1. Introduction
For the needs of large companies engaged in trade, services and other related activities, an important problem is the constant collection of information about the characteristics of customers and their preferences for various goods or services.
Small companies can collect information without using complex computing resources. This can be done with simple computing devices that do not require much complexity in servicing [
1]. However, for large companies there is a need to analyze the data of many users. Regional, national or international companies work with the data of millions of people [
2].
In this case, it is advisable to apply other approaches to the organization of the computer system. Even with increasing the capacity of the computing device that processes user data, the risk of failure due to heavy workload increases.
For effective data analysis, it is necessary to use sufficiently complex algorithms that are able to process information about the user and reject the insignificant. For example, if the user of the online store ordered all the things from the autumn collection, there is no need to store data about each favorite thing separately, in order to then conclude that the user of the store likes this style of things [
3]. This is impractical in terms of memory usage and computing power of user data processing systems [
4].
Large companies, which provide certain services to customers, use special recommendation systems to form recommendations to users in the form of advertising for new products or services based on previous preferences [
5,
6,
7].
In such tables on one axis there aredata about the user, on the other axis there aredata about goods, and at the intersection there are user ratings for a certain product. This can be a certain average value, which is determined by certain actions of the user on a product: photo preferences in social networks, an Internet search, a purchase, etc. On the basis of such tables, you can see the visual statistics of different products and services and find certain regularities with regard to user behavior.
In the simplest case, when the number of users is small, it is possible to manually collect data on their actions and understand the relevance of certain products. It is also possible to immerse users, such as students, musicians, seniors and the like, in certain features. Based on this, we can assume that if a certain product is popular among many members of the group, it can be offered to a user who has not yet givena single evaluation. Detailed process of the recommendation system is presented in
Figure 1 [
8,
9].
Thus, recommendation systems are able to learn from the information obtained and fill in the blanks in the preferences table. However, for systems with millions of users, special information analysis methods must be used. One of them is the Singular Value Decomposition (SVD) method [
10], which, unlike other methods, is easier to use and provides less data processing time.
However, more and more commercial companies are now switching to online mode. This puts even more strain on referral systems. If the operation of the data processing algorithm is supported only by the node server, then sooner or later it will not be able to process real-time data, and there may be delays in providing recommendations. It is also possible for the computing device to fail and, if it alone processes all the data, the system goes completely out of order.
It is proposed to use distributed data processing systems to improve efficiency. In them, all the data that require processing aredivided into smaller parts and processed simultaneously on different computing devices. In this case, data processing time is reduced and the risk of system failures is reduced.
For the operation of distributed systems, it is advisable to use different technologies of distributed data processing. The simplest is MPI (Message Passing Interface) technology. In it, the data aresimply distributed by the central node at the part level and sent to the working nodes for processing [
11]. This is communicated between nodes in the system using a special messaging protocol. As the amount of data in the system increases, service messages acquire significant volumes, which has a negative effect on computing performance. Hadoop technology is more efficient, in which there are no such service messages, the data aresimply sent to the working devices, written to its non-volatile memory, processed and sent to the central node. After processing, the data aredeleted from the device memory [
12,
13,
14]. It is the process of writing and deleting data from non-volatile memory that negatively affects the computation time, especially with large amounts of data. Spark technology solves this problem because the data arenot written to non-volatile memory, but to Random Access Memory (RAM), which speeds up the computation process [
15]. It is also worth noting a concept such as distributed agents [
16,
17]. These are intelligent devices in a distributed system that are able to exchange messages with each other and determine the optimal load on each node.
With the increasing volume of data, the speed of providing users with quality recommendations among large volumes of information has become a serious problem. With the spread of mobile services usage the speed of response to the request also has become an important indicator of quality user services. Nowadays, in recommendation systems that use the Internet as a communication bus, there is a technical problem with the guaranteed quality of services by the criteria of response time of the service. Since the total response time for the provided service consists of the processing time of requests on application servers and network latency introduced by switches and routers, mobile gateways, the task of delivering the requested service response time requires proper management of both communication and computing resources [
18,
19,
20,
21].
The remainder of the paper is organized as follows. In
Section 2, we present existing work related to different aspects of our approach. Then we propose our Singular Value Decomposition method used to reduce the dimensionality of the data in recommendation systems in
Section 3. We report the experimental validation in
Section 4.
Section 5 discusses the results and how they can be interpreted in future studies and finally conclude the paper in
Section 6.
2. Related Works
In this part, we illustrate the research status of the development of recommendation systems for data processing. Nowadays humanity is completely absorbed by the information space: goods, films, books, articles, news, etc., and it is difficult to determine which product is more suitable for a particular person. Accordingly, there is a need for technologies that can quickly process large amounts of data and allocate only theinformation that is useful for a particular customer. Recommendations systems are one of the most powerful technologies for solving such problems. Data processing of large volumes is an urgent problem. Because of this, many scientific papers contain research on this topic. Handri, K.E. et al. [
22] proposedhybrid recommendation systems based on Spark Cloud. In this article, the author presented a new parallel algorithm in a distributed recommendation system based on the Apache Spark platform. The main idea of this approach was to implement a multi-criteria approach to support decision-making and query dominance using matrix factorization.
Zheng-Yi Chai et al. [
23] proposed the algorithm based on SVD and Multi-Objective Immune Algorithm (MOIA), or SVD-MOIA. In this research MOIA was used to optimize the conflicting goals of accuracy and diversity. However, the authors only modified the algorithm in terms of determining the optimal number of parameters to provide recommendations. The question of applying the obtained method to large amounts of data remains unresolved. Therefore, in our research we modified the SVD method to be able to ensure the effective operation of the recommendation algorithms, even with increasing data.Y. Ji et al. [
24] proposed to regularize the method of singular decomposition based on the selection of parameters. In paper [
25] the adaptation of recommendation systems for the needs of data processing on publications wasconsidered by authors T.Achakulvisut et al.
Li G. et al. [
26] proposed a combination of the Singular Decomposition Method and statistical methods for the operation of the travel guide system, but theydidnot present an adaptation of the SVD method for use in distributed systems.Guo X. et al. [
27] proposed a method of combining element attribute information with a historical rating matrix to predict potential user preferences. This method combines attribute and temporal information in a decomposition matrix model. The described method is an effective way to solve the problem of cold start of new elements. Methods of a data processing system that analyzes data about movies based on client-oriented algorithms werediscussedV. Chen et al. in paper [
28].
