
Approximation of Permanent Magnet Motor Flux Distribution by Partially Informed Neural Networks



Abstract
:1. Introduction
- collecting the numerical data which allow for identifying the model of the drive, including the model of the motor,
- constructing and identifying the model using the data,
- designing the controller according to the control aim.
- to develop an artificial neural model of flux distribution,
- to equip the neural network modeling the flux with any available reliable information about the motor,
- to obtain a fast and accurate model allowing practical applications.
- a new method of neural network approximation of discrete data is proposed, which improves the accuracy of approximation by including any preliminary, reliable information into the network structure,
- a new, convenient method of d/q flux distribution modeling is proposed, its reliability is tested and demonstrated and practical applicability is demonstrated.
2. Motor Flux Distribution Modeling
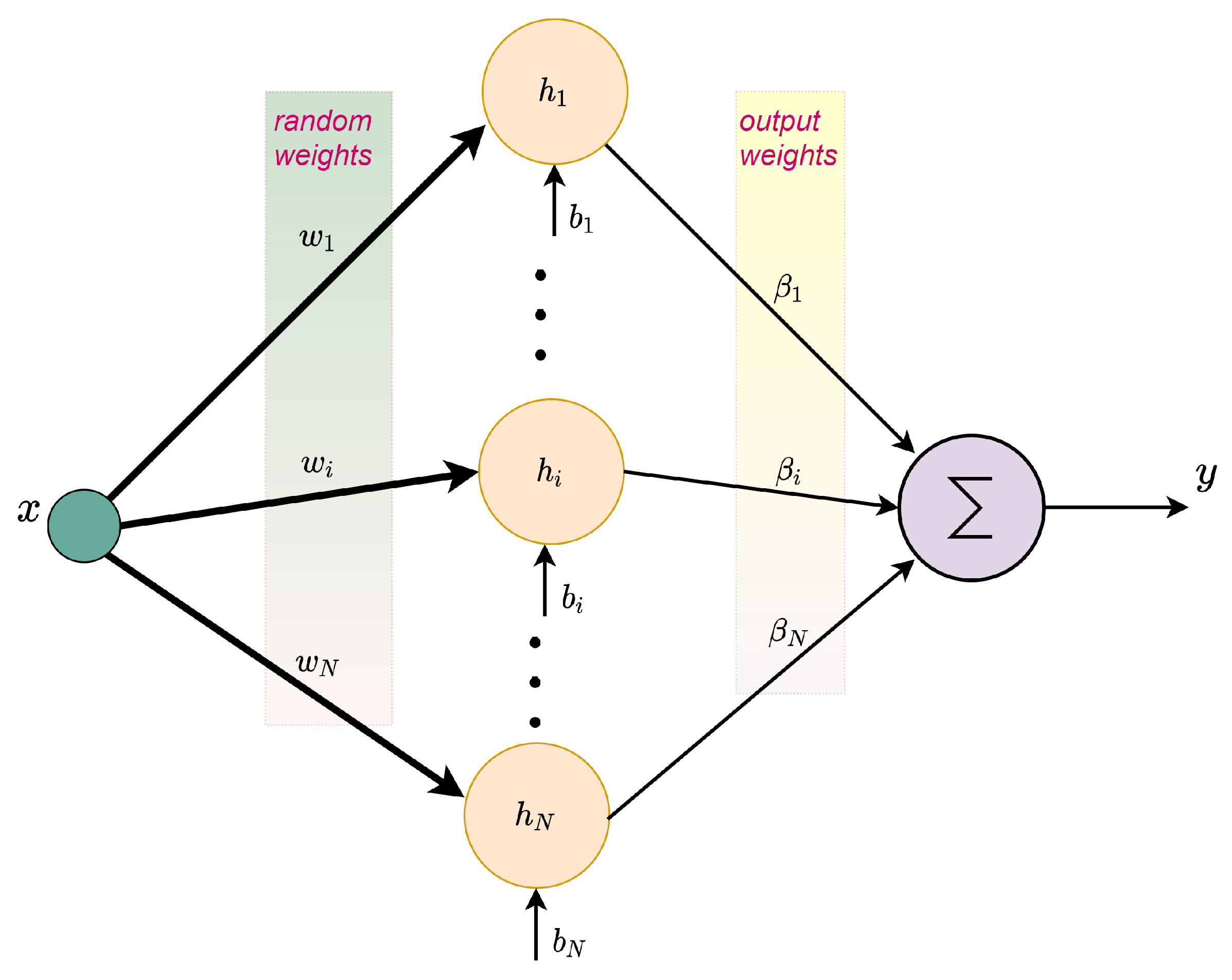
3. Standard ELM
4. ELM with Input-Dependent Output Weights
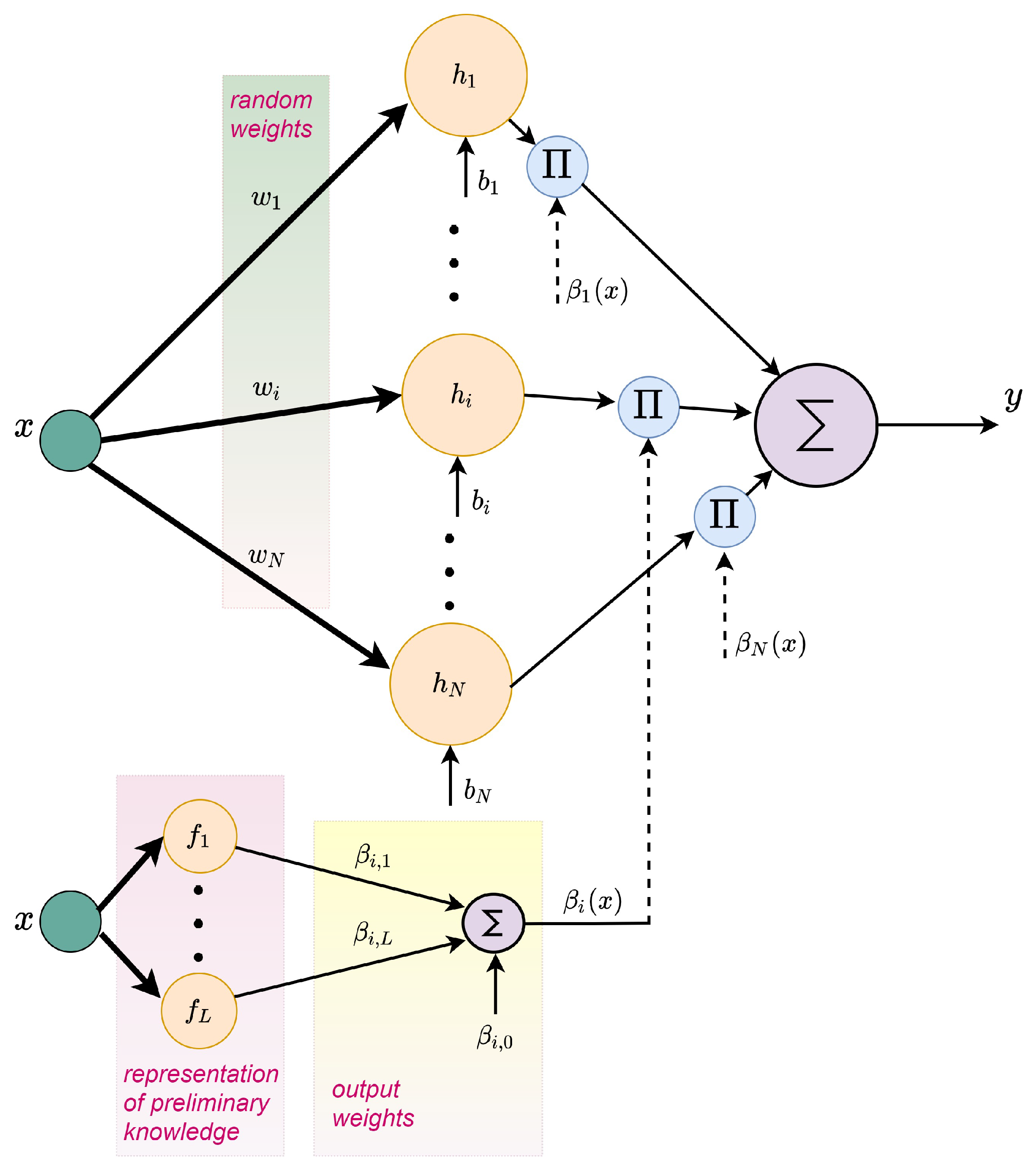
4.1. New Network Structure
4.2. Reduction of Output Weight Number
5. Comparison of Networks
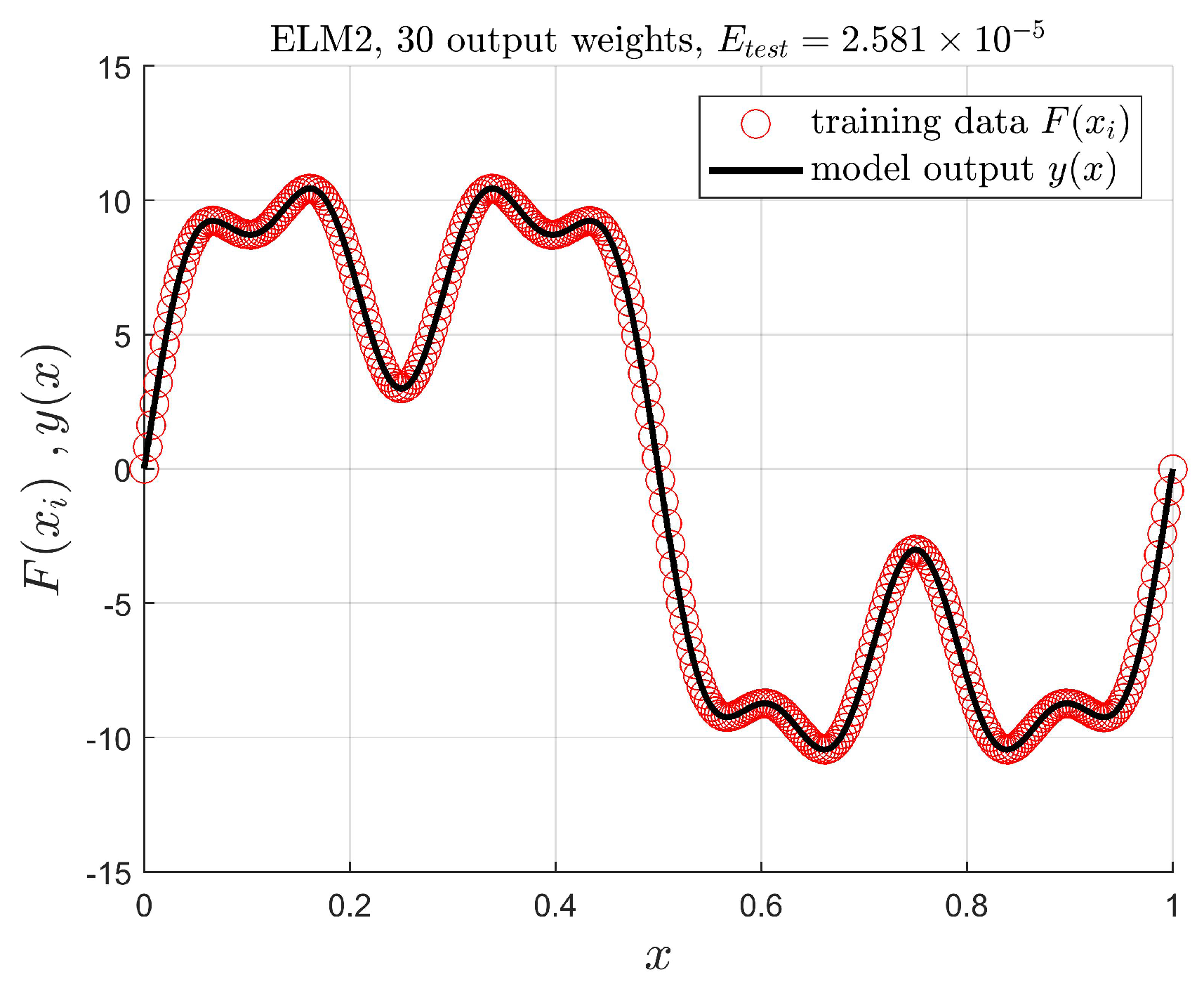
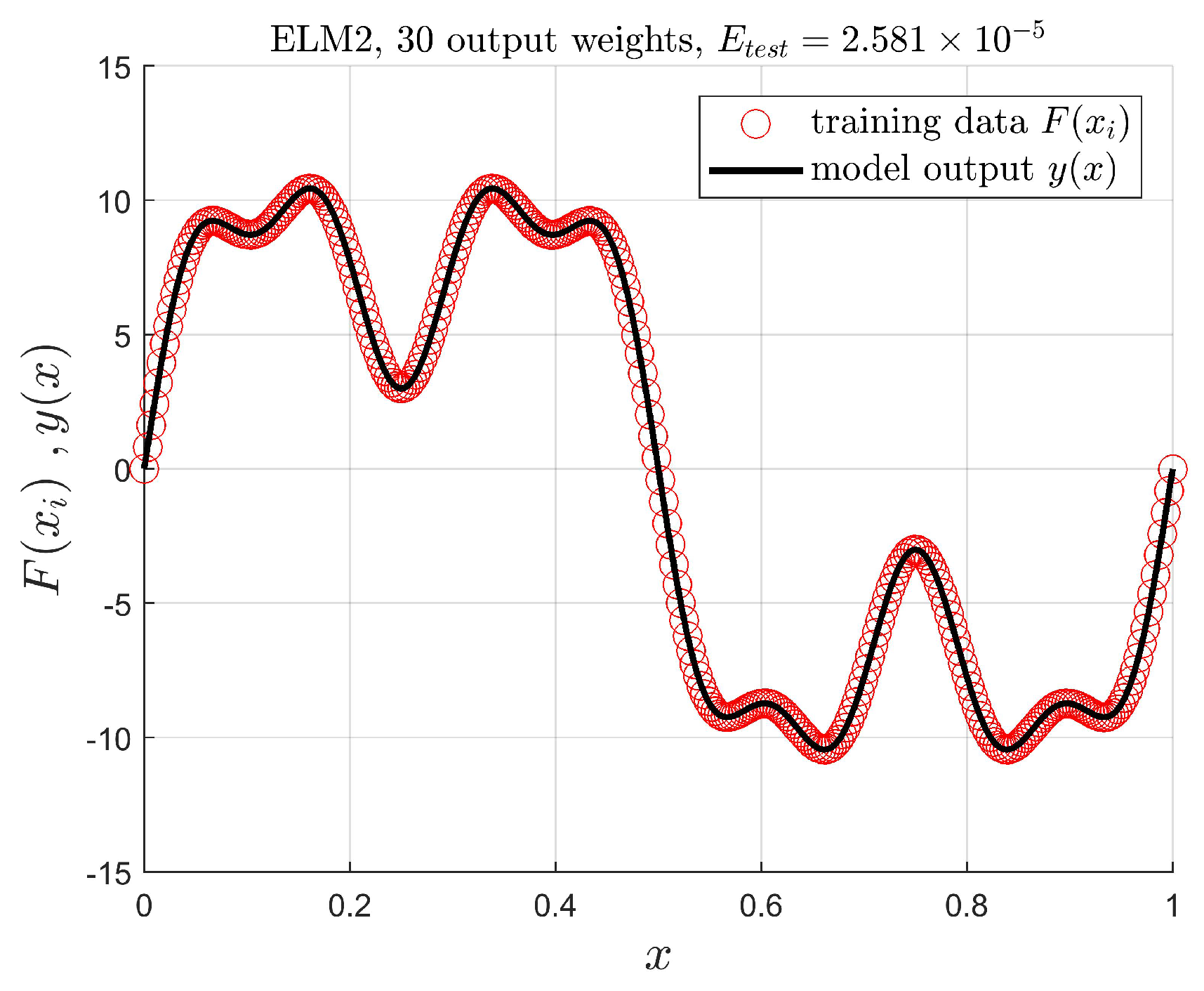
5.1. Introductory Example
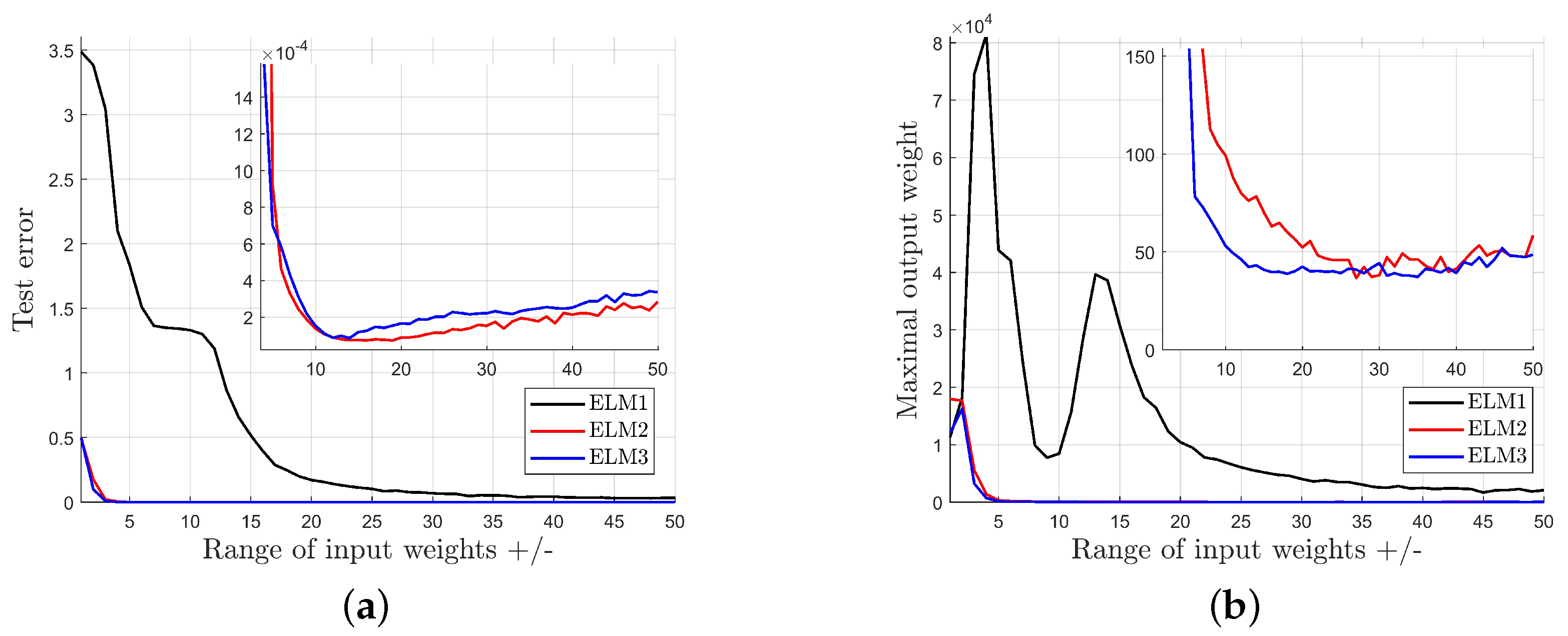
- ELM1: The standard ELM given by (5), (7) with the input weights and biases selected randomly, according to the enhanced variation mechanism (8) with , .
- ELM2: The network with input-dependent output weights, according to (9):where the partial knowledge about the output is used.
- ELM3: The network modified according to (14):where , are selected at random from the interval [−1,1].
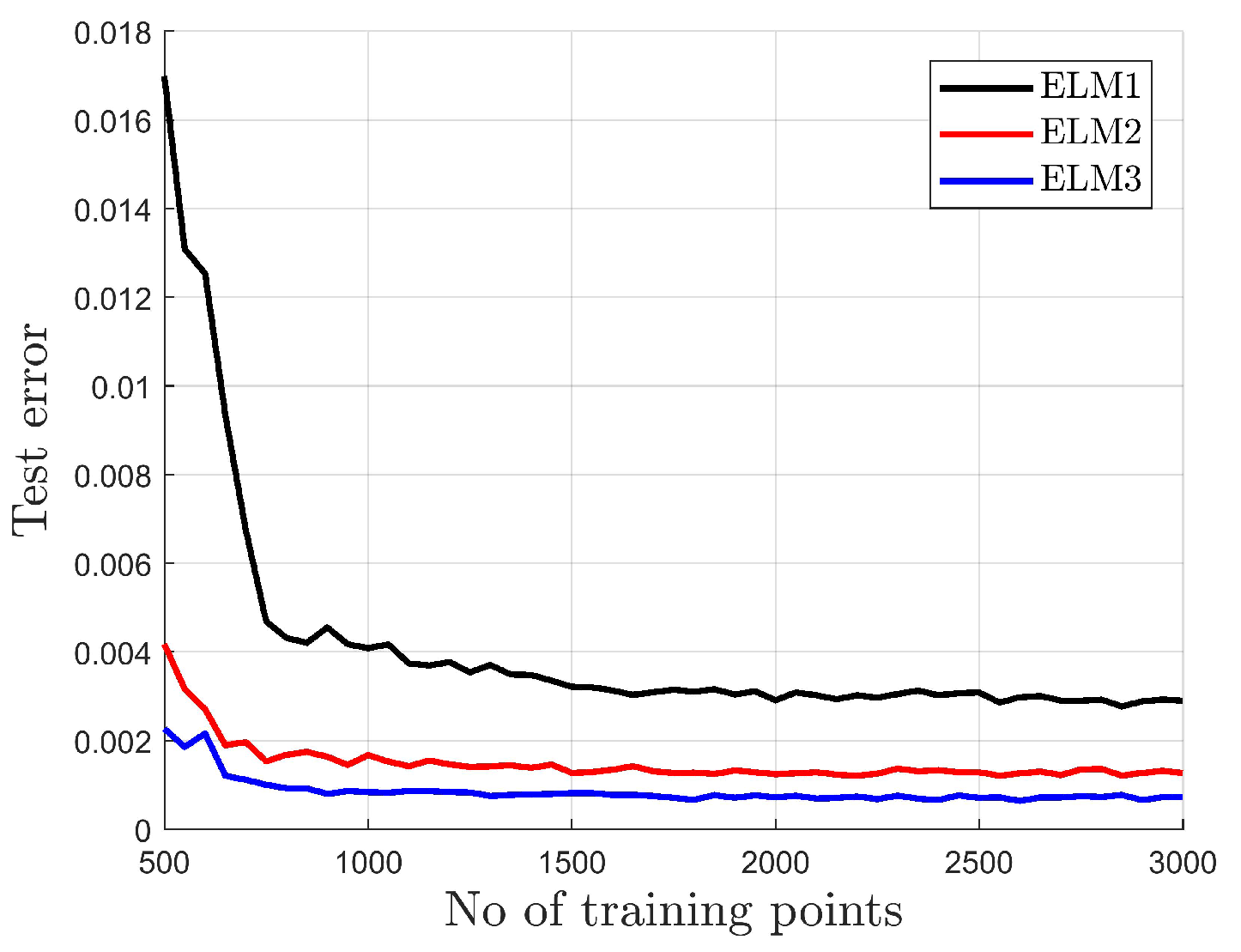
- The standard network (ELM1) is far more sensitive to a small range of input weights than modified networks (ELM2 and ELM3).
