
Energy Consumption Forecasting in Korea Using Machine Learning Algorithms

Abstract
:1. Introduction
2. Theoretical Background
2.1. Literature Review
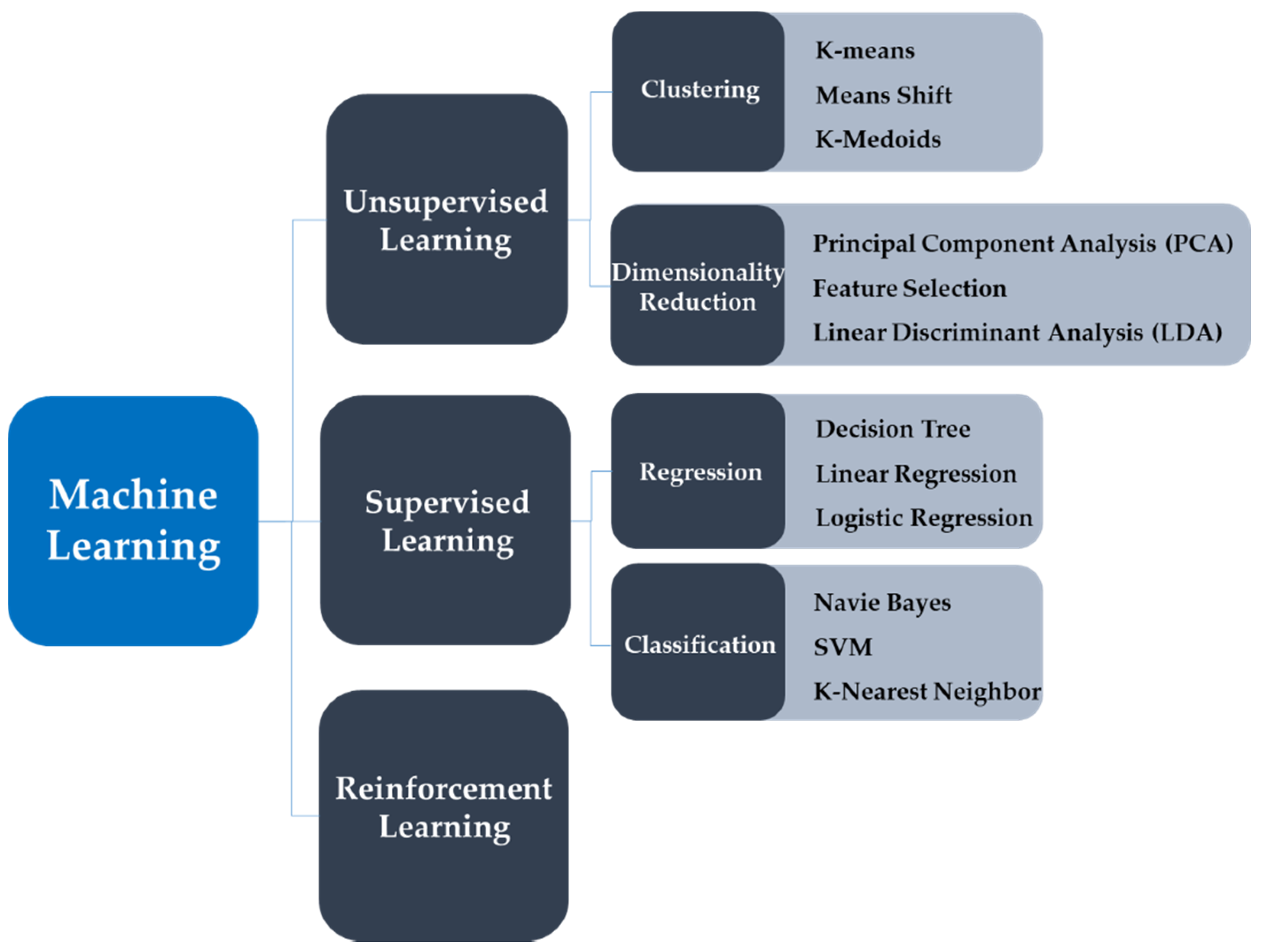
2.2. Attribute of Machine Learning Algorithms
2.2.1. Random Forest
2.2.2. XGBoost
| Algorithm 1. Tree boosting with XGBoost [38]. |
|
2.2.3. LSTM
3. Data and Methodology
3.1. Data
3.1.1. Total Energy Supply
3.1.2. The Trend of Energy Consumption in Korea
3.1.3. COVID-19 Crisis on Global Energy Supply and Demand
3.1.4. Independent Variables
3.2. Methodology
3.3. Evaluating Forecast Accuracy
4. Korea Energy Consumption Forecasting Model
4.1. Random Forest Model
4.2. XGBoost Model
4.3. LSTM Model
5. Results and Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ha, Y.H.; Byrne, J. The rise and fall of green growth: Korea’s energy sector experiment and its lessons for sustainable energy policy. Wiley Interdiscip. Rev. Energy Environ. 2019, 8, e335. [Google Scholar] [CrossRef] [Green Version]
- Geem, Z.W.; Roper, W.E. Energy demand estimation of South Korea using artificial neural network. Energy Policy 2009, 37, 4049–4054. [Google Scholar] [CrossRef]
- Suganthi, L.; Samuel, A.A. Energy models for demand forecasting—A review. Renew. Sustain. Energy Rev. 2012, 16, 1223–1240. [Google Scholar] [CrossRef]
- Zhu, Q.; Guo, Y.; Feng, G. Household energy consumption in China: Forecasting with BVAR model up to 2015. In Proceedings of the 2012 Fifth International Joint Conference on Computational Sciences and Optimization, Harbin, China, 23–26 June 2012; pp. 654–659. [Google Scholar]
- Herrera, G.P.; Constantino, M.; Tabak, B.M.; Pistori, H.; Su, J.-J.; Naranpanawa, A. Long-term forecast of energy commodities price using machine learning. Energy 2019, 179, 214–221. [Google Scholar] [CrossRef]
- Chavez, S.G.; Bernat, J.X.; Coalla, H.L. Forecasting of energy production and consumption in Asturias (northern Spain). Energy 1999, 24, 183–198. [Google Scholar] [CrossRef]
- Ceylan, H.; Ozturk, H.K. Estimating energy demand of Turkey based on economic indicators using genetic algorithm approach. Energy Convers. Manag. 2004, 45, 2525–2537. [Google Scholar] [CrossRef]
- Crompton, P.; Wu, Y. Energy consumption in China: Past trends and future directions. Energy Econ. 2005, 27, 195–208. [Google Scholar] [CrossRef]
- Mohamed, Z.; Bodger, P. Forecasting electricity consumption in New Zealand using economic and demographic variables. Energy 2005, 30, 1833–1843. [Google Scholar] [CrossRef] [Green Version]
