
Outage Estimation in Electric Power Distribution Systems Using a Neural Network Ensemble



Abstract
:1. Introduction
2. Outage and Weather Data
3. Deep Neural Network Ensemble Approach
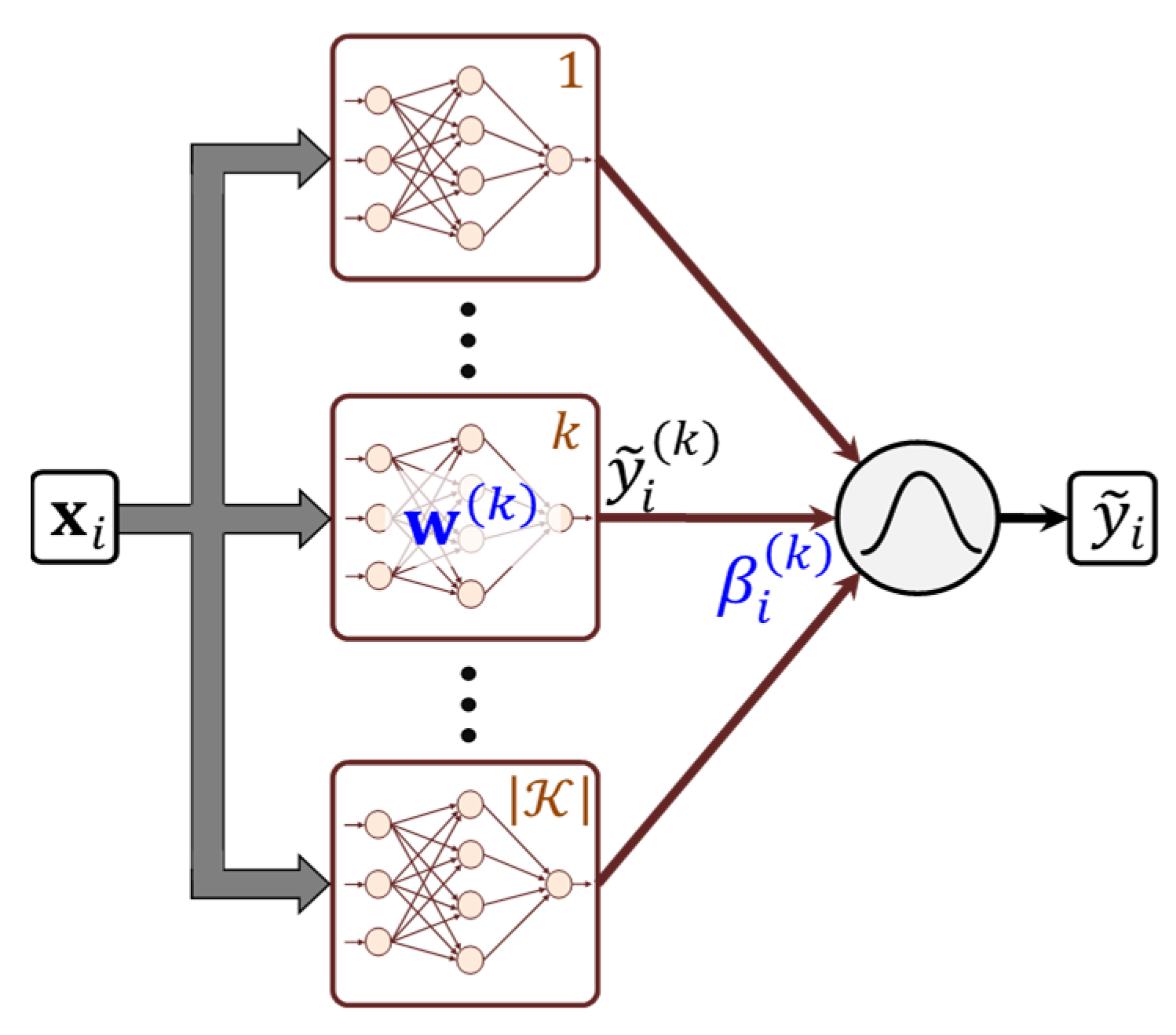
3.1. Layout of the Deep Neural Network Ensemble
3.2. Supervised Learning in Sub-Networks
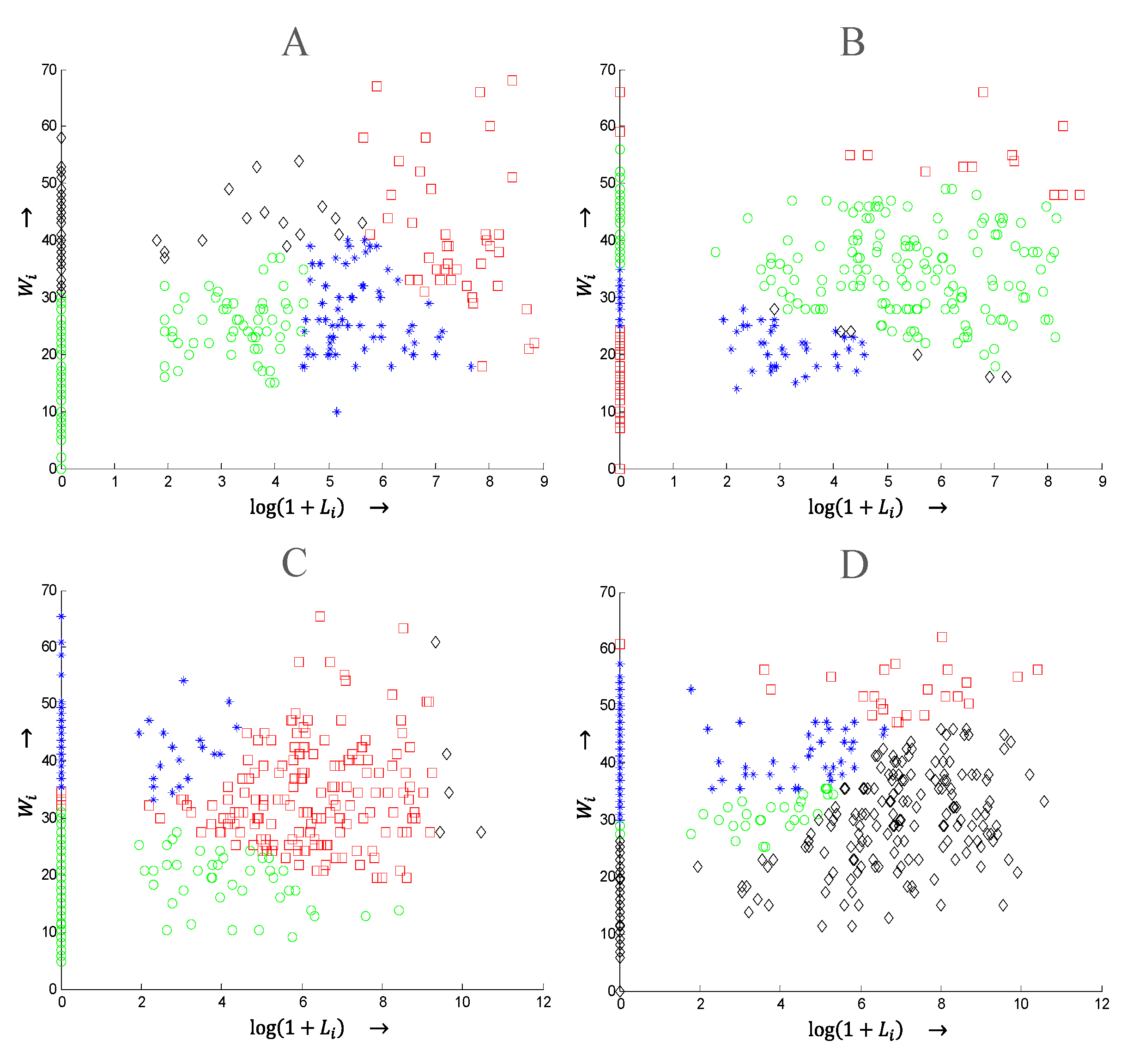
3.3. Partitioning Using Unsupervised Learning
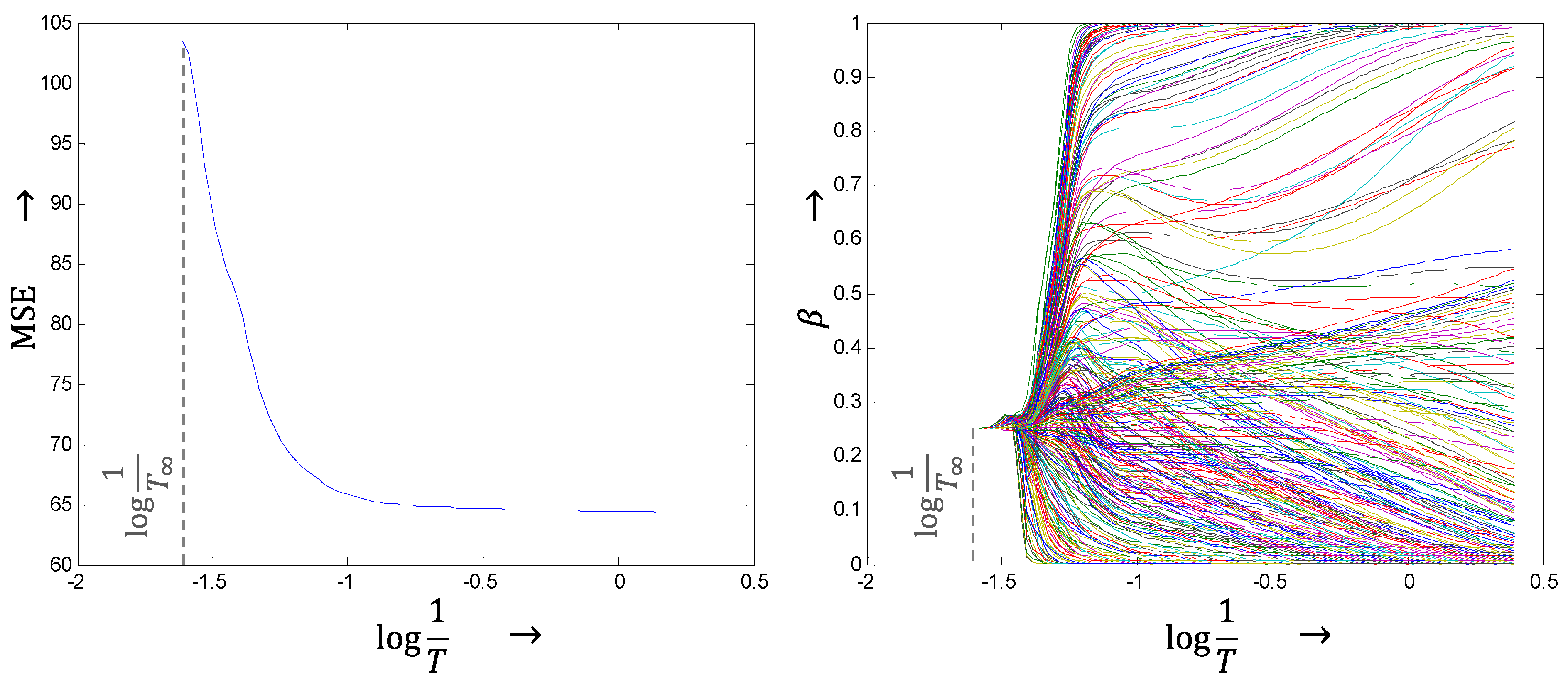
4. Theoretical Framework
4.1. Gaussian Distribution Assumption
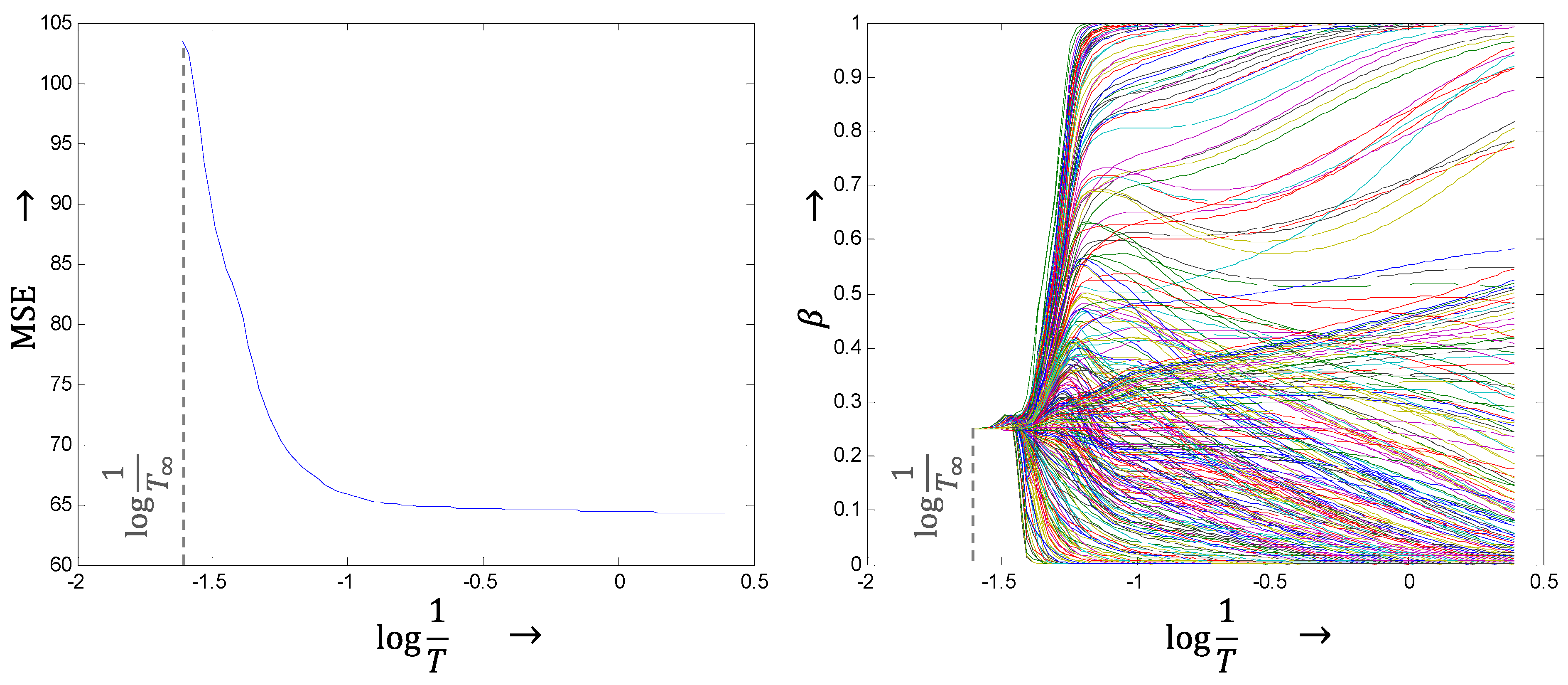
4.2. Markov Random Field Viewpoint
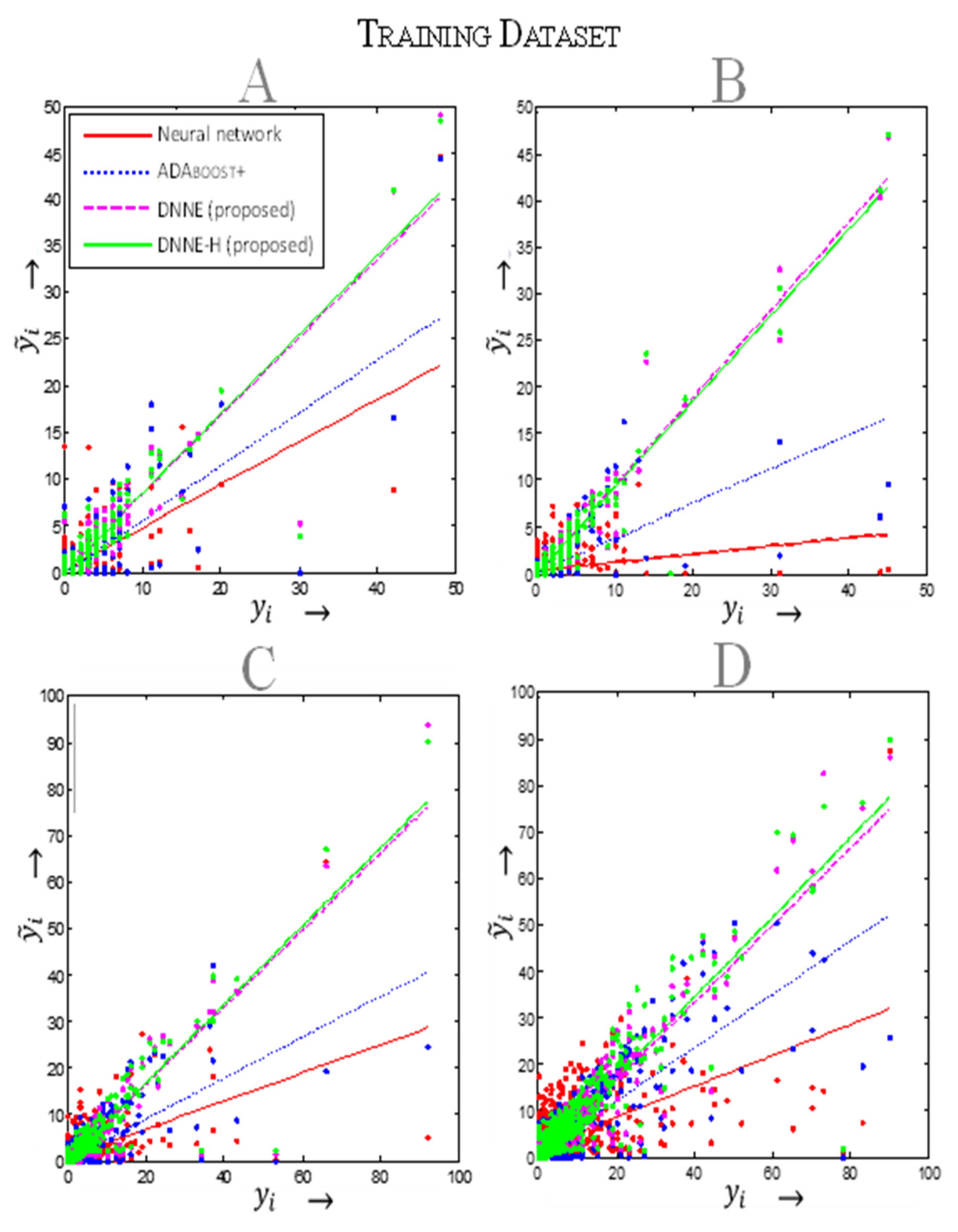
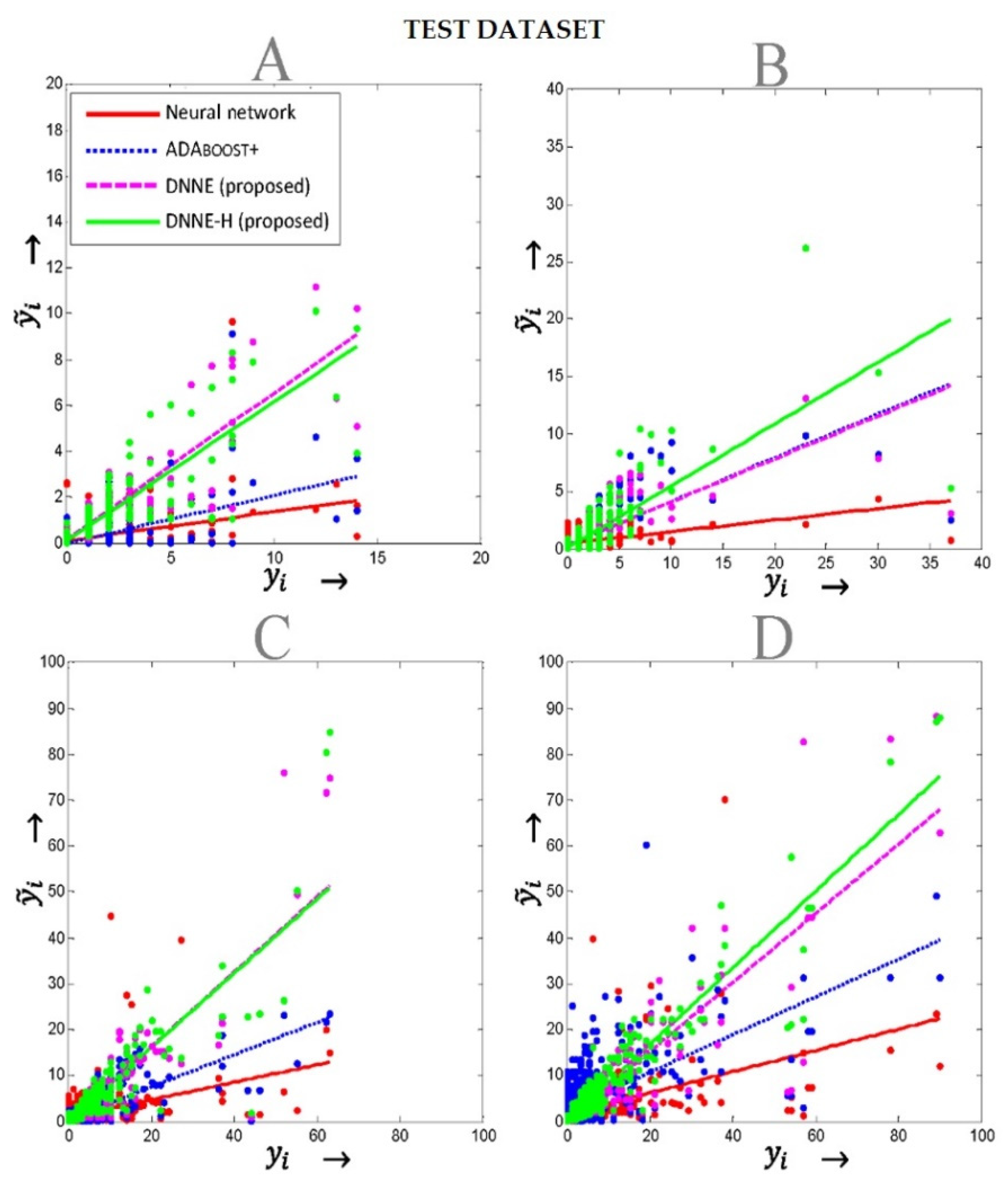
5. Results
5.1. Performance Metrics
- (i)
- Mean Absolute Error:
- (ii)
- Mean Squared Error:
- (iii)
- Slope: This is the slope of the best linear fit that passes through the origin.
- (iv)
- Coefficient of Correlation:
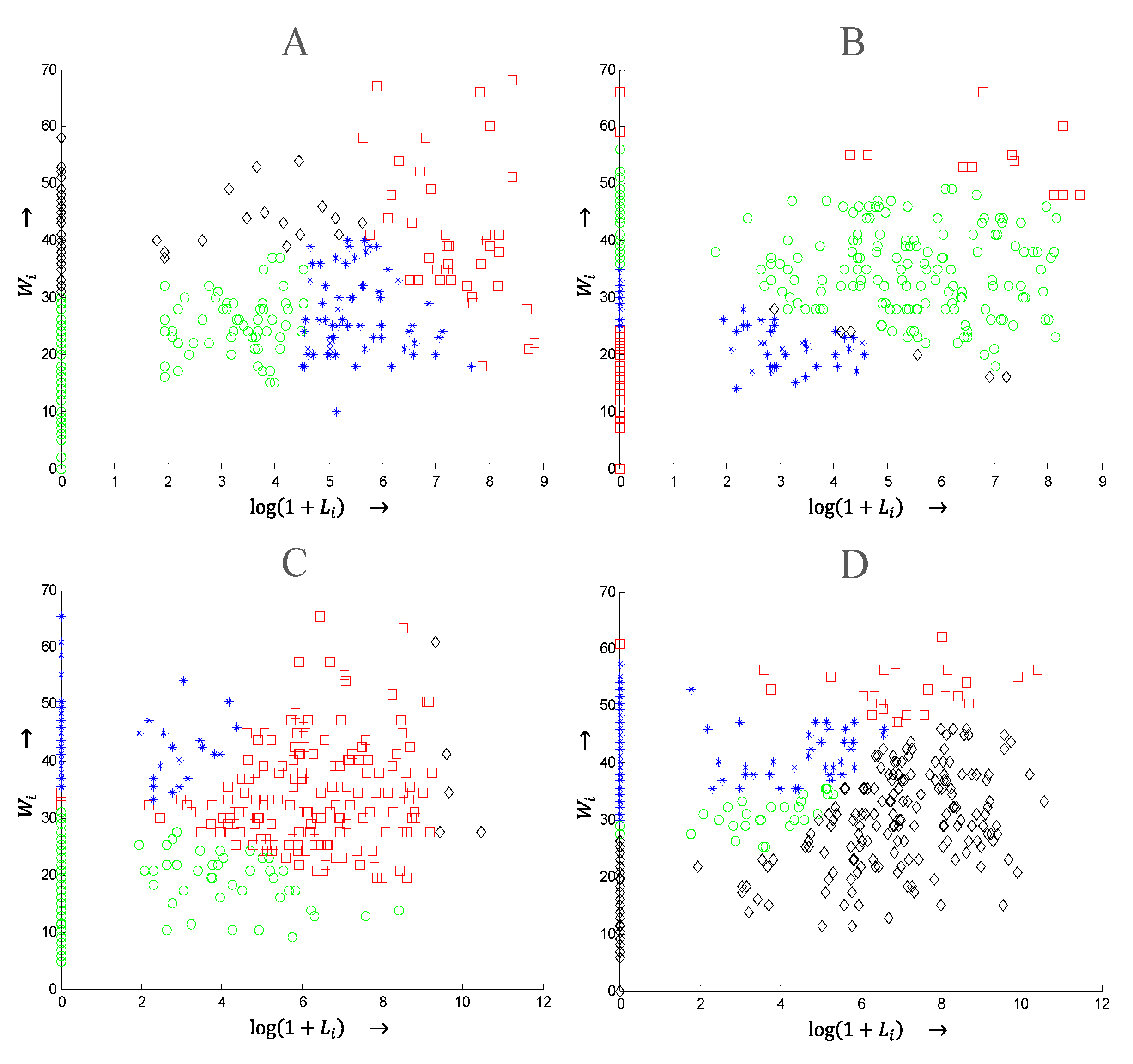
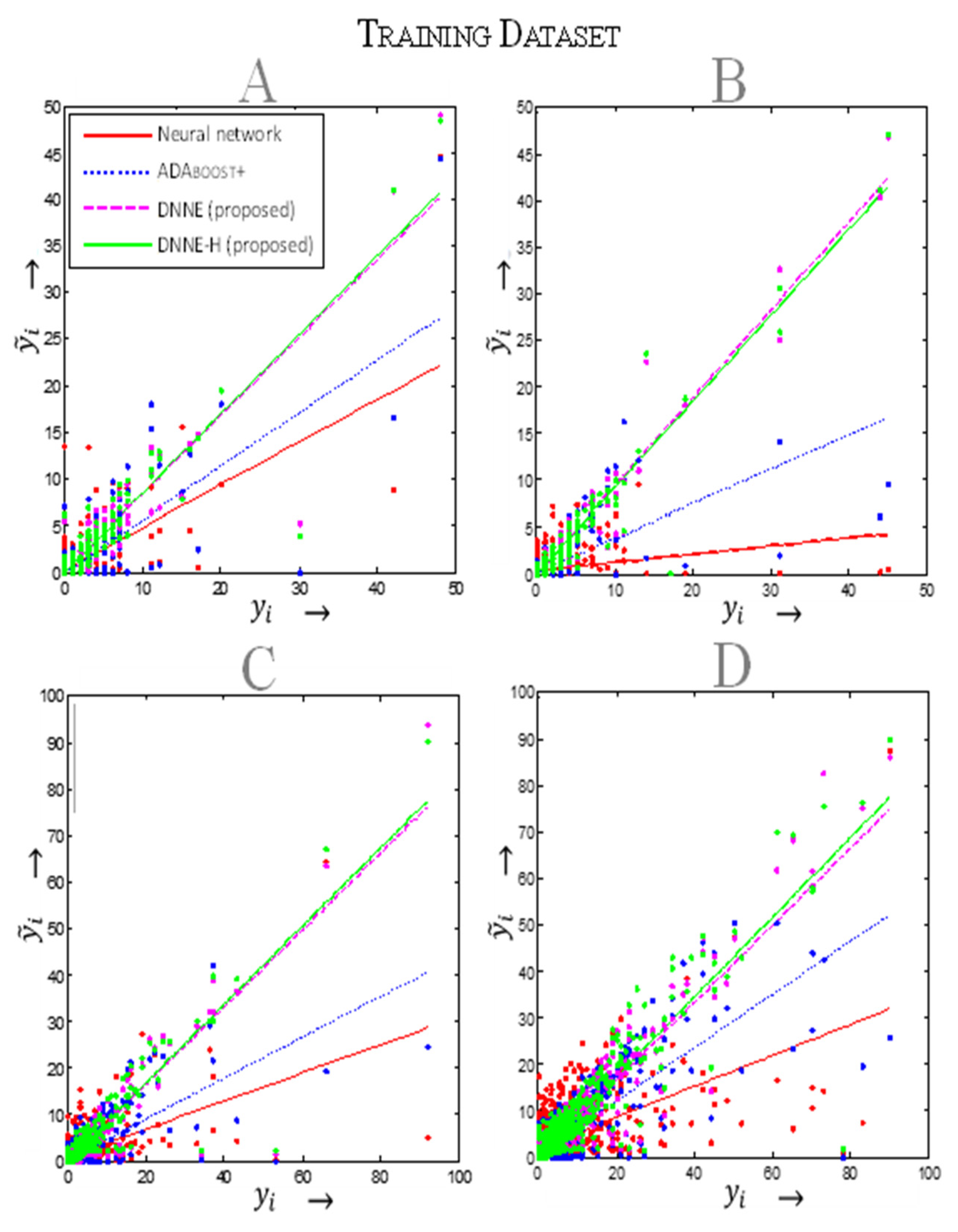
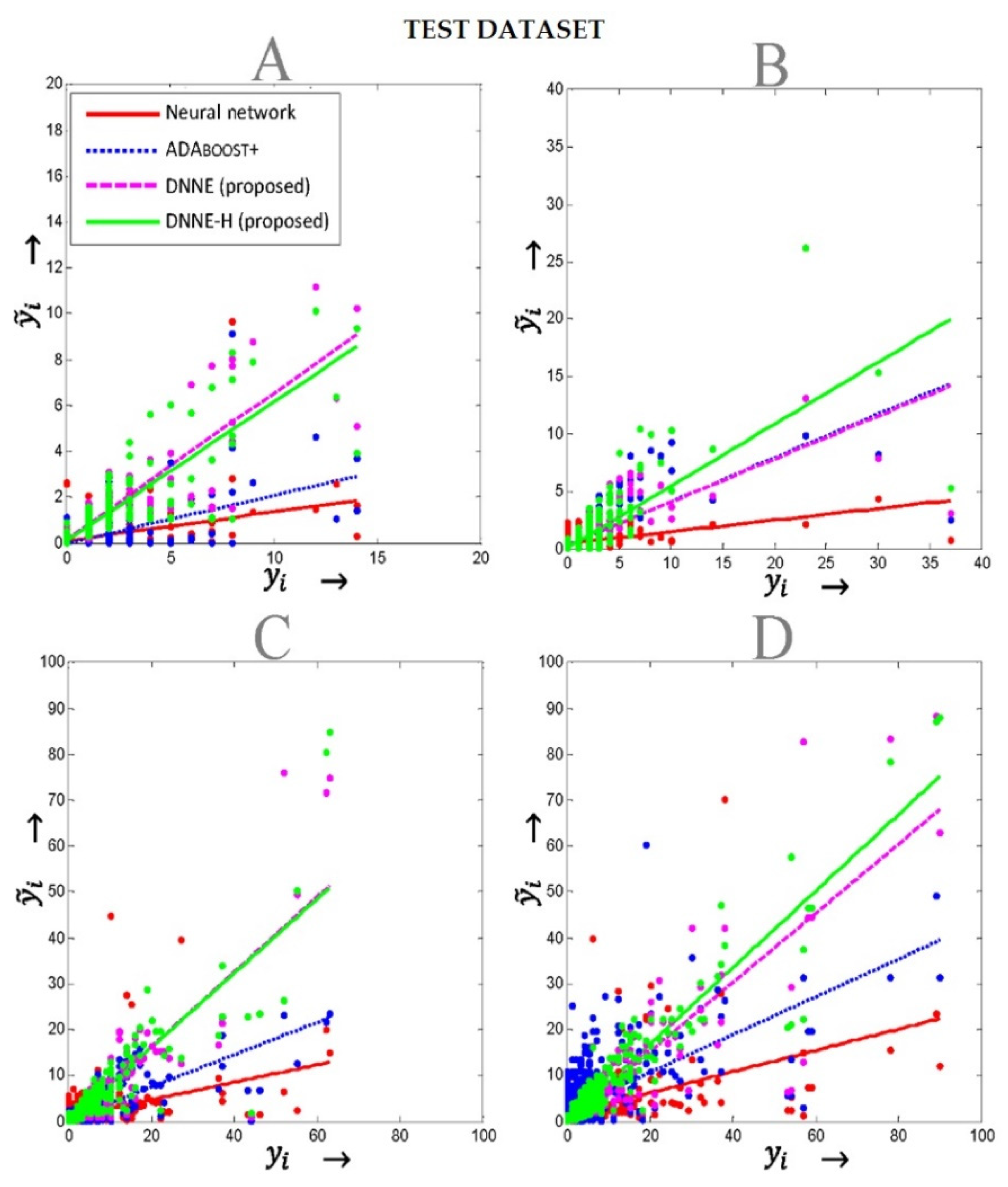
5.2. Weather-Related Outage Prediction
5.3. Animal-Related Outage Prediction
6. Conclusions
7. Nomenclature
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Caswell, H.; Forte, V.; Fraser, J.; Pahwa, A.; Short, T.; Thatcher, M.; Verner, V. Weather Normalization of Reliability Indices. IEEE Trans. Power Deliv. 2011, 26, 1273–1279. [Google Scholar] [CrossRef]
- Kankanala, P.; Pahwa, A.; Das, S. Regression Models for Outages Due to Wind and Lightning on Overhead Distribution Feeders. In Proceedings of the IEEE PES General Meeting 2011, Detroit, MI, USA, 24–28 July 2011. [Google Scholar]
- Kankanala, P.; Pahwa, A.; Das, S. Exponential Regression Models for Wind and Lightning Caused Outages on Overhead Distribution Feeders. In Proceedings of the North America Power Symposium (NAPS), Boston, MA, USA, 4–6 August 2011. [Google Scholar]
