
Forecasting Short-Term Electricity Load Using Validated Ensemble Learning

Abstract
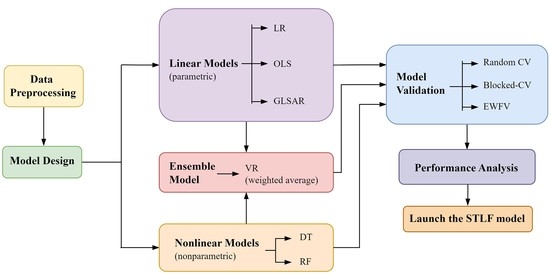
1. Introduction
Main Contributions
- We extended our previous work in [4] using the same dataset and data grouping approach to use cross-validation. In our previous work, we used the test error to check the model’s performance, which might have resulted in overly good test performance due to over-fitting the test data.
- We considered linear regression models with decision tree and random forest methods. We combined the forecasting models via a simple fixed-weight ensemble learning with the weights selected manually to improve the forecasting performance. Although simple, this ensemble learner outperforms all other individual forecasting models.
- We show via the augmented Dickey–Fuller (ADF) test that our data are stationary and have high confidence levels. This means we can use the cross-validation schemes for our time-series data.
- For each forecasting model, we evaluated the performances of three validation schemes and found that most of the time, the Blocked-CV scheme gives the best performance, and these results are also the closest to those of the ensemble model.
- Using this validation scheme, the test results show that the ensemble learning model outperforms all its individual predictors.
2. Related Works
2.1. Categories of Load Forecasting Based on the Prediction Horizon
2.2. Factors Affecting the Electric Energy Demand
2.3. Importance of Grouping the Dataset
2.4. Predictive Methods
2.5. Model Validation Techniques
- 1.
- the AR process should be stationary,
- 2.
- the model should be purely auto-regressive,
- 3.
- the model should be nonlinear and non-parametric (preferably an ML model), and
- 4.
- the fitted model should have uncorrelated errors/residuals.
2.6. Ensemble Methods
3. Methods
3.1. Data Preparation
- •
- Group 1: train = 896, test = 239
- •
- Group 2: train = 336, test = 87
- •
- Group 3: train = 142, test = 39
- •
- Group 4: train = 1374, test = 365
3.2. Prediction Horizon
3.3. Model Design
3.3.1. Parametric Models
- 1.
- OLS/LR: for i.i.d errors I
- 2.
- GLSAR: for AR(p) errors
3.3.2. Nonparametric Models
3.3.3. Ensemble Model
3.3.4. Model Evaluation
3.3.5. Performance Analysis
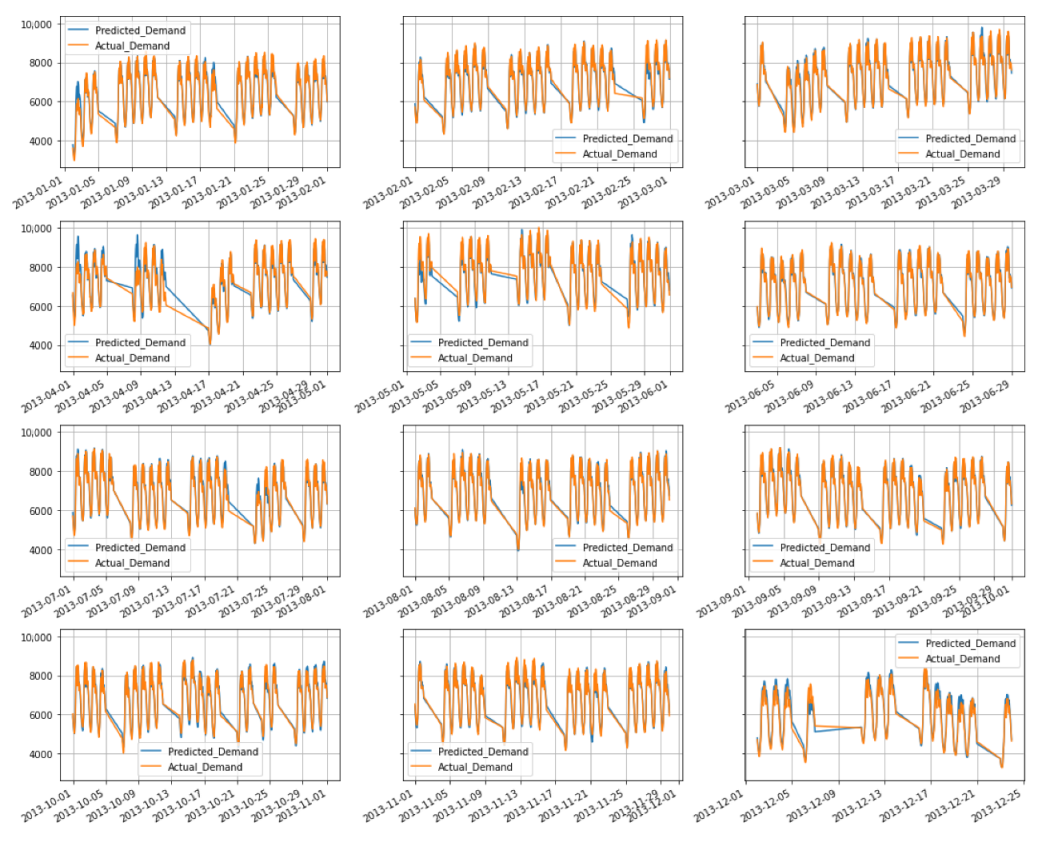
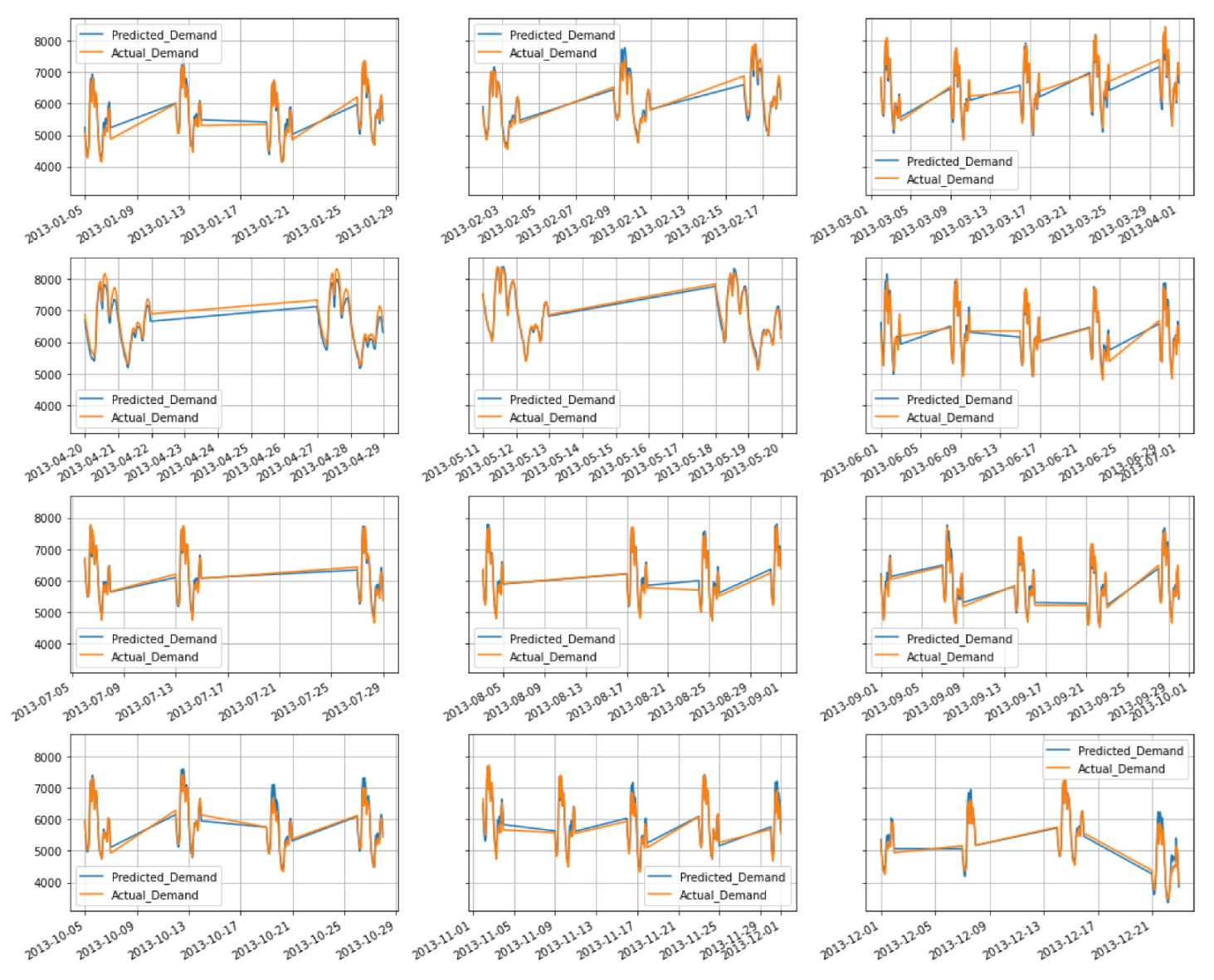
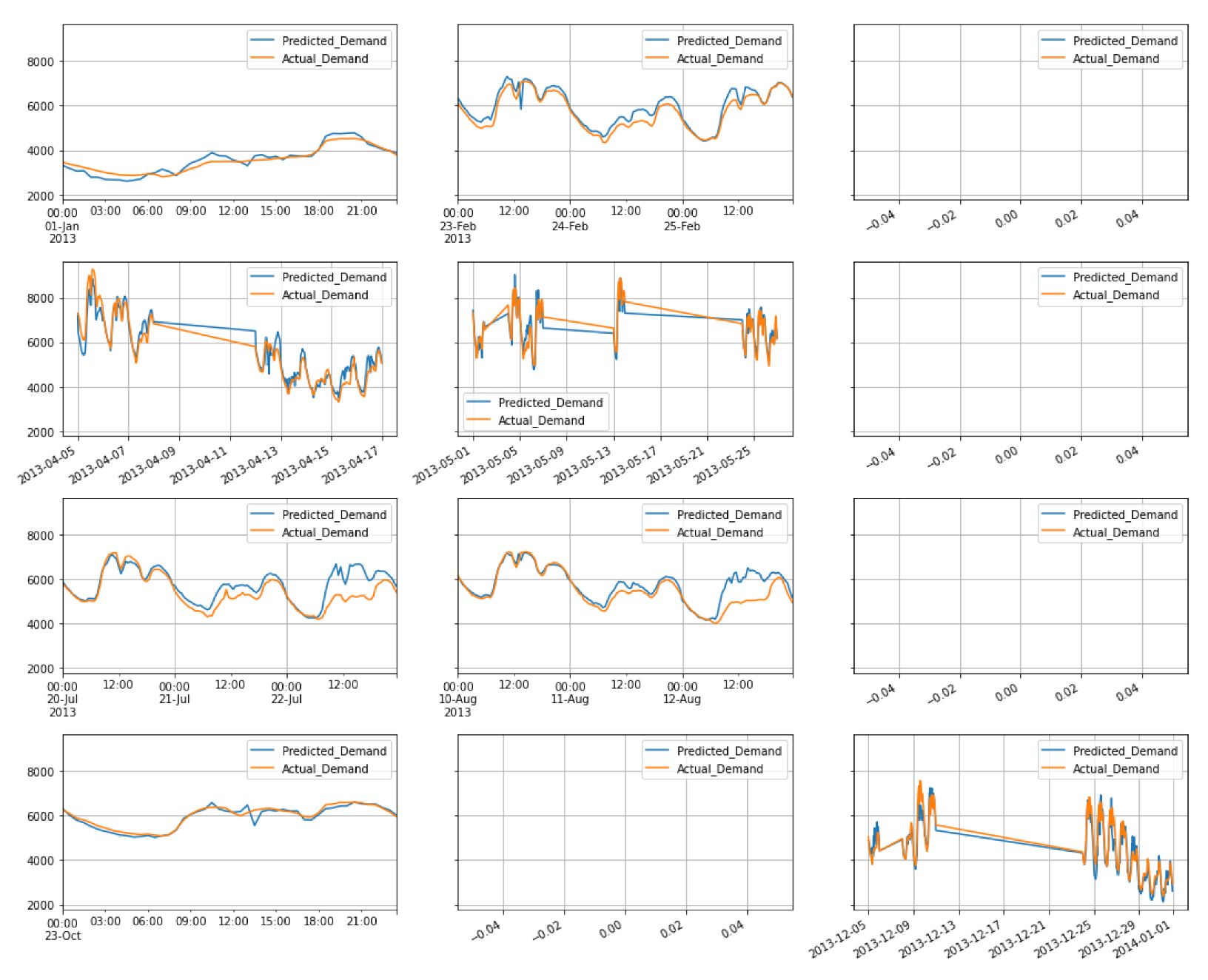
4. Results and Discussion
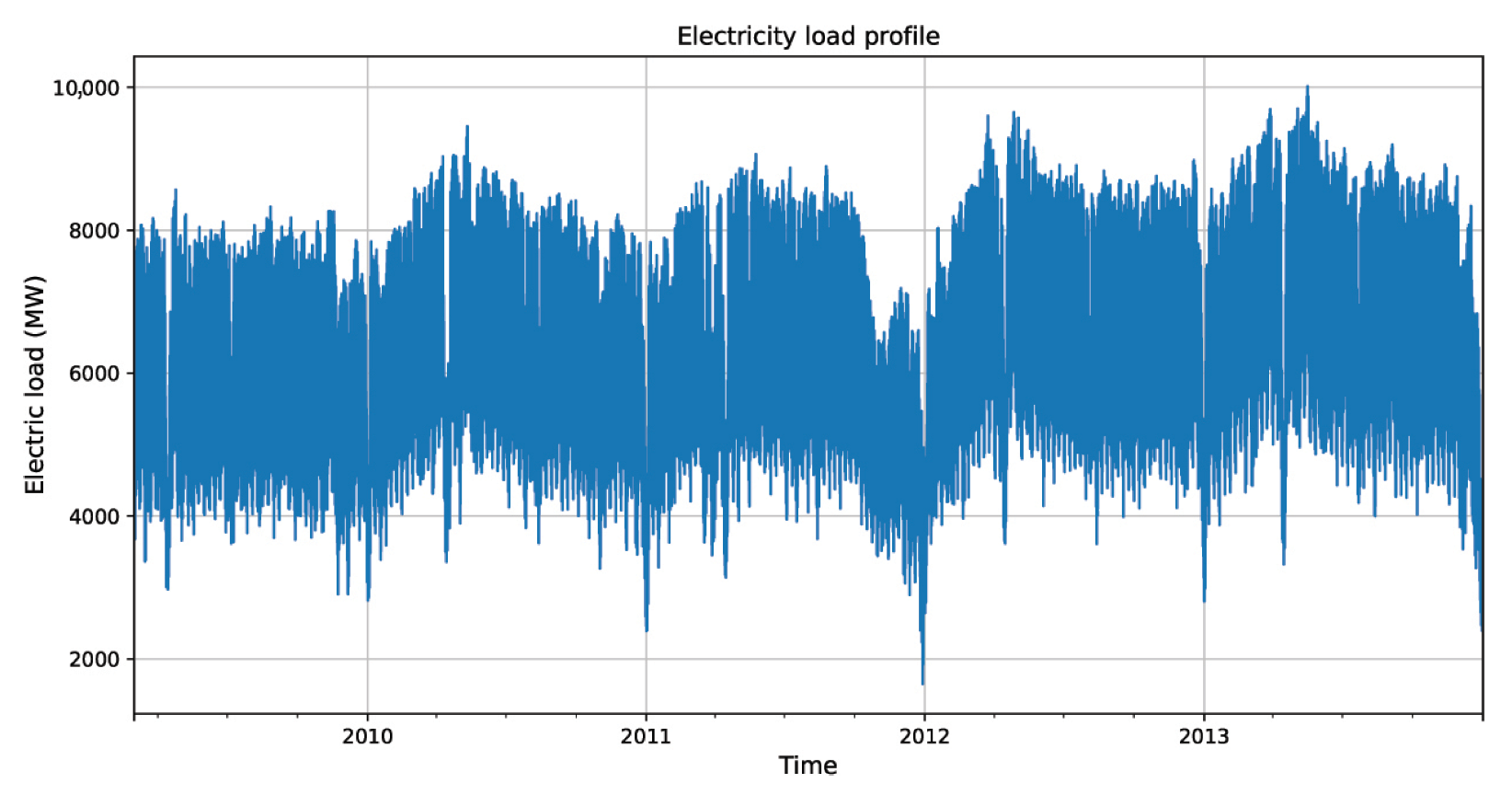
4.1. Checking for the Stationarity of Time-Series Data
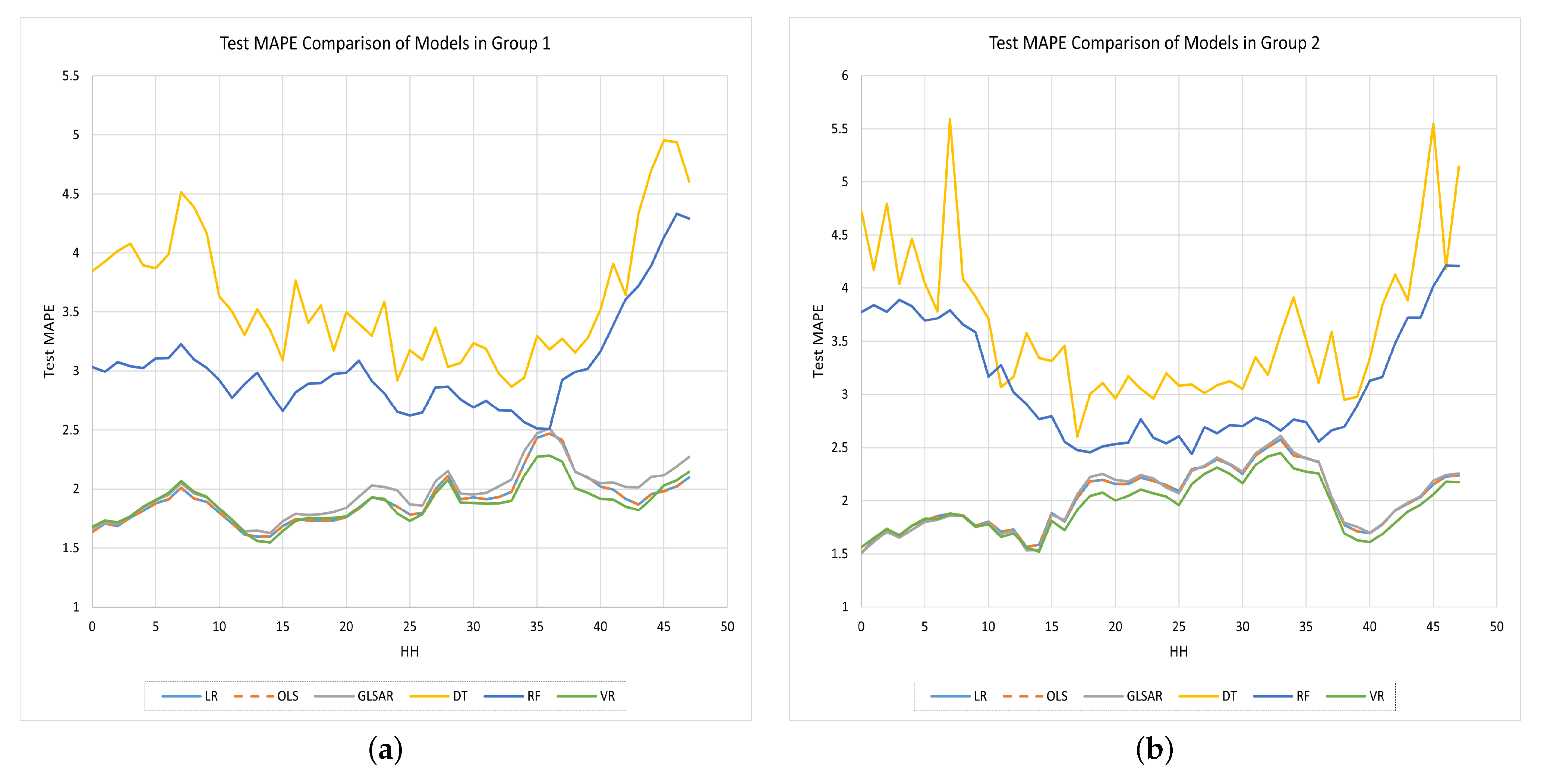
4.2. Model Selection
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| STLF | Short-Term Load Forecasting |
| ML | Machine Learning |
| EL | Ensemble Learning |
| VR | Voting Regression |
| MLR | Multiple Linear Regression |
| LR | Linear Regression |
| OLS | Ordinary Least Square |
| GLSAR | Generalized Least Square Auto Regression |
| DT | Decision tree |
| RF | Random Forest |
| TSF | Time Series Forecasting |
| CV | Cross-validation |
| EWFV | Expanding Window Forward Validation |
| EGAT | Electricity Generating Authority of Thailand |
| MAPE | Mean Absolute Percentage Error |
| ARMAX | Auto-regressive Moving Average with Exogenous Variable |
| FV | Forward Validation |
| HH | Half-hour |
| ADF | Augmented Dickey-Fuller |
| DW | Durbin-Watson |
Appendix A. Extended Results
Appendix A.1. Feature Identification

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Types | Features | Description | Group |
|---|---|---|---|
| Deterministic | WD | Week day dummy (Mon, Tue, …, Sat, Sun) | 3 |
| MD | Month dummy (Jan, Feb, …, Nov, Dec) | 1,2,4 | |
| DayAfterHoliday | Binary 0 or 1 | 1,2,4 | |
| DayAfterLongHoliday | Binary 0 or 1 | 1,4 | |
| DayAfterSongkran | Binary 0 or 1 | 1,4 | |
| Flood | Binary 0 or 1 | 1,2,4 | |
| Year | Year (2009, …, 2013) | 1,2,3,4 | |
| HolidayType | Type of the holiday (Songkran, Newyear, …, etc) | - | |
| Temperature | MaxTempYesterday | 1-day ahead maximum temperature | 1,2,3 |
| MaxTemp | Maximum forecasted temperature | 1,2 | |
| MA2pmTemp | Moving avearage of temperature at 2:00 p.m. | 2 | |
| Temp | Forecasted temperature | - | |
| Lagged | Load2pmYesterday | 1-day ahead load at 2:00 p.m. | 1 |
| load7d | 7-days ahead load | 1,2,3,4 | |
| load14d | 14-days ahead load | 1,2,3,4 | |
| load21d | 21-days ahead load | 1,2,3,4 | |
| load28d | 28-days ahead load | 1,2,3,4 | |
| load1d_cut2pm | 1-day ahead untill 2:00 p.m. and 2-days ahead after 2:00 p.m. load | - | |
| load2d_cut2pm | 2-days ahead untill 2:00 p.m. and 3-days ahead after 2:00 p.m. load | - | |
| Interaction | WD:Temp | Interaction of week day dummy to temperature | 2,3,4 |
| MD:Temp | Interaction of month dummy to temperature | 1,4 | |
| WD:load1d_cut2pm | Interaction of week day dummy to load1d_cut2pm | 1,3,4 | |
| WD:load2d_cut2pm | Interaction of week day dummy to load2d_cut2pm | 2 | |
| WD:Load2pmYesterday | Interaction of week day dummy to Load2pmYesterday | 2,3,4 | |
| HolidayType:Load2pmYesterday | Interaction of HolidayType dummy to Load2pmYesterday | 3,4 | |
| MD:load1d_cut2pm | Interaction of month dummy to load2d_cut2pm | 2 |
| load | load7d | load14d | load21d | load28d | load1d _cut2pm | temp | load2d _cut2pm | |
|---|---|---|---|---|---|---|---|---|
| load | 1.0000 | 0.8227 | 0.8159 | 0.8019 | 0.7950 | 0.7578 | 0.6728 | 0.6598 |
| load7d | 0.8227 | 1.0000 | 0.8239 | 0.8216 | 0.8051 | 0.6545 | 0.5740 | 0.6057 |
| load14d | 0.8159 | 0.8239 | 1.0000 | 0.8250 | 0.8219 | 0.6369 | 0.5755 | 0.5703 |
