
Low-Cost Sensors for Indoor PV Energy Harvesting Estimation Based on Machine Learning


Abstract
1. Introduction
2. Experimental Setup
2.1. Low-Cost Analysis Device
- The first sensor, the TSL2561 from TAOS [19], is based on two photodiodes: (i) the first one is a broadband (BB) photodiode, sensible to the whole visible + near infrared 300 nm to 1100 nm wavelengths, returning a digital BB value and (ii) the second one is a narrower near infrared (IR) photodiode, sensible from 500 nm to 1100 nm wavelengths, returning a digital IR value. From these two photodiodes, an ambient light level value in lux could be derived using an empirical formula to approximate the human eye response. This value is returned as the digital LUX value.
- The second sensor, the ISL29125 from RENESAS [20], uses a matrix of three photodiodes, each sensible to different parts of the visible spectrum: blue, green and red. It provides a set of three digital values R, G, and B.
2.2. Classification and Training
2.3. Spectral Reconstruction and Calculation of the Harvestable Energy
2.4. Instrumented Prototype: Energy Harvester
3. Classification of Light Sources
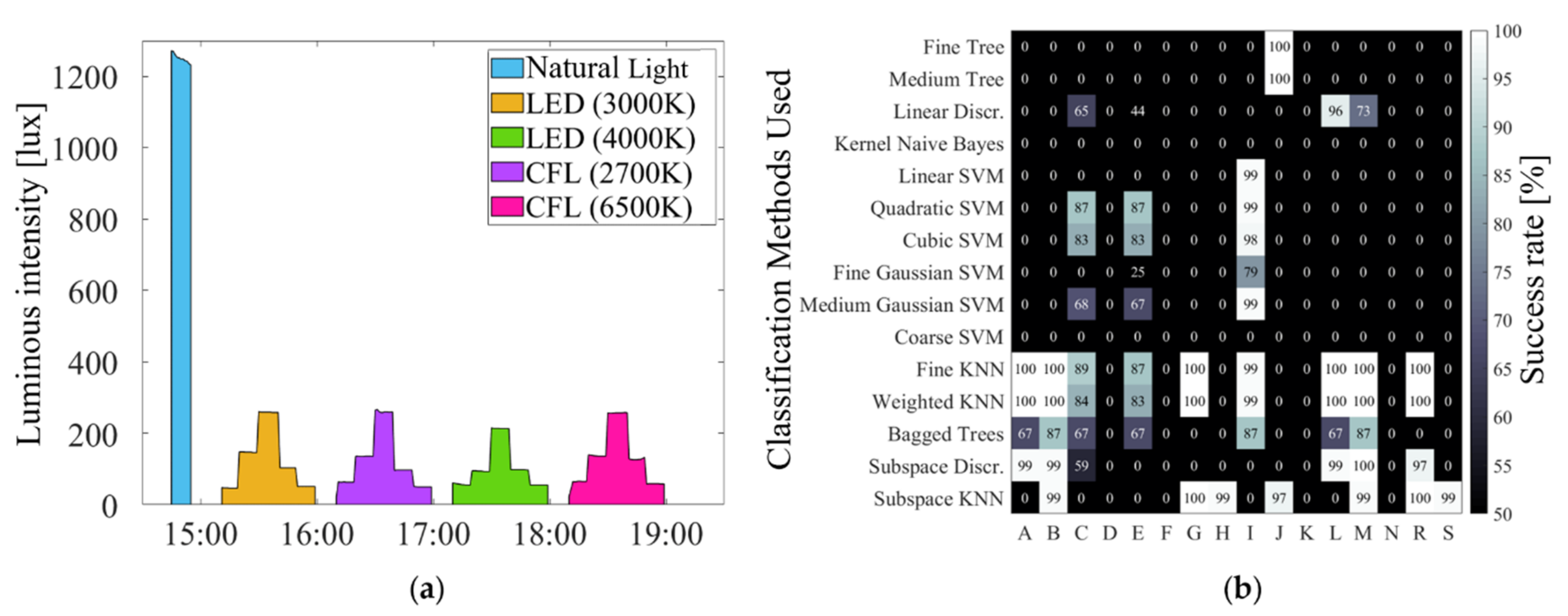
