
Short-Term Deterministic Solar Irradiance Forecasting Considering a Heuristics-Based, Operational Approach




Abstract
:1. Introduction
1.1. Statistical Forecasting Methods: Introduction and Challenges
1.2. Emergence and Challenges of Artificial Intelligence as Forecasting Tool
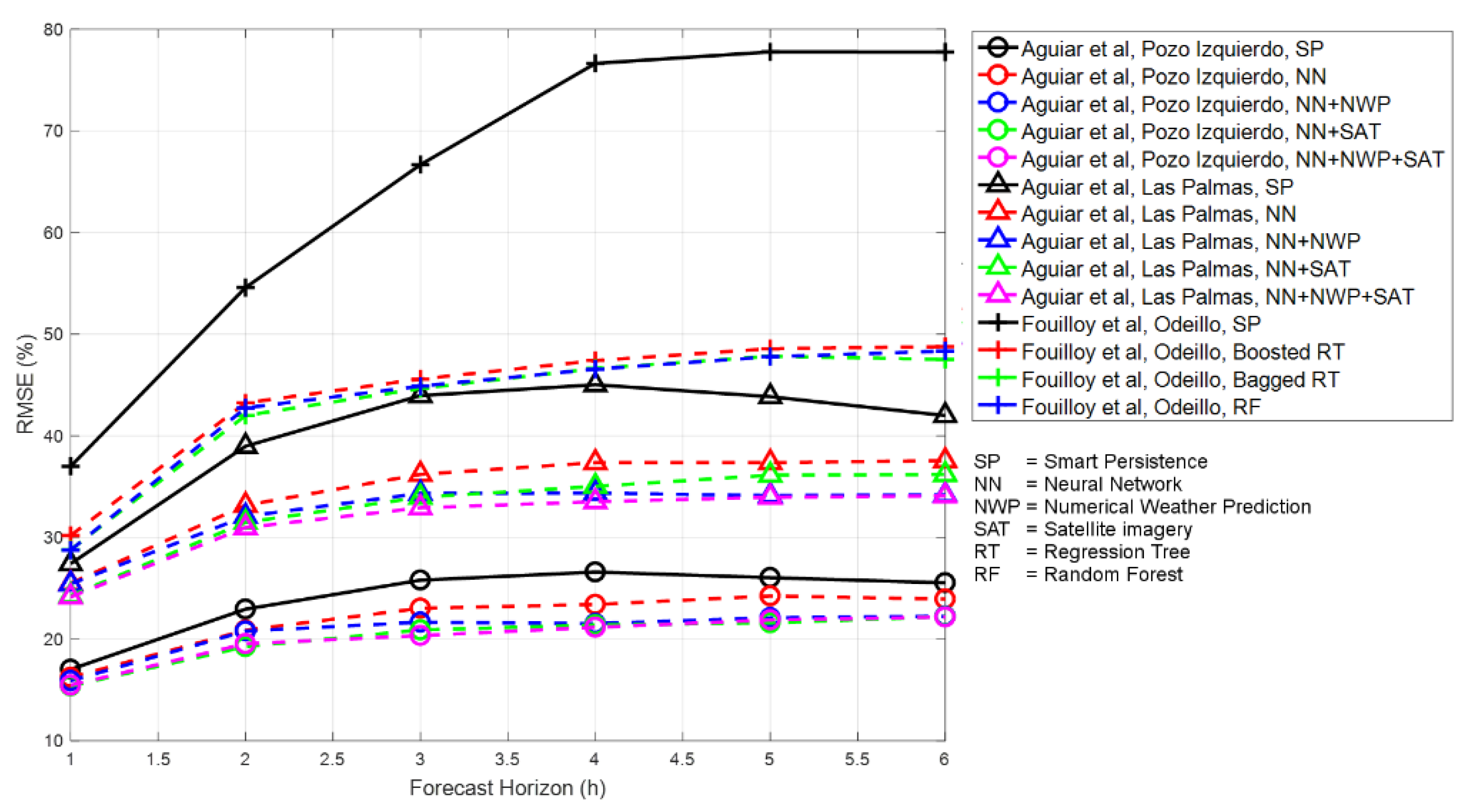
1.3. Current State of the Art in Solar Power Forecasting Performance Assessment
1.4. Present Work and Scientific Contributions
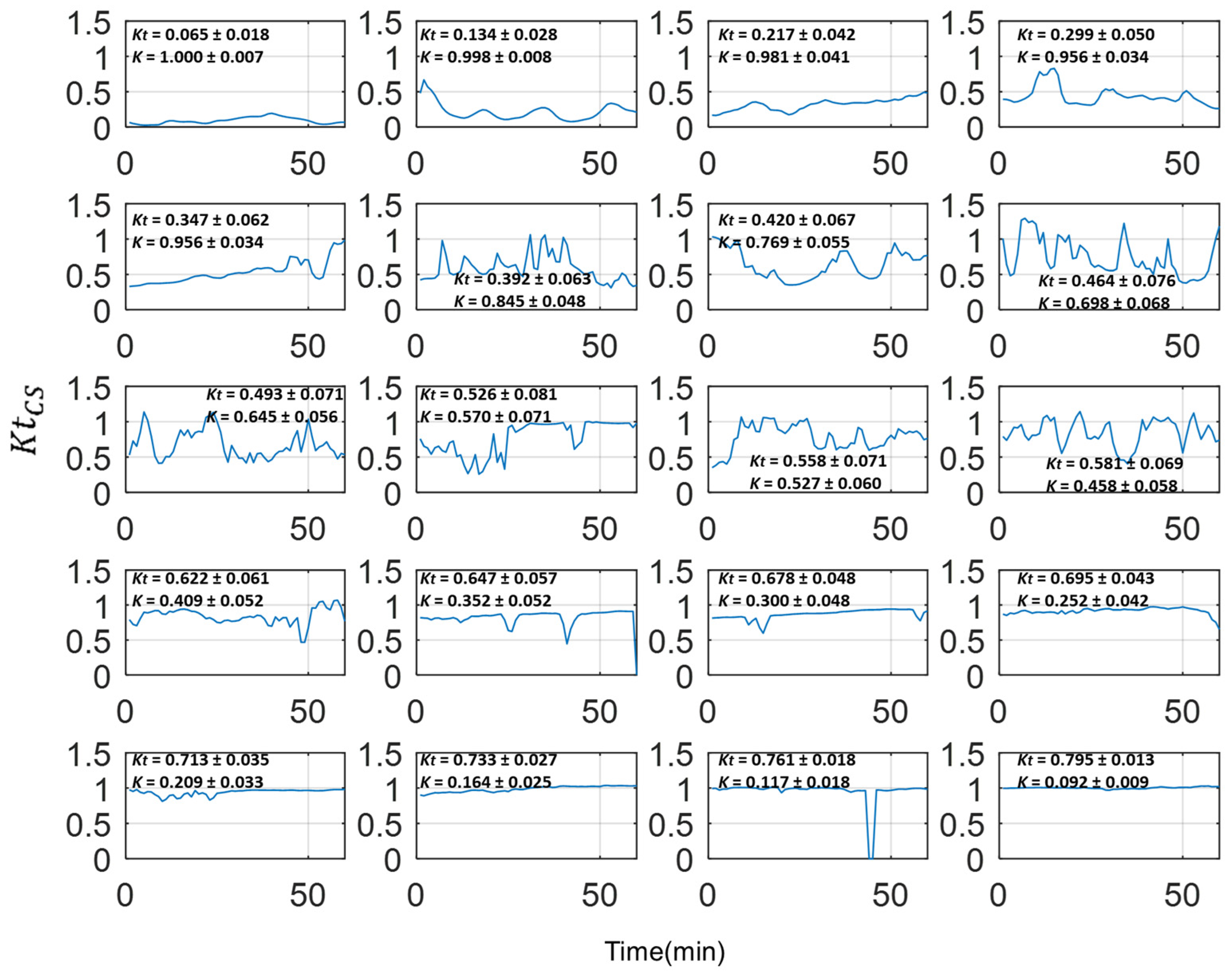
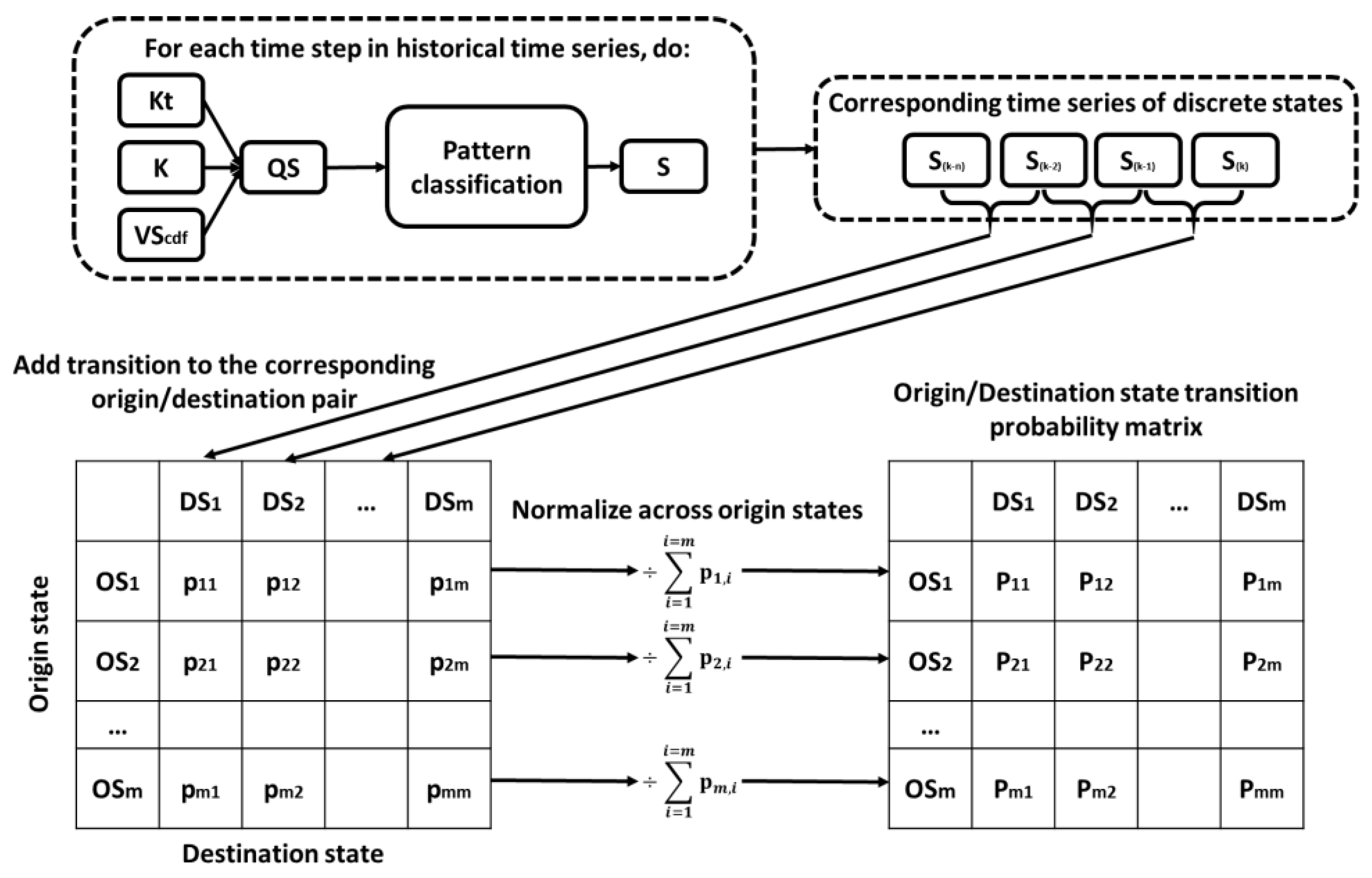
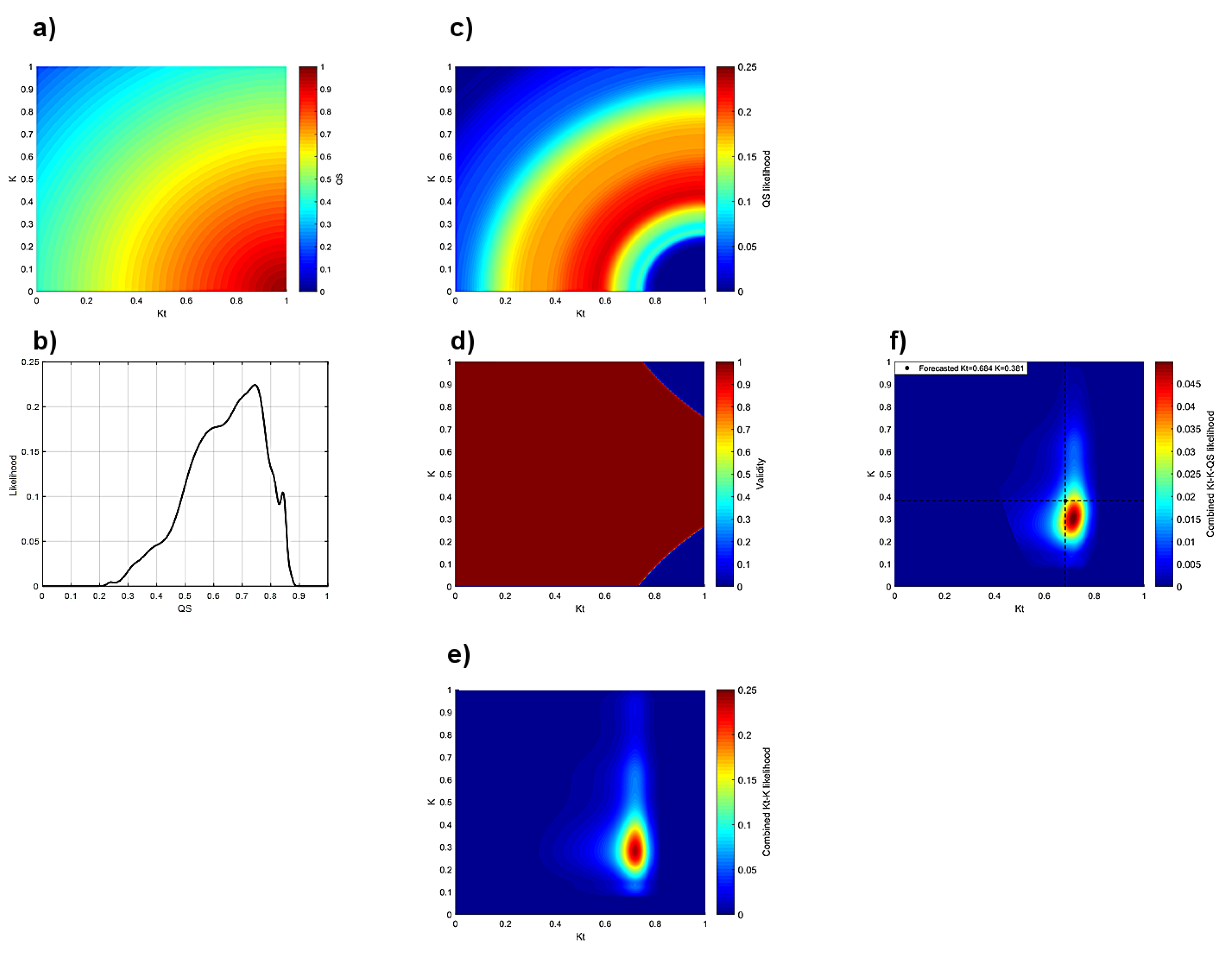
- A novel solar radiation forecasting method was developed based on pattern identification and classification, probability and heuristic methodology, considering operational needs of decision-making parties. The heuristic method developed for this application presents an intuitive, explainable, interpretable and effective way to forecast solar irradiance, by relying on concepts of probability, possibility and human reasoning, overcoming the limitation of complex mathematical abstraction and black-box characteristics of advanced state-of-the-art statistical and artificial intelligence methods.
- A generalized explicit irradiance pattern classification scheme was employed for performance assessment and forecasting, by classifying irradiance patterns through an analytical expression that yields similar results to clustering techniques, with the advantage of easy implementation across studies.
