1. Introduction
In December 2015, 196 countries agreed on an international treaty for limiting global climate change by reducing global warming. The main goal is to limit global warming to well below 2 °C by limiting the use of fossil fuels [
1]. Due to both the availability and the cheap price of electricity in first world countries, and with the increase in the number of devices that need electricity to operate and the appearance of new ones such as electric cars, electrical grids and their growing effect on nature have become a significant concern.
Consequently, transition policies from fossils such as coal have been discussed in [
2] while suggesting an increase in the use of renewable energies. In fact, the research in [
3] predicts that the return of investment (ROI) for renewable energies is growing and will eventually become, in the future, similar to the ROI of fossils. This means that the economic expense that prevents governments from using renewable energies at large scales will eventually disappear with time. Indeed, this article is a part of the MAESHA project [
4], which is funded by the European Union through the H2020 program. The goal of this project is the decarbonization of the future energy used in Mayotte and other islands by transforming the usual electrical grid into a smart grid that is able to manage the demand side to be adapted to the available generation at any time.
Moreover, different challenges arise when trying to manage the electrical grid of isolated areas because it is impossible to receive electricity from other countries or regions in the case of excessive demand, which can cause a blackout.
In addition, even though renewable energies are the main key to achieving the decarbonization of energy systems, their production varies significantly within short times due to environmental factors, such as the radiation of the sun or the speed of the wind, which can cause problems during peaks on the demand side.
Indeed, this brings the need for a smart grid that can detect, predict, and adapt to changes in order to match and manage the demand side with the availability on the supply side. As a consequence, predicting electrical load in advance is a very important challenge for demand-side management (DSM), especially in isolated areas [
5].
Moreover, most of the current machine learning models are built to predict and are tested on the load demand of one region or country only, without taking into consideration the reusability of their models.
In fact, to predict the load of multiple islands with acceptable accuracy, it is important to build a flexible model in both space and time. First, as for the space, in order to predict the load in multiple regions without having to create different prediction models, it could be interesting to build a model combining standard machine learning models that are known to give good predictions with acceptable accuracy for the different situations or regions, thus having a reusable prediction model that can be used directly or with minimal changes on different regions, islands, countries, or even multiple buildings. The second challenge is how to simply build a flexible model that can predict in the range of multiple days or a week with an acceptable accuracy; at the same time, it should be able to predict a shorter range (the next 30 min or 24 h) with high accuracy.
Although some researchers have taken into consideration the testing of their models for multiple datasets, such as in [
6], and other researchers have tried to build models that can predict for multiple months with relatively high accuracy [
7], to our knowledge, none of the previous studies have taken into consideration the flexibility of their models in both space and time. The advantage of having generalized and reusable models is that they can, in general, save resources and time. More specifically, in cases such as the presented work in this article, the model can be simply applied to multiple regions (islands, cities, or whole countries).
For this reason, we propose in this paper a flexible hybrid model that relies on four neural network models to give a prediction, instead of relying on one single model. The advantage of this approach is that we already know some models can perform better for some regions and during some days or specific periods of time in general, while other algorithms can perform better in other regions and/or during other periods of time. Using a weights function that dynamically attributes weights to each algorithm depending on its previous error and accuracy, models that predict better in a specific period of time will, consequently, have a higher weight.
To validate the proposed model, it has been tested on two different datasets. The first dataset, provided by Electricity of Mayotte (EDM), consists of the previous loads registered from 2015 to 2020, with all-weather forecasts, and holiday data with a data granularity of 1 point every 30 min. The second dataset is “Panama Electricity Load Forecasting” from Kaggle. It has similar features with the exception of data granularity, which is 1 point per hour.
The paper is structured as follows:
Section 2 presents the literature review about consumption forecasting/prediction. A brief description of Mayotte’s grid and the provided data is given in
Section 3. Our approach is shown and detailed in
Section 4. Experiments to validate our method are provided in
Section 5. Conclusions and future perspectives are presented in
Section 6.
2. Literature Review
Since energy demand is a set of ordered values representing an evolution of a quantity over time, it is handled as a time series forecasting problem.
Predicting energy consumption is frequently done in the short term: almost 60% of the studies employing data-driven models make hourly predictions [
8]. It is equally interesting to see that the load in general is highly affected by cooling/heating (HVAC). Indeed, HVAC represents between 40% and 50% of the overall consumption of big buildings, such as offices, schools, or hotels [
9]. Forecasting this consumption is often easier since the HVAC is fairly continuous over time and depends on external parameters such as local weather or time of the year [
10].
