An Intelligent Model to Predict Energy Performances of Residential Buildings Based on Deep Neural Networks


Abstract
1. Introduction
2. Literature Review
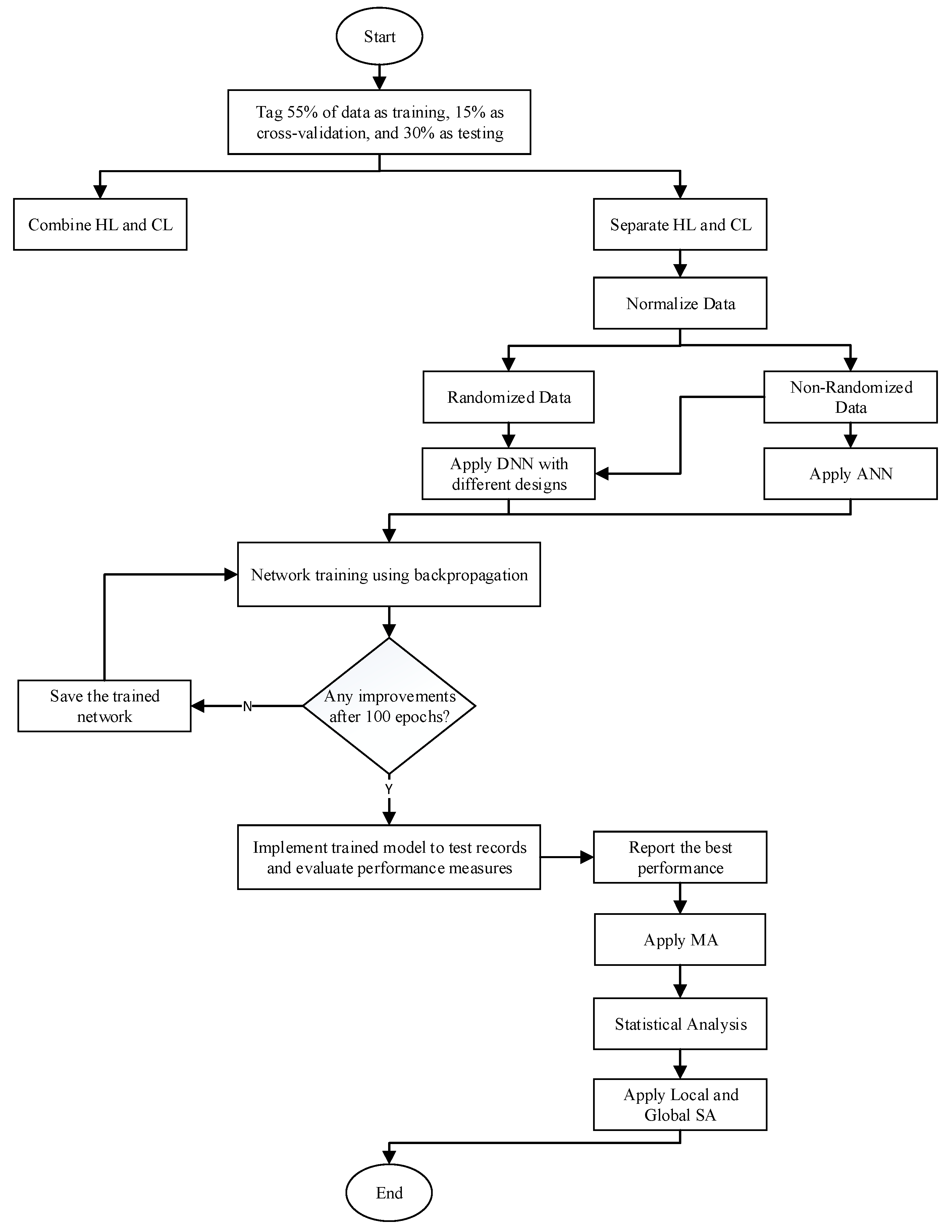
3. Methodology
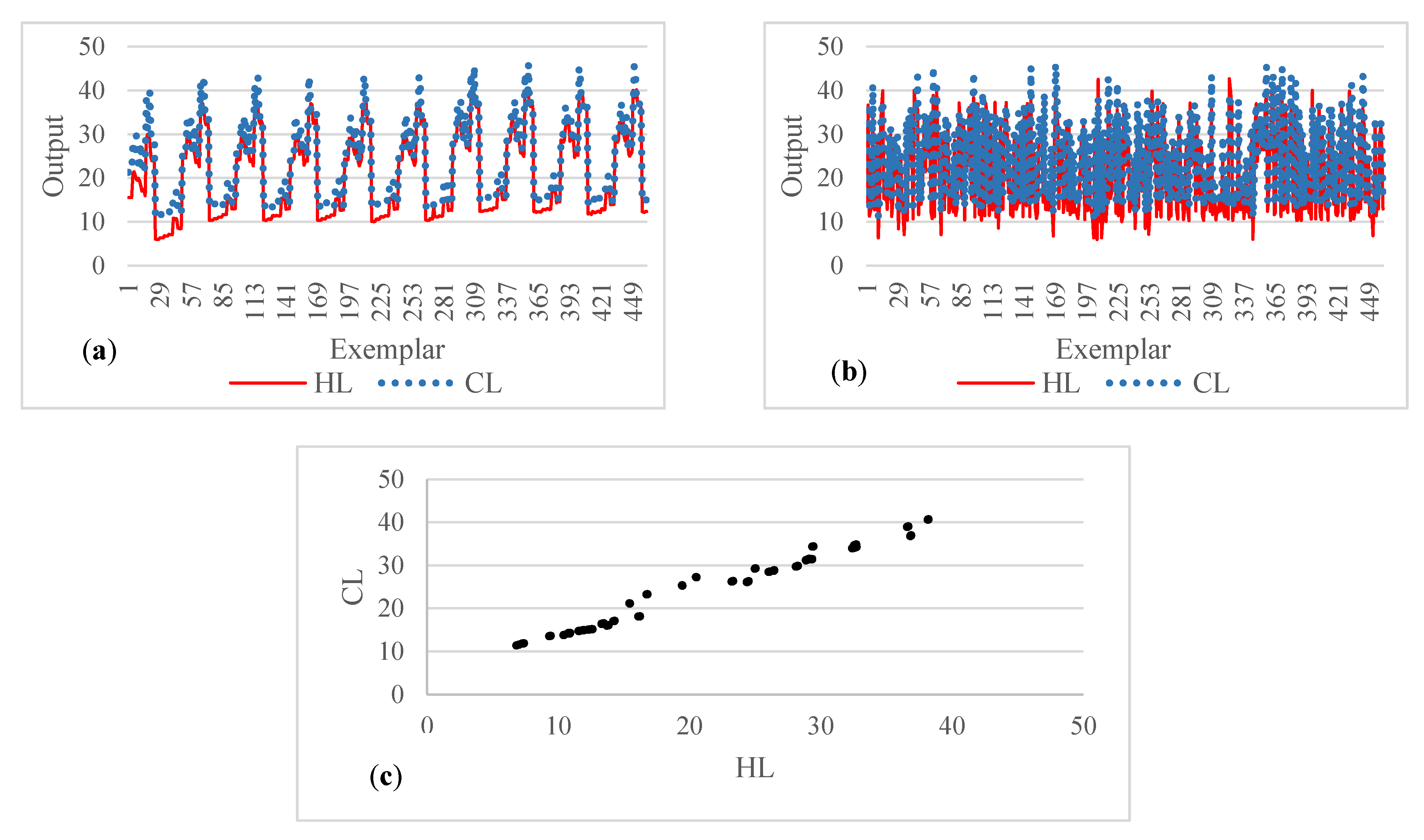
3.1. Description of the Dataset
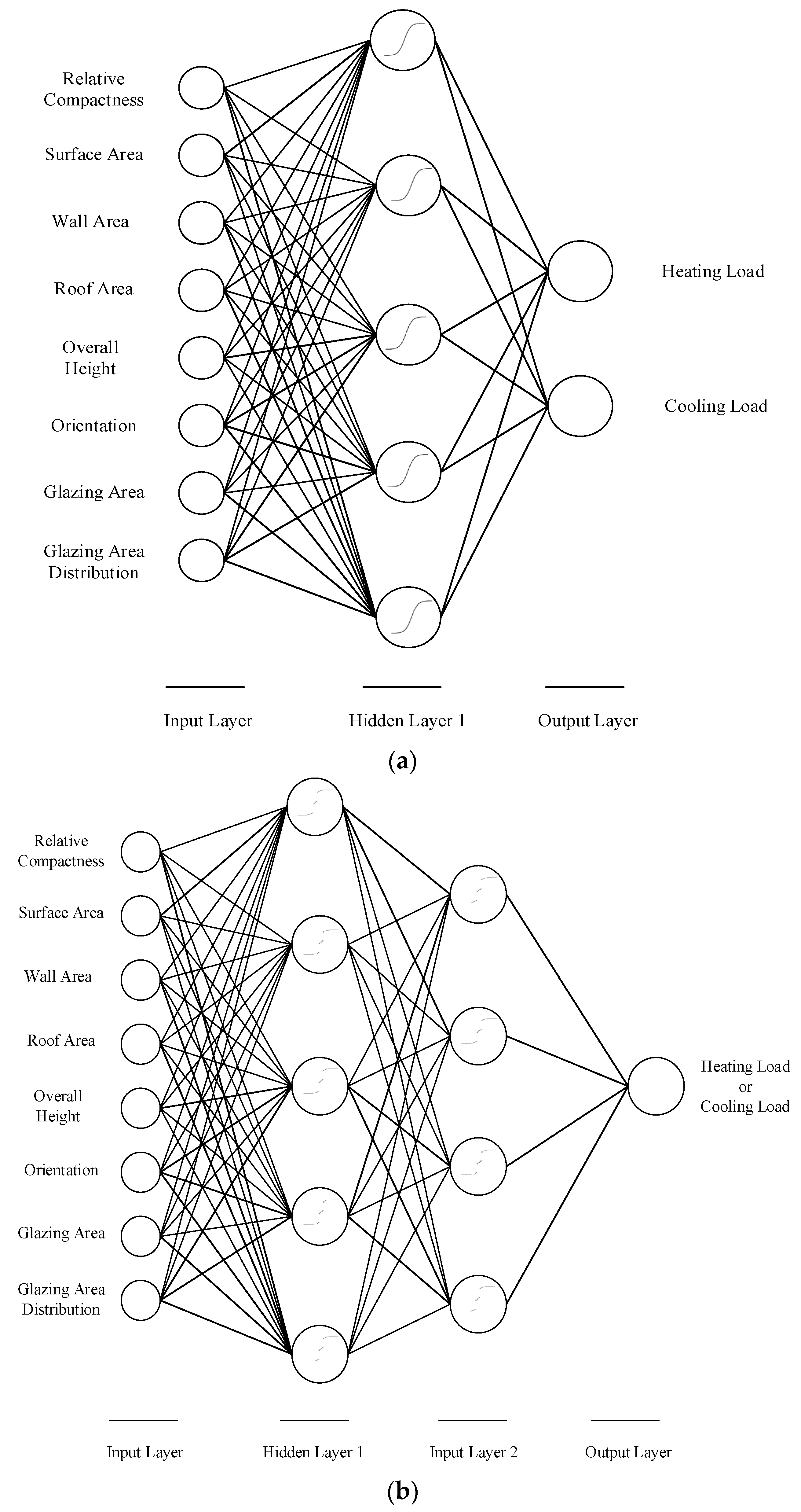
3.2. Experimental Characteristics
3.3. Performance Measures
4. Results
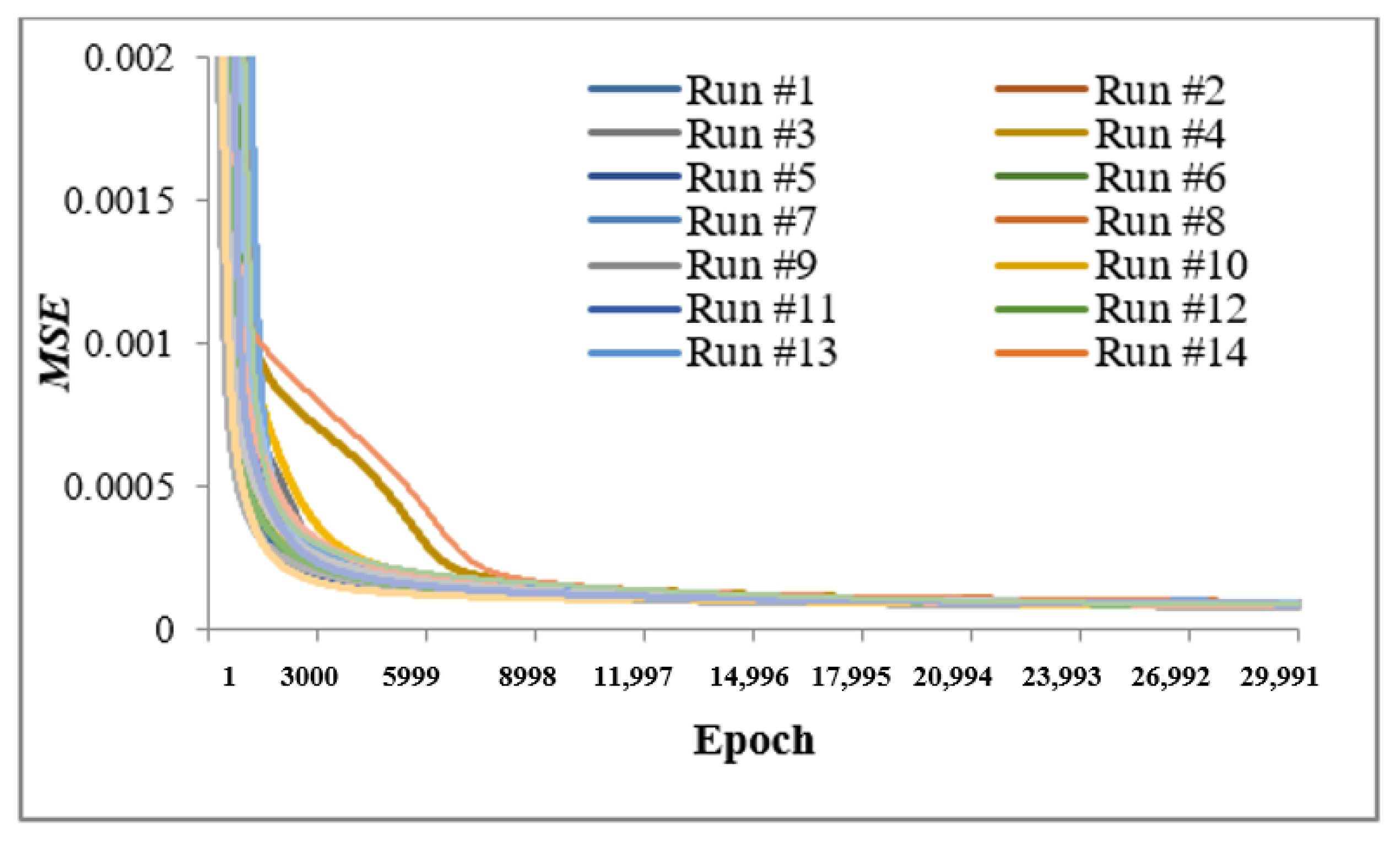
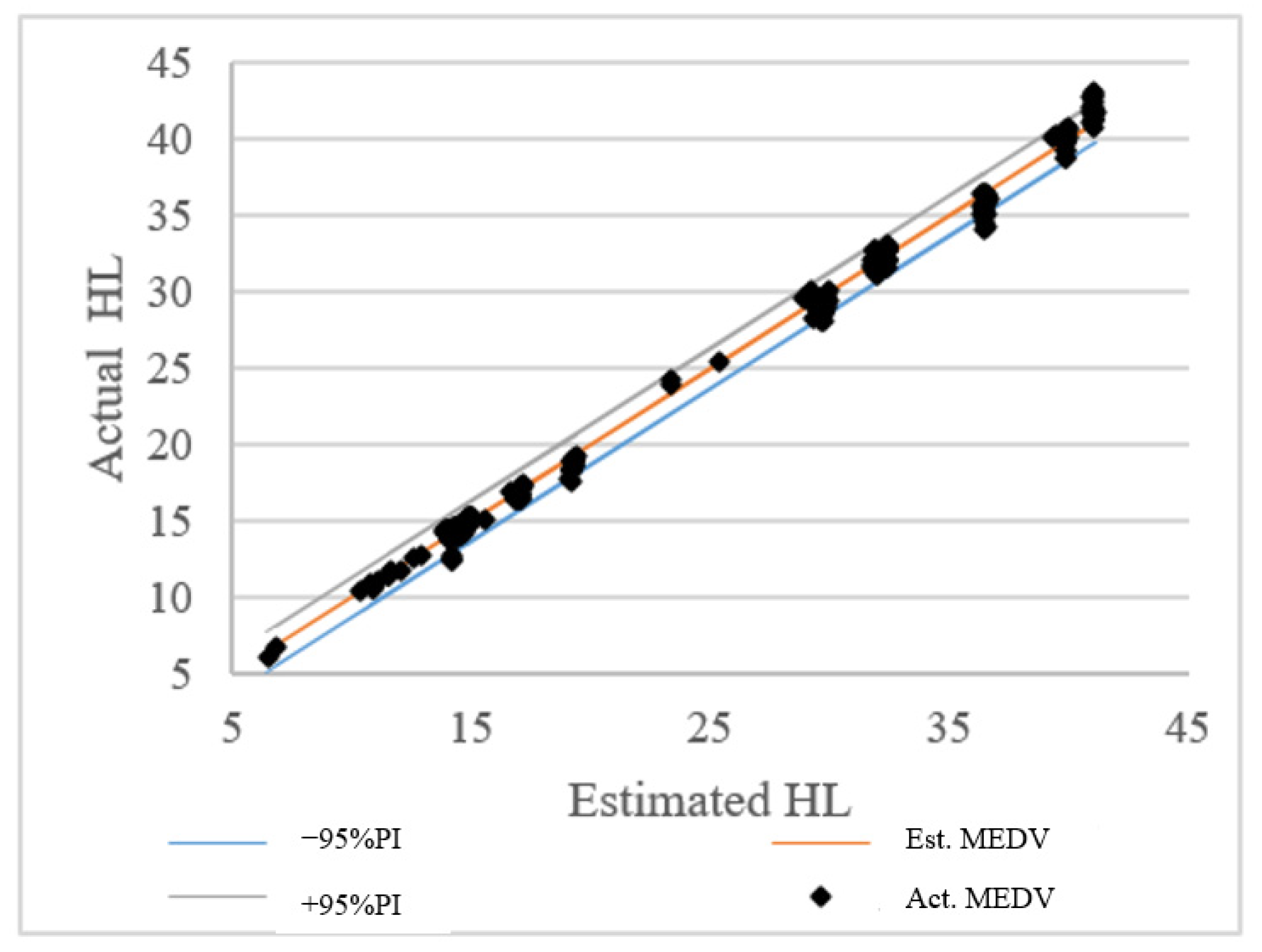
4.1. Comparison of ANN and DNN Performance
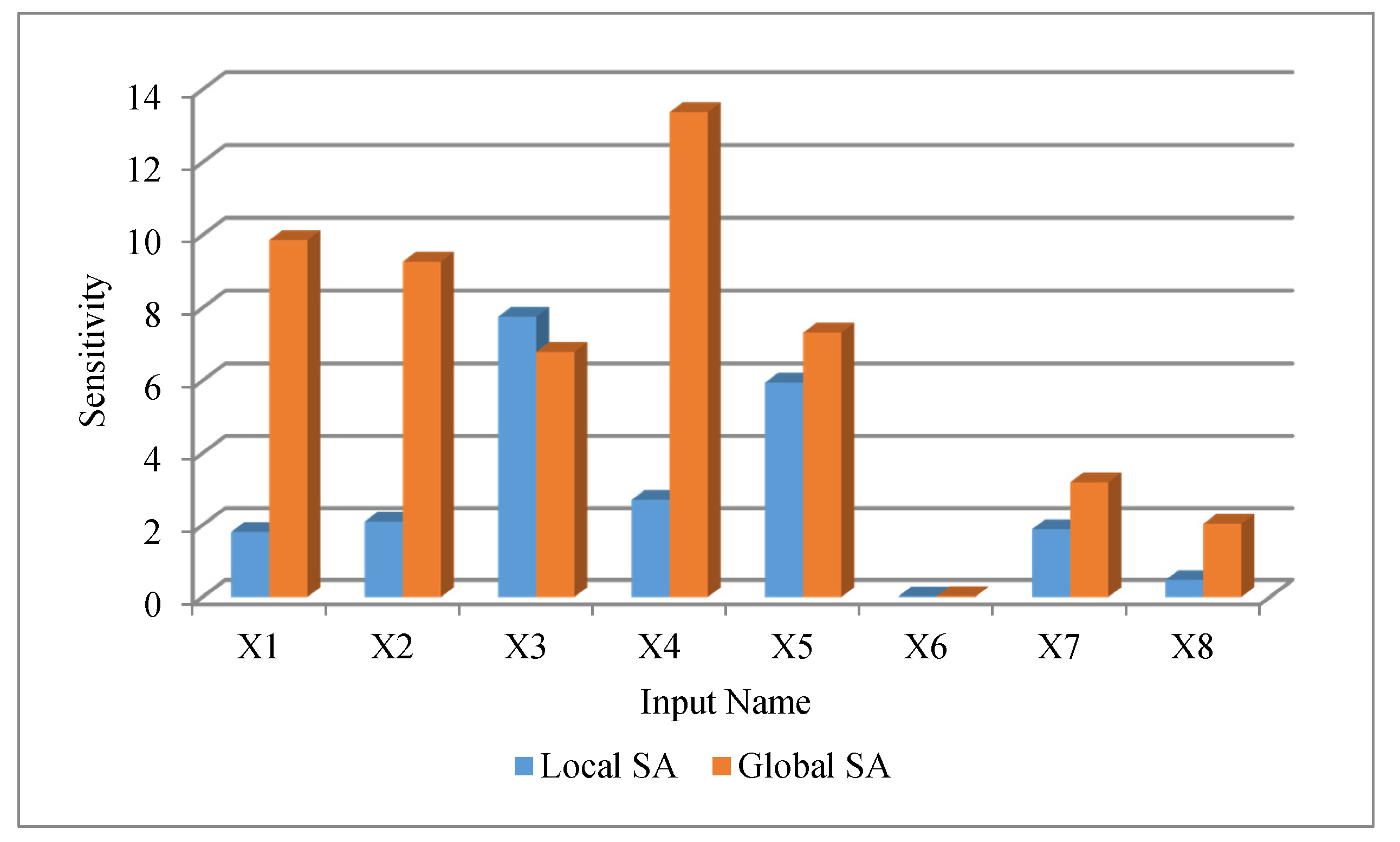
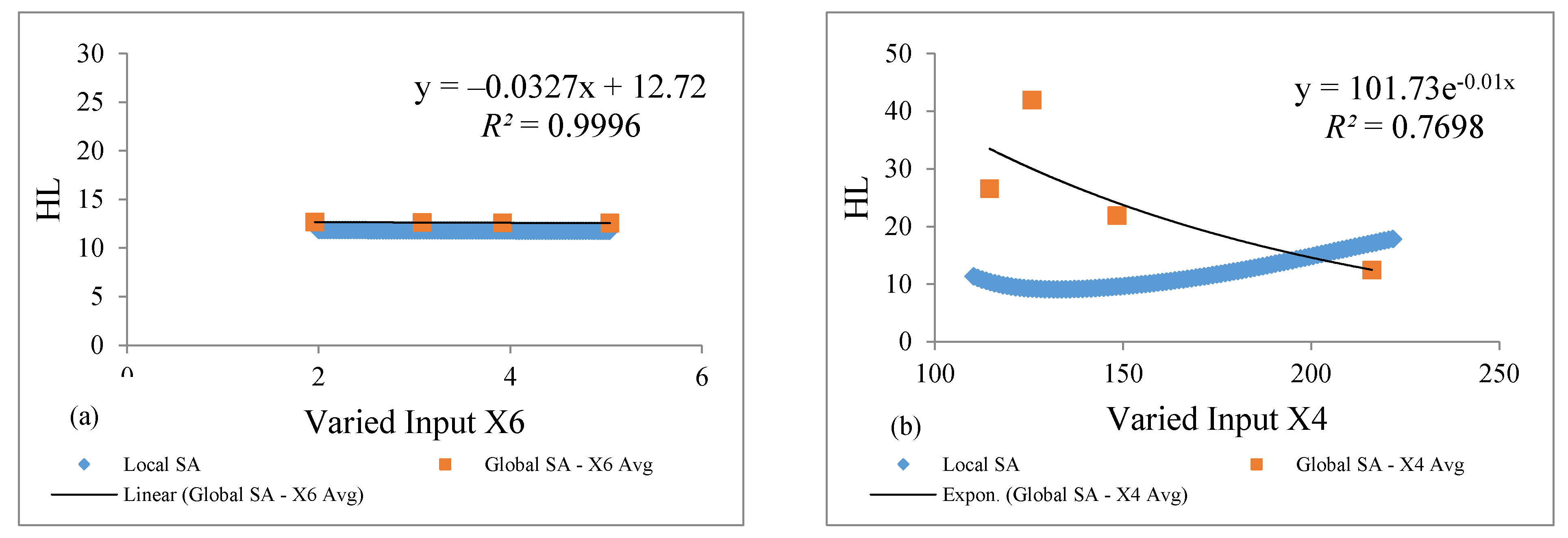
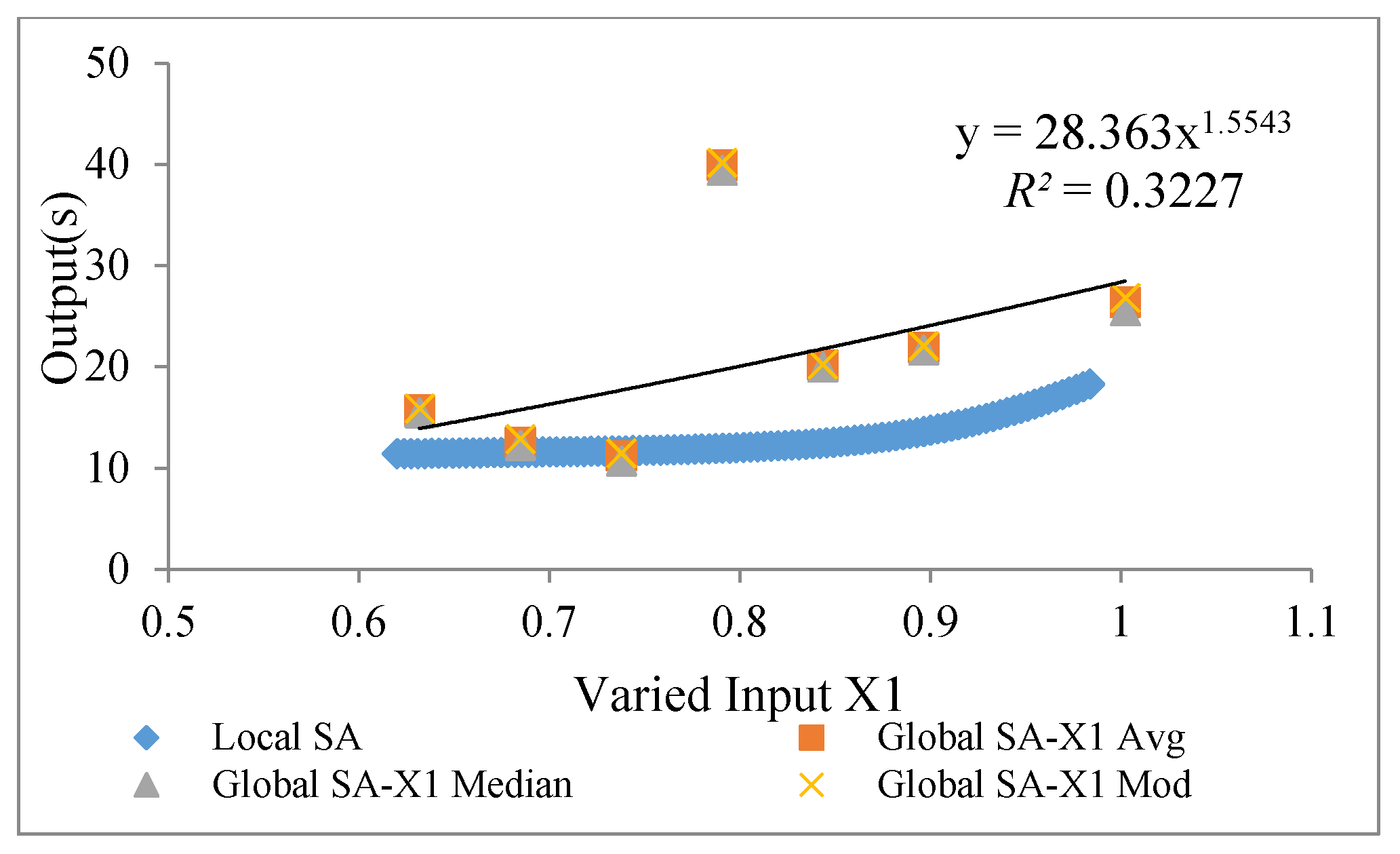
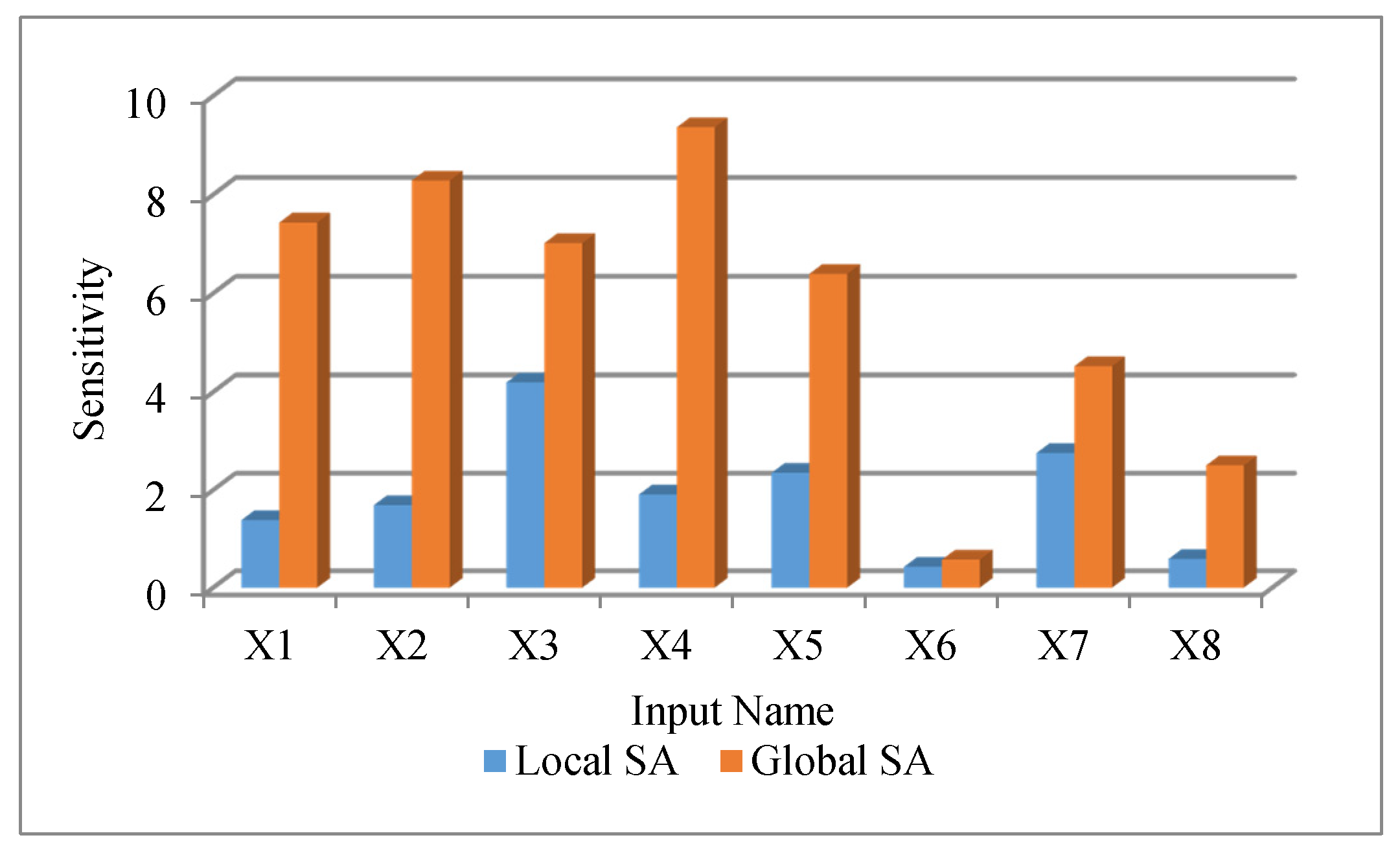
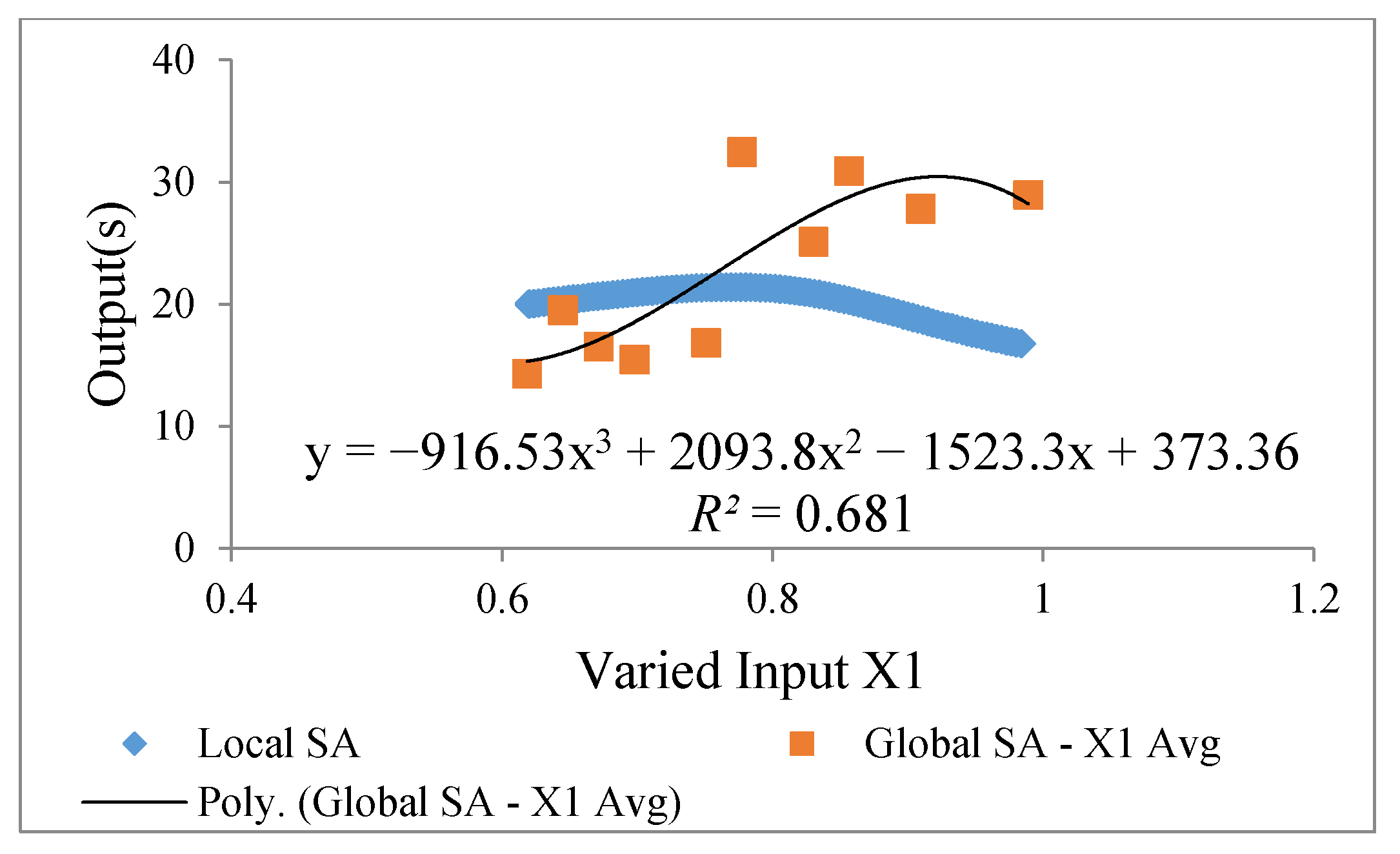
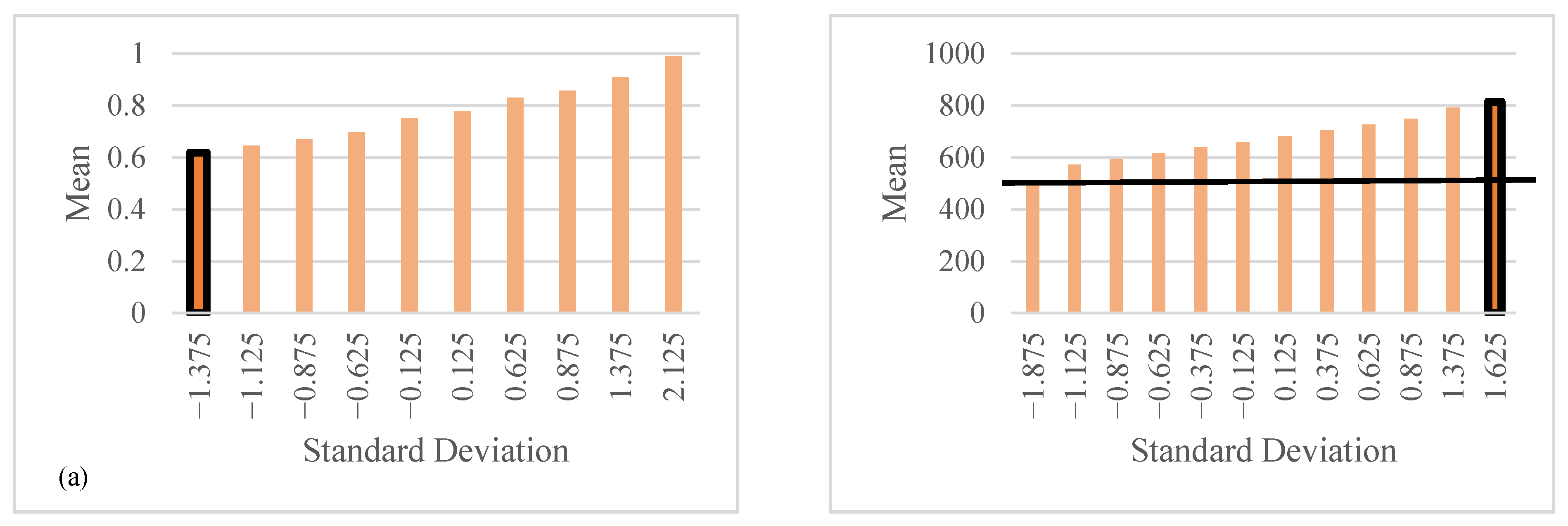
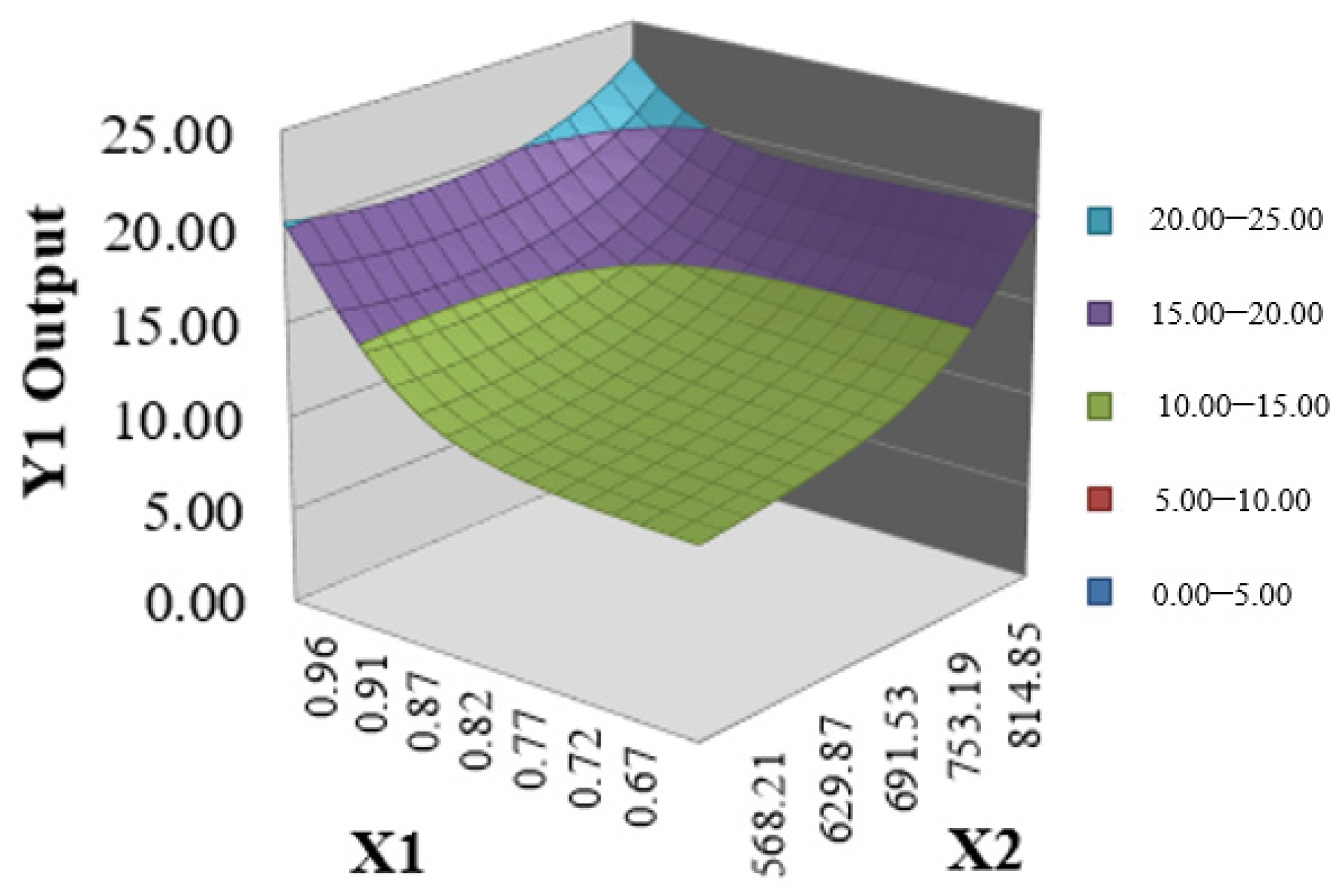
4.2. Local and Global SA
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Nomenclature
| Abbreviation | Description | Abbreviation | Description |
| EMARS | Evolutionary Multivariate Adaptive Regression Splines | OLS | Ordinary Least Squares |
| MARS | Multivariate Adaptive Regression Splines | PLS | Partial Least Squares |
| MI | Mutual Information | GPR | Gaussian Process Regression |
| IRLS | Iteratively Reweighted Least Squares | MPMR | Minimax Probability Machine Regression |
| RF | Random Forest | MAE | Mean Absolute Error |
| DT | Decision Tree | RMAE | Root Mean Absolute Error |
| SVR | Support Vector Machine | MAPE | Mean Absolute Percentage Error |
| ABC-KNN | Artificial Bee Colony-Based K-Nearest Neighbor | WMAPE | Weighted Mean Absolute Percentage Error |
| GA-KNN | Genetic Algorithm-Based K-Nearest Neighbor | MSE | Mean Square Error |
| GA-ANN | Adaptive Artificial Neural Network with Genetic Algorithm | RMSE | Root Mean Square Error |
| ABC-ANN | Adaptive ANN with Artificial Bee Colony | R2 | Coefficient of Determination |
| SVR | Support Vector Regression | VAF | Variance Accounted For |
| ANOVA | Analysis of Variance | RAAE | Relative Average Absolute Error |
| ANFIS | Adaptive Neuro-Fuzzy Inference System | NS | Nash-Sutcliffe |
| ELM | Extreme Learning Machine | MRE | Mean Relative Error |
| SD | Standard Deviation | r | Pearson Correlation Coefficient |
| SI | Synthesis Index | RRSE | Root Relative Square Error |
| EM | Expected Maximization | RAE | Relative Absolute Error |
| PCA | Principal Component Analysis |
References
- International Energy Agency (IEA). Transition to Sustainable Buildings; International Energy Agency (IEA): Paris, France, 2013; ISBN 978-92-64-20241-2. [Google Scholar]
- International Energy Agency (IEA). Energy Efficiency: Buildings; International Energy Agency (IEA): Paris, France, 2018. [Google Scholar]
