data circulation, and data sharing strategies. The main contributions are in the following areas:
(1) A data sharing and data access control model scheme based on an effective combination of smart contracts and CP-ABE is proposed.
(2) Based on the centralized data center and data hub, we propose a system architecture for data sharing and control of blockchain systems, including main chain, side chain, data sharing, and cross-chain information interaction.
(3) Adopt a hyper ledger open source framework to build the underlying blockchain service platform. The platform is mainly composed of the main chain, side chain, and business application chain, which regulates the information interaction between cross-chains, collaborative management between the main chain and side chain, and has the ability of overall operation status monitoring, cross-chain interaction management, and application chain entry business supervision.
This paper consists of six chapters. Section 2 discusses the relevant technical characteristics and applicability for multi service data sharing and external service demand and application of the power grid. The model of data sharing and block integration is to build an information encryption system based on grid cloud business and form information aggregation with the blockchain in Section 3. Section 4 introduces the function of data sharing and storage. Section 5 analyzes the application characteristics of the model and system from the business chain based on the smart grid business scenario, and designs a system architecture that includes the whole chain of data across the chain (business). The last part is the analysis and summary.
2. Data and Blockchain Technology
2.1. Blockchain
Since Satoshi Nakamoto published their paper Bitcoin: A Peer-to-Peer (P2P) Electronic Cash System in 2008, the blockchain concept, technical system, system, and industrial applications have been continuously developed and iterated.
Blockchain is a technology in which everyone participates in recording and storing information. Running on a distributed P2P network with sophisticated authentication mechanisms can guarantee the integrity, continuity, and consistency of information (ledger). The key points involved in blockchain technology include decentralization, trust, collective maintenance, reliable database, timestamp, asymmetric cryptography, etc. Moreover, blockchain is a distributed database (or distributed shared ledger) that contains distributed storage of data and distributed bookkeeping of data (maintained collectively by system participants).
2.2. Cryptography Technology
Cryptography is the core technology to ensure information security in the data world. In blockchain technology, multiple cryptography technologies are used to connect data and blocks in chronological order to form a chained data structure that is difficult to tamper with and forge. These technologies include the hash algorithm, encryption algorithm, digital signature, Merkel tree, etc. Among them, the hash algorithm technology guarantees the integrity of the blockchain; encryption algorithm technology ensures the confidentiality of the blockchain; digital signature technology guarantees the integrity and non-repudiation of digital content; and Merkel trees reduce the cost of verifying integrity. In addition, some modern cryptography technologies have been applied to the blockchain, and the combination of these technologies has guaranteed the long-term healthy development of the blockchain.
2.3. Smart Contract
Smart contract was proposed by Nick Szabo in 1995. His definition is as follows, “A smart contract is a set of promises defined in digital form, including the agreement on which contract participants can implement these commitments.” Essentially, smart contracts work like statements in computer programs. Smart contracts interact with real world assets in this way. When a pre-prepared condition is triggered, the smart contract executes the corresponding contract terms. Smart contracts based on blockchain technology are generally divided into three categories:
- Smart contract code, also known as blockchain code.
- Smart legal contract is used to refer to specific applications of this technology, such as the way to supplement or replace existing legal contracts with blockchain, which becomes the integration of smart contract code and traditional legal language. For example, the Eris Industries dual integrated system, Primavera de Filipi legal framework for encrypted ledger transactions and Corda, and the smart contract system of blockchain alliance R3, follow this basic idea.
- Smart replacement contract means to create a new form of contract with commercial value by using smart contract code, such as M2M (machine to machine) business model.
A smart contract is a computer protocol designed to spread, verify, or execute contracts in an information-based way. The smart contract in the blockchain field has the following characteristics:
(1) Rules are open and transparent, and the rules and data in the contract are visible to the outside.
(2) All transactions are open and visible, and there will be no false or hidden transactions.
2.4. Cross-Chain of Blockchain
In 2012, Ripple Lab proposed the Inter Ledger protocol to solve the coordination problem between different blockchain systems. Herlihy [27] proposed the atomic transfer (atomic swap) on the Bitcoin Talk forum, which means that the sub-transactions constituting a complete cross-chain transaction occur or do not occur at the same time [28]. After improvement, the scheme becomes a main cross-chain mode, namely, hash locking mode. In October 2014, Block Stream explicitly proposed the concept of side chain for the first time. The sidechain uses the two-way peg mechanism to transfer encrypted assets between the side chain and the main chain at a certain exchange rate. In December 2016, Block Stream further proposed the sidechain with strong federation, which effectively reduced the delay between the side chain and the main chain and improved interoperability by introducing multi-signature addresses controlled by multiple parties. In 2017, the cross-chain project Polkadot and Cosmos proposed a plan to build a cross-chain basic platform, which can be compatible with all blockchain applications.
Due to the complexity of power grid services, data exchange under a single chain is difficult to achieve because of the strong isolation between different generated services due to security constraints. We use the cross-chain mechanism to explore the key points of data “all in one network”, such as information interaction, reliable transmission, real-time verification, privacy protection, and consensus synchronization, to solve the problems of data circulation, process traceability, and information security in data sharing across services, platforms, and fields, and to improve inter-chain connectivity and smooth exchange of data assets.
2.4.1. Notary Mechanism
When the trading parties across different chains distrust each other and have asymmetric information, the simplest way is to find intermediaries that both parties trust. The notary mechanism, also known as the witness mechanism, verifies whether a specific event has occurred on blockchain Y and proves to the nodes on blockchain X by electing one or a group of trusted nodes as the notary. The notary community reaches a consensus on whether the event occurs through a specific consensus algorithm.
The notary community reaches a consensus on whether the event occurs through a specific consensus algorithm. The notary model is the most widely used model at present, and the largest single notary is the exchange. A notary mechanism is one of the easier solutions to achieve interoperability between blockchains. It does not require complex proof of workload or proof of equity and is easy to interface with existing blockchain systems. Typical projects adopting a notary mechanism include Corda launched by R3 and The Inter Ledger Protocol (ILP) proposed by Ripple Laboratory.
