1. Introduction
Load forecasting generally refers to the future load forecast in a certain time range. The time span can be divided into short-term and long-term load forecasting. According to the forecast objects, one is the forecast of aggregation load, and the other is the forecast of individual user load: industrial and commercial load and residential load.
The differences in scenarios lead to different predicted objects. For aggregation load forecasting, the predicted object is the sum of loads of all users on a node or bus. The number of users owned by the power trading company is far less than that of all users on the bus. Even the load curve aggregated and superimposed by all users still has large randomness, so it is more difficult for the power trading company to predict the target in the mid-term and long-term. Therefore, the results of medium and long-term forecasts have little reference value for electricity sales companies.
This research focused on short-term load forecasting for individual users. Short-term load forecasting can assist power sales companies in buying electricity in the day-ahead market. The electricity price changes according to certain time intervals in the spot market, such as 15 min or 1 h. Therefore, the day-ahead load forecasting target is usually the load aggregated by users in 15 min or 1 h in the future, that is, the so-called 96-point or 24-point load curve. This load curve is an important reference for retailers to purchase electricity from the spot market [
1]. Accurate day-ahead load forecasting can better meet users’ electricity demand and reduce the risk of retailers purchasing electricity from the real-time market the next day. In addition, through short-term load forecasting, the user’s load in a few hours is known, and then users are selected to participate in demand response.
The difficulty of load forecasting mainly comes from the randomness of electricity consumption behavior. Because electricity consumption behavior is still random, the series lack stationarity when the load data are treated as time series for the time series analysis. Additionally, traditional linear models, such as multiple linear regression, ARMA, etc., are difficult to fit the high nonlinearity of load series. On the other hand, load forecasting is a regression problem. The difference between regression and classification problems is that image classification algorithms usually have interpretable feature extraction methods, such as convolution and pooling operations, to extract local features and combine them into whole features. At the same time, the samples of classification problems can often correspond to clear labels. In contrast, the regression problem does not have a feature extraction method with strong general interpretability and a definite mapping relationship from historical data to predicted values.
The data that can be used in load forecasting are historical load data. Exogenous variables such as temperature and weather also have an impact on the day-ahead load and should be considered when data exist.
In recent years, many researchers have proposed related methods for load prediction. These methods can be divided into two categories; one is the traditional regression prediction method.
For example, the gray forecast prediction method [
2,
3] was used to predict the total power consumption and industrial power consumption. Tingting Fand et al. [
4] proposed a multiple linear regression model and SARIMA model, and Genkin A et al. [
5] proposed a simple Bayesian logistic regression method. Logistic regression [
6], ridge regression [
7,
8,
9] and the least absolute shrinkage and selection operator (LASSO) [
10,
11] have also been used to predict power loads. Dorugade A V et al. [
12] proposed a new method for estimating ridge parameters in both situations of ordinary ridge regression (ORR) and generalized ridge regression (GRR). To accommodate high-dimensional data, kernel methods [
13,
14] are incorporated into LASSO. However, the existing time series regression methods are not suitable for the feature dimension of the data set. It is difficult to real-time forecast the rapidly changing data and achieve reasonable dimension reduction compression with complex characteristics and fast dynamic changes.
Another prediction method is based on a neural network [
15,
16]. Sepp Hochreiter [
17] and Jürgen Schmidhuber proposed a long short-term memory network (Long Short-Term Memory). The long interval in the sequence is effectively preserved through the cooperation of the input gate, forget gate, and output gate. To a certain extent, the problem of gradient disappearance is reduced. Ünlü, K.D. [
18] proposed a method to forecast short to midterm electricity load utilizing recurrent neural networks, and the forecasting results on the test set showed that the best performance is achieved by LSTM. However, this method is still subject to the LSTM model, and the LST-TCN model proposed in this paper performs better than LSTM.