- Roy, S.S.; Roy, R.; Balas, V.E. Estimating heating load in buildings using multivariate adaptive regression splines, extreme learning machine, a hybrid model of MARS and ELM. Renew. Sustain. Energy Rev. 2018, 82, 4256–4268. [Google Scholar]
- Sekhar, S.; Pijush, R.; Ishan, S.; Hemant, N.; Vishal, J. Forecasting heating and cooling loads of buildings: A comparative performance analysis. J. Ambient Intell. Humaniz. Comput. 2019, 1–12. [Google Scholar] [CrossRef]
- Bouktif, S.; Fiaz, A.; Ouni, A.; Serhani, M. Optimal Deep Learning LSTM Model for Electric Load Forecasting using Feature Selection and Genetic Algorithm: Comparison with Machine Learning Approaches. Energies 2018, 11, 1636. [Google Scholar] [CrossRef]
- Yu, W.; Li, B.; Lei, Y.; Liu, M. Analysis of a Residential Building Energy Consumption Demand Model. Energies 2011, 4, 475–487. [Google Scholar] [CrossRef]
- Seyedzadeh, S.; Rahimian, F.P.; Glesk, I.; Roper, M. Machine learning for estimation of building energy consumption and performance: A review. Vis. Eng. 2018, 6, 5. [Google Scholar] [CrossRef]
- Bagheri, A.; Feldheim, V.; Ioakimidis, C. On the Evolution and Application of the Thermal Network Method for Energy Assessments in Buildings. Energies 2018, 11, 890. [Google Scholar] [CrossRef]
- Ardjmand, E.; Millie, D.F.; Ghalehkhondabi, I.; Ii, W.A.Y.; Weckman, G.R. A State-Based Sensitivity Analysis for Distinguishing the Global Importance of Predictor Variables in Artificial Neural Networks. Adv. Artif. Neural Syst. 2016, 2016, 2303181. [Google Scholar] [CrossRef]
- Weckman, G.R.; Millie, D.F.; Ganduri, C.; Rangwala, M.; Young, W.; Rinder, M.; Fahnenstiel, G.L. Knowledge Extraction from the Neural ‘Black Box’ in Ecological Monitoring Knowledge Extraction from the Neural ‘Black Box’ in Ecological Monitoring. Int. J. Ind. Syst. Eng. 2009, 3, 38–55. [Google Scholar]
- Millie, D.F.; Weckman, G.R.; Young, W.A.; Ivey, J.E.; Carrick, H.J.; Fahnenstiel, G.L. Environmental Modelling & Software Modeling microalgal abundance with artificial neural networks: Demonstration of a heuristic ‘Grey-Box’ to deconvolve and quantify environmental influences. Environ. Model. Softw. 2012, 38, 27–39. [Google Scholar]
- Saltelli, A.; Tarantola, S.; Campolongo, F.; Ratto, M. Sensitivity Analysis in Practice: A Guide to Assessing Scientific Models; Wiley: Chichester, UK, 2004. [Google Scholar]
- Yeung, D.S.; Cloete, I.; Shi, D.; Ng, W.W.Y. Sensitivity Analysis for Neural Networks; Springer: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Tsanas, A.; Xifara, A. Accurate quantitative estimation of energy performance of residential buildings using statistical machine learning tools. Energy Build. 2012, 49, 560–567. [Google Scholar] [CrossRef]
