2.1. Battery EOL Prediction Models
To address the first research question, we investigate existing battery EOL prediction models. Battery EOL prediction is an active research area with many relevant studies using machine learning approaches emerging in recent years. With intelligent techniques [
2,
3,
4], Refs. [
5,
6] used simpler algorithms that achieved better accuracy levels compared to adaptive filter techniques but are lacking in analyzing uncertainty of the measurement results [
7]. Generally, these algorithms also require more training samples to improve accuracy.
Adaptive filtering models [
8,
9,
10] improved the accuracy of battery health prognostics. However, they are highly influenced by the variability in current and temperatures. In [
11], Ng et al. used a Naive Bayes (NB) model and showed that it achieves comparable results to Support Vector Machine (SVM). However, they also mentioned that NB loses on accuracy at the critical point when the capacity of the battery reaches the specified threshold; SVM has better predictive power at this phase.
The Gaussian Process Mixture (GPM) approach in [
12] compared its performance with Gaussian Process Regression (GPR) and SVM, where the GPM method produced better prediction accuracies. The accuracy metric used is by comparing between the actual number of charge discharge cycles and the predicted number of charge discharge cycles until the battery reaches the EOL threshold. GPM achieved less than one cycle of error while GPR and SVM obtained more than three cycles of error. However, the prediction accuracy of GPM also depends on the amount of training data available to improve its performance.
