1. Introduction
Electricity is a major infrastructural prerequisite for developing nations and a key factor in most human activities. Electrical energy can help flourish many other sectors such as food, health, education, security, transportation, and industrial production. Modern energy services are a vital driving force for economic development toward sustainable growth. The more efficiently a developing country is able to utilize available energy, the faster it will grow and achieve overall better progress. That is why the socioeconomic development of a nation is measured by per capita energy utilization. Statistically, 73.8% of global electricity output in 2018–2019 was from non-renewable energy sources, while only 26.2% from renewable sources [
1]. However, the trend toward clean energy is on a steady rise these days. In 2019, a high annual increase was recorded globally in renewable energy generation—almost 181 GW [
2]. Most of the mentioned percentage of renewable electricity was obtained from hydropower which generated 15.8%, with other sources including wind 5.5%, bio-power 2.2%, solar-PV 2.4%, and 0.4% from geothermal and concentrated solar power (CSP) [
3].
Wind is the most abundantly available natural energy resource, present everywhere and waiting to be harvested, providing the most reliable option for clean energy production [
4]. Wind speed and wind power can be estimated accurately if an appropriate dataset is available. The accuracy of wind speed and wind power estimation depends upon the quality of past data on wind speed and wind power at the given wind turbine (WT) site. The accurate estimation of WT output power requires careful consideration of stochastic factors such as wind speed and power coefficient (C
P). Different input factors are considered in the estimation, including wind speed, wind direction, temperature, air density, etc., but C
P has not been considered by most of the researchers. The main purpose of this study is to accurately estimate WT power output based on maximal stochastic factors. Wind energy is cheap and environment friendly. But efficiently use of wind as a viable source of energy requires accurate estimates of annual power output (kWh per year) to determine whether a particular WT will produce sufficient electricity to meet the relevant energy demand. Such estimations prove extremely helpful in power generation planning and energy management. They are also indispensable in the efforts to replace conventional non-renewable energy resources with multi-GW wind farms. However, the quality of such estimations depends on the availability of reliable and comprehensive data for the given WT site. Erroneous estimates due to unreliable datasets or wrong methodology can be detrimental to correct load management. Different input factors are used in the context of WT output power estimation, e.g., wind speed, air pressure, temperature, air density, WT characteristic curve, etc.
There are three primary types of methods of power estimation: physical, statistical, and learning [
5,
6,
7]. Physical methods rely on weather modeling to estimate effective wind speeds and then use WT characteristic curves for wind power estimation. However, this method requires considerable computation due to its computational complexity. Statistical methods use historical wind data, but this method is only effective for small datasets and a limited number of inputs. Learning methods establish the relationship between inputs and outputs using artificial intelligence, which makes these methods very useful and highly effective. Different deep learning algorithms are developed for this purpose and are widely used in a variety of applications [
8].
Several software solutions have been developed to study WT characteristics and behavior in different weather conditions using simulations and soft-computing algorithms. For instance, Jinhua Zhang et al. [
9] proposed a long short-term memory (LSTM) network algorithm using a deep learning network for short-term estimation of the output power of three WTs and used a Gaussian Mixture Model (GMM) for the uncertainty analysis of the WTs power while using wind speed and wind direction as input factors. A short-term network was trained in [
9] and employed the expectation-maximization (EM) algorithm for the estimation of parameters that were then used by the GMM. RNN was used for wind power estimation by Z. O. Olaofe et al. [
10], who estimated wind power generation in real-time over the one-hour horizon of up to 288 h ahead based on the time series data on a 1.3 megawatt (MW) WT, obtained from a 50 m hub, and using wind speed, wind direction, temperature, atmospheric pressure, wind distribution, and WT characteristic curve as input parameters. In [
10], the authors first calculated the electric power output of the WT generator relative to the efficiency of gearbox and generator, and then utilized the WT characteristic curve for the estimation. It is pertinent to mention that wind speed is the most used input parameter in wind power estimation because WT output power depends upon the cube of wind speed [
6].
In [
11], Iulian Munteanu et al. used a 24-h model-based wind park simulator to estimate the output power of an off-shore wind farm. The data used in the study was collected by meteorological masts, and the stochastic input parameters used in the estimation were wind speed and wind direction. The wake effect and effective wind speed for every turbine were considered while estimating the output power of each WT. However, [
8] made assumptions about certain parameters including the location of the WTs, the effect of park wakes, wind speed, pitch angle, and wind power. M. Hayashi et al. [
9] first estimated the wind speed, and then used that data to project WT power output using the Jacobian Matrix Estimation Method (JMEM). The time series analysis and estimation were done using the deterministic chaos approach (chaos fractal). The data structure was analyzed using fractal dimensional analysis and Lyapunov spectrum analysis. Another study [
12] used historical wind speed data collected from multiple areas around the targeted WT site and estimated wind speeds for periods from several hours to up to 24 h ahead. Next, the data were used along with the WT power curve for the estimation of the WT output power. As wind speed increases with altitude, the data used for the estimation of any WT’s output power should be in accordance with its hub height.
In [
13], a sparsified vector auto-regressive (VAR) model was introduced by Miao He et al. for the short-term estimation of a wind farm’s output power in a multivariate time series model developed by VAR for wind power generation. The sparse structure of the autoregressive coefficient matrix was taken into account while obtaining the parameters of the VAR model based on the most likely estimation of real-time measurement data. The authors of [
13] considered the hub height of a WT while collecting data and used wind speed and wind direction at that height to improve their estimation. They compared their results with autoregressive (AR) and multiple autoregressive (MAR) models and measured the accuracy of singular estimations relative to the mean absolute error (MAE), MAPE, and RMSE, and used continuous rank probability score (CRPS) for probability estimations. Saeed Zolfaghari et al. [
14] suggested that the estimation of a WT’s power output yields several inaccuracies if the characteristic curve provided by the manufacturer is used. Hence, they proposed a new method employing power probability distribution functions (PPDFs) instead of the characteristic curve when estimating the output power of a WT. First, the PPDFs-based actual data on speed and corresponding wind power for each WT is used to calculate the individual output power. Then, the output power of the wind farm is computed probabilistically by assigning statistical spatial distribution (i.e., Poisson distribution) for wind speeds over the wind farm based on the calculated PPDFs.
A method of short-term estimation of wind power was suggested by Shuang Hu et al. [
15], in which multivariate variables such as wind speed, wind direction, temperature, and air pressure were converted into low dimensional variables using a principal component analysis (PCA) to obtain a simplified network. Then, Elman artificial networks were used to train and optimize the network path, and final estimations were calculated. M. M. BA et al. [
16] measured wind speed frequency distribution using Weibull probability density function and assessed wind speeds based on experimental data collected over five years and estimated the output power of small WTs in urban areas. The authors used raw data on wind speed and wind direction recorded using data loggers, which they then compared to experimental results using RMSE. Mantas Marciukaitis et al. [
17] used five months of data on the direction and speed of wind to determine a WT power curve using a non-linear regression model and concluded that wind direction was not a significant factor in terms of accuracy of the estimation [
17].