- Yezioro, A.; Dong, B.; Leite, F. An applied artificial intelligence approach towards assessing building performance simulation tools. Energy Build. 2008, 40, 612–620. [Google Scholar] [CrossRef]
- Bourdeau, M.; Nefzaoui, E.; Guo, X.; Chatellier, P. Modeling and forecasting building energy consumption: A review of data-driven techniques. Sustain. Cities Soc. 2019, 48, 101533. [Google Scholar] [CrossRef]
- Park, S.; Ryu, S.; Choi, Y.; Kim, J.; Kim, H. Data-Driven Baseline Estimation of Residential Buildings for Demand Response. Energies 2015, 8, 10239–10259. [Google Scholar] [CrossRef]
- Chou, J.; Bui, D. Modeling heating and cooling loads by artificial intelligence for energy-efficient building design. Energy Build. 2014, 82, 437–446. [Google Scholar] [CrossRef]
- Cheng, M.; Cao, M. Accurately predicting building energy performance using evolutionary multivariate adaptive regression splines. Appl. Soft Comput. J. 2014, 22, 178–188. [Google Scholar] [CrossRef]
- Ahmed, A.; Srihari, K.; Khasawneh, M.T. Integrating Artificial Neural Networks and Cluster Analysis to Assess Energy Efficiency of Buildings. In Proceedings of the 2014 Industrial and Systems Engineering Research Conference, Montreal, QC, Canada, 31 May–3 June 2014. [Google Scholar]
- Sonmez, Y.; Guvenc, U.; Kahraman, H.T.; Yilmaz, C. A Comperative Study on Novel Machine Learning Algorithms for Estimation of Energy Performance of Residential Buildings. In Proceedings of the 2015 3rd International Istanbul Smart Grid Congress and Fair (ICSG), Istanbul, Turkey, 29–30 April 2015; pp. 1–7. [Google Scholar]
- Alam, A.G.; Baek, C.; Han, H. Prediction and Analysis of Building Energy Efficiency Using Artificial Neural Network and Design of Experiments Prediction and Analysis of Building Energy Efficiency using Artificial Neural Network and Design of Experiments. Appl. Mech. Mater. 2016, 819, 541–545. [Google Scholar]
- Fei, Y.; Pengdong, G.; Yongquan, L. Evolving Resilient Back-Propagation Algorithm for Energy Efficiency. MATEC Web Conf. 2016, 77, 06016. [Google Scholar]
- Regina, G.; Capriles, P. Prediction of energy load of buildings using machine learning methods database and machine learnig methods. In Proceedings of the Conference of Computational Interdisciplinary Science, São José dos Campos, Barzil, 7–10 November 2016. [Google Scholar]
- Naji, S.; Shamshirband, S.; Basser, H.; Keivani, A. Application of adaptive neuro-fuzzy methodology for estimating building energy consumption. Renew. Sustain. Energy Rev. 2016, 53, 1520–1528. [Google Scholar] [CrossRef]