Ferreira, D et al. [
29] proposed to use an autocoder based on the Singular Value Decomposition algorithm. W. Hong-Xia et al. [
30] comparedthe methods of classical collaborative filtering and the method of singular decomposition.
The methods of data processing in polymer systems by means of an algorithm of singular decomposition have been discussed. Methods of data processing in polymer systems using a Singular Value Decomposition algorithm have beengiven. I. Koprinarov and his colleagues proposedto improve the performance of recommendation systems by identifying hidden relationships between elements [
31].
A. Al-Sabaawi et al. [
32] offered the new model by integrating three sources of information: user-point matrix, explicit and implicit relationships. The key strategy of this research is to use the Multistage Resource Allocation (MSRA) method to identify hidden relationships in the social information. First, explicit social information is used to determine similarities between each pair of users. Second, for each pair of users who are not friends, the MSRA method is used to determine the probability of their relationships. If the probability exceeds a threshold value, a new relationship is established. All sources are then included in the Singular Value Decomposition (SVD) method to calculate the missing forecast values.
The authors of [
33] offered a new model of recommendations based on the time correlation coefficient and an improved cuckoo search K-tool (CSK-tool) called TCCF (the novel collaborative filtering algorithm based on CSK-means). The clustering method can cluster similar users for further fast and accurate recommendations. H. Luo et al. [
34] proposed a system of drug repositioning guidelines (MDRs) for predicting new drug readings by integrating relevant data sources and evidence-based information on drugs and diseases. The authors used a fast Singular Value Threshold (SVT) algorithm to fill the adjunct matrix between drugs and diseases with predicted scores for unknown drug pairs. Full experimental results showed that DRRS (drug repositioning recommendation system) increases the accuracy of predictions compared to other modern approaches. In addition, case studies on several selected drugs once again demonstrated the practical utility of the presented method. In work [
35,
36], the authors provided a combination of random algorithms and matrix decomposition in recommended distributed systems.
In work [
37], modifications of the SVD algorithm were considered J. Wu et al. in order to provide not only exact, but also various recommendations to users.
Despite the considerable amount of related work, itdoes not fully describe the work of the Singular Value Decomposition method in distributed systems and application of distributed data processing technologies. These issues are discussed in thearticle below.
In the articles presented here, methods of improving the operation of the SVD algorithm were described. In particular, the principles of improving the accuracy of recommendations and anticipation of user preferences wereconsidered.
However, no article studied the modification of the SVD algorithm to work in distributed systems. In this article westudied of the dependence of the algorithm on the architecture of a distributed system.
In particular, it was proposed to distribute certain operations of the same type between different computing resources. To do this, a number of operations have been identified that can be performed in a distributed manner. To use the modified algorithm with maximum efficiency, the algorithm is modeled by changing the following parameters: the number of operations performed in a distributed manner, the number of computing resources and the amount of data received at the input of the algorithm.
The proposed approach allowed to determine the optimal number of operations to be performed in a distributedmanner for different architectures of distributed systems and data volume. It is determined that the greatest efficiency of the proposed modified algorithm shows a large number of processors in the system.
3. Research and Modeling of the Method of Collaborative Data Filtering
In order to process data more effectively and make recommendations to users, it is not enough to use a model that simply takes into account that a certain user liked a certain subject. It is necessary to pass to the more exact description in which the general tendencies for certain categories of users to be interested in any subjects are considered.
It also eliminates the problem of too much data. Instead of using a large number of product evaluation vectors to evaluate user preferences, a much more compact preference vector is used.
This section will discuss the Singular Value Decomposition method used to reduce the dimensionality of the data. It is used in problems of finding matrices of hidden characteristics of system users and objects of interest [
10].
In a singular decomposition, the rating matrix R (m × n) can be decomposed into the product of three matrices: U (m × k), Σ (k × k) and V (k × n) (k varies depending on the degree of detail of the schedule). Matrices U and V are responsible for the hidden characteristics of users and objects (age, region of residence, price, etc.).
3.1. The Method of Singular Value Decomposition
The method of Singular Value Decomposition (SVD) is that the matrix
, whose dimension is
can be represented as the product of lower order matrices:
where
and
are matrices
,
.
These matrices contain orthogonal columns, which are eigenvectors (for nonzero values) for and matrix.
It should also be borne in mind that
where
is the identity matrix in which the elements located on the main diagonal are equal to one, and all the others are zero.
is a matrix of size
:
is a diagonal matrix that contains positive elements along the main diagonal. These items are sorted in descending order:
SVD is an extension of the original data in the coordinate system, where the covariance matrix is diagonal.
The operation of the Singular Value Decomposition method is shown in
Figure 2.
The initial matrix M is divided into the product of orthogonal matrices U and V and the diagonal matrix Σ.
You can select a certain k maximum number of elements of the diagonal of the matrix Σ and discard other rows and columns. In the matrices U and V, respectively, we also leave only k rows. After multiplying the new submatrices, we obtain a data matrix that repeats with high accuracy the characteristics of the initial M, but has a smaller dimension, because it does not take into account redundant and unnecessary information.
The work of the SVD method consists of finding eigenvalues and eigenvectors (denoted
and
) [
22]. Eigenvectors
correspond to the columns of the matrix V. Eigenvectors
correspond to the columns of the matrix U.
The elements of the matrix S correspond to the square roots of the eigenvalues or vectors or .
The elements of the matrix S are arranged in descending order. They always belong to real numbers.
- (1)
Application of the Singular Value Decomposition in Recommendation Systems
To apply a singular decomposition in recommendation systems, we first search for the user that most closely resembles the current one, using a matrix U that has a reduced dimension. For such a search special algorithms of finding of similarity between elements are applied.
The necessary assessment is then provided. To do this, we use a matrix of elements. It searches for items that are most similar to those previously rated by this user. The estimate of this element can be used for prediction.
Rows and columns of matrices are called vectors. The row of the matrix U corresponds to the users of the system, the column of the matrix Vcontains the elements that are evaluated.If user vectors are similar, we can assume that users have similar preferences. In the method of Singular Value Decomposition, the most attention is paid to finding similar users or elements. To calculate the similarity, such methods are used as: finding the Euclidean distance between the elements, calculating the Pearson correlation coefficient, etc.
