
Multi-Step Short-Term Building Energy Consumption Forecasting Based on Singular Spectrum Analysis and Hybrid Neural Network


Abstract
:1. Introduction
- We proposed a new hybrid neural network model for real-world building energy consumption forecasting based on SSA. Compared with traditional forecasting models, the proposed model achieved the highest prediction accuracy and had stronger peak and valley capture ability, which effectively alleviated the lag of extreme point data forecasting;
- The simulation results demonstrated that the proposed model still had excellent forecasting precision and stability in the multi-step ahead forecasting scenario, meeting the basic building energy consumption forecasting requirements;
- We compared and analyzed the forecasting effects of neural network models optimized by five decomposition algorithms in the multi-step ahead forecasting scenario. The simulation results showed that the SSA method was a suitable feature extractor that reduced the computational burden and improved the forecast accuracy of the model.
2. Related Work
3. Methodology
3.1. Singular Spectrum Analysis
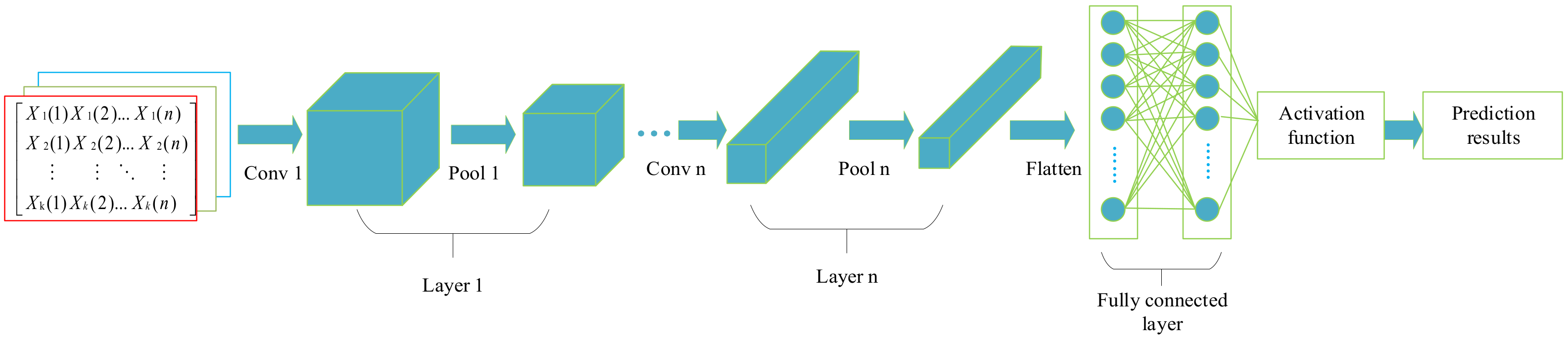
3.2. Convolutional Neural Network
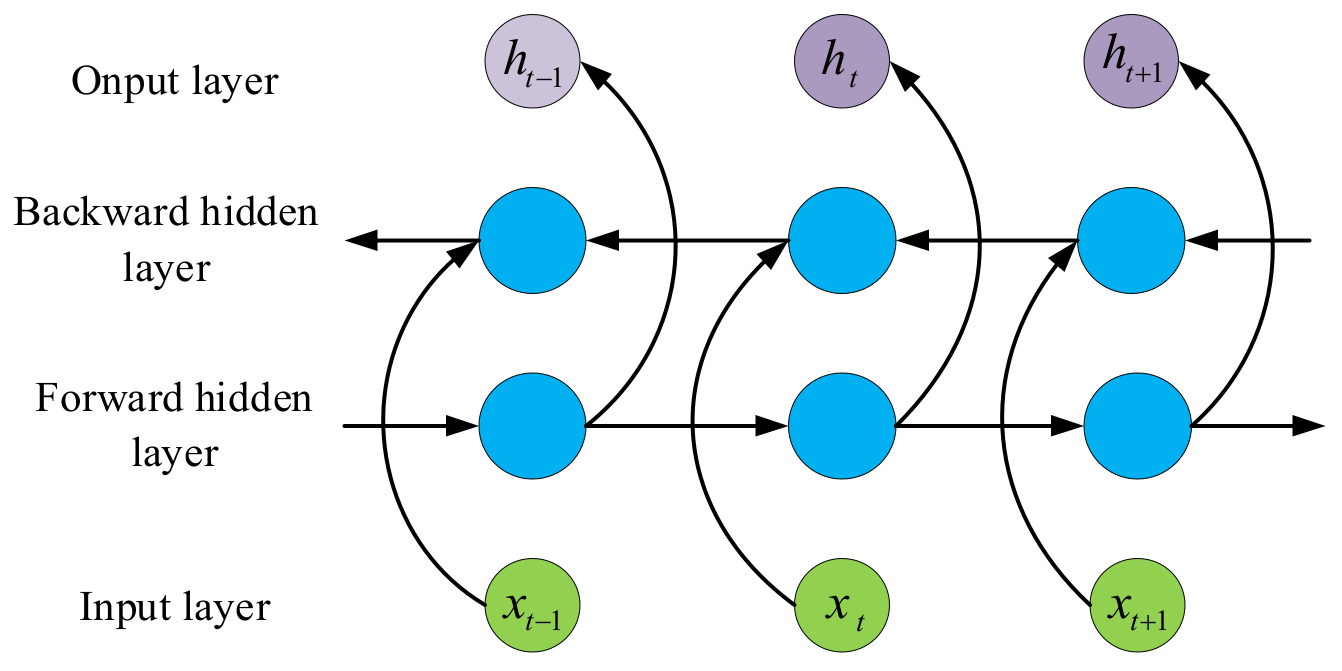
3.3. Bidirectional Gated Neural Network
3.4. Multi-Step Forecasting Strategy
4. The Hybrid Multi-Step Forecast Model
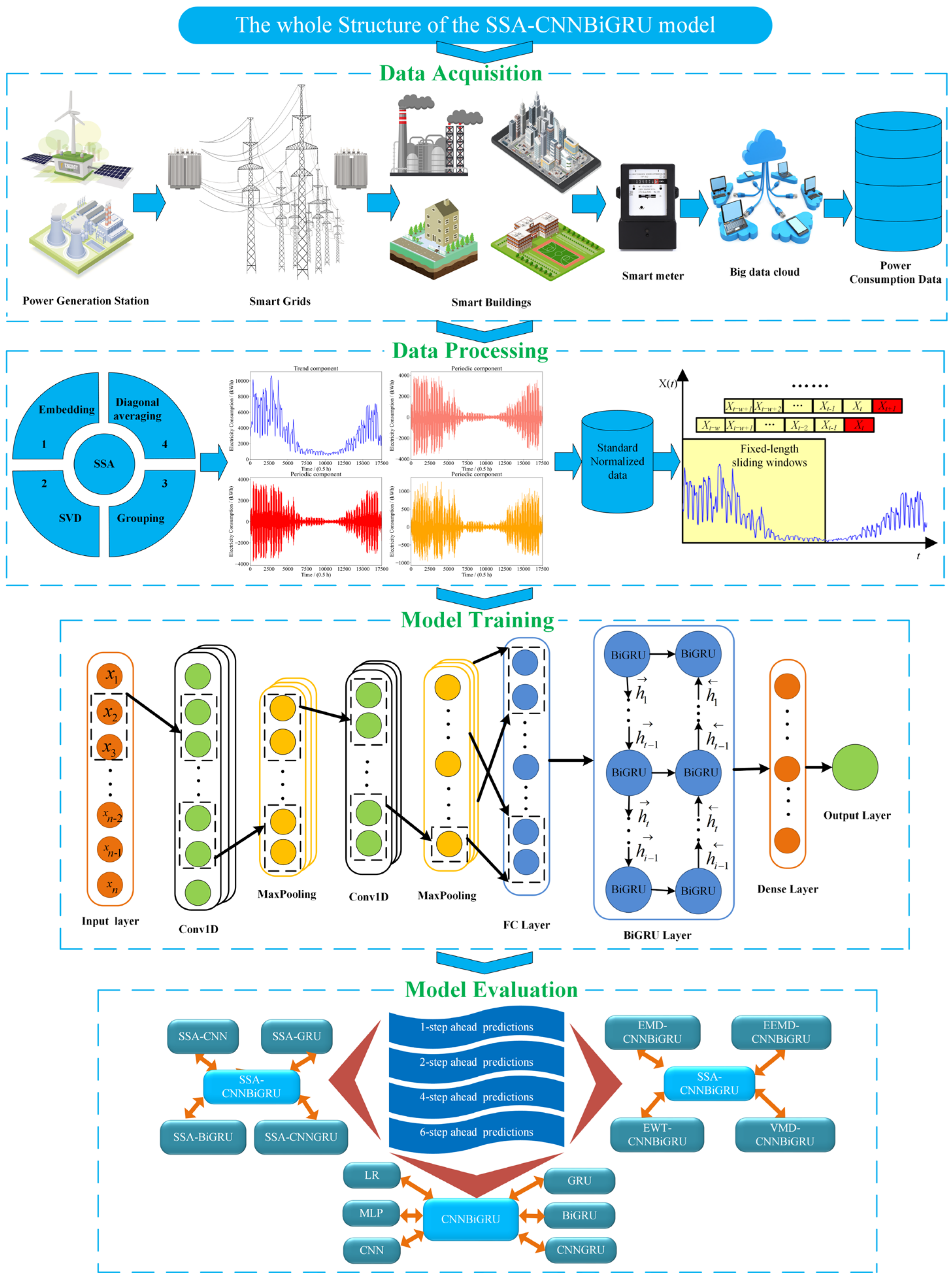
4.1. The Framework of the Proposed Model
4.2. SSA Data Preprocessing
4.3. Experimental Environment and Network Hyperparameter Setting
5. Case Studies and Results
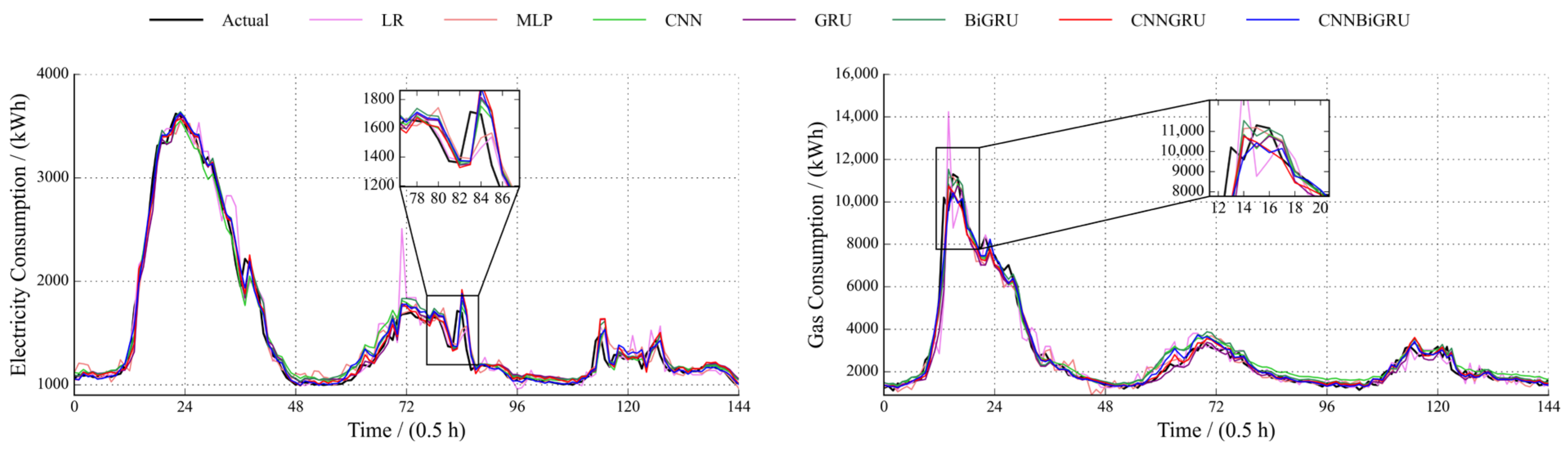
5.1. Comparison of Direct Forecast Results through Different Models
5.2. Comparison of Forecast Results of Different Models under Singular Spectrum Decomposition
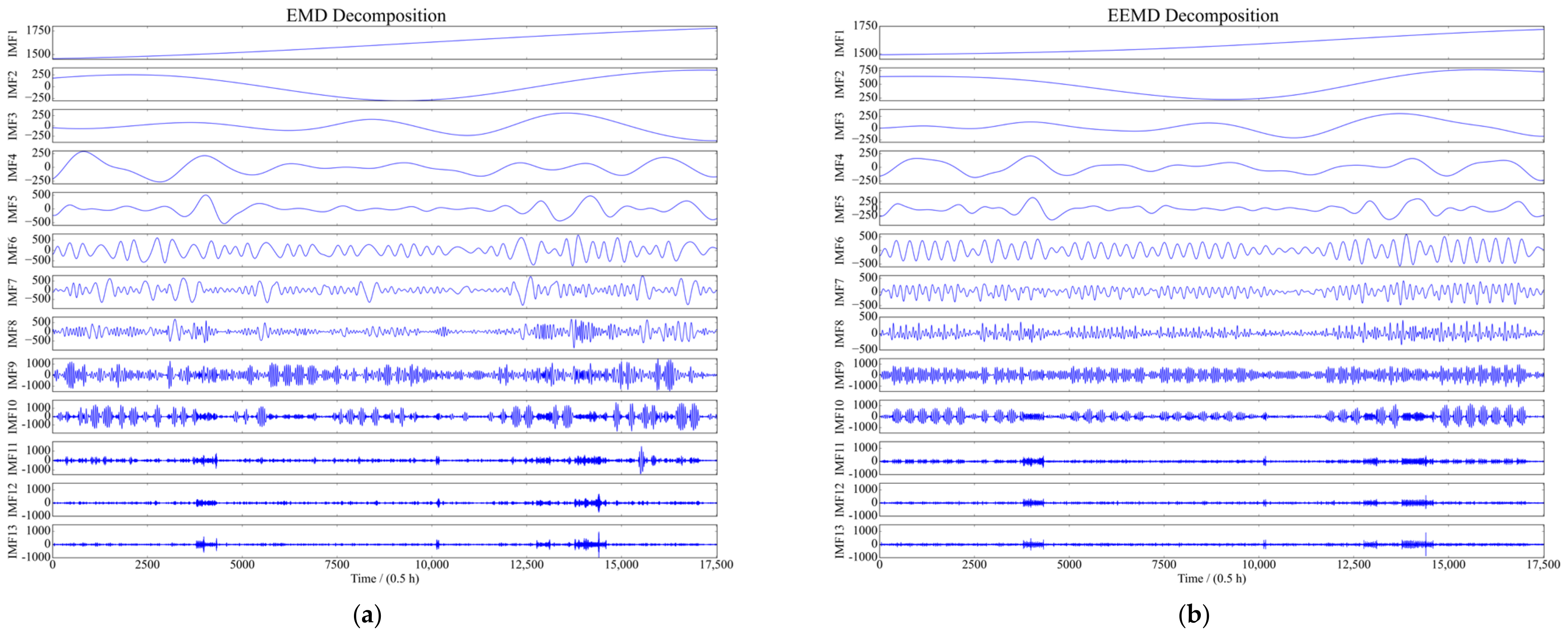
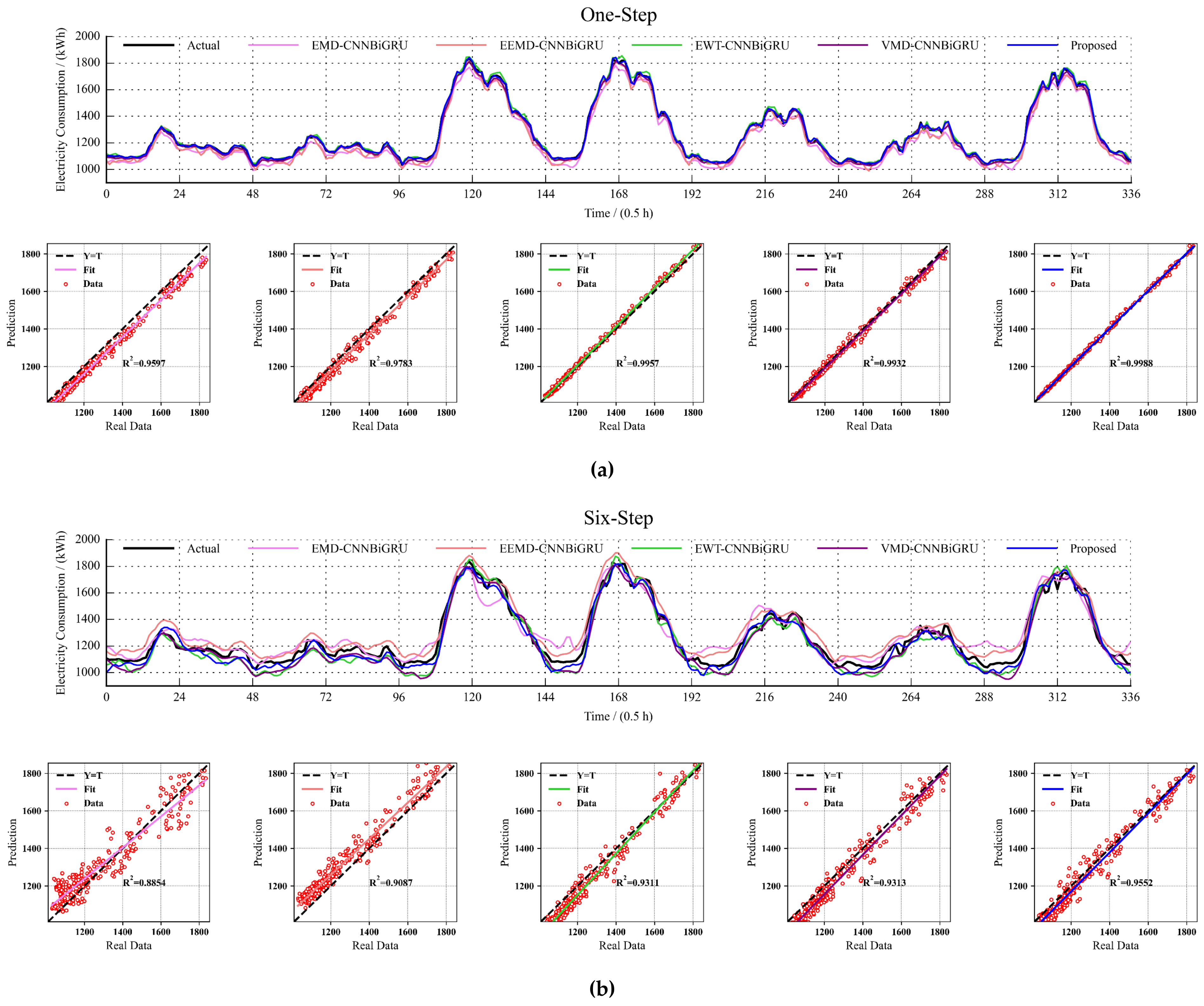
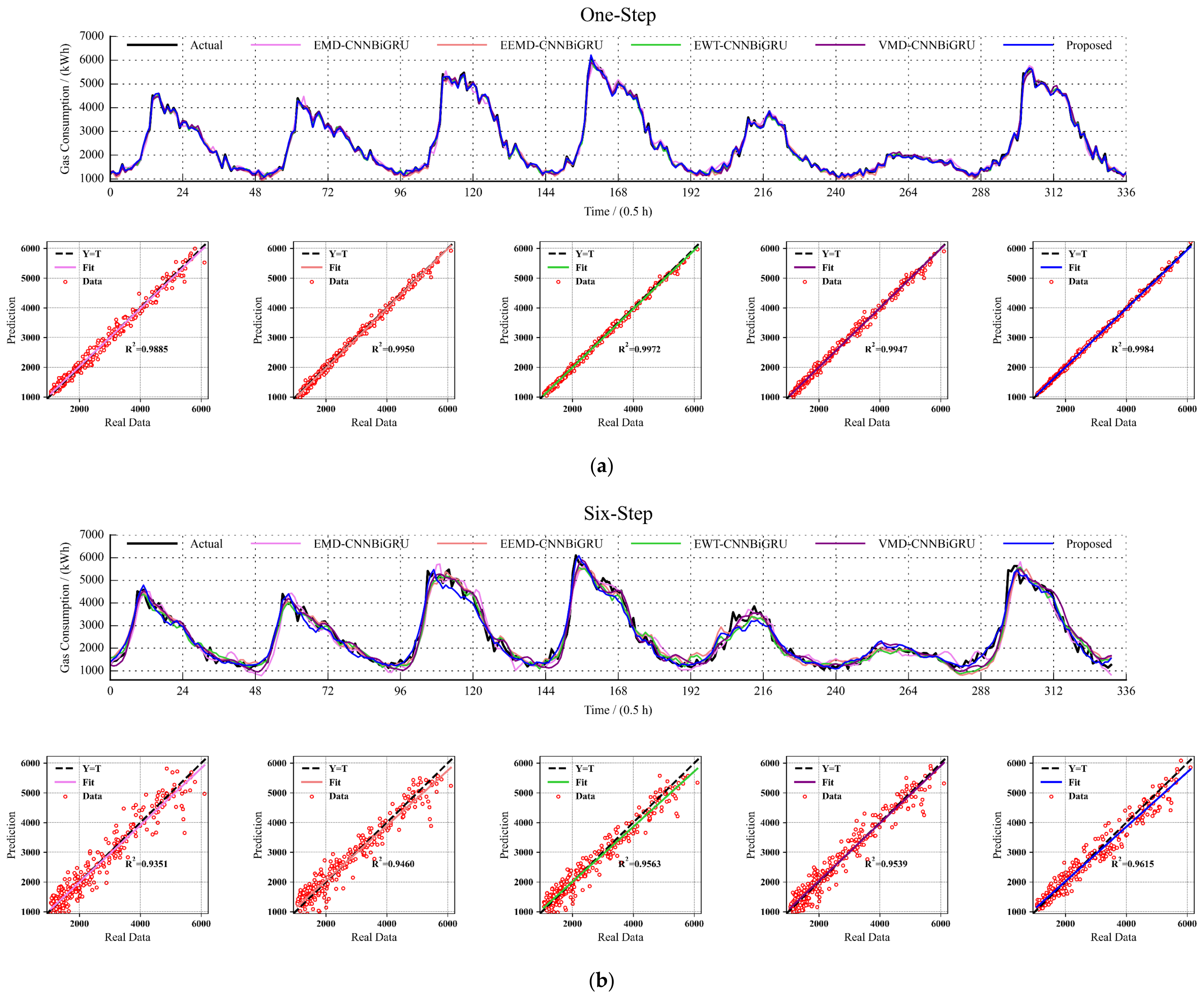
5.3. Comparison of Forecast Results under Different Decomposition Algorithms
6. Conclusions and Future Works
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Aversa, P.; Donatelli, A.; Piccoli, G.; Luprano, V.A.M. Improved Thermal Transmittance Measurement with HFM Technique on Building Envelopes in the Mediterranean Area. Sel. Sci. Pap.-J. Civ. Eng. 2016, 11, 39–52. [Google Scholar] [CrossRef] [Green Version]
