
Towards Data-Driven Models in the Prediction of Ship Performance (Speed—Power) in Actual Seas: A Comparative Study between Modern Approaches



Abstract
:1. Introduction
2. Semi-Empirical Formulas, Model Tests and CFD Models
3. Data-Driven Models
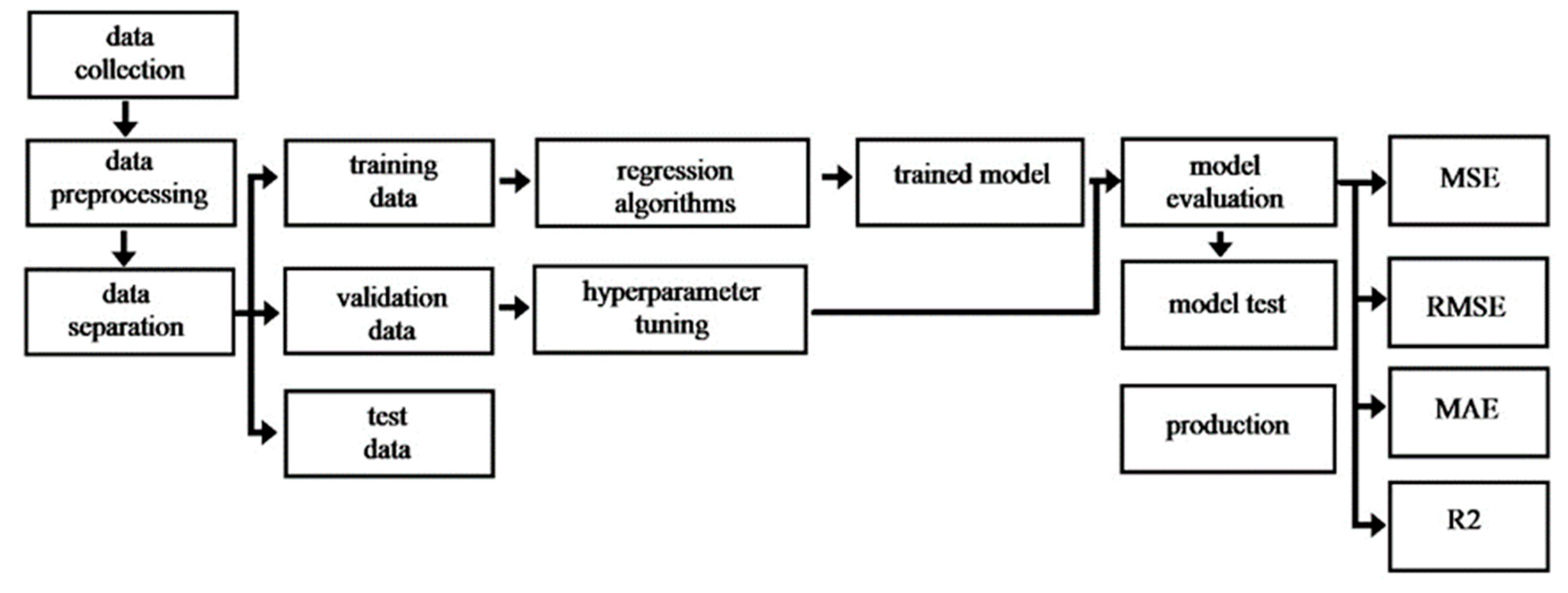
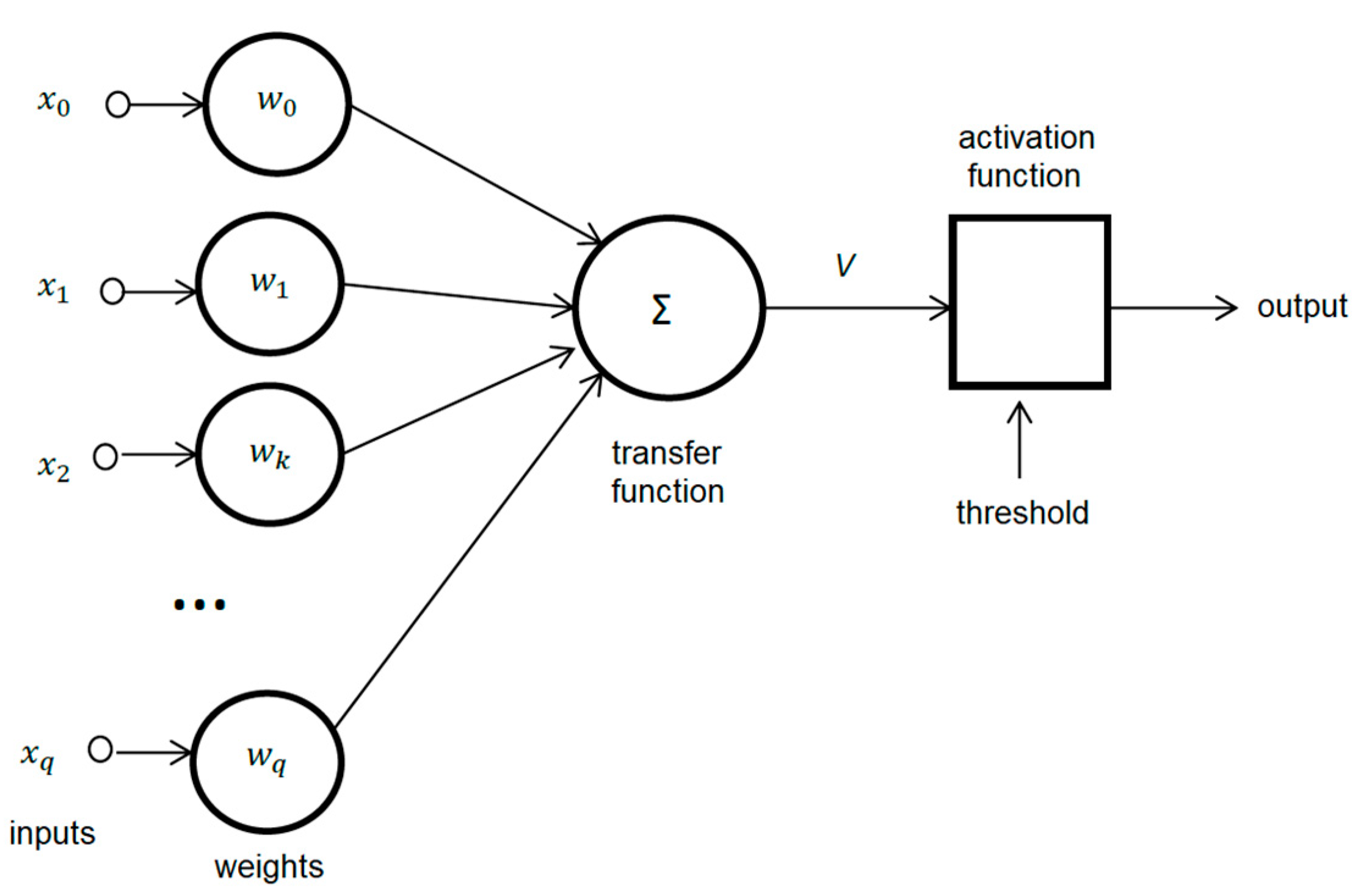
3.1. Machine Learning Approach Basics
- Collection of the labeled data that will be used for training;
- Determination of input and output features;
- Preprocess of the labeled input data;
- Separation of these data into three groups: training, validation and test data sets;
- Determination of the suitable algorithm for the model;
- Optimization of the parameters that affect the operation of the above algorithm (hyperparameter optimization);
- Validation of the model;
- Test of the prediction accuracy of the model by providing the test set;
- Model ready for new predictions.
