
Application of the BORUTA Algorithm to Input Data Selection for a Model Based on Rough Set Theory (RST) to Prediction Energy Consumption for Building Heating



Abstract
1. Introduction
- k-nearest neighbors [34],
2. Materials and Methods
- Confirmed.
- Tentative.
- Rejected.
- MBE index ± 5%,
- CV RMSE index 15%,
- SET 1–the subset of features indicated by the algorithm as “confirmed”.
- SET 2–a subset of the features indicated as “confirmed” by the algorithm, with the top 10 (indicated by the algorithm) features selected for analysis.
- SET 3–a subset of the features indicated as “confirmed” by the algorithm, with the top 3 (indicated by the algorithm) features selected for analysis.
- SET 4–the subset of features indicated by the algorithm as “confirmed “+”tentative”.
3. Results and Discussion
4. Conclusions and Perspectives
- Evaluating the usefulness of the different sets of variables according to the indices proposed by ASHARE, it was found that the use of the feature sets indicated by the BORUTA algorithm in the prediction model yielded errors for the test set of: MAPE 9.2–10.7%; MBE 2.4–4.7%; CV RMSE 5.49–5.89%; and R2 0.85–0.81,
- The data set consisting of 14 descriptive characteristics marked by the BORUTA algorithm as “confirmed” is the best fit of the model to the real data, confirmed by the values of all evaluation indicators,
- Limiting the number of conditional attributes to 10, had little effect on changing the size of the evaluation indices. Analogous results were obtained when selecting 3 conditional attributes indicated by the algorithm as the best, so the model based on a limited number of input variables can be considered suitable for practical application,
- The method of data classification indicated in this paper together with the forecasting model will make it possible to quickly determine the energy saving potential of buildings without the need to perform detailed (and thus expensive) engineering calculations. Three data describing the building before thermomodernization can be sufficient to estimate energy consumption (after thermal improvement): index of final energy demand for heating before modernization (calculated from measurements of actual energy consumption for heating), shape coefficient of buildings (the ratio surface to volume) and calculated thermal transmittance of peak walls components,
- Increasing the number of conditional attributes beyond those indicated as “confirmed” by the BORUTA algorithm yields poorer predictive performance. This indicates that an increased number of attributes negatively affects the predictive quality of the model,
- In further research, the authors plan to test the usefulness of the presented set of methods for predicting energy consumption in other types of real buildings, such as single-family residential buildings, schools, kindergartens, and others. This will allow a broader assessment of the usefulness of the BORUTA algorithm for input data selection in an energy consumption forecasting model based on rough set theory. It is also planned to compare other methods of classification of input variables based on these objects, i.e., real ones.
- To be able to compare the quality of the predictions with the results in other works, the authors plan to use publicly available databases such as “ASHRAE - Great Energy Predictor III, the Kaggle competition” [65] to evaluate the performance of the algorithms. This will allow to test and compare the applicability of the presented method on data that are used by other researchers in building prediction models.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhang, L.; Wen, J.; Li, Y.; Chen, J.; Ye, Y.; Fu, Y.; Livingood, W. A review of machine learning in building load prediction. Appl. Energy 2021, 285, 116452. [Google Scholar] [CrossRef]