- The standard network (ELM1) generates a higher test error than modified networks (ELM2 and ELM3), in spite of the range of the input weights.
- The standard network (ELM1) generates much higher output weights than modified networks (ELM2 and ELM3), so the standard model demonstrates much worse numerical properties.
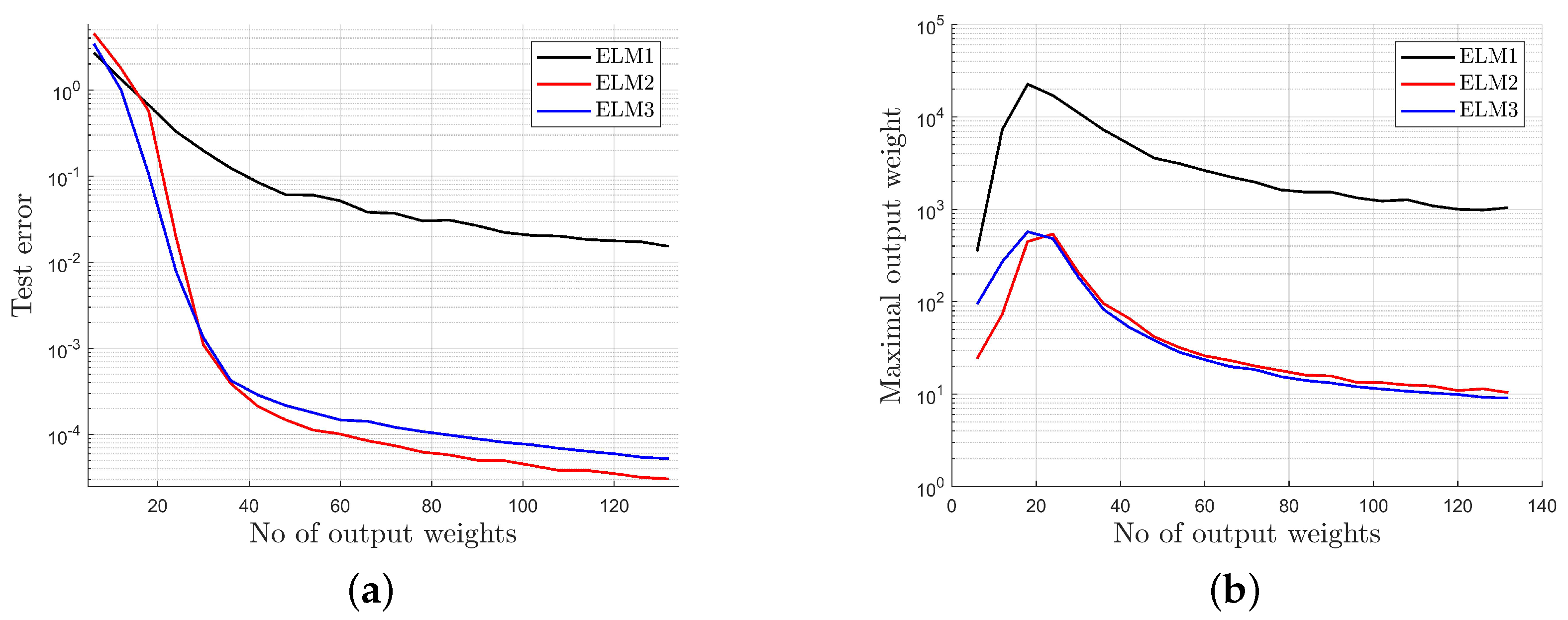
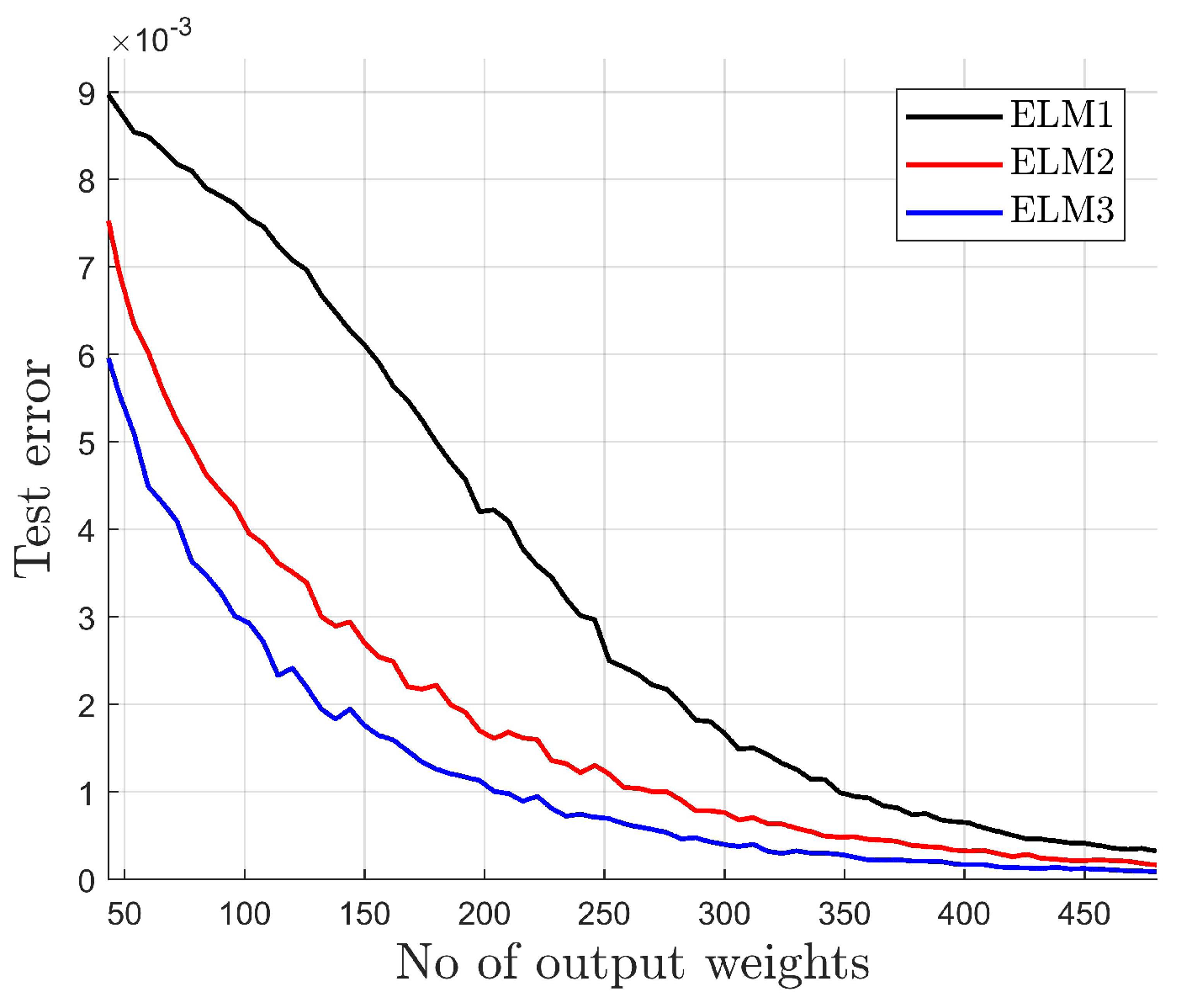
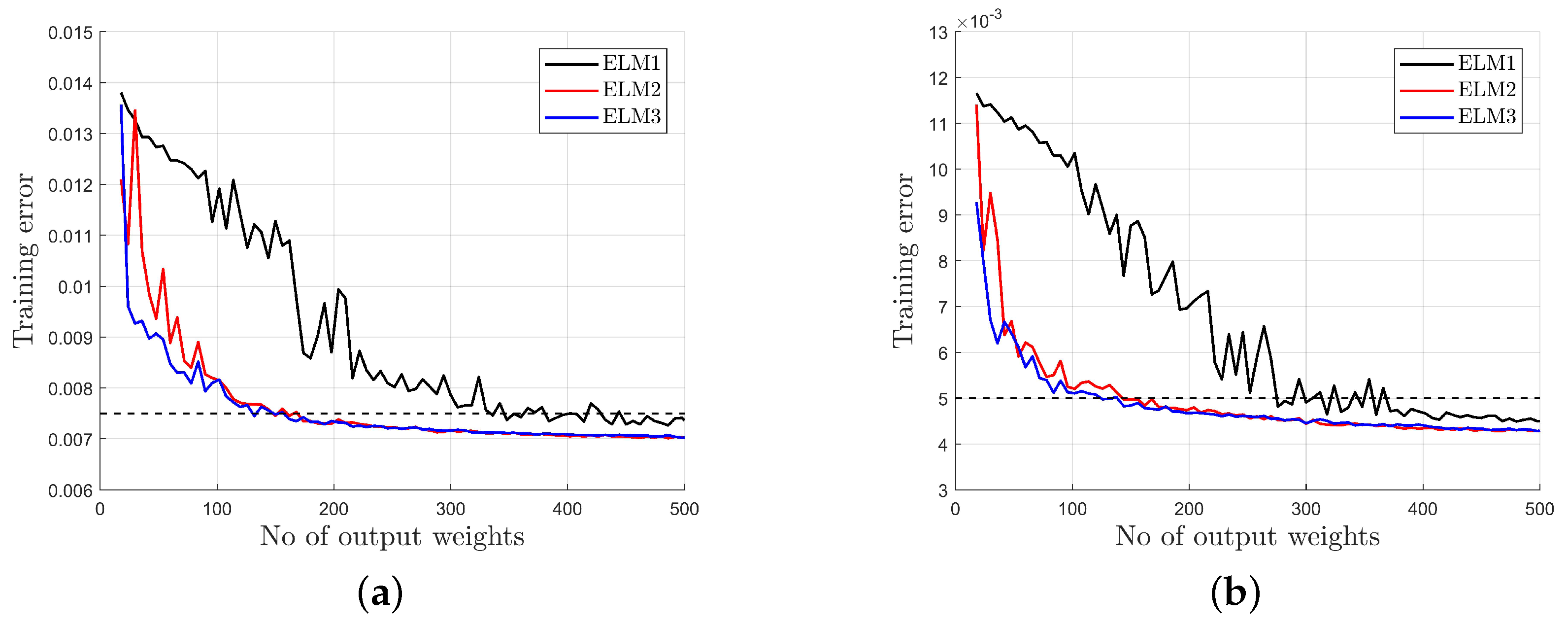
- The standard network (ELM1) generates higher test error than modified networks (ELM2 and ELM3) for the same number of output weights and requires a much larger number of hidden neurons to obtain a similar test error as ELM2 or ELM3.
- The standard network (ELM1) generates much higher output weights for any number of hidden neurons than modified networks (ELM2 and ELM3), so the standard model demonstrates much worse numerical properties.
- The standard network (ELM1) generates a much higher test error for any C than modified networks (ELM2 and ELM3).