Moreover, since load prediction is a time series forecasting problem, wavelet transform (WT) is an important tool to help find the different time and frequency features of the load curve [
11]. Indeed, the use of WT in [
12,
13] was proven to be an important preprocessing step for the prediction. Ref. [
14] has even proposed a framework of wavelet neural networks (WNN). Indeed, wavelet transform has been tried with different types of traditional and modern types of machine learning layers, such as feed-forward or convolutional layers [
15].
On the other hand, it is not surprising to find familiar methods for time series, such as auto-regressive integrated moving average (ARIMA) [
16,
17,
18], support vector machines (SVM) [
19,
20], and artificial neural networks (ANN), applied to this field, as shown in [
21].
However, the review in [
22] shows that artificial neural networks are the most efficient prediction models for load forecasting in the smart grids domain in general and for demand-side management specifically.
Indeed, ANNs are the most used methods in forecasting electrical load. They are widely employed in this field for their numerous advantages. In fact, the complexity of this task is considerable due to several factors/parameters, such as weather and holidays (linear and non-linear relationships), which is a well-suited problem for ANNs and their capacity to deal with non-linear relationships. ANNs are extremely robust and flexible, especially the multilayer perceptron (MLP); they do not need to be programmed but require data to train on. They are easy to implement but require some specialized knowledge to configure. They can be used alone [
23], but they can also be combined with other models to obtain a hybrid prediction [
16,
18]. One of the disadvantages is the massive amount of data required to train the network. If there are not enough data to train the ANN, it will have difficulties generalizing and risk overfitting.
Another type of neural network widely used in the field of time series forecasting is the long short-term memory (LSTM). It is an artificial recurrent neural network architecture that can process entire sequences of data, making it a privileged model for handwriting recognition, speech recognition, and time-series data. It can be used alone [
24,
25] or with a convolutional layer for better results [
26]. Some models combine neural networks with more classical models of time series forecasting. This combination aims to strengthen predictions and increase performance. This combination is designated as a hybrid model.
Hybrid Models
They represent combinations of two or more machine learning techniques. These models are more robust, as they have the advantages of the individual techniques involved and improve the forecasting accuracy. By combining separate models, complex structures can be modelled more accurately. More and more papers use a hybrid approach thanks to their performance [
27,
28,
29]. They often combine linear with nonlinear models to be more robust and more accurate. The most traditional hybrid models are a combination of ARIMA for linear relationships and SVM or ANN to model the nonlinear component [
17,
18]. However, various methods and algorithms have been used in the prediction models, such as empirical mode decomposition (EMD), the extended Kalman filter (EKF), characteristic load decomposition (CLD), and the radial basis function neural network (RBFNN).
Table 1 provides a brief review of these articles for load predictions covering short-term, mid-term, and long-term predictions and covering the various prediction algorithms used.
Although some of the previous research, such as [
6], has been tested on multiple datasets from different countries, to our knowledge, none of them have been built to be general enough to be applied to any case, nor are they easily reusable without modifications to the code (especially isolated areas such as Mayotte where blackouts happen regularly because of high load consumption).
In addition, all previous articles have concentrated on having one prediction range (i.e., 1 h, 24 h, 1 week, etc.). However, having a prediction for 30 min can provide a higher accuracy than having a prediction for 1 week, and as a consequence, having multiple prediction ranges at the same time (very short-term prediction with very high accuracy and short- or mid-term prediction with slightly lower accuracy) can provide more stable results for the smart grid systems that have to interact and make decisions for one or more days in real-time.
Thus, in this paper, a generalized and reusable hybrid method is presented in
Section 4. The proposed method is managed by an automatic process to optimize its hybrid parameters and to provide the best forecast at any time, in any region, and at multiple prediction ranges in the future.