- (2)
Standard Method of Singular Value Decomposition
In order to implement the standard method of singular decomposition of matrices, the following steps should be performed:
For the initial matrix A, its QR–schedule is searched;
We present the matrix of recommendations RT in the form of the product of three matrices: . It is worth noting that the matrix is a two-diagonal matrix;
We representthe matrix as a product of three matrices: (matrix has a diagonal appearance).
- (3)
Finding a QR–schedule
To find the decomposition of the input matrix, its representation is performed as the product of the matrix Q, which is orthogonal, and the matrix R (which is upper triangular).
These operations can be performed using the Givens rotation method.
Consecutive transformation of all elements located under the main diagonal of a matrix to zero is carried out. To do this, we multiply the matrix by a certain rotation matrix (denoted as G):
- (4)
Bringing the RT Matrix to a Two-Diagonal Form
The matrix R is upper triangular, respectively,
is lower triangular. There is a gradual zeroing of the elements under the main diagonal (first, the lower columns of the matrix
). This can be done by multiplying
on the left matrix of turns of Givens [
37].
It should be noted that in each iteration of the method, the element of the matrix may be nonzero. In cases of fairness of the condition we must multiply the matrix on the right matrix of rotation of Givens on the right that the given element was equal to zero.
Therefore, only the elements of the matrix thatare located on the main diagonal and directly above it are not zero:
The result of such operations is a matrix D
2 (which is characterized by dual diagonality):
- (5)
Bringing the Matrix D2 to a Diagonal Form
To make it diagonal, we will gradually assign a zero value to elements that are not on the main matrix diagonal (as long as at least one element is larger than the set value).
When operations are performed with elements below the main diagonal, the matrix is multiplied by the left rotation matrix. When processing the elements located above the main diagonal, multiplication by the right rotation matrix is performed.
After iterative processing of the matrix
it is gradually reduced to a diagonal form. Then the resulting diagonal matrix
:
3.2. QR Matrix Schedule
QR–schedule is a conversion of an input matrix with dimension into the product of matrices: Q, dimension , which is orthogonal, and matrix , which is upper triangular.
There are many methods of obtaining a QR–schedule. Among the most common is the method of rotation (it is also called the Givens method).
The method of rotation gradually brings the matrix, which was at the entrance, to the upper triangular shape. The method works as follows: at each stage for the matrix a certain rotation matrix is calculated , to make the item from the matrix equal to zero.
The Givens rotation is called the transformation (linear) of the vector plane. This transformation corresponds to the rotation of the two coordinate axes in the plane by a certain angle.
To reset a certain element of the matrix, it is necessary to calculate the rotation matrix corresponding to the initial matrix, then these two matrices are multiplied.
The rotation matrix is as follows:
where
,
,
is the angle of rotation of the matrix.
For example, find the QR–schedule of a matrix of this kind:
We use the rotation method for this.
We will process the elements of the matrix gradually. First, we select the left column, and the elements in it are calculated from top to bottom. Then we work with the second column on the left, and so on.
At the first stage, we calculate the rotation matrix of the element
. Rotation matrix
:
It is not necessary to explicitly calculate the angle
, but simply determine it by the following formulas:
After the multiplication of matrices
and only the lines corresponding to the indexes of the rows where they are located are changed
and
.
Let us perform the same transformations for the elements b
1 and c
2 by analogy:
After the calculations, the matrices Q and R are obtained. The matrix Q is orthogonal, and R is triangular. Then:
3.3. Application of Eigenmatrix Values for Singular Decomposition
To calculate the Singular Value Decomposition, it is necessary to find the eigenvalues and eigenvectors of the matrices that can be decomposed.
By definition, the eigenvector of the matrix A is called a vector k such that:
where l is the eigenvalue for A.
According to the theory of the Singular Value Decomposition method,
. Note that U and V have orthogonality properties:
where I is the identity matrix in which the elements located on the main diagonal are equal to one, and all the others are zero.
This is an easy conclusion to draw:
After analyzing the last two formulas, it becomes obvious that the eigenvectors for the matrix are columns from the matrix , eigenvectors for the matrix. Note that eigenvalues for matrices and there are numbers .
To find the matrices V and U, we calculate the matrix of the form
or
. Then we calculate the second matrix, using:
The matrix S is diagonal:
For example, we describe the operation of the method for finding the eigenvalues and vectors of the initial matrix.
The basic principle of the QR method is to gradually bring to the maximum similarity of the initial matrix (A) with a similar matrix An. This method is used for this purpose. Since the initial and approximate matrices are very similar, they have the same eigenvalues.
Provided that the initial matrix has real and different eigenvalues, the QR method leads to the resulting matrix, on the diagonal there are eigenvalues, and the matrix itself is upper triangular.
However, the eigenvalues of the initial matrix can also be complex numbers. Then the result of the method will be a block upper triangular matrix of the result. On the diagonal of such a matrix are placed blocks (first and second orders). The first-order blocks have their own real numbers. In the blocks of the second are complex numbers.
It should be noted that complex eigenvalues do not exist in symmetric matrices, so it is convenient to use them in such methods.
The QRmethod is performed in the following stages:
The input of the method receives the matrix A;
The matrix Rn (upper triangular) and Qn (diagonal) arecalculated. The product of these matrices corresponds to the initial matrix ;
We calculated ;
In the event that Ai is not upper triangular, the method returns to the second stage. If the matrix is triangularwe assume that the diagonals of the matrix are its own values. Also, the matrix formed by multiplying the matrices Q of each iteration of the method contains the eigenvectors of the initial matrix.
3.4. Application of the Modified Method for Carrying Out Singular Value Decomposition
With increasing data dimension, there is a need to process data not on a single computing device, but in a distributed computing system. In such systems, it is possible to modify the Singular Value Decomposition method, in which the same type of operations, such as adding data or multiplying matrices, are divided into smaller parts and processed simultaneously by different devices. Thanks to this approach, it is possible to speed up the running time of the method and, accordingly, to give recommendations to users faster. More detailed implementation of the data processing model using distributed systems is discussed in the next section.
4. Experimental Study of Data Arrays Processing in a Distributed System
To conduct an experimental study of the effectiveness of the proposed method of distribution, Singular Value Decomposition, it was proposed to create a software model in Java.
