
Machine Learning Algorithms for Identifying Dependencies in OT Protocols


 and
and 
Abstract
1. Introduction
2. Related Work
- -
- Stuxnet (2010): an attack on Iranian nuclear facilities. This attack was highly sophisticated. The attack exploited four zero-day vulnerabilities and targeted specific PLCs manufactured by Siemens. The attack aimed to damage uranium enrichment lines [15,16]. The attack was a multi-stage attack. In the final stage, the attackers took control of the centrifuges and modified the values of the control signals, ultimately damaging the equipment.
- -
- Attack on a German steel plant (2014): the attack was based on spearfishing. They used the plant’s email to gain access to the network. Once inside, they made several system changes, including critical changes to security systems [17]. The attack resulted in an uncontrolled furnace shutdown, causing significant financial losses.
- -
- Cyber-attack on the power grid in Ukraine (2015): the attack aimed to deprive the population of their access to energy [18]. As a result of the attack, more than 200,000 people could not use electricity for several hours. The attack was a two-stage attack. During the first step, computers were infected via a malicious attachment in the mail. During the second step, once the resources were accessed, the contents of the hard drives were destroyed using KillDisk software.
3. Test Environment
3.1. Static Data Simulator
3.2. Dynamic Data Simulator
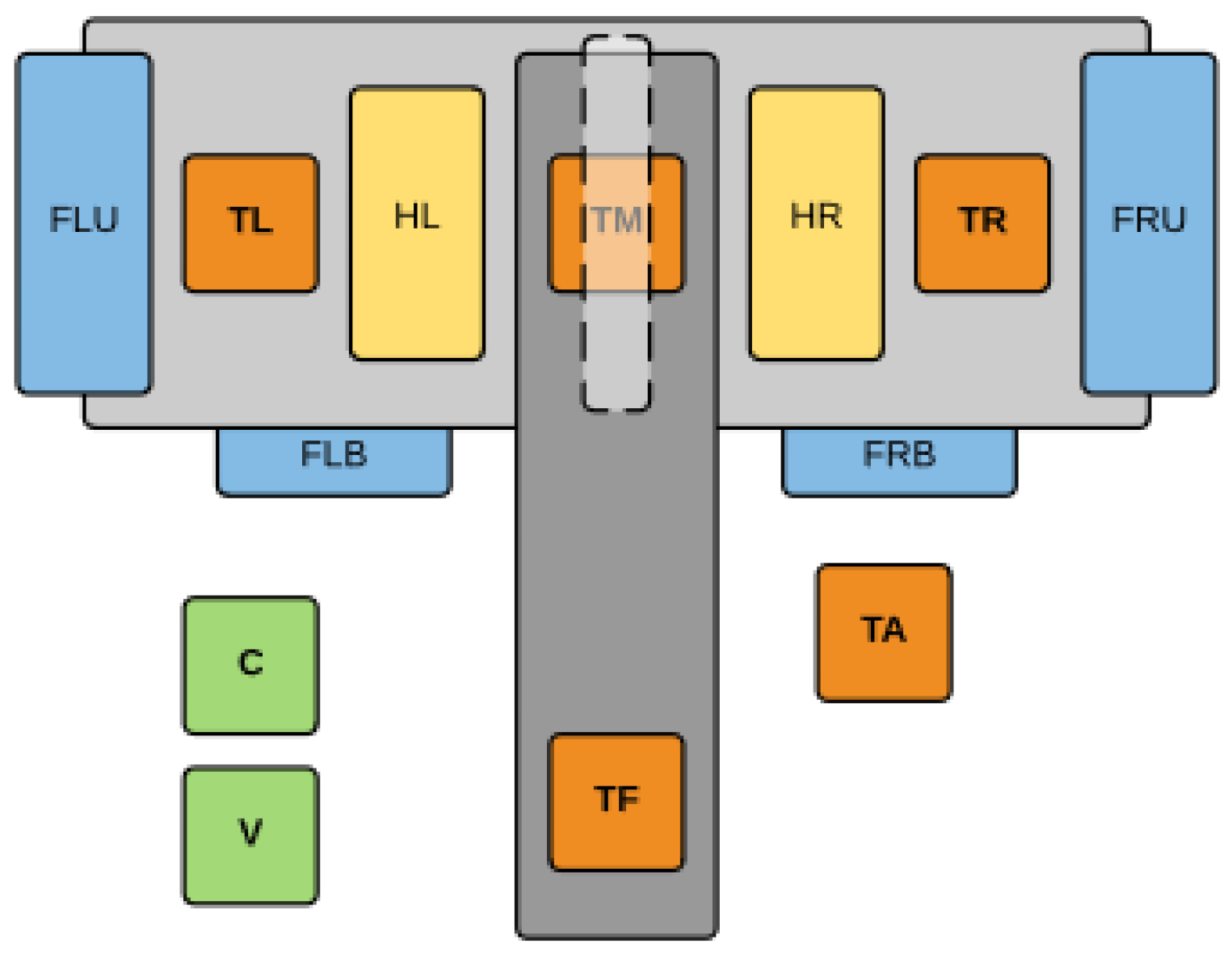
3.3. Laboratory Thermal Stand
- FLU, FLB, FRU, FRB fans, values from 0 (0% power) to 1000 (100% power),
- HL, HR heaters, values from 0 (0% power) to 1000 (100% power).
- TL, TM, TR, TF bench temperature, values from −55.0 °C to +125.0 °C,
- TA ambient temperature, values from −55.0 °C to +125.0 °C,
- C current measurement,
- V voltage measurement.
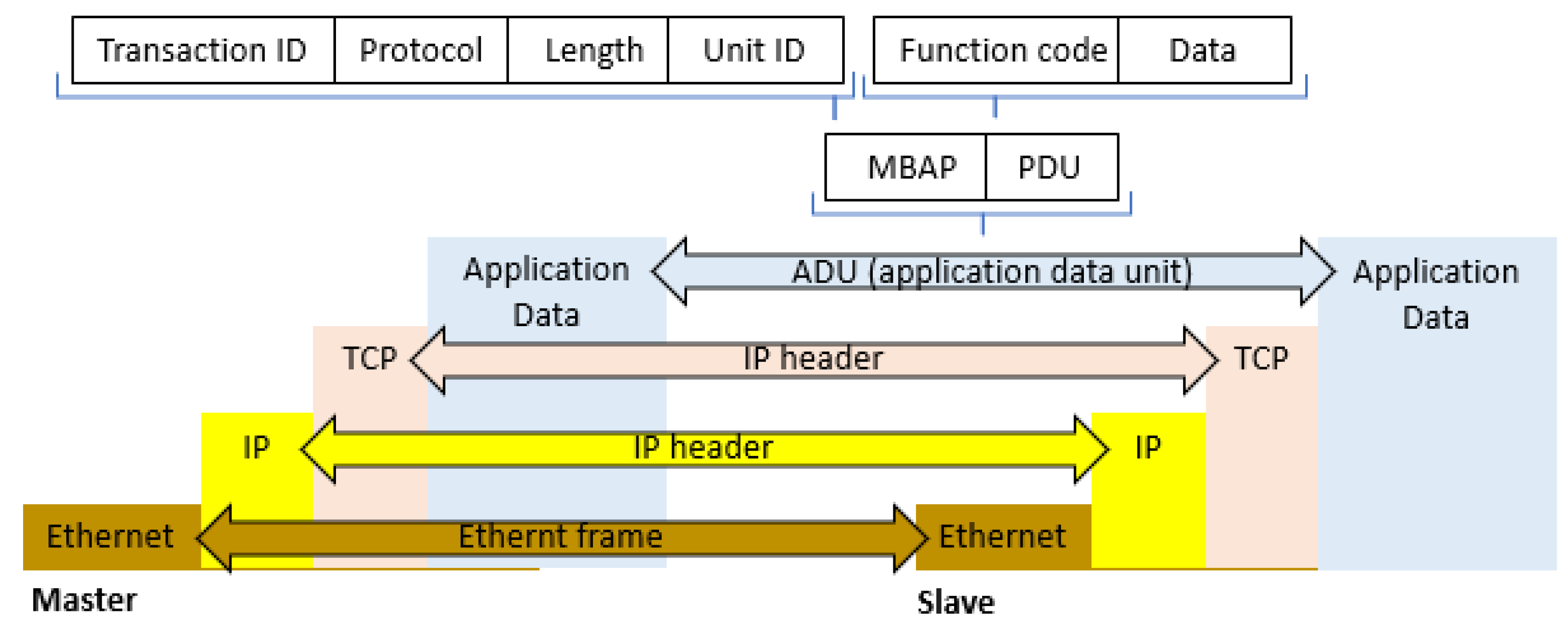
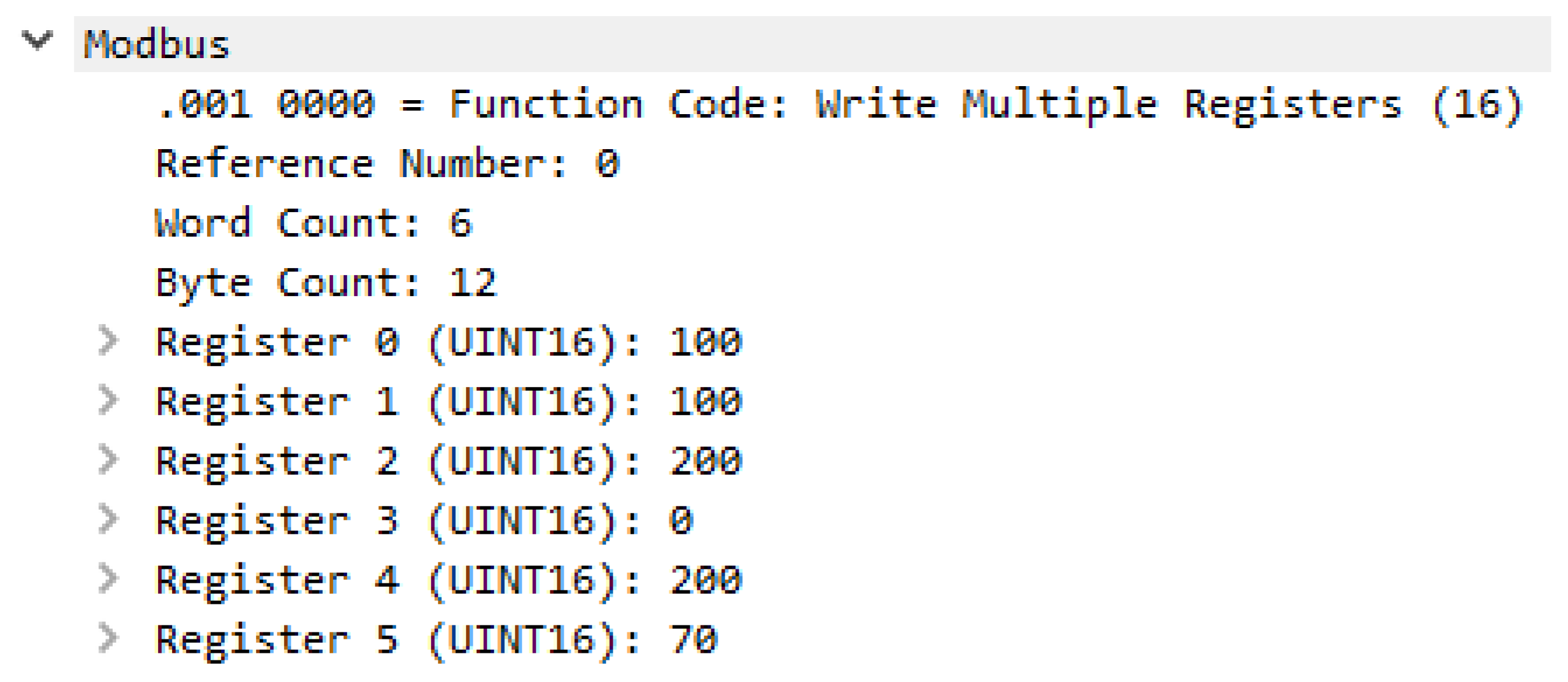
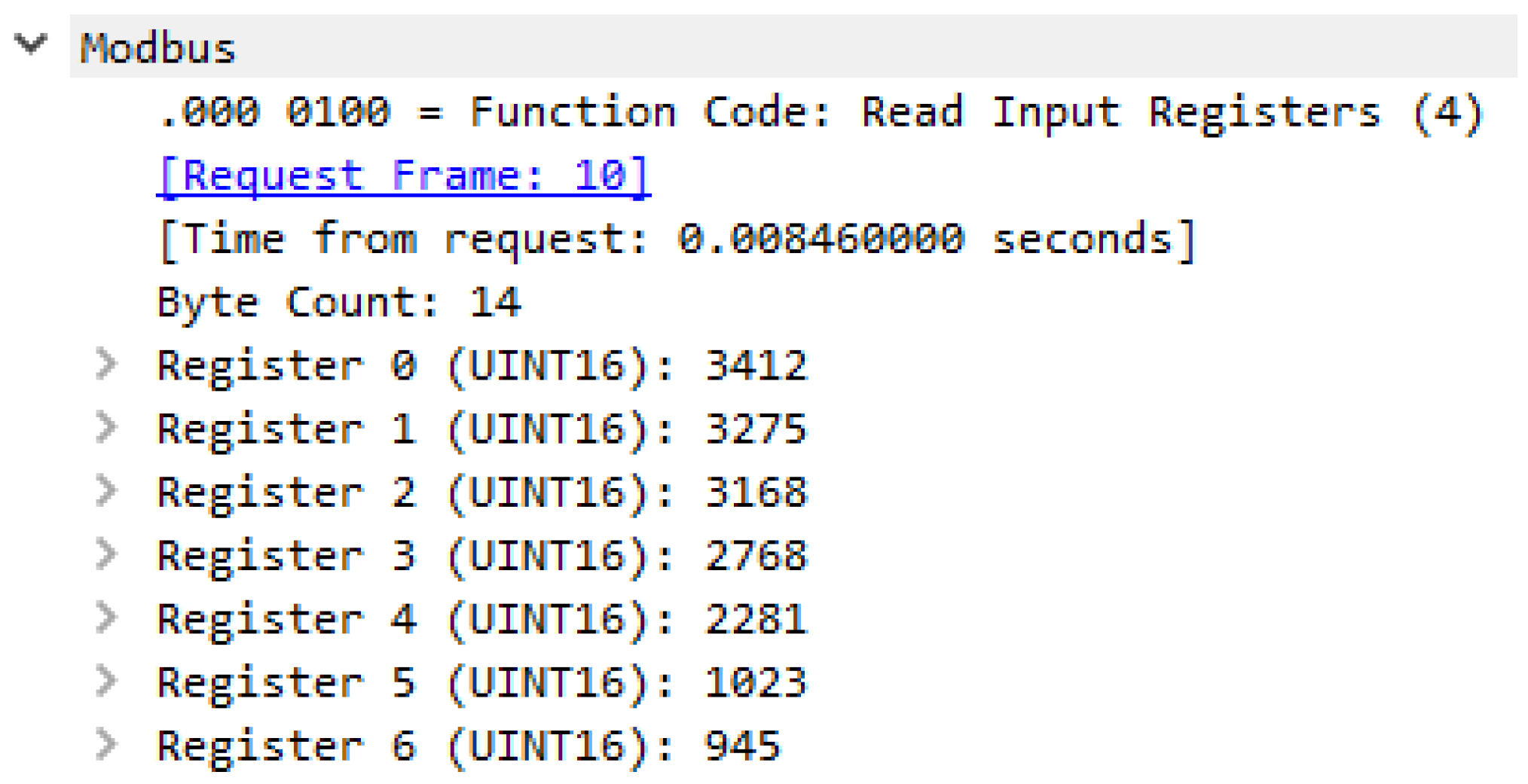
3.4. Modbus Protocol Modbus TCP/IP Data Frame
- 2-bytes Transaction Identifier—used by the client to properly pair received responses with requests. This is necessary when multiple messages are sent simultaneously over a TCP link. This value is determined and placed in the request frame by the master, and then it is copied and placed in the response frame.
- 2-bytes Protocol ID—this is always set to 0, and it corresponds with the Modbus protocol designation.
- 2-bytes Message Size—the number of remaining message bytes, which consists of the device ID (Unit ID), function code, and the number of data fields. This field was introduced due to the possibility of splitting a single message into separate TCP/IP packets.
- 1-byte Unit ID—can be relevant, for example, when communicating with Modbus devices equipped with serial interface via gateways (Modbus Data Gateway). In a typical Modbus TCP server application, this field is set to 0 or FF and it is ignored by the server. The server, in its response, duplicates the value received by the client.
