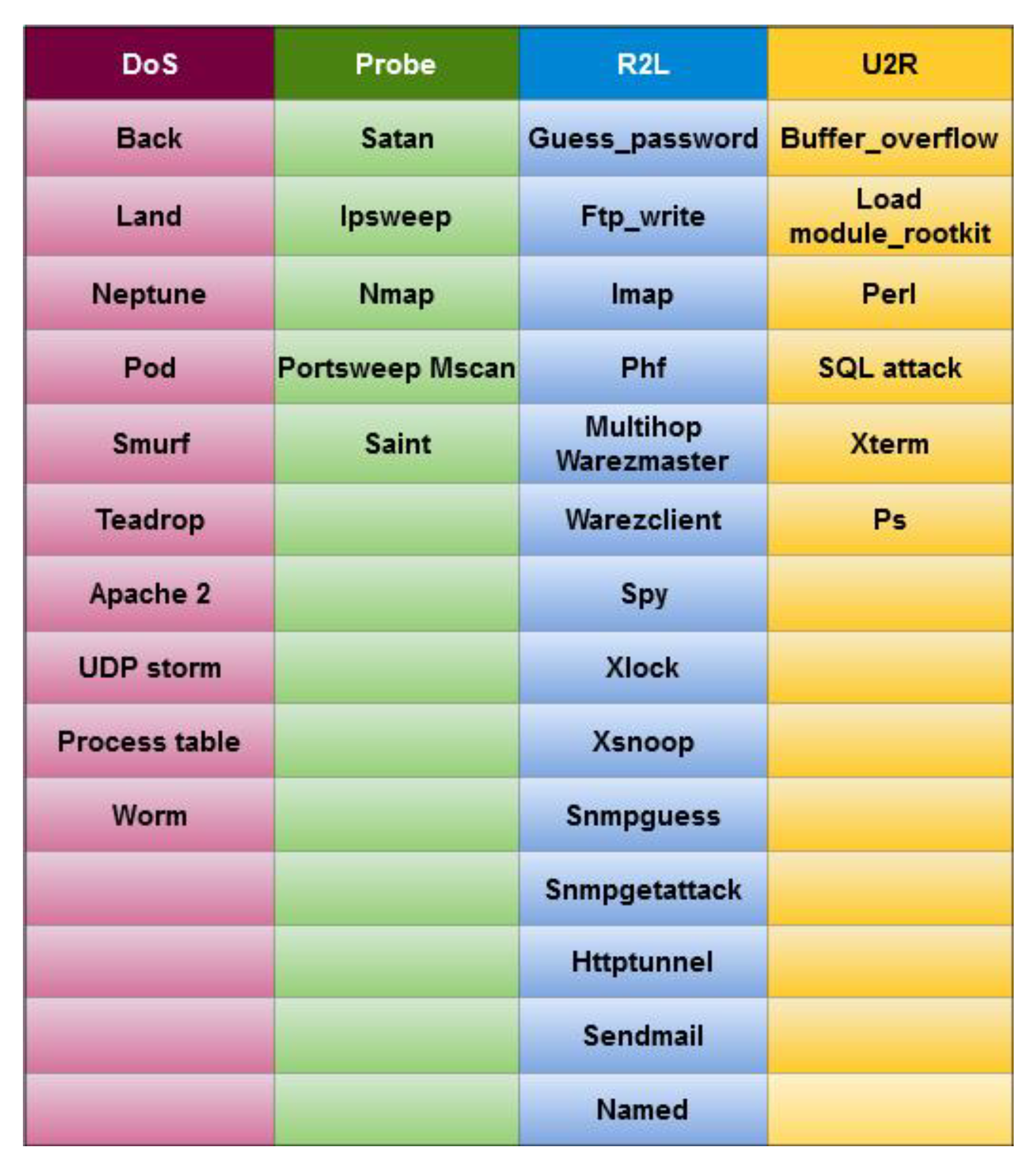
1. Introduction
Supervisory control and data acquisition (SCADA) [
1,
2] is a software application system extensively utilized in many industrial sectors to monitor, control, and analyze manufacturing units. Due to its increased efficiency and performance, SCADA is utilized worldwide in different fields and industries to facilitate proper industrial operations. Additionally, SCADA systems [
3,
4,
5] are mainly used to monitor, control, and automate the industrial processes by collecting the data from remote units and equipment, such as human machine interfaces (HMI), programmable logic controllers (PLC), and remote terminal units (RTU). However, providing security to SCADA against network attacks [
6,
7] is one of the most challenging and difficult tasks in the current era due to the rapid increase in attacks. Therefore, to safeguard SCADA systems, the intrusion detection system (IDS) has been developed to help identify harmful intrusions or attacks against networking operations [
8,
9]. Additionally, it directs the attacking alerts to the network administrators in order to ensure the security of systems. Typically, the IDS is considered as the most suitable and alternative security approach, and it is highly preferred by many researchers [
10]. In this framework, the software program can be used to monitor and detect malicious activities, such as breaking of protocols, interrupting the network communication/data transmission, and data theft. Moreover, it is more suitable [
11,
12] for detecting both the known and unknown attacks in the network created by internal/external attackers. However, most of the conventional IDS approaches are not able to handle the complex nature of cyber-attacks. Hence, ensuring the security of SCADA systems remains a challenging process.
Some of the existing works [
13,
14] aim to incorporate the clustering, optimization, and classification methodologies with the IDS framework to resolve this problem. Recently, machine learning and deep learning techniques are increasingly utilized by many researchers to detect network intrusions by extracting dataset features [
15]. These include the mechanisms [
16,
17] of the naïve Bayes (NB), the support vector machine (SVM), logistic regression (LR), linear discriminant analysis (LDA), the decision tree (DT), the random forest (RF), the multilayer perceptron (MLP), ensemble learning (EL), the deep neural network (DNN), the recurrent neural network (RNN), and the convolutional neural network (CNN). Yet, it faces problems [
18,
19] and challenges related to complex computational operations, increased time consumption for training and testing, and a high misclassification and error rate. Hence, the proposed work intends to implement an intelligent and hybrid IDS framework using sophisticated optimization and classification methodologies for spotting intrusions from SCADA IDS datasets. The novelty of this system is to group the attributes into the form of clusters before selecting the optimal number of features for training the classifier. The main contribution of the proposed work is to detect intrusions from the given SCADA datasets with reduced computational complexity and increased accuracy. For this purpose, a combination of methodologies are used to construct a simple and efficient intrusion detection framework for ensuring the security of SCADA systems. Additionally, the proposed objective is to implement intelligent and advanced clustering, optimization, and classification methodologies for developing the proposed security framework.
The primary objectives of the research methodology are as follows:
To preprocess and normalize the given IDS dataset by grouping the attributes into the form of clusters, the multifacet data clustering model (MDCM) is implemented, which helps to simplify the process of classification.
To optimally select the features for increasing the efficiency of classifier training, the gradient descent spider monkey optimization (GDSMO) mechanism is utilized, which minimizes the time of processing and increases the convergence rate.
To exactly spot the intrusions from the clustered datasets based on the optimal set of features, the deep sequential long short term memory (DS-LSTM) technique is employed.
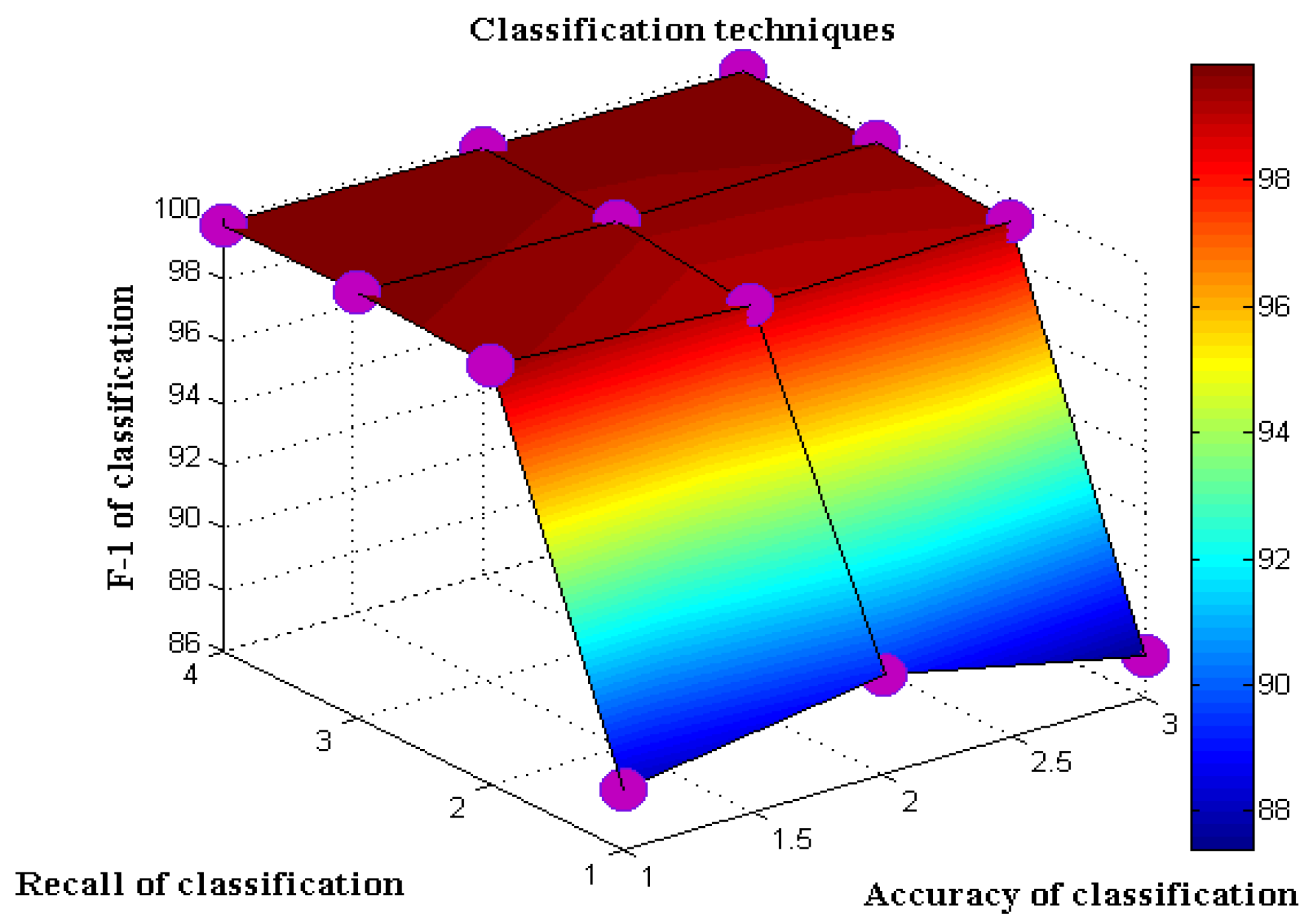
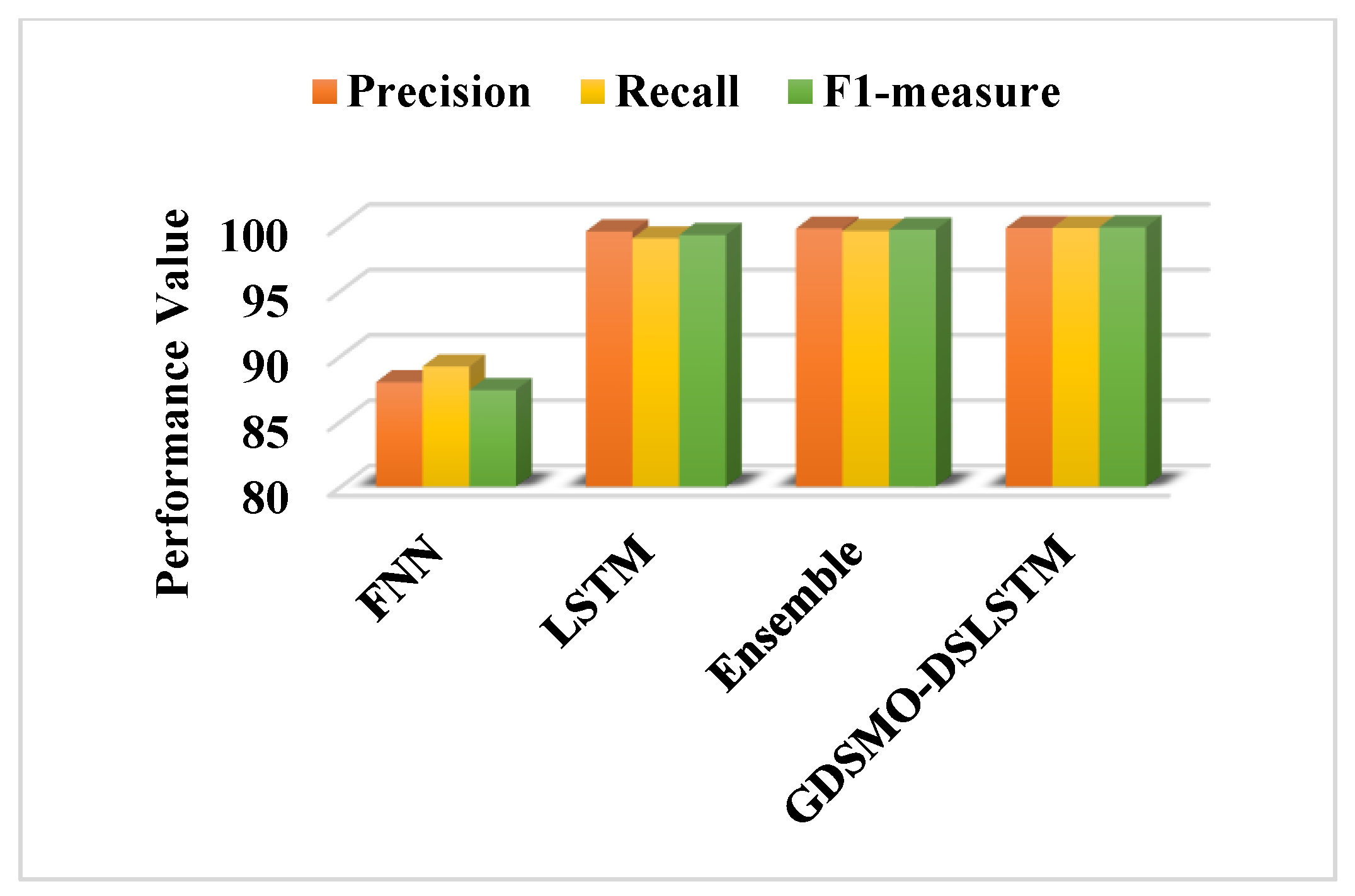
To assess the performance of the proposed GDSMO-DSLSTM-based IDS framework, various evaluation measures have been utilized, and the obtained results are compared with other recent IDS approaches.