Three technologies were used to implement distributed computing:
MPI (Message Passing Interface)—between the nodes that perform data calculations and the main node are exchangeda large number of service messages. As the amount of data that needs to be processed increases, the number of service messages can take up a significant portion of computing resources, which leads to a deterioration in system performance;
Hadoop does not use a significant number of service messages. All data received for calculation are written to the permanent memory of the device and, after processing, are deleted. The time of recording and deleting data in this technology slows down;
Spark technology is similar to Hadoop, but uses RAM (random access memory) instead of persistent memory. It is especially advisable to use this technology when processing large amounts of data.
4.1. Calculation of Singular Value Decomposition in Systems Using MPI
The standard method for searching for a singular matrix decomposition described in the previous section was implemented. During the experiment, the dependences of the program execution time on the method of computing and data dimension were investigated.
To create a testing environment we used software tools and built-in methods to simulate the operation of distributed systems based on MPI, Hadoop and Spark technologies.
The number of computational processes in the distributed system varied from 1 to 16 to determine the benefits of using the proposed modified algorithm. The load distribution in the simulated system was carried out by a software control process, the data were distributed for processing equally amongall available processes. This took into account the possible minor delays in the processing of individual computational processes of their tasks. Therefore, when individual processors were busy, the data weresent to another free one.
This approach significantly increasedthe efficiency of the algorithm, especially when we needed to process Big Data. The reliability of information processing wasalso increased because the load wasdistributed amongseveral processors, and problems or unavailability of one of them didnot stop the whole algorithm.
Distributed algorithm of recommendations. The SVD algorithm is widely used in information systems for data processing. Given that in our study we proposed the use of distributed data processing systems, it was decided to modify the existing SVD algorithm and divide it into two parts: operations that couldbe performed in parallel by different computing devices; and operations that weretoo difficult to perform in parallel, so it was decided to use traditional sequential data processing.
Thus, some operations that wereof the same type, such as multiplication of matrices andexponentiation, were distributed amongseveral computational processes, which speededup the algorithm. An experimental determination of the number of operations to be parallelized was performed in order to achieve maximum efficiency of the modified algorithm.
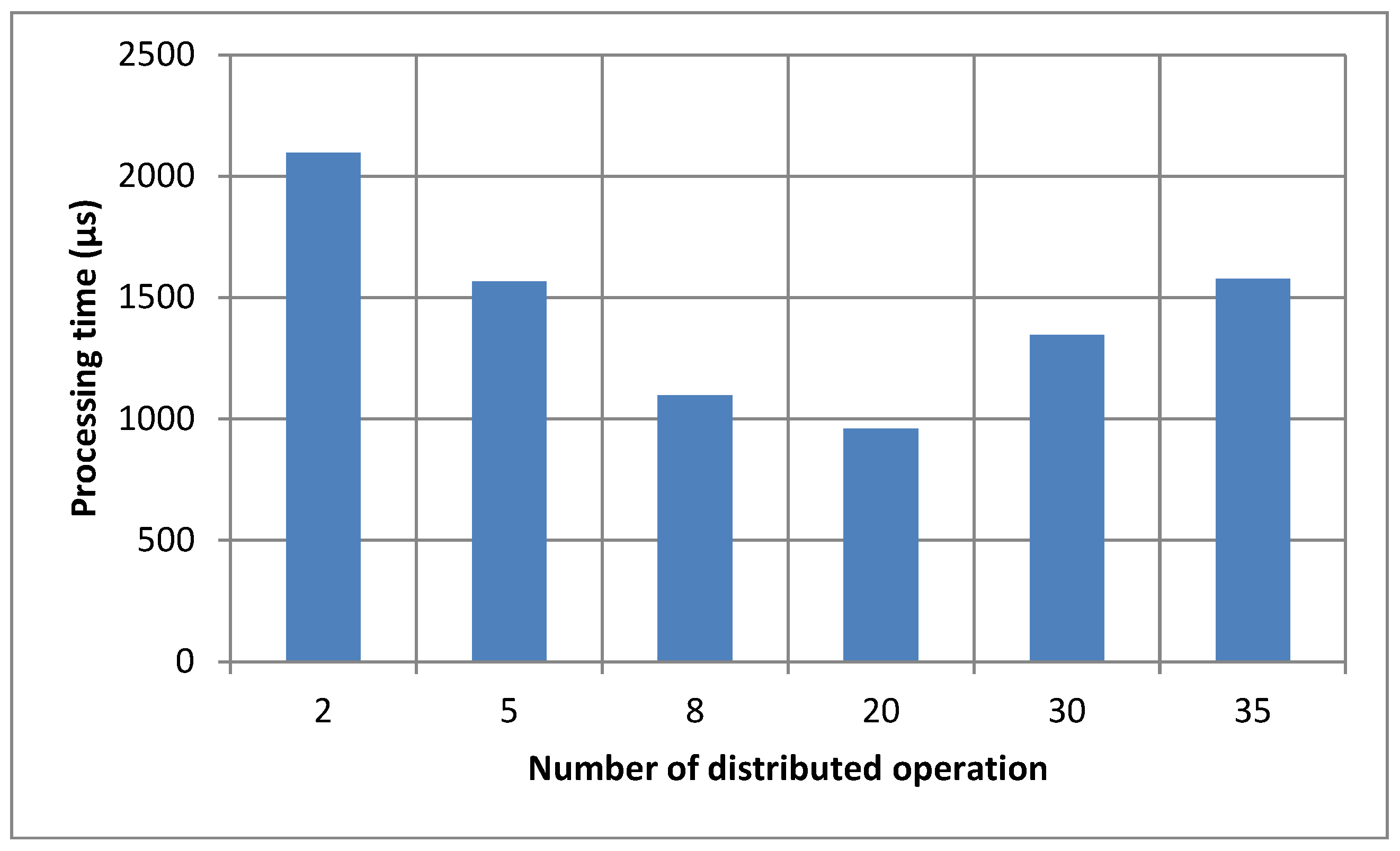
Figure 3 shows the algorithm for modifying the SVD method in distributed systems.
According to
Figure 3, the algorithm performeda sequential execution of the classical SVD algorithm. However, at each step where it wasnecessary to perform a certain action on the data, the possibility of its slave division for processing by different processors waschecked. When modeling the operation of this algorithm, a 4-processor architecture of a distributed system was used. The simulation results are shown in
Figure 4.