4. Models of Knowledge Discovery
4.1. EBM—Explainable Boosting Machines
4.2. XGBoost—Extreme Gradient Boosting
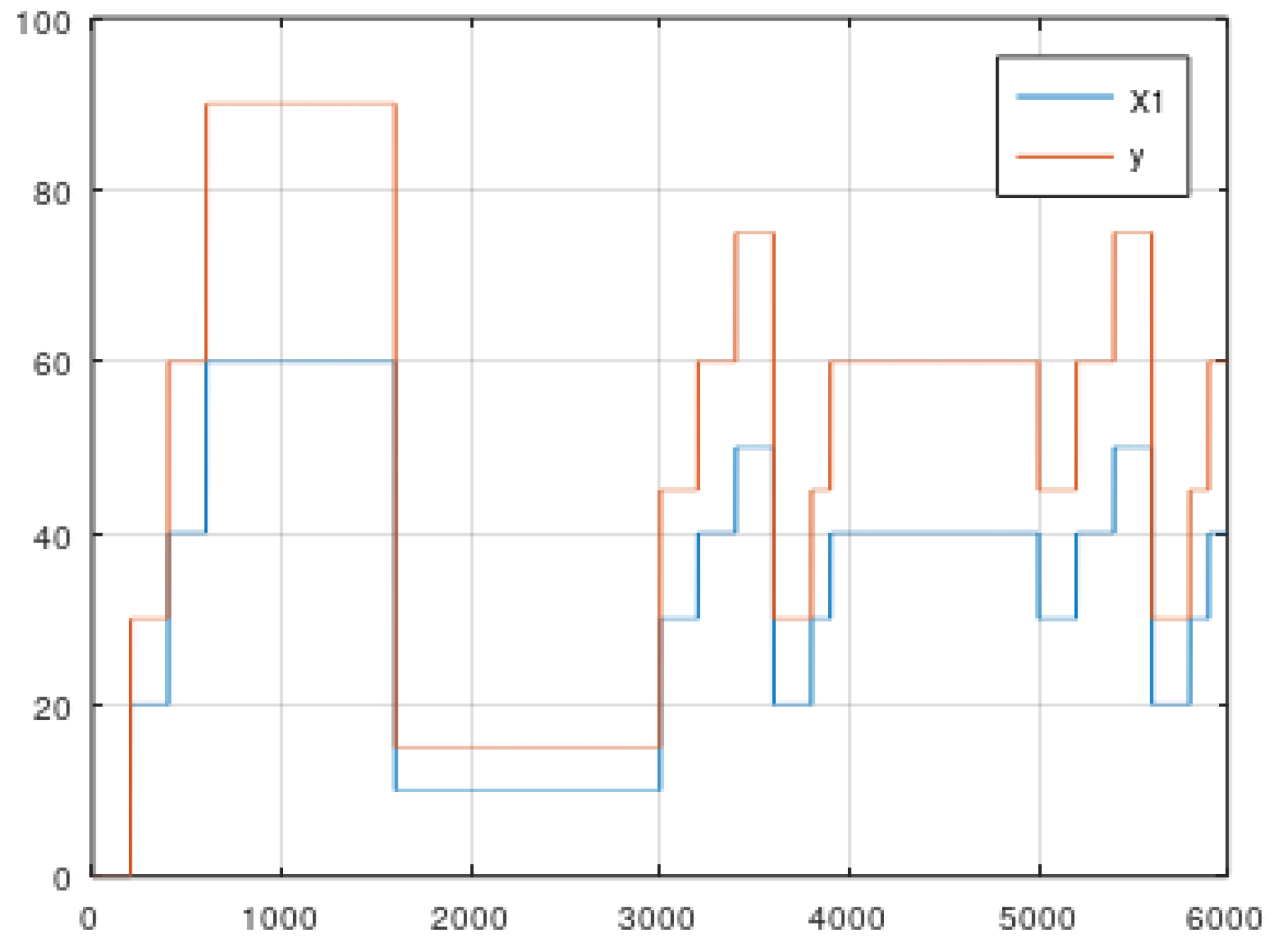
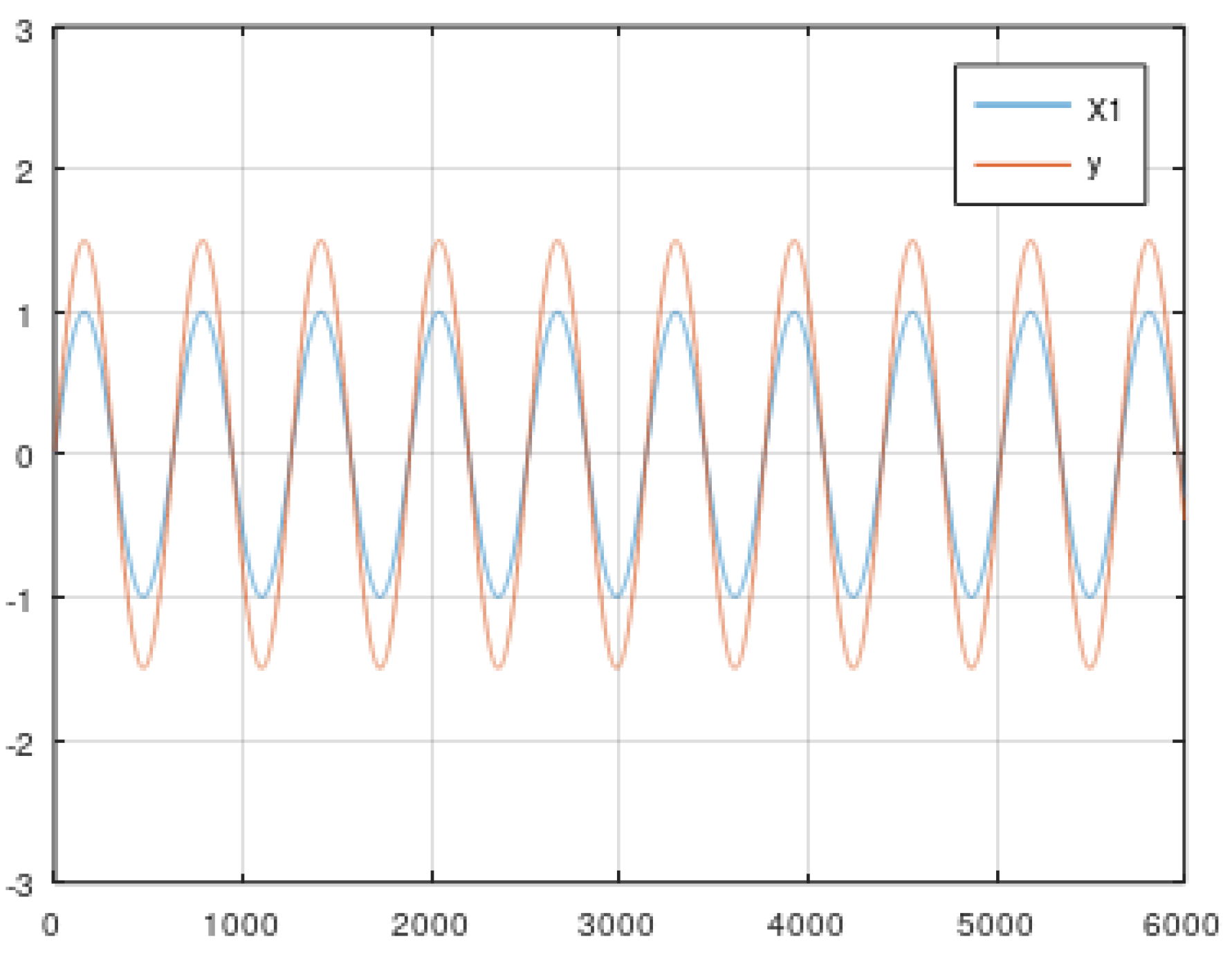
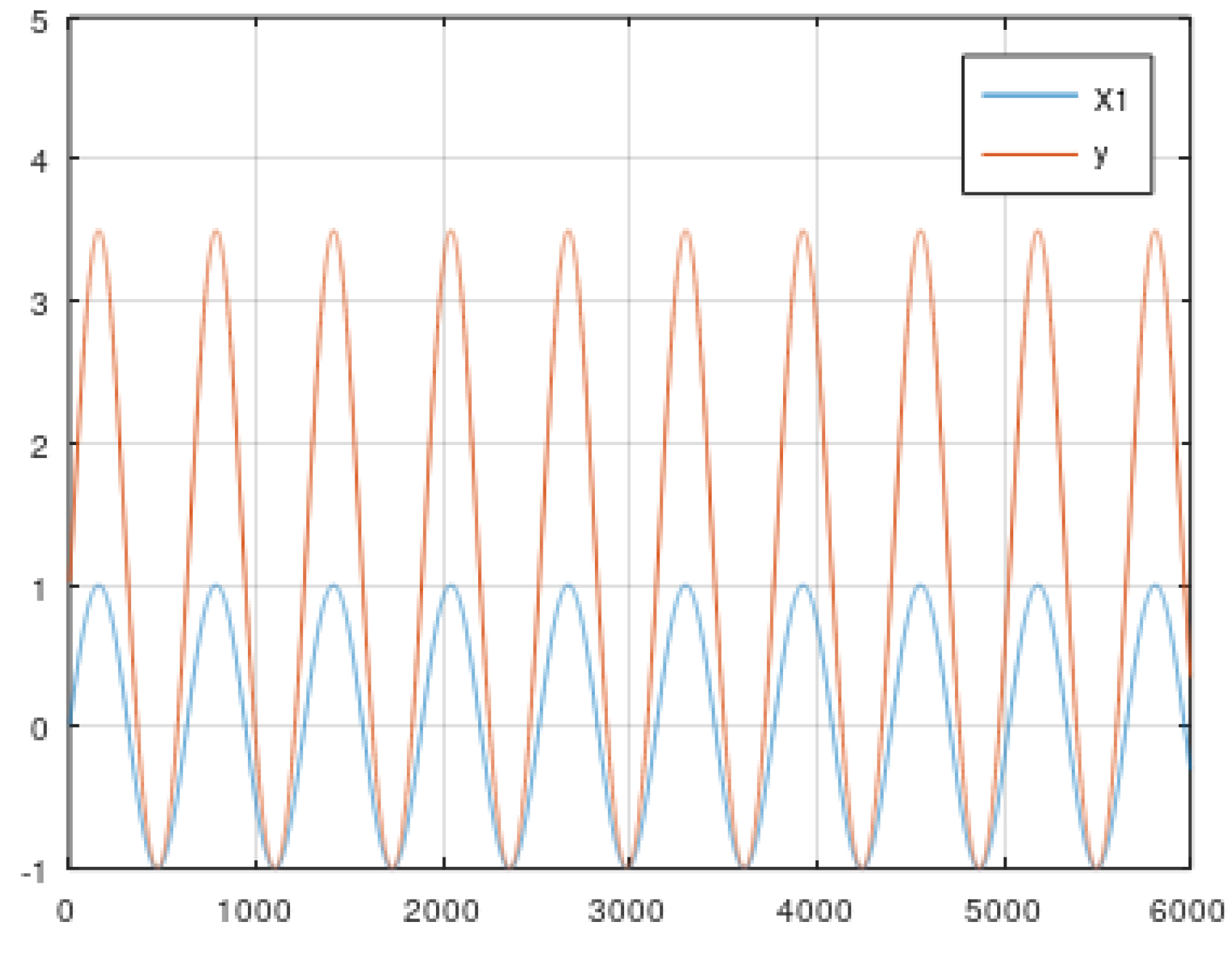
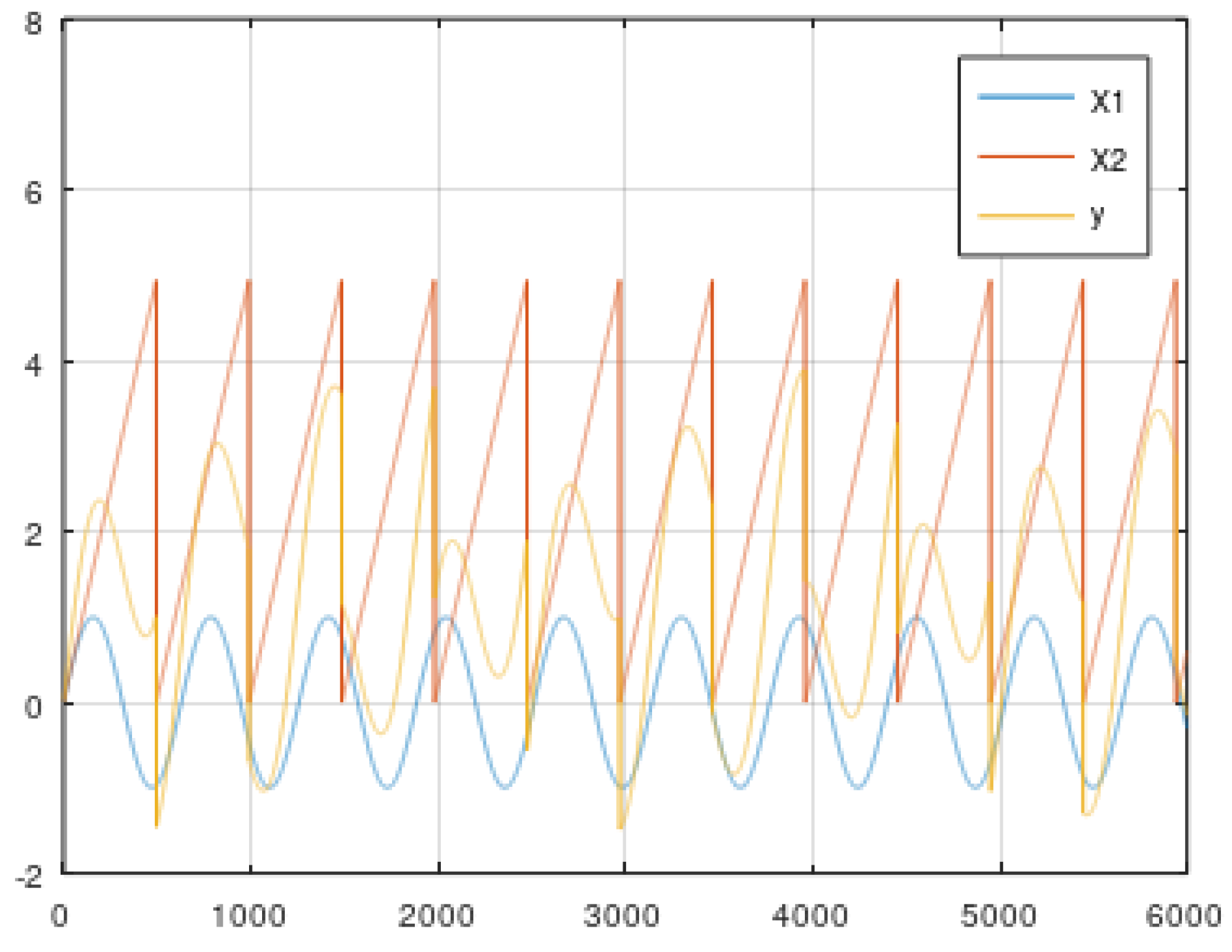
5. Data
5.1. Static Data from Simulator
- (a)
- Simple linear function (Equations (3) and (4)).
- (b) Rescaled periodic function (Equations (5) and (6)).
- (c) Composition of a rescaled periodic and power function (Equations (7) and (8)).
- (d) Composition of a rescaled periodic and modulo function (Equations (9)–(11)).
- (e) Composition of a rescaled periodic, exponential, and modulo function (Equations (12)–(14)).
- (f) Composition of a rescaled periodic, exponential, modulo, and square root function (Equations (15)–(17)).
