
An Adaptive Early Fault Detection Model of Induced Draft Fans Based on Multivariate State Estimation Technique

Abstract
:1. Introduction
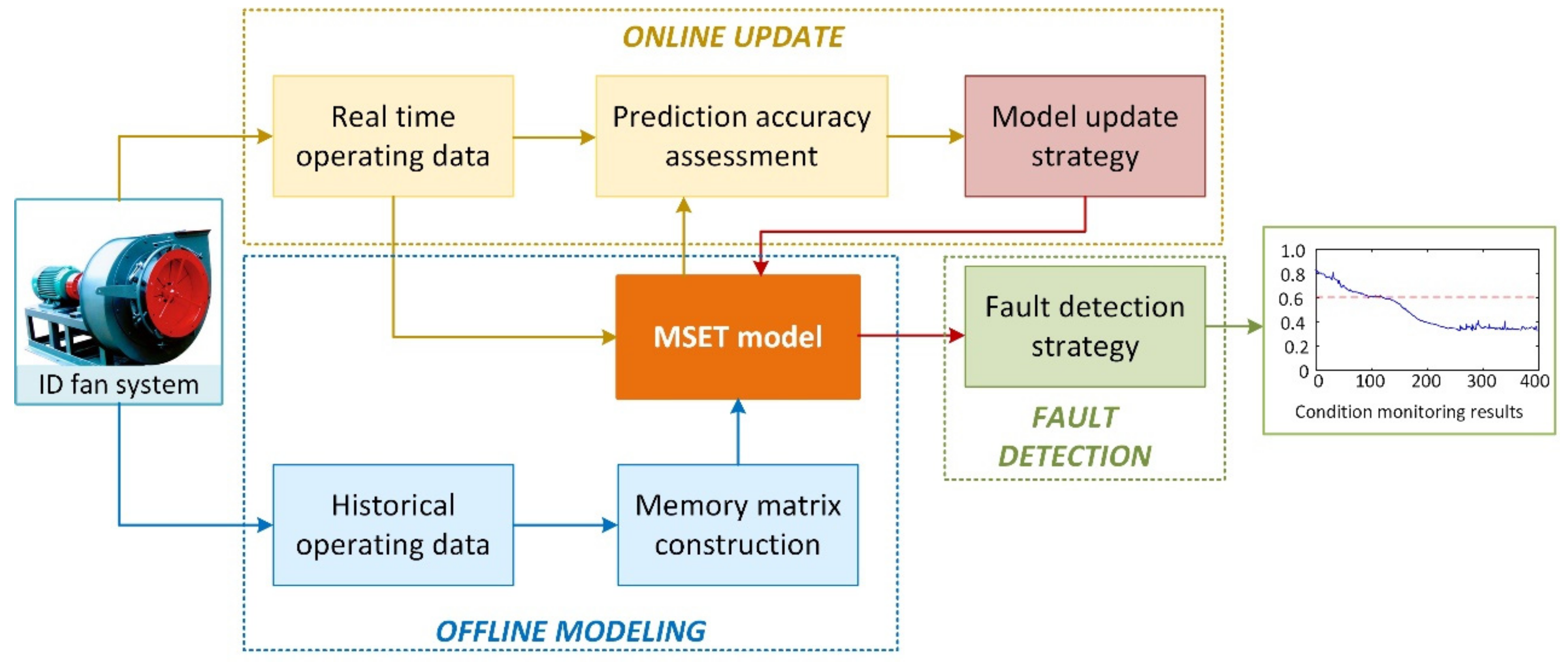
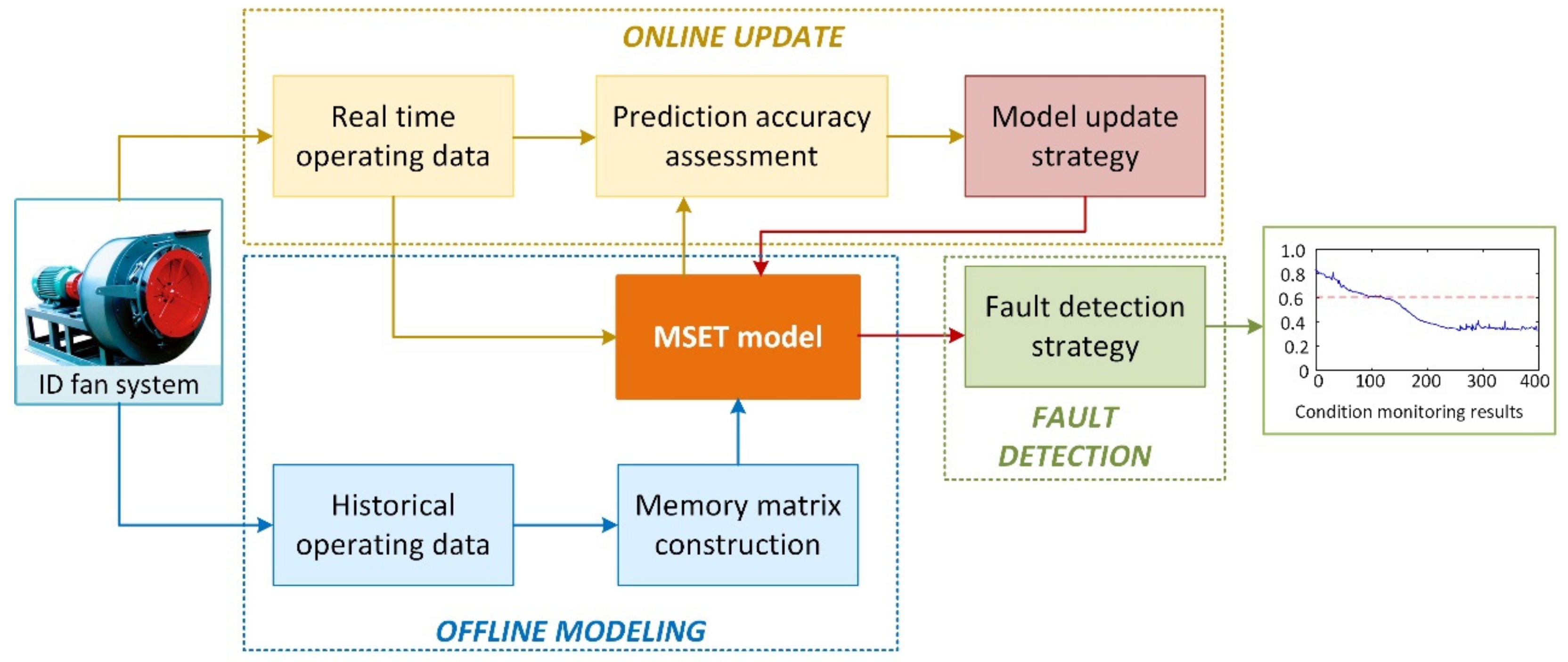
2. Adaptive Early Fault Detection Model Framework
2.1. Model Structure
2.2. MSET Theory
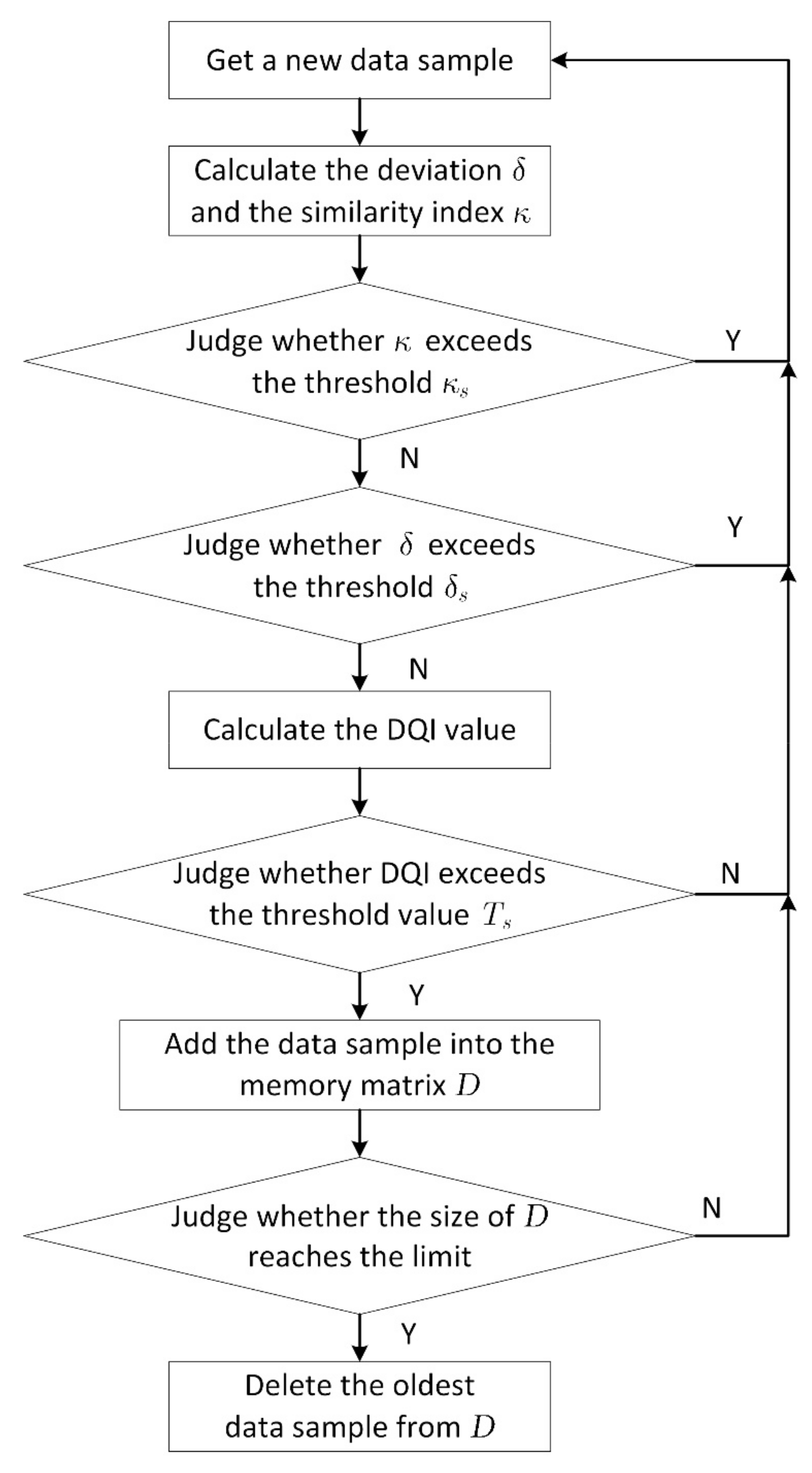
2.3. Fault Detection
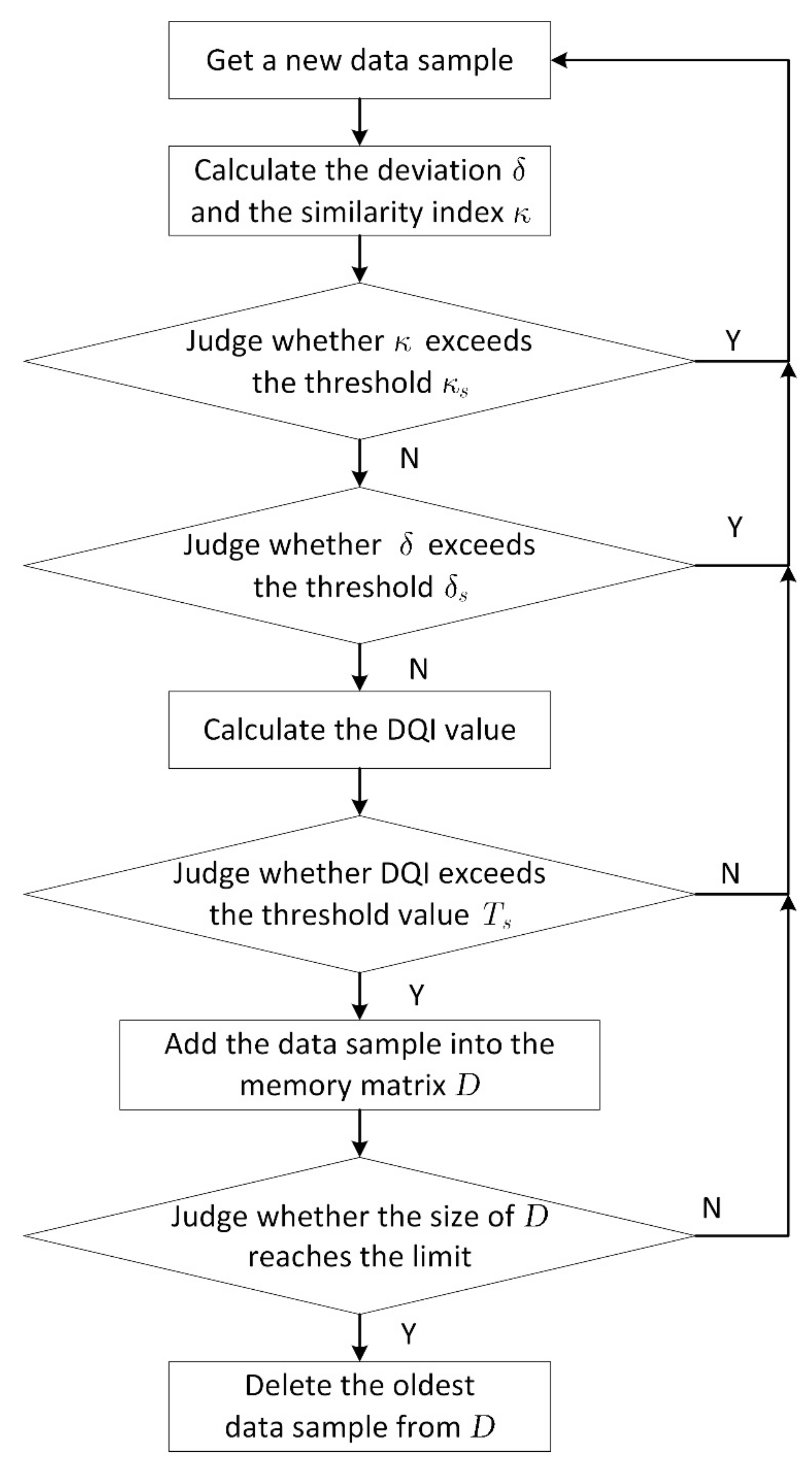
2.4. MSET Update
3. Industrial Case Study
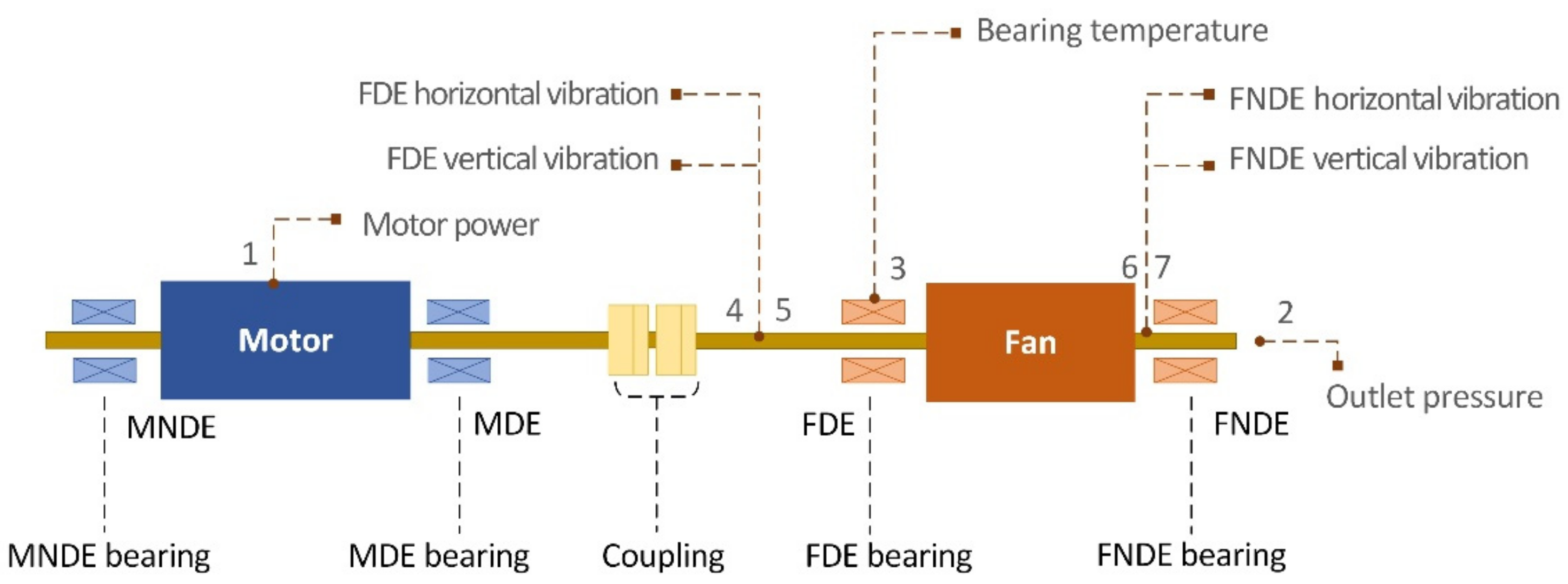
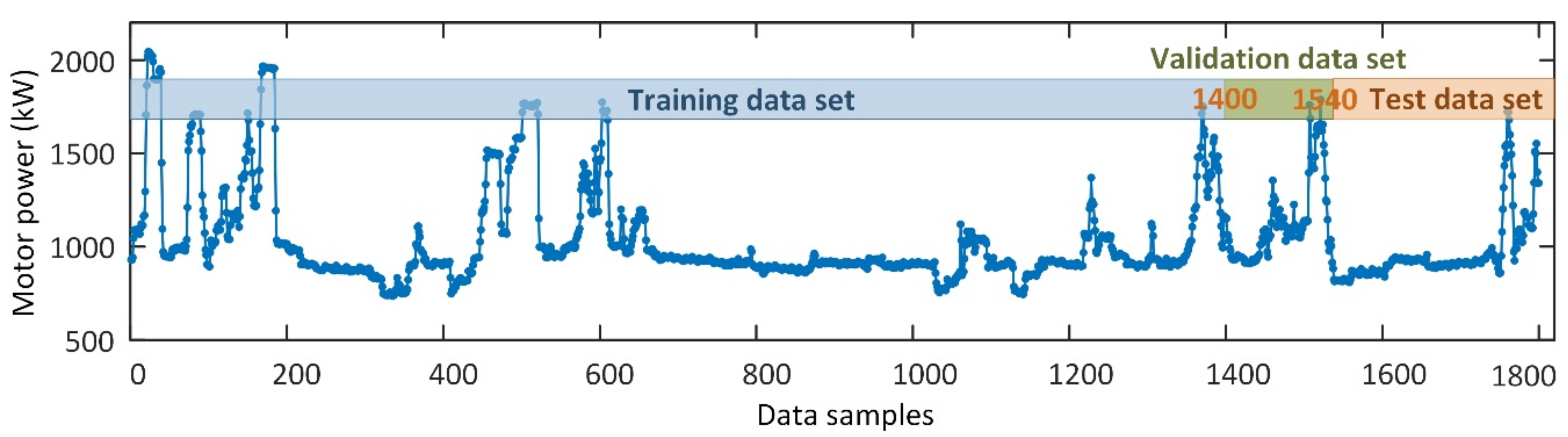
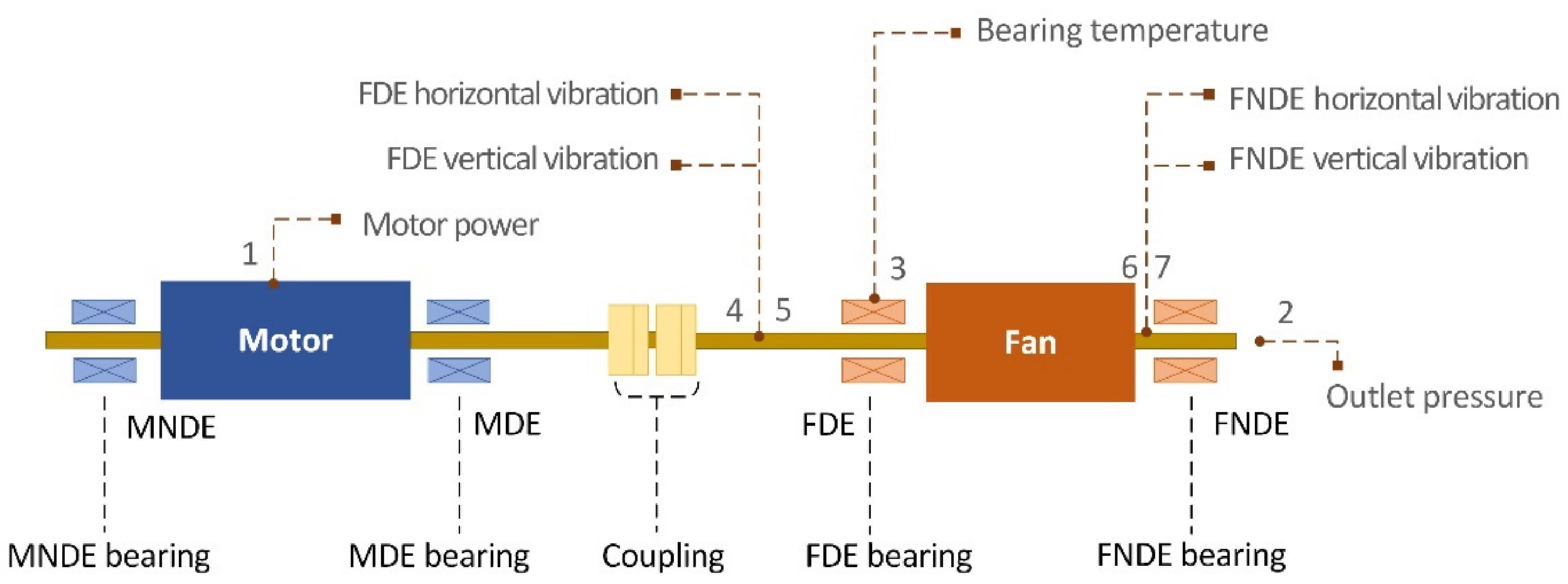
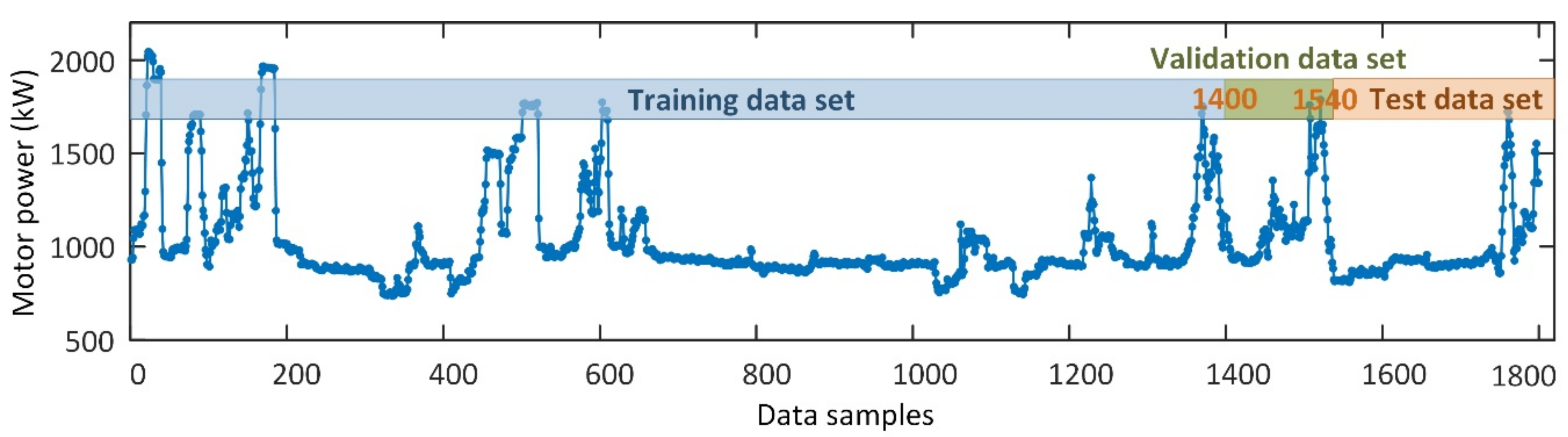
3.1. Data Preparation
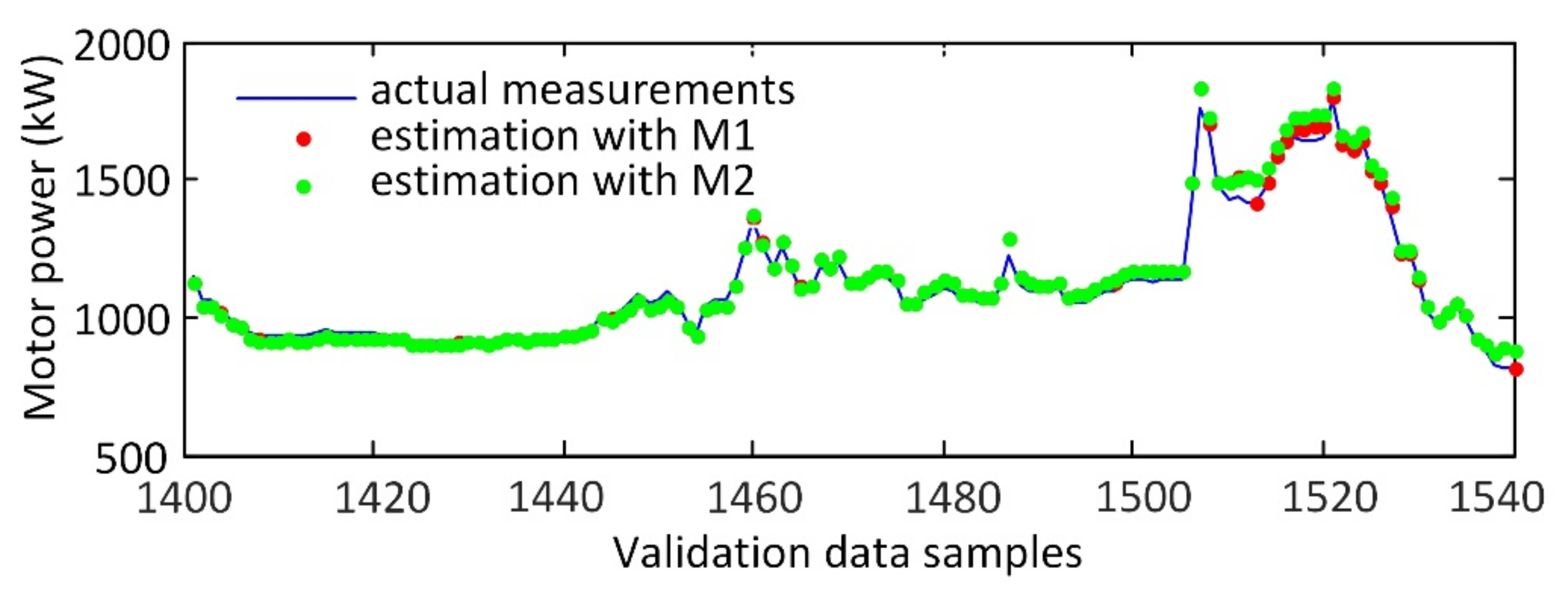
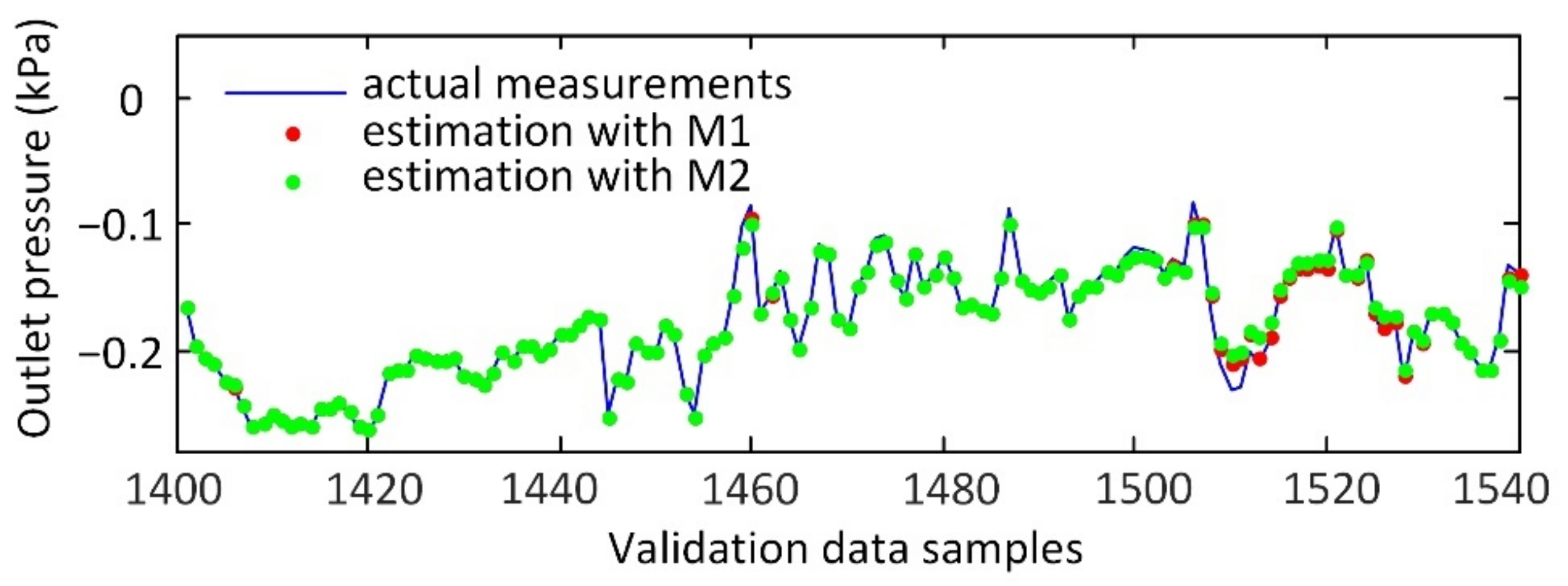
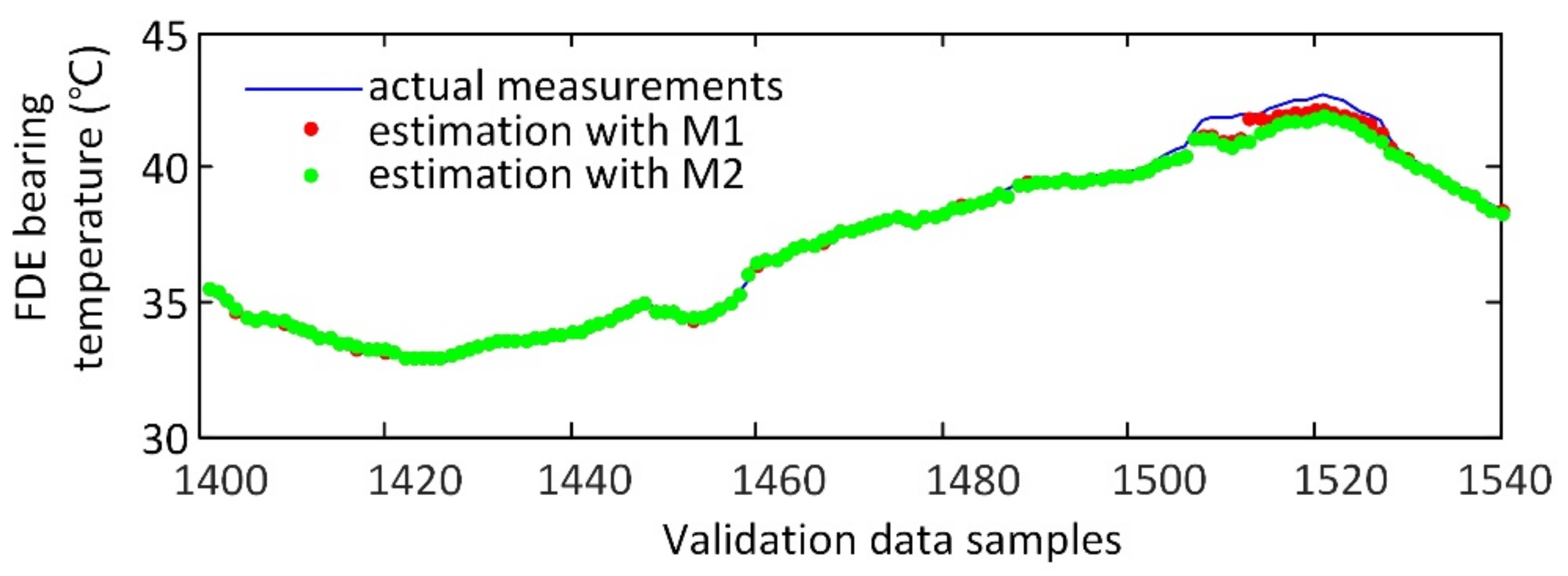
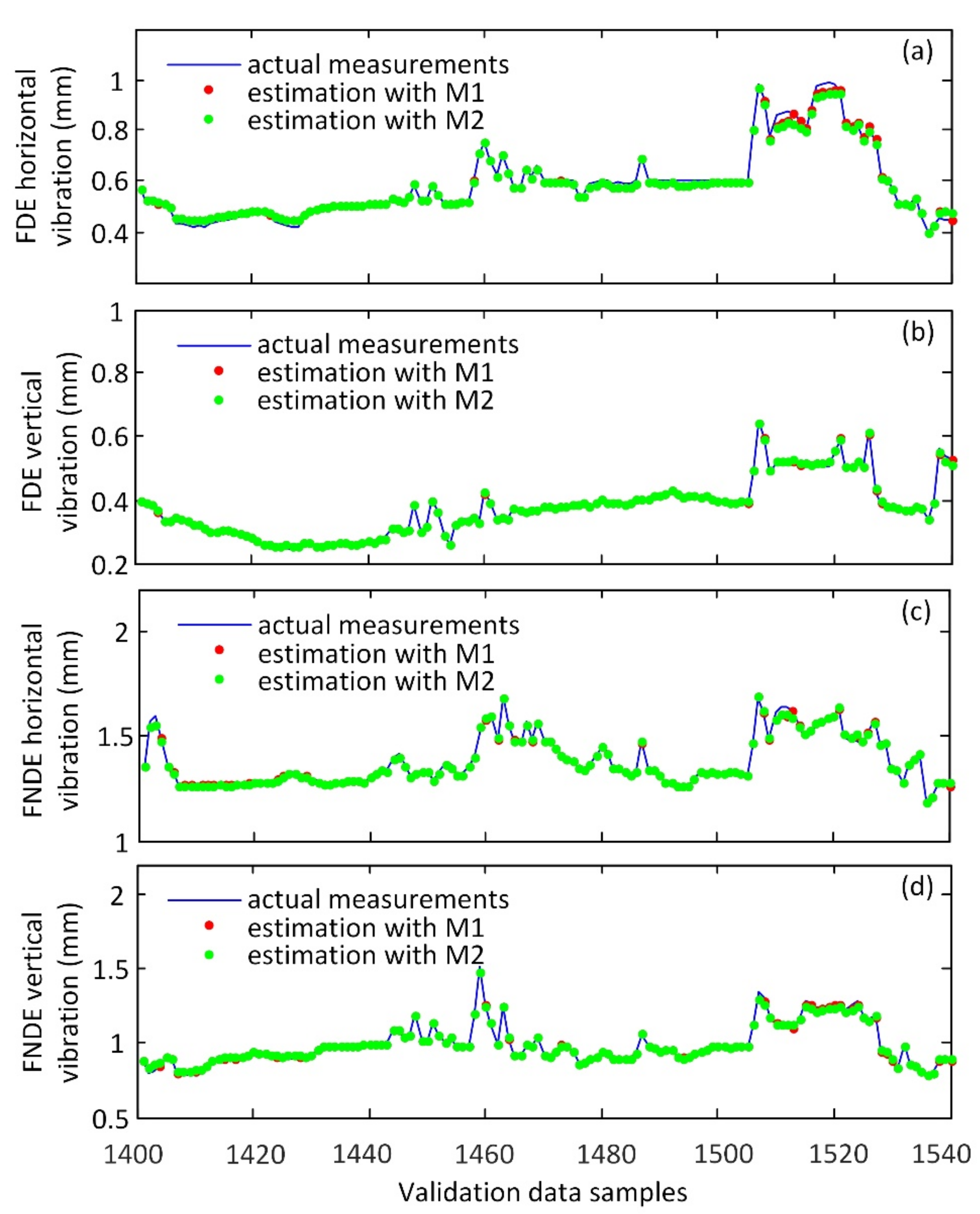
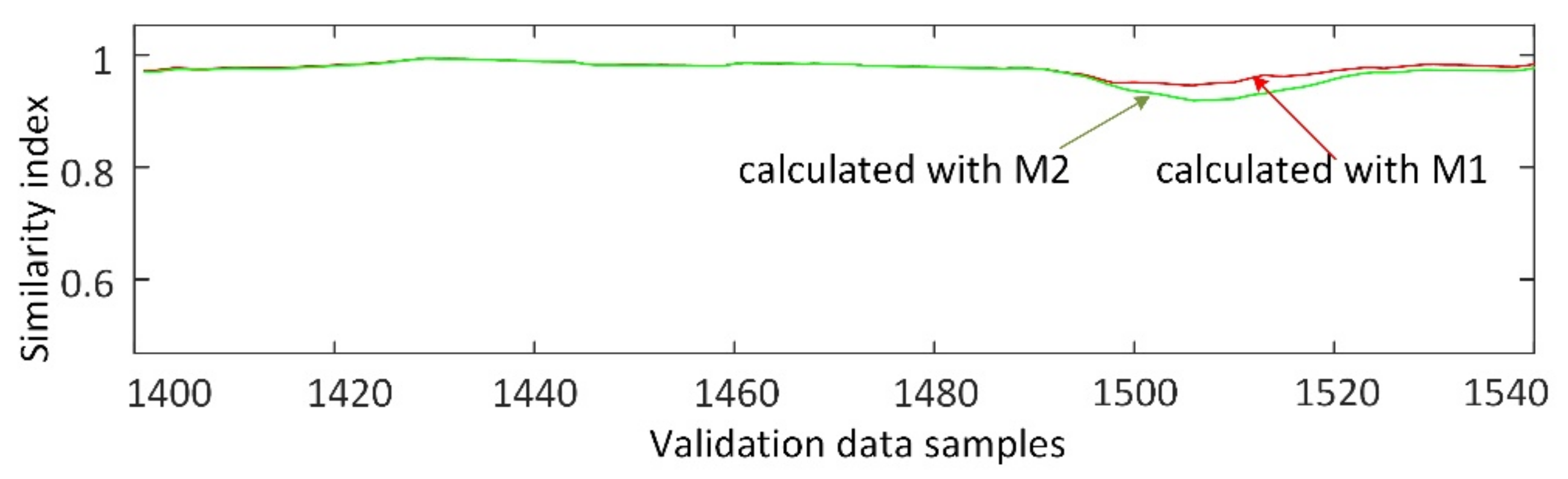
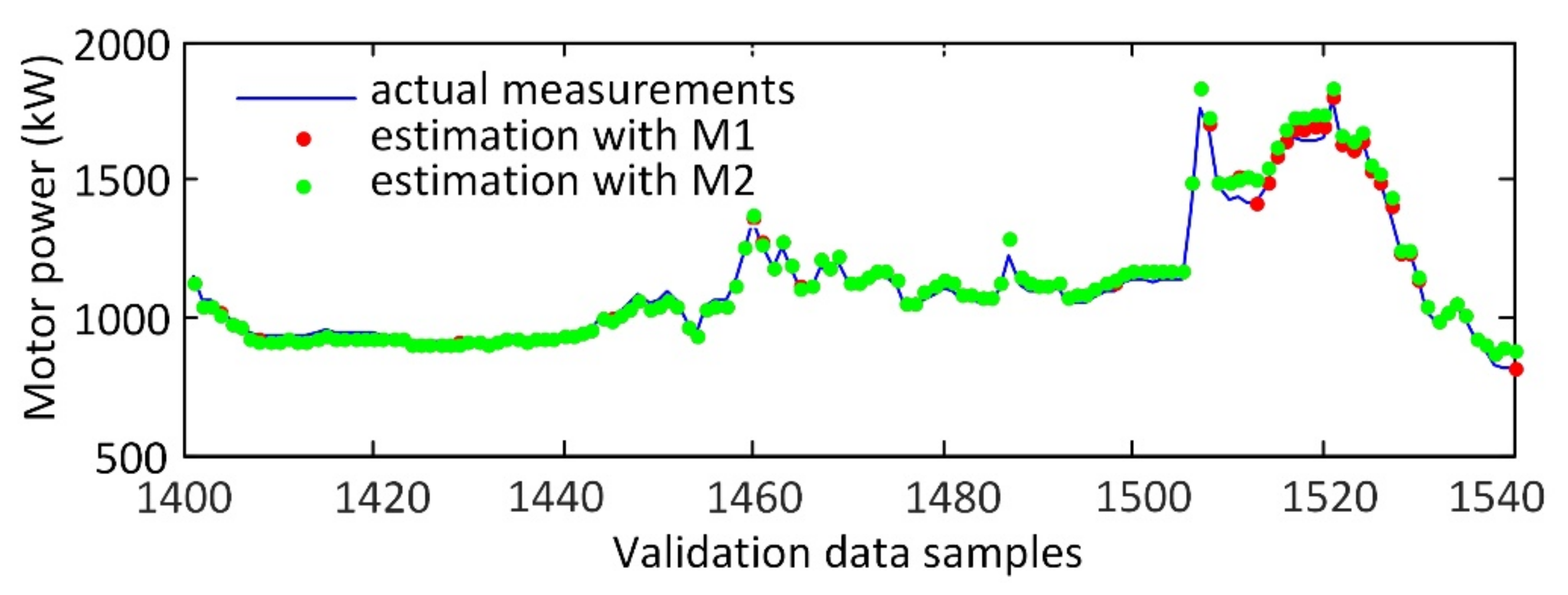
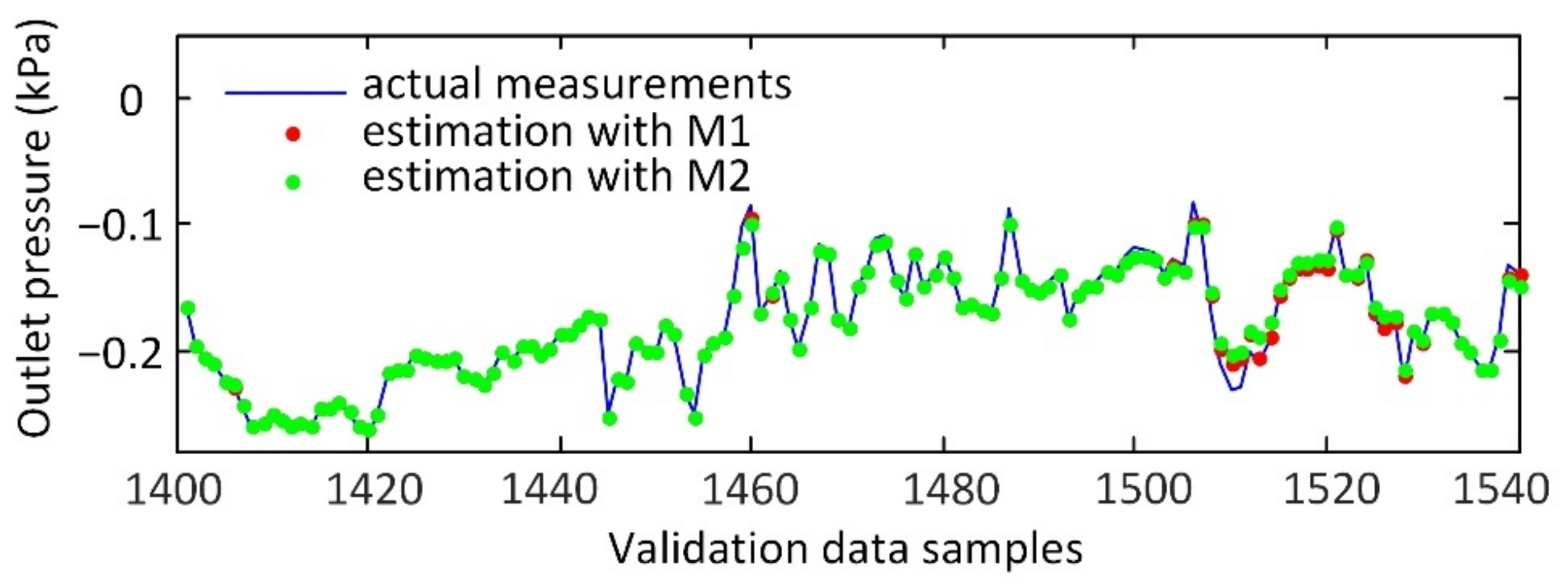
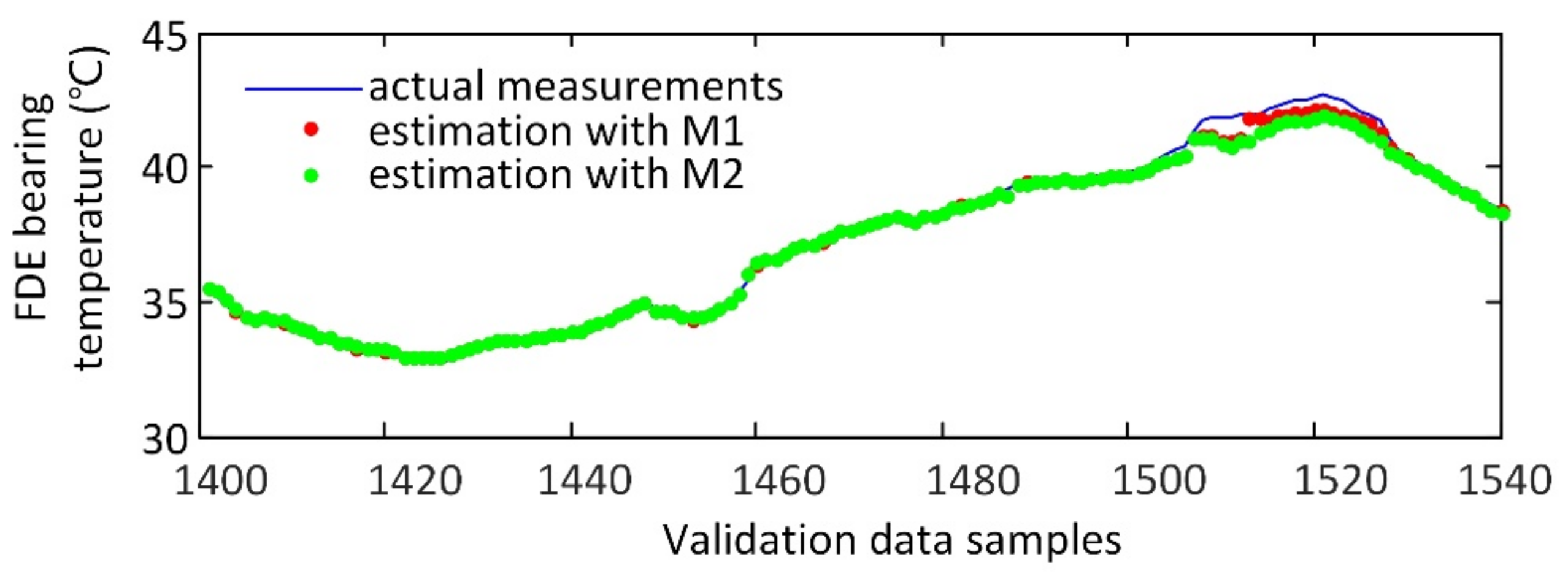
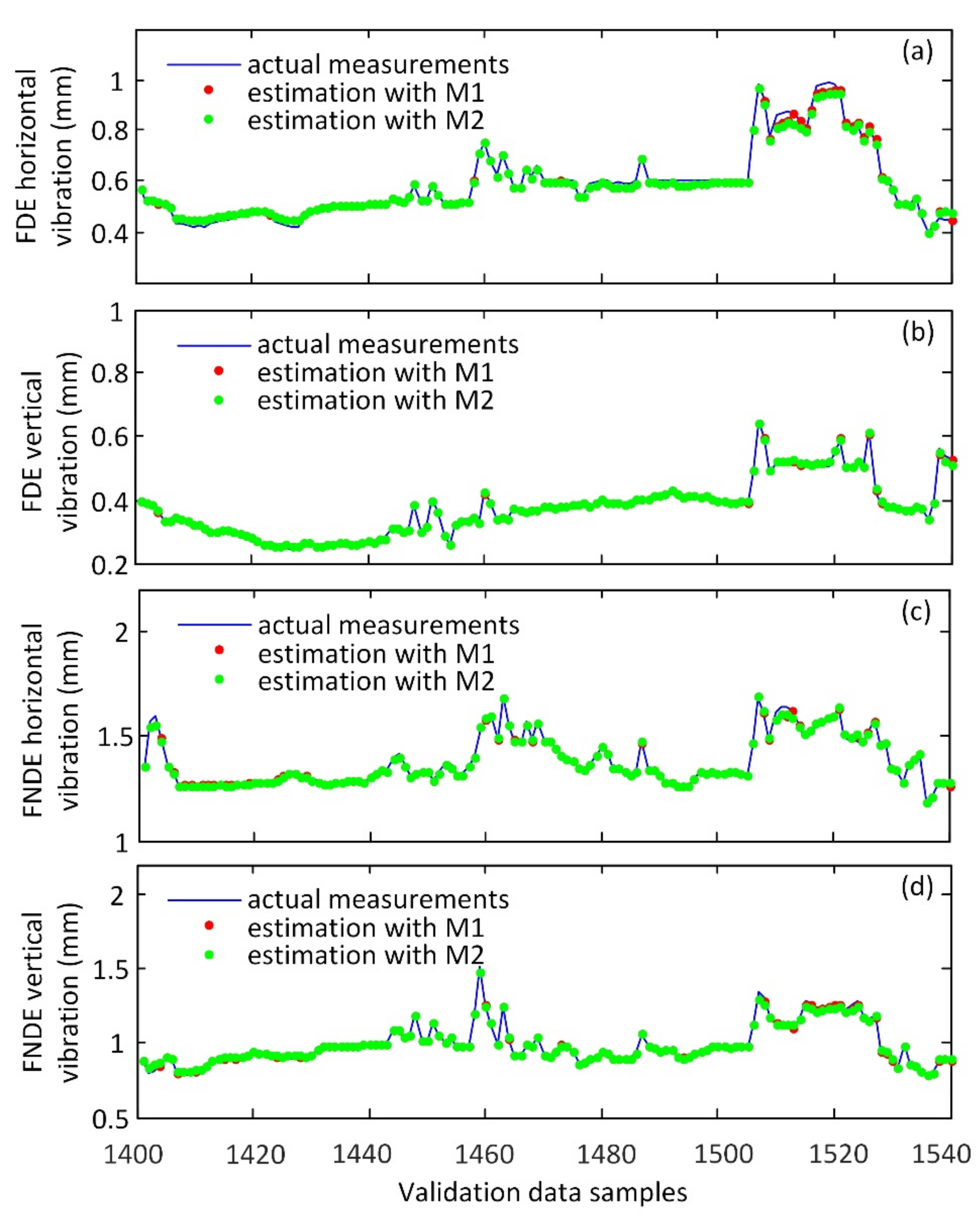
3.2. Modeling Results and Discussion
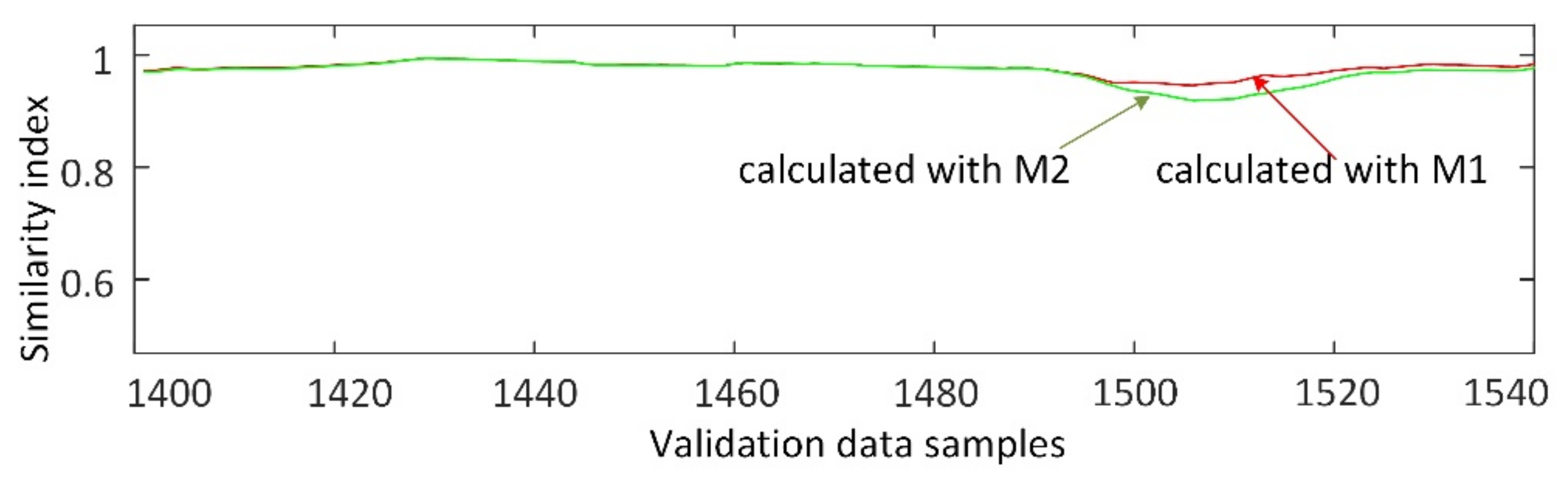
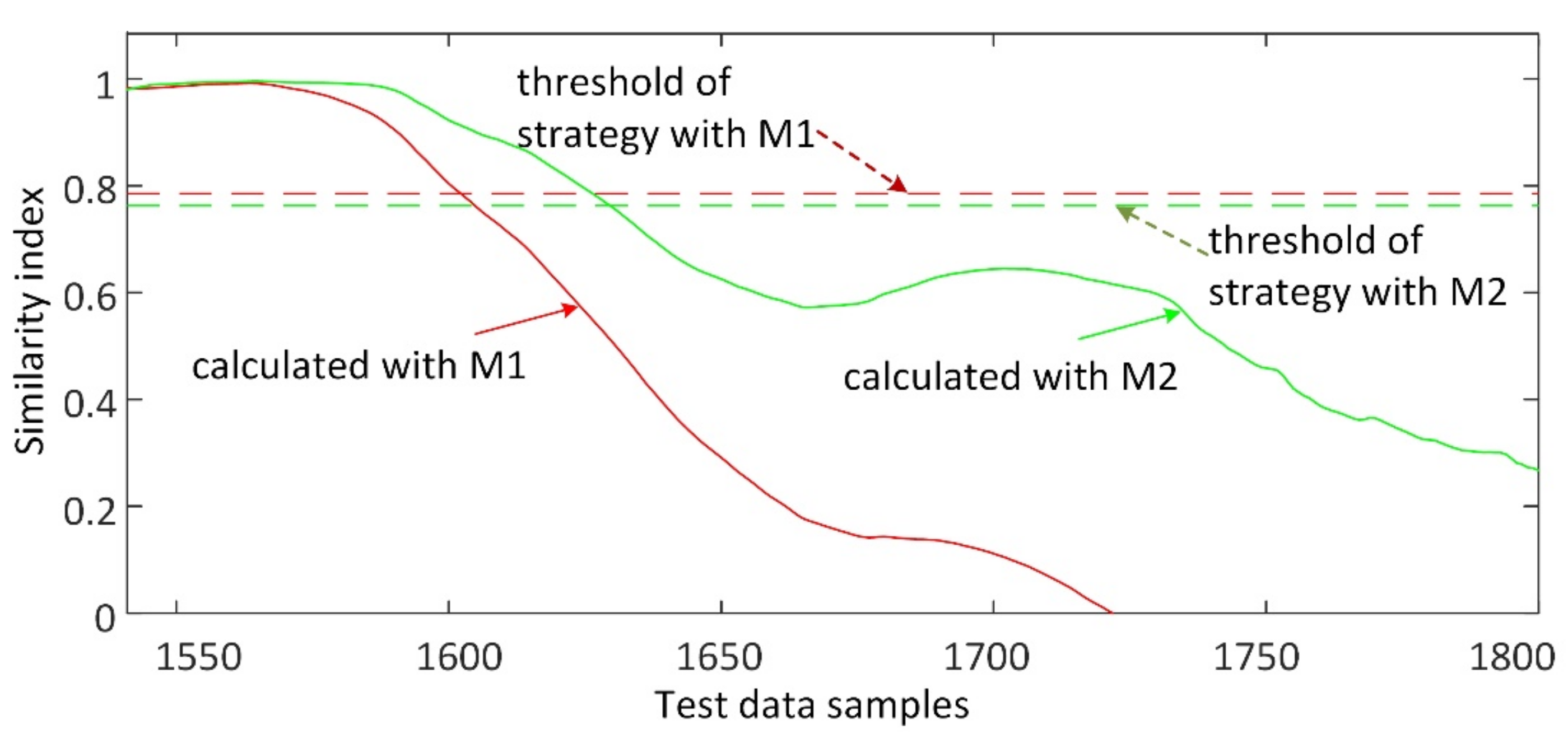
3.3. Fault Detection Based on Similarity Index
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, Y.; Tan, H.; Dong, K.; Liu, H.; Xiao, J.; Zhang, J. Study of ash fouling on the blade of induced fan in a 330 MW coal-fired power plant with ultra-low pollutant emission. Appl. Therm. Eng. 2017, 118, 283–291. [Google Scholar] [CrossRef]
- Du, J.; Liang, J.; Zhang, L. Research on the failure of the induced draft fan’s shaft in a power boiler. Case Study Eng. Fail. Anal. 2016, 5–6, 51–58. [Google Scholar] [CrossRef] [Green Version]