According to the results obtained in
Figure 4, we concluded that with increasing the number of operations performed distributed, the duration of calculations first decreasedand then increased. This wasbecause distributed computations of small operations take more time than their simple sequential execution. Therefore, for further research, we used a distributed execution of no more than 20 operations.
The proposed algorithm allowedto determine the required degree of modification of the SVD algorithm for different architectures of distributed systems with the highest efficiency.
The implementation of the Singular Value Decomposition method in a distributed system is shown in
Figure 5.
Figure 5 shows the operation of an unmodified Singular Value Decomposition method, in which all data is processed by one processor, and a modified one, in which the task is distributed to several processors. Distributed processing can increase the efficiency of the computing system. Elements of the modified method are highlighted in red.
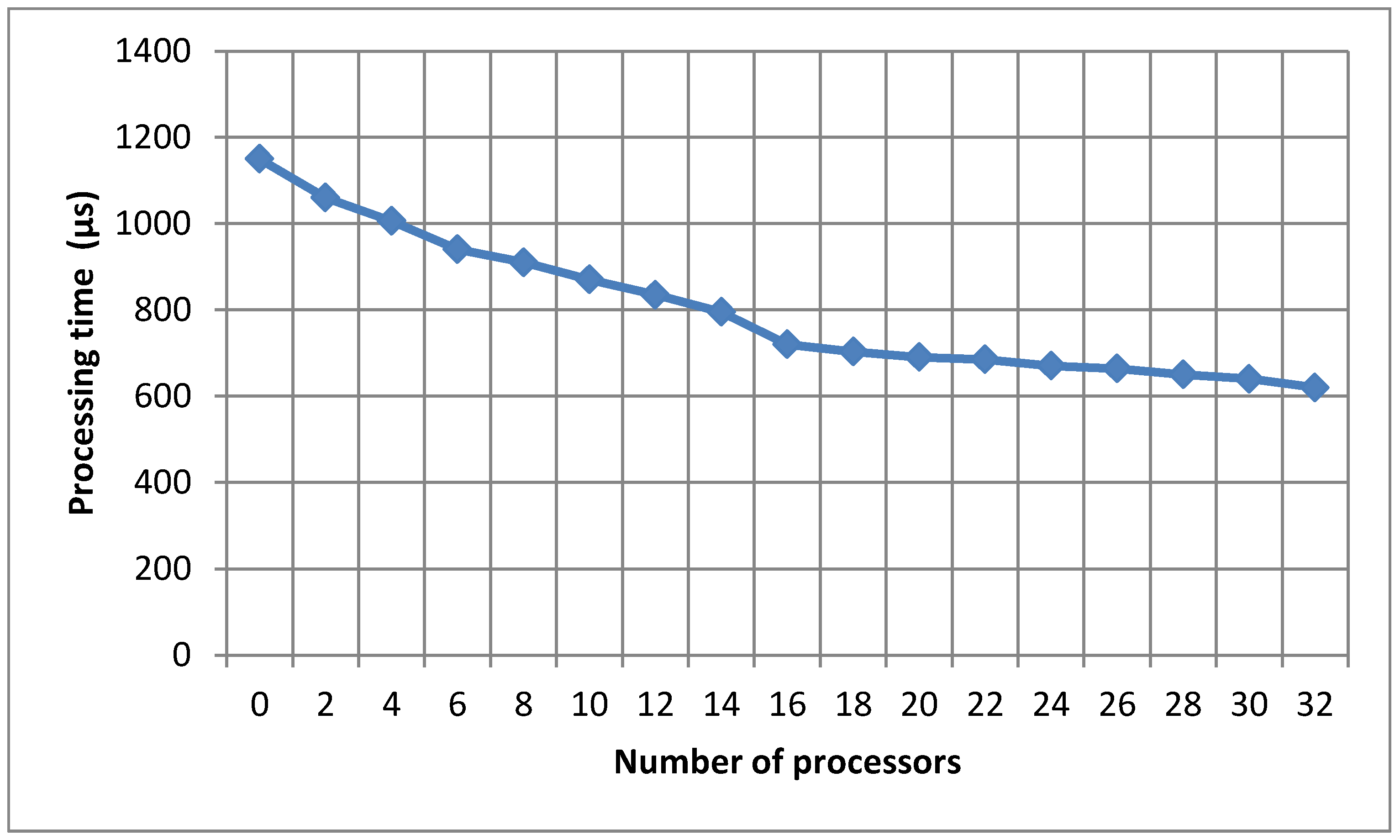
Figure 6 and
Table 1 show the result of the experiment. The dependence of the execution time of a Singular Value Decomposition of a matrix with a dimension of 120 rows and 120 columns depending on the number of computational processes is given.
From
Table 1 and
Figure 6 we concluded that increasing the number of processes reducedthe processing time calculations because the data weredivided into smaller parts that wereprocessed faster by the processor.
