
Machine Learning and Data Segmentation for Building Energy Use Prediction—A Comparative Study




Abstract
:1. Introduction
2. State of the Art
2.1. MLR
2.2. ANN
2.3. SVR
2.4. Machine Learning Method Comparison Summary
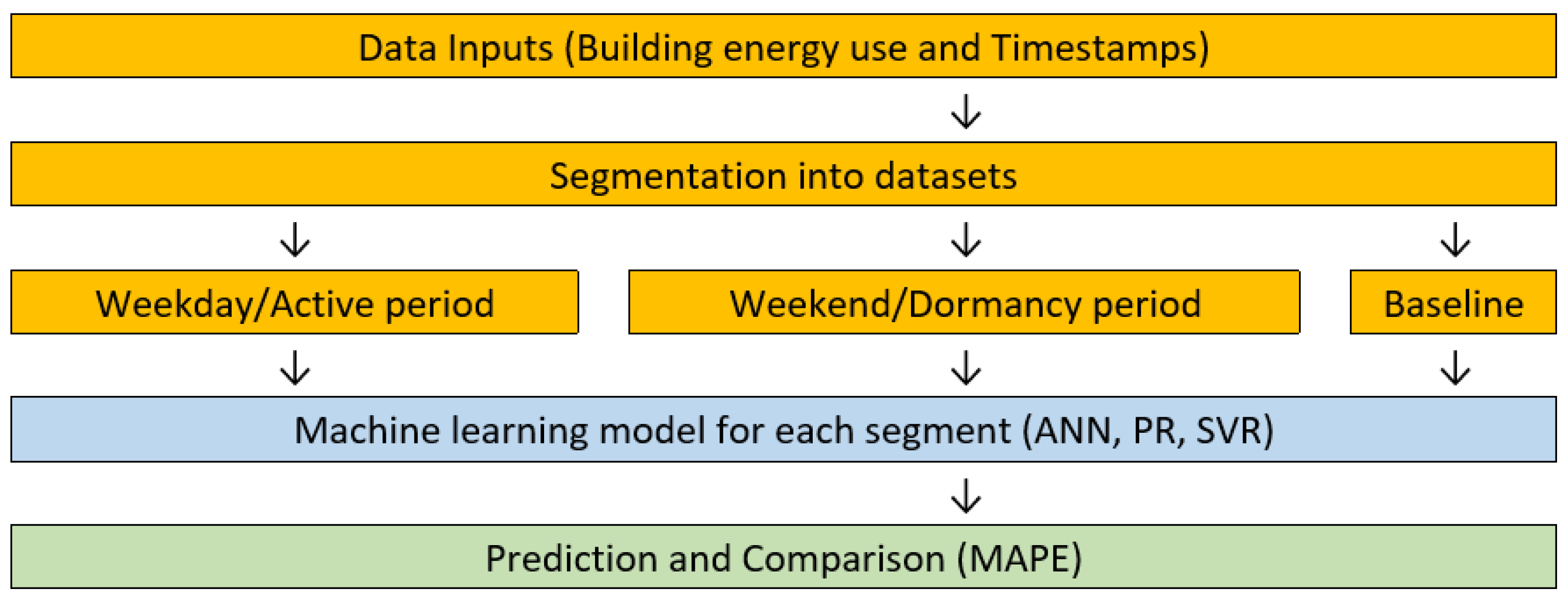
3. Research Method
4. Forecasting Model Calibration
4.1. ANN Calibration
4.1.1. Training Algorithm Selection
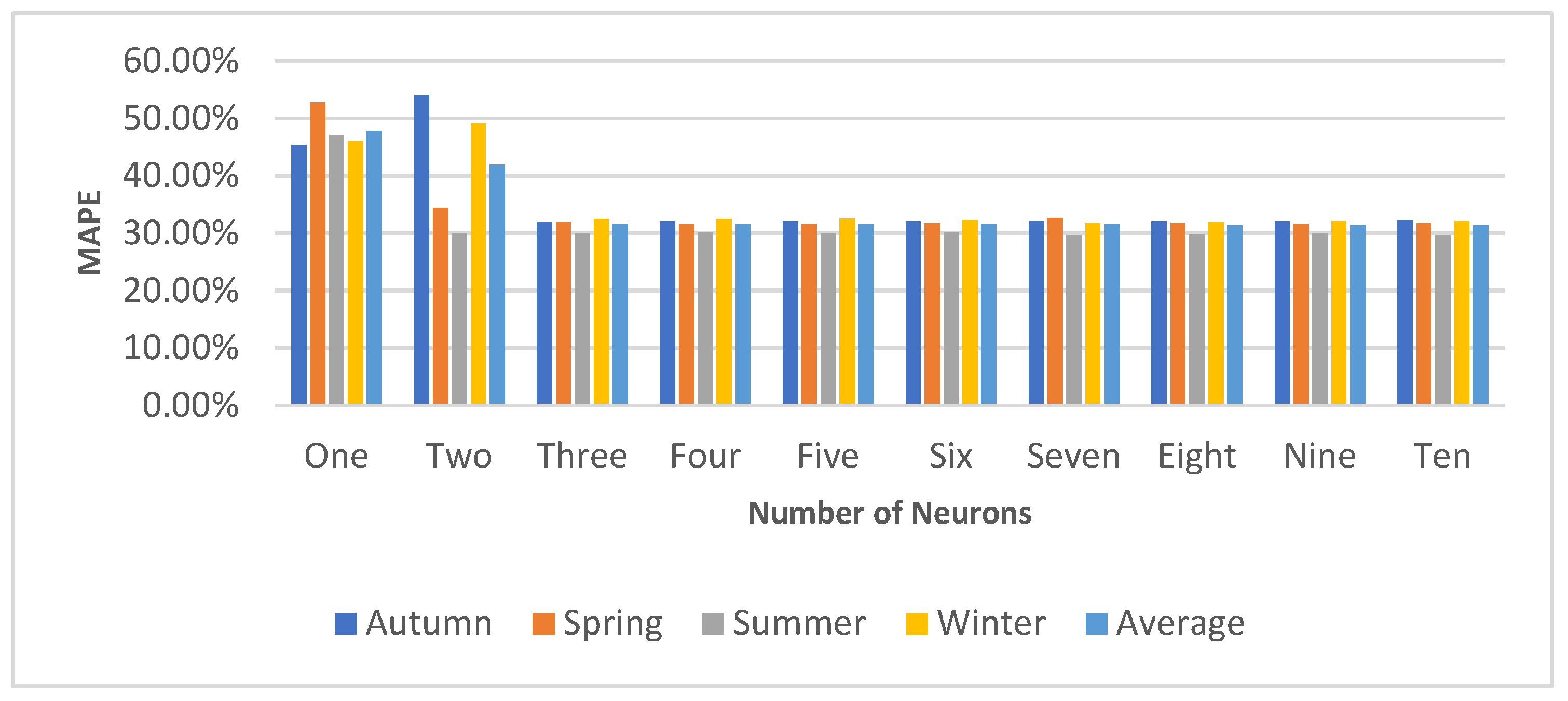
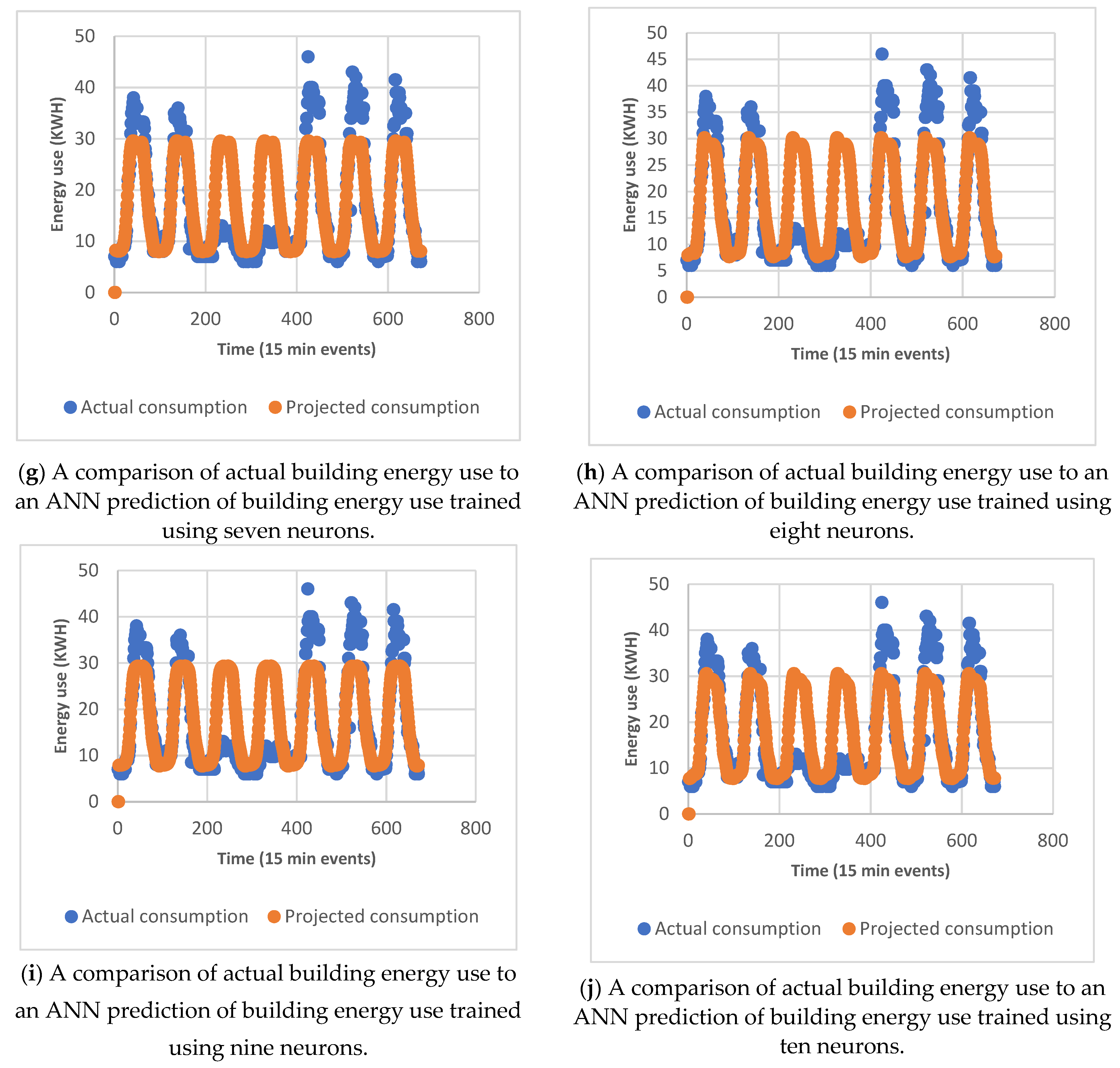
4.1.2. Neuron Selection
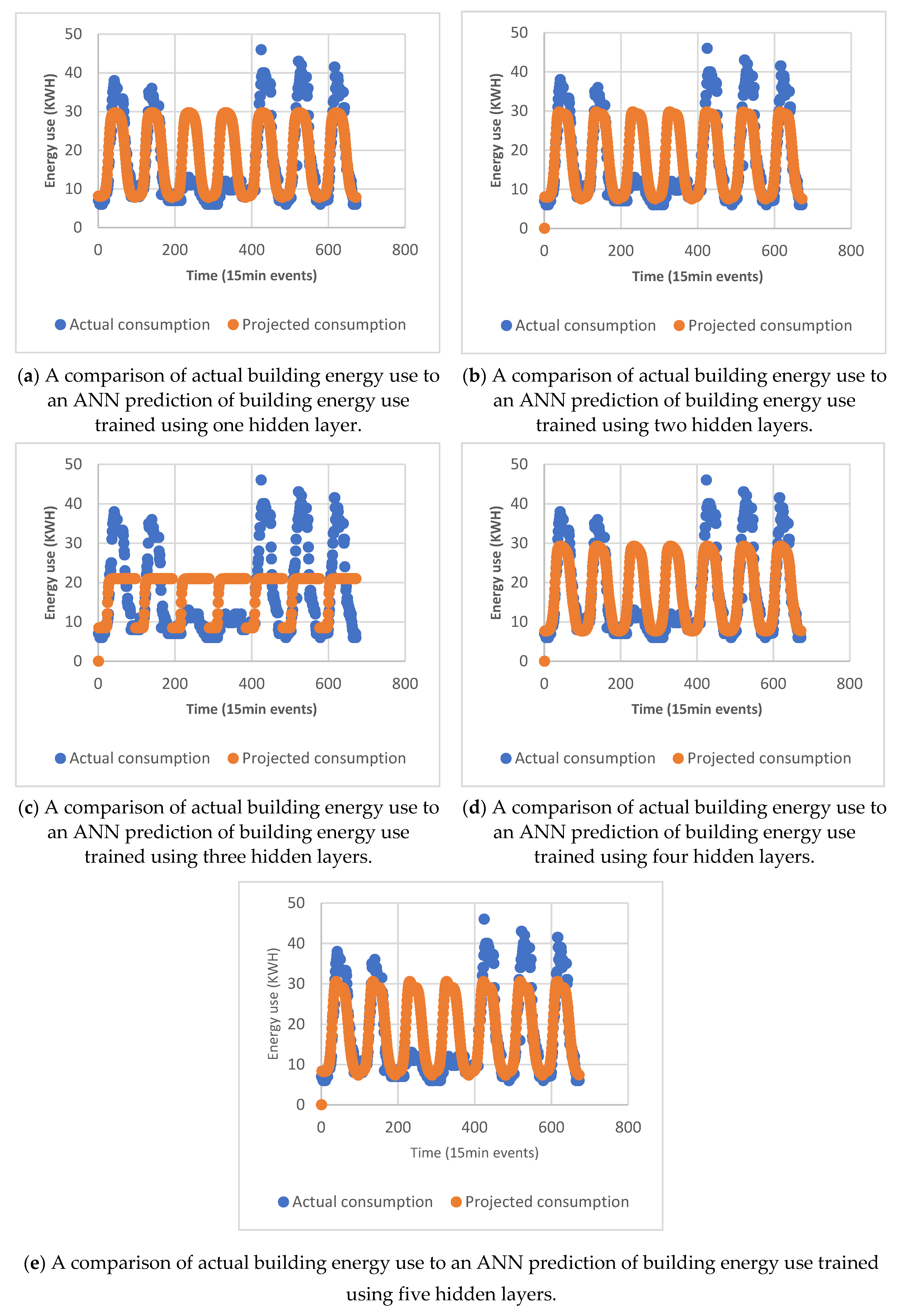
4.1.3. Hidden Layer Selection
4.2. SVR Calibration
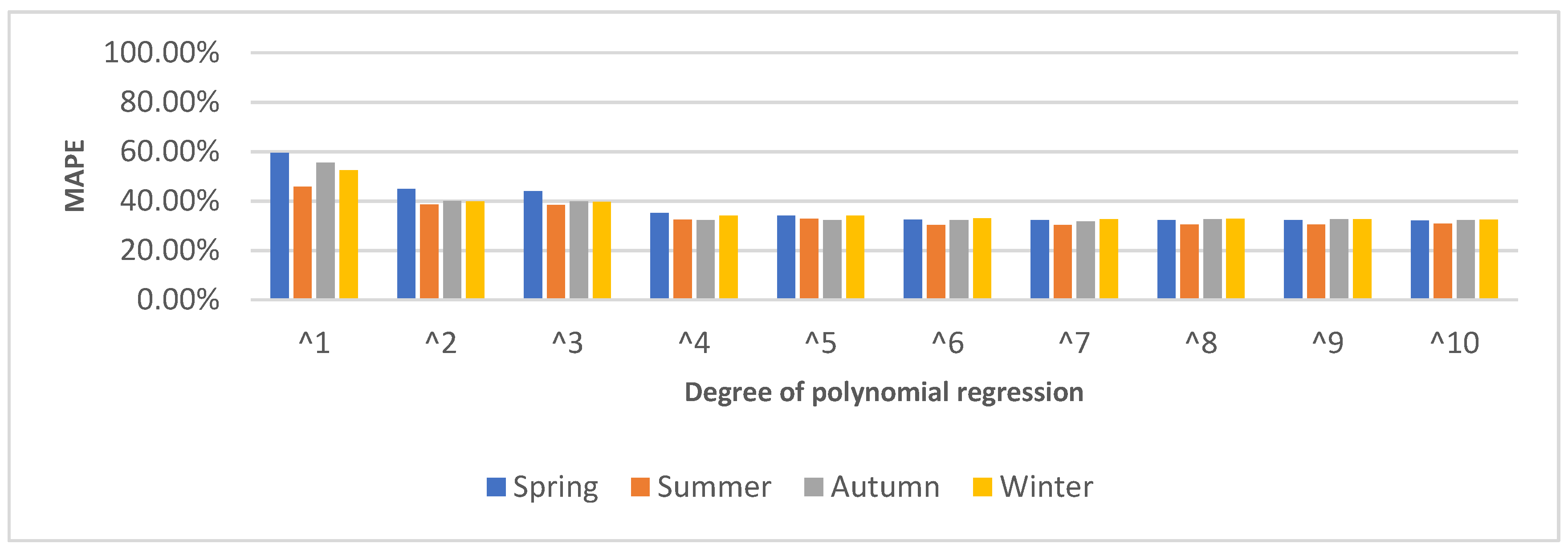
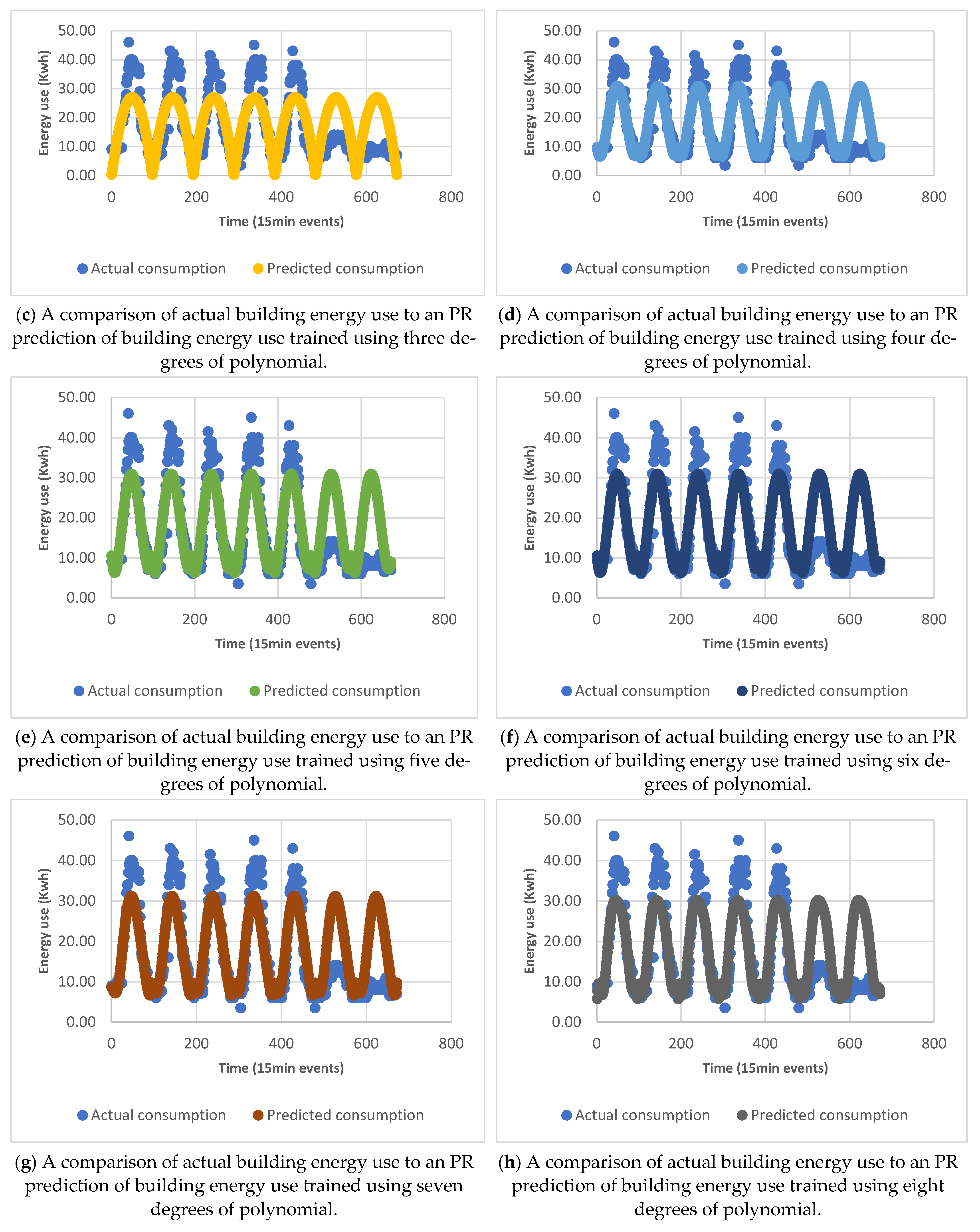
4.3. PR Calibration
5. Results and Discussion
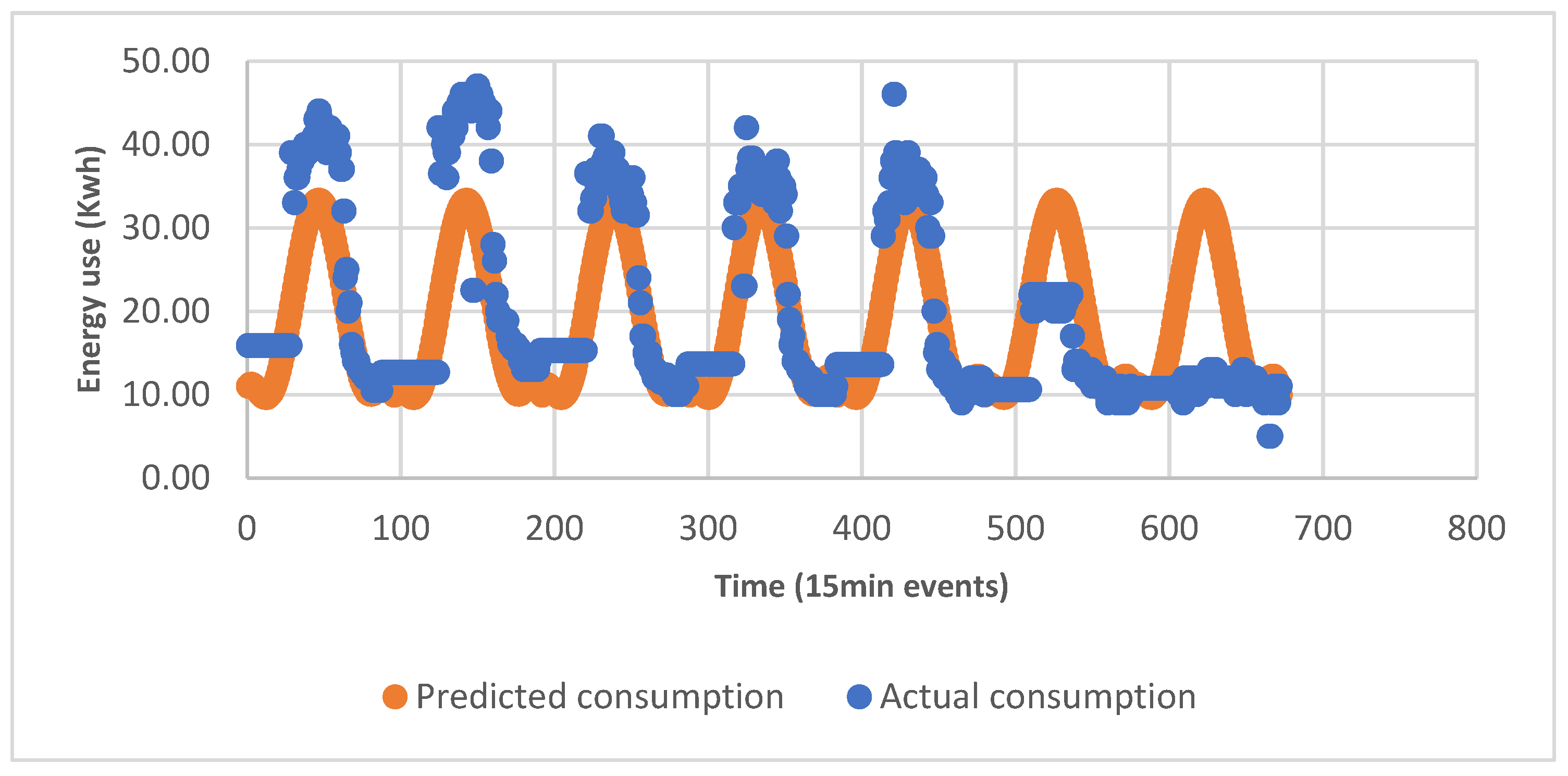
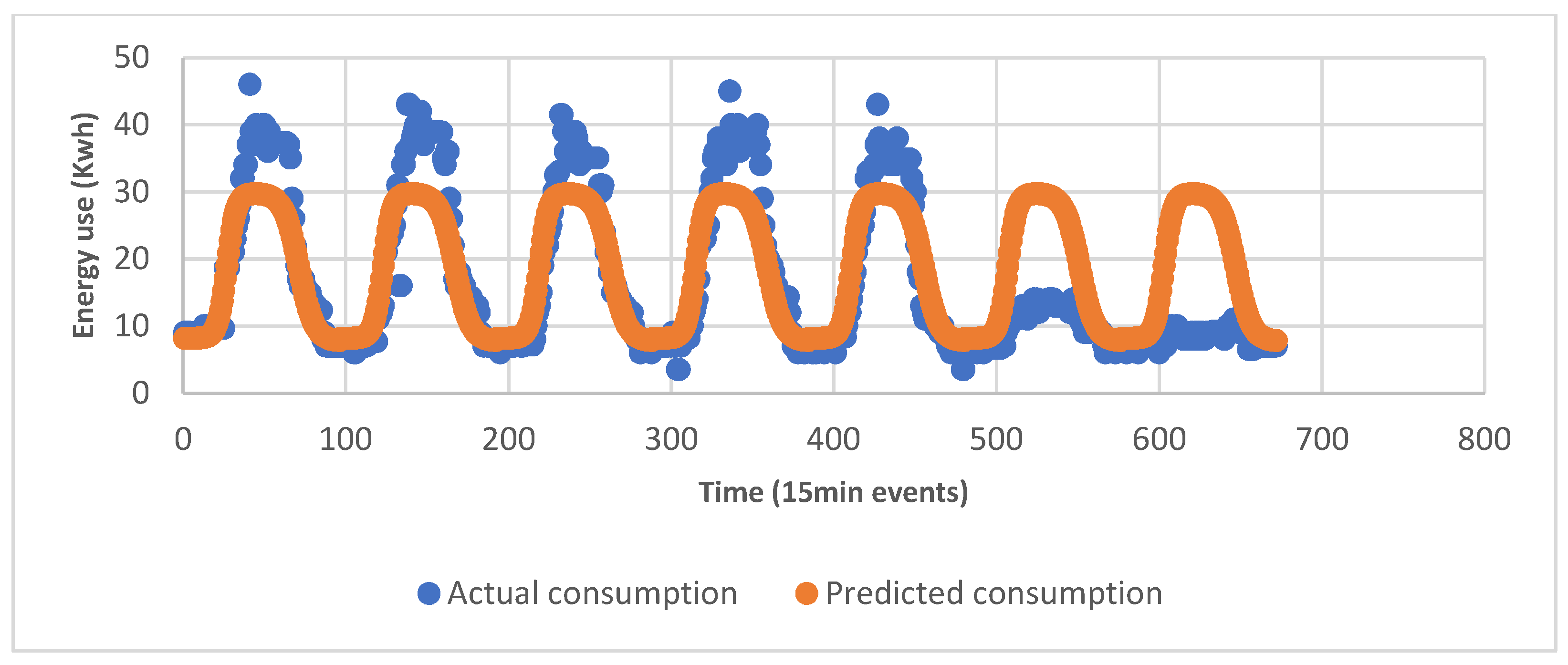
5.1. Forecasting Result Based on Polynomial Regression
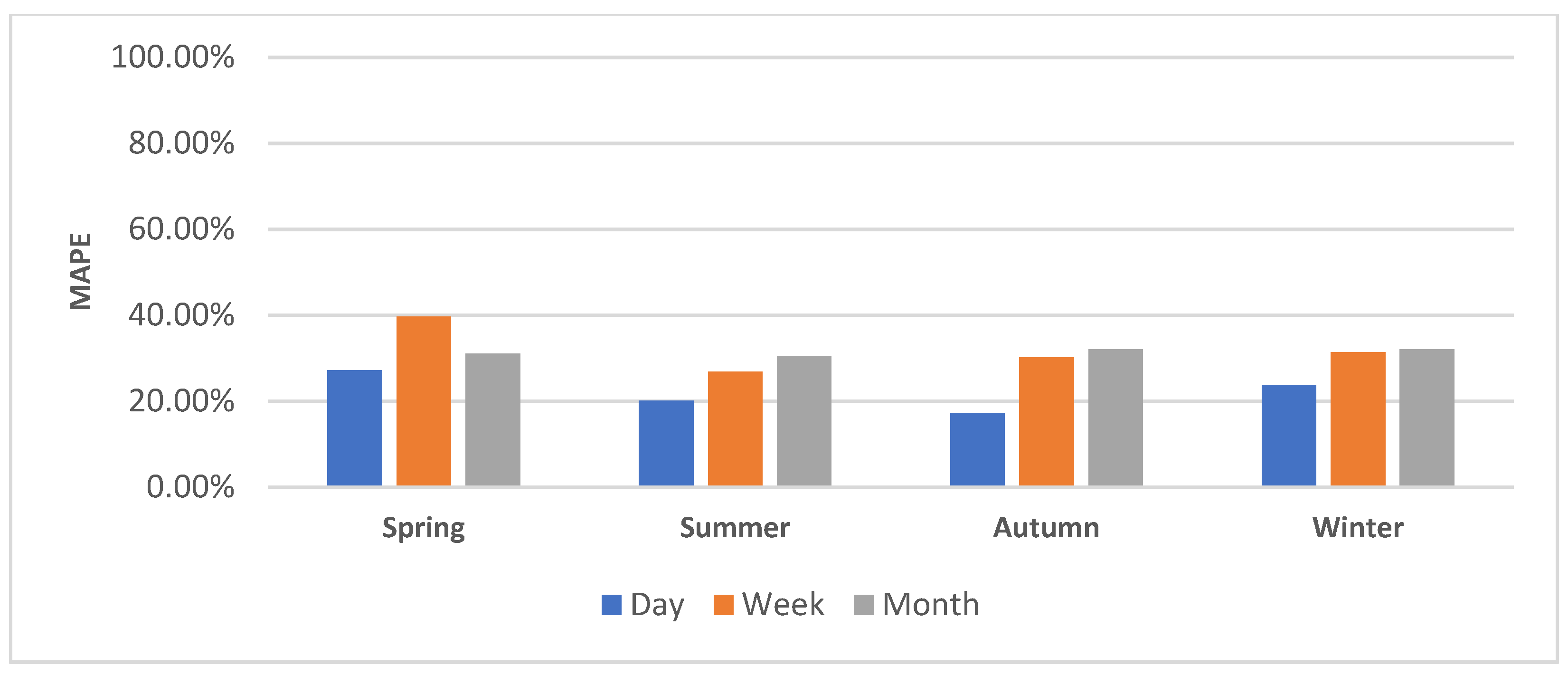
5.1.1. Daily, Weekly, and Monthly Control Building Energy Predictions
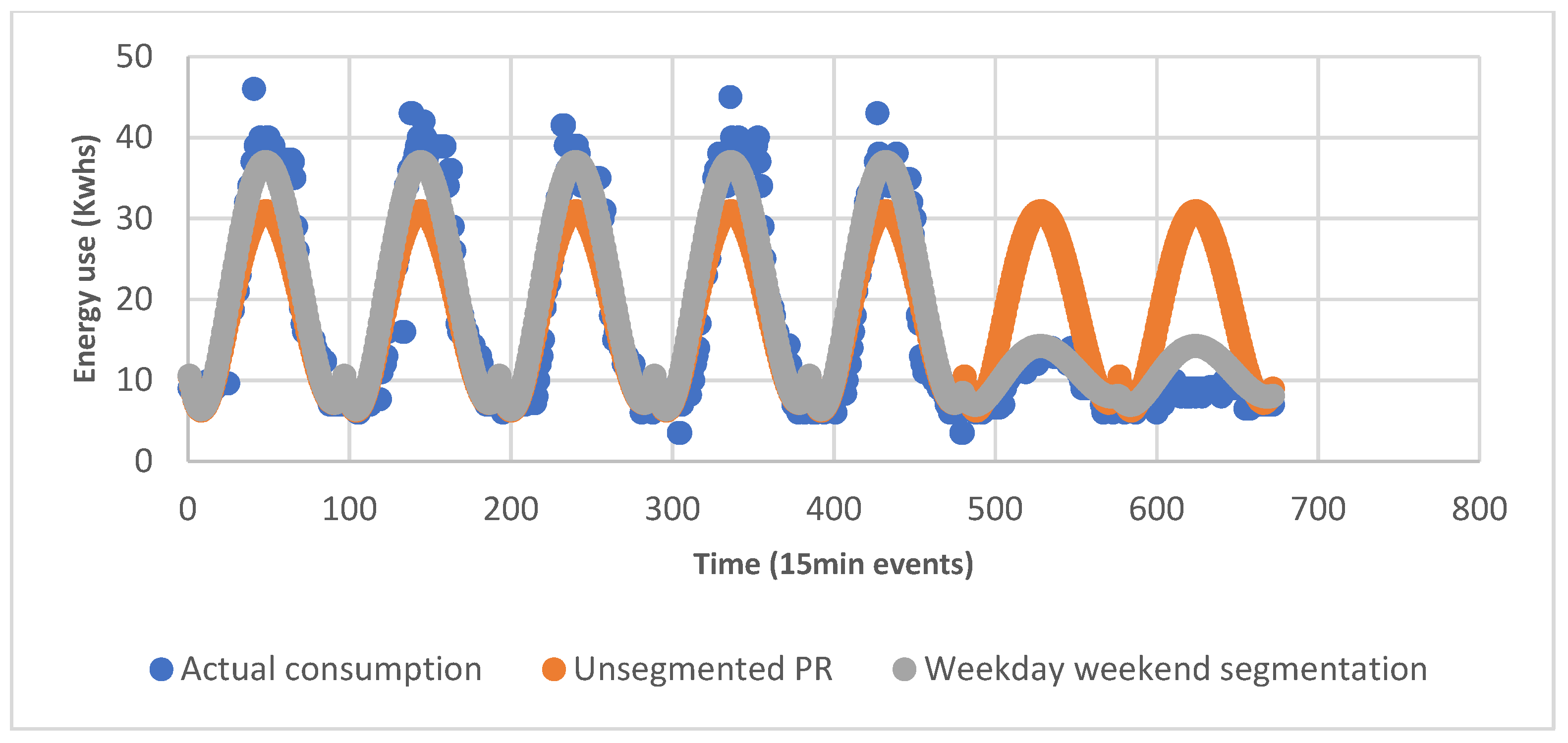
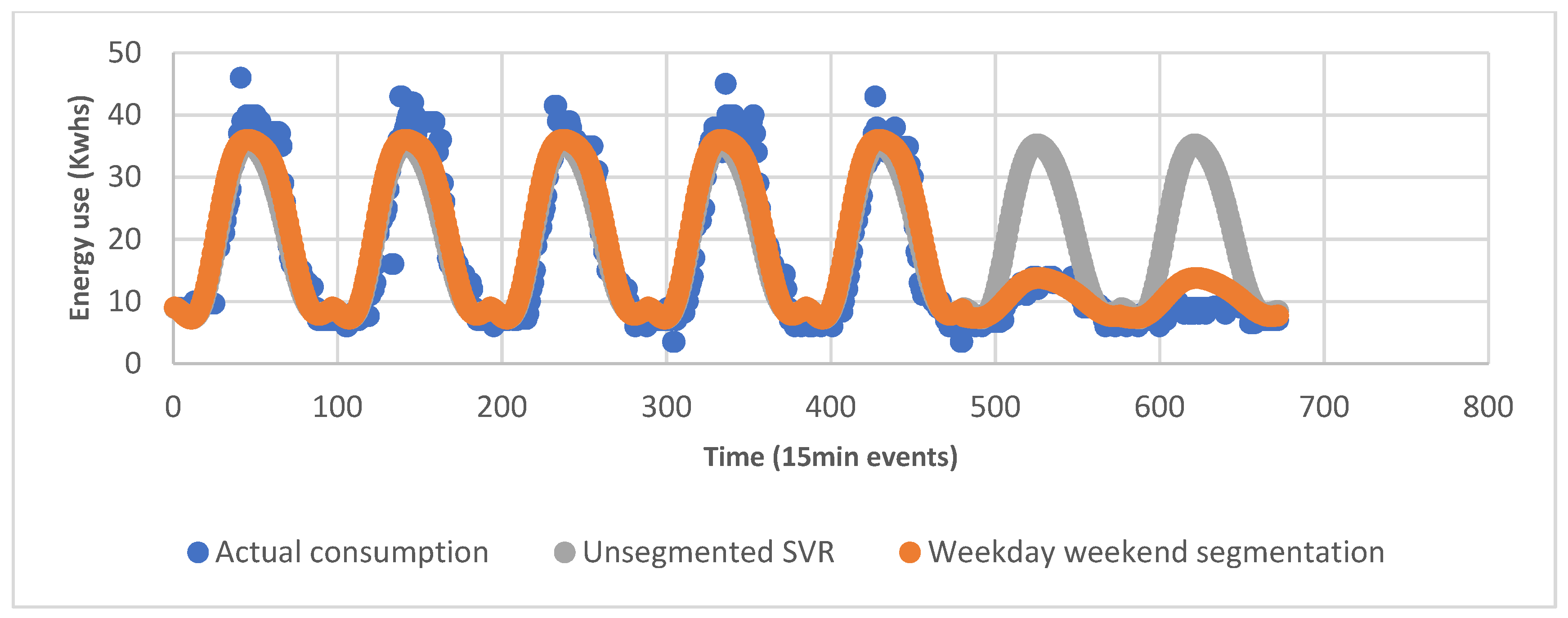
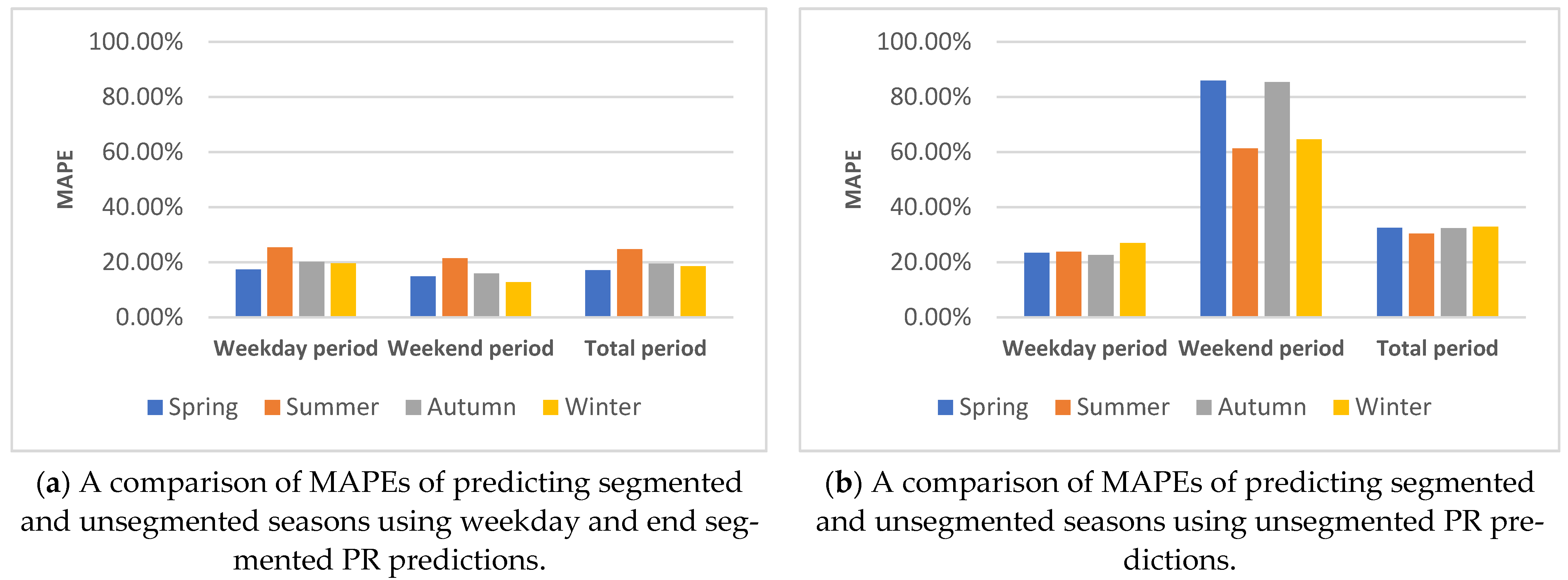
5.1.2. Weekend and Day Data Segmentation
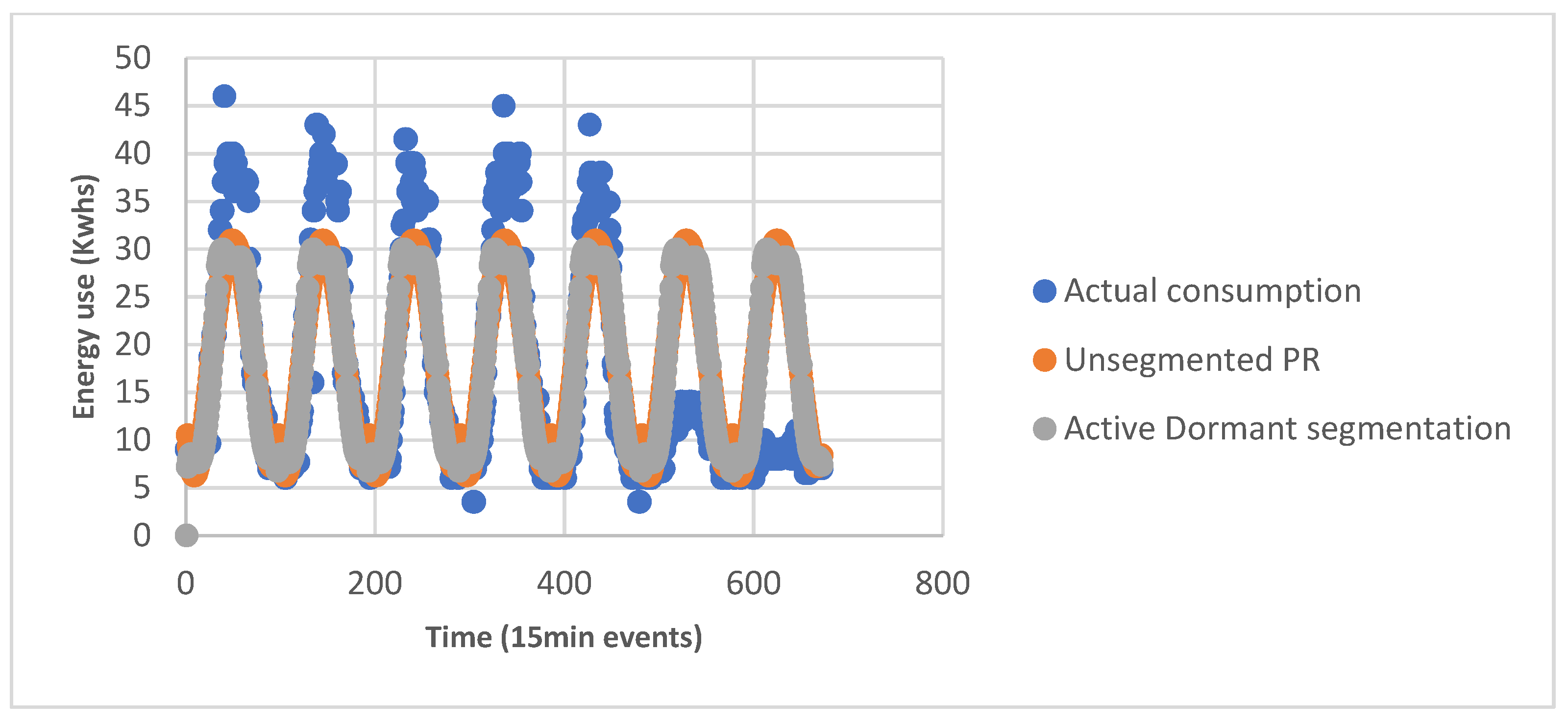
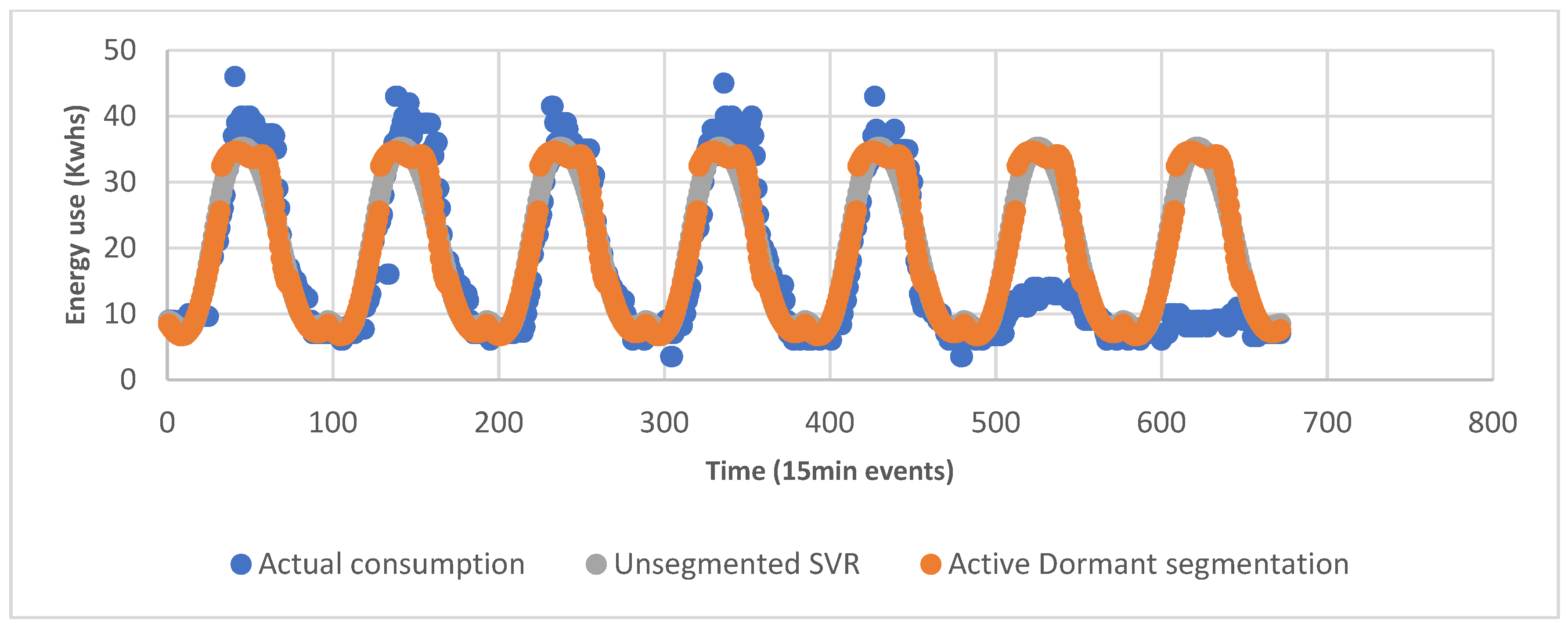
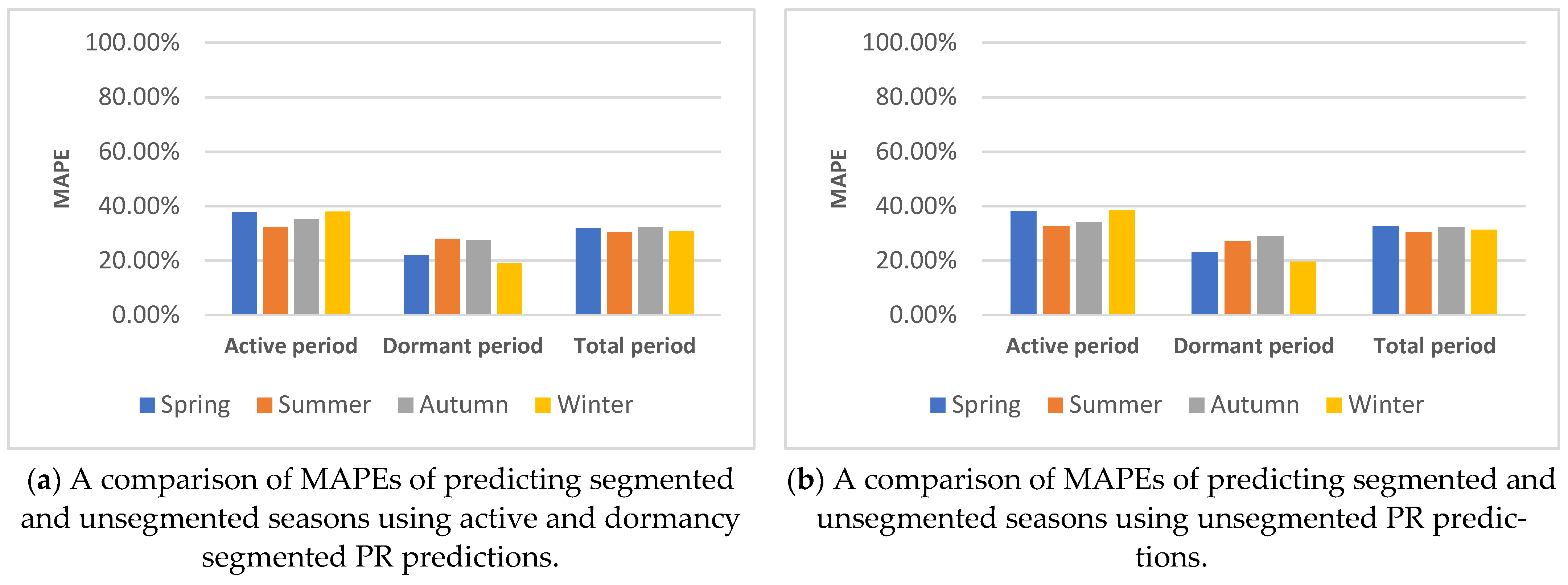
5.1.3. Active and Dormancy Period Segmentation
5.2. Forecasting Result Based on Articifial Neural Networks
5.2.1. Daily, Weekly and Monthly Control Building Energy Predictions
