1. Introduction
A brain–machine interface (BMI) is a direct and unconventional communication link between the brain and a physical device [
1,
2]. It enables the study of neuronal activity, representing cognitive processes of planning and mental simulation of action sequences. BMI is classified into reactive and proactive (cognitive) types. The reactive mode denotes actions generated by flexibly responding to the environmental stimuli from sensory inputs in unpredictable situations. The proactive mode, on the other hand, denotes actions that are generated to accomplish intended goals based on active intentions in predictable situations. In the field of cognitive neuroscience, BMI introduces a new opportunity for smart environmental control by human–environment interaction.
Multifunctional Brain–Computer Interface (BCI) [
3] and electroencephalogram (EEG) technology have been adopted as the BMI for applications of environmental control [
3], accelerated information seeking [
4], and neuro-controlled upper limb prosthesis [
5]. However, the biomedical signals of these applications do not provide cognitive properties for proactive control. The SI-CODE [
6] introduced a bidirectional BMI for decoding multiunit neural activity and transmitting information back to the brain by electrical stimulation. Although the multiunit activities do provide rich cognitive properties of the brain, the project does not take advantage of the cognitive properties. In the industry, big tech companies such as Microsoft, Facebook, and Neuralink are also researching next-generation BMI products [
7,
8,
9]. However, these research projects are reactive, such that reflexive and cumbersome behaviors dominate the outcomes, instead of primary cognitive (proactive) human traits—e.g., planning and mental simulation of actions—where a large amount of interest lies. Plan4Act (In Plan4Act, the main goal is to exploit the neuronal signatures of upcoming, planned actions of an agent to proactively support it during the execution of these forthcoming activities. P.M. is the PI of the work package 3 in Plan4Act. J.C.L and N.S.H are responsible for the research development of the energy-efficient neural decoder hardware accelerator in Plan4Act.) [
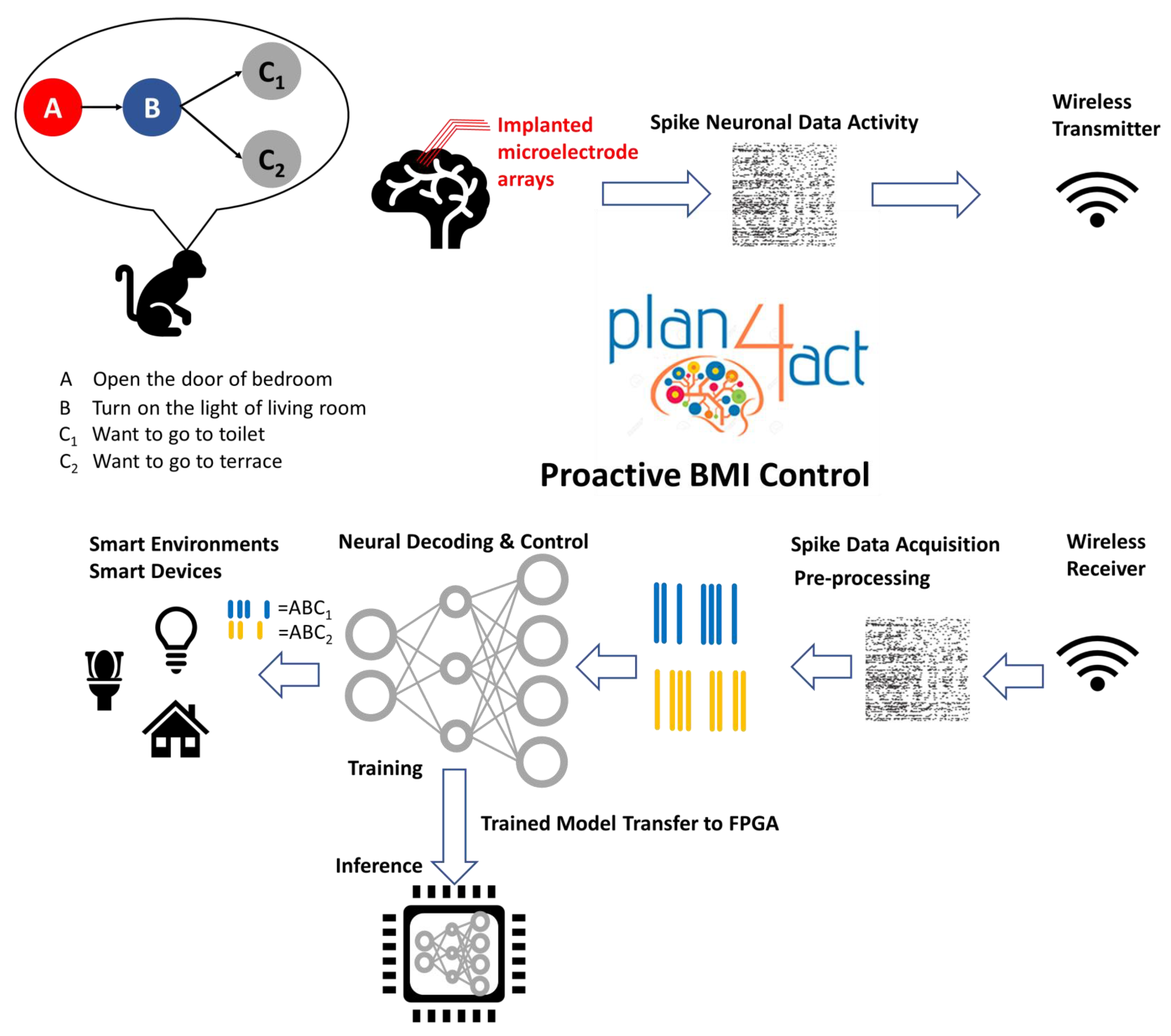
10] is a unique project for studying proactive predictions of future planned actions with online decoding. Its uniqueness lies in the fact that it has a proactive BMI composed of wireless data acquisition for receiving neural brain activity [
11] and a neural network decoder for processing the recorded sequence-predicting neural activity and inferring predicted action sequences for proactive control in real time.
