A Framework to Generate and Label Datasets for Non-Intrusive Load Monitoring


Abstract
1. Introduction
1.1. Related Work
2. Materials and Methods
2.1. Smart Meter
2.2. Distributed Meters
2.3. Additional Sensors
- Smart lighting:Many light bulbs are nowadays substituted with smart light bulbs. Most of these can be controlled via a ZigBee gateway. Such a gateway can be incorporated to pass information if a light bulb changes its state, dimm state, or color. We have implemented a Python script which interfaces with such a gateway to log the state changes of all light bulbs connected to the gateway using our MQTT-API. This allows for deriving power consumption estimates without intrusively metering each light individually and provides further room occupancy information.
- Sensors:We show an example flow of how a custom sensor can be developed using the provided MQTT-API in Figure 3. The ESP32 has WiFi built-in and provides certain inter-system interfaces such as SPI, I2C, or UART. This allows for rapid prototyping different sensors like temperature or occupancy.
- Bridges:The same system overview as shown in Figure 3 can be used to develop different gateways. As an example, we developed a 433 gateway that logs state changes of switchable sockets, wall switches, or remote button presses of devices that are equipped with 433 . We further implemented an infrared sniffer that logs all commands received from off-the-shelf remotes to MQTT. This helps to capture interactions with televisions, HiFi systems, and air conditioners.
2.4. Extracting Events
2.4.1. Event Detection
2.4.2. Unique Event Identification
2.4.3. High Variance Filtering
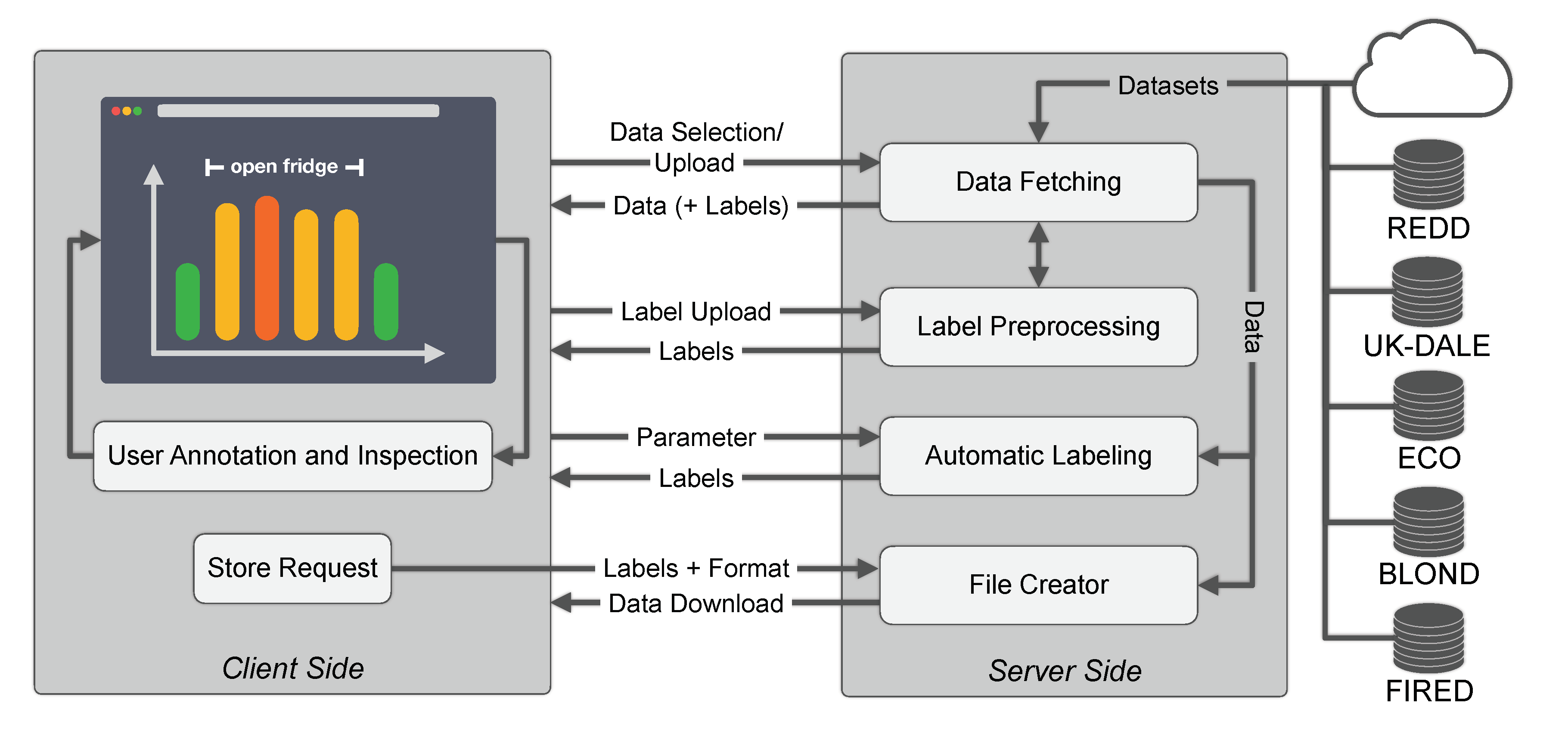
2.5. Human Supervision
3. Results
3.1. Data Records
3.1.1. Voltage and Current Data
3.1.2. Power Data
3.1.3. Logs