3.1. Classification Methods Training Performances on Raw Data
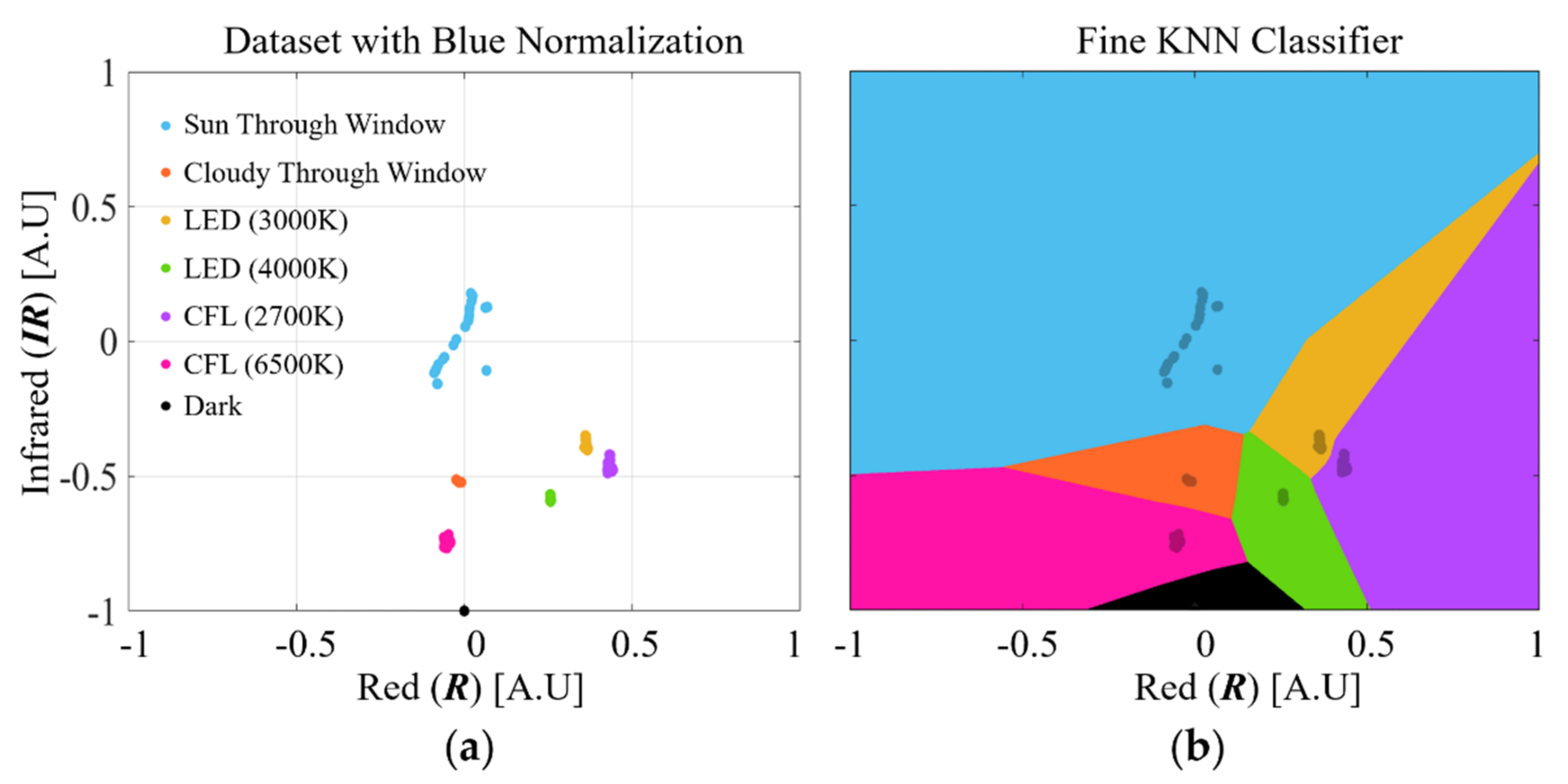
3.2. Normalization Impact on Classification Performances
3.3. Successfully Trained Classifiers in Confrontation to New Controlled Pseudo-Spectra
3.4. Trained Classifiers Performances on Pseudo-Spectra from Uncontrolled Light Environment
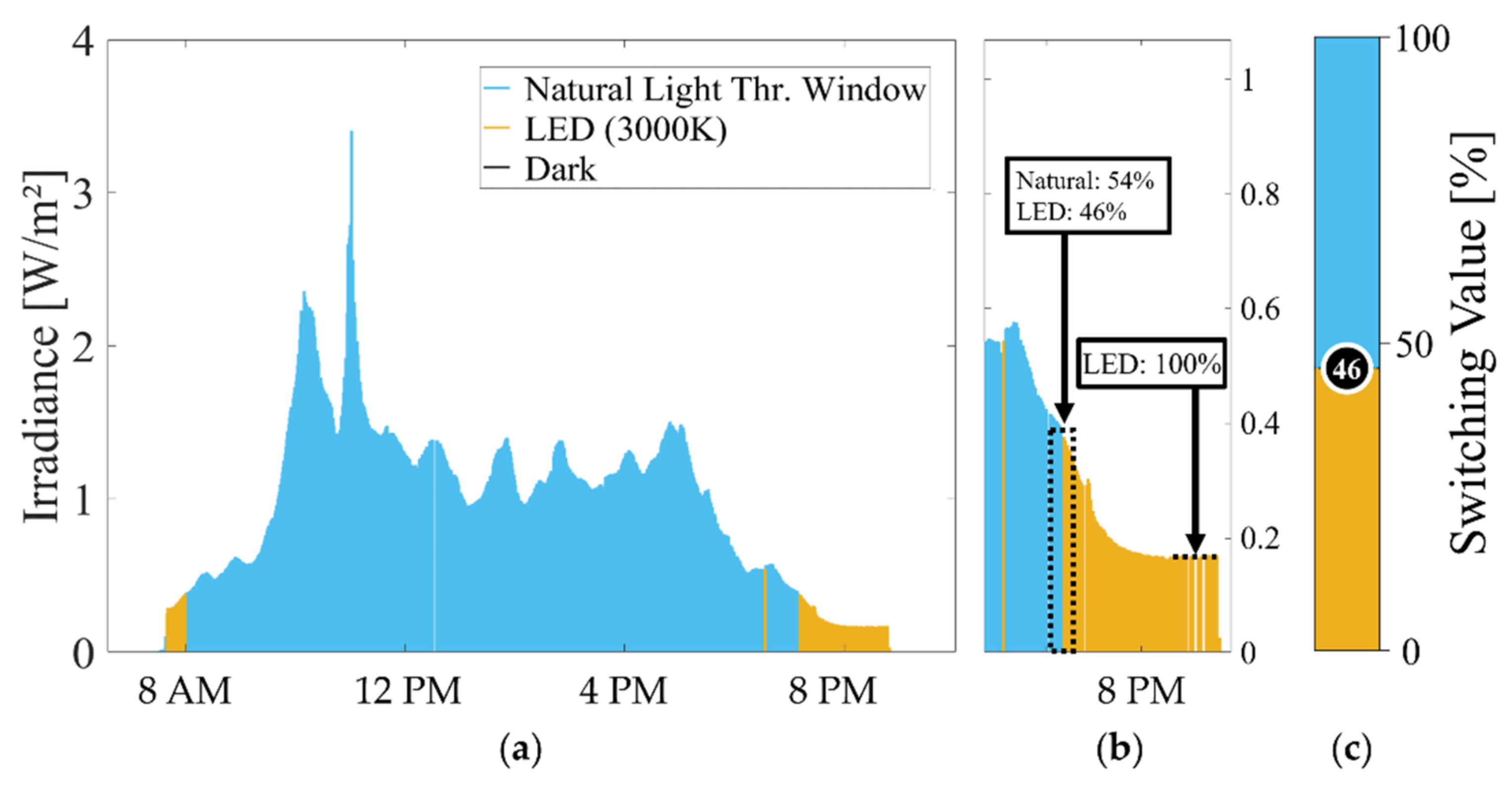
4. Harvestable Energy Calculation
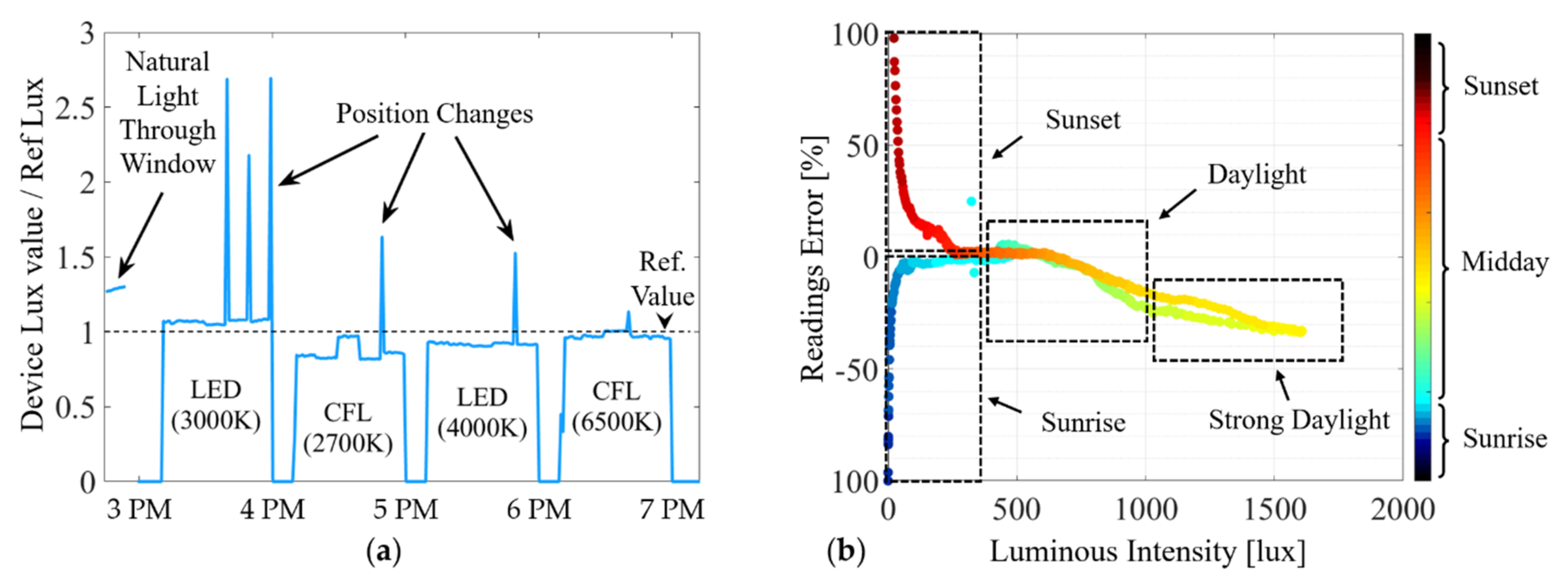
4.1. Sources of Error for Spectra Reconstruction
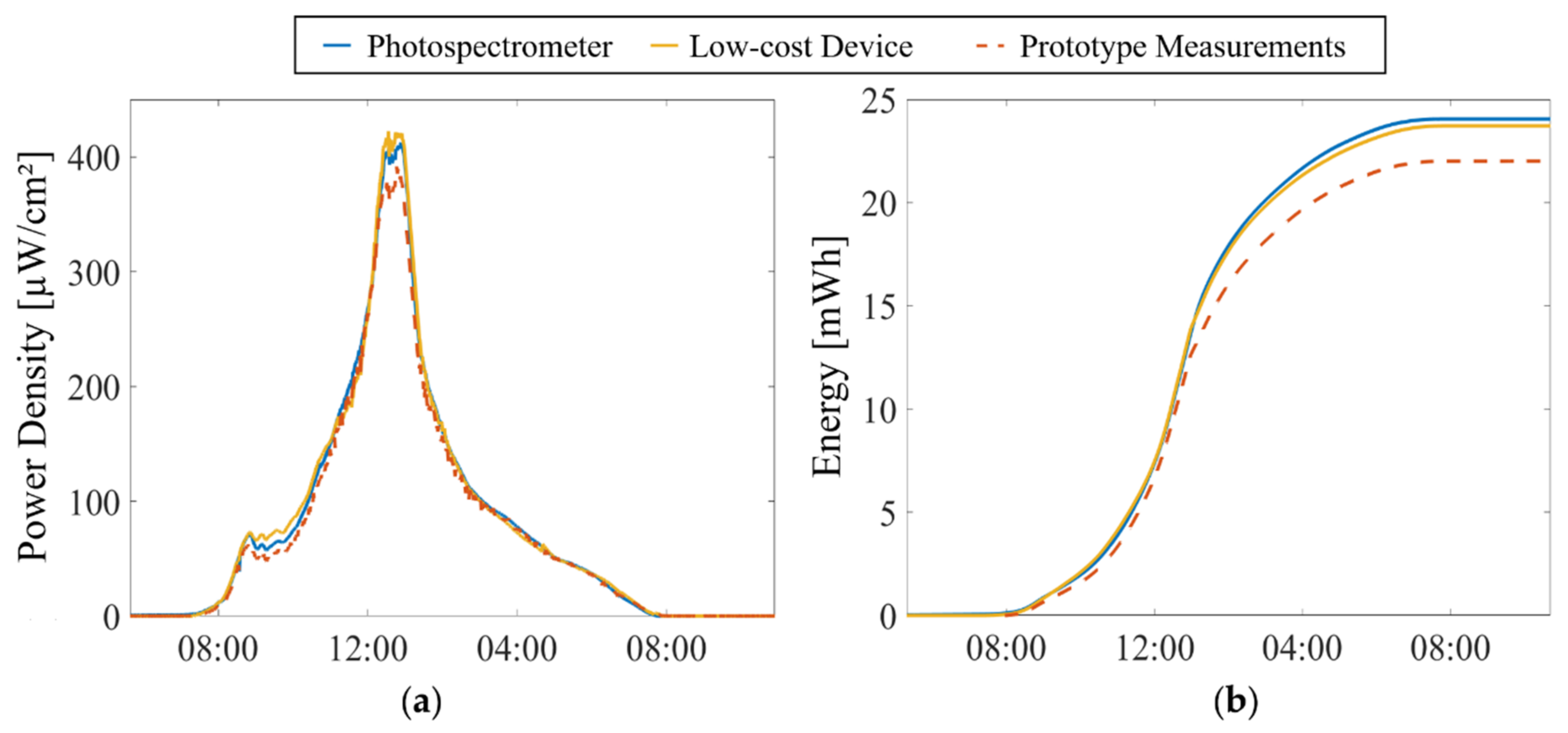
4.2. Harvestable Energy Calculation Results Using the Low-Cost Sensor
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Carvalho, C.; Paulino, N. On the Feasibility of Indoor Light Energy Harvesting for Wireless Sensor Networks. Procedia Technol. 2014, 17, 343–350. [Google Scholar] [CrossRef][Green Version]
- Wang, Y.; Liu, Y.; Wang, C.; Li, Z.; Sheng, X.; Lee, H.G.; Chang, N.; Yang, H. Storage-Less and Converter-Less Photovoltaic Energy Harvesting with Maximum Power Point Tracking for Internet of Things. IEEE Trans. Comput. Des. Integr. Circuits Syst. 2015, 35, 173–186. [Google Scholar] [CrossRef]