With the widespread use of neural network approaches in recent years, Zhang et al. [
2] used the Recurrent Neural Network (RNN) approach, where results were compared against a simple recurrent neural network (SimRNN), particle filter (PF) and SVM approach. Generally, the long short-term memory recurrent neural network (LSTM-RNN) approach provided better prediction results but still suffers from longer computational time. In [
13], the authors applied transfer learning using neural network, but the model still required a lot of training data and known EOL points, which is sometimes a challenge to obtain especially in testing environments.
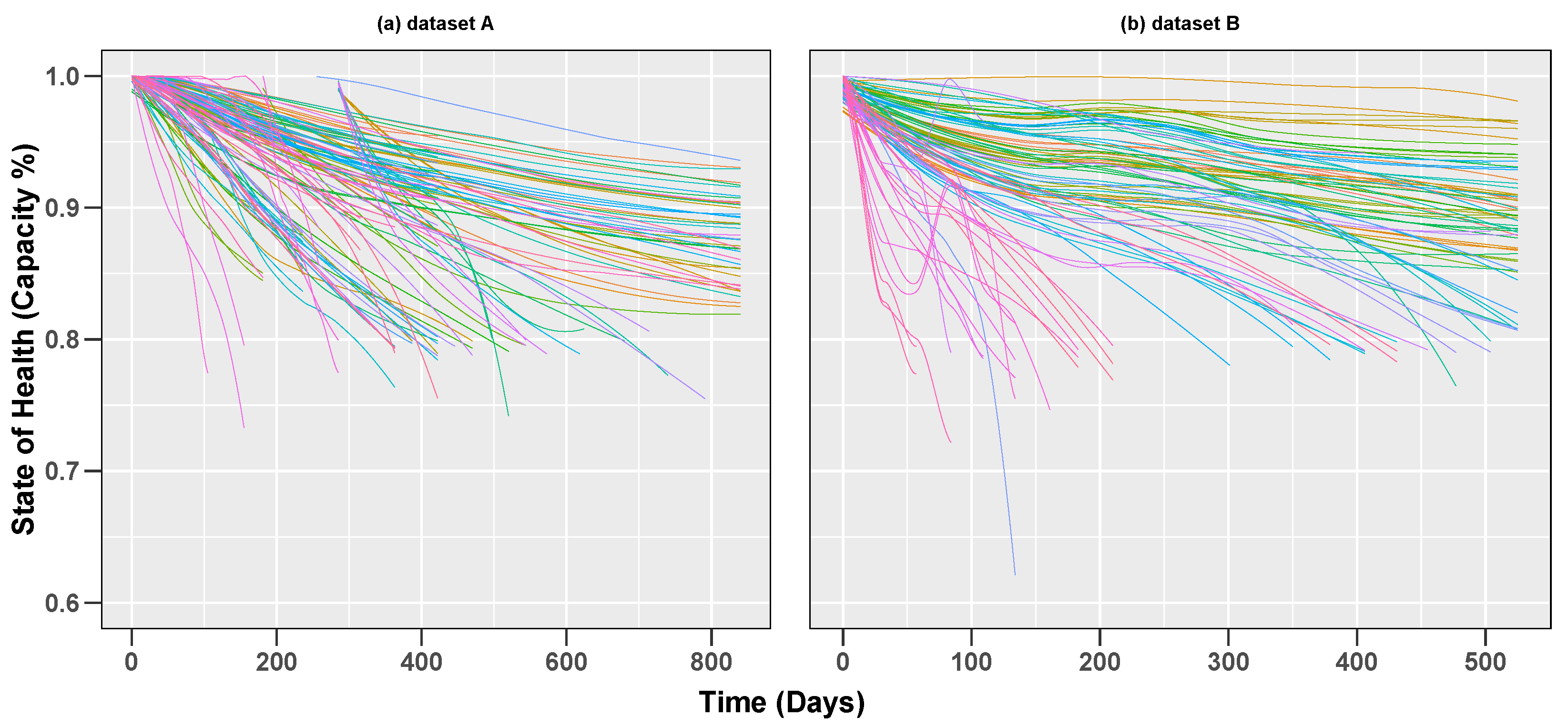
Common among these studies is the availability of cell data reaching EOL. Usually, this is not the case in practice though. The datasets used were obtained from internal testing experiments. The number of cells used to build and test the prediction models were also small. This is important as battery aging characteristics could differ from one battery to another; therefore, using more battery cells would give better generalization of the expected battery lifespan.
A closely related work by Severson et al. [
14] aimed to predict battery cell EOL at an earlier stage by just using the battery cell charge discharge cycle data from the first 100 cycles. The features are based on the log variance of the discharge voltage curve that has a high correlation with the battery cycle life. The authors used an Elastic Net regression method to select the relevant features which combine the strengths of the lasso and ridge regression methods. They developed three models