Vaswani A et al. [
19] proposed the Transformer, a model architecture allowing for significantly more parallelization and can reach a new state of the art in translation quality on an attention mechanism. Cho K et al. [
20] proposed GRU as a variant of LSTM; GRU can achieve the same functions as standard LSTM. Because GRU replaces forget gates and input gates with update gates, it also makes decisions about input data and the input of the previous sequence item, which simplifies the unit structure and improves training efficiency. Aaron van den Oord et al. [
21] proposed WaveNet for speech generation. The TCN proposed by Shaojie Bai et al. [
22] refers to WaveNet’s 1-dimensional fully convolutional network. This paper sorts out the effects of this network model on several sequence problems. The author claims that the effects of TCN, the model’s parameters, and the training time are significantly better than those of circular neural networks in speech generation, machine translation, and other problems.
This paper selected the TCN model and considers its optimization in power forecasting. The user’s electricity consumption data depend on the user’s production and lifestyle, and a certain periodicity can be observed from the load sequence data. Moreover, people usually use the same electrical equipment at certain times of the day. Based on this, the model proposed in this paper needs to consider relatively stable long-term data and periodic short-term data, namely long-term TCN and short-term TCN. Finally, the two were combined to obtain a new model, called Long Short-Term TCN (LST-TCN).
In this paper, the load forecasting could be modeled as a supervised learning problem, and the data set could be captured for training and verification from the load time series using a sliding window. represents the ith sample in the data set, where is one predicted data point, and is the latest historical load for model learning.
Take day-ahead load forecasting as an example. As shown in
Figure 1, when the load on day
is predicted on day
, the load value on day
is missing. The lasted known load record point is the 24th hour on day
, and the time range of the load point to be predicted is from the 1st hour to the 24th hour on day
; thus, in this sample, the last time point of the data to be predicted and the last time point of the input data is 48 h apart. When making each training sample, this requirement should be met. The time point corresponding to the sample label is 48 h away from the last time point of the sample feature.
Training set establishes a mapping : from the input space to the output space , and then uses to predict the unknown load in practical application.
The proposed LST-TCN model refers to the 1-D fully convolution network, causal convolution, and void convolution structure, and the residual connection layer was added to the convolution layer. When predicting the final value, the model uses two networks to extract features from long-term data and periodic short-term data, respectively, and integrates the two features for calculation.