- Doostan, M.; Chowdhury, B. Statistical Analysis of Animal-Related Outages in Power Distribution Systems–A Case Study. In Proceedings of the IEEE Power & Energy Society General Meeting (PESGM), Atlanta, GA, USA, 4–6 August 2019. [Google Scholar]
- Kankanala, P.; Pahwa, A.; Das, S. Estimation of Overhead Distribution Outages Caused by Wind and Lightning Using an Artificial Neural Network. In Proceedings of the 9th International Conference on Power System Operation and Planning, Nairobi, Kenya, 16–19 January 2012. [Google Scholar]
- Sahai, S.; Pahwa, A. A Probabilistic Approach for Animal–Caused Outages in Overhead Distribution Systems. In Proceedings of the Probability Methods Applications to Power Systems Conference, Stockholm, Sweden, 11–15 June 2006. [Google Scholar]
- Gui, M.; Pahwa, A.; Das, S. Bayesian Network Model with Monte Carlo Simulations for Analysis of Animal-Related Outages in Overhead Distribution Systems. IEEE Trans. Power Syst. 2011, 26, 1618–1624. [Google Scholar] [CrossRef]
- Kankanala, P.; Das, S.; Pahwa, A. AdaBoost+: An Ensemble Learning Approach for Estimating Weather-Related Outages in Distribution Systems. IEEE Trans. Power Syst. 2014, 29, 359–367. [Google Scholar] [CrossRef] [Green Version]
- Kankanala, P.; Pahwa, A.; Das, S. Estimating Animal-Related Outages on Overhead Distribution Feeders using Boosting. In Proceedings of the 9th IFAC Symposium on Control of Power and Energy Systems, Delhi, New Delhi, 9–11 December 2015. [Google Scholar]
- Sarwat, A.I.; Amini, M.; Domijan, A., Jr.; Damnjanovic, A.; Kaleem, F. Weather–based Interruption Prediction in the Smart Grid Utilizing Chronological Data. J. Mod. Power Syst. Clean Energy 2016, 4, 308–315. [Google Scholar] [CrossRef] [Green Version]
