ForecastTB—An R Package as a Test-Bench for Time Series Forecasting—Application of Wind Speed and Solar Radiation Modeling




Abstract
1. Introduction
- Reduction in efforts and time consumption: The ForecastTB package is designed to reduce the efforts and time consumption for the time series forecasting analysis. It avoids the repetitive steps in the analysis and leads to the promising comparative results report generation.
- Truthful comparison assurance: The ForecastTB package ensures a truthful and unbiased comparison of forecasting methods. Hence, this package may be considered a reliable tool for forecasting models based on industrial reports generation or scientific publications.
- Reproducible research: Along with unbiased comparisons, the ForecastTB package provides ease in reproducible research with minimum efforts. In other words, the forecasting comparison can be reproduced several times easily with the help of the ForecastTB package.
- Stepping stone in machine learning automation: Forecasting methods play a very important role in machine learning applications [24]. The ForecastTB package aims to evaluate the best performing forecasting method for a given time series dataset and this can be presented as a stepping stone in machine learning automation modeling. For example, on changing nature and patterns of the time series dataset, a machine learning application could automatically replace the existing forecasting methods based on the output of the ForecastTB package.
- A handy tool: The ForecastTB package is a handy tool, especially for researchers who are not comfortable with computer coding, since it is a plug-and-play module based package. A very simple syntax leads to very impressive and accurate forecasting comparison analysis.
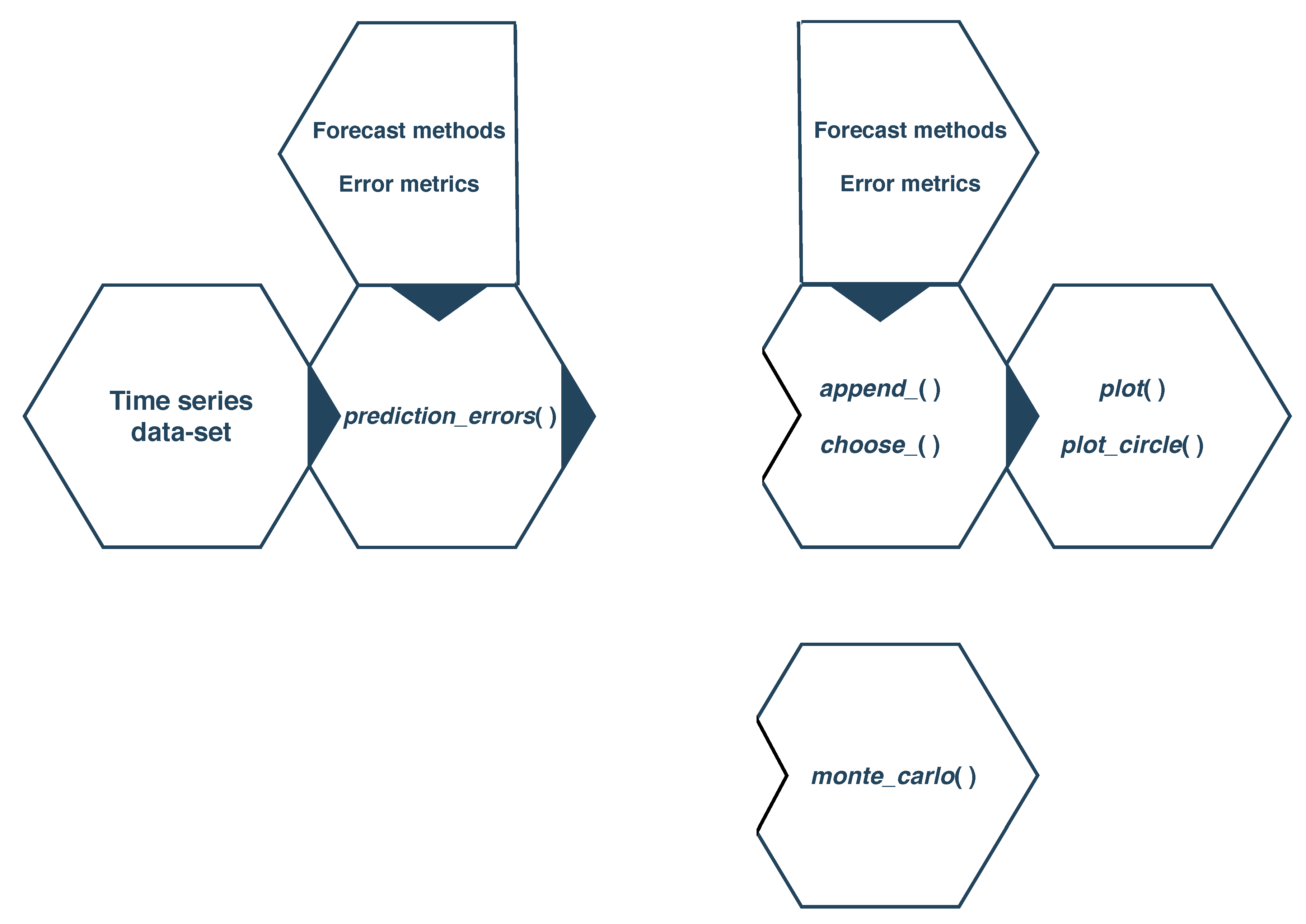
2. Overview of ForecastTB
2.1. The prediction_errors() function

2.2. The append_() and choose_() functions
2.3. The plot.prediction_errors() and plot_circle() functions
2.4. The monte_carlo() function
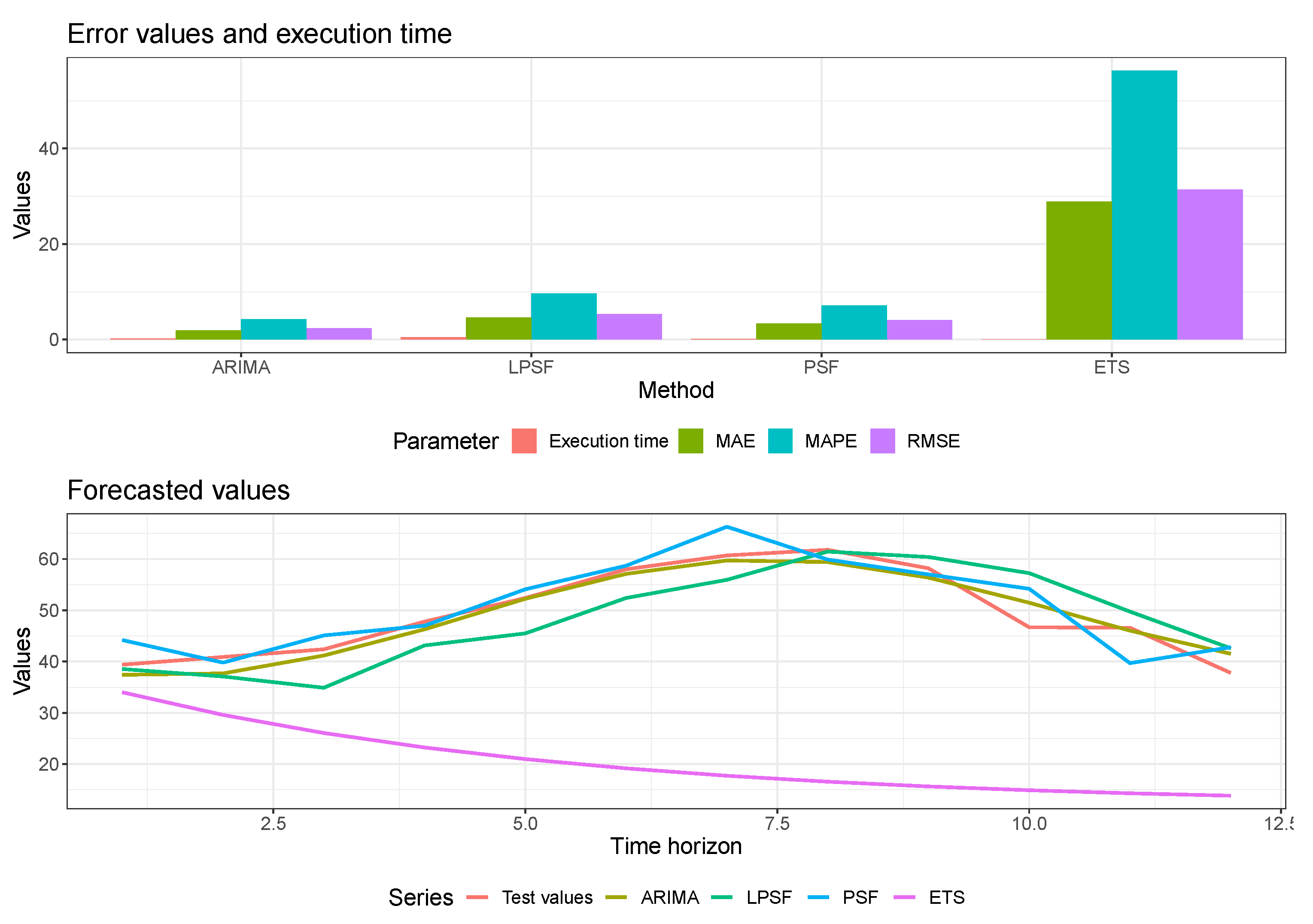
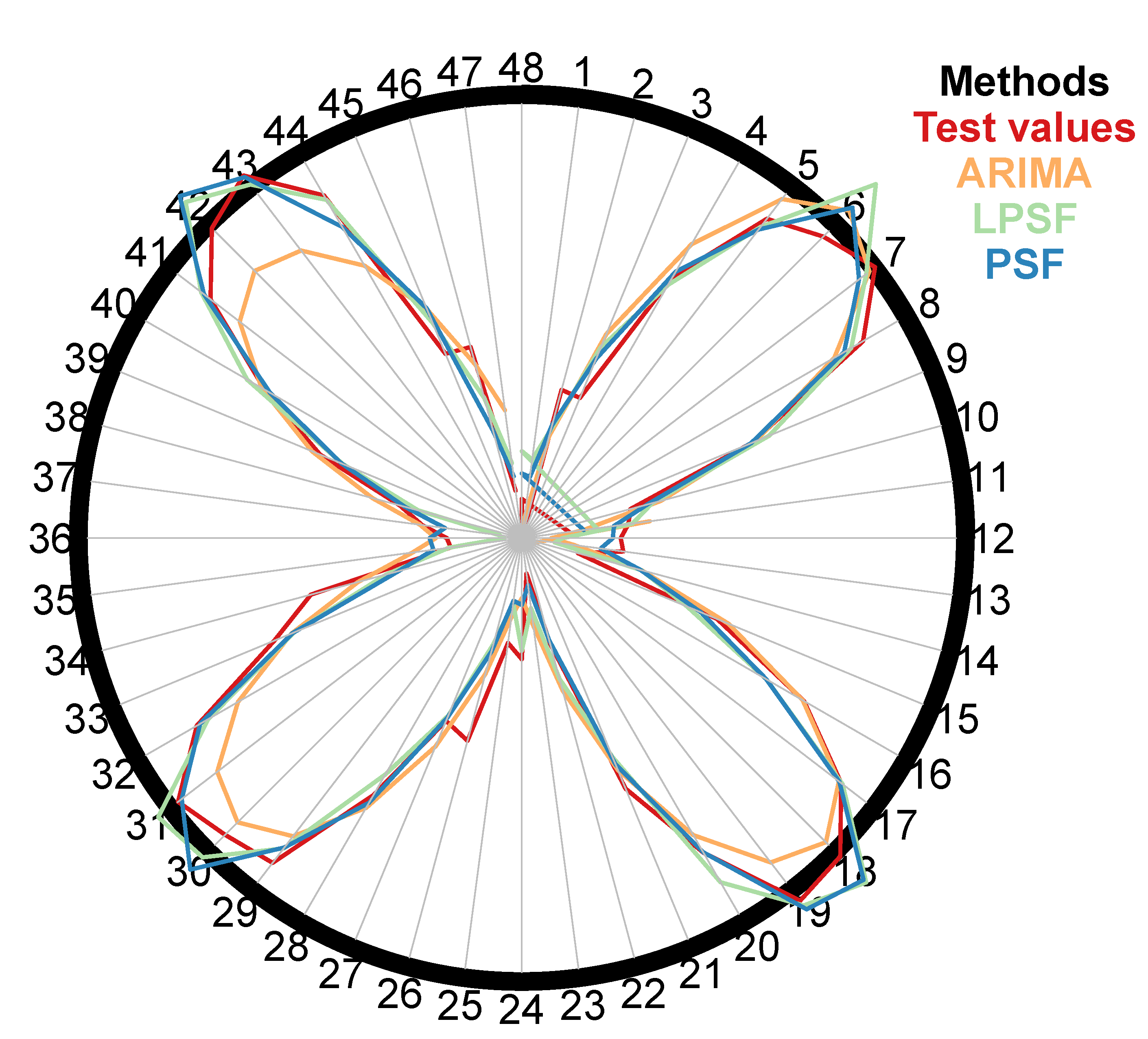