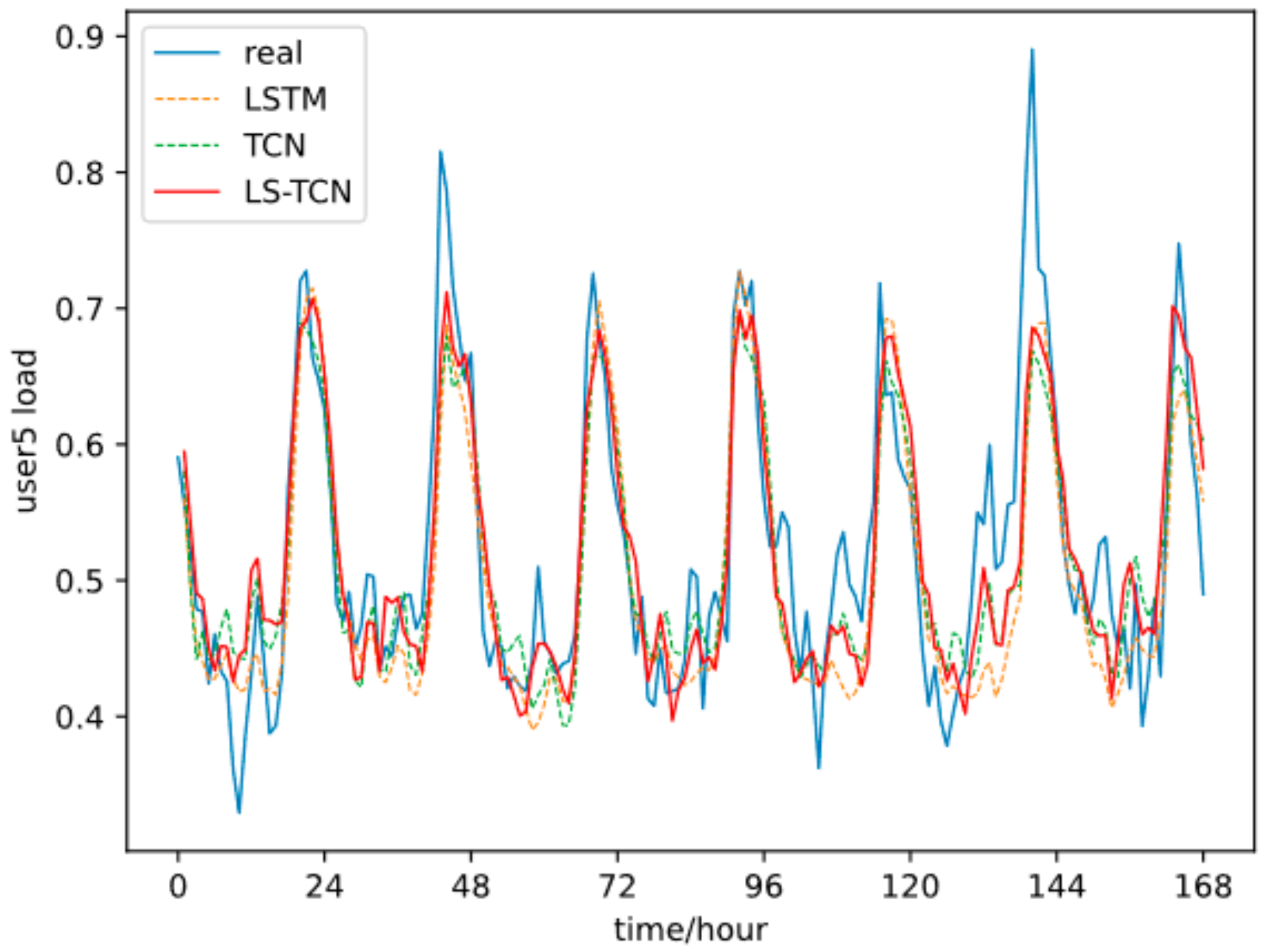
The authors qualitatively analyzed the trained LST-TCN by comparing its scores with those given by the existing translation model, such as LSTM and TCN. The qualitative analysis shows that the LST-TCN has better generalization effects and smaller prediction errors.
Our contributions are as follows:
The paper takes the periodicity of load sequence into account;
The paper provides an efficient model of short-term load forecasting;
The paper provides an experimental evaluation of using the framework and comparison with other models.
2. TCN Model
The cyclic neural network splits the input data into multiple time steps and calculates them chronologically. The output of each time step is affected by the hidden state of the previous time step. Models such as RNN, LSTM, and seq2seq are usually the first to model sequence data. LSTM solved the problems of vanishing gradient and gradient explosion to a certain extent through the gate mechanism. However, it is still difficult to deal with the dependence on long series, and the serial computing mechanism leads to slow speed.
The convolutional neural network is mainly used in the field of computer vision, and its advantage lies in its powerful image feature extraction ability. According to different input data forms, the convolution operation forms of 1-D convolution, 2-D convolution, and 3-D convolution correspond to 1-D, 2-D, and 3-D tensors. Causal convolution, dilated convolution, and other technologies are also proposed to achieve a specific convolution effect.
Using a one-dimensional convolutional network to process one-dimensional load sequence data was considered. This research point is based on the time convolutional neural network for load forecasting and can take advantage of the computational parallelism of the convolutional neural network and the perceptual field of vision superior to the recurrent neural network.
The so-called time convolution neural network is a type of network based on the convolution principle, suitable for processing time-series data. For example, Aaron van den Oord et al. proposed WaveNet [
21] for speech generation, and Colin Lea et al. [
23] used encoder and decoder networks to realize segmentation and recognition actions based on convolution structure. In 2018, the TCN proposed by ShaojieBai et al. [
22] referred to the 1-D full convolution network of WaveNet, causal convolution, and dilated convolution structure. The main difference is that the residual connection layer is added to the convolution layer; the paper organizes the effects of this network model on several sequence problems. The author claims that the effects of TCN on speech generation, machine translation and other problems, the parameters, and the training time of the model are significantly better than those of the circular neural network. The structure of each part of TCN is introduced below.