2.4.2. Side Chain/Relay
The side chain is a concept relative to the main chain. Side chain protocol is essentially a special cross-chain solution. This solution can realize the value transfer from chain X to chain Y and later from chain Y back to chain X. Generally, chain X is called the primary chain, and chain Y is called the side chain.
When the performance of the main chain becomes a bottleneck or some functions cannot be expanded, transfer the assets to the side chain, and related transactions can be executed on the side chain, to share the pressure of the main chain and expand the performance and functions of the main chain.
2.4.3. Hash Lock
The hash lock is a mechanism that relies on the one-way and low collision of hash functions and takes advantage of the delayed execution of transactions in the blockchain. The trading party will publish the transaction setting the puzzle to the chain, and obtain the pledged deposit of the transaction if it can solve the puzzle within a specified time. Among them, the puzzle is implemented by hash locking. The first project to use hash-locking technology is Bitcoin’s lightning network project. The intention for the Lightning Network is to realize a real-time massive transaction network that does not require the participation of a trusted third party.
2.5. Distributed Data Storage Principle
One of the key principles of distributed data storage is redundancy, which is achieved by storing data in multiple locations and multiple physical nodes to ensure data availability and reliability.
As the volume of data continues to grow, another key principle is scalability. Distributed data storage enables new storage nodes to be added as needed without requiring significant changes to the underlying infrastructure. Then again, security is an important consideration. By storing data in multiple locations, the risk of data loss due to security breaches can be reduced. In addition, encryption and other security measures can be implemented to protect data at rest and in transit.
By utilizing the principles of redundancy, scalability, security, and cost savings, organizations can achieve a reliable, scalable, and secure data storage solution to meet their business needs.
Therefore, build a data storage system based on blockchain for cross-regional, cross-unit, and cross-department storage, break the data island effect in the traditional data sharing and storage process, and achieve unified data storage management.
According to the characteristics of power grid business data, this paper proposes a storage scalable model of blockchain (as shown in Figure 1). The node includes three roles, application node, storage node, and authentication node. The application node is the owner of the original data, the storage node is the keeper of the copy, and the verification node is the verifier of the stability of the storage node. A node can have two or three roles at the same time.
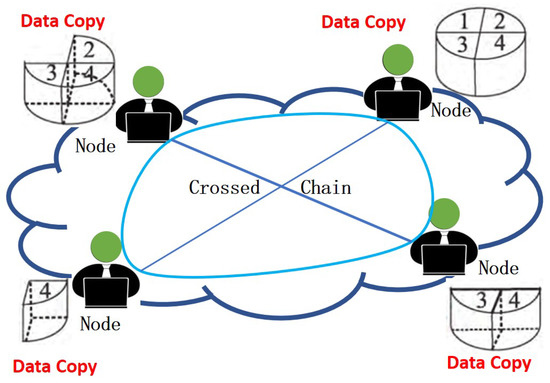
Figure 1.
Distributed data storage architecture.
2.6. Application Summary
In the blockchain network, the data in the entire network are visible to each node and user by default, which brings some potential data privacy security risks. In the power grid application scenario, the most sensitive data requirements cannot be synchronized, transmitted, and shared in plaintext across the network. In order to solve the security and privacy problems caused by the transparency of network node data, the blockchain Hyperledger multi-channel data isolation mechanism has greatly enhanced the protection of data privacy. However, since channel data are still visible to nodes in the same channel, the following problems still exist in this mechanism. (i) Data leakage risk: once a node is attacked by an attacker, all the plaintext data will be mastered by the attacker. (ii) The data privacy protection granularity is too coarse, and this channel based coarse granularity data privacy protection method is not applicable in some fine-grained data access control scenarios.
Therefore, relying on the technologies and methods related to Section 2.1, Section 2.2, Section 2.3, Section 2.4 and Section 2.5, we design a smart contract-based data access control strategy to ensure the security of polymorphic data production and consumption. In the process of data circulation, a data-sharing architecture based on multi-layer multi-chain blockchain architecture is established to achieve reliable integration and sharing of traffic on the polymorphic data chain.
3. Data Sharing Security and Strategy
3.1. Encryption under the Characteristics of Power Grid Data
The grid data have the following characteristics:
(1) Massive data. The remarkable feature of the electric power industry is its large number, which includes not only a large number of users and electric power enterprises, but also many levels involved in the production, transmission and management of electric power. Power data involve the whole process of production, transmission, management, and use.
(2) Multiple data types. In the power system, the types of data involved are often diverse, which is significantly different from big data in other industries. Power big data include not only structured data, such as numbers and symbols, but also unstructured data, such as images and videos, and also semi-structured data.
(3) High data transmission rate. For the operation process of the power industry, the speed of data analysis and processing is a key factor. We must vigorously popularize equipment with high speed and high intelligence to improve the accuracy and timeliness of the use of power big data and ensure that the value of power big data can be fully played.
(4) High security requirements. Electric power data includes power generation, transmission, distribution, transformation, and power consumption. It involves national security, user privacy, stable grid operation, and is closely related to the development of the national economy. Therefore, users of data sharing must use it under certain encryption rules.
Based on the data encryption technology under the cloud system, this paper mainly combines the blockchain and attribute-based encryption (ABE) to develop the data sharing mechanism and system strategy under the multi-service integration to solve the characteristics of large data volume, strong timeliness, complex types, and high security requirements. The message is encrypted based on attributes. Only users who meet the attribute requirements can decrypt the ciphertext, ensuring the confidentiality of the data. In addition, the user keys in ABE are related to random polynomials or random numbers. The keys of different users cannot be combined to prevent users from conspiring to attack and avoid a 51% attack risk.
3.2. CP-ABE
In CP-ABE, the access structure associated with ciphertext is also constructed as an access tree, where the internal nodes of the tree are all a threshold gate, described by their child nodes and thresholds. If is the number of its child nodes and is its threshold, then . The gate and the gate can be constructed as threshold gates. When , it is the gate, and when , it is the gate. The leaf node is associated with the attribute and is described by the attribute value and threshold . In order to facilitate the use of access numbers, some functions are also defined. represents the parent node of the node in the tree. represents the attribute associated with the leaf node in the tree. This function is defined only when the x node is a leaf node. For the child nodes of a node, the child nodes need to be numbered. returns the index value of the child node.