3. A Case Study: Performance of Forecasting Methods on Standard Natural Time Series





3.1. Adding New Error Metrics



3.2. A Polar Plot

3.3. Monte-Carlo Strategy



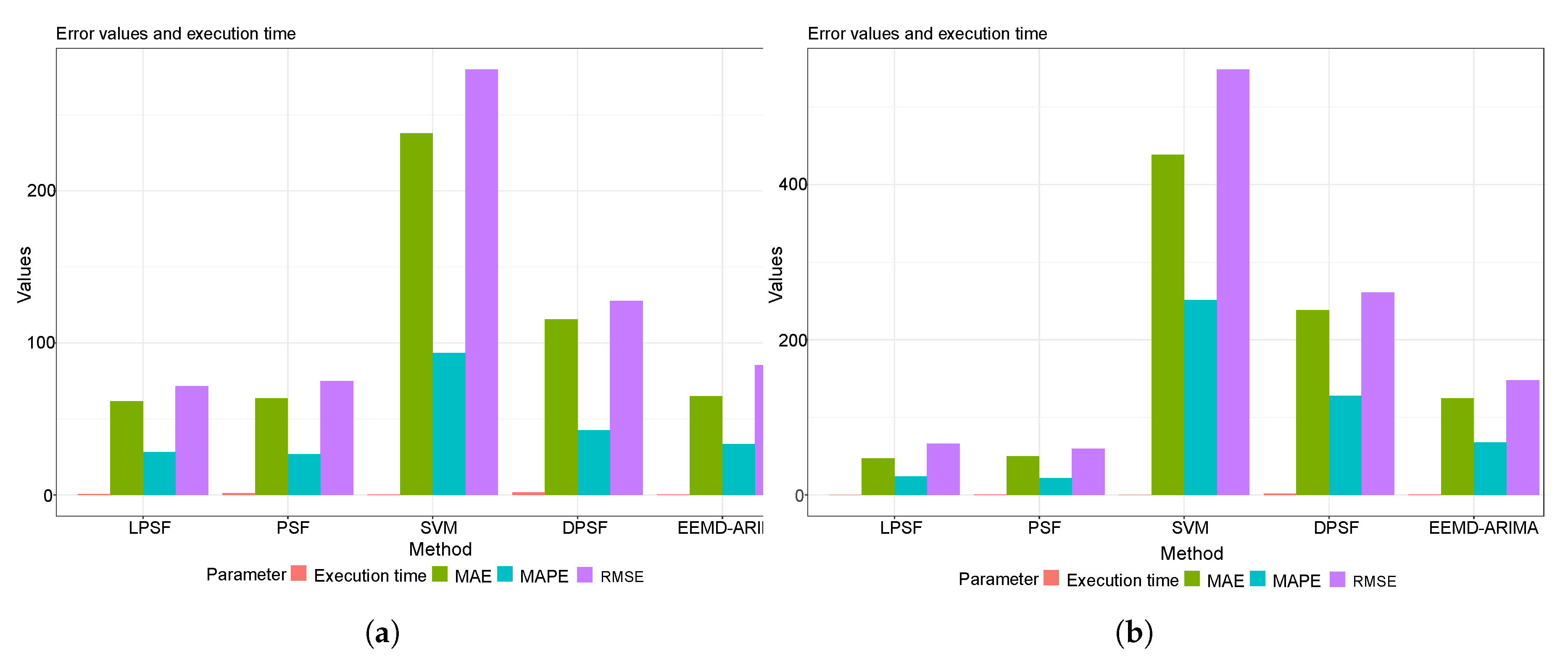
4. Case Study Related to the Energy Application
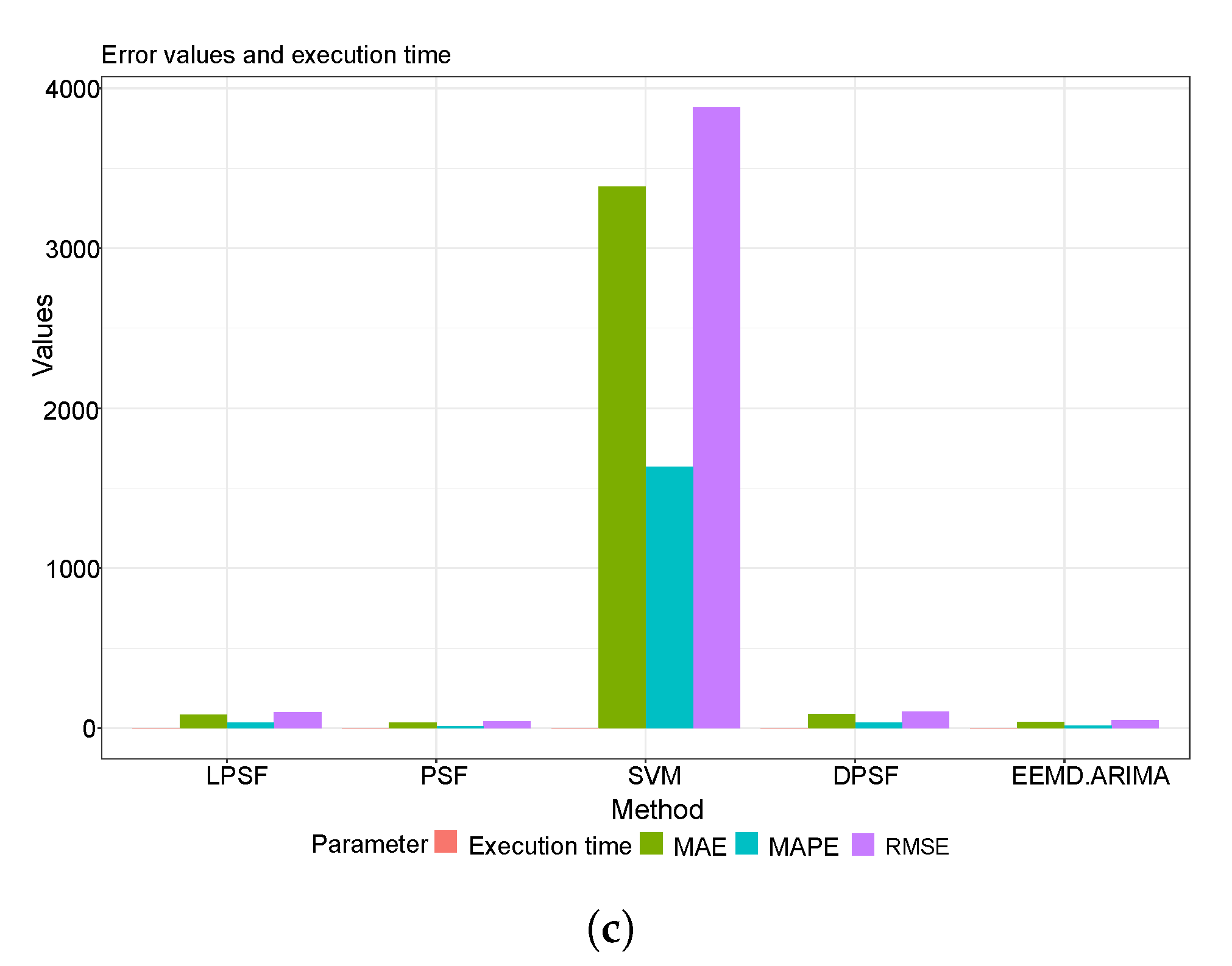
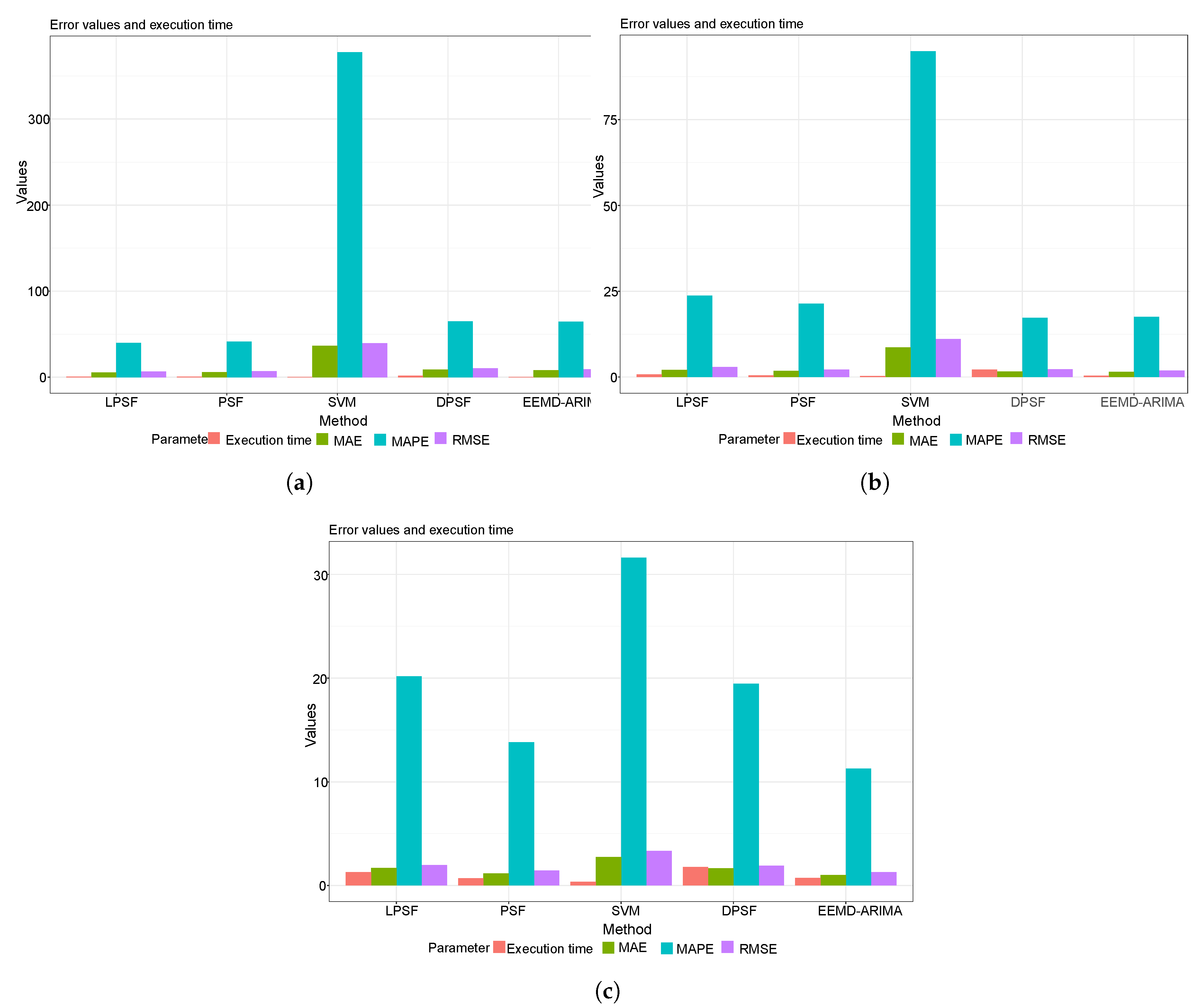
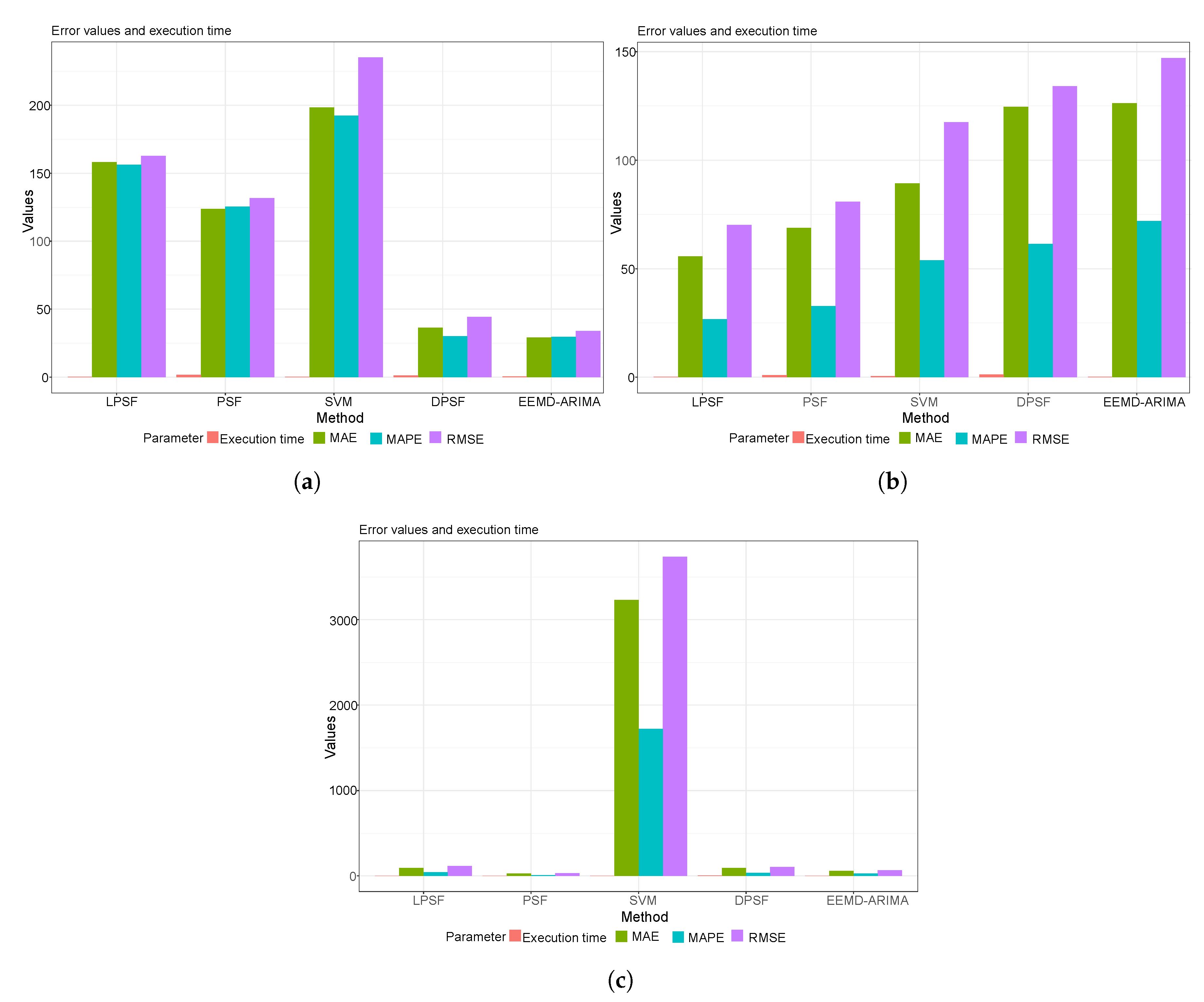
4.1. Statistical Performance Metrics Results
4.2. The Graphical Presentation of the Developed Forecasting Models
5. Discussion
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| ARIMA | Auto Regressive Integrated Moving Average |
| CRAN | The Comprehensive R Archive Network |
| ETS | Error, Trend, Seasonal |
| LPSF | Modified Pattern Sequence based Forecast |
| MATLAB | Matrix Laboratory |
| MAE | Mean Absolute Error |
| MAPE | Mean Absolute Percentage Error |
| PCV | Percent Change in Variance |
| PSF | Pattern Sequence based Forecast |
| RMSE | Root Mean Square Error |
References
- Sagheer, A.; Kotb, M. Time series forecasting of petroleum production using deep LSTM recurrent networks. Neurocomputing 2019, 323, 203–213. [Google Scholar] [CrossRef]
