
Heuristic Intrusion Detection Based on Traffic Flow Statistical Analysis



Abstract
:1. Introduction
1.1. Rationale
1.2. Related Works
1.3. Contributions
- The authors have chosen heuristic detection approach based on traffic flow statistical analysis. It supports attack detection in encrypted network traffic.
- The process of searching the hyperparameter space to create neural network with high performance in detecting network attacks was presented. The assessment is focused on the score metric, which prioritises marking packets as representing an attack over reducing false alarms.
- A modified normalization method was used. This solution provides better performance during the conducted trials.
2. Cybersecurity and Artificial Intelligence
2.1. Artificial Neural Networks
2.2. Performance Indexes
3. Dataset
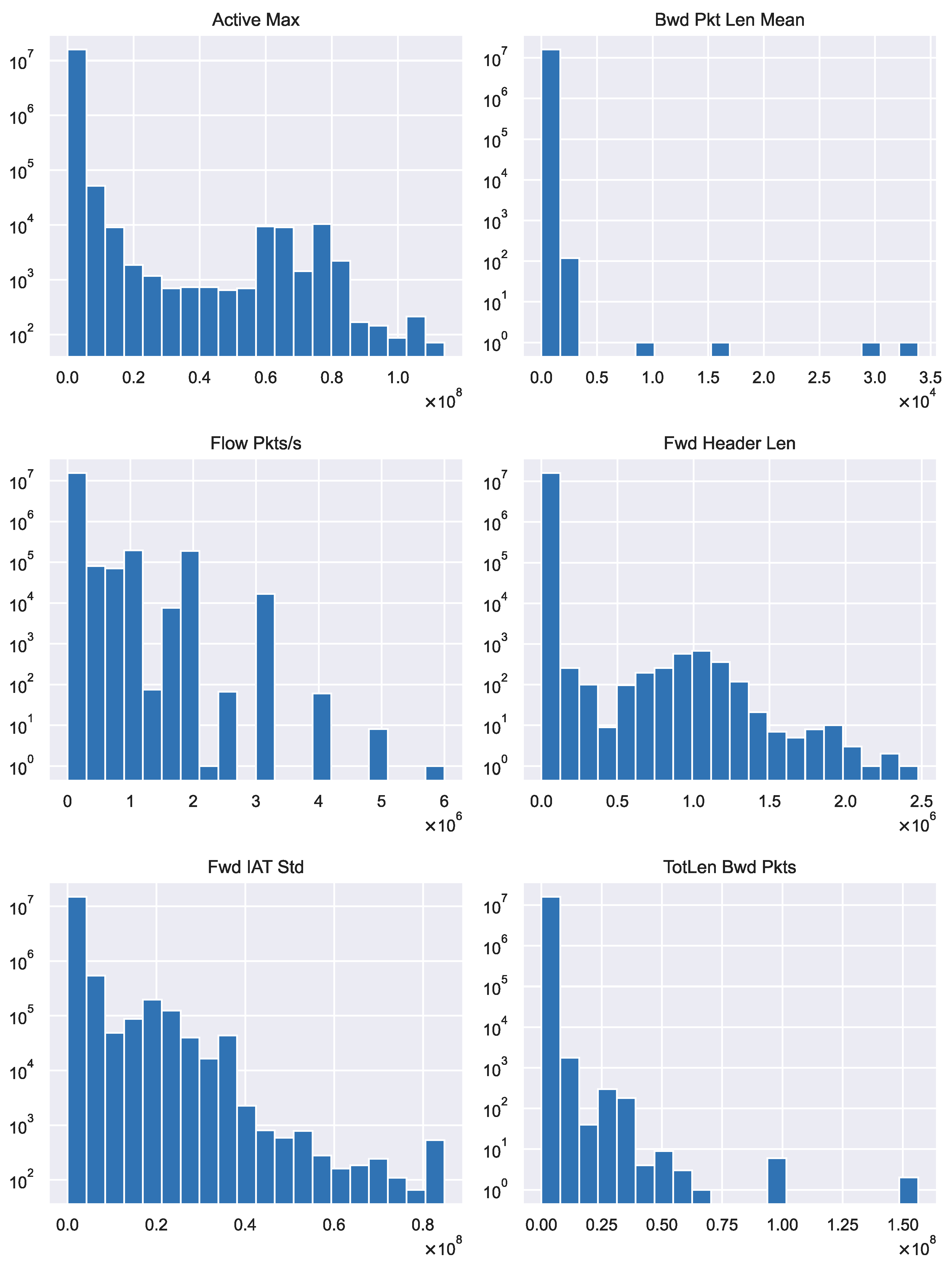
3.1. Dataset Description
3.2. Data Cleaning
3.3. Dataset Manipulation
4. Model and Training
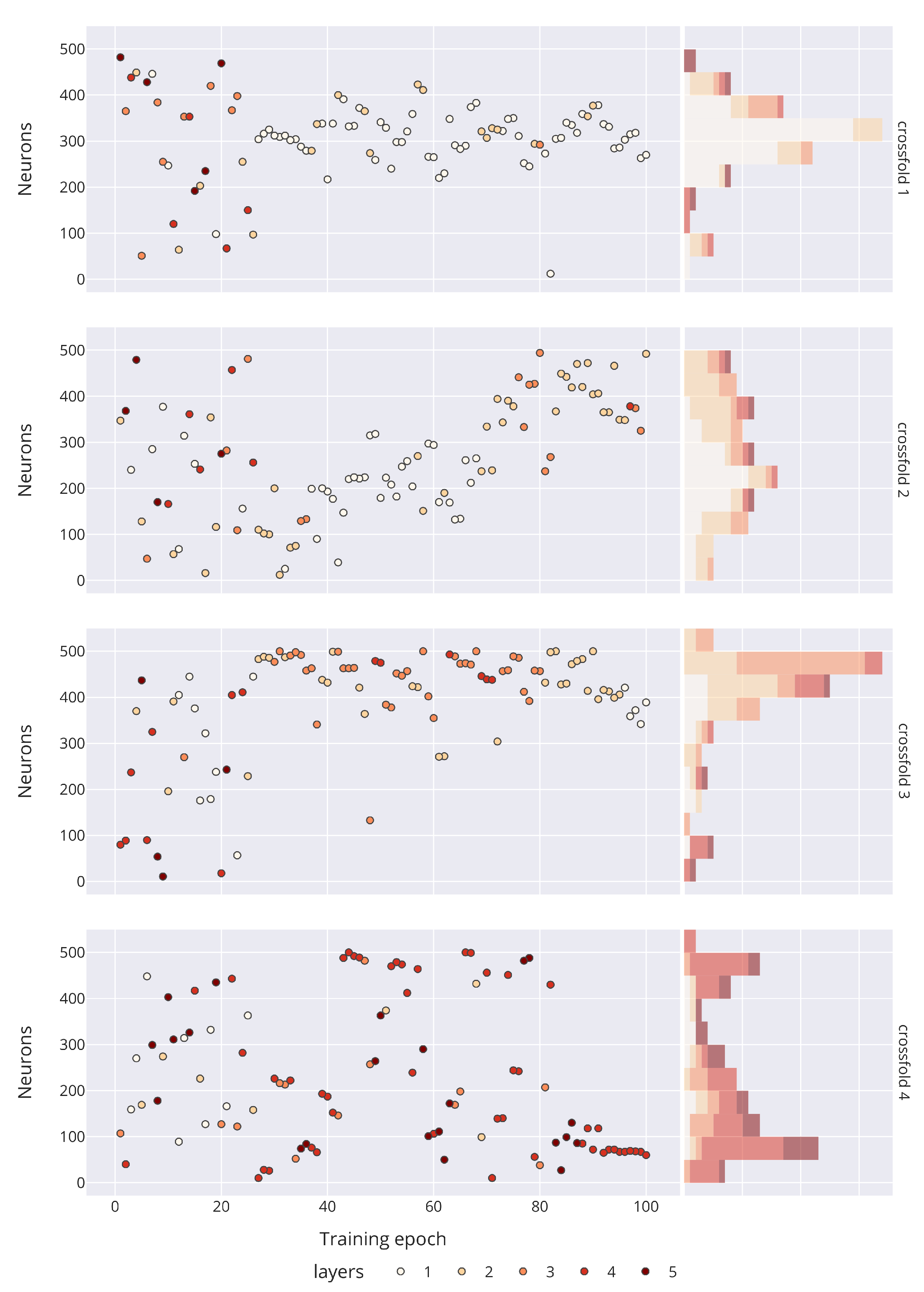
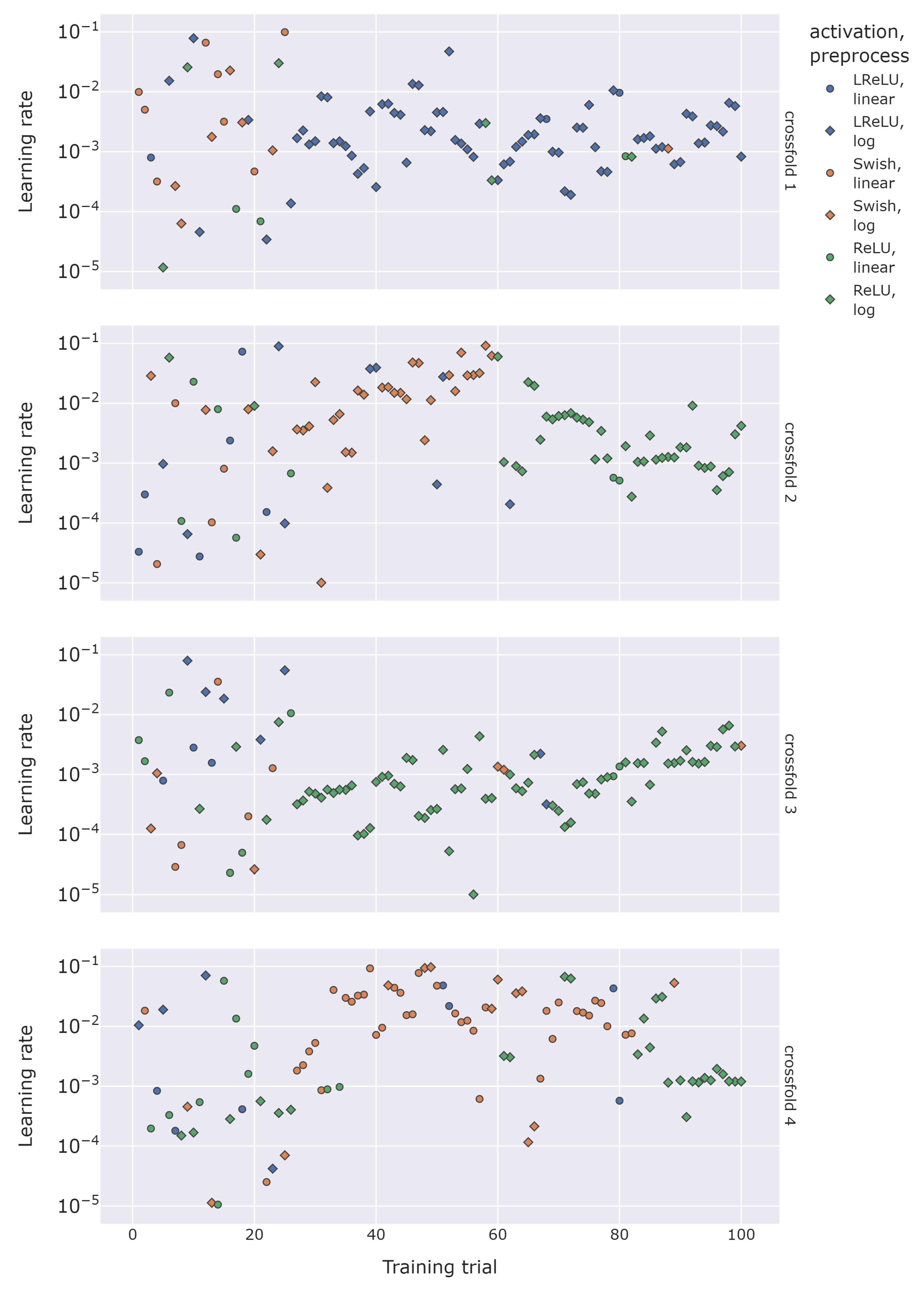
4.1. Model Architecture Exploration
4.2. Training Phase Setup
5. Results
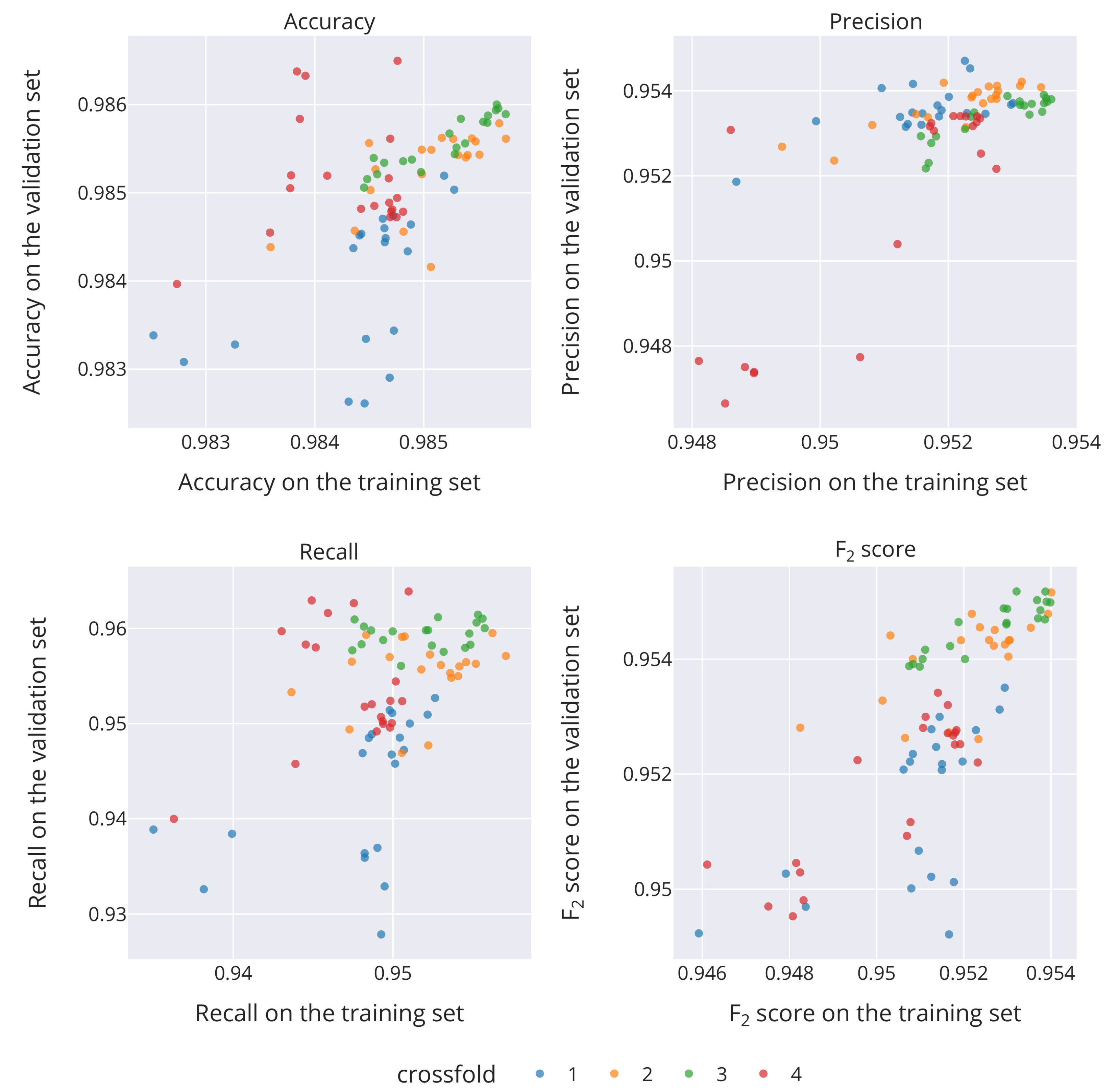
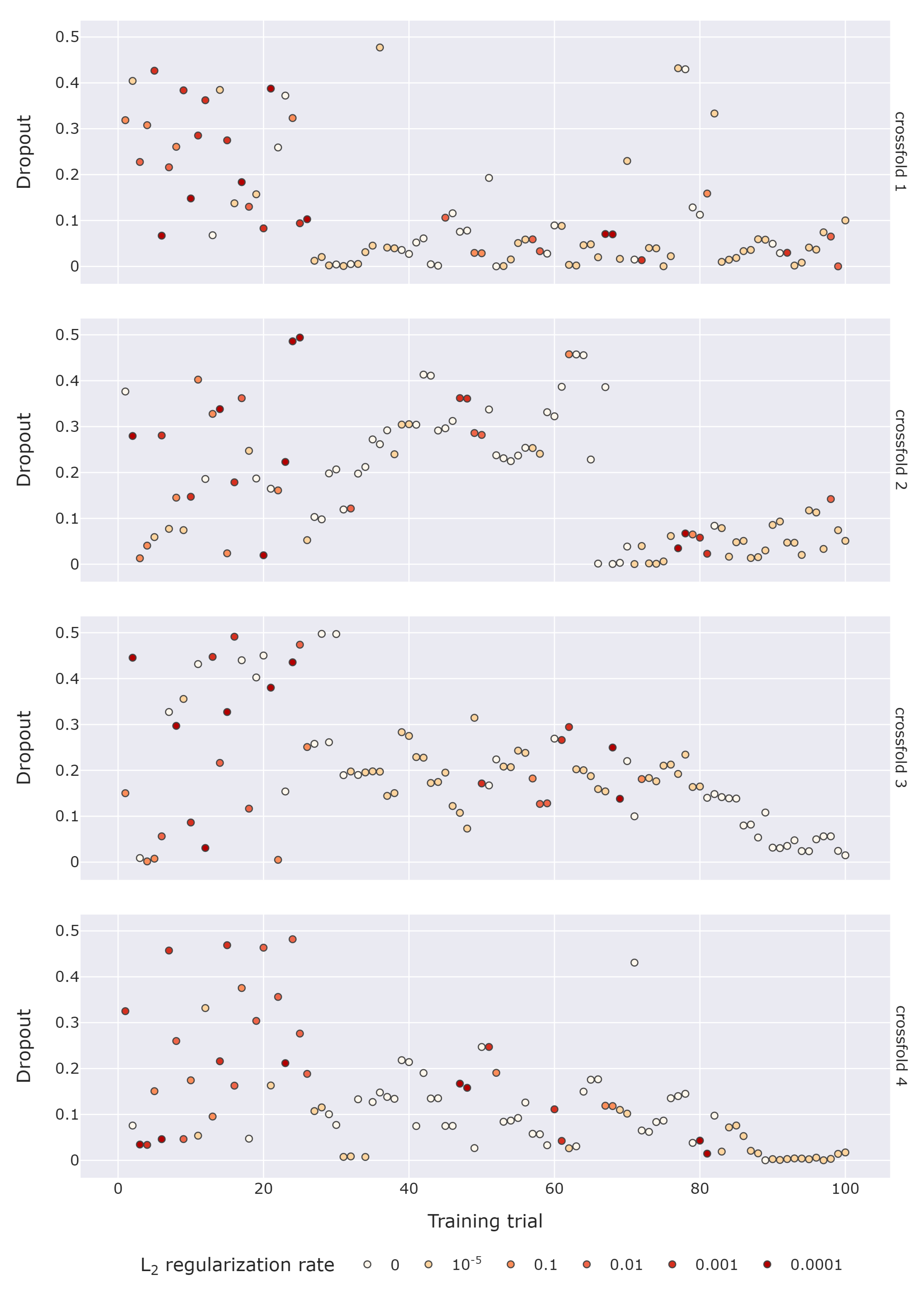
5.1. Analysis of Crossfolds
5.2. Complete Dataset
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Tufail, S.; Parvez, I.; Batool, S.; Sarwat, A. A Survey on Cybersecurity Challenges, Detection, and Mitigation Techniques for the Smart Grid. Energies 2021, 14, 5894. [Google Scholar] [CrossRef]
- Liang, G.; Zhao, J.; Luo, F.; Weller, S.R.; Dong, Z.Y. A Review of False Data Injection Attacks Against Modern Power Systems. IEEE Trans. Smart Grid 2017, 8, 1630–1638. [Google Scholar] [CrossRef]
- Alghassab, M. Analyzing the Impact of Cybersecurity on Monitoring and Control Systems in the Energy Sector. Energies 2022, 15, 218. [Google Scholar] [CrossRef]
- Nait Belaid, Y.; Coudray, P.; Sanchez-Torres, J.; Fang, Y.P.; Zeng, Z.; Barros, A. Resilience Quantification of Smart Distribution Networks—A Bird’s Eye View Perspective. Energies 2021, 14, 2888. [Google Scholar] [CrossRef]