- Wei, Y.; Li, Y.; Xu, M.; Huang, W. A Review of Early Fault Diagnosis Approaches and Their Applications in Rotating Machinery. Entropy 2019, 21, 409. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Aguilar, J.; Garces, A.; Avendaño, A.; Macias, F.; White, C.; Gomez-Pulido, J.; De Mesa, J.G.; Garces-Jimenez, A. An Autonomic Cycle of Data Analysis Tasks for the Supervision of HVAC Systems of Smart Building. Energies 2020, 13, 3103. [Google Scholar] [CrossRef]
- Liu, J.; Bai, M.; Long, Z.; Liu, J.; Ma, Y.; Yu, D. Early Fault Detection of Gas Turbine Hot Components Based on Exhaust Gas Temperature Profile Continuous Distribution Estimation. Energies 2020, 13, 5950. [Google Scholar] [CrossRef]
- Cong, X.; Zhang, C.; Jiang, J.; Zhang, W.; Jiang, Y.; Zhang, L. A Comprehensive Signal-Based Fault Diagnosis Method for Lithium-Ion Batteries in Electric Vehicles. Energies 2021, 14, 1221. [Google Scholar] [CrossRef]
- Zhang, M.; Wang, T.Z.; Tang, T.T.; Liu, Z.; Claramunt, C. A Synchronous Sampling Based Harmonic Analysis Strategy for Marine Current Turbine Monitoring System under Strong Interference Conditions. Energies 2019, 12, 2117. [Google Scholar] [CrossRef] [Green Version]
- Shen, C.; Xie, J.; Wang, D.; Jiang, X.; Shi, J.; Zhu, Z. Improved Hierarchical Adaptive Deep Belief Network for Bearing Fault Diagnosis. Appl. Sci. 2019, 9, 3374. [Google Scholar] [CrossRef] [Green Version]
- Wang, H.; Wang, H.; Jiang, G.; Li, J.; Wang, Y. Early Fault Detection of Wind Turbines Based on Operational Condition Clustering and Optimized Deep Belief Network Modeling. Energies 2019, 12, 984. [Google Scholar] [CrossRef] [Green Version]
- Pozo, F.; Vidal, Y. Wind Turbine Fault Detection through Principal Component Analysis and Statistical Hypothesis Testing. Energies 2016, 9, 3. [Google Scholar] [CrossRef] [Green Version]
- Dai, J.; Tang, J.; Shao, F.; Huang, S.; Wang, Y. Fault Diagnosis of Rolling Bearing Based on Multiscale Intrinsic Mode Function Permutation Entropy and a Stacked Sparse Denoising Autoencoder. Appl. Sci. 2019, 9, 2743. [Google Scholar] [CrossRef] [Green Version]