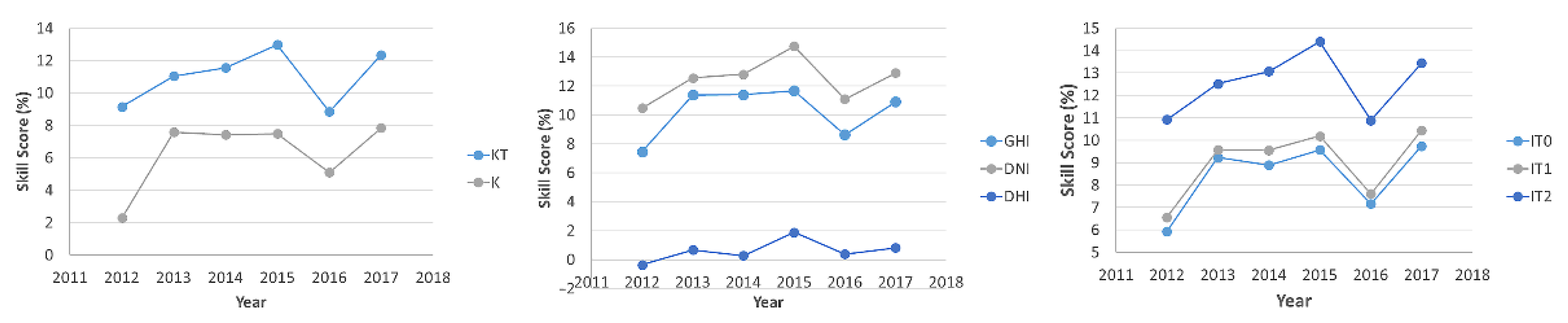
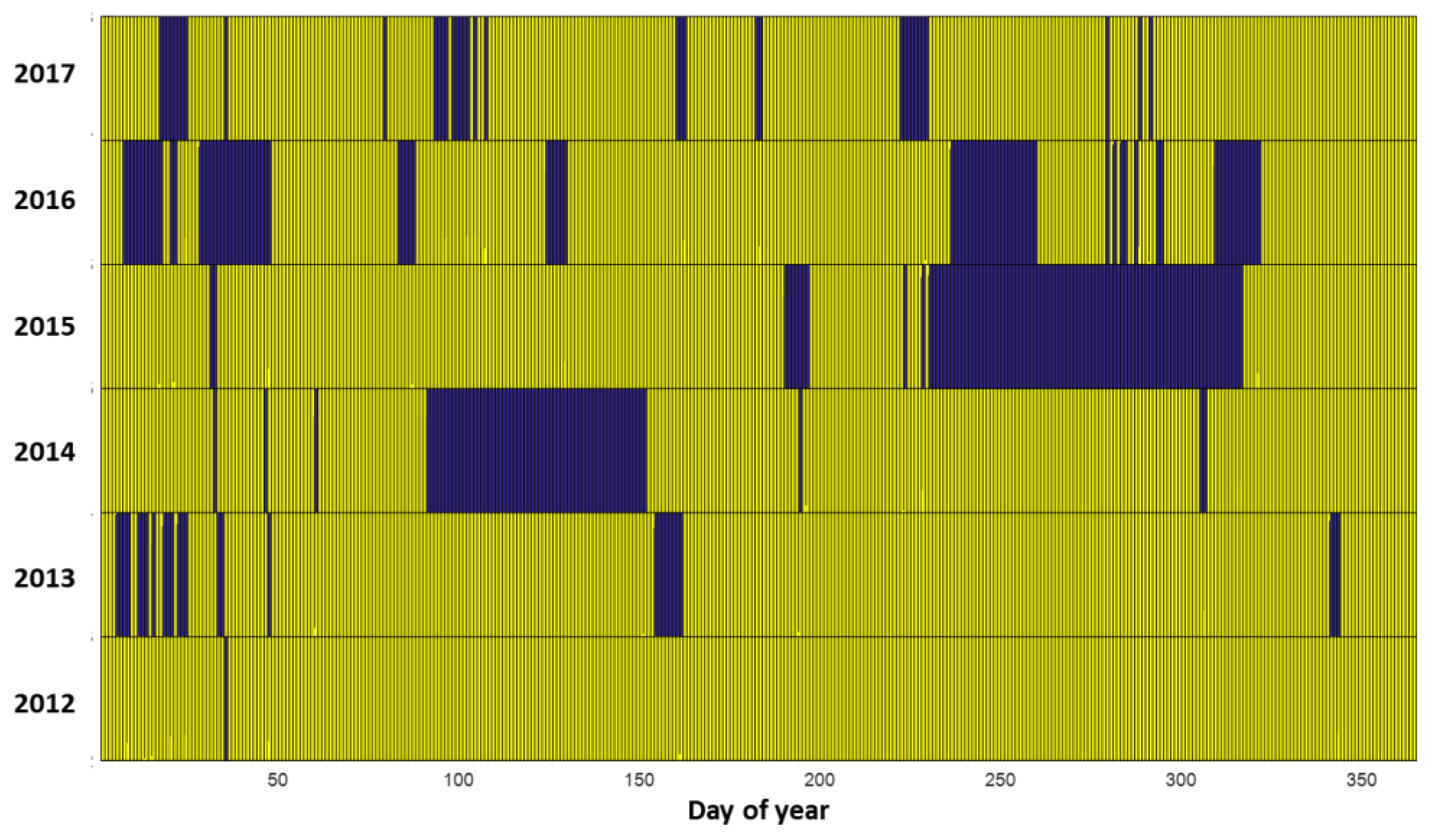
- A comprehensive performance assessment framework was developed to analyze not only how forecasting performance changes as a function of forecast horizon and lead time, but to evaluate the effect of data aggregation into the knowledge base has on forecasting skill, how quality control and/or data gaps affect performance assessment and how the forecaster performs under different objectively defined day types.
2. Data Sources and Methodology
3. Assessment Methodology
4. Results and Discussion
4.1. Data Aggregation Effect on Forecasting Performance
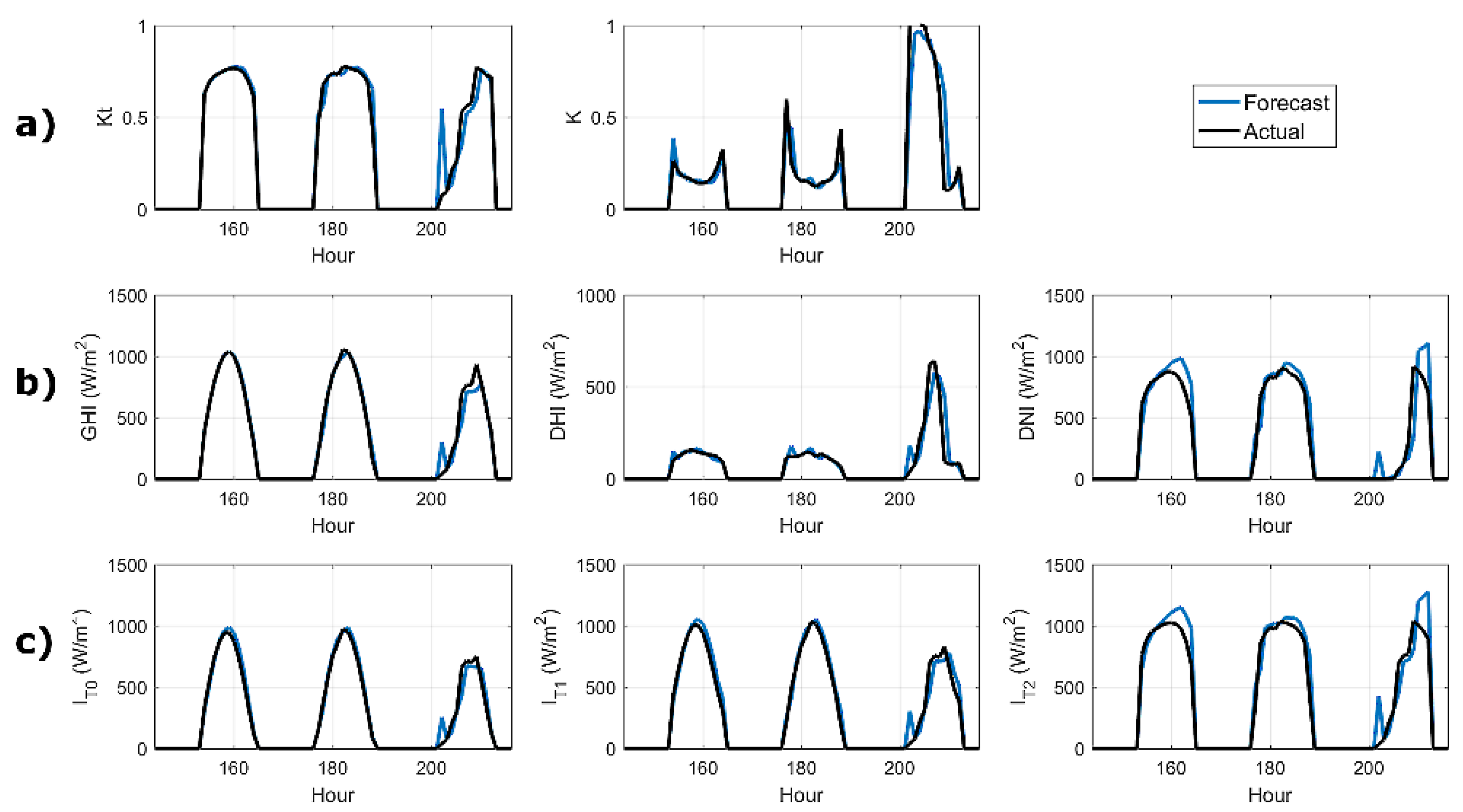
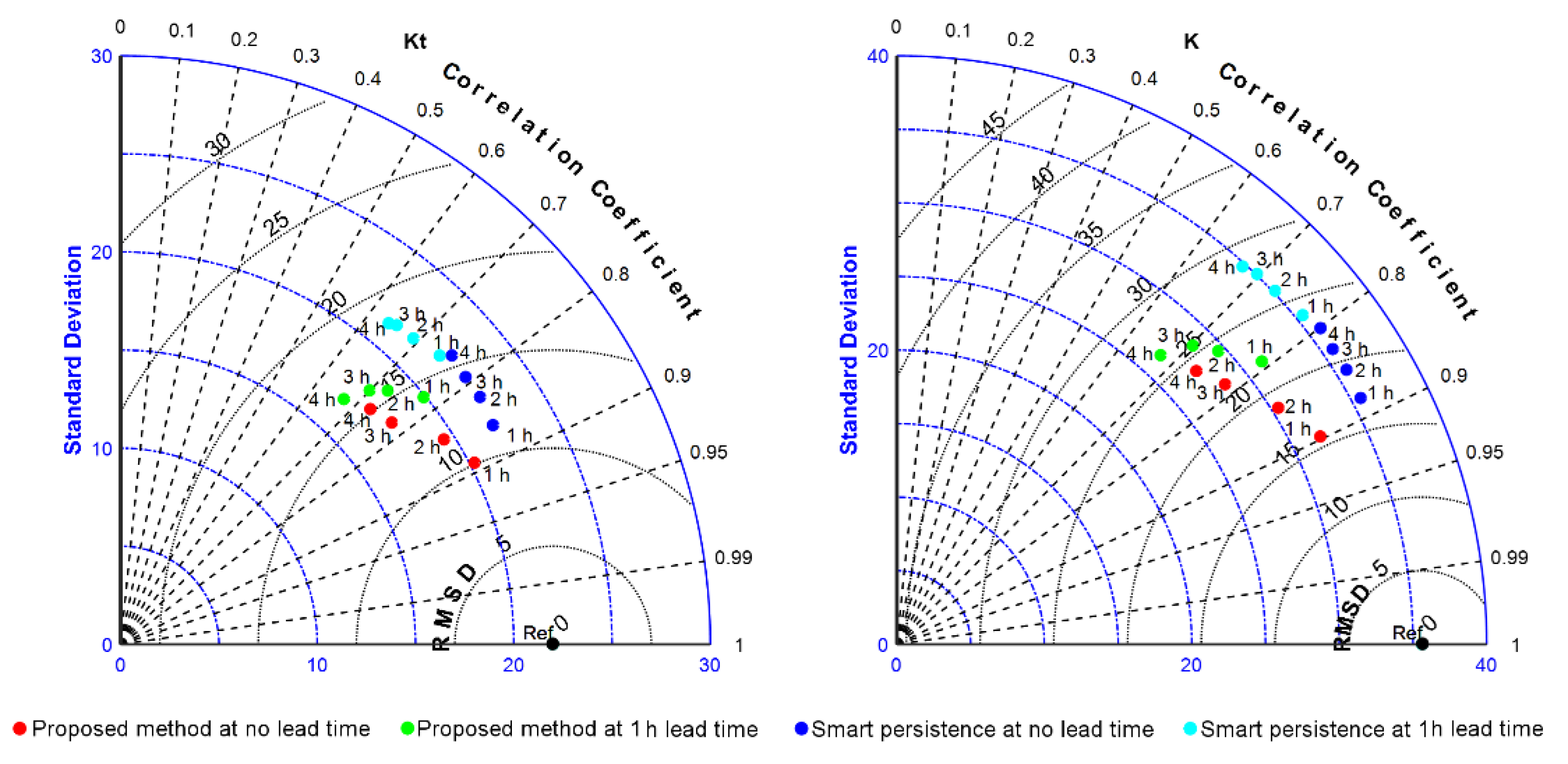
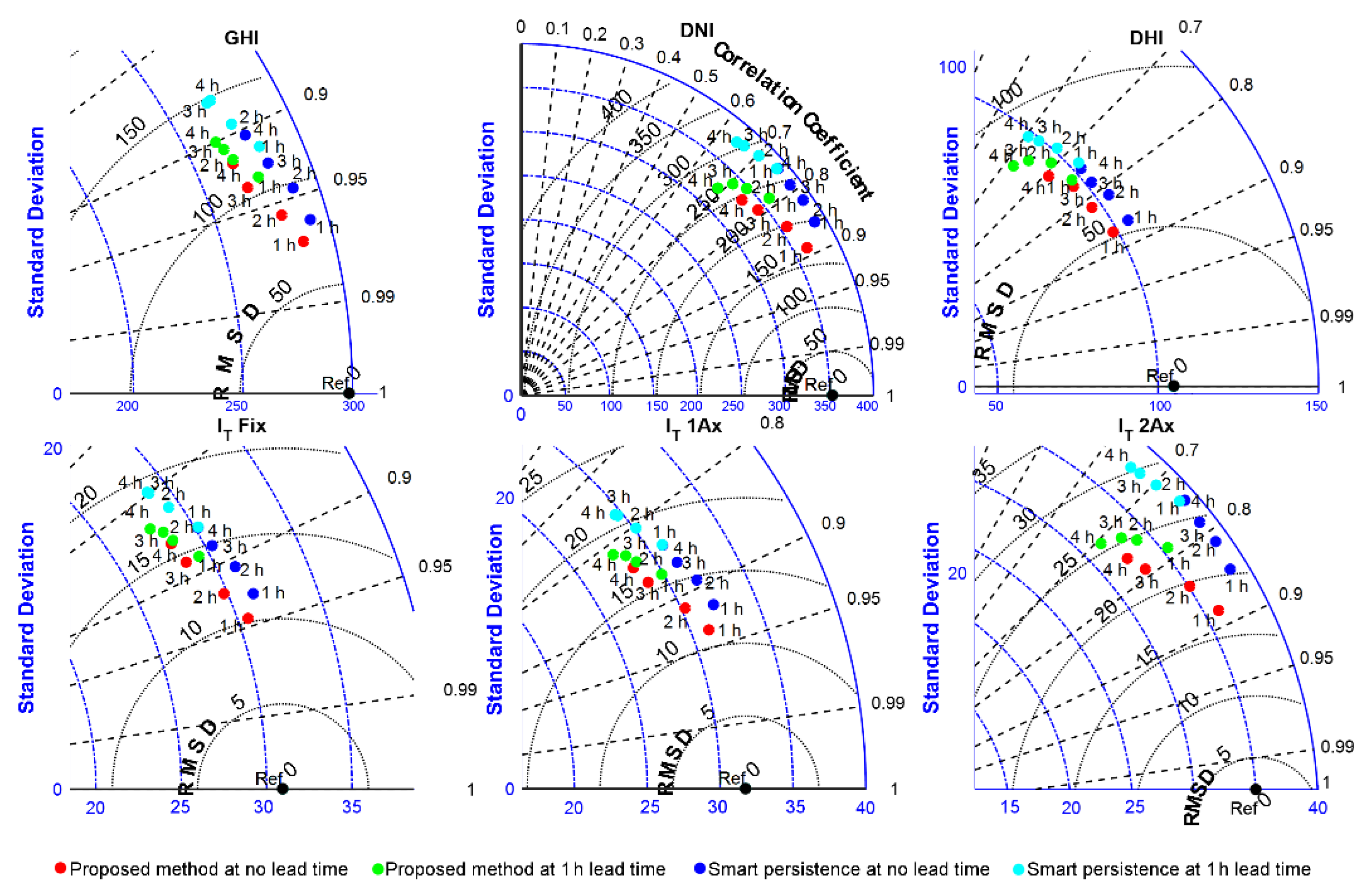
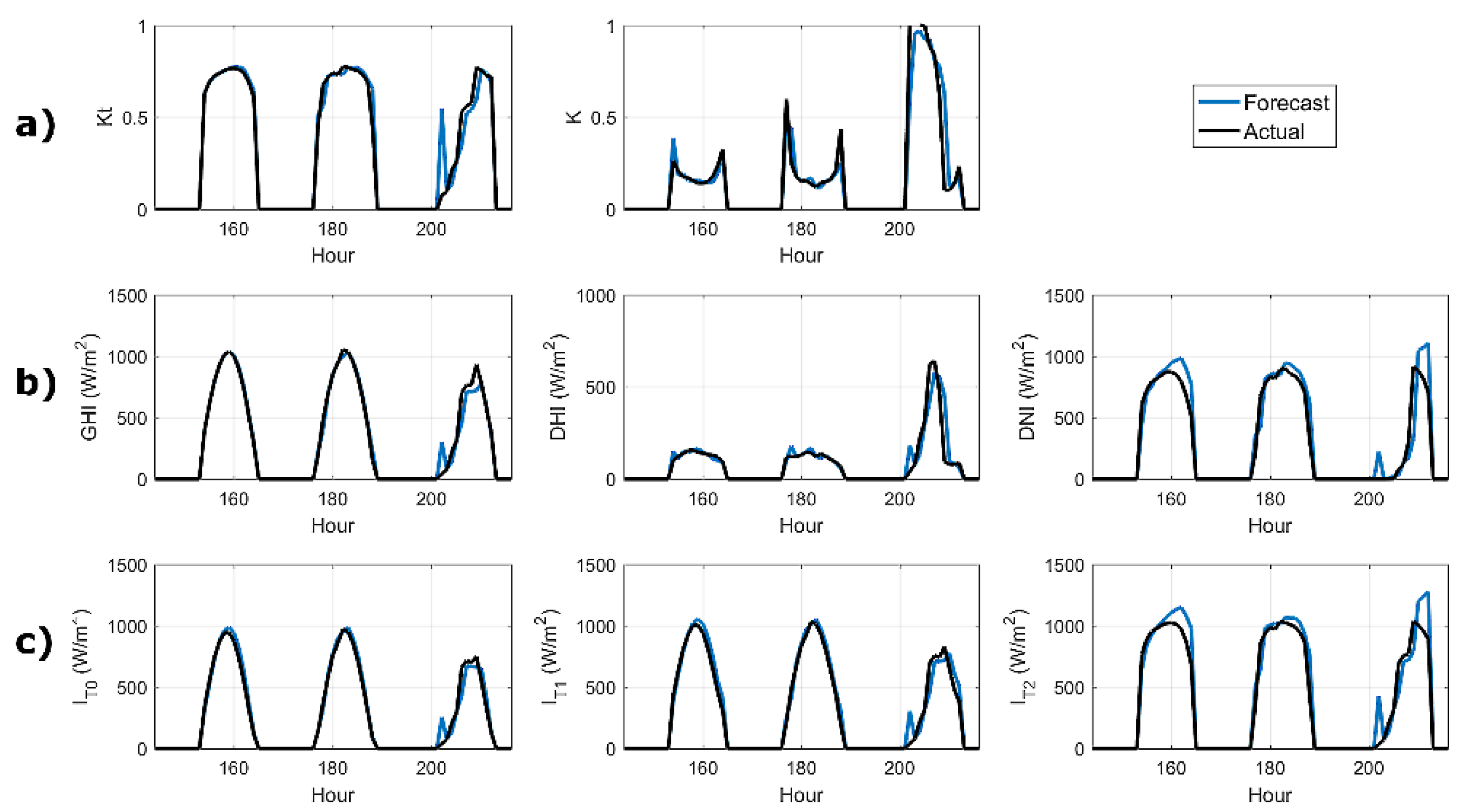
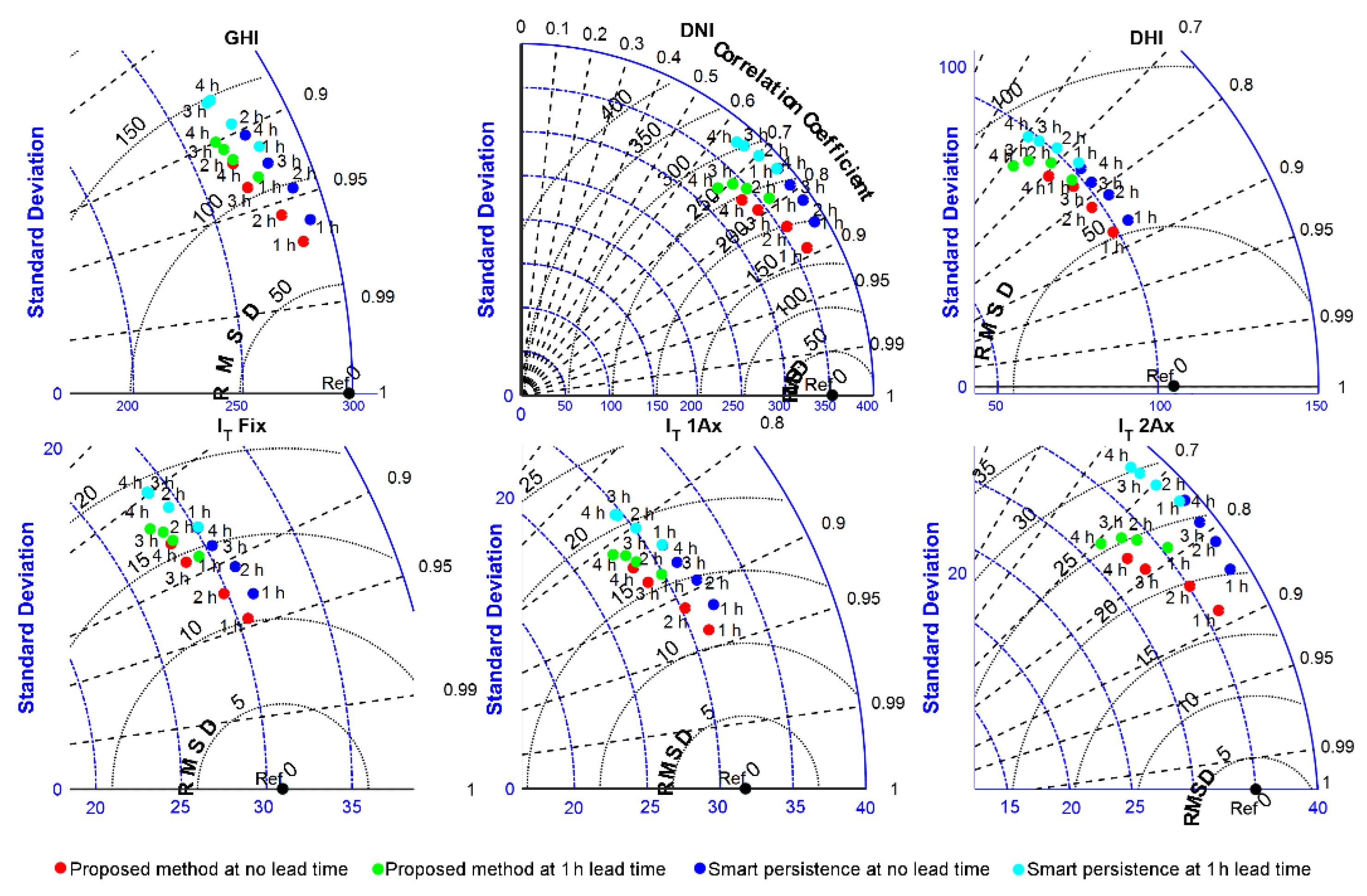
4.2. Effect of Forecast Horizon and Lead Time in Forecasting Performance
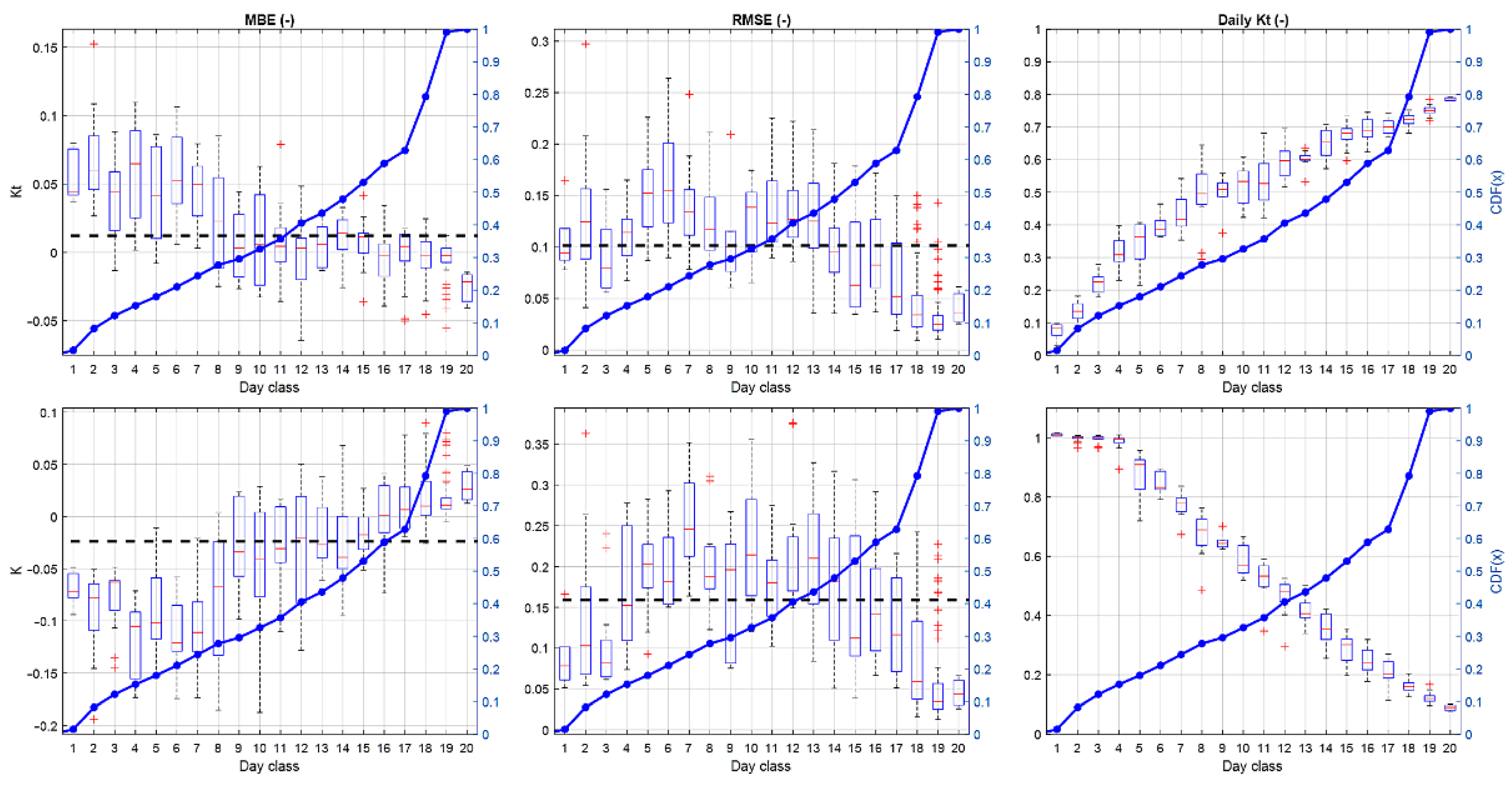
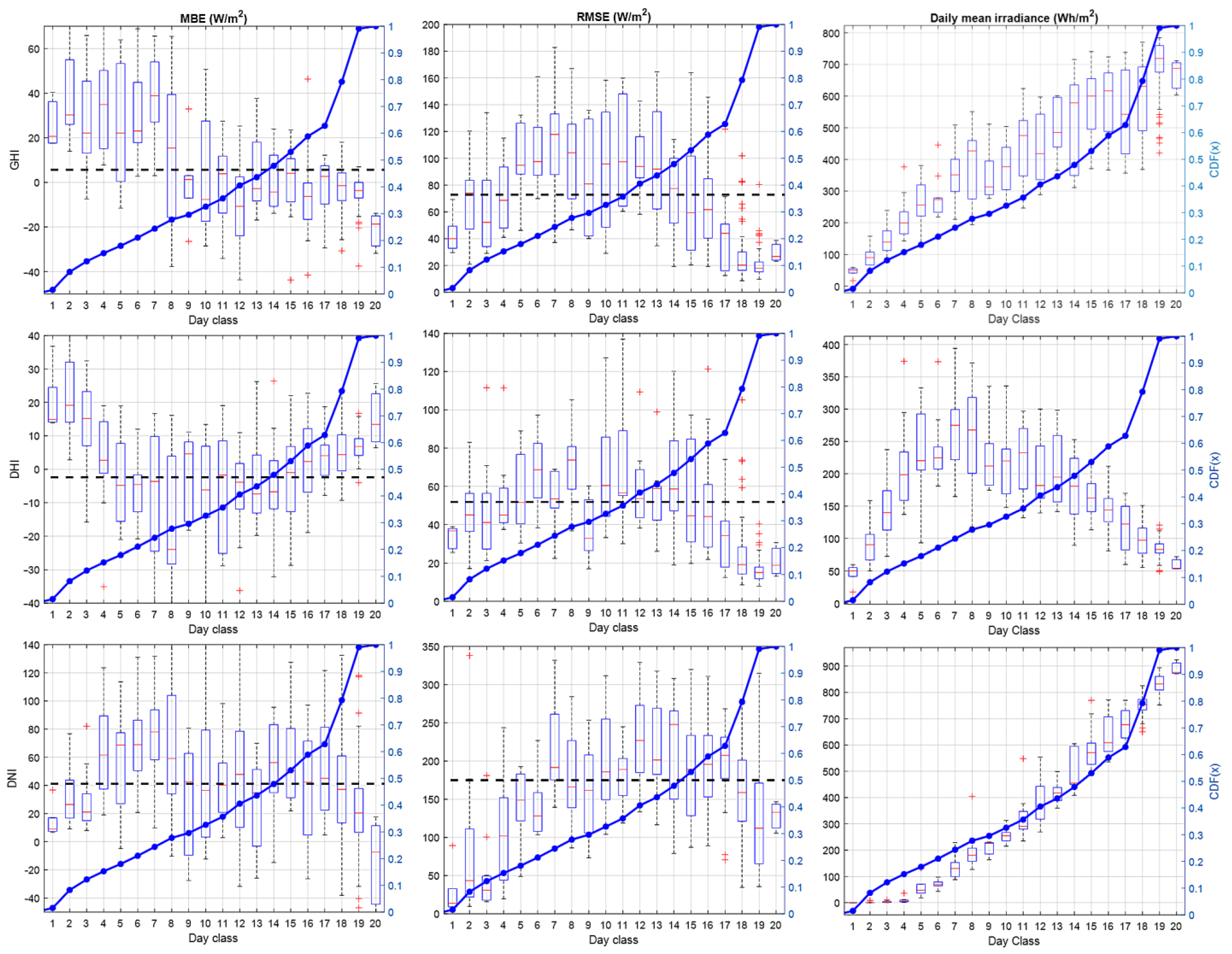
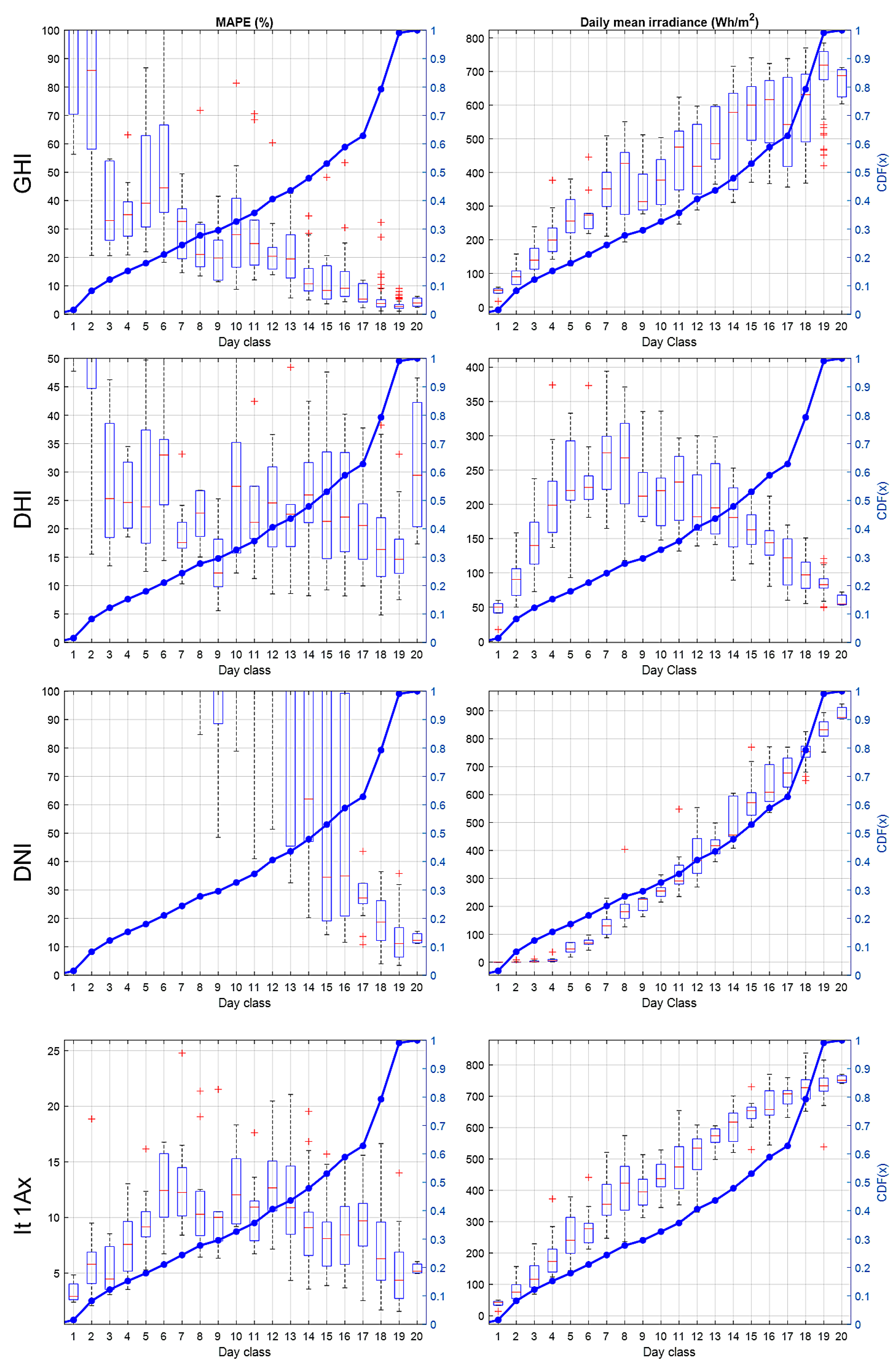
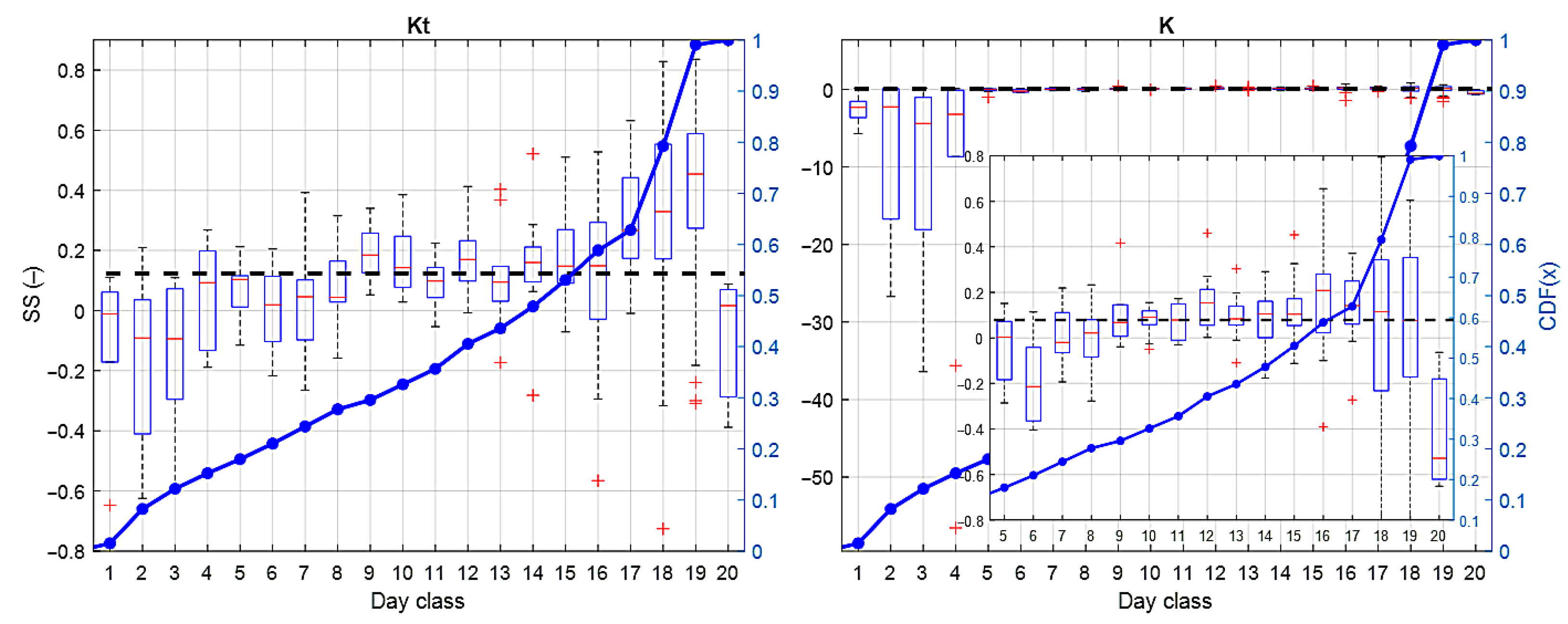
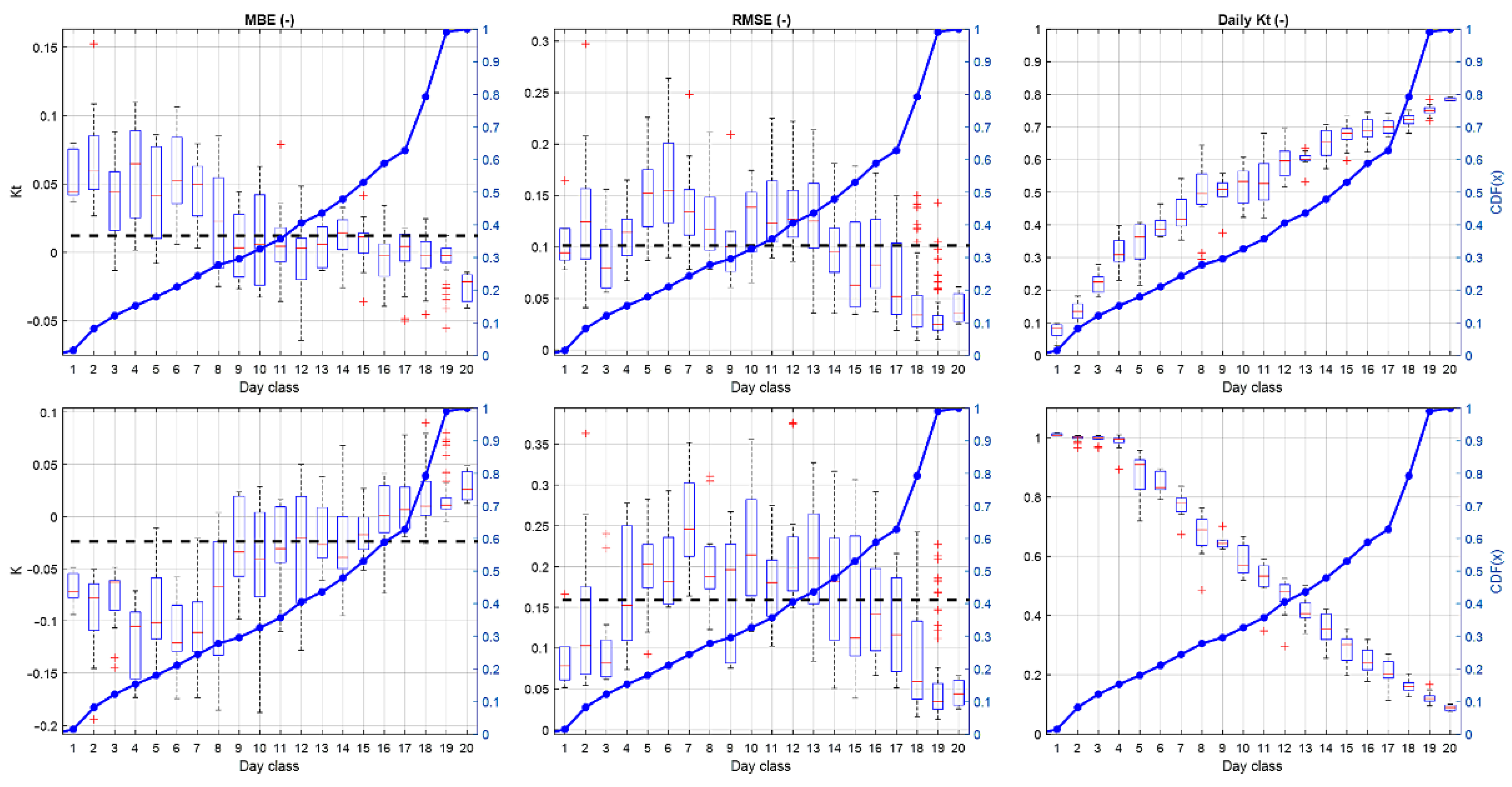
4.3. Forecast Performance Assessment as a Function of Day Type
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A
References
- Denholm, P.; Mai, T. Timescales of Energy Storage Needed for Reducing Renewable Energy Curtailment Timescales of Energy Storage Needed for Reducing Renewable Energy Curtailment; National Renewable Energy Laboratory (NREL): Golden, CO, USA, 2017.
- Denholm, P.; Margolis, R. The Potential for Energy Storage to Provide Peaking Capacity in California under Increased Penetration of Solar Photovoltaics; National Renewable Energy Laboratory (NREL): Golden, CO, USA, 2018.
- Diagne, M.; David, M.; Lauret, P.; Boland, J.; Schmutz, N. Review of solar irradiance forecasting methods and a proposition for small-scale insular grids. Renew. Sustain. Energy Rev. 2013, 27, 65–76. [Google Scholar] [CrossRef] [Green Version]
- Antonanzas, J.; Osorio, N.; Escobar, R.; Urraca, R.; Martinez-de-Pison, F.J.; Antonanzas-Torres, F. Review of photovoltaic power forecasting. Sol. Energy 2016, 136, 78–111. [Google Scholar] [CrossRef]
- Voyant, C.; Notton, G.; Kalogirou, S.; Nivet, M.-L.; Paoli, C.; Motte, F.; Fouilloy, A. Machine learning methods for solar radiation forecasting: A review. Renew. Energy 2017, 105, 569–582. [Google Scholar] [CrossRef]
- Sobri, S.; Koohi-Kamali, S.; Rahim, N.A. Solar photovoltaic generation forecasting methods: A review. Energy Convers. Manag. 2018, 156, 459–497. [Google Scholar] [CrossRef]