- Liu, X.; Song, Y.; Li, Z. Dummy Data Attacks in Power Systems. IEEE Trans. Smart Grid 2020, 11, 1792–1795. [Google Scholar] [CrossRef]
- Al-Asli, M.; Ghaleb, T.A. Review of Signature-based Techniques in Antivirus Products. In Proceedings of the 2019 International Conference on Computer and Information Sciences (ICCIS), Sakaka, Saudi Arabia, 3–4 April 2019; pp. 1–6. [Google Scholar]
- Samrin, R.; Vasumathi, D. Review on anomaly based network intrusion detection system. In Proceedings of the 2017 International Conference on Electrical, Electronics, Communication, Computer, and Optimization Techniques (ICEECCOT), Mysuru, India, 15–16 December 2017. [Google Scholar]
- Sun, C.C.; Sebastian Cardenas, D.J.; Hahn, A.; Liu, C.C. Intrusion Detection for Cybersecurity of Smart Meters. IEEE Trans. Smart Grid 2021, 12, 612–622. [Google Scholar] [CrossRef]
- Musleh, A.S.; Chen, G.; Dong, Z.Y. A Survey on the Detection Algorithms for False Data Injection Attacks in Smart Grids. IEEE Trans. Smart Grid 2020, 11, 2218–2234. [Google Scholar] [CrossRef]
- Karimipour, H.; Dehghantanha, A.; Parizi, R.M.; Choo, K.K.R.; Leung, H. A Deep and Scalable Unsupervised Machine Learning System for Cyber-Attack Detection in Large-Scale Smart Grids. IEEE Access 2019, 7, 80778. [Google Scholar] [CrossRef]
- Dini, P.; Saponara, S. Analysis, Design, and Comparison of Machine-Learning Techniques for Networking Intrusion Detection. Designs 2021, 5, 9. [Google Scholar] [CrossRef]
- Kao, M.T.; Sung, D.Y.; Kao, S.J.; Chang, F.M. A Novel Two-Stage Deep Learning Structure for Network Flow Anomaly Detection. Electronics 2022, 11, 1531. [Google Scholar] [CrossRef]
- Ullah, S.; Khan, M.A.; Ahmad, J.; Jamal, S.S.; e Huma, Z.; Hassan, M.T.; Pitropakis, N.; Arshad; Buchanan, W.J. HDL-IDS: A Hybrid Deep Learning Architecture for Intrusion Detection in the Internet of Vehicles. Sensors 2022, 22, 1340. [Google Scholar] [CrossRef] [PubMed]