- Kim, I.; Kim, W. Development and Validation of a Data-Driven Fault Detection and Diagnosis System for Chillers Using Machine Learning Algorithms. Energies 2021, 14, 1945. [Google Scholar] [CrossRef]
- Xiao, Y.; Pan, W.; Guo, X.; Bi, S.; Feng, D.; Lin, S. Fault Diagnosis of Traction Transformer Based on Bayesian Network. Energies 2020, 13, 4966. [Google Scholar] [CrossRef]
- Shin, J.-H.; Kim, J.-O. On-Line Diagnosis and Fault State Classification Method of Photovoltaic Plant. Energies 2020, 13, 4584. [Google Scholar] [CrossRef]
- Zhou, Y.; Yang, X.; Tao, L.; Yang, L. Transformer Fault Diagnosis Model Based on Improved Gray Wolf Optimizer and Probabilistic Neural Network. Energies 2021, 14, 3029. [Google Scholar] [CrossRef]
- Suh, S.; Lee, H.; Jo, J.; Lukowicz, P.; Lee, Y.O. Generative Oversampling Method for Imbalanced Data on Bearing Fault Detection and Diagnosis. Appl. Sci. 2019, 9, 746. [Google Scholar] [CrossRef] [Green Version]
- Vidal, Y.; Pozo, F.; Tutivén, C. Wind Turbine Multi-Fault Detection and Classification Based on SCADA Data. Energies 2018, 11, 3018. [Google Scholar] [CrossRef] [Green Version]
- Guo, Z.; Liu, M.; Qin, H.; Li, B. Mechanical Fault Diagnosis of a DC Motor Utilizing United Variational Mode Decomposition, SampEn, and Random Forest-SPRINT Algorithm Classifiers. Entropy 2019, 21, 470. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gross, K.C.; Singer, R.M.; Wegerich, S.W.; Herzog, J.P. Application of a model-based fault detection system to nuclear plant signals. In Proceedings of the 9th International Conference on Intelligent Systems Application to Power System, Seoul, Korea, 6–10 July 1997; pp. 212–218. [Google Scholar]