The remaining units of this paper are segregated into the following: some of the conventional clustering, optimization, and classification techniques used to increase SCADA systems’ security are reviewed with their advantages and disadvantages in
Section 2. The working methodology of the proposed system is illustrated with its overall flow and algorithmic representations in
Section 3. The performance analysis of the proposed IDS framework is validated and compared by using various evaluation metrics in
Section 4. Finally, the overall paper is summarized with its future scope in
Section 5.
2. Related Works
This section reviews some of the conventional approaches used for developing an IDS in SCADA systems. Additionally, it investigates the benefits and limitations of each mechanism based on its characteristics and working operations.
Ref. [
20] implemented a deep learning model for detecting intrusions in SCADA systems, where the network-based cyber-attack primitives were highly concentrated. Additionally, it mainly aims to extract the features and salient temporal patterns of individual packets by using the convolutional neural network (CNN) algorithm. [
21] presented a comprehensive review of various IDS methodologies for increasing the security of SCADA systems. The primary factor of this work was to analyze the different types of methodologies used for detecting the attacks, which include the following types: intrusion detection technologies, intrusion detection methodologies, and intrusion detection approaches. Moreover, an effective IDS should satisfy the following constraints:
Ref. [
22] implemented a hybrid multilevel (HML) IDS mechanism incorporated with the nearest neighbor rule algorithm for detecting industrial attacks. The main purpose of this work was to exactly detect the anomalies with reduced false positives and an increased detection rate. Here, three different feature selection mechanisms have been analyzed and compared for improving the dimensionality of features. In addition to that, the Bloom filtering approach was utilized for categorizing the normal network patterns and anomalies by constructing the hash lookup table. The key advantages of this work were optimal performance and minimal resource consumption. Yet, it faced the problems of complex analysis, as well as the inability to handle different types of attacks. Ref. [
23] developed an anomaly-based IDS (Ab-IDS) for spotting cyber-attacks in SCADA systems. This work mainly aims to identify malicious packets in the network with reduced system disturbances and network traffic. For validating the performance of this approach, two different IDS security tools, such as Snort and Bro, have been utilized.
Ref. [
24] employed a long short term memory (LSTM) classification technique for detecting intrusions in the SCADA system. This work mainly aimed to identify temporal uncorrelated attacks by analyzing the specific features from the given dataset. It includes nearly 19 different types of features, such as port number, sequence number, traffic type, threshold value, speed, register data, etc. Typically, LSTM is a kind of deep learning-based classification technique that helps to predict accurate labels for given problems. Here, the many-to-many (MTM) and many-to-one (MTO) architectures have been developed for improving the performance of attack detection. Still, it has limits, such as the problems of increased time consumption for forming the hidden layers, and complexity in handling the large data. Ref. [
25] presented a novel intrusion detection framework for identifying malicious activities in SCADA systems. This paper analyzed the performance and efficiency of two different and popular IDS technologies, such as Snort and Suricata, for categorizing the types of intrusions. Moreover, it investigated some of the security challenges in SCADA systems, which includes the following: lack of security in communication, inefficient data training, authentication, and controlling.
Ref. [
26] deployed an auto-encoder-based network IDS for locating critical attacks in SCADA systems based on the 17 distinct data features. Here, the distributed network protocol 3 (DNP3) has been utilized for ensuring reliable communication in the network. In addition to this, hyper-parameter optimization was performed in this work for training the auto-encoder based on the hyper-parameters. Additionally, the effectiveness of this model has been validated and compared based on the measures of accuracy, precision, recall, and false positives [
15]. The benefits of this work were minimized error value and processing time due to the hyper-parameter tuning. Ref. [
27] employed a feed-forward neural network (FNN) mechanism for identifying correlated and uncorrelated attacks with ensured performance outcomes. Here, the omni attack detector has been developed for distinguishing the different types of attacks. The detection performance of this work could be enhanced based on the features of communication traffic and threshold value. Yet, it has the drawbacks of reduced scalability, reliability, and real-time monitoring was not possible in this system. Ref. [
28] presented a comprehensive analysis of various machine learning techniques used for detecting intrusions in SCADA networks, which include the mechanisms of the support vector machine (SVM), the random forest (RF), the J48 classifier, the naïve Bayes (NB), and the decision tree. The key factor of this work was to select the most suitable technique used for increasing the performance of IDS. Based on this study, it was identified that the random forest classifier technique outperforms the other techniques with reduced error rate and false positives.
Ref. [
29] implemented an elephant herding optimization (EHO)-based recurrent neural network (RNN) classification technique for detecting intrusions in IoT-SCADA systems. Here, the Caesar ciphering model integrated with the elliptic curve cryptography mechanism was utilized for improving the security level of SCADA systems. The primary advantages of this work were increased detection accuracy, security, and reduced training time. Ref. [
30] introduced a new SCADA framework for industrial applications with ensured security and reliable data communication. This work mainly intends to analyze the major risk factors that could affect the performance of SCADA systems. Here, some of the common characteristics, such as data base injections, communication, and prioritization of tasks have been investigated for improving the performance of SCADA systems. Moreover, the detailed vulnerability assessment test has been conducted for validating the detection efficiency of intrusion detection and classification. Ref. [
31] examined the performance of various machine learning classification approaches, such as SVM, RF, DT, logistic regression, NB, and KNN for developing an efficient SCADA-IDS. For this analysis, the online real-time traffic data has been utilized, while the training and testing assessments were performed for attack identification and categorization.
Ref. [
32] introduced a new framework named as the Dnp3 intrusion detection prevention system (DIDEROT) for increasing the security of SCADA systems. Here, the attack detection was performed based on the analysis of network topology, and the developed framework was used to mitigate both the anomalies and DNP3 cyber-attacks. Moreover, it includes the modules of preprocessing, training and prediction, in which the data preprocessing could be performed based upon min-max scaling, normalization, and robust scaling. After that, the machine learning classification methodology was implemented to train the preprocessed data to detect the anomalies. The key benefit of this work was that it was capable of operating in both NIDS and HIDS. Ref. [
33] developed a biased intrusion scheme for increasing the security of SCADA systems, which comprises the phases of optimization, classification, and security. Here, the modified GWO technique was implemented to analyze the features of data in order to sort the malfunctions. Then, the entropy-based ELM technique was utilized to detect the intruders based on the parameters of date, time, and file location. Finally, a hybrid ECC technique was employed to select the trusted routing path [
34] for securing the information against the attackers. Ref. [
35] aimed to identify the potential breaches and vulnerabilities in the SCADA systems by providing some recommendations to ensure the security of network. Here, the different types of overflow vulnerabilities, such as stack-based, multiple buffer, heap-based, multiple heap-based, multiple stack-based, and buffer overflows could be investigated with the strategy of attacks and interruptions. Ref. [
36] employed a chicken swarm optimization-based deep CNN technique for detecting cracks on the concrete structures. The main purpose of this work was to analyze the structural condition of concretes for identifying the damages of cracks, spalling, exposure, and rebar buckling. Here, group statistical evaluation metrics have been used to validate the results of this scheme. Ref. [
37] utilized a GA-based CNN technique for detecting the concrete cracks with increased accuracy. Here, the hyper-parameter optimization [
38] could be performed for tuning the parameters of learning rate, number of layers, and optimization function.
According to this review, it is studied that the existing works are highly concentrating on developing the IDS frameworks with the data clustering, optimization, and classification approaches. Yet, this approach faces the problems and challenges related to the following:
Inability in handling large datasets
High false positives and error outputs
Misclassification results
Requires high time consumption for training data
Follows complex computational operations for classification
Hence, the proposed work aims to develop an advanced and intelligent optimization -based classification methodology for developing the intrusion detection framework in SCADA systems.
3. Proposed Methodology
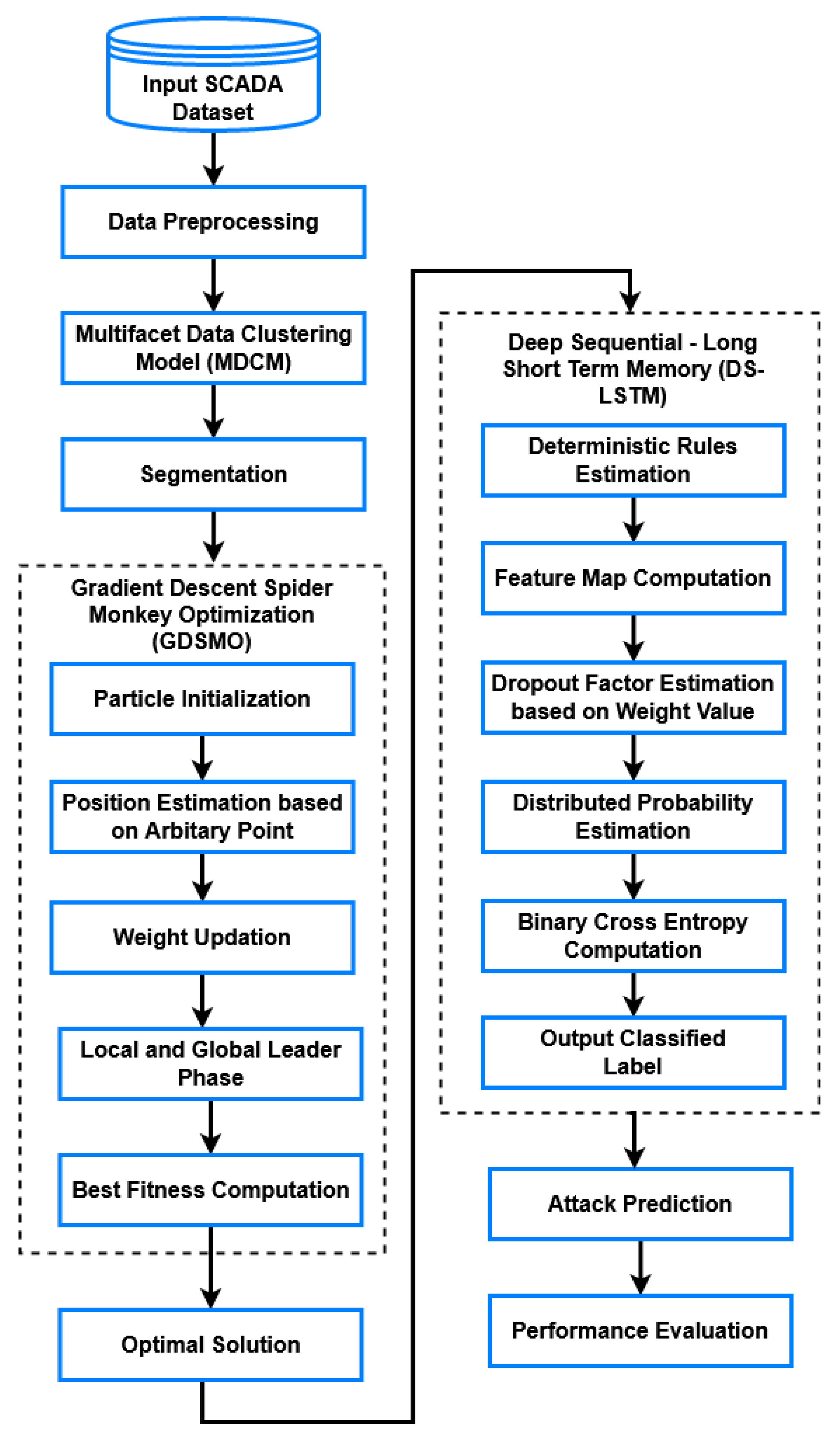
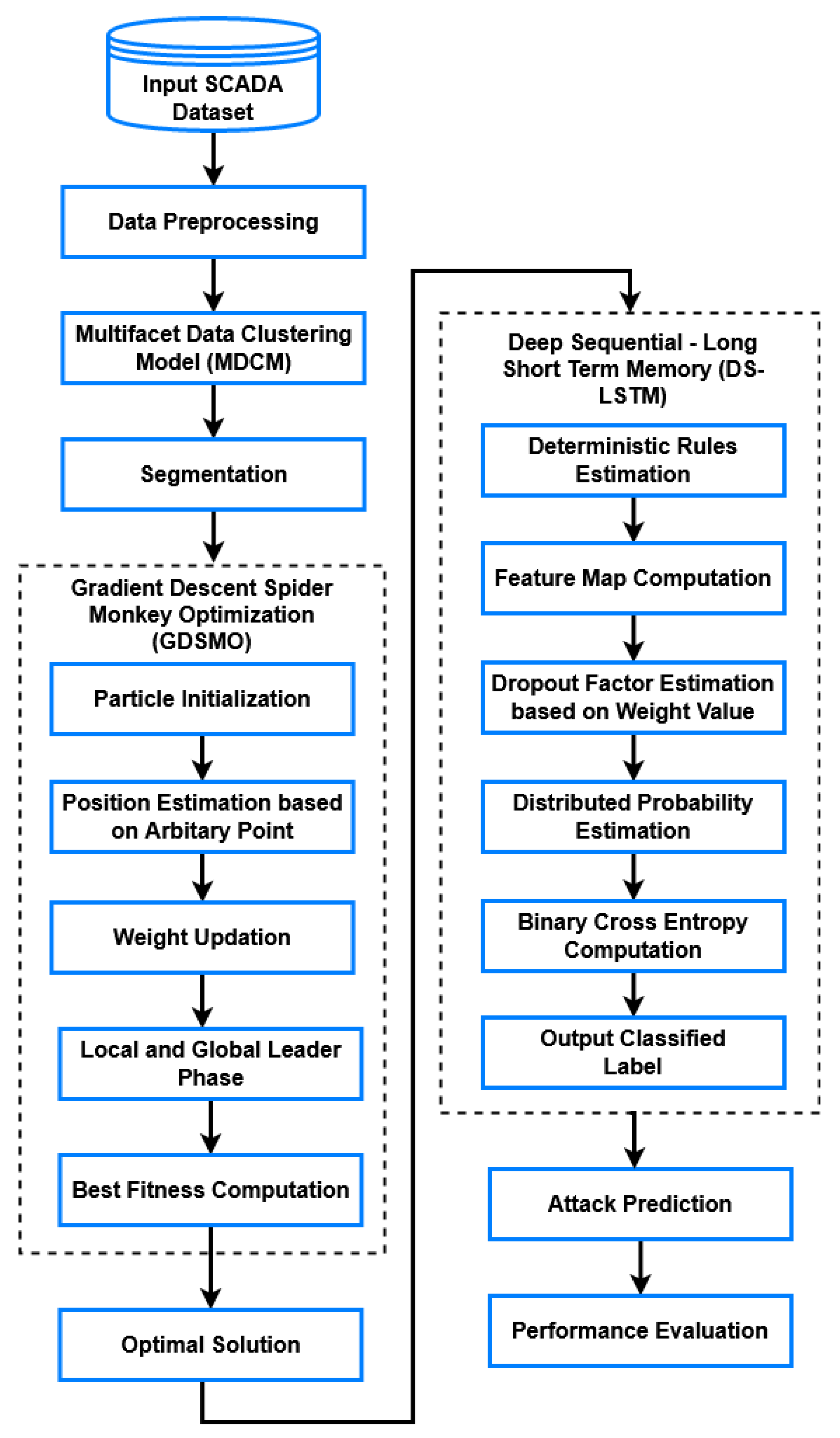
This section presents the working methodology of the proposed IDS system used for detecting intrusions from the SCADA systems. The primary objective of this work is to accurately spot the intrusions from the IDS datasets by using a combination of clustering, optimization, and classification methodologies with reduced computational complexity and time consumption. For accomplishing this process, a multifacet data clustering model (MDCM), gradient descent spider monkey optimization (GDSMO), and deep sequential long short term memory (DS-LSTM) have been implemented. The novel contribution of the proposed system is to select the optimal features from the clustered dataset based on the best fitness value for detecting and categorizing the type of intrusions with an efficient data training model. Here, the SCADA IDS datasets have been taken as the inputs for processing, which comprises some irrelevant attribute information, random values, and a missing field of attributes. Hence, it must be preprocessed and clustered to improve the quality of input datasets, because the unbalanced dataset can affect the performance of IDS with increased misclassification results and error values. So, the proposed work intends to utilize the MDCM technique for normalizing and clustering the data attributes of the input dataset, which helps to improve the efficiency and accuracy of classification. After that, the GDSMO mechanism is implemented for optimally selecting the most-suited features from the clustered dataset, based on the best fitness value. Here, the main advantages of using the GDMO technique are as follows: it efficiently identified the best global optimal solution with minimum iterations, increased convergence rate, and was fast in processing. Moreover, the DS-LSTM mechanism is employed to detect the intrusions from the desired datasets by using the set of optimal features. This is because it supports the aim of efficiently training the model of classifier with reduced time consumption and increased accuracy. Finally, the classifier produces the predicted label as whether normal or intrusion.