- Pao, H.-T. Comparing linear and nonlinear forecasts for Taiwan’s electricity consumption. Energy 2006, 31, 2129–2141. [Google Scholar] [CrossRef]
- Toksarı, M.D. Ant colony optimization approach to estimate energy demand of Turkey. Energy Policy 2007, 35, 3984–3990. [Google Scholar] [CrossRef]
- Ekonomou, L. Greek long-term energy consumption prediction using artificial neural networks. Energy 2010, 35, 512–517. [Google Scholar] [CrossRef] [Green Version]
- Lee, Y.-S.; Tong, L.-I. Forecasting energy consumption using a grey model improved by incorporating genetic programming. Energy Convers. Manag. 2011, 52, 147–152. [Google Scholar] [CrossRef]
- Ardakani, F.; Ardehali, M. Long-term electrical energy consumption forecasting for developing and developed economies based on different optimized models and historical data types. Energy 2014, 65, 452–461. [Google Scholar] [CrossRef]
- Barak, S.; Sadegh, S.S. Forecasting energy consumption using ensemble ARIMA–ANFIS hybrid algorithm. Int. J. Electr. Power Energy Syst. 2016, 82, 92–104. [Google Scholar] [CrossRef] [Green Version]
- Kim, Y.; Park, H. Modeling and Predicting South Korea’s Daily Electric Demand Using DNN and LSTM. J. Clim. Res. 2021, 12, 241–253. [Google Scholar]
- Sözen, A.; Arcaklioğlu, E.; Özkaymak, M. Turkey’s net energy consumption. Appl. Energy 2005, 81, 209–221. [Google Scholar] [CrossRef]
- Ediger, V.Ş.; Akar, S. ARIMA forecasting of primary energy demand by fuel in Turkey. Energy Policy 2007, 35, 1701–1708. [Google Scholar] [CrossRef]
- Bianco, V.; Manca, O.; Nardini, S. Electricity consumption forecasting in Italy using linear regression models. Energy 2009, 34, 1413–1421. [Google Scholar] [CrossRef]
- Kankal, M.; Akpınar, A.; Kömürcü, M.İ.; Özşahin, T.Ş. Modeling and forecasting of Turkey’s energy consumption using socio-economic and demographic variables. Appl. Energy 2011, 88, 1927–1939. [Google Scholar] [CrossRef]
- Park, K.-R.; Jung, J.-Y.; Ahn, W.-Y.; Chung, Y.-S. A study on energy consumption predictive modeling using public data. In Proceedings of the Korean Society of Computer Information Conference, Seoul, Korea, 10 July 2012; pp. 329–330. [Google Scholar]
- Xiong, P.-P.; Dang, Y.-G.; Yao, T.-X.; Wang, Z.-X. Optimal modeling and forecasting of the energy consumption and production in China. Energy 2014, 77, 623–634. [Google Scholar] [CrossRef]
- Yuan, C.; Liu, S.; Fang, Z. Comparison of China’s primary energy consumption forecasting by using ARIMA (the autoregressive integrated moving average) model and GM (1, 1) model. Energy 2016, 100, 384–390. [Google Scholar] [CrossRef]