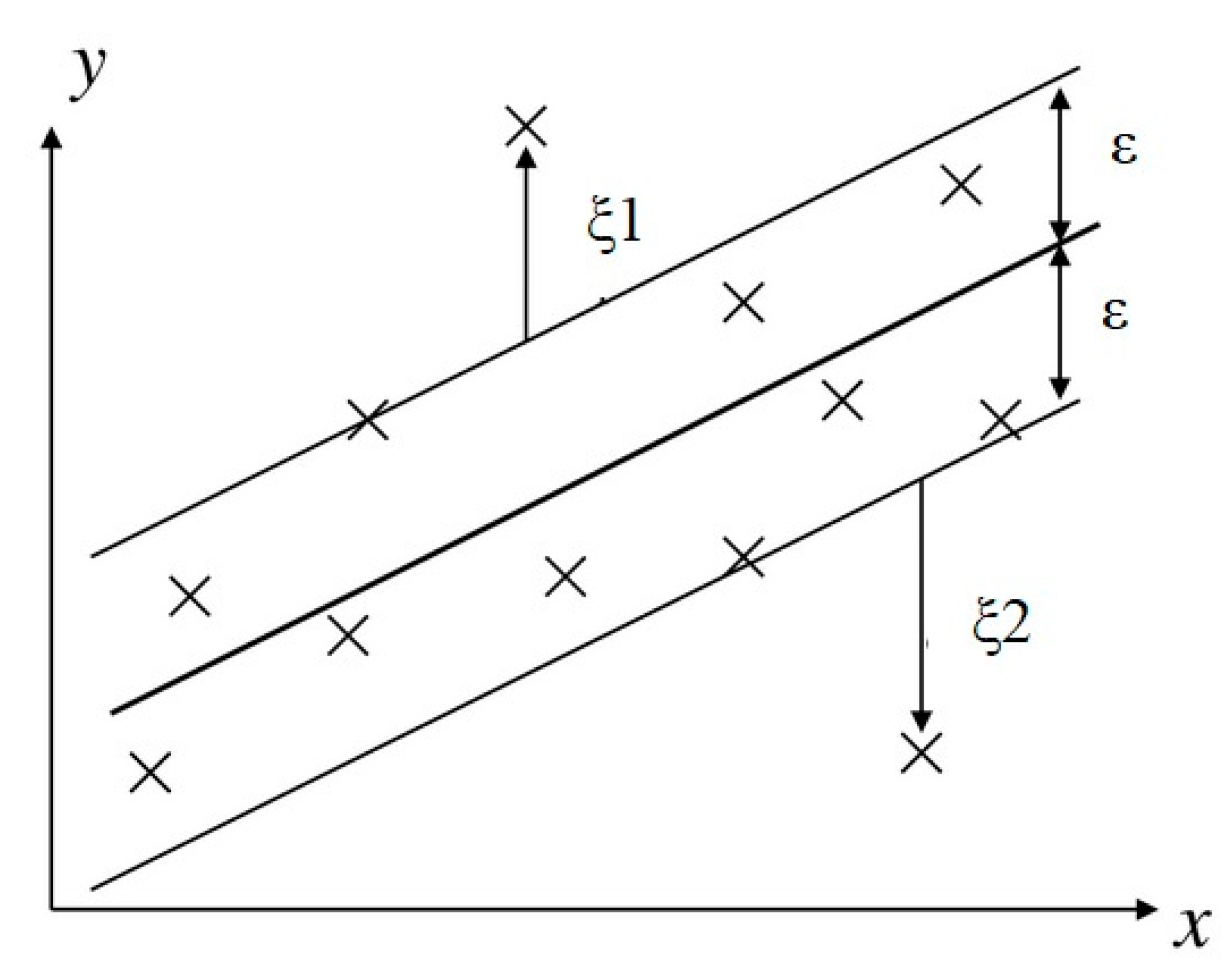
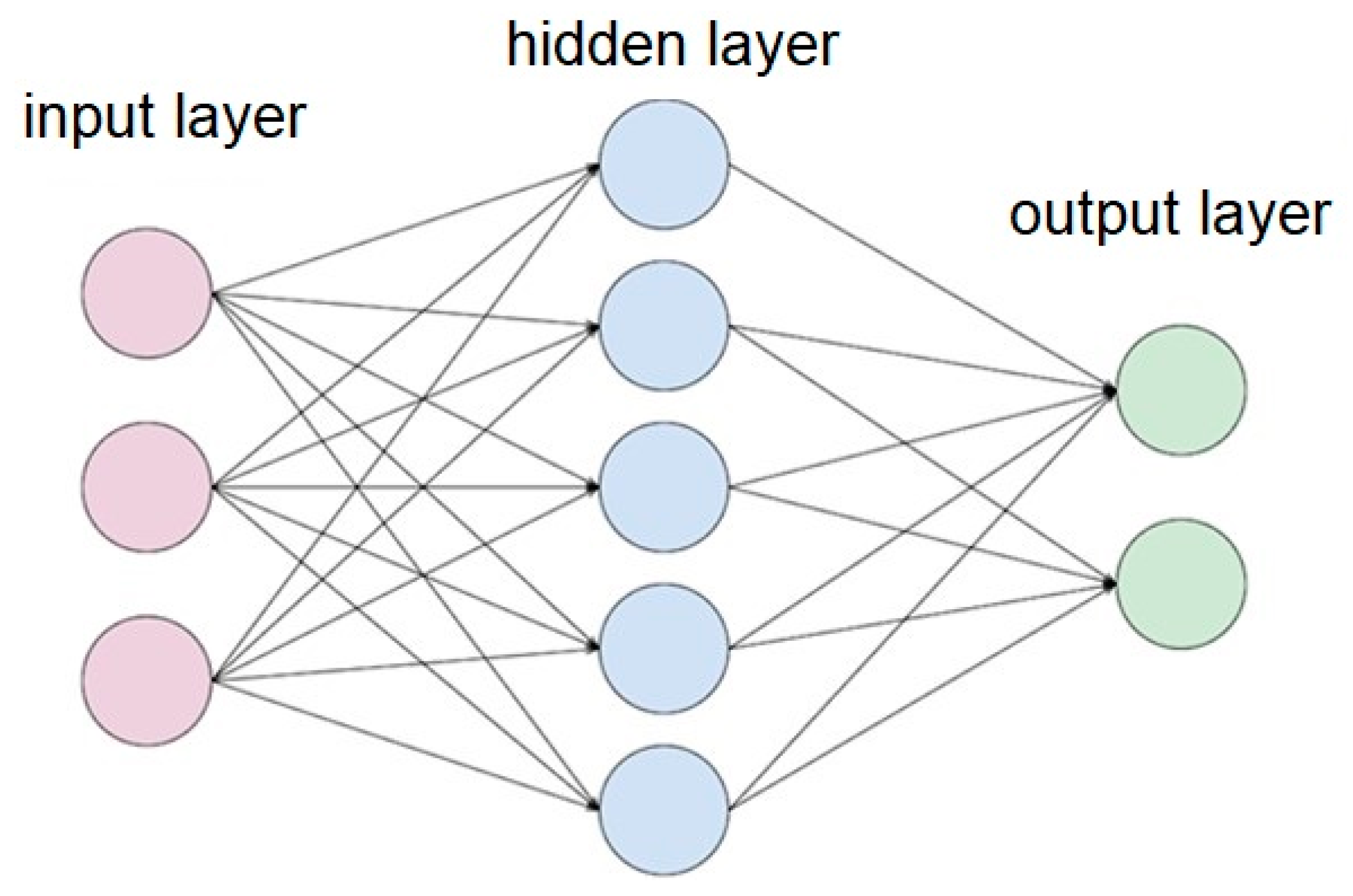
3.2. Basic ML Algorithm Categories Used for Regression
3.3. Prediction Assessment Metrics
- Mean absolute error (MAE). It is the average of the absolute differences between predictions and actual (true) values of the attribute of interest [35]. If N is the number of observations, is the actual (true) value, and is the predicted one. Then, the mathematical equation of MAE is:
- Mean squared error (MSE). MSE takes the average of the square of the difference between predictions and actual (true) values. Because of the use of error squares, the effect of larger errors becomes more pronounced. The mathematical equation of MSE is:
- Root mean squared error (RMSE). This is the square root of MSE. RMSE is more sensitive to variance than MAE because it is more affected by outliers in the results [30]. RMSE is mathematically expressed with the following equation:
- Finally, R square (R2). This focuses more on the operation of the algorithm and not on the results. It specifies the degree to which any variations in the values of the dependent variable (target attribute) can be explained by changes in the values of the independent variables (data set). If is the mean of all values, then it is mathematically expressed as:
4. Implementation of Machine Learning in Ship Performance Prediction
4.1. Input Data Sources
- Noon reports;
- Data acquisition systems (DAS) installed on board;
- Meteorological ocean data from weather services;
- Route data from Global Positioning System (GPS) or Automatic Identification System (AIS);
- Hybrid methods;
- Databases/simulated by external software.