- Li, X.; Wen, J. Review of building energy modeling for control and operation. Renew. Sustain. Energy Rev. 2014, 37, 517–537. [Google Scholar] [CrossRef]
- Zhao, H.; Magoulès, F. A review on the prediction of building energy consumption. Renew. Sustain. Energy Rev. 2012, 16, 3586–3592. [Google Scholar] [CrossRef]
- Bourdeau, M.; Zhai, X.-Q.; Nefzaoui, E.; Guo, X.; Chatellier, P. Modelling and forecasting building energy consumption: A review of data-driven techniques. Sustain. Sustain. Cities Soc. 2019, 48, 101533. [Google Scholar] [CrossRef]
- Fumo, N. A review on the basics of building energy estimation. Renew. Sustain. Energy Rev. 2014, 31, 53–60. [Google Scholar] [CrossRef]
- Foucquier, A.; Robert, S.; Suard, F.; Stéphan, L.; Jay, A. State of the art in building modelling and energy performances prediction: A review. Renew. Sustain. Energy Rev. 2013, 23, 272–288. [Google Scholar] [CrossRef]
- Fan, C.; Xiao, F.; Zhao, Y. A short-term building cooling load prediction method using deep learning algorithms. Appl. Energy 2017, 195, 222–233. [Google Scholar] [CrossRef]
- Peng, Y.; Rysanek, A.; Nagy, Z.; Schlüter, A. Using machine learning techniques for occupancy-prediction-based cooling control in office buildings. Appl. Energy 2018, 211, 1343–1358. [Google Scholar] [CrossRef]
- Chou, J.-S.; Bui, D.-K. Modeling heating and cooling loads by artificial intelligence for energy-efficient building design. Energy Build. 2014, 82, 437–446. [Google Scholar] [CrossRef]
- Aydinalp-Koksal, M.; Ugursal, V.I. Comparison of neural network, conditional demand analysis, and engineering approaches for modeling end-use energy consumption in the residential sector. Appl. Energy 2008, 85, 271–296. [Google Scholar] [CrossRef]
- Hygh, J.S.; DeCarolis, J.F.; Hill, D.B.; Ranjithan, S.R. Multivariate regression as an energy assessment tool in early building design. Build. Environ. 2012, 57, 165–175. [Google Scholar] [CrossRef]
- Azadeh, A.; Saberi, M.; Seraj, O. An integrated fuzzy regression algorithm for energy consumption estimation with non-stationary data: A case study of Iran. Energy 2010, 35, 2351–2366. [Google Scholar] [CrossRef]
- Ahmad, M.W.; Mourshed, M.; Rezgui, Y. Trees vs. Neurons: Comparison between random forest and ANN for high-resolution prediction of building energy consumption. Energy Build. 2017, 147, 77–89. [Google Scholar] [CrossRef]
- Yu, Z.; Haghighat, F.; Fung, B.C.M.; Yoshino, H. A decision tree method for building energy demand modeling. Energy Build. 2010, 42, 1637–1646. [Google Scholar] [CrossRef]
- Ahmad, T.; Chen, H. Short and medium-term forecasting of cooling and heating load demand in building environment with data-mining based approaches. Energy Build. 2018, 166, 460–476. [Google Scholar] [CrossRef]
- Yun, K.; Luck, R.; Mago, P.J.; Cho, H. Building hourly thermal load prediction using an indexed ARX model. Energy Build. 2012, 54, 225–233. [Google Scholar] [CrossRef]
- Yao, Y.; Lian, Z.; Liu, S.; Hou, Z. Hourly cooling load prediction by a combined forecasting model based on Analytic Hierarchy Process. Int. J. Therm. Sci. 2004, 43, 1107–1118. [Google Scholar] [CrossRef]
- Szul, T.; Nęcka, K.; Mathia, T.G. Neural Methods Comparison for Prediction of Heating Energy Based on Few Hundreds Enhanced Buildings in Four Season’s Climate. Energies 2020, 13, 5453. [Google Scholar] [CrossRef]
- Ekici, B.B.; Aksoy, U.T. Prediction of building energy needs in early stage of design by using ANFIS. Expert Syst. Appl. 2011, 38, 5352–5358. [Google Scholar] [CrossRef]