We use the following methods to determine whether the user attributes satisfy the access tree. Use to represent an access tree, and to represent a subtree with x as the root node. When the attribute set s satisfies , we mark it as . Calculate by iteration. If x is a non-leaf node, calculate all child nodes of x, and when , . If x is a leaf node, when belongs to s.
The above is the basic way for encryptors to express authorization attributes. CP-ABE includes four basic algorithms (Figure 2): , , , and .

Figure 2.
CP-ABE algorithm structure for multiple data service agents.
- System initialization: Setup() → {}Enter security parameters , Output system public key and system master private key
- Private key generation: KeyGen() →Enter the public key , primary private key , attribute set S, and user key
- Data encryption: Encrypt(, , M)→Enter the system public key PK, access structure , plaintext M, and output ciphertext
- Data decryption: Decrypt() →MEnter public key , ciphertext , user private key , and output plaintext M Otherwise, decryption fails
3.3. Data Access Control Model Based on Blockchain
3.3.1. Construct a Framework
The data access control model based on blockchain mainly includes five subjects, Trust Center (TC), Data Owner (DO), Data Request User (DRU), Consortium Blackchain (CB), and Cloud Storage Service Provider (CSP). The data access framework is shown in Figure 3.
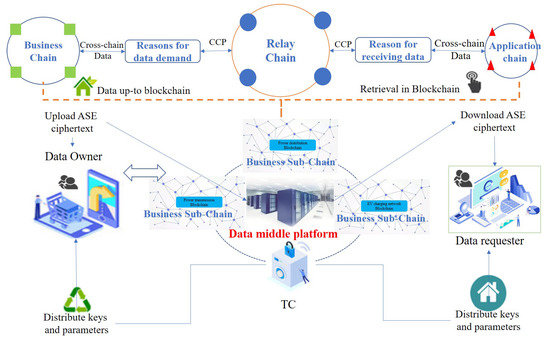
Figure 3.
Data sharing access control model.
In order to strengthen the supervision and traceability of data and ensure the security of access nodes, this model uses semi-centralized CB. In addition, this model uses homomorphic encryption algorithm to encrypt and protect data digest and keywords. The CP-ABE mechanism is used to realize the fine-grained access control and confidentiality requirements for the original file. The consistency of the data is determined by comparing the signature values. In terms of data retrieval, first of all, some illegal accesses are filtered through the smart contract mechanism, and then the keyword index ciphertext is introduced into CB to achieve fast retrieval.
(1) TC is responsible for issuing digital certificates to each user who enters CB for the first time. Each data user submits relevant registration information (identity information, organization, job title, confidentiality level, etc.) to TC, and can only obtain public and private keys, attribute private keys, and digital certificates after TC identity authentication authorization.
(2) DOs mainly share data with other DRUs. The fine-grained access control and confidentiality of data are mainly achieved by formulating smart contract rules and access control policy structure trees, and the data information summary is extracted and encrypted for fuzzy processing to achieve data preview.
(3)To obtain data, the DRU must meet the corresponding permissions to access the data.
(4) CB nodes are composed of units in different departments, units at different levels in the same department, other research institutions, etc., and jointly maintain the blockchain. CB stores data digest ciphertext and metadata to prevent data from being tampered with maliciously.
(5) CSP provides the function of storing encrypted data.
The data access control model based on blockchain is mainly divided into three stages, the system initialization stage, the data storage stage, and the data search and sharing stage.
3.3.2. Operation of Framework
Based on the above-designed data sharing and access framework, we develop a three-stage strategy to guarantee data security and transaction reliability. There are the initialization phase of the complex access control strategy for CP-AEB encrypted data, the data storage process phase of DO, and the data search and sharing mechanism design phase.
(1) Initialization stage.
This stage is based on the initialization of the CP-AEB key for the data middle(DM)/DC establishment TC and consists of two steps, setup and key generation.
- step.TC inputs the security parameter and attribute set A, and outputs the public parameter PK and master key . Enter the security parameter , let p be a large prime number, define as two multiplicative cyclic groups of order g, let g be the generator of group , and define the bilinear mapping . The security parameter lamd determines the size of the group. TC randomly selects two random numbers , calculate and , and generate public parameters and master key .
- step.represents the attribute set of users in the system, is the weight attribute partition set corresponding to attribute A, , and b is the sum of the weight attribute partition set corresponding to attribute and represents all parameter sets of the user’s attributes in the system. TC inputs DRU with all parameter sets of user attributes and master key , and outputs attribute weight private key . The system randomly selects , and selects a random value for each attribute of , then the private key of attribute weight is . And then it generates the key, , where , .
(2) Data storage stage.
The DO calculates the metadata storage index ciphertext , data keyword and digest ciphertext , original data hash value , respectively, and stores them in to realize off chain computing and on chain storage. The specific calculation steps are as follows:
- Obtain the symmetric key from the TC, and symmetrically encrypt the plaintext data M to obtain the ciphertext , . Upload to the cloud storage server to obtain the storage location index .
- Construct the access policy T, add the weights of each attribute through preprocessing to obtain the sum of the weight values b as the leaf node, thus reducing the cost of CP-ABE calculation.
- Through CP-ABE, access policy T, storage location index , symmetric key are encrypted to obtain ciphertext . If the root node satisfies , and is the set of all parameters of the attribute, then Equation (1):
- Select the random number to calculate the key sub and the encrypted ciphertext of the data digest.
- Calculate the hash value () of metadata.
- Store metadata format in .
(3) Data search and sharing stage.
The flow of DRU accessing data is shown in Figure 4.

Figure 4.
Data search and sharing access process.
The process first verifies the user’s identity secret level and the security period of the file through the smart contract mechanism, If it meets the requirements, query the CB’s data keywords and summary information, and verify the access policy structure tree through CP-ABE to obtain the index address and symmetric key of the data after verification and decryption. After verification, the ciphertext data are downloaded from the data middle platform (DMP) or ECS, and so it has decrypted the plaintext using the symmetric key, and by comparing the hash value to ensure the integrity of the data.