- The standard network (ELM1) requires strong regularization (small C to decrease output weights), resulting in poor modeling accuracy. The modified networks (ELM2, ELM3) preserve moderate output weights for any C—regularization is not necessary.
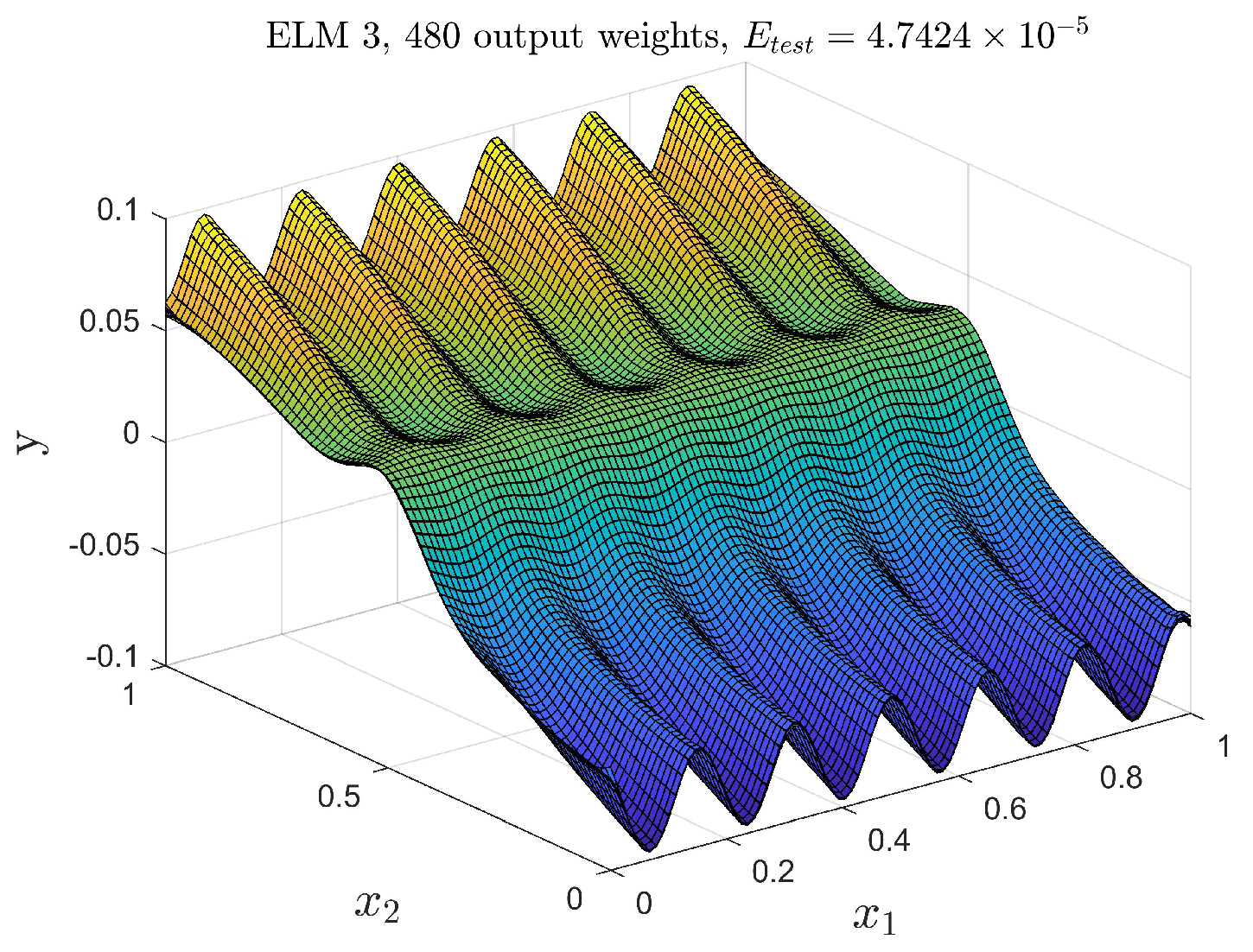
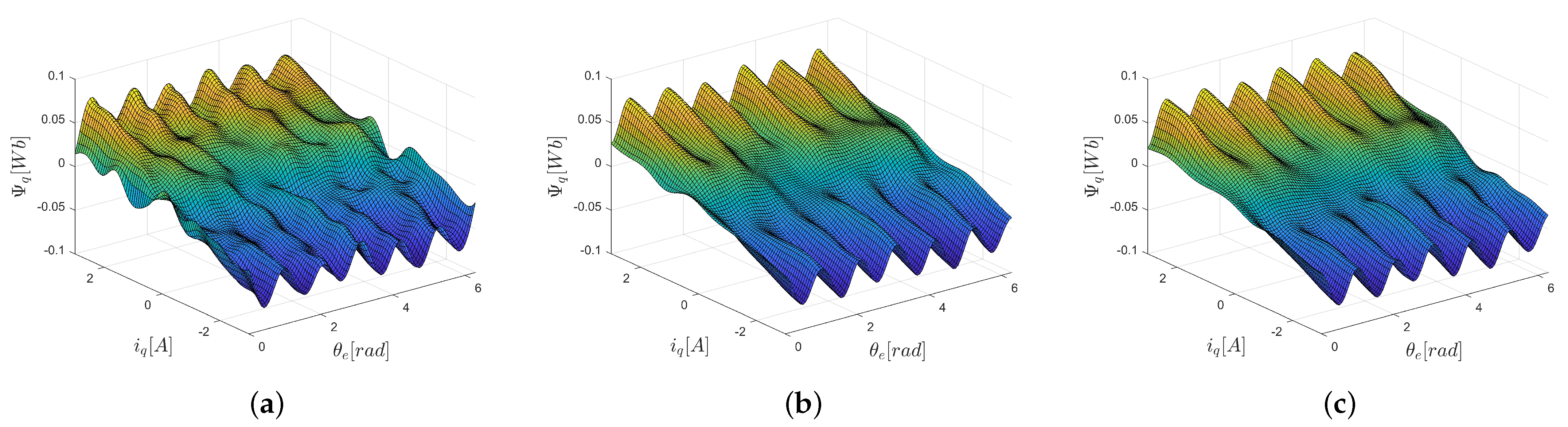
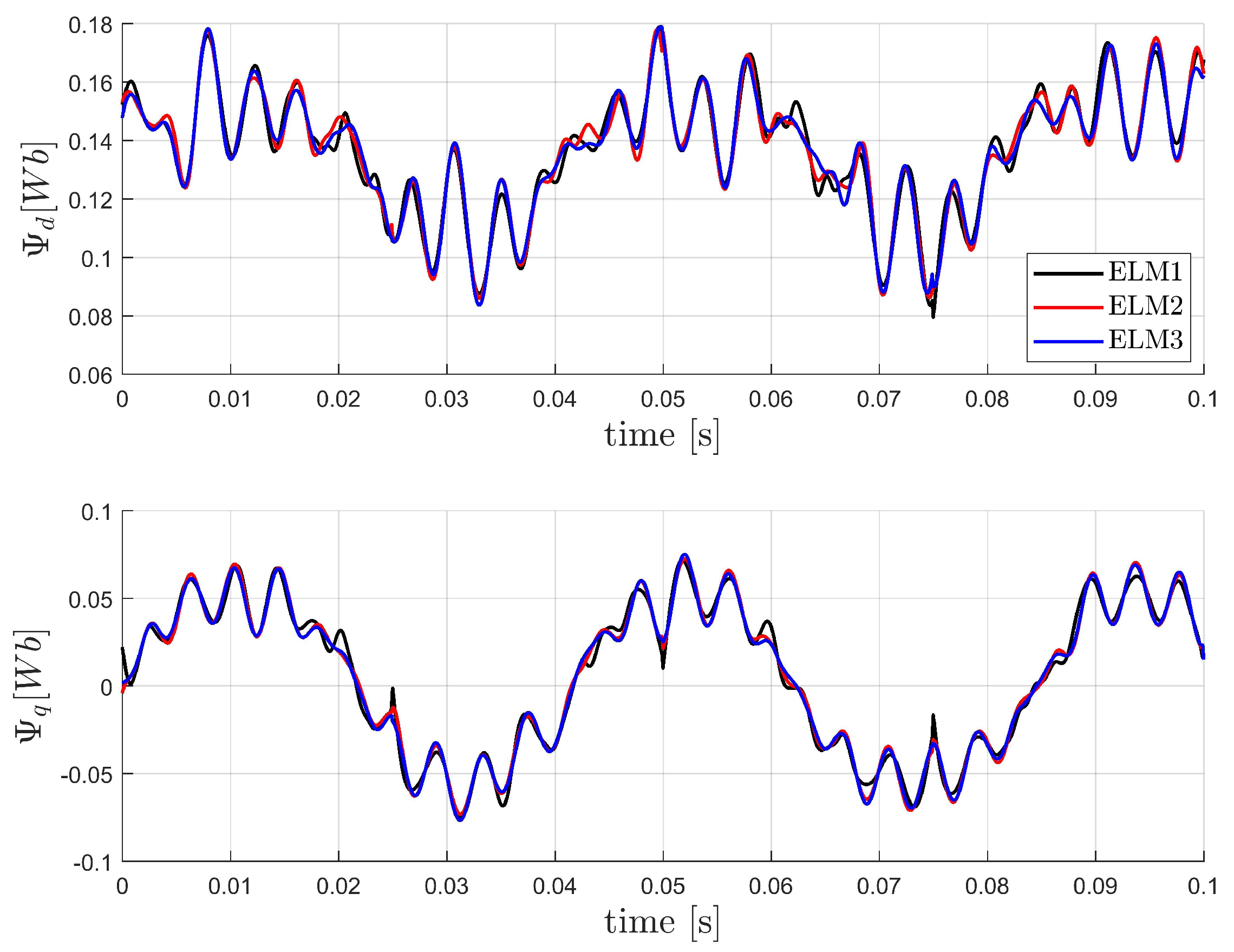
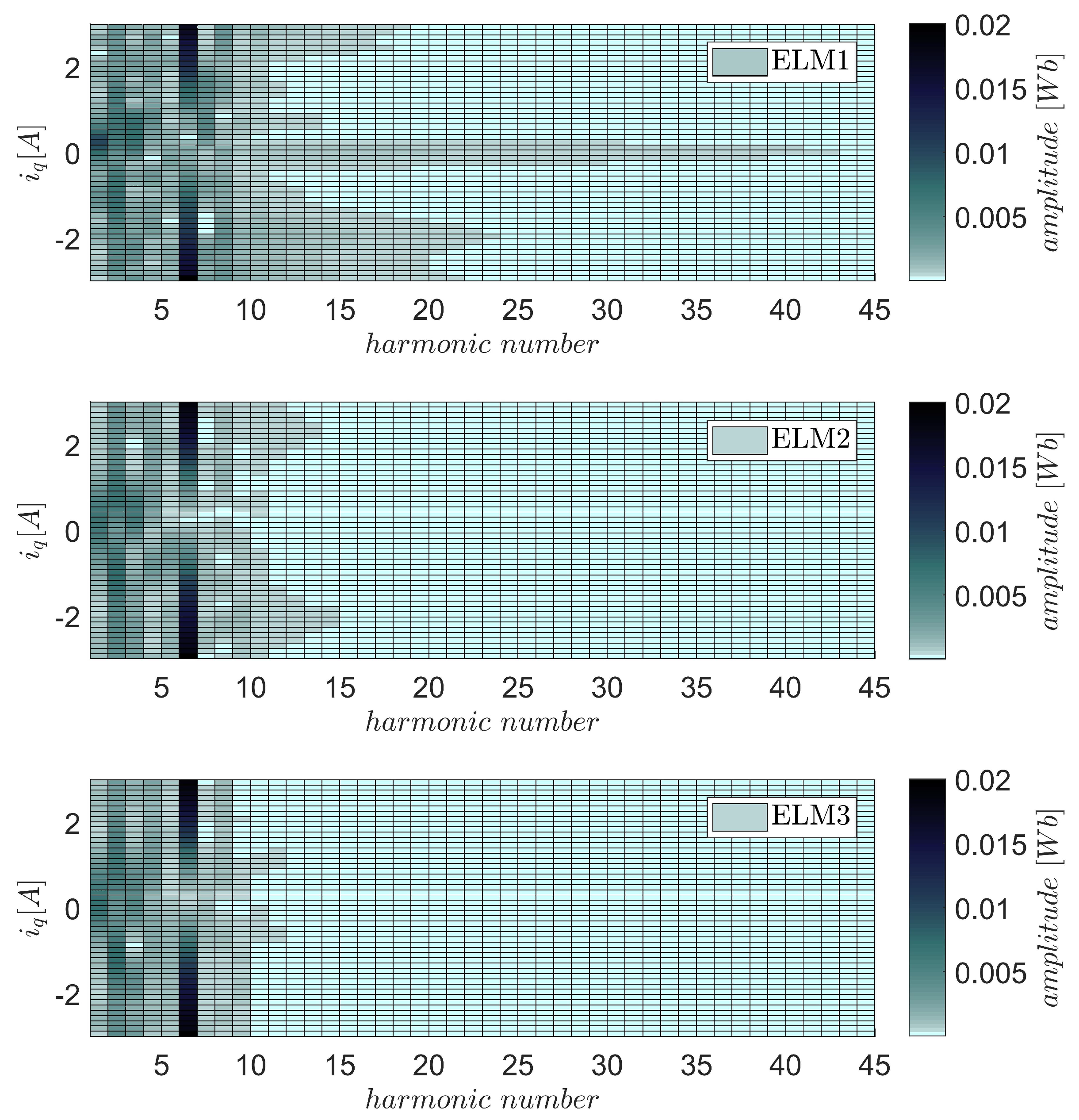
