
Bayesian Workflow and Hidden Markov Energy-Signature Model for Measurement and Verification


Abstract
:1. Introduction
1.1. Motivation: Uncertainty Estimation in M&V
- A numerical model is trained during a baseline observation period (before ECMs are applied);
- The trained model predicts energy consumption in the conditions of the reporting period (after energy-conservation measures);
- The adjusted energy savings are the difference between these predictions and the measured consumption of the reporting period.
“Savings uncertainty can only be determined exactly when energy use is a linear function of some independent variable(s). For more complicated models of energy use, such as change-point models, and for data with serially autocorrelated errors, approximate formulas must be used. These approximations provide reasonable accuracy when compared with simulated data, but in general it is difficult to determine their accuracy in any given situation.One alternative method for determining savings uncertainty to any desired degree of accuracy is to use a Bayesian approach.”
- Bayesian models are probabilistic: uncertainty of all variables is automatically quantified.
- Bayesian models are universal and flexible. They can be very simple or very sophisticated, and are not restricted to the usual hypotheses of ordinary least squares regression.
- The Bayesian framework allows including prior information regarding expert knowledge.
1.2. Outline and Related Work
- The ability to accurately estimate savings uncertainty, regardless of the model structure;
- The ability to use models of any complexity in order to account for occupancy, additional weather variables, and higher time resolution;
- The ability to validate complex models thanks to the regularisation features of prior distributions.
2. A Bayesian Workflow for Measurement and Verification
2.1. Principles of Bayesian Data Analysis
- An observational model , or likelihood function, which describes the relationship between the data y and the model parameters . The choice of observational model is the same step as with any other M&V approach: ordinary linear regression, change-point models, polynomials, time-series models… There are no constraints on the number of parameters and independent variables.