- Yang, D.; Kleissl, J.; Gueymard, C.A.; Pedro, H.T.C.; Coimbra, C.F.M. History and trends in solar irradiance and PV power forecasting: A preliminary assessment and review using text mining. Sol. Energy 2018, 168, 60–101. [Google Scholar] [CrossRef]
- Guermoui, M.; Melgani, F.; Gairaa, K.; Mekhalfi, M.L. A comprehensive review of hybrid models for solar radiation forecasting. J. Clean. Prod. 2020, 258, 120357. [Google Scholar] [CrossRef]
- Ljung, L. Identification: Theory for the User; Prentice Hall: Hoboken, NJ, USA, 1987. [Google Scholar]
- Box, G.E.P.; Jenkins, G.M.; Day, H. Time Series Analysis: Forecasting and Control; Holden-Day: San Francisco, CA, USA, 1976; ISBN 9780816211043. [Google Scholar]
- Alkhayat, G.; Mehmood, R. A Review and Taxonomy of Wind and Solar Energy Forecasting Methods Based on Deep Learning. Energy AI 2021, 4, 100060. [Google Scholar] [CrossRef]
- Cai, M.; Pipattanasomporn, M.; Rahman, S. Day-ahead building-level load forecasts using deep learning vs. traditional time-series techniques. Appl. Energy 2019, 236, 1078–1088. [Google Scholar] [CrossRef]
- Lan, H.; Zhang, C.; Hong, Y.Y.; He, Y.; Wen, S. Day-ahead spatiotemporal solar irradiation forecasting using frequency-based hybrid principal component analysis and neural network. Appl. Energy 2019, 247, 389–402. [Google Scholar] [CrossRef]
- Theocharides, S.; Makrides, G.; Livera, A.; Theristis, M.; Kaimakis, P.; Georghiou, G.E. Day-ahead photovoltaic power production forecasting methodology based on machine learning and statistical post-processing. Appl. Energy 2020, 268, 115023. [Google Scholar] [CrossRef]
- Du Plessis, A.A.; Strauss, J.M.; Rix, A.J. Short-term solar power forecasting: Investigating the ability of deep learning models to capture low-level utility-scale Photovoltaic system behaviour. Appl. Energy 2021, 285, 116395. [Google Scholar] [CrossRef]
- Wang, H.; Cai, R.; Zhou, B.; Aziz, S.; Qin, B.; Voropai, N.; Gan, L.; Barakhtenko, E. Solar irradiance forecasting based on direct explainable neural network. Energy Convers. Manag. 2020, 226, 113487. [Google Scholar] [CrossRef]
- Sethi, T.S.; Kantardzic, M. Data driven exploratory attacks on black box classifiers in adversarial domains. Neurocomputing 2018, 289, 129–143. [Google Scholar] [CrossRef] [Green Version]
- Wang, F.; Xuan, Z.; Zhen, Z.; Li, K.; Wang, T.; Shi, M. A day-ahead PV power forecasting method based on LSTM-RNN model and time correlation modification under partial daily pattern prediction framework. Energy Convers. Manag. 2020, 212, 112766. [Google Scholar] [CrossRef]