In [
18], 24-h input data on wind speed and power measured in 10-min intervals were used by G.W. Chang et al. for short-term estimation of wind speed and wind farm power, which employed an improved radial basis function neural network-based model with an error feedback (IRBFNN-EF) scheme. They verified the accuracy of the method using MAPE and RMSPE, and compared their results with other neural network methods. In [
19,
20], Aamer Bilal Asghar et al. used aerodynamic simulations in FAST code, and estimated WT C
P and effective wind speed, respectively, using TSR, β, and rotor speed as input parameters processed in an adaptive neuro-fuzzy inference system (ANFIS). In [
21], the author estimated optimal rotor speed for MPPT of a variable-speed WT using previously estimated effective wind speed.
As follows from the above analysis, WT mechanical power has already been well explored and estimated using input factors such wind speed, wind direction, WT characteristic curve, temperature, pressure, and wind distribution. There is no doubt that wind speed is the most important factor in the calculation of the WT mechanical power as the output power is directly proportional to the cube of wind speed. However, as wind speed data is recorded by an anemometer placed on the nacelle, the wind reaching the anemometer is turbulent as it first passes through the WT blades. Thus, the recorded wind speed data cannot be considered highly accurate. The same goes for wind direction, because wind direction data are recorded by a wind vane which is also placed over the nacelle, beside anemometer, and faces the turbulent wind coming from the WT blades. WT characteristic curve is also unreliable in terms of WT output power estimation as such information is provided by the WT manufacturer and gathered in controlled environmental conditions, without considering any practical issues such as stochastic weather conditions that may include wind gusts and sudden variations in wind speed [
22].
Incident wind power depends on air density, rotor swept area, and the cube of effective wind speed. A WT converts this incident wind power into mechanical power, where the ratio of this mechanical power and incident power is CP and never exceeds a certain limit. The power coefficient is expressed as a non-linear function of tip speed ratio (TSR) and collective blade pitch angle (β). TSR is the ratio of the instantaneous velocity of the rotor blade tip to the wind speed. CP reaches its maximum value CPmax at the optimum value of TSR (λopt), i.e., the optimal operating point of the WT. This means that a change in wind speed can cause a change in TSR and β, which in turn can affect CP.
It can therefore be concluded that the mechanical power of a WT depends on two variables that are constantly changing, i.e., wind speed and CP. This is exactly why the WT output power is so difficult to estimate and why electricity generated by WTs is relatively hard to manage. The accuracy of wind speed and wind power estimations depends on the quality of historical wind speed and wind power data collected at the given WT site.
Hence, unlike other works discussed above, this paper proposes a methodology that includes PM estimation using additional stochastic input factors including wind speed, rotor speed, collective pitch angle, and power coefficient of WT. Different variants of neural networks are employed for this purpose in MATLAB to conduct simulations and compare results. The main features of the proposed methodology are as follows:
This study presents the optimal selection of several hidden layers, activation functions, and learning rates to achieve the best performance of FFBPNN and RNN.
It is characterized by very low computational complexity.
It does not require environmental inputs such as air pressure, temperature, air density etc., which reduces sensor cost as well as overall system complexity.
The following text is organized as follows: The basic working concept of WTs and characteristics of NREL 5 MW offshore WTs with the dataset are explained in
Section 2.
Section 3 elaborates the basic concepts of FFBPNN and RNN. Results and discussion are presented in
Section 4. Finally,
Section 5 summarizes the work and outlines future research directions.
4. Results and Discussion
The output power estimation was performed for a NREL 5 MW WT using 2297 data samples. Four nonlinear parameters were selected as inputs due to their stochastic nature and included wind speed, rotor speed, pitch angle, and power coefficient of the WT. Results were collected through MATLAB simulations.
The PC used for this purpose was Intel® Core™ i5-7200U CPU at 2.50 GHz (4 CPUs), ~2.7 GHz with 8 GB RAM, and Windows 10 Pro operating system. Each network was trained under five different conditions based on the number of hidden layers and activation functions assigned to each hidden layer, at four different learning rates; thus, generating twenty different results for each variant. The input layer in each case consisted of four nodes as four nonlinear parameters were used in the training, i.e., wind speed, angular speed of the rotor, blade pitch angle, and power coefficient of the WT. There were no weights, biases, or activation functions associated with this layer because the function of this layer was only to transfer input data to the hidden layers. The output layer in each case contains one node with a linear activation function.
The training conditions designed for the estimation were as follows:
Case 1: The network consisted of two layers, i.e., one hidden layer with 100 nodes and a single-node output layer. The hidden layer was assigned a tan-sigmoid (tansig) activation function.
Case 2: A three-layer network was designed with 100 nodes in the first hidden layer and 50 nodes in the second hidden layer. The activation functions assigned were tansig and logsig, respectively. The output layer contained a single purelin node.
Case 3: The network consisted of a four-layer network. The first hidden layer contained 100 tansig nodes, the second hidden layer contained 50 logsig nodes, and the third hidden layer contained 25 tansig nodes. The output layer had a single purelin node.
Case 4: This was similar to case 3 with one alteration, i.e., the second hidden layer was assigned with a tansig activation function, and the third hidden layer was assigned with a logsig function.
Case 5: The designed network contained five layers with four hidden layers and an output layer. There were 100 nodes in the first hidden layer, 50 nodes in the second hidden layer, 25 nodes in the third hidden layer, and 12 nodes in the fourth hidden layer. The first and second hidden layers were assigned with a tansig activation function, and a logsig activation function was assigned to the third and fourth hidden layers. The above five cases are summarized in
Table 3.
Each case was repeated at four different learning rates, i.e., 0.05, 0.03, 0.01, and 0.005. Thus, 20 results were recorded for each variant, yielding a total of 40 outcomes. Both networks were trained for 10,000 epochs under similar conditions and their performance was compared using MAPE and RMSE the primary testing factor and training time as the secondary factor. The target error was set to e
−7 in each case, and the criterium for ending the training (learning) process was either the achievement of the target error or the completion of 10,000 epochs, whichever came first. Each network was trained using the SCG algorithm due to its smaller memory requirement. The Levenberg-Marquardt (LM) algorithm is faster than SCG, but it is only feasible for smaller data samples (i.e., about 100) and also requires more memory [
50]. The Bayesian regularization (BR) algorithm is suitable for the small and noisy datasets and requires more training time.
Therefore, SCG was selected for this study. The MAPE and RMSE values were calculated while training the network, in each case to check the training performance of the respective network. After training the network with 70% data, a remaining 20% of the data was used to test the network performance, and the last 10% to validate and test of the calculated MAPE and RMSE values. The results recorded for each case are discussed below.