- Huld, T.; Müller, R.; Gambardella, A. A new solar radiation database for estimating PV performance in Europe and Africa. Sol. Energy 2012, 86, 1803–1815. [Google Scholar] [CrossRef]
- Randall, J.F.; Jacot, J. Is AM1.5 applicable in practice? Modelling eight photovoltaic materials with respect to light intensity and two spectra. Renew. Energy 2003, 28, 1851–1864. [Google Scholar] [CrossRef]
- Sarik, J.; Kim, K.; Gorlatova, M.; Kymissis, I.; Zussman, G. More than meets the eye—A portable measurement unit for characterizing light energy availability. In Proceedings of the 2013 IEEE Global Conference on Signal and Information Processing, Austin, TX, USA, 3–5 December 2013; pp. 387–390. [Google Scholar] [CrossRef]
- Kasemann, M.; Kokert, J.; Torres, S.M.; Ruhle, K.; Reindl, L.M. Monitoring of indoor light conditions for photovoltaic energy harvesting. In Proceedings of the 2014 IEEE 11th International Multi-Conference on Systems, Signals and Devices, SSD 2014, Barcelona, Spain, 11–14 February 2014. [Google Scholar] [CrossRef]
- Minnaert, B.; Veelaert, P. A Proposal for Typical Artificial Light Sources for the Characterization of Indoor Photovoltaic Applications. Energies 2014, 7, 1500–1516. [Google Scholar] [CrossRef]