- Ahmed, R.; Sreeram, V.; Mishra, Y.; Arif, M.D. A review and evaluation of the state-of-the-art in PV solar power forecasting: Techniques and optimization. Renew. Sustain. Energy Rev. 2020, 124, 109792. [Google Scholar] [CrossRef]
- Wang, F.; Zhang, Z.; Liu, C.; Yu, Y.; Pang, S.; Duić, N.; Shafie-khah, M.; Catalão, J.P.S. Generative adversarial networks and convolutional neural networks based weather classification model for day ahead short-term photovoltaic power forecasting. Energy Convers. Manag. 2019, 181, 443–462. [Google Scholar] [CrossRef]
- Yang, D.; Alessandrini, S.; Antonanzas, J.; Antonanzas-Torres, F.; Badescu, V.; Beyer, H.G.; Blaga, R.; Boland, J.; Bright, J.M.; Coimbra, C.F.M.; et al. Verification of deterministic solar forecasts. Sol. Energy 2020, 210, 20–37. [Google Scholar] [CrossRef]
- Yang, D. Making reference solar forecasts with climatology, persistence, and their optimal convex combination. Sol. Energy 2019, 193, 981–985. [Google Scholar] [CrossRef]
- Paulescu, M.; Paulescu, E.; Badescu, V. Nowcasting solar irradiance for effective solar power plants operation and smart grid management. In Predictive Modelling for Energy Management and Power Systems Engineering; Elsevier: Amsterdam, The Netherlands, 2021; pp. 249–270. [Google Scholar]
- Coimbra, C.F.M.; Pedro, H.T.C. Stochastic-Learning Methods. In Solar Energy Forecasting and Resource Assessment; Elsevier: Amsterdam, The Netherlands, 2013; pp. 383–406. [Google Scholar]
- Notton, G.; Voyant, C. Forecasting of Intermittent Solar Energy Resource. In Advances in Renewable Energies and Power Technologies; Elsevier: Amsterdam, The Netherlands, 2018; pp. 77–114. [Google Scholar]
- Rodríguez-Benítez, F.J.; Arbizu-Barrena, C.; Huertas-Tato, J.; Aler-Mur, R.; Galván-León, I.; Pozo-Vázquez, D. A short-term solar radiation forecasting system for the Iberian Peninsula. Part 1: Models description and performance assessment. Sol. Energy 2020, 195, 396–412. [Google Scholar] [CrossRef]
- Aguiar, L.M.; Pereira, B.; Lauret, P.; Díaz, F.; David, M. Combining solar irradiance measurements, satellite-derived data and a numerical weather prediction model to improve intra-day solar forecasting. Renew. Energy 2016, 97, 599–610. [Google Scholar] [CrossRef] [Green Version]
- Fouilloy, A.; Voyant, C.; Notton, G.; Duchaud, J.-L. Regression trees and solar radiation forecasting: The boosting, bagging and ensemble learning cases. In Proceedings of the 2nd International Web Conference on Forecasting, Online, 15–17 October 2018. [Google Scholar]