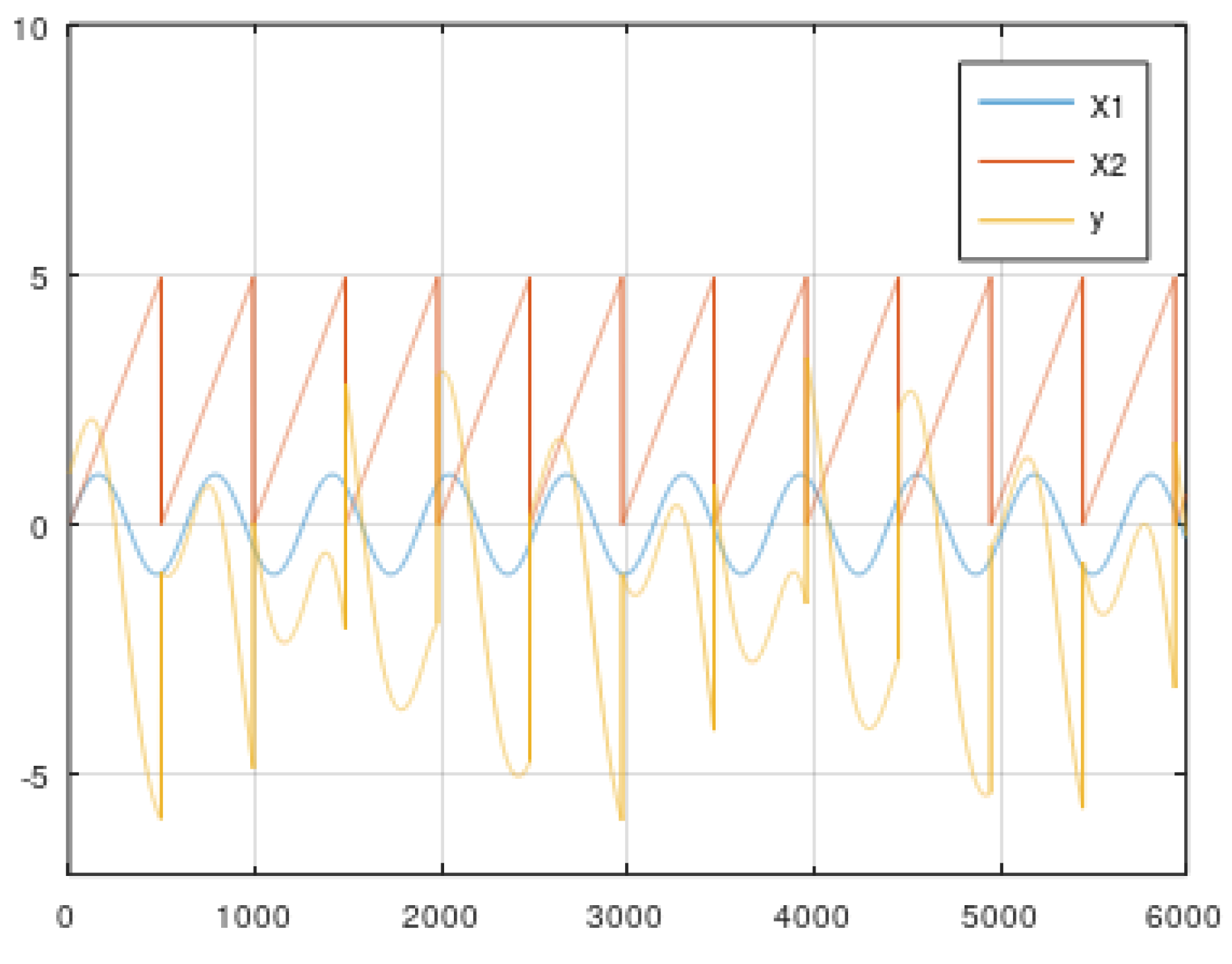
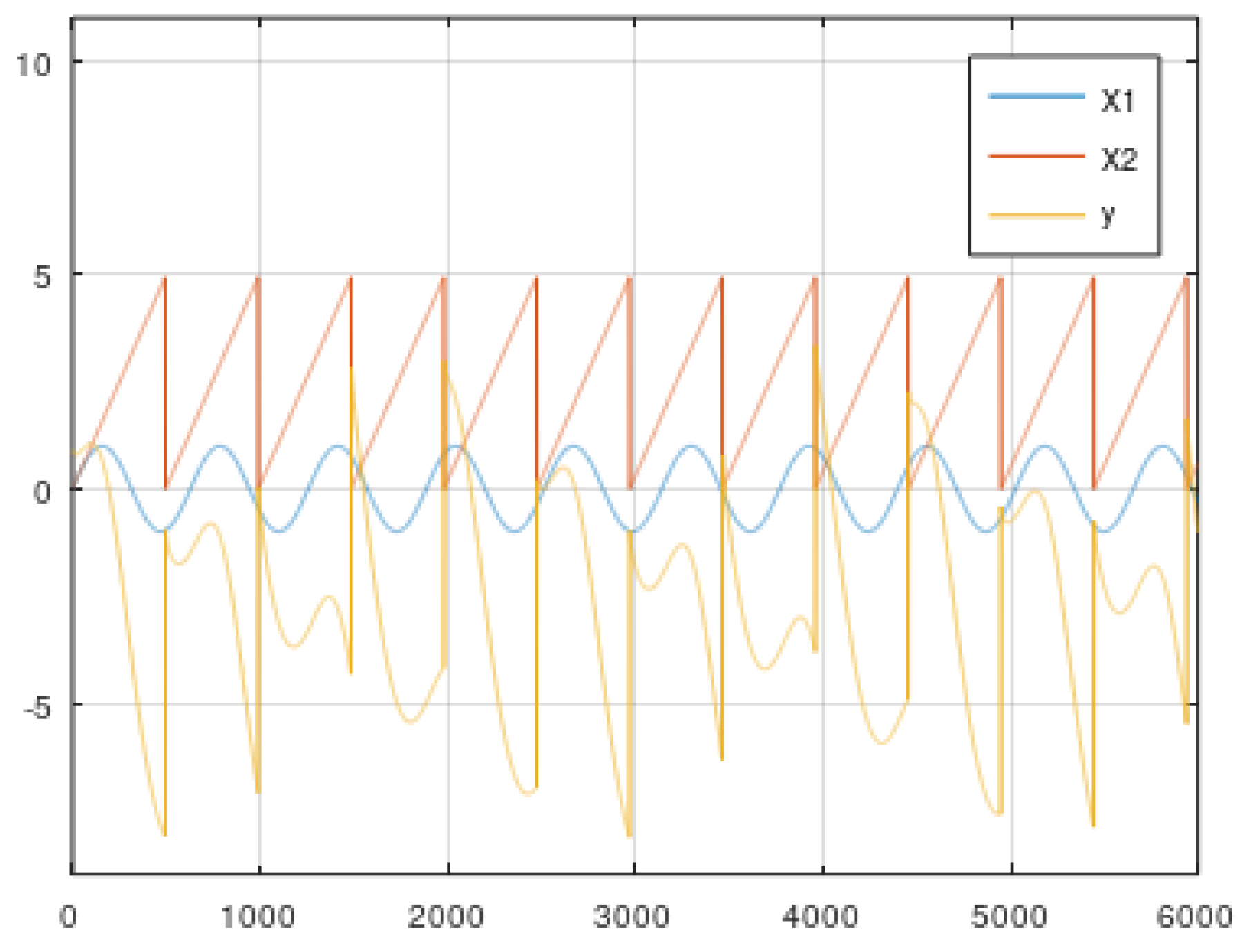
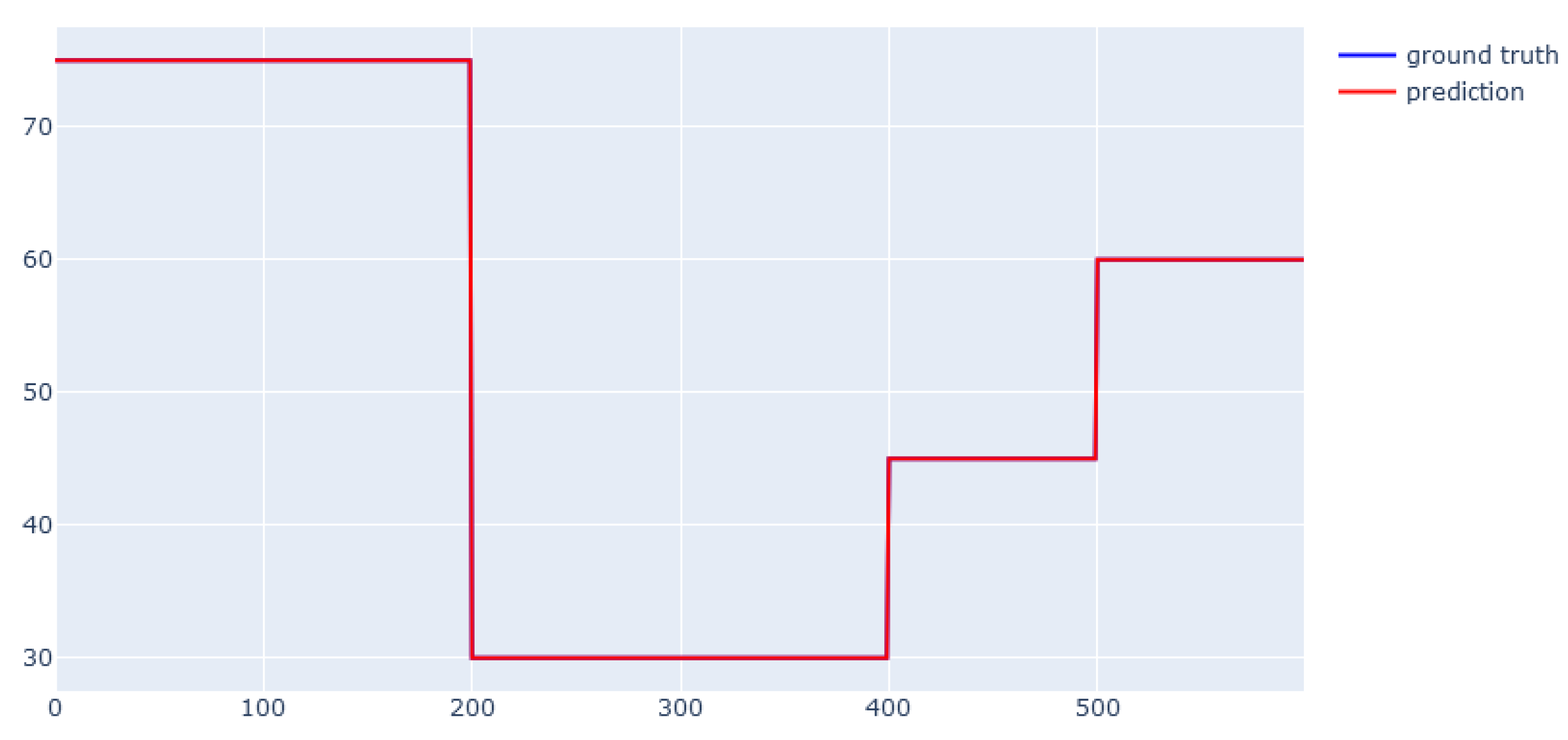
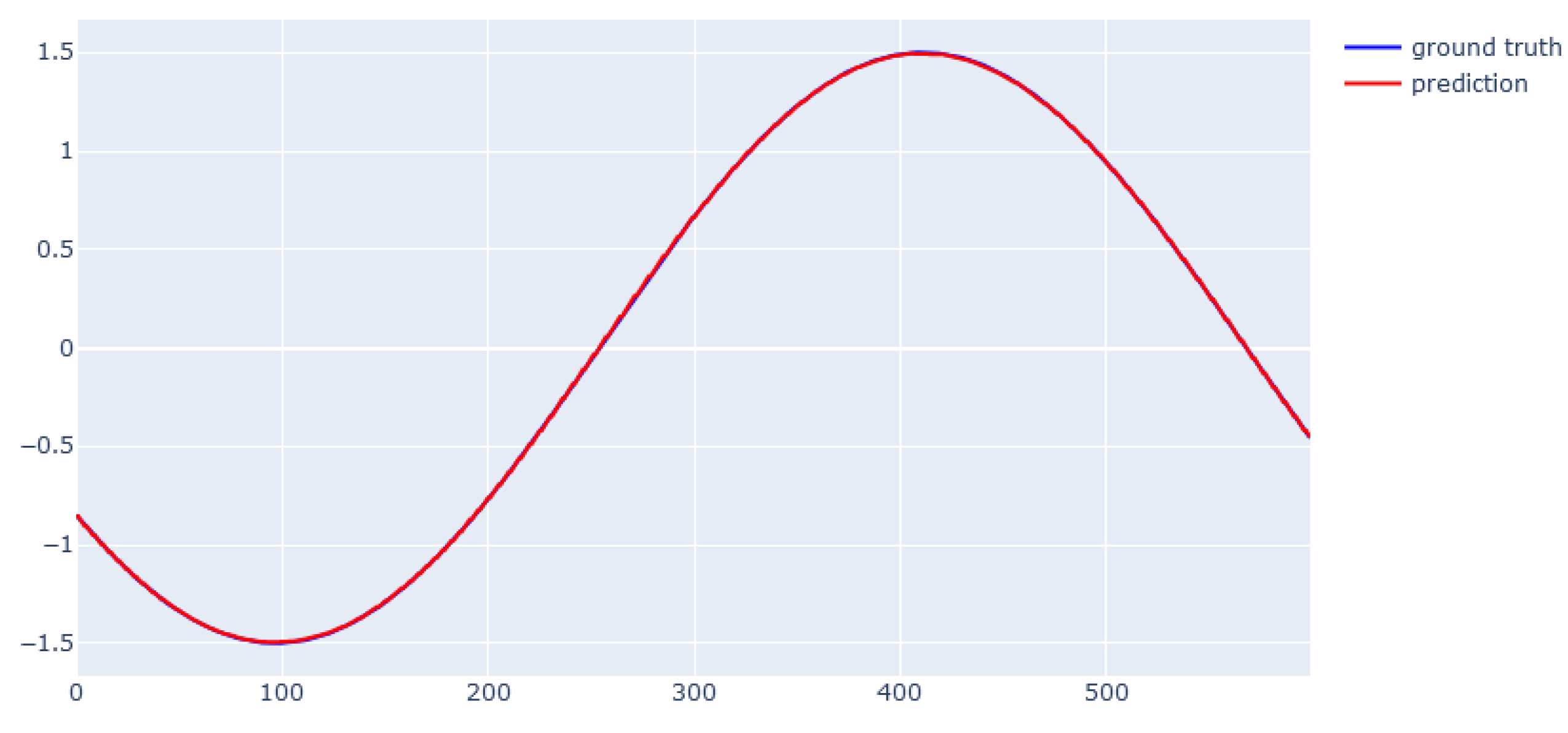
5.2. Dynamic Data from the Simulator
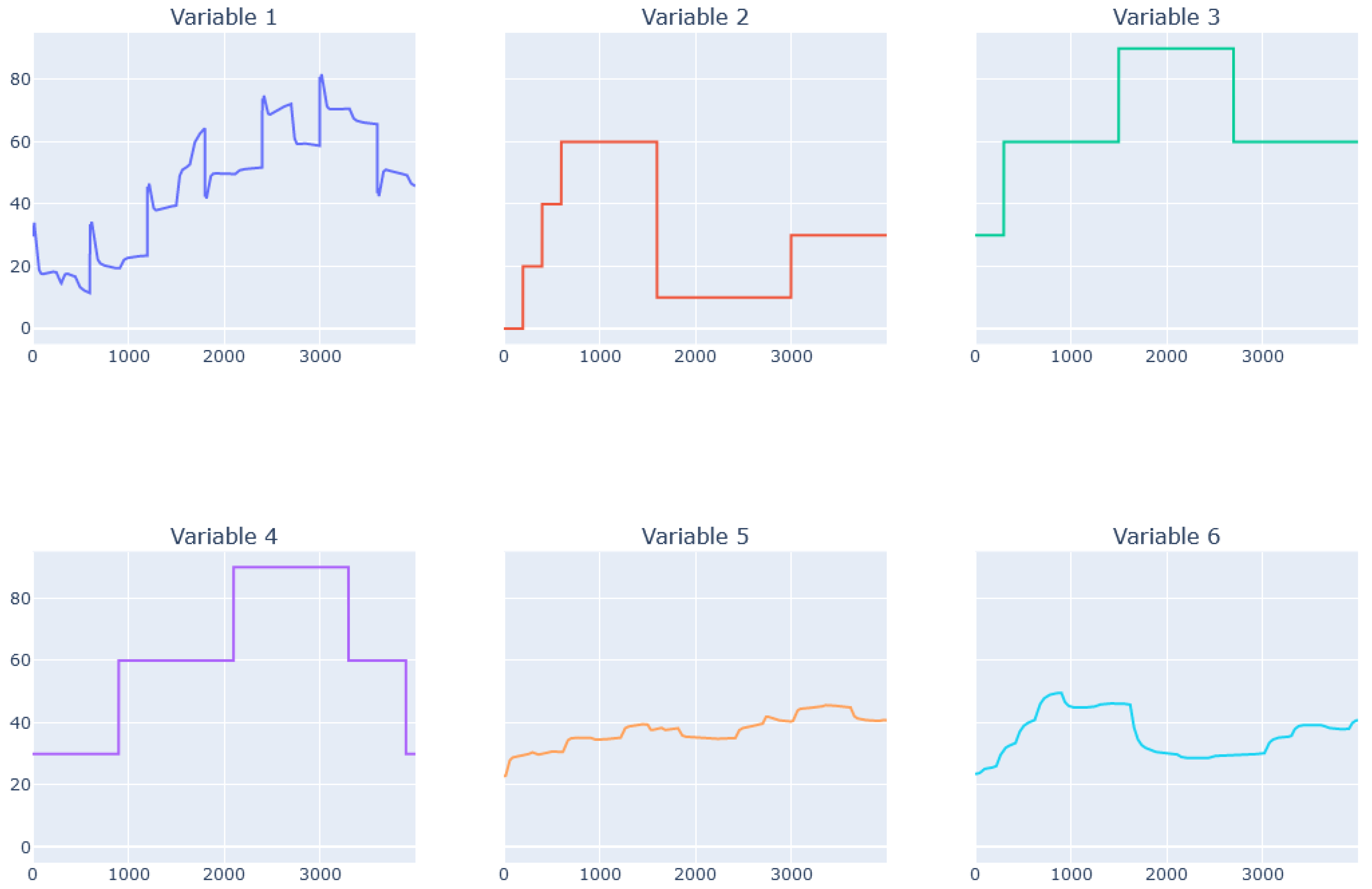
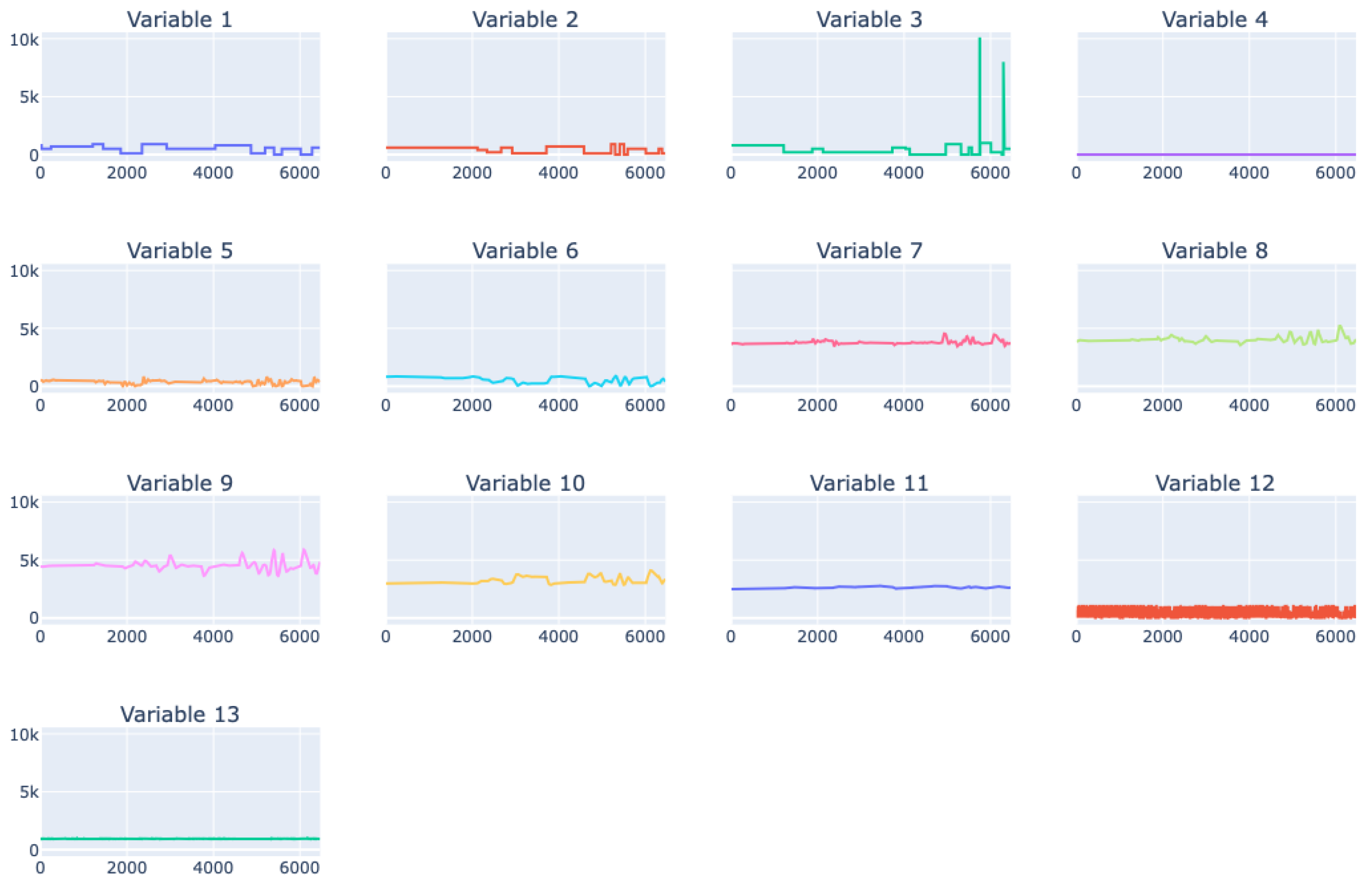
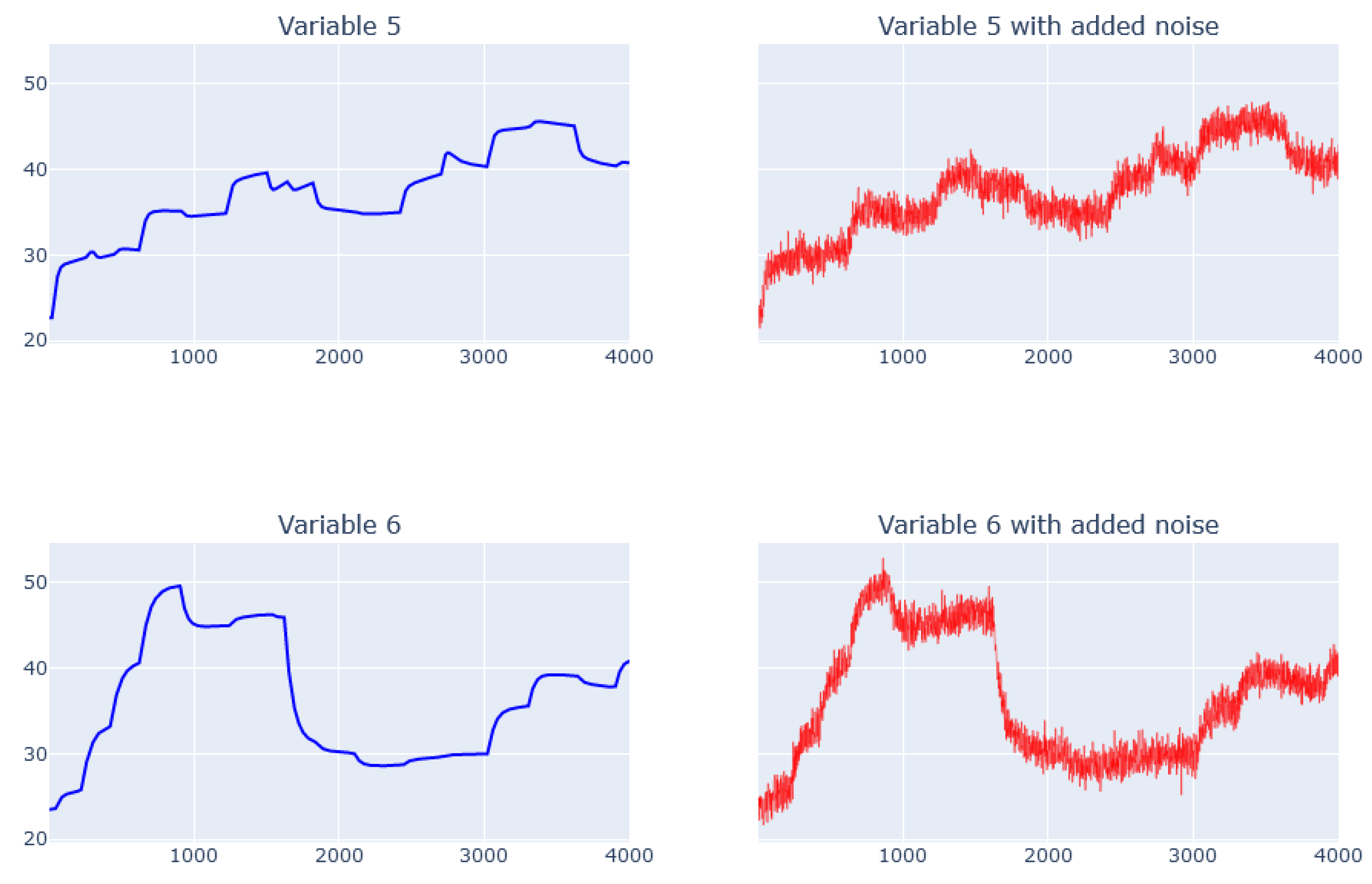