The working flow and methodology of the proposed IDS in SCADA systems is shown in
Figure 1, which involves the following modules of operations:
3.1. Data Preprocessing and Clustering
At first, the input dataset preprocessing and normalization processes have been performed for balancing the attributes by filling the missing values, and eliminating the irrelevant information and random values. Additionally, dataset clustering is one of the most essential operation that needs to be accomplished for segmenting the dataset into the group of attribute information in the form of clusters. This is because the large and unbalanced datasets are highly difficult to process, and they also affects performance of classification with increased error values and false positives. Hence, this work aims to implement an advanced clustering technique, named as the multifacet data clustering model (MDCM), for normalizing and clustering the original input datasets, which helps to improve the performance of the classifier. The key factors of using this technique are reduced detection time, increased speed of processing, and classifier accuracy. This stage includes the following stages:
Attribute normalization
Distance computation
Clustering
Here, the attribute normalization is mainly performed for standardizing the data values by extracting the relevant features, where the data is normalized between the values of 0 to 1 as shown in the following equation:
where,
indicates the normalized feature value,
and
denote the minimum and maximum values of the dataset DS, respectively, and the feature value of
. Then, the distance computation is performed to estimate the similarity between the multiple features of the data, which is computed according to the minimum distance and increased similarity value. Consider the input dataset having two objects with N number of attributes as
. and
. After that, the correlation between the data is estimated based on the formation of a covariance matrix as illustrated in the equation below:
where,
indicates the distance function, and
is the generated covariance matrix. Moreover, the estimated distance function is mainly used to compute the similarity of multi-features in the dataset. Consequently, the symmetry similarity matrix
has been constructed according to the closeness of data objects as illustrated in the equation below:
Furthermore, the best clustering effects has been obtained by using the following Equation (4):
where,
indicates the clustering result, and
denotes the center of the
j-th cluster. Based on the minimum distance value, the clustering dataset has been generated, which is used for further operations, such as optimization and classification.
3.2. Gradient Descent Spider Monkey Optimization (GDSMO)
After preprocessing, the optimal number of features are selected from the clustered dataset based on global fitness function by using the proposed hybrid Gradient Descent Spider Monkey Optimization (GDSMO). The conventional SMO technique can easily fall into the problem of local optimum, hence it could not be suitable for all kinds of applications. Hence, the proposed work intends to incorporate the gradient descent (GD) with SMO technique, which efficiently avoids the local optimum problem by adding the fraction of past weight update with the current weight update value. Additionally, it acts like a simulated annealing algorithm, where the randomness is hosted to avoid the local minimum of optimization. In this technique, the parameters are initialized with the random values, and the derivatives are computed to adjust the weight value according to the objective function.
The main purpose of using this technique is to select the best features with a reduced number of iterations, increased convergence rate, and speed of processing. Additionally, it is a technique inspired by a stochastic optimization mechanism, which helps to efficiently reduce the learning time of the classifier [
39]. Typically, the increased number of features can degrade the performance of classification with an increased time consumption and misprediction rate. Hence, it is most essential to optimally select the best suited features in order to train the data model of a classifier for intrusion identification and classification. Here, the parameter tuning is performed for simplifying the process of classification, due to the fact that it is more suitable for solving the complex multi-objective optimization problems. In this technique, the local iterative search is enabled for calculating the functions having a local minimum. Consider that the multivariate function
is distinctive from the neighboring points
k, and that
is decreased with the negative gradient of
, denoted as the gradient descent. Then, the next position
P of the gradient corresponding to the current position
k is illustrated as follows:
where,
indicates the weight factor. The function
must be satisfied to confirm the sufficient level of
. Consequently, the sequence of attributes
and
are considered with an arbitrary point
, and the local minimum value is computed as follows:
Based on the step function, the expected local point is optimally identified with improved convergence. This optimization algorithm performs the following operations for computing the best fitness value:
Initialization
Local Leader Selection
Global Leader Selection
Learning module
Decision module
During initialization, there are
E number of spider monkeys which have been initialized, in which each monkey has the set of the
G dimensional vector as
, where
indicates the
i-th spider monkey
B at the
j-th direction. This is represented as follows:
where,
and
are the minimum and maximum limits of the spider monkey
, and the function rand (0, 1) indicates the random value lies in the range of 0 to 1. After initialization, the local leader is selected from the group of local members, and the fitness is computed according to its new position. If the estimated fitness value is greater than the new fitness value, the spider monkeys have updated their position as shown in the equation below:
where,
is the new position of the spider monkey,
indicates the
v-th local group leader with dimension
j, and
denotes the random
r-th spider monkey with dimension
j,
. Subsequently, the global leader is elected based on the experience, and during this stage, all spider monkeys have to update their positions. Then, the experience of both local and global leader members are determined as follows:
where,
indicates the global leader with dimension
j and random index of
. Then, the positions of all spider monkeys
have been updated according to the probability value of
. This value can be determined with respect to the fitness value and, based on this, the best global leader candidate is selected using the probability value as shown below:
where,
indicates the estimated probability function, and
is the fitness value of the
i-th spider monkey. Furthermore, the learning phase has been executed with the local and global leaders. During this process, the spider monkey having the highest fitness value is considered as the global leader of all spider monkeys, and its position does not update. Similar to that, the local leader has been selected from each group of members, and its position is also does not update. During the decision making module, the group members have to update their positions once the local limit reaches the threshold value, as shown in the equation below:
Similar to that, the global leader could split the population into small number groups, until it reached the maximum number of splits. If its position is not updated, all groups are integrated into a single group. Based on the optimal solution, the final best subset of features have been selected for improving the accuracy of classification. These selected features are further utilized for training the classifier that helps to increase the overall accuracy of intrusion detection and classification system. The algorithmic procedure of the proposed IDS is presented in Algorithm 1.
| Algorithm 1 Gradient Descent Spider Monkey Optimization (GDSMO) |
;
;
;
with the maximum number of iterations;
do.
Randomly select the spider monkeys for computing the fitness function by using Equations (5)–(7);
for computing the fitness value;
do
into g number of groups;
//Local and global leader phase
Update the position of monkeys and global leader as shown in Equations (8)–(10);
//Learning phase
Select the best global leader based on the probability as defined in Equation (11);
Update the position of global & local leaders, and compute the fitness value for the leaders;
Group members can update their position by using Equation (12);
;
End;
then
; //Replace the old solution with the new solution;
End if;
then
Re-initialize the entire population with the group members;
Obtain the global best solution;
End if;
//Old solution is replaced with the new solution
;
; //Arrange the most feasible solutions for determining the current best solution;Increment the count l by 1;
;
End; |
3.3. Deep Sequential Long Short Term Memory (DS-LSTM) Classification Model
In this stage, the selected optimal number of features have been utilized by the classifier for training the model. Here, the deep sequential long short term memory (DS-LSTM) mechanism is employed to identify the intrusions from the SCADA dataset, based on the optimal number of features. It is a kind of machine learning classification mechanism and is more suitable for solving the complex prediction problems. The hyper-parameters play a vital role in the deep learning classification techniques, because they have a great impact on determining the performance of a classifier. In the existing works, the hyper-parameter tuning is performed in the deep learning models based on the random and grid search, but it is not more efficient. Hence, the proposed work aims to utilize an optimization technique for tuning the hyper-parameters. Typically, optimizing the hyper-parameters is one of the crucial processes, so it is required for deep understanding of the underlying model. Hence, the proposed work utilizes an optimization model for optimizing the hyper-parameters of a classifier, which helps to obtain improved performance results. Then, the RMSprop optimizer has been used to optimize the value of the hyper-parameters, which helps to obtain an increased training and testing accuracy. Here, the main purpose of optimizing the hyper-parameters is to increase the training and testing accuracy of classifier. In the proposed system, the different types of hyper-parameters used in the classification are as follows: learning rate, number of epochs, hidden layers, and batch size. The primary advantages of using this technique are reduced time consumption for training and testing, increased accuracy, detection rate, and minimized misclassification rate. In the proposed system, the parameter tuning process [
40] has been performed by using the optimization technique that helps to efficiently improve the detection rate of proposed IDS. During this process, the optimal set of features, learning model, and label are taken as the inputs, and the predicted label is produced as the classified output. Initially, the deterministic rules
are computed according to the logical vector
and featured data
, as shown below:
After that, the feature map has been extracted by applying the convolutional operation across two set of data as shown below:
Based on the value of target vector, the trail vector is computed by using the following model:
where,
indicates the trail vector,
is the classified label, and
is the convolutional vector. According to the weight value, the dropout factor is estimated for the
v-th target vector, in which the neurons are randomly selected with respect to the specialization function as shown below:
where,
is the training data,
indicates the dropout factor,
denotes the weight value, and
is the target vector. Consequently, the memory cells are updated with the forward pass as shown below:
where,
is the memory cells, and
comprises both the feature map and feedback. Subsequently, the obtained feature values are passed to the sigmoid layer of the LSTM, where the distributed probability is estimated for each class as shown below:
where,
is the distributed probability of sigmoid function,
denotes the output class, and
indicates the output value with
d-th class. Then, the binary cross entropy is estimated for analyzing the disparity across the definite segments that are used to attain the probability distribution function as shown below:
At last, the output predicted label is obtained as follows:
Then, the RMSprop optimizer has been used to optimize the value of the hyper-parameters, (as showing in Algorithm 2) which helps to obtain an increased training and testing accuracy.
| Algorithm 2 Deep Sequential Long Short Term Memory (DS-LSTM) Classification |
Input:;
Output:;
by using Equation (13);
Step 2: Estimate the feature map based on the convolutional operation as shown in Equation (14);
Step 3: Compute the trail vector according to the target vector by using Equation (15);
is estimated as shown in Equation (16);
are updated with the feature map and feedback value as represented in Equation (17);
function is computed for each class of data by using Equation (18);
Step 7: Compute the binary cross entropy for the definite segments as shown in Equation (19);
is predicted as represented in Equation (20); |
5. Conclusions
This paper presents a classy multifacet clustering-based optimization and classification methodology for detecting intrusions from the SCADA systems. The main contribution of this work is to develop an intelligent IDS framework by using the fusion of methods for obtaining an increased detection accuracy, reduced false positives, error rate, and complexity. The most popular IDS datasets have been utilized to implement and validate the proposed security system. The dataset normalization and preprocessing operations have been performed to eliminate irrelevant attributes and balance the data. Consequently, the MDCM technique is applied to group the attributes into the form of clusters based on the distance value. The main purpose of implementing the clustering technique is to simplify the process of intrusion detection and classification with an increased speed of processing. Then, the GDSMO technique is employed to optimally select the best features for training the classifier model, which helps reduce the time taken for dataset training and testing. The switching probability, weight value, and fitness value have been computed during this process for selecting the optimal parameters to improve the classification.