Case 1:
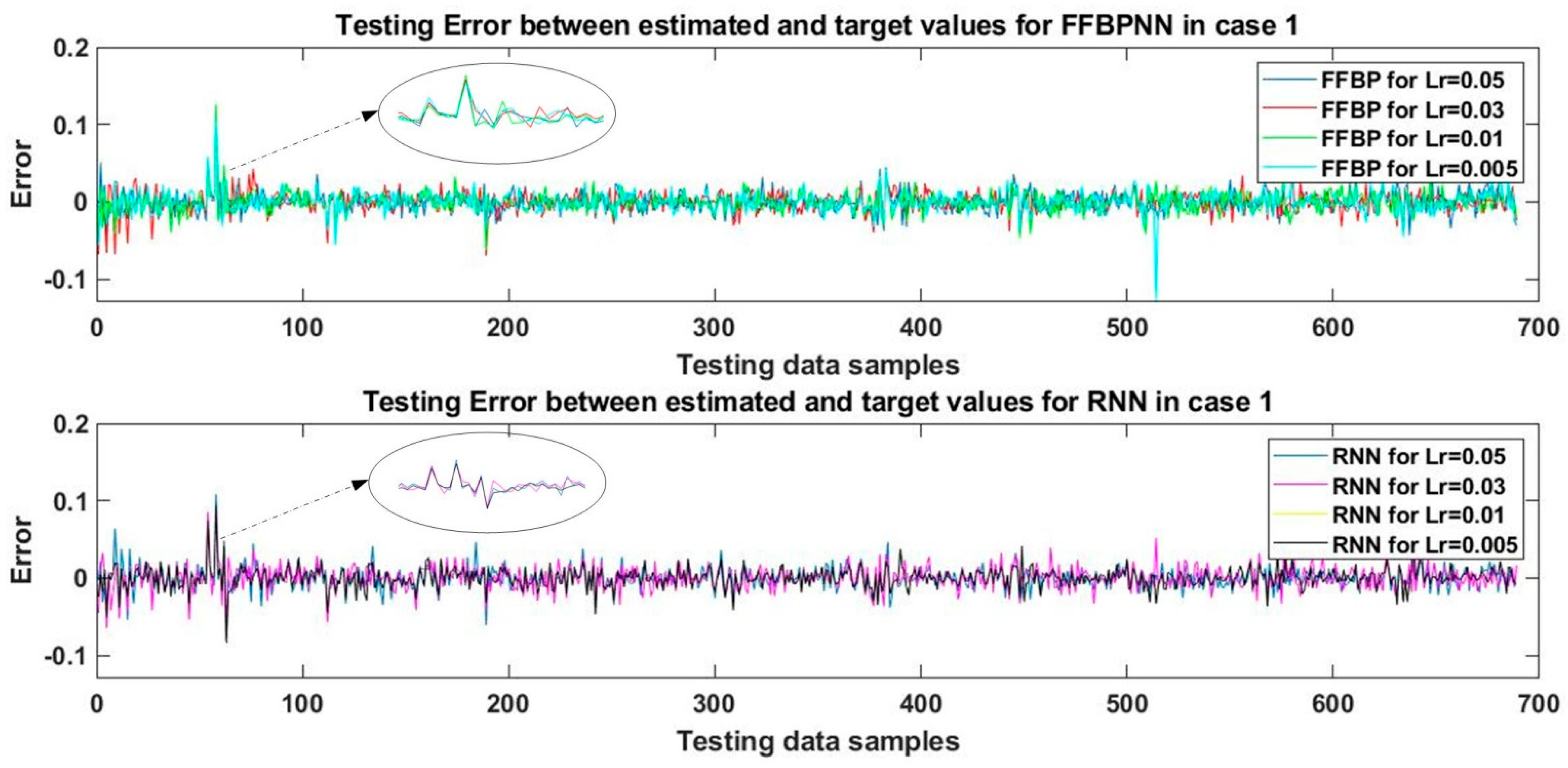
In the first case, a two-layered network was designed for FFBPNN and RNN with 100 tansig nodes in the hidden layer and one purelin node in the output layer. Both networks were trained at four learning rates, i.e., 0.05, 0.03, 0.01, and 0.005. The networks were trained with approximately 70% of the training data samples for 10,000 epochs, then tested with 20% of the testing data samples and validated using the remaining 10%.
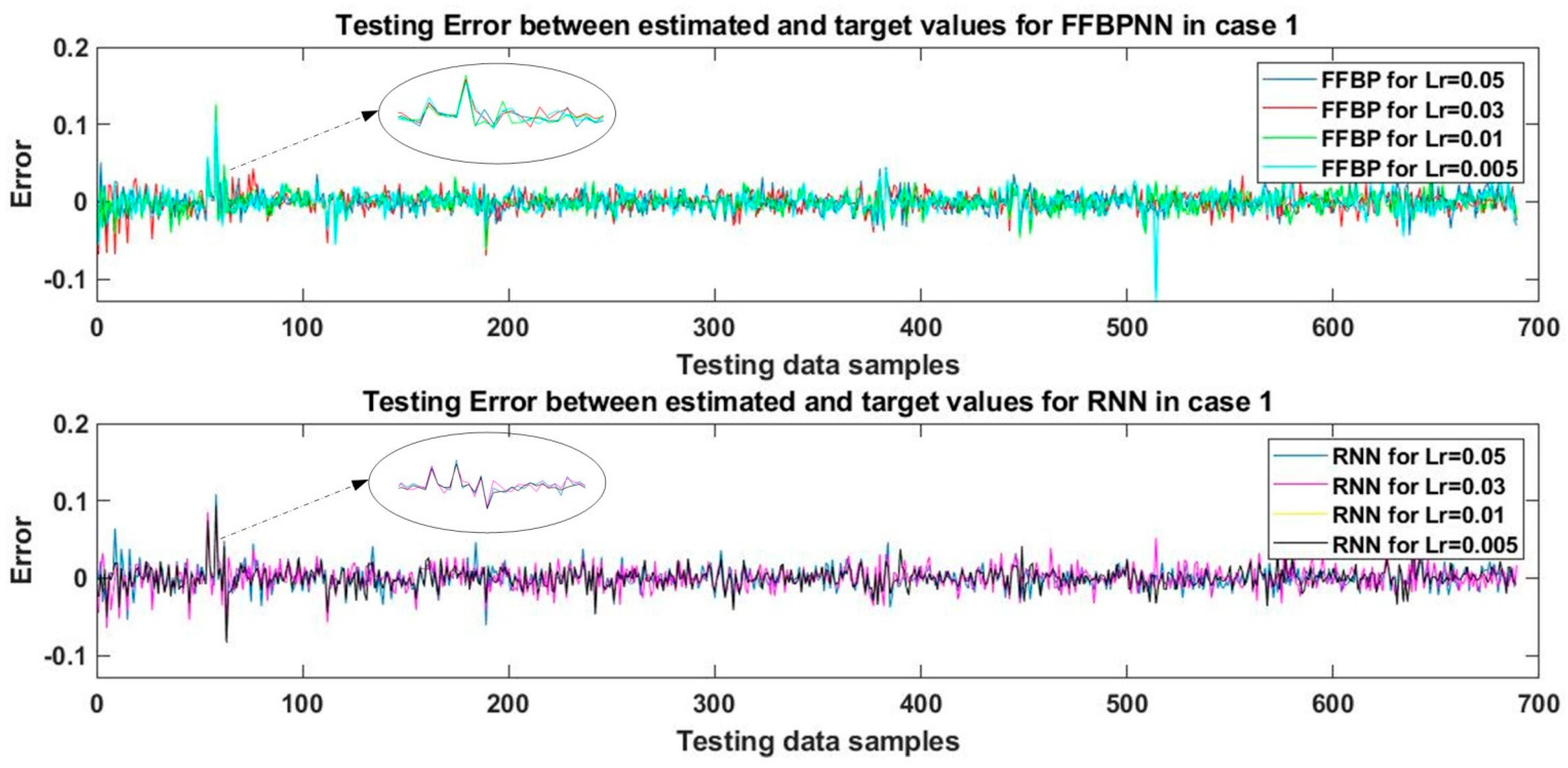
The trained network was tested using the
sim command in MATLAB to obtain the estimated values of WT output mechanical power. The estimated values were then compared to the actual values of output mechanical power in test data samples, and errors were plotted in
Figure 4. The performance of the networks was verified by calculating the MAPE and RMSE for the estimated test data results-the results are shown in
Table 4. It can be seen that the test MAPE of 5.59% was the lowest in the case of FFBPNN for the learning rate of 0.005.