- Almaraz-Rivera, J.G.; Perez-Diaz, J.A.; Cantoral-Ceballos, J.A. Transport and Application Layer DDoS Attacks Detection to IoT Devices by Using Machine Learning and Deep Learning Models. Sensors 2022, 22, 3367. [Google Scholar] [CrossRef]
- Le, K.H.; Nguyen, M.H.; Tran, T.D.; Tran, N.D. IMIDS: An Intelligent Intrusion Detection System against Cyber Threats in IoT. Electronics 2022, 11, 524. [Google Scholar] [CrossRef]
- Kurt, M.N.; Ogundijo, O.; Li, C.; Wang, X. Online Cyber-Attack Detection in Smart Grid: AReinforcement Learning Approach. IEEE Trans. Smart Grid 2019, 10, 5174–5185. [Google Scholar] [CrossRef] [Green Version]
- Boyaci, O.; Narimani, M.R.; Davis, K.R.; Ismail, M.; Overbye, T.J.; Serpedin, E. Joint Detection and Localization of Stealth False Data Injection Attacks in Smart Grids Using Graph Neural Networks. IEEE Trans. Smart Grid 2022, 13, 807–819. [Google Scholar] [CrossRef]
- He, Y.; Mendis, G.J.; Wei, J. Real-Time Detection of False Data Injection Attacks in Smart Grid: A Deep Learning-Based Intelligent Mechanism. IEEE Trans. Smart Grid 2017, 8, 2505–2516. [Google Scholar] [CrossRef]
- Singer, P.W.P.W. Cybersecurity and Cyberwar: What Everyone Needs to Know; Oxford University Press: Cary, NC, USA, 2014. [Google Scholar]
- Smolarczyk, M.; Plamowski, S.; Pawluk, J.; Szczypiorski, K. Anomaly Detection in Cyclic Communication in OT Protocols. Energies 2022, 15, 1517. [Google Scholar] [CrossRef]
- Mittal, M.; de Prado, R.P.; Kawai, Y.; Nakajima, S.; Muñoz-Expósito, J.E. Machine Learning Techniques for Energy Efficiency and Anomaly Detection in Hybrid Wireless Sensor Networks. Energies 2021, 14, 3125. [Google Scholar] [CrossRef]
- Niemiec, M.; Kościej, R.; Gdowski, B. Multivariable Heuristic Approach to Intrusion Detection in Network Environments. Entropy 2021, 23, 776. [Google Scholar] [CrossRef] [PubMed]