- Naji, S.; Keivani, A.; Shamshirband, S.; Alengaram, U.J.; Zamin, M.; Lee, M. Estimating building energy consumption using extreme learning machine method. Energy 2016, 97, 506–516. [Google Scholar] [CrossRef]
- Nilashi, M.; Dalvi-esfahani, M.; Ibrahim, O.; Bagherifard, K. A soft computing method for the prediction of energy performance of residential buildings. Measurement 2017, 109, 268–280. [Google Scholar] [CrossRef]
- Nwulu, N.I. An artificial neural network model for predicting building heating and cooling loads. In Proceedings of the 2017 International Artificial Intelligence and Data Processing Symposium (IDAP), Malatya, Turkey, 16–17 September 2017; pp. 0–4. [Google Scholar]
- Duarte, G.R.; Vanessa, P.; Capriles, Z.; Celso, A.; Lemonge, D.C. Comparison of machine learning techniques for predicting energy loads in buildings. mbiente Construído 2017, 17, 103–115. [Google Scholar] [CrossRef]
- Kavaklioglu, K. Robust modeling of heating and cooling loads using partial least squares towards efficient residential building design. J. Build. Eng. 2018, 18, 467–475. [Google Scholar] [CrossRef]
- Kumar, S.; Pal, S.K.; Pal, R. Intra ELM variants ensemble based model to predict energy performance in residential buildings. Sustain. Energy Grids Netw. 2018, 16, 177–187. [Google Scholar] [CrossRef]
- Al-Rakhami, M.; Gumaei, A.; Alsanad, A.; Alamri, A.; Hassan, M.M. An Ensemble Learning Approach for Accurate Energy Load Prediction in Residential Buildings. IEEE Access 2019, 7, 48328–48338. [Google Scholar] [CrossRef]
- Cariboni, J.; Gatelli, D.; Liska, R.; Saltelli, A. The role of sensitivity analysis in ecological modelling. Ecol. Modell. 2006, 3, 167–182. [Google Scholar] [CrossRef]
- Saltelli, A.; Ratto, M.; Andres, T.; Campolongo, F.; Cariboni, J.; Saisana, M. Global Sensitivity Analysis: The Primer; John Wiley & Sons: Hoboken, NJ, USA, 2008. [Google Scholar]
- Bache, M.L.K. UCI Machine Learning Repository; University of California: Irvine, CA, USA, 2012. [Google Scholar]
- Schunn, C.D.; Wallach, D. Evaluating Goodness-of-Fit in Comparison of Models to Data. Psychol. Kognit. Reden Vor. Anlässlich Emeritierung Werner Tack 2005, 1, 115–135. [Google Scholar]
- Geletka, V.; Sedlákováa, A. Shape of buildings and energy consumption. Czas. Tech. Bud. 2012, 109, 124–129. [Google Scholar]
- Saxena, A.; Agarwal, N.; Srivastava, G. Energy savings parameters in households of Uttar Pradesh, India. TERI Inf. Dig. Energy Environ. 2012, 11, 179–188. [Google Scholar]