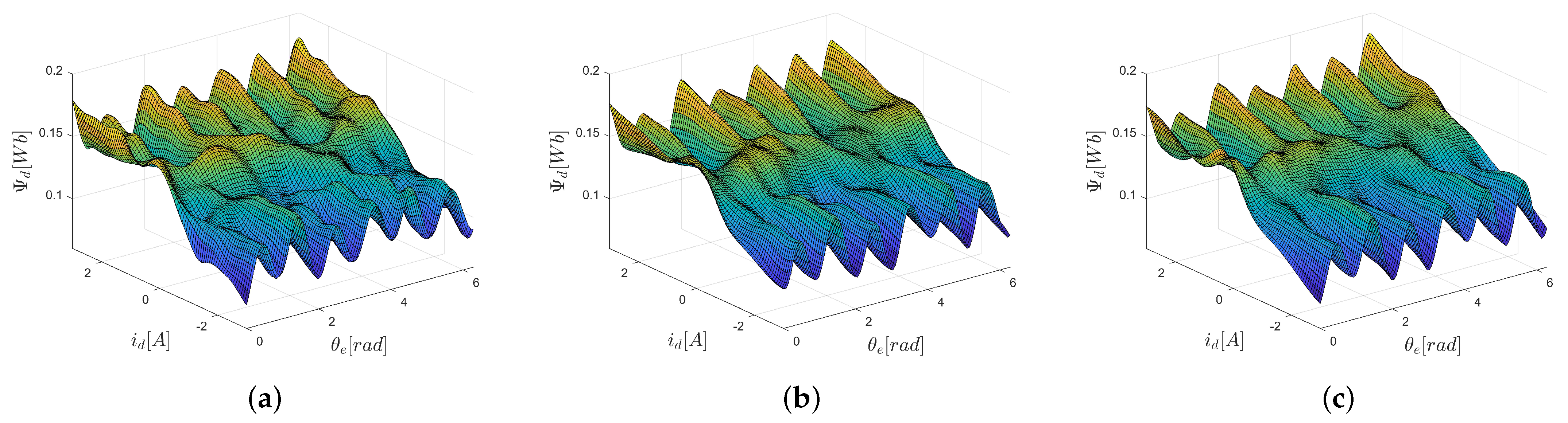
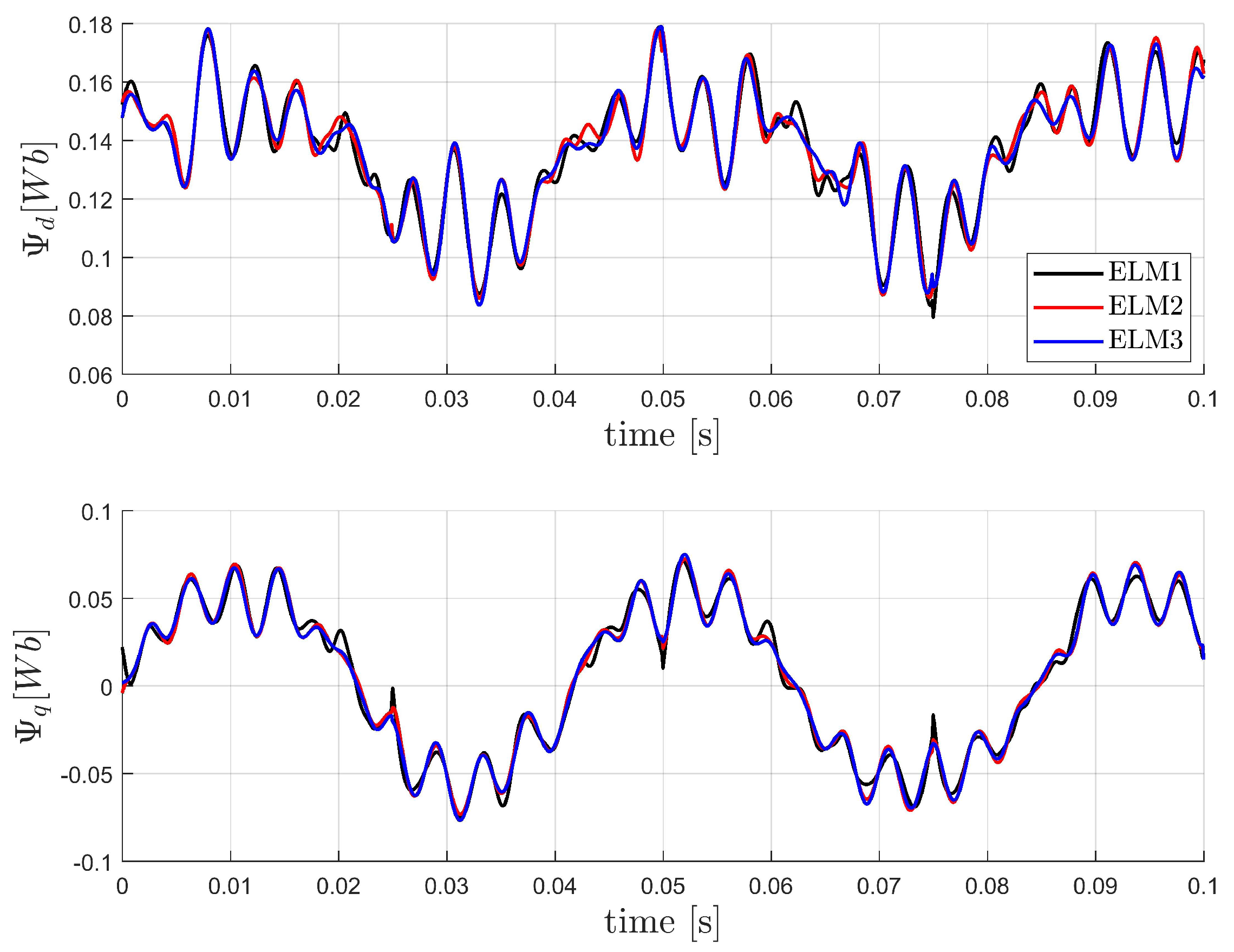
5.2. Motor Flux Modeling
- training data , , where are randomly selected from the input area [0,1] × [0,1],
- training data corrupted by noise , , where is a random variable possessing normal distribution ,
- testing data , randomly selected from the input area [0,1] × [0,1], different from the training data. is used for all experiments.