- Runge, J.; Zmeureanu, R. A Review of Deep Learning Techniques for Forecasting Energy Use in Buildings. Energies 2021, 14, 608. [Google Scholar] [CrossRef]
- Bourdeau, M.; Zhai, X.Q.; Nefzaoui, E.; Guo, X.; Chatellier, P. Modeling and forecasting building energy consumption: A review of data-driven techniques. Sustain. Cities Soc. 2019, 48, 101533. [Google Scholar] [CrossRef]
- López Gómez, J.; Troncoso Pastoriza, F.; Fariña, E.A.; Oller, P.E.; Álvarez, E.G. Use of a numerical weather prediction model as a meteorological source for the estimation of heating demand in building thermal simulations. Sustain. Cities Soc. 2020, 62, 102403. [Google Scholar] [CrossRef]
- Li, Y.; Tong, Z.; Tong, S.; Westerdahl, D. A data-driven interval forecasting model for building energy prediction using attention-based LSTM and fuzzy information granulation. Sustain. Cities Soc. 2022, 76, 103481. [Google Scholar] [CrossRef]
- Mariano-Hernández, D.; Hernández-Callejo, L.; Solís, M.; Zorita-Lamadrid, A.; Duque-Perez, O.; Gonzalez-Morales, L.; Santos-García, F. A Data-Driven Forecasting Strategy to Predict Continuous Hourly Energy Demand in Smart Buildings. Appl. Sci. 2021, 11, 7886. [Google Scholar] [CrossRef]
- Fang, X.; Gong, G.; Li, G.; Chun, L.; Li, W.; Peng, P. A hybrid deep transfer learning strategy for short term cross-building energy prediction. Energy 2021, 215, 119208. [Google Scholar] [CrossRef]
- Calvillo, C.F.; Sánchez-Miralles, A.; Villar, J. Energy management and planning in smart cities. Renew. Sustain. Energy Rev. 2016, 55, 273–287. [Google Scholar] [CrossRef] [Green Version]
- Lü, X.; Lu, T.; Kibert, C.J.; Viljanen, M. Modeling and forecasting energy consumption for heterogeneous buildings using a physical–statistical approach. Appl. Energy 2015, 144, 261–275. [Google Scholar] [CrossRef]
- Kong, W.; Dong, Z.Y.; Jia, Y.; Hill, D.J.; Xu, Y.; Zhang, Y. Short-Term Residential Load Forecasting Based on LSTM Recurrent Neural Network. IEEE Trans. Smart Grid 2019, 10, 841–851. [Google Scholar] [CrossRef]