- Shaukat, K.; Luo, S.; Varadharajan, V.; Hameed, I.A.; Chen, S.; Liu, D.; Li, J. Performance Comparison and Current Challenges of Using Machine Learning Techniques in Cybersecurity. Energies 2020, 13, 2509. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Arora, R.; Basu, A.; Mianjy, P.; Mukherjee, A. Understanding Deep Neural Networks with Rectified Linear Units. arXiv 2016, arXiv:1611.01491. [Google Scholar] [CrossRef]
- Ramachandran, P.; Zoph, B.; Le, Q.V. Searching for Activation Functions. arXiv 2017, arXiv:1710.05941. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Tieleman, T.; Hinton, G. Lecture 6.5-rmsprop: Divide the gradient by a running average of its recent magnitude. Neural Netw. Mach. Learn. 2012, 4, 26–31. [Google Scholar]
- Duchi, J.; Hazan, E.; Singer, Y. Adaptive subgradient methods for online learning and stochastic optimization. J. Mach. Learn. Res. 2011, 12, 2121–2159. [Google Scholar]
- Cortes, C.; Mohri, M.; Rostamizadeh, A. L2 Regularization for Learning Kernels. In Proceedings of the Twenty-Fifth Conference on Uncertainty in Artificial Intelligence, Montreal, QC, Canada, 18–21 June 2009; AUAI Press: Arlington, VI, USA, 2009; pp. 109–116. [Google Scholar]
- Hinton, G.E.; Srivastava, N.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R.R. Improving neural networks by preventing co-adaptation of feature detectors. arXiv 2012, arXiv:1207.0580. [Google Scholar]
- Sharafaldin, I.; Lashkari, A.H.; Ghorbani, A.A. Toward generating a new intrusion detection dataset and intrusion traffic characterization. ICISSP 2018, 1, 108–116. [Google Scholar] [CrossRef]
- CICFlowMeter. Available online: https://www.unb.ca/cic/research/applications.html#CICFlowMeter (accessed on 16 May 2022).
- A Realistic Cyber Defense Dataset (CSE-CIC-IDS2018). Available online: https://registry.opendata.aws/cse-cic-ids2018/ (accessed on 16 May 2022).
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the 13th International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010; JMLR Workshop and Conference Proceedings. pp. 249–256. [Google Scholar]