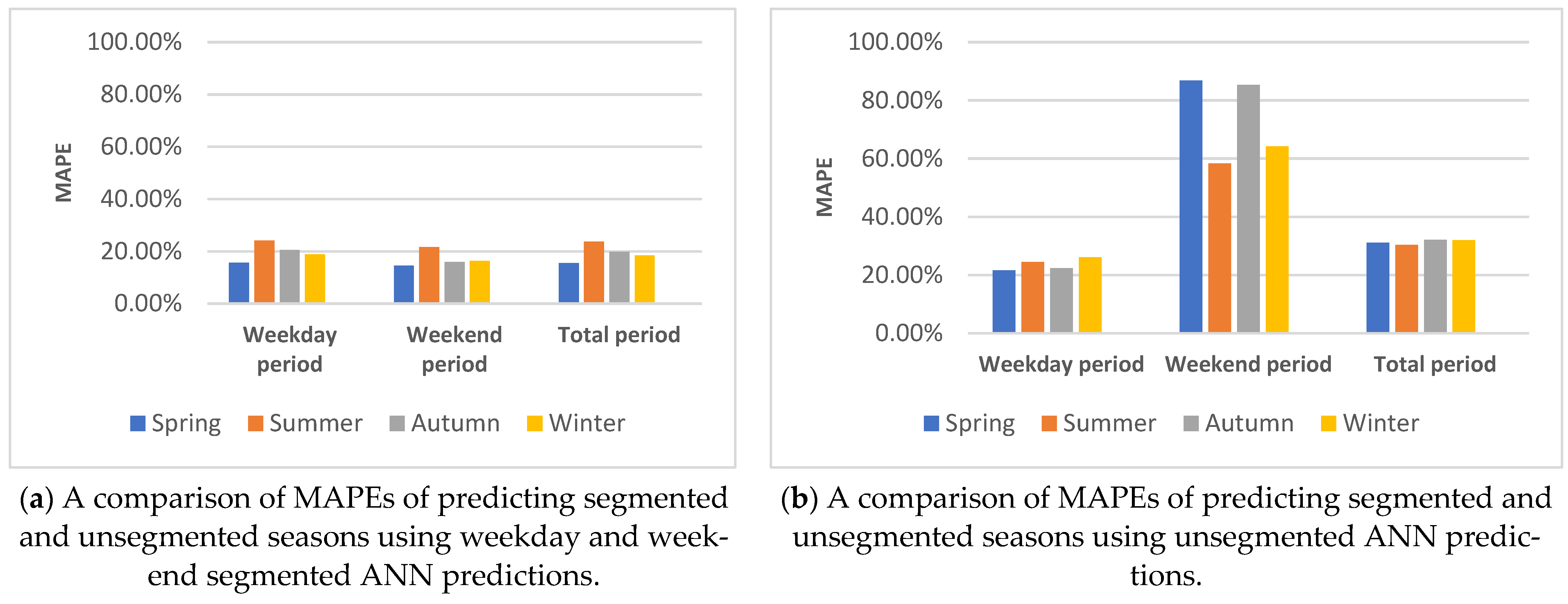
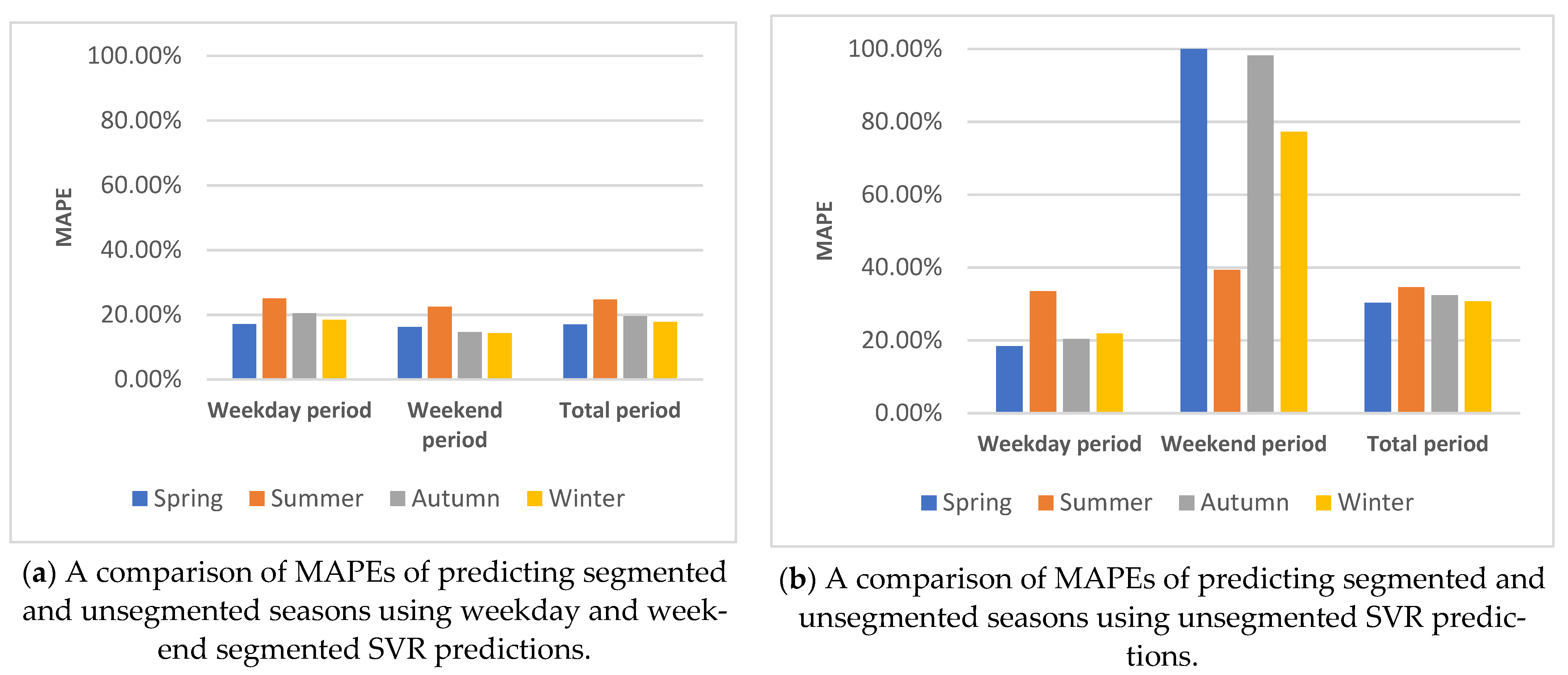
5.2.2. Weekend and Day Data Segmentation
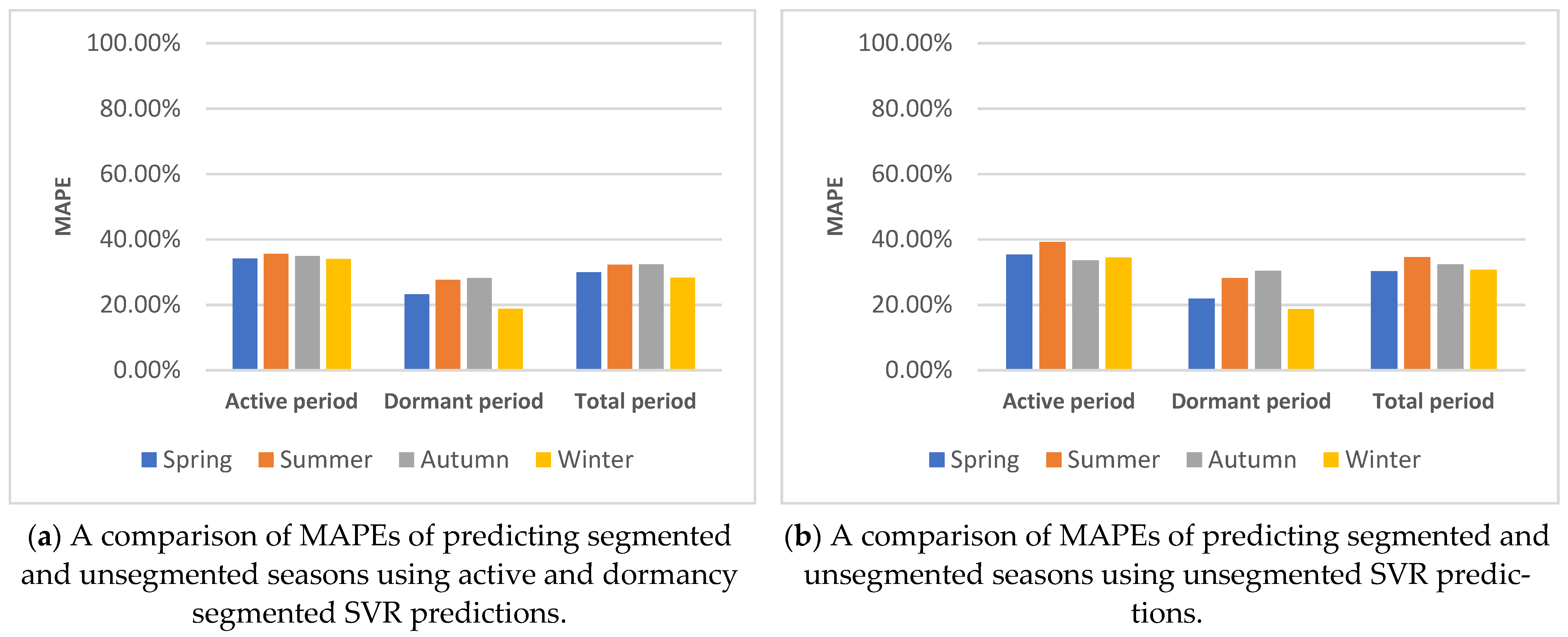
5.2.3. Active and Dormancy Period Segmentation
5.3. Forecasting Result Based on Support Vector Regression
5.3.1. Daily, Weekly and Monthly Control Building Energy Predictions
5.3.2. Weekend and Day Data Segmentation
5.3.3. Active and Dormancy Period Segmentation
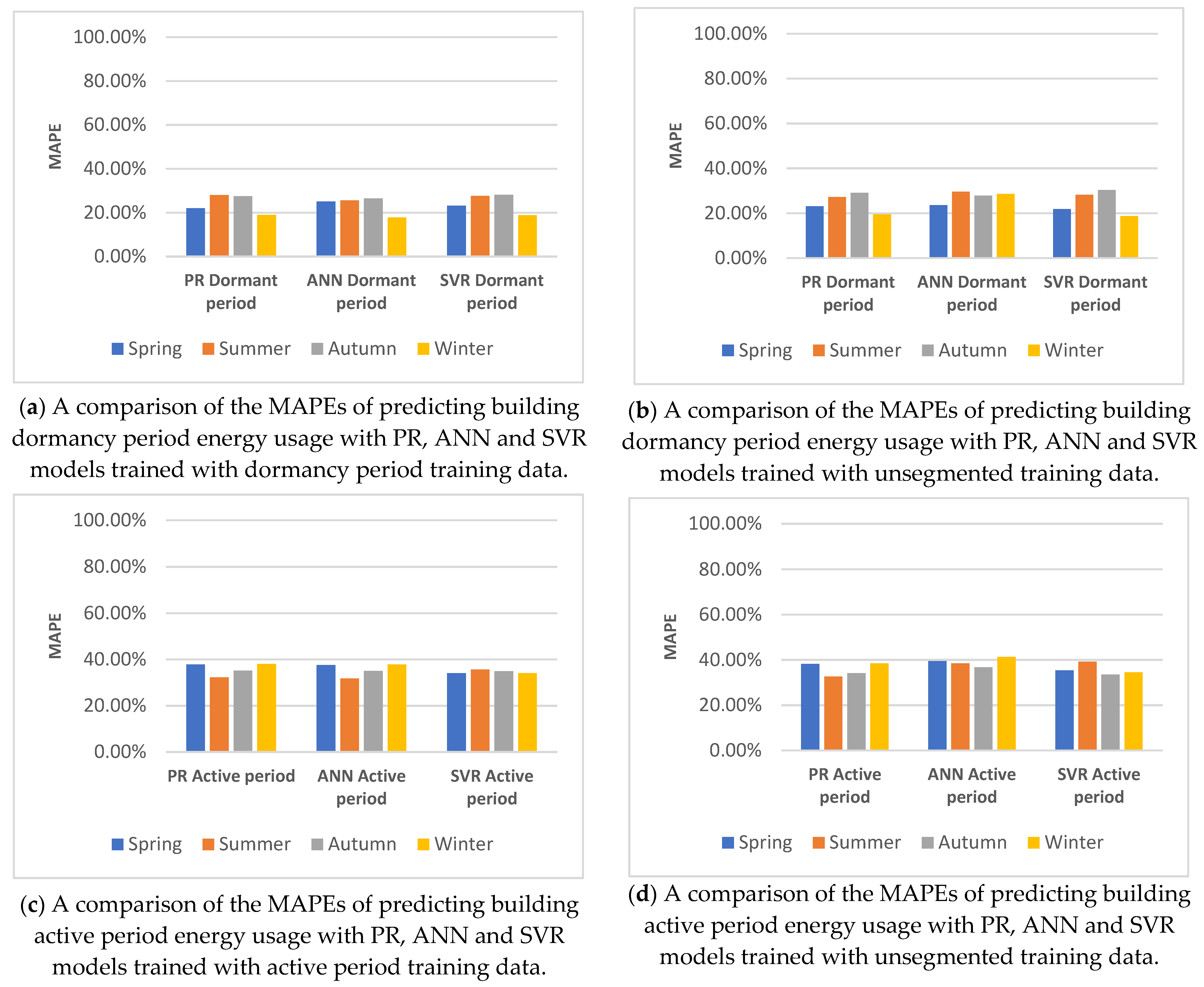
5.4. Comparison and Discussion
5.4.1. Daily, Weekly and Monthly Predictions
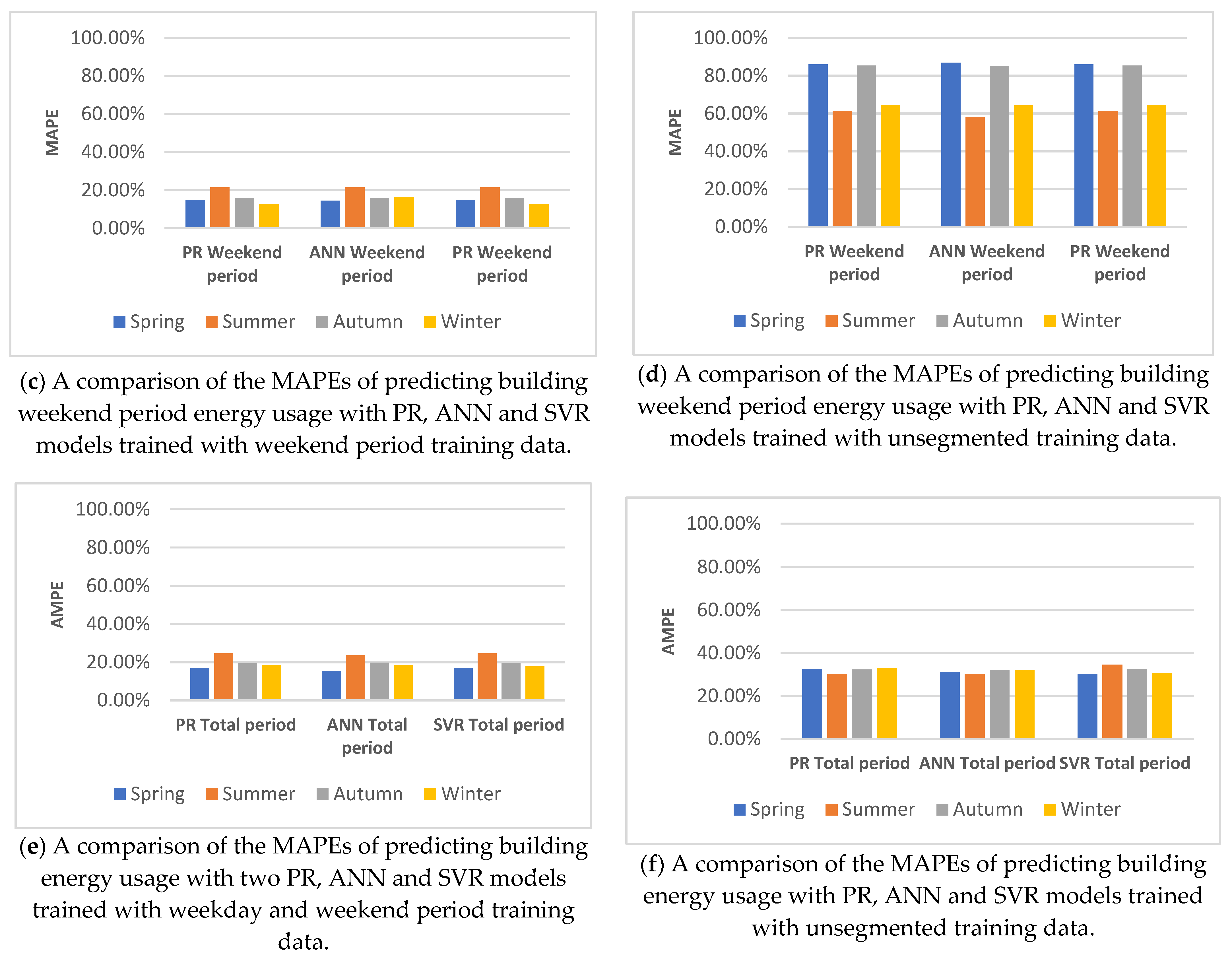
5.4.2. Building Active/Dormancy Segmented Predictions
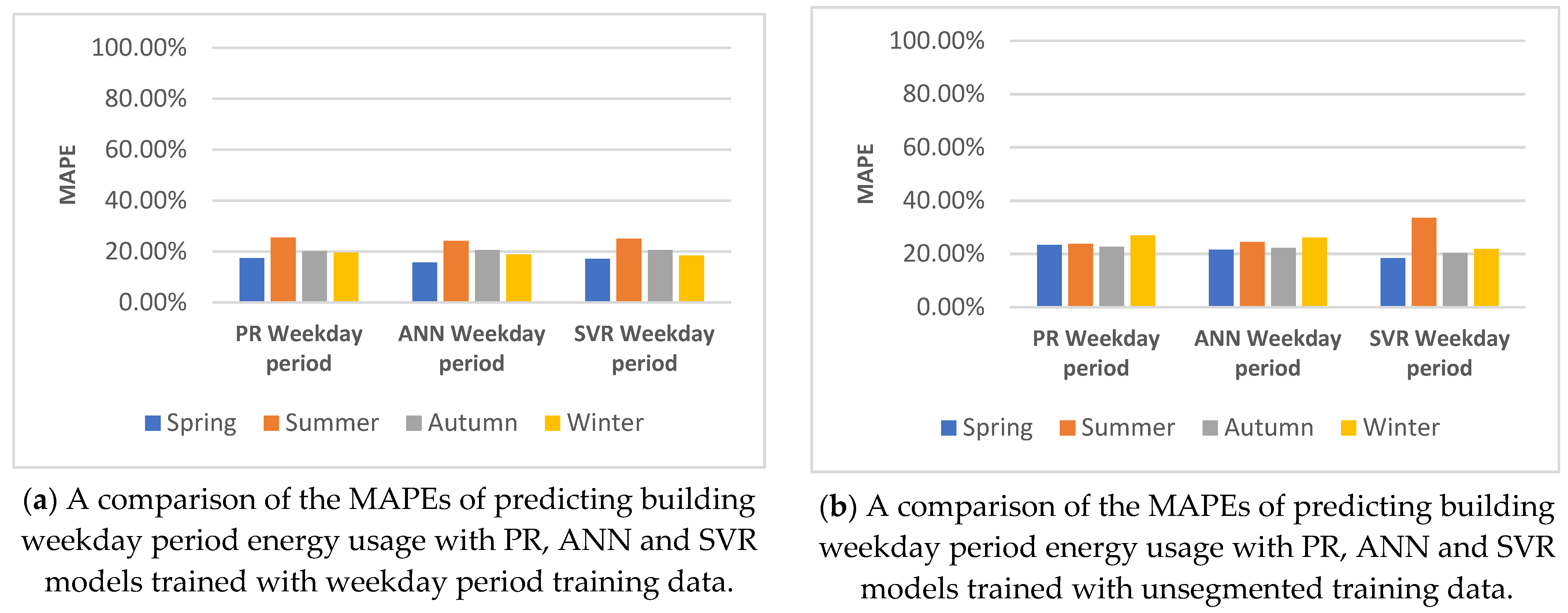
5.4.3. Building Weekday/Weekend Segmented Predictions
5.4.4. Impact of Seasonality on Prediction Results
- -
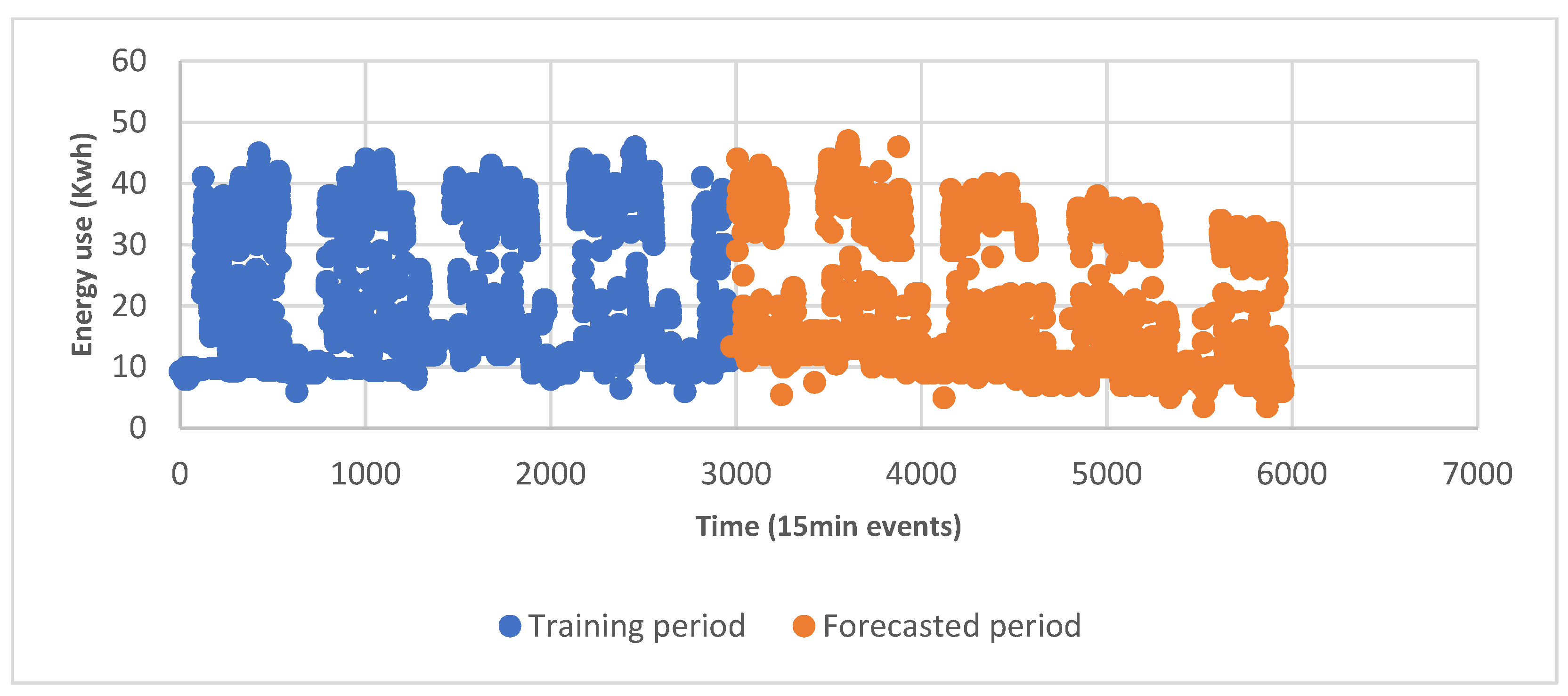
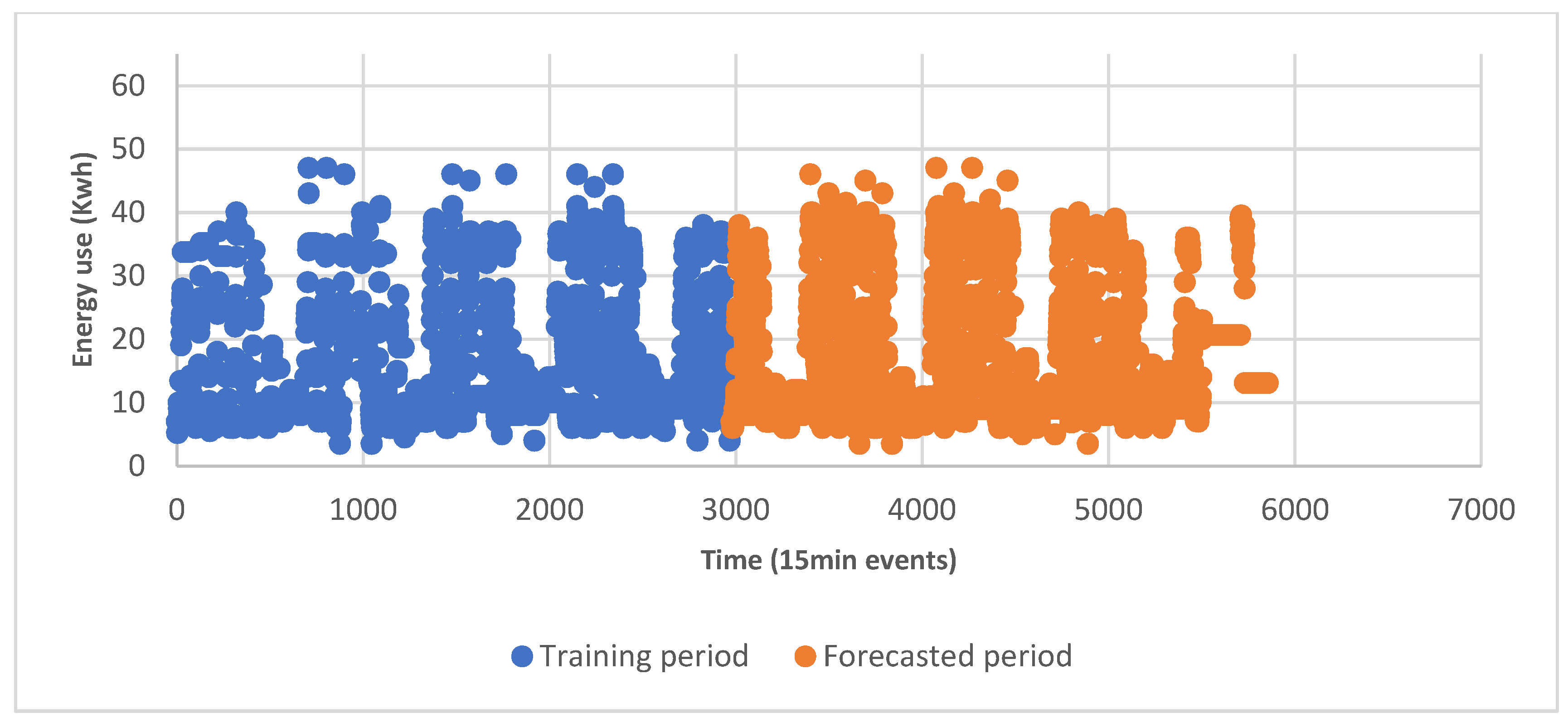
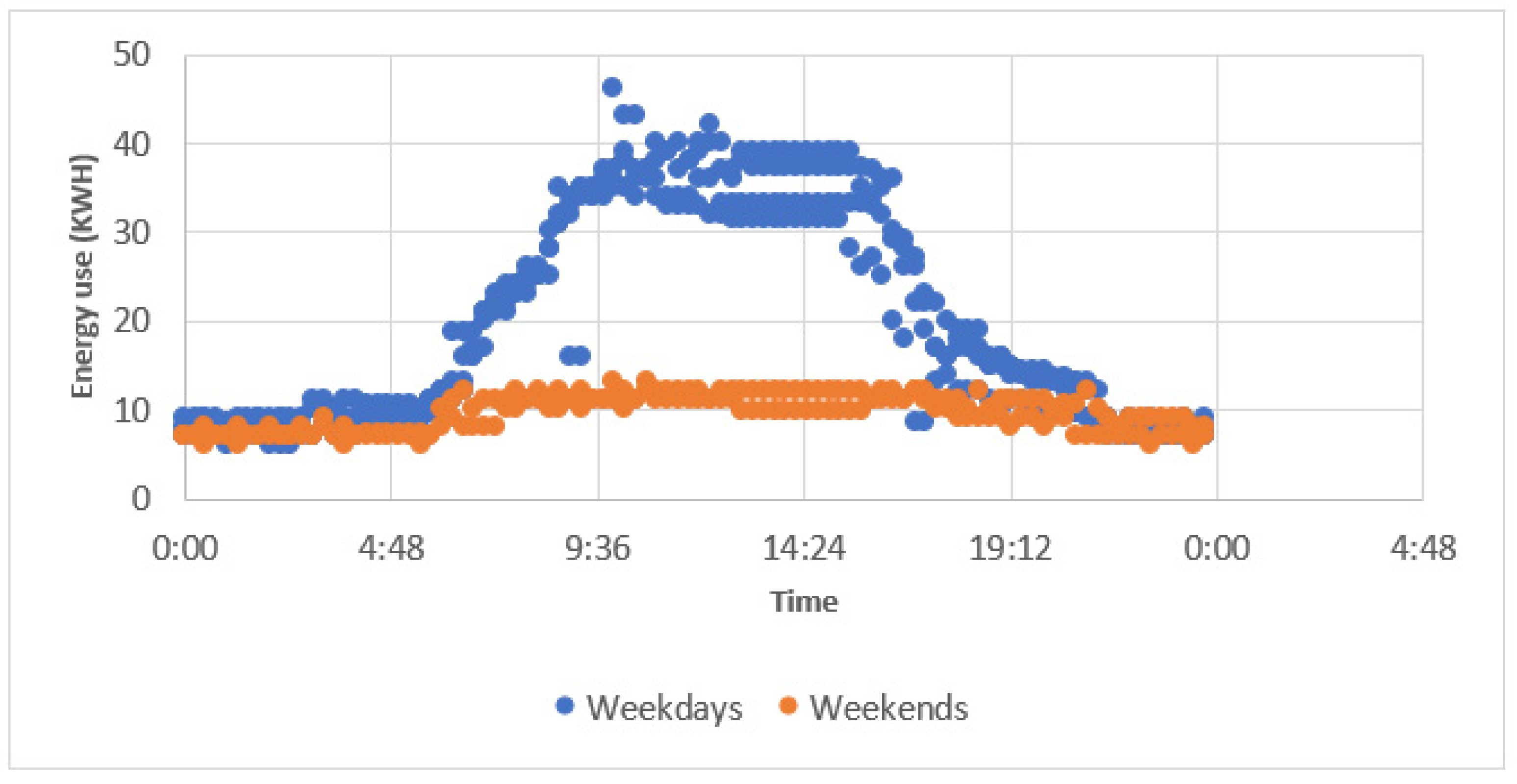
- During weekdays, the Clarendon building had higher peaks of energy use during the spring than the summer. There was a three day dormancy period in the first two weeks of the spring period that disrupted the normal building energy usage patterns. Removing this period from long-term spring ANN predictions (the most accurate predictor of this period) resulted in a reduction in the MAPE of 3%. (This occurred between event 370 and 660 in Figure 23). However, the remaining and significant difference in the MAPE of 5.4% between the spring and summer predictions suggested this may not have been the main reason for the difference in the error.