- A prior model which encodes eventual assumptions regarding model parameters, independently of the observed data. Specifying prior densities is not mandatory.
- Other distributions than the Normal distribution can be used in the observational model;
- Hierarchical modelling is possible: parameters can be assigned a prior distribution with parameters which have their own (hyper)prior distribution;
- Heteroscedasticity can be encoded by assuming a relationship between the error term and explanatory variables, etc.
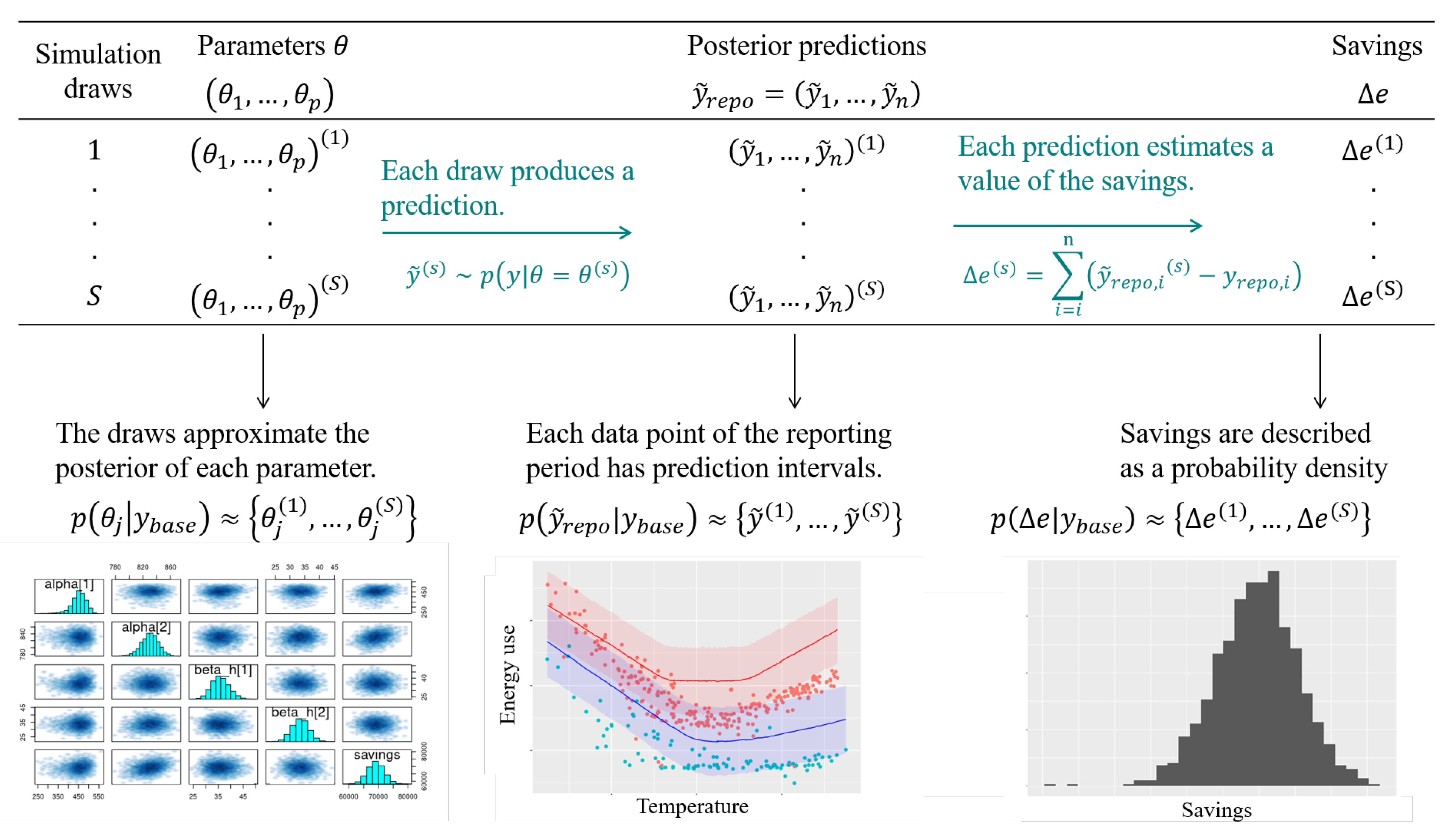
2.2. A Bayesian M&V Workflow
- As with standard approaches, choose a model structure to describe the data with, and formulate it as an observation model. Formulate eventual “expert knowledge” assumptions in the form of prior probability distributions.
- Run a MCMC (or other) algorithm to obtain a set of samples which approximates the posterior distribution of p parameters conditioned on the baseline data . Validate the inference by checking convergence diagnostics: R-hat, ESS, etc.
- Validate the model by computing its predictions during the baseline period . This can be achieved by taking all (or a representative set of) samples individually, and running a model simulation for each. This set of simulations generates the posterior predictive distribution of the baseline period, from which any statistic can be derived (mean, median, prediction intervals for any quantile, etc.). The measures of model validation (, net determination bias, t-statistic…) can then be computed either from the mean, or from all samples in order to obtain their own probability densities.
- Compute the reporting period predictions in the same discrete way: each sample generates a profile , and this set of simulations generates the posterior predictive distribution of the reporting period.
- Since each reporting period prediction can be compared with the measured reporting period consumption , we can obtain S values for the energy savings , the distribution of which approximates the posterior probability of savings.