- Sholahudin, S.; Han, H. Simplified dynamic neural network model to predict heating load of a building using Taguchi method. Energy 2016, 115, 1672–1678. [Google Scholar] [CrossRef]
- Massana, J.; Pous, C.; Burgas, L.; Melendez, J.; Colomer, J. Short-term load forecasting in a non-residential building contrasting models and attributes. Energy Build. 2015, 92, 322–330. [Google Scholar] [CrossRef]
- Li, K.; Su, H. Forecasting building energy consumption with hybrid genetic algorithm-hierarchical adaptive network-based fuzzy inference system. Energy Build. 2010, 42, 2070–2076. [Google Scholar] [CrossRef]
- Mohammadi, M.; Talebpour, F.; Safaee, E.; Ghadimi, N.; Abedinia, O. Small-Scale Building Load Forecast based on Hybrid Forecast Engine. Neural Process. Lett. 2018, 48, 329–351. [Google Scholar] [CrossRef]
- Li, K.; Su, H.; Chu, J. Forecasting building energy consumption using neural networks and hybrid neuro-fuzzy system: A comparative study. Energy Build. 2011, 43, 2893–2899. [Google Scholar] [CrossRef]
- Mocanu, E.; Phuong, H.; Nguyen, P.H.; Gibescu, M.; Klinget, W.L. Deep learning for estimating building energy consumption. Sustain. Energy Grids Netw. 2016, 6, 91–99. [Google Scholar] [CrossRef]
- Mocanu, E.; Nguyen, P.H.; Kling, W. L; Gibescu., M. Unsupervised energy prediction in a smart grid context using reinforcement cross-building transfer learning. Energy Build. 2016, 116, 646–655. [Google Scholar] [CrossRef]
- Jain, R.K.; Smith, K.M.; Culligan, P.J.; Taylor, J.E. Forecasting energy consumption of multi-family residential buildings using support vector regression: Investigating the impact of temporal and spatial monitoring granularity on performance accuracy. Appl. Energy 2014, 123, 168–178. [Google Scholar] [CrossRef]
- Dong, B.; Cao, C.; Lee, S.E. Applying support vector machines to predict building energy consumption in tropical region. Energy Build. 2005, 37, 545–553. [Google Scholar] [CrossRef]
- Zhao, H.X.; Magoulès, F. Parallel support vector machines applied to the prediction of multiple buildings energy consumption. J. Algorith. Comput. Technol. 2010, 4, 231–249. [Google Scholar] [CrossRef]
- Wang, J.; Li, L.; Niu, D.; Tanaet, Z. An annual load forecasting model based on support vector regression with differential evolution algorithm. Appl. Energy 2012, 94, 65–70. [Google Scholar] [CrossRef]
- Xue, J.; Xu, Z.; Watada, J. Building an integrated hybrid model for short-term and mid-term load forecasting with genetic optimization. Int. Innovat. Comput. Inform. Control. 2012, 8, 7381–7391. [Google Scholar]
- Nie, H.; Liu, G.; Liu, X.; Wang, Y. Hybrid of ARIMA and SVMs for short-term load forecasting. Energy Procedia 2012, 16, 1455–1460. [Google Scholar] [CrossRef]
- Brown, M.; Barrington-Leigh, C.; Brown, Z. Kernel regression for real-time building energy analysis. J. Build. Perform. Simul. 2012, 5, 263–276. [Google Scholar] [CrossRef]
- Sudheer, G.; Suseelatha, A. Short term load forecasting using wavelet transform combined with Holt-Winters and weighted nearest neighbor models. Int. J. Electr. Power Energy Syst. 2015, 64, 340–346. [Google Scholar] [CrossRef]
- Szul, T.; Kokoszka, S. Application of Rough Set Theory (RST) to Forecast Energy Consumption in Buildings Undergoing Thermal Modernization. Energies 2020, 13, 1309. [Google Scholar] [CrossRef]
- Howaniec, H. Zaangażowanie Społeczne Przedsiębiorstw Jako Element Marketingu Wartości/Corporate Social Involvement as an Element of Value-Based Marketing; CeDeWu: Warszawa, Poland, 2019; ISBN 978-83-8102-265-1. Available online: https://cedewu.pl/Zaangazowanie-spoleczne-przedsiebiorstw-jako-element-marketingu-wartosci-p2438?pdf= (accessed on 25 February 2021).