The RMSE of 1.32% was the lowest in the case of FFBPNN for the learning rate of 0.01. RNN showed the best performance with the MAPE score of 6.69% and the corresponding RMSE of 1.56%, for the learning rate of 0.05. With RMSE of 1.35%, RNN performed best for the learning rates of 0.01 and 0.005, but shorter training time is required for the learning rate of 0.01, which is why this learning rate was preferable. In terms of MAPE, the training time for the learning rate of 0.005 in the case of FFBPNN was also shorter, hence, this learning rate was selected for training.
It is evident that for a two-layered network trained with the SCG algorithm, the learning rate of 0.005 yielded the best performance for FFBPNN in terms of testing MAPE, while for RMSE, the learning rate of 0.01 returned the best performance for both FFBPNN and RNN, but FFBPNN performed better than RNN in terms of testing RMSE and training time. FFBPNN also outperformed RNN regarding training time. Hence, FFBPNN proved overall superior to RNN in this case.
Case 2:
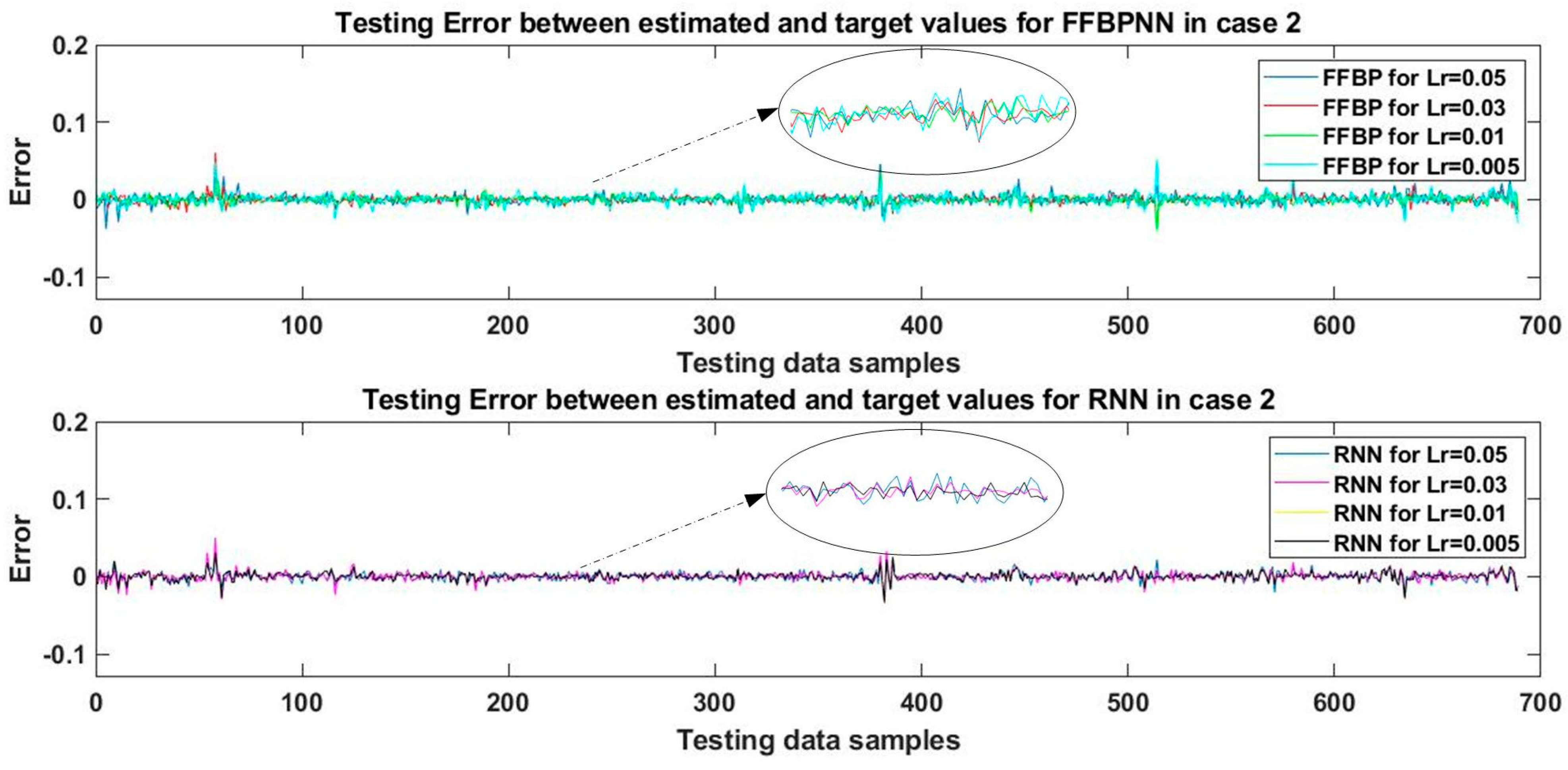
Three-layered FFBPNN and RNN models were designed for this case. Each network contained 100 tansig nodes and 50 logsig nodes in their first and second hidden layers, respectively. Both networks contained a single node in the output layer with a linear activation function. Both networks were trained with the SCG algorithm using training data samples for 10,000 epochs and the training process was repeated at four learning rates. The eight trained networks were then tested against the test data samples, validated, and the estimated values of WT mechanical output power were generated. The estimates were then compared to the target values of mechanical power, and the inconsistencies between estimated values and the target values are plotted in
Figure 5. The performance estimate was verified by calculating the MAPE and RMSE between the estimated and target values of the test data, and the results are presented in
Table 5.