that show increasing prediction accuracy as more features were used, but these features were mainly derived from the discharge voltage curve. The results of this study showed that using data generated from cell testing without any prior knowledge of the aging and degradation mechanisms can be used to predict battery EOL. However, it did not consider other aging factors that can occur in real life battery usage. This information is especially useful for determining battery warranty periods by battery manufacturers and for engineers to optimize battery design for longer lifetimes.
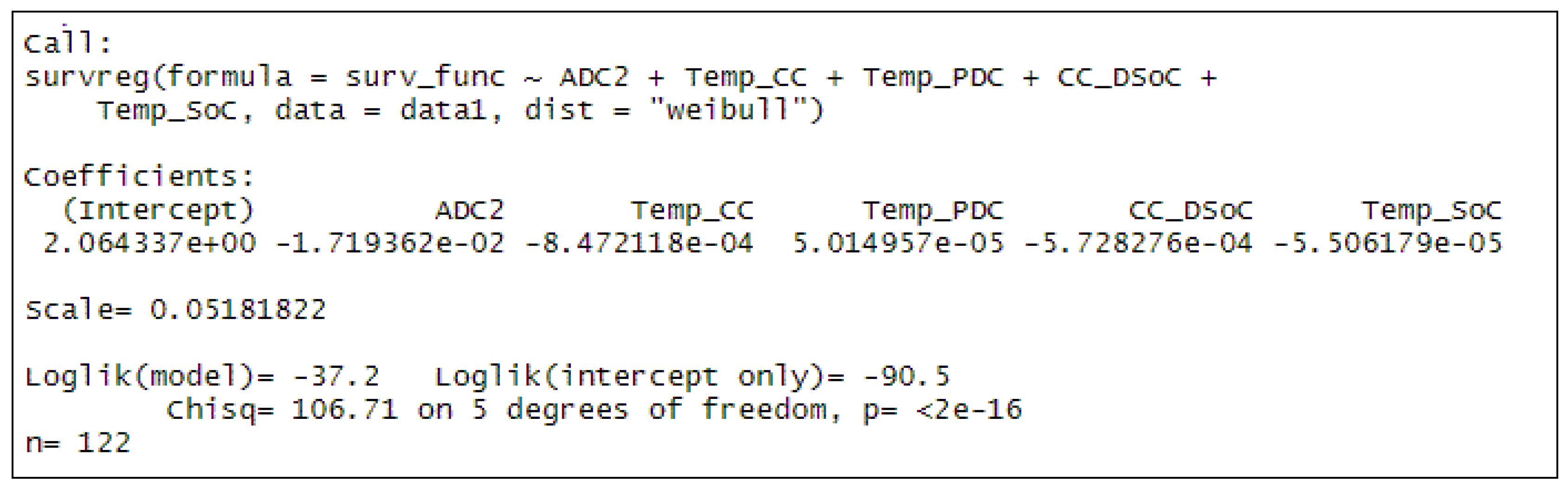
Survival analysis has been used for battery lifetime prediction in the past. For example, Voronov et al. used heavy fleet data for a specific type of cell chemistry [
15], while Zhang et al. combined survival analysis with neural networks [
16]. Here, we use survival analysis for RQ1, while making sure that the models are transparent enough for transfer, as demanded by RQ2.
For the purpose of model verification and validation, several methods can be considered. Based on the state-of-the-art approaches in reliability engineering, the AVL Load Matrix
TM methodology [
17], for example, provides a systematic approach for the definition, optimization and monitoring of the reliability targets in the product development life cycle. This process is designed to ensure high accelerated validation of components as well as target oriented design. Furthermore, it provides a predictive lifetime solution for durability/reliability-relevant components using a physics of failure-based damage model approach. The key elements being the trade-off between the in-field customer usage profile, the optimized and balanced test program and the demonstration of the reliability/durability coverage.