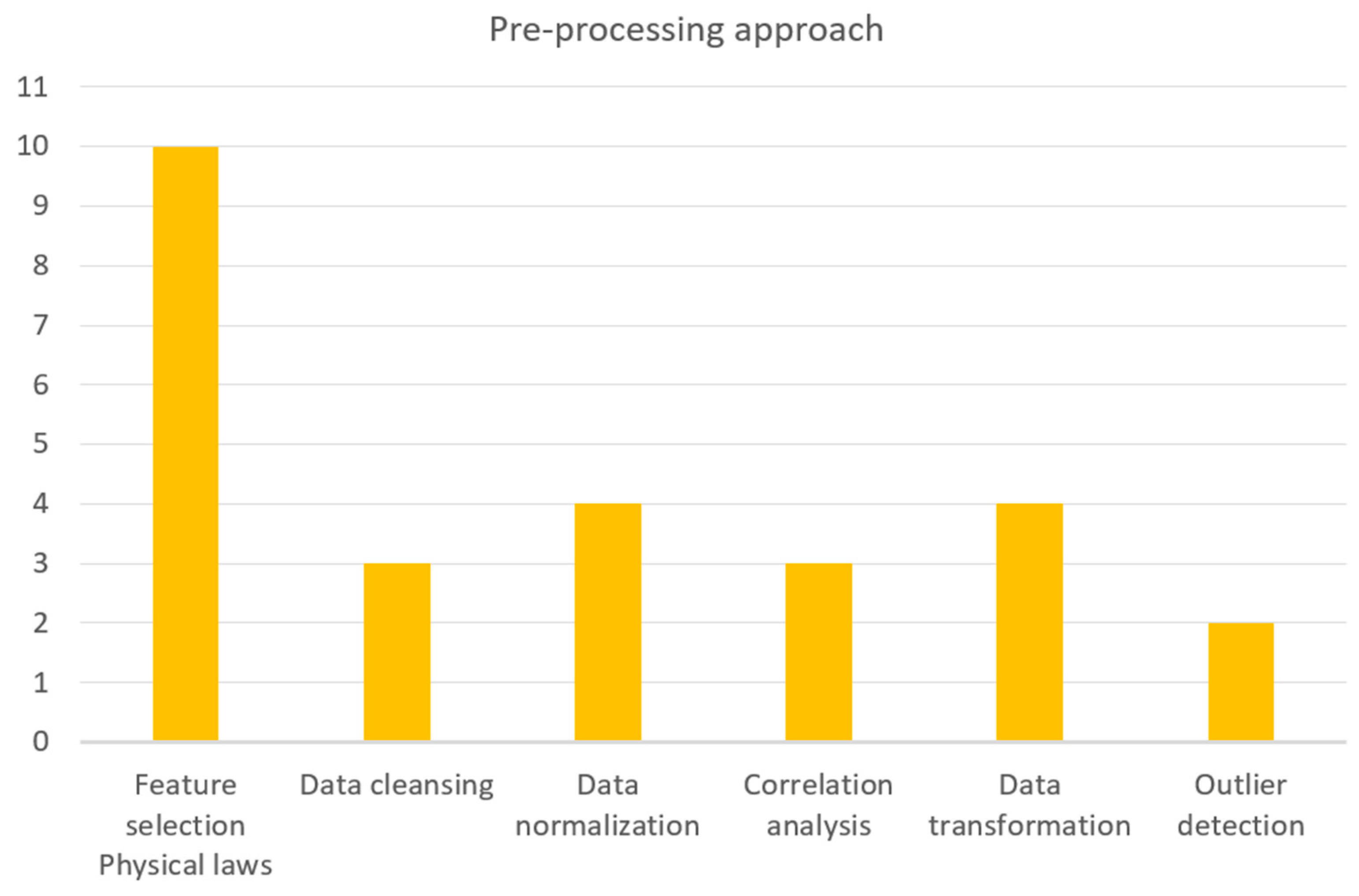
4.2. Preprocessing Methods
- Feature selection driven by physical laws;
- Feature selection with the use of a high correlation filter;
- Correlation analysis;
- Data normalization;
- Data cleansing using clustering;
- Data cleansing by operational limitations;
- Feature engineering; data transformation based on physical laws;
- Downsampling input data by calculating the average values;
- Principal component analysis (PCA) to reduce the dimensionality;
- Outlier detection and discarding based on z-scores.
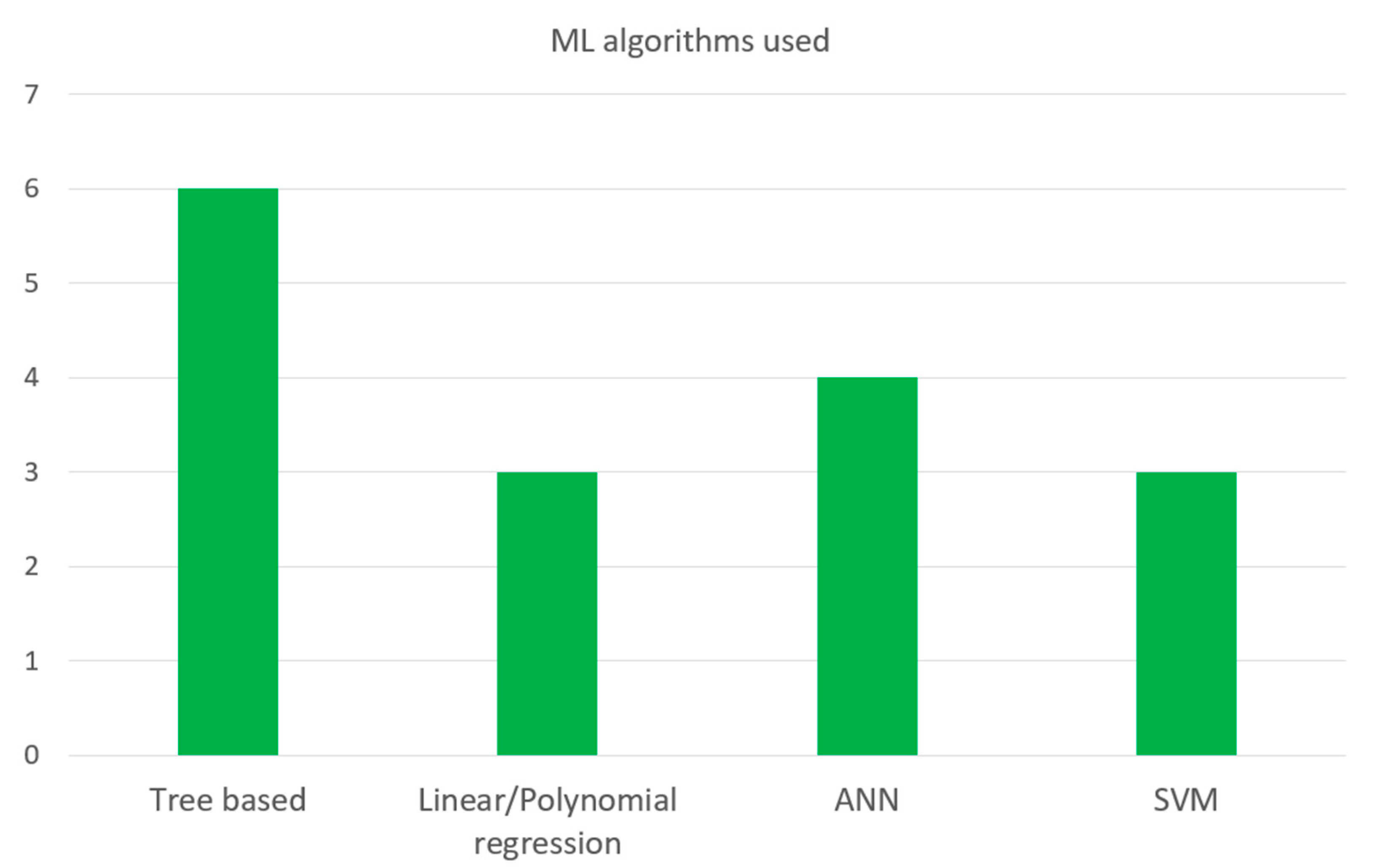
4.3. ML Algorithms Used/Hyperparameter Tuning
4.4. Validation/Verification
5. Discussion
6. Conclusions
- Increased frequency methods (onboard data acquisition systems) are starting to replace noon reports as the data input method of choice.