- Pathan, A.; Timmerberg, J.; Mylvaganam, S. Some Case Studies of Power Outages with Possible Machine Learning Strategies for Their Predictions. In Proceedings of the 28th EAEEIE Annual Conference (EAEEIE), Hafnarfjordur, Iceland, 26–28 September 2018. [Google Scholar]
- Tervo, R.; Karjalainen, J.; Jung, A. Predicting Electricity Outages Caused by Convective Storms. In Proceedings of the IEEE Data Science Workshop (DSW), Lausanne, Switzerland, 4–6 June 2018. [Google Scholar]
- Nazmul Huda, A.S.; Živanović, R. An Efficient Method for Distribution System Reliability Evaluation Incorporating Weather Dependent Factors. In Proceedings of the 2019 IEEE International Conference on Industrial Technology (ICIT), Melbourne, Australia, 13–15 February 2019. [Google Scholar]
- Sadegh Bashkari, M.; Sami, A.; Rastegar, M. Outage Cause Detection in Power Distribution Systems Based on Data Mining. IEEE Trans. Ind. Inform. 2021, 17, 640–649. [Google Scholar] [CrossRef]
- Du, Y.; Liu, Y.; Wang, X.; Fang, J.; Sheng, G.; Jiang, X. Predicting Weather–Related Failure Risk in Distribution SystemsUsing Bayesian Neural Network. IEEE Trans. Smart Grid 2021, 12, 350–360. [Google Scholar] [CrossRef]
- Sze, V.; Chen, Y.; Yang, T.; Emer, J.S. Efficient Processing of Deep Neural Networks: A Tutorial and Survey. Proc. IEEE 2017, 105, 2295–2329. [Google Scholar] [CrossRef] [Green Version]
- Chiroma, H.; Abdullahi, U.A.; Abdulhamid, S.M.; Alarood, A.A.; Gabralla, L.A.; Rana, N.; Shuib, L.; Hashem, I.A.T.; Gbenga, D.E.; Abubakar, A.I.; et al. Progress on Artificial Neural Networks for Big Data Analytics: A Survey. IEEE Access 2019, 7, 70535–70551. [Google Scholar] [CrossRef]