- Smart lights:State changes of each light in the apartment is logged. The filenames of these logs have the form:room is the room the light is installed in, deviceName represents how this light is used (e.g., ceiling light) and deviceModel matches the light model name. The file’s second column represents the state of the light (on or off), the third column is the light’s intensity (0% to 100%) while the last column represents the light’s hex color. If setting different colors is not supported by the light, the column only shows None values.light__<room>__<deviceName>__<deviceModel>.csvAs individual measurements of the apartment’s lighting have shown, the installed smart lights consume constant apparent power linearly increasing with the light’s intensity (dimm setting). As information of the lights’ state and dimm setting is available for the complete recording duration, this information can be used to estimate the power consumption of each light.
- Sensor readings:The readings of temperature and humidity sensors are stored in files following the name scheme:sensorType is either hum or temp for humidity or temperature readings. Each file’s second column represents the sensor reading. Temperature readings are stored in degrees Celsius and humidity readings in %, respectively. All values have floating point precision. Samples are not acquired equidistantly, as the sensors only send new values if they have changed.sensor__<room>__<sensorType>.csv
- Device info:Certain smart devices or bridges as explained in Section 2.3 allow for capturing events of devices in the apartment, e.g., pressing a certain key of the television remote. These events are logged in files with the following name format:Each file’s second column gives information about the current device state or happened event. The file of the HiFi system, for instance, includes key-presses such as power or vol_up. Figure 10 shows the logs for the television, the HiFi system, and the espresso machine.device__<room>__<deviceName>__<deviceModel>.csv