- Bokde, N.; Feijóo, A.; Kulat, K. Analysis of differencing and decomposition preprocessing methods for wind speed prediction. Appl. Soft Comput. 2018, 71, 926–938. [Google Scholar] [CrossRef]
- Arce, P.; Antognini, J.; Kristjanpoller, W.; Salinas, L. Fast and Adaptive Cointegration Based Model for Forecasting High Frequency Financial Time Series. Comput. Econ. 2019, 54, 99–112. [Google Scholar] [CrossRef]
- Gonzalez-Vidal, A.; Jimenez, F.; Gomez-Skarmeta, A.F. A methodology for energy multivariate time series forecasting in smart buildings based on feature selection. Energy Build. 2019, 196, 71–82. [Google Scholar] [CrossRef]
- Divina, F.; García Torres, M.; Goméz Vela, F.A.; Vázquez Noguera, J.L. A comparative study of time series forecasting methods for short term electric energy consumption prediction in smart buildings. Energies 2019, 12, 1934. [Google Scholar] [CrossRef]
- Shih, H.; Rajendran, S. Comparison of time series methods and machine learning algorithms for forecasting Taiwan Blood Services Foundation’s blood supply. J. Healthc. Eng. 2019, 2019, 6123745. [Google Scholar] [CrossRef]