| load21d | 0.8019 | 0.8216 | 0.8250 | 1.0000 | 0.8260 | 0.6306 | 0.5555 | 0.5717 |
| load28d | 0.7950 | 0.8051 | 0.8219 | 0.8260 | 1.0000 | 0.6208 | 0.5494 | 0.5543 |
| load1d_cut2pm | 0.7578 | 0.6545 | 0.6369 | 0.6306 | 0.6208 | 1.0000 | 0.6221 | 0.8103 |
| temp | 0.6728 | 0.5740 | 0.5755 | 0.5555 | 0.5494 | 0.6221 | 1.0000 | 0.5966 |
| load2d_cut2pm | 0.6598 | 0.6057 | 0.5703 | 0.5717 | 0.5543 | 0.8103 | 0.5966 | 1.0000 |
Appendix A.2. Hyper-Parameter Tuning of the Nonlinear Models
| random _state | max _depth | min_samples _split | min_samples _leaf | max _features | max_leaf _nodes | |||
|---|---|---|---|---|---|---|---|---|
| 42 | max | 2 | 1 | max | max | 0 | 4.6386 | 4.0080 |
| 42 | 20 | 2 | 1 | max | max | 0.0225 | 4.6249 | 4.0110 |
| 42 | 5 | 2 | 1 | max | max | 2.7819 | 4.6158 | 3.8731 |
| 42 | 5 | 4 | 2 | max | max | 2.8021 | 4.6111 | 3.8433 |
| 42 | 5 | 4 | 2 | 15 | 10 | 3.7598 | 4.6004 | 4.8738 |
| 42 | 10 | 2 | 1 | max | max | 1.0252 | 4.5467 | 3.9288 |
| 42 | max | 4 | 2 | max | max | 0.7222 | 4.4841 | 3.8579 |
| 42 | 20 | 4 | 2 | max | max | 0.7278 | 4.4792 | 3.8521 |
| 42 | max | 10 | 5 | max | max | 1.6775 | 4.2785 | 3.6142 |
| n_jobs | random _state | n _estimators | max _depth | min _samples _split | min _samples _leaf | max _features | |||
|---|---|---|---|---|---|---|---|---|---|
| max | 42 | 100 | 5 | 4 | 1 | max | 2.3844 | 3.8418 | 3.3234 |
| max | 42 | 200 | 5 | 4 | 1 | max | 2.3757 | 3.8360 | 3.3168 |
| max | 42 | 100 | 10 | 2 | 2 | 15 | 1.4864 | 3.6119 | 3.2806 |
| max | 42 | 200 | max | 10 | 5 | 20 | 1.7615 | 3.5757 | 3.2076 |
| max | 42 | 100 | max | 10 | 5 | max | 1.6615 | 3.4842 | 3.0356 |
| max | 42 | 200 | max | 10 | 5 | max | 1.6493 | 3.4831 | 3.0311 |
| max | 42 | 500 | max | 10 | 5 | max | 1.6467 | 3.4827 | 3.0336 |
| max | 42 | 100 | max | 2 | 1 | max | 0.9444 | 3.4733 | 3.0753 |
| max | 42 | 500 | max | 2 | 1 | max | 0.9241 | 3.4707 | 3.052 |
| max | 42 | 200 | max | 2 | 1 | max | 0.9266 | 3.4674 | 3.0536 |
| max | 42 | 100 | max | 6 | 2 | max | 1.2059 | 3.4574 | 3.0324 |
| max | 42 | 100 | max | 4 | 2 | max | 1.1043 | 3.4557 | 3.0299 |
Appendix A.3. Weight Identification of the VR Model
| Weights of VR | Performance of VR | |||||
|---|---|---|---|---|---|---|
| OLS | GLSAR | LR | DT | RF | ||
| 0.1 | 0.1 | 0.2 | 0.3 | 0.3 | 2.8821 | 2.3769 |
| 0.3 | 0.3 | 0 | 0.25 | 0.15 | 2.6714 | 2.1047 |
| 0.2 | 0.2 | 0.2 | 0.2 | 0.2 | 2.6438 | 2.0797 |
| 0.3 | 0.3 | 0 | 0.15 | 0.25 | 2.6220 | 2.0589 |
| 0.4 | 0.3 | 0.3 | 0 | 0 | 2.6120 | 1.9055 |
| 0.3 | 0.3 | 0.3 | 0.05 | 0.05 | 2.5643 | 1.8818 |
| 0.6 | 0.1 | 0.2 | 0.05 | 0.05 | 2.5636 | 1.8817 |
Appendix A.4. Tables and Figures for More Detailed Information
| Group 1 | Group 2 | Group 3 | Group 4 | |||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| HH | LR | OLS | GLSAR | DT | RF | VR | LR | OLS | GLSAR | DT | RF | VR | LR | OLS | GLSAR | DT | RF | VR | LR | OLS | GLSAR | DT | RF | VR |
| 0 | 2.4310 | 2.4299 | 2.4337 | 4.1803 | 3.3336 | 2.3592 | 2.3608 | 2.3607 | 2.3631 | 5.1452 | 4.2357 | 2.3766 | 5.0767 | 5.0768 | 5.0343 | 14.5507 | 13.0661 | 4.9545 | 2.5302 | 2.5303 | 2.5321 | 5.3576 | 4.0958 | 2.4239 |
| 1 | 2.3847 | 2.3839 | 2.3875 | 4.1356 | 3.3681 | 2.3039 | 2.4382 | 2.4392 | 2.4462 | 5.1728 | 4.3240 | 2.4689 | 4.9403 | 4.9401 | 4.8714 | 14.7321 | 12.4802 | 4.8272 | 2.5563 | 2.5561 | 2.5588 | 5.3745 | 4.0761 | 2.4488 |
| 2 | 2.4754 | 2.4729 | 2.4766 | 4.3037 | 3.3953 | 2.4159 | 2.5159 | 2.5159 | 2.5133 | 4.7368 | 4.2390 | 2.5095 | 4.8118 | 4.8180 | 4.7540 | 14.9982 | 12.4134 | 4.7558 | 2.6295 | 2.6296 | 2.6306 | 5.4003 | 4.1432 | 2.5282 |
| 3 | 2.5367 | 2.5382 | 2.5431 | 4.2700 | 3.4242 | 2.4779 | 2.7899 | 2.7888 | 2.7757 | 5.0234 | 4.2097 | 2.7596 | 4.8839 | 4.8784 | 4.8793 | 14.4652 | 12.6275 | 4.8979 | 2.7224 | 2.7223 | 2.7223 | 5.3164 | 4.1148 | 2.6072 |
| 4 | 2.6573 | 2.6588 | 2.6646 | 4.3606 | 3.4047 | 2.6006 | 2.9581 | 2.9590 | 2.9474 | 4.8961 | 4.2375 | 2.8844 | 4.8992 | 4.8978 | 4.9006 | 13.9103 | 12.5296 | 4.8601 | 2.8637 | 2.8642 | 2.8653 | 5.2812 | 4.1902 | 2.7505 |
| 5 | 2.6780 | 2.6793 | 2.6839 | 4.2868 | 3.3695 | 2.6093 | 2.9689 | 2.9660 | 2.9549 | 4.9948 | 4.0980 | 2.9036 | 4.9312 | 4.9281 | 4.9286 | 14.8110 | 12.4283 | 4.9341 | 2.8520 | 2.8522 | 2.8536 | 5.2874 | 4.1909 | 2.7326 |
| 6 | 2.7262 | 2.7258 | 2.7310 | 4.4684 | 3.3811 | 2.6439 | 2.9260 | 2.9268 | 2.9202 | 4.6655 | 4.0699 | 2.8786 | 5.0590 | 5.0588 | 5.0727 | 14.4617 | 12.6898 | 4.9504 | 2.8612 | 2.8606 | 2.8629 | 5.3842 | 4.1731 | 2.7535 |
| 7 | 2.7183 | 2.7188 | 2.7247 | 4.2299 | 3.3399 | 2.6326 | 2.8419 | 2.8419 | 2.8413 | 4.9227 | 4.1071 | 2.7927 | 4.9746 | 4.9716 | 4.9888 | 15.4364 | 12.5801 | 4.9189 | 2.8309 | 2.8299 | 2.8333 | 5.4080 | 4.0853 | 2.7267 |
| 8 | 2.7640 | 2.7636 | 2.7691 | 4.2383 | 3.3699 | 2.6778 | 2.8957 | 2.8920 | 2.8743 | 4.9668 | 3.9018 | 2.8535 | 5.0222 | 5.0250 | 5.0440 | 15.9058 | 12.4580 | 4.9319 | 2.8640 | 2.8643 | 2.8665 | 5.3119 | 4.1192 | 2.7678 |
| 9 | 2.7015 | 2.7023 | 2.7071 | 4.2491 | 3.2892 | 2.6027 | 2.7930 | 2.7912 | 2.7781 | 4.8386 | 3.7447 | 2.7680 | 5.2220 | 5.2236 | 5.2528 | 13.9452 | 12.6082 | 5.0923 | 2.8160 | 2.8154 | 2.8176 | 5.0545 | 4.0188 | 2.7143 |
| 10 | 2.6154 | 2.6131 | 2.6182 | 4.0768 | 3.2658 | 2.5341 | 2.7143 | 2.7130 | 2.7036 | 4.0346 | 3.4320 | 2.6326 | 4.9934 | 4.9956 | 5.0156 | 14.0617 | 12.1876 | 4.8153 | 2.7305 | 2.7304 | 2.7328 | 4.9439 | 3.9075 | 2.6501 |