3.1.4. Data Labeling
3.2. Data Statistics
3.3. Technical Validation
3.3.1. Calibration
3.3.2. Residual Power
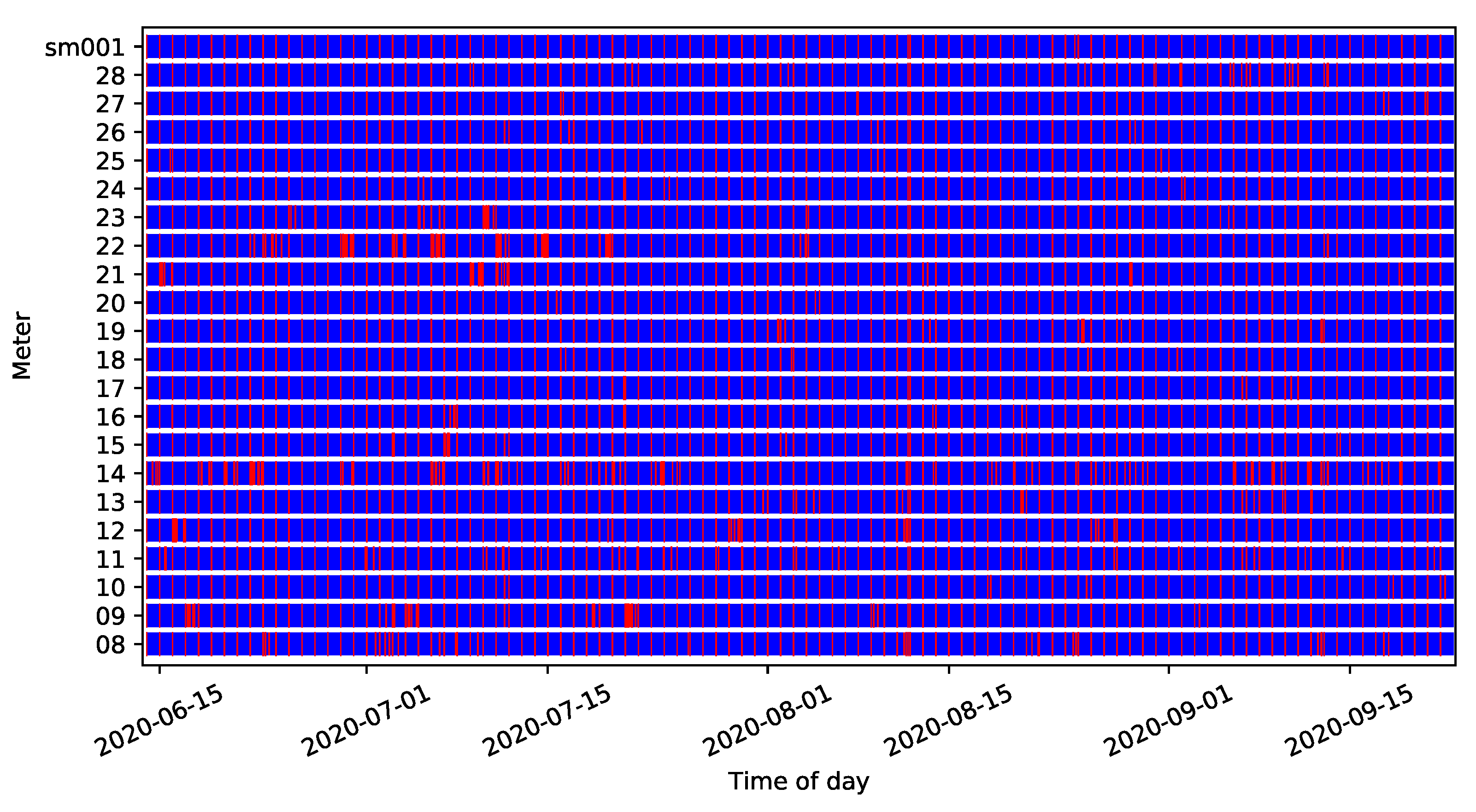
3.3.3. Availability
3.3.4. Clock Synchronization
3.4. Data and Code Availability
4. Discussion
5. Conclusions
- We defined a set of challenges that an electricity dataset needs to address so that it can be used to evaluate a large set of electricity and smart meter related algorithms such as event-based and event-less Non-Intrusive Load Monitoring.
- We proposed an expandable framework comprised of the hardware and software components required to record datasets that meet these challenges.
- We introduced and evaluated a novel dataset to the community, which, compared to other residential electricity datasets such as BLUED, REDD or UK-DALE, features simultaneous high frequency recordings of the aggregated mains’ signal and of individual household appliances as well as two weeks of fully labeled appliance events.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ILM | Intrusive Load Monitoring |
| NILM | Non-Intrusive Load Monitoring |
| RTC | Real Time Clock |
| FIRED | Fully-labeled hIgh-fRequency Electricity Disaggregation |
| CSV | Comma-Separated Values |
| SRT | SubRip Text |
| RMSE | Root-Mean-Square Error |
| TP | True Positives |
| FP | False Positives |
| FN | False Negatives |
| NTP | Network Time Protocol |
References
- Nations, U. About the Sustainable Development Goals—United Nations Sustainable Development. Available online: https://www.un.org/sustainabledevelopment/sustainable-development-goals (accessed on 29 August 2020).