3. Models
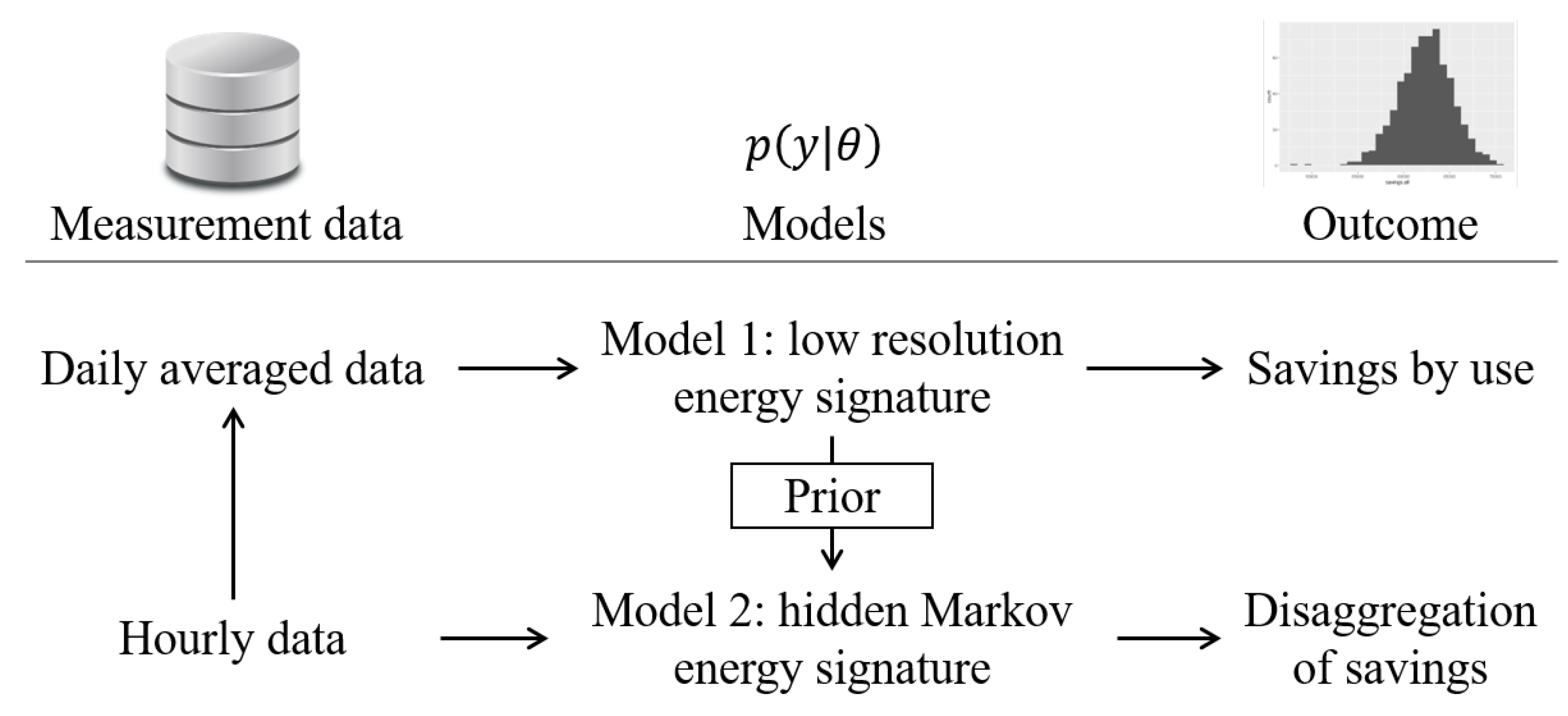
3.1. Model 1: Energy Signature Model for Low Resolution Data
3.2. Model 2: Hidden Markov Energy Signature Model for High Resolution Data and Occupancy Detection
- A sequence of hidden states , each of which can take a finite number of values: .
- An observed variable
- An initial probability which is the likelihood of each state at time . is a K-simplex, i.e., a K-vector which components sum to 1.
- A one-step transition probability matrix so thatis the probability at time t for the hidden variable to switch from state i to state j. Like , each row of must sum to 1.
- Emission probabilities , i.e., the probability distribution of the output variable given each possible state.