- Wang, Q.; Li, S.; Li, R. Forecasting energy demand in China and India: Using single-linear, hybrid-linear, and non-linear time series forecast techniques. Energy 2018, 161, 821–831. [Google Scholar] [CrossRef]
- Oh, W.; Lee, K. Causal relationship between energy consumption and GDP revisited: The case of Korea 1970–1999. Energy Econ. 2004, 26, 51–59. [Google Scholar] [CrossRef]
- Shin, J.; Yang, H.; Kim, C. The relationship between climate and energy consumption: The case of South Korea. Energy Sources Part A: Recovery Util. Environ. Eff. 2019, 1–16. [Google Scholar] [CrossRef]
- Lee, S.; Jung, S.; Lee, J. Prediction model based on an artificial neural network for user-based building energy consumption in South Korea. Energies 2019, 12, 608. [Google Scholar] [CrossRef] [Green Version]
- Moon, J.; Kim, Y.; Son, M.; Hwang, E. Hybrid short-term load forecasting scheme using random forest and multilayer perceptron. Energies 2018, 11, 3283. [Google Scholar] [CrossRef] [Green Version]
- Mitchell, T.M.; Carbonell, J.G.; Michalski, R.S. Machine Learning: A Guide to Current Research; Springer Science & Business Media: Berlin/Heidelberg, Germany, 1986. [Google Scholar]
- Domingos, P. A few useful things to know about machine learning. CACM 2012, 55, 78–87. [Google Scholar] [CrossRef] [Green Version]
- Berry, M.W.; Mohamed, A.; Yap, B.W. (Eds.) Supervised and Unsupervised Learning for Data Science; Springer Nature: Berlin/Heidelberg, Germany, 2019. [Google Scholar]
- Vieira, S.; Lopez Pinaya, W.H.; Garcia-Dias, R.; Mechelli, A. Chapter 9—Deep neural networks. In Machine Learning; Mechelli, A., Vieira, S., Eds.; Academic Press: Cambridge, MA, USA, 2020; pp. 157–172. [Google Scholar]
- Mohammed, M.; Khan, M.B.; Bashier, E.B.M. Machine Learning: Algorithms and Applications, 1st ed.; CRC Press: Boca Raton, FL, USA, 2016. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. An Introduction to Statistical Learning; Springer: New York, NY, USA, 2013; Volume 103. [Google Scholar]
- Lee, C. Estimating Single-Family House Prices Using Non-Parametric Spatial Models and an Ensemble Learning Approach. Ph.D. Thesis, Seoul National University, Seoul, Korea, 2015. [Google Scholar]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Friedman, J.H. Stochastic gradient boosting. Comput. Stat. Data Anal. 2002, 38, 367–378. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Olah, C. Understanding LSTM Networks. 2015. Available online: http://colah.github.io/posts/2015-08-Understanding-LSTMs/ (accessed on 18 April 2022).