- Sharizatul, W.; Rashdi, S.W.M.; Embi, M.R. Analysing Optimum Building Form in Relation to Lower Cooling Load. Procedia Soc. Behav. Sci. 2016, 222, 782–790. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Related Studies | Machine Learning Method | Variable Importance Method | Combined Outputs | Evaluation Criteria |
|---|---|---|---|---|
| Tsanas and Xifara [14] | IRLS, RF | Spearman rank correlation coefficient and p-value, MI | - | MAE, MSE, MRE |
| Chou and Bui [18] | Ensemble approach (SVR + ANN), SVR | - | - | RMSE, MAE, MAPE, R, SI |
| Cheng and Cao [19] | EMARS | MARS | - | RMSE, MAPE, MAE, R2 |
| Ahmed et al. [20] | ANN and cluster analysis | - | ✓ | Silhouette Score |
| Sonmez et al. [21] | ABC-KNN GA-KNN GA-ANN ABC-ANN | - | - | MAE, SD |
| Alam et al. [22] | ANN | ANOVA | - | RMSE |
| Fei et al. [23] | ANN | - | - | MSE |
| Regina and Capriles [24] | DT, MLP, RF, SVR | - | - | MAE, RMSE, MRE, R2 |
| Naji et al. [25] | ANFIS | - | - | RMSE, r, R2 |
| Naji et al. [26] | ELM | - | ✓ | RMSE, r, R2 |
| Nilashi et al. [27] | EM, PCA, ANFIS | PCA | - | MAE, MAPE, RMSE |
| Nwulu [28] | ANN | - | - | RMSE, RRSE, MAE, RAE, R2 |
| Duarte et al. [29] | DT, MLP, RF, SVM | - | - | MAE, RMSE, MAPE, R2 |
| Roy et al. [3] | multivariate adaptive regression splines, ELM, a hybrid model of MARS and ELM | MARS | - | RMSE, MAPE, MAE, R2, WMAPE, Time |
| Kavaklioglu [30] | OLS, PLS | - | - | RMSE, R2, Goodness of fit |
| Kumar et al. [31] | ELM, Online Sequential ELM, Bidirectional ELM | - | - | MAE, RMSE |
| Al-Rakhami et al. [32] | Ensemble Learning using XG Boost | - | - | RMSE, R2, MAE, MAPE |
| Sekhar et al. [4] | DNN, GRP, MPMR | - | - | VAF, RAAE, RMAE, R2, MAPE, NS, RMSE, WMAPE |
| Variable Type | Description | Parameters | #Possible Values | Type of Parameter | Units | Min | Max | Average |
|---|---|---|---|---|---|---|---|---|
| Input Variables | Relative Compactness | (X1) | 12 | Real | None | 0.62 | 0.98 | 0.76 |
| Surface Area | (X2) | 12 | Real | m2 | 514.50 | 808.50 | 671.71 | |
| Wall Area | (X3) | 7 | Real | m2 | 245.00 | 416.50 | 318.50 | |
| Roof Area | (X4) | 4 | Real | m2 | 110.25 | 220.50 | 176.60 | |
| Overall Height | (X5) | 2 | Real | M | 3.50 | 7.00 | 5.25 | |
| Orientation | (X6) | 4 | Integer | None | 2 | 5 | 3.50 | |
| Glazing Area | (X7) | 4 | Real | None | 0 | 0.40 | 0.23 | |
| Glazing Area Distribution | (X8) | 6 | Integer | None | 0 | 5 | 2.81 | |
| Output Variables | Heating Load | (Y1) | 586 | Real | kWh/m2 | 6.01 | 43.10 | 22.31 |
| Cooling Load | (Y2) | 636 | Real | kWh/m2 | 10.90 | 48.03 | 24.59 |
| Experiment | Output | Hidden Layer | PEs per Layer | Randomization | MA | Neural Network |
|---|---|---|---|---|---|---|
| 1 | HL and CL | 1 | 5 | - | - | ANN |
| 2 | HL | 1 | 5 | - | - | ANN |
| 3 | HL | 2 | 5,4 | - | - | DNN |