- DO sets smart contract rules, and sets the confidentiality level and confidentiality period of data. The DRU calls the smart contract to verify the consistency of its own confidentiality level and the confidentiality level of the data, and reviews the confidentiality period of the data. Follow next step if the confidentiality level and confidentiality period meet the requirements of the smart contract. Otherwise, access is directly denied. Set the timed polling detection function of the smart contract. If there is a problem with the file deadline, the data owner will be directly reminded to change the CB metadata and re-link. The specific algorithm pseudo code is described below.
- The DRU obtains the data file index ciphertext and hash value of the keyword or digest ciphertext in the query. Use the attribute weight private key to verify whether the DRU meets the access control tree T, where q is a node of T. Set . It is a root node of the access control tree T. If it is satisfied, calculate Equation (2):Obtain the file index and symmetric key of the original .
- Download the data ciphertext from the cloud storage server, and decrypt the data to obtain the plaintext as Equation (3).
- Finally, calculate the hash value and verify the consistency of the data.
3.4. Multi-Chain Structure for Data Storage and Sharing
According to Section 2.5, we establish two new blockchains in the data storage model: position chain (p-chain) and proofs of retrievability chain (POR-chain). POR-chain is saved in the application node, and each copy of the record data is saved in the storage node. POR-chain is saved in the verification node to record the reliability evaluation of each storage node. Storage expandable model of blockchain as Figure 5, and the process of data storage and reading as the Algorithm 1.
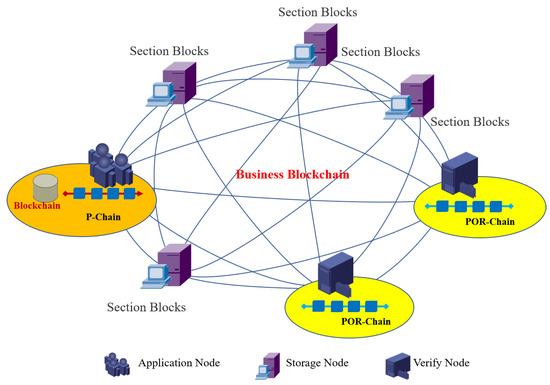
Figure 5.
Storage expandable model of blockchain.
The storage node location information and the reliability evaluation of the storage node are written into the p-chain and POR-chain based on the blockchain technology, which also makes use of the characteristics of the blockchain that cannot be tampered with to ensure data security. The key steps of the extensible model include data storage and reading, reliability verification of storage nodes, data replica allocation, etc.
| Algorithm 1: The process of data storage-based POR-Chain |
 |
In the data storage and reading process of Storage Node, Application Node, and Verify Node in Figure 5, the relationship and responsibilities between the three types of nodes are described as follows.
It encrypts each block in the application node using a POR chain to first obtain the corresponding ciphertext and key. Then the application node calculates the number of copies to be saved for each block. Then, the model saves the key generated by the POR chain into the local memory, sends it to the verification node for saving, and saves the encrypted block data into the storage node. The model will access the reliability information of the storage nodes saved in the verification node and find out the storage node with a higher reliability value to save each block data from it. The validation node saves the storage node reliability information in the POR chain to ensure that it will not be tampered with maliciously.
When performing data reading, first the application node accesses the P-chain in the local disk to obtain the location information of each block storage and finds the corresponding storage node based on the location information. Then, the storage node returns the saved data to the application node. The application node recovers the received ciphertext data according to the key generated by the locally saved POR chain to obtain the original data.
The reliability verification process of storage nodes in the blockchain storage capacity scalability model is as follows. In practical application, the following methods can be used to evaluate the reliability of storage nodes. First, the model will assign the same reliability value to each storage node. Then, the verification node checks the reliability of the stored node data every other period, and the interval time is determined according to the specific situation of the data security requirements. When the data in the storage node are complete, its reliability value remains unchanged.
When the storage node data are modified or lost, their reliability value is reduced and saved in the POR chain. Finally, when the model selects a storage node with high reliability, the reliability value of each POR-chain storage node is used to measure the data replica allocation strategy.
4. Multilayer Application Architecture Design of Blockchain Power Grid
The previous chapter analyzes and studies the data storage, data security access, and security sharing strategies. This section will use the above related methods, models, strategies, etc., to design a set of platform technical frameworks for the cross department, organization, regional and level sharing applications of a large number of multi-source heterogeneous data sources involved in the grid “all in one network” application, and build an object-oriented and scalable data chain management method to achieve efficient data storage, retrieval, and safe sharing.
4.1. Overall Application Architecture
According to the grid business characteristics, data attributes, and the application characteristics of the analysis model and system from the business chain, we designed the overall system architecture that includes the whole chain of data across the chain (business). The architecture (as shown in Figure 6) can be divided into three layers, hardware layer, blockchain layer, and application layer.

Figure 6.
Blockchain multi-tier application framework for specific services.
The hardware layer is composed of the physical transmission and distribution network in the power grid and measurement, storage, communication, and other equipment, which provides the hardware foundation for the blockchain layer and is responsible for data linking and other work.
The blockchain layer includes different types of nodes, data chains, consensus mechanisms, etc. The application layer provides platform support to achieve its specific functions.
The application layer is based on the business functions realized by smart contracts and interacts with users. Each layer completes a core function, and each layer cooperates with each other to achieve a decentralized trust mechanism for data within the department.
In the design of the blockchain layer, the blockchain layer is the key. We specifically analyze different business applications, and determine the selection and positioning of blockchain types, consensus algorithms, blockchain node functions, etc. Blockchain types include public chain, alliance chain, and private chain, and the consensus algorithm includes workload proof, equity proof, practical Byzantine fault tolerance, etc. The types of blockchain nodes located according to their functions include, but are not limited to, consensus nodes, storage nodes, and light nodes. Therefore, according to the functional positioning of each power business, we designed the corresponding blockchain node type construction scheme for different participants to support specific applications in the business field.