- Brownlee, J. Introduction to Time Series Forecasting with Python; Machine Learning Mastery: San Francisco, CA, USA, 2019. [Google Scholar]
- Energy Agency (IEA). Energy Statistics Manual; IEA: Paris, France, 2004. [Google Scholar]
- Energy Agency (IEA). World Energy Balances; IEA: Paris, France, 2020. [Google Scholar]
- BP. Statistical Review of World Energy, 69th ed.; BP: London, UK, 2020. [Google Scholar]
- Korea Energy Economics Institute. Monthly Energy Statistics (2021.12); Korea Energy Economics Institute: Ulsan, Korea, 2021; Volume 37-12, p. 7. [Google Scholar]
- Korea Energy Economics Institute. Yearbook of Energy Statistics; Korea Energy Economics Institute: Ulsan, Korea, 2021; Volume 606, pp. 20–21. [Google Scholar]
- Bahmanyar, A.; Estebsari, A.; Ernst, D. The impact of different COVID-19 containment measures on electricity consumption in Europe. Energy Res. Soc. Sci. 2020, 68, 101683. [Google Scholar] [CrossRef] [PubMed]
- Gopinath, G. The great lockdown: Worst economic downturn since the great depression. IMF Blog 2020, 14, 2020. [Google Scholar]
- IEA Ukraine. Global Energy Review 2020. Ukraine, 2020. Available online: https://www.iea.org/countries/ukraine (accessed on 10 September 2020).
- Korea Energy Economics Institute. Monthly Energy Statistics (2021.8); Korea Energy Economics Institute: Ulsan, Korea, 2021; Volume 37-08, p. 7. [Google Scholar]
- Gürkaynak, R.S.; Kısacıkoğlu, B.; Rossi, B. Do DSGE Models Forecast More Accurately Out-Of-Sample than VAR Models? In VAR Models in Macroeconomics—New Developments and Applications: Essays in Honor of Christopher A. Sims; Advances in Econometrics; Emerald Group Publishing Limited: Bingley, UK, 2013; Volume 32, pp. 27–79. [Google Scholar]
- Makridakis, S.; Wheelwright, S.C.; Hyndman, R.J. Forecasting Methods and Applications; John Wiley & Sons: Hoboken, NJ, USA, 2008. [Google Scholar]
- Korea Energy Economics Institute. Korea Mid-Term Energy Demand Outlook (2020–2025); Korea Energy Economics Institute: Ulsan, Korea, 2021. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Srivastava, N. Improving Neural Networks with Dropout. Master’s Thesis, University of Toronto, Toronto, ON, Canada, 2013. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Blanchard, M.; Desrochers, G. Generation of autocorrelated wind speeds for wind energy conversion system studies. Solar Energy 1984, 33, 571–579. [Google Scholar] [CrossRef]
- Brown, B.G.; Katz, R.W.; Murphy, A.H. Time series models to simulate and forecast wind speed and wind power. J. Appl. Meteorol. Climatol. 1984, 23, 1184–1195. [Google Scholar] [CrossRef]
- Kamal, L.; Jafri, Y.Z. Time series models to simulate and forecast hourly averaged wind speed in Quetta, Pakistan. Solar Energy 1997, 61, 23–32. [Google Scholar] [CrossRef]
- Ho, S.L.; Xie, M. The use of ARIMA models for reliability forecasting and analysis. Comput. Ind. Eng. 1998, 35, 213–216. [Google Scholar] [CrossRef]
- Saab, S.; Badr, E.; Nasr, G. Univariate modeling and forecasting of energy consumption: The case of electricity in Lebanon. Energy 2001, 26, 1–14. [Google Scholar] [CrossRef]
- Zhang, G.P. Time series forecasting using a hybrid ARIMA and neural network model. Neurocomputing 2003, 50, 159–175. [Google Scholar] [CrossRef]
- Ho, S.L.; Xie, M.; Goh, T.N. A comparative study of neural network and Box-Jenkins ARIMA modeling in time series prediction. Comput. Ind. Eng. 2002, 42, 371–375. [Google Scholar] [CrossRef]
- Korea Energy Economics Institute. Korea Energy Demand Outlook; Korea Energy Economics Institute: Ulsan, Korea, 2019; Volume 21, pp. 55–56. [Google Scholar]