- -
- By comparison, in spring, during weekends, energy usage behaved similarly to that during winter and autumn weekends, when the building entered a low energy use state. During the summer period on Sundays, the Clarendon building entered a dormancy state, whereas, on Saturdays, the energy use of the building was roughly half that of weekdays. (This occurred at event 340 and 1000 in orange in Figure 23).
6. Conclusions and Recommendations
6.1. Conclusions
6.2. Recommendations
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| Terms | Description |
| ANN | Artificial Neural Network |
| BMS | Building Management System |
| BR | Bayesian Regularisation |
| DLS | Damped Least-Squares (Method) |
| ELM | Extreme Learning Machine |
| GPU | General Processing Unit |
| HVAC | Heating Ventilation and Air Conditioning |
| LM | Levenberg-Marquardt |
| LR | Linear Regression |
| MAPE | Mean Absolute Percent Error |
| MLR | Multilinear Regression |
| OECD | Organisation for Economic Cooperation and Development |
| PR | Polynomial Regression |
| RMSE | Root Mean Squared Error |
| SCG | Scaled Conjugate Gradient |
| SE | Standard Error |
| SVR | Support Vector Regression |
| UK | United Kingdom |
Appendix A



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of Neurons | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| kWh | One | Two | Three | Four | Five | Six | Seven | Eight | Nine | Ten |
| Spring (RMSE) | 12.03 | 9.17 | 8.83 | 8.84 | 8.84 | 8.82 | 8.87 | 8.83 | 8.84 | 8.84 |
| Summer (RMSE) | 9.79 | 7.41 | 7.32 | 7.43 | 7.40 | 7.42 | 7.29 | 7.32 | 7.41 | 7.40 |
| Autumn (RMSE) | 9.44 | 10.52 | 7.44 | 7.45 | 7.43 | 7.49 | 7.47 | 7.48 | 7.47 | 7.54 |
| Winter (RMSE) | 10.96 | 11.36 | 8.28 | 8.29 | 8.30 | 8.27 | 8.21 | 8.23 | 8.26 | 8.22 |
| Spring (SE) | 0.22 | 0.17 | 0.16 | 0.16 | 0.16 | 0.16 | 0.16 | 0.16 | 0.16 | 0.16 |
| Summer (SE) | 0.18 | 0.13 | 0.13 | 0.13 | 0.13 | 0.13 | 0.13 | 0.13 | 0.13 | 0.13 |
| Autumn (SE) | 0.17 | 0.20 | 0.14 | 0.14 | 0.14 | 0.14 | 0.14 | 0.14 | 0.14 | 0.14 |
| Winter (SE) | 0.20 | 0.21 | 0.15 | 0.15 | 0.15 | 0.15 | 0.15 | 0.15 | 0.15 | 0.15 |
| Number of Hidden Layers | |||||
|---|---|---|---|---|---|
| kWh | One | Two | Three | Four | Five |
| Spring (RMSE) | 8.76 | 8.73 | 12.99 | 8.75 | 8.72 |
| Summer (RMSE) | 7.20 | 7.26 | 7.26 | 7.26 | 9.78 |
| Autumn (RMSE) | 7.49 | 7.51 | 9.44 | 7.42 | 7.55 |
| Winter (RMSE) | 8.24 | 8.32 | 8.23 | 10.98 | 8.26 |
| Spring (SE) | 0.16 | 0.16 | 0.24 | 0.16 | 0.16 |
| Summer (SE) | 0.13 | 0.13 | 0.13 | 0.13 | 0.18 |
| Autumn (SE) | 0.14 | 0.14 | 0.18 | 0.14 | 0.14 |
| Winter (SE) | 0.15 | 0.15 | 0.15 | 0.20 | 0.15 |



References