- Ehrhardt-Martinez, K.; Donnelly, K.A.; Laitner, S. Advanced Metering Initiatives and Residential Feedback Programs: A Meta-Review for Household Electricity-Saving Opportunities; American Council for an Energy-Efficient Economy: Washington, DC, USA, 2010. [Google Scholar]
- Bundesministerium für Wirtschaft und Energie (BMWi). Gesetz zur Digitalisierung der Energiewende. 2016. Available online: https://www.bmwi.de/Redaktion/DE/Downloads/Gesetz/gesetz-zur-digitalisierung-der-energiewende.pdf (accessed on 29 August 2020).
- Hart, G.W. Nonintrusive appliance load monitoring. Proc. IEEE 1992, 80, 1870–1891. [Google Scholar] [CrossRef]
- Norford, L.K.; Leeb, S.B. Non-intrusive electrical load monitoring in commercial buildings based on steady-state and transient load-detection algorithms. Energy Build. 1996, 24, 51–64. [Google Scholar] [CrossRef]
- Bundesministerium für Wirtschaft und Energie (BMWi). Information on the Funding Program Entitled ‘Smart Energy Showcases—Digital Agenda for the Energy Transition’ (SINTEG). 2016. Available online: https://www.bmwi.de/Redaktion/EN/Downloads/bmwi-papier-sinteg-kernbotschaften.pdf?__blob=publicationFile&v=3 (accessed on 29 August 2020).
- Armel, K.C.; Gupta, A.; Shrimali, G.; Albert, A. Is disaggregation the holy grail of energy efficiency? The case of electricity. Energy Policy 2013, 52, 213–234. [Google Scholar] [CrossRef]
- Hsu, C.Y.; Zeitoun, A.; Lee, G.H.; Katabi, D.; Jaakkola, T. Self-supervised learning of appliance usage. In Proceedings of the 8th International Conference on Learning Representations (ICLR), Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Kolter, J.Z.; Johnson, M.J. REDD: A public data set for energy disaggregation research. In Proceedings of the Workshop on Data Mining Applications in Sustainability (SIGKDD), San Diego, CA, USA, 21–24 August 2011; Volume 25, pp. 59–62. [Google Scholar]
- Batra, N.; Kelly, J.; Parson, O.; Dutta, H.; Knottenbelt, W.; Rogers, A.; Singh, A.; Srivastava, M. NILMTK: An open source toolkit for non-intrusive load monitoring. In Proceedings of the 5th International Conference on Future Energy Systems, Cambridge, UK, 11–13 June 2014; pp. 265–276. [Google Scholar]
- Kelly, J.; Knottenbelt, W. The UK-DALE dataset, domestic appliance-level electricity demand and whole-house demand from five UK homes. Sci. Data 2015, 2, 150007. [Google Scholar] [CrossRef] [PubMed]
- Kriechbaumer, T.; Jacobsen, H.A. BLOND, a building-level office environment dataset of typical electrical appliances. Sci. Data 2018, 5, 180048. [Google Scholar] [CrossRef] [PubMed]
- Anderson, K.; Ocneanu, A.; Benitez, D.; Carlson, D.; Rowe, A.; Berges, M. BLUED: A fully labeled public dataset for event-based non-intrusive load monitoring research. In Proceedings of the 2nd KDD Workshop on Data Mining Applications in Sustainability (SustKDD), Beijing, China, 8 December 2012; Volume 7. [Google Scholar]
- Belley, C.; Gaboury, S.; Bouchard, B.; Bouzouane, A. An efficient and inexpensive method for activity recognition within a smart home based on load signatures of appliances. Pervasive Mob. Comput. 2014, 12, 58–78. [Google Scholar] [CrossRef]
- Alcalá, J.M.; Ureña, J.; Hernández, Á.; Gualda, D. Assessing human activity in elderly people using non-intrusive load monitoring. Sensors 2017, 17, 351. [Google Scholar] [CrossRef] [PubMed]