2.1. Causal Convolution
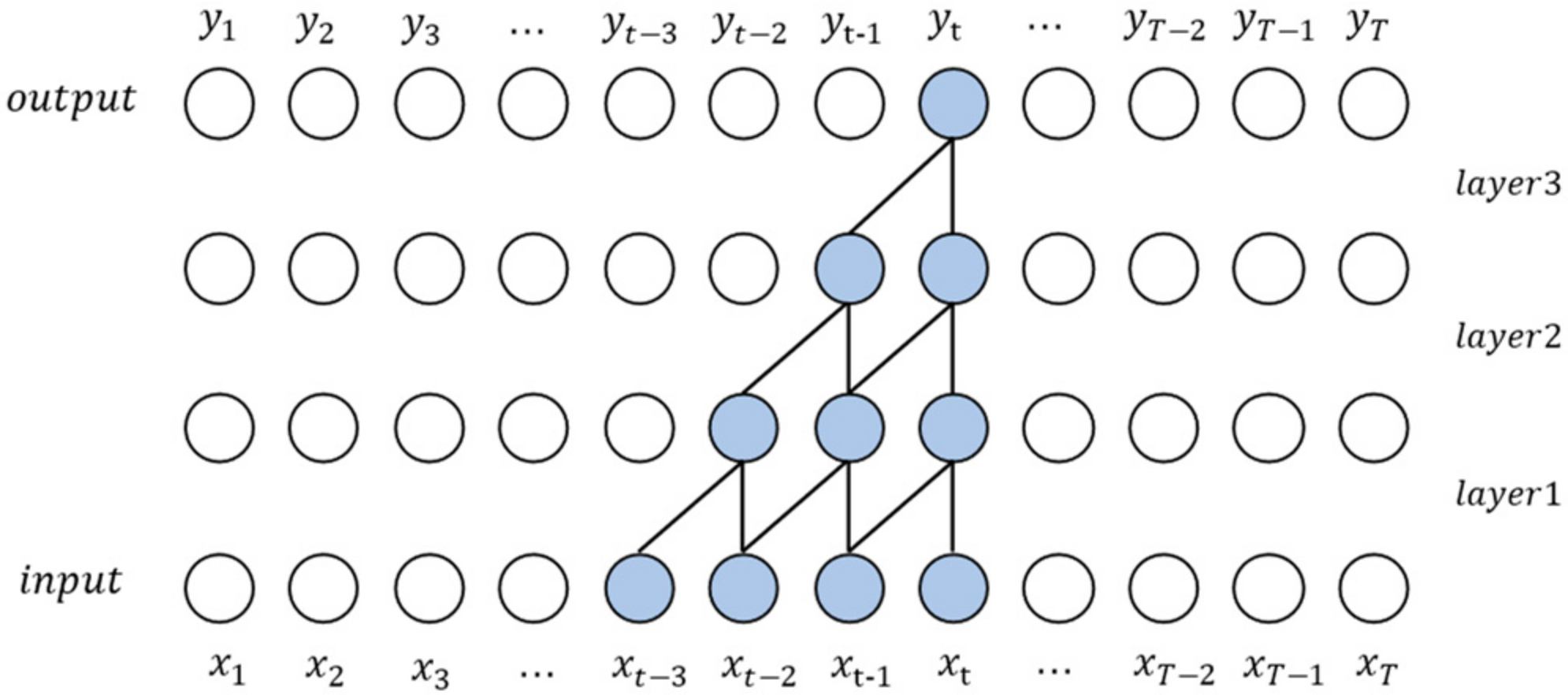
Similar to RNN, the sequence model needs to meet two principles: 1. The output length of the model is equal to the input length; 2. When processing the current time step, the leaked information of the future time step cannot be known. TCN uses a 1-D fully convolution network and padding to ensure that the length of each hidden layer is equal to that of the input layer. Causal convolution can ensure that future information does not leak from the past.
WaveNet is based on the concept of causal convolution, which inserts input sequence data
into the causal convolution network, and the output corresponding to each time step is
. The structure of causal convolution ensures that the output
at time t only depends on the input
and is not affected by
at time
and later.
Figure 2 shows the structure of multi-layer causal convolution with each layer padding on the leftmost side. The perceptual field of vision of
is
, where
is the number of network layers, and
is the size of the convolution kernel. The perceptual field of vision increases linearly by increasing the convolution kernel and deepening the network. When the length of the input sequence is long, for example, 1000, it is difficult to fully bring the input into the field of vision because the too large convolution kernel and the too deep network inevitably bring a huge number of parameters, and at the same time, the network that is too deep has problems such as gradient vanishing problem and gradient exploding problem during training.