- Korea Energy Economics Institute. Korea Mid-Term Energy Demand Outlook (2016~2021); Korea Energy Economics Institute: Ulsan, Korea, 2017; p. 93. [Google Scholar]
- Gonzalez, J.; Yu, W. Non-linear system modeling using LSTM neural networks. IFAC-Pap. 2018, 51, 485–489. [Google Scholar] [CrossRef]
- Han, J.G. The Politics of Expertise in Korean Energy Policy: The Sociology of Energy Modelling (Publication No.000864823). Ph.D. Thesis, College of Social Sciences, Kookmin University, Seoul, Korea, 2015. [Google Scholar]
- Korea Energy Economics Institute. Korea Mid-Term Energy Demand Outlook (2017~2022); Korea Energy Economics Institute: Ulsan, Korea, 2018; p. 97. [Google Scholar]
- Zeng, Y.-R.; Zeng, Y.; Choi, B.; Wang, L. Multifactor-influenced energy consumption forecasting using enhanced back-propagation neural network. Energy 2017, 127, 381–396. [Google Scholar] [CrossRef]
- Krauss, C.; Do, X.A.; Huck, N. Deep neural networks, gradient-boosted trees, random forests: Statistical arbitrage on the S&P 500. Eur. J. Oper. Res. 2017, 259, 689–702. [Google Scholar]
- Armstrong, J.S.; Collopy, F. Error measures for generalizing about forecasting methods: Empirical comparisons. Int. J. Forecast. 1992, 8, 69–80. [Google Scholar] [CrossRef] [Green Version]
- Mullainathan, S.; Spiess, J. Machine learning: An applied econometric approach. J. Econ. Perspect. 2017, 31, 87–106. [Google Scholar] [CrossRef] [Green Version]
- Lipton, Z.C. The mythos of model interpretability: In machine learning, the concept of interpretability is both important and slippery. Queue 2018, 16, 31–57. [Google Scholar] [CrossRef]
- Kauffman, R.J.; Kim, K.; Lee, S.Y.T.; Hoang, A.P.; Ren, J. Combining machine-based and econometrics methods for policy analytics insights. Electron. Commer. Res. Appl. 2017, 25, 115–140. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Authors | Method Used | Forecasting Scope | Forecast Energy Type | Energy Market |
|---|---|---|---|---|
| Chav, Bernat and Coalla [6] | ARIMA | Monthly | Energy production and consumption | Asturias (northern Spain) |
| Ceylan and Ozturk [7] | GAEDM | Annual | Energy demand | Turkey |
| Crompton and Wu [8] | Bayesian vector autoregression | Annual | Energy consumption | China |
| Mohamed and Bodger [9] | Multiple linear regression | Annual | Electricity consumption | New Zealand |
| Sözen, et al. [17] | ANN | Annual | Net energy consumption | Turkey |
| Pao [10] | ANN, linear and non-linear statistical models | Annual | Electricity consumption | Taiwan |
| Ediger and Akar [18] | ARIMA, SARIMA | Annual | Primary energy demand by fuel | Turkey |
| Toksarı [11] | ACO (Ant Colony Optimization) | Annual | Energy demand | Turkey |
| Bianco, et al. [19] | Linear regression | Annual | Electricity consumption | Italy |
| Geem and Roper [3] | ANN | Annual | Energy demand | Korea |
| Ekonomou [11] | ANN | Annual | Energy consumption | Greece |
| Kankal, et al. [20] | ANN | Annual | Energy consumption | Turkey |
| Zhu, Guo and Feng [4] | BVAR | Annual | Household energy consumption | China |
| Park, et al. [21] | Markov Process | Monthly | Energy consumption | Korea |
| Xiong, et al. [22] | GM (1, 1) | Annual | Energy production and consumption | China |
| Ardakani and Ardehali [13] | Multivariable regression, ANN | Annual | Electrical energy consumption | Iran, United States |
| Yuan, et al. [23] | GM (1, 1) and ARIMA | Annual | Energy consumption | China |
| Wang et al. [24] | DNN, ANN | Annual | Energy demand | China, India |
| Kim, Y. and Park, H. [15] | DNN, LSTM | Short term (Daily) | Electric Demand | Korea |
| Algorithms | Description | Pros | Cons |
|---|---|---|---|
| Random Forest |
|
|
|
|
| ||
|
|
| |
| |||
| XGBoost |
|
|
|
|
|
| |
|
| ||
|
| ||
| LSTM |