- Asgari, S.; MirhoseiniNejad, S.; Moazamigoodarzi, H.; Gupta, R.; Zheng, R.; Puri, I.K. A Gray-box model for real-time transient temperature predictions in data centres. Appl. Therm. Eng. 2020, 185, 116319. [Google Scholar] [CrossRef]
- Boegli, M.; Stauffer, Y. SVR based PV models for MPC based energy flow management. Energy Procedia 2017, 122, 133–138. [Google Scholar] [CrossRef]
- Chen, Y.; Tan, H.; Song, X. Day-ahead Forecasting of Non-stationary Electric Power Demand in Commercial Buildings: Hybrid Support Vector Regression Based. Energy Procedia 2017, 105, 2101–2106. [Google Scholar] [CrossRef]
- Chen, Y.; Tan, H. Short-term prediction of electric demand in building sector via hybrid support vector regression. Appl. Energy 2017, 204, 1363–1374. [Google Scholar] [CrossRef]
- Ding, Y.; Zhang, Q.; Yuan, T. Research on short-term and ultra-short-term cooling load prediction models for office buildings. Energy Build. 2017, 154, 254–267. [Google Scholar] [CrossRef]
- Goudarzi, S.; Anisi, M.H.; Kama, N.; Doctor, F.; Soleymani, S.A.; Sangaiah, A.K. Predictive modelling of building energy consumption based on a hybrid nature-inspired optimization algorithm. Energy Build. 2019, 196, 83–93. [Google Scholar] [CrossRef]
- Dolničar, S.; Grün, B.; Leisch, F. Market Segmentation Analysis: Understanding It, Doing It, and Making It Useful; Springer: Berlin/Heidelberg, Germany, 2018; p. 6. [Google Scholar]