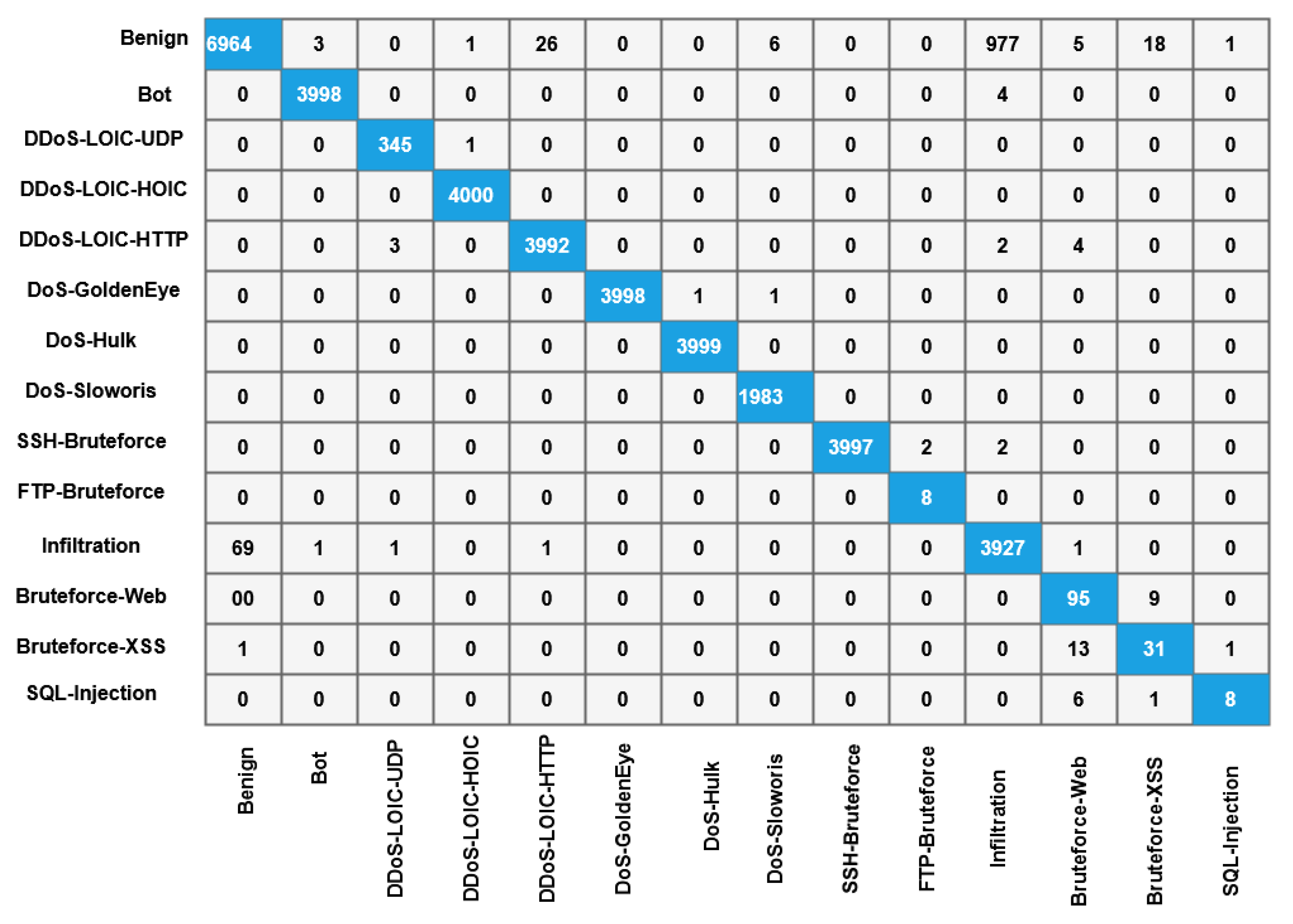
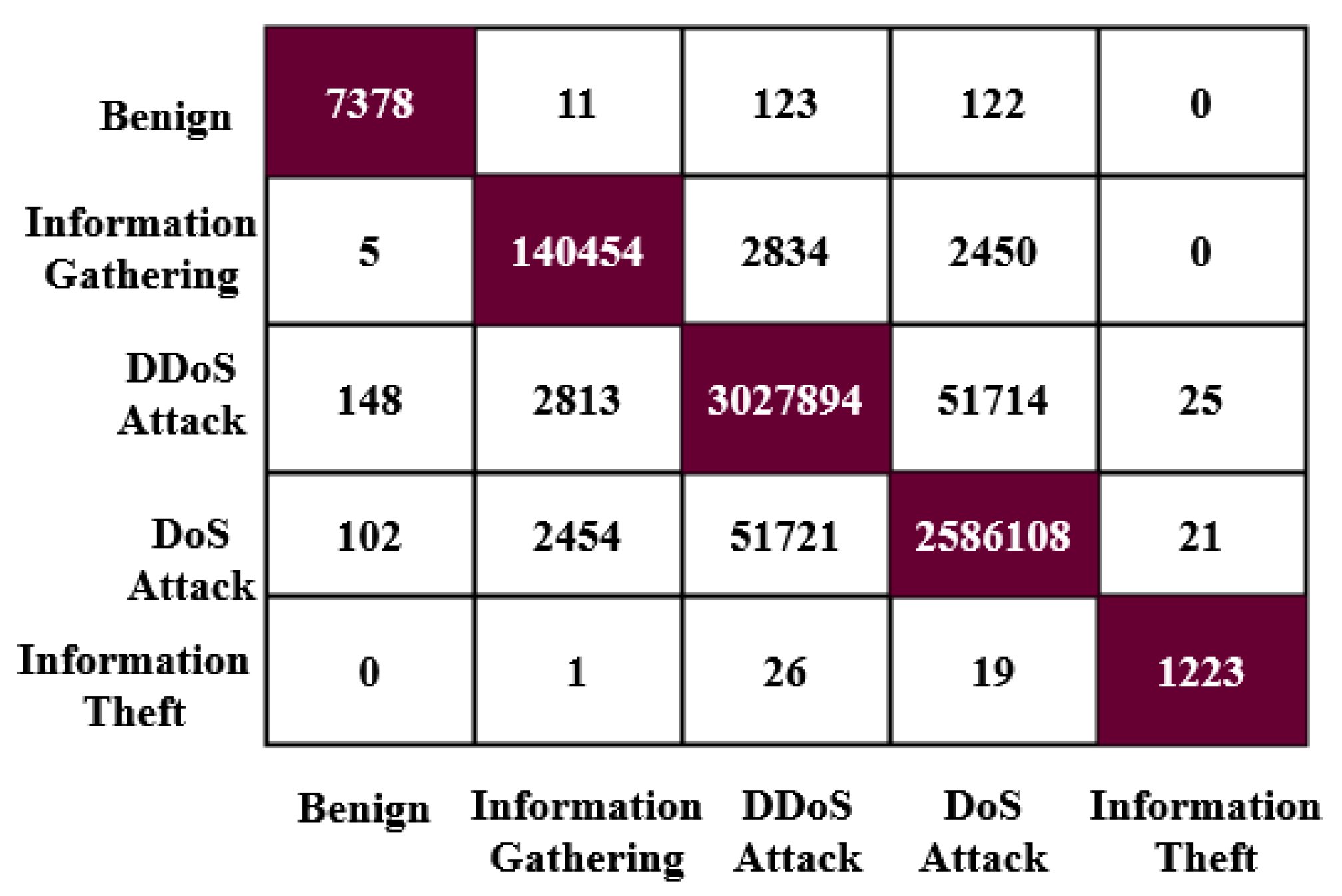
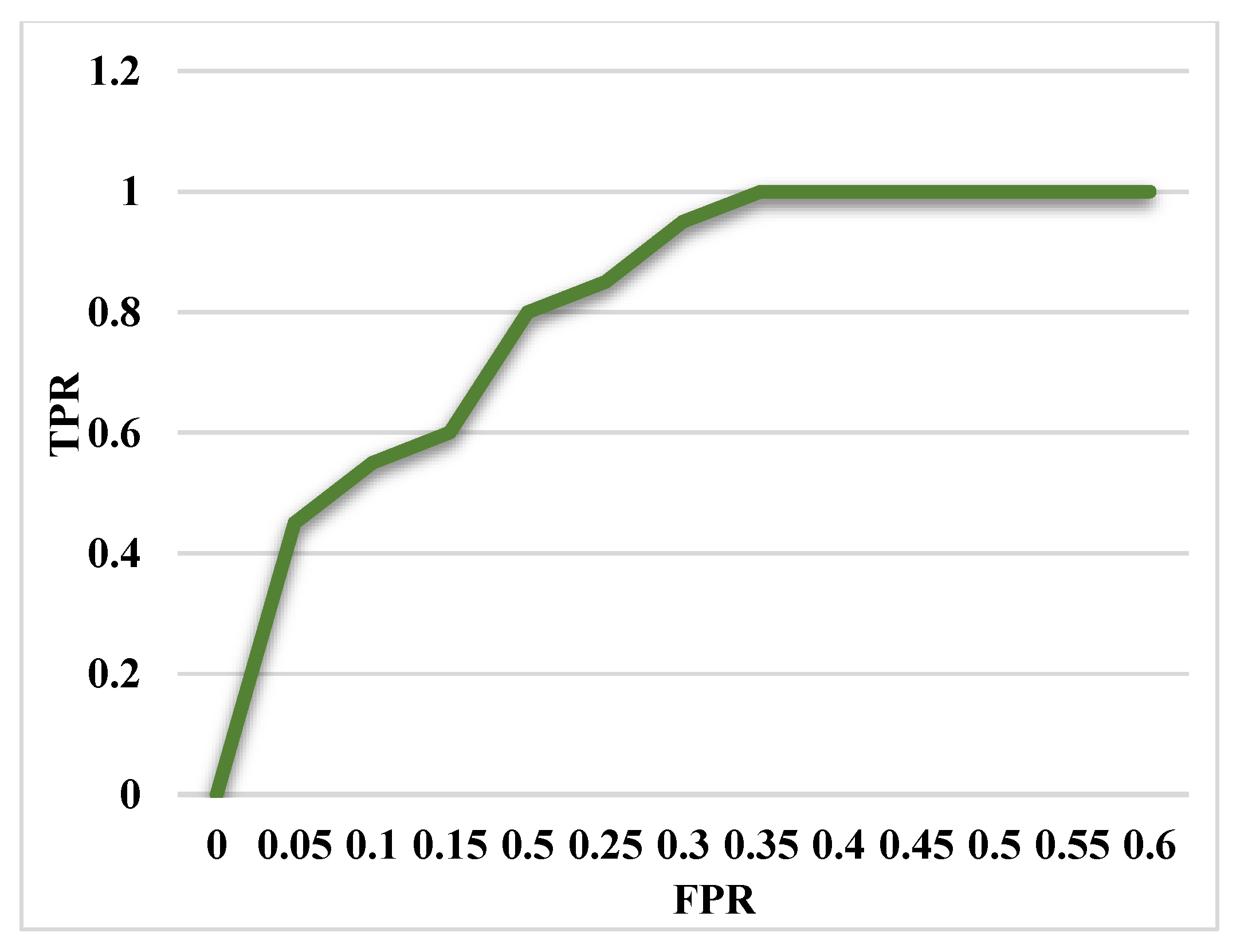
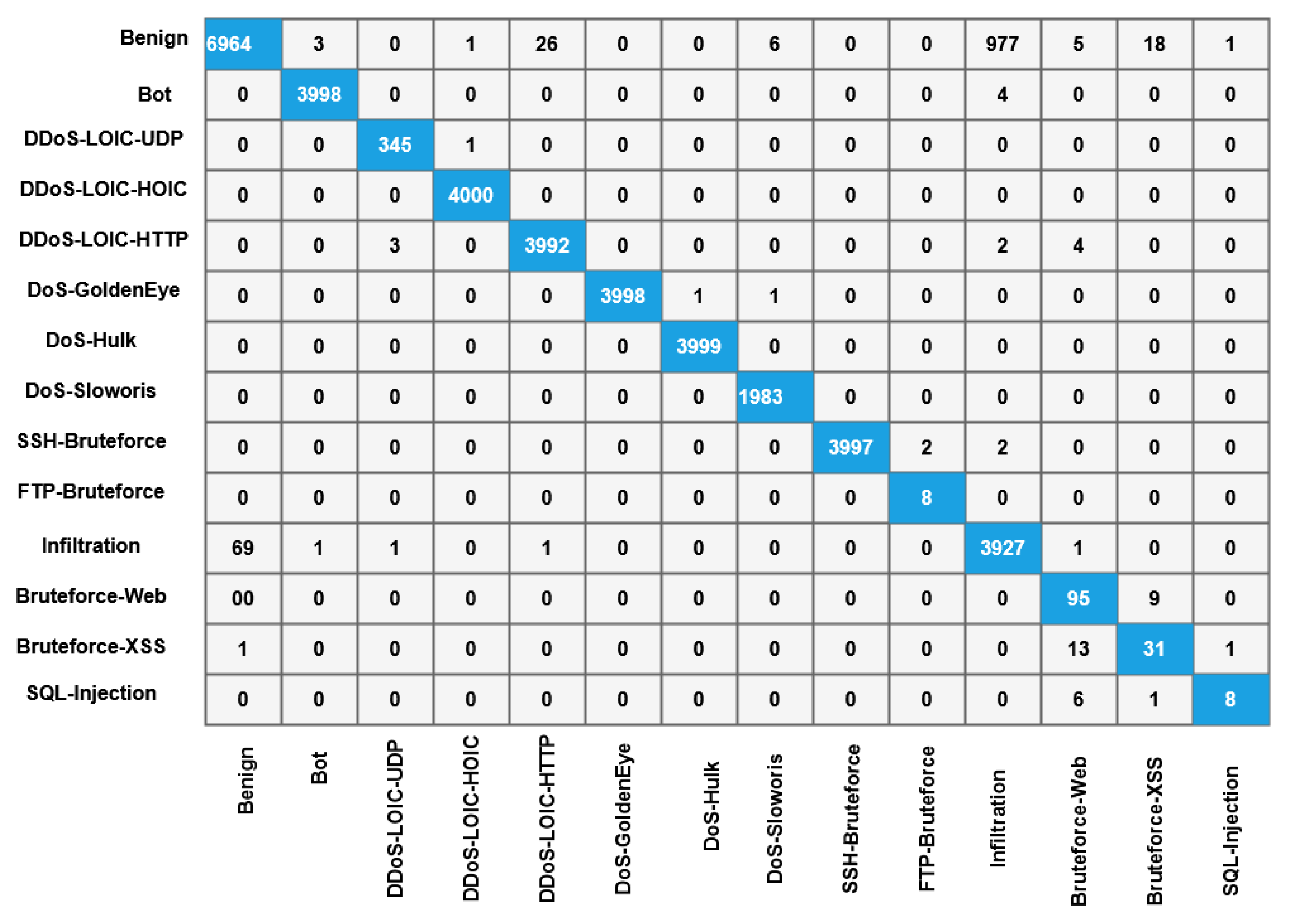
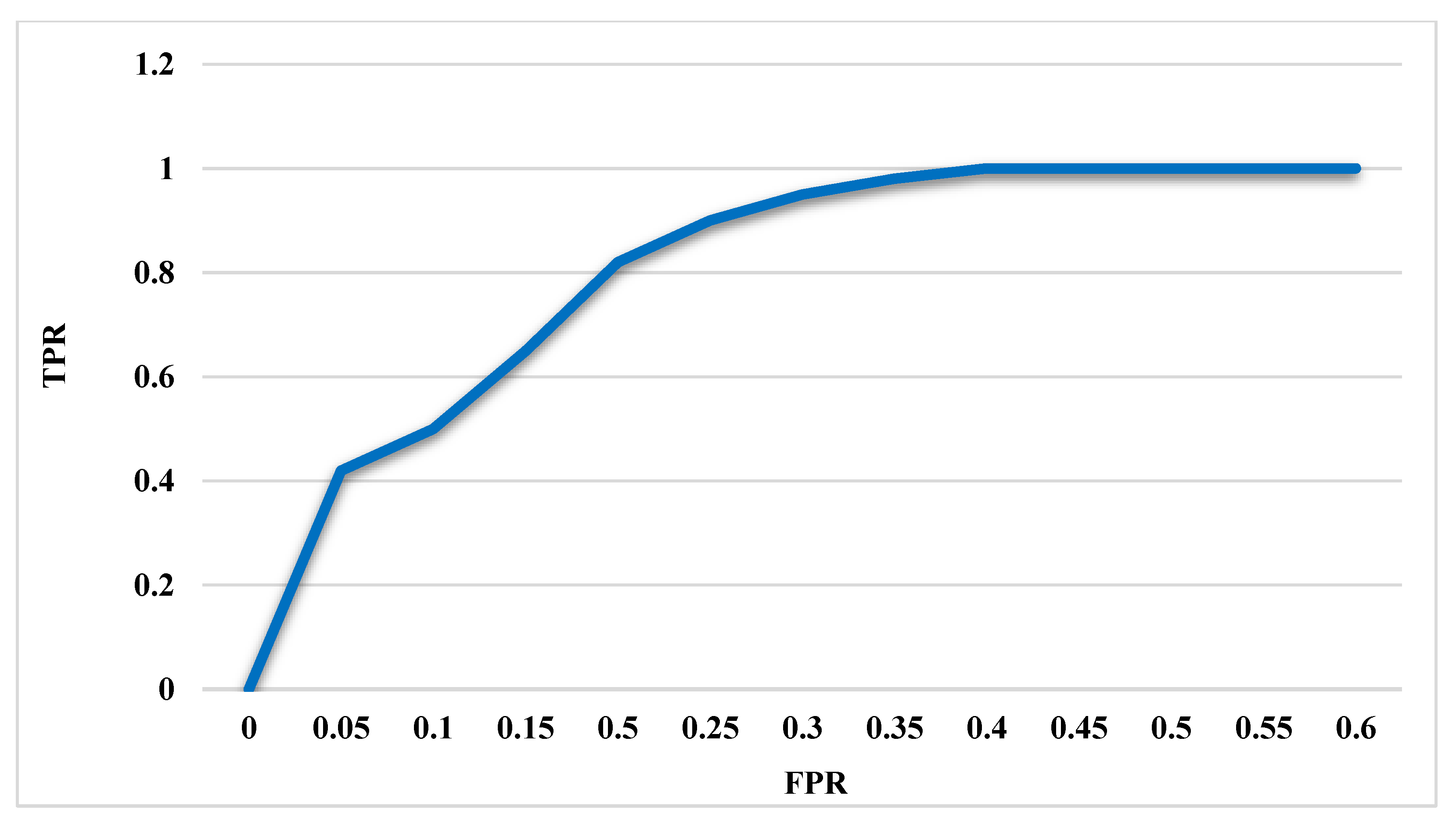
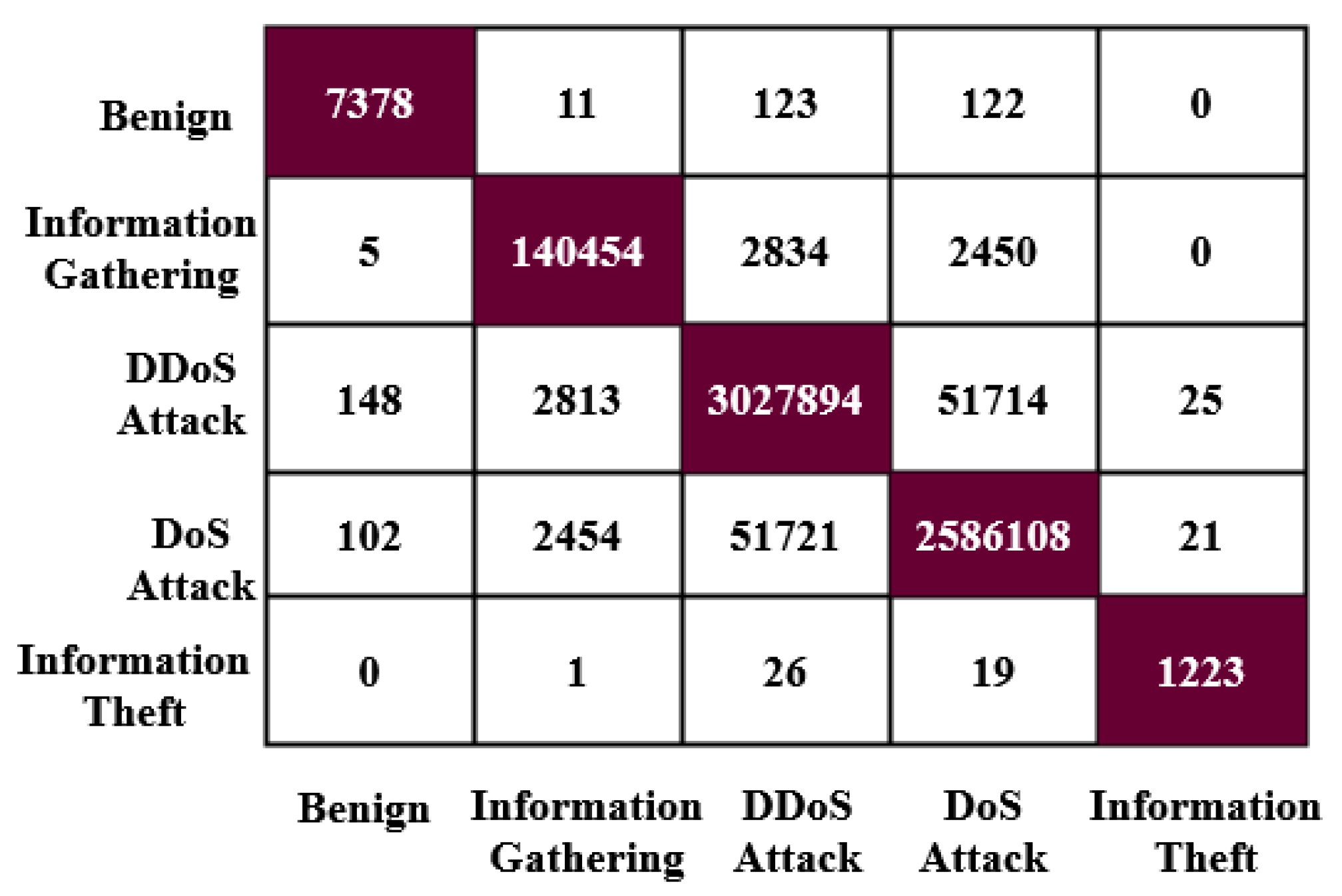
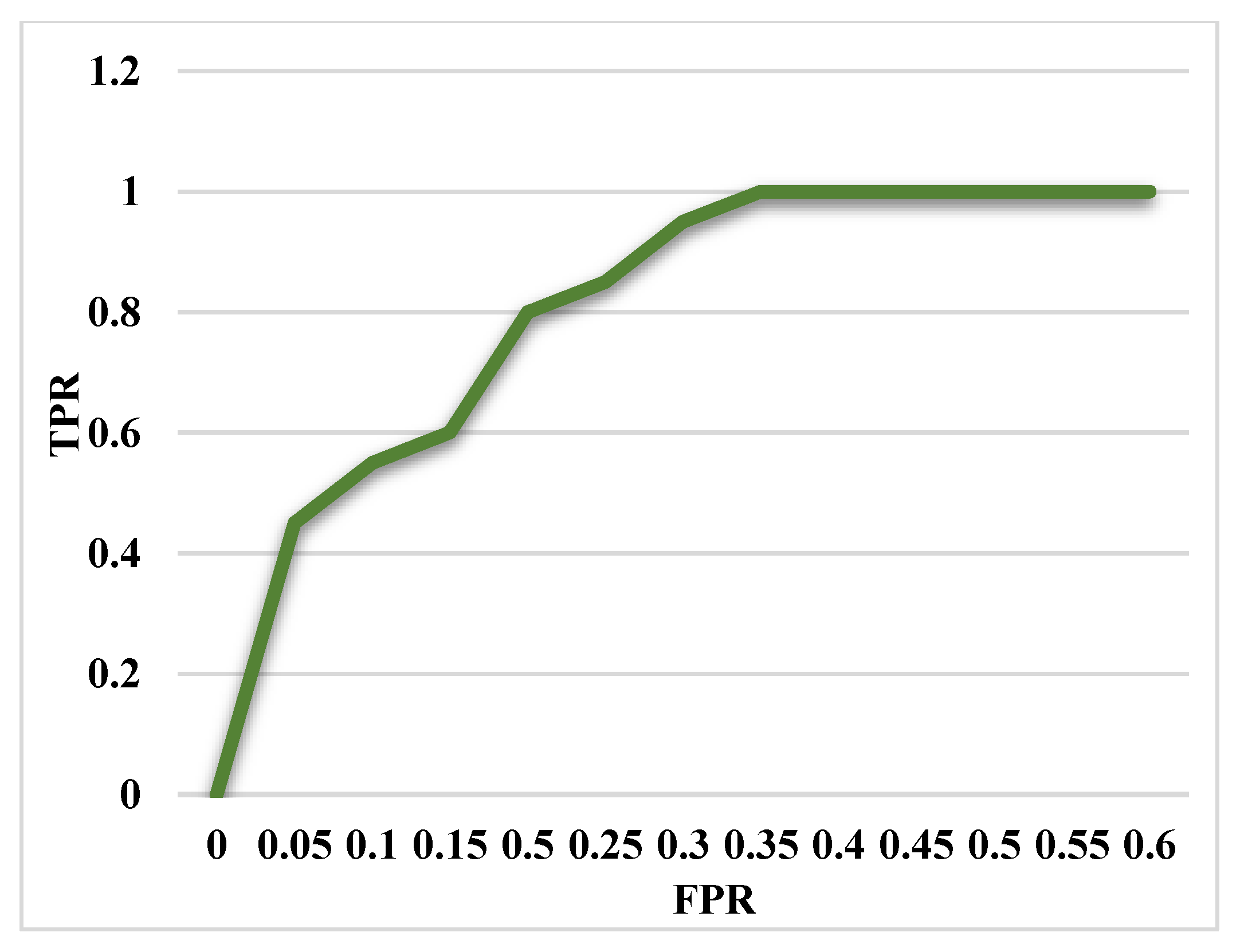
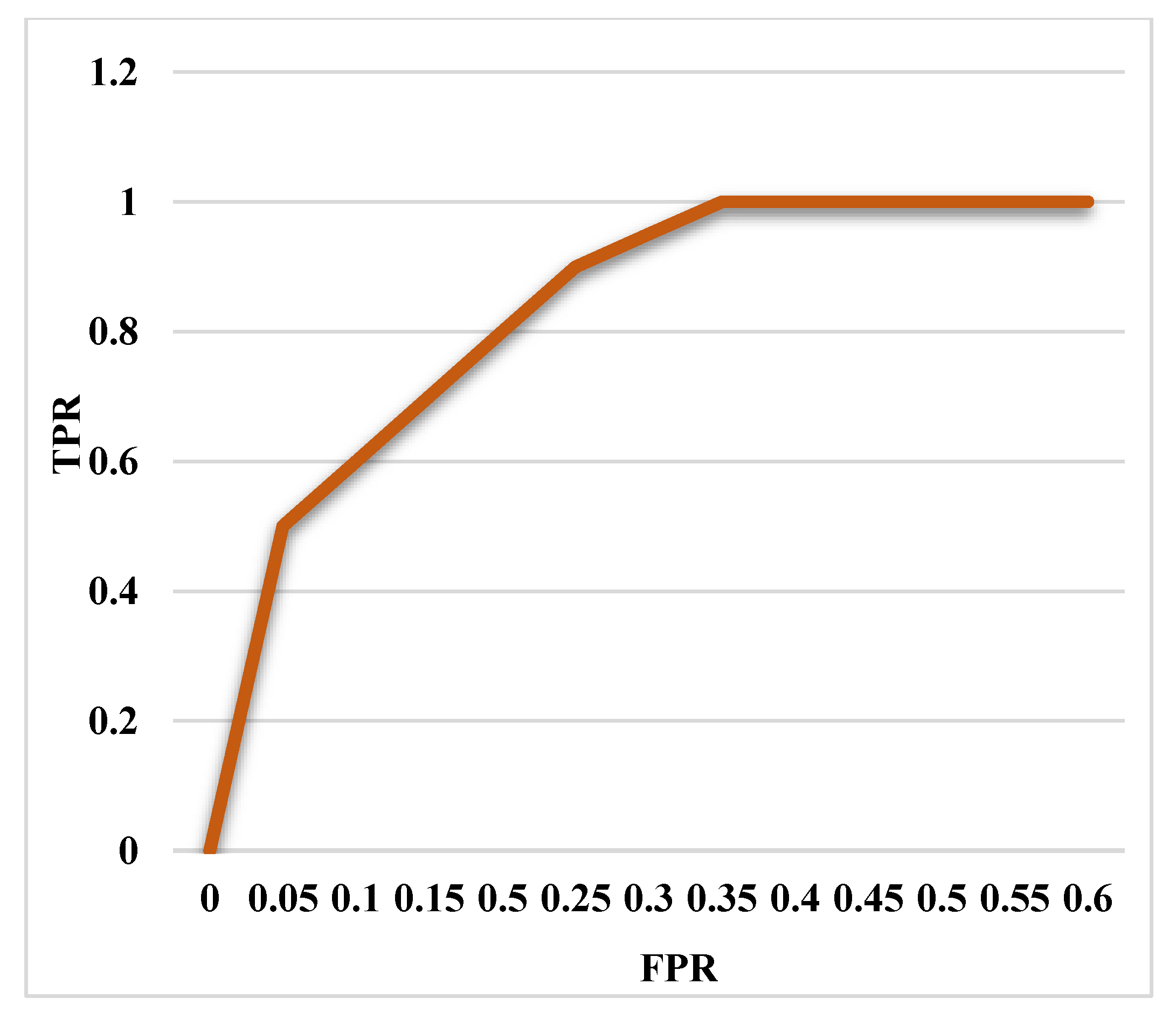
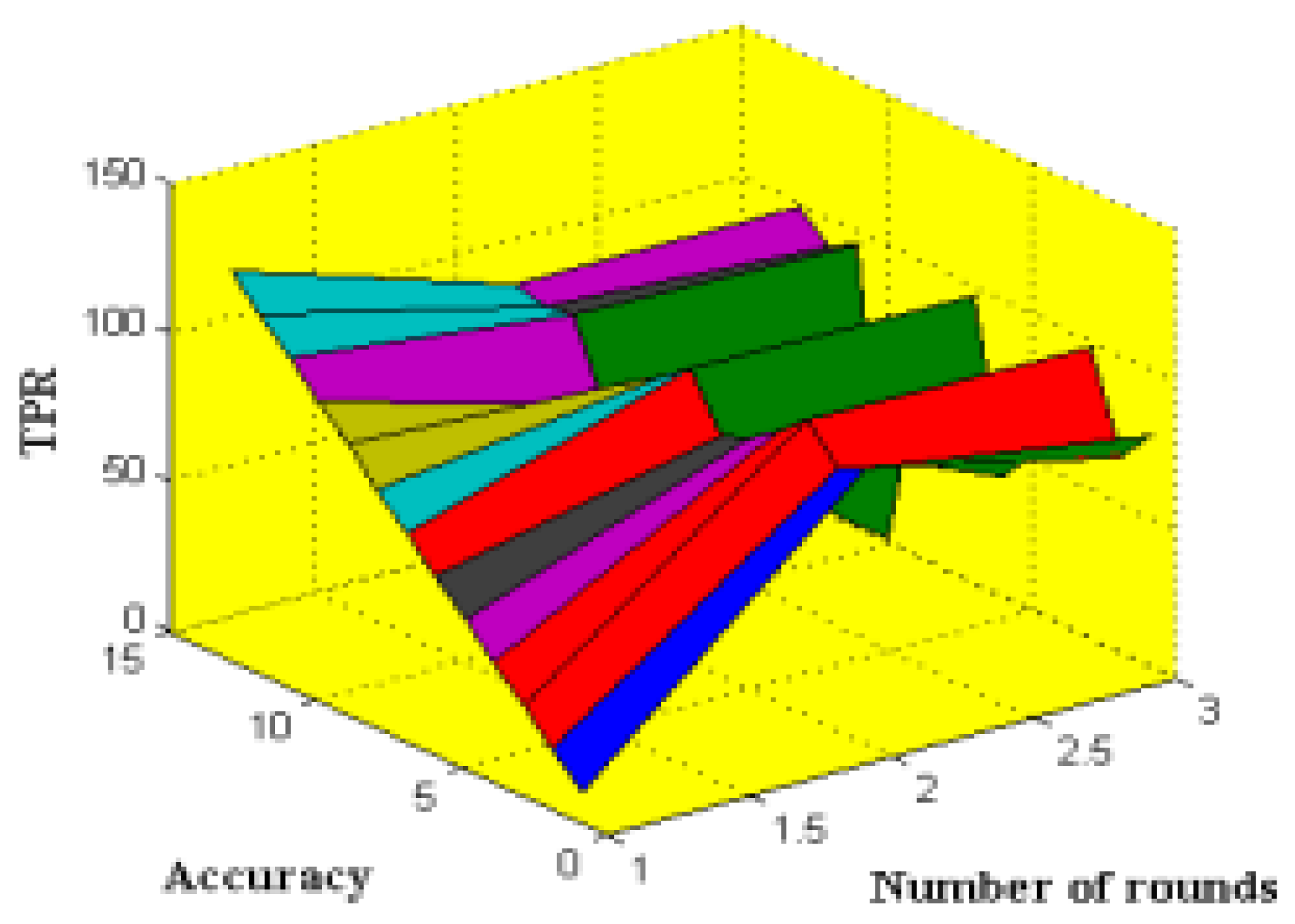