The development of a neural network decoder for proactive BMI control has two major challenges: adaptivity and power consumption. As the implanted floating microwire arrays (FMAs) move relative to the recorded cells and the information represented by a specific neuron’s activity may change due to neuroplasticity, the decoder from day one cannot be leveraged to work in different experimental sessions on the day
n later [
12,
13]. As a result, the neural network decoder needs to adapt to the above situations on day
n with a modification of the topology and a retrain procedure for recalibration. The modification related to neural network implementation is a time-consuming process leading to a potential delay for the whole project. On the other hand, the neural decoder of the BMI is a battery-powered real-time embedded system, which requires a highly energy-efficient computing unit [
14] for irregular parallelism and custom data types [
15]. To address the above challenges, it is believed that the neural network decoder on a field-programmable gate array (FPGA) with a concurrent optimization of performance, power, and area (PPA) [
14] is a promising solution. In [
16], two high-performance hardware coprocessors for the probabilistic neural network and neural ensemble decoding based on Kalman filter were implemented on FPGA for real-time BMI applications. Apart from that, it is well known that fixed-point implementation consumes fewer resources and less power than floating-point implementations in FPGA literature [
15,
17].
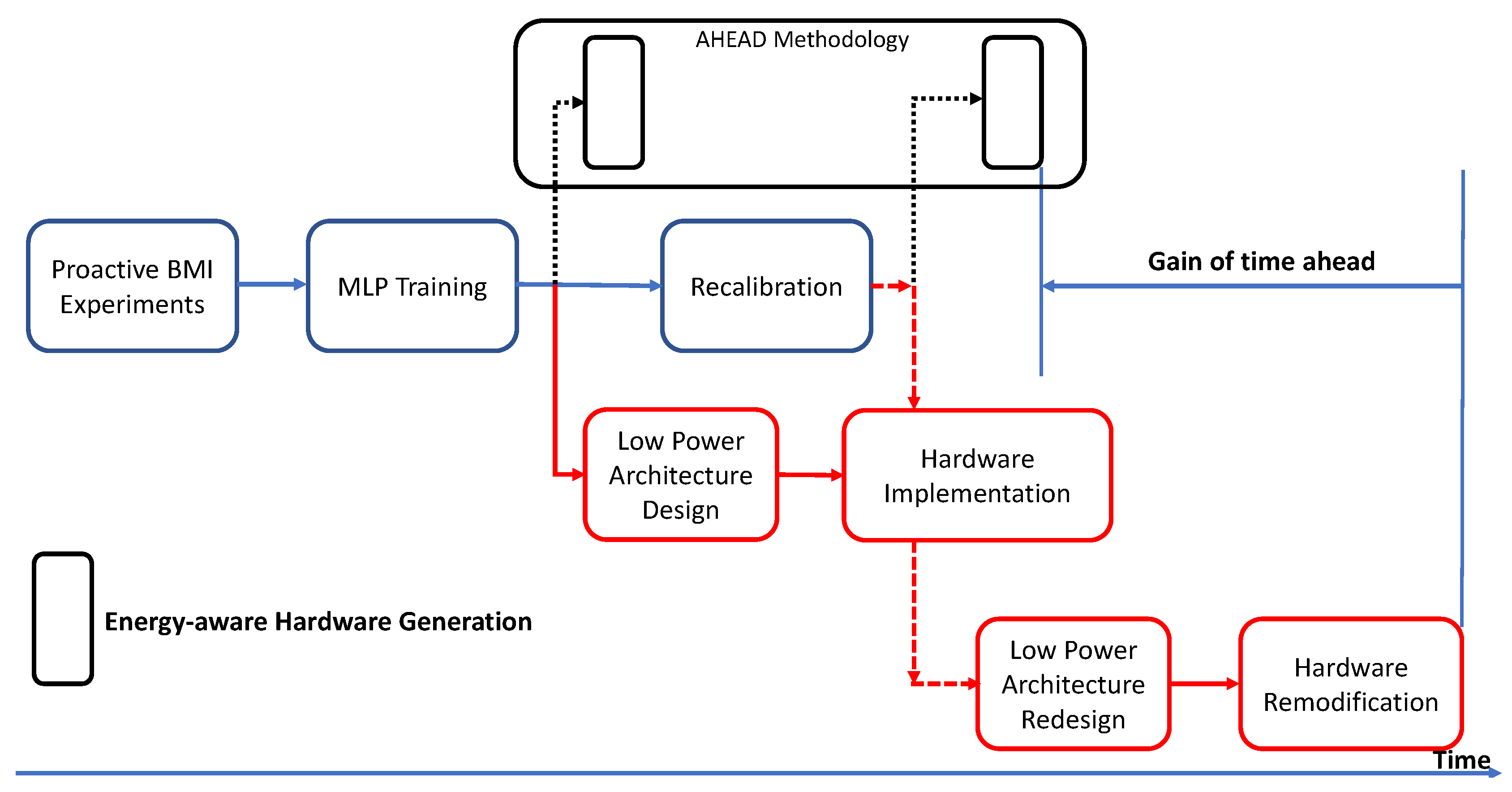
To address the aforementioned challenges, an automatic holistic energy-aware design (AHEAD) methodology is introduced for the design automation of an energy-efficient neural network decoder for the proactive BMI. The core processing component of the neural network decoder is a multilayer perceptron [
18] (MLP) inference that has features of uniformity, innate parallelism, scalability, dynamically adaptivity, and fault tolerance [
19,
20,
21]. The MLP will be trained by the golden datasets for the initial weights. AHEAD extracts the network feature from MLP and creates the corresponding hardware model and test bench. AHEAD adopts fixed-point number representation for the hardware implementation of the MLP because of the comparable accuracy in finite-precision performance [
22], shorter latency, reduction of logic, memory area, and power consumption on an FPGA [
17,
23] compared to its floating-point implementation. Since the floating-point to fixed-point conversion is a nonconvex NP-hard optimization problem [
24] and requires language-specific programs [
25,
26,
27,
28], AHEAD develops a bit-width identification (BWID) loop method for the tedious conversion because of the close synergy between fixed-point parameter estimation and configurable hardware generation. The BWID automatically estimates the required fixed-point bit-width parameters with the least loss of accuracy and bit-width through the reconstruction of the given MLP neural network from the MLP parameters and golden datasets without the user’s program code. To simplify and accelerate the system implementation on an FPGA, AHEAD encompasses a high-level synthesis (HLS) [
29] design flow that automatically generates a register-transfer level (RTL) for the PPA-optimized system with fixed-point bit-width MLP, pipelines, and parallel low-power microarchitectures.