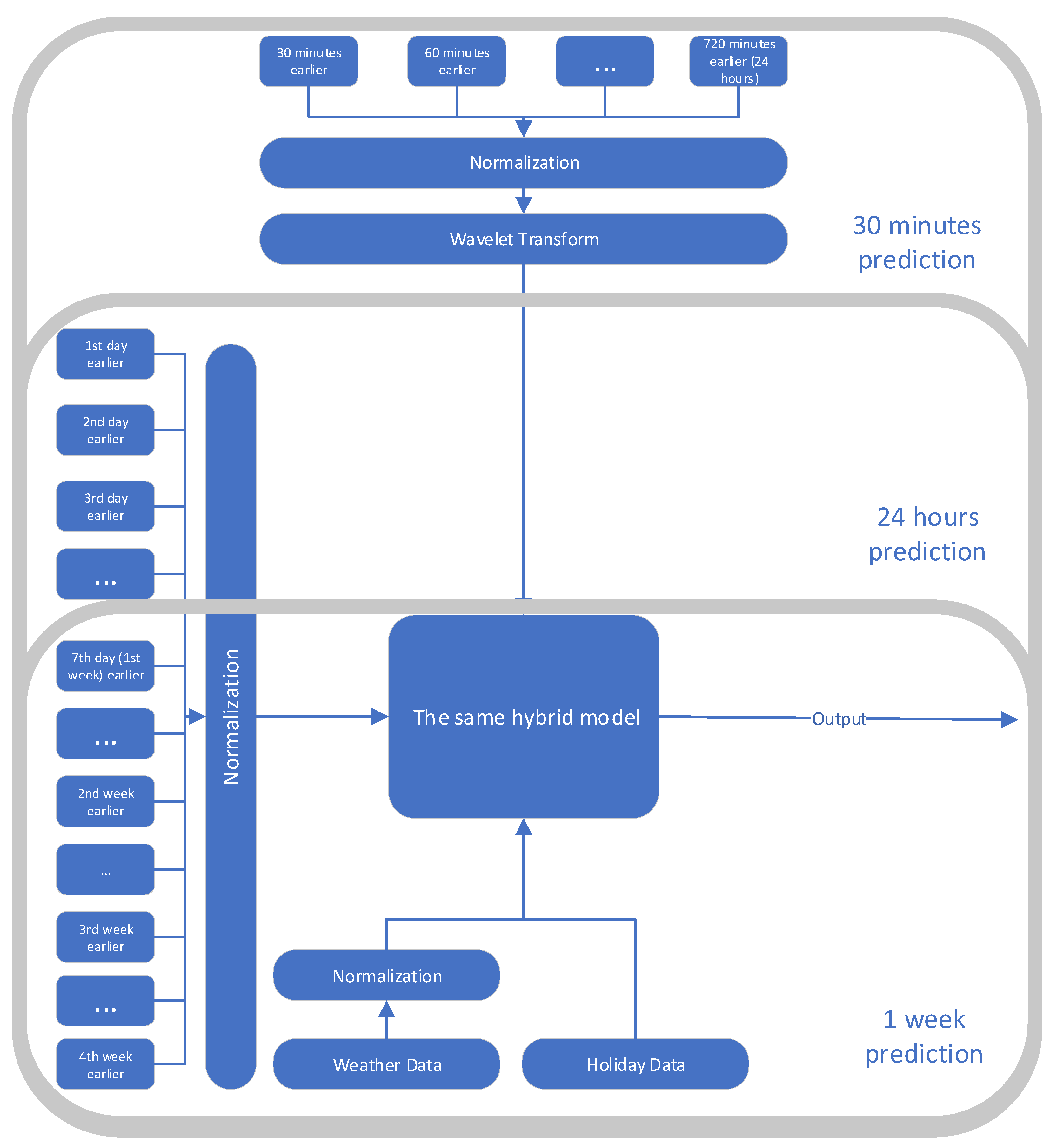
4. Our Approach
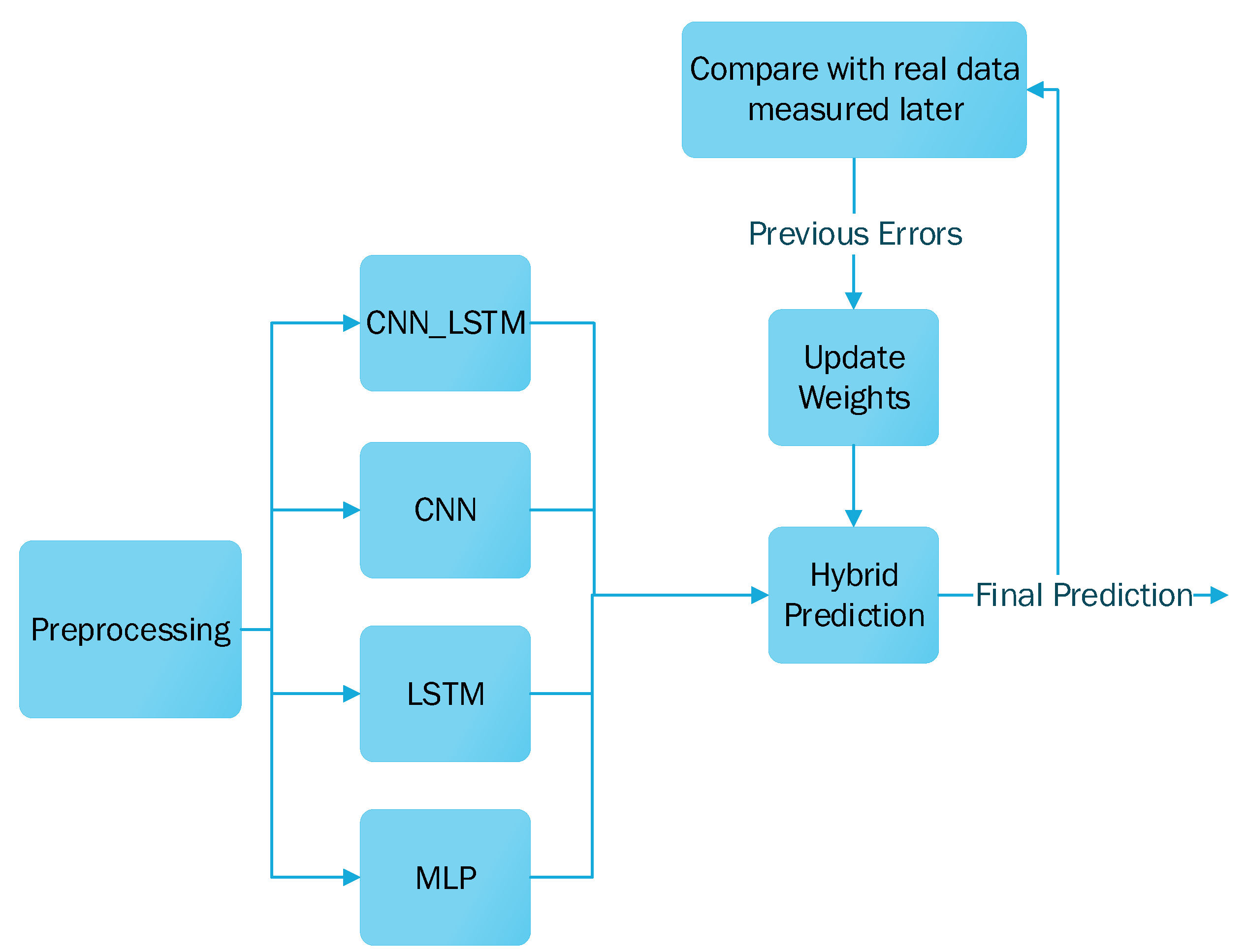
In this paper, to forecast the electrical load in different regions such as Mayotte, we propose a hybrid prediction method. This method is composed of four deep learning models for time series analysis. Each model has its own characteristics and usefulness in different situations and periods of time. The combination of these four models will be able to handle any time series. To make the hybrid prediction, we decompose our approach into three steps:
- A.
Preprocessing and feature selection to obtain the best results from the dataset;
- B.
Hybrid model to combine four deep learning models for time series analysis;
- C.
Weights function to optimize the forecast from the hybrid model.
4.1. Preprocessing and Feature Selection
The objective of our model is to perform a short-term forecast and to make a prediction of up to 30 min, one day, and/or one week. The dataset consists of multiple columns, including the previous load data, the temperature (min, max, mean), the wind speed (min, max, mean), the global radiation, and more. We computed the correlation matrix of these columns to determine what features are most correlated with the data. The features selected were the previous load, the mean temperature, the public holidays, school holidays, and Ramadan days.