- Abiodun, O.I.; Jantan, A.; Omolara, A.E.; Dada, K.V.; Umar, A.M.; Linus, O.U.; Kazaure, A.A.; Gana, U.; Kiru, M.U. Comprehensive Review of Artificial Neural Network Applications to Pattern Recognition. IEEE Access 2019, 7, 158820–158846. [Google Scholar] [CrossRef]
- Alimi, O.A.; Ouahada, K.; Abu-Mahfouz, A.M. A Review of Machine Learning Approaches to Power System Security and Stability. IEEE Access 2020, 8, 113512–113531. [Google Scholar] [CrossRef]
- Quan, H.; Khosravi, A.; Yang, D.; Srinivasan, D. A Survey of Computational Intelligence Techniques for Wind Power Uncertainty Quantification in Smart Grids. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 4582–4599. [Google Scholar] [CrossRef] [PubMed]
- Massaoudi, M.; Abu-Rub, H.; Refaat, S.S.; Chihi, I.; Oueslati, F.S. Deep Learning in Smart Grid Technology: A Review of Recent Advancements and Future Prospects. IEEE Access 2021, 9, 54558–54578. [Google Scholar] [CrossRef]
- Opitz, D.; Maclin, R. Popular ensemble methods: An empirical study. J. Artif. Intell. Res. 1999, 11, 169–198. [Google Scholar] [CrossRef]
- Yang, J.; Zeng, X.; Zhong, S.; Wu, S. Effective Neural Network Ensemble Approach for Improving Generalization Performance. IEEE Trans. Neural Netw. Learn. Syst. 2013, 24, 878–887. [Google Scholar] [CrossRef] [PubMed]
- Kim, E.; Oh, S.; Pedrycz, W.; Fu, Z. Reinforced Fuzzy Clustering-Based Ensemble Neural Networks. IEEE Trans. Fuzzy Syst. 2020, 28, 569–582. [Google Scholar] [CrossRef]
- Soares, S.; Antunes, C.H.; Araújo, R. Comparison of a genetic algorithm and simulated annealing for automatic neural network ensemble development. Neurocomputing 2013, 121, 498–511. [Google Scholar] [CrossRef] [Green Version]