- Deb, C.; Zhang, F.; Yang, J.; Lee, S.E.; Shah, K.W. A review on time series forecasting techniques for building energy consumption. Renew. Sustain. Energy Rev. 2017, 74, 902–924. [Google Scholar] [CrossRef]
- Hao, Z.; Liu, G.; Zhang, H. Correlation filter-based visual tracking via adaptive weighted CNN features fusion. IET Image Process. 2018, 12, 1423–1431. [Google Scholar] [CrossRef]
- Hochreiter, S.S.J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Cho, K.; van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Zhang, H.; Yang, Y.; Zhang, Y.; He, Z.; Yuan, W.; Yang, Y.; Qiu, W.; Li, L. A combined model based on SSA, neural networks, and LSSVM for short-term electric load and price forecasting. Neural Comput. Appl. 2021, 33, 773–788. [Google Scholar] [CrossRef]
- Afshar, K.; Bigdeli, N. Data analysis and short term load forecasting in Iran electricity market using singular spectral analysis (SSA). Energy 2011, 36, 2620–2627. [Google Scholar] [CrossRef]
- An, L.; Hao, Y.; Yeh, T.-C.J.; Liu, Y.; Liu, W.; Zhang, B. Simulation of karst spring discharge using a combination of time–frequency analysis methods and long short-term memory neural networks. J. Hydrol. 2020, 589, 125320. [Google Scholar] [CrossRef]
- Mi, X.; Zhao, S. Wind speed prediction based on singular spectrum analysis and neural network structural learning. Energy Convers. Manag. 2020, 216, 112956. [Google Scholar] [CrossRef]
- Wang, C.; Zhang, H.; Ma, P. Wind power forecasting based on singular spectrum analysis and a new hybrid Laguerre neural network. Appl. Energy 2020, 259, 114139. [Google Scholar] [CrossRef]
- Liu, H.; Mi, X.; Li, Y.; Duan, Z.; Xu, Y. Smart wind speed deep learning based multi-step forecasting model using singular spectrum analysis, convolutional Gated Recurrent Unit network and Support Vector Regression. Renew. Energy 2019, 143, 842–854. [Google Scholar] [CrossRef]
- Massana, J.; Pous, C.; Burgas, L.; Melendez, J.; Colomer, J. Short-term load forecasting in a non-residential building contrasting models and attributes. Energy Build. 2015, 92, 322–330. [Google Scholar] [CrossRef] [Green Version]
- Blázquez-García, A.; Conde, A.; Milo, A.; Sánchez, R.; Barrio, I. Short-term office building elevator energy consumption forecast using SARIMA. J. Build. Perform. Simul. 2020, 13, 69–78. [Google Scholar] [CrossRef]