4.1.1. Interpolation
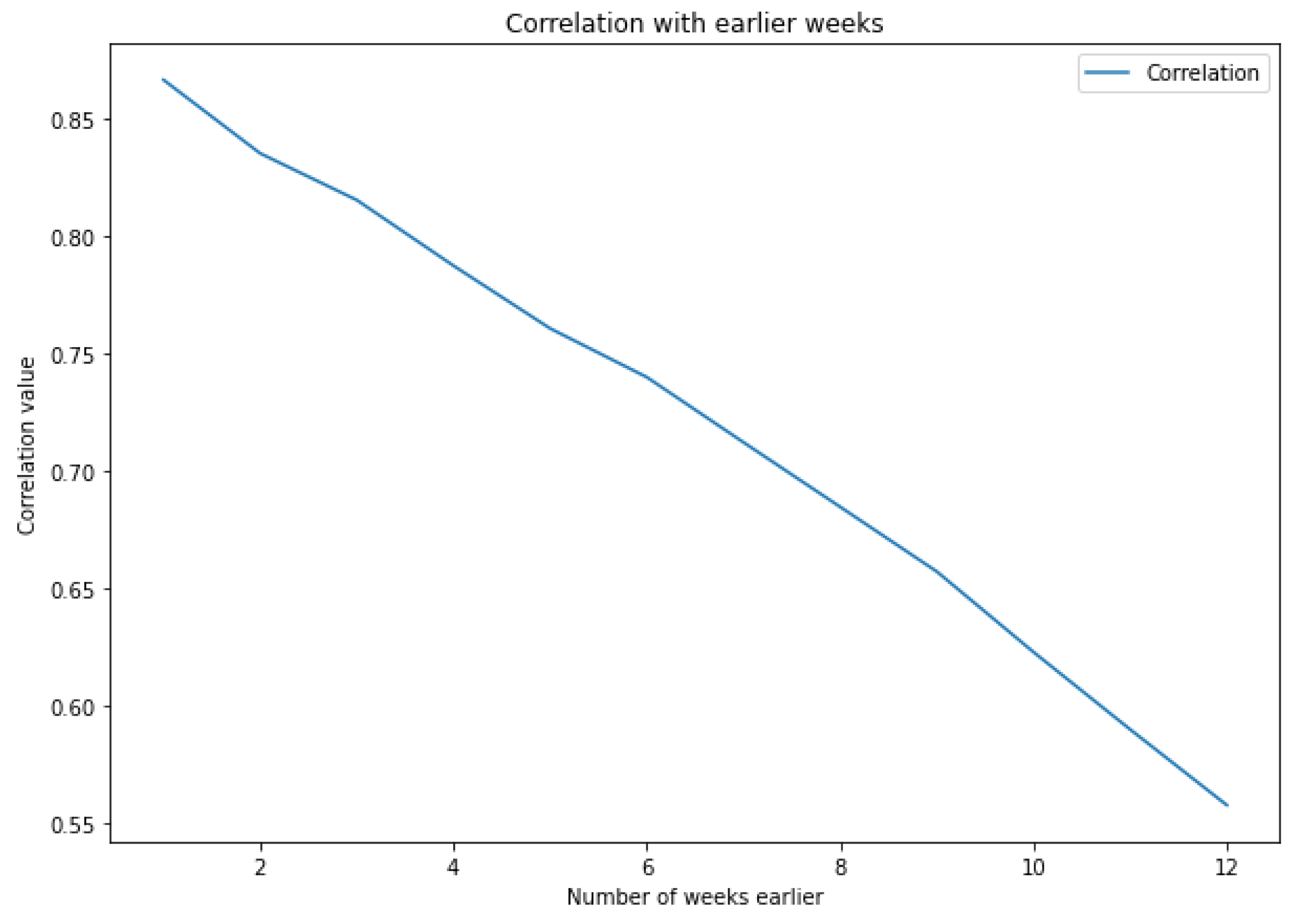
ML algorithms work better in time series that are relatively smooth. To minimize the large variations in the load curve, we tried to train the ML algorithms on both the original curve and the interpolated curve of the load. The prediction on the interpolated graph gave better results than the prediction on the original graph. While the interpolation is not directly used in our model, it was an important step because it helped in justifying and showing what kind of data are the more useful in order to obtain the best predictions. Indeed, following this logic of minimizing variations, we calculated the correlation with previous days and previous weeks to find the points that are the most similar to the point that we want to predict, and as a second step, we calculated the normalization which can minimize the margin of the curve without changing the general form of the curve.
4.1.2. Correlation and Seasonality
As for the previous load measurements, we noticed that all four models give better predictions when their input is relatively similar to the load that is being predicted. Thus, taking seasonality into consideration is an important factor in the prediction process [
40].
4.1.3. Normalization
To evenly minimize the variations in the data, we wanted to smooth the general curve without changing its general form, so we used the Z-score normalization as defined in Formula (
1):
where
x refers to the original curve;
is the mean of
x;
is the standard deviation of
x; and
Z is the resulting curve after normalization. The normalization was implemented on each value separately and does not not affect the shape or the number of inputs.
4.1.4. Wavelet Transform
Wavelet transform is a time-frequency transformation that takes into consideration two parameters: scaling and shifting. Wavelet transform is generally used for denoising and compression. We use it here to obtain a compressed approximation of the last 24 h of the demand for electricity, in addition to the previously chosen data in
Section 4.1.2. The advantage of using the approximated curve obtained by the wavelet transform is that it has a smaller size in the memory (compression) with less noise (denoising).