- Caesarendra, W.; Lee, J.M.; Ha, J.M.; Choi, B.K. Slew Bearing Early Damage Detection Based on Multivariate State Estimation Technique and Sequential Probability Ratio Test. In Proceedings of the IEEE/ASME International Conference on Advanced Intelligent Mechatronics (AIM), Busan, Korea, 7–11 July 2015; pp. 1161–1166. [Google Scholar]
- Guo, P.; Bai, N. Wind Turbine Gearbox Condition Monitoring with AAKR and Moving Window Statistic Methods. Energies 2011, 4, 2077–2093. [Google Scholar] [CrossRef] [Green Version]
- Zhang, W.; Liu, J.; Gao, M.; Pan, C.; Huusom, J.K. A fault early warning method for auxiliary equipment based on multivariate state estimation technique and sliding window similarity. Comput. Ind. 2019, 107, 67–80. [Google Scholar] [CrossRef]
- Cui, C.; Lin, W.; Yang, Y.; Kuang, X.; Xiao, Y. A novel fault measure and early warning system for air compressor. Measurement 2019, 135, 593–605. [Google Scholar] [CrossRef]
- Wang, Z.; Liu, C. Wind turbine condition monitoring based on a novel multivariate state estimation technique. Measurement 2021, 168. [Google Scholar] [CrossRef]
- Long, D.; Zheng, H.; Hong, F. Condition Monitoring of Industrial Equipment Based on Multi-Variables State Estimate Technique. Appl. Sci. 2020, 10, 5637. [Google Scholar] [CrossRef]
- Caesarendra, W.; Tjahjowidodo, T.; Kosasih, B.; Tieu, A.K. Integrated Condition Monitoring and Prognosis Method for Incipient Defect Detection and Remaining Life Prediction of Low Speed Slew Bearings. Machines 2017, 5, 11. [Google Scholar] [CrossRef] [Green Version]
- Lv, Y.; Fang, F.; Yang, T.T.; Liu, J.Z. An early fault detection method for induced draft fans based on MSET with informative memory matrix selection. ISA Trans. 2020, 102, 325–334. [Google Scholar] [CrossRef]