- Liaw, R.; Liang, E.; Nishihara, R.; Moritz, P.; Gonzalez, J.E.; Stoica, I. Tune: A Research Platform for Distributed Model Selection and Training. arXiv 2018, arXiv:1807.05118. [Google Scholar]
- Moritz, P.; Nishihara, R.; Wang, S.; Tumanov, A.; Liaw, R.; Liang, E.; Elibol, M.; Yang, Z.; Paul, W.; Jordan, M.I.; et al. Ray: A Distributed Framework for Emerging AI Applications. In Proceedings of the 13th USENIX Symposium on Operating Systems Design and Implementation (OSDI 18), Carlsbad, CA, USA, 8–10 October 2018; pp. 561–577. [Google Scholar]
- Akiba, T.; Sano, S.; Yanase, T.; Ohta, T.; Koyama, M. Optuna: A Next,-generation Hyperparameter Optimization Framework. In Proceedings of the 25rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Anchorage, AK, USA, 4–8 August 2019. [Google Scholar]
- Bergstra, J.; Bardenet, R.; Bengio, Y.; Kégl, B. Algorithms for hyper-parameter optimization. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2011; Volume 24. [Google Scholar]
- Li, L.; Jamieson, K.; Rostamizadeh, A.; Gonina, E.; Hardt, M.; Recht, B.; Talwalkar, A. A System for Massively Parallel Hyperparameter Tuning. arXiv 2020, arXiv:1810.05934. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Count |
|---|---|
| Benign | 13,390,234 |
| DDOS attack-HOIC | 686,012 |
| DDoS attacks-LOIC-HTTP | 576,191 |
| DoS attacks-Hulk | 461,912 |
| Bot | 286,191 |
| FTP-BruteForce | 193,354 |
| SSH-Bruteforce | 187,589 |
| Infiltration | 160,639 |
| DoS attacks-SlowHTTPTest | 139,890 |
| DoS attacks-GoldenEye | 41,508 |
| DoS attacks-Slowloris | 10,990 |
| DDOS attack-LOIC-UDP | 1730 |
| Brute Force -Web | 611 |
| Brute Force -XSS | 230 |
| SQL Injection | 87 |
| Id/ Crossfold | Train. Accuracy | Train. Recall | Train. Precision | Train. | Valid. Accuracy | Valid. Recall | Valid. Precision | Valid. |
|---|---|---|---|---|---|---|---|---|
| 1/1 | 0.985279 | 0.953011 | 0.952642 | 0.952938 | 0.985035 | 0.953709 | 0.952691 | 0.953505 |
| 2/1 | 0.985187 | 0.952982 | 0.952175 | 0.952821 | 0.985194 | 0.953672 | 0.950938 | 0.953124 |