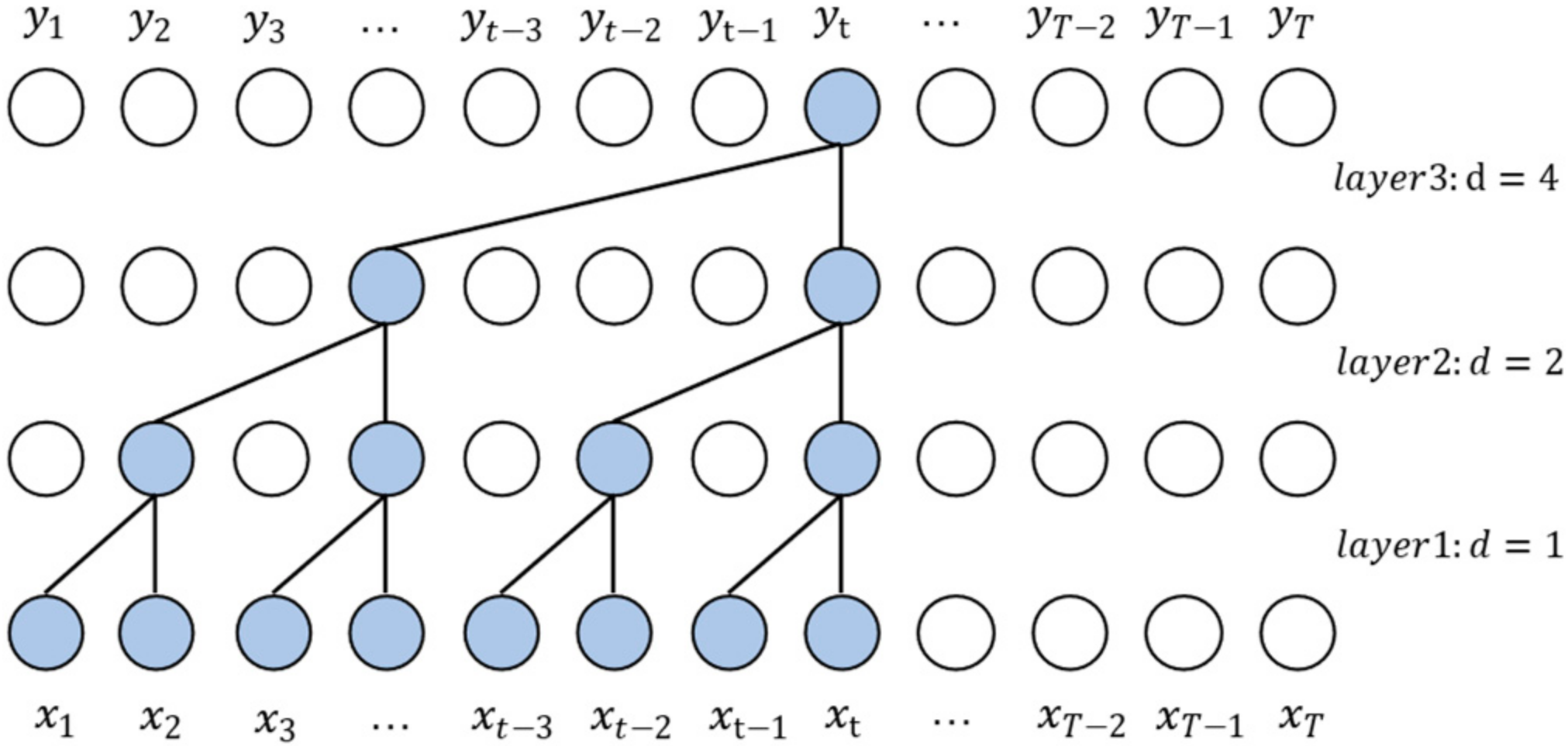
2.2. Dilated Convolution
In order to solve the problem of insufficient perception field of view, TCN uses dilated convolution. Dilated convolution is a type of convolution idea that is proposed for the problem of image semantic segmentation, which reduces the resolution of the image and loses information; by adding holes, the perceptual field of vision can be expanded. The convolution layer introduces a dilated rate parameter, which defines the size of convolution holes. For the 1-D sequence data
and filter
, the convolution result of the hole convolution operation
and the input sequence position
is defined as follows.
where
is the hole size and
is the convolution kernel size.
