


Imaging Domain Seismic Denoising Based on Conditional Generative Adversarial Networks (CGANs)



Abstract
:1. Introduction
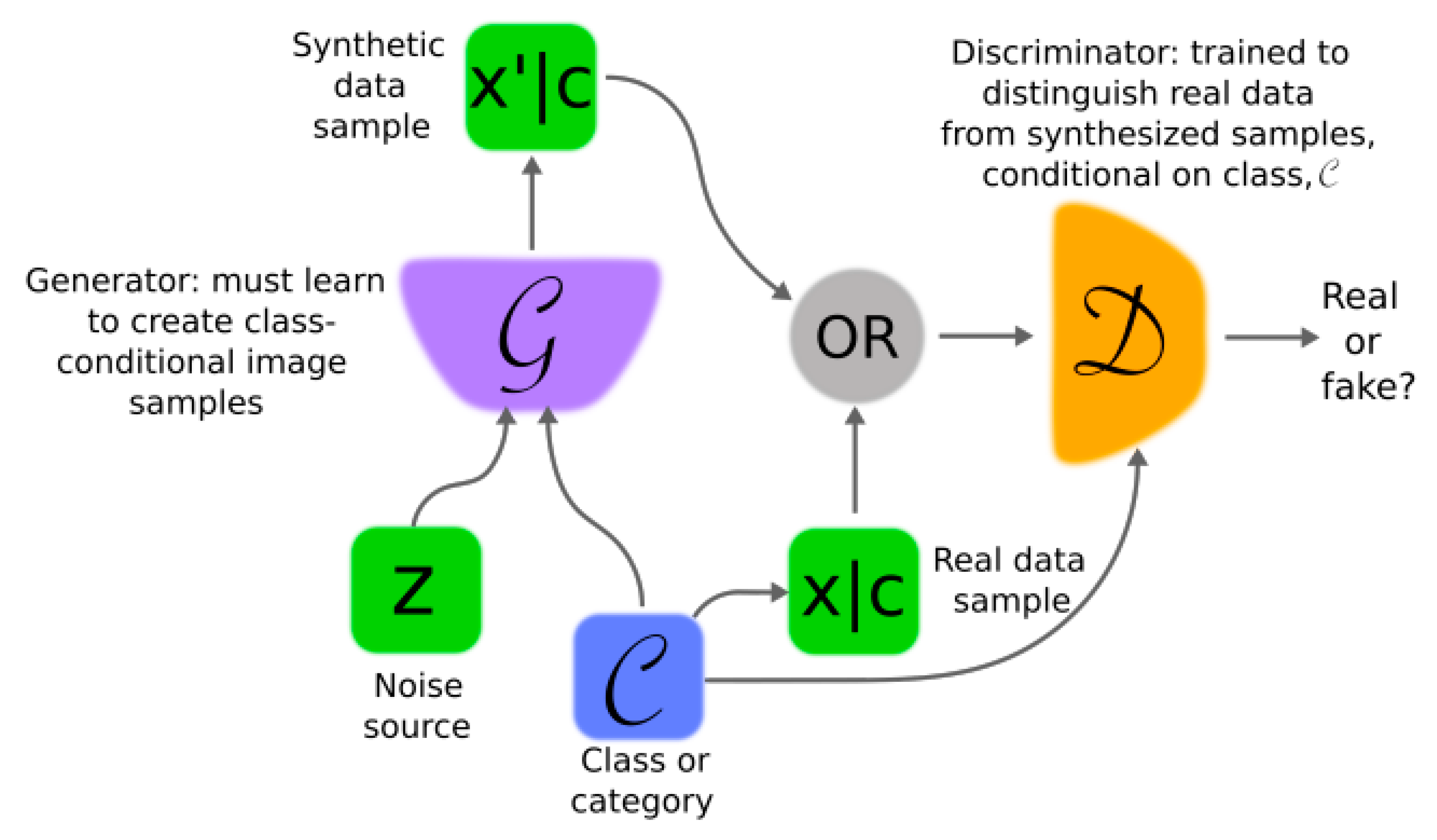
2. Theory and Methodology
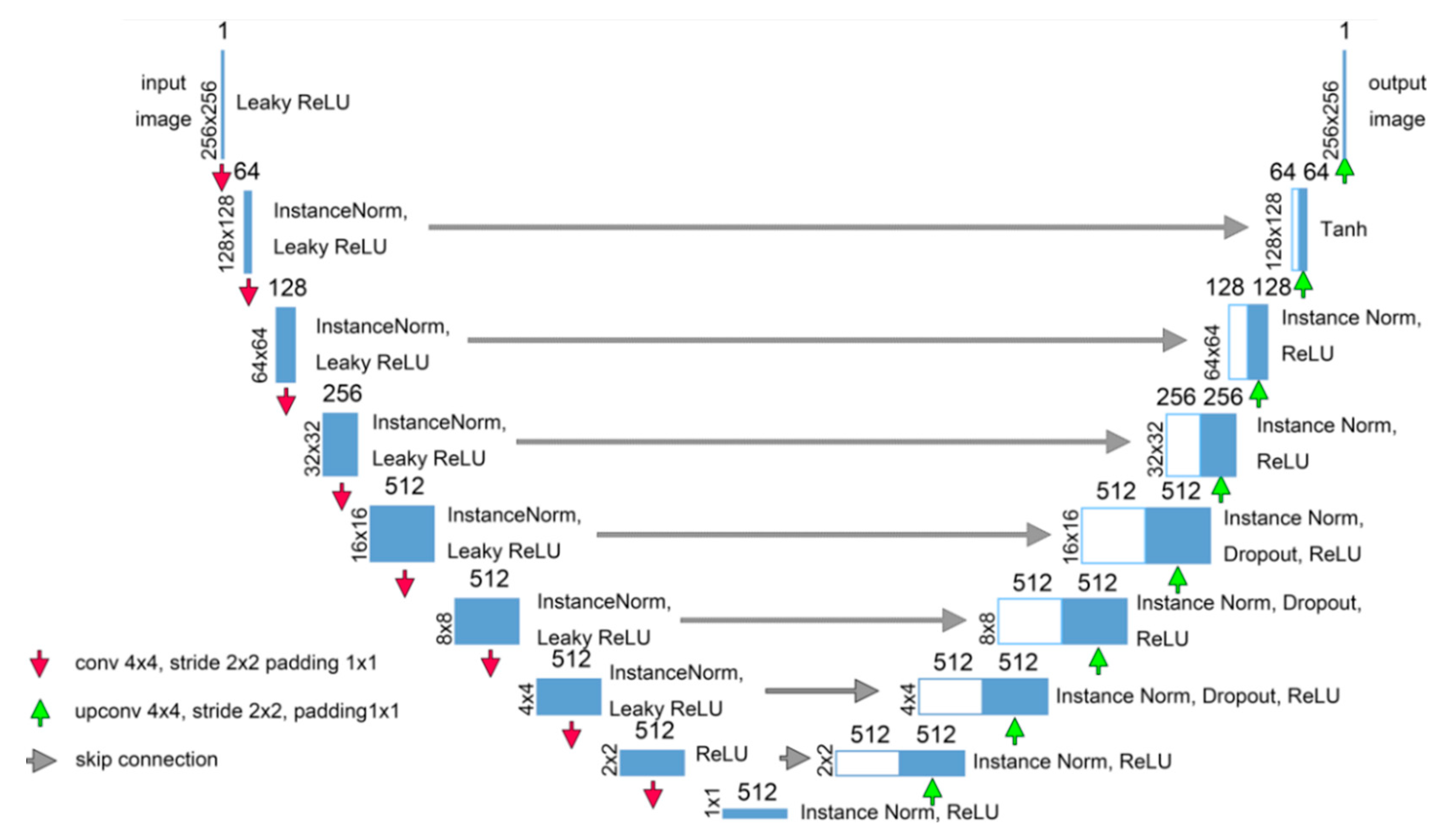
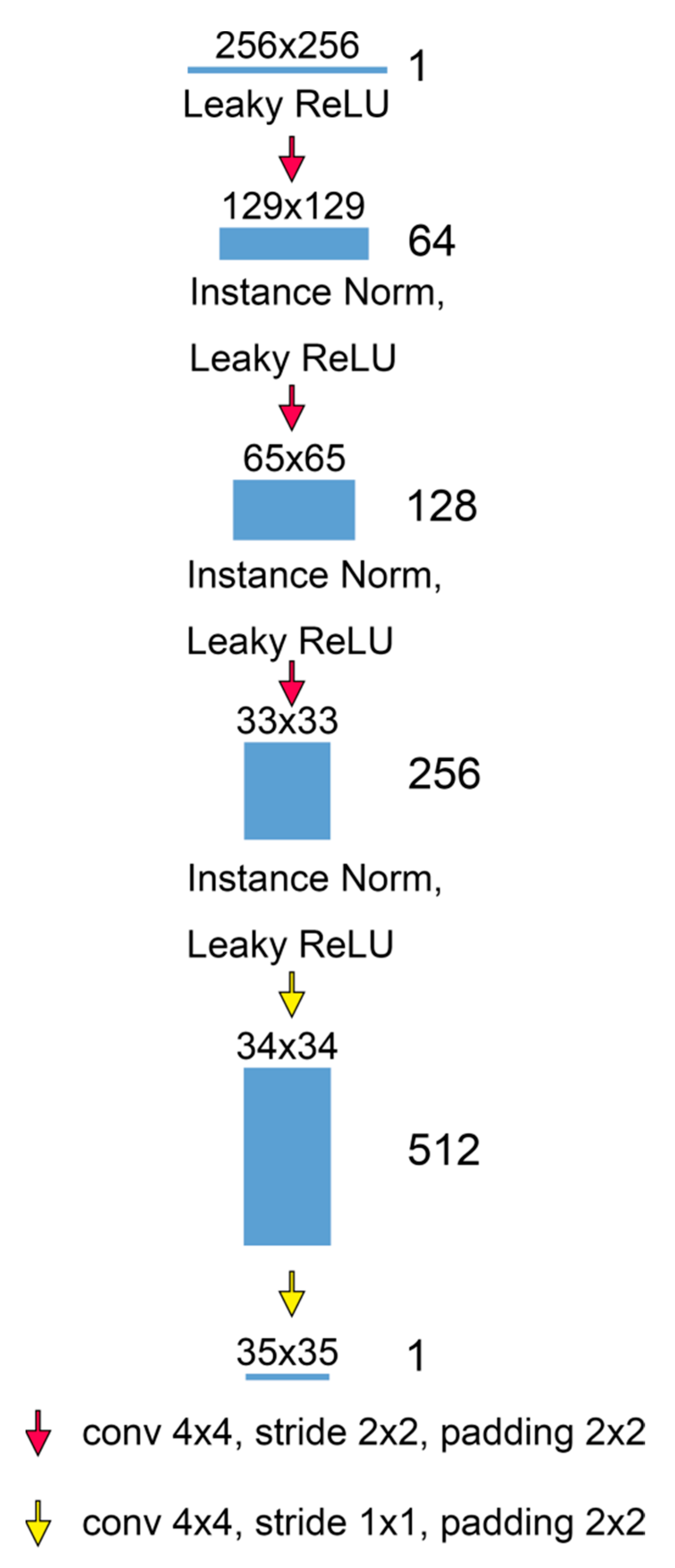
3. The Architecture of the Conditional GAN for Seismic Imaging Denoising
4. Data Preparation
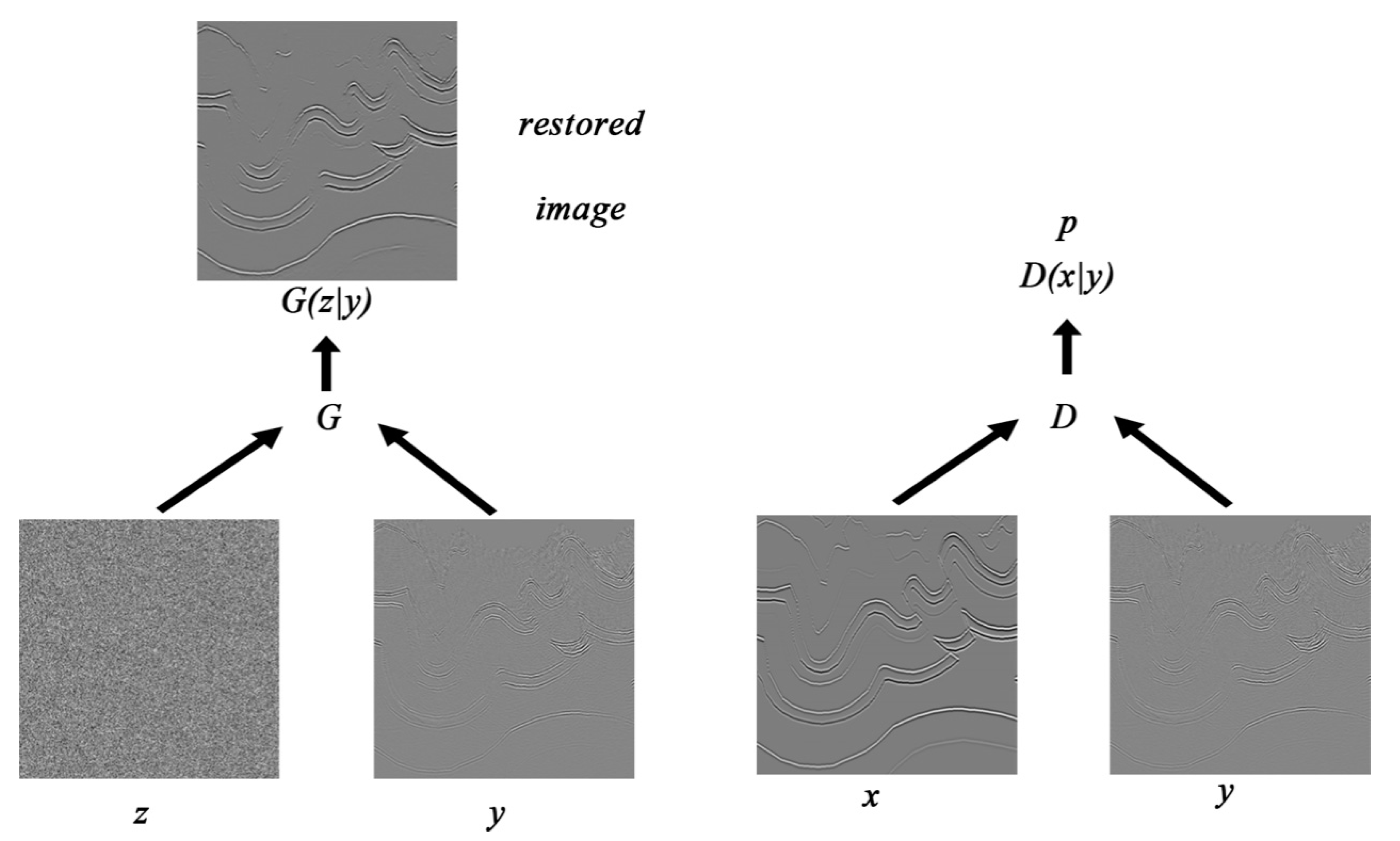
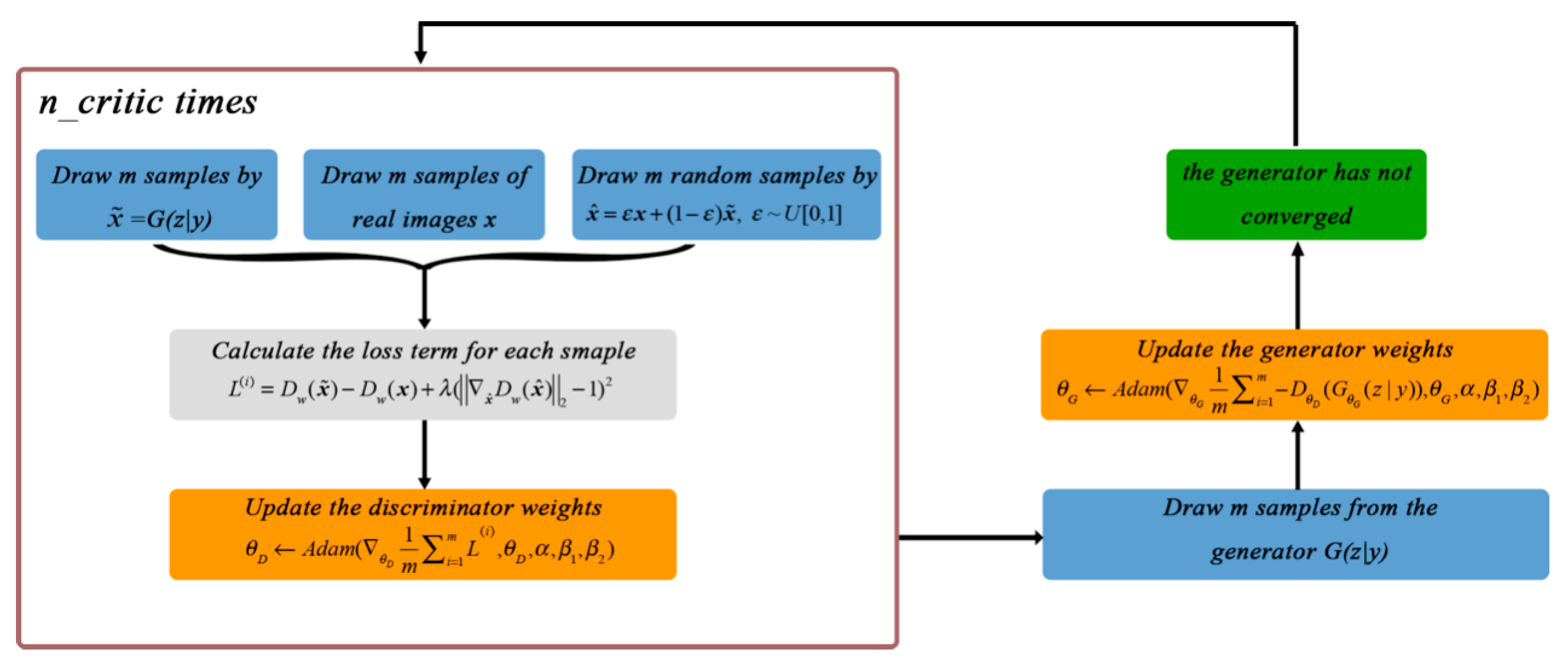
5. Objective Function
6. Loss Function of the Discriminator
7. Loss Function of the Generator
8. Performance Evaluation
9. Examples
10. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Liu, W.; Chen, W. Recent advancements in empirical wavelet transform and its applications. IEEE Access 2019, 7, 103770–103780. [Google Scholar] [CrossRef]
- Siahsar, M.A.N.; Abolghasemi, V.; Chen, Y. Simultaneous denoising and interpolation of 2D seismic data using data-driven non-negative dictionary learning. Signal Process. 2017, 141, 309–321. [Google Scholar] [CrossRef]
- Yilmaz, Ö.; Tanir, I.; Gregory, C.; Zhou, F. Interpretive imaging of seismic data. Lead. Edge 2001, 20, 132–144. [Google Scholar] [CrossRef]
- Chen, Y.; Fomel, S. Random noise attenuation using local signal-and-noise or- thogonalization. Geophysics 2015, 80, WD1–WD9. [Google Scholar] [CrossRef]
- Liu, G.; Chen, X.; Du, J.; Wu, K. Random noise attenuation using f-x regularized nonstationary autoregression. Geophysics 2012, 77, V61–V69. [Google Scholar] [CrossRef]