|
|
|
|
| Ranking | Total Energy Supply (TES) (1) (Million Toe) | Oil Consumption (2) (Million Tonnes) | Oil Refinery Capacity (2) (Thousand Barrels Daily) | Electricity Consumption (1) (TWh) | TES/Population (1) (Toe per Capita) | Electricity Consumption/Population (1) (kWh per Capita) |
|---|---|---|---|---|---|---|
| 1 | China | United States | United States | China | Iceland | Iceland |
| 3211 | 842 | 18,974 | 6880 | 17.4 | 54,605 | |
| 2 | United States | China | China | United States | Qatar | Norway |
| 2231 | 650 | 16,199 | 4194 | 15.6 | 24,047 | |
| 3 | India | India | Russia | India | Trinidad and Tobago | Bahrain |
| 919 | 242 | 6721 | 1309 | 12.25 | 18,618 | |
| 4 | Russia | Japan | India | Russia | Bahrain | Qatar |
| 759 | 174 | 5008 | 997 | 9.08 | 16,580 | |
| 5 | Japan | Saudi Arabia | Korea | Japan | Brunei | Finland |
| 426 | 159 | 3393 | 955 | 8.62 | 15,804 | |
| 6 | Germany | Russia | Japan | Canada | Curaçao | Canada |
| 302 | 151 | 3343 | 572 | 8.29 | 15,438 | |
| 7 | Canada | Korea | Saudi Arabia | Korea | Kuwait | Kuwait |
| 298 | 120 | 2835 | 563 | 8.22 | 15,402 | |
| 8 | Brazil | Brazil | Iran | Germany | Canada | Luxembourg |
| 287 | 110 | 2405 | 559 | 8.03 | 13,476 | |
| 9 | Korea | Germany | Brazil | Brazil | United Arab Emirates | Sweden |
| 282 | 107 | 2290 | 553 | 7.02 | 13,331 | |
| 10 | Iran | Canada | Germany | France | Korea (15th) | Korea (13th) |
| 266 | 103 | 2085 | 474 | 5.47 | 11,082 | |
| World | 14,282 | 4445 | 101,340 | 19,278 | 1.88 | 3260 |
| Variable | Unit | Average | Max | Min | Median | Standard Deviation |
|---|---|---|---|---|---|---|
| Oil Prices (Dubai) | $/bbl. | 55.6 | 131.3 | 10.1 | 53.7 | 30.8 |
| Index of Manufacturing Production | 2015 = 100 | 78.8 | 118.8 | 31.0 | 84.0 | 25.0 |
| Population | 1000 Persons | 49,224.1 | 51,821.7 | 45,953.6 | 49,307.8 | 1817.4 |
| Average Temperature | °C | 12.9 | 28.8 | −7.2 | 14.0 | 9.9 |
| Power Generation | GWh | 35,079.6 | 53,394.2 | 16,228.0 | 36,458.5 | 10,093.8 |
| Period 1 | RF | XGB | LSTM |
|---|---|---|---|
| RMSE | 0.061 | 0.074 | 0.052 |
| MAPE | 0.070 | 0.096 | 0.079 |
| Parameter | Estimator: 300 | Estimator: 100 | Activation: Relu |
| Learning rate: 0.05 | Unit: 16 | ||
| Max Depth: 5 | Max depth: 3 | Learning rate: 0.001 | |
| Batch: 16 | |||
| Period 2 | RF | XGB | LSTM |
| RMSE | 0.040 | 0.050 | 0.080 |
| MAPE | 0.047 | 0.053 | 0.062 |
| Parameter | Estimator: 500 | Estimator: 100 | Activation: Relu |
| Learning rate: 0.1 | Unit: 16 | ||
| Max Depth: 6 | Max depth: 7 | Learning rate: 0.05 | |
| Batch: 32 |
| Year | True Value | Predicted Value | ||
|---|---|---|---|---|
| Machine Learning | ARIMA | ARDL | ||
| 2017 | 302,490 | 297,017 | 299,485 | 302,500 |
| 2018 | 307,557 | 304,200 | 311,663 | 308,800 |
| 2019 | 303,092 | 301,897 | 318,726 | 314,000 |
| 2020 | 292,076 | 299,244 | 311,664 | 320,300 |
| The first half of 2021 | 150,188 | 150,277 | 158,250 | 162,450 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shin, S.-Y.; Woo, H.-G. Energy Consumption Forecasting in Korea Using Machine Learning Algorithms. Energies 2022, 15, 4880. https://doi.org/10.3390/en15134880
Shin S-Y, Woo H-G. Energy Consumption Forecasting in Korea Using Machine Learning Algorithms. Energies. 2022; 15(13):4880. https://doi.org/10.3390/en15134880
Chicago/Turabian StyleShin, Sun-Youn, and Han-Gyun Woo. 2022. "Energy Consumption Forecasting in Korea Using Machine Learning Algorithms" Energies 15, no. 13: 4880. https://doi.org/10.3390/en15134880
APA StyleShin, S.-Y., & Woo, H.-G. (2022). Energy Consumption Forecasting in Korea Using Machine Learning Algorithms. Energies, 15(13), 4880. https://doi.org/10.3390/en15134880