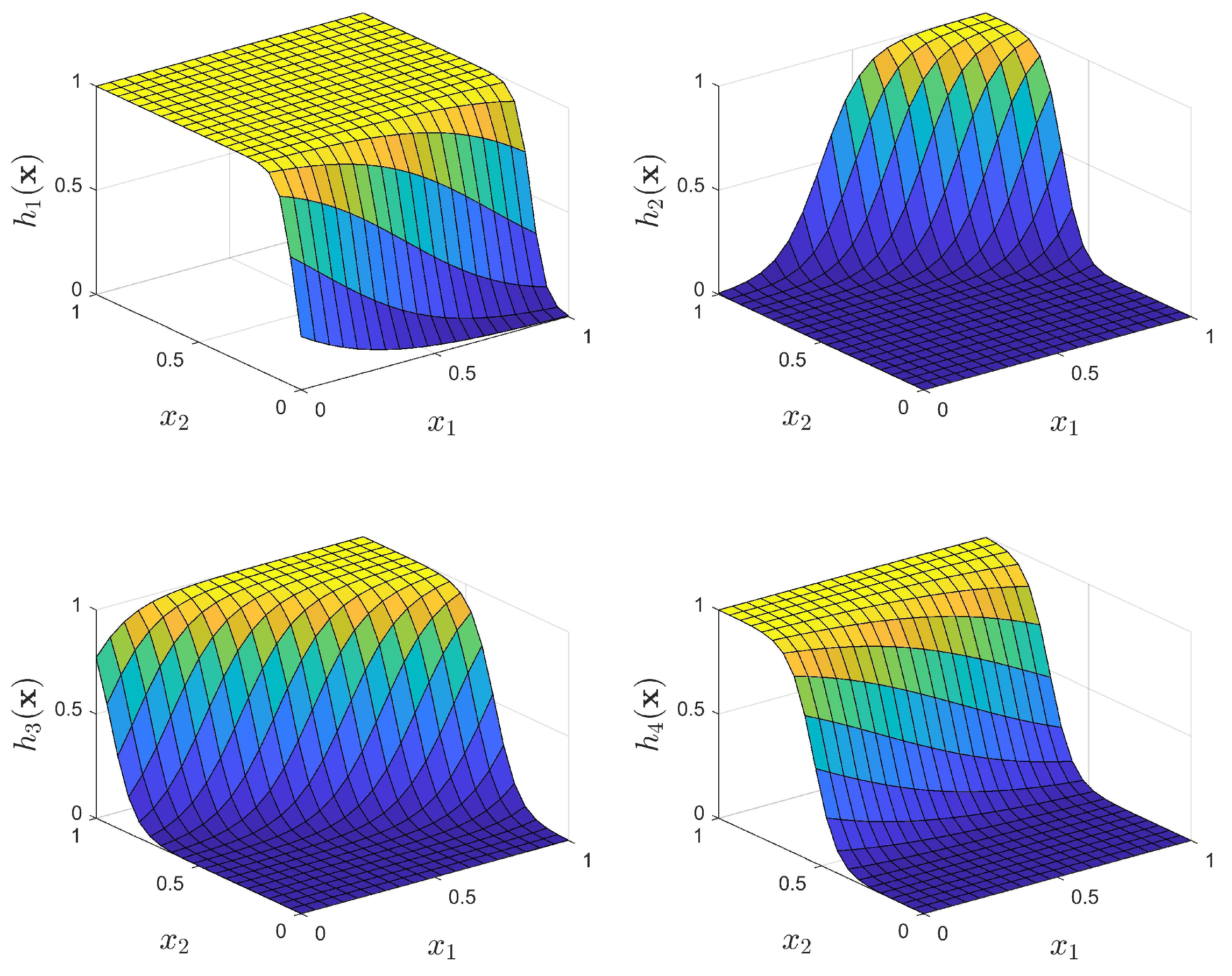
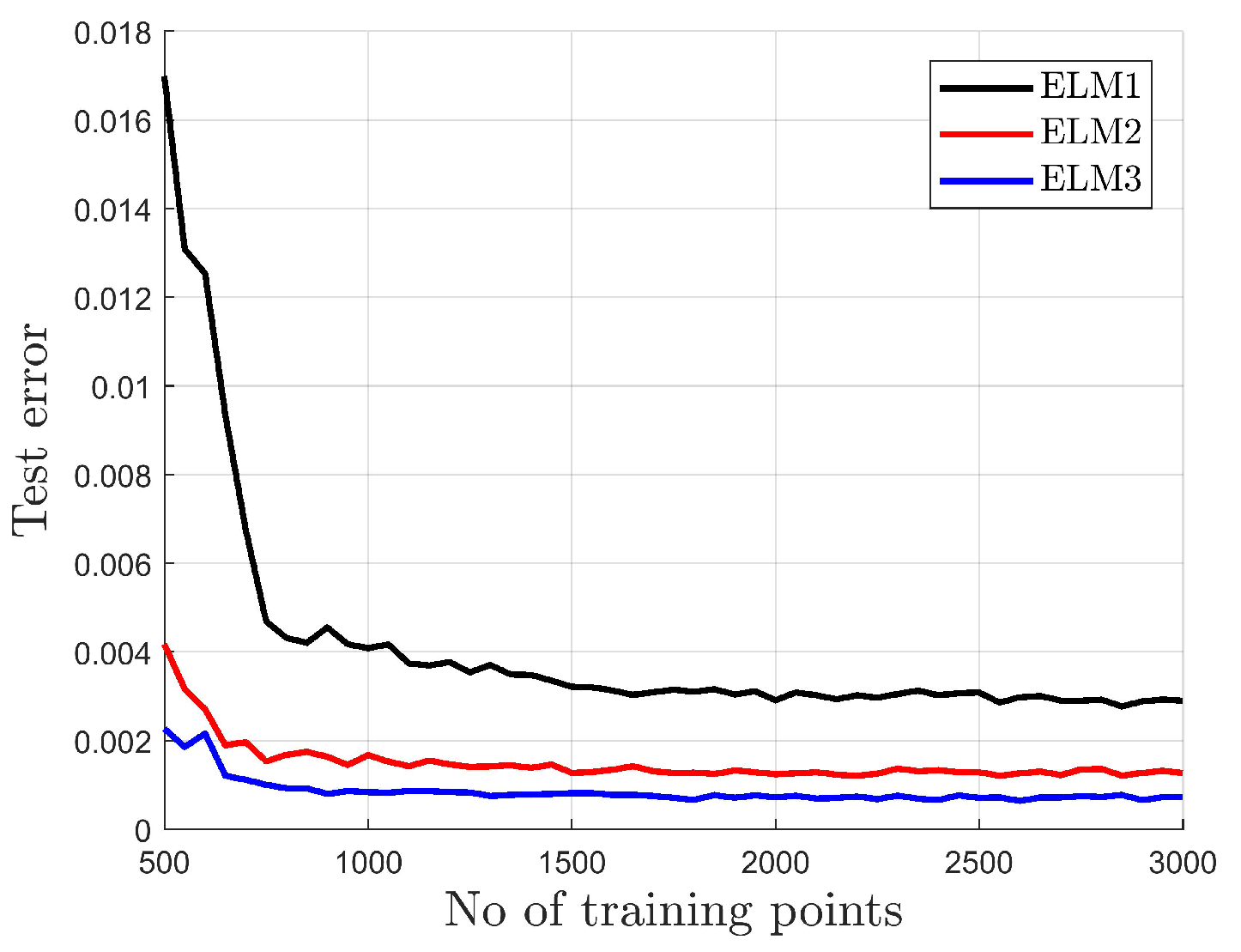
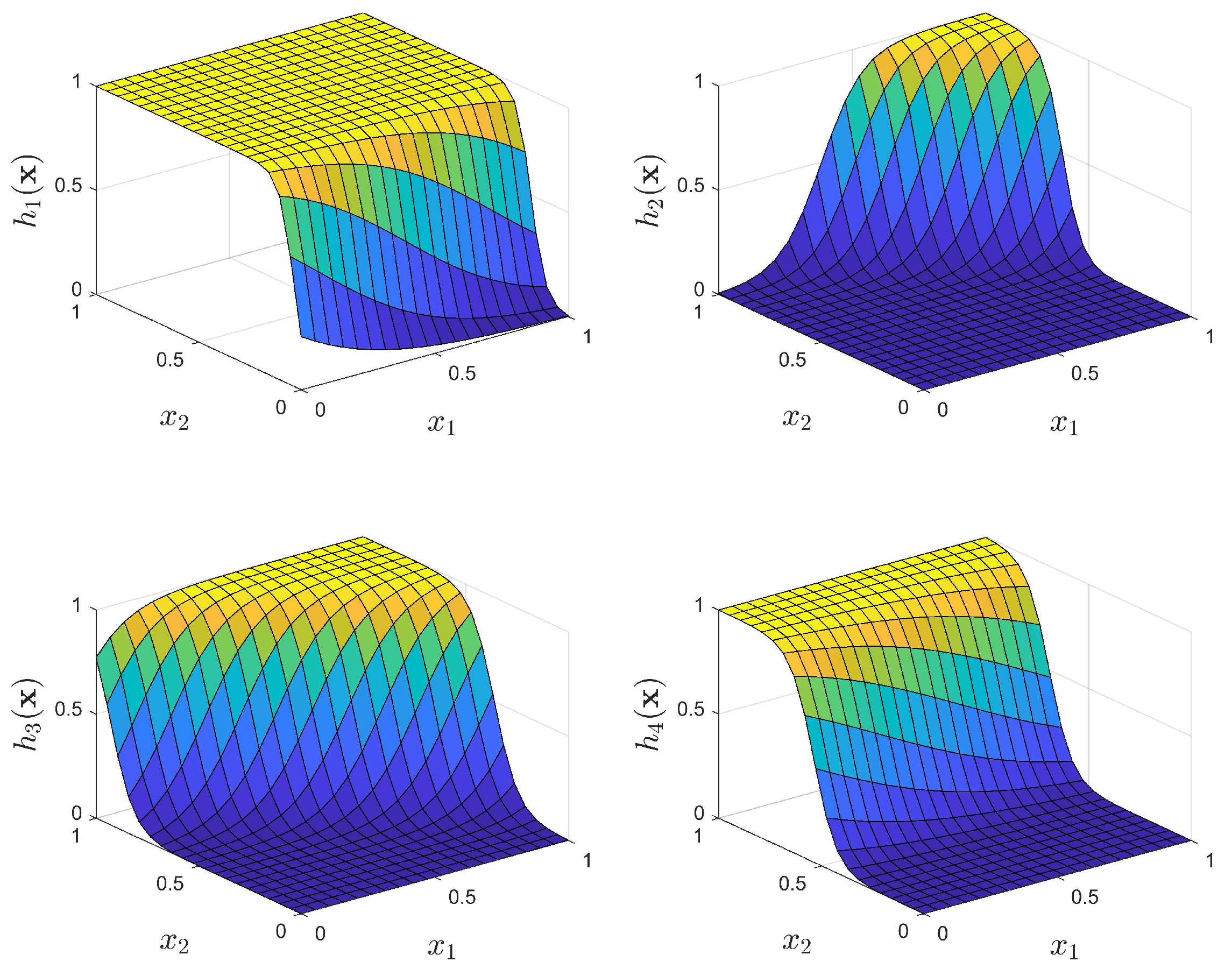
- ELM1: The standard ELM given by (5), (7) with the input weights selected randomly, according to a uniform distribution, from the interval and the biases selected according to (8) for , This approach provides activation functions with a sufficient variance, as presented in Figure 11.
- ELM2: The network with input-dependent output weights, according to (9):where the knowledge about the motor construction (number of pole pairs) is used to propose , .
- ELM3: The network with input-dependent output weights, according to (14):where , are selected at random from interval [−1,1].