- Naghizadeh, M.; Sacchi, M.D. Multicomponent seismic random noise attenuation via vector autoregressive operators. Geophysics 2012, 77, V91–V99. [Google Scholar] [CrossRef]
- Gan, S.; Wang, S.; Chen, Y.; Chen, X.; Xiang, K. Separation of simultaneous sources using a structural-oriented median filter in the flattened dimension. Comput. Geosci. 2016, 86, 46–54. [Google Scholar] [CrossRef]
- Liu, G.; Chen, X. Noncausal f−x−y regularized nonstationary prediction filtering for random noise attenuation on 3D seismic data. J. Appl. Geophys. 2013, 93, 60–66. [Google Scholar] [CrossRef]
- Liu, Y. Noise reduction by vector median filtering. Geophysics 2013, 78, V79–V87. [Google Scholar] [CrossRef]
- Fomel, S.; Liu, Y. Seislet transform and seislet frame. Geophysics 2010, 75, V25–V38. [Google Scholar] [CrossRef] [Green Version]
- Mousavi, S.M.; Langston, C.A.; Horton, S.P. Automatic microseismic denoising and onset detection using the synchrosqueezed continuous wavelet transform. Geophysics 2016, 81, V341–V355. [Google Scholar] [CrossRef]
- Zu, S.; Zhou, H.; Ru, R.; Jiang, M.; Chen, Y. Dictionary learning based on dip patch selection training for random noise attenuation. Geophysics 2019, 84, V169–V183. [Google Scholar] [CrossRef]
- Huang, W.; Wang, R.; Chen, Y.; Li, H.; Gan, S. Damped multichannel singular spectrum analysis for 3D random noise attenuation. Geophysics 2016, 81, V261–V270. [Google Scholar] [CrossRef]