5.3. Real Data from Physical Bench Working in Network
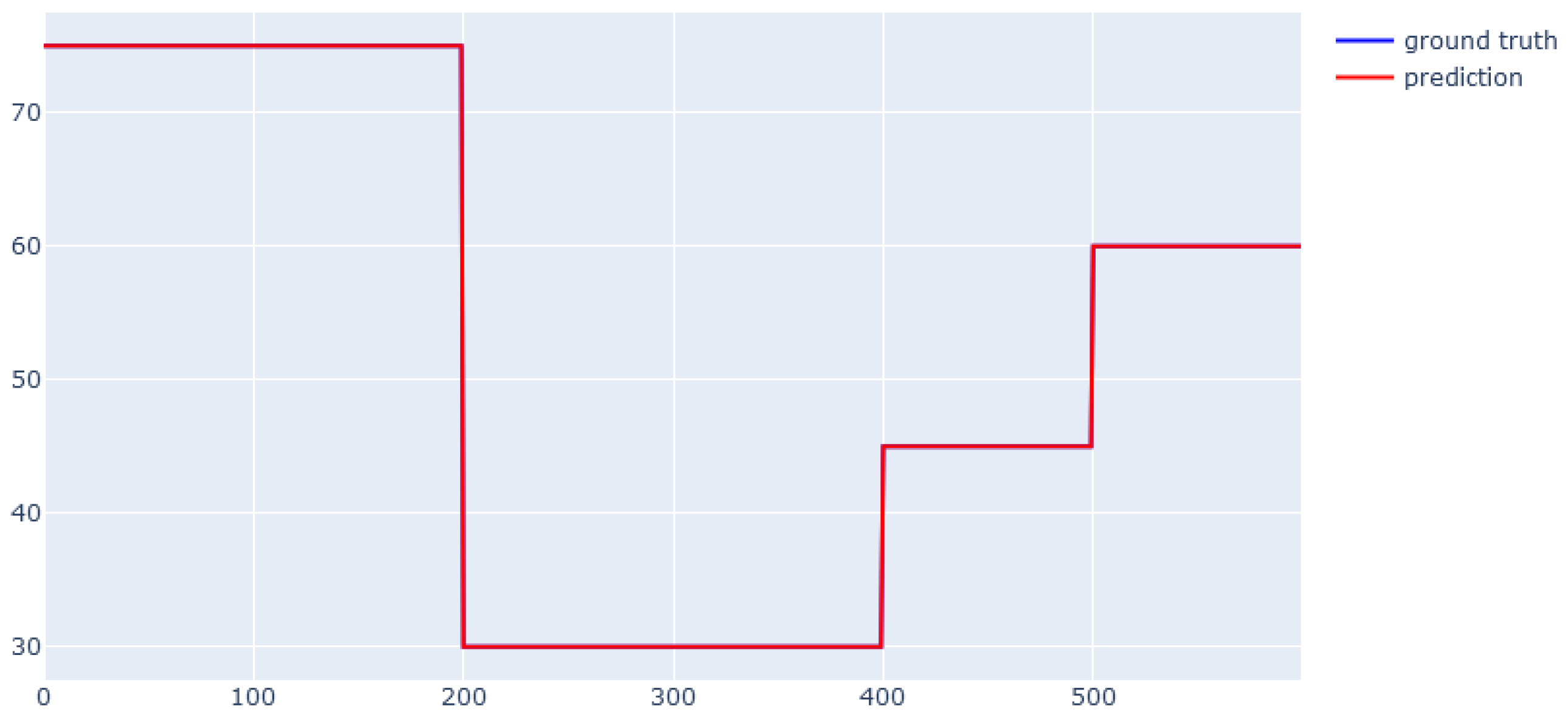
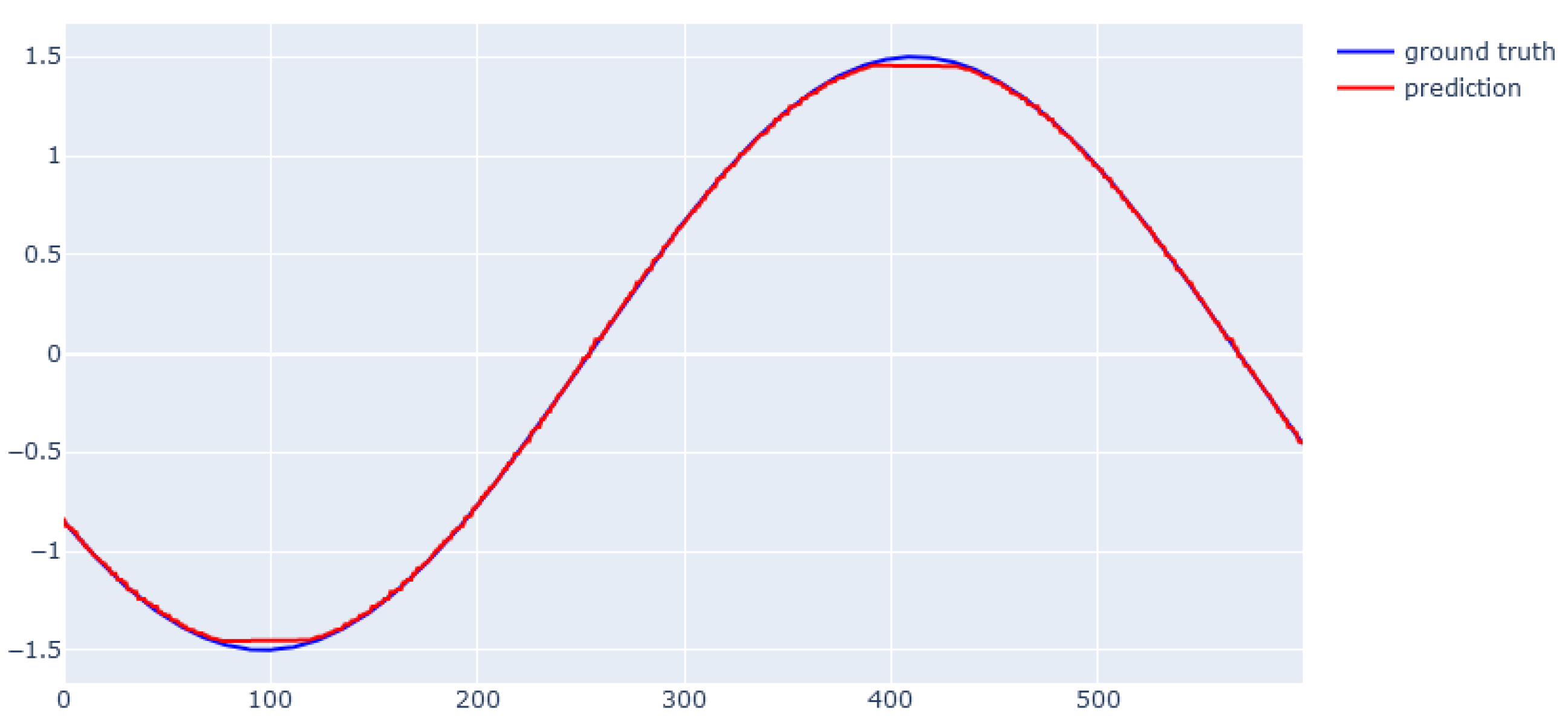
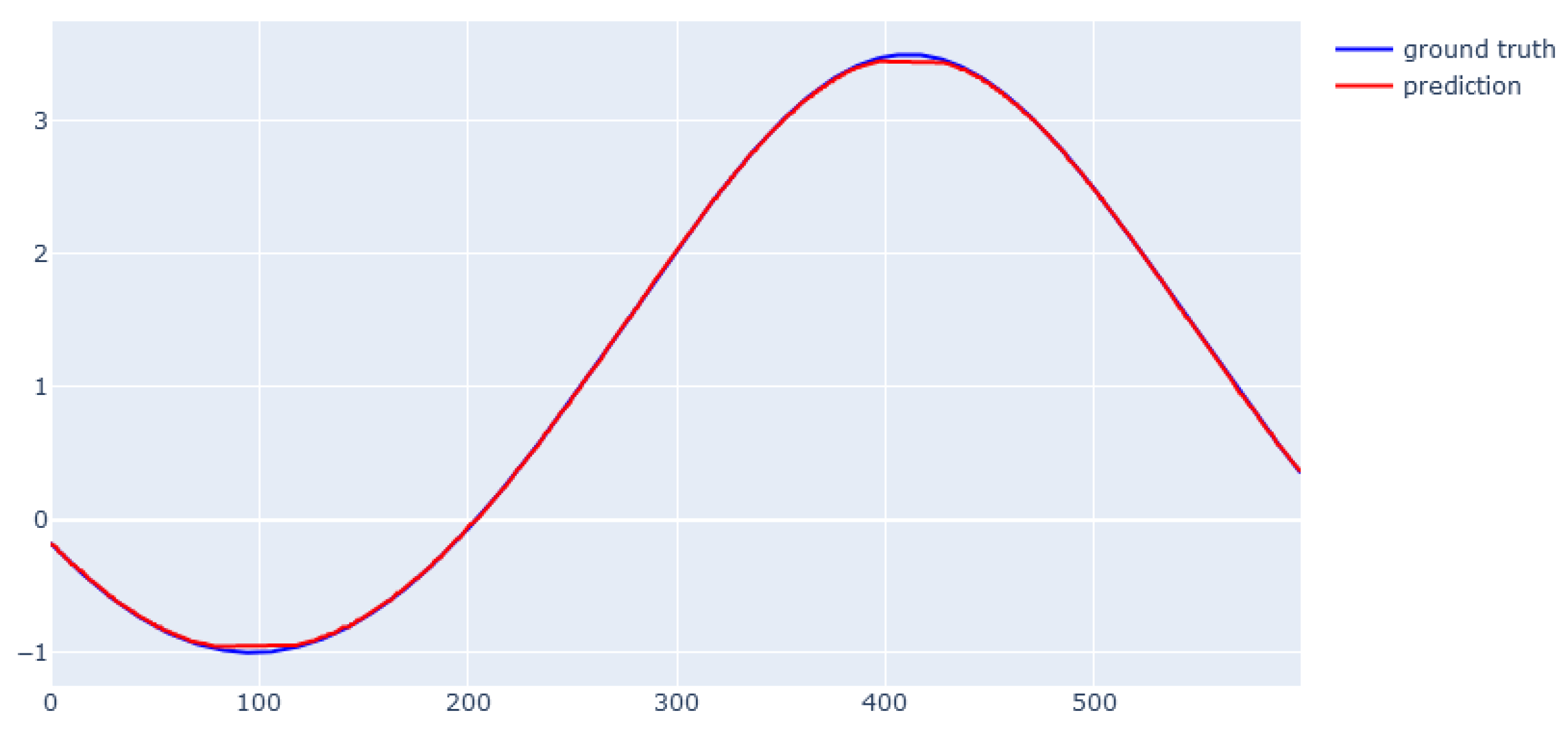
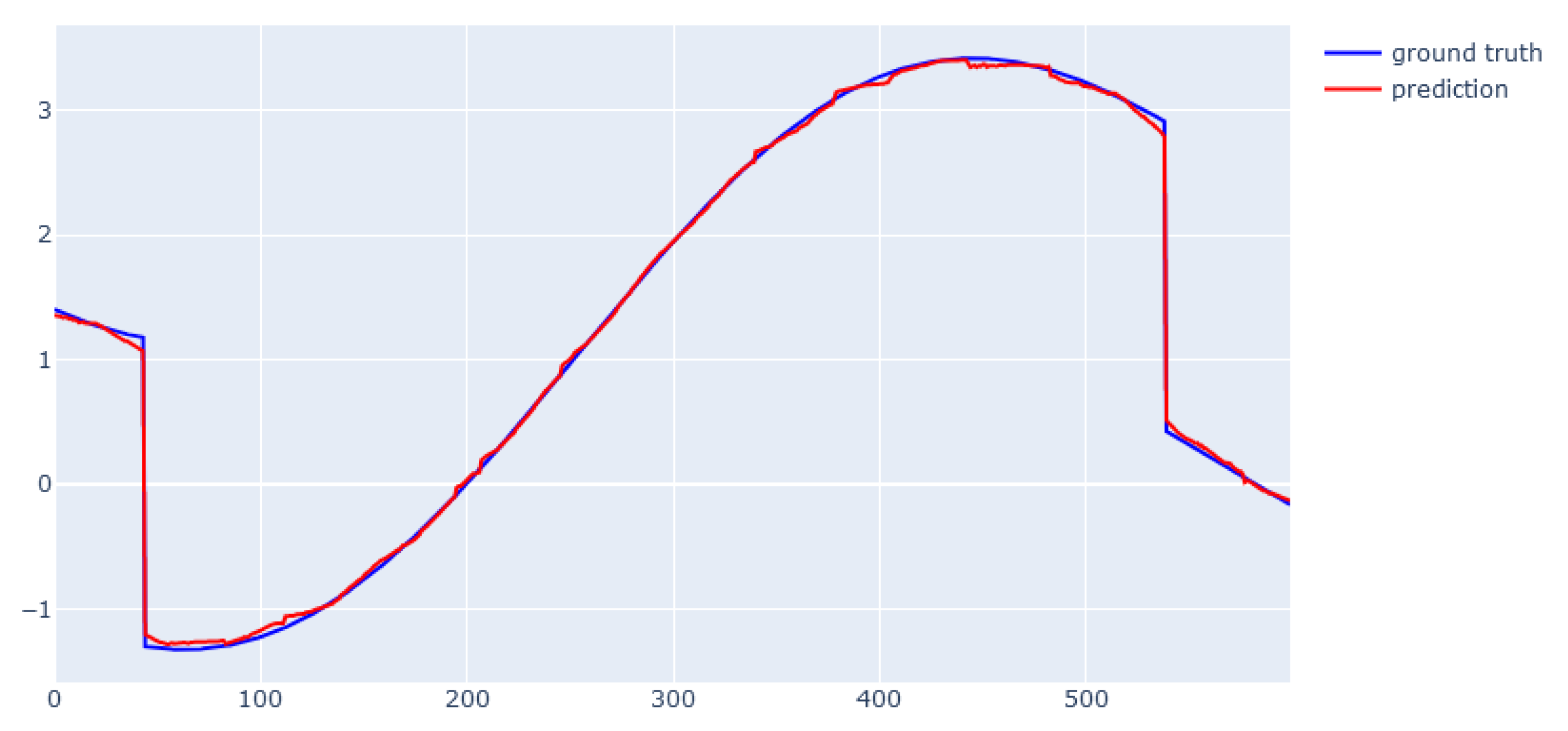
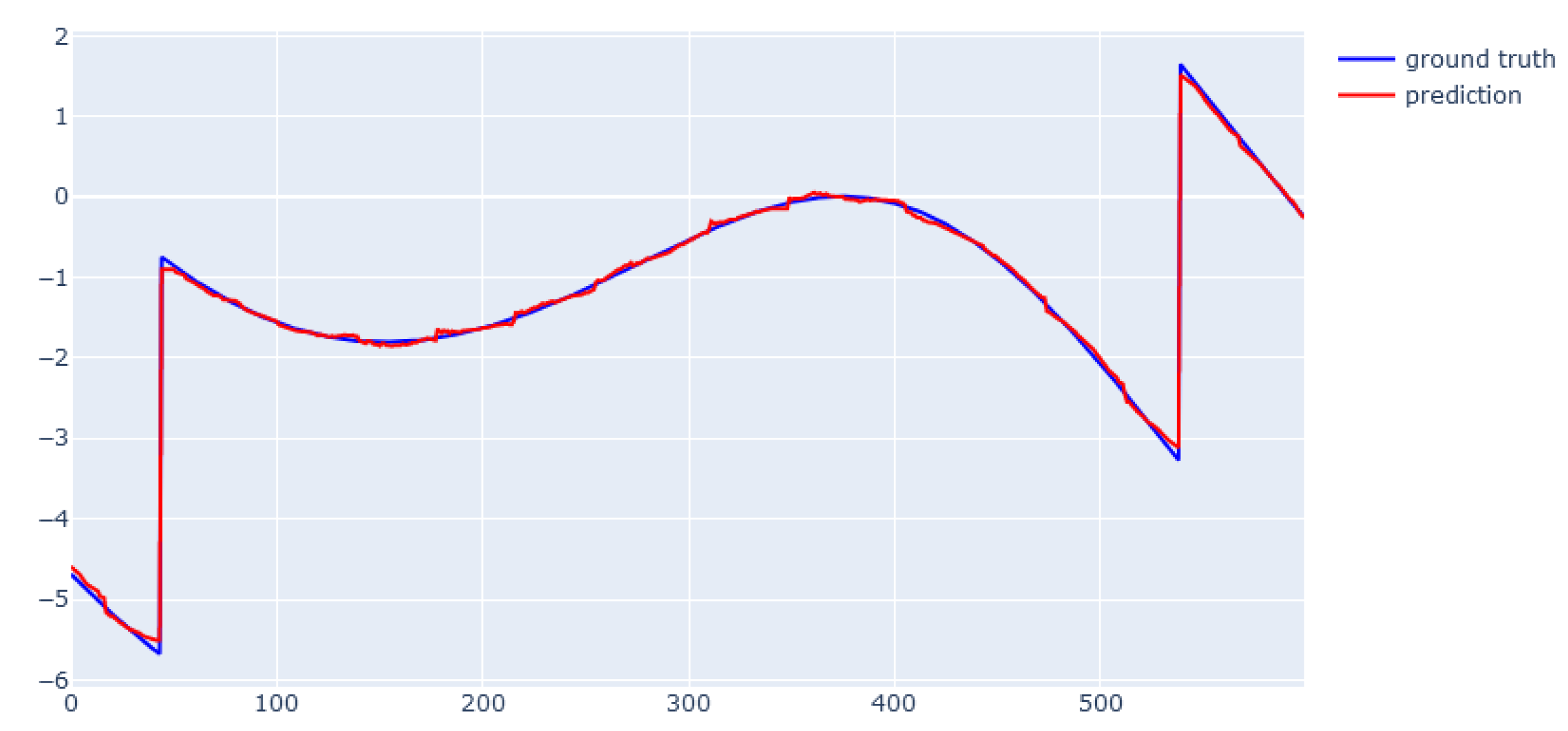
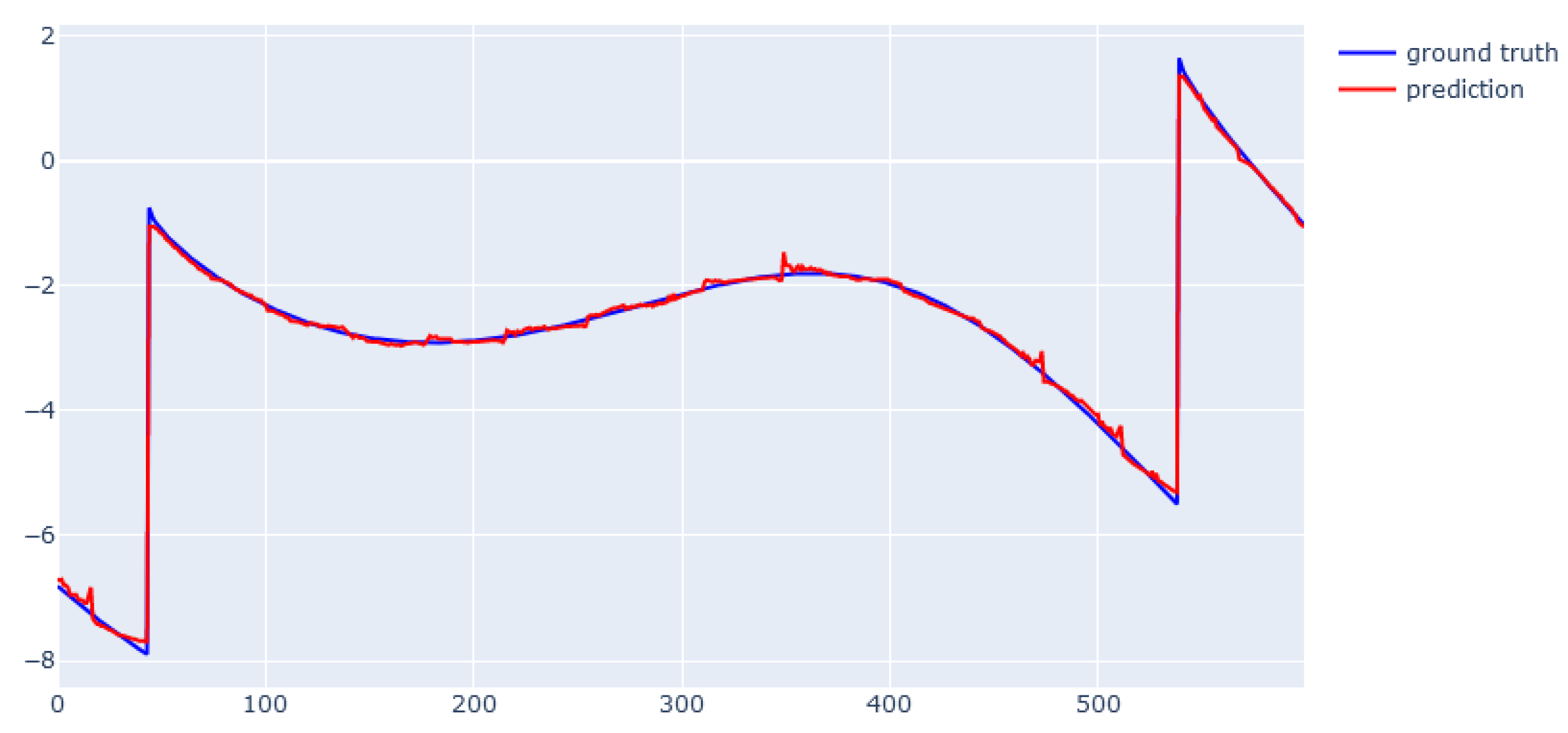
6. Modeling Results
- min child weight: 1, 5, 10,
- gamma: 0.5, 1, 1.5, 2, 5,
- subsample: 0.6, 0.8, 1.0,
- max depth: 3, 4, 5.
- learning rate: 0.001, 0.005, 0.01, 0.03,
- interactions: 5, 10, 15,
- max interaction bins: 10, 15, 20,
- min samples leaf: 2, 3, 5,
- max leaves: 3, 5, 10.