The wavelet transform
for a time series function
is mathematically defined as in Formula (
2):
where
(
t) is the mother wavelet,
a is the scaling parameter that deals with the frequency domain, and
b is the shifting parameter that deals with the time domain.
4.2. Hybrid Model
Our approach is based on a hybrid method that combines multiple deep learning models. Indeed, we used four deep learning models to have a generalizable and adaptive method for several time series or ranges of predictions. Our hybrid model is composed of multilayer perceptron (MLP), long short-term memory (LSTM), convolutional neural network (CNN), and CNN_LSTM, which is a combination of CNN and LSTM.
4.2.1. MultiLayer Perceptron (MLP)
MLP is a deep robust and reliable neural network and the most standard machine learning algorithm that can be used on most types of prediction problems.
4.2.2. Long-Short-Term-Memory (LSTM)
With LSTM layers, a special cell structure can order values of a given window to learn a sequence between them. The model learns a mapping from inputs to outputs and learns what context from the input sequence is useful for the mapping. In some cases, it should give better results compared to MLP since it captures and learns the sequence from a given window. Hence, it could be effective with the load’s curve showing sequences of marked steps. Very sensitive, it may become unstable with huge white noise.
4.2.3. Convolutional Neural Network (CNN)
CNNs are well-known for image processing and recognition, especially in computer vision. In our context, a conv1d layer synthesizes the time series, reduces the noise, and catches important seasoning. Its ability to learn and extract features from raw input may be useful for time series with complex relationships between input and output (previous values and future values).
4.2.4. CNN_LSTM
This consists of adding a conv1d layer before the LSTM cells. Overall, it seems to return better results than the others in many cases. It is used frequently in time series forecasting and is often considered to be one of the most precise models. The drawbacks are the need for a large amount of data to train it. Similar to classical CNN, it is better to train it with the original time series.
Some models will perform better on certain periods of time, while other models can outperform in other periods. The combination of models and how the most efficient models are preferred for a prediction are described in
Section 4.3.
4.3. Weight Function
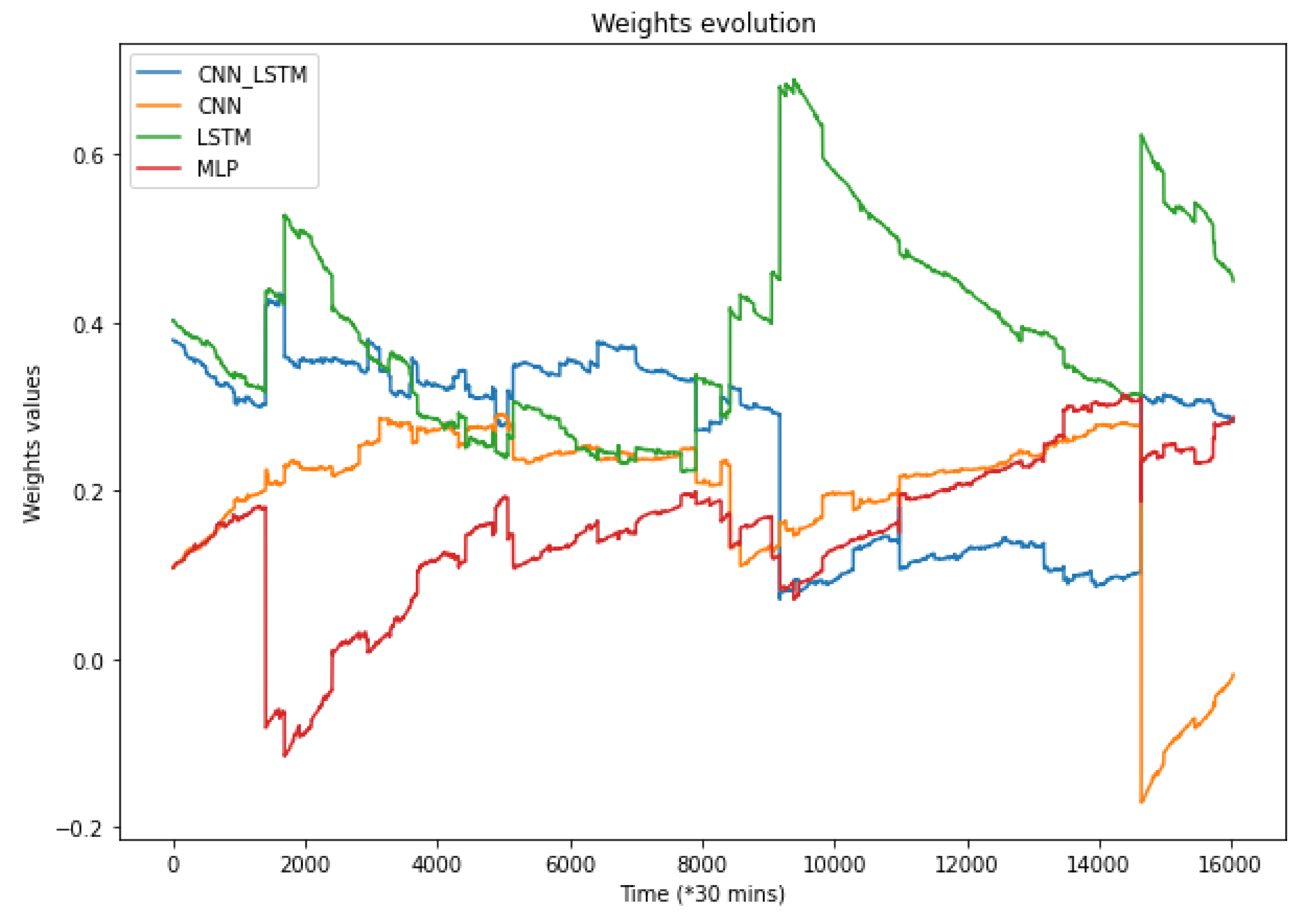
