The electricity reserves in the ESS resulting from the energy generation and consumption of prosumer constantly change even if there is no trading, and the energy trading determines the trading action according to the reserves in the ESS changed by the previous trading, consumption, or generation. Therefore, if the currency value of the assets held in stock trading is used as an evaluation criterion of the trading, it is impossible to accurately evaluate the trading results owing to the changes in energy generation and consumption. Therefore, we define an evaluation criterion as the sum of the gains from participating in P2P energy trading compared with not participating in it.
The total profit from participating in the P2P energy trading proposed in this paper is defined as the sum of four gains. The first gain is the change in the electricity bill. When energy trading is completed, since the result of the trading changes the amount of electricity held in the ESS, the amount of electricity available to the prosumer in the ESS is changed, and the amount of electricity supply used is also changed accordingly. For example, if the amount of electricity held in the ESS is less than the amount consumed, the electricity bill can be reduced by purchasing electricity through P2P energy trading rather than through the supply electricity. Conversely, while the amount of electricity held in the ESS is greater than the amount consumed, selling through P2P energy trading can result in profit, although it may involve the use of supply electricity, which may increase the electricity bill. Therefore, if only the gain from the trading is considered without the electricity bill, there may be a situation in which additional electricity bills are paid more than the gain from the trading, resulting in loss. The gain from the change in electricity bill can be expressed as follows:
where
;
is the electricity bill paid by the prosumer who does not participate in P2P energy trading in state
and
is the electricity bill paid by the prosumer who participates in P2P energy trading in state
. In both situations, the difference in electricity bills is
, which is the gain from the change in the electricity bill for participating in energy trading, where
t is the number of states that have elapsed from the start of the electricity bill calculation to the hour-by-hour period, and
T is the total number of states from the time the final electricity bill is calculated. We assume that the time before the trading is established, the electricity is transferred, and the ESS is completely charged/dischargid is within 1 h, thereby setting the trading participation decision interval to 1 h. Therefore,
t increases in units of 1 h. The second gain is the trading gain from P2P energy trading. When a prosumer participates in a P2P electricity trading, the prosumer takes one of three actions: buying, selling, and nonparticipation, and the prosumer’s assets change as a result of the trading. The amount of change in these assets is equal to the gain achieved only through trading, and it can be defined as
where
represents the maximum storage capacity of the ESS, and
represents the efficiency of the ESS.
and
represent the trading purchase and sale volume, respectively, and
represents the trading price.
and
represent the cost spent on purchases and the profits from sales, respectively. At this time,
represents the trading fee.
and
, which are the total amount of asset changes through trading, are calculated as the difference between the total amount of revenue and the expenditure up to
t. When the prosumer does not participate in P2P trading, the asset changes through trading
are zero, and, therefore, the gain from the P2P energy trading
is equal to
. Since the trading is based on the ESS, the amount of electricity that can be traded is limited. Therefore, the trading volume should consider the amount of electricity held in the ESS or the remaining storage capacity of the ESS, and it cannot exceed the maximum ESS capacity. In addition, trading fees may also be considered in P2P energy trading, which should be further considered in the settlement of trading costs. The third gain is for virtual losses from over-generation. If electricity is generated while the electricity in the ESS is fully charged, the generated electricity cannot be stored in the ESS, resulting in losses. However, this can be prevented through the sales from P2P energy trading before these losses occur. Therefore, it is possible to perform an efficient trading action considering the electricity generation by the prosumer and the losses from over-generation depending on whether or not P2P energy trading is involved. The gain on virtual losses from over-generation can be expressed as follows:
where
and
are the amount of electricity loss from over-generation, and
is the instantaneous gain on the currency value of the virtual loss in state
.