- Conti, J.; Holtberg, P.; Diefenderfer, J.; LaRose, A.; Turnure, J.T.; Westfall, L. International Energy Outlook 2016 with Projections to 2040. Tech. Rep. 2016. [Google Scholar] [CrossRef] [Green Version]
- Smith, W. Product differentiation and market segmentation as alternative marketing strategies. J. Mark. 1956, 21, 3–8. [Google Scholar] [CrossRef]
- Zhou, J.; Zhai, L.; Pantelous, A.A. Market segmentation using high-dimensional sparse consumers data. Expert Syst. Appl. 2020, 145, 113136. [Google Scholar] [CrossRef]
- Do, H.; Cetin, K.S. Evaluation of the causes and impact of outliers on residential building energy use prediction using inverse modeling. Build. Environ. 2018, 138, 194–206. [Google Scholar] [CrossRef]
- Grolinger, K.; L’Heureux, A.; Capretz, M.A.M.; Seewald, L. Energy Forecasting for Event Venues: Big Data and Prediction Accuracy. Energy Build. 2016, 112, 222–233. [Google Scholar] [CrossRef] [Green Version]
- Seyedzadeh, S.; Rahimian, F.; Glesk, I.; Roper, M. Machine learning for estimation of building energy consumption and performance: A review. Vis. Eng. 2018, 6, 5. [Google Scholar] [CrossRef]
- Boisson, P.; Bault, S.; Rodriguez, S.; Breukers, S.; Charlesworth, R.; Bull, S.; Perevozchikov, I.; Sisinni, M.; Noris, F.; Tarco, M.T.; et al. DR-BoB D5.1. 2017. Available online: https://www.dr-bob.eu/wpcontent/uploads/2018/10/DRBOB_D5.1_CSTB_Update_2018–10–19.pdf (accessed on 12 May 2020).