It can be observed by comparing
Table 4 and
Table 5 that increasing a hidden layer in the network substantially improved the results, i.e., MAPE and RMSE values were significantly decreased. In the case of FFBPNN, the best result for testing data with the lowest RMSE of only 0.49% was recorded at learning rate of 0.01. In terms of MAPE, the best result for FFBPNN was achieved at the learning rate of 0.03, where MAPE was 2.19%. The RMSE of 0.49% for testing data was significantly lower than the lowest value of RMSE achieved in case 1, i.e., 1.32%recorded at the learning rate of 0.01 but the training time was increased in this case. MAPE also improved as compared to case 1 where it was 5.59% for the learning rate of 0.005. In the case of RNN, the best result was recorded for the learning rates of 0.01 and 0.005 where the value of RMSE was 0.52%.
For MAPE, RNN showed better result as compared to FFBPNN for the learning rates of 0.01 and 0.005, but the training time for the learning rate 0.01 is shorter, rendering this result better. It is very interesting to observe that for RNN, in case of the learning rates of 0.01 and 0.005, other test and validation parameters such as gradient, MAPE, and RMSE were similar, but the training time required at the learning rate of 0.005 was approximately eight times longer relative to the learning rate of 0.01.
This shows that the learning rate can significantly affect the training time of the network. Hence, the learning rate should be chosen wisely. In
Figure 5, the yellow and black graphs representing the learning rates of 0.01 and 0.005 for RNN overlap completely, that is why the yellow graph is not visible. This verifies the data shown in
Table 5. Consequently, in this case, FFBPNN showed better performance (for RMSE) than RNN, while RNN performed better in terms of MAPE.
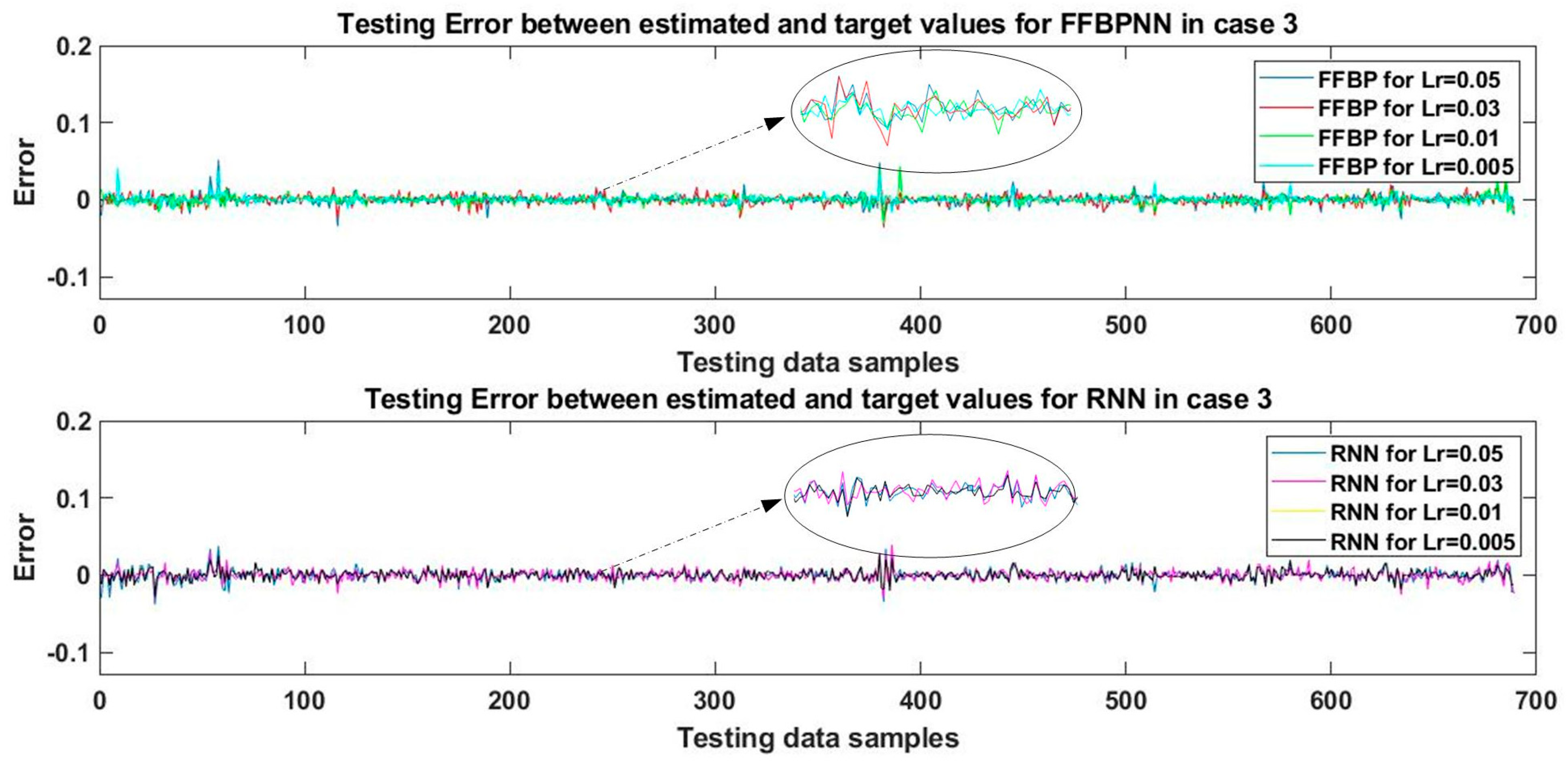
Case 3:
In this case, a new hidden layer with 25 nodes was added in both networks. Thus, each network consisted of four layers. The first, second, and third hidden layers contained 100, 50, and 25 nodes, respectively, and the activation functions assigned were tansig, logsig, and tansig, respectively. The output layer contained a single purelin node. The networks were trained with the SCG algorithm at four different learning rates and the training continues for 10,000 epochs.
After training, the networks were tested against the 465 test data samples and validated using the sim command in MATLAB to obtain the estimates. These estimations were then compared to the target values of the test data samples and the errors were plotted in a graph, as shown in
Figure 6. The RMSE and MAPE of the test results were calculated and presented in
Table 6.
In the case of FFBPNN, the best result was obtained for the learning rate of 0.005 with the RMSE of 0.55%. The best result for MAPE, i.e., 1.9%, was recorded for the learning rate of 0.01. For RNN, the best performance was achieved at the learning rates of 0.01 and 0.005, where RMSE was 0.59%, and MAPE was 2.18%, achieved for the learning rate of 0.01. Again, it can be observed that in the case of RNN, the network’s behavior was similar to case 2. In both instances, at the learning rates of 0.01 and 0.005, the values of gradient, testing, and validation results for RMSE and MAPE were the same.