- Kumar, S.; Pal, S.K.; Singh, R.P. A novel method based on extreme learning machine to predict heating and cooling load through design and structural attributes. Energy Build. 2018, 176, 275–286. [Google Scholar] [CrossRef]
- Monfet, D.; Corsi, M.; Choinière, D.; Arkhipova, E. Development of an energy prediction tool for commercial buildings using case-based reasoning. Energy Build. 2014, 81, 152–160. [Google Scholar] [CrossRef]
- Wi, Y.-M.; Joo, S.-K.; Song, K.-B. Holiday load forecasting using fuzzy polynomial regression with weather feature selection and adjustment. IEEE Trans. Power Syst. 2011, 27, 596–603. [Google Scholar] [CrossRef]
- Song, K.-B.; Baek, Y.-S.; Hong, D.H.; Jang, G. Short-Term Load Forecasting for the Holidays Using Fuzzy Linear Regression Method. IEEE Trans. Power Syst. 2005, 20, 96–101. [Google Scholar] [CrossRef]
- Guyon, I.; Elisseeff, A. An introduction to variable and feature selection. J. Mach. Learn. Res. 2003, 3, 1157–1182. [Google Scholar] [CrossRef][Green Version]
- Kusiak, A.; Li, M.; Zhang, Z. A data-driven approach for steam load prediction in buildings. Appl. Energy 2010, 87, 925–933. [Google Scholar] [CrossRef]
- Jurado, S.; Nebot, À.; Mugica, F.; Avellana, N. Hybrid methodologies for electricity load forecasting: Entropy-based feature selection with machine learning and soft computing techniques. Energy 2015, 86, 276–291. [Google Scholar] [CrossRef]
- Zhao, H.-X.; Magoulès, F. Feature selection for predicting building energy consumption based on statistical learning method. J. Algorith. Comput. Technol. 2012, 6, 59–77. [Google Scholar] [CrossRef]
- Szul, T. Ocena Efektywności Energetycznej Budynków/Energy Efficiency Rating of Buildings; Wydawnictwo Naukowe INTELLECT: Waleńczów, Poland, 2018; ISBN 978-83-950526-3-7. [Google Scholar]
- Sala-Cardoso, E.; Delgado-Prieto, M.; Kampouropoulos, K.; Romeral, L. Activity-aware HVAC power demand forecasting. Energy Build. 2018, 170, 15–24. [Google Scholar] [CrossRef]
- Ghofrani, M.; Ghayekhloo, M.; Arabali, A. A hybrid short-term load forecasting with a new input selection framework. Energy 2015, 81, 777–786. [Google Scholar] [CrossRef]
- Dodier, R.H.; Henze, G.P. Statistical analysis of neural networks as applied to building energy prediction. J. Sol. Energy Eng. 2004, 126, 592–600. [Google Scholar] [CrossRef]
- Ceperic, E.; Ceperic, V.; Baric, A. A strategy for short-term load forecasting by support vector regression machines. IEEE Trans. Power Syst. 2013, 28, 4356–4364. [Google Scholar] [CrossRef]
- Jovanović, R.Ž.; Sretenović, A.A.; Živković, B.D. Ensemble of various neural networks for prediction of heating energy consumption. Energy Build. 2015, 94, 189–199. [Google Scholar] [CrossRef]
- Fan, C.; Xiao, F.; Wang, S. Development of prediction models for next-day building energy consumption and peak power demand using data mining techniques. Appl. Energy 2014, 127, 1–10. [Google Scholar] [CrossRef]
- Son, H.; Kim, C. Forecasting short-term electricity demand in residential sector based on support vector regression and fuzzy-rough feature selection with particle swarm optimization. Procedia Eng. 2015, 118, 1162–1168. [Google Scholar] [CrossRef]
- Zhang, L.; Wen, J. A systematic feature selection procedure for short-term data driven building energy forecasting model development. Energy Build. 2019, 183, 428–442. [Google Scholar] [CrossRef]
- Kursa, M.B.; Rudnicki, W.R. Feature Selection with the Boruta Package. J. Stat. Softw. 2010, 36, 11. [Google Scholar] [CrossRef]
- Pawlak, Z. Rough Sets. Theoretical Aspects of Reasoning about Data; Kluwer Academic Press: Dordrecht, The Netherlands, 2012; Available online: http://bcpw.bg.pw.edu.pl/Content/2026/RoughSetsRep29.pdf (accessed on 5 November 2020).