Figure 3 shows the structure of dilated convolution. In the multi-layer hole convolution network, the hole size in each layer increases exponentially with the number of layers in the network, the hole size in the first layer
, and the perceptual field of view =
. Therefore, only the network depth of
is needed to obtain the corresponding perceptual field of vision for sequences with length
For example, when the sequence length is 1024 and the convolution kernel
= 2, the number of network layers should be 12.
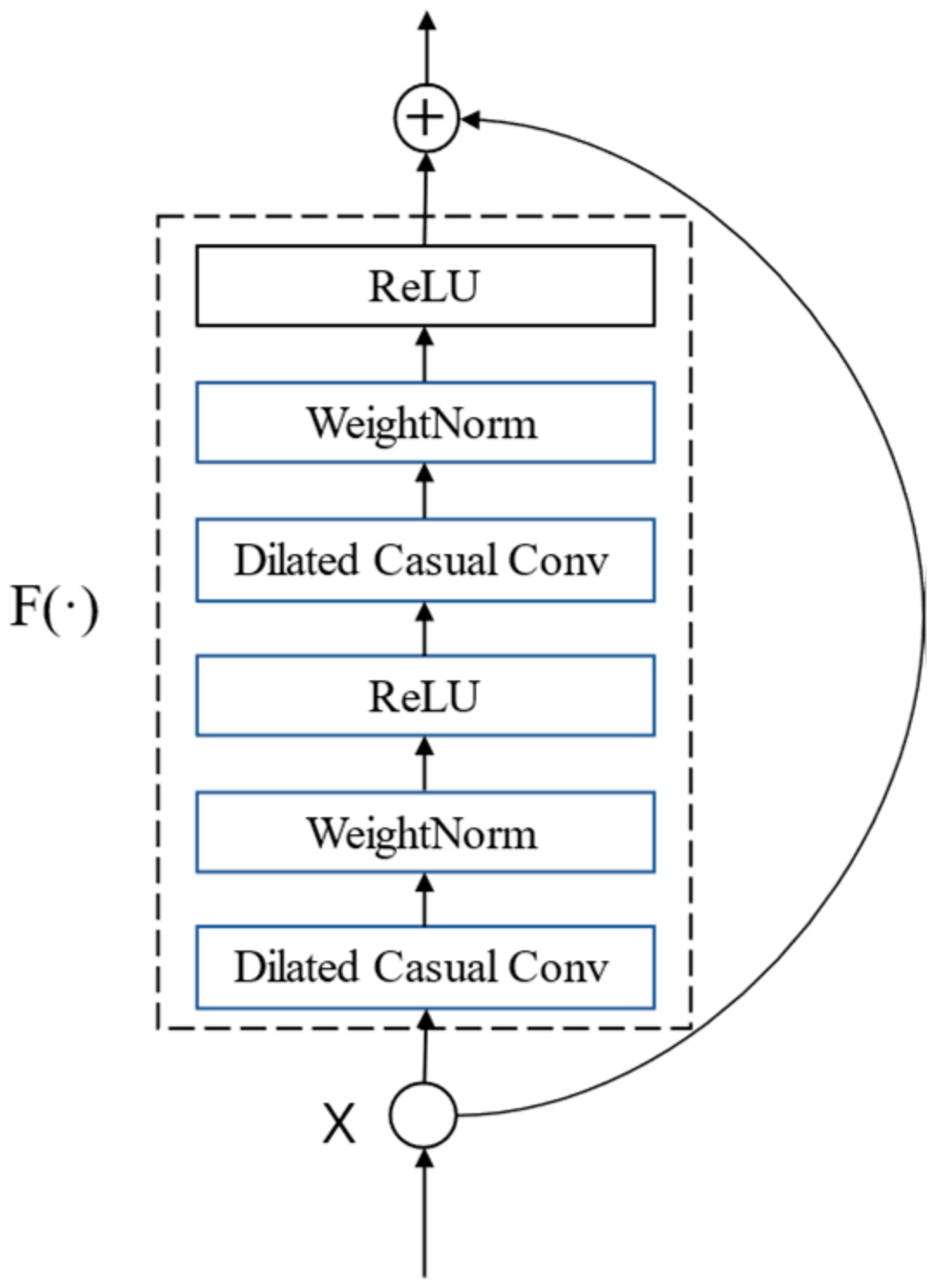
2.3. Residual Connection
With the deepening of the network, the difficulty of training the network increases, the network degenerates, and the accuracy of the training set decreases. He et al. invented the residual connection module to solve the problem caused by the increase in the number of network layers and applied it to ResNet to train a 152-layer convolutional network, refreshing the scoring record of CNN in ImageNet. For a stacked-layer structure, when the input is
, the learned feature is recorded as
, and now the residual
is hoped to learn because residual learning is easier than direct learning of the original features. As mentioned earlier, when the historical information with the length of
needs to be considered in the prediction result, a 12-layer network is needed to obtain the perception field of
, which is still a deep network, so residual connection is introduced for better training. The residual module is used to replace the original convolution layer in TCN. TCN residual module contains two layers of dilated residual convolution and ReLU activation function, as shown in
Figure 4.
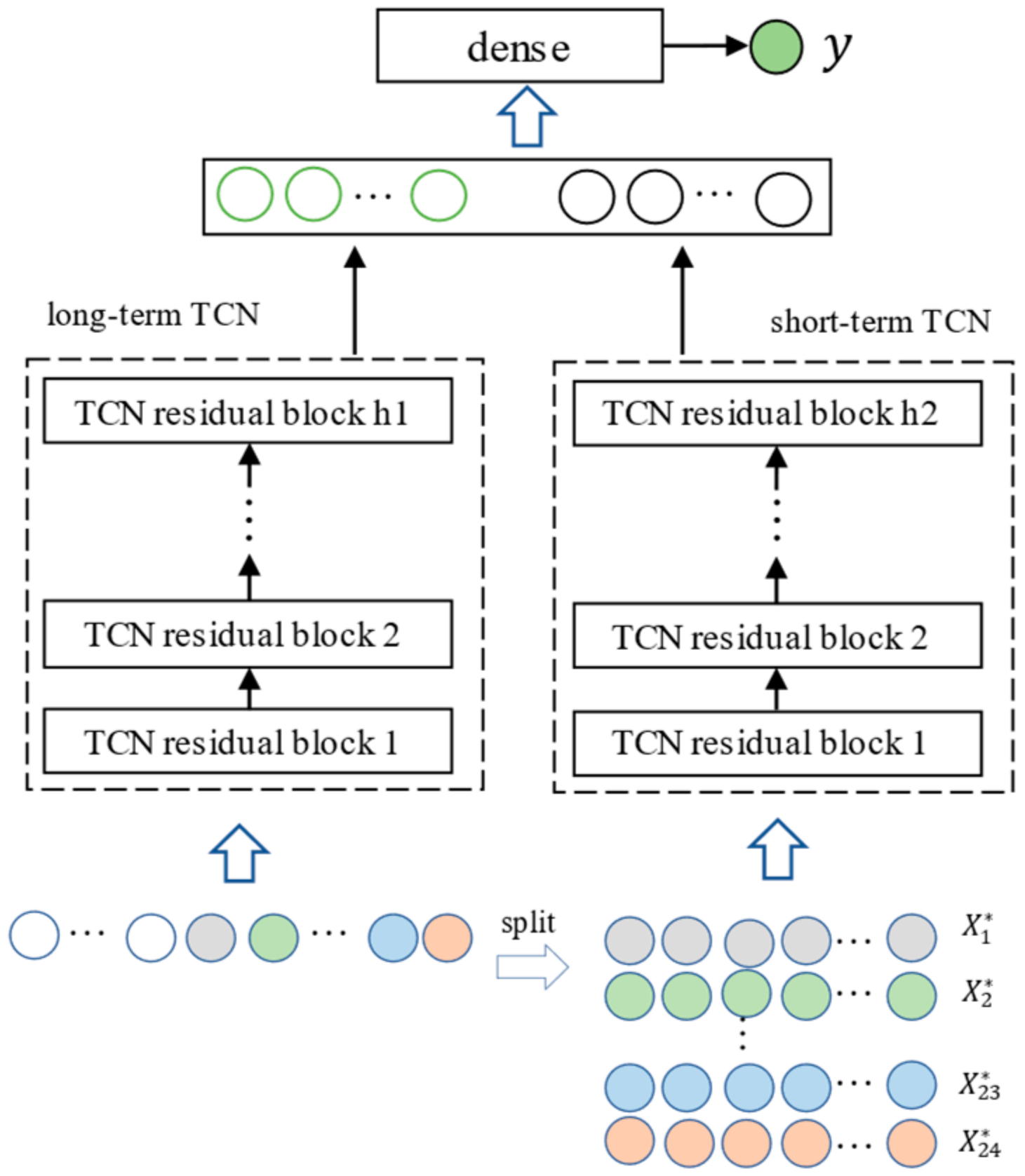
3. LST-TCN Module