- Bui, D.K.; Nguyen, T.N.; Ngo, T.D.; Nguyen-Xuan, H. An artificial neural network (ANN) expert system enhanced with the electromagnetism-based firefly algorithm (EFA) for predicting the energy consumption in buildings. Energy 2020, 190, 116370. [Google Scholar] [CrossRef]
- Dagdougui, H.; Bagheri, F.; Le, H.; Dessaint, L. Neural network model for short-term and very-short-term load forecasting in district buildings. Energy Build. 2019, 203, 109408. [Google Scholar] [CrossRef]
- Li, K.; Xie, X.; Xue, W.; Dai, X.; Chen, X.; Yang, X. A hybrid teaching-learning artificial neural network for building electrical energy consumption prediction. Energy Build. 2018, 174, 323–334. [Google Scholar] [CrossRef]
- Kim, M.K.; Kim, Y.S.; Srebric, J. Predictions of electricity consumption in a campus building using occupant rates and weather elements with sensitivity analysis: Artificial neural network vs. linear regression. Sustain. Cities Soc. 2020, 62, 102385. [Google Scholar] [CrossRef]
- Iruela, J.; Ruiz, L.; Pegalajar, M.; Capel, M. A parallel solution with GPU technology to predict energy consumption in spatially distributed buildings using evolutionary optimization and artificial neural networks. Energy Convers. Manag. 2020, 207, 112535. [Google Scholar] [CrossRef]
- Alnaqi, A.A.; Moayedi, H.; Shahsavar, A.; Nguyen, T.K. Prediction of energetic performance of a building integrated photovoltaic/thermal system thorough artificial neural network and hybrid particle swarm optimization models. Energy Convers. Manag. 2019, 183, 137–148. [Google Scholar] [CrossRef]
- Jang, J.; Baek, J.; Leigh, S.-B. Prediction of optimum heating timing based on artificial neural network by utilizing BEMS data. J. Build. Eng. 2018, 22, 66–74. [Google Scholar] [CrossRef]
- Xu, X.; Wang, W.; Hong, T.; Chen, J. Incorporating machine learning with building network analysis to predict multi-building energy use. Energy Build. 2019, 186, 80–97. [Google Scholar] [CrossRef] [Green Version]
- Zhou, G.; Moayedi, H.; Bahiraei, M.; Lyu, Z. Employing artificial bee colon and particle swarm techniques for optimizing a neural network in prediction of heating and cooling loads of residential buildings. J. Clean. Prod. 2020, 254, 120082. [Google Scholar] [CrossRef]
- Magalhães, S.M.C.; Leal, V.M.S.; Horta, I.M. Modelling the relationship between heating energy use and indoor temperatures in residential buildings through Artificial Neural Networks considering occupant behavior. Energy Build. 2017, 151, 332–343. [Google Scholar] [CrossRef]
- Wei, Y.; Xia, L.; Pan, S.; Wu, J.; Zhang, X.; Han, M.; Zhang, W.; Xie, J.; Li, Q. Prediction of occupancy level and energy consumption in office building using blind system identification and neural networks. Appl. Energy 2019, 240, 276–294. [Google Scholar] [CrossRef]
- Arregi, B.; Garay, R. Regression analysis of the energy consumption of tertiary buildings. Energy Procedia 2017, 122, 9–14. [Google Scholar] [CrossRef] [Green Version]
- Mcculloch, W.S.; Pitts, W.H. A logical calculus of the ideas immanent in nervous activity Bull. Math. Biophys. 1943, 5, 115–133. [Google Scholar] [CrossRef]
- Reynolds, J.; Rezgui, Y.; Kwan, A.; Piriou, S. A zone-level, building energy optimisation combining an artificial neural network, a genetic algorithm, and model predictive control. Energy 2018, 151, 729–739. [Google Scholar] [CrossRef]
- Koschwitz, D.; Frisch, J.; van Treeck, C. Data-driven heating and cooling load predictions for non-residential buildings based on support vector machine regression and NARX Recurrent Neural Network: A comparative study on district scale. Energy 2018, 165, 134–142. [Google Scholar] [CrossRef]
- Ciulla, G.; D’Amico, A. Building energy performance forecasting: A multiple linear regression approach. Appl. Energy 2019, 253, 113500. [Google Scholar] [CrossRef]
- Wang, Z.; Hong, T.; Piette, M.A. Building thermal load prediction through shallow machine learning and deep learning. Appl. Energy 2020, 263, 114683. [Google Scholar] [CrossRef] [Green Version]
- Zhou, Y.; Zheng, S. Machine-learning based hybrid demand-side controller for high-rise office buildings with high energy flexibilities. Appl. Energy 2020, 262, 114416. [Google Scholar] [CrossRef]
- Pombeiro, H.; Santos, R.; Carreira, P.; Silva, C.A.S.; Sousa, J.M.C. Comparative assessment of low-complexity models to predict electricity consumption in an institutional building: Linear regression vs. fuzzy modeling vs. neural networks. Energy Build. 2017, 146, 141–151. [Google Scholar] [CrossRef]
- Huang, Y.; Yuan, Y.; Chen, H.; Wang, J.; Guo, Y.; Ahmad, T. A novel energy demand prediction strategy for residential buildings based on ensemble learning. Energy Procedia 2019, 158, 3411–3416. [Google Scholar] [CrossRef]
- Nasruddin; Sholahudin; Satrio, P.; Mahlia, T.M.I.; Giannetti, N.; Saito, K. Optimization of HVAC system energy consumption in a building using artificial neural network and multi-objective genetic algorithm. Sustain. Energy Technol. Assess. 2019, 35, 48–57. [Google Scholar] [CrossRef]
- Guo, Y.; Li, G.; Chen, H.; Wang, J.; Huang, Y. A thermal response time ahead energy demand prediction strategy for building heating system using machine learning methods. Energy Procedia 2017, 142, 1003–1008. [Google Scholar] [CrossRef]
- Alamin, Y.I.; Álvarez, J.D.; Castilla, M.D.M.; Ruano, A. An Artificial Neural Network (ANN) model to predict the electric load profile for an HVAC system. IFAC-PapersOnLine 2018, 51, 26–31. [Google Scholar] [CrossRef]
- Zhong, H.; Wang, J.; Jia, H.; Mu, Y.; Lv, S. Vector field-based support vector regression for building energy consumption prediction. Appl. Energy 2019, 242, 403–414. [Google Scholar] [CrossRef]
- Gao, Y.; Ruan, Y.; Fang, C.; Yin, S. Deep learning and transfer learning models of energy consumption forecasting for a building with poor information data. Energy Build. 2020, 223, 110156. [Google Scholar] [CrossRef]
- Zhang, F.; Deb, C.; Lee, S.E.; Yang, J.; Shah, K.W. Time series forecasting for building energy consumption using weighted Support Vector Regression with differential evolution optimization technique. Energy Build. 2016, 126, 94–103. [Google Scholar] [CrossRef]
- Tao, Y.; Yan, H.; Gao, H.; Sun, Y.; Li, G. Application of SVR optimized by Modified Simulated Annealing (MSA-SVR) air conditioning load prediction model. J. Ind. Inf. Integr. 2019, 15, 247–251. [Google Scholar] [CrossRef]
- Shen, M.; Sun, H.; Lu, Y. Household Electricity Consumption Prediction Under Multiple Behavioural Intervention Strategies Using Support Vector Regression. Energy Procedia 2017, 142, 2734–2739. [Google Scholar] [CrossRef]
- Mounter, W.; Dawood, H.; Dawood, N. The impact of data segmentation on modelling building energy usage. In Proceedings of the International Conference on Energy and Sustainable Futures (ICESF), Nottingham Trent, UK, 9–11 September 2019. [Google Scholar]
- Yang, Y.; Che, J.; Deng, C.; Li, L. Sequential grid approach based support vector regression for short-term electric load forecasting. Appl. Energy 2019, 238, 1010–1021. [Google Scholar] [CrossRef]
- Fan, C.; Sun, Y.; Zhao, Y.; Song, M.; Wang, J. Deep learning-based feature engineering methods for improved building energy prediction. Appl. Energy 2019, 240, 35–45. [Google Scholar] [CrossRef]
- Candanedo, L.M.; Feldheim, V.; Deramaix, D. Data driven prediction models of energy use of appliances in a low-energy house. Energy Build. 2017, 140, 81–97. [Google Scholar] [CrossRef]
- Stigler, S.M. The History of Statistics: The Measurement of Uncertainty before 1900; Belknap Press of Harvard University Press: Cambridge, UK, 1986. [Google Scholar]
- Zeng, A.; Liu, S.; Yu, Y. Comparative study of data driven methods in building electricity use prediction. Energy Build. 2019, 194, 289–300. [Google Scholar] [CrossRef]
- Troup, L.; Phillips, R.; Eckelman, M.J.; Fannon, D. Effect of window-to-wall ratio on measured energy consumption in US office buildings. Energy Build. 2019, 203, 109434. [Google Scholar] [CrossRef]
- Katsatos, A.L.; Moustris, K.P. Application of Artificial Neuron Networks as energy consumption forecasting tool in the building of Regulatory Authority of Energy, Athens, Greece. Energy Procedia 2019, 157, 851–861. [Google Scholar] [CrossRef]
- Gassar, A.A.A.; Yun, G.Y.; Kim, S. Data-driven approach to prediction of residential energy consumption at urban scales in London. Energy 2019, 187, 115973. [Google Scholar] [CrossRef]
- Mathew, A.; Sreekumar, S.; Khandelwal, S.; Kumar, R. Prediction of land surface temperatures for surface urban heat island assessment over Chandigarh city using support vector regression model. Sol. Energy 2019, 186, 404–415. [Google Scholar] [CrossRef]
- Pham, A.-D.; Ngo, N.-T.; Truong, T.T.H.; Huynh, N.-T.; Truong, N.-S. Predicting energy consumption in multiple buildings using machine learning for improving energy efficiency and sustainability. J. Clean. Prod. 2020, 260, 121082. [Google Scholar] [CrossRef]
- Boser, B.E.; Guyon, I.M.; Vapnik, V.N. A training algorithm for optimal margin classifiers. In Proceedings of the Fifth Annual Workshop on Computational Learning Theory—COLT ‘92, Pittsburgh, PA, USA, 27–29 August 1992; pp. 144–152. [Google Scholar] [CrossRef]
- D’Amico, A.; Ciulla, G.; Traverso, M.; Brano, V.L.; Palumbo, E. Artificial Neural Networks to assess energy and environmental performance of buildings: An Italian case study. J. Clean. Prod. 2019, 239, 117993. [Google Scholar] [CrossRef]
- Bre, F.; Gimenez, J.M.; Fachinotti, V.D. Prediction of wind pressure coefficients on building surfaces using artificial neural networks. Energy Build. 2018, 158, 1429–1441. [Google Scholar] [CrossRef]
- Qiang, G.; Zhe, T.; Yan, D.; Neng, Z. An improved office building cooling load prediction model based on multivariable linear regression. Energy Build. 2015, 107, 445–455. [Google Scholar] [CrossRef]
- Wu, J.; Lian, Z.; Zheng, Z.; Zhang, H. A method to evaluate building energy consumption based on energy use index of different functional sectors. Sustain. Cities Soc. 2020, 53, 101893. [Google Scholar] [CrossRef]
- Zubair, M.U.; Zhang, X. Explicit data-driven prediction model of annual energy consumed by elevators in residential buildings. J. Build. Eng. 2020, 31, 101278. [Google Scholar] [CrossRef]
- Aghdaei, N.; Kokogiannakis, G.; Daly, D.; McCarthy, T. Linear regression models for prediction of annual heating and cooling demand in representative Australian residential dwellings. Energy Procedia 2017, 121, 79–86. [Google Scholar] [CrossRef]
- Li, Q.; Augenbroe, G.; Brown, J. Assessment of linear emulators in lightweight Bayesian calibration of dynamic building energy models for parameter estimation and performance prediction. Energy Build. 2016, 124, 194–202. [Google Scholar] [CrossRef]
- Wang, R.; Lu, S.; Li, Q. Multi-criteria comprehensive study on predictive algorithm of hourly heating energy consumption for residential buildings. Sustain. Cities Soc. 2019, 49, 101623. [Google Scholar] [CrossRef]
- Wang, R.; Lu, S.; Feng, W. A novel improved model for building energy consumption prediction based on model integration. Appl. Energy 2020, 262, 114561. [Google Scholar] [CrossRef]
- Escandón, R.; Ascione, F.; Bianco, N.; Mauro, G.M.; Suárez, R.; Sendra, J.J. Thermal comfort prediction in a building category: Artificial neural network generation from calibrated models for a social housing stock in southern Europe. Appl. Therm. Eng. 2019, 150, 492–505. [Google Scholar] [CrossRef]
- Mohandes, S.R.; Zhang, X.; Mahdiyar, A. A comprehensive review on the application of artificial neural networks in building energy analysis. Neurocomputing 2019, 340, 55–75. [Google Scholar] [CrossRef]
- Park, S.K.; Moon, H.J.; Min, K.C.; Hwang, C.; Kim, S. Application of a multiple linear regression and an artificial neural network model for the heating performance analysis and hourly prediction of a large-scale ground source heat pump system. Energy Build. 2018, 165, 206–215. [Google Scholar] [CrossRef]
- Sun, S.; Li, G.; Chen, H.; Guo, Y.; Wang, J.; Huang, Q.; Hu, W. Optimization of support vector regression model based on outlier detection methods for predicting electricity consumption of a public building WSHP system. Energy Build. 2017, 151, 35–44. [Google Scholar] [CrossRef]
- Papadopoulos, S.; Azar, E. Integrating building performance simulation in agent-based modeling using regression surrogate models: A novel human-in-the-loop energy modeling approach. Energy Build. 2016, 128, 214–223. [Google Scholar] [CrossRef]
- Oh, S.; Kim, K.H. Change-point modeling analysis for multi-residential buildings: A case study in South Korea. Energy Build. 2020, 214, 109901. [Google Scholar] [CrossRef]
- Ahmad, T.; Chen, H.; Huang, R.; Yabin, G.; Wang, J.; Shair, J.; Akram, H.M.A.; Mohsan, S.A.H.; Kazim, M. Supervised based machine learning models for short, medium, and long-term energy prediction in distinct building environment. Energy 2018, 158, 17–32. [Google Scholar] [CrossRef]
- Li, Y.; Che, J.; Yang, Y. Subsampled support vector regression ensemble for short term electric load forecasting. Energy 2018, 164, 160–170. [Google Scholar] [CrossRef]
- Chen, Y.; Xu, P.; Chu, Y.; Li, W.; Wu, Y.; Ni, L.; Bao, Y.; Wang, K. Short-term electrical load forecasting using the Support Vector Regression (SVR) model to calculate the demand response baseline for office buildings. Appl. Energy 2017, 195, 659–670. [Google Scholar] [CrossRef]
- Wang, Z.; Wang, Y.; Zeng, R.; Srinivasan, R.; Ahrentzen, S. Random Forest based hourly building energy prediction. Energy Build. 2018, 171, 11–25. [Google Scholar] [CrossRef]
- Ma, Z.; Ye, C.; Ma, W. Support vector regression for predicting building energy consumption in southern China. Energy Procedia 2019, 158, 3433–3438. [Google Scholar] [CrossRef]
- Drucker, H.; Burges, C.C.; Kaufman, L.; Smola, A.J.; Vapnik, V.N. Support Vector Regression Machines, in Advances in Neural Information Processing Systems 9; MIT Press: Cambridge, MA, USA, 1996; pp. 155–161. [Google Scholar]
- Trainlm. 2021. Available online: https://uk.mathworks.com/help/deeplearning/ref/trainlm.html (accessed on 12 May 2021).