- Heydari, A.; Astiaso Garcia, D.; Keynia, F.; Bisegna, F.; De Santoli, L. A novel composite neural network based method for wind and solar power forecasting in microgrids. Appl. Energy 2019, 251, 113353. [Google Scholar] [CrossRef]
- Kumari, P.; Toshniwal, D. Extreme gradient boosting and deep neural network based ensemble learning approach to forecast hourly solar irradiance. J. Clean. Prod. 2021, 279, 123285. [Google Scholar] [CrossRef]
- Rafati, A.; Joorabian, M.; Mashhour, E.; Shaker, H.R. High dimensional very short-term solar power forecasting based on a data-driven heuristic method. Energy 2021, 219, 119647. [Google Scholar] [CrossRef]
- Betti, A.; Pierro, M.; Cornaro, C.; Moser, D.; Moschella, M.; Collino, E.; Ronzio, D.; van der Meer, D.; Visser, L.; Widen, J.; et al. Regional Solar Power Forecasting 2020; IEA-PVPS: Paris, France, 2020. [Google Scholar]
- Castillejo-Cuberos, A.; Escobar, R. Understanding solar resource variability: An in-depth analysis, using Chile as a case of study. Renew. Sustain. Energy Rev. 2020, 120, 109664. [Google Scholar] [CrossRef]
- Yang, D.; Wu, E.; Kleissl, J. Operational solar forecasting for the real-time market. Int. J. Forecast. 2019, 35, 1499–1519. [Google Scholar] [CrossRef]
- Castillejo-Cuberos, A.; Escobar, R. Detection and characterization of cloud enhancement events for solar irradiance using a model-independent, statistically-driven approach. Sol. Energy 2020, 209, 547–567. [Google Scholar] [CrossRef]
- Rigollier, C.; Bauer, O.; Wald, L. On the clear sky model of the ESRA—European Solar Radiation Atlas—With respect to the heliosat method. Sol. Energy 2000, 68, 33–48. [Google Scholar] [CrossRef] [Green Version]
- Ghimire, S.; Deo, R.C.; Raj, N.; Mi, J. Deep solar radiation forecasting with convolutional neural network and long short-term memory network algorithms. Appl. Energy 2019, 253, 113541. [Google Scholar] [CrossRef]
- Bhardwaj, S.; Sharma, V.; Srivastava, S.; Sastry, O.S.; Bandyopadhyay, B.; Chandel, S.S.; Gupta, J.R.P. Estimation of solar radiation using a combination of Hidden Markov Model and generalized Fuzzy model. Sol. Energy 2013, 93, 43–54. [Google Scholar] [CrossRef]
- Sanjari, M.J.; Gooi, H.B. Probabilistic Forecast of PV Power Generation Based on Higher Order Markov Chain. IEEE Trans. Power Syst. 2017, 32, 2942–2952. [Google Scholar] [CrossRef]
- Lave, M.; Reno, M.J.; Broderick, R.J. Characterizing local high-frequency solar variability and its impact to distribution studies. Sol. Energy 2015, 118, 327–337. [Google Scholar] [CrossRef]
- Zadeh, L.A. Fuzzy sets. Inf. Control 1965, 8, 338–353. [Google Scholar] [CrossRef] [Green Version]