- Oropeza, V.; Sacchi, M. Simultaneous seismic data denoising and reconstruction via multichannel singular spectrum analysis. Geophysics 2011, 76, V25–V32. [Google Scholar] [CrossRef]
- Lecun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the18th International Conference, Munich, Germany, 5–9 October 2015; Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics);. Volume 9351, pp. 234–241. [Google Scholar]
- Zhang, K.; Zuo, W.; Gu, S.; Zhang, L. Learning Deep CNN Denoiser Prior for Image Restoration. In Proceedings of the IEEE Conference on Computer Vision and Pattern, Honolulu, HI, USA, 21–26 July 2017; pp. 3929–3938. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; Volume 31, pp. 3431–3440. [Google Scholar]
- Yuan, S.; Liu, J.; Wang, S.; Wang, T.; Shi, P. Seismic Waveform Classification and First-Break Picking Using Convolution Neural Networks. IEEE Geosci. Remote Sens. Lett. 2018, 15, 272–276. [Google Scholar] [CrossRef]
- Wu, X.M.; Liang, L.; Shi, Y.; Fomel, S. FaultSeg3D: Using synthetic data sets to train an end-to-end convolutional neural network for 3D seismic fault segmentation. Geophysics 2019, 84, IM35–IM45. [Google Scholar] [CrossRef]
- Xiong, W.; Ji, X.; Ma, Y.; Wang, Y.; AlBinHassan, N.; Ali, M.; Luo, Y. Seismic fault detection with convolutional neural network. Geophysics 2018, 83, O97–O103. [Google Scholar] [CrossRef]
- Lewis, W.; Vigh, D. Deep learning prior models from seismic images for full-waveform inversion. In SEG Technical Program Expanded Abstracts 2017; Society of Exploration of Geophysicists: Houston, TX, USA, 2017; pp. 1512–1517. [Google Scholar]