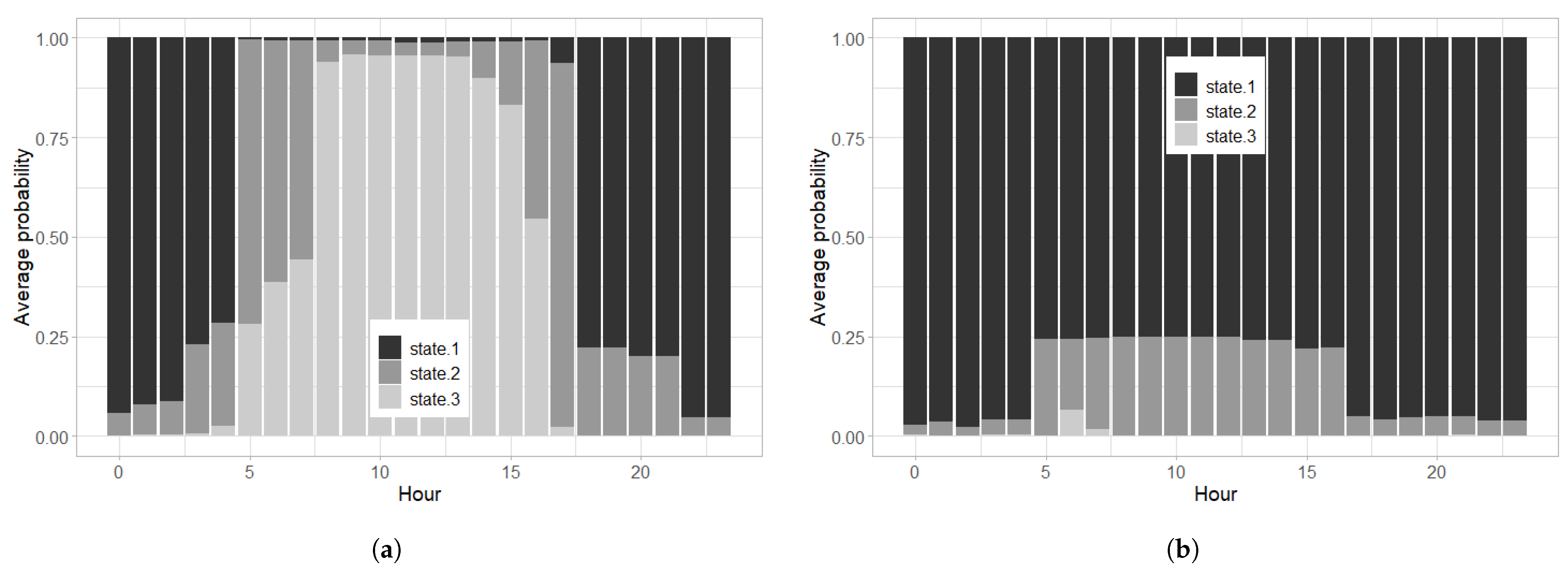
- The energy use of a building at time t follows a different ES model for each possible occupancy state . This is how we allow the parameters of the ES model to depend on the occupancy.
- The occupancy state at each time t is unknown, and described by a hidden Markov chain. We define a transition probability matrix for each hour of the day h and day of the week d
4. Case Study and Tools
4.1. Case Study
4.2. Tools
5. Results and Discussion
5.1. Es Model: Bayesian M&V with Daily Resolution
5.1.1. Posterior Distributions
5.1.2. Posterior Predictive Distributions
5.1.3. Savings
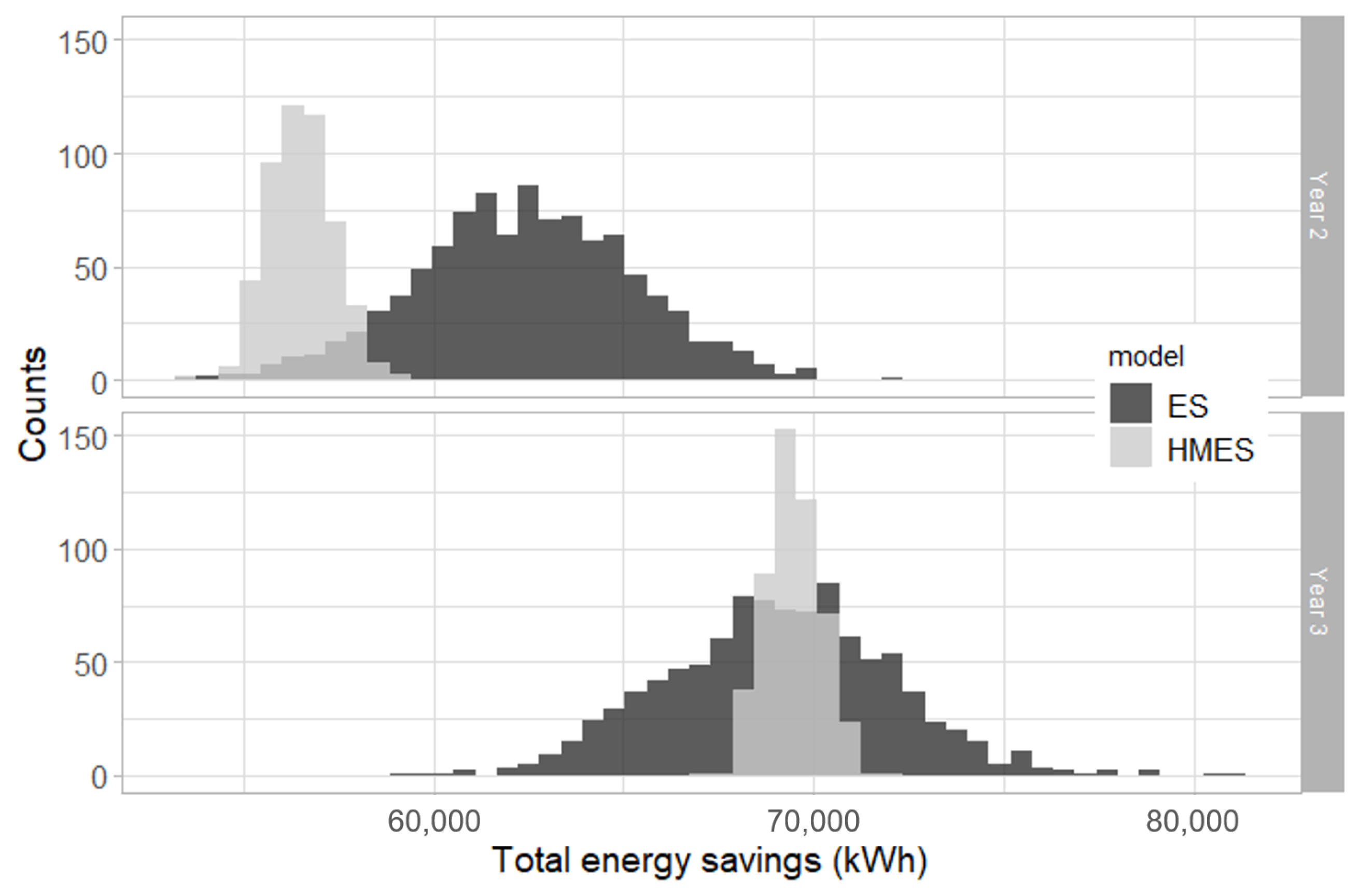
- There is a large overlap between estimated savings during both reporting years, suggesting that no additional ECM was performed between years 2 and 3.
- Most energy savings after the ECM are found on the “base” (temperature-independent) energy consumption, and mostly during working days.
- The probability of cooling savings is centred around zero for weekends and working days during both years.
- The heating savings are likely negative during working days: this energy consumption is likely to have slightly increased after the ECM. This may be caused by a rebound effect, as it occurs when the building is occupied.