Since the loss of each model is different, a weight function aims to keep the best forecast for each prediction. Weight refers to a percentage. This percentage represents the importance attributed to a model for the final prediction. For a single model, its estimation will be multiplied by the weight related to this model. The final prediction is computed from the sum of all model predictions multiplied by their weights.
As the final prediction is calculated from the weights of each model, they all participate in the prediction of the final value with a greater or lesser weight depending on their previous results. Since the loss of each model is variable over time, the standard deviation is used to punish the models which would have too much dispersion in their predictions. Conversely, the more stable models with a constant error would be rewarded. Algorithm 1 explains the weights update process.
| Algorithm 1: Weights calculation |
Input: Sequence of model errors values Output: Returns the updated weights - 1:
← 0.1 - 2:
models_last_values ← the last 30 model errors - 3:
Sequence_values[] ← [] - 4:
Sequence_stds[] ← [] - 5:
for in do - 6:
value ← - 7:
add in - 8:
end for - 9:
for in do - 10:
std ← standardDeviation() - 11:
add in - 12:
end for - 13:
for in do - 14:
std ← - 15:
end for - 16:
new_weights ← + * * - 17:
return new_weights
|
The weights are updated at each iteration, allowing us to keep constant control of the prediction and to ensure the best model will always have more importance compared to others. Thus, it is common to have a certain model with a high weight for a given period, and, for another, this model could have lower importance in the final prediction and therefore a lower weight due to its increasing errors.
Weights are updated at each new prediction more or less quickly depending on the learning rate. For a learning rate around
, there will be more variations in the importance of the models, whereas with a much smaller learning rate, such as
, the weights will take more time to update, and they will be more stable. The higher the learning rate is, the faster the weights update will be. The weights function is defined by an iterative equation:
where
refers to a normalized array (a normalized value is inversely proportional to the value; the sum of all values is equal to one) of the weights of the function at the current prediction;
refers to a normalized array of the weights at the previous prediction;
refers to the learning rate;
is a normalized array of the current error; and
is a normalized array of the previous standard deviation during the last predictions.
The final prediction is then obtained by summing each prediction algorithm result multiplied by its weight, as shown in the next equation:
where
i is the index of the corresponding algorithm.