- Völker, B.; Pfeifer, M.; Scholl, P.M.; Becker, B. Annoticity: A Smart Annotation Tool and Data Browser for Electricity Datasets. In Proceedings of the 5th International Workshop on Non-Intrusive Load Monitoring, Yokohama, Japan, 18 November 2020; pp. 1–5. [Google Scholar]
- Völker, B.; Pfeifer, M.; Scholl, P.M.; Becker, B. FIRED: A Fully-labeled hIgh-fRequency Electricity Disaggregation Dataset. In Proceedings of the 7th ACM International Conference on Systems for Energy-Efficient Buildings, Cities, and Transportation, Yokohama, Japan, 19–20 November 2020; pp. 294–297. [Google Scholar]
- Beckel, C.; Kleiminger, W.; Cicchetti, R.; Staake, T.; Santini, S. The ECO data set and the performance of non-intrusive load monitoring algorithms. In Proceedings of the 1st ACM Conference on Embedded Systems for Energy-Efficient Buildings, Memphis, TN, USA, 4–6 November 2014; pp. 80–89. [Google Scholar]
- Makonin, S.; Popowich, F.; Bartram, L.; Gill, B.; Bajić, I.V. AMPds: A public dataset for load disaggregation and eco-feedback research. In Proceedings of the 2013 IEEE Electrical Power & Energy Conference, Halifax, NS, Canada, 21–23 August 2013; pp. 1–6. [Google Scholar]
- Makonin, S.; Wang, Z.J.; Tumpach, C. RAE: The rainforest automation energy dataset for smart grid meter data analysis. Data 2018, 3, 8. [Google Scholar] [CrossRef]
- Pereira, L. Developing and evaluating a probabilistic event detector for non-intrusive load monitoring. In Proceedings of the 2017 Sustainable Internet and ICT for Sustainability (SustainIT), Funchal, Portugal, 6–7 December 2017; pp. 1–10. [Google Scholar]
- Völker, B.; Scholls, P.M.; Schubert, T.; Becker, B. Towards the Fusion of Intrusive and Non-intrusive Load Monitoring: A Hybrid Approach. In Proceedings of the Ninth International Conference on Future Energy Systems, Karlsruhe, Germany, 12–15 June 2018; pp. 436–438. [Google Scholar]
- Völker, B.; Scholl, P.M.; Becker, B. Semi-Automatic Generation and Labeling of Training Data for Non-Intrusive Load Monitoring. In Proceedings of the Tenth International Conference on Future Energy Systems, Phoenix, AZ, USA, 25–28 June 2019. [Google Scholar]
- Völker, B.; Pfeifer, M.; Scholl, P.M.; Becker, B. A Versatile High Frequency Electricity Monitoring Framework for Our Future Connected Home. In Proceedings of the International Conference on Sustainable Energy for Smart Cities, Braga, Portugal, 4–6 December 2019; pp. 221–231. [Google Scholar]
- Analog Devices. ADE9000—High Performance, Multiphase Energy, and Power Quality Monitoring IC; Analog Devices: Norwood, MA, USA, 2017; Rev. A. [Google Scholar]
- STMicroelectronics. STPM32, STPM33, STPM3—ASSP for Metering Applications with up to Four Independent 24-bit 2nd Order Sigma-Delta ADCs, 4 MHz OSF and 2 Embedded PGLNA; STMicroelectronics: Geneva, Switzerland, 2016; Rev. 5. [Google Scholar]
- OASIS. The MQTT 5.0 standard—A Machine-to-Machine (M2M) “Internet of Things” Connectivity Protocol. 2020. Available online: https://www.mqtt.org/ (accessed on 29 August 2020).
- Pereira, L.; Nunes, N.J. Semi-automatic labeling for public non-intrusive load monitoring datasets. In Proceedings of the Sustainable Internet and ICT for Sustainability (SustainIT), Madrid, Spain, 14–15 April 2015; pp. 1–4. [Google Scholar]
- Matroska, N.P.O. The Matroska File Format. 2020. Available online: https://www.matroska.org/ (accessed on 29 August 2020).