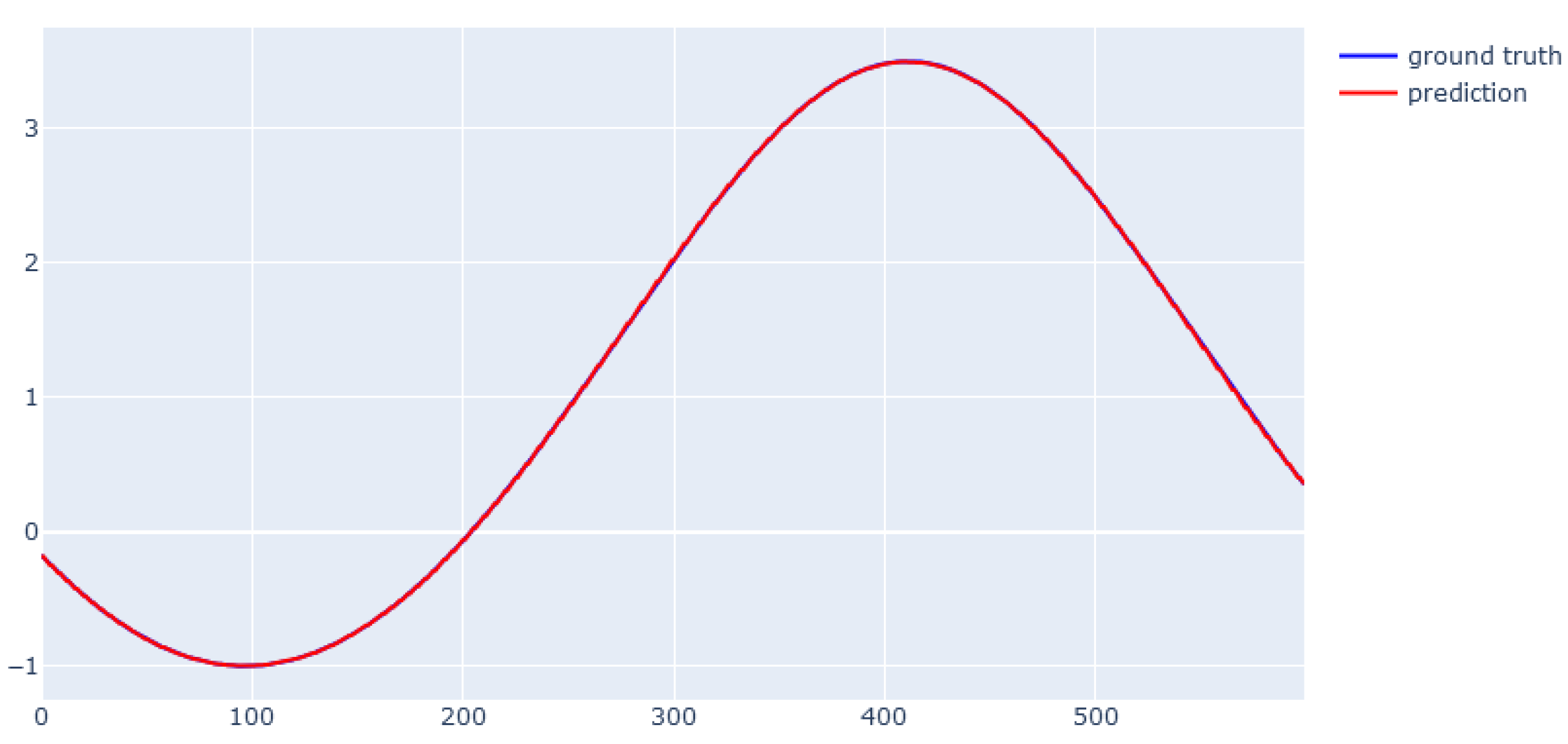
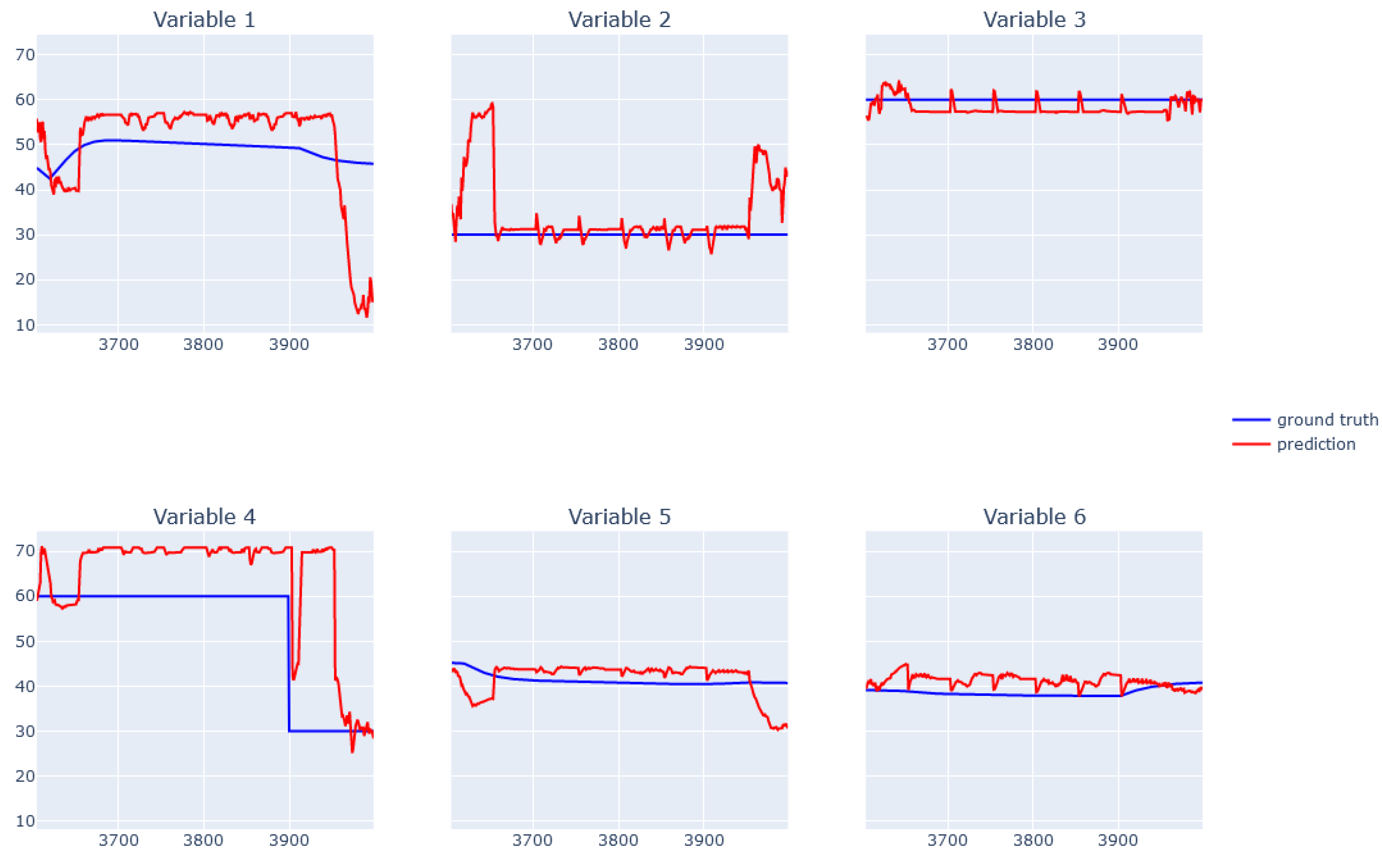
6.1. XGBoost for Static Data from Simulator
6.2. EBM for Static Data from Simulator
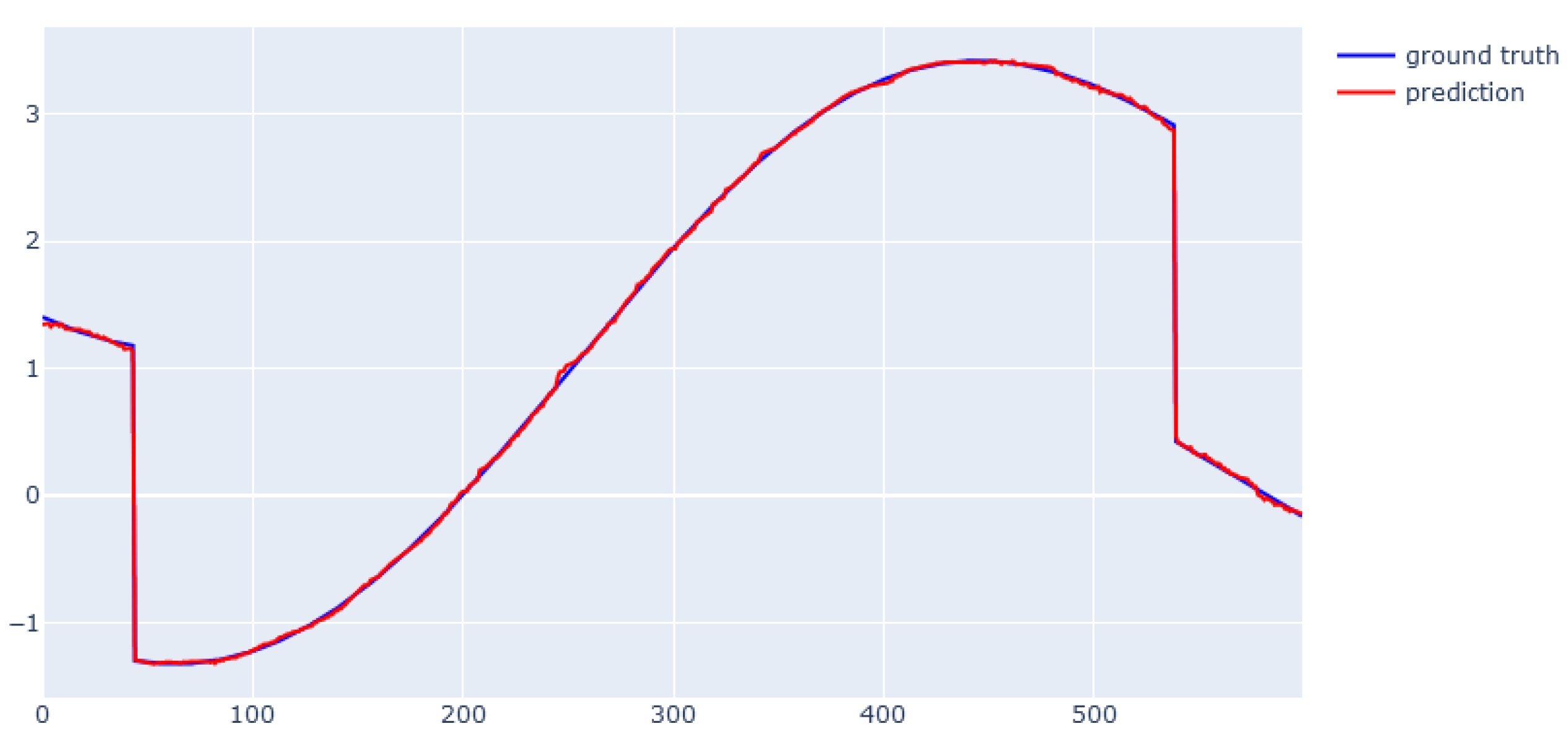
6.3. XGBoost for Dynamic Data from Simulator
6.4. EBM for Dynamic Data from Simulator
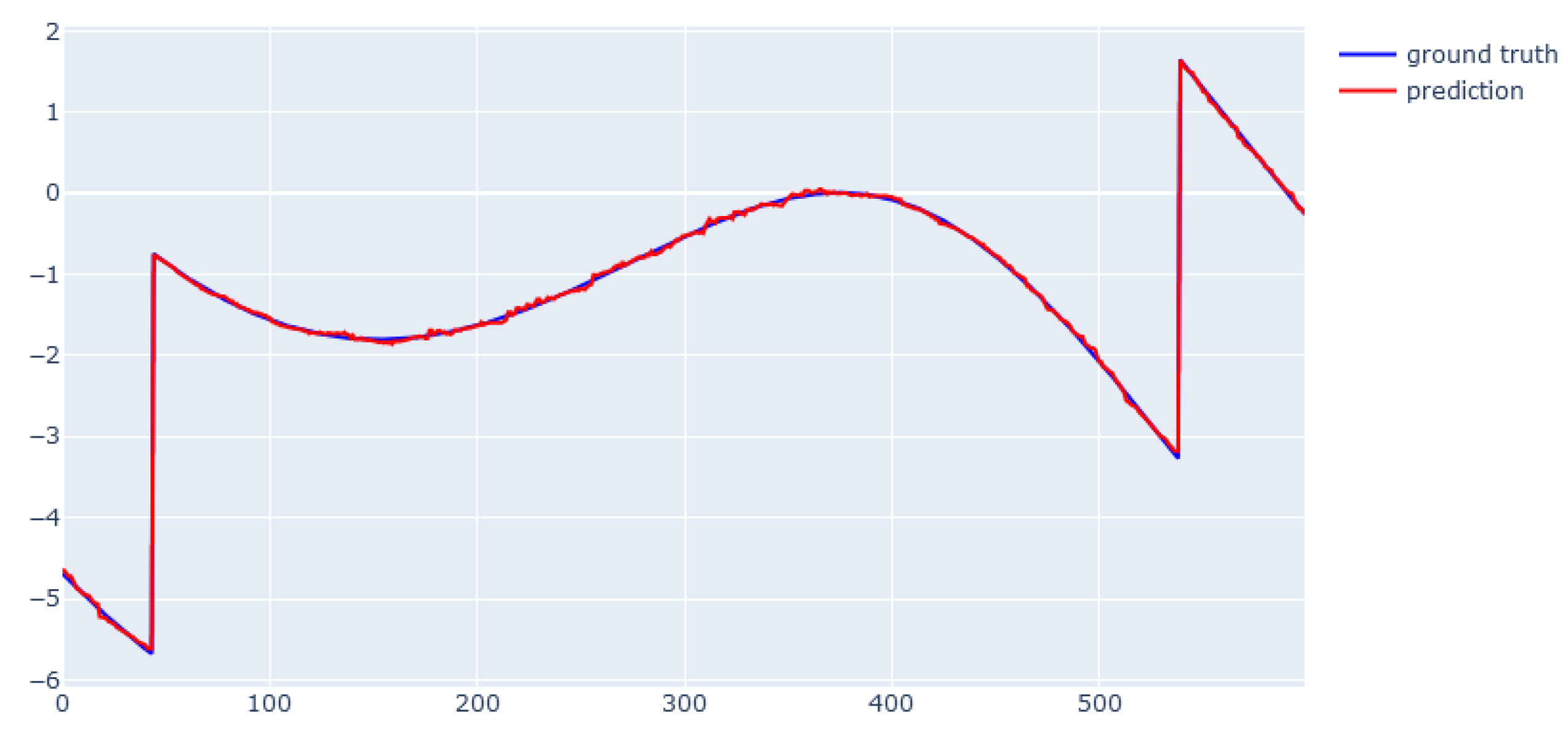
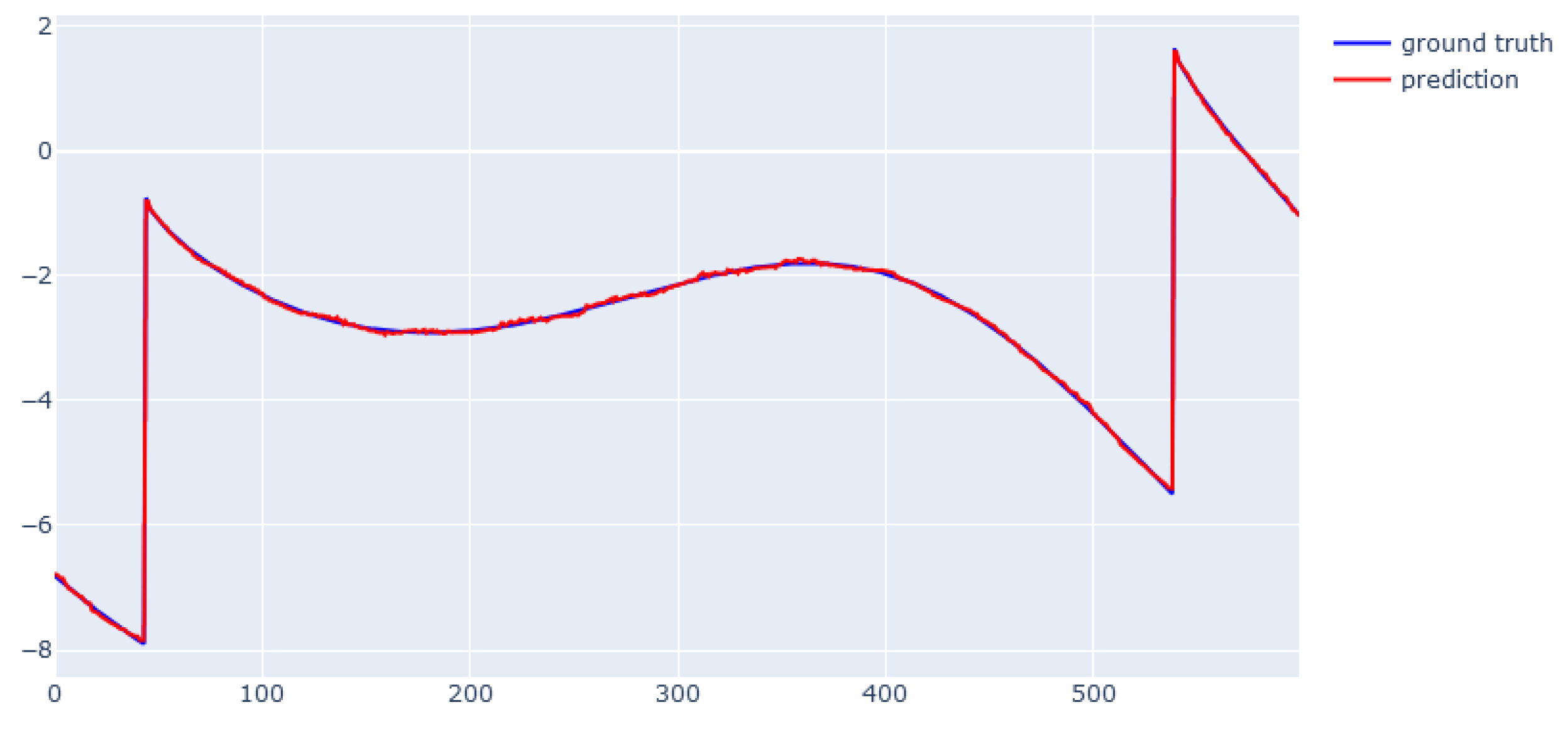
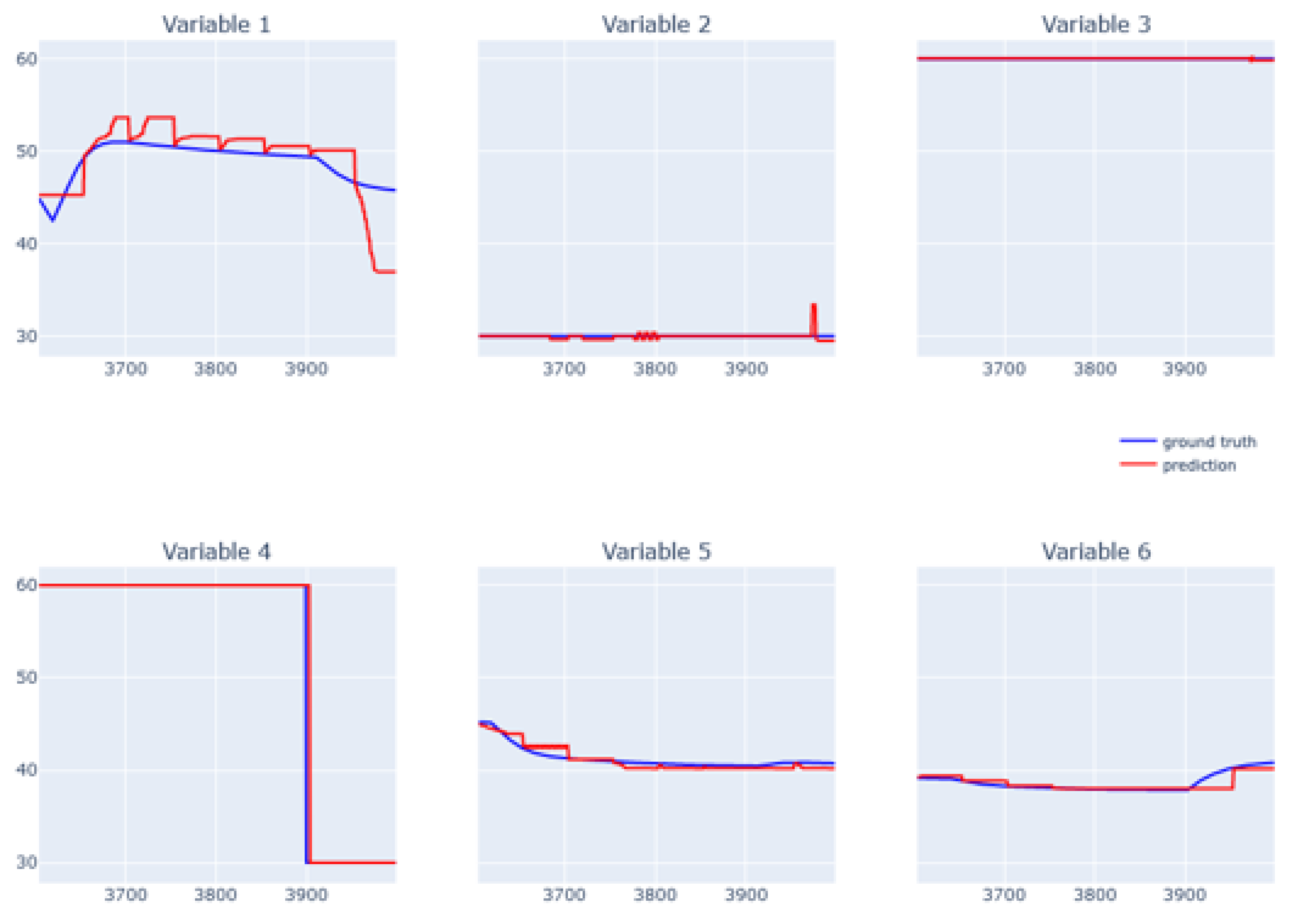
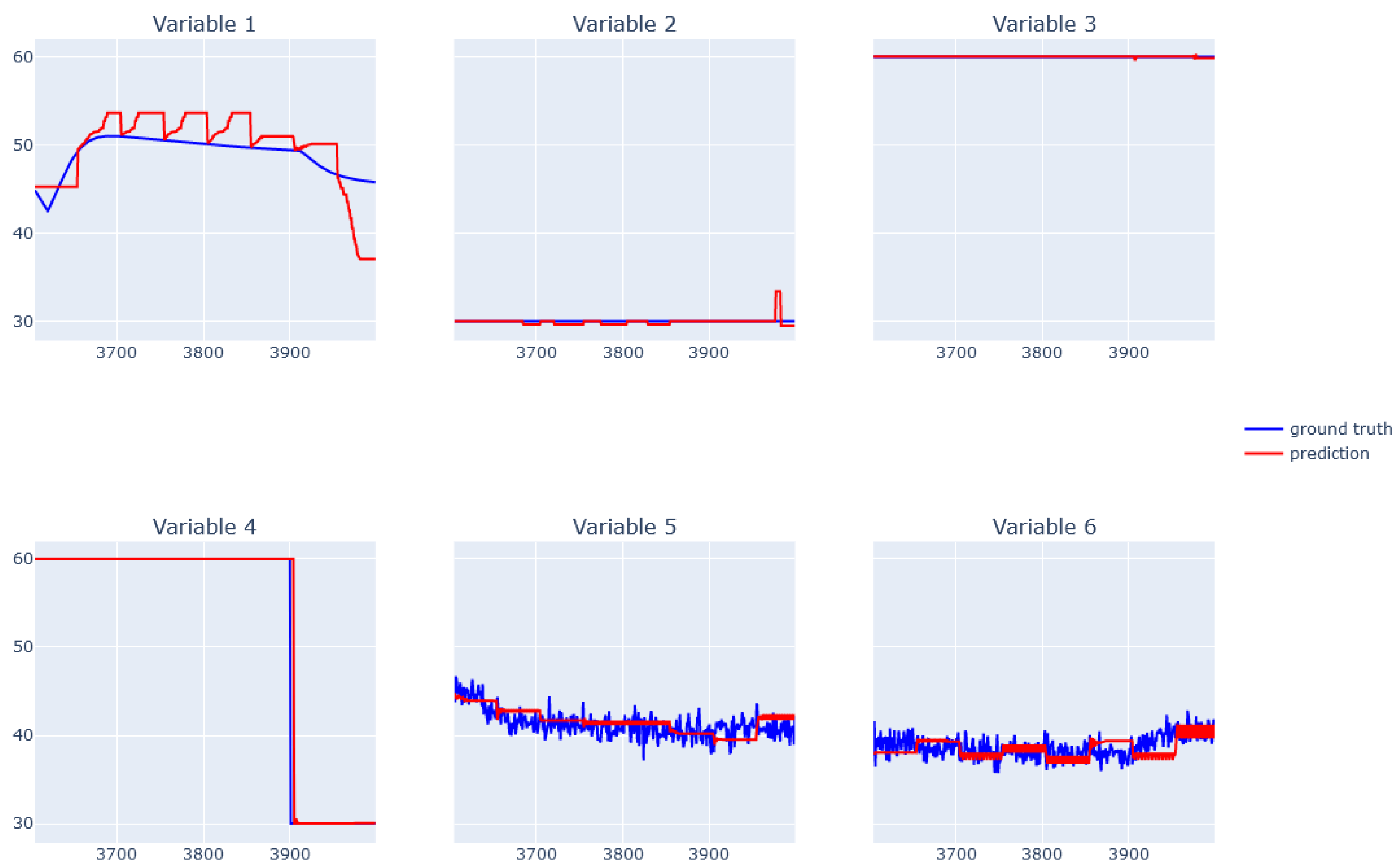
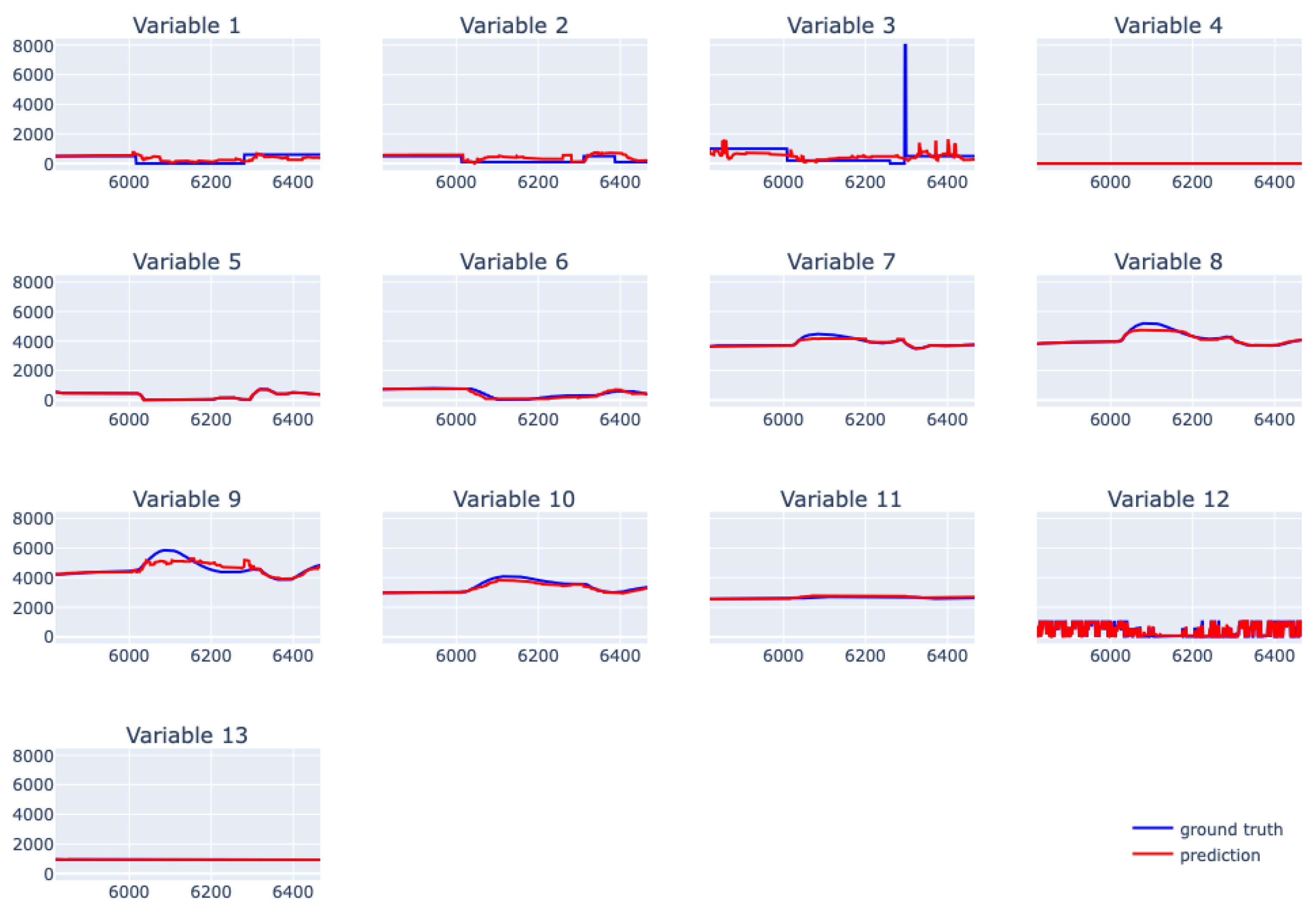
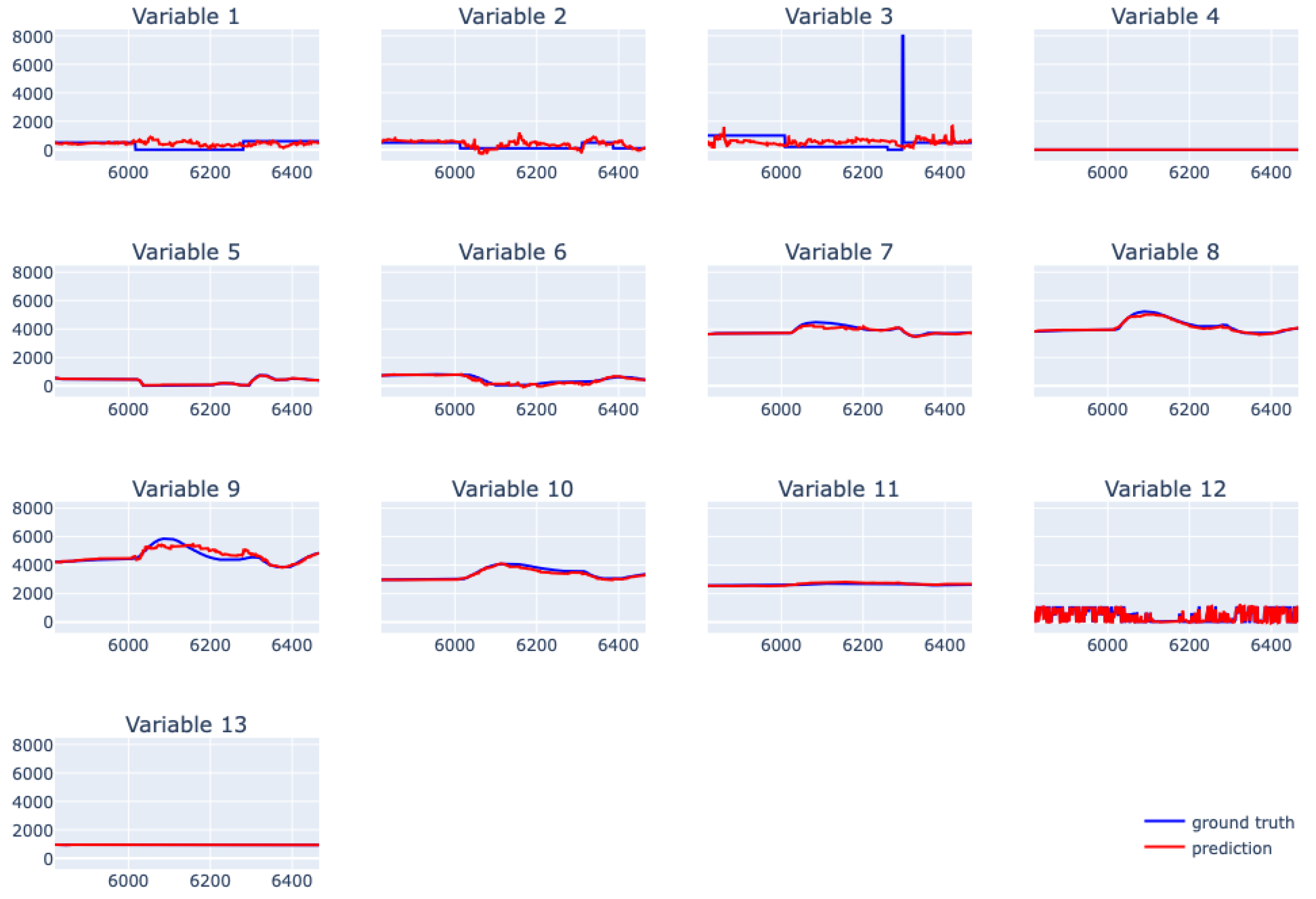
6.5. XGBoost for Real Data from Physical Bench Working in Network
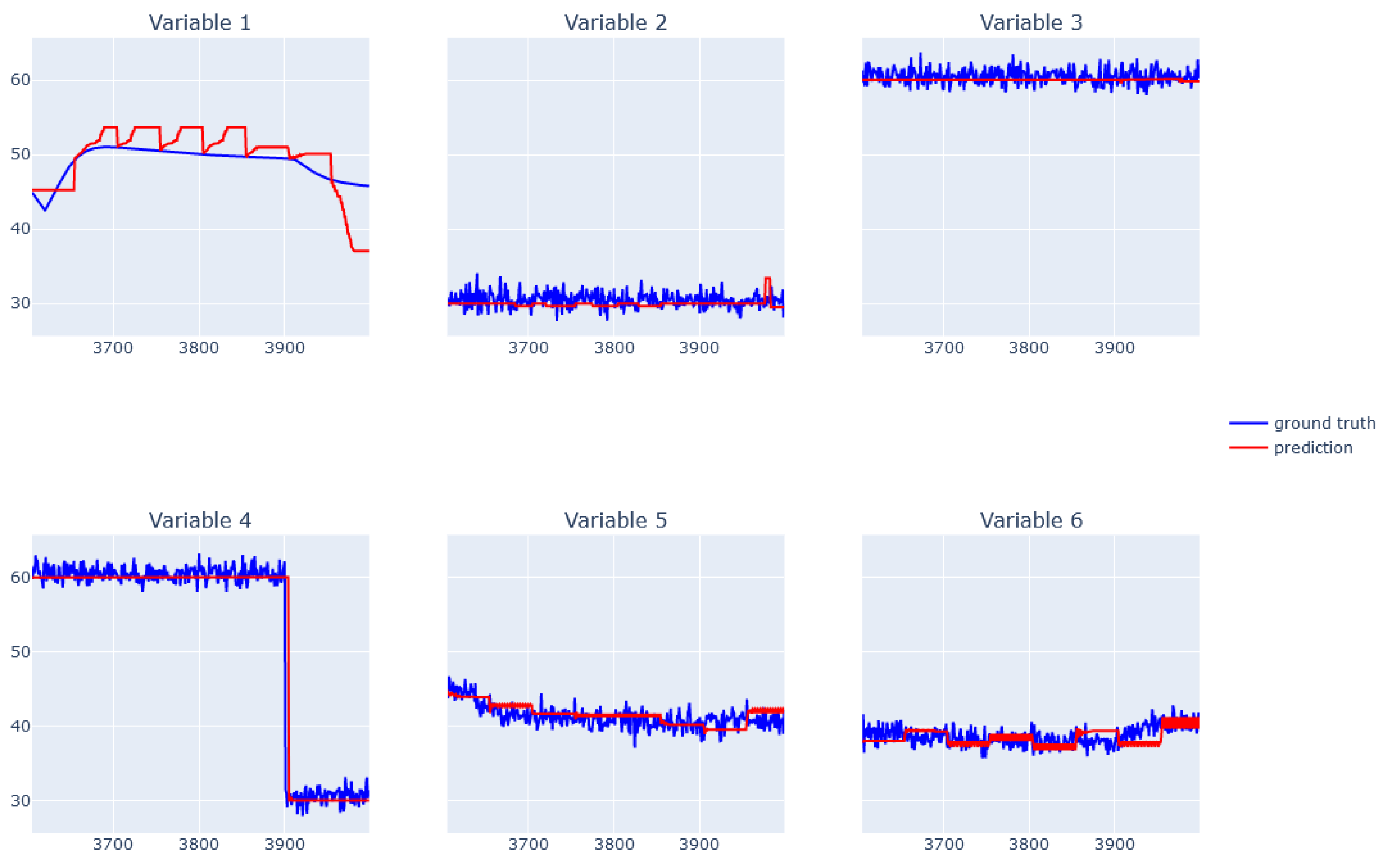
6.6. EBM for Real Data from Physical Bench Working in Network
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Wang, D. Building value in a world of technological change: Data analytics and Industry 4.0. IEEE Eng. Manag. Rev. 2018, 46, 32–33. [Google Scholar] [CrossRef]
- Ancarani, A.; Di Mauro, C. Reshoring and Industry 4.0: How often do they go together? IEEE Eng. Manag. Rev. 2018, 46, 87–96. [Google Scholar] [CrossRef]