The AHEAD methodology can implement an energy-efficient MLP hardware accelerator, including integration with the embedded processor as a full system, within an hour. Not only is the development effort minimized, but also the development time is significantly reduced from several days to an hour. Furthermore, the generated design, without a loss of accuracy, is about 4X faster in execution time, 5.97X better in energy efficiency, 3X lower in slice look-up tables (LUTs), 8X lower in slice registers, 243X lower in DSP48Es, and 5X lower in block rams (BRAMs) compared to the floating-point implementation in the experiment. Thus, the AHEAD methodology can deliver a rapid, low-power design and implementation of the MLP neural decoder to meet the power requirements [
30] for the FPGA implementation for BMI applications.
The contributions of this paper to the problem of the design of the low-power MLP hardware accelerator for proactive BMI control edge devices are as follows:
A novel holistic design methodology, for the first time, bridges the gap between the BMI developers and the hardware developers for automatic energy-aware MLP hardware generation with trained MLP parameters and golden datasets.
An energy-aware MLP hardware generation for proactive BMI control with automatic nonuniform fixed-point bit-width identification capabilities.
Fully automatic methodology frees the resources of domain experts across the developers to do the iterative, tedious, labor-intensive, error-prone floating-to-fixed point conversion and low-power hardware design task.
The design methodology is independent of machine learning tools and programming languages.
The rest of this paper is organized as follows.
Section 2 describes the background of the system architecture of the proactive BMI control and the MLP neural network decoder.