- The new data acquisition systems that are installed onboard ships paved the way for the implementation of methods that rely on complex ML algorithms that achieve remarkable results. These algorithms were the privilege of other scientific fields until recently.
- Researchers prefer to use methods for data preprocessing that rely on physical laws rather than purely computational alternative methods.
- The above preference for research studies with physical laws as a tool for various steps in the data-driven methods pipeline indicate that the computational tools are not a good alternative for this application and must be improved upon in the future.
- ANNs in various forms are starting to dominate as the ML algorithm of choice mainly due to the increased computational power available.
- The accuracy of the prediction results of data-driven models is starting to increase in levels that offer a credible alternative for practical implementations.
- In the absence of specific information of ship design (which is usually the prerogative of the shipyards that built the ship), which are necessary for implementing CFD or other deterministic methods, ML algorithms can currently fill the gap in predicting ship performance.
- The “universal” nature of data-driven methods and the fact that computer science drives the evolution of these methods at a fast pace can lead to the total domination of these methods in shipping.
- The level of uncertainty of input data heavily increases when implementing data-driven methods in real weather conditions. This drawback creates a demand for the development of specific preprocessing procedures in the future.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Oil 2021 Analysis and Forecast to 2026, International Energy Agency; IEA Publications: Paris, France, 2021.
- IMO. Initial IMO Strategy on Reduction of GHG Emissions from Ships; Resolution MEPC: London, UK, 2018; p. 304. [Google Scholar]
- IMO. Guidelines on the Method of Calculation of the Attained Energy Efficiency Design Index (EEDI) for New Ships; MEPC: London, UK, 2014; Volume 245. [Google Scholar]
- IMO. Guidance for Voluntary Use of the Ship Energy Efficiency Operational Indicator (EEOI); MEPC: London, UK, 2009. [Google Scholar]
- IMO. Guidelines for the Development of a Ship Energy Efficiency Management Plan (SEEMP); MEPC: London, UK, 2016. [Google Scholar]
- IMO. Guidance on Treatment of Innovative Energy Efficiency Technologies for Calculation and Verification of the Attained EEDI and EEXI; MEPC: London, UK, 2021. [Google Scholar]
- IMO. Guidelines on the Operational Carbon Intensity Rating of Ships (CII Rating Guidelines, G4); MEPC: London, UK, 2021. [Google Scholar]
- Carlton, J. Marine Propellers and Propulsion, 4th ed.; Butterworth-Heinemann: Oxford, UK, 2012. [Google Scholar]
- Kuroda, M.; Takagi, K.; Tsujimoto, M.; Fujisawa, J. Measurement of Added Resistance in Irregular Waves and Estimation of the Long-period Components. Jpn. Soc. Nav. Archit. Ocean. Eng. 2017, 24, 181–188. [Google Scholar]
- Kundu, P.K.; Cohen, I.M.; Dowling, D.R. Fluid Mechanics, 6th ed.; Elsevier Academic Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Patey, M. Performance Monitoring Information Feedback to Design. In Proceedings of the 4th Hull Performance & Insight Conference, Gubbio, Italy, 6–8 May 2019. [Google Scholar]
- Logan, K.P. Using a ship’s propeller for hull condition monitoring, ASNE Intelligent Ships Symp, IX. Philadelphia 2011, 124, 71–87. [Google Scholar]
- Gkerekos, C.; Lazakis, I.; Theotokatos, G. Machine learning models for predicting ship main engine Fuel Oil Consumption: A comparative study. Ocean. Eng. 2019, 188, 106282. [Google Scholar] [CrossRef]
- Wang, J.; Bielicki, S.; Kluwe, F.; Orihara, H.; Xin, G.; Kume, K.; Feng, P. Validation study on a new semi-empirical method for the prediction of added resistance in waves of arbitrary heading in analyzing ship speed trial results. Ocean. Eng. 2021, 240, 109959. [Google Scholar] [CrossRef]
- Sasa, K.; Chen, C.; Fujimatsu, T.; Shoji, R.; Maki, A. Speed loss analysis and rough wave avoidance algorithms for optimal ship routing simulation of 28,000-DWT bulk carrier. Ocean. Eng. 2021, 228, 108800. [Google Scholar] [CrossRef]
- Liu, L.; Chen, M.; Wang, X.; Zhang, Z.; Yu, J.; Feng, D. CFD prediction of full-scale ship parametric roll in head wave. Ocean. Eng. 2021, 233, 109180. [Google Scholar] [CrossRef]
- Lang, X.; Mao, W. A semi-empirical model for ship speed loss prediction at head sea and its validation by full-scale measurements. Ocean. Eng. 2020, 209, 107494. [Google Scholar] [CrossRef]
- Kim, M.; Hizir, O.; Turan, O.; Day, S.; Incecik, A. Estimation of added resistance and ship speed loss in a seaway. Ocean. Eng. 2017, 141, 465–476. [Google Scholar] [CrossRef] [Green Version]
- Sulovsky, I.; Prpic-Oršic, J. Mathematical Model of Ship Speed Drop on Irregular Waves; University of Rijeka: Rijeka, Croatia, 2021. [Google Scholar]
- Liu, S.; Papanikolaou, A. Prediction of the Side Drift Force of Full Ships Advancing in Waves at Low Speeds. Mar. Sci. Eng. 2020, 8, 377. [Google Scholar] [CrossRef]
- Korkmaz, K.B.; Werner, S.; Bensow, R. Verification and Validation of CFD Based Form Factors as a Combined CFD/EFD Method. Mar. Sci. Eng. 2021, 9, 75. [Google Scholar] [CrossRef]
- Gao, Q.; Song, L.; Yao, J. RANS Prediction of Wave-Induced Ship Motions, and Steady Wave Forces and Moments in Regular Waves. Mar. Sci. Eng. 2021, 9, 1459. [Google Scholar] [CrossRef]
- Ntouras, D.; Papadakis, G.; Belibassakis, K. Ship Bow Wings with Application to Trim and Resistance Control in Calm Water and in Waves. Mar. Sci. Eng. 2022, 10, 492. [Google Scholar] [CrossRef]