| 11 | 2.6489 | 2.6483 | 2.6534 | 4.1290 | 3.2771 | 2.5706 | 2.8387 | 2.8382 | 2.8289 | 3.9373 | 3.3386 | 2.7100 | 5.3051 | 5.3026 | 5.3141 | 16.8615 | 12.2315 | 5.1550 | 2.7734 | 2.7729 | 2.7748 | 5.0152 | 3.8752 | 2.7102 |
| 12 | 2.5487 | 2.5481 | 2.5522 | 4.2710 | 3.6706 | 2.5260 | 2.8805 | 2.8819 | 2.8976 | 3.7443 | 3.3776 | 2.7490 | 5.9025 | 5.9050 | 5.9160 | 14.8501 | 11.4190 | 5.7377 | 2.7857 | 2.7859 | 2.7893 | 4.9289 | 3.9853 | 2.7237 |
| 13 | 2.6199 | 2.6209 | 2.6267 | 4.7805 | 4.2020 | 2.6234 | 3.0707 | 3.0710 | 3.0713 | 4.1452 | 3.4535 | 2.9094 | 6.9625 | 6.9665 | 6.9501 | 14.8089 | 10.9926 | 6.7743 | 2.9199 | 2.9203 | 2.9229 | 5.2390 | 4.0780 | 2.8668 |
| 14 | 2.4680 | 2.4678 | 2.4734 | 4.3759 | 3.8379 | 2.4628 | 3.1698 | 3.1713 | 3.1560 | 4.0283 | 3.3103 | 3.0208 | 7.6285 | 7.6417 | 7.5528 | 13.0677 | 10.7485 | 7.2710 | 2.9345 | 2.9343 | 2.9337 | 4.9286 | 3.7233 | 2.8373 |
| 15 | 2.3192 | 2.3192 | 2.3245 | 3.8180 | 3.0699 | 2.2535 | 2.9338 | 2.9336 | 2.9354 | 3.5930 | 3.1931 | 2.7774 | 9.1358 | 9.1324 | 9.1473 | 14.7006 | 11.5698 | 8.7516 | 2.9968 | 2.9968 | 2.9985 | 4.8726 | 3.6422 | 2.8903 |
| 16 | 2.2770 | 2.2780 | 2.2807 | 3.5099 | 2.8977 | 2.1981 | 2.8742 | 2.8737 | 2.8834 | 3.5018 | 2.9611 | 2.6975 | 9.5672 | 9.5684 | 9.3278 | 15.2502 | 11.9663 | 9.0885 | 3.1494 | 3.1497 | 3.1529 | 4.9302 | 3.7474 | 3.0233 |
| 17 | 2.2949 | 2.2920 | 2.2939 | 3.6023 | 2.8936 | 2.2207 | 2.8523 | 2.8528 | 2.8582 | 3.6948 | 2.8584 | 2.6911 | 10.1200 | 10.1222 | 9.9444 | 17.8848 | 13.8165 | 9.8507 | 3.3877 | 3.3878 | 3.3914 | 5.5057 | 4.1115 | 3.2874 |
| 18 | 2.3298 | 2.3295 | 2.3310 | 3.5937 | 2.9724 | 2.2817 | 2.7523 | 2.7509 | 2.7594 | 3.6490 | 2.7941 | 2.6278 | 10.2235 | 10.2238 | 10.1268 | 18.4897 | 13.5299 | 9.9867 | 3.4666 | 3.4659 | 3.4710 | 5.3508 | 4.2055 | 3.3545 |
| 19 | 2.4463 | 2.4455 | 2.4486 | 3.7609 | 3.0535 | 2.4077 | 2.7545 | 2.7540 | 2.7625 | 3.6742 | 2.8081 | 2.6412 | 10.3383 | 10.3301 | 10.3237 | 18.1362 | 13.5328 | 10.0900 | 3.4802 | 3.4817 | 3.4853 | 5.3353 | 4.2748 | 3.3880 |
| 20 | 2.3249 | 2.3249 | 2.3266 | 3.5042 | 2.9751 | 2.2835 | 2.6421 | 2.6421 | 2.6511 | 3.7607 | 2.8449 | 2.5315 | 10.3026 | 10.3132 | 10.2866 | 18.3225 | 13.5937 | 10.0236 | 3.3571 | 3.3557 | 3.3594 | 5.4750 | 4.2942 | 3.2909 |
| 21 | 2.3755 | 2.3754 | 2.3779 | 3.5245 | 2.9570 | 2.3378 | 2.7240 | 2.7233 | 2.7316 | 3.5530 | 2.8973 | 2.6071 | 10.1516 | 10.1678 | 10.1015 | 16.7778 | 13.4937 | 9.7635 | 3.3871 | 3.3883 | 3.3894 | 5.2987 | 4.3717 | 3.3225 |
| 22 | 2.4530 | 2.4536 | 2.4565 | 3.6941 | 3.0099 | 2.4147 | 2.6803 | 2.6803 | 2.6908 | 3.6570 | 2.7732 | 2.5770 | 10.5812 | 10.5889 | 10.6145 | 16.6486 | 13.2651 | 10.1759 | 3.4422 | 3.4427 | 3.4426 | 5.6606 | 4.2954 | 3.3650 |
| 23 | 2.3838 | 2.3829 | 2.3855 | 3.6749 | 2.9099 | 2.3517 | 2.7296 | 2.7289 | 2.7401 | 4.0742 | 2.8609 | 2.6346 | 10.9435 | 10.9433 | 10.9876 | 17.5554 | 13.2557 | 10.4482 | 3.4018 | 3.4031 | 3.4023 | 5.5804 | 4.3388 | 3.3397 |
| 24 | 2.4414 | 2.4405 | 2.4433 | 3.7372 | 2.9975 | 2.4024 | 2.4964 | 2.4960 | 2.4958 | 3.7271 | 3.0056 | 2.4127 | 9.5198 | 9.5205 | 9.4444 | 15.7245 | 12.1110 | 9.0714 | 3.2490 | 3.2520 | 3.2513 | 5.8991 | 4.3881 | 3.1848 |
| 25 | 2.2794 | 2.2799 | 2.2820 | 3.7491 | 3.0241 | 2.2565 | 2.5303 | 2.5301 | 2.5328 | 3.8511 | 2.9307 | 2.4609 | 9.2112 | 9.2151 | 9.0467 | 14.8980 | 11.7713 | 8.8157 | 3.1091 | 3.1084 | 3.1071 | 5.3412 | 4.1004 | 3.0365 |
| 26 | 2.2700 | 2.2699 | 2.2725 | 3.7980 | 3.0146 | 2.2573 | 2.4627 | 2.4621 | 2.4618 | 3.7410 | 2.8511 | 2.3922 | 10.0324 | 10.0382 | 9.9816 | 15.8001 | 12.3047 | 9.5261 | 3.2374 | 3.2382 | 3.2385 | 6.0164 | 4.3722 | 3.1798 |
| 27 | 2.3078 | 2.3080 | 2.3111 | 3.5546 | 3.0050 | 2.2893 | 2.6820 | 2.6816 | 2.6923 | 4.0488 | 2.9787 | 2.6317 | 10.4021 | 10.3987 | 10.5198 | 17.5354 | 13.3845 | 9.8853 | 3.4246 | 3.4250 | 3.4232 | 5.6049 | 4.3240 | 3.3531 |
| 28 | 2.3061 | 2.3024 | 2.3051 | 3.4559 | 2.9577 | 2.2765 | 2.7188 | 2.7199 | 2.7302 | 3.9525 | 2.9552 | 2.6464 | 9.6605 | 9.6674 | 10.0588 | 18.1763 | 13.4573 | 9.3535 | 3.7014 | 3.3914 | 3.3916 | 5.7529 | 4.3940 | 3.3453 |
| 29 | 2.2945 | 2.2940 | 2.2954 | 3.6082 | 3.0618 | 2.2670 | 2.8088 | 2.8101 | 2.8267 | 3.9818 | 3.0073 | 2.7288 | 10.1999 | 10.2077 | 10.4019 | 19.5539 | 13.5246 | 9.9131 | 3.4451 | 3.4453 | 3.4450 | 5.6108 | 4.3841 | 3.3787 |
| 30 | 2.2628 | 2.2619 | 2.2634 | 3.6372 | 3.1594 | 2.2406 | 2.7414 | 2.7424 | 2.7516 | 4.1532 | 2.9923 | 2.6777 | 10.8234 | 10.8347 | 10.9037 | 18.7007 | 13.3191 | 10.3823 | 3.3823 | 3.3830 | 3.3831 | 5.1741 | 4.3662 | 3.2969 |
| 31 | 2.2842 | 2.2839 | 2.2859 | 3.8607 | 3.2394 | 2.2879 | 2.7868 | 2.7860 | 2.7960 | 4.0731 | 3.1156 | 2.7275 | 10.9546 | 10.9515 | 10.8792 | 18.5521 | 13.5019 | 10.3829 | 3.4121 | 3.4112 | 3.4109 | 5.6027 | 4.4686 | 3.3430 |
| 32 | 2.2711 | 2.2693 | 2.2713 | 3.8630 | 3.1900 | 2.2627 | 2.8520 | 2.8519 | 2.8605 | 3.9364 | 3.0828 | 2.7570 | 10.5977 | 10.6088 | 10.6220 | 16.4207 | 13.5917 | 9.9075 | 3.3707 | 3.3703 | 3.3702 | 5.4776 | 4.4276 | 3.3079 |
| 33 | 2.2898 | 2.2884 | 2.2904 | 3.9588 | 3.2651 | 2.2765 | 2.8206 | 2.8224 | 2.8251 | 4.0672 | 3.2204 | 2.7431 | 10.3175 | 10.3146 | 10.2315 | 21.1591 | 13.2674 | 9.7591 | 3.3268 | 3.3282 | 3.3271 | 5.6921 | 4.4517 | 3.2554 |
| 34 | 2.5191 | 2.5188 | 2.5213 | 4.0084 | 3.4432 | 2.4947 | 2.6407 | 2.6399 | 2.6507 | 3.9064 | 3.0917 | 2.5732 | 9.5576 | 9.5711 | 9.7515 | 16.6259 | 12.3087 | 9.0861 | 3.3523 | 3.3520 | 3.3495 | 5.4837 | 4.3731 | 3.2843 |
| 35 | 2.7271 | 2.7267 | 2.7299 | 4.5934 | 3.6465 | 2.6975 | 2.5716 | 2.5711 | 2.5834 | 3.7845 | 3.0696 | 2.4757 | 8.8375 | 8.8404 | 8.9474 | 13.3173 | 11.2307 | 8.3728 | 3.4163 | 3.4169 | 3.4142 | 5.3478 | 4.3906 | 3.3441 |