- Zadeh, L.A. Discussion: Probability Theory and Fuzzy Logic Are Complementary Rather Than Competitive. Technometrics 1995, 37, 271–276. [Google Scholar] [CrossRef]
- Zadeh, L.A. Fuzzy sets as a basis for a theory of possibility. Fuzzy Sets Syst. 1999, 100, 9–34. [Google Scholar] [CrossRef]
- Kovalerchuk, B. Relationships Between Probability and Possibility Theories. In Uncertainty Modeling; Springer: Cham, Switzerland, 2017; Volume 683, pp. 97–122. ISBN 9783319510514. [Google Scholar]
- Natvig, B. Possibility versus probability. Fuzzy Sets Syst. 1983, 10, 31–36. [Google Scholar] [CrossRef]
- Barragán, A. Síntesis de Sistemas de Control Borroso Estables por Diseño. Ph.D. Thesis, Universidad de Huelva, Huelva, Spain, 2009. [Google Scholar]
- Long, C.; Shi, Y. The QCRad Value Added Product: Surface Radiation Measurement Quality Control Testing, Including Climatology Configurable Limits; U.S. Department of Energy, Office of Science Atmospheric Radiation Measurement Program: Washington, DC, USA, 2006.
- Journée, M.; Bertrand, C. Quality control of solar radiation data within the RMIB solar measurements network. Sol. Energy 2011, 85, 72–86. [Google Scholar] [CrossRef]
- Duffie, J.A.; Beckman, W.A. Solar Engineering of Thermal Processes; Wiley: New York, NY, USA, 2013. [Google Scholar]
- Antonanzas-Torres, F.; Urraca, R.; Polo, J.; Perpiñán-Lamigueiro, O.; Escobar, R. Clear sky solar irradiance models: A review of seventy models. Renew. Sustain. Energy Rev. 2019, 107, 374–387. [Google Scholar] [CrossRef]
- Polo, J.; Antonanzas-Torres, F.; Vindel, J.M.; Ramirez, L. Sensitivity of satellite-based methods for deriving solar radiation to different choice of aerosol input and models. Renew. Energy 2014, 68, 785–792. [Google Scholar] [CrossRef]
- Beyer, H.; Martinez, J.P.; Suri, M.; Torres, J.; Lorenz, E.; Müller, S.; Hoyer-Klick, C.; Ineichen, P. Report on Benchmarking of Radiation Products; Management and Exploitation of Solar Resource Knowledge (MESOR): Cologne, Germany, 2009. [Google Scholar]
- Taylor, K.E. Summarizing multiple aspects of model performance in a single diagram. J. Geophys. Res. Atmos. 2001, 106, 7183–7192. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Source | Method | Dataset |
|---|---|---|
| Lan et al. [13] | Combination of frequency analysis to identify irradiance patterns, principal component analysis to identify characteristic features and neural networks are used to forecast future features of irradiance that are translated back to an irradiance forecast. | One year of data |