Section 3 presents the new holistic design methodology for the low-power MLP hardware design in the proactive BMI control, which includes a description of the solution methodology and lists the main architecture of the framework.
Section 4 elaborates on the implementation of the methodology, which comprises the automatic energy-aware MLP hardware generation.
Section 5 presents the results of the benchmarking cases with comparisons in terms of accuracy, power, performance, and area.
Section 6 provides discussions regarding future work.
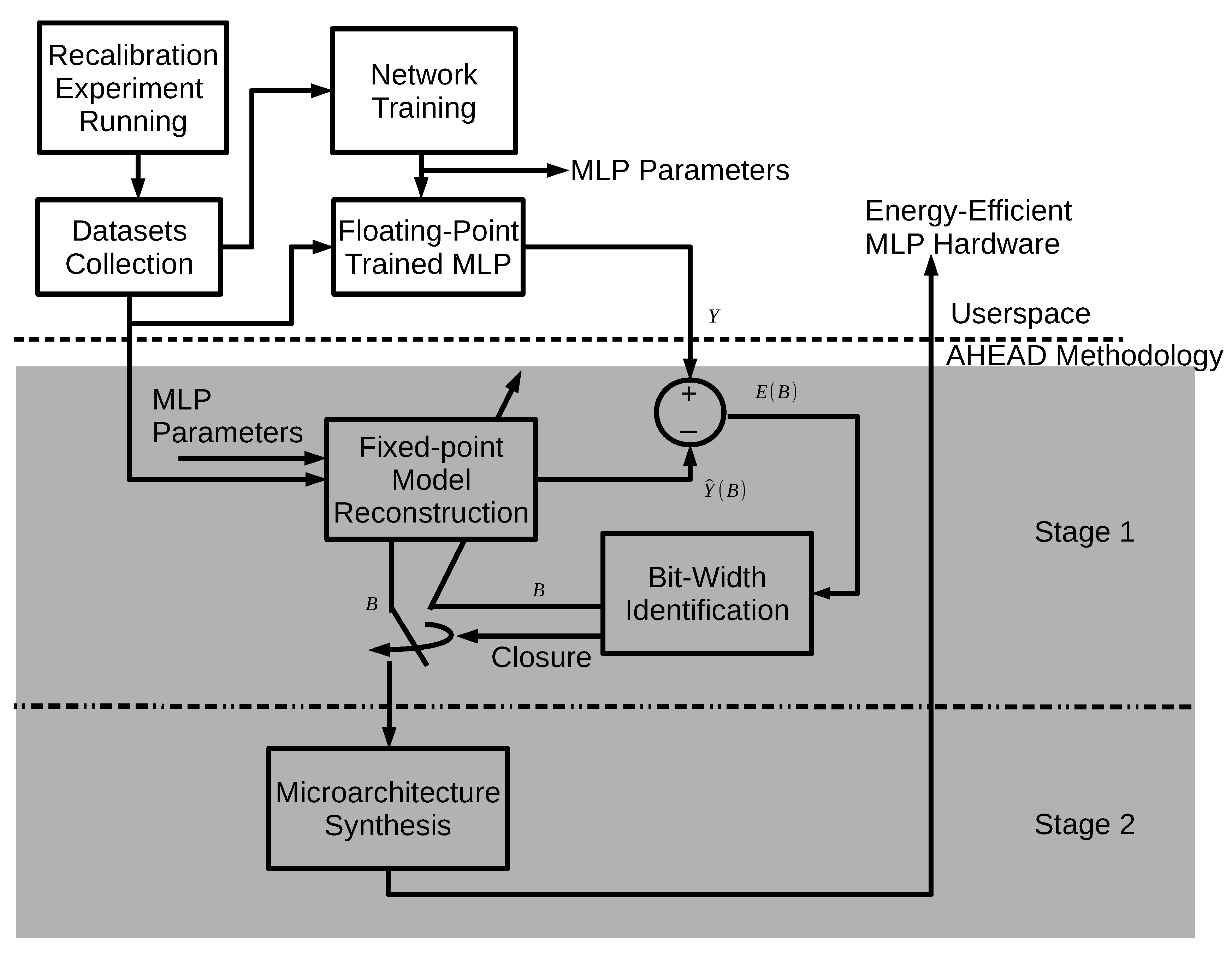
4. Detailed Realization of the AHEAD Methodology
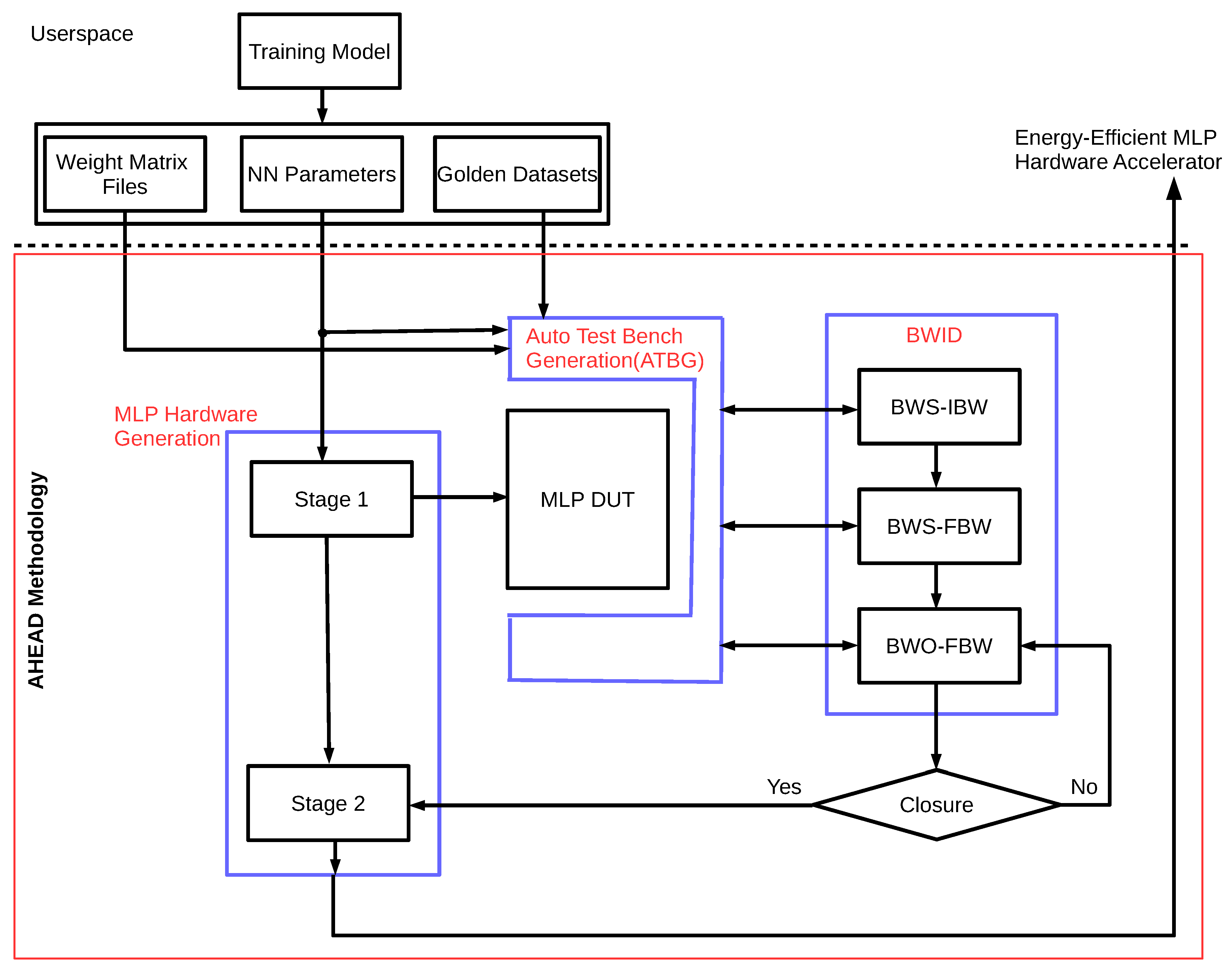
This section describes key implementation details of the AHEAD methodology, including three major components: MLP hardware generation, automatic test bench generation (ATBG), and bit-width identification (BWID). The complete implementation of the data and control flow with the building blocks for the AHEAD methodology is detailed in
Figure 9.
Figure 9 demonstrates the implementation of the AHEAD methodology shown earlier in
Figure 5. The userspace layer is the working environment of the proactive BMI developer for network model training and performance validation after dataset collection from the BMI recalibration experiments. For the generation of the energy-efficient MLP hardware accelerator, the metadata of the trained MLP parameters were required, including weight files and golden datasets. For the three major components, Stage 1 in the MLP hardware generation provides the reconstructed MLP hardware model for the BWID loop, and Stage 2 generates the energy-efficient MLP hardware accelerator. The ATBG creates the test bench with automatic bit-true simulation environments for BWID. The BWID controls the whole bit-true simulation.