The data sharing is realized by the blockchain layer, and the construction of information encryption system is guaranteed by the CP-ABE security strategy. It forms an information aggregation with the blockchain, and builds a blockchain ecosystem of main chain and side chain collaboration, namely, the main chain and side chain. The main chain contains all business data certificates and is responsible for data supervision, but does not require a large number of users to connect. Different business departments in different regions need to be connected to the side chain to handle the data query needs of power users.
4.2. Cross-Chain Data Service of Power Grid
The side-chain and the main-chain can interact across chains to realize data sharing in different regions and businesses.
Cross-chain architecture (as shown in Figure 7) is adopted to realize multi-chain information interaction (as described in Section 2.4). Based on cross-chain interoperability, a general inter-chain message transmission protocol is provided, and, based on this protocol, cross-chain technical services that support transactions between homogeneous and heterogeneous blockchains are implemented, enabling asset exchange, information exchange, and service complementation between heterogeneous chains. The cross-chain service platform is composed of relay chain, application chain, and cross-chain gateway. It has three core functional characteristics, general cross-chain transmission protocol, heterogeneous transaction verification engine and multi-level routing, ensuring the security, flexibility, and reliability of cross-chain transactions.

Figure 7.
Cross-chain business undertaking framework.
4.3. Multi-Party Interconnection and Cooperation System
The data application is discussed according to the actual situation of data sharing construction in National Grid Company.
At present, the power grid company has built DMP and energy big data center, we address some important data application processes, there are data interconnection and data source consistency are poor, data security sharing is difficult, and other cross-sector, cross-regional, cross-industry, and other problems. Establishing a blockchain-based multiparty interconnection and cooperation system (as shown in Figure 8), using the blockchain’s tamper-proof, confirmable, and traceable technical features to realize the shared application of internal cross-professional data on DMP and the interconnection and exchange of external data in the energy data center.

Figure 8.
Multi-party interconnection and cooperation system and power data sharing application design based on blockchain.
5. Common Functions
Combining the blockchain multi-layer application framework (Figure 6), the cross-chain organization form (Figure 7), and the grid data application system scheme (Figure 7), we obtain the basic functions of data storage and sharing under cross-chain based conditions. For the data-sharing platform of cross-business multi-data fusion, the architecture is designed, mainly the business management layer, technical support layer, and application layer.
(1) Platform management
Responsible for blockchain management services, including user rights management, channel management, operation management, smart contract interaction interface, etc.
(2) Technical support layer
This is the platform blockchain infrastructure, including block construction and synchronization, consensus algorithm, smart contract, cross-chain protocol, CP-ABE, CA, privacy protection, and other basic functions. The technical support layer includes the underlying support modules of the blockchain, such as privacy protection, blockchain governance, data management, and trusted data sources. We implement blockchain applications such as contract engines, consensus algorithm libraries, hybrid storage, and P2P network.
- Efficient consensus algorithm. On the premise of ensuring the strong consistency of node data, improve the overall transaction throughput capacity and system stability of the system. TPS (number of data sharing/transactions processed per second) reaches more than 20,000, and the delay can be controlled within 300 ms.
- Smart contract engine.Support EVM and other smart contract engines, support SOLIDITY and other programming languages, provide complete contract lifecycle management, and have the characteristics of friendly programming, safe contract, and efficient execution to adapt to changing and complex business scenarios.
- Data sharing security.The CP-ABE encryption scheme is integrated with fine-grained access control for encrypted data. Users are revoked through a fixed-length revocation list record. The revocation process does not need to update the secret keys of the system and related users, reducing the computational overhead caused by the revocation.
- Privacy protection.This design provides two mechanisms of partition consensus and privacy transaction to achieve privacy protection. The partition consensus can support the isolation of the storage and execution space of sensitive transaction data, enabling some blockchain nodes to create their partitions, and data transactions and storage between partition members are invisible to nodes in other partitions. The private transaction refers to the relevant party of the transaction that can be specified at the time of sending. The transaction details are only stored in the relevant party.
- Cross-chain design.Cross-chain interoperability realizes the inter-chain message transmission protocol. Based on this protocol, cross-chain technical services that support transactions between homogeneous and heterogeneous blockchains are implemented, enabling asset exchange, information exchange, and service complementarity between heterogeneous chains. The cross-chain service platform is composed of a relay chain, application chain, and cross-chain gateway.
(3) Application layer
It is mainly responsible for providing support functions for business applications and responsible for data lifecycle circulation management, including data transaction, certificate storage, and sharing, permission configuration, and providing corresponding common functions for different business applications.
Two functions, contract certificate management and key certificate management in the main chain, support the application of certificate business. The main-chain certificate provides safety stores for the business layer and provides queries business for other chains through cross-chain services.
The circulation side chain includes seven functional items, including data sharing/transaction concurrency optimization, point-to-point transaction, sharing/transaction data privacy protection, sharing/transaction data preservation, transaction identity certificate service, credit evaluation, and renewable energy excess consumption responsibility weight, to achieve the basic service capability of blockchain data flow and sharing business.
The business data chain supports the company’s data protection, data supervision, data sharing, and data value-added services through five functional items, data resource management, data privacy service, data account management, data uplink management, and data contract management, to achieve full life cycle data management and data capitalization, build a reliable source of power data, transparent data call and calculation process, accurate data analysis results, and improve the ability of reliable sharing and application of power data.
6. Case Study
6.1. Test Verification Environment
In this work, the Hyperledger [29] open-source framework is used to build the underlying blockchain service platform. The main chain is mainly responsible for overall operation status monitoring, the cross-chain interaction management and application chain certificate storage business supervision, verifying the legitimacy of node identity, verifying the legitimacy of transactions, synchronizing new blocks generated by the network, and maintaining the integrity of the entire blockchain. The side chain is the data-sharing business chain extended by the underlying service platform.
In this case, three types of nodes are deployed according to roles, super node, supervision node, and ordinary node. Combined with the contents in Section 3.2 and Section 3.3 and the Figure 2 and Figure 4, it can be implemented by embedding CP-ABE in Fabric CA (FCA), which is equivalent to FCA as a trusted third party in CP-ABE scheme. At this time, FCA not only manages the certificates required by users in the original Fabric network, but also has the initialization of the CP-ABE scheme and the generation and distribution of user attribute private key .