| 36 | 3.0137 | 3.0132 | 3.0162 | 4.2830 | 3.8438 | 2.9219 | 2.4448 | 2.4439 | 2.4634 | 3.9042 | 3.2980 | 2.3588 | 8.6497 | 8.6406 | 8.5422 | 14.2890 | 10.9366 | 8.2917 | 3.5467 | 3.5456 | 3.5433 | 5.2865 | 4.3017 | 3.4337 |
| 37 | 2.9683 | 2.9708 | 2.9736 | 4.6466 | 4.0361 | 2.9010 | 2.5074 | 2.5080 | 2.5062 | 3.8764 | 3.2969 | 2.4096 | 8.3557 | 8.3437 | 8.4651 | 12.8407 | 10.2389 | 8.0618 | 3.3961 | 3.3956 | 3.3952 | 5.3841 | 4.2240 | 3.2938 |
| 38 | 2.7927 | 2.7928 | 2.7953 | 4.4861 | 3.8681 | 2.7598 | 2.2789 | 2.2793 | 2.2758 | 3.8734 | 3.0221 | 2.1839 | 8.7827 | 8.7853 | 8.6908 | 12.5255 | 10.6675 | 8.4454 | 3.2535 | 3.2534 | 3.2512 | 5.0492 | 4.1021 | 3.1333 |
| 39 | 2.8005 | 2.8008 | 2.8035 | 4.7368 | 3.7627 | 2.7701 | 2.2517 | 2.2517 | 2.2668 | 3.7167 | 3.0445 | 2.1798 | 8.7165 | 8.7213 | 8.5595 | 11.7371 | 10.7161 | 8.3071 | 3.2247 | 3.2243 | 3.2230 | 5.1346 | 3.9667 | 3.1279 |
| 40 | 2.8227 | 2.8226 | 2.8255 | 5.2978 | 3.7520 | 2.8116 | 2.3243 | 2.3235 | 2.3175 | 3.9169 | 3.1175 | 2.2502 | 8.6953 | 8.6932 | 8.5612 | 13.4336 | 11.0261 | 8.3184 | 3.1801 | 3.1804 | 3.1794 | 4.8376 | 3.9637 | 3.0695 |
| 41 | 2.8740 | 2.8744 | 2.8770 | 5.3450 | 3.9833 | 2.8551 | 2.4151 | 2.4154 | 2.4137 | 4.0154 | 3.2747 | 2.3485 | 8.3157 | 8.3150 | 8.1973 | 10.8769 | 10.7859 | 7.9863 | 3.1614 | 3.1615 | 3.1596 | 5.0513 | 3.9854 | 3.0622 |
| 42 | 2.9742 | 2.9749 | 2.9766 | 5.1515 | 4.0987 | 2.9452 | 2.6318 | 2.6328 | 2.6350 | 4.3298 | 3.4965 | 2.5497 | 8.4364 | 8.4322 | 8.2487 | 13.5478 | 11.1704 | 8.1240 | 3.2441 | 3.2442 | 3.2430 | 5.0109 | 4.0892 | 3.1414 |
| 43 | 3.0585 | 3.0580 | 3.0598 | 6.1914 | 4.1821 | 3.0422 | 2.7106 | 2.7117 | 2.7197 | 4.7270 | 3.6933 | 2.6344 | 8.3101 | 8.3106 | 8.1429 | 13.5850 | 11.5459 | 8.0354 | 3.2874 | 3.2855 | 3.2849 | 5.1292 | 4.1768 | 3.1860 |
| 44 | 3.1740 | 3.1747 | 3.1757 | 6.2450 | 4.3388 | 3.1361 | 2.8910 | 2.8902 | 2.8926 | 5.0446 | 3.9648 | 2.8144 | 8.3835 | 8.3744 | 8.2210 | 15.6902 | 12.5735 | 8.2382 | 3.4036 | 3.4010 | 3.3996 | 5.4993 | 4.4079 | 3.3121 |
| 45 | 3.3814 | 3.3807 | 3.3819 | 5.1909 | 4.2938 | 3.2771 | 3.2774 | 3.2764 | 3.2859 | 5.6486 | 4.2257 | 3.1977 | 8.5802 | 8.5824 | 8.3227 | 14.1206 | 12.6343 | 8.3030 | 3.6111 | 3.6120 | 3.6119 | 5.8413 | 4.5127 | 3.5006 |
| 46 | 3.5135 | 3.5135 | 3.5154 | 5.5094 | 4.4850 | 3.4153 | 3.4986 | 3.5001 | 3.5104 | 5.4973 | 4.2966 | 3.3805 | 9.2393 | 9.2346 | 9.0166 | 14.4375 | 13.1417 | 9.0219 | 3.7508 | 3.7518 | 3.7514 | 5.9089 | 4.7459 | 3.6242 |
| 47 | 3.5365 | 3.5370 | 3.5376 | 5.4243 | 4.5555 | 3.4188 | 3.5786 | 3.5790 | 3.5872 | 5.5784 | 4.3191 | 3.4559 | 9.5150 | 9.5216 | 9.2795 | 14.7160 | 13.6729 | 9.2377 | 3.8003 | 3.8017 | 3.8018 | 6.0642 | 4.8822 | 3.6697 |
| avg | 2.6113 | 2.6110 | 2.6142 | 4.2786 | 3.4557 | 2.5636 | 2.7506 | 2.7505 | 2.7534 | 4.2450 | 3.4046 | 2.6665 | 8.2515 | 8.2530 | 8.2161 | 15.4770 | 12.3826 | 7.9559 | 3.1880 | 3.1817 | 3.1822 | 5.3634 | 4.2054 | 3.0910 |
| stdev | 0.3294 | 0.3298 | 0.3296 | 0.6812 | 0.4642 | 0.3164 | 0.2732 | 0.2733 | 0.2728 | 0.5933 | 0.5173 | 0.2588 | 2.1118 | 2.1132 | 2.1120 | 2.1049 | 0.9900 | 1.9788 | 0.3189 | 0.3116 | 0.3109 | 0.3017 | 0.2372 | 0.3140 |
| Group 1 | Group 2 | Group 3 | Group 4 | |||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| HH | LR | OLS | GLSAR | DT | RF | VR | LR | OLS | GLSAR | DT | RF | VR | LR | OLS | GLSAR | DT | RF | VR | LR | OLS | GLSAR | DT | RF | VR |
| 0 | 1.6367 | 1.6361 | 1.6585 | 3.8487 | 3.0361 | 1.6798 | 1.5067 | 1.5080 | 1.5074 | 4.7329 | 3.7762 | 1.5605 | 5.6291 | 5.6286 | 5.7646 | 11.9988 | 11.7283 | 4.4163 | 1.8075 | 1.8087 | 1.8165 | 4.9079 | 4.1017 | 1.7786 |
| 1 | 1.7090 | 1.7087 | 1.7178 | 3.9278 | 2.9936 | 1.7324 | 1.6345 | 1.6338 | 1.6149 | 4.1714 | 3.8416 | 1.6473 | 4.3676 | 4.3702 | 4.7070 | 12.8359 | 11.9655 | 3.4100 | 1.8417 | 1.8401 | 1.8755 | 5.1429 | 4.1813 | 1.8206 |
| 2 | 1.6873 | 1.6869 | 1.7052 | 4.0163 | 3.0758 | 1.7159 | 1.7313 | 1.7302 | 1.7078 | 4.7978 | 3.7795 | 1.7379 | 4.1892 | 4.1820 | 4.3853 | 12.2196 | 12.6604 | 3.5080 | 1.8131 | 1.8133 | 1.8602 | 5.0090 | 4.2415 | 1.8013 |
| 3 | 1.7573 | 1.7576 | 1.7702 | 4.0782 | 3.0425 | 1.7689 | 1.6785 | 1.6789 | 1.6525 | 4.0380 | 3.8914 | 1.6729 | 4.2924 | 4.2971 | 4.3590 | 12.2234 | 12.4522 | 3.5620 | 1.8887 | 1.8887 | 1.9209 | 4.9116 | 4.2535 | 1.8974 |
| 4 | 1.8142 | 1.8138 | 1.8436 | 3.8964 | 3.0276 | 1.8526 | 1.7655 | 1.7651 | 1.7279 | 4.4654 | 3.8314 | 1.7674 | 4.6843 | 4.6848 | 4.7217 | 11.2544 | 11.7404 | 3.8847 | 1.9417 | 1.9416 | 1.9745 | 4.9659 | 4.2764 | 1.9315 |
| 5 | 1.8797 | 1.8799 | 1.9034 | 3.8721 | 3.1085 | 1.9065 | 1.8163 | 1.8164 | 1.7993 | 4.0471 | 3.6953 | 1.8308 | 4.3780 | 4.3809 | 4.4250 | 13.0530 | 12.0709 | 3.6945 | 1.9840 | 1.9840 | 2.0379 | 4.7122 | 4.1702 | 1.9925 |
| 6 | 1.9133 | 1.9122 | 1.9527 | 3.9877 | 3.1096 | 1.9667 | 1.8562 | 1.8563 | 1.8226 | 3.7828 | 3.7183 | 1.8301 | 4.6323 | 4.6358 | 4.6616 | 11.5247 | 10.8906 | 3.9251 | 2.0164 | 2.0169 | 2.0837 | 4.9342 | 4.1356 | 2.0407 |
| 7 | 2.0101 | 2.0090 | 2.0492 | 4.5166 | 3.2271 | 2.0659 | 1.8784 | 1.8783 | 1.8583 | 5.5931 | 3.7931 | 1.8810 | 4.4459 | 4.4457 | 4.4550 | 10.9201 | 10.9253 | 3.6281 | 2.0743 | 2.0747 | 2.1967 | 5.2218 | 4.1787 | 2.1504 |
| 8 | 1.9201 | 1.9198 | 1.9632 | 4.3884 | 3.0976 | 1.9757 | 1.8643 | 1.8641 | 1.8567 | 4.0883 | 3.6567 | 1.8571 | 4.6663 | 4.6652 | 4.6433 | 9.9826 | 10.4138 | 3.9403 | 2.0180 | 2.0188 | 2.1500 | 4.9877 | 4.0030 | 2.0776 |