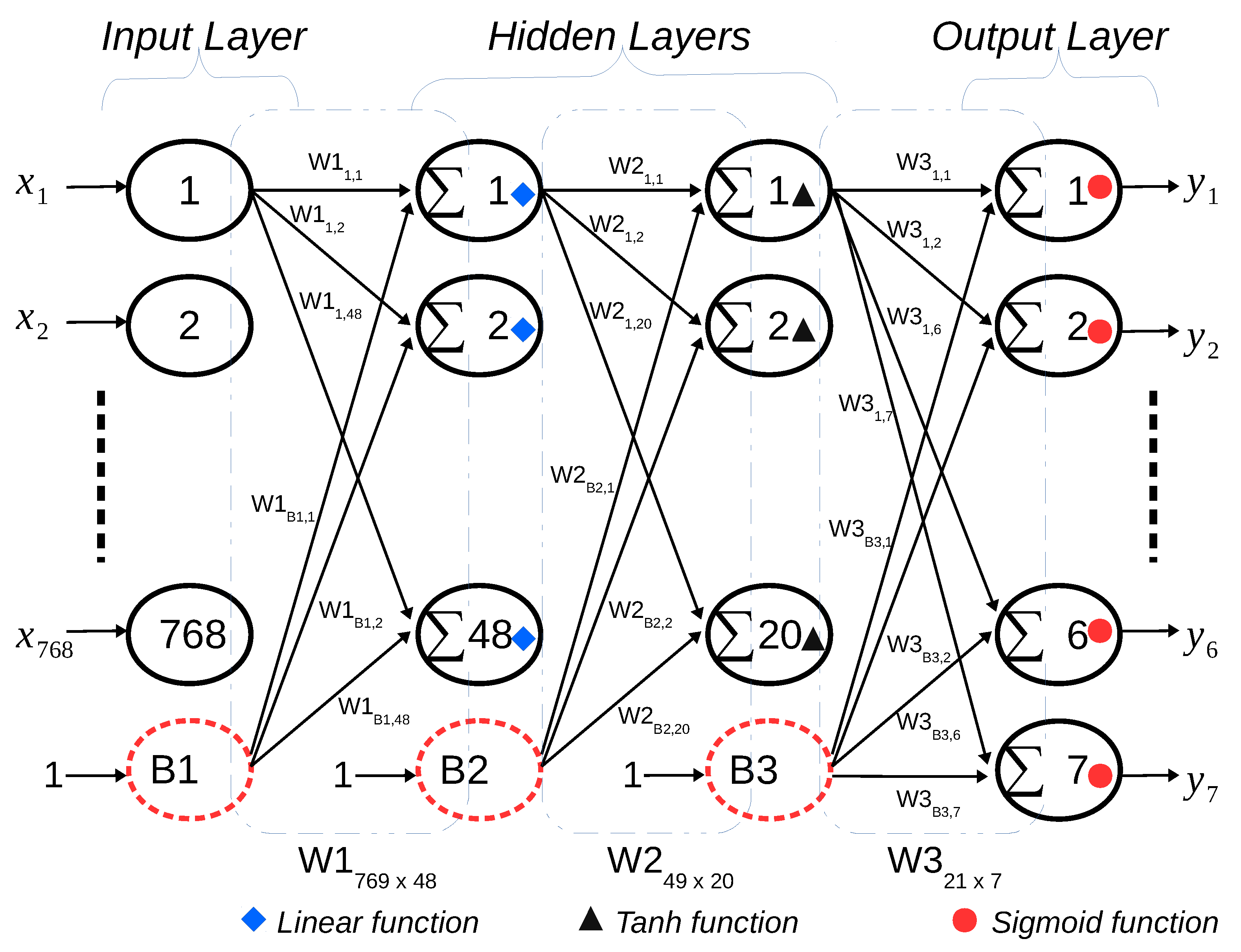
4.1. MLP Hardware Generation
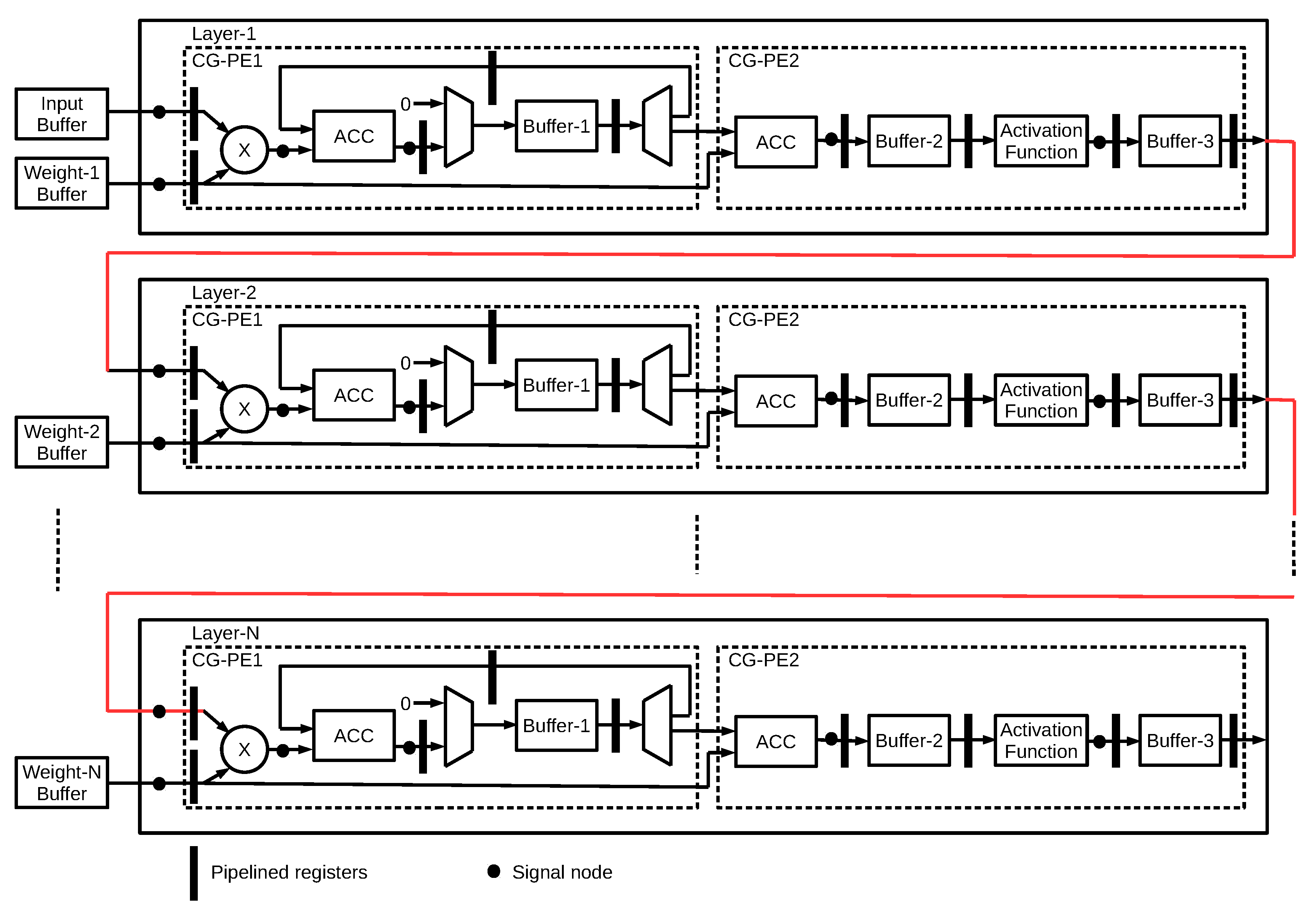
The MLP hardware generation plays a dual role in the AHEAD methodology. In Stage 1, it generates the reconstructed fixed-point hardware model denoted as the MLP design under test (DUT), but the values of the fixed-point bit-width parameters are undetermined. The generated output is used for further identification of the fixed-point parameters from the given MLP model parameters. Hence, the requirement to reconstruct the model is only the correctness of the MLP function. In Stage 2, after the fixed-point parameters are identified, it is used by the microarchitecture synthesis to generate the final low-power hardware accelerator. Furthermore, it performs the fully parallel and pipelined microarchitecture synthesis for all neural network layers, as illustrated in
Figure 6. The final output is the fixed-point hardware design in terms of either Verilog or VHDL code that users can integrate into the top design of the proactive BMI control subsystem in the edge device.