- Dede, M.A.; Aptoula, E.; Genc, Y. Deep Network Ensembles for Aerial Scene Classification. IEEE Geosci. Remote. Sens. Lett. 2019, 16, 732–735. [Google Scholar] [CrossRef]
- Perrone, M.P.; Cooper, L.N. When Networks Disagree: Ensemble Methods for Hybrid Neural Networks. In Neural Networks for Speech and Image Processing; Mammone, R.J., Ed.; Chapman-Hall: London, UK, 1993. [Google Scholar]
- Musikawan, P.; Sunat, K.; Kongsorot, Y.; Horata, P.; Chiewchanwattana, S. Parallelized Metaheuristic-Ensemble of Heterogeneous Feedforward Neural Networks for Regression Problems. IEEE Access 2019, 7, 26909–26932. [Google Scholar] [CrossRef]
- Freno, A.; Trentin, E. Markov Random Fields. In Hybrid. Random Fields: A Scalable Approach to Structure and Parameter Learning in Probabilistic Graphical Models (Intelligent Systems Reference Library); Springer: Berlin/Heidelberg, Germany, 2011; pp. 43–68. [Google Scholar]
- Strauss, D.J. Hammersley-Clifford theorem. Encyclopedia of Statistical Sciences; Campbell, S.K., Read, B., Balakrishnan, N., Vidakovic, B., Johnson, N.L., Eds.; Wiley Interscience: Hoboken, NJ, USA, 2004; pp. 570–572. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| City A (Weather) | ||||||||
|---|---|---|---|---|---|---|---|---|
| Dataset | Training | Test | ||||||
| Metric | MAE | MSE | S | R | MAE | MSE | S | R |
| Neural Network | 0.6009 | 2.4879 | 0.4555 | 0.6761 | 0.6433 | 2.3370 | 0.1254 | 0.4335 |
| ADAboost+ | 0.3691 | 1.8251 | 0.5694 | 0.7860 | 0.5578 | 2.0558 | 0.2083 | 0.6079 |
| DNNE | 0.2611 | 0.7044 | 0.8406 | 0.9225 | 0.2802 | 0.6679 | 0.6400 | 0.8715 |
| DNNE-H | 0.2078 | 0.6390 | 0.8504 | 0.9294 | 0.2516 | 0.7266 | 0.6046 | 0.8674 |
| City B (Weather) | ||||||||
| Dataset | Training | Test | ||||||