| 4 | HL | 3 | 5,4,4 | - | - | DNN |
| 5 | HL | 3 | 10,8,8 | - | - | DNN |
| 6 | HL | 4 | 10,8,8,8 | - | - | DNN |
| 7 | HL | 2 | 5,4 | ✓ | - | DNN |
| 8 | HL | 3 | 5,4,4 | ✓ | - | DNN |
| 9 | HL | 3 | 10,8,8 | ✓ | - | DNN |
| 10 | HL | 3 | 30,24,24 | ✓ | - | DNN |
| 11 | CL | 1 | 5 | - | - | ANN |
| 12 | CL | 2 | 5,4 | - | - | DNN |
| 13 | CL | 3 | 5,4,4 | - | - | DNN |
| 14 | CL | 3 | 10,8,8 | - | - | DNN |
| 15 | CL | 4 | 10,8,8,8 | - | - | DNN |
| 16 | CL | 2 | 5,4 | ✓ | - | DNN |
| 17 | CL | 3 | 5,4,4 | ✓ | - | DNN |
| 18 | CL | 3 | 10,8,8 | ✓ | - | DNN |
| 19 | CL | 3 | 30,24,24 | ✓ | - | DNN |
| 20 | HL | 3 | 10,8,8 | ✓ | ✓ | DNN |
| 21 | CL | 3 | 10,8,8 | ✓ | ✓ | DNN |
| Exp. | Output | Neural Network | RMSE (kW) | MAE (kW) | R2 | Score (%) |
|---|---|---|---|---|---|---|
| 1 | HL and CL | ANN | (1.9269, 2.3491) | (1.6850, 2.0527) | (0.9906, 0.9535) | (96.3351, 95.0842) |
| 2 | HL | ANN | 2.4378 | 1.9611 | 0.9892 | 95.9005 |
| 3 | HL | DNN | 1.7384 | 1.5378 | 0.9930 | 96.5646 |
| 4 | HL | DNN | 1.8653 | 1.4783 | 0.9892 | 96.3879 |
| 5 | HL | DNN | 1.2079 | 1.0305 | 0.9918 | 97.0908 |
| 6 | HL | DNN | 2.2209 | 1.8576 | 0.9777 | 95.7743 |
| 7 | HL | DNN | 0.7116 | 0.5846 | 0.9958 | 97.8955 |
| 8 | HL | DNN | 1.0217 | 0.7694 | 0.9912 | 97.3968 |
| 9 | HL | DNN | 0.6719 | 0.4828 | 0.9960 | 97.9669 |
| 10 | HL | DNN | 0.9261 | 0.66341 | 0.9936 | 97.5763 |
| 11 | CL | ANN | 1.998 | 1.5461 | 0.9649 | 95.7065 |
| 12 | CL | DNN | 1.7088 | 1.1785 | 0.9647 | 96.0625 |
| 13 | CL | DNN | 3.009 | 2.0288 | 0.9114 | 93.6079 |
| 14 | CL | DNN | 2.117 | 1.5439 | 0.9671 | 95.6793 |
| 15 | CL | DNN | 2.2232 | 1.6871 | 0.9663 | 95.5631 |
| 16 | CL | DNN | 1.6808 | 1.1572 | 0.9704 | 96.2431 |
| 17 | CL | DNN | 1.7466 | 1.1809 | 0.9667 | 96.0941 |
| 18 | CL | DNN | 1.057 | 0.7644 | 0.9880 | 97.2973 |
| 19 | CL | DNN | 1.5461 | 1.0251 | 0.9773 | 96.5457 |
| 20 | HL | DNN | 0.5621 | 0.4012 | 0.9987 | 97.9999 |
| 21 | CL | DNN | 1.3929 | 1.0696 | 0.9859 | 96.8377 |
| Experiment | Output | Neural Network Type | RMSE (kW) | MAE (kW) | R2 | Score (%) |
|---|---|---|---|---|---|---|
| 1 | HL and CL | ANN | (0.7070, 1.8612) | (0.5486, 1.3954) | (0.9946, 0.9590) | (97.8051, 95.6846) |
| 2 | HL | ANN | 0.9752 | 0.7453 | 0.9896 | 97.3294 |
| 3 | HL | DNN | 0.5088 | 0.3692 | 0.9972 | 98.1863 |
| 4 | HL | DNN | 0.7535 | 0.5707 | 0.9939 | 97.7245 |
| 5 | HL | DNN | 0.408 | 0.2947 | 0.9982 | 98.3921 |
| 6 | HL | DNN | 0.5118 | 0.3294 | 0.9972 | 98.1916 |
| 7 | HL | DNN | 0.4055 | 0.3050 | 0.9980 | 98.4461 |
| 8 | HL | DNN | 0.4825 | 0.3600 | 0.9974 | 98.2921 |
| 9 | HL | DNN | 0.3786 | 0.285 | 0.9984 | 98.5026 |
| 10 | HL | DNN | 0.2633 | 0.2001 | 0.9999 | 98.8582 |