| 3/1 | 0.984720 | 0.951857 | 0.949798 | 0.951445 | 0.984740 | 0.953398 | 0.951399 | 0.952997 |
| 4/1 | 0.984624 | 0.951583 | 0.949958 | 0.951257 | 0.984706 | 0.953201 | 0.951103 | 0.952781 |
| 5/1 | 0.984882 | 0.952582 | 0.951060 | 0.952277 | 0.984641 | 0.953459 | 0.950000 | 0.952765 |
| 6/2 | 0.985692 | 0.953451 | 0.956237 | 0.954007 | 0.985788 | 0.954082 | 0.959513 | 0.955164 |
| 7/2 | 0.984982 | 0.952545 | 0.950739 | 0.952183 | 0.985490 | 0.953705 | 0.959159 | 0.954791 |
| 8/2 | 0.985753 | 0.953149 | 0.957078 | 0.953932 | 0.985614 | 0.954214 | 0.957105 | 0.954790 |
| 9/2 | 0.985165 | 0.952379 | 0.952324 | 0.952368 | 0.985624 | 0.953886 | 0.957250 | 0.954557 |
| 10/2 | 0.985511 | 0.953122 | 0.955194 | 0.953535 | 0.985433 | 0.954117 | 0.956280 | 0.954549 |
| 11/3 | 0.985379 | 0.953305 | 0.952827 | 0.953210 | 0.985560 | 0.953694 | 0.961175 | 0.955181 |
| 12/3 | 0.985684 | 0.953531 | 0.955238 | 0.953872 | 0.985958 | 0.953829 | 0.960620 | 0.955179 |
| 13/3 | 0.985661 | 0.953270 | 0.955329 | 0.953681 | 0.985936 | 0.953439 | 0.961442 | 0.955029 |
| 14/3 | 0.985669 | 0.953469 | 0.955617 | 0.953898 | 0.986002 | 0.953506 | 0.961032 | 0.955002 |
| 15/3 | 0.985751 | 0.953546 | 0.955750 | 0.953986 | 0.985892 | 0.953739 | 0.960023 | 0.954990 |
| 16/4 | 0.984692 | 0.951712 | 0.950179 | 0.951405 | 0.985614 | 0.953164 | 0.954426 | 0.953416 |
| 17/4 | 0.984678 | 0.952081 | 0.949842 | 0.951632 | 0.985164 | 0.953404 | 0.952390 | 0.953201 |
| 18/4 | 0.984547 | 0.951736 | 0.948676 | 0.951123 | 0.984852 | 0.953241 | 0.952025 | 0.952997 |
| 19/4 | 0.984425 | 0.951777 | 0.948229 | 0.951065 | 0.984818 | 0.953062 | 0.951772 | 0.952804 |
| 20/4 | 0.984702 | 0.952451 | 0.949359 | 0.951831 | 0.984788 | 0.953401 | 0.950232 | 0.952765 |
| Id/ Crossfold | Layers | Neurons | Activation | Learing Rate | reg. | Dropout | Train. | Valid. |
|---|---|---|---|---|---|---|---|---|
| 1/1 | 1 | 332 | LReLU | 0 | 0.001494 | 0.952938 | 0.953505 | |
| 2/1 | 1 | 312 | LReLU | 0 | 0.004133 | 0.952821 | 0.953124 | |