| Metric | MAE | MSE | S | R | MAE | MSE | S | R |
| Neural Network | 0.6973 | 4.3621 | 0.0871 | 0.2958 | 0.8778 | 5.0176 | 0.1012 | 0.4130 |
| ADAboost+ | 0.3095 | 2.6210 | 0.3662 | 0.6947 | 0.4340 | 3.0395 | 0.3825 | 0.7173 |
| DNNE | 0.1815 | 0.2603 | 0.9414 | 0.9724 | 0.3856 | 2.9584 | 0.3743 | 0.7382 |
| DNNE-H | 0.1722 | 0.3762 | 0.9217 | 0.9610 | 0.4516 | 2.3559 | 0.5390 | 0.7867 |
| City C (Weather) | ||||||||
| Dataset | Training | Test | ||||||
| Metric | MAE | MSE | S | R | MAE | MSE | S | R |
| Neural Network | 1.3913 | 12.9613 | 0.3016 | 0.5494 | 2.4418 | 37.1506 | 0.1909 | 0.4231 |
| ADAboost+ | 0.7070 | 8.8922 | 0.4409 | 0.7448 | 1.4621 | 22.9910 | 0.3530 | 0.7928 |
| DNNE | 0.4493 | 3.0957 | 0.8276 | 0.9138 | 1.0227 | 9.6359 | 0.8172 | 0.8871 |
| DNNE-H | 0.4475 | 2.8011 | 0.8402 | 0.9217 | 0.9915 | 9.4382 | 0.8080 | 0.8882 |
| City D (Weather) | ||||||||
| Dataset | Training | Test | ||||||
| Metric | MAE | MSE | S | R | MAE | MSE | S | R |
| Neural Network | 2.8051 | 35.9343 | 0.3312 | 0.5756 | 3.2873 | 76.7436 | 0.2314 | 0.4003 |
| ADAboost+ | 1.4615 | 18.4254 | 0.5755 | 0.8263 | 2.4409 | 48.0201 | 0.3271 | 0.7963 |
| DNNE | 0.9677 | 8.1498 | 0.8289 | 0.9225 | 1.4358 | 18.6595 | 0.7524 | 0.8883 |
| DNNE-H | 0.0944 | 7.6422 | 0.8556 | 0.9262 | 1.1823 | 9.2845 | 0.8330 | 0.9473 |
| City A (Animal) | ||||||||
|---|---|---|---|---|---|---|---|---|
| Dataset | Training | Test | ||||||
| Metric | MAE | MSE | S | R | MAE | MSE | S | R |
| Neural Network | 2.1843 | 9.8982 | 0.3021 | 0.5593 | 5.1144 | 1.8683 | 0.2867 | 0.3885 |
| ADAboost+ | 0.8592 | 1.6513 | 0.8219 | 0.9518 | 0.6566 | 1.3111 | 0.5847 | 0.8325 |
| DNNE | 0.8246 | 1.5039 | 0.8576 | 0.9467 | 0.5576 | 0.9390 | 0.6624 | 0.8859 |