is the cumulative gain from reducing over-generation. Setting up a trading strategy in such a way as to reduce losses from over-generation not only can reduce the losses of prosumers but also can have the effect of reducing the total amount of supply electricity on the power system. The fourth gain is the change in the currency value of the amount of electricity held in the ESS. The electricity held in the ESS is the result of consumption, generation, and trading, and it includes the result of the changes due to the trading actions. The gain from the change in the currency value of the amount of electricity in the ESS can be expressed as follows:
where
and
respectively represent the amount of ESS charged and discharged owing to the generation and consumption of the prosumer from state
to state
. Moreover,
and
respectively represent the amount of electricity charged and discharged by the prosumer through P2P energy trading.
and
represent the amount of electricity in the ESS. In addition, because the effect (charge or discharge) of the trading result in state
is not immediately apparent but is shown in the next state
, the amount of electricity in the ESS
after the prosumer’s P2P energy trading utilizes the trading volume in the previous state
rather than the current trading volume in state
.
represents the gain from the currency value of the electricity held in the ESS. Finally, the profit
for participating in P2P energy trading, which has been redefined as the trading evaluation criterion, is defined as follows:





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
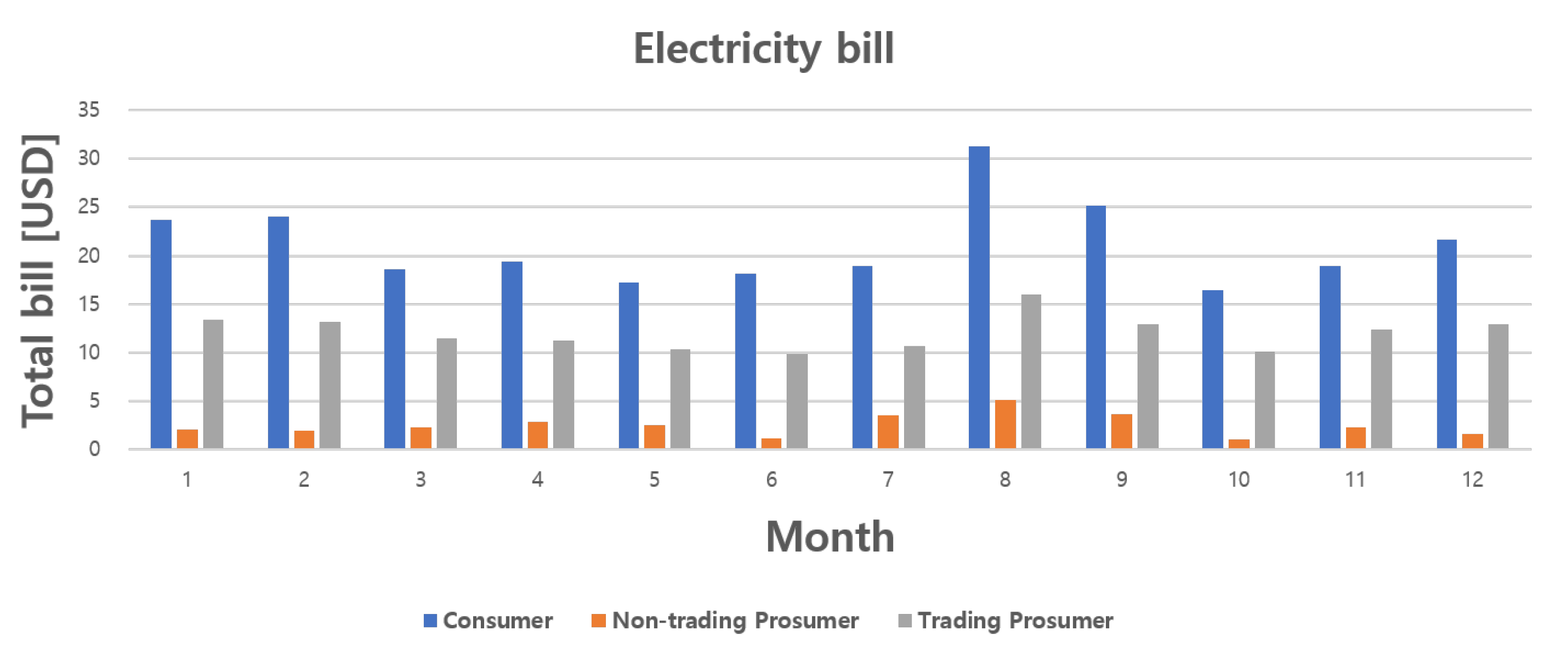{kind=link}
{kind=link}
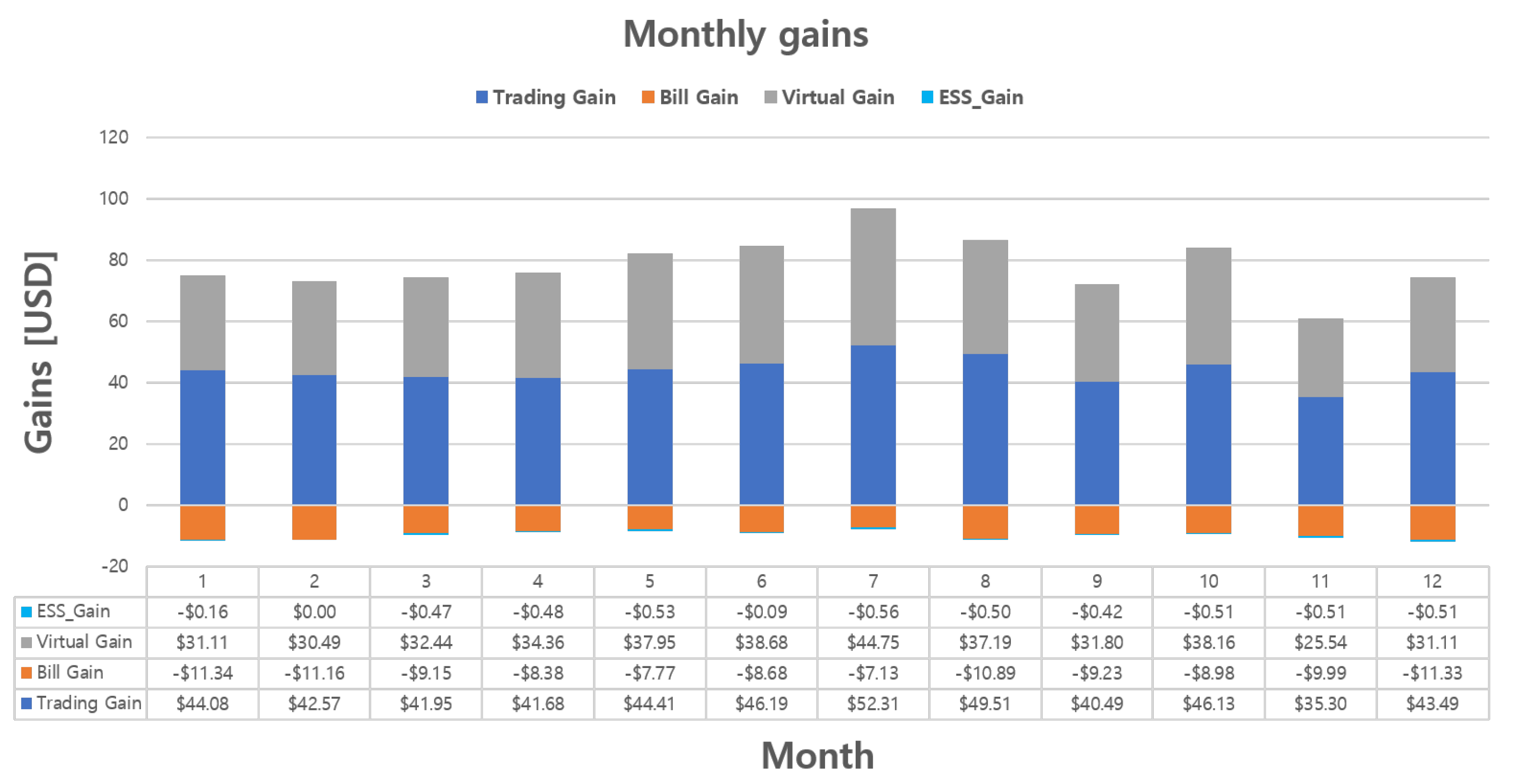{kind=link}
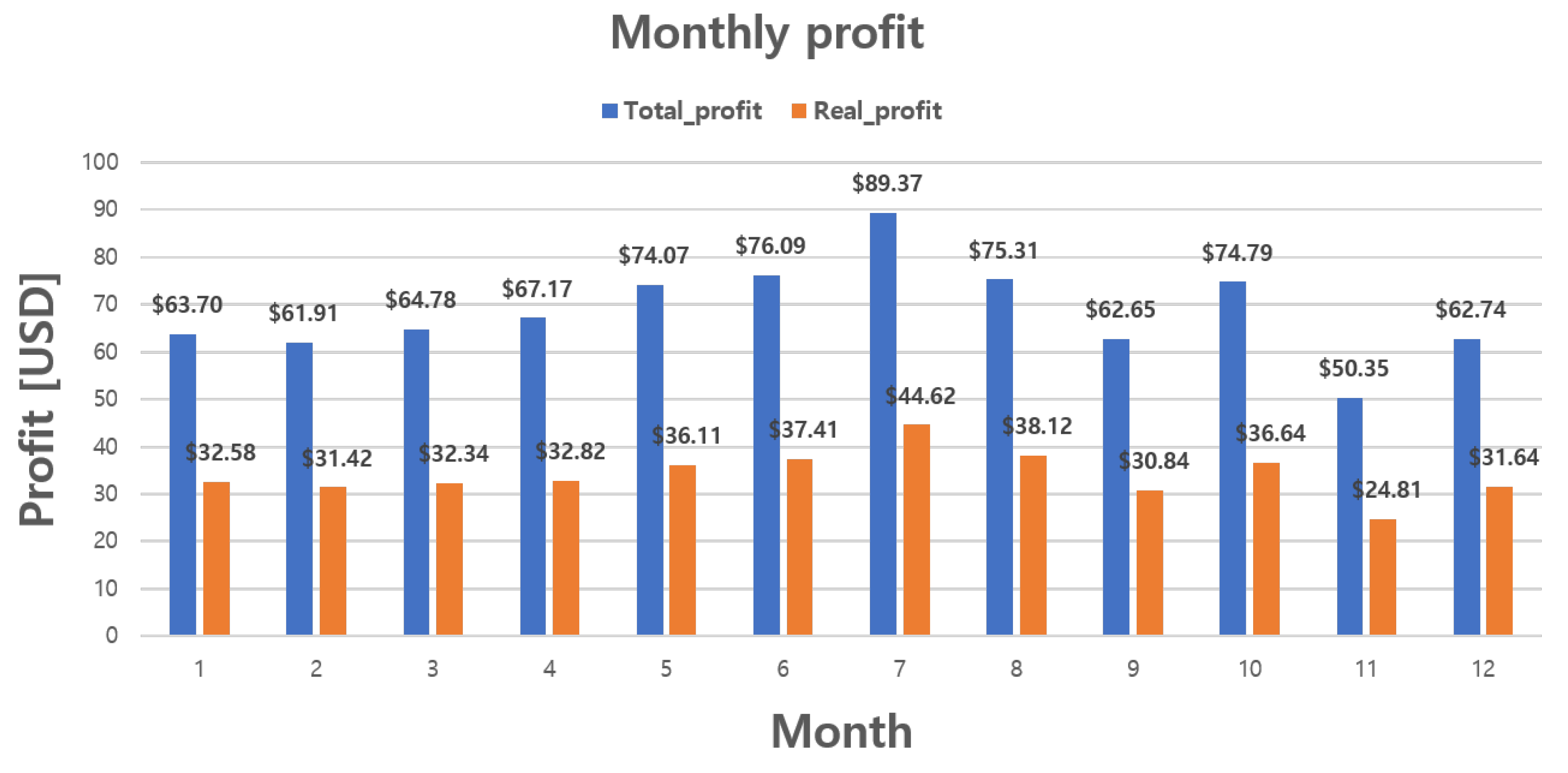{kind=link}
{kind=link}
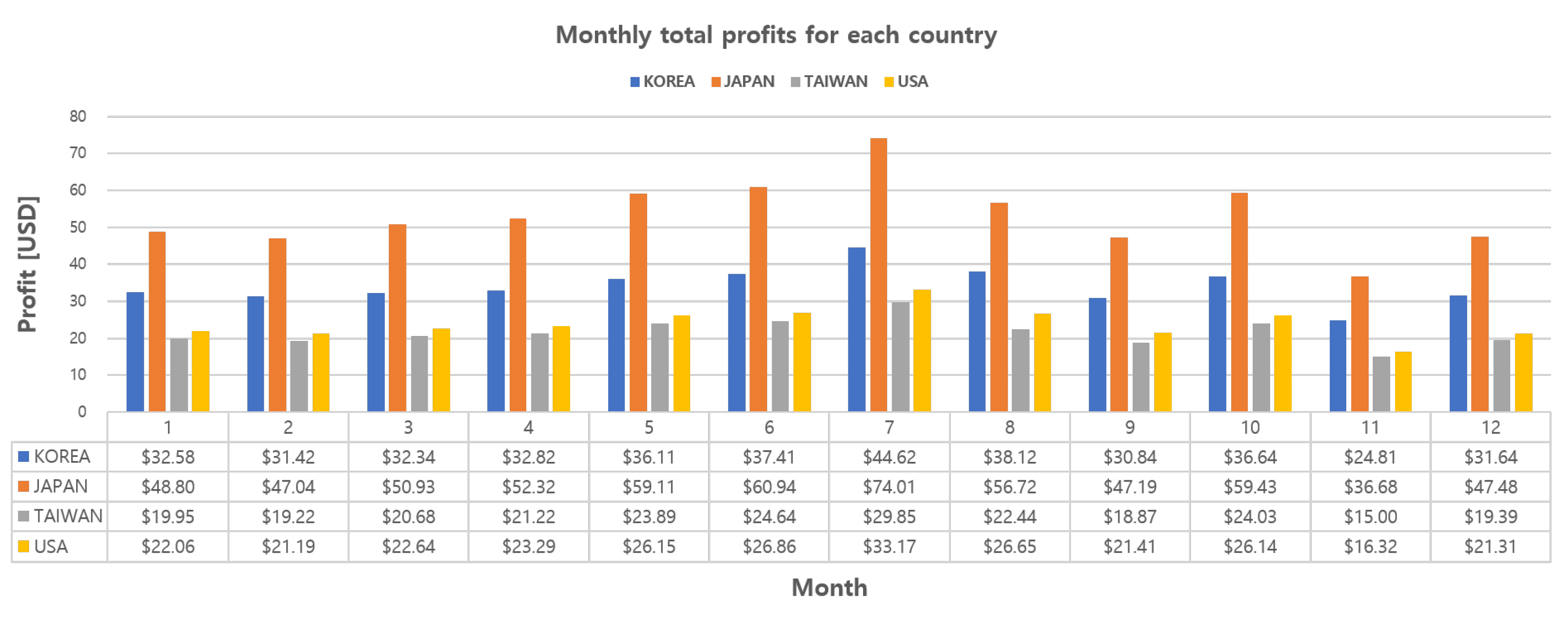{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}