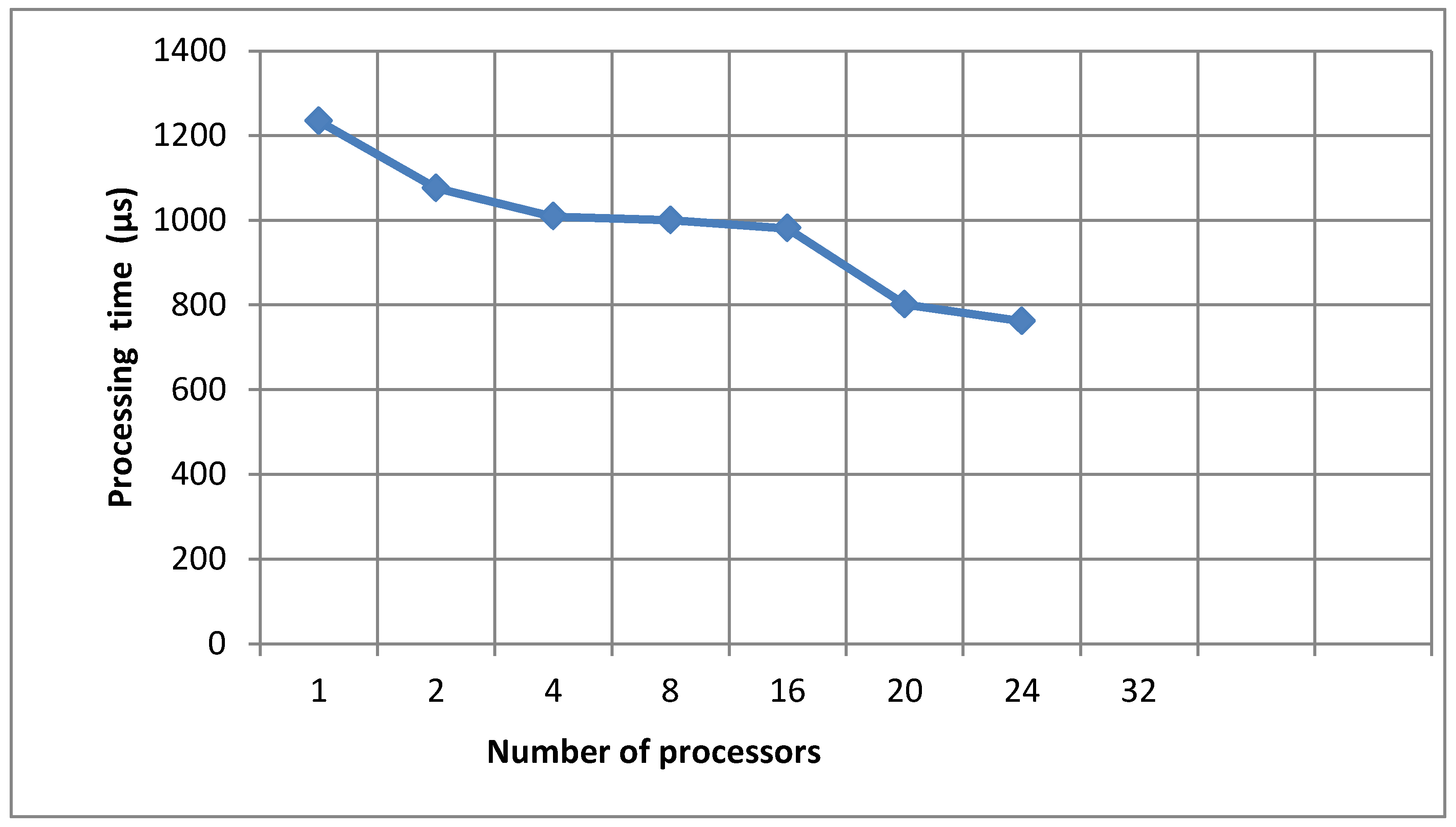
Figure 7 and
Table 2 present the dependence of the processing time of calculations on the size of the array of calculated data during processing in a dual-processor system.
From
Table 2 and
Figure 7 we concluded that with increasing the dimension of the data the processing time increased. To perform calculations more efficiently it wasnecessary to increase the number of processors, as shown in
Figure 6.
From the results of experiments we concluded that the execution time of the software algorithm increasedwith decreasing the number of computing devices. For a single-processor system, which is therefore not distributed, the computation time wasthe longest.
4.2. Comparison of MPIApplication Efficiency for Distributed Computation for Different Data Volumes
We conducted experiments to calculate the QR–schedule of the matrix for matrices of different sizes, using different numbers of process devices in a distributed system.
This amount of data was considered small.
Each element of the matrix wasof type double (8 bytes). Then the total amount was:
The number of processors varied sequentially from 1 to 32.
The results of the experiment appear in
Figure 8.
From the graph we concluded that as the number of processors increased, the processing time decreased.
- 2.
We increased the amount of data. To calculate, we took a matrix of rank 200 × 200. The amount of information:
The result is shown in
Figure 9. We concluded that the processing time increased significantly. However, as the number of processors increased, the time was reduced.
- 3.
To calculate, we took a matrix of rank 1500 × 1500. The amount of information: 8 × 1500 × 1500 = 18,000,000 bytes = 18 MB (
Figure 10).
The graph shows that the computation time decreasedwith increasing the number of processors.
General results for the experiments are shown in
Table 3.
From the results of the experiments we concluded that with increasing data volumes, the computation time wasconstantly increasing. In order to increase the productivity of the system, it wasnecessary to carry out distributed information processing. For example, computing a two-dimensional data array represented as a rank 20 matrix on a conventional unallocated processor tookmore than 20 ms. When using a distributed system consisting of 32 processors, processing time washalved. Similar figures couldbe observed for other volumes of input data. Thus, for a matrix size of 200 × 200, the processing time wasreduced from 1564 μs on one processor to 762 μs on 32. For the largest data array of rank 1500, it wasalso possible to halve the processing time by using a distributed system with many computing devices. From the research we concluded that for the processing of large data sets it wasnecessary to use distributed computing systems, with a significant number of processors that provided the required performance of the computing system.
5. Dependence of Data Processing Efficiency on Hidden Factors
To form recommendations, it is often not enough to calculate the Singular Value Decomposition of the preference matrix. It is necessary to take into account certain initial conditions, in case the system does not yet have enough information to form a result. Adjustment coefficients are also added to the result of the work in order to take into account possible changes in preferences and to ensure the possibility of automatic training of the system of forming recommendations.
A different number of singular numbers were selected for the modified distributed algorithm. As a result, we found a relationship between computational speed and accuracy of the algorithm.
Modeling of the modified algorithm for additional reduction of time of giving of recommendations was carried out. To achieve that we changed the number of singular numbers. The results of research showed the possibility to improve the efficiency of the SVD algorithm if it wasnot necessary to take into account such indicators as, for example, the user’s affiliation to a particular profession, place of residence or other factorthat increasedthe precision of personal recommendations.
The dependence of the processing time of calculations in the system (using MPI) of the matrix of rank 120 on the control coefficients isshown in
Figure 11.
The predictive regularization factor usedadditional information about the user to adjust the provision of recommendations after a certain time;the initial learning factor introducedcertain initial values to provide recommendations;the learning speed ratio allowedus to calculate data faster by considering more parameters that characterize the user.
Figure 11 shows that with increasing the values of the control coefficients of the formation of recommendations, which should increase the reliability of the results, the processing time increased.