| 3/1 | 1 | 338 | LReLU | 0 | 0.035715 | 0.951445 | 0.952997 | |
| 4/1 | 2 | 321 | LReLU | 0.016339 | 0.951257 | 0.952781 | ||
| 5/1 | 1 | 325 | LReLU | 0.002084 | 0.952277 | 0.952765 | ||
| 6/2 | 2 | 237 | ReLU | 0 | 0.003140 | 0.954007 | 0.955164 | |
| 7/2 | 2 | 367 | ReLU | 0.078722 | 0.952183 | 0.954791 | ||
| 8/2 | 1 | 265 | ReLU | 0 | 0.000635 | 0.953932 | 0.954790 | |
| 9/2 | 2 | 419 | ReLU | 0.050924 | 0.952368 | 0.954557 | ||
| 10/2 | 1 | 261 | ReLU | 0 | 0.001476 | 0.953535 | 0.954549 | |
| 11/3 | 2 | 414 | ReLU | 0 | 0.108125 | 0.953210 | 0.955181 | |
| 12/3 | 2 | 396 | ReLU | 0 | 0.030578 | 0.953872 | 0.955179 | |
| 13/3 | 1 | 421 | ReLU | 0 | 0.049736 | 0.953681 | 0.955029 | |
| 14/3 | 1 | 342 | ReLU | 0 | 0.024507 | 0.953898 | 0.955002 | |
| 15/3 | 2 | 500 | ReLU | 0 | 0.031615 | 0.953986 | 0.954990 | |
| 16/4 | 4 | 67 | ReLU | 0.005776 | 0.951405 | 0.953416 | ||
| 17/4 | 4 | 85 | ReLU | 0.015252 | 0.951632 | 0.953201 | ||
| 18/4 | 1 | 166 | ReLU | 0.163120 | 0.951123 | 0.952997 | ||
| 19/4 | 4 | 67 | ReLU | 0.014062 | 0.951065 | 0.952804 | ||
| 20/4 | 4 | 65 | ReLU | 0.002810 | 0.951831 | 0.952765 |
| Id | Train. Accuracy | Train. Recall | Train. Precision | Train. | Valid. Accuracy | Valid. Recall | Valid. Precision | Valid. |
|---|---|---|---|---|---|---|---|---|
| 1 | 0.985487 | 0.953338 | 0.953400 | 0.953351 | 0.985623 | 0.954242 | 0.960193 | 0.955426 |
| 2 | 0.985770 | 0.953545 | 0.955593 | 0.953954 | 0.986016 | 0.954449 | 0.959681 | 0.955491 |
| 3 | 0.985740 | 0.953497 | 0.956524 | 0.954101 | 0.985968 | 0.953800 | 0.959513 | 0.954937 |
| 4 | 0.985785 | 0.953557 | 0.956156 | 0.954075 | 0.985951 | 0.954351 | 0.959907 | 0.955457 |
| 5 | 0.985790 | 0.953463 | 0.956371 | 0.954043 | 0.986057 | 0.953903 | 0.961583 | 0.955430 |
| 6 | 0.985799 | 0.953694 | 0.955807 | 0.954116 | 0.985986 | 0.954495 | 0.958517 | 0.955297 |
| 7 | 0.985114 | 0.952619 | 0.951175 | 0.952330 | 0.985563 | 0.952987 | 0.960972 | 0.954573 |