- Sony, M.; Naik, S.S. Ten lessons for managers while implementing Industry 4.0. IEEE Eng. Manag. Rev. 2019, 47, 45–52. [Google Scholar] [CrossRef]
- Malik, A.K.; Emmanuel, N.; Zafar, S.; Khattak, H.A.; Raza, B.; Khan, S.; Al-Bayatti, A.H.; Alassafi, M.O.; Alfakeeh, A.S.; Alqarni, M.A. From Conventional to State-of-the-Art IoT Access Control Models. Electronics 2020, 9, 1693. [Google Scholar] [CrossRef]
- Zafar, F.; Khan, A.; Anjum, A.; Maple, C.; Shah, M.A. Location Proof Systems for Smart Internet of Things: Requirements, Taxonomy, and Comparative Analysis. Electronics 2020, 9, 1776. [Google Scholar] [CrossRef]
- Knapp, E.D.; Langill, J.T. Industrial Network Security Securing Critical Infrastructure Networks for Smart Grid, SCADA, and Other Industrial Control Systems; Elsevier: Amsterdam, The Netherlands, 2015. [Google Scholar]
- SP 800-82 Rev. 2; Guide to Industrial Control Systems (ICS) Security. National Institute of Standards and Technology: Gaithersburg, MD, USA, 2015.