- Guo, P.; Infield, D.; Yang, X. Wind turbine generator condition-monitoring using temperature trend analysis. IEEE Trans. Sustain. Energy 2012, 3, 124–133. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Infield, D. Supervisory control and data acquisition data-based non-linear state estimation technique for wind turbine gearbox condition monitoring. IET Renew. Power Gener. 2013, 7, 350–358. [Google Scholar] [CrossRef]
- Xu, G.; Guo, W.; Zhao, Y.; Zhou, Y.; Zhang, Y.; Liu, X.; Xu, G.; Li, G. Online Learning Based Underwater Robotic Thruster Fault Detection. Appl. Sci. 2021, 11, 3586. [Google Scholar] [CrossRef]
- Liu, W.; Ran, W.; Nantogma, S.; Xu, Y. Adaptive Information Sharing with Ontological Relevance Computation for Decentralized Self-Organization Systems. Entropy 2021, 23, 342. [Google Scholar] [CrossRef]
- Chen, X.; Liu, Z.; Wang, J.; Yang, C.; Long, B.; Zhou, X. An Adaptive Prediction Model for the Remaining Life of an Li-Ion Battery Based on the Fusion of the Two-Phase Wiener Process and an Extreme Learning Machine. Electronics 2021, 10, 540. [Google Scholar] [CrossRef]
- Kadlec, P.; Grbić, R.; Gabrys, B. Review of adaptation mechanisms for data-driven soft sensors. Comput. Chem. Eng. 2011, 35. [Google Scholar] [CrossRef]
- Liu, Y.; Gao, Z.; Li, P.; Wang, H. Just-in-time kernel learning with adaptive parameter selection for soft sensor modeling of batch processes. Ind. Eng. Chem. Res. 2012, 51, 4313–4327. [Google Scholar] [CrossRef]
- Shi, H.; Guo, J.; Bai, X.; Guo, L.; Liu, Z.; Sun, J. Research on a Nonlinear Dynamic Incipient Fault Detection Method for Rolling Bearings. Appl. Sci. 2020, 10, 2443. [Google Scholar] [CrossRef] [Green Version]
- Ammiche, M.; Kouadri, A.; Bensmail, A. A modified moving window dynamic PCA with Fuzzy Logic Filter and application to fault detection. Chemom. Intell. Lab. Syst. 2018, 177, 100–113. [Google Scholar] [CrossRef]
- Sheriff, M.Z.; Mansouri, M.; Karim, M.N.; Nounou, H.; Nounou, M. Fault detection using multiscale PCA-based moving window GLRT. J. Process Control 2017, 54, 47–64. [Google Scholar] [CrossRef]