- Inno, G.; Michael, S.; Hrvoje, J. Investigating Trim Optimisation in Waves for an AFRAMAX Tanker Using CFD. In Proceedings of the 5th Hull Performance & Insight Conference, Tullamore, Ireland, 26–28 October 2020. [Google Scholar]
- Inno, G.; David, B. Calculating Speed Loss Due to Swell using CFD. In Proceedings of the 6th Hull Performance & Insight Conference, Pontignano, Italy, 30 August–1 September 2021. [Google Scholar]
- Shigunov, V.; el Moctar, O.; Papanikolaou, A.; Potthoff, R.; Liu, S. International benchmark study on numerical simulation methods for prediction of maneuverability of ships in waves. Ocean Eng. 2018, 165, 365–385. [Google Scholar] [CrossRef]
- Alexiou, K.; Pariotis, E.G.; Zannis, T.C.; Leligou, H.C. Prediction of a Ship’s Operational Parameters Using Artificial Intelligence Techniques. Mar. Sci. Eng. 2021, 9, 681. [Google Scholar] [CrossRef]
- Aurelien, G. Hands-on Machine Learning with Scikit-Learn, Keras, and TensorFlow; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2019; ISBN 978-1-492-03264-9. [Google Scholar]
- Andriy, B. The Hundred-Page Machine Learning Book; Andriy Burkov: Quebec City, QC, Canada, 2019; ISBN 978-1-9995795-0-0. [Google Scholar]
- Haykin, S. Neural Networks: A Comprehensive Foundation; Prentice Hall: Hoboken, NJ, USA, 1999. [Google Scholar]
- Abhigyan. Retrieved from Understanding Polynomial Regression. Available online: https://medium.com (accessed on 2 August 2020).
- Fan, J. Local Polynomial Modelling and Its Applications: From linear regression to nonlinear regression. In Monographs on Statistics and Applied Probability; Chapman & Hall/CRC: Boca Raton, FL, USA, 1996. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-Vector Networks. Kluwer Acad. Publ. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- What is a Decision Tree? Available online: https://towardsdatascience.com/what-is-a-decision-tree-22975f00f3e1 (accessed on 1 June 2022).
- Abebe, M.; Shin, Y.; Noh, Y.; Lee, S.; Lee, I. Machine Learning Approaches for Ship Speed Prediction towards Energy Efficient Shipping. Appl. Sci. 2020, 10, 2325. [Google Scholar] [CrossRef] [Green Version]
- Gonzalez, C.; Lund, B.; Hagestuen, E. Case Study: Ship Performance Evaluation by Application of Big Data. In Proceedings of the 3rd Hull Performance & Insight Conference, Durham, UK, 12–14 March 2018. [Google Scholar]
- ISO 19030; Ships and marine technology—Measurement of changes in hull and propeller performance. ISO: London, UK, 2016.
- Cepowski, T. The prediction of ship added resistance at the preliminary design stage by the use of an artificial neural network. Ocean Eng. 2019, 195, 106657. [Google Scholar] [CrossRef]
- Duan, W.; Yang, K.; Huang, L.; Jing, Y.; Ma, S. A DFN-based method for fast prediction of ships’ added resistance in heading waves. Ocean. Eng. 2020, 245, 110484. [Google Scholar] [CrossRef]
- Tarelko, W.; Rudzki, K. Applying artificial neural networks for modelling ship speed and fuel consumption. Neural Comput. Appl. 2020, 32, 17379–17395. [Google Scholar] [CrossRef]
- Lang, X.; Wu, D.; Mao, W. Comparison of supervised machine learning methods to predict ship propulsion power at sea. Ocean. Eng. 2022, 245, 110387. [Google Scholar] [CrossRef]
- Antonic, R.; Valcic, M.; Tomas, V. Ship speed prediction in real sea environment using advanced technologies. In Proceedings of the 11th WSEAS International Conference on Applied Computer and Applied Computational Science Conference, Rovaniemi, Finland, 18–20 April 2012. [Google Scholar]
- Bassam, A.M.; Phillips, A.B.; Turnock, S.R.; Wilson, P.A. Ship speed prediction based on machine learning for efficient shipping operation. Elsevier 2022, 245, 110449. [Google Scholar] [CrossRef]
- Brandsæter, A.; Vanem, E. Ship speed prediction based on full scale sensor measurements of shaft thrust and environmental conditions. Elsevier 2018, 162, 316–330. [Google Scholar] [CrossRef] [Green Version]
- Tran, T.A. Comparative analysis on the fuel consumption prediction model for bulk carriers from ship launching to current states based on sea trial data and machine learning technique. J. Ocean Eng. Sci. 2021, 6, 317–339. [Google Scholar] [CrossRef]
- Mittendorf, M.; Nielsen, U.D.; Bingham, H.B. Data-driven prediction of added-wave resistance on ships in oblique waves—A comparison between tree-based ensemble methods and artificial neural networks. Appl. Ocean. Res. 2022, 118, 102964. [Google Scholar] [CrossRef]
- Coraddu, A.; Oneto, L.; Baldi, F.; Cipollini, F.; Atlar, M.; Savio, S. Data-driven ship digital twin for estimating the speed loss caused by the marine fouling. Ocean. Eng. 2019, 186, 106063. [Google Scholar] [CrossRef]
- Yan, R.; Wang, S.; Du, Y. Development of a two-stage ship fuel consumption prediction and reduction model for a dry bulk ship. Elsevier 2020, 138, 101930. [Google Scholar] [CrossRef]
- Moreira, L.; Vettor, R.; Guedes Soares, C. Neural Network Approach for Predicting Ship Speed and Fuel Consumption. Mar. Sci. Eng. 2021, 9, 119. [Google Scholar] [CrossRef]
- Lee, J.B.; Roh, M.I.; Kim, K.S. Prediction of ship power based on variation in deep feed-forward neural network. Int. J. Nav. Archit. Ocean. Eng. 2021, 13, 641–649. [Google Scholar] [CrossRef]
- Kiriakos, A.E.P. Comparative evaluation of Machine Learning algorithms and Physical based models for the prediction of Vessel Speed in real life applications. In Proceedings of the PCI 2021: 25th Pan-Hellenic Conference on Informatics, Volos, Greece, 26–28 November 2021. [Google Scholar]
- Bellman, R. Rand Corporation. In Dynamic Programming; Princeton University Press: Princeton, NJ, USA, 1957. [Google Scholar]