- Zhang, F.; Deb, C.; Lee, S.E.; Yang, J.; Shah, K.W. Time series forecasting for building energy consumption using weighted Support Vector Regression with differential evolution optimization technique. Energy Build. 2016, 126, 94–103. [Google Scholar] [CrossRef]
- Culaba, A.B.; Del Rosario, A.J.; Ubando, A.T.; Chang, J.S. Machine learning-based energy consumption clustering and forecasting for mixed-use buildings. Int. J. Energy Res. 2020, 44, 9659–9673. [Google Scholar] [CrossRef]
- Wang, Z.; Wang, Y.; Zeng, R.; Srinivasan, R.; Ahrentzen, S. Random Forest based hourly building energy prediction. Energy Build. 2018, 171, 11–25. [Google Scholar] [CrossRef]
- Naji, S.; Keivani, A.; Shamshirband, S.; Alengaram, U.J.; Jumaat, M.Z.; Mansor, Z.; Lee, M. Estimating building energy consumption using extreme learning machine method. Energy 2016, 97, 506–516. [Google Scholar] [CrossRef]
- Olu-Ajayi, R.; Alaka, H.; Sulaimon, I.; Sunmola, F.; Ajayi, S. Building energy consumption prediction for residential buildings using deep learning and other machine learning techniques. J. Build. Eng. 2022, 45, 103406. [Google Scholar] [CrossRef]
- Fan, C.; Sun, Y.; Zhao, Y.; Song, M.; Wang, J. Deep learning-based feature engineering methods for improved building energy prediction. Appl. Energy 2019, 240, 35–45. [Google Scholar] [CrossRef]
- Wen, L.; Zhou, K.; Yang, S. Load demand forecasting of residential buildings using a deep learning model. Electr. Power Syst. Res. 2020, 179, 106073. [Google Scholar] [CrossRef]
- Khan, Z.A.; Hussain, T.; Ullah, A.; Rho, S.; Lee, M.; Baik, S.W. Towards Efficient Electricity Forecasting in Residential and Commercial Buildings: A Novel Hybrid CNN with a LSTM-AE based Framework. Sensors 2020, 20, 1399. [Google Scholar] [CrossRef] [Green Version]
- Somu, N.; Raman MR, G.; Ramamritham, K. A deep learning framework for building energy consumption forecast. Renew. Sustain. Energy Rev. 2021, 137, 110591. [Google Scholar] [CrossRef]
- Eseye, A.T.; Lehtonen, M. Short-Term Forecasting of Heat Demand of Buildings for Efficient and Optimal Energy Management Based on Integrated Machine Learning Models. IEEE Trans. Ind. Inform. 2020, 16, 7743–7755. [Google Scholar] [CrossRef]