| 9 | 1.8929 | 1.8940 | 1.9301 | 4.1726 | 3.0299 | 1.9369 | 1.7663 | 1.7665 | 1.7552 | 3.9210 | 3.5847 | 1.7571 | 4.3969 | 4.4032 | 4.3971 | 9.3415 | 10.2251 | 3.7622 | 1.9853 | 1.9854 | 2.1084 | 5.2605 | 4.0177 | 2.0574 |
| 10 | 1.7993 | 1.8005 | 1.8382 | 3.6361 | 2.9246 | 1.8295 | 1.8059 | 1.8060 | 1.7940 | 3.7150 | 3.1701 | 1.7818 | 4.3415 | 4.3386 | 4.2674 | 12.3501 | 10.0841 | 3.6820 | 1.9002 | 1.9004 | 2.0053 | 5.2082 | 3.9547 | 2.0039 |
| 11 | 1.7079 | 1.7078 | 1.7405 | 3.5043 | 2.7747 | 1.7388 | 1.7110 | 1.7096 | 1.6916 | 3.0716 | 3.2750 | 1.6583 | 4.9343 | 4.9350 | 4.9137 | 13.9500 | 10.4617 | 4.3503 | 1.8078 | 1.8074 | 1.8772 | 4.7536 | 3.8269 | 1.9113 |
| 12 | 1.6149 | 1.6157 | 1.6419 | 3.3080 | 2.8904 | 1.6297 | 1.7307 | 1.7311 | 1.7171 | 3.1682 | 3.0185 | 1.6949 | 4.7098 | 4.7100 | 4.7209 | 12.8405 | 9.3243 | 4.0224 | 1.7963 | 1.7970 | 1.8422 | 4.3946 | 3.6452 | 1.8840 |
| 13 | 1.5999 | 1.5998 | 1.6494 | 3.5240 | 2.9851 | 1.5624 | 1.5635 | 1.5660 | 1.5348 | 3.5772 | 2.9075 | 1.5625 | 4.5434 | 4.5442 | 4.6086 | 12.5053 | 8.7819 | 4.4405 | 1.9098 | 1.9093 | 1.9561 | 4.1432 | 3.5129 | 1.9441 |
| 14 | 1.5981 | 1.5981 | 1.6280 | 3.3478 | 2.8135 | 1.5492 | 1.5868 | 1.5866 | 1.5388 | 3.3429 | 2.7710 | 1.5193 | 4.6398 | 4.6364 | 4.6364 | 10.1939 | 9.1903 | 4.6103 | 1.9381 | 1.9372 | 1.9714 | 3.7320 | 3.3390 | 1.9397 |
| 15 | 1.6871 | 1.6871 | 1.7268 | 3.0921 | 2.6594 | 1.6456 | 1.8848 | 1.8859 | 1.8666 | 3.3138 | 2.7956 | 1.8103 | 6.1097 | 6.1102 | 5.8105 | 13.3971 | 10.2593 | 6.0091 | 2.1382 | 2.1394 | 2.1613 | 3.7353 | 3.4160 | 2.1178 |
| 16 | 1.7447 | 1.7452 | 1.7886 | 3.7680 | 2.8206 | 1.7287 | 1.8050 | 1.8049 | 1.8176 | 3.4590 | 2.5555 | 1.7256 | 6.8598 | 6.8730 | 6.4473 | 12.2772 | 11.0759 | 6.6563 | 2.2850 | 2.2854 | 2.3070 | 5.0796 | 3.7683 | 2.3454 |
| 17 | 1.7324 | 1.7324 | 1.7801 | 3.4065 | 2.8912 | 1.7539 | 2.0269 | 2.0273 | 2.0601 | 2.6043 | 2.4779 | 1.9137 | 6.7337 | 6.7292 | 6.3091 | 13.2202 | 12.3810 | 6.7267 | 2.5190 | 2.5185 | 2.5421 | 4.5503 | 3.6690 | 2.5422 |
| 18 | 1.7318 | 1.7321 | 1.7863 | 3.5546 | 2.8993 | 1.7520 | 2.1813 | 2.1810 | 2.2258 | 3.0049 | 2.4579 | 2.0463 | 6.8644 | 6.8517 | 6.6157 | 13.2933 | 12.8977 | 6.9302 | 2.6147 | 2.6140 | 2.6307 | 4.4570 | 3.6682 | 2.6135 |
| 19 | 1.7335 | 1.7331 | 1.8046 | 3.1733 | 2.9719 | 1.7544 | 2.1962 | 2.1969 | 2.2532 | 3.1087 | 2.5132 | 2.0800 | 6.6093 | 6.6081 | 6.6867 | 14.4944 | 13.3143 | 6.4417 | 2.6408 | 2.6413 | 2.6691 | 4.3263 | 3.8538 | 2.6375 |
| 20 | 1.7611 | 1.7611 | 1.8439 | 3.4976 | 2.9870 | 1.7666 | 2.1591 | 2.1592 | 2.1959 | 2.9587 | 2.5326 | 2.0015 | 6.6658 | 6.6457 | 6.2722 | 14.6045 | 13.1461 | 6.7571 | 2.6105 | 2.6091 | 2.6400 | 4.1426 | 3.8740 | 2.5860 |
| 21 | 1.8325 | 1.8326 | 1.9352 | 3.4019 | 3.0901 | 1.8456 | 2.1599 | 2.1600 | 2.1837 | 3.1736 | 2.5457 | 2.0478 | 6.6145 | 6.6105 | 5.8697 | 19.9865 | 13.1463 | 6.7895 | 2.6523 | 2.6526 | 2.6827 | 4.2094 | 3.8363 | 2.6311 |
| 22 | 1.9306 | 1.9300 | 2.0283 | 3.3023 | 2.9146 | 1.9285 | 2.2163 | 2.2160 | 2.2403 | 3.0524 | 2.7686 | 2.1059 | 6.2122 | 6.2248 | 5.9416 | 13.6551 | 12.9035 | 6.2240 | 2.7196 | 2.7190 | 2.7549 | 4.2051 | 3.7889 | 2.6920 |
| 23 | 1.9081 | 1.9081 | 2.0180 | 3.5875 | 2.8123 | 1.9169 | 2.1875 | 2.1871 | 2.2100 | 2.9604 | 2.5927 | 2.0702 | 6.8548 | 6.8433 | 6.6324 | 12.9296 | 13.2213 | 6.5592 | 2.6962 | 2.6965 | 2.7376 | 4.1782 | 3.7667 | 2.6702 |
| 24 | 1.8508 | 1.8510 | 1.9880 | 2.9187 | 2.6553 | 1.7913 | 2.1481 | 2.1485 | 2.1241 | 3.1980 | 2.5408 | 2.0395 | 5.9710 | 5.9584 | 6.0463 | 12.9834 | 12.1305 | 5.8795 | 2.5942 | 2.5976 | 2.6421 | 3.9819 | 3.7987 | 2.5728 |
| 25 | 1.7835 | 1.7828 | 1.8714 | 3.1748 | 2.6232 | 1.7292 | 2.0919 | 2.0920 | 2.0709 | 3.0854 | 2.6058 | 1.9582 | 5.6360 | 5.6597 | 5.9139 | 13.4519 | 11.6664 | 5.5132 | 2.4915 | 2.4905 | 2.5223 | 5.3190 | 3.8630 | 2.5128 |
| 26 | 1.7962 | 1.7952 | 1.8626 | 3.0945 | 2.6468 | 1.7858 | 2.2956 | 2.2935 | 2.2803 | 3.0970 | 2.4413 | 2.1597 | 7.3781 | 7.3823 | 7.4255 | 14.7204 | 13.0661 | 6.7933 | 2.6680 | 2.6680 | 2.6950 | 4.4811 | 3.9217 | 2.6486 |
| 27 | 1.9972 | 1.9967 | 2.0636 | 3.3686 | 2.8610 | 1.9656 | 2.3185 | 2.3176 | 2.3293 | 3.0128 | 2.6944 | 2.2508 | 8.4802 | 8.4751 | 8.1987 | 14.9524 | 14.0359 | 7.9946 | 2.9433 | 2.9434 | 2.9704 | 4.7949 | 4.1568 | 2.9190 |
| 28 | 2.1108 | 2.1107 | 2.1538 | 3.0343 | 2.8674 | 2.0766 | 2.3895 | 2.3918 | 2.4082 | 3.0882 | 2.6322 | 2.3122 | 6.5325 | 6.5156 | 6.3160 | 15.5854 | 13.9909 | 6.5177 | 3.1055 | 3.0530 | 3.0690 | 4.5689 | 4.1671 | 3.0140 |
| 29 | 1.9152 | 1.9152 | 1.9598 | 3.0687 | 2.7613 | 1.8865 | 2.3397 | 2.3395 | 2.3463 | 3.1281 | 2.7131 | 2.2520 | 6.4698 | 6.5033 | 6.3301 | 14.7285 | 13.9816 | 6.4056 | 2.9336 | 2.9348 | 2.9827 | 4.6562 | 3.9694 | 2.9090 |
| 30 | 1.9293 | 1.9293 | 1.9535 | 3.2359 | 2.6917 | 1.8815 | 2.2512 | 2.2512 | 2.2718 | 3.0524 | 2.7030 | 2.1671 | 6.5025 | 6.5104 | 6.3932 | 15.3273 | 14.3000 | 6.4288 | 2.9679 | 2.9664 | 3.0119 | 4.8461 | 4.0491 | 2.9335 |
| 31 | 1.9155 | 1.9154 | 1.9665 | 3.1895 | 2.7471 | 1.8770 | 2.4261 | 2.4261 | 2.4474 | 3.3497 | 2.7834 | 2.3360 | 6.5862 | 6.5499 | 6.4458 | 18.9477 | 14.1629 | 6.3601 | 3.0281 | 3.0291 | 3.0843 | 4.7192 | 4.0481 | 2.9974 |
| 32 | 1.9320 | 1.9320 | 2.0227 | 2.9762 | 2.6672 | 1.8804 | 2.5064 | 2.5066 | 2.5258 | 3.1862 | 2.7402 | 2.4174 | 6.1470 | 6.1470 | 6.2769 | 22.5275 | 13.4003 | 6.3989 | 3.0207 | 3.0203 | 3.0875 | 4.3495 | 4.0039 | 2.9419 |