| City B (Animal) | ||||||||
| Dataset | Training | Test | ||||||
| Metric | MAE | MSE | S | R | MAE | MSE | S | R |
| Neural Network | 3.1250 | 15.8521 | 0.4680 | 0.6857 | 3.7601 | 19.7885 | 0.4075 | 0.4263 |
| ADAboost+ | 1.3293 | 3.5305 | 0.8170 | 0.9407 | 0.9759 | 2.4946 | 0.6102 | 0.8594 |
| DNNE | 1.2829 | 3.1367 | 0.8423 | 0.9468 | 0.9125 | 2.2260 | 0.6530 | 0.8739 |
| City C (Animal) | ||||||||
| Dataset | Training | Test | ||||||
| Metric | MAE | MSE | S | R | MAE | MSE | S | R |
| Neural Network | 6.8084 | 84.4520 | 0.5896 | 0.7729 | 5.7810 | 54.3965 | 0.7059 | 0.7552 |
| ADAboost+ | 2.8002 | 22.0193 | 0.8337 | 0.9485 | 2.6823 | 20.9659 | 0.7065 | 0.9589 |
| DNNE | 2.2725 | 11.0242 | 0.9344 | 0.9736 | 2.1174 | 11.4240 | 0.8028 | 0.9425 |
| City D (Animal) | ||||||||
| Dataset | Training | Test | ||||||
| Metric | MAE | MSE | S | R | MAE | MSE | S | R |
| Neural Network | 8.6310 | 154.8318 | 0.5912 | 0.7800 | 6.2469 | 68.8767 | 0.9819 | 0.7399 |
| ADAboost+ | 3.2699 | 33.8051 | 0.8637 | 0.9569 | 2.2847 | 12.5119 | 0.7104 | 0.9082 |
| DNNE | 2.8531 | 19.7962 | 0.9320 | 0.9741 | 1.8747 | 7.5639 | 0.8686 | 0.9333 |
| Symbol | Meaning |
|---|---|
| Set of partitions (or sub-networks) | |
| Dimensionality of input space | |
| Number of hidden neurons in each sub-network | |
| Input space | |
| Index of a partition or sub-network | |
| Partition with index | |
| Vector of all weights (and biases) of sub-network | |
| Dataset of samples (either training or test) | |
| Subset of samples included in | |
| Estimated centroid, i.e., mean of samples in | |
| Index of a sample | |
| input vector in any sample | |
| Real outage frequency in any sample | |
| Estimated outage frequency in any sample | |