- Sun, H.; Zhai, W.; Wang, Y.; Yin, L.; Zhou, F. Privileged information-driven random network based non-iterative integration model for building energy consumption prediction. Appl. Soft Comput. 2021, 108, 107438. [Google Scholar] [CrossRef]
- Gao, X.; Qi, C.; Xue, G.; Song, J.; Zhang, Y.; Yu, S.-A. Forecasting the Heat Load of Residential Buildings with Heat Metering Based on CEEMDAN-SVR. Energies 2020, 13, 6079. [Google Scholar] [CrossRef]
- Kim, S.H.; Lee, G.; Kwon, G.-Y.; Kim, D.-I.; Shin, Y.-J. Deep Learning Based on Multi-Decomposition for Short-Term Load Forecasting. Energies 2018, 11, 3433. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.; Tan, H. Short-term prediction of electric demand in building sector via hybrid support vector regression. Appl. Energy 2017, 204, 1363–1374. [Google Scholar] [CrossRef]
- Zhang, L.; Alahmad, M.; Wen, J. Comparison of time-frequency-analysis techniques applied in building energy data noise cancellation for building load forecasting: A real-building case study. Energy Build. 2021, 231, 110592. [Google Scholar] [CrossRef]
- Yuan, Z.; Wang, W.; Wang, H.; Mizzi, S. Combination of cuckoo search and wavelet neural network for midterm building energy forecast. Energy 2020, 202, 117728. [Google Scholar] [CrossRef]
- Kuo, P.; Huang, C. A High Precision Artificial Neural Networks Model for Short-Term Energy Load Forecasting. Energies 2018, 11, 213. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Liao, W.; Chang, Y. Gated Recurrent Unit Network-Based Short-Term Photovoltaic Forecasting. Energies 2018, 11, 2163. [Google Scholar] [CrossRef] [Green Version]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Index | Definition | Formula |
|---|---|---|
| Mean absolute error | ||
| Root mean square error | ||
| Mean absolute percentage error | ||
| Coefficient of determination | ||
| Promoting percentages of mean absolute error | ||
| Promoting percentages of root mean square error | ||
| Promoting percentages of mean absolute percentage error |
| Consumption Type | Statistic Indices | |||||
|---|---|---|---|---|---|---|
| Mean (kWh) | Max (kWh) | Min (kWh) | Std | Skew. (Skewness) | Kurt. (Kurtosis) | |