For the learning rate of 0.005, approximately six times more training time was required with no improvement in performance. Those data can also be verified against
Figure 6, where the yellow graph for the RNN learning rate 0.01 and the black graph for the RNN learning rate 0.005 overlap completely. Therefore, the yellow graph is not visible in
Figure 6. The learning rate of 0.01 appears to have been the best choice for both FFBPNN and RNN in the case of MAPE. From these results, it can be concluded that FFBPNN performed better in this case in terms of both MAPE and RMSE.
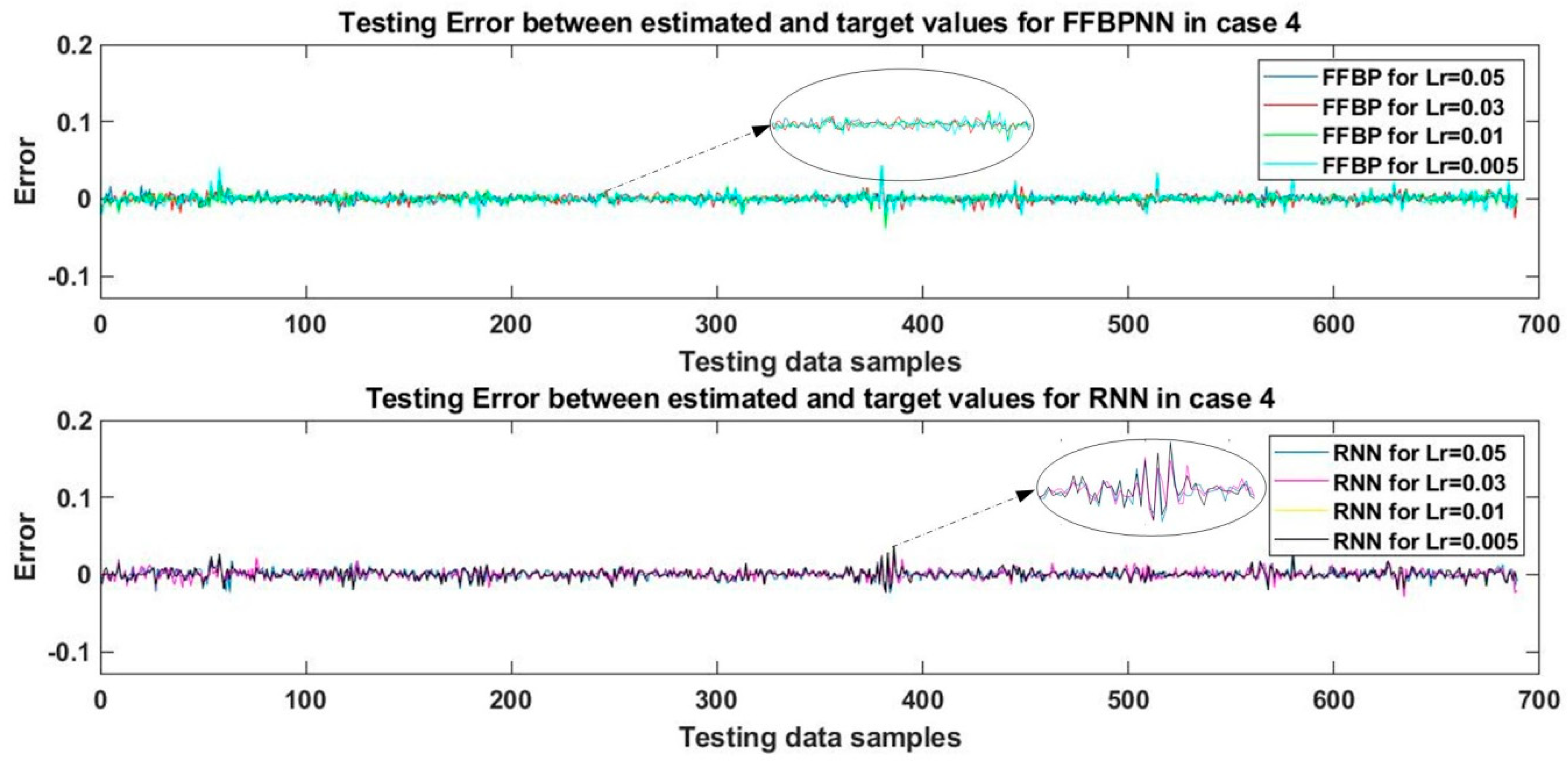
Case 4:
The networks designed in this case contained four layers each. The first and second hidden layers contained 100 and 50 tansig nodes, respectively. The third hidden layer contained 25 nodes with a log-sigmoid activation function, and the fourth layer was the output layer with a single purelin node. The networks were trained using the SCG algorithm for 10,000 epochs at the four learning rates mentioned above.
After training, the networks’ performance was tested and validated, and the estimated WT mechanical output power was calculated. The results were then compared to the actual values of WT mechanical output power from the test data samples, and the errors were plotted in the graph shown in
Figure 7. The value of RMSE relative to the estimated and actual values of WT mechanical output power was calculated for every tested network and the results are presented in
Table 7.
The results displayed in
Table 6 and
Table 7 are for networks with a similar number of hidden layers, the same number of nodes in each layer, and trained with the same algorithm for an equal number of epochs. There was only one difference between these two cases, i.e., the assigned activation functions. Specifically, the activation functions for the second and third hidden layers in the respective cases were swapped. By comparing the data in
Table 6 and
Table 7, it can be observed that the results improved in case 4 for both FFBPNN and RNN. This shows the importance of assigning activation functions to each layer of the network. In the case of FFBPNN, the best performance was achieved at the learning rates of 0.05 and 0.01 where the value of RMSE was 0.5%. Of the two, the training time for the learning rate of 0.01 is lower, hence was preferable. The best value of MAPE (1.33%) was also achieved for the learning rate of 0.01. In the case of RNN, the best performance with RMSE of 0.6% and MAPE of 2.69% was recorded for the learning rate of 0.03. Once again, a repetition of RNN results for the learning rates of 0.01 and 0.005 was observed. This behavior was also verified with the graph shown in
Figure 7, where the yellow and black graphs representing the learning rates of 0.01 and 0.005, respectively, overlap in the case of RNN, hence rendering the yellow graph invisible. This behavior shows that for cases 2, 3, and 4, decreasing the learning rate does not affect the output of the RNN network. Overall, FFBPNN outperformed RNN in this case.