The concept of design reuse is taken into account at the beginning of the implementation stage to maximize the benefit of the hardware implementation in minimizing the design effort with risk, while also improving design productivity. Therefore, the realization of the MLP hardware generation opts to exploit the high-level synthesis methodology over low-level HDLs, which facilitates the achievement of design reuse. It decouples the design for functionality from the design for the hardware architecture to some extent compared to traditional HDLs techniques. In HLS, the function behavior of the design specification is captured by the HLS C/C++ design file; though the specific details about underlying hardware architecture and implementation choices are described by separate compiler directives files. For example, the parallel and nonparallel versions of a given design requirement require two different RTL implementation codes. However, when it comes to HLS, the HLS C/C++ implementation code is the same and only the design constraint files are different. Thus, the MLP microarchitecture is implemented in HLS by configurable PPA options per network layer, which encapsulates the HLS compiler directives into easy-to-use commands, including parallel, pipeline, and memory partition.
4.2. Automatic Test Bench Generation (ATBG)
The purpose of the ATBG is to generate a bit-true simulation platform to iteratively compute and track the output with the golden reference value in the golden datasets, which is a vital infrastructure in the realization of the BWID loop. The block receives the following inputs. First, the MLP model parameters are utilized to configure the HLS C/C++ test bench template for the generation of the test bench with new signal nodes. Second, the dynamic range measurement functions are added to profile the dynamic range of each signal node in order to pave the road for the following IBW determination in BWID. Third, the weight matrix files and golden datasets are configured to create the stimulus generator of the reference and scoreboard-checking models, respectively. Each simulation result is recorded and maintained via the scoreboard for automatic comparison. Then, a sequencer is generated to serve as a coordinator between these verification components, as mentioned above. Finally, the MLP DUT is instantiated in the generated HLS C/C++ test bench for bit-true simulation.
4.3. Bit-Width Identification (BWID)
BWID aims to estimate the optimal IBW and FBW values subject to the minimum constraints of
and bit-width values. The implementation is to realize Equation (
9) by initiating the fixed-point bit-true Simulation-in-the-Loop (SIL) on top of the generated test bench. It is assumed that the delivered solution is a nonuniform bit-width in some sense. A nonuniform bit-width is used to employ different bit-width values for each variable in the MLP algorithm instead of the same bit-width value. It can further reduce the area resources and power consumption of the hardware implementation.
For each signal node in the design, IBW is determined by dynamic range analysis, and FBW is explored by sensitivity-based precision analysis. The whole flow of the BWID is shown in the right of
Figure 9. It consists of three steps: bit-width selection (BWS)-IBW, BWS-FBW, and bit-width optimization (BWO)-FBW, as elaborated in the following.
BWS-IBW: The bit-width selection (BWS) is carried out to determine the value of IBW for each signal node in the reconstructed MLP. The dynamic range analysis is conducted directly by running the reconstructed bit-true fixed-point simulation in which the environment has been constructed from the ATBG. The profiled IBW values are forwarded to the next step once the BWID is finished.
BWS-FBW: Sensitivity analysis is adopted for the determination of the FBW candidates for each FBW in the BWS-FBW step. It is an iterative and sweeping process. There is only one FBW variable that can be replaced with the target value under exploration, and all other variables are initialized with the perfect IBW and FBW value in each simulation run. The perfect xBW results from allocating as large a fixed-point bit-width as possible to reduce the finite bit-width effect while dynamic range profiling, the default of which is 20 bits. The minimum FBW value with the best decoding performance against the golden datasets is the output of BWS-FBW for this FBW variable. Then, it iterates to the next candidate in the FBW variable list. For example, if an MLP has five layers and five signal nodes for each layer, there are a total of 25 FBW variables under analysis. For the sweeping experiments of all FBW variables, if it ranges from 2 bits to 20 bits with a step size of 1 bit, 25*19 = 475 simulation runs are required to perform the whole sensitivity analysis. In the end, the searched values serve as the FBW candidates of the MLP as an initial solution of fixed-point parameters. Instead, the work employs the binary search algorithm to reduce the number of simulation runs dramatically for speed-up.
BWO-FBW: The FBW values determined in the previous section are done so under the assumption that other noncontrol signal nodes are perfect FBW, which is too optimistic. Hence, the strategy of in-place bit-width optimization (BWO) for FBW is executed for the final adjustment. It utilizes these FBW values explored in the BWS-FBW step as a set of coarse-grained initial values for further minimization optimization via a stochastic local search method. In this work, the stochastic hill-climbing algorithm is used. An objective function is used to indicate the quality of the parameters under minimization optimization. The objective function is leveraged from the study [
37] and modified as follows:
where
is a hyperparameter,
X is the list of FBW parameters,
P is decoding performance,
is the average FBW, and
is the perfect FBW. The term (1 −
P) is defined as the loss of accuracy as compared with the golden outputs in the datasets. The idea for Equation (
10) is to be able to find the appropriate FBW parameters that make a trade-off balance between the loss of accuracy and minimum average FBW.
Finally, the BWID ends when it reaches the closure, and the list of final IBW and FBW values are forwarded to the microarchitecture synthesis in Stage 2 as the best fixed-point bit-width parameters for the ultimate energy-efficient MLP hardware generation.
5. Experimental Results
In this section, the effectiveness of the AHEAD methodology is validated with two cases from proactive BMI recalibration experiments that demonstrate the full range of the methodology’s capabilities. The two case studies of the trained MLP decoders were generated after the BMI recalibration.
Table 1 shows the MLP parameters of the two cases. These MLP parameters, along with the associated golden datasets, were used by the AHEAD methodology to produce the associated fixed-point hardware accelerator. In addition, to evaluate the quantitative effectiveness, corresponding MLP hardware accelerators with FP32 and FP16, which are based on the same MLP microarchitecture, were implemented as benchmarks, respectively.