| 33 | 1.9776 | 1.9775 | 2.0804 | 2.8687 | 2.6626 | 1.9005 | 2.5740 | 2.5738 | 2.6109 | 3.5626 | 2.6591 | 2.4501 | 5.8889 | 5.8828 | 6.1075 | 16.4594 | 12.9743 | 5.8477 | 3.0362 | 3.0361 | 3.1352 | 4.9549 | 3.9206 | 2.9912 |
| 34 | 2.2148 | 2.2152 | 2.3214 | 2.9426 | 2.5662 | 2.1100 | 2.4254 | 2.4254 | 2.4569 | 3.9142 | 2.7658 | 2.3056 | 5.4776 | 5.4584 | 5.6478 | 16.1051 | 12.1423 | 5.3629 | 3.0231 | 3.0235 | 3.1645 | 4.9954 | 3.9200 | 2.9757 |
| 35 | 2.4356 | 2.4360 | 2.4722 | 3.2967 | 2.5142 | 2.2747 | 2.4039 | 2.4037 | 2.3993 | 3.5119 | 2.7404 | 2.2724 | 5.3207 | 5.3470 | 5.2972 | 11.1930 | 11.0185 | 5.2752 | 3.1171 | 3.1154 | 3.2348 | 4.9084 | 3.7610 | 3.0318 |
| 36 | 2.4718 | 2.4718 | 2.5148 | 3.1825 | 2.5080 | 2.2837 | 2.3640 | 2.3636 | 2.3693 | 3.1140 | 2.5571 | 2.2546 | 5.4205 | 5.4655 | 5.4019 | 12.4659 | 10.1291 | 5.4197 | 3.0019 | 3.0000 | 3.1635 | 4.9833 | 3.6132 | 2.9209 |
| 37 | 2.4166 | 2.4164 | 2.3820 | 3.2724 | 2.9239 | 2.2316 | 2.0302 | 2.0301 | 2.0359 | 3.5874 | 2.6618 | 1.9783 | 5.3484 | 5.3473 | 5.1592 | 14.2433 | 10.1949 | 5.4401 | 2.7159 | 2.7172 | 2.9048 | 4.7924 | 3.7090 | 2.6561 |
| 38 | 2.1496 | 2.1494 | 2.1473 | 3.1581 | 2.9911 | 2.0065 | 1.7730 | 1.7728 | 1.7947 | 2.9492 | 2.6962 | 1.6923 | 4.7065 | 4.7122 | 4.7101 | 13.1695 | 10.0878 | 4.8308 | 2.4779 | 2.4784 | 2.7116 | 4.6642 | 3.6428 | 2.4327 |
| 39 | 2.0988 | 2.0989 | 2.0935 | 3.2778 | 3.0187 | 1.9675 | 1.7133 | 1.7131 | 1.7563 | 2.9783 | 2.8938 | 1.6264 | 4.6079 | 4.5998 | 4.6976 | 12.6184 | 10.3253 | 4.6022 | 2.4122 | 2.4077 | 2.6515 | 4.2397 | 3.5762 | 2.3620 |
| 40 | 2.0218 | 2.0215 | 2.0487 | 3.5231 | 3.1678 | 1.9188 | 1.6979 | 1.6978 | 1.7017 | 3.3371 | 3.1308 | 1.6100 | 4.4625 | 4.4631 | 4.6587 | 14.5196 | 10.1323 | 4.4438 | 2.3730 | 2.3728 | 2.6656 | 4.5839 | 3.8152 | 2.3629 |
| 41 | 1.9955 | 1.9954 | 2.0542 | 3.9092 | 3.3902 | 1.9116 | 1.7766 | 1.7767 | 1.7821 | 3.8420 | 3.1656 | 1.6858 | 4.4382 | 4.4432 | 4.5411 | 14.4521 | 10.2084 | 4.3087 | 2.4245 | 2.4242 | 2.7310 | 4.7599 | 4.0107 | 2.4278 |
| 42 | 1.9173 | 1.9173 | 2.0173 | 3.6457 | 3.6099 | 1.8530 | 1.9073 | 1.9072 | 1.9092 | 4.1288 | 3.4838 | 1.7953 | 4.5725 | 4.5710 | 4.5610 | 13.5601 | 10.8684 | 4.2087 | 2.4651 | 2.4648 | 2.8231 | 4.7594 | 4.3021 | 2.4469 |
| 43 | 1.8691 | 1.8688 | 2.0136 | 4.3373 | 3.7218 | 1.8215 | 1.9699 | 1.9693 | 1.9820 | 3.8866 | 3.7234 | 1.8968 | 4.9545 | 4.9569 | 4.4934 | 15.4543 | 10.8141 | 4.4234 | 2.4896 | 2.4912 | 2.8950 | 5.4263 | 4.4711 | 2.5055 |
| 44 | 1.9571 | 1.9558 | 2.1006 | 4.7005 | 3.8959 | 1.9164 | 2.0320 | 2.0320 | 2.0444 | 4.6403 | 3.7243 | 1.9594 | 5.2391 | 5.2444 | 4.4896 | 14.3310 | 11.7746 | 4.5557 | 2.6096 | 2.6091 | 3.0196 | 6.1245 | 4.7135 | 2.6394 |
| 45 | 1.9823 | 1.9813 | 2.1174 | 4.9546 | 4.1335 | 2.0284 | 2.1564 | 2.1563 | 2.1888 | 5.5487 | 4.0188 | 2.0612 | 5.1455 | 5.1339 | 4.6784 | 14.9741 | 12.0457 | 4.5503 | 2.7342 | 2.7334 | 3.1286 | 6.1233 | 5.0097 | 2.7527 |
| 46 | 2.0228 | 2.0215 | 2.1910 | 4.9381 | 4.3341 | 2.0727 | 2.2272 | 2.2272 | 2.2413 | 4.1861 | 4.2146 | 2.1790 | 5.3204 | 5.3213 | 5.1635 | 14.6814 | 12.2625 | 4.6947 | 2.8441 | 2.8441 | 3.2520 | 6.5123 | 5.2278 | 2.8897 |
| 47 | 2.0994 | 2.0999 | 2.2738 | 4.6027 | 4.2919 | 2.1488 | 2.2398 | 2.2403 | 2.2546 | 5.1449 | 4.2108 | 2.1774 | 5.3899 | 5.4018 | 5.4611 | 14.2930 | 12.2648 | 4.7329 | 2.8921 | 2.8891 | 3.2993 | 6.1935 | 5.3407 | 2.9244 |
| avg | 1.9055 | 1.9053 | 1.9661 | 3.6142 | 3.0299 | 1.8817 | 2.0161 | 2.0161 | 2.0201 | 3.6391 | 3.0927 | 1.9458 | 5.5077 | 5.5084 | 5.4305 | 13.7666 | 11.7341 | 5.1858 | 2.4577 | 2.4564 | 2.5760 | 4.8106 | 4.0102 | 2.4549 |
| stdev | 0.2010 | 0.2010 | 0.2079 | 0.5372 | 0.4214 | 0.1671 | 0.2800 | 0.2799 | 0.2939 | 0.6966 | 0.5477 | 0.2497 | 1.0041 | 1.0024 | 0.9277 | 2.3560 | 1.4314 | 1.1870 | 0.4248 | 0.4230 | 0.4660 | 0.5825 | 0.4042 | 0.3978 |





References
- Dobschinski, J.; Bessa, R.; Du, P.; Geisler, K.; Haupt, S.E.; Lange, M.; Mohrlen, C.; Nakafuji, D.; De La Torre Rodriguez, M. Uncertainty Forecasting in a Nutshell: Prediction Models Designed to Prevent Significant Errors. IEEE Power Energy Mag. 2017, 15, 40–49. [Google Scholar] [CrossRef]
- Phuangpornpitak, N.; Prommee, W. A Study of Load Demand Forecasting Models in Electric Power System Operation and Planning. GMSARN Int. J. 2016, 10, 19–24. [Google Scholar]
- Chapagain, K.; Kittipiyakul, S. Performance analysis of short-term electricity demand with atmospheric variables. Energies 2018, 11, 2015–2018. [Google Scholar] [CrossRef]
- Chapagain, K.; Kittipiyakul, S.; Kulthanavit, P. Short-term electricity demand forecasting: Impact analysis of temperature for Thailand. Energies 2020, 13, 2–5. [Google Scholar] [CrossRef]
- Bergmeir, C.; Hyndman, R.J.; Koo, B. A note on the validity of cross-validation for evaluating autoregressive time series prediction. Comput. Stat. Data Anal. 2018, 120, 70–83. [Google Scholar] [CrossRef]
- Géron, A. Book Review: Hands-on Machine Learning with Scikit-Learn, Keras, and Tensorflow, 2nd ed.; Géron, A., Ed.; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2020; Volume 43, pp. 1135–1136. [Google Scholar] [CrossRef]
- Hong, T.; Fan, S. Probabilistic electric load forecasting: A tutorial review. Int. J. Forecast. 2016, 32, 914–938. [Google Scholar] [CrossRef]
- Chapagain, K.; Kittipiyakul, S. Short-term electricity load forecasting for Thailand. In Proceedings of the ECTI-CON 2018—15th International Conference on Electrical Engineering/Electronics, Computer, Telecommunications and Information Technology, Chiang Rai, Thailand, 18–21 July 2018; pp. 521–524. [Google Scholar] [CrossRef]