- Trainbr. 2021. Available online: https://uk.mathworks.com/help/deeplearning/ref/trainbr.html (accessed on 12 May 2021).
- Trainscg. 2021. Available online: https://uk.mathworks.com/help/deeplearning/ref/trainscg.html (accessed on 12 May 2021).
- Ghaderpour, E.; Vujadinovic, T. The Potential of the Least-Squares Spectral and Cross-Wavelet Analyses for Near-Real-Time Disturbance Detection within Unequally Spaced Satellite Image Time Series. Remote Sens. 2020, 12, 2446. [Google Scholar] [CrossRef]


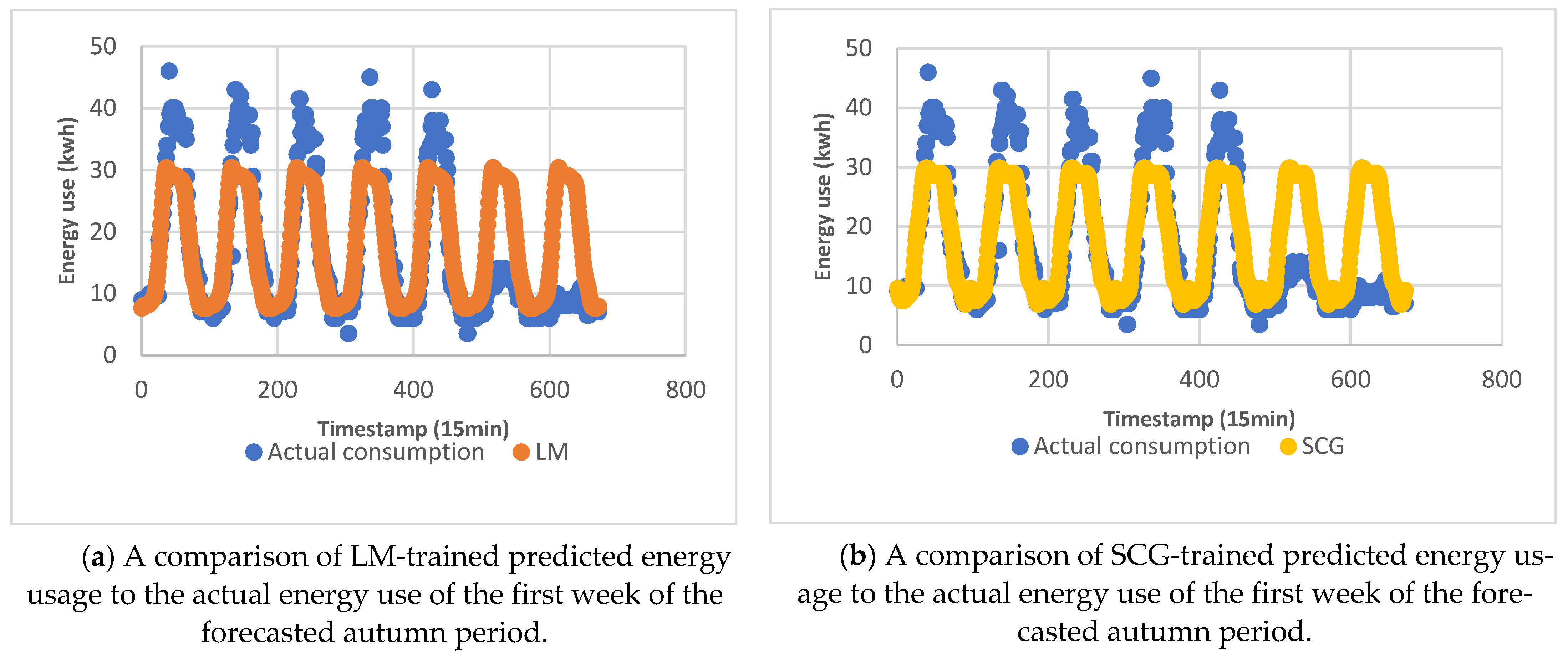
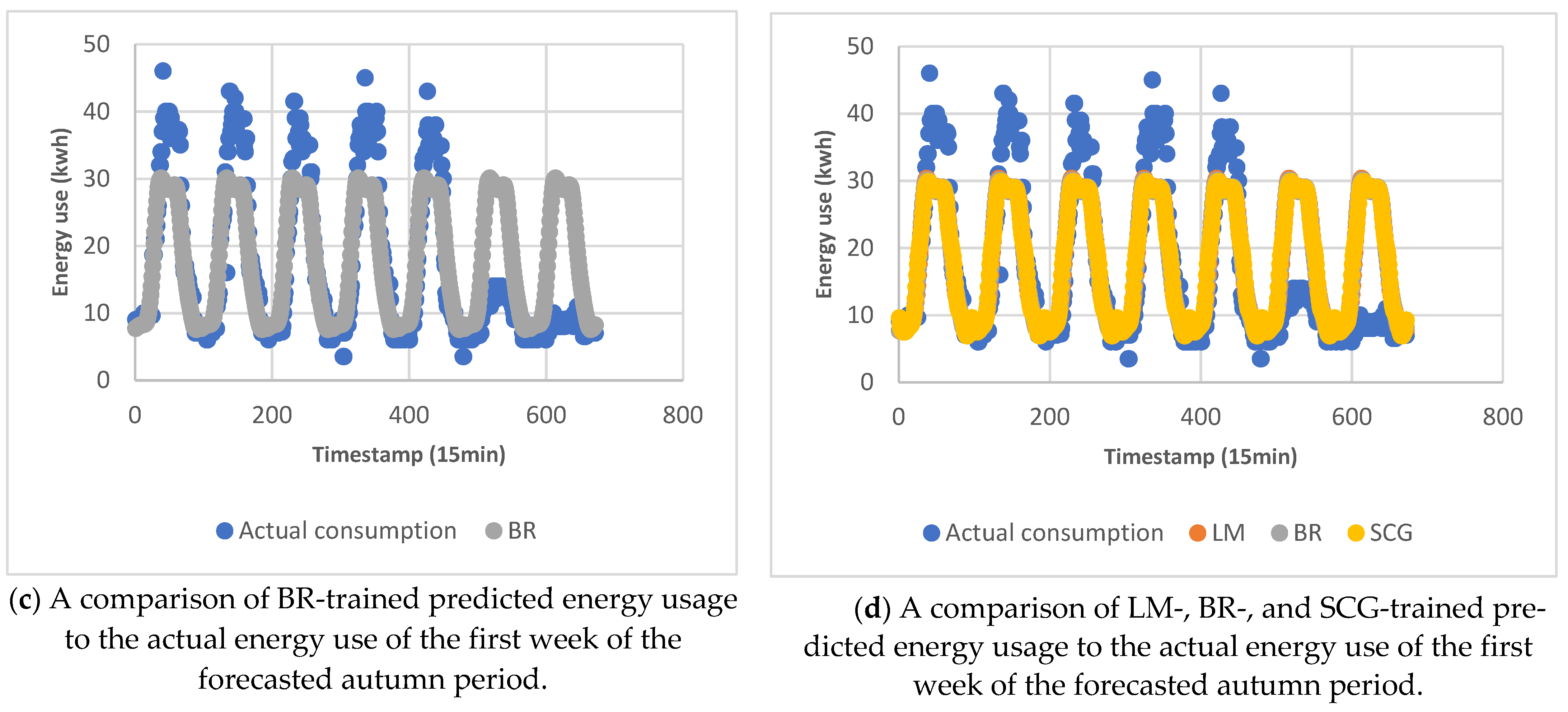






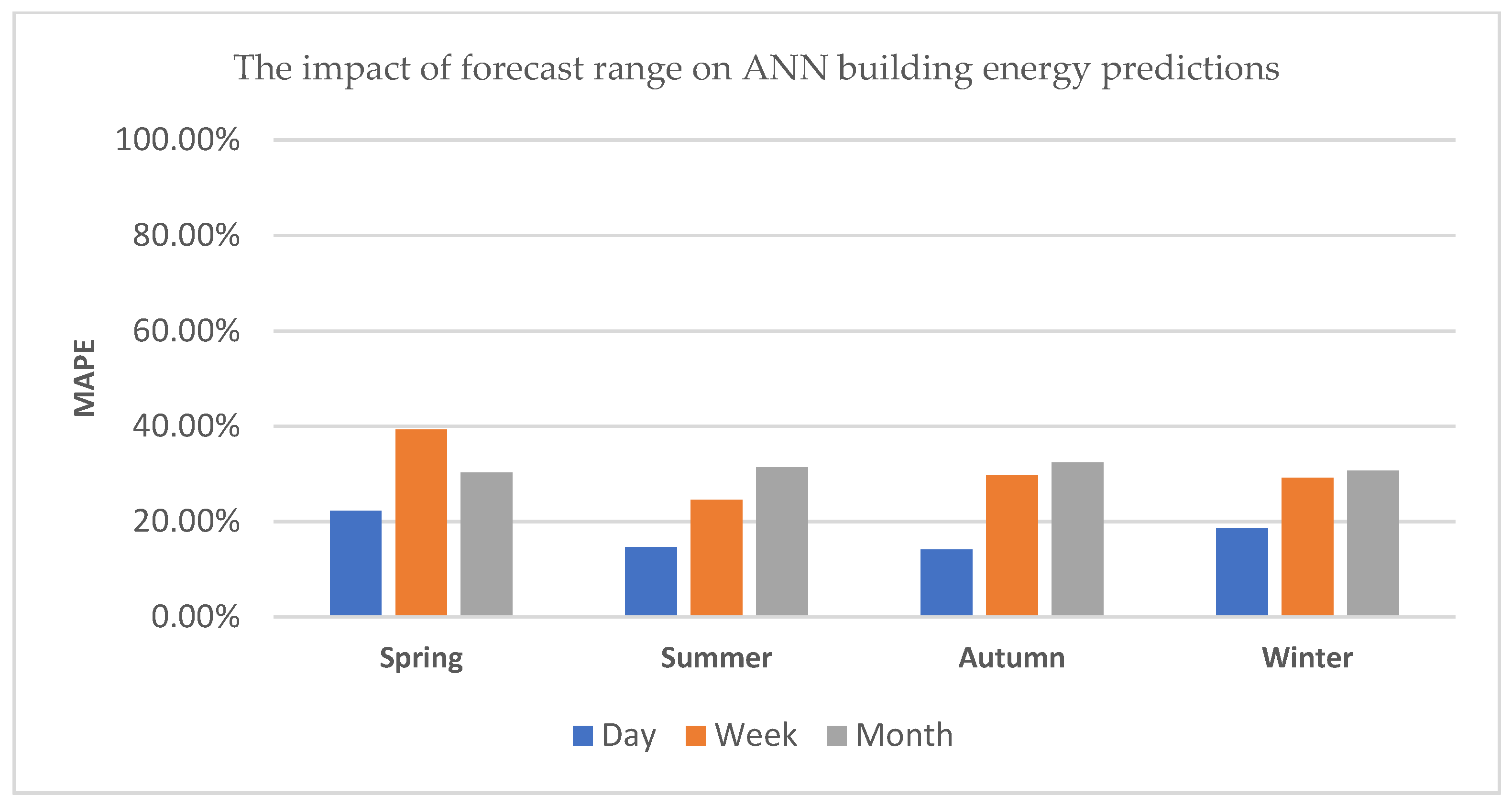



| Season | ||||
|---|---|---|---|---|
| Difference between Training and Testing Datasets | Spring | Summer | Autumn | Winter |
| Mean energy use (kWh) | −0.7 | −0.78 | −0.96 | 1 |
| Mean percent energy use (%) | −3.65% | −4.47% | −5.66% | 5.30% |
| Type of Data Segmentation | PR | ANN | SVR |
|---|---|---|---|
| Unsegmented trained model prediction | PR was outperformed by ANN and SVR in all daily, weekly and monthly forecasts. | ANN outperformed PR, but was in turn outperformed by SVR in all daily, weekly and monthly forecasts. | SVR outperformed ANN and SVR in all daily, weekly and monthly forecasts. |
| Building active/dormancy period trained model prediction | There was no significant impact of segmenting the training data and predictions of PR building energy use. We specifically note a lack of any improvement in the prediction of the active or dormancy period. PR was still outperformed by ANN and SVR in all daily, weekly and monthly forecasts. | There was no significant impact of segmenting the training data and predictions of PR building energy use, with specific note of a lack of any improvement to the prediction of the active or dormancy period. ANN still outperformed PR, and was in turn outperformed by SVR in all daily, weekly and monthly forecasts. | There was no significant impact of segmenting the training data and predictions of PR building energy use, with specific note of a lack of any improvement to the prediction of the active or dormancy period. SVR still outperformed ANN and SVR in all daily, weekly and monthly forecasts. |
| Building weekday/weekend trained model prediction | There was a significant positive impact of segmenting the training data and predictions of PR building energy use, compared to unsegmented predictions. Minor improvements were made to the predictive accuracy of weekday periods, and major improvements to the accuracy of weekend periods. PR was still outperformed by ANN and SVR in daily, weekly and monthly forecasts. | There was a significant positive impact of segmenting the training data and predictions of PR building energy use, compared to unsegmented predictions, with minor improvements in the predictive accuracy of weekday periods, and major improvements in the accuracy of weekend periods. A variation of note was that in weekday/weekend segmented predictions, on average, the monthly ANN forecasts were outperformed by monthly SVR forecasts. ANN was outperformed by SVR in daily and weekly forecasting. | There was a significant positive impact of segmenting the training data and predictions of PR building energy use, compared to unsegmented predictions, with minor improvements in the predictive accuracy of weekday periods, and major improvements in the accuracy of weekend periods. A variation of note was that in weekday/weekend segmented predictions, on average, the monthly SVR forecasts were outperformed by monthly SVR forecasts. SVR outperformed ANN in daily and weekly forecasting. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mounter, W.; Ogwumike, C.; Dawood, H.; Dawood, N. Machine Learning and Data Segmentation for Building Energy Use Prediction—A Comparative Study. Energies 2021, 14, 5947. https://doi.org/10.3390/en14185947
Mounter W, Ogwumike C, Dawood H, Dawood N. Machine Learning and Data Segmentation for Building Energy Use Prediction—A Comparative Study. Energies. 2021; 14(18):5947. https://doi.org/10.3390/en14185947
Chicago/Turabian StyleMounter, William, Chris Ogwumike, Huda Dawood, and Nashwan Dawood. 2021. "Machine Learning and Data Segmentation for Building Energy Use Prediction—A Comparative Study" Energies 14, no. 18: 5947. https://doi.org/10.3390/en14185947
APA StyleMounter, W., Ogwumike, C., Dawood, H., & Dawood, N. (2021). Machine Learning and Data Segmentation for Building Energy Use Prediction—A Comparative Study. Energies, 14(18), 5947. https://doi.org/10.3390/en14185947