- Vázquez, M.; Melin, P.; Prado-Arechiga, G. Hybrid Neural-Fuzzy Modeling and Classification System for Blood Pressure Level Affectation. In Hybrid Intelligent Systems in Control, Pattern Recognition and Medicine; Springer: Berlin/Heidelberg, Germany, 2020; pp. 257–269. [Google Scholar]
- Mithiya, D.; Datta, L.; Mandal, K. Time Series Analysis and Forecasting of Oilseeds Production in India: Using Autoregressive Integrated Moving Average and Group Method of Data Handling–Neural Network. Asian J. Agric. Ext. Econ. Sociol. 2019, 30, 1–14. [Google Scholar] [CrossRef][Green Version]
- Gupta, A.; Bokde, N.; Kulat, K. Hybrid leakage management for water network using PSF algorithm and soft computing techniques. Water Resour. Manag. 2018, 32, 1133–1151. [Google Scholar] [CrossRef]
- Kim, J.; Lee, H. A study on predictive model for forecasting anti-aircraft missile spare parts demand based on machine learning. Korean Data Inf. Sci. Soc. 2019, 30, 587–596. [Google Scholar]
- Eze, N.; Asogwa, O.; Obetta, A.; Ojide, K.; Okonkwo, C. A Time Series Analysis of Federal Budgetary Allocations to Education Sector in Nigeria (1970–2018). Am. J. Appl. Math. Stat. 2020, 8, 1–8. [Google Scholar]
- Li, M.; Hinnov, L.; Kump, L. Acycle: Time-series analysis software for paleoclimate research and education. Comput. Geosci. 2019, 127, 12–22. [Google Scholar] [CrossRef]
- Adamuthe, A.C.; Thampi, G.T. Technology forecasting: A case study of computational technologies. Technol. Forecast. Soc. Chang. 2019, 143, 181–189. [Google Scholar] [CrossRef]
- Patil, J.; Bokde, N.; Mishra, S.K.; Kulat, K. PSF-Based Spectrum Occupancy Prediction in Cognitive Radio. In Advanced Engineering Optimization Through Intelligent Techniques; Springer: Berlin/Heidelberg, Germany, 2020; pp. 609–619. [Google Scholar]
- Maroufpoor, S.; Maroufpoor, E.; Bozorg-Haddad, O.; Shiri, J.; Yaseen, Z.M. Soil moisture simulation using hybrid artificial intelligent model: Hybridization of adaptive neuro fuzzy inference system with grey wolf optimizer algorithm. J. Hydrol. 2019, 575, 544–556. [Google Scholar] [CrossRef]