| Electricity | 1601.19 | 4700.72 | 717.98 | 774.77 | 1.10 | 0.23 |
| Gas | 3204.10 | 19,084.96 | 269.42 | 3567.91 | 2.04 | 3.76 |
| Layer Type | Hyperparameter Configuration |
|---|---|
| Conv1D | Filters: 16 kernel size: 3 activation: Relu padding: same |
| Max-pooling | Pool size: 2 stride: 1 padding: same |
| Conv1D | Filters: 32 kernel size: 3 activation: Relu padding: same |
| Max-pooling | Pool size: 2 stride: 1 padding: same |
| Dense | Hidden node: 32 activation: Relu |
| BiGRU | Hidden node: 64 activation: tanh |
| Dense | Hidden node: 32 activation: Relu |
| Dense | Hidden node: 1/2/4/6 activation: linear |
| Types | Models | MAE (kWh) | RMSE (kWh) | MAPE (%) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1-Step | 2-Step | 4-Step | 6-Step | 1-Step | 2-Step | 4-Step | 6-Step | 1-Step | 2-Step | 4-Step | 6-Step | ||
| Electricity consumption | LR | 120.06 | 145.24 | 171.62 | 198.26 | 210.62 | 246.06 | 288.81 | 338.95 | 5.74 | 6.96 | 8.18 | 9.77 |
| MLP | 89.00 | 119.48 | 150.14 | 170.78 | 149.55 | 188.62 | 232.99 | 266.02 | 4.62 | 5.75 | 7.48 | 8.43 | |
| CNN | 101.11 | 122.21 | 178.00 | 175.30 | 164.75 | 201.43 | 278.31 | 276.53 | 5.24 | 6.22 | 8.27 | 9.25 | |
| GRU | 87.00 | 121.16 | 153.83 | 172.19 | 153.54 | 197.55 | 242.81 | 268.86 | 4.46 | 6.10 | 7.33 | 8.29 | |
| BiGRU | 81.51 | 105.39 | 140.12 | 159.43 | 144.28 | 175.18 | 219.34 | 253.77 | 4.26 | 5.32 | 7.25 | 8.17 | |
| CNNGRU | 81.71 | 111.69 | 134.05 | 160.28 | 141.51 | 183.40 | 214.67 | 257.08 | 4.04 | 5.53 | 6.62 | 7.77 | |
| CNNBiGRU | 70.06 | 91.35 | 116.35 | 139.09 | 123.82 | 151.38 | 178.67 | 214.92 | 3.55 | 4.65 | 6.20 | 7.41 | |
| Gas consumption | LR | 413.44 | 492.57 | 577.35 | 661.04 | 694.47 | 856.17 | 987.44 | 1151.58 | 12.53 | 14.40 | 16.92 | 19.36 |
| MLP | 358.77 | 456.35 | 477.81 | 532.61 | 531.03 | 653.25 | 708.74 | 815.10 | 12.59 | 13.38 | 14.70 | 16.31 | |
| CNN | 358.09 | 482.50 | 474.26 | 525.21 | 526.86 | 702.83 | 688.95 | 793.38 | 13.90 | 16.40 | 16.93 | 17.44 | |
| GRU | 363.33 | 448.09 | 505.15 | 529.22 | 522.63 | 716.50 | 800.26 | 837.83 | 11.69 | 12.64 | 14.13 | 15.19 | |