- Chen, K.; Liang, Y.; Gao, Z.; Liu, Y. Just-in-Time Correntropy Soft Sensor with Noisy Data for Industrial Silicon Content Pre-diction. Sensors 2017, 17, 1830. [Google Scholar] [CrossRef] [Green Version]
- Ahmad, I.; Ayub, A.; Mohammad, N.; Kano, M. Data-Based Prediction and Stochastic Analysis of Entrained Flow Coal Gasification under Uncertainty. Sensors 2019, 19, 1626. [Google Scholar] [CrossRef] [Green Version]
- Jiang, J.; Xiao, Z.; Wang, J.; Song, J. Sequential Method with Incremental Analysis Update to Retrieve Leaf Area Index from Time Series MODIS Reflectance Data. Remote Sens. 2014, 6, 9194–9212. [Google Scholar] [CrossRef] [Green Version]
- Kaneko, H.; Funatsu, K. Adaptive database management based on the database monitoring index for long-term use of adaptive soft sensors. Chemom. Intell. Lab. Syst. 2015, 146, 179–185. [Google Scholar] [CrossRef] [Green Version]
- Lv, Y.; Lv, X.; Fang, F.; Yang, T.; Romero, C.E. Adaptive Selective Catalytic Reduction Model Development Using Typical Operating Data in Coal-Fired Power Plants. Energy 2020, 192, 116589. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variables | Measurement Location | Unit | Operating Range |
|---|---|---|---|
| Motor power | 1 | kW | 730~2050 |
| Outlet pressure | 2 | kPa | −0.33~−0.03 |
| FDE bearing temperature | 3 | °C | 32.2~42.7 |
| FDE horizontal vibration | 4 | mm | 0.21~1.30 |
| FDE vertical vibration | 5 | mm | 0.21~1.30 |
| FNDE horizontal vibration | 6 | mm | 0.75~2.05 |
| FNDE vertical vibration | 7 | mm | 0.75~2.05 |
| Models | From 1401th to 1510th Data Samples | From 1511th to 1540th Data Samples | Entire Validate Dataset | ||||||
|---|---|---|---|---|---|---|---|---|---|
| RMSE (kW) | NRMSE (%) | MAE (kW) | RMSE (kW) | NRMSE (%) | MAE (kW) | RMSE (kW) | NRMSE (%) | MAE (kW) | |