- Shi, Y.; Wu, X.; Fomel, S. Automatic salt-body classification using deep-convolutional neural network. In SEG Technical Program Expanded Abstracts 2018; Society of Exploration of Geophysicists: Anaheim, CA, USA, 2018; pp. 1971–1975. [Google Scholar]
- Zhang, Y.; Liu, Y.; Zhang, H.; Xue, H. Seismic facies analysis based on deep learning. IEEE Geosci. Remote Sens. Lett. 2019, 17, 1119–1123. [Google Scholar] [CrossRef]
- Jin, Y.; Wu, X.; Chen, J.; Han, Z.; Hu, W. Seismic Data Denoising by Deep Residual Networks. In SEG Technical Program Expanded Abstracts 2018; Society of Exploration of Geophysicists: Anaheim, CA, USA, 2018; pp. 4593–4597. [Google Scholar]
- Sang, W.J.; Yuan, S.Y.; Yong, X.S.; Jiao, X.Q.; Wang, S.X. DCNNs-Based Denoising With a Novel Data Generation for Multidimensional Geological Structures Learning. IEEE Geosci. Remote Sens. Lett. 2021, 18, 1861–1865. [Google Scholar] [CrossRef]
- Yuan, S.; Jiao, X.; Luo, Y.; Sang, W.; Wang, S. Double-scale supervised inversion with a data-driven forward model for low-frequency impedance recovery. Geophysics 2022, 87, R165–R181. [Google Scholar] [CrossRef]
- Wang, W.; Ma, J. Velocity model building in a crosswell acquisition geometry with image-trained artificial neural networks. Geophysics 2020, 85, U31–U46. [Google Scholar] [CrossRef]