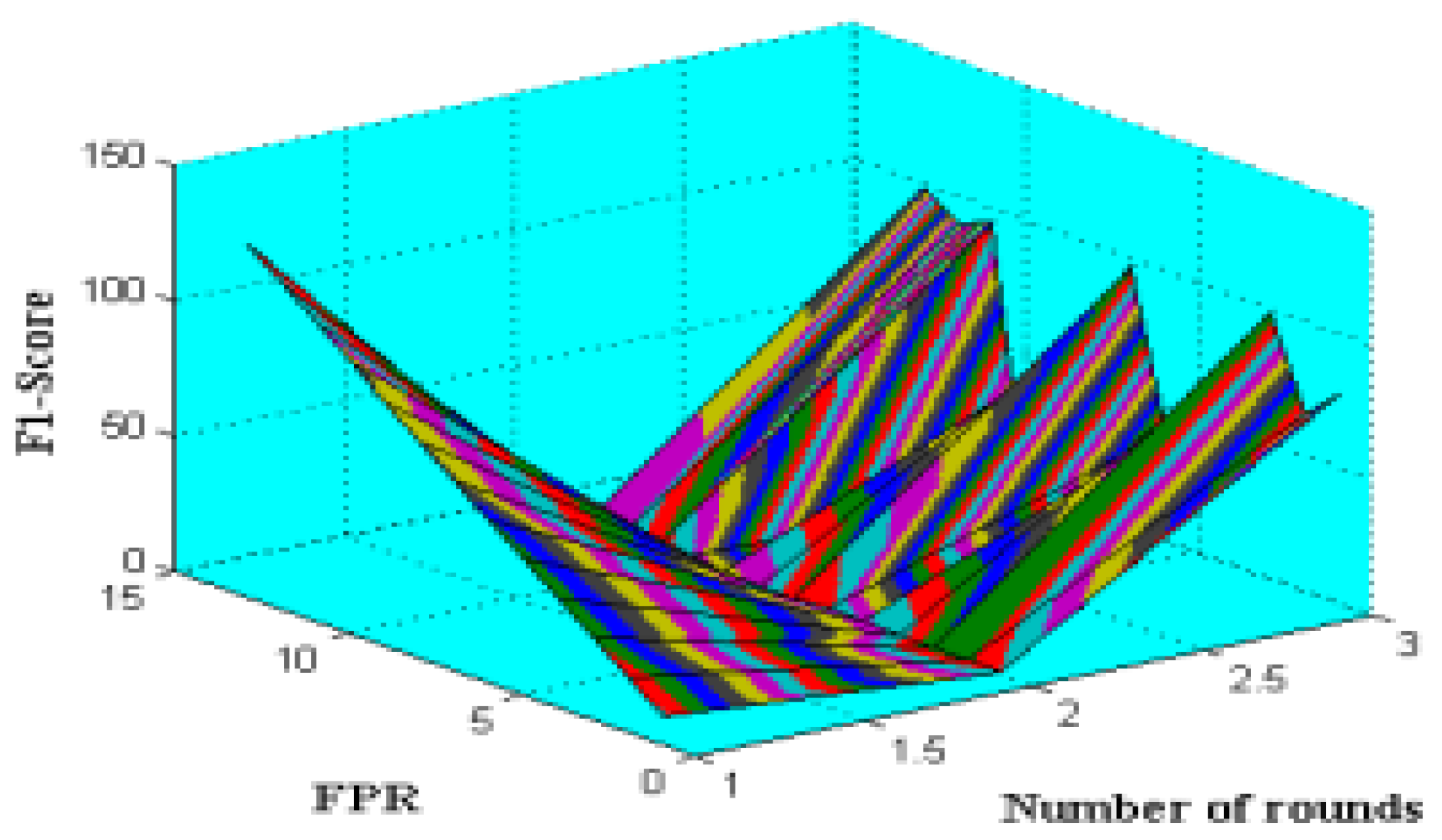
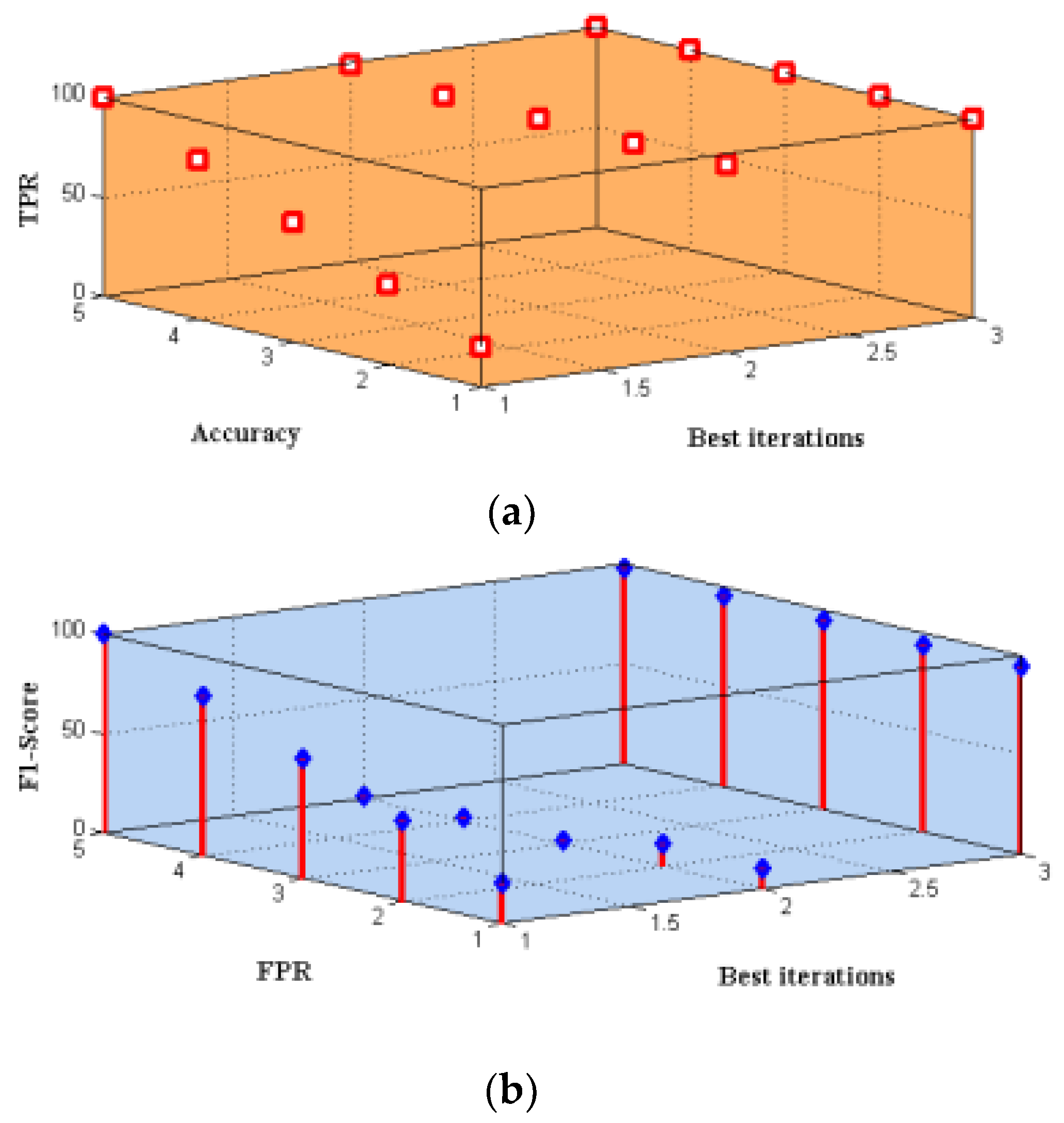
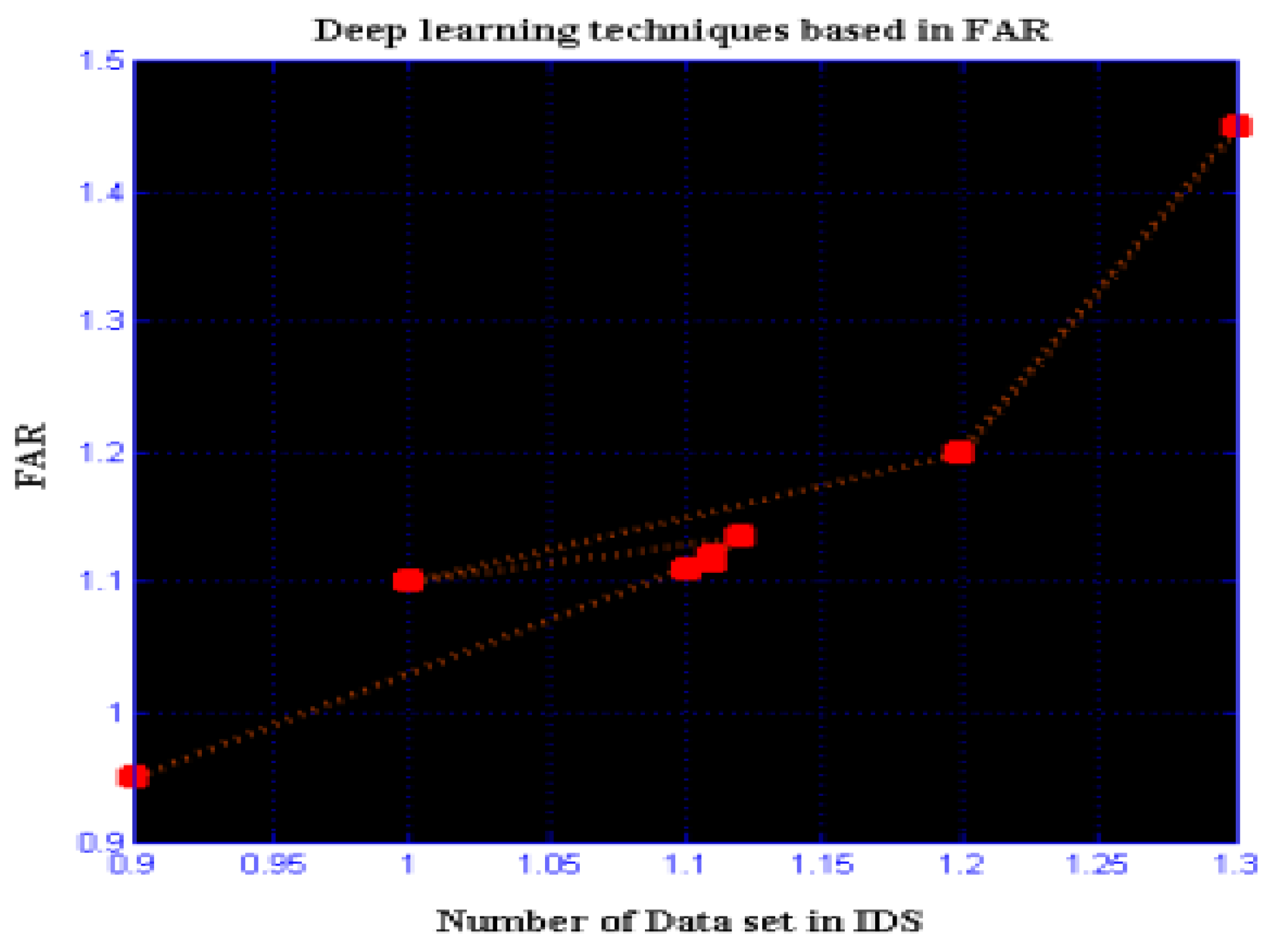
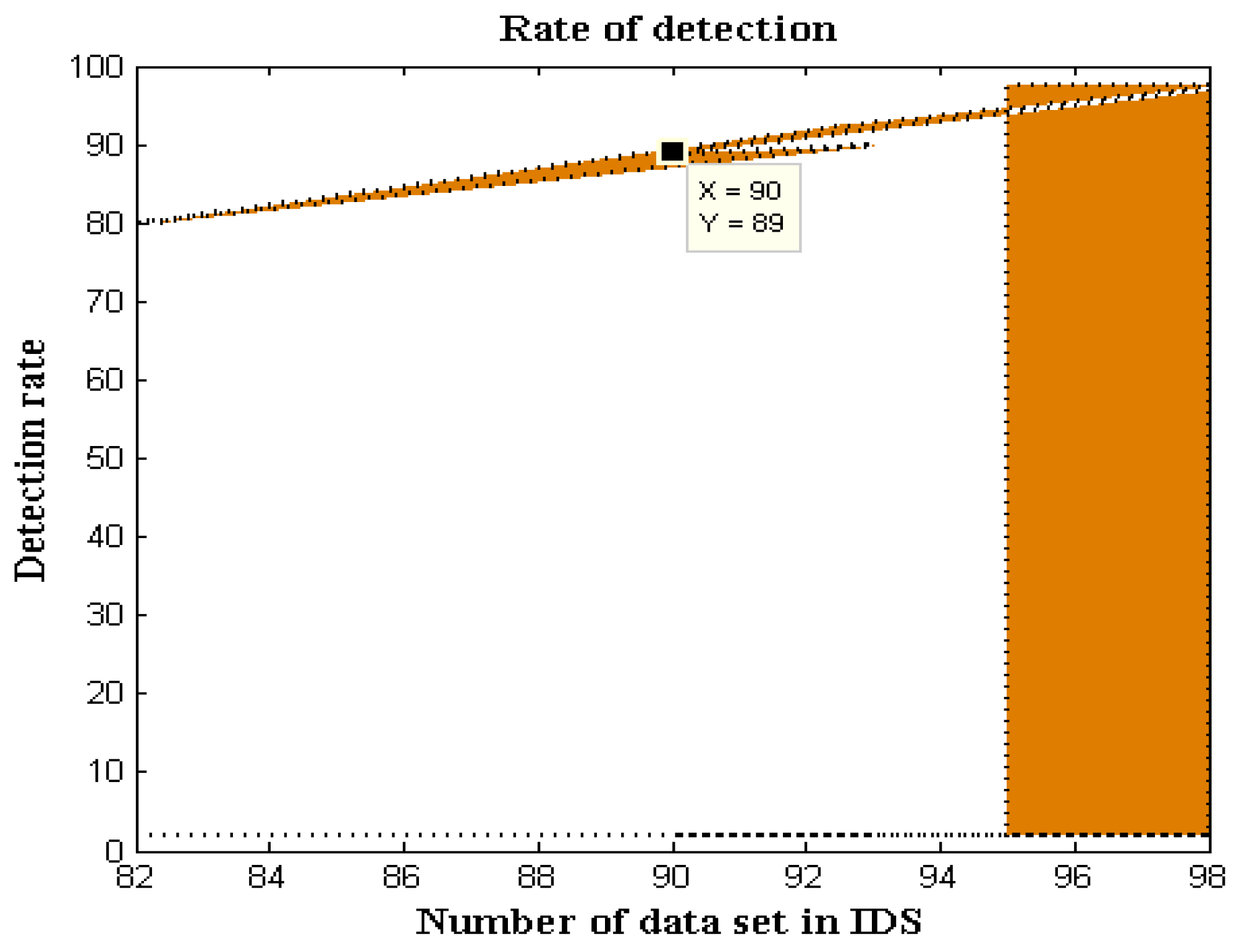
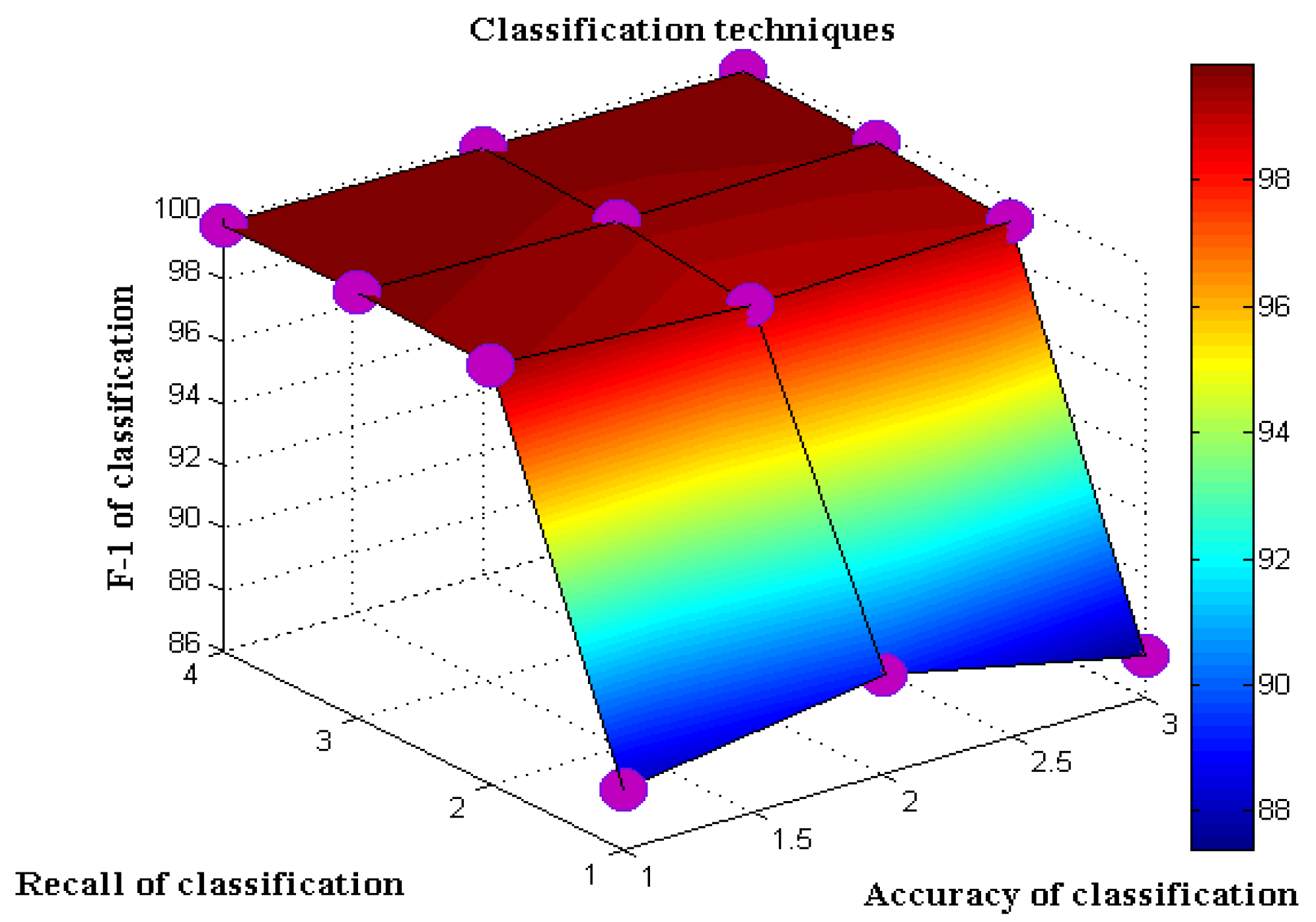
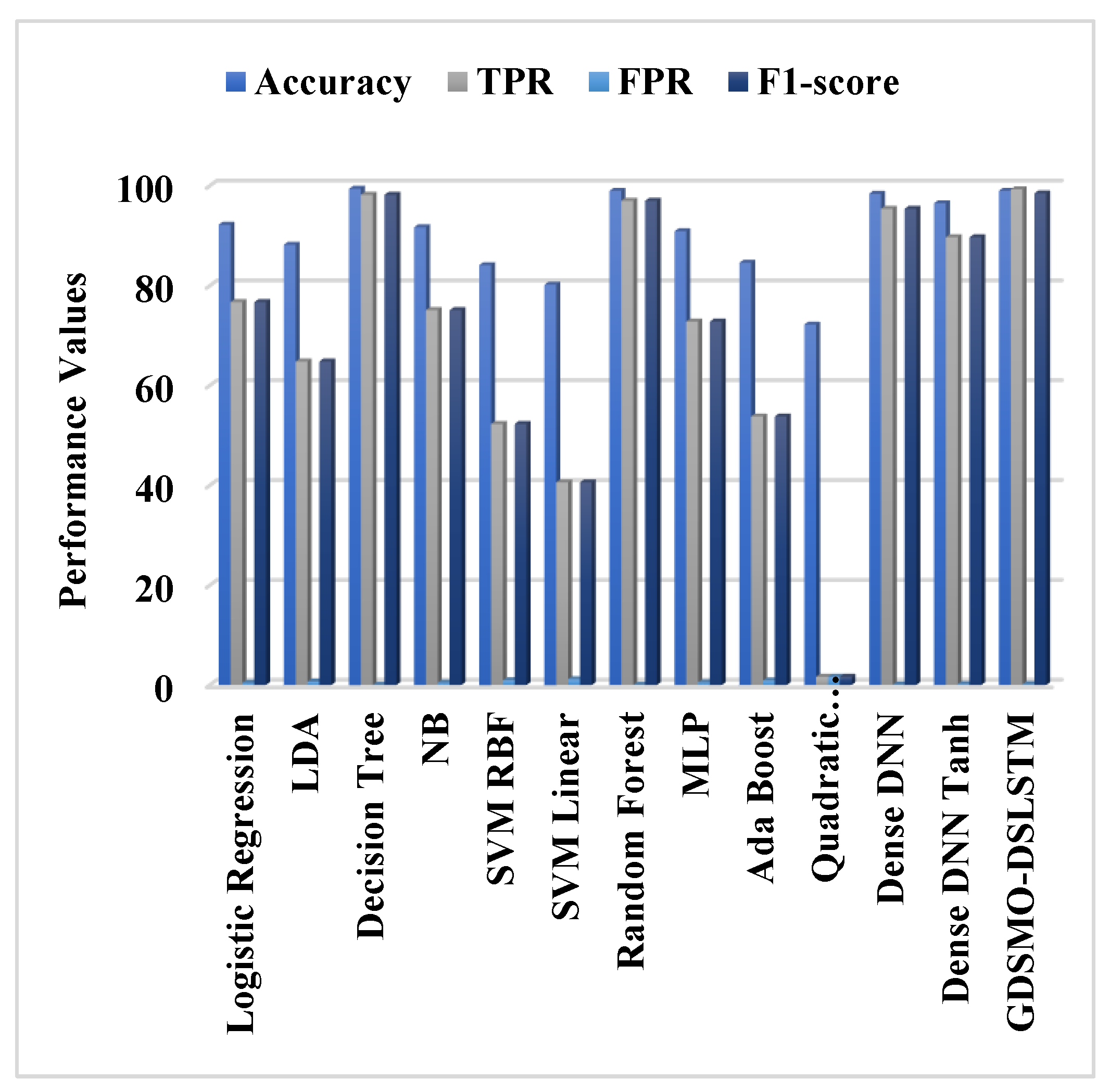
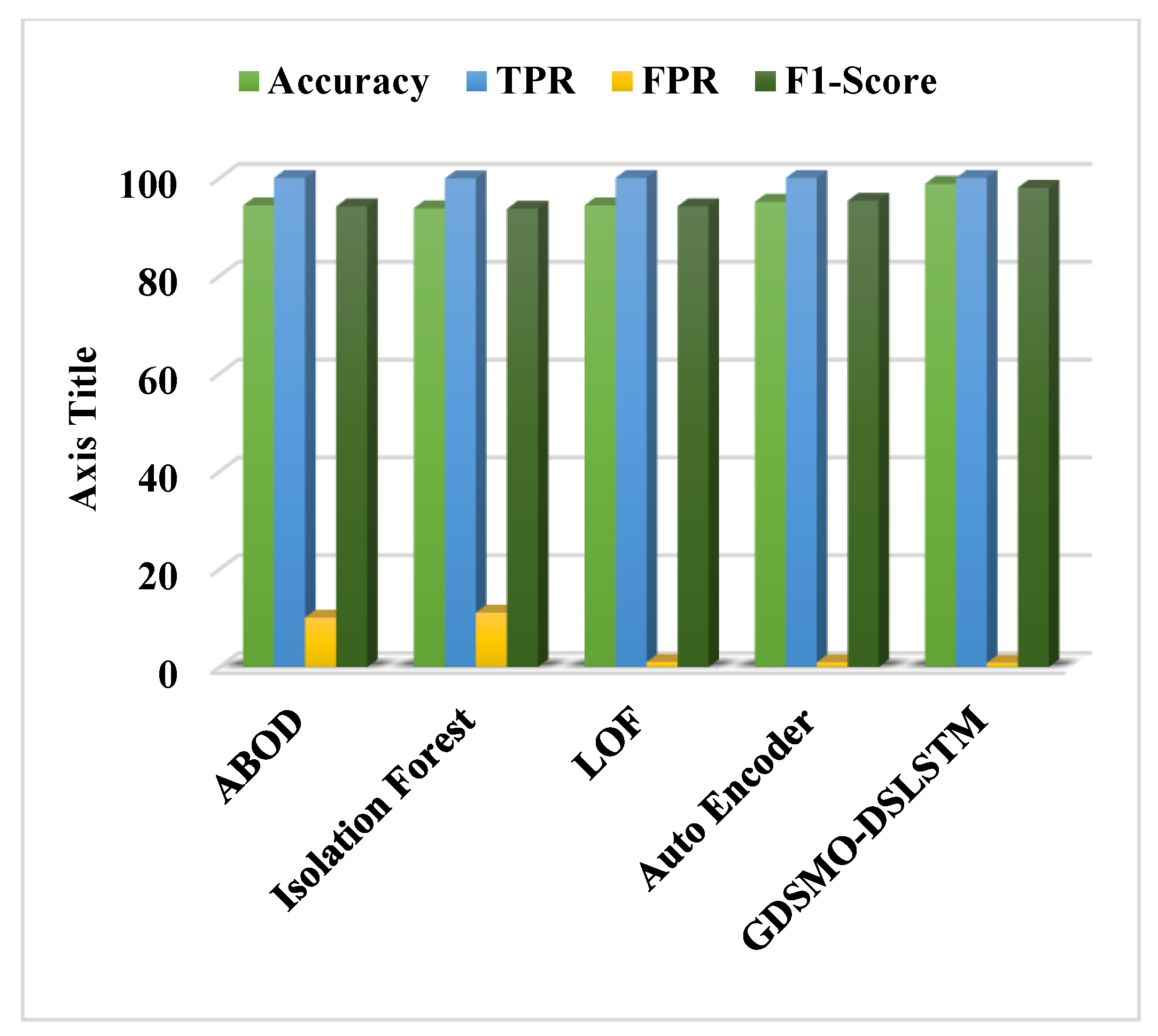
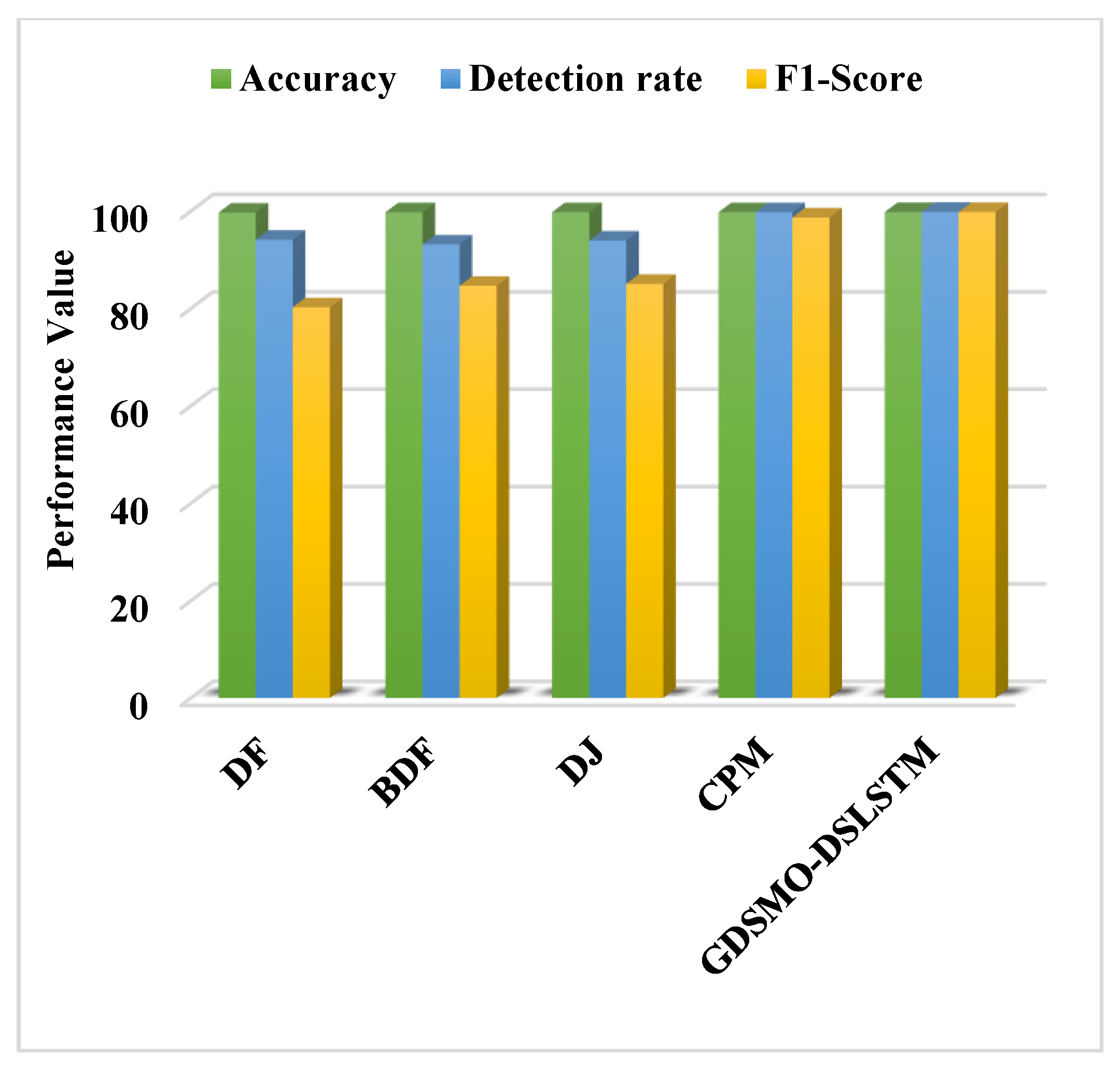
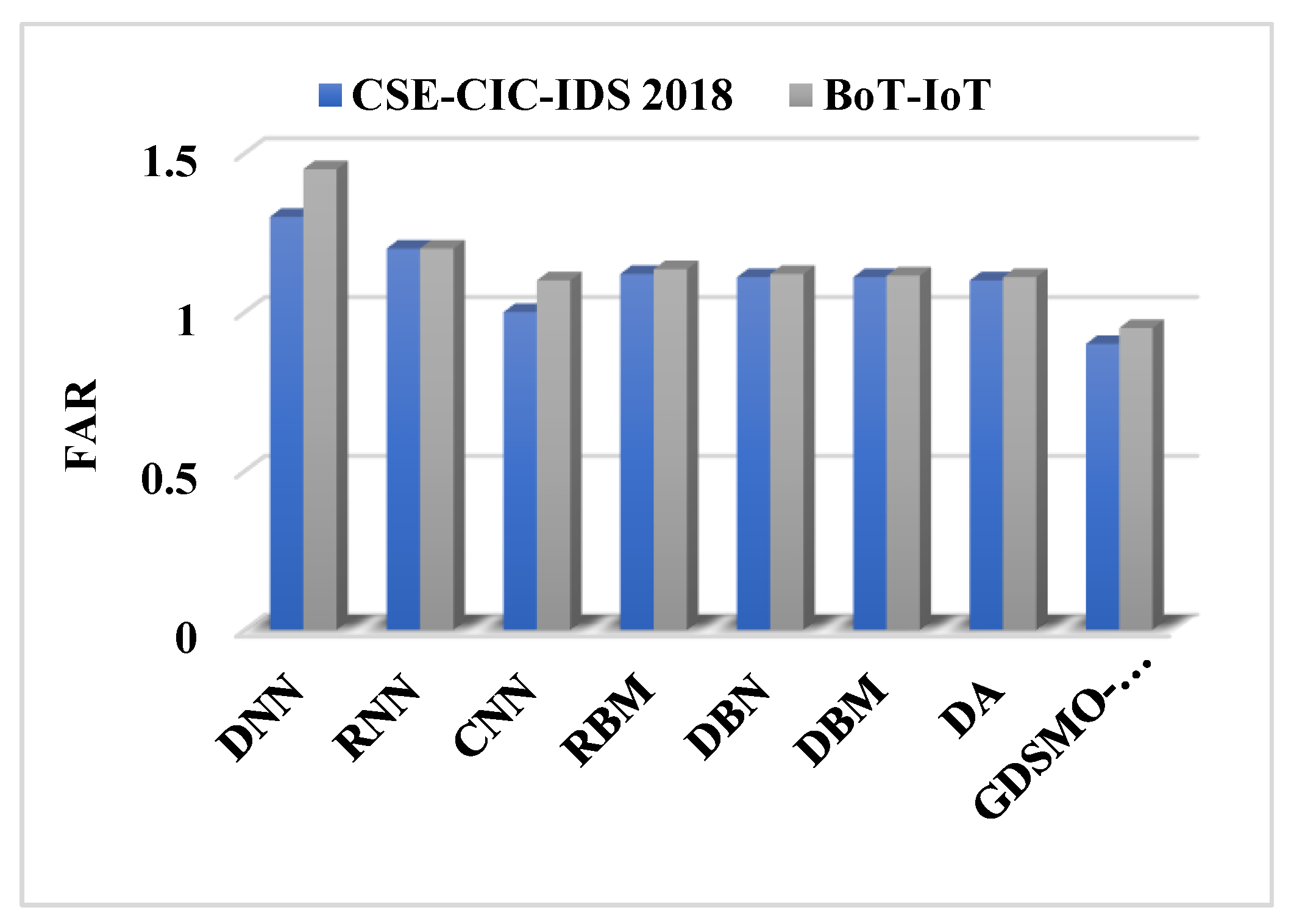
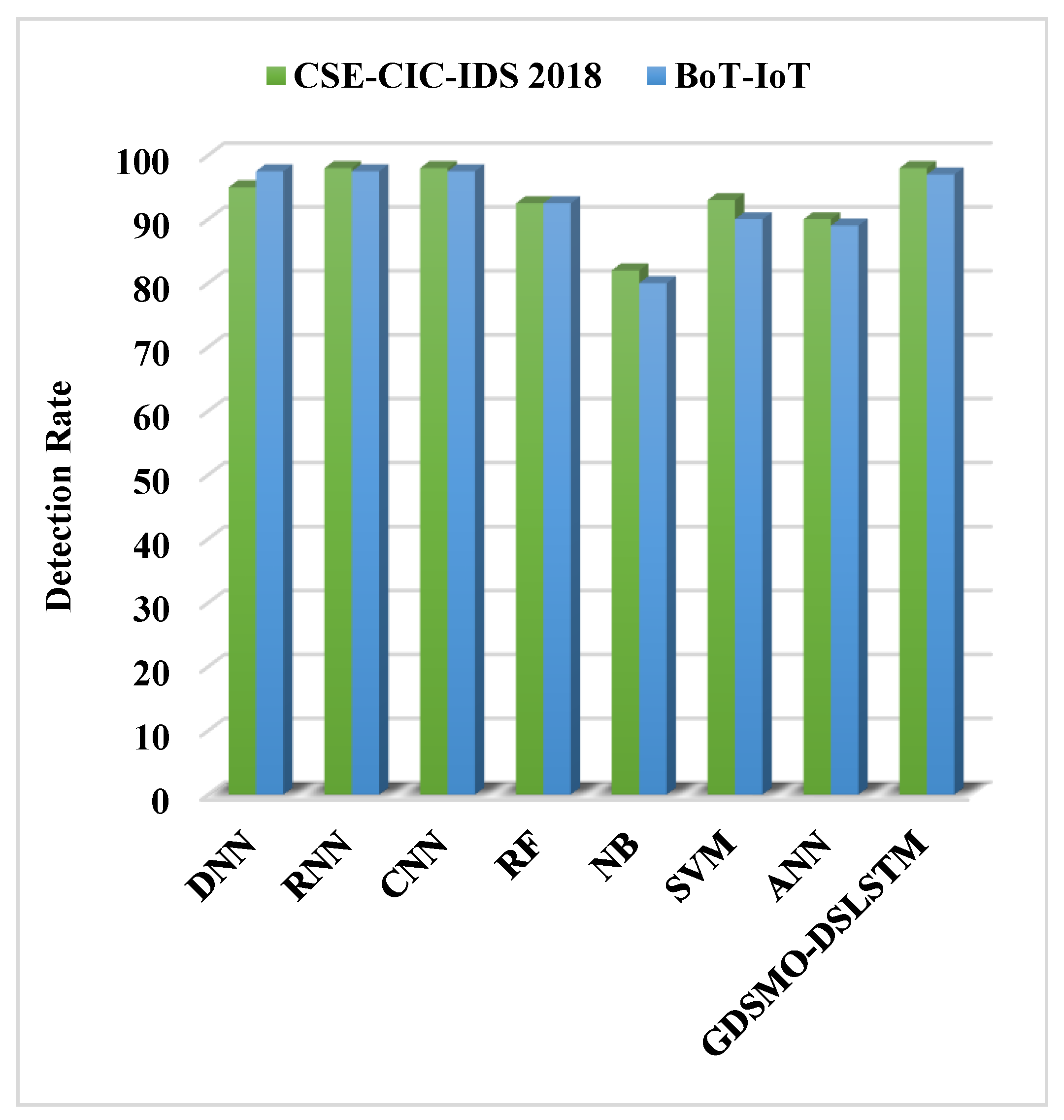