- Scholl, P.M.; Völker, B.; Becker, B.; Van Laerhoven, K. A multi-media exchange format for time-series dataset curation. In Human Activity Sensing; Springer: Berlin, Germany, 2019; pp. 111–119. [Google Scholar]
- WavPack. Hybrid Lossless Audio Compression. 2020. Available online: http://www.wavpack.com (accessed on 29 August 2020).
- Group, T.H. THE HDF5 LIBRARY & FILE FORMAT. 2020. Available online: https://www.hdfgroup.org/solutions/hdf5/ (accessed on 11 December 2020).
- co2online. Der Stromspiegel für Deutschland 2019. 2020. Available online: https://www.stromspiegel.de/stromverbrauch-verstehen/stromverbrauch-3-personen-haushalt/ (accessed on 29 August 2020).
- Ag, C.E. Voltcraft Energy Logger 4000. 2020. Available online: http://www.voltcraft.ch/index.html (accessed on 29 August 2020).















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | Challenge |
|---|---|
| C1 | Simultaneous recordings of a home’s aggregated electricity consumption and the consumption of the individual appliances. The individual data can be used to validate the appliance estimates of NILM algorithms. Furthermore, it can be explored how semi-supervised hybrid NILM algorithms such as [22] can benefit from individual appliance data. |
| C2 | High sampling rates of the aggregated and individual appliance data. This allows for the extraction of high frequency features from the individual waveforms which might further improve traditional NILM algorithms. Kriechbaumer et al. [12] focused on recording a dataset with a very high sampling rate but, therefore, require to download ≈75 of data per day. To not sacrifice usability, a trade-off between high sampling rates and file size needs to be examined. |
| C3 | Continuous data recording for multiple days is crucial to understand and explore different consumption behavior based on the time-of-day or day-of-week. |
| C4 | High quality dataset labels to evaluate event-based NILM and event detection algorithms. These labels should consist of a timestamp describing when the event occurred, the device responsible for the event and a textual description of the event. |
| C5 | High temporal accuracy of the data and its labels is required. Labels should always reflect the associated change in the signal. This requires that the data streams are in sync and do not drift apart. |
| C6 | Usability is one of the most underrated factors of a dataset. However, researchers should be able to explore and utilize a dataset in a quick and easy way. |
| ID | Connected Appliance | Brand | Model | P | |||
|---|---|---|---|---|---|---|---|
| 08 | Baby Heat Lamp | Reer | FeelWell | 600 | 2 | 611.93 | 0.30 |
| 09 | Fridge | IKEA | HUTTRA | 1000 | 3 | 1138.79 | 18.02 |
| 10 | Smartphone Charger #1 | - | 2 Port USB | 10 | 3 | 12.74 | 1.68 |
| 11 | Changing Device | 3 | 1898.71 | 3.10 | |||
| 12 | Smartphone Charger #2 | - | 4 Port USB | 25 | 1 | 27.86 | 2.77 |
| 13 | Coffee Grinder | Graef | Cm800 | 128 | 3 | 206.89 | 0.17 |
| 14 | Smart Speaker | Apple | HomePod | 15 | 3 | 3.60 | 0.23 |