- ISA-99.00.01; Security for Industrial Automation and Control Systems—Part 1: Terminology, Concepts and Models. American National Standard: Washington, DC, USA, 2007.
- Tsiknas, K.; Taketzis, D.; Demertzis, K.; Skianis, C. Cyber Threats to Industrial IoT: A Survey on Attacks and Countermeasures. IoT 2021, 2, 163–186. [Google Scholar] [CrossRef]
- Inayat, U.; Zia, M.F.; Mahmood, S.; Khalid, H.M.; Benbouzid, M. Learning-Based Methods for Cyber Attacks Detection in IoT Systems: A Survey on Methods, Analysis, and Future Prospects. Electronics 2022, 11, 1502. [Google Scholar] [CrossRef]
- Maxwell, A.E.; Sharma, M.; Donaldson, K.A. Explainable Boosting Machines for Slope Failure Spatial Predictive Modeling. Remote Sens. 2021, 13, 4991. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Slammer Worm and David-Besse Nuclear Plant. 2015. Available online: http://large.stanford.edu/courses/2015/ph241/holloway2/ (accessed on 20 October 2021).
- Neubert, T.; Claus Vielhauer, C. Kill Chain Attack Modelling for Hidden Channel Attack Scenarios in Industrial Control Systems. IFAC-PapersOnLine 2020, 53, 11074–11080. [Google Scholar] [CrossRef]
- Nourian, A.; Madnick, S. A systems theoretic approach to the security threats in cyber physical systems applied to stuxnet. IEEE Trans. Dependable Secur. Comput. 2015, 15, 2–13. [Google Scholar] [CrossRef]
- Chen, T. Stuxnet, the real start of cyber warfare? IEEE Netw. 2010, 24, 2–3. [Google Scholar]
- Lee, R.M.; Assante, M.J.; Conway, T. German steel mill cyberattack. Ind. Control Syst. 2014, 30, 62. [Google Scholar]
- Xiang, Y.; Wang, L.; Liu, N. Coordinated attacks on electric power systems in a cyber-physical environment. Electr. Power Syst. Res. 2017, 149, 156–168. [Google Scholar] [CrossRef]
- Yang, D.; Usynin, A.; Hines, J. Anomaly-based intrusion detection for SCADA systems. In Proceedings of the Fifth International Topical Meeting on Nuclear Plant Instrumentation, Control and Human–Machine Interface Technologies, Albuquerque, NM, USA, 12–16 November 2006; pp. 12–16. Available online: https://citeseerx.ist.psu.edu/document?repid=rep1&type=pdf&doi=1af84c9c62fb85590c41b7cfc9357919747842b2 (accessed on 10 February 2023).
- Tsang, C.; Kwong, S. Multi-agent intrusion detection system for an industrial network using ant colony clustering approach and unsupervised feature extraction. In Proceedings of the IEEE International Conference on Industrial Technology, Hong Kong, China, 14–17 December 2005; pp. 51–56. [Google Scholar]
- Gao, W.; Morris, T.; Reaves, B.; Richey, D. On SCADA control system command and response injection and intrusion detection. In Proceedings of the eCrime Researchers Summit, Dallas, TX, USA, 18–20 October 2010; pp. 1–9. [Google Scholar]
- Digital Bond, Modbus TCP Rules, Sunrise, Florida. Available online: www.digitalbond.com/tools/quickdraw/modbus-tcp-rules (accessed on 10 February 2023).
- Javadpour, A.; Wang, G. cTMvSDN: Improving resource management using combination of Markov-process and TDMA in software-defined networking. J. Supercomput. 2021, 78, 3477–3499. [Google Scholar] [CrossRef]
- Naess, E.; Frincke, D.; McKinnon, A.; Bakken, D. Configurable middleware-level intrusion detection for embedded systems. In Proceedings of the Twenty-Fifth IEEE International Conference on Distributed Computing Systems, Columbus, OH, USA, 6–10 June 2005; pp. 144–151. [Google Scholar]
- Valdes, A.; Cheung, S. Communication pattern anomaly detection in process control systems. In Proceedings of the IEEE Conference on Technologies for Homeland Security, Waltham, MA, USA, 11–12 May 2009; pp. 22–29. [Google Scholar]
- Valdes, A.; Cheung, S. Intrusion monitoring in process control systems. In Proceedings of the Forty-Second Hawaii International Conference on System Sciences, Waikoloa, HI, USA, 5–8 January 2009. [Google Scholar]
- Roesch, M. Snort—Lightweight intrusion detection for networks. In Proceedings of the Thirteenth USENIX Conference on System Administration, Seattle, WA, USA, 7–12 December 1999; pp. 226–238. [Google Scholar]
- Alshammari, A.; Aldribi, A. Apply machine learning techniques to detect malicious network traffic in cloud computing. J. Big Data 2021, 8, 90. [Google Scholar] [CrossRef]
- Smolarczyk, M.; Plamowski, S.; Pawluk, J.; Szczypiorski, K. Anomaly Detection in Cyclic Communication in OT Protocols. Energies 2022, 15, 1517. [Google Scholar] [CrossRef]
- Jędrzejczyk, A.; Firek, K.; Rusek, J. Convolutional Neural Network and Support Vector Machine for Prediction of Damage Intensity to Multi-Storey Prefabricated RC Buildings. Energies 2022, 15, 4736. [Google Scholar] [CrossRef]
- Najwa Mohd Rizal, N.; Hayder, G.; Mnzool, M.; Elnaim, B.M.E.; Mohammed, A.O.Y.; Khayyat, M.M. Comparison between Regression Models, Support Vector Machine (SVM), and Artificial Neural Network (ANN) in River Water Quality Prediction. Processes 2022, 10, 1652. [Google Scholar] [CrossRef]
- Adugna, T.; Xu, W.; Fan, J. Comparison of Random Forest and Support Vector Machine Classifiers for Regional Land Cover Mapping Using Coarse Resolution FY-3C Images. Remote Sens. 2022, 14, 574. [Google Scholar] [CrossRef]
- Nhu, V.-H.; Zandi, D.; Shahabi, H.; Chapi, K.; Shirzadi, A.; Al-Ansari, N.; Singh, S.K.; Dou, J.; Nguyen, H. Comparison of Support Vector Machine, Bayesian Logistic Regression, and Alternating Decision Tree Algorithms for Shallow Landslide Susceptibility Mapping along a Mountainous Road in the West of Iran. Appl. Sci. 2020, 10, 5047. [Google Scholar] [CrossRef]
- Dabija, A.; Kluczek, M.; Zagajewski, B.; Raczko, E.; Kycko, M.; Al-Sulttani, A.H.; Tardà, A.; Pineda, L.; Corbera, J. Comparison of Support Vector Machines and Random Forests for Corine Land Cover Mapping. Remote Sens. 2021, 13, 777. [Google Scholar] [CrossRef]
- Rath, S.K.; Sahu, M.; Das, S.P.; Bisoy, S.K.; Sain, M. A Comparative Analysis of SVM and ELM Classification on Software Reliability Prediction Model. Electronics 2022, 11, 2707. [Google Scholar] [CrossRef]
- Shin, S.-Y.; Woo, H.-G. Energy Consumption Forecasting in Korea Using Machine Learning Algorithms. Energies 2022, 15, 4880. [Google Scholar] [CrossRef]
- Jafari, S.; Shahbazi, Z.; Byun, Y.-C. Lithium-Ion Battery Health Prediction on Hybrid Vehicles Using Machine Learning Approach. Energies 2022, 15, 4753. [Google Scholar] [CrossRef]
- Yang, S.; Wu, J.; Du, Y.; He, Y.; Chen, X. Ensemble learning for short-term traffic prediction based on gradient boosting machine. J. Sens. 2017, 2017, 7074143. [Google Scholar] [CrossRef]
- Shahbazi, Z.; Byun, Y.C. Computing focus time of paragraph using deep learning. In Proceedings of the 2019 IEEE Transportation Electrification Conference and Expo, Asia-Pacific (ITEC Asia-Pacific), Seogwipo, Republic of Korea, 8–10 May 2019; pp. 1–4. [Google Scholar]
- Shahbazi, Z.; Byun, Y.C. LDA Topic Generalization on Museum Collections. In Smart Technologies in Data Science and Communication; Springer: Singapore, 2020; pp. 91–98. [Google Scholar]
- Shahbazi, Z.; Byun, Y.C.; Lee, D.C. Toward representing automatic knowledge discovery from social media contents based on document classification. Int. J. Adv. Sci. Technol. 2020, 29, 14089–14096. [Google Scholar]
- Shahbazi, Z.; Byun, Y.C. Topic prediction and knowledge discovery based on integrated topic modeling and deep neural networks approaches. J. Intell. Fuzzy Syst. 2021, 41, 2441–2457. [Google Scholar] [CrossRef]
- Walters, B.; Ortega-Martorell, S.; Olier, I.; Lisboa, P.J.G. How to Open a Black Box Classifier for Tabular Data. Algorithms 2023, 16, 181. [Google Scholar] [CrossRef]

































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Gamma | Max Depth | Min Child Weight | Subsample |
|---|---|---|---|---|
| 1 | 0.5 | 3 | 10 | 0.6 |
| 2 | 2 | 5 | 1 | 0.6 |
| 3 | 5 | 5 | 5 | 0.6 |
| 4 | 0.5 | 3 | 5 | 0.6 |
| 5 | 0.5 | 3 | 1 | 1.0 |
| 6 | 0.5 | 4 | 1 | 1.0 |
| Variable | Interactions | Learning Rate | Max Interactions Bins | Max Leaves | Min Samples Leaf |
|---|---|---|---|---|---|
| 1 | 5 | 0.03 | 10 | 3 | 2 |
| 2 | 5 | 0.03 | 20 | 3 | 2 |
| 3 | 5 | 0.03 | 20 | 3 | 2 |
| 4 | 5 | 0.03 | 10 | 5 | 2 |
| 5 | 5 | 0.03 | 15 | 3 | 2 |
| 6 | 5 | 0.03 | 10 | 3 | 2 |
| Variable | Gamma | Max Depth | Min Child Weight | Subsample |
|---|---|---|---|---|
| 1 | 0.5 | 3 | 10 | 1 |
| 2 | 0.5 | 5 | 1 | 0.6 |
| 3 | 2 | 4 | 10 | 0.6 |
| 4 | 0.5 | 3 | 1 | 0.8 |
| 5 | 5 | 3 | 1 | 0.6 |
| 6 | 1 | 3 | 10 | 0.6 |
| 7 | 0.5 | 4 | 10 | 0.8 |
| 8 | 5 | 4 | 5 | 0.6 |
| 9 | 2 | 5 | 10 | 0.6 |
| 10 | 5 | 4 | 10 | 0.6 |
| 11 | 1.5 | 3 | 5 | 0.6 |
| 12 | 0.5 | 3 | 10 | 0.6 |
| 13 | 1.5 | 3 | 10 | 0.8 |
| Variable | RMSE |
|---|---|
| 1 | 230.400962 |
| 2 | 349.570717 |
| 3 | 604.089026 |
| 4 | 0.000013 |
| 5 | 28.216980 |
| 6 | 92.831780 |
| 7 | 105.422982 |
| 8 | 152.271105 |
| 9 | 300.535097 |
| 10 | 147.651014 |
| 11 | 40.982248 |
| 12 | 107.979691 |
| 13 | 4.392808 |
| Variable | Interactions | Learning Rate | Max Interactions Bins | Max Leaves | Min Samples Leaf |
|---|---|---|---|---|---|
| 1 | 10 | 0.01 | 20 | 3 | 2 |
| 2 | 10 | 0.01 | 20 | 3 | 2 |
| 3 | 10 | 0.01 | 10 | 3 | 2 |
| 4 | 10 | 0.01 | 20 | 3 | 2 |
| 5 | 10 | 0.01 | 10 | 3 | 2 |
| 6 | 10 | 0.01 | 15 | 3 | 2 |
| 7 | 10 | 0.01 | 20 | 3 | 2 |
| 8 | 10 | 0.01 | 20 | 3 | 2 |
| 9 | 10 | 0.01 | 20 | 3 | 2 |
| 10 | 5 | 0.01 | 20 | 3 | 2 |
| 11 | 10 | 0.01 | 15 | 3 | 2 |
| 12 | 10 | 0.01 | 20 | 3 | 2 |
| 13 | 10 | 0.01 | 20 | 3 | 2 |
| Variable | RMSE |
|---|---|
| 1 | 323.577118 |
| 2 | 237.924763 |
| 3 | 675.113722 |
| 4 | 0.000000 |
| 5 | 38.752803 |
| 6 | 96.573082 |
| 7 | 128.493062 |
| 8 | 83.705900 |
| 9 | 277.835994 |
| 10 | 119.786830 |
| 11 | 57.369146 |
| 12 | 121.508004 |
| 13 | 4.637388 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Smolarczyk, M.; Pawluk, J.; Kotyla, A.; Plamowski, S.; Kaminska, K.; Szczypiorski, K. Machine Learning Algorithms for Identifying Dependencies in OT Protocols. Energies 2023, 16, 4056. https://doi.org/10.3390/en16104056
Smolarczyk M, Pawluk J, Kotyla A, Plamowski S, Kaminska K, Szczypiorski K. Machine Learning Algorithms for Identifying Dependencies in OT Protocols. Energies. 2023; 16(10):4056. https://doi.org/10.3390/en16104056
Chicago/Turabian StyleSmolarczyk, Milosz, Jakub Pawluk, Alicja Kotyla, Sebastian Plamowski, Katarzyna Kaminska, and Krzysztof Szczypiorski. 2023. "Machine Learning Algorithms for Identifying Dependencies in OT Protocols" Energies 16, no. 10: 4056. https://doi.org/10.3390/en16104056
APA StyleSmolarczyk, M., Pawluk, J., Kotyla, A., Plamowski, S., Kaminska, K., & Szczypiorski, K. (2023). Machine Learning Algorithms for Identifying Dependencies in OT Protocols. Energies, 16(10), 4056. https://doi.org/10.3390/en16104056