| BiGRU | 334.96 | 391.52 | 425.03 | 467.70 | 509.77 | 647.71 | 670.21 | 735.65 | 10.37 | 11.70 | 13.40 | 14.95 | |
| CNNGRU | 301.79 | 399.83 | 437.00 | 490.90 | 468.57 | 619.00 | 693.82 | 777.07 | 10.12 | 13.31 | 13.82 | 14.42 | |
| CNNBiGRU | 272.20 | 326.78 | 386.46 | 460.75 | 449.99 | 515.56 | 614.03 | 718.12 | 8.33 | 9..99 | 11.25 | 13.72 | |
| Types | Models | MAE (kWh) | RMSE (kWh) | MAPE (%) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1-Step | 2-Step | 4-Step | 6-Step | 1-Step | 2-Step | 4-Step | 6-Step | 1-Step | 2-Step | 4-Step | 6-Step | ||
| Electricity consumption | SSA-CNN | 37.69 | 56.95 | 82.71 | 94.41 | 60.48 | 87.41 | 134.18 | 152.30 | 2.05 | 3.10 | 4.00 | 4.71 |
| SSA-GRU | 34.04 | 54.12 | 75.16 | 99.34 | 60.49 | 98.91 | 130.94 | 149.43 | 1.71 | 2.67 | 3.75 | 5.02 | |
| SSA-BiGRU | 28.57 | 44.84 | 63.69 | 85.28 | 53.78 | 83.89 | 114.29 | 134.62 | 1.39 | 2.28 | 3.18 | 4.35 | |
| SSA-CNNGRU | 27.87 | 37.36 | 47.17 | 79.78 | 50.16 | 70.36 | 81.32 | 122.05 | 1.27 | 1.68 | 2.33 | 3.97 | |
| SSA-CNNBiGRU | 18.52 | 25.41 | 38.87 | 50.96 | 38.01 | 49.05 | 64.41 | 74.86 | 0.86 | 1.21 | 1.94 | 2.72 | |
| Gas consumption | SSA-CNN | 106.34 | 136.73 | 184.41 | 234.30 | 149.51 | 186.67 | 260.81 | 330.70 | 3.61 | 4.85 | 6.59 | 8.19 |
| SSA-GRU | 103.08 | 135.29 | 193.23 | 237.25 | 140.02 | 196.97 | 255.59 | 326.18 | 3.25 | 4.63 | 6.24 | 7.88 | |
| SSA-BiGRU | 92.37 | 115.18 | 152.40 | 227.28 | 130.57 | 160.13 | 225.64 | 295.99 | 2.85 | 3.57 | 4.68 | 6.85 | |
| SSA-CNNGRU | 84.97 | 98.23 | 135.15 | 183.68 | 124.59 | 145.89 | 212.55 | 278.61 | 2.32 | 3.07 | 4.29 | 6.04 | |
| SSA-CNNBiGRU | 60.71 | 78.02 | 119.33 | 172.31 | 93.52 | 115.36 | 174.24 | 247.75 | 1.78 | 2.44 | 3.86 | 5.67 | |
| Models | Electricity Consumption | Gas Consumption | ||||
|---|---|---|---|---|---|---|
| /% | /% | /% | /% | /% | /% | |
| CNN | 62.72 | 63.29 | 60.88 | 70.30 | 71.22 | 74.03 |
| GRU | 60.87 | 60.60 | 61.66 | 71.63 | 73.21 | 72.20 |
| BiGRU | 64.95 | 62.73 | 67.37 | 72.42 | 74.39 | 72.51 |
| CNNGRU | 65.89 | 64.55 | 68.56 | 71.84 | 73.41 | 77.07 |
| CNNBiGRU | 76.85 | 69.30 | 75.77 | 77.70 | 79.22 | 78.63 |
| Types | Models | MAE (kWh) | RMSE (kWh) | MAPE (%) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1-Step | 2-Step | 4-Step | 6-Step | 1-Step | 2-Step | 4-Step | 6-Step | 1-Step | 2-Step | 4-Step | 6-Step | ||