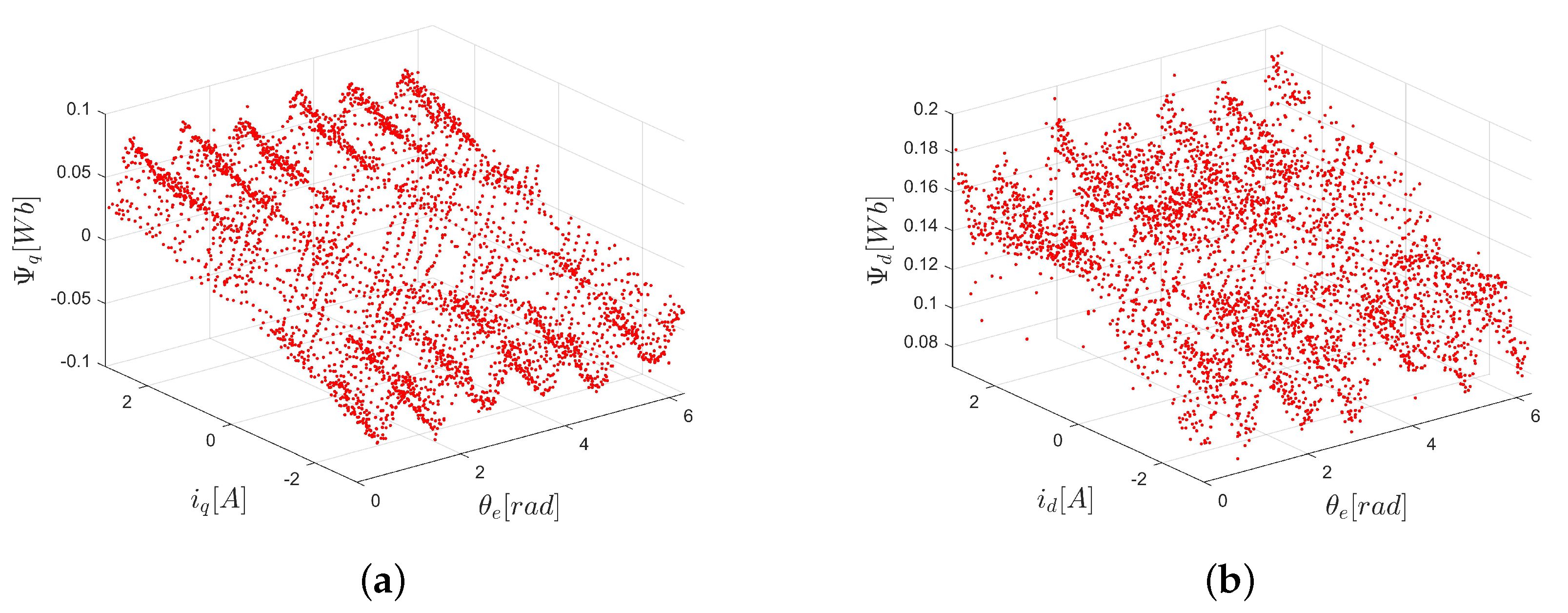
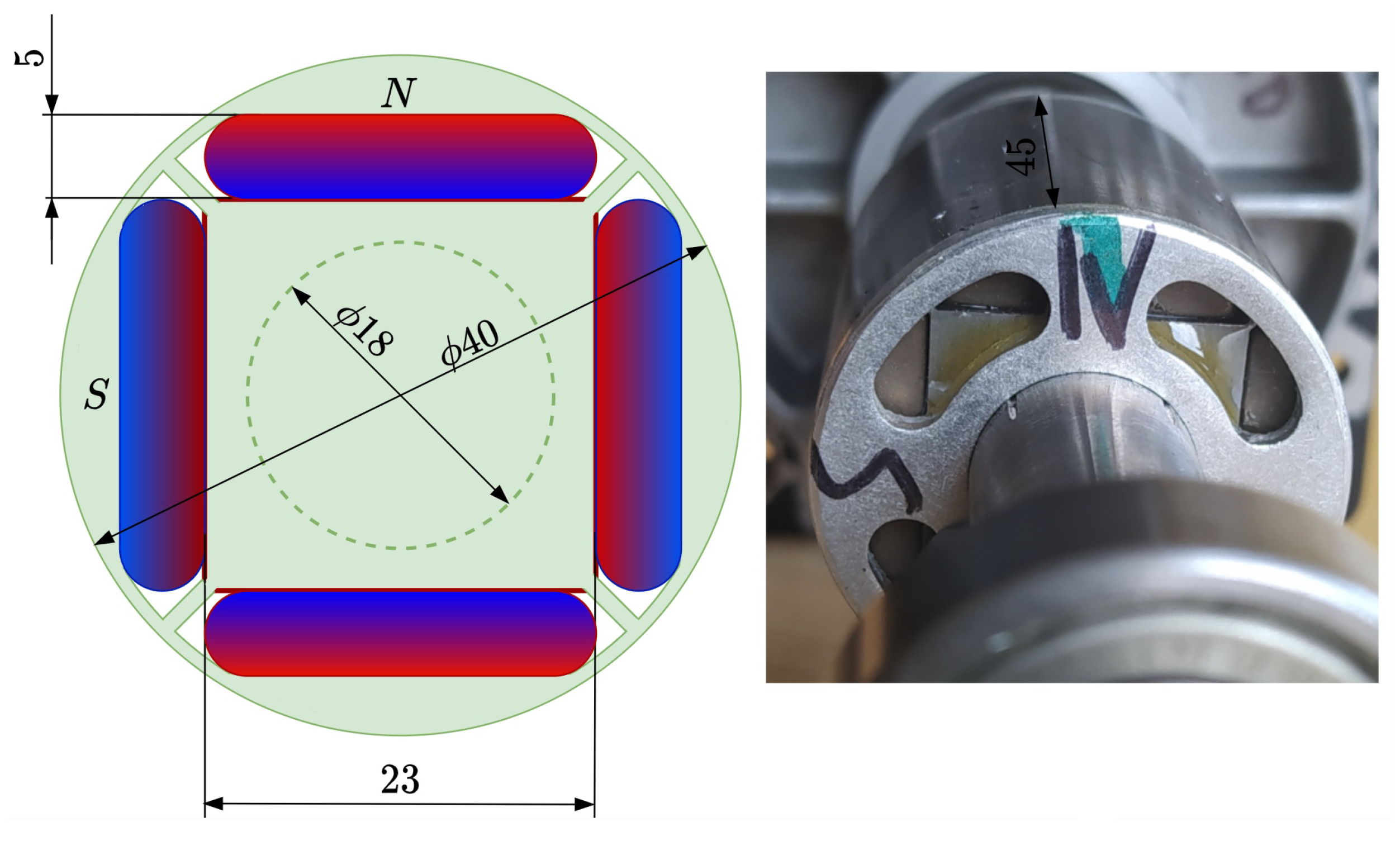
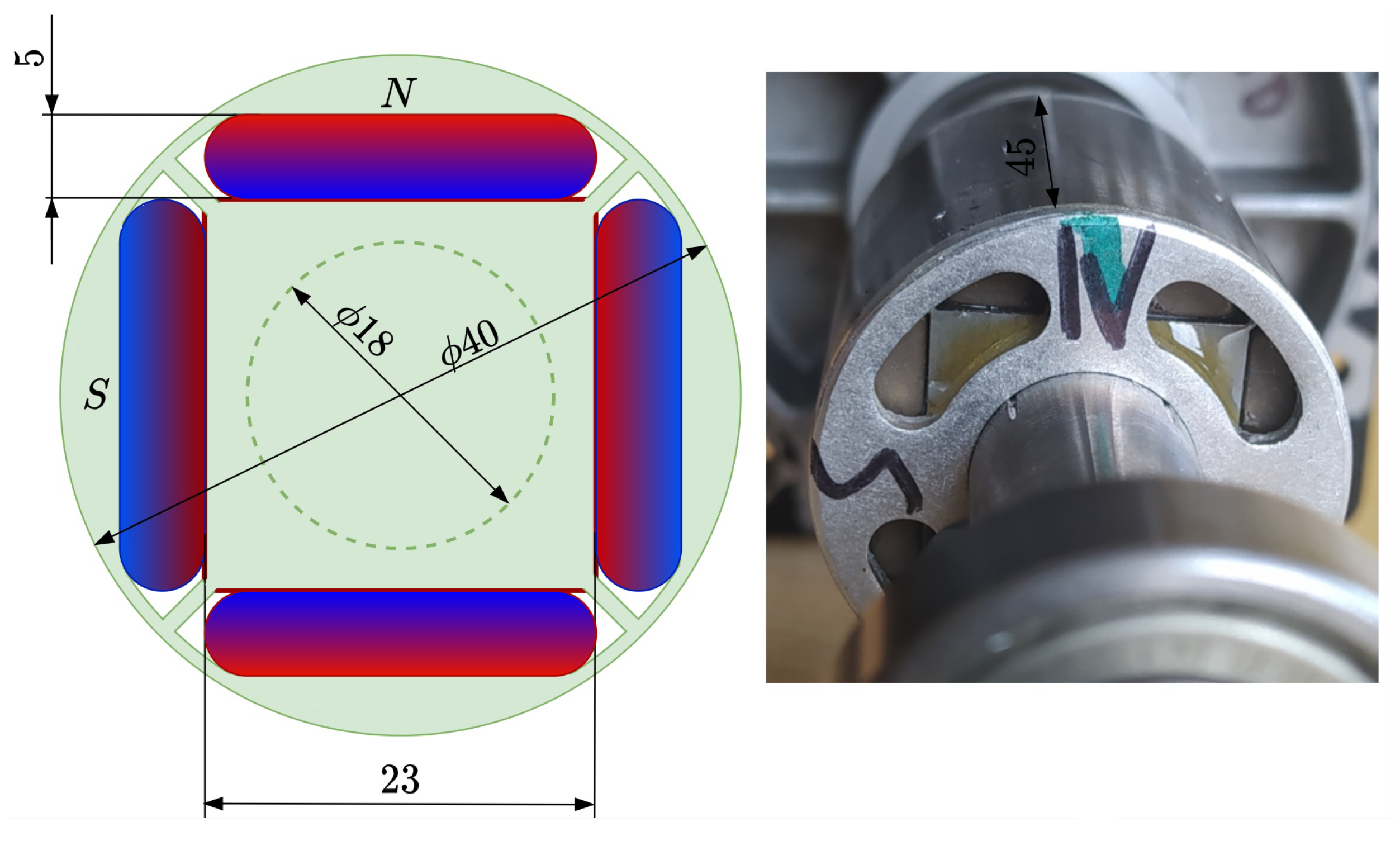
5.3. Modeling of Experimental Data
6. Conclusions
- the universal approximation property,
- fast, random selection of parameters of activation functions,
- extremely short learning time, as learning is not an iterative process, but is reduced to a single algebraic operation.