For the BMI recalibration, the network training was conducted on a laptop with a simulation environment created on mlpack [
38], which is an open-source machine learning software library for C++, built on top of the Armadillo C++ linear algebra library [
39].
The proposed AHEAD methodology was implemented in Python and shell script on a laptop. The laptop ran on Ubuntu 16.04 LTS OS, which was installed on an HP EliteBook 820 G3 machine equipped with an Intel Core i5-6200U processor (two cores running at 2.3 GHz, 3 MB cache) and 8 GB of RAM. The hardware generations were targeted at 100 MHz on Xilinx FPGAs (Xilinx Instrument, San Jose, CA) using Xilinx Vivado HLS 2019.2 for high-level synthesis [
40] and Vivado 2019.2 for synthesis and physical implementation [
41].
5.1. BMI Recalibration Case 1
For the parameters of Case 1, as shown in
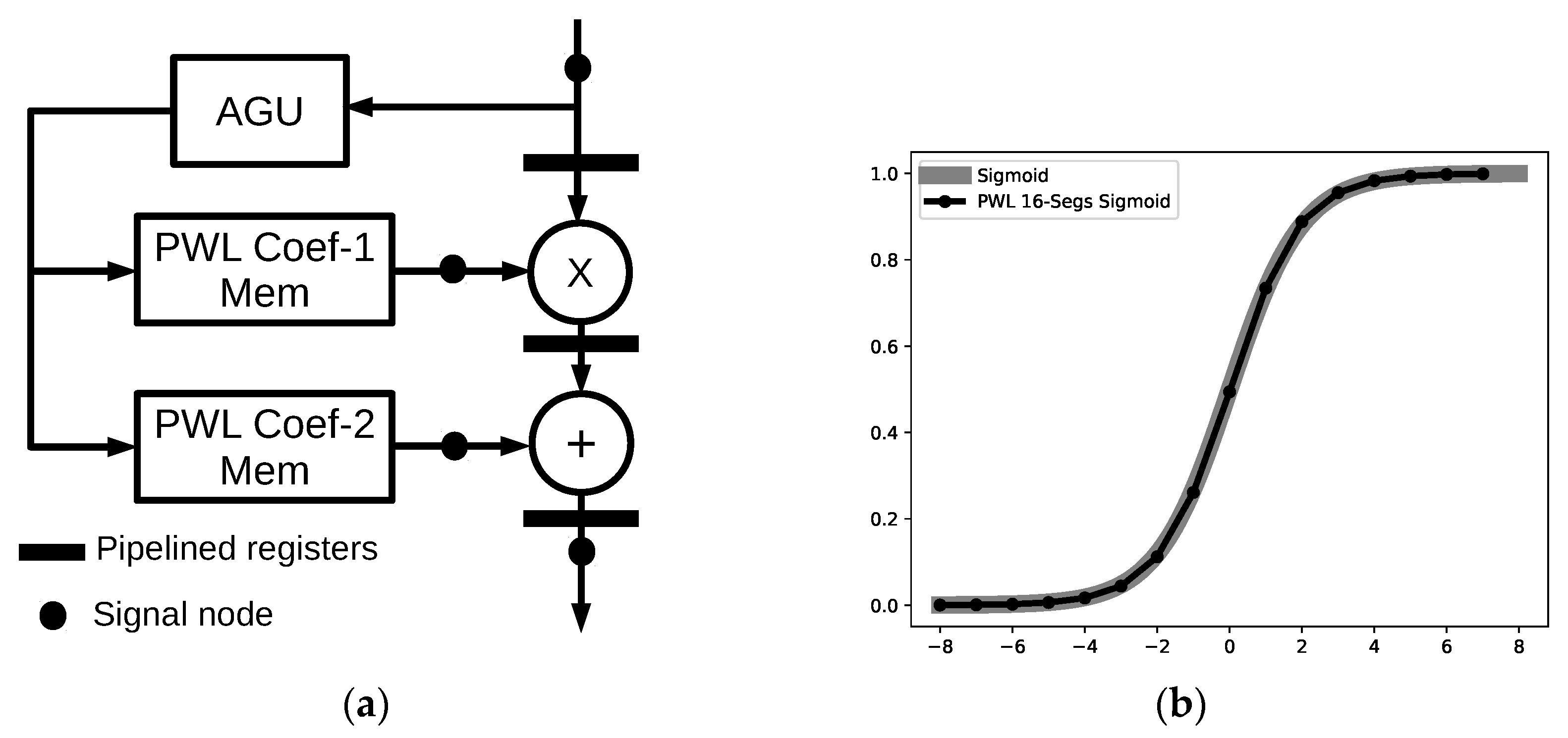
Table 1, the network structure consisted of three layers with 800 neurons in the input layer, 20 neurons in the hidden layer, and two neurons in the output layer. In addition, there are 6*3=18 signal nodes for BWID due to the the 3-layer MLP neural network, and each layer has six signal nodes. The activation function of the hidden and output layer was the sigmoid function. The target FPGA technology was xc7z020clg400-1 on the Xilinx PYNQ-Z1 development board with a 100-MHz clock constraint.
Table 2 illustrates the total execution time of Case 1. The total generation time of the AHEAD methodology was less than 25 minutes, with the most time-consuming steps being the BWS-FWL and BWO-FWL.
As shown in
Table 3, the evaluation metrics include accuracy, performance, power, and area (APPA). For the accuracy, the delivered design (results in nonuniform bit-widths with the average bit-width of 7.47 bits) achieved a 0% loss of accuracy. The loss of accuracy is compared to the results of the golden datasets provided by floating-point MLP model training.
For performance benchmarking, the maximum frequency of the generated design was 106.2 MHz, which is slightly higher than the FP32 and FP16 implementation. However, the latency archived 8.01 us and delivered up to approximately 4X the speed in the inference engine execution in comparison with the FP32 and FP16 implementations. The throughput, which is defined as decoding times per second, demonstrates the same trend. Furthermore, the power consumption was reduced by approximately 4.63X and 2.3X with respect to FP32 and FP16 implementations, respectively. The proposed work achieves more significant results in performance and power than the other two benchmarks because of the reduction of the bit-widths identified automatically by the BWID loop.