Data users can interact with FCA and blockchain network through Client, which mainly includes registering with FCA to obtain corresponding certificates and user attribute private keys of CP-ABE scheme, encrypting plaintext data with the obtained private key and user-specified access control strategy, and then sending the ciphertext to blockchain network in the form of transaction for uplink storage of encrypted data. The overall workflow of the scheme can be roughly divided into three stages, key generation stage, data encryption uplink stage, and access control stage, including six steps, Setup, KeyGen, Encrypt, Update, Download, and Decrypt.
In order to show the specific process of the scheme more objectively, we take the interaction between DR-A and DO-A as an example (DO-A wants to encrypt private data on the chain, and DR-A wants to access the plaintext corresponding to the ciphertext). Suppose that DR-A interacts with the blockchain network and FCA through the application node Node-B and DO-A through the business data administration node Node-A. The specific implementation details are shown in Figure 9.

Figure 9.
Overall work flow of the scheme.
The deployment of this verification system is tested by referring to the structure of a power enterprise’s multi data center, provincial and municipal data center, and cloud service center. According to the minimum design requirements of the data center, it simulates the distributed data centers in East China, North China, and Northwest China, and deploys a multi-service main chain to form a star computing node. The core management trust center (TC) is deployed in the North China Center, and the other two are used as storage nodes. The provincial (administrative region) business partition is used to build data management nodes and cross-business application nodes. Data management, application authorization, and data flow control are centralized in the data side chain under the main chain and provincial and municipal management. The application node can be flexibly deployed according to its size and authorization mode.
6.2. Performance Analysis
In order to verify the feasibility of this scheme, the data demand node uses a general server, and the node resource configuration is operating system CentOS 8, 8 GB memory, and two core processors allocated to hardware resources.
Considering that this scheme will not change the transaction process of the original super ledger network, it only replaces the plaintext data on the chain in the original blockchain network with the ciphertext data encrypted by CP-ABE. This change is transparent to the underlying transaction process and will not affect the original operational efficiency of the super ledger network. In the scheme designed in this paper, the attribute private key involved in the CP-ABE scheme can contain up to three attributes, channel ID, organization ID, user ID, etc. Analyze the time efficiency of data sharing encryption and decryption (as shown in Figure 10).

Figure 10.
Relationship between CP-ABE encryption and decryption time and data size.
By analyzing the impact of the generation time of the user attribute private key and the size of the data to be encrypted and decrypted on the encryption and decryption time, it is known that the encryption and decryption time increases in a linear trend. When the data size is 10 MB, the encryption time is about 0.07 s, the decryption time is about 0.06 s, and the execution time is within an acceptable range of increments. Therefore, the blockchain data access control mechanism based on CP-ABE algorithm implemented on the original super ledger network operating mechanism has good feasibility.
7. Power Data Sharing and Discussion
The increasingly open network environment brings new challenges to the safe operation of the system. Therefore, to improve the reliability of the power business data platform can not only rely on the optimization of the platform design stage but also find and control potential risks through effective risk assessment and risk prediction during the operation process. Due to the high requirements of timeliness, security, and privacy of power data, data sharing risk assessment needs to establish systems and methods to ensure.
7.1. Risk Assessment for Data Sharing
7.1.1. Risk Identification Scheme for Polymorphic Data Sharing
First of all, consider the grid operation, trading, planning and other business forms, and comprehensively consider the data source of the power “one network for all” multi data sharing. Then, analyze the risk sources in the link of polymorphic data sharing, and establish a risk identification scheme. During risk management, data sharing risks are divided into three categories by consulting experts, user representatives and other schemes:
- Data loss.The risk of data loss may occur in the process of data upload, storage, and consumption. The loss of power data will lead to the failure of power trading and planning decisions.
- Data leakage.The risk of data leakage may occur in the process of data storage and consumption. The loss of power data will lead to unauthorized data sharing participants obtaining corresponding data, endanger data security, and damage the privacy and fairness of data sharing.
- Data tampering.The risk of data tampering may occur in the process of data generation, upload, storage and consumption. Power data tampering endangers the normal operation of power systems, and also has a serious impact on the normal operation of data sharing systems.
7.1.2. Build a Risk Measurement System
We analyze the identified risk factors, sort out and analyze the historical data of relevant risk factors, analyze and evaluate the risks according to the probability of risk occurrence and the severity of the consequences in combination with expert experience and knowledge, quantify the risk factors of data sharing, assign a certain weight value and grade, and establish a risk assessment matrix. The analysis process is:
- Establish risk function.The risk function is established with the binary function. Where P is the probability of risk occurrence, and I is the degree of impact of risk occurrence.
- Determine the risk impact.The risk impact level is based on the characteristics of each participant in the data sharing system and the degree of risk acceptance. It is divided into several risk severity levels.
- Analyze risk probability.According to historical data and expert opinions, the probability of risk occurrence is divided into several levels.
- Draw the risk matrix.According to the risk acceptance degree determined in advance, the risk evaluation matrix is drawn, and the risk level is preliminarily determined by the risk function value.
7.1.3. Risk Assessment Strategy
On the basis of data sharing risk measurement system, the comprehensive evaluation system of power data sharing risk is established by using the analytic hierarchy process. The specific process is:
- Establish the hierarchical analysis structure model.Hierarchical arrangement of risk factors to form a hierarchical model (as shown in Figure 11).
 Figure 11. Risk assessment strategy for power polymorphic data sharing.
Figure 11. Risk assessment strategy for power polymorphic data sharing. - The judgment matrix of each layer is constructed.The judgment matrix A (as shown in Equation (4)) is constructed according to the risk structure chart and the relative weight of the risk factors, which represents the importance of the risk between the factors of the same layer on the previous layer:In the formula, represents the relative weight obtained by comparing scheme and scheme with respect to an intermediate layer element.
- Weight calculation.Geometric average method, arithmetic average method, least square method, and eigenvector method are used to calculate the weight of judgment matrix A. The formula is Equation (5)where is the maximum eigenvalue of matrix A and W is the eigenvector corresponding to . Z finally obtains the risk degree weight value of risk factors. The risk assessment results of polymorphic data sharing of “all in one network” are obtained.