- Li, Y.; Grabham, N.J.; Beeby, S.P.; Tudor, M.J. The effect of the type of illumination on the energy harvesting performance of solar cells. Sol. Energy 2015, 111, 21–29. [Google Scholar] [CrossRef]
- Ma, X.; Bader, S.; Oelmann, B. Characterization of Indoor Light Conditions by Light Source Classification. IEEE Sens. J. 2017, 17, 3884–3891. [Google Scholar] [CrossRef]
- Randall, J.F. On the Use of Photovoltaic Ambient Energy Sources for Powering Indoor Electronic Devices, Ph.D. Thesis. Ecole Polytechnique de Lausanne, Lausanne, Switzerland, 2003. [CrossRef]
- Bader, S.; Ma, X.; Oelmann, B. One-diode photovoltaic model parameters at indoor illumination levels—A comparison. Sol. Energy 2019, 180, 707–716. [Google Scholar] [CrossRef]
- Muller, M.; Wienold, J.; Walker, W.D.; Reindl, L.M. Characterization of indoor photovoltaic devices and light. In Proceedings of the 34th IEEE Photovoltaic Specialists Conference (PVSC), Philadelphia, PA, USA, 7–12 June 2009; pp. 000738–000743. [Google Scholar] [CrossRef]
- Hande, A.; Polk, T.; Walker, W.; Bhatia, D. Indoor solar energy harvesting for sensor network router nodes. Microprocess. Microsystems 2007, 31, 420–432. [Google Scholar] [CrossRef]
- Afsar, Y.; Sarik, J.; Gorlatova, M.; Zussman, G.; Kymissis, I. Evaluating photovoltaic performance indoors. In Proceedings of the 38th IEEE Photovoltaic Specialists Conference (PVSC), Austin, TX, USA, 3–8 June 2012; pp. 1948–1951. [Google Scholar] [CrossRef]
- Teran, A.S.; Wong, J.; Lim, W.; Kim, G.; Lee, Y.; Blaauw, D.; Phillips, J.D. AlGaAs Photovoltaics for Indoor Energy Harvesting in mm-Scale Wireless Sensor Nodes. IEEE Trans. Electron Devices 2015, 62, 2170–2175. [Google Scholar] [CrossRef]
- Mathews, I.; King, P.J.; Stafford, F.; Frizzell, R. Performance of III–V Solar Cells as Indoor Light Energy Harvesters. IEEE J. Photovoltaics 2016, 6, 230–235. [Google Scholar] [CrossRef]
- Freitag, M.; Teuscher, J.; Saygili, Y.; Zhang, X.; Giordano, F.; Liska, P.; Hua, J.; Zakeeruddin, S.M.; Moser, J.-E.; Grätzel, M.; et al. Dye-sensitized solar cells for efficient power generation under ambient lighting. Nat. Photon. 2017, 11, 372–378. [Google Scholar] [CrossRef]
- Tinsley, N.F.; Witts, S.T.; Ansell, J.M.R.; Barnes, E.; Jenkins, S.M.; Raveendran, D.; Merrett, G.V.; Weddell, A.S. Enspect: A complete tool using modeling and real data to assist the design of energy harvesting systems. In Proceedings of the 3rd International Workshop on Energy Harvesting & Energy Neutral Sensing Systems, Seoul, South Korea, 1 November 2015; pp. 27–32. [Google Scholar] [CrossRef]
- Politi, B.; Parola, S.; Gademer, A.; Pegart, D.; Piquemil, M.; Foucaran, A.; Camara, N. Practical PV energy harvesting under real indoor lighting conditions. Sol. Energy 2021, 224, 3–9. [Google Scholar] [CrossRef]
- Ma, X.; Bader, S.; Oelmann, B. Power Estimation for Indoor Light Energy Harvesting Systems. IEEE Trans. Instrum. Meas. 2020, 69, 7513–7521. [Google Scholar] [CrossRef]
- Beck, P.S.A.; Atzberger, C.; Høgda, K.A.; Johansen, B.; Skidmore, A.K. Improved monitoring of vegetation dynamics at very high latitudes: A new method using MODIS NDVI. Remote Sens. Environ. 2006, 100, 321–334. [Google Scholar] [CrossRef]
- Michaels, H.; Rinderle, M.; Freitag, R.; Benesperi, I.; Edvinsson, T.; Socher, R.; Gagliardi, A.; Freitag, M. Dye-sensitized solar cells under ambient light powering machine learning: Towards autonomous smart sensors for internet of things. Chem. Sci. 2020, 11, 2895–2906. [Google Scholar] [CrossRef] [PubMed]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tree | Discriminant | Naive Bayes | Support Vector Machine (SVM) | K-Nearest Neighbor (KNN) | Ensembles |