- Shai, S.-S.; Shai, B.-D. Understanding Machine Learning: From Theory to Algorithms; Cambridge University Press: New York, NY, USA, 2014; ISBN 978-1-107-05713-5. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A.; Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning (Adaptive Computation and Machine Learning Series); The MIT Press: Cambridge, MA, USA, 2016; ISBN 0-262-03561-8. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study (Reference) | Aim | Method Used | Application System | Results/Conclusions |
|---|---|---|---|---|
| [14] | Validation of the SHOPERANTUA-NTU-MARIC (wave-added resistance prediction method. | Semi-empirical (SNNM) validated by Pearson’s correlation coefficient R and mean square error (MSE) | Model test results of 29 different type vessels | Pearson correlation Coefficient R equal to 0.86 and 0.94. The relative error distribution μ = 0.0% and σ = 2.0%. Furthermore, 75% of samples are within ±2% intervals, and 93% of the samples are within ±4%, while almost all sample points are within ±6%. |
| [15] | Simulation of optimal ship route with speed loss analysis in conditions including rough sea voyage. | Semi-empirical. Comparison of the results with measurement data | 28,000 DWT-class bulk carrier | Results vary with different weather conditions. Further validations are needed to produce more reliable simulations. |
| [16] | CFD prediction of a full-scale ship parametric roll in a regular head wave. | Reynolds-averaged Navier–Stokes (URANS) CFD, detached eddy simulation (DES), and large eddy simulation (LES). | Container ship | The occurrence of parametric roll can be simulated well, and the roll amplitude and period can be predicted accurately. |
| [17] | Semi-empirical model to estimate a ship’s speed loss at head sea. | A proposed theoretical weather factor prediction model | PCTC and a chemical tanker. | Sufficiently accurate approximations compared to the other existing well-known approaches. |
| [18] | Prediction of the added resistance and attainable ship speed under actual weather conditions | 2-D and 3-D potential flow method and CFD with unsteady Reynolds-averaged Navier–Stokes (URANS) | Container ship | Numerical results were found to agree reasonably well with the experimental data in regular head and oblique seas. |
| [19] | Estimation of the speed of a vessel in rough seas | Simplified analytical method | Container ship | Analytical approximation has room for improvement. |
| [20] | Analysis of the experimental results of the mean sway forces at low speeds in regular waves of various directions | Empirical formula | Six full-type ships | Empirical formula can satisfactorily capture the mean sway force acting on full-type ships, at both zero and non-zero low speeds. |
| [21] | Prediction of the propulsive power of ships and comparison with 1978 ITTC Performance Prediction Method | Combination of towing tank EFD testing and CFD (Reynolds-averaged Navier–Stokes (RANS)) | Fourteen common cargo vessels | Proposed method can provide immediate improvements to the 1978 ITTC Performance Prediction Method |
| [22] | Prediction of the wave-induced motions, and steady wave forces and moments in regular head and oblique waves | CFD Reynolds-averaged Navier–Stokes (RANS) | Oil tanker KVLCC2 | (1) The computed added resistance as well as the steady wave sway force and yaw moment with inertia effects due to the wave-induced motions agree well with the available experimental data. (2) The comparison of the computed resistances using two wave amplitudes indicates that added resistance is not proportional to the square of wave amplitude. (3) RANS solver can be used as a tool for ship seakeeping analysis. |
| [23] | Test case focused on the resistance and thedynamic behavior of the wing–vessel configuration in calm water conditions and in head waves. | Experiments conducted in the towing tank and CFD. | Ferry ship hull model | (1) Bow wing in static mode can be used for trim-control of a vessel by altering the angle of attack, leading to a possible drop in wave resistance both in calm water and in waves. (2) Utilizing the wing in head waves results in a significant reduction in the pitching and heaving responses of the vessel. |
| [24] | Trim Optimization in Waves | CFD simulation and use of JONSWAP spectrum to determine the individual wave components | AFRAMAX Tanker | There is an economic benefit in performing trim optimization studies for full hull forms, at least those sailing on longer routes. |
| [25] | Investigation of speed lost due to swell | CFD simulations using Stokes’ second wave theory | Capesize and Handysize vessel | (1) With a minimum warranted speed of 13 kn, speed loss of the Capesize vessel is 0.67 kn, while for the Handysize vessel, it is 1.85 kn. (2) More attention needs to be given to swell when observing the performance of a vessel. |
| Study (Reference) | Input Data Source | Input Data |
|---|---|---|
| [27] | Data acquisition system | Ship, engine data and environmental data from onboard sensors |
| [35] | AIS and noon reports | Ship operational data and metocean data |
| [38] | Experimental research | Geometric parameters |
| [39] | Experimental research and calculated data | Geometric parameters |
| [40] | Experimental research and sea trials | Ship operational data and metocean data |
| [41] | Data acquisition system | Ship operational data and metocean data |
| [42] | Database | metocean data |
| [43] | Data acquisition system | Ship operational data |
| [44] | Data acquisition system | Ship operational data and metocean data |
| [45] | Data acquisition system | Ship, engine data and metocean data |