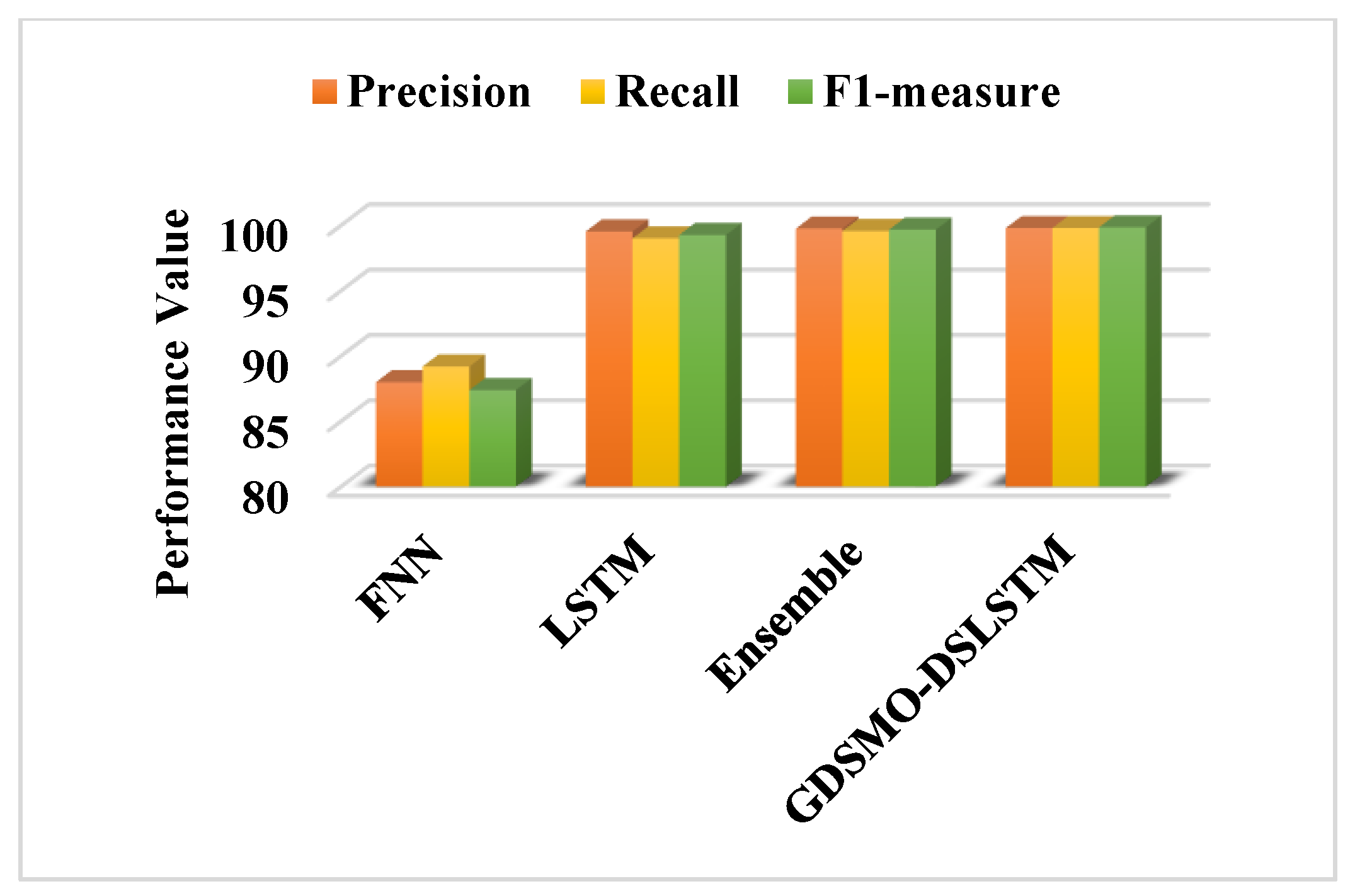
Moreover, the DS-LSTM-based deep learning classifier is deployed for spotting the intrusions from the clustered datasets based on the optimal set of features. The primary advantages of using this technique are reduced time consumption for training and testing, increased accuracy and detection rate, and minimized misclassification rate. Finally, the performance of the proposed GDSMO-DSLSTM-based IDS is validated and compared with the recent state-of-the-art models by using the measures of accuracy, precision, recall, F1-score, FAR, and detection rate. The evaluation states that the proposed GDSMO-DSLSTM technique outperforms the other approaches with improved performance values.
In future, the proposed work can be enhanced by developing a secured communication medium for protecting the SCADA systems from internal and external threats. Additionally, the major properties such as integrity, scalability, intrusion tolerance, and self-healing can be satisfied by designing an effectively secured SCADA architecture.





 ,
, 












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}