- offering better modeling accuracy for the same number of output weights and a smaller number of parameters, while assuring the same accuracy, therefore reducing the problem of dimensionality,
- generating lower output weights and better numerical conditioning of output weight calculation,
- being more flexible for Tikhonov regularization,
- being more robust against data noise,
- being more robust against small training data sets.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Waide, P.; Brunner, C.U. Energy-Efficiency Policy Opportunities for Electric Motor-Driven Systems; International Energy Agency: Paris, France, 2011; 132p. [Google Scholar] [CrossRef]
- Melfi, M.J.; Rogers, S.D.; Evon, S.; Martin, B. Permanent Magnet Motors for Energy Savings in Industrial Applications. In Proceedings of the 2006 Record of Conference Papers—IEEE Industry Applications Society 53rd Annual Petroleum and Chemical Industry Conference, Philadelphia, PA, USA, 11–15 September 2006; pp. 1–8. [Google Scholar] [CrossRef]
- Baek, S.K.; Oh, H.K.; Park, J.H.; Shin, Y.J.; Kim, S.W. Evaluation of Efficient Operation for Electromechanical Brake Using Maximum Torque per Ampere Control. Energies 2019, 12, 1869. [Google Scholar] [CrossRef] [Green Version]
- Tochenko, O. Energy Efficient Speed Control of Interior Permanent Magnet Synchronous Motor. In Applied Modern Control; IntechOpen: London, UK, 2019. [Google Scholar] [CrossRef] [Green Version]
- Mellor, P.; Wrobel, R.; Holliday, D. A Computationally Efficient Iron Loss Model for Brushless AC Machines That Caters for Rated Flux and Field Weakened Operation. In Proceedings of the 2009 IEEE International Electric Machines and Drives Conference, Miami, FL, USA, 3–6 May 2009; pp. 490–494. [Google Scholar] [CrossRef]
- Tseng, K.; Wee, S. Analysis of Flux Distribution and Core Losses in Interior Permanent Magnet Motor. IEEE Trans. Energy Convers. 1999, 14, 969–975. [Google Scholar] [CrossRef]
- Chakkarapani, K.; Thangavelu, T.; Dharmalingam, K.; Thandavarayan, P. Multiobjective Design Optimization and Analysis of Magnetic Flux Distribution for Slotless Permanent Magnet Brushless DC motor using evolutionary algorithms. J. Magn. Magn. Mater. 2019, 476, 524–537. [Google Scholar] [CrossRef]
- Lee, J.G.; Lim, D.K. A Stepwise Optimal Design Applied to an Interior Permanent Magnet Synchronous Motor for Electric Vehicle Traction Applications. IEEE Access 2021, 9, 115090–115099. [Google Scholar] [CrossRef]
- Liang, P.; Pei, Y.; Chai, F.; Zhao, K. Analytical Calculation of D- and Q-axis Inductance for Interior Permanent Magnet Motors Based on Winding Function Theory. Energies 2016, 9, 580. [Google Scholar] [CrossRef] [Green Version]
- Michalski, T.; Acosta-Cambranis, F.; Romeral, L.; Zaragoza, J. Multiphase PMSM and PMaSynRM Flux Map Model with Space Harmonics and Multiple Plane Cross Harmonic Saturation. In Proceedings of the IECON 2019—45th Annual Conference of the IEEE Industrial Electronics Society, Lisbon, Portugal, 14–17 October 2019; Volume 1, pp. 1210–1215. [Google Scholar] [CrossRef]
- Hua, W.; Cheng, M.; Zhu, Z.Q.; Howe, D. Analysis and Optimization of Back EMF Waveform of a Flux-Switching Permanent Magnet Motor. IEEE Trans. Energy Convers. 2008, 23, 727–733. [Google Scholar] [CrossRef]
- Khan, A.A.; Kress, M.J. Identification of Permanent Magnet Synchronous Motor Parameters. In Proceedings of the WCX™ 17: SAE World Congress Experience, Detroit, MI, USA, 4–6 April 2017; SAE International: Warrendale, PA, USA, 2017. [Google Scholar] [CrossRef]
- Kumar, P.; Bhaskar, D.V.; Muduli, U.R.; Beig, A.R.; Behera, R.K. Disturbance Observer based Sensorless Predictive Control for High Performance PMBLDCM Drive Considering Iron Loss. IEEE Trans. Ind. Electron. 2021. [Google Scholar] [CrossRef]
- Rehman, A.U.; Choi, H.H.; Jung, J.W. An Optimal Direct Torque Control Strategy for Surface-Mounted Permanent Magnet Synchronous Motor Drives. IEEE Trans. Ind. Inform. 2021, 17, 7390–7400. [Google Scholar] [CrossRef]
- Jastrzębski, M.; Kabziński, J.; Mosiołek, P. Adaptive and Robust Motion Control in Presence of LuGre-type Friction. In Proceedings of the 2017 22nd International Conference on Methods and Models in Automation and Robotics (MMAR), Miedzyzdroje, Poland, 28–31 August 2017; pp. 113–118. [Google Scholar] [CrossRef]
- Kabziński, J.; Orłowska-Kowalska, T.; Sikorski, A.; Bartoszewicz, A. Adaptive, Predictive and Neural Approaches in Drive Automation and Control of Power Converters. Bull. Pol. Acad. Sci. Tech. Sci. 2020, 68, 959–962. [Google Scholar] [CrossRef]
- Kabziński, J. Advanced Control of Electrical Drives and Power Electronic Converters; Springer: Cham, Switzerland, 2017. [Google Scholar] [CrossRef]
- Sun, J.; Lin, C.; Xing, J.; Jiang, X. Online MTPA Trajectory Tracking of IPMSM Based on a Novel Torque Control Strategy. Energies 2019, 12, 3261. [Google Scholar] [CrossRef] [Green Version]
- Dianov, A.; Anuchin, A. Adaptive Maximum Torque per Ampere Control of Sensorless Permanent Magnet Motor Drives. Energies 2020, 13, 5071. [Google Scholar] [CrossRef]
- Zhou, Z.; Gu, X.; Wang, Z.; Zhang, G.; Geng, Q. An Improved Torque Control Strategy of PMSM Drive Considering On-Line MTPA Operation. Energies 2019, 12, 2951. [Google Scholar] [CrossRef] [Green Version]
- Yoon, K.Y.; Baek, S.W. Performance Improvement of Concentrated-Flux Type IPM PMSM Motor with Flared-Shape Magnet Arrangement. Appl. Sci. 2020, 10, 6061. [Google Scholar] [CrossRef]
- Huynh, T.A.; Hsieh, M.F. Performance Analysis of Permanent Magnet Motors for Electric Vehicles (EV) Traction Considering Driving Cycles. Energies 2018, 11, 1385. [Google Scholar] [CrossRef] [Green Version]
- Jang, H.; Kim, H.; Liu, H.C.; Lee, H.J.; Lee, J. Investigation on the Torque Ripple Reduction Method of a Hybrid Electric Vehicle Motor. Energies 2021, 14, 1413. [Google Scholar] [CrossRef]
- Krishnan, R. Permanent Magnet Synchronous and Brushless DC Motor Drives; CRC Press: Boca Raton, FL, USA, 2010. [Google Scholar]
- Kabzinski, J. Fuzzy Modeling of Disturbance Torques/Forces in Rotational/Linear Interior Permanent Magnet Synchronous Motors. In Proceedings of the 2005 European Conference on Power Electronics and Applications, Dresden, Germany, 11–14 September 2005; p. 10. [Google Scholar] [CrossRef]
- De Castro, A.G.; Guazzelli, P.R.U.; Lumertz, M.M.; de Oliveira, C.M.R.; de Paula, G.T.; Monteiro, J.R.B.A. Novel MTPA Approach for IPMSM with Non-Sinusoidal Back-EMF. In Proceedings of the 2019 IEEE 15th Brazilian Power Electronics Conference and 5th IEEE Southern Power Electronics Conference (COBEP/SPEC), Santos, Brazil, 1–4 December 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Lin, H.; Hwang, K.Y.; Kwon, B.I. An Improved Flux Observer for Sensorless Permanent Magnet Synchronous Motor Drives with Parameter Identification. J. Electr. Eng. Technol. 2013, 8, 516–523. [Google Scholar] [CrossRef] [Green Version]
- Sobieraj, T. Selection of the Parameters for the Optimal Control Strategy for Permanent-Magnet Synchronous Motor. Prz. Elektrotech. 2018, 94, 91–94. [Google Scholar] [CrossRef]
- Wójcik, A.; Pajchrowski, T. Application of Iterative Learning Control for Ripple Torque Compensation in PMSM Drive. Arch. Electr. Eng. 2019, 68, 309–324. [Google Scholar] [CrossRef]
- Mosiołek, P. Sterowanie Adaptacyjne Silnikiem PMSM z Dowolnym Rozkładem Strumienia. Prz. Elektrotech. 2014, 90, 103–108. [Google Scholar] [CrossRef]
- Kabziński, J. Oscillations and Friction Compensation in Two-Mass Drive System with Flexible Shaft by Command Filtered Adaptive Backstepping. IFAC-Pap. 2015, 48, 307–312. [Google Scholar] [CrossRef]
- Veeser, F.; Braun, T.; Kiltz, L.; Reuter, J. Nonlinear Modelling, Flatness-Based Current Control, and Torque Ripple Compensation for Interior Permanent Magnet Synchronous Machines. Energies 2021, 14, 1590. [Google Scholar] [CrossRef]
- Kabziński, J.; Sobieraj, T. Auto-Tuning of Permanent Magnet Motor Drives with Observer Based Parameter Identifiers. In Proceedings of the 10th International Conference on Power Electronics and Motion Control, Dubrovnik & Cavtat, Croatia, 9–11 September 2002. [Google Scholar]
- Huang, G.B.; Zhu, Q.Y.; Siew, C.K. Extreme Larning Machine: Theory and Applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Huang, G.B.; Zhou, H.; Ding, X.; Zhang, R. Extreme Learning Machine for Regression and Multiclass Classification. IEEE Trans. Syst. Man Cybern. Part B (Cybern.) 2012, 42, 513–529. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tikhonov, A.N.; Goncharsky, A.V.; Stepanov, V.V.; Yagola, A.G. Numerical Methods for the Solution of Ill-Posed Problems; Springer: Dordrecht, The Netherlands, 1995. [Google Scholar] [CrossRef]
- Huang, G.; Huang, G.B.; Song, S.; You, K. Trends in Extreme Learning Machines: A Review. Neural Netw. 2015, 61, 32–48. [Google Scholar] [CrossRef] [PubMed]
- Kabziński, J. Rank-Revealing Orthogonal Decomposition in Extreme Learning Machine Design. In Artificial Neural Networks and Machine Learning—ICANN 2018; Kůrková, V., Manolopoulos, Y., Hammer, B., Iliadis, L., Maglogiannis, I., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 3–13. [Google Scholar]
- Akusok, A.; Björk, K.M.; Miche, Y.; Lendasse, A. High-Performance Extreme Learning Machines: A Complete Toolbox for Big Data Applications. IEEE Access 2015, 3, 1011–1025. [Google Scholar] [CrossRef]
- Kabziński, J. Extreme learning machine with diversified neurons. In Proceedings of the 2016 IEEE 17th International Symposium on Computational Intelligence and Informatics (CINTI), Budapest, Hungary, 17–19 November 2016; pp. 000181–000186. [Google Scholar] [CrossRef]
- Miche, Y.; Sorjamaa, A.; Bas, P.; Simula, O.; Jutten, C.; Lendasse, A. OP-ELM: Optimally Pruned Extreme Learning Machine. IEEE Trans. Neural Netw. 2010, 21, 158–162. [Google Scholar] [CrossRef] [PubMed]
- Feng, G.; Lan, Y.; Zhang, X.; Qian, Z. Dynamic Adjustment of Hidden Node Parameters for Extreme Learning Machine. IEEE Trans. Cybern. 2015, 45, 279–288. [Google Scholar] [CrossRef]
- Miche, Y.; van Heeswijk, M.; Bas, P.; Simula, O.; Lendasse, A. TROP-ELM: A Double-Regularized ELM Using LARS and Tikhonov Regularization. Neurocomputing 2011, 74, 2413–2421. [Google Scholar] [CrossRef]
- Parviainen, E.; Riihimäki, J. A Connection Between Extreme Learning Machine and Neural Network Kernel. Commun. Comput. Inf. Sci. 2013, 272, 122–135. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Signal/Parameter | Unit |
|---|---|---|
| d-axis inductance | [H] | |
| q-axis inductance | [H] | |
| phase resistance | [] | |
| d and q permanent magnet flux components | [Vs/rad] | |
| d current dependant and magnet flux components | [Vs/rad] | |
| q current dependant and magnet flux components | [Vs/rad] | |
| d flux derivative with respect to currents | [H] | |
| q flux derivative with respect to currents | [H] | |
| electric rotor position | [rad] | |
| electric rotor velocity | [rad/s] | |
| , | d- and q-axis voltages | [V] |
| Notation | Signal/Parameter |
|---|---|
| Rated power | 1.5 kW |
| Rated velocity | 6200 r/min |
| Rated torque | 2.59 Nm |
| Rated current | 5 A |
| Inertia | kgm |
| EMF constant | 0.1147 Vs |
| Torque constant | 0.49 Nm/ARMS |
| Phase resistance | 2.34 |
| Phase inductance | 25 mH |
| Axis | ELM1 | ELM2 | ELM3 | |
|---|---|---|---|---|
| q | No of hidden neurons | 336 | 50 | 64 |
| No of output weights | 336 | 150 | 128 | |
| d | No of hidden neurons | 276 | 48 | 63 |
| No of output weights | 276 | 144 | 126 |
| DSP Board | ELM1 | ELM2 | ELM3 |
|---|---|---|---|
| DS1104 | 470 s | 70 s | 70 s |
| DS1006 | 30 s | 12 s | 12 s |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jastrzębski, M.; Kabziński, J. Approximation of Permanent Magnet Motor Flux Distribution by Partially Informed Neural Networks. Energies 2021, 14, 5619. https://doi.org/10.3390/en14185619
Jastrzębski M, Kabziński J. Approximation of Permanent Magnet Motor Flux Distribution by Partially Informed Neural Networks. Energies. 2021; 14(18):5619. https://doi.org/10.3390/en14185619
Chicago/Turabian StyleJastrzębski, Marcin, and Jacek Kabziński. 2021. "Approximation of Permanent Magnet Motor Flux Distribution by Partially Informed Neural Networks" Energies 14, no. 18: 5619. https://doi.org/10.3390/en14185619
APA StyleJastrzębski, M., & Kabziński, J. (2021). Approximation of Permanent Magnet Motor Flux Distribution by Partially Informed Neural Networks. Energies, 14(18), 5619. https://doi.org/10.3390/en14185619