| 11 | CL | ANN | 1.5687 | 1.0936 | 0.9708 | 96.2696 |
| 12 | CL | DNN | 1.6140 | 1.0993 | 0.9720 | 96.3331 |
| 13 | CL | DNN | 3.2281 | 2.5404 | 0.8889 | 92.8027 |
| 14 | CL | DNN | 1.6289 | 1.1313 | 0.9686 | 96.1579 |
| 15 | CL | DNN | 1.5931 | 1.0604 | 0.9700 | 96.2362 |
| 16 | CL | DNN | 1.6149 | 1.1165 | 0.9708 | 96.3094 |
| 17 | CL | DNN | 1.58 | 1.06503 | 0.9724 | 96.3901 |
| 18 | CL | DNN | 0.7386 | 0.5601 | 0.9936 | 97.8248 |
| 19 | CL | DNN | 1.0359 | 0.7151 | 0.9916 | 97.4158 |
| 20 | HL | DNN | 0.3514 | 0.2491 | 0.9987 | 98.5635 |
| 21 | CL | DNN | 0.6896 | 0.4846 | 0.9944 | 97.8871 |
| Paper | Train | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| NMAE | MAE | NRMSE | RMSE | R2 | ||||||
| HL | CL | HL | CL | HL | CL | HL | CL | HL | CL | |
| Tsanas and Xifara [14] | - | - | - | - | - | - | - | - | - | - |
| Chou and Bui [18] | - | - | - | - | - | - | - | - | - | - |
| Cheng and Cao [19] | - | - | 0.34 | 0.68 | - | - | 0.46 | 0.97 | 1 | 0.99 |
| Sonmez et al. [21] | - | - | - | - | - | - | - | - | - | - |
| Alam et al. [22] | - | - | - | - | - | - | - | - | - | - |
| Regina and Capriles [24] | - | - | - | - | - | - | - | - | - | - |
| Naji et al. [25] | - | - | - | - | - | - | 40.85 | 40.85 | 0.99 | 0.99 |
| Naji et al. [26] | - | - | - | - | - | - | - | - | - | - |
| Nilashi et al. [27] | - | - | - | - | - | - | - | - | - | - |
| Nwulu [28] | - | - | - | - | - | - | - | - | - | - |
| Duarte et al. [29] | - | - | - | - | - | - | - | - | - | - |
| Roy et al. [3] | - | - | - | - | - | - | - | - | - | - |
| Kavaklioglu [30] | - | - | - | - | - | - | 2.859 | 3.204 | - | - |
| Kumar et al. [31] | - | - | 0.132 | 0.127 | - | - | 0.312 | 0.636 | - | - |
| Al-Rakhami et al. [32] | - | - | - | - | - | - | - | - | - | - |
| Sekhar et al. [4] | - | - | - | - | - | - | - | - | - | - |
| Current paper | 0.005 | 0.013 | 0.2 | 0.485 | 0.007 | 0.019 | 0.263 | 0.69 | 1 | 0.994 |
| Paper | Test | Cross-Validation | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| NMAE | MAE | NRMSE | RMSE | R2 | |||||||
| HL | CL | HL | CL | HL | CL | HL | CL | HL | CL | ||
| Tsanas and Xifara [14] | - | - | 0.51 | 1.42 | - | - | - | - | - | - | ✓ |
| Chou and Bui [18] | - | - | 0.236 | 0.89 | - | - | 0.346 | 1.566 | - | - | ✓ |
| Cheng and Cao [19] | - | - | 0.35 | 0.71 | - | - | 0.47 | 1 | 1 | 0.99 | ✓ |
| Sonmez et al. [21] | - | - | 0.61 | 1.25 | - | - | - | - | - | - | |
| Alam et al. [22] | - | - | - | - | - | - | 0.19 | 1.42 | - | - | |
| Regina and Capriles [24] | - | - | 0.246 | 0.39 | - | - | 1.094 | 1.284 | 0.99 | 0.98 | ✓ |
| Naji et al. [25] | - | - | - | - | - | - | 74.02 | 74.02 | 0.99 | 0.99 | |