The user’s electricity consumption data depend on the user’s production and lifestyle, and a certain periodicity from the load series data can be observed. For example, there is a big difference between the electricity consumption on weekends and that of the week in a weekly cycle due to vacations on weekends. The load at night is smaller than that in the daytime, and people usually use the same electrical equipment at a fixed time each day. Based on this, the proposed algorithm considers the daily periodicity of the load sequence, uses two networks to extract features from long-term data and periodic short-term data, respectively, and fuses the two features to calculate the final predicted value.
TCN receives one-dimensional sequence data and outputs a one-dimensional sequence through the dilated causal convolution and residual connection module. TCN can be used as an overall independent structure for processing sequence data to extract the sequence feature results.
Let the feature of a sample be , and the dimension of is , where represents the time step of the input data.
3.1. Long-Term TCN
The so-called long-term TCN is a TCN network that takes a complete as input to extract the long-term dependence of the input sequence data. There are not many skills in this part. Input directly into TCN, record the output as out, and the dimension of out as . Take the last time step out . According to the structural characteristics of TCN, vector has the ability and should consider the information of all time-steps of input data.
3.2. Short-Term TCN
As mentioned earlier, our forecast target is the value of the sequence at a certain time step in the future, that is, the load within a certain hour in the future. Because a day is the basic cycle of people’s activities, the electricity consumption behavior of a certain hour of the day is similar to the electricity consumption behavior of that period in the past. Split the input data into 24 sub-sequences , is composed of all the values of the ith hour in , and separately consider the influence of the sub-sequences corresponding to each hour to the predicted value. Input to into TCN, as with long-term TCN; take out the last time step of the output layer; and obtain 24 vectors, . The dimension of is .