6. Conclusions and Future Works
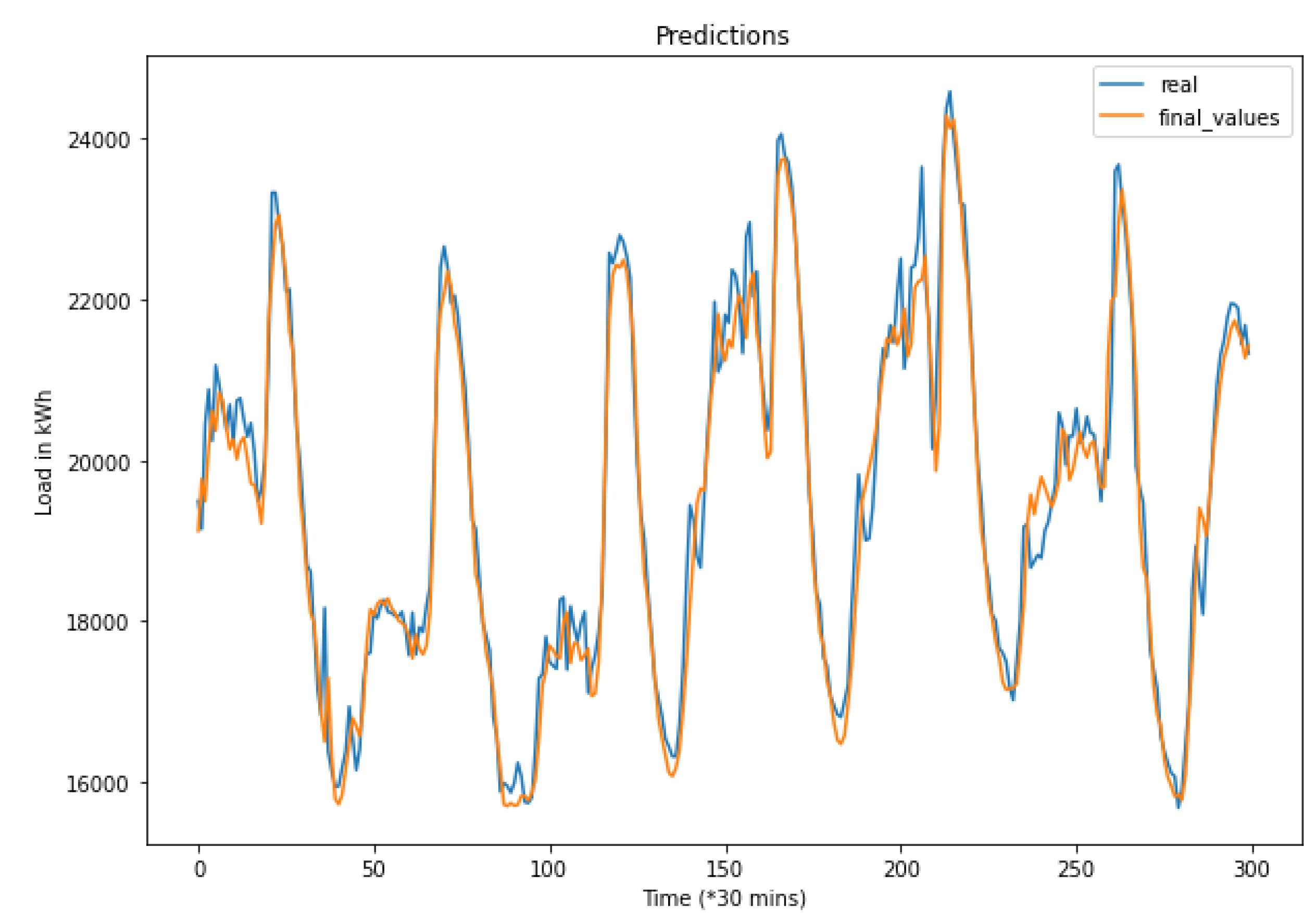
In this paper, we proposed a generalizable hybrid method using multiple standard deep learning models for electrical load short-term forecasting on the island of Mayotte. The results and applications show that the hybrid prediction is a generalizable method that can be used to predict different short-term ranges with only minor changes in the preprocessing phase and that can also be used to predict the load for different regions or countries without the need for any changes in the code.
Moreover, using all four models allows for obtaining more accurate results in a longer scale of time, as it minimizes the effects of changing seasons, holidays, and other events that might cause an increase in the prediction errors for some algorithms. Indeed, the weights assigned to each model and their continuous update maintain the best models for each time, and thus, this allows the proposed method to adapt according to the period of time that we are predicting. This weight system also brings stability and robustness to the prediction compared to stand-alone models.
In future work, this model can be applied to different regions, larger countries, or even continents such as Europe without being limited to special characteristics of some regions or cultures. This work is a first step for building a multi-agent smart grid that can predict and manage the electrical load using demand-side management (DSM), in accordance with the available renewable energies produced and where agents can choose the adequate prediction range while taking into consideration the accuracy of these predictions. The final goal is to decarbonize the production of electrical grids by relying on renewable energies only.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}