For data-driven models, several recent works included model validation and verification techniques [
18,
19]. In [
18], Weihan et al. employed a processor-in-the-loop approach and combined nominal and noisy data to validate model robustness. In [
19], the authors implemented a validation and verification framework using Monte-Carlo simulation and K-L divergence to ensure the accuracy of the prediction models developed.
2.2. Basics of Transfer Learning
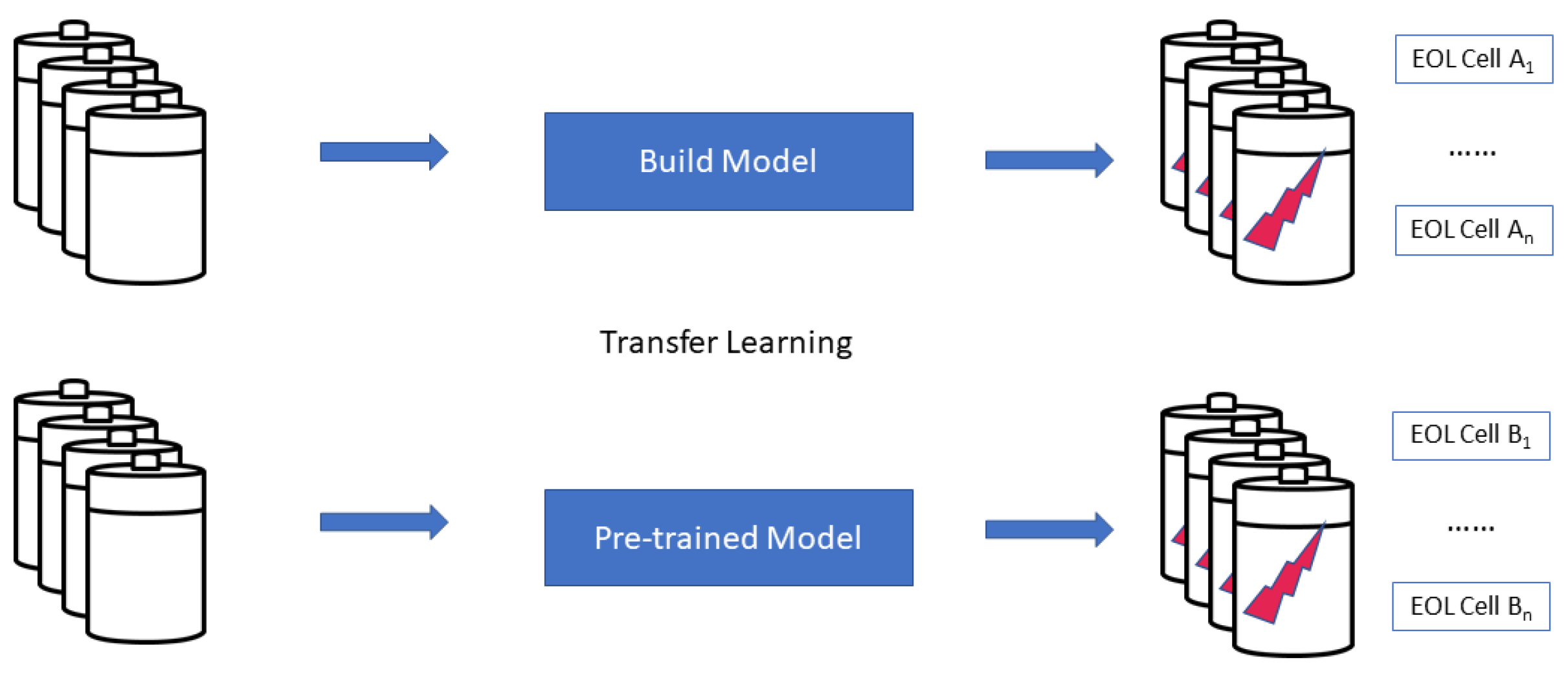
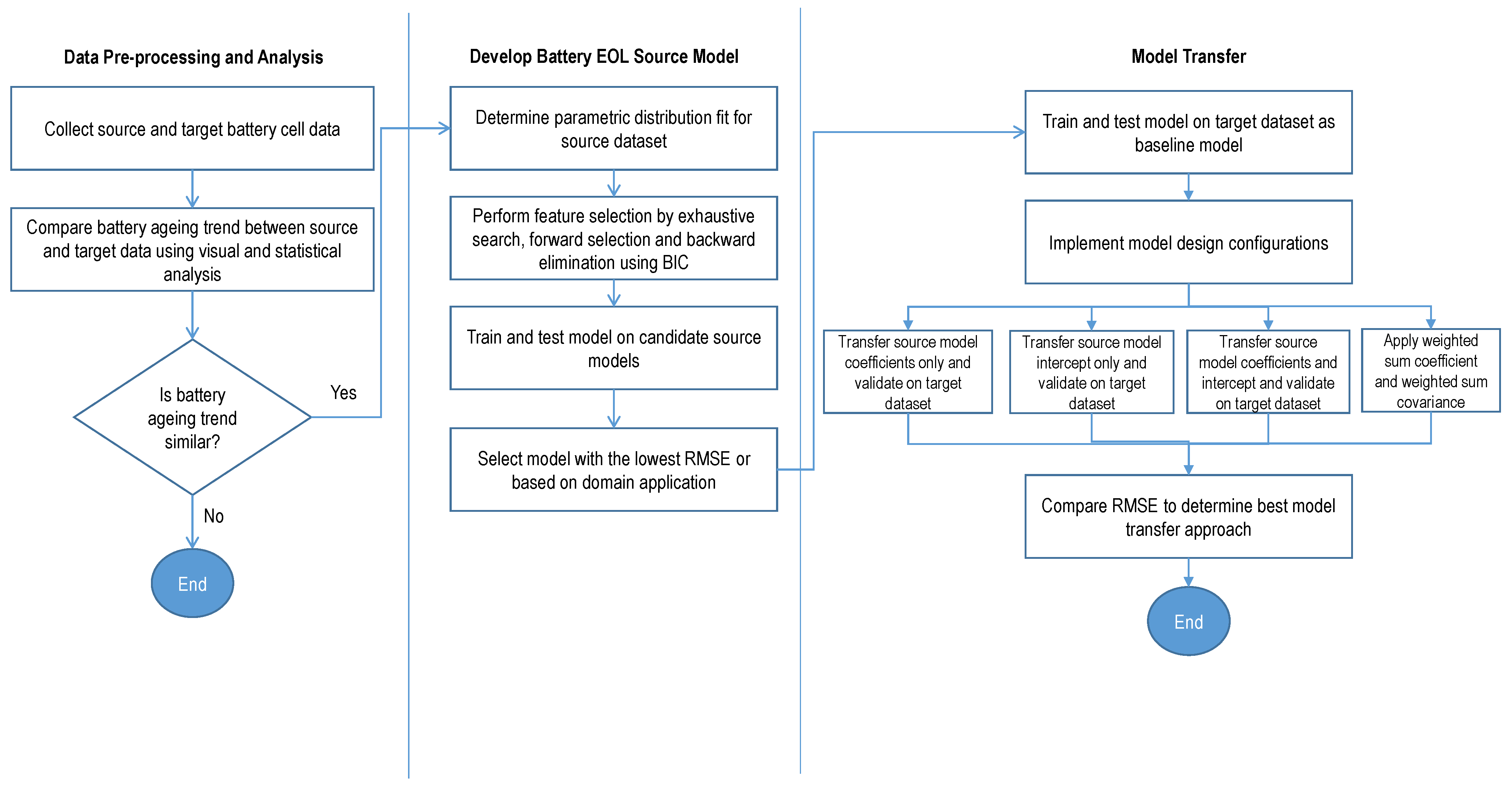
RQ2 refers to the transferability of prediction models. To do this, we investigate the use of transfer learning as an approach to facilitate the transfer of knowledge from the source domain to a target domain. The target dataset usually consists of a much smaller data sample (compared to the source dataset).
Transfer learning involves determining when, what and how knowledge should be transferred from a source domain to a target domain [
20]. In this paper, the authors discussed the fundamental questions of
what to transfer? and
how to transfer?. The question on
when to transfer? can be addressed upon evaluating the prediction performance of the target model. If the predictions for the target dataset becomes worse by using a transfer model compared to using the model trained on the target dataset, then we can conclude that using a transfer learning approach may not be the best approach. This is because it can lead to a situation referred to as negative transfer. To answer the question on
what to transfer?, we perform an initial analysis on the source and target dataset. We would either have the same set of features or overlapping features in the source and target datasets.
There are three main ways for a model to be transferred from the source domain to the target domain as described in [
20]. The instance based method aims to leverage overlapping features between the source and target dataset where a part of the source dataset is assumed to be reusable for learning the target dataset. The instance transfer can be performed using two major techniques, which are the instance re-weighting and importance sampling [
20].
The feature based method considers projecting features to provide a common representation for the model transfer. The first step using this method is to identify by learning a set of ideal or good features from the source domain. The definition of good or ideal features depends on the domain experts. This set of features are then transferred to the target domain by means of encoding the learned feature representation [
20].
The two approaches above need information at the data level, and because of this, it requires domain knowledge. The third approach, i.e., the model parameter-based method, rather concentrates at the parameter level. At the model level, the main assumption is that the source and target tasks have model hyper-parameter values that follow a common distribution shape. Therefore, the transfer of knowledge is performed by re-using the hyper-parameter values of the source model into the target model [
20].











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}