- Dilhani, M.H.; Jeenanunta, C. Daily electric load forecasting: Case of Thailand. In Proceedings of the 7th International Conference on Information Communication Technology for Embedded Systems 2016 (IC-ICTES 2016), Bangkok, Thailand, 20–22 March 2016; pp. 25–29. [Google Scholar] [CrossRef]
- Pannakkong, W.; Aswanuwath, L.; Buddhakulsomsiri, J.; Jeenanunta, C.; Parthanadee, P. Forecasting medium-term electricity demand in Thailand: Comparison of ANN, SVM, DBN, and their ensembles. In Proceedings of the International Conference on ICT and Knowledge Engineering, Bangkok, Thailand, 20–22 November 2019. [Google Scholar] [CrossRef]
- Parkpoom, S.; Harrison, G.P. Analyzing the impact of climate change on future electricity demand in Thailand. IEEE Trans. Power Syst. 2008, 23, 1441–1448. [Google Scholar] [CrossRef]
- Divina, F.; Gilson, A.; Goméz-Vela, F.; Torres, M.G.; Torres, J.F. Stacking ensemble learning for short-term electricity consumption forecasting. Energies 2018, 11, 949. [Google Scholar] [CrossRef]
- Sharma, E. Energy forecasting based on predictive data mining techniques in smart energy grids. Energy Inform. 2018, 1, 44. [Google Scholar] [CrossRef]
- Chapagain, K.; Kittipiyakul, S. Short-Term Electricity Demand Forecasting with Seasonal and Interactions of Variables for Thailand. In Proceedings of the iEECON 2018—6th International Electrical Engineering Congress, Krabi, Thailand, 7–9 March 2018. [Google Scholar] [CrossRef]
- Jeenanunta, C.; Abeyrathna, D. Combine Particle Swarm Optimization with Artificial Neural Networks for Short-Term Load Forecasting; Technical Report 1; SIIT, Thammasat University: Bangkok, Thailand, 2017. [Google Scholar]
- Chapagain, K.; Kittipiyakul, S. Short-term Electricity Load Forecasting Model and Bayesian Estimation for Thailand Data. In MATEC Web of Conferences; EDP Sciences: Les Ulis, France, 2016; Volume 55. [Google Scholar] [CrossRef]
- Huang, S.J.; Shih, K.R. Short-term load forecasting via ARMA model identification including non-Gaussian process considerations. IEEE Trans. Power Syst. 2003, 18, 673–679. [Google Scholar] [CrossRef]
- Harvey, A.; Koopman, S.J. Forecasting Hourly Electricity Demand Using Time-Varying Splines. J. Am. Stat. Assoc. 1993, 88, 1228. [Google Scholar] [CrossRef]
- Chapagain, K.; Soto, T.; Kittipiyakul, S. Improvement of performance of short term electricity demand model with meteorological parameters. Kathford J. Eng. Manag. 2018, 1, 15–22. [Google Scholar] [CrossRef][Green Version]
- Ramanathan, R.; Engle, R.; Granger, C.W.; Vahid-Araghi, F.; Brace, C. Short-run forecasts of electricity loads and peaks. Int. J. Forecast. 1997, 13, 161–174. [Google Scholar] [CrossRef]
- Li, B.; Lu, M.; Zhang, Y.; Huang, J. A Weekend Load Forecasting Model Based on Semi-Parametric Regression Analysis Considering Weather and Load Interaction. Energies 2019, 12, 3820. [Google Scholar] [CrossRef]
- Darbellay, G.A.; Slama, M. Forecasting the short-term demand for electricity: Do neural networks stand a better chance? Int. J. Forecast. 2000, 16, 71–83. [Google Scholar] [CrossRef]
- Srinivasan, D.; Chang, C.S.; Liew, A.C. Demand Forecasting Using Fuzzy Neural Computation, With Special Emphasis On Weekend Additionally, Public Holiday Forecasting. IEEE Trans. Power Syst. 1995, 10, 1897–1903. [Google Scholar] [CrossRef]
- Su, W.H.; Chawalit, J. Short-term Electricity Load Forecasting in Thailand: An Analysis on Different Input Variables. In IOP Conference Series: Earth and Environmental Science; IOP Publishing: Bristol, UK, 2018; Volume 192. [Google Scholar] [CrossRef]
- Abeyrathna, K.D.; Jeenanunta, C. Hybrid particle swarm optimization with genetic algorithm to train artificial neural networks for short-term load forecasting. Int. J. Swarm Intell. Res. 2019, 10, 1–14. [Google Scholar] [CrossRef]
- Taylor, J.W.; de Menezes, L.M.; McSharry, P.E. A comparison of univariate methods for forecasting electricity demand up to a day ahead. Int. J. Forecast. 2006, 22, 1–16. [Google Scholar] [CrossRef]
- Chapagain, K.; Sato, T.; Kittipiyakul, S. Performance analysis of short-term electricity demand with meteorological parameters. In Proceedings of the ECTI-CON 2017—2017 14th International Conference on Electrical Engineering/Electronics, Computer, Telecommunications and Information Technology, Phuket, Thailand, 27–30 June 2017; pp. 330–333. [Google Scholar] [CrossRef]
- Bonetto, R.; Rossi, M. Machine learning approaches to energy consumption forecasting in households. arXiv 2017, arXiv:1706.09648. [Google Scholar]
- Peng, L.; Wang, L.; Xia, D.; Gao, Q. Effective energy consumption forecasting using empirical wavelet transform and long short-term memory. Energy 2022, 238, 121756. [Google Scholar] [CrossRef]
- Lisi, F.; Shah, I. Forecasting Next-Day Electricity Demand and Prices Based on Functional Models; Springer: Berlin/Heidelberg, Germany, 2020; Volume 11, pp. 947–979. [Google Scholar] [CrossRef]
- Jan, F.; Shah, I.; Ali, S. Short-Term Electricity Prices Forecasting Using Functional Time Series Analysis. Energies 2022, 15, 3423. [Google Scholar] [CrossRef]
- Shah, I.; Iftikhar, H.; Ali, S.; Wang, D. Short-term electricity demand forecasting using components estimation technique. Energies 2019, 12, 2532. [Google Scholar] [CrossRef]
- Shah, I.; Iftikhar, H.; Ali, S. Modeling and Forecasting Medium-Term Electricity Consumption Using Component Estimation Technique. Forecasting 2020, 2, 163–179. [Google Scholar] [CrossRef]