| Theocharides et al. [14] | Several neural networks were developed to produce GHI forecasts, which are then clusterized and finally, through statistical processing, the final forecast is produced as a linear combination of the clusters. | 210 days |
| Du Plessis et al. [15] | Several neural networks were developed for meteorological data to forecast a photovoltaic plant output at the subunit level and then scaled up to plant-wide production. | Two years training and 1 year of validation data. |
| Source | Issue or Concern |
|---|---|
| Wang et al. [16] and Sethi and Kantardzic [17] | Neural networks/deep learning approaches have not seen sufficient adoption, despite growing interest in them, due to their complex black-box nature and lack of explainability and interpretability |
| Wang. et al. [18] | These approaches are prone to model overfitting and insufficient generalization ability, being hyperspecific. |
| Wang. et al. [16] | Explainability is of great importance, therefore, proposed a new approach through direct explainable neural networks that can provide further insights in the input–output relationship to assist in result interpretation and model explanation. |
| Ahmed et al. [19] | Appropriate weather classification is important for solar photovoltaic power forecasting assessment, and there are challenges to overcome in these classifications, presenting that most authors employ four or less classes. |
| Wang et al. [20] | Separate forecast models for each weather class should improve forecasting performance; therefore, having a higher number of classes would be beneficial. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Castillejo-Cuberos, A.; Boland, J.; Escobar, R. Short-Term Deterministic Solar Irradiance Forecasting Considering a Heuristics-Based, Operational Approach. Energies 2021, 14, 6005. https://doi.org/10.3390/en14186005
Castillejo-Cuberos A, Boland J, Escobar R. Short-Term Deterministic Solar Irradiance Forecasting Considering a Heuristics-Based, Operational Approach. Energies. 2021; 14(18):6005. https://doi.org/10.3390/en14186005
Chicago/Turabian StyleCastillejo-Cuberos, Armando, John Boland, and Rodrigo Escobar. 2021. "Short-Term Deterministic Solar Irradiance Forecasting Considering a Heuristics-Based, Operational Approach" Energies 14, no. 18: 6005. https://doi.org/10.3390/en14186005
APA StyleCastillejo-Cuberos, A., Boland, J., & Escobar, R. (2021). Short-Term Deterministic Solar Irradiance Forecasting Considering a Heuristics-Based, Operational Approach. Energies, 14(18), 6005. https://doi.org/10.3390/en14186005