Figure 11 shows that although the values of the coefficients wereinsignificant (from 0.001 to 0.01), the duration of the calculations increased from 0.4 to 0.5 ms. This result may increase with more data, so fewer factors need to be considered to improve computational speed.
Next, we considered the processing of singular numbers of data matrices. In the matrix Σ, which is an integral part of the Singular Value Decomposition of the matrix M, on the main diagonal are the singular numbers of the latter in descending order of value. To reduce the amount of computational data, it wassufficient to consider only the k largest singular numbers, and discard the rest. We couldalso take into account k the first rows of matrices U and V. When multiplying we obtained a matrix M1, which repeatedthe parameters of the initial M, but smaller in volume.
The dependence of the processing time of calculations of the matrix of rank 200 on the number of singular numbers isshown in
Figure 12.
From the graph we concluded that the data processing time of the calculations decreasedwith increasing the number of rejected singular numbers.
Figure 12 shows that when the number of singular numbers was 20, the duration of the calculations was 0.05 ms. When the number increasedto 200, the computation time increasedto 1.5 ms.
The results showed that when using many singular numbers, the duration of the calculations increases, but this leads to an increase in the accuracy of the algorithm.However, for the effective operation of the method for the formation of recommendations, it is advisable to get rid of as few as possible with values close to zero.
It should be noted that when using a distributed SVD algorithm wecoulduse a larger number of singular numbers for the same duration of calculations (
Figure 13).
Figure 13 shows the durations of calculating the same number of singular numbers for the unmodified SVD algorithm and one modified using MPItechnology.
The unmodified algorithm completed the work taking into account the maximum number of additional parameters for 1.5 ms. The modified algorithmprocessedthis amount of data in approximately 1.2 ms.
Therefore, the proposed modification of the SVD algorithm operating in distributed systems can be used as an effective way to increase the speed and accuracy of calculations.
Data Processing Using Hadoop and Spark Technology
This model of distributed computing of the modified method of SVD can be used to determine the feasibility of using a complex computer system to solve problems.
The input of the model provides the parameters of the amount of data to be processed, and the output is the processing time for different numbers of computing devices. For companies that depend on a quick response to changing user preferences, a few seconds are crucial to making recommendations. For example, a site user searches an online store for a specific product, specifying specifications and a reasonable price. The recommendation system, which analyzes its needs in 3 s and provides a similar and interesting proposal, increases the likelihood of selecting the right product. Instead, if it takes 20–30 s to form recommendations, the user, without finding many interesting suggestions, can simply leave the site without making a purchase. Such situations happen quite often, and a significant part of the profits of sales companies depends on them. This is especially important now that many stores are online.
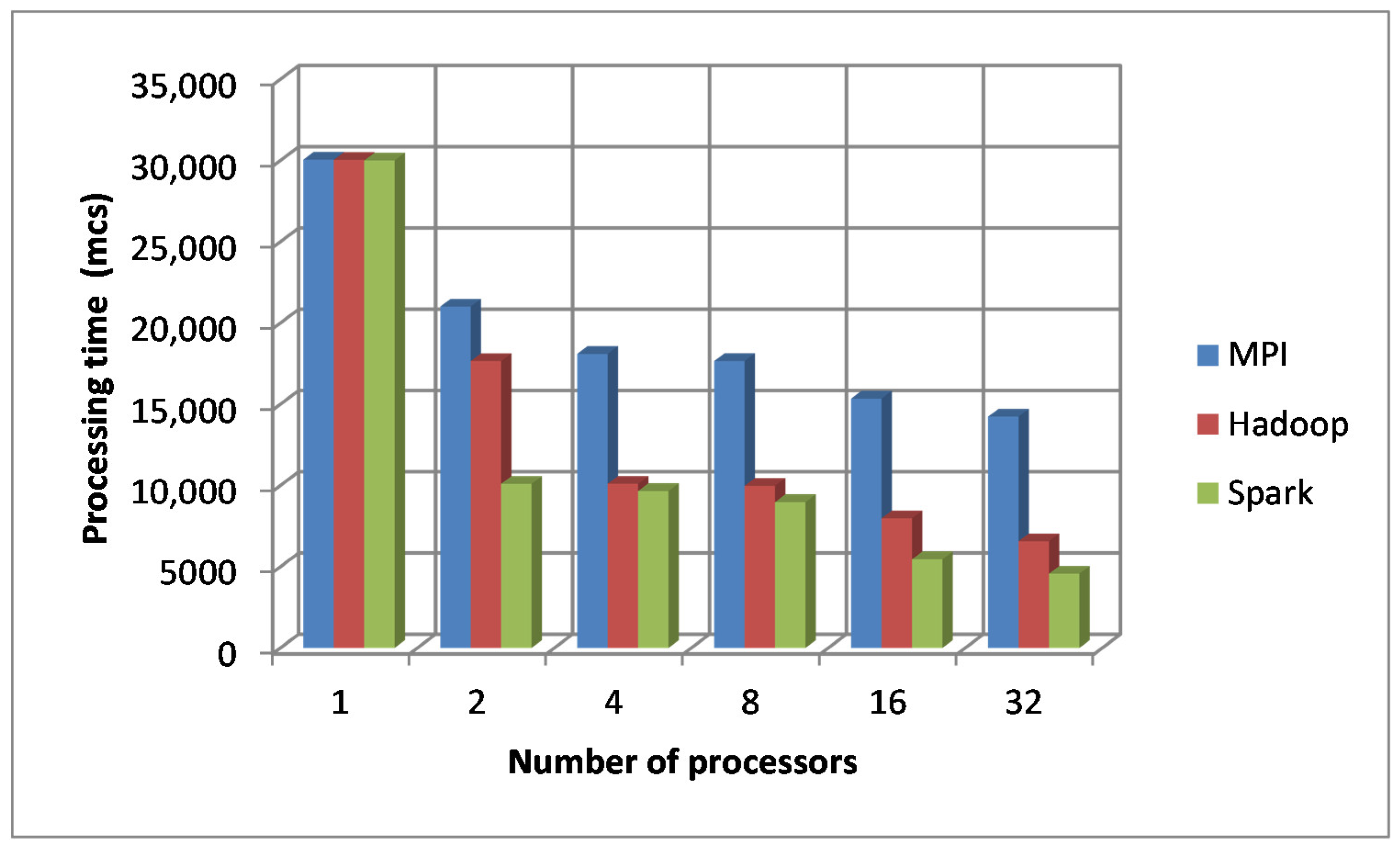
Figure 14 shows the dependence of the processing time of calculation of data matrix size 1500 for different technologies of distributed data processing depending on the number of processors.