- Ruiz, G.R.; Bandera, C.R. Validation of Calibrated Energy Models: Common Errors. Energies 2017, 10, 1587. [Google Scholar] [CrossRef]
- ASHRAE. American Society of Heating, Ventilating, and Air Conditioning Engineers (ASHRAE). Guideline 14-2014, Measurement of Energy and Demand Savings; Technical Report; American Society of Heating, Ventilating, and Air Conditioning Engineers: Atlanta, GA, USA, 2014; Available online: https://scholar.google.com/scholar_lookup?title=American+Society+of+Heating,+Ventilating,+and+Air+Conditioning+Engineers+(ASHRAE).+Guideline+14-2014,+Measurement+of+Energy+and+Demand+Savings&author=ASHRAE&publication_year=2014 (accessed on 22 February 2021).
- Regulation of the Minister of Infrastructure and Development of 27 February 2015 on the Methodology for Determining the Energy Performance of a Building or Part of a Building and Energy Performance Certificates. Dz.U. 2015 poz. 376. Poland. Available online: http://isap.sejm.gov.pl/isap.nsf/download.xsp/WDU20150000376/O/D20150376.pdf (accessed on 11 February 2021).
- CEN. European Standard: Heating Systems in Buildings; ISO 12831-1:2017-08; CEN: Brussels, Belgium, 2017. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Nguyen, D.V.; Yamada, K.; Unehara, M. Extended Tolerance Relation to Define a New Rough Set Model in Incomplete Information Systems. AFS 2013, 372091. [Google Scholar] [CrossRef]
- Renigier-Biłozor, M. Zastosowanie Teorii Zbiorów Przybli Żonych do Masowej Wyceny Nieruchomości na Małych Rynkach (Application of Rough Set Theory for Mass Valuation of Real Estate in Small Markets). Acta Sci. Pol. Adm. Locorum 2008, 7, 35–51. Available online: http://tnn.org.pl/tnn/publik/19/TNN_Tom_XIX_1.pdf (accessed on 1 March 2021).
- Szul, T.; Nęcka, K.; Knaga, J. Application of Rough Set Theory to Establish the Amount of Waste in Households in Rural Areas. Ecol. Chem. Eng. S. 2017, 24, 311–325. [Google Scholar] [CrossRef][Green Version]
- Rough Set Exploration System 2.1. Available online: http://logic.mimuw.edu.pl/∼rses (accessed on 7 January 2021).