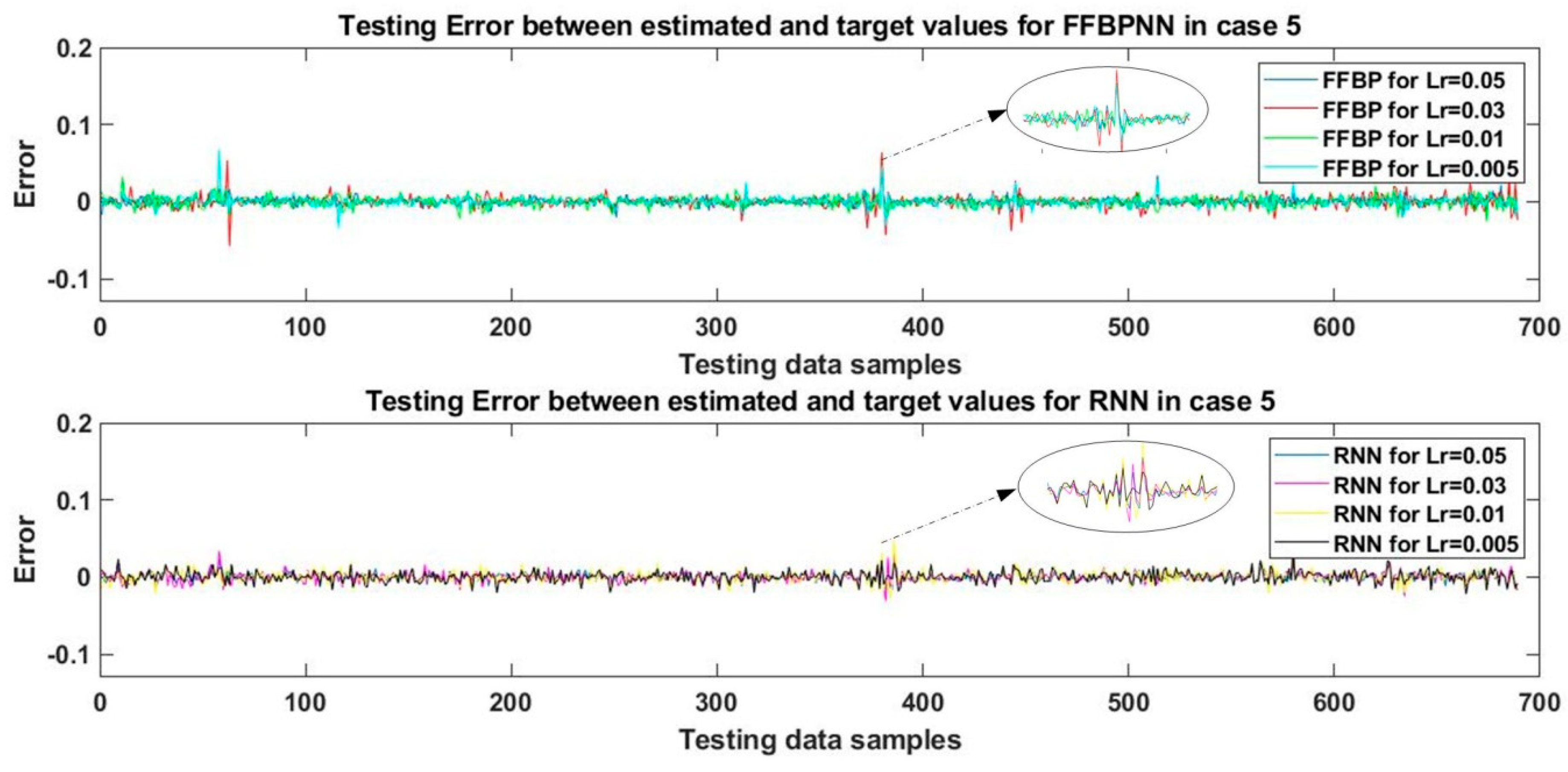
Case 5:
In the final case, five-layered networks were designed for FFBPNN and RNN. The first and second hidden layers contained 100 and 50 nodes, respectively, with a tan-sigmoid activation function, and the third and fourth hidden layers contained 25 and 12 nodes, respectively, with a log-sigmoid activation function. The fifth layer was the output layer with a single purelin node. The training process in both networks was repeated at four learning rates. The networks were trained using the SCG algorithm and the performance of every trained network was tested and validated to obtain the estimated value of WT output mechanical power. This estimated result was then compared to the actual values of mechanical power and the errors were plotted in the graph shown in
Figure 8. The performance of the networks was evaluated by calculating RMSE and MAPE in each case. The training and testing results are shown in
Table 8.
In the case of FFBPNN, the best performance was achieved for the learning rate of 0.05 where the value of RMSE was 0.56%. The best result for MAPE was 1.81% recorded at the learning rate of 0.03. The second-best performance, in this case, was observed for the learning rate of 0.005 with the RMSE value of 0.62%. Although there was a 0.06% performance discrepancy, the corresponding difference in training time was quite substantial. The training time for the learning rate of 0.05 was forty times longer than that in the case of 0.005.
Thus, in this case, a 0.06% error can be absorbed if training time is a critical factor. to the ultimate choice will depend on the priorities applicable to the given practical situation. In the case of RNN, the best performance with the lowest value of RMSE (0.55%) was achieved for the learning rate of 0.05. This was the only case where RNN actually outperformed FFBPNN by 0.01%, with a training time for the learning rate of 0.05 approximately twenty times shorter compared to FFBPNN. In terms of MAPE, RNN yielded the best result for the learning rate of 0.05, with MAPE at the level of 2.86%, which was higher than the 1.81% observed in case of FFBPNN.
As follows from the above discussion, FFBPNN performed better in the first four cases, while RNN yielded better results only in the last case, with a 0.01% improvement in RMSE value. As for MAPE, FFBPNN also performed better in four out of the five cases.
Table 9 summarizes all the results sorted by the learning rate. It must be noted that the performance of different NNs depends upon the complexity of the dataset, so these results can only be generalized for cases where there are four input parameters and a single output variable. Based on the above, it can be concluded that the performance of the NNs depended on various factors that include several hidden layers, assigned activation functions, and different values of learning rates. The number of nodes assigned to each layer also affected the performance, but this aspect was not considered in this study and will be elaborated in future research.
Five different cases were examined with a view to finding the best estimation achievable using two different NN variants, i.e., FFBPNN and RNN. The effect of changing the number of hidden layers was best observed in case 1 and case 2 where the network performance in the second case improved by over 50%. In the subsequent cases, the performance of the networks was not significantly affected by further increasing the number of hidden layers. This shows that if networks are modeled under similar conditions, better performance can be achieved using two hidden layers.
The importance of assigning a suitable activation function can be observed in cases 3 and 4, where the second and third hidden layers were assigned with log-sigmoid and tan-sigmoid activation functions for FFBPNN, and tan-sigmoid and log-sigmoid activation functions for RNN, respectively. The tan-sigmoid activation function limits its output range to −1–1, while the log-sigmoid activation function gives the output in the range from 0 to 1. Therefore, these activation functions are not assigned to the output layer if the required output value lies outside said ranges. For that reason, the output node in every case considered in this study was assigned with a linear activation function to allow for outputs outside the range of −1 and 1. By swapping the activation functions for the second and third hidden layers in case 3 and case 4, respectively, the results of FFBPNN improved at the learning rates of 0.05, 0.03, and 0.01, while the learning rate of 0.005 yielded worse result in case 4. For RNN, the learning rates of 0.05 and 0.03 showed improved performance in case 4, while the learning rates of 0.01 and 0.005 showed better performance in case 3. The value of the learning rate controls the rate of the network’s adaptation to the given problem. Generally, this value lies between 0 and 1. Four different values of learning rates were used in this study, namely 0.05, 0.03, 0.01, and 0.005. However, the changing learning rates had a random impact on performance. In the case of FFBPNN, the performance of the network was random for the first case. In the second case, the network performance improved with the learning rates (Lr) decreasing from 0.05 to 0.01, but further decrease deteriorated the network performance.