| M1 | 24.0 | 2.83 | 19.8 | 32.9 | 3.38 | 23.0 | 26.2 | 2.69 | 20.5 |
| M2 | 24.6 | 2.90 | 20.5 | 50.0 | 5.14 | 40.0 | 31.8 | 3.27 | 24.7 |
| Models | From 1401th to 1510th Data Samples | From 1511th to 1540th Data Samples | Entire Validate Dataset | ||||||
|---|---|---|---|---|---|---|---|---|---|
| RMSE (kPa) | NRMSE (%) | MAE (kPa) | RMSE (kPa) | NRMSE (%) | MAE (kPa) | RMSE (kPa) | NRMSE (%) | MAE (kPa) | |
| M1 | 0.0045 | 2.44 | 0.0024 | 0.0055 | 4.33 | 0.0029 | 0.0047 | 2.57 | 0.0025 |
| M2 | 0.0050 | 2.77 | 0.0026 | 0.0088 | 6.92 | 0.0055 | 0.0060 | 3.32 | 0.0032 |
| Models | From 1401th to 1510th Data Samples | From 1511th to 1540th Data Samples | Entire Validate Dataset | ||||||
|---|---|---|---|---|---|---|---|---|---|
| RMSE (°C) | NRMSE (%) | MAE (°C) | RMSE (°C) | NRMSE (%) | MAE (°C) | RMSE (°C) | NRMSE (%) | MAE (°C) | |
| M1 | 0.16 | 1.78 | 0.10 | 0.37 | 8.63 | 0.29 | 0.22 | 2.23 | 0.14 |
| M2 | 0.18 | 1.93 | 0.10 | 0.60 | 13.92 | 0.49 | 0.32 | 3.17 | 0.19 |
| Models | From 1401th to 1510th Data Samples | From 1511th to 1540th Data Samples | Entire Validate Dataset | ||||||
|---|---|---|---|---|---|---|---|---|---|
| RMSE (mm) | NRMSE (%) | MAE (mm) | RMSE (mm) | NRMSE (%) | MAE (mm) | RMSE (mm) | NRMSE (%) | MAE (mm) | |
| M1 | 0.013 | 2.3 | 0.011 | 0.018 | 3.0 | 0.013 | 0.014 | 2.4 | 0.011 |
| M2 | 0.014 | 2.4 | 0.011 | 0.023 | 4.0 | 0.017 | 0.016 | 2.8 | 0.012 |
| Models | From 1401th to 1510th Data Samples | From 1511th to 1540th Data Samples | Entire Validate Dataset | ||||||
|---|---|---|---|---|---|---|---|---|---|
| RMSE (mm) | NRMSE (%) | MAE (mm) | RMSE (mm) | NRMSE (%) | MAE (mm) | RMSE (mm) | NRMSE (%) | MAE (mm) | |
| M1 | 0.004 | 0.9 | 0.002 | 0.008 | 3.0 | 0.007 | 0.005 | 1.2 | 0.003 |
| M2 | 0.004 | 0.9 | 0.002 | 0.009 | 3.2 | 0.008 | 0.005 | 1.3 | 0.004 |