- Miller, C.; Arjunan, P.; Kathirgamanathan, A.; Fu, C.; Roth, J.; Park, J.Y.; Balbach, C.; Gowri, K.; Nagy, Z.; Fontanini, A.D.; et al. The ASHRAE Great Energy Predictor III competition: Overview and results. Sci. Technol. Built Environ. 2020, 26, 1427–1447. [Google Scholar] [CrossRef]


{kind=link}
| Attribute | Unit | Min | Max | Average | Coefficient of Variation * |
|---|---|---|---|---|---|
| v1–the heated volume of building (EM) | m3 | 1308.0 | 22935.6 | 6393.1 | 62.9 |
| v2–total (net internal area) (IM) | m2 | 384.9 | 5077.2 | 1764.0 | 54.4 |
| v3–surface of heated floors (IM) | m2 | 372.7 | 4985.0 | 1568.5 | 53.4 |
| v4–surface of roof projection area (net) (EM) | m2 | 87.2 | 1253.0 | 467.0 | 55.5 |
| v5–total walls surface (net) area (EM) | m2 | 296.3 | 3897.3 | 1096.8 | 49.7 |
| v6–surface of floor from interior measurements (floor over basement or floor on the ground) (IM) | m2 | 12.2 | 1075.1 | 395.4 | 58.8 |
| v7–total windows area (EM) | m2 | 69.7 | 838.3 | 290.7 | 54.1 |
| v8–number of residential flats, premises | pc. | 6.0 | 142.0 | 32.4 | 62.8 |
| v9–number of living persons per building | Nb. | 14.0 | 425.0 | 73.9 | 67.6 |
| v10–shape coefficient of buildings (the ratio surface to volume) | m−1 | 0.21 | 1.92 | 0.46 | 43.7 |
| v11–calculated thermal transmittance of walls components | W∙m−2·K−1 | 0.43 | 1.89 | 1.09 | 31.9 |
| v12–calculated thermal transmittance of peak walls (side, narrower building walls) components | W∙m−2·K−1 | 0.32 | 3.09 | 1.01 | 47.7 |
| v13–calculated thermal transmittance of roof projections components | W∙m−2·K−1 | 0.18 | 3.56 | 1.25 | 85.1 |
| v14–calculated thermal transmittance of floors components (floor over basement) | W∙m−2·K−1 | 0.26 | 2.43 | 1.17 | 37.8 |
| v15–calculated thermal transmittance of floor components on the ground | W∙m−2·K−1 | 0.38 | 3.51 | 1.61 | 51.7 |
| v16–thermal transmittance of windows (commercial data) | W∙m−2·K−1 | 1.2 | 3.5 | 1.88 | 30.7 |
| v17–information whether the wall to be thermal improved | - | 0 | 1 | 0.98 | 13.7 |
| v18–information whether the peak wall (side, narrower building wall) to be thermal improved | - | 0 | 1 | 0.93 | 28.3 |
| v19–information whether the roof to be thermal improved | - | 0 | 1 | 0.52 | 96.0 |