From
Figure 14 we concluded that with increasing the requirements for computing resources, it wasadvisable to use a distributed system with more processors. Spark technology wasthe most time-efficient.
When using one computational process, the computation time for all technologies was 30 ms. However, when the number of processors doubled, the MPItechnology calculateda similar amount of data in 20 ms, Hadoop in about 17 ms, and Spark in 10 ms.
When using 32 processors, we sawthat MPI, Hadoop and Spark technologies performed calculations for 13, 6 and 4 ms, respectively. This provedthat Spark technology performedthe calculation of large amounts of data the fastest of all the technologies considered in the study.
Figure 15 shows the dependence of the processing time of the calculation of recommendations to users depending on the dimension of the input data for distributed systems and distributed using different data processing technologies:
In
Figure 15 we see that the SVD method, which workedwithout modification, showed aworse performance, compared to the modified method, which workedin distributed systems. To improve the efficiency of calculations, depending on the requirements for the processing time of calculations, it wasadvisable to use Hadoop and Spark technologies.
According to
Figure 15 we concluded that the Hadoop and Spark technologies weremost effective when used in distributed systems with large amounts of data. For these technologies, the calculation time of the data matrix of rank 1500 didnot exceed 10 ms. Instead, for MPI technology, the computation time was 20 ms.
The results showed that Spark demonstratedthe greatest efficiency among the studied technologies of distributed computing. The advantage over Hadoop in the duration of calculations wasan average of 0.5 ms. For recommendation systems this determines the duration of processing a piece of user data. There are often many such fragments, so if the system needs to provide recommendations quickly for calculations it is suggested to choose Spark technology.
Figure 16 shows a relationship similar to that shown in
Figure 15, but by analyzing the data obtained in the previous graphs, the duration of the calculations is for larger amounts of data. Thus, it is clear that it is necessary to use distributed computing systems to process large amounts of data.
According to
Figure 16, it was concluded that among the distributed technologies, MPI technology processeddata for the longest time (from 10 to 35 ms, depending on the amount of data). The data matrix with a maximum size of 15,000 was processedby Hadoop in 20 ms, Spark in 15 ms.
Figure 16 shows the relationship that allows us to conclude that to process large amounts of data it wasadvisable to use Spark technology. MPI and Hadoop technologies also hadadvantages over a conventional unallocated system. This dependence allowedto choose the optimal method of data processing on the basisof the required processing time and data volume. If it is economically profitable for a large company to spend resources on a powerful computing system and quickly process data, then the best choice of technology is Spark. Compared to an undistributed system, a system using Spark technology can calculate data 2–3 times faster.
The study used a volume of data that could not be processed on the equipment used in the experiment without modifying the data processing method and using distributed computing. Therefore, we can say that for this study the work was done with Big Data. The results obtained can be used to continue research on more powerful equipment and improve the efficiency of Big Data calculations.
From the simulation results we can also conclude not only about the comparison of unallocated and distributed systems using the algorithm SVD but also about the analysis of work in different architectures of distributed systems. The number of computational processes has changed in the modeling process. The results showed that the modified algorithm gives the most advantages in distributed systems with a large number of computing devices and a significant load on them. In addition to changing the number of processors we used various technologies: MPI, Hadoop, Spark. This allowed us to create several different distributed SVD algorithms with different results. Using the obtained research results it waspossible to predict the operation of the SVD algorithm in different distributed systems with different amounts of processed data. This also allowedto choose a distributed implementation of the algorithm that gave the best result for certain requirements and conditions in a particular system.
6. Discussion
In this work, a study was conducted on the processing of large volumes of data in reference systems. For this purpose, a modified method Singular Value Decomposition was used, which was proposed for use in distributed processing systems.
MPI, Hadoop and Spark technologies were used for the work method in distributed systems. Based on the obtained results, a model was built that allowedto determine the expediency of using distributed systems and the method of unambiguous decomposition was modified depending on the tasks being solved.
This method can be improved in the future by applying machine learning techniques, which will allow the proposed method to learn itself and give more accurate recommendations to users. This topic is also promising for further research and experimentation with new distributed data processing technologies and computing platforms in order to find optimal ways to improve the efficiency of processing large volumes of data.
7. Conclusions
The growth of data requires the introduction of new approaches to organizing calculations. In this regard, distributed and parallel processing technologies are widely used.
The paper consideredthe use of distributed infocommunication systems in the processing of large amounts of data. The work of recommendation systems of information analysis wasinvestigated. An overview of approaches to reduce computing using collaborative data filtering methods wasreviewed.
The introduction of methods for optimizing data sets in distributed systems wasinvestigated. An example wasthe method of SVD. The novelty of this approach wasthat it allowedusto organize information and discard redundant data, which led to faster and more efficient processing. System user information collected from various sources wassorted and analyzed. Based on that, recommendations wereformed on the services of the system that may be of interest to its customers. Because the data obtained from the recommendation systems werelarge, distributed computing was used to process them to ensure the required performance.
The operation of the SVD in the processing of large arrays of information wassimulated. The data size and number of nodes of the distributed system were changed using the MPI protocol to obtain optimal values of productivity. It wasdetermined that when the number of computing devices increased from 1 to 32, the computation time washalved for different amounts of data. The singular decomposition of the matrix of rank 1500 in the distributed 32–x processor system wasperformed in approximately 10 ms and in the unallocatedin 20 ms.
Simulation of SVD in systems using MPImessaging protocol and MapReduce software model wasperformed. The results showed that for small computations it is more efficient to use MPI, and when processing more than 10 MB of information it is advisable to use MapReduce due to simple implementation and faster operation.
We also compared the efficiency of Hadoop and Spark technologies, which indicated the feasibility of using the latter when it is necessary to quickly process large amounts of data. In particular, the use of a modified SVD method together with Hadoop and Spark technologies allowed to process data 2–3 times faster than when using an unmodified method in an unallocated system.
In the field of distributed systems, new research and improvements will always be relevant. This work can serve as a basis for further research in the field of processing large data sets using distributed or parallel computations.


 ,
, 


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}