| Naji et al. [26] | - | - | - | - | - | - | 98 | 85 | 0.99 | 0.95 | |
| Nilashi et al. [27] | - | - | 0.16 | 0.52 | - | - | 0.26 | 0.81 | - | - | ✓ |
| Nwulu [28] | - | - | 0.977 | 1.654 | - | - | 1.228 | 2.111 | 0.99 | 0.97 | ✓ |
| Duarte et al. [29] | - | - | 0.315 | 0.565 | - | - | 0.223 | 0.837 | 0.99 | 0.99 | ✓ |
| Roy et al. [3] | - | - | 0.037 | 0.127 | - | - | 0.053 | 0.195 | 0.99 | 0.964 | ✓ |
| Kavaklioglu [30] | - | - | - | - | - | - | 3.16 | 3.122 | - | - | ✓ |
| Kumar et al. [31] | - | - | 0.138 | 0.134 | - | - | 0.321 | 0.646 | - | - | ✓ |
| Al-Rakhami et al. [32] | - | - | 0.175 | 0.307 | - | - | 0.265 | 0.47 | 0.99 | 0.99 | ✓ |
| Sekhar et al. [4] | - | - | - | - | - | - | 0.059 | 0.079 | 0.99 | 0.99 | |
| Current paper | 0.018 | 0.03 | 0.2 | 0.485 | 0.025 | 0.039 | 0.263 | 0.69 | 1 | 0.994 | ✓ |
| X1 | X2 | X3 | X4 | X5 | X6 | X7 | X8 | Y1 | Y2 | |
|---|---|---|---|---|---|---|---|---|---|---|
| X1 | 1.00000 | |||||||||
| X2 | −0.99190 | 1.00000 | ||||||||
| X3 | −0.20378 | 0.19550 | 1.00000 | |||||||
| X4 | −0.86882 | 0.88072 | −0.29232 | 1.00000 | ||||||
| X5 | 0.82775 | −0.85815 | 0.28098 | −0.97251 | 1.00000 | |||||
| X6 | 0.00000 | 0.00000 | 0.00000 | 0.00000 | 0.00000 | 1.00000 | ||||
| X7 | 0.00000 | 0.00000 | 0.00000 | 0.00000 | 0.00000 | 0.00000 | 1.00000 | |||
| X8 | 0.00000 | 0.00000 | 0.00000 | 0.00000 | 0.00000 | 0.00000 | 0.21296 | 1.00000 | ||
| Y1 | 0.62227 | −0.65812 | 0.45567 | −0.86183 | 0.88943 | −0.00259 | 0.26984 | 0.08737 | 1.00000 | |
| Y2 | 0.63434 | −0.67300 | 0.42712 | −0.86255 | 0.89579 | 0.01429 | 0.20750 | 0.05053 | 0.97586 | 1.00000 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sadeghi, A.; Younes Sinaki, R.; Young, W.A., II; Weckman, G.R. An Intelligent Model to Predict Energy Performances of Residential Buildings Based on Deep Neural Networks. Energies 2020, 13, 571. https://doi.org/10.3390/en13030571
Sadeghi A, Younes Sinaki R, Young WA II, Weckman GR. An Intelligent Model to Predict Energy Performances of Residential Buildings Based on Deep Neural Networks. Energies. 2020; 13(3):571. https://doi.org/10.3390/en13030571
Chicago/Turabian StyleSadeghi, Azadeh, Roohollah Younes Sinaki, William A. Young, II, and Gary R. Weckman. 2020. "An Intelligent Model to Predict Energy Performances of Residential Buildings Based on Deep Neural Networks" Energies 13, no. 3: 571. https://doi.org/10.3390/en13030571
APA StyleSadeghi, A., Younes Sinaki, R., Young, W. A., II, & Weckman, G. R. (2020). An Intelligent Model to Predict Energy Performances of Residential Buildings Based on Deep Neural Networks. Energies, 13(3), 571. https://doi.org/10.3390/en13030571