7.2. Risk Prediction with Data-Sharing Lifecycle
With a large number of low-carbon energy systems using renewable energy for power generation running on the Internet, the smart grid’s requirement of “one network for all” has found effective solutions to problems, such as data sharing, data lifecycle management, data security, and user information privacy.
In the aspect of risk prediction for power data network, some scholars put forward a risk prediction mechanism for a power data network based on an entropy weight grey model to solve the problem of overall network risk prediction. The Software Engineering Institute (SEI) proposed a continuous risk management (CRM) model to build a software risk management framework consisting of continuous risk management, team management, and risk assessment. The basic process of the risk management model is:
- Identify and evaluate potential risk factors.
- Prioritize the assessed risks.
- Formulate risk response strategies according to the priority of risks, and monitor the implementation effect of the strategies.
7.3. Polymorphic Data Sharing and Discussion
The polymorphic data sharing is a technique that enables different types of data to be shared across different systems. This technique is widely used in modern software development, but it also poses significant risks to data security and privacy. One of the primary risks associated with polymorphic data sharing is the potential for data breaches. When different types of data are shared across different systems, it becomes challenging to maintain data security. This is because each system may have different security protocols, and it can be difficult to ensure that all systems are adequately protected. As a result, hackers can exploit vulnerabilities in one system to gain access to other systems, leading to data breaches and loss of sensitive information.
Another risk associated with polymorphic data sharing is the potential for data corruption. When different types of data are shared across different systems, there is a risk that the data may become corrupted or altered. This can happen when data are transferred between systems, or when different systems interpret the data differently. As a result, the integrity of the data can be compromised, leading to errors and inaccuracies.
To mitigate these risks, it is essential to implement robust security protocols and data management practices. This includes implementing strong encryption and access control measures, as well as regularly monitoring and auditing data access and usage. Additionally, it is crucial to establish clear data-sharing policies and procedures and to ensure that all stakeholders are aware of these policies and adhere to them.
Polymorphic data sharing is a powerful technology that enables efficient data sharing between different systems; however, it also poses significant risks to data security and privacy.
8. Conclusions
According to the characteristics of large data volume, multiple data types, high data rate, and high security requirements of power grid data, this paper mainly studies data service sharing, data storage involved in applications, security and privacy inclusion of data circulation, data sharing strategies, etc. Firstly, the technologies related to smart contract, cross-chain and security encryption are introduced, and the characteristics of multi-service integration of grid data are analyzed. Based on the effective combination of smart contract and CP-ABE, a data sharing scheme is proposed. In the scheme, data sharing mechanism and data access control model under multi-service integration are developed.
According to the characteristics of power grid business, data attributes, and the application characteristics of the analysis model and system from the business chain, this paper designs the overall architecture of the system including the whole chain of cross-chain data, multi chain information interaction methods, and designs a data access control strategy based on smart contracts to ensure the security of polymorphic data production and consumption; in the process of data circulation, we establish a data-sharing architecture based on multi-layer and multi-chain blockchain architecture to achieve reliable integration and sharing of the flow on the polymorphic data chain. In terms of system deployment and application, cross-chain data sharing is carried out with business systems supporting blockchain networks through alliance chains, cross-chain collaboration and other ways; (i) data sharing is carried out with power grids and external applications (such as government systems) that do not support blockchain networks through API calls; (ii) it should ensuring the security and reliability of information on the chain through the identity authorization management mechanism and cross verification mechanism.
This paper uses the Hyperledger open source framework to build the underlying blockchain service platform. The platform is mainly composed of the main chain, side chain, and business application chain standardized information interaction between cross-chains, collaborative management between the main-chain and side-chain, and has the capabilities of overall operation status monitoring, cross-chain interaction management, and application chain depository business supervision.
Finally, in combination with the actual deployment design requirements of a domestic power grid company’s blockchain, according to the requirements of the data center, verification center, and blockchain distributed nodes, we deploy the platform to verify the feasibility of the scheme. The case proves that the blockchain data access control mechanism based on CP-ABE algorithm implemented on the original super ledger network operating mechanism is feasible. According to the actual needs of data sharing, this paper proposes the systematization, methods and security strategies of data sharing risk assessment. It provides technical exploration and technical basis for data security sharing.
Author Contributions
All the authors contributions to various degrees to ensure the quality of this work. Conceptualization, methodology, supervision, writing—original draft preparation, formal analysis Q.H., M.W. and M.Z.; software and validation, L.J.; funding acquisition, investigation, data curation, resources, Y.L. and Z.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Science and Technology Project of SGCC OF FUNDER grant number 5700-202153179A-0-0-00. Funders are involved in data curation, formal analysis, supervision validation, visualization, and project management.
Data Availability Statement
Restrictions apply to the availability of these data.Restrictions apply to the availability of these data. Data were obtained from the energy companies and are unavailable due to onfidentiality agreements.