| v20–information whether the floor over basement to be thermal improved | - | 0 | 1 | 0.32 | 146.1 |
| v21–information whether the floor on the ground to be thermal improved | - | 0 | 1 | 0.06 | 383.5 |
| v22–information whether replacement windows | - | 0 | 1 | 0.06 | 416.2 |
| v23–heating consumed power | kW | 36.5 | 413.5 | 129.8 | 57.0 |
| v24–index of final energy demand for heating before modernization (calculated from measurements of actual energy consumption for heating) | kWh∙m−2·year−1 | 83.0 | 566.1 | 253.4 | 43.6 |
| d–index of final energy demand for heating after modernization | kWh∙m−2·year−1 | 51.2 | 389.2 | 143.6 | 46.1 |
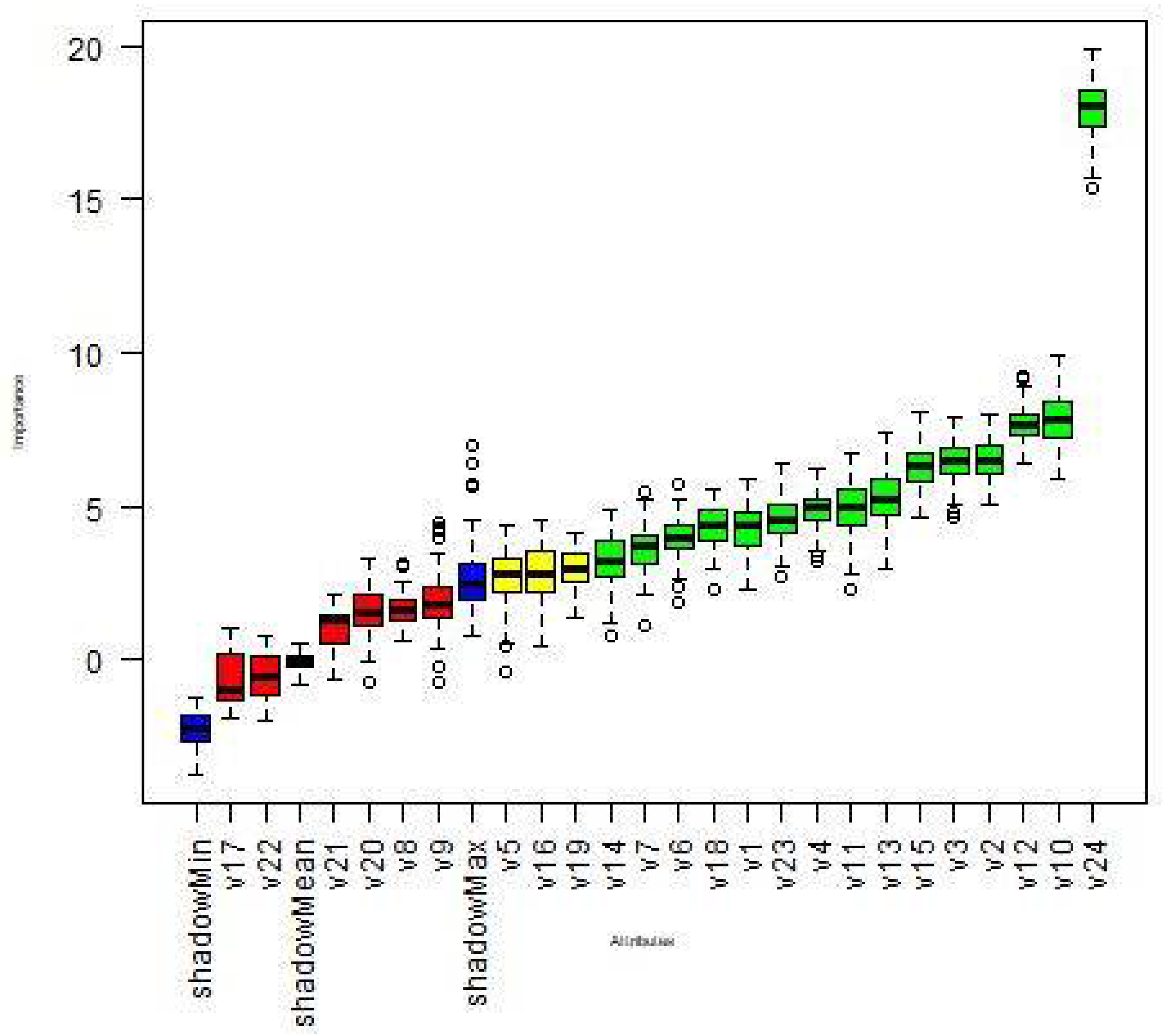
| No. | Attribute | Mean Imp | Median Imp | Min Imp | Max Imp | NormHits | Decision |
|---|---|---|---|---|---|---|---|
| 1 | v24 | 17.906 | 18.077 | 15.326 | 19.881 | 1 | Confirmed |
| 2 | v10 | 7.854 | 7.816 | 5.915 | 9.887 | 1 | Confirmed |
| 3 | v12 | 7.672 | 7.64 | 6.404 | 9.203 | 1 | Confirmed |
| 4 | v2 | 6.461 | 6.466 | 5.071 | 7.989 | 0.97 | Confirmed |
| 5 | v3 | 6.433 | 6.455 | 4.668 | 7.938 | 0.97 | Confirmed |
| 6 | v15 | 6.278 | 6.32 | 4.626 | 8.065 | 0.96 | Confirmed |
| 7 | v13 | 5.26 | 5.225 | 2.953 | 7.372 | 0.95 | Confirmed |
| 8 | v11 | 4.934 | 4.999 | 2.242 | 6.756 | 0.92 | Confirmed |
| 9 | v4 | 4.893 | 4.929 | 3.23 | 6.224 | 0.92 | Confirmed |
| 10 | v23 | 4.577 | 4.53 | 2.715 | 6.355 | 0.91 | Confirmed |
| 11 | v18 | 4.359 | 4.373 | 2.278 | 5.549 | 0.879 | Confirmed |
| 12 | v1 | 4.279 | 4.374 | 2.259 | 5.923 | 0.899 | Confirmed |
| 13 | v6 | 3.958 | 3.952 | 1.88 | 5.736 | 0.859 | Confirmed |
| 14 | v7 | 3.632 | 3.724 | 1.079 | 5.457 | 0.778 | Confirmed |
| 15 | v14 | 3.234 | 3.242 | 0.814 | 4.884 | 0.687 | Confirmed |
| 16 | v19 | 2.962 | 2.951 | 1.332 | 4.122 | 0.637 | Tentative |
| 17 | v16 | 2.805 | 2.821 | 0.447 | 4.563 | 0.607 | Tentative |
| 18 | v5 | 2.678 | 2.78 | −0.413 | 4.376 | 0.607 | Tentative |
| 19 | v9 | 1.861 | 1.805 | −0.711 | 4.501 | 0.304 | Rejected |
| 20 | v8 | 1.658 | 1.595 | 0.609 | 3.157 | 0.031 | Rejected |
| 21 | v20 | 1.602 | 1.555 | −0.732 | 3.316 | 0.213 | Rejected |