| Output of sub-network for any sample | |
| Supervised learning rate | |
| Weight applied to any sample in sub-network | |
| (Optional) regularization parameter | |
| (Optional) regularization function | |
| Sub-network output as a function of input and weights | |
| Boltzmann parameter | |
| Initial value of | |
| Error in the output of sub-network for sample (normalized) | |
| Partition function | |
| Cooling rate | |
| Set of all weights and centroids in the deep neural network ensemble | |
| Mean absolute error | |
| Mean squared error | |
| Slope of regression line | |
| Correlation coefficient | |
| Total daily lightning strikes corresponding to sample | |
| Maximum daily wind gust speed corresponding to sample | |
| Level of fair-weather days in the week corresponding to sample | |
| Month type of the week corresponding to sample | |
| Level of outages in the previous week |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Das, S.; Kankanala, P.; Pahwa, A. Outage Estimation in Electric Power Distribution Systems Using a Neural Network Ensemble. Energies 2021, 14, 4797. https://doi.org/10.3390/en14164797
Das S, Kankanala P, Pahwa A. Outage Estimation in Electric Power Distribution Systems Using a Neural Network Ensemble. Energies. 2021; 14(16):4797. https://doi.org/10.3390/en14164797
Chicago/Turabian StyleDas, Sanjoy, Padmavathy Kankanala, and Anil Pahwa. 2021. "Outage Estimation in Electric Power Distribution Systems Using a Neural Network Ensemble" Energies 14, no. 16: 4797. https://doi.org/10.3390/en14164797
APA StyleDas, S., Kankanala, P., & Pahwa, A. (2021). Outage Estimation in Electric Power Distribution Systems Using a Neural Network Ensemble. Energies, 14(16), 4797. https://doi.org/10.3390/en14164797