| Models | From 1401th to 1510th Data Samples | From 1511th to 1540th Data Samples | Entire Validate Dataset | ||||||
|---|---|---|---|---|---|---|---|---|---|
| RMSE (mm) | NRMSE (%) | MAE (mm) | RMSE (mm) | NRMSE (%) | MAE (mm) | RMSE (mm) | NRMSE (%) | MAE (mm) | |
| M1 | 0.008 | 1.7 | 0.005 | 0.014 | 3.1 | 0.011 | 0.010 | 1.9 | 0.006 |
| M2 | 0.008 | 1.8 | 0.005 | 0.016 | 3.5 | 0.013 | 0.010 | 2.0 | 0.007 |
| Models | From 1401th to 1510th Data Samples | From 1511th to 1540th Data Samples | Entire Validate Dataset | ||||||
|---|---|---|---|---|---|---|---|---|---|
| RMSE (mm) | NRMSE (%) | MAE (mm) | RMSE (mm) | NRMSE (%) | MAE (mm) | RMSE (mm) | NRMSE (%) | MAE (mm) | |
| M1 | 0.011 | 1.5 | 0.006 | 0.012 | 2.4 | 0.009 | 0.011 | 1.6 | 0.007 |
| M2 | 0.013 | 1.7 | 0.007 | 0.017 | 3.4 | 0.014 | 0.014 | 1.9 | 0.009 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, R.; Zhang, G.; Zhang, Q.; Zhou, L.; Yu, H.; Lei, M.; Lv, Y. An Adaptive Early Fault Detection Model of Induced Draft Fans Based on Multivariate State Estimation Technique. Energies 2021, 14, 4787. https://doi.org/10.3390/en14164787
Guo R, Zhang G, Zhang Q, Zhou L, Yu H, Lei M, Lv Y. An Adaptive Early Fault Detection Model of Induced Draft Fans Based on Multivariate State Estimation Technique. Energies. 2021; 14(16):4787. https://doi.org/10.3390/en14164787
Chicago/Turabian StyleGuo, Ruijun, Guobin Zhang, Qian Zhang, Lei Zhou, Haicun Yu, Meng Lei, and You Lv. 2021. "An Adaptive Early Fault Detection Model of Induced Draft Fans Based on Multivariate State Estimation Technique" Energies 14, no. 16: 4787. https://doi.org/10.3390/en14164787
APA StyleGuo, R., Zhang, G., Zhang, Q., Zhou, L., Yu, H., Lei, M., & Lv, Y. (2021). An Adaptive Early Fault Detection Model of Induced Draft Fans Based on Multivariate State Estimation Technique. Energies, 14(16), 4787. https://doi.org/10.3390/en14164787