In the area usage comparison, the generated design also had the highest area efficiency among these cases. The breakdown of the area consumption is as follows: 5.19% in slice LUTs, 1.51% in slice registers, 9.55% in DSP48E1s, and 6.07% in on-chip block rams (BRAMs) in terms of utilization on the target FPGA. Our design exhibits the following reduction in area utilization on FPGA: 9.29% in BRAMs, 27.72% in DSP48E1s, 7% in slice registers, and 7.88% in slice LUTs, with the same loss of accuracy compared to the FP16 implementation due to the lower bit representation. It is worth noting that FP32 and FP16 implementations consume a significant number of DSP48E1s due to the use of floating-point addition and multiplication arithmetic operations. Furthermore, the low hardware resource utilization on FPGA implies that the proactive BMI edge device could accommodate a lot more hardware functions, further raising its value.
5.2. BMI Recalibration Case 2
In order to evaluate the capability of scalability in terms of different network topologies and the growth of neural networks sizes, the four-layer MLP network was used in Case 2, with 768 neurons in the input layer, 48 neurons in hidden layer 1, 20 neurons in hidden layer 2, and 2 neurons in the output layer, as indicated in
Table 1. Apart from that, the MLP topology results in 6*4 = 24 signal nodes for BWID. It targeted Xilinx xc7z030sbg485-1 FPGA on the PicoZed development board with the same clock constraint since the FP32 implementation of Case 2 does not fit on the xc7z020clg400-1.
As can be seen in
Table 4, the total hardware generation time took less than 35 minutes, with the BWO-FWS occupying approximately 60% of the total execution time. The increase in execution time is due to Case 2 having much more signal nodes for BWID, which increases the bit-width exploration space.
Table 5 presents the comparison of the APPA results of the generated implementation against the FP32 and FP16 implementations under the same MLP microarchitecture. The resultant fixed-point implementation had the average bit-width of 6.95 bits without loss of accuracy.
The latency and throughput of the resultant fixed-point implementation were about 4X faster than the FP32 and FP16 implementations when compared with the performance. Besides, regarding the total energy consumption, the resultant fixed-point design was approximately 5.97X more energy-efficient than the FP32 implementation and used 2.73X less power than the FP16 implementation. This reveals that the proactive BMI edge device can have a faster decoding time with lower power consumption, which is crucial for portable proactive BMI edge devices.
Finally, the experimental results show that the resultant fixed-point implementation had approximately a 9.86% reduction in slice LUTs, 10.68% less slice registers, a 48.25% reduction in DSP48E1s, and 14.72% less BRAMs compared to the FP16 implementation. It is interesting to note that the resultant fixed-point implementation used 15.33% in slice LUTs and 0.25% in DSP48E1s due to the resultant average bit-width being lower and causing the Xilinx synthesis engine to adjust the synthesis strategy to use slice LUTs for logic function synthesis.
6. Discussion
The hurdles to the development of proactive BMI control edge devices on FPGA are achieving low power consumption and meeting the reconfigurable requirement of the MLP hardware configuration due to the need for portable edge devices and BMI recalibration, respectively. As indicated in the literature [
29], it takes much effort and resources from the hardware team to modify or even redesign the low-power MLP hardware accelerator because of the induced specification change. Moreover, the analysis of fixed-point bit-widths is a tedious and labor-intensive task [
24,
27] which must be executed by either the software team or hardware team. Instead, the AHEAD methodology tackles the issue by automating the complete fixed-point hardware analysis to digital design flow in order to reduce the development efforts and time of redesign, reverification, and reimplementation. Thus, it can have a rapid hardware update for the BMI edge devices on FPGA due to BMI recalibration.
This work aims to address the aforementioned design gap to create an autonomous design methodology that analyzes the problems from a holistic view, including the recalibration needs of proactive BMI experiments, the run change after network retraining, the low-power design, and the hardware design flow concurrently. The experimental results in
Section 5 indicate that high-performance, low-power, fixed-point hardware accelerators can be generated automatically. Moreover, the resultant fixed-point hardware consumes fewer area resources and less power while retaining comparable results in terms of decoding performance, as compared with golden datasets. This is achieved by taking advantage of the synergy between the BWID loop and design reuse in an autonomous way. The design reuse is realized by configurable MLP hardware generation. In addition, the configurable HLS template-based hardware accelerator serves as a platform for not only the BWID loop but also low-power hardware generation. Thus, the significant advantages of the work include boosting the design productivity and facilitating the generation process of the low-cost and low-power hardware design for proactive BMI control edge devices on FPGA.
The energy-aware hardware generation was devised using the holistic cross-layer low-power design methodology, which spans from the architecture to microarchitecture level. The use of the fixed-point arithmetic also improves performance, as demonstrated. From the perspective of the bit-width selection, the quantization of large-scale neural networks has been intensively studied [
42,
43,
44]. However, previous works normally quantize all the layers uniformly. Moreover, prior methods require domain knowledge of both machine learning and hardware architecture to explore where to retain more bits to extract the low-level features in a specific layer. Compared with prior works, the proposed AHEAD methodology employs the characteristic of a neural network in which different layers have different redundancy to results in nonuniform bit-widths for different layers in terms of mixed precision. Additionally, the BWID method, which is inspired by system identification, facilitates to automatically reconstruct the fixed-point hardware model to explore the appropriate bit-widths configurations from given metadata in terms of MLP parameters instead of providing any C/C++ implementation code.
From the viewpoint of the software and FPGA hardware developers, our methodology acts as an autonomous agent and frees up the resources in fixed-point precision analysis and low-power hardware design. Furthermore, the proposed methodology does not pose any restriction in the choice of neural network training software tools or programming language.
Future research will be dedicated to the inclusion of automatically efficient piecewise linear approximation of an arbitrary nonlinear activation function, including the number of linear segments and associated fixed-point coefficients in the AHEAD framework. Then, future work can extend to the energy-efficient hardware generation of radial basis function (RBF) neural network and echo state network (ESN) in AHEAD. In RBF, each neuron in the hidden layer employs different Gaussian activation functions. RBF and ESN are vital methods in temporal nonlinear neural signal processing, such as in biorobotics and biomedical engineering. Finally, to fully extend the AHEAD methodology to other applications, the standard format of metadata could be designed to support different neural networks.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}