- Woollam, J.; Rietbrock, A.; Bueno, A.; De Angelis, S. Convolutional Neural Network for Seismic Phase Classification, Performance Demonstration over a Local Seismic Network. Seismol. Res. Lett. 2019, 90, 491–502. [Google Scholar] [CrossRef]
- Zhang, H.; Han, J.G.; Li, Z.X.; Zhang, H. Extracting Q Anomalies from Marine Reflection Seismic Data Using Deep Learning. IEEE Geosci. Remote Sens. Lett. 2022, 19, 7501205. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Networks. arXiv 2014, arXiv:1406.2661. [Google Scholar] [CrossRef]
- Li, Y.; Xiao, N.; Ouyang, W. Improved boundary equilibrium generative adversarial networks. IEEE Access 2018, 6, 11342–11348. [Google Scholar] [CrossRef]
- Mao, X.; Li, Q.; Xie, H.; Lau, R.Y.K.; Wang, Z.; Smolley, S.P. Least Squares Generative Adversarial Networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2794–2802. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional Generative Adversarial Nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 105–114. [Google Scholar]
- Kupyn, O.; Budzan, V.; Mykhailych, M.; Mishkin, D.; Matas, J. DeblurGAN: Blind Motion Deblurring Using Conditional Adversarial Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8183–8192. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 5967–5976. [Google Scholar]
- Maas, A.L.; Hannun, A.Y.; Ng, A.Y. Rectifier nonlinearities improve neural network acoustic models. In Proceedings of the 30th International Conference on Machine Learning, ICML’13, Atlanta, GA, USA, 16–21 June 2013. [Google Scholar]