In case 3, the network performance improved with the learning rates decreasing from 0.05 to 0.005. Case 4 has showed the most promising results for the learning rates from 0.05 to 0.01 where the value of RMSE ranges from 0.5% to 0.51%.
However, further decrease of the learning rate had a negative impact on network performance. In the fifth case, the best performance was observed for the learning rate of 0.05, but decreasing the value of the learning rate to 0.03 drastically degraded the network performance. Further decrease of the learning rates somewhat improved the network performance but never reaching the level recorded for the learning rate of 0.05. In the case of RNN, the network performed randomly for the learning rates of 0.05 and 0.03. However, it must be noted that in the first four cases, the networks showed similar behavior when the learning rate was decreased from 0.01 to 0.005. In the fifth case, the testing results deteriorated for learning rates from 0.05 to 0.01. A further decrease in the learning rate showed some improvement in the quality of estimations results but not enough to outdo the result achieved at the learning rate of 0.05.
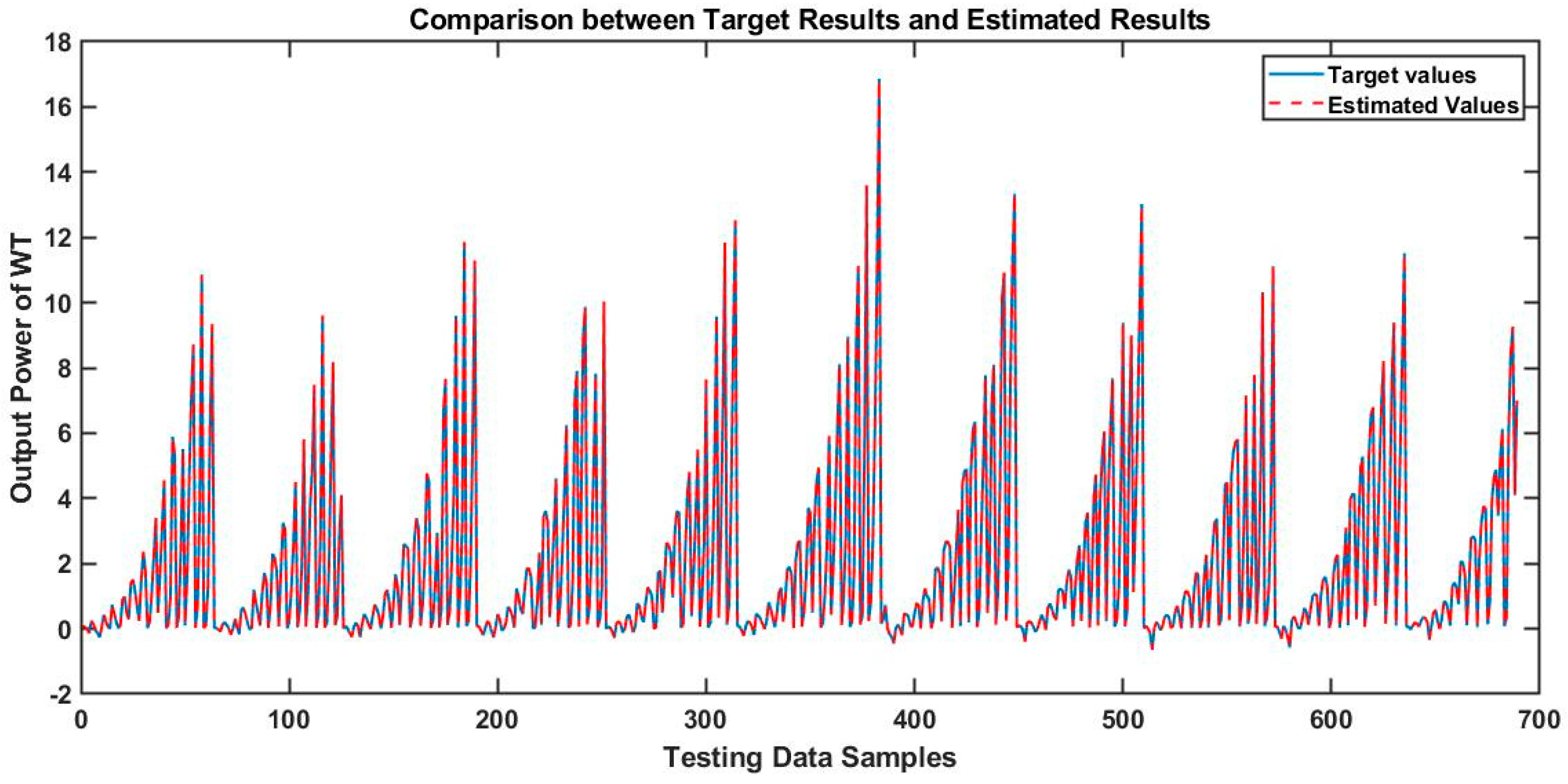
Consequently, it can be concluded that RNN will not improve performance if the learning rate is decreased beyond 0.01, provided that the network is designed for a similar problem. In terms of FFBPNN, the best overall result was observed for the learning rate of 0.01 using case 2 with two hidden layers comprising 100 tansig and 50 logsig nodes in first and second hidden layers, respectively, where the value of RMSE was 0.49%. As for MAPE, FFBPNN once again outperformed the alternative showing the best results in case 4 with three hidden layers. A graph comparing the target and estimated values is provided in
Figure 9. It shows that the estimated results were very close to the actual target values.
The second-best result was achieved for the same value of learning rate using case 4 with three hidden layers comprising 100 and 50 tansig nodes in the first and second hidden layers, and 25 logsig nodes in the third hidden layer, where the value of RMSE was 0.5%. However, the training time for case 4 was approximately nine times shorter than in case 2. Therefore, deepening on the priority applicable to a given situation, one can choose between methods yielding the lowest values of RMSE, MAPE, or the shortest training time. Notably, however, training time can be also improved if GPUs are used instead of CPUs.
For comparison purposes, an advanced variant of RNN was also used, i.e., long short-term memory (LSTM), for the estimations in all five cases, and the average test errors are summarized in
Table 10. The training times of LSTM for all five cases are recorded as 17:69, 20:28, 23:74, 29:69, and 32:34 s. The best LSTM result was recorded for case 1, where RMSE was 0.36345 and MAPE was 118.273, i.e., considerably worse than the results of either FFBPNN or RNN. As follows from the juxtaposition, FFBPNN overall outperformed both RNN and LSTM.


 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}