- Nielsen, A. Practical Time Series Analysis Preview Edition; O’Reilly: Sebastopol, CA, USA, 2019; p. 45. [Google Scholar]
- Schnaubelt, M. A Comparison of Machine Learning Model Validation Schemes for Non-Stationary Time Series Data; No. 11/2019. FAU Discussion Papers in Economics; Friedrich-Alexander-Universität Erlangen-Nürnberg, Institute for Economics: Nürnberg, Germany, 2019; pp. 1–42. [Google Scholar] [CrossRef]
- Bibi, N.; Shah, I.; Alsubie, A.; Ali, S.; Lone, S.A. Electricity Spot Prices Forecasting Based on Ensemble Learning. IEEE Access 2021, 9, 150984–150992. [Google Scholar] [CrossRef]
- Dickey, D.A.; Fuller, W.A. Distribution of the Estimators for Autoregressive Time Series With a Unit Root. J. Am. Stat. Assoc. 1979, 74, 427. [Google Scholar] [CrossRef]
- Fuller, W.A. Introduction to Statistical Time Series; Wiley: Hoboken, NJ, USA, 1996; p. 698. [Google Scholar]









| Forecasting | Prediction Horizon | Applications | References |
|---|---|---|---|
| VSTLF | Few minutes to hours | Predict instant electric demand, power consumption monitoring | [7,8] |
| STLF | Hours to weeks | Day-to-day energy management, economic dispatch (ED), unit commitment (UC) | [2,4,9] |
| MTLF | Weeks to months | Fuel allocation, system maintenance schedules, energy trading | [2,10] |
| LTLF | Months to years | Planning generation expansion, energy policy reforms | [8,11] |
| Dataset | Methods Used | Major Results | Work |
|---|---|---|---|
| 2009–2013 | OLS, GLSAR, FF-ANN | OLS and GLSAR models showed a better forecasting accuracy than FF-ANN. | [4] |
| 2009–2013 | OLS | Addition of interaction variables to the model has improved the prediction accuracy. | [14] |
| 2009–2013 | OLS and Bayesian estimation | Addition of a temperature variable to the model has improved the prediction accuracy by 20%. | [8] |
| 2009–2013 | MLR with AR(2) | Bayesian estimation provides better and more consistent performance than that of OLS estimation | [16] |
| 2013 | PSO with ANN | PSO outperforms the backpropagation training algorithm to train the ANN for STLF. | [15] |
| 2013 | PSO + GA with ANN | PSO + GA outperforms the backpropagation and PSO training algorithms. | [25] |
| 2013 | ANN | Addition of a temperature variable to the model has improved the prediction accuracy. | [9] |
| Test Statistic | −18.18469 |
| p-value | 2.427935 × 10 |
| #lags used | 64 |
| number of observations used | 84751 |
| critical value (1%) | −3.430427 |
| critical value (5%) | −2.861574 |
| critical value (10%) | −2.566788 |
| Group # | Error Type | LR | OLS | GLSAR (rho = 1) | DT | RF | VR |
|---|---|---|---|---|---|---|---|
| 1 | 1.7929 | 1.7929 | 1.8809 | 1.6775 | 1.1043 | 1.6816 | |
| 2.6740 | 2.6754 | 4.2787 | 3.4503 | 2.6257 | |||
| 2.6113 | 2.6110 | 2.6142 | 4.2785 | 3.4557 | 2.5636 | ||
| 3.1891 | 3.1891 | 4.2930 | 3.7216 | ||||
| 1.9055 | 1.9053 | 1.9661 | 3.6142 | 3.0299 | 1.8817 | ||
| 2 | 1.6163 | 1.6163 | 1.6274 | 1.6718 | 1.1103 | 1.5171 | |
| 2.7604 | 2.7598 | 2.7814 | 4.2924 | 3.4702 | 2.6976 | ||
| 2.7506 | 2.7505 | 2.7535 | 4.2450 | 3.4046 | 2.6665 | ||
| 3.0149 | 3.0132 | 3.0074 | 4.2301 | 3.3950 | 2.8311 | ||
| 2.0161 | 2.0161 | 2.0201 | 3.6391 | 3.0927 | 1.9458 | ||
| 3 | 4.4025 | 4.4025 | 4.6923 | 6.8680 | 4.6377 | 4.1866 | |
| 9.2514 | 9.2524 | 9.3811 | 15.4341 | 12.6259 | 8.8199 | ||
| 8.2515 | 8.2530 | 8.2161 | 15.4770 | 12.3826 | 7.9559 | ||
| 10.8780 | 10.8790 | 10.9010 | 14.8387 | 12.4338 | 10.3365 | ||
| 5.5077 | 5.5084 | 5.4306 | 13.7666 | 11.7341 | 5.1858 | ||
| 4 | 2.3238 | 2.3225 | 2.4048 | 2.3436 | 1.5115 | 2.1789 | |
| 3.2325 | 3.2329 | 5.3151 | 4.1512 | ||||
| 3.1880 | 3.1817 | 3.1822 | 5.3634 | 4.2053 | 3.0910 | ||
| 3.7141 | 3.7106 | 5.2222 | 4.3171 | ||||
| 2.4577 | 2.4564 | 2.5760 | 4.8106 | 4.0102 | 2.4549 |
| Group # | Validation Scheme | LR | OLS | GLSAR (rho = 1) | DT | RF | VR |
|---|---|---|---|---|---|---|---|
| 1 | Random CV | 0.7687 | 0.7093 | 0.6645 | 0.4204 | 0.7440 | |
| Blocked-CV | 0.7058 | 0.7057 | 0.6481 | 0.6643 | 0.4258 | 0.6819 | |
| EWFV | 1.2838 | 1.223 | 0.6788 | 0.6917 | |||
| 2 | Random CV | 0.7443 | 0.7437 | 0.7613 | 0.6533 | 0.3775 | 0.7518 |
| Blocked-CV | 0.7345 | 0.7344 | 0.7334 | 0.6059 | 0.3119 | 0.7207 | |
| EWFV | 0.9988 | 0.9971 | 0.9873 | 0.5640 | 0.3023 | 0.8853 | |
| 3 | Random CV | 3.7437 | 3.744 | 3.9505 | 1.6675 | 0.8918 | 3.6341 |
| Blocked-CV | 2.7438 | 2.7446 | 2.7855 | 1.7104 | 0.6485 | 2.7701 | |
| EWFV | 5.3703 | 5.3706 | 5.4704 | 1.0700 | 0.6997 | 5.1507 | |
| 4 | Random CV | 0.7761 | 0.6569 | 0.5045 | 0.1410 | ||
| Blocked-CV | 0.7303 | 0.7253 | 0.6062 | 0.5528 | 0.1951 | 0.6361 | |
| EWFV | 1.2577 | 1.1346 | 0.4116 | 0.3069 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sankalpa, C.; Kittipiyakul, S.; Laitrakun, S. Forecasting Short-Term Electricity Load Using Validated Ensemble Learning. Energies 2022, 15, 8567. https://doi.org/10.3390/en15228567
Sankalpa C, Kittipiyakul S, Laitrakun S. Forecasting Short-Term Electricity Load Using Validated Ensemble Learning. Energies. 2022; 15(22):8567. https://doi.org/10.3390/en15228567
Chicago/Turabian StyleSankalpa, Chatum, Somsak Kittipiyakul, and Seksan Laitrakun. 2022. "Forecasting Short-Term Electricity Load Using Validated Ensemble Learning" Energies 15, no. 22: 8567. https://doi.org/10.3390/en15228567
APA StyleSankalpa, C., Kittipiyakul, S., & Laitrakun, S. (2022). Forecasting Short-Term Electricity Load Using Validated Ensemble Learning. Energies, 15(22), 8567. https://doi.org/10.3390/en15228567