| Electricity consumption | EMD-CNNBiGRU | 51.76 | 59.30 | 73.55 | 98.33 | 78.97 | 92.04 | 114.78 | 157.24 | 2.85 | 3.16 | 4.00 | 5.43 |
| EEMD-CNNBiGRU | 40.25 | 50.33 | 63.12 | 81.60 | 54.31 | 68.74 | 87.30 | 111.75 | 2.26 | 3.04 | 3.75 | 5.00 | |
| EWT-CNNBiGRU | 29.03 | 42.33 | 50.59 | 64.45 | 43.45 | 58.10 | 73.83 | 92.39 | 1.46 | 2.29 | 2.63 | 3.44 | |
| VMD-CNNBiGRU | 35.84 | 42.70 | 56.66 | 69.83 | 55.46 | 68.00 | 87.49 | 103.14 | 1.88 | 2.24 | 2.96 | 3.69 | |
| SSA-CNNBiGRU | 18.52 | 25.41 | 38.87 | 50.96 | 38.01 | 49.05 | 64.41 | 74.86 | 0.86 | 1.21 | 1.94 | 2.72 | |
| Gas consumption | EMD-CNNBiGRU | 139.77 | 186.33 | 254.38 | 310.73 | 204.47 | 278.29 | 381.10 | 443.92 | 5.04 | 6.67 | 9.37 | 11.83 |
| EEMD-CNNBiGRU | 118.56 | 127.31 | 181.13 | 236.61 | 159.43 | 175.42 | 258.87 | 332.68 | 4.45 | 4.82 | 6.60 | 8.82 | |
| EWT-CNNBiGRU | 76.84 | 91.44 | 135.77 | 180.54 | 105.79 | 122.88 | 187.76 | 252.64 | 2.98 | 3.51 | 5.05 | 6.71 | |
| VMD-CNNBiGRU | 103.94 | 111.57 | 158.78 | 190.49 | 142.72 | 156.61 | 219.46 | 268.57 | 3.80 | 4.10 | 5.88 | 6.79 | |
| SSA-CNNBiGRU | 60.71 | 78.02 | 119..33 | 172.31 | 93.52 | 115.36 | 174.24 | 247.75 | 1.78 | 2.44 | 3.86 | 5.67 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wei, S.; Bai, X. Multi-Step Short-Term Building Energy Consumption Forecasting Based on Singular Spectrum Analysis and Hybrid Neural Network. Energies 2022, 15, 1743. https://doi.org/10.3390/en15051743
Wei S, Bai X. Multi-Step Short-Term Building Energy Consumption Forecasting Based on Singular Spectrum Analysis and Hybrid Neural Network. Energies. 2022; 15(5):1743. https://doi.org/10.3390/en15051743
Chicago/Turabian StyleWei, Shangfu, and Xiaoqing Bai. 2022. "Multi-Step Short-Term Building Energy Consumption Forecasting Based on Singular Spectrum Analysis and Hybrid Neural Network" Energies 15, no. 5: 1743. https://doi.org/10.3390/en15051743
APA StyleWei, S., & Bai, X. (2022). Multi-Step Short-Term Building Energy Consumption Forecasting Based on Singular Spectrum Analysis and Hybrid Neural Network. Energies, 15(5), 1743. https://doi.org/10.3390/en15051743