3.3. LST-TCN Overall Structure
The feature vectors output by the long-term TCN and the short-term TCN can be concatenated into
, and the dimension of
is
. Input
to the fully connected layer and output the final prediction result
.
Figure 5 shows the overall structure of LST-TCN.
6. Conclusions
Day-ahead load forecasting can provide strategic support for electricity sales companies. Accurate load forecasting can be very important for decision makers in orderly electricity regulation and generation planning.
The existing TCN model has better prediction performance; the model’s parameters and the training time are significantly better than those of circular neural networks in speech generation, machine translation, and other problems. However, its power prediction can be improved to adapt to the power characteristics of the data.
In this paper, a neural network model called the LST-TCN model was proposed for short-term load forecasting. The proposed algorithm considers the daily periodicity of the load sequence, uses two networks to extract features from long-term data and periodic short-term data, respectively, and fuses the two features to calculate the final predicted value. The LST-TCN model often achieves a lower prediction error than the ones reported by other models on some selected samples.
Furthermore, the lack of rules for hyperparameter selection is the shortcoming of this model, and it is also one of the future research directions. Methods such as meta-heuristic algorithms can be considered for optimization. Extending LST-TCN to support more situations is also a direction for future work.
In conclusion, LST-TCN is a great choice for short-term electricity forecasting and power trading companies, and decision makers can benefit from the model.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}