Acknowledgments
This paper is supported by the scientific and technological project of State Grid Corporation of China: Research on Digital Mutual Trust and Cross domain Sharing Technology of Power All in One Network. At the same time, with the great help of BCNL research team of Beijing University of Posts and Telecommunications, the laboratory provides an experimental environment and effective support for system model simulation testing. In the process of compiling materials, we have received a lot of support and assistance from State Grid Gansu Electric Power Company and Gansu Tongxing Intelligent Technology Development Co., Ltd.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Jiang, L.; Ye, Z.; Dong, G. Research on power data management architecture based on blockchain. Power Big Data 2021, 24, 19–24. [Google Scholar]
- Wen, L.; Zhang, L.; Li, J. Application of Blockchain Technology in Data Management: Advantages and Solutions; Springer International Publishing: Cham, Switzerland, 2019; pp. 239–254. [Google Scholar]
- Zhang, L.; Cao, Y.; Zhang, G. Microgrid data security sharing scheme based on blockchain. Comput. Eng. 2022, 48, 43–50. [Google Scholar]
- Wu, Z.; Liang, Y.; Kang, J.; Yu, R.; He, Z. Smart grid data security storage and sharing system based on alliance blockchain. Comput. Appl. 2017, 37, 2742–2747. [Google Scholar]
- Yu, K.; Guo, L.; Yin, H.; Yan, X. The High-Value Data Sharing Model Based on Blockchain and Game Theory for Data Centers. Netinfo Secur. 2022, 22, 73–85. [Google Scholar]
- Yu, K.; Guo, L.; Yao, M. Design of Blockchain-based High-value Data Sharing System. Netinfo Secur. 2021, 21, 75–84. [Google Scholar]
- Zhang, L.; Wang, X.; Hu, F. Smart grid data sharing model based on dual alliance chain. Comput. Appl. 2021, 41, 963–969. [Google Scholar]
- Qi, S.; Lu, Y.; Zheng, Y.; Li, Y.; Chen, X. Cpds: Enabling Compressed and Private Data Sharing for Industrial Internet of Things Over Blockchain. IEEE Trans. Ind. Inform. 2021, 17, 2376–2387. [Google Scholar] [CrossRef]
- He, Q.; Duan, J.; Min, J.; Hao, W.; Ye, J.; Xu, J.; Wu, M.; Zhao, M. Task Scheduling Algorithm Based on Time and Cost in Smart Grid Cloud Computing; Institute of Electrical and Electronics Engineers Inc.: New York, NY, USA, 2022; pp. 847–852. [Google Scholar]
- Ge, L.; Ji, X.; Jiang, T.; Jiang, Y. Security mechanism for Internet of things information sharing based on blockchain technology. J. Comput. Appl. 2019, 39, 458–463. [Google Scholar]
- Wang, J.; Xu, M.; Lu, K. The Research of Adaptive Data Desensitization Method Based on Middle Platform. Wirel. Commun. Mob. Comput. 2022, 2022, 1530–8669. [Google Scholar] [CrossRef]
- Mao, Z.J.; Wu, J.Y.; Qiao, Y.L.; Yao, H. Government data governance framework based on a data middle platform. Aslib J. Inf. Manag. 2022, 2, 289–310. [Google Scholar] [CrossRef]
- Song, J.; Dai, B.; Jiang, L.; Zhao, Y.; Li, C.; Wang, X. Data governance collaborative method based on blockchain. J. Comput. Appl. 2018, 38, 2500–2506. [Google Scholar]
- Grabis, J.; Stankovski, V.; Zarins, R. Blockchain Enabled Distributed Storage and Sharing of Personal Data Assets. In Proceedings of the 2020 IEEE 36th International Conference on Data Engineering Workshops (ICDEW), Dallas, TX, USA, 20–24 April 2020; pp. 11–17. [Google Scholar] [CrossRef]
- Zeng, H.; Xi, N.; Xie, Q.; Lu, J.; Cui, Z.; Ma, J. Decentralized ciphertext sharing based on blockchain. J. Xidian Univ. 2022, 49, 135–145. [Google Scholar]
- Zhang, Z.; Ren, X. Data security sharing method based on CP-ABE and blockchain. J. Intell. Fuzzy Syst. 2021, 40, 2767–2777. [Google Scholar] [CrossRef]
- Zhao, Y.; Ren, M.; Jiang, S.; Zhu, G.; Xiong, H. An efficient and revocable storage CP-ABE scheme in the cloud computing. Computing 2019, 101, 1041–1065. [Google Scholar] [CrossRef]
- Zhang, W.; Zhang, Z.; Xiong, H.; Qin, Z. PHAS-HEKR-CP-ABE: Partially policy-hidden CP-ABE with highly efficient key revocation in cloud data sharing system. J. Ambient. Intell. Humaniz. Comput. 2022, 13, 613–627. [Google Scholar] [CrossRef]
- Liang, X.; Wu, J.; Zhao, Y.; Yin, K.T. Review of blockchain data security management and privacy protection technology research. J. Zhejiang Univ. Sci. 2022, 56, 1–15. [Google Scholar]
- Raj, S.N.; Sherly, E. Blockchain-Based Shared Security Architecture. In Cognitive Informatics and Soft Computing; Mallick, P., Balas, V., Bhoi, A., Chae, G.S., Eds.; Advances in Intelligent Systems and Computing; Springer: Singapore, 2020; Volume 1040. [Google Scholar] [CrossRef]
- Hao, Y.; Piao, C.; Zhao, Y.; Jiang, X. Privacy Preserving Government Data Sharing Based on Hyperledger Blockchain. In Advances in E-Business Engineering for Ubiquitous Computing, Proceedings of the 16th International Conference on e-Business Engineering (ICEBE 2019); Springer International Publishing: New York, NY, USA, 2020. [Google Scholar] [CrossRef]
- Zhai, M.; Wang, J. Architecture and key technologies of power grid dispatching wide area distributed real-time database system. Power Syst. Autom. 2013, 37, 67–71. [Google Scholar]
- Wang, Z.; Tian, Y.; Zhu, J. Data Sharing and Tracing Scheme Based on Blockchain. In Proceedings of the 2018 8th International Conference on Logistics, Informatics and Service Sciences (LISS), Toronto, ON, Canada, 3–6 August 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Zhang, G.; Wang, R. Blockchain shard storage model based on threshold secret sharing. J. Comput. Appl. 2019, 39, 2617–2622. [Google Scholar]
- Fan, T.; He, Q.; Nie, E.; Chen, S. A Study of Pricing and Trading Model of Blockchain & Big Data-Based Energy-Internet Electricity; IOP Publishing Ltd.: Bristol, UK, 2018. [Google Scholar]
- Huang, H.; Chen, X.; Wang, J. Blockchain-based multiple groups data sharing with anonymity and traceability. Sci.-China-Inf. Sci. 2020, 63, 1–13. [Google Scholar] [CrossRef]
- Herlihy, M. Atomic Cross-Chain Swaps. arXiv 2018, arXiv:1801.09515. [Google Scholar]
- Deshpande, A.; Herlihy, M. Privacy-Preserving Cross-Chain Atomic Swaps. In Financial Cryptography and Data Security. FC 2020: Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2020; Volume 12063. [Google Scholar] [CrossRef]
- Available online: https://github.com/hyperledger/fabric (accessed on 10 September 2022).
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).