- Ulyanov, D.; Vedaldi, A.; Lempitsky, V. Instance Normalization: The Missing Ingredient for Fast Stylization. arXiv 2016, arXiv:1607.08022. [Google Scholar]
- Zeiler, M.D.; Taylor, G.W.; Fergus, R. Adaptive Deconvolutional Networks for Mid and High Level Feature Learning. In Proceedings of the IEEE International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2018–2025. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified Linear Units Improve Restricted Boltzmann Machines. In Proceedings of the 27th International Conference on Machine Learning (ICML’10), Haifa, Israel, 21–24 June 2010. [Google Scholar]
- Hinton, G.E.; Srivastava, N.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R.R. Improving neural networks by preventing co-adaptation of feature detectors. arXiv 2012, arXiv:1207.0580v1. [Google Scholar]
- Son, J.; Park, S.J.; Jung, K.-H. Retinal Vessel Segmentation in Fundoscopic Images with Generative Adversarial Networks. arXiv 2017, arXiv:1706.09318. [Google Scholar]
- Yang, P.; Gao, J.; Wang, B. RTM using effective boundary saving: A staggered grid GPU implementation. Comput. Geosci. 2014, 68, 64–72. [Google Scholar] [CrossRef]
- Liu, Q.; Zhang, J.; Gao, H. Reverse-time migration from rugged topography using irregular, unstructured mesh. Geophys. Prospect. 2017, 65, 453–466. [Google Scholar] [CrossRef]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A. Improved Training of Wasserstein GANs. arXiv 2017, arXiv:1704.00028. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein GAN. arXiv 2017, arXiv:1701.07875. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Member, S.; Simoncelli, E.P.; Member, S. Image Quality Assessment: From Error Visibility to Structural Similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [Green Version]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model Name | Model Size | RTM Method |
|---|---|---|
| foothill | 1568 × 900 | Grid method |
| Hess | 3617 × 1500 | Grid method |
| BGP-salt | 3000 × 1400 | Grid method |
| Marmousi | 2181 × 751 | Finite difference |
| Pluto | 6960 × 1201 | Finite difference |
| Sigsbee | 3201 × 1201 | Finite difference |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, H.; Wang, W. Imaging Domain Seismic Denoising Based on Conditional Generative Adversarial Networks (CGANs). Energies 2022, 15, 6569. https://doi.org/10.3390/en15186569
Zhang H, Wang W. Imaging Domain Seismic Denoising Based on Conditional Generative Adversarial Networks (CGANs). Energies. 2022; 15(18):6569. https://doi.org/10.3390/en15186569
Chicago/Turabian StyleZhang, Hao, and Wenlei Wang. 2022. "Imaging Domain Seismic Denoising Based on Conditional Generative Adversarial Networks (CGANs)" Energies 15, no. 18: 6569. https://doi.org/10.3390/en15186569
APA StyleZhang, H., & Wang, W. (2022). Imaging Domain Seismic Denoising Based on Conditional Generative Adversarial Networks (CGANs). Energies, 15(18), 6569. https://doi.org/10.3390/en15186569