- Sanikhani, H.; Deo, R.C.; Samui, P.; Kisi, O.; Mert, C.; Mirabbasi, R.; Gavili, S.; Yaseen, Z.M. Survey of different data-intelligent modeling strategies for forecasting air temperature using geographic information as model predictors. Comput. Electron. Agric. 2018, 152, 242–260. [Google Scholar] [CrossRef]
- Yaseen, Z.M.; Tran, M.T.; Kim, S.; Bakhshpoori, T.; Deo, R.C. Shear strength prediction of steel fiber reinforced concrete beam using hybrid intelligence models: A new approach. Eng. Struct. 2018, 177, 244–255. [Google Scholar] [CrossRef]
- Casdagli, M. Chaos and deterministic versus stochastic non-linear modelling. J. R. Stat. Soc. Ser. B (Methodol.) 1992, 54, 303–328. [Google Scholar]
- Shumway, R.H.; Stoffer, D.S. Time series analysis and its applications. Stud. Inform. Control 2000, 9, 375–376. [Google Scholar]
- Box, G.E.; Jenkins, G.M.; Reinsel, G.C.; Ljung, G.M. Time Series Analysis: Forecasting and Control; John Wiley & Sons: Hoboken, NJ, USA, 2015. [Google Scholar]
- Yaseen, Z.M.; Mohtar, W.H.M.W.; Ameen, A.M.S.; Ebtehaj, I.; Razali, S.F.M.; Bonakdari, H.; Salih, S.Q.; Al-Ansari, N.; Shahid, S. Implementation of univariate paradigm for streamflow simulation using hybrid data-driven model: Case study in tropical region. IEEE Access 2019, 7, 74471–74481. [Google Scholar] [CrossRef]
- Beyaztas, U.; Salih, S.Q.; Chau, K.W.; Al-Ansari, N.; Yaseen, Z.M. Construction of functional data analysis modeling strategy for global solar radiation prediction: Application of cross-station paradigm. Eng. Appl. Comput. Fluid Mech. 2019, 13, 1165–1181. [Google Scholar] [CrossRef]
- Yozgatligil, C.; Aslan, S.; Iyigun, C.; Batmaz, I. Comparison of missing value imputation methods in time series: The case of Turkish meteorological data. Theor. Appl. Climatol. 2013, 112, 143–167. [Google Scholar] [CrossRef]
- Tao, H.; Salih, S.Q.; Saggi, M.K.; Dodangeh, E.; Voyant, C.; Al-Ansari, N.; Yaseen, Z.M.; Shahid, S. A Newly Developed Integrative Bio-Inspired Artificial Intelligence Model for Wind Speed Prediction. IEEE Access 2020, 8, 83347–83358. [Google Scