1. Introduction
To date, the global mean temperature continues to rise, and emissions continue to grow, creating great risk to humanity. Efforts and pathways are drawn by many jurisdictions to limit warming to 2 °C and reach net zero CO
emissions [
1]. This is largely due to the outdated electrical energy system operation and infrastructure, which causes the largest share of emissions of all sectors. Electrical energy systems are, however, witnessing a transition, consequently causing a growth in the scale and complexity of their planning and operation problems. The changing grid topology, decarbonization, electricity market decentralization, and grid modernization mean innovations and new elements are continuously introduced to the inventory of factors considered in grid operation and planning. Moreover, with the accelerating technological landscape and policy changes, the number of potential future paths to Net-Zero increases, and finding the optimal transition plan becomes an inconceivable task.
The use of parallel techniques becomes inescapable, and defaulting HPC competence by the electrical energy and power system community is inevitable in the face of the presumed future and its upcoming challenges. With some algorithmic modifications, parallel computing unlocks the potential to solve huge power system problems that are conventionally intractable. This helps in the reduction of cost and CO
emissions indirectly through detailed models that help us find less conservative operational solutions—which reduce thermal generation commitment and dispatch—and plan the transition to a net-zero grid with optimal placement of the continually growing inventory of Renewable Energy (RE) resources and smart component investment—which help us achieve the Net-Zero goal and future proof the grid. Moreover, parallel processing on multiple units is inherently more efficient and reduces energy use. Using multi-threading causes the energy consumption of multi-processors to increase drastically [
2]. Thus, in the case of resource abundance, it is more efficient to distribute work on separate hardware. Resource sharing is more effective than resource distribution, which reduces the demand for hardware investment and larger servers. All of these factors make it increasingly important for electrical engineering scientists to familiarize themselves with efficient resource allocation and parallel computation strategies.
North America [
3], the EU [
4], and many other countries [
5] set a target to completely retire coal plants earlier than 2035 and decarbonize the power system by 2050. In addition, the development of Carbon Capture and Storage Facilities is growing [
6]. Renewable energy penetration targets are set, with evidence of fast-growing proliferation across the globe, including both transmission-connected Variable Renewable Energy (VRE) [
7] and behind the meter distributed resources [
8]. The demand profile is changing with increased electrification of various industrial sectors [
9] and the transportation sector [
10] building electrification, energy efficiency [
11,
12], and the venture into a Sharing Economy [
13].
The emerging IoT, facilitated by low latency, low-cost next-generation 5G communication networks, helps roll out advanced control technologies and Advanced Metering Infrastructure [
14,
15]. This gives more options for contingency remedial operational actions to increase the grid reliability, and cost-effectiveness, such as Transmission Switching [
16], Demand Response [
17], adding more micro-grids, and other Transmission–Distribution coordination mechanisms [
18]. Additionally, they allow lower investment in transmission lines and look for other future planning solutions, such as flow management devices and FACTs [
19], Distributed Variable Renewable Energy [
20], and Bulk Energy Storage [
21].
Moreover, the future grid faces non-parametric uncertainties in the form of new policies such different as carbon taxation, pricing and certifications schemes [
22], feed-in-tariffs [
23] and time of use tariffs [
24], and other incentives. More uncertainties are introduced in smart grid visions and network topological and economic model conceptual transformations. These include the Internet of Energy [
25], Power-to-X integration [
26], and the transactive grid through Peer-to-Peer energy trading facilitated by distributed ledgers or Blockchain Energy [
27]. Such disruptions create access to cheap renewable energy and potential revenue streams for prosumers and encourage load shifting and dynamic pricing. Many of these concepts already have pilot projects in various locations in the world [
28]. Due to all the factors mentioned above, cost-effective real-time operations and decision-making while maintaining reliability becomes extremely difficult, as does planning the network transition to sustain such a dynamic nature and stochastic future.
Many current electrical system operational models are non-convex, mixed-integer, and non-linear programming problems [
29] and incorporate stochastic framework accounting for weather, load, and contingency planning [
30]. Operators must solve such problems for day-ahead and real-time electricity markets and ensure reliability standards are met. In NERC, for example, the reliability standards require transmission operators to perform a real-time reliability assessment every 30 min [
31]. The computational burden to solve these decision-making problems, even with our current grid topology and standards, forces the recourse to cutting-edge computational technology and high-performance computing strategies for online real-time applications and offline calculations to achieve tractability. This is part of the reason for the increased funding for High-Performance algorithms for complex energy systems and processes [
32].
Operators already use high-performance computation facilities or services in areas such as Transmission and Generation Investment Planning, Grid Control, Cost Optimization, Losses Reduction, Power System Simulation, and Analysis and Control Room Visualization, as seen in [
33,
34]. However, for operational purposes where problems need to be solved on a short time horizon, system models are usually simplified, and heuristic methods are used, relying on the experience of operators, such as in [
35]. As a consequence, these models tend to be conservative in fashion, reaching a reliable solution at the expense of reduced efficiency [
36]. According to The Federal Energy Regulatory Commission, finding more accurate solution techniques for complex problems such as AC Optimal Power Flow (ACOPF) could save billions of dollars [
37]. This motivates the search for methods to produce high-quality solutions in a reasonable time, and one of the ways to push the wall of speed up is through parallel techniques and HPC. Finding appropriate techniques, formulations, and proper parallel implementation of HPC for electrical system studies has been a research area of interest. Progress has been made to make solving complex, accurate power system models for real-time decisions favorable.
The first work loosely related to parallelism on a high-level task in a power system might have been that of Harvey H. Happ in 1969 [
38], in which a hierarchical decentralized multi-computer configuration was suggested, targeting Unit Commitment (UC) and Economic Dispatch (ED). Other similar work in multi-level multi-computer frameworks followed, soon targeting Security and voltage control in the 1970s [
39,
40,
41]. P. M. Anderson from the Electrical Power Research Institute created a special report in 1977, collecting various studies and simulations performed at the time, which explored the potential applications for power system analysis on parallel processing machines [
42]. Additionally, several papers came out suggesting new hardware to accommodate power-system-related calculations [
43].
In 1992, C. Tylasky et al. made what might be the first comprehensive review of the state-of-the-art of parallel processing for power systems studies [
44]. They discussed challenges still relevant today, such as different machine architectures, transparency, and portability of the codes used. A few parallel power system study reviews have been conducted throughout the development of computational hardware. Some had similar goals to this paper reviewing HPC applications for power systems [
45,
46] and on distributed computing for online real-time applications [
47]. Computational paradigms changed exponentially, reducing those reviews to pieces of history. The latest relevant, comprehensive reviews on the topic were by R. C. Green et al. for general power system applications [
48], and again focused on innovative smart grid applications [
49]. These two handle a variety of topics in power systems. This work adds to existing reviews, providing a fresh overview of the state-of-the-art. It distinguishes itself by providing the full context and history of parallel computation and HPC in electrical system optimization and its development up to the latest work in the field. It also provides a thorough base and background for newcomers to the field of power system optimization in terms of both computational paradigms and applied algorithms. It highlights the importance of defaulting HPC utilization in a net-zero future grid. Finally, it brings to light the necessity of integrating HPC in future studies amidst the energy transition and suggests a framework that encourages future collaboration to accelerate HPC deployment.
Table 1 shows a side-by-side comparison of related reviews.
Most of the existing work in the literature applies to classical problems that are still relevant to the future grid. For example, the electrical system stability problems only become bigger and more complex with the new grid paradigms, especially with the introduction of synthetic inertia coming from massive wind and solar plants at many data points. However, the amount of HPC and cloud computing consolidation to the future smart grid vision is small, so only one section of this work introduces frameworks of cloud-smart grid integration with different network architectures and topologies. Accompanying cloud usage in future studies is important, as it introduces new considerations and complications, such as optimal resource allocation and cloud security issues.
This paper is organized as follows:
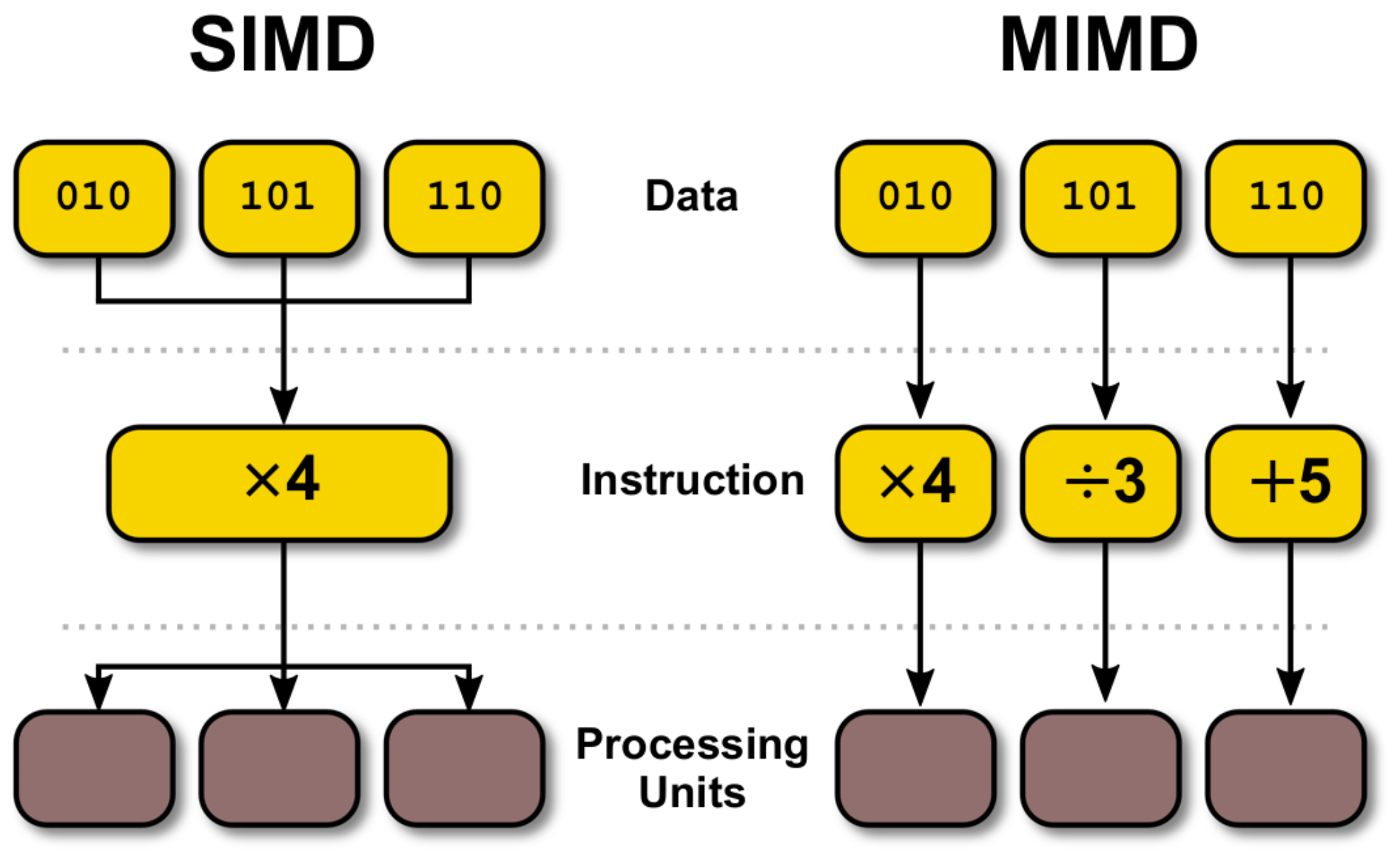
Section 2 and
Section 3 identify the main HPC components and parallel computation paradigms. The next six sections review parallel algorithms under both Multiple Instruction Multiple Data (MIMD) and Single Instruction Multiple Data (SIMD) paradigms split into their early development and state-of-the-art for each study, starting with
Section 4 PF.
Section 5 Optimal Power Flow (OPF).
Section 6 UC.
Section 7 reviews power system stability studies.
Section 8 System State Estimation (SSE).
Section 9 reviews unique formulations and studies.
Section 10 reviews gird and cloud computation applications of classical problems.
Section 11 reviews smart grid cloud-based applications. In these studies, novel approaches and algorithms and modifications to existing complex models are made and parallelized to achieve tractability, or their processing time is reduced below that needed for real-time applications. Many studies showed promising outcomes and made a strong case for further opportunities in using complex system models on HPC and Cloud for operational applications.
Section 12 highlights and discusses the present challenges in the studies, re-projects the future of HPC in power systems and energy markets, and recommends a framework for future studies.
Section 13 concludes the review.
Table 1.
Previous work and related reviews.
Table 1.
Previous work and related reviews.
| Paper | [44] | [45] | [46] | [47] | [48] | [49] | This Work |
|---|
| Year | 1992 | 1993 | 1996 | 1996 | 2011 | 2013 | 2022 |
| Focus | AR 1 | DS 2 | AR | OA 3 | AR | SG 4 | AR |
| Historical Overview | • | • | • | | | | • |
| Comprehensive Review | • | | • | | • | • | • |
| Leading edge (2013–2022) | | | | | | | • |
| Critical Review | | | | | | | • |
| HPC Tutorial | | | • | • | | • | • |
| Cloud/Smart Grid | | | | | | • | • |
| RE and Net-Zero | | | | | | | • |
| Guideline and Recommendations | | | | | | | • |
This review does not include machine learning or meta-heuristic parallel applications such as particle swarm and genetic algorithms. Furthermore, while it does include some studies related to the co-optimization of Transmission and Distribution systems, the study excludes parallel analysis and simulations of distribution systems. It is also important to note that this review does not include Transmission and generation system planning problems or models related to grid transitioning because of the lack of parallel or HPC application in the literature on such models, which is addressed in the discussion section.
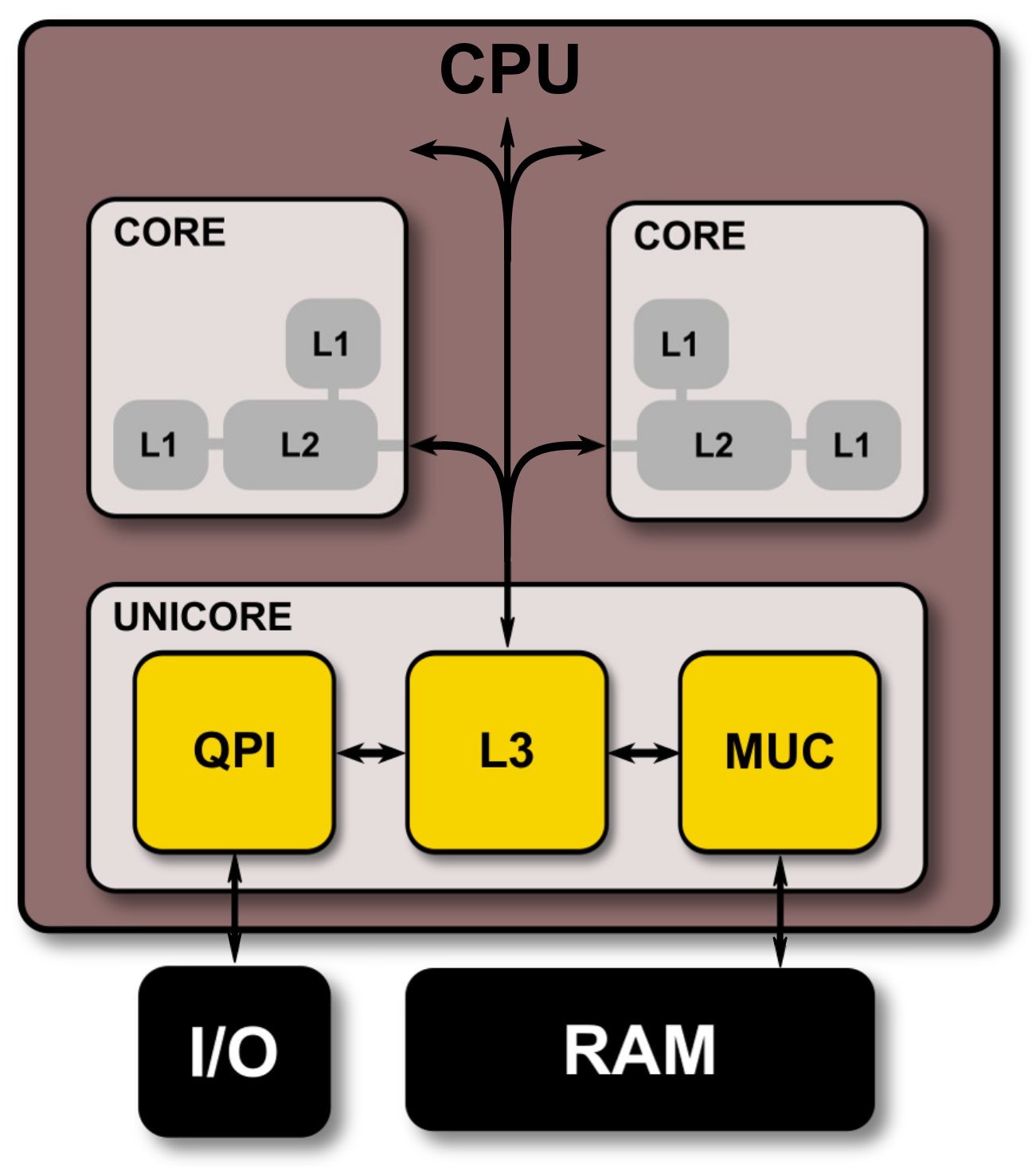
3. Aggregation and Paradigms
In the late 1970s, project ARPANET took place [
63] UNIX was developed [
64], and advancement in networking and communication hardware was achieved. The first commercial LAN clustering system/adaptor, ARCNET, was released in 1977 [
65], and hardware abstraction sprung in the form of virtual memory, such as OpenVM, which was adopted by operating systems and supercomputers [
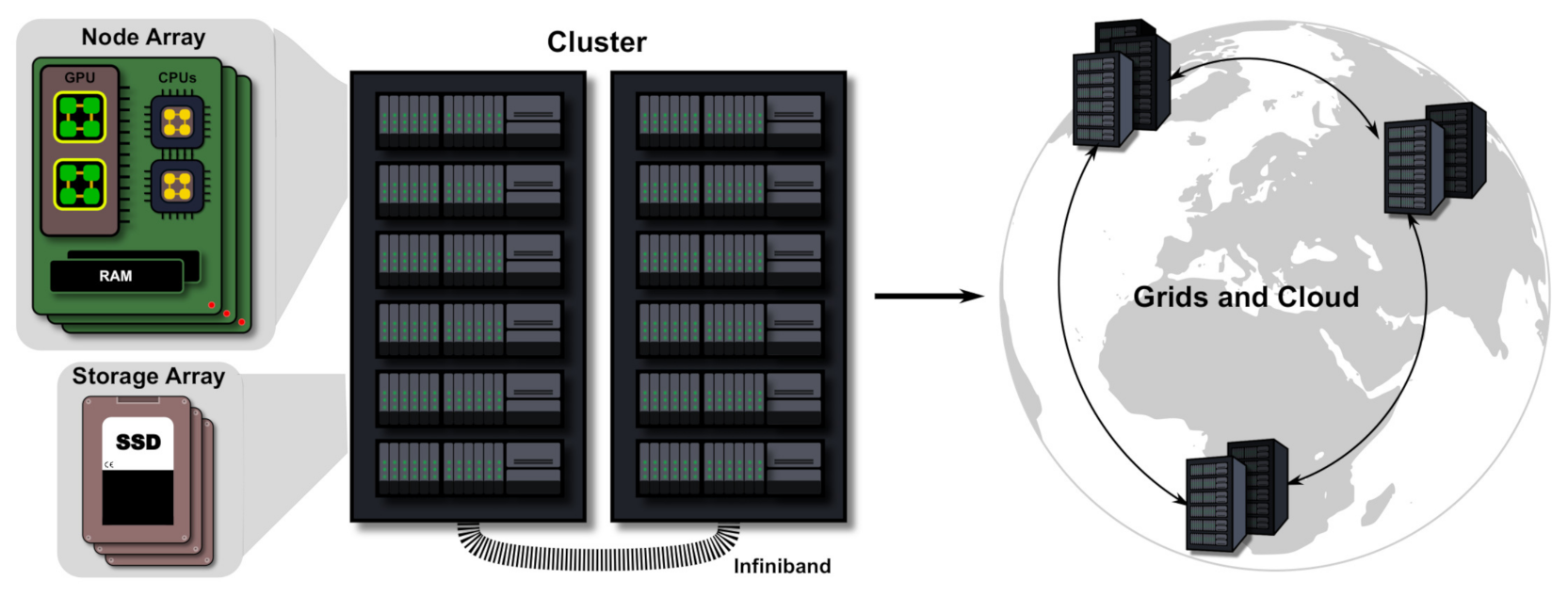
66]. Around that same time, the concept of computer clusters was forming. Many research facilities and customers of commercial supercomputers started developing their in-house clusters of more than one supercomputer. Today’s HPC facilities are highly scalable and are comprised of specialized aggregate hardware, as displayed in
Figure 4. The communication between processes through aggregate hardware is aided by high-level software such as MPI, which is available in various implementations and packages such as Mpi4py in python or Apache, Slurm, and mrjob, to aid in data management, job scheduling, and other routines.
Specific clusters might be designed or equipped with components geared more toward specific computing needs or paradigms. HPC usually includes tasks with rigid time constraints (minutes to days or maybe weeks) that require a large amount of computation. The High-Throughput Computing (HTC) paradigm involves long-term tasks that require a large amount of computation (months to years) [
67]. The Many Task Computing (MTC) paradigm involves computing various distinct HPC tasks and revolves around applications that require a high level of communication and data management [
68]. Grid or Cloud facilities provide the flexibility to adopt all the mentioned paradigms.
3.1. Grid Computing
The information age spurring in the 1990s set off the trend of wide-area distributed computing and “Grid Computing”, the predecessor of the Cloud. Ian Foster coined the term with Carl Kesselman and Steve Tuecke, who developed the Globus toolkit that provides grid computing solutions [
69]. Many Grid organizations exist today, such as Organizations such as NASA 3-EGEE and Open Science Grid. Grid computing shaped the field of “Metacomputing”, which revolves around the decentralized management and coordination of Grid resources, often carried out by virtual organizations with malleable boundaries and responsibilities. The infrastructure of grids tends to be very secure and reliable, with an exclusive network of users (usually scientists and experts), discouraging virtualization and interactive applications. Hardware is not available on demand; thus, it is only suitable for sensitive, close-ended, non-urgent applications. Grid computing features provenance performance monitoring and is mainly adopted by research organizations.
3.2. Cloud Computing
Cloud computing is essentially the commercialization and effective scaling of Grid Computing driven by demand, and it is all about the scalability of computational resources for the masses. It mainly started with Amazon’s demand for computational resources for its e-commerce activities, which precipitated Amazon to start the first successful infrastructure as a service-providing platform with Elastic Compute Cloud [
70] for other businesses that conduct similar activities.
The distinction between Cloud and Grid is an implication of their business model. Cloud computing is way more flexible and versatile than Grid when it comes to accommodating different customers and applications. It relies heavily on virtualization and resource sharing. This makes Cloud inherently less secure, less efficient in performance than Grid, and more challenging to manage, yet way more scalable, on-demand, and overall more resource efficient. It achieves a delicate balance between efficiency and the cost of computation.
Today, AWS, Microsoft Azure, Oracle Cloud, Google Cloud, and many other cloud commercial services provide massive computational resources for various companies such as Netflix, Airbnb, ESPN, HSBC, GE, Shell, and the NSA. It only makes sense that the electrical industry will adopt the Cloud.
3.2.1. Virtualization
The appearance of virtualization caused a considerable leap in massive parallel computing, especially after the software tool Parallel Virtual Machines (PVM) [
71] was created in 1989. Since then, tens and hundreds of virtualization platforms have been developed, and are used today on the smallest devices with processing power [
72]. Virtualization allows resources to be shared in a pool, where multiple instances of different types of hardware can be emulated on the same metal. This means less hardware can be allocated or invested in Cloud computing for a more extensive user base. Often, the percentage of hardware used is low compared to the requested hardware. Idle hardware is reallocated to other user processes that need it. The instances initiated by users float on the hardware, such as clouds shifting and moving or shrinking and expanding depending on the actual need of the process.
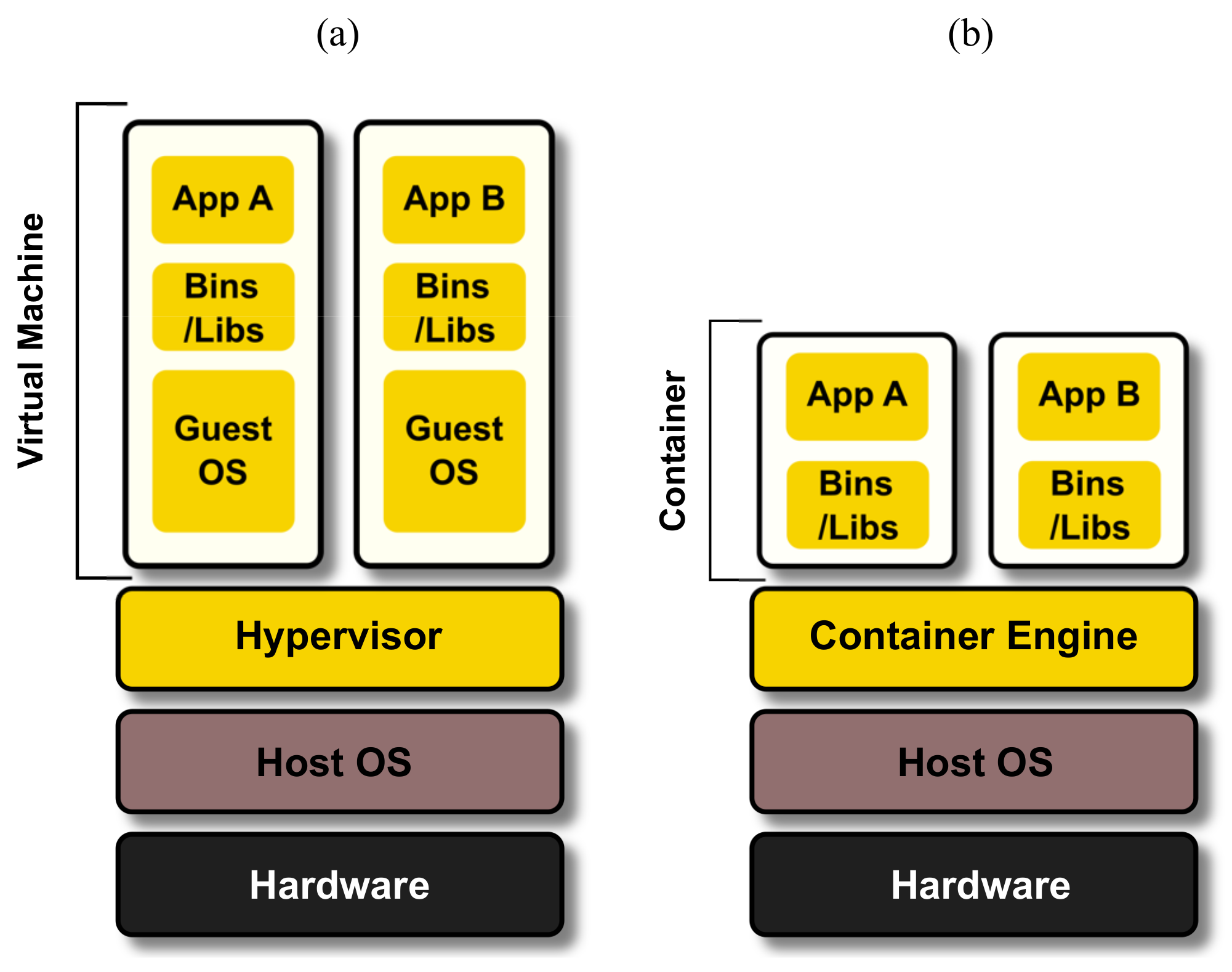
3.2.2. Containers
While virtualization makes hardware processes portable, containers make software portable. Developing applications, software, or programs in containers allows them to be used on any Operating System (OS) as long as it supports container engines. That means one can develop a Linux-based software (e.g., that works on Ubuntu 20.04) in a container and run that same application on a machine with Windows OS or iOS installed. This flexibility applies to service-based applications that utilize HPC facilities. An application can be developed on containers, and clients can use it on their cluster or a cloud service.
Figure 5 compares virtual machines with container layers. While this shows that a host OS is required, they can also run on bare metal, removing latency and development complexity. Docker and Apptainer (formerly known as singularity) are commonly used containerization engines in Cloud and Grid, respectively [
73,
74].
3.2.3. Fog Computing
Cloudlets, edge nodes, and edge computing are all related to an emerging IoT trend, Fog Computing. Fogs are computed nodes associated with a cloud that are geographically closer to the end-user or control devices. Fogs mediate between extensive data or cloud computing centers and users. This topology aims to achieve data locality, offering several advantages, such as low latency, higher efficiency, and decentralized computation.
3.3. Volunteer Computing
Volunteer computing is an interesting distributed computing model that originated in 1996 via a Great Internet Mersenne Prime Search [
75], allowing individuals connected to the internet to donate their personal computer’s idle resources for a scientific research computing task. Volunteer computing remains active today, with many users and various middleware and projects, both scientific and non-scientific, primarily based on BOINC [
76], and in commercial services such as macOS Server Resources [
77].
3.4. Granularity
Fine-grained parallelism appears in algorithms that frequently repeat a simple homogeneous operation on a vast dataset. They are often associated with embarrassingly parallel problems. The problems can be divided into many highly, if not wholly symmetrical simple tasks, providing high throughput. Fine-grained algorithms are also often associated with multi-threading and shared memory resources. Coarse-grained algorithms imply moderate or low task parallelism that sometimes involves heterogeneous operations. Today, coarse-grained algorithms are almost synonymous with Multi-Processing, where the algorithms use distributed memory resources to divide tasks into different processors or logical CPU cores.
3.5. Centralized vs. Decentralized
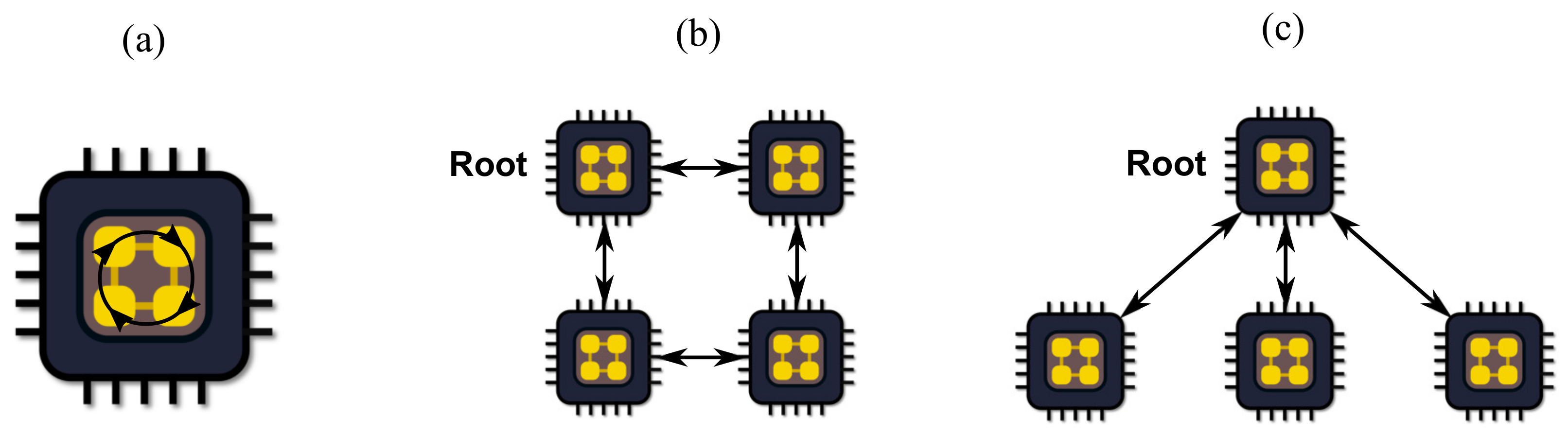
Centralized algorithms refer to problems with a single task or objective function, solved by a single processor, with data stored at a single location. When a centralized problem is decomposed into N subproblems, sent to N number of processors to be solved, and retrieved by the central controller to update variables, re-iterate, and verify convergence, the algorithm becomes a “Distributed” algorithm. The terms distributed and decentralized are often used interchangeably and are often confused in the literature. There is an important distinction to make between them. A Decentralized Algorithm is one in which the decomposed subproblems do not have a central coordinator or a master problem. Instead, the processes responsible for the subproblems communicate with neighboring processes to reach a solution consensus (several local subproblems with coupling variables where subproblems communicate without a central coordinator). The value of each type is not only determined by computational performance but the decision-making policy.
In large-scale complex problems, distributed algorithms sometimes outperform centralized algorithms. The speedup keeps growing with the problem size if the problem has “strong scalability”. Distributed algorithms’ subproblems share many global variables. This means a higher communication frequency, as all the variables need to be communicated back and forth to the central coordinator. Moreover, in some real-life problems, central coordination of distributed computation might not be possible. Fully decentralized algorithms solve this problem as their processes communicate laterally, and only neighboring processes have shared variables.
Figure 6 illustrates the three schemes.
3.6. Synchronous vs. Asynchronous
Synchronous algorithms are ones in which the algorithm does not move forward until the parallel tasks at a certain step or iteration are executed. Synchronous algorithms are more accurate and efficient for tasks with symmetrical data and complexity. However, that is usually not the case in power system optimization studies. The efficiency of these algorithms suffers, however, when the tasks are not symmetrical. Asynchronous algorithms allow idling workers to take on new tasks, even if not all the adjacent processes are complete. This is possible only at the cost of accuracy when there are dependencies between parallel tasks. To achieve better accuracy in asynchronous algorithms, “Formation” needs to be ensured, meaning that while subproblems may have a deviation in the direction of convergence, they should keep a global tendency toward the solution.
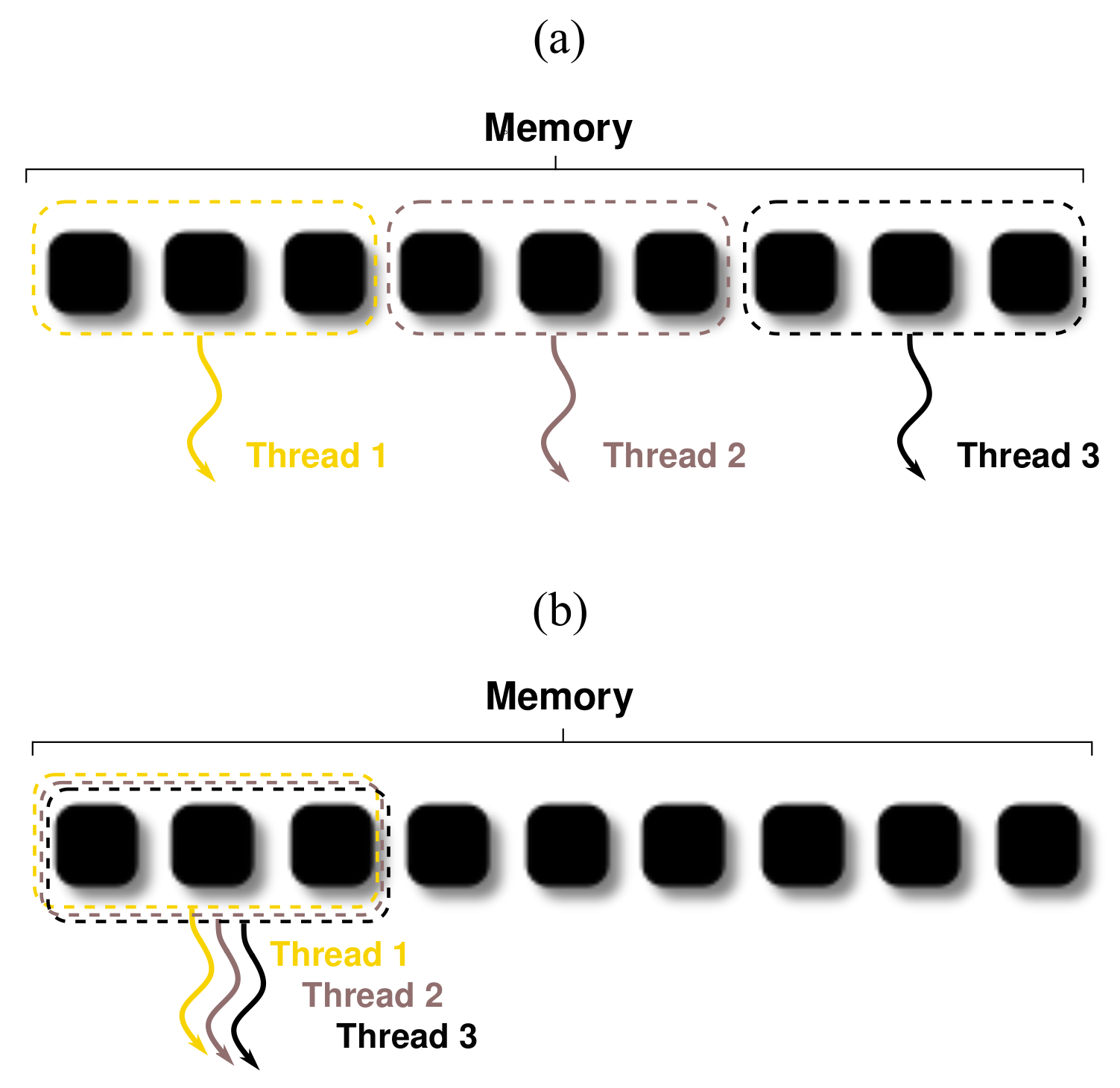
3.7. Problem Splitting and Task Scheduling
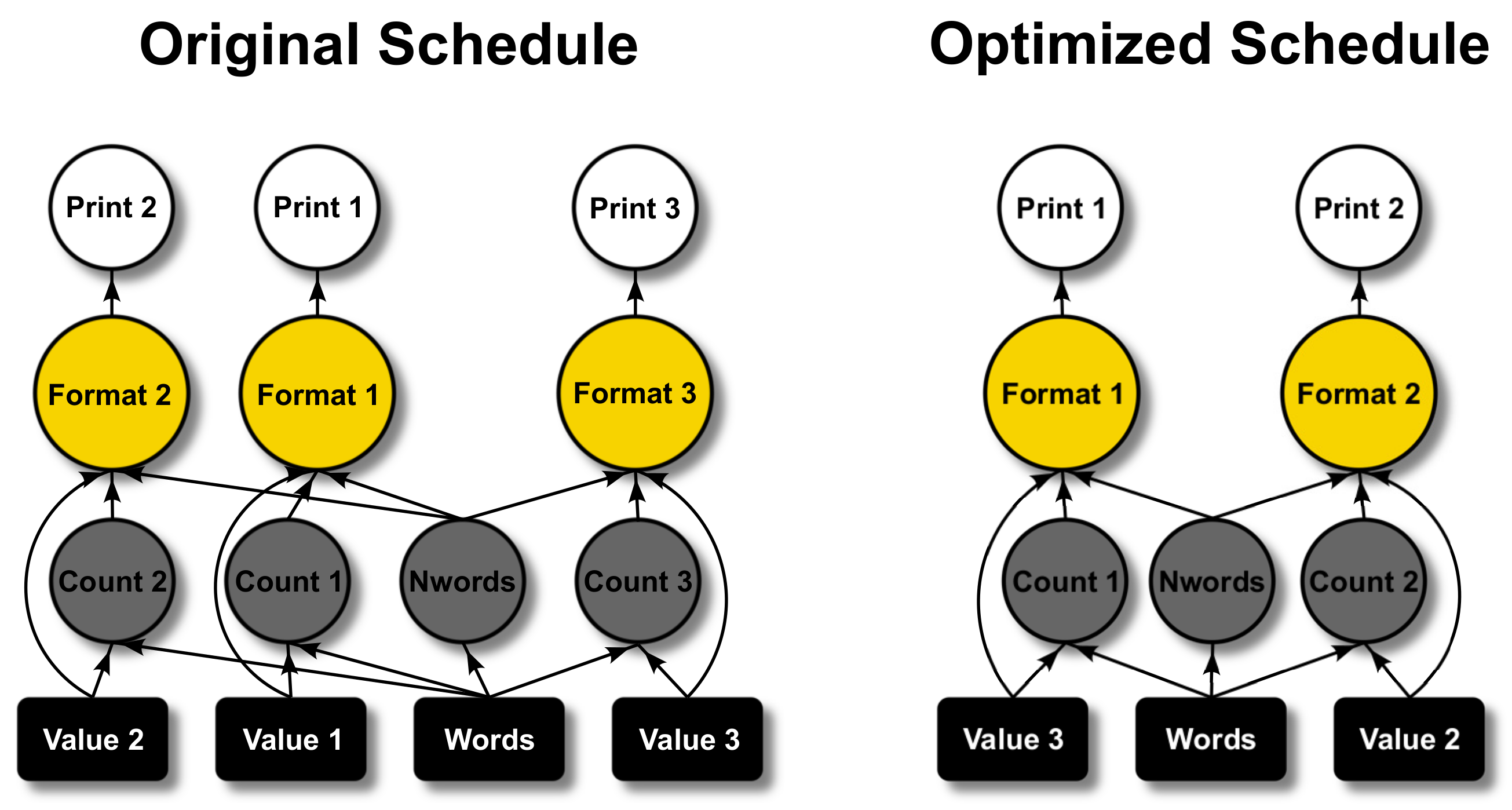
Large emphasis must be placed on task scheduling when designing parallel algorithms. In multi-threading, synchronization of tasks is required to avoid “Race Conditions” that cause numerical errors due to multiple threads accessing the same memory location simultaneously. Hence, synchronization does not necessarily imply that processes will execute every instruction simultaneously but rather in a coordinated manner. Coordination mechanisms involve pipe-lining or task overlapping, which can increase efficiency and reduce the latency of parallel performance. For example, sub-tasks that take the longest time in synchronous algorithms can utilize idle workers of completed sub-tasks if no dependencies prevent such allocation. Dependency analysis is occasionally carried out when splitting tasks. In an elaborate parallel framework, such as in multi-domain simulations or smart grid applications, task scheduling becomes its own complex optimization problem, which is often solved heuristically. However, there exist packages such as DASK [
78], which can help with optimal task planning and parallel task scheduling, as shown in
Figure 7. DASK is a python library for parallel computing which allows easy task planning and parallel task scheduling optimization. The boxes in
Figure 7 represent data and circles represent operations.
3.8. Parallel Performance Metrics
Solution time and accuracy are the main measures of the success of the parallel algorithm. According to the Amhals law of strong scaling, there is an upper limit to the speedup achieved for a fixed-size problem. Dividing a specific fixed-size problem into more subproblems does not result in a linear speedup. However, if the parallel portion of the algorithm increases, then proportionally increasing the subproblems or the number of processors could continuously increase the speedup, according to Gustafson’s Law of strong scaling. The good news is that Gustafson’s law applies to large decomposed power system problems.
There are three types of metrics most frequently used in the literature, as shown in Equation (
1)–(
3).
A Linear Speedup is considered optimal, while a sublinear speedup is a norm because there is always a serial portion in a parallel code. Efficiency and scalability are vaguely related. Efficiency is mostly used to compare a specific parallel setup to a sequential one, whereas scalability is used to see how the parallel algorithm scales with increased hardware. A scalable algorithm is not necessarily an efficient one. When creating a parallel algorithm, emphasis on the quality of the serial portion of the algorithm must be ensured. A parallel algorithm, after all, is contained and executed by a serial code. Both sequential and parallel programs are vulnerable to major random errors caused by the Cosmic Ray Effect [
79], which has been known to cause terrestrial computational problems [
80]. Soft errors might be of some concern regarding real-time power system applications. However, in parallel programming, especially in multi-processing, reordering floating-point computations is unavoidable; thus, a tiny deviation in accuracy from the sequential counterpart is expected and should be tolerated, given that the speedup achieved justifies it. All the computing paradigms mentioned above are points to tweak and consider when creating and applying any parallel algorithm.
10. Grid and Cloud-Computing-Based Studies
Table 11 summarizes the latest contributions in Grid and Cloud-based studies. The use of HPC facilities in the electrical power industry is not uncommon in various offline (and some online) applications, especially ones related to smart grids and microgrid planning [
46]. For example, California Independent System Operator (CAISO) uses HPC to perform various real-time assessments of the network, such as reliability assessments [
34]. Facing the huge computational load, ISO-NE installed an on-premise computer cluster in 2007 using EnFuzion as a job manager [
304]. They later faced challenges in choosing the optimal size for clusters and investment in computational power, since the peak computing jobs and average ones were very different. Hence, it made sense to move some non-emergent applications to Cloud. In fact, ISO-NE had already initiated a project to adopt cloud computing with emphasis on achieving privacy and security [
305,
306]. When facilities begin to struggle to meet the increasing requirement of deployed power system applications, it makes sense to resort to cloud services. Cloud computing really expands the realm in which algorithms and systems can be parallelized and exhausted. Regulators and players will not have to worry about the availability of resources any more. Instead, they will squeeze out every inch of performance and manage the “rented” resources. Unneeded capital investment can be avoided, and real-time data can be shared with third parties.
When it comes to Grid and Cloud computing studies, performance enhancement is often sought through scalability and resource availability rather than optimizing for specific hardware. While this works very well, the combination of fine optimization would be much more powerful. However, this might be only possible through the Grid rather than the Cloud model, since it is more controllable. Most of the work in this area is very recent, but it starts with a few studies on Grid Computing. In an application that is very similar to the Cloud computing paradigm, the work by Morante et al. [
307] might have been the first modular and hardware scalable implementation of parallel contingency analysis on a grid of eight heterogeneous computers. A middleware called Hierarchical Metacomputers (HiMM) was used to allocate resources economically based on resource adequacy and a given budget value. By increasing the budget value, their middleware managed to lower the execution time by exploiting more expensive, more powerful resources. Other papers from the time explored the idea of monitoring and control of the power system using decentralized schemes on grid computing [
308]. A few more studies explored Grid-based frameworks and applications, such as Huang et al. [
309,
310] and Ali M. [
311], load flow on Grid by Al-Khannak et al. [
312], and dynamic security assessment by Xingzhi Wang et al. [
313].
There were a few recent studies that showcased large-scale cloud implementations. One study was part of a diverse paper showcasing the challenges and experiences gained by ISO-Newengland in moving to cloud services. In their move, they used Axceleon CloudFuzion [
314] job balancer, which provides high failure tolerance and job monitoring. The work involves heuristics and operational decisions, providing a great insight into the methodologies and equations used to choose the number of instances and squeeze every bit out of the rented hour. An N-2 contingency analysis was performed on a test case that takes 470 h on a regular workstation; the case jobs were carried out in less than an hour with their scheme. CloudFuzaion was not flawless, however, as its workflow was often interrupted by manual steps (which meant it had to be monitored). Thus, ISO-NE started a project with Axceleon to develop an independent power system simulation platform for cloud computing that addresses that issue, fully automating processes after receiving the user input. In a 2019 study [
304], they demonstrated that their platform managed to run multiple instances reaching near 100% CPU utilization of the instances launched for certain jobs and capable of many task computing and co-simulations.
Security becomes a major issue when using cloud facilities, and while the work above used a service-level security mechanism, Sarker and Wang [
315] wanted to ensure security, assuming that the cloud in-house security infrastructure is compromised. They transform the ED problem into a Confidentiality-Preserving Linear Programming (CPLP) formulation [
316,
317] to achieve holistic security, such that all sensitive information remains unknown by competitors. The approach protects against attacks from passive and active entities on the Cloud (administrators and customers). It works by converting inequality to equality constraints and multiplying the coefficients by randomly generated positive real numbers twice (a mononomial matrix U then H), which are held privately. The resultant constraint matrix is sent to the Cloud, and the equipment information implied in the constraint coefficients remains obscure to any attackers. This work enhances the security matrix reduction of CPLP. Since the feasible region of the CPLP that is produced after those operations is the same as the original LP problem, solving for those new constraints, (the CPLP) yields the same solution as the LP. A test of the algorithm was performed on a 2383-bus Polish system, including 327 generators solved using CPLEX, comparing its performance on four different cloud instances. The method showed scalability, but it was not tested against a regular ED algorithm.
Another paradigm that Cloud facilitates is the Many Task Computing paradigm. It facilitates Co-Simulations, which involve solving many optimization problems and performing many studies apart and then connecting them. In [
318], they perform a large co-simulation by decomposing a network into heterogeneous partitions that are unique to each other, creating different problems for each partition (e.g., generators, passive components, loads, etc.). The dynamic resource allocation ability fits well with large-scale co-simulations because 1—different components have different transient reactions. 2—They might require different timesteps depending on transient status. 3—Each problem could have a different formulation (NLP, MILP, etc.) and require different solution times. The paper demonstrates the achievable co-simulation performance and interfacing on the Cloud using existing commercial tools. For example, in one instance, the network was divided into multiple Simulink models, launching Matlab script simulations in different processes. In another trial, a compiled MPI C code was used, and Simulink executables were to run the simulation.
In [
319], a fine scope was taken on task management of massive parallel contingency analysis using the Hadoop Distributed File System on the Cloud. They applied an N-1 transmission line contingency analysis and used the NR method to solve the power flows. First, the system distributes the contingency and other parameters to separate nodes such that each node solves a contingency case. What is unique about their job management scheme is that when the number of cores increases, the network bandwidth automatically increases as well, further increasing the performance. With this approach, they could perform a full AC contingency analysis for a real network in less than 40 s.
Table 11.
Grid & Cloud Computing state-of-the-art studies.
Table 11.
Grid & Cloud Computing state-of-the-art studies.
| Paper | Contribution |
|---|
| [307] | First modular and hardware scalable implementation of parallel contingency analysis |
| [314] | Showcase the challenges and experiences by ISO-Newengland in moving to cloud |
| [304] | Many task computing management, near 100% utilization of CPU instances |
| [315] | ED specific cloud security algorithmic re-reinforcement |
| [318] | Large EMT co-simulation decomposing a network into heterogeneous partitions |
| [319] | Parallel contingency analysis using Cloud Hadoop Distributed File System |
11. Smart Grid and Renewable Integration Applications
A summary of the contributions of studies covered in this section is availalbe in
Table 12. In 2010, the literature almost completely shifted towards cloud computing and particularly an integrated framework combining smart grids with the Cloud, given the advent of AMI and big data at the dawn of that year. Several frameworks and models for smart grid co-ordination [
320,
321], and power system assessment [
206] using Cloud appeared that year and later [
322]. Ideas such as cloud-based demand response were being explored [
323], and many papers suggested network architecture and control topologies that are realizable with cloud [
324]. Concepts such as Cloud assisted IoT could help us achieve a much more efficient network of sensors for future power systems. An example of such a system is an architecture for RPL-based IoT application, which specifies the application of RPL focusing on reforming industrial operations through cutting-edge technologies [
325]. The versatility of cloud infrastructure is an excellent complement to the smart grid future, and its applications are covered in this review as it involves distributed work, which is the core of parallel computation. The diagram in
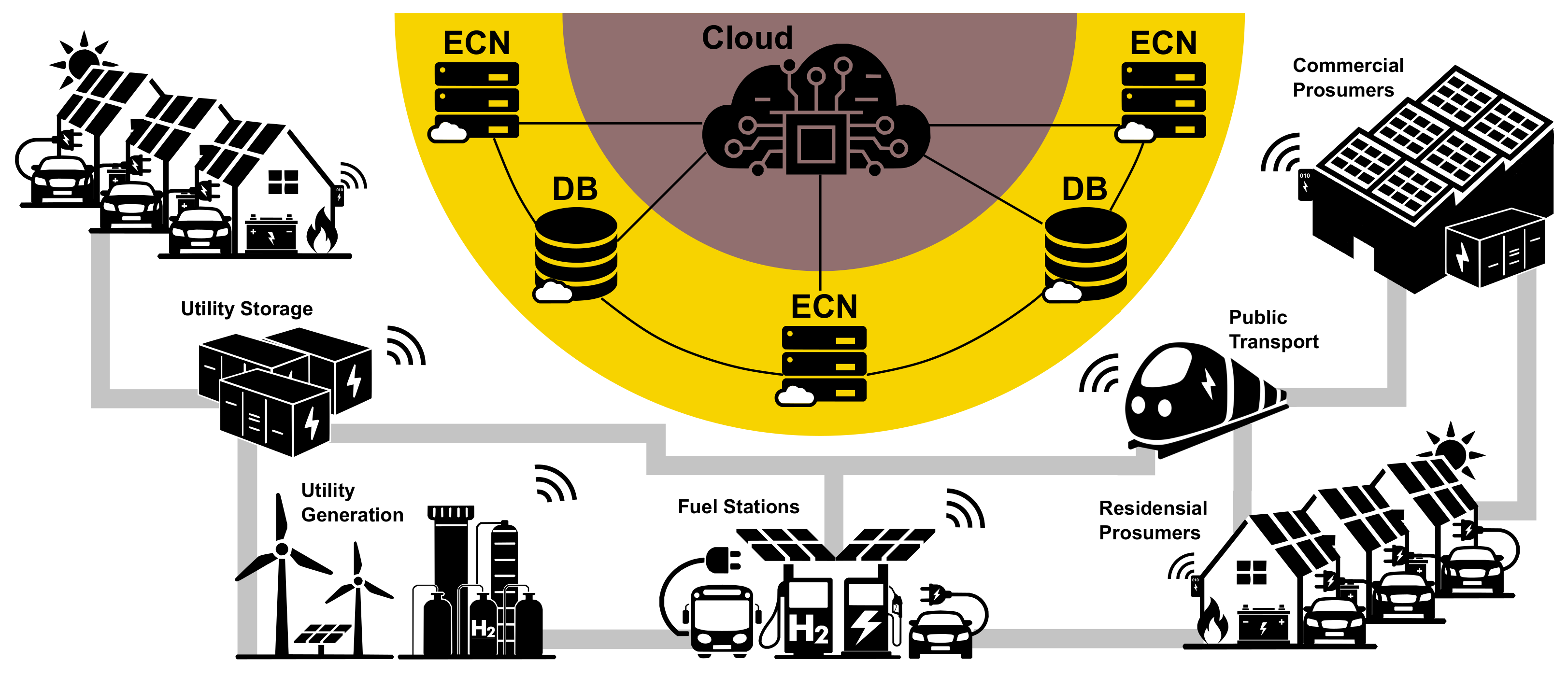
Figure 13 shows a typical multi-layer vision shared across the Cloud integrated smart grid literature.
Interesting network paradigms could be created given that computational resources can be flexible and scaled as cloud services provide. Sheikhi [
326] explores the idea of an “Energy Hub” where customers can be active in Demand Response Management by reducing their direct electricity consumption and using the output of the combined heat and power from the energy hub that the gas supplier supplies. This does not change customers’ electricity consumption level, but the demand has reduced from the electrical supplier’s point of view. This Energy Hub + Smart meter is now a Smart Energy Hub, and single or multiple customers could share it. The problem was formulated in a game theory approach where the Smart Energy hub is a price anticipator, which tries to predict the consequences of its own action on the price and chooses the optimal load-shifting schedule to reduce the cost on customers on those bases. In a similar fashion to [
327], the smart energy hubs read and control the outputs and send data to the Cloud to be aggregated and computed for decision-making, solving the game according to the cost function. They simulated their approach and showed that it resulted in a decrease in energy price compared to no Demand Side Management (DSM) game. They also compared the communication cost of direct messaging configuration vs. cloud configuration, where the Cloud showed lower cost, making the platform more suitable for such applications.
Figure 13.
The general idea is to have a network of databases and compute nodes (which includes smart meters) to keep essential local data and computation locally where quick responses and decisions are needed, while the cloud is overseas and sends signals coordinating the system at a higher level. DB: Remote Data Base, ECN: Edge Compute Node.
Figure 13.
The general idea is to have a network of databases and compute nodes (which includes smart meters) to keep essential local data and computation locally where quick responses and decisions are needed, while the cloud is overseas and sends signals coordinating the system at a higher level. DB: Remote Data Base, ECN: Edge Compute Node.
For certain applications, such as DSM, fixed resources become an even greater issue as the amount of information processing and the computational requirement fluctuates based on the availability/flexibility of demand-side resources, which dictates the complexity of the problem at every instance. One of the options that are becoming more attractive is using cloud computing services, which could be much cheaper than expanding existing facilities. Using such services means an optimal allocation of the computational resource becomes much more crucial as cloud services are often billed based on the consumed resources, and pay-as-you-go terms [
328]. In 2016 Z. Cao et al. [
329] handled this issue with a source allocation algorithm that finds the optimal cloud computing resources for DSM instances. Commercial cloud computing resources differ from regular HPC clusters in the sense that there exists a greater variety in architecture, and the performance compactness might be lower than that of specialized HPCs used in research.
On a much more refined and more local scale, Wang et al. [
330] attempt to decentralize the problem of Dynamic Economic Dispatch (DED), i.e., energy management in real time, by using inverter Digital Signal Processor (DSP) chips and cloud computing. The paper solves a multi-parametric quadratic programming optimization problem, which has been highly applied in the area of coordinated power system ED and TSO-DSO network coordinated dispatch. The solution involves two parts and is decomposed into two subproblems: 1—An offline calculation that Cloud carries out. 2—Real-time decision making that the DSP carries out. In the cloud computing part, distributed renewable generation and loads are forecasted to create piecewise expressions. Every 4 h, the expressions and information are sent to inverters so that the DSP chip can solve and optimize the output based on the real-time input of load and RE. The Cloud provides flexibility and handles the highest computation burden while simplifying the subproblem solved by the inverter.
Using a 14-node test case with PV, wind, Grid, diesel, and battery systems, the authors drew a comparison between their approach and a traditional implementation on an i7 regular laptop. Amazon Web Services (AWS) instances were created, and a real DSP chip was used. Their test showed that by moving offline computations to Cloud, it was solved within 34 s compared to the traditional algorithm (372 ms). This is a colossal speedup, but it might not be fair, since the traditional algorithm creates a whole new deterministic problem every time it collects new values. The main gist is that it achieves the needed solution time for using DSP, since the calculations on the inverter must be lower than 100 s so as not to cause issues and interruptions. Sharing the inverter’s chip rather than adding local controllers lowers investment and maintenance costs, and the distributed nature makes it robust against single-point failure. However, care needs to be taken in the job timing such that the control functionality of the inverter is not interrupted.
Addressing the security concerns of the Cloud, F. Ma et al. also proposed a cost-oriented model to optimize computing resource allocation, specifically for demand-side management problems using simulated annealing and modified priority list algorithms [
33]. The objective function parameters are based on actual Amazon cloud service pricing. This cost-oriented model was compared to a traditional O2O model, which allocates resources based on the peak computational load for the renting period. The proposed optimization method showed a significant cost reduction over the traditional source allocation method. There is a security concern that comes with outsourcing sensitive processes. For other players in a free market, there is an economic benefit to engaging in cyberattacks and accessing information from competitor rs’ processes, such as ED, as it could help with their bidding strategies. In their study, they explain the use of the Virtual Private Cloud (VPC) scheme, which isolates their portion of the Cloud such that their resources are not shared with other organizations or applications, even if idle. It is supposed to increase the security of the outsourcing process. Yet, one can see how the spread of such a strategy would create an impediment to the scalability and efficiency of the Cloud.
Table 12.
SmartGrid & Renewable Integration state-of-the-art studies.
Table 12.
SmartGrid & Renewable Integration state-of-the-art studies.
| Paper | Contribution |
|---|
| [326] | Explores the idea of an “Energy Hub” with active demand response |
| [327] | Energy hub cloud-based aggregated computation |
| [329] | Optimal cloud resource allocation based on available demand response |
| [330] | Decentralization of Dynamic Economic Dispatch using Digital Signal Processors on AMI |
| [33] | Demand side management using simulated annealing and modified priority list |
12. Discussion
Parallel Applications for power systems started showing up around the late 1960s and early 1970s, around the same time when a commercial market for supercomputers and clusters was sprouting. At that stage, parallel computers were still experimental in nature, and their design often targeted a specific problem type or structure. Very few computers were suitable for power system studies, as most had low arithmetic precision that is equal to or less than 32-bit, which has been shown to be inadequate for direct solution methods [
331].
At an abstract level, computer hardware architecture and its uses in power system studies are still the same. What used to be a “computer” or “host” is today’s CPU, and SIMDs such as array processors were used just like today’s GPUs would be used for power system studies. Algorithms that include diakoptics/tearing and tree graphs used to be a common theme at the start of vectorization and fine-grained parallelism, and it is still used in current GPU power system studies. Another example of similarity is that one of the issues faced at the time was that transient simulation timestep iterations sometimes required substantial logic and data to model for each node [
332]. This means it would create a burden on the computer that hosts the array processes and could cause communication bottlenecks. This is very analogous to what happens today in GPU-CPU optimization algorithms. Ironically, S. Jose argued in 1982 [
332] for the need for a general-purpose processor to tackle the previous issues since vector/array computers pose software hurdles and challenges that are too great to justify the enhancements achieved. Yet the same challenges are faced today, just at a different scale and magnitude (i.e., GPU-CPU interfacing/Cloud Implementations). A major shift in the field occurred around the 1990s; around the same time, general-purpose processors experienced significant innovation and cost reduction, and more parallel optimization algorithms started appearing. Studies in power system stability became abundant, and UC algorithms debuted with most papers using metaheuristics to solve the problem. While implementation would have been arguably doable, simulations of parallel hardware still existed because more care was placed on implementation optimization and ensuring the practicality/portability of the parallel algorithms. The meaning or extent of what is considered coarse-grained and fine-grained algorithms shifted over time.
The main direction for HPC incorporation in power system studies applications is moving towards real-time applications, much more so than offline applications. From the literature, it seems that renewable energy generation is the urgent driver for resorting to using AC formulations in real-time applications, followed by annual cost savings of replacing DC formulations. Benders decomposition and Lagrangian relaxation seem to be the most common combination in decomposing stochastic full AC problems. In larger systems, the application of parallel computation is clearly more advantageous, while in smaller systems, serial programming performs better or at least matches parallel computational approaches, mainly due to the communication overhead, as an increased number of processes means longer and more communication time between them. The extent of this effect depends highly on the strategies used in parallelization, as well as the cluster architecture and hardware used. GPUs, for example, exhibit extreme parallelism in processing architecture, yet have superior performances over more coarse CPU implementation shown previously [
333]. Many organizations and research teams are developing public tools and frameworks to help incorporate HPC into power system studies. PNNL developed HIPPO [
334], a tool to help grid operators tackle SCUC by leveraging optimization algorithms for HPC deployment. PNNL also initialized the development of another framework for power system simulations called GridPack, which falls under a larger suite called GridOPTICS [
335]. While such tools facilitate the use of multi-processor parallelization, others such as Nividia CUDA [
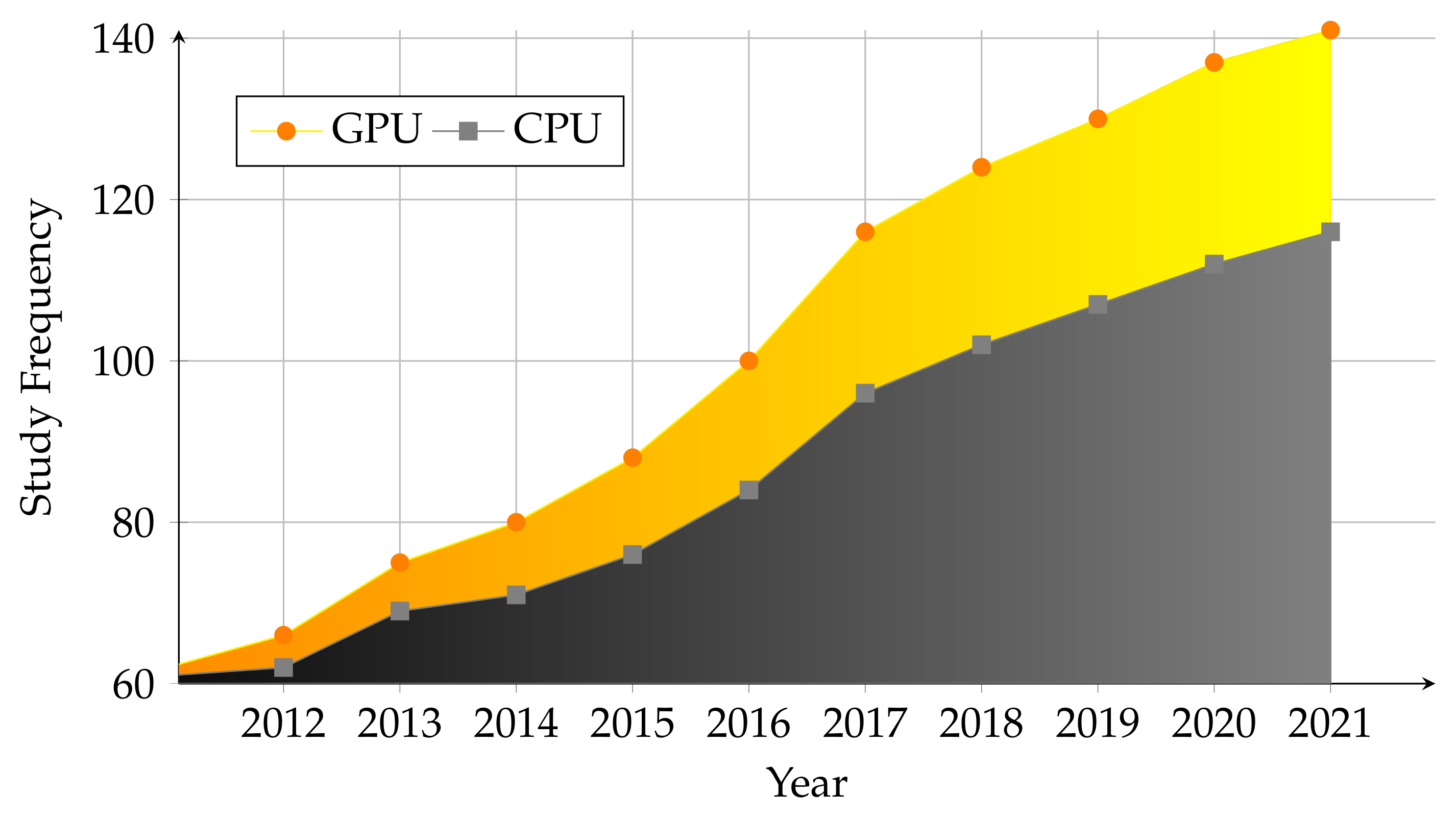
336] evolved GPUs—which have an immensely parallel architecture—to become easily programmable and sprouted the trend of using GPUs for scientific calculations showing a promising future. This trend can be observed in
Figure 14.
On-premise HPC is not future proof, as the grid organism keeps on evolving. A power system with n components, with each component having m states, can have over all possible states. The Grid is quickly adding more components in terms of quantity and variety, AMI, EVs, IoT, etc. All power studies will keep on growing, and control rooms and operators will also need immediate visualizations for easy information analysis. This means that power system operators will inevitably resort to Cloud services. However, cloud computing has many of its own challenges related to policy, security, and cooperation before any solid adaptation is made. The Optimal placement of data centers depends on various stochastic factors, and the lack of interoperability between providers of cloud services does not make this problem any easier. Regulatory compliance in terms of security and access is extremely hard to ensure. Data and process locations are unknown, and it becomes hard to investigate any dysfunction or intrusion. An efficient recovery mechanism needs to always be in place, and even if the host company’s structure or ownership changes, long-term data viability must be in place. Moreover, the business case for moving to cloud computing needs to be established first, which is different for every entity, and it is difficult to predict the future costs of the services. Lots of preparation and tools need to be created locally to ensure stable operation and inseparability and security, such as handling software licensing issues and data coordination/processing.
Computation aggregation evolved from a single processor to a processor and accelerator to a multi-processor system, Beowulf clusters, and multi-core processors, then a grid. Even at a small level, much like the way vector arrays and ALUs were added to processors, future CPUs and GPUs will be integrated into the same device, and the cycle continues. In the future, the Cloud will be an integral part of all operational entities, including the electrical industry. The future electrical Grid and Cloud will look very different from today; both will be dynamic and transactive and will have a reciprocal relationship in which the Cloud acts as the brain of the electrical network, and both will probably be driven by similar forces.
12.1. Software and Solvers
Commercial solver use can be traced back to the sixties with solvers such as the LP/90/94 [
337] in conjunction with the development of the field of mathematical programming. Thus, today, there is an abundance of open-source and commercial solvers that race to employ the best techniques to solve standard problem formulations. This is evident in
Figure 15, showing the variety of solvers used.
To a large degree, commercial solvers simplified optimization for engineers, allowing them to focus on modeling, leading to the subfield of model decomposition. Nevertheless, a few challenges arise when using commercial solvers instead of employing a specific solution algorithm to the problem. The heuristics involved in solver design could create a vast disparity in performance, even for solvers within the same caliber solving the same type of problem. Additionally, the ability of a solver to identify and exploit the structure of the model heavily determines whether the model can be solved within a reasonable time. If the solver fails to accomplish this step, it might exhibit exponential growth in running time, as indicated by complexity analysis. Moreover, hidden bugs and issues with the source code of the solvers could exist. This is particularly true for commercial solvers.
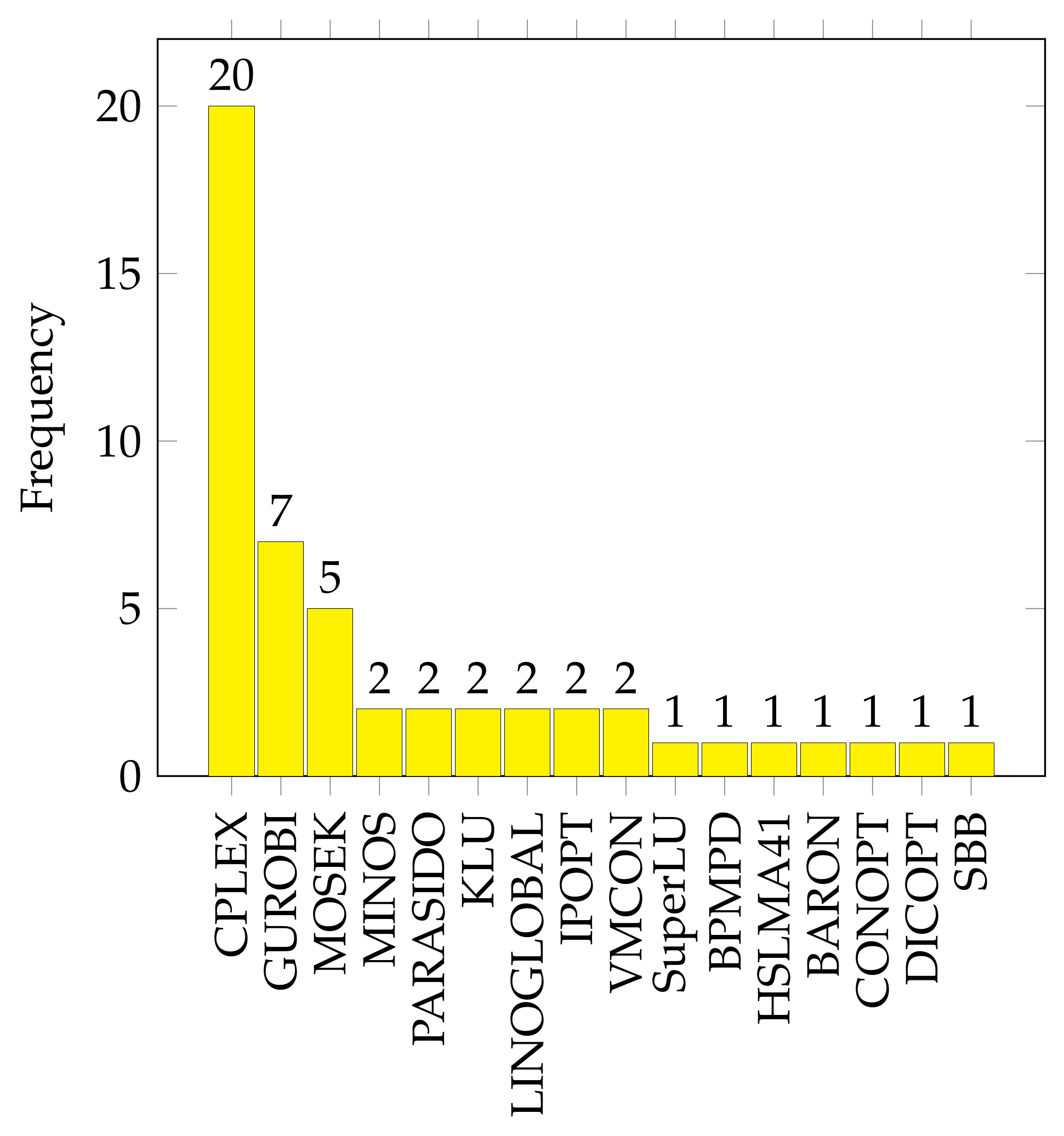
Established commercial solvers with full-time development teams, such as CPLEX and Gurobi, exhibit a more comprehensive dictionary of identifiable problem structures to accommodate the large user base. They are robust, scalable, and capable of handling large search spaces with multithreading and HPC exploitation capabilities. Moreover, they are easy to install and interface with many programming languages.
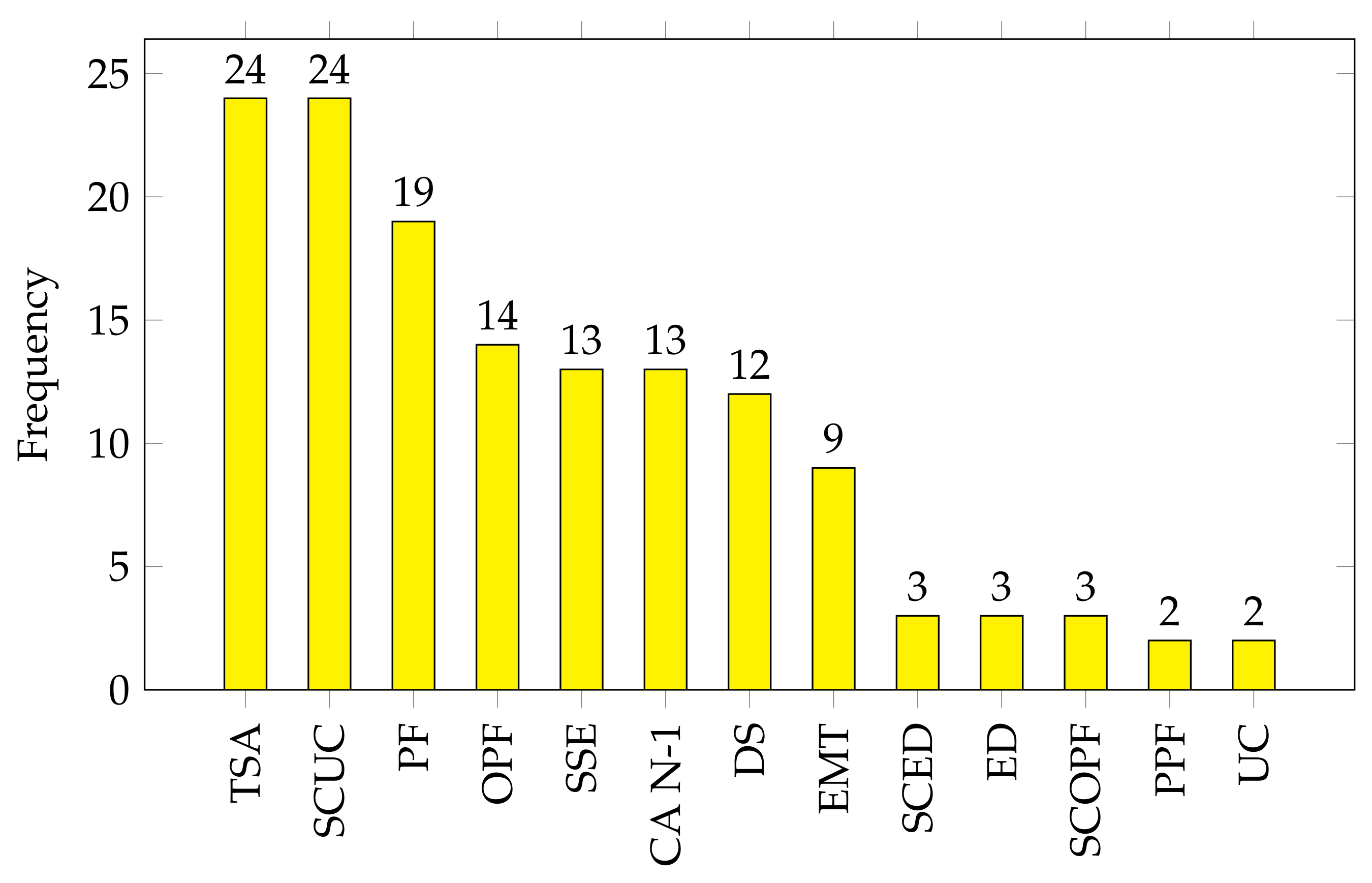
Figure 15 shows the hierarchy of occurrences of different solvers in the surveyed literature, and it can be observed that the previously mentioned solvers dominate the literature for the previously mentioned reasons. However, this should not deter us from experimenting with non-commercial solvers, as they may be superior for specific problems. It is also worth noting that all the well-established general solvers in the tier of CPLEX and Gurobi are CPU based, and none exploit GPUs in their processes, which is an area worth exploring [
338].
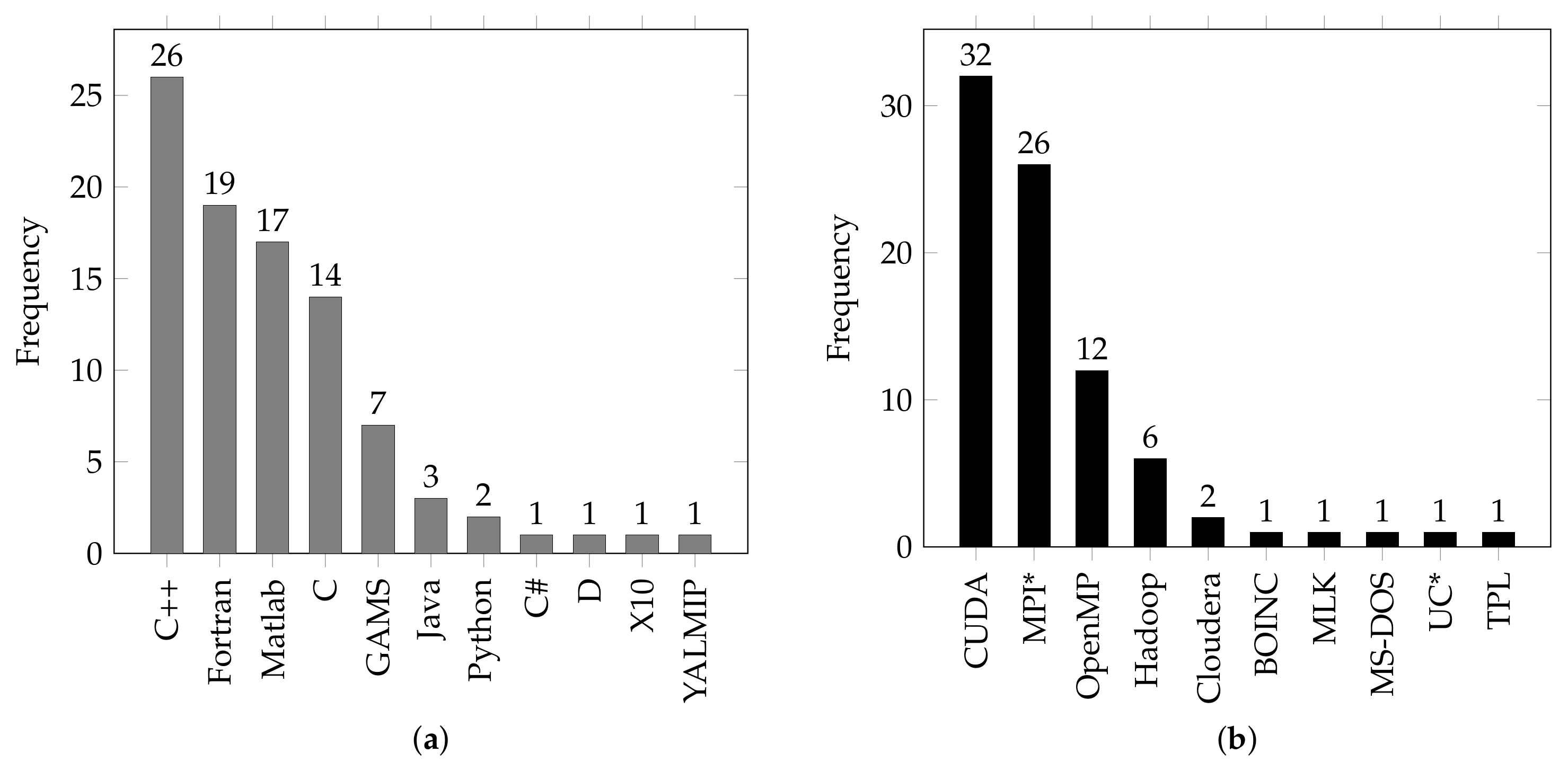
Compiled and procedural languages, such as C and Fortran, dominate the literature due to their superior performance, as shown in
Figure 16a. However, other multi-paradigm multi-paradigm and object-oriented languages (Matlab and python) started to infiltrate the literature due to their simplicity and convenient libraries. Other concurrent programming-oriented languages that might be of interest include Charm, Chapel, Cython, and Julia. Chapel has more advanced parallelism than Julia, while Julia has gained huge popularity since its recent release. Julia is expected to populate future literature due to its heavy emphasis on optimization and C-like performance. In terms of Parallel APIs, the fast adaptation of CUDA as shown in
Figure 16b testifies the thirst for massive throughput and suggests that in terms of GPU-based power system optimization studies, there is more to come.
There exist some integrated high-level frameworks designed to scale certain power system studies on HPC, such as BELTISTOS [
129], which solves multi-period, security-constrained, and stochastic OPF problems incorporating a multilevel solution strategy implemented in PARADISO. However, when compared to GridPack, this framework seems quite limited. As part of the HIPPO project mentioned earlier [
199], PNNL developed the software framework GridPack
that lowers the barrier for power system research and analysis in creating parallel models for HPC implementation [
339].
Grid pack automates processes such as determining the Y-Bus of the network and solving PF equations, integrating algebraic differential equations, coupling simulation components, distributing network and matrix representations of the network, and employing linear and non-linear solvers. GridPack has a partitioner that partitions the network module buses into several processors, where it maximizes the interconnections between buses within the same processor and minimizes the ones between separate processors. It is based on “Parmetis” partitioning software, which achieves graph mesh partitioning, matrix reordering, etc. The matrices of the distributed matrices of the partitioned network are then distributed by mappers, which determine the contribution buses and branches from each processor by getting the dimensions and locations of elements. The math module generates those matrices and supplies linear and non-linear solvers built on the PETSc library. GridPack also has libraries of already developed, ready-to-use parallel applications. This includes different types of contingency analysis, initialization of dynamic simulation, power flow, and voltage stability analysis.
12.2. Challenges in the Literature
This review did not delve into deep comparisons between the different approaches due to the lack of standardization in various aspects of the studies, making it hard to draw meaningful comparisons. These challenges start with network topologies, sizes, a difference in hardware, and a mere lack of information. This is further discussed later in this subsection and can be observed in
Table S1. One common point to note is the strong focus on simplifying power flow equations which the dominance of Gauss–Newton and LU-decomposition methods in the literature entails, as shown in
Figure 17.
First, the variety of test cases between studies causes a solution universality issue. Many solution approaches exploit the structure and properties of the problem, such as sparsity and asymmetry, which vary with different network topologies and the number of bus interconnections. The effect of that was evident in [
122] where the parallel FDPF scheme performed better on the Pan-European system than the Polish system because it had a more orderly topology. Some studies boast remarkable results on massive synthetic bus systems that are an augmentation of the same small bus system connected with tie lines, such as in [
274], where the IEEE-39 case was copied and connected over 6000 times. This creates a level of symmetry that does not exist in natural systems, one that certainly affects the performance rendition. Moreover, some SIMD-based studies use made-up or modified power systems that are very dense, which suits what the hardware is designed for but presents a false or exaggerated sense of performance accomplishment, since real systems are generally sparse. Moreover, the speedup metric is often used unfairly. For example, in decomposition algorithms, solving subproblems is parallelized, then the performance comparison is drawn against the same serial algorithm (i.e., the scalability equation used but referred to as speedup). The parallel algorithm must be compared to the best serial algorithm that can achieve the same task to have a truly fair comparison. This alludes to the fact that there are several approaches for the speedup metric, which should be discussed in parallel algorithm studies for higher transparency, as shown in [
256]. Additionally, there are cases in which superlinear speedup is achieved in some studies. This is often due to a playfield change and deep modifications in algorithms’ features, leading to unfair comparisons. For example, when the parallel algorithm’s cache memory usage is optimized or distributed, memory is used, allowing faster access to memory than serial processes.
The second challenge is the lack of details in the experimentation setup essential for replication. Some papers provide the model of the hardware used without the number of threads or processes used and vice versa. Others claim a parallel application without mentioning the communication scheme used or the number of subproblems created. Furthermore, some papers use or compare iterative algorithms such as “Traditional ADMM/LR” or other generic algorithms without providing the user-adjusted parameters/heuristics involved in tweaking such algorithms, making it impossible to replicate and verify the results. Additionally, barely any of the studies explicitly mention the number and type of constraints and variables generated by the formulation and test cases used. There is also no standardization in the metrics used to evaluate performance. Some studies use absolute speedup; some use relative speedups. Some compare their parallel approach to a different parallel approach, which is weak because the comparison loses its meaning if the proposed parallel approach is inferior to a sequential one. Some suffice by comparing their own parallelized approach to itself applied sequentially (scalability metric), which is problematic because a decomposed task could perform worse than a coupled one when applied sequentially.
The third challenge is the lack of parallel implementation of long-term grid planning models akin to Transmission System Planning or Generation System Planning or their combination. This type of study that helps us plan the transition to the future network struggles with a very small number of factors, accuracy, and uncertainty, and on small test cases that many studies started resorting to decomposition algorithms [
340], mainly benders decomposition to decouple investment variables in the models. Yet, it seems that almost none of the studies use or resort to parallel and high-performance computing, which is a huge lost opportunity, as we need to add as many factors as possible to find the real optimal path of transitioning and investment given all the future policies technologies and scenarios that we can speculate at the moment.
The final significant challenge is the lack of standardization in the software and hardware used in the studies. The main issue with software is the variety of solvers used in papers that employ model decomposition schemes. Commercial solvers operate as black boxes that use different techniques, some of which are trade secrets. They are coded with different efficacies and have their bugs and problems, amplifying the confusion in interpretation.
The lack of hardware standardization in the literature has been highlighted since the 1990s [
341]. Even very recently, within supposedly comparative work where four different parallel schemes were compared, each scheme was performed on a different supercomputer, and a different test case [
248]. The single study that provided a meaningful cross-hardware comparison was [
108]. They experimented with different CUDA routines on different but closely related NIVIDIA GPU models, showing that their approach was not superior on every model and proving the importance of hardware normalization.
One way to help tackle the challenge of hardware standardization is by using cloud service instances, such as AWS, as a benchmark, as they are easily accessible globally. Especially since Virtual CPUs (vCPUs) handle the standardization of the heterogeneous hardware and usage (an Elastic Compute Unit is equivalent to the computing power of a 1.0–1.2 GHz 2007 Opteron or 2007 Xeon Processor [
342]. Moreover, it fits the industry’s trend of shifting computational power to the Cloud. Additionally, these services come with metric tools that allow the user to look into the actual hardware usage and CPU and memory efficiency of their algorithm. This leads us to the last point: most previous studies merely glance over memory and treat memory resources as a bottleneck rather than a shared and finite resource. More focus on data and memory efficiency is needed. Future studies need to mention the maximum amount of data that needs to be processed and the actual memory usage of their approaches.
12.3. Future and Recommendations
At this point, the role cloud computation would play in power system HPC applications, and the future Grid is almost unquestionable due to its sheer scale and versatility. The Cloud acting as the brain of the Grid fits the notion of the living organism envisioned by many for the Future Grid. In a few studies, the Cloud has been recognized as the centerpiece for distributed computing paradigms such as fog computing and AMI resource leveraging. With that said, the increasing dependence on centralized cloud computing services is antithetical to the goal of energy decentralization/independence. Yet the trend could not be more natural, manifesting a cycle that almost recreates the onset of electrical generation monopolies. The decentralization of computational resources for power systems over micro users, however, does not seem to be that far-fetched of an idea, especially with currently existing applications such as blockchains and volunteer computing.
A lot of the earlier parallel computing studies for power systems modified or created the hardware around algorithms used [
81]. This hardware manipulation to suit limited computational purposes is making a comeback due to moors law and other limitations. Analog computing hardware is making a comeback, as it is way more efficient in matrix multiplications. Rather than turning on and off, analog transistors encode a range of numbers based on the conductance magnitude, which is dictated by the gate. Their level of precision, however, makes them mainly suitable for AI chips and algorithms. Provided that their future precision becomes comparable to digital computers, they might be a contender for GPUs in mathematical optimization matrix operations.
The advancement in Quantum Computing research is creating a creeping disruptor of classical computation and algorithms as we know them. It has been shown that current Quantum Computers can solve combinatorial optimization problems that resemble ones related to energy system problems. Namely on the IBMs D-WAVE solving facility location problem [
343]. The potential of applying quantum computation for dynamic stability simulations, OPF, and UC was discussed in the early 2000s [
344]. In fact, the mixed-integer quadratic UC problem can be transformed into a Quadratic Unconstrained Binary Optimization (QUBO) by discretizing the problem space, a form that can be turned into a quantum program. In a merely experimental effort, this was actually implemented by [
343]. The test systems were very small, from 3 to 12 units, and the solutions of the D-Wave were accurate for a smaller number of units, but quickly started deviating. The DC power flow was also implemented on the D-Wave with an HHL algorithm process on a 3-bus test case showing accuracy [
345]. These might be the first experimental efforts employing quantum computation for operational power system studies.
Looking back at the studies, one can observe that our current parallel studies do not come anywhere near covering the potential variables of the future Grid. The models are highly simplified and filled with assumptions. The amount of detail, planning factors, and uncertainties are not close to what needs to be considered in grid modernization and future transition. Yet the accuracy and computational performance of the solutions are sometimes unimpressive. Even when decomposition techniques are used, and the created parallel structures are exploited with HPC, we are often faced with not-so-impressive outcomes, probably due to the lack of understanding and ingenuity in employing the parallel and decomposition and parallel techniques. The hardware that is used in many of the studies is often limited to a multi-core processor limiting the potential throughput. A complicated brain is needed to operate the complicated organism that is the future Grid. In the face of the Grid transformational changes, the power system community needs to start heavily adapting HPC techniques and utilization, incorporating them into future operational and planning studies. Moreover, a high level of transparency and collaboration is needed to accelerate the adaptation of parallel techniques, making such knowledge the norm in power system studies for the Future Grid.
The lack of standardization makes it very hard to replicate techniques from different works. Therefore, it is very important to have a standard framework and minimum information requirements in future power system study publications. This is especially important to ensure published models and techniques’ validity, given the scientific reproducibility crisis [
346,
347,
348]. The following points should serve as a guideline for future parallel studies in the field:
- 1.
A small validation test case, including any modifications, should be presented with all of the parameters and results.
- 2.
All the model expressions must be fully indexed without brevity or detail omissions. This includes both the model pre and post-decomposition. If possible, the full extended model specific to the validation test case should be provided.
- 3.
The pseudocode of the algorithm and flow chart demonstrating the parallel task splitting and synchronization should be included. The values of any tuning factors or heuristic parameters used should be provided.
- 4.
All the platforms, software tools used, parallel strategies, and metrics should be specified. This includes:
Operating system (e.g., Windows 10).
Coding language (e.g., Python or Julia).
Commercial solvers & version (e.g., Gurobi 9.0.1).
Parallelization API or pacakge (e.g., mpi4py).
Processes communication protocol (e.g., point-to-point or collective, etc.).
Machine used (e.g., local university cluster, personal laptop).
Type of worker allocated and all its model specs (e.g., 8-core 2.1 GHz 4MB intel i-7400).
Memory allocated and technology (e.g., 10GB DDR5 RAM).
Number of processes, threads & allocation per worker (e.g., the 100 subproblems were divided on 5CPUs (20 sub-problem/processes per CPU, each subproblem was solved using six threads (12 hyper-threads) automatically allocated by the solver.
Average and Peak efficiency of memory and CPU usage. (e.g., CPUs efficiency: 100% peak and 91% average. Memory utilization: 80% peak and 40% average.
- 5.
A test should be carried out on test cases incrementally increasing in size with a variety of network topologies to demonstrate the scalability and universality of the proposed method. An effort should be made to compare the speedup to the fastest known algorithm.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
