| [46] | Calculated data | Geometric parameters |
| [47] | Data acquisition system | Ship, engine data and environmental data from onboard sensors |
| [48] | Noon Reports | Ship, engine data and metocean data |
| [49] | Simulated by route planning software | Engine data and metocean data |
| [50] | Database | Ship operational data and ocean environmental data |
| Study (Reference) | Preprocessing Approach |
|---|---|
| [27] | Feature selection driven by physical laws; data cleansing by operational limitations; data transformation based on physical laws; data normalization |
| [35] | Feature selection driven by physical laws; outlier detection and discarded based on the z-scores; data cleansing by operational limitations; correlation analysis |
| [38] | Feature selection driven by physical laws |
| [39] | Data transformation based on physical laws, added extra input layer |
| [40] | Data cleansing using clustering |
| [41] | Feature selection driven by physical laws |
| [42] | Feature selection driven by physical laws |
| [43] | Correlation analysis; feature engineering: data transformation based on physical laws; data normalization |
| [44] | Feature selection driven by physical laws; outlier detection and discarded based on the z-scores |
| [45] | Feature selection driven by physical laws; correlation analysis |
| [46] | Feature engineering; data transformation; data normalization |
| [47] | Data normalization; downsampling input data by calculating the average values |
| [48] | Feature selection driven by physical laws |
| [49] | Data transformation based on physical laws |
| [50] | Data transformation based on physical laws |
| Study (Reference) | Algorithm Used | Tuning/Hyperparameter Tuning |
|---|---|---|
| [27] | Random Forest, Linear Regression, K-NN, ANN, Decision Tree Regressor, AdaBoost | Yes/(Random) |
| [35] | Decision Tree Regressor, Random Forest Regressor, Extra Trees Regressor, Gradient Boosting Regressor, Extreme Gradient Boosting Regressor | Yes (k-fold) (Cross-validation) |
| [38] | Generalized Regression ANN (GRNN), Multilayer Perceptron (MLP), Radial Basis Function Network (RBF), Linear Network | Not Stated |
| [39] | Discrete Fracture Network | Not Stated |
| [40] | Multilayer Perceptron (MLP) ANN | Not Stated |
| [41] | Linear Regression, Support Vector Regression, Polynomial Regression, Generalized Additive Model, XGBoost, ANN | Yes (Grid search) |
| [42] | Adaptive Neuro-Fuzzy Inference ANFIS | Not Stated |
| [43] | Multiple Linear Regression, Regression Trees, Support Vector Regression, Gaussian Process Regression | Yes (Bayesian optimization) |
| [44] | Linear Regression, Generalized Additive Models, Projection Pursuit Regression | Not Stated |
| [45] | ANN | Not Stated |
| [46] | Random Forests, Extreme Gradient Boosting Trees, ANN | Yes (Bayesian optimization) |
| [47] | Deep Extreme Learning Machine ANN | Yes (Algorithm adopting) |
| [48] | Random Forests | Not Stated |
| [49] | Multilayer Perceptron (MLP) ANN | Not Stated |
| [50] | Deep Feed-Forward ANN | Yes (trial and error) |
| Study (Reference) | Validation | Verification |
|---|---|---|
| [27] | Extracted validation data set | MAE, MSE, RMSE, R2 (error less than 3%) |
| [35] | Extracted validation data set | Mean absolute percentage error of the Random Forest regressor = 7.91% |
| [38] | Extracted validation data set | MSE values between 0.98 and 1.1 comparisons with STAWAVE-2 |
| [39] | Extracted validation data set | RMSE (smaller approx. 10–12%) |
| [40] | Extracted validation data set | R2 > 0.95, 0.8–2.8% accuracy |
| [41] | Extracted validation data set | MAE, RMSE, R2 (XGBoost most stable and reliable predictive ability) |
| [42] | Extracted validation data set | RMSE = 0.161 |
| [43] | Cross validation | MAE, MSE, RMSE, R2 comparison |
| [44] | Cross validation | Linear regression and generalized additive models increased accuracy of 16 and 12% |
| [45] | Extracted validation data set | R2 > 0.9055 Comparison with simulation software |
| [46] | Cross validation | RMSE, MAE comparison Verified with numerical and experimental data |
| [47] | Extracted validation data set | Better prediction accuracy and reliability, with respect to the ISO 19030 |
| [48] | Cross validation | Comparison with real values |
| [49] | Extracted validation data set | RMSE, R2 comparison |
| [50] | Cross validation | Satisfactory accuracy using as input data only the information about the sea conditions |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alexiou, K.; Pariotis, E.G.; Leligou, H.C.; Zannis, T.C. Towards Data-Driven Models in the Prediction of Ship Performance (Speed—Power) in Actual Seas: A Comparative Study between Modern Approaches. Energies 2022, 15, 6094. https://doi.org/10.3390/en15166094
Alexiou K, Pariotis EG, Leligou HC, Zannis TC. Towards Data-Driven Models in the Prediction of Ship Performance (Speed—Power) in Actual Seas: A Comparative Study between Modern Approaches. Energies. 2022; 15(16):6094. https://doi.org/10.3390/en15166094
Chicago/Turabian StyleAlexiou, Kiriakos, Efthimios G. Pariotis, Helen C. Leligou, and Theodoros C. Zannis. 2022. "Towards Data-Driven Models in the Prediction of Ship Performance (Speed—Power) in Actual Seas: A Comparative Study between Modern Approaches" Energies 15, no. 16: 6094. https://doi.org/10.3390/en15166094
APA StyleAlexiou, K., Pariotis, E. G., Leligou, H. C., & Zannis, T. C. (2022). Towards Data-Driven Models in the Prediction of Ship Performance (Speed—Power) in Actual Seas: A Comparative Study between Modern Approaches. Energies, 15(16), 6094. https://doi.org/10.3390/en15166094