|---|---|---|---|---|---|
| Fine | Linear | Gaussian | Linear | Fine | Boosted Trees |
| Medium | Quadratic | Kernal | Quadratic | Medium | Bagged Trees |
| Coarse | Cubic | Coarse | Subspace Discrimination | ||
| Fine Gaussian | Cubic | Subspace KNN | |||
| Medium Gaussian | Cosine | RUSBoosted Trees | |||
| Coarse Gaussian | Weighted |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Politi, B.; Foucaran, A.; Camara, N. Low-Cost Sensors for Indoor PV Energy Harvesting Estimation Based on Machine Learning. Energies 2022, 15, 1144. https://doi.org/10.3390/en15031144
Politi B, Foucaran A, Camara N. Low-Cost Sensors for Indoor PV Energy Harvesting Estimation Based on Machine Learning. Energies. 2022; 15(3):1144. https://doi.org/10.3390/en15031144
Chicago/Turabian StylePoliti, Bastien, Alain Foucaran, and Nicolas Camara. 2022. "Low-Cost Sensors for Indoor PV Energy Harvesting Estimation Based on Machine Learning" Energies 15, no. 3: 1144. https://doi.org/10.3390/en15031144
APA StylePoliti, B., Foucaran, A., & Camara, N. (2022). Low-Cost Sensors for Indoor PV Energy Harvesting Estimation Based on Machine Learning. Energies, 15(3), 1144. https://doi.org/10.3390/en15031144