5.2. HMES Model: High Resolution Bayesian M&V with Occupancy Detection
5.2.1. Posterior Distributions
5.2.2. Occupancy Detection
5.2.3. Savings
5.3. Drawbacks of a Bayesian Method and Limitations of This Work
6. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Stan Code
Appendix A.1. Energy-Signature Model
Appendix A.2. HMES Model
References
- ASHRAE. Measurement of Energy, Demand, and Water Savings; ASHRAE Guideline 14-2014; ASHRAE: Atlanta, GA, USA, 2014. [Google Scholar]
- Efficiency Valuation Organization. International Performance Measurement and Verification Protocol—Core Concepts; Efficiency Valuation Organization: Washington, DC, USA, 2022. [Google Scholar]
- Granderson, J.; Touzani, S.; Custodio, C.; Sohn, M.D.; Jump, D.; Fernandes, S. Accuracy of automated measurement and verification (M&V) techniques for energy savings in commercial buildings. Appl. Energy 2016, 173, 296–308. [Google Scholar]
- Heo, Y.; Zavala, V.M. Gaussian process modeling for measurement and verification of building energy savings. Energy Build. 2012, 53, 7–18. [Google Scholar] [CrossRef]
- Dong, B.; Cao, C.; Lee, S.E. Applying support vector machines to predict building energy consumption in tropical region. Energy Build. 2005, 37, 545–553. [Google Scholar] [CrossRef]
- Zhang, Y.; O’Neill, Z.; Dong, B.; Augenbroe, G. Comparisons of inverse modeling approaches for predicting building energy performance. Build. Environ. 2015, 86, 177–190. [Google Scholar] [CrossRef]
- Walter, T.; Price, P.N.; Sohn, M.D. Uncertainty estimation improves energy measurement and verification procedures. Appl. Energy 2014, 130, 230–236. [Google Scholar] [CrossRef] [Green Version]
- ISO. Guide to the Expression of Uncertainty in Measurement (GUM); ISO: Geneva, Switzerland, 2008. [Google Scholar]
- Lira, I. The GUM revision: The Bayesian view toward the expression of measurement uncertainty. Eur. J. Phys. 2016, 37, 025803. [Google Scholar] [CrossRef]
- Carstens, H.; Xia, X.; Yadavalli, S. Bayesian energy measurement and verification analysis. Energies 2018, 11, 380. [Google Scholar] [CrossRef] [Green Version]
- Efficiency Valuation Organization. Uncertainty Assessment for IPMVP; Efficiency Valuation Organization: Washington, DC, USA, 2019. [Google Scholar]
- Rouchier, S. Building Energy Statistical Modelling. 2021. Available online: https://buildingenergygeeks.org/ (accessed on 5 May 2022).
- Gelman, A.; Carlin, J.B.; Stern, H.S.; Dunson, D.B.; Vehtari, A.; Rubin, D.B. Bayesian Data Analysis; CRC Press: Boca Raton, FL, USA, 2013. [Google Scholar]
- Kennedy, M.C.; O’Hagan, A. Bayesian calibration of computer models. J. R. Stat. Soc. Ser. B 2001, 63, 425–464. [Google Scholar] [CrossRef]
- Chong, A.; Menberg, K. Guidelines for the Bayesian calibration of building energy models. Energy Build. 2018, 174, 527–547. [Google Scholar] [CrossRef]
- Burkhart, M.C.; Heo, Y.; Zavala, V.M. Measurement and verification of building systems under uncertain data: A Gaussian process modeling approach. Energy Build. 2014, 75, 189–198. [Google Scholar] [CrossRef]
- Maritz, J.; Lubbe, F.; Lagrange, L. A practical guide to Gaussian process regression for energy measurement and verification within the Bayesian framework. Energies 2018, 11, 935. [Google Scholar] [CrossRef] [Green Version]
- Rasmussen, C.; Bacher, P.; Calì, D.; Nielsen, H.A.; Madsen, H. Method for scalable and automatised thermal building performance documentation and screening. Energies 2020, 13, 3866. [Google Scholar] [CrossRef]
- Candanedo, L.M.; Feldheim, V.; Deramaix, D. A methodology based on Hidden Markov Models for occupancy detection and a case study in a low energy residential building. Energy Build. 2017, 148, 327–341. [Google Scholar] [CrossRef]
- Chen, Z.; Jiang, C.; Xie, L. Building occupancy estimation and detection: A review. Energy Build. 2018, 169, 260–270. [Google Scholar] [CrossRef]
- Andersen, P.D.; Iversen, A.; Madsen, H.; Rode, C. Dynamic modeling of presence of occupants using inhomogeneous Markov chains. Energy Build. 2014, 69, 213–223. [Google Scholar] [CrossRef]
- Chen, Z.; Zhu, Q.; Masood, M.K.; Soh, Y.C. Environmental sensors-based occupancy estimation in buildings via IHMM-MLR. IEEE Trans. Ind. Inform. 2017, 13, 2184–2193. [Google Scholar] [CrossRef]
- Murphy, K.P. Dynamic Bayesian Networks: Representation, Inference and Learning; University of California: Berkeley, CA, USA, 2002. [Google Scholar]
- Wolf, S.; Møller, J.K.; Bitsch, M.A.; Krogstie, J.; Madsen, H. A Markov-Switching model for building occupant activity estimation. Energy Build. 2019, 183, 672–683. [Google Scholar] [CrossRef]
- Stan Development Team. Stan Language Reference Manual, Version 2.22. Available online: https://mc-stan.org/users/documentation/ (accessed on 5 May 2022).