| 22 | v21 | 0.939 | 1.252 | −0.669 | 2.113 | 0.021 | Rejected |
| 23 | v22 | −0.48 | −0.608 | −1.964 | 0.777 | 0 | Rejected |
| 24 | v17 | −0.684 | −1.001 | −1.926 | 1.002 | 0 | Rejected |
| No. | Feature | Sets of Features | |||
|---|---|---|---|---|---|
| Set 1 | Set 2 | Set 3 | Set 4 | ||
| 1 | v24 | 1 | 1 | 1 | 1 |
| 2 | v10 | 1 | 1 | 1 | 1 |
| 3 | v12 | 1 | 1 | 1 | 1 |
| 4 | v2 | 1 | 1 | 1 | |
| 5 | v3 | 1 | 1 | 1 | |
| 6 | v15 | 1 | 1 | 1 | |
| 7 | v13 | 1 | 1 | 1 | |
| 8 | v11 | 1 | 1 | 1 | |
| 9 | v4 | 1 | 1 | 1 | |
| 10 | v23 | 1 | 1 | 1 | |
| 11 | v18 | 1 | 1 | ||
| 12 | v1 | 1 | 1 | ||
| 13 | v6 | 1 | 1 | ||
| 14 | v7 | 1 | 1 | ||
| 15 | v14 | 1 | 1 | ||
| 16 | v19 | 1 | |||
| 17 | v16 | 1 | |||
| 18 | v5 | 1 | |||
| Assessment Parameters | Sets of Features | |||
|---|---|---|---|---|
| Set 1 | Set 2 | Set 3 | Set 4 | |
| MAPE (%) | 9.2 | 10.7 | 10.3 | 14.2 |
| MBE (%) | 2.4 | 3.6 | 4.7 | 0.48 |
| CV RMSE (%) | 5.49 | 5.51 | 5.89 | 5.92 |
| R2 (-) | 0.85 | 0.82 | 0.81 | 0.79 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Szul, T.; Tabor, S.; Pancerz, K. Application of the BORUTA Algorithm to Input Data Selection for a Model Based on Rough Set Theory (RST) to Prediction Energy Consumption for Building Heating. Energies 2021, 14, 2779. https://doi.org/10.3390/en14102779
Szul T, Tabor S, Pancerz K. Application of the BORUTA Algorithm to Input Data Selection for a Model Based on Rough Set Theory (RST) to Prediction Energy Consumption for Building Heating. Energies. 2021; 14(10):2779. https://doi.org/10.3390/en14102779
Chicago/Turabian StyleSzul, Tomasz, Sylwester Tabor, and Krzysztof Pancerz. 2021. "Application of the BORUTA Algorithm to Input Data Selection for a Model Based on Rough Set Theory (RST) to Prediction Energy Consumption for Building Heating" Energies 14, no. 10: 2779. https://doi.org/10.3390/en14102779
APA StyleSzul, T., Tabor, S., & Pancerz, K. (2021). Application of the BORUTA Algorithm to Input Data Selection for a Model Based on Rough Set Theory (RST) to Prediction Energy Consumption for Building Heating. Energies, 14(10), 2779. https://doi.org/10.3390/en14102779