| 8 | 0.985877 | 0.953384 | 0.958321 | 0.954367 | 0.985748 | 0.954353 | 0.959537 | 0.955385 |
| 9 | 0.985319 | 0.952743 | 0.952580 | 0.952711 | 0.985581 | 0.953927 | 0.958010 | 0.954741 |
| 10 | 0.985503 | 0.953170 | 0.955167 | 0.953569 | 0.985391 | 0.954318 | 0.956221 | 0.954698 |
| 11 | 0.985487 | 0.953093 | 0.953714 | 0.953217 | 0.985589 | 0.954371 | 0.955108 | 0.954518 |
| 12 | 0.984550 | 0.951748 | 0.949164 | 0.951230 | 0.984963 | 0.953843 | 0.950701 | 0.953213 |
| 13 | 0.984738 | 0.951941 | 0.949854 | 0.951523 | 0.985582 | 0.953640 | 0.953506 | 0.953613 |
| 14 | 0.985280 | 0.953007 | 0.952763 | 0.952959 | 0.985375 | 0.954340 | 0.953199 | 0.954112 |
| 15 | 0.984895 | 0.952168 | 0.950591 | 0.951852 | 0.985389 | 0.953303 | 0.960285 | 0.954691 |
| 16 | 0.984724 | 0.951835 | 0.950323 | 0.951532 | 0.984730 | 0.954145 | 0.949748 | 0.953263 |
| 17 | 0.984427 | 0.951339 | 0.948442 | 0.950758 | 0.984880 | 0.953596 | 0.953865 | 0.953650 |
| 18 | 0.984565 | 0.951510 | 0.949802 | 0.951168 | 0.984657 | 0.954147 | 0.947953 | 0.952902 |
| 19 | 0.984889 | 0.952499 | 0.951215 | 0.952242 | 0.984685 | 0.954169 | 0.949517 | 0.953235 |
| 20 | 0.984774 | 0.952610 | 0.949929 | 0.952073 | 0.985427 | 0.954007 | 0.952854 | 0.953776 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Szczepanik, W.; Niemiec, M. Heuristic Intrusion Detection Based on Traffic Flow Statistical Analysis. Energies 2022, 15, 3951. https://doi.org/10.3390/en15113951
Szczepanik W, Niemiec M. Heuristic Intrusion Detection Based on Traffic Flow Statistical Analysis. Energies. 2022; 15(11):3951. https://doi.org/10.3390/en15113951
Chicago/Turabian StyleSzczepanik, Wojciech, and Marcin Niemiec. 2022. "Heuristic Intrusion Detection Based on Traffic Flow Statistical Analysis" Energies 15, no. 11: 3951. https://doi.org/10.3390/en15113951
APA StyleSzczepanik, W., & Niemiec, M. (2022). Heuristic Intrusion Detection Based on Traffic Flow Statistical Analysis. Energies, 15(11), 3951. https://doi.org/10.3390/en15113951