| 15 | Espresso Machine | Rocket | Appartamento | 1200 | 3 | 1230.62 | 29.82 |
| 16 | Kettle | Aigostar | Adam 30GOM | 2200 | 3 | 1958.76 | 2.89 |
| 17 | Hairdryer | Remington | D3190 | 2200 | 1 | 1934.85 | 1.00 |
| 18 | Router #1 | Apple | Airport Extreme A1521 | 10.3 | 1 | 27.97 | 19.34 |
| Router #2 | Telekom | Speedport Smart 1 | 10 | ||||
| Telephone | Gigaset | A400 | 1 | ||||
| 19 | Printer | EPSON | Stylus SX435W | 15 | 1 | 21.45 | 0.16 |
| 20 | Office PC | Apple | Mac Mini A1993 | 85 | 2 | 236.08 | 59.49 |
| 27” Display | Apple | Thunderbolt display | 200 | ||||
| Speaker | Logitech | Z2300 | 240 | ||||
| Smartphone Charger #3 | Apple | MD813ZM/A | 5 | ||||
| Access Point #2 | Apple | Airport Express A1264 | 8 | ||||
| 21 | Media PC | Apple | Mac Mini A1347 | 85 | 3 | 45.38 | 12.98 |
| 22 | HiFi System | Onkyo | TX-SR507 | 160 | 3 | 85.86 | 15.27 |
| Subwoofer | Onkyo | SKW-501E | 105 | ||||
| 23 | Television | Samsung | UE48JU6450 | 64 | 3 | 150.96 | 12.31 |
| 24 | Light+Driver | IKEA | - | 40 | 3 | 36.56 | 1.75 |
| 25 | Oven | IKEA | MIRAKULÖS | 3480 | 3 | 2491.03 | 9.69 |
| 26 | Access Point #3 | Apple | Airport Express A1392 | 2.2 | 3 | 2.67 | 2.21 |
| 27 | Router #3 | Netgear | R6250 | 30 | 1 | 56.91 | 15.74 |
| Recording PC | Intel | NUC8v5PNK | 60 | ||||
| 28 | Fume Extractor | IKEA | WINDIG | 250 | 3 | 249.26 | 1.11 |
| Group | Appliance | Events | TP | FP | FN | F1 |
|---|---|---|---|---|---|---|
| #1 | Baby Heat Lamp | 6 | 6 | 0 | 0 | 100.00 |
| Fridge | 1006 | 863 | 2 | 143 | 92.25 | |
| Coffee Grinder | 348 | 250 | 114 | 98 | 70.22 | |
| Espresso Machine | 1880 | 1760 | 0 | 120 | 96.70 | |
| Kettle | 30 | 30 | 0 | 0 | 100.00 | |
| Hairdryer | 18 | 17 | 0 | 1 | 97.14 | |
| Hifi System, Subwoofer | 45 | 44 | 37 | 1 | 69.84 | |
| Television | 79 | 65 | 4 | 14 | 87.84 | |
| Kitchen Spot Light | 12 | 12 | 0 | 0 | 100.00 | |
| Oven | 138 | 138 | 1 | 0 | 99.64 | |
| Fume Extractor | 47 | 47 | 1 | 0 | 98.95 | |
| Sum | 3609 | 3232 | 159 | 377 | 92.34 | |
| #2 | Smartphone Charger #1 | 96 | 83 | 1491 | 13 | 9.94 |
| Smartphone Charger #2 | 63 | 45 | 7999 | 18 | 1.11 | |
| Office Pc | 583 | 410 | 85,367 | 173 | 0.95 | |
| Media Pc | 28 | 10 | 26,632 | 18 | 0.07 | |
| Sum | 770 | 548 | 121,489 | 222 | 0.89 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Völker, B.; Pfeifer, M.; Scholl, P.M.; Becker, B. A Framework to Generate and Label Datasets for Non-Intrusive Load Monitoring. Energies 2021, 14, 75. https://doi.org/10.3390/en14010075
Völker B, Pfeifer M, Scholl PM, Becker B. A Framework to Generate and Label Datasets for Non-Intrusive Load Monitoring. Energies. 2021; 14(1):75. https://doi.org/10.3390/en14010075
Chicago/Turabian StyleVölker, Benjamin, Marc Pfeifer, Philipp M. Scholl, and Bernd Becker. 2021. "A Framework to Generate and Label Datasets for Non-Intrusive Load Monitoring" Energies 14, no. 1: 75. https://doi.org/10.3390/en14010075
APA StyleVölker, B., Pfeifer, M., Scholl, P. M., & Becker, B. (2021). A Framework to Generate and Label Datasets for Non-Intrusive Load Monitoring. Energies, 14(1), 75. https://doi.org/10.3390/en14010075