- Betancourt, M. A conceptual introduction to Hamiltonian Monte Carlo. arXiv 2017, arXiv:1701.02434. [Google Scholar]
- McElreath, R. Statistical Rethinking: A Bayesian Course with Examples in R and Stan; CRC Press: Boca Raton, FL, USA, 2016. [Google Scholar]
- Lundström, L.; Akander, J. Bayesian calibration with augmented stochastic state-space models of district-heated multifamily buildings. Energies 2020, 13, 76. [Google Scholar] [CrossRef] [Green Version]
- Vehtari, A.; Gelman, A.; Simpson, D.; Carpenter, B.; Bürkner, P.C. Rank-normalization, folding, and localization: An improved R for assessing convergence of MCMC. Bayesian Anal. 2021, 1, 1–28. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Weekends | Working Days | |||||||
|---|---|---|---|---|---|---|---|---|
| Mean | sd | neff | Rhat | Mean | sd | neff | Rhat | |
| (kW) | 18.7 | 1.59 | 1654 | 1.00 | 34.6 | 0.53 | 4869 | 1.00 |
| (C) | 9.81 | 1.47 | 2073 | 1.00 | 6.5 | 0.81 | 3860 | 1.00 |
| (C) | 16.21 | 4.50 | 982 | 1.01 | 15.8 | 3.89 | 7578 | 1.00 |
| (kW/K) | 1.50 | 0.145 | 5324 | 1.00 | 1.39 | 0.120 | 5205 | 1.00 |
| (kW/K) | 0.626 | 0.393 | 685 | 1.01 | 1.22 | 0.140 | 5409 | 1.00 |
| 4.29 | 0.162 | 7578 | 1.00 | |||||
| State 1 | State 2 | State 3 | ||||
|---|---|---|---|---|---|---|
| Mean | sd | Mean | sd | Mean | sd | |
| 16.7 | 0.29 | 26.0 | 0.39 | 33.6 | 0.40 | |
| 7.39 | 0.24 | 13.5 | 0.29 | 14.0 | 0.23 | |
| 2.01 | 0.81 | 7.46 | 0.32 | 5.98 | 0.27 | |
| 1.27 | 0.026 | 1.29 | 0.028 | 1.69 | 0.031 | |
| 0.24 | 0.012 | 1.43 | 0.029 | 1.64 | 0.020 | |
| 3.98 | 0.031 | |||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rouchier, S. Bayesian Workflow and Hidden Markov Energy-Signature Model for Measurement and Verification. Energies 2022, 15, 3534. https://doi.org/10.3390/en15103534
Rouchier S. Bayesian Workflow and Hidden Markov Energy-Signature Model for Measurement and Verification. Energies. 2022; 15(10):3534. https://doi.org/10.3390/en15103534
Chicago/Turabian StyleRouchier, Simon. 2022. "Bayesian Workflow and Hidden Markov Energy-Signature Model for Measurement and Verification" Energies 15, no. 10: 3534. https://doi.org/10.3390/en15103534
APA StyleRouchier, S. (2022). Bayesian Workflow and Hidden Markov Energy-Signature Model for Measurement and Verification. Energies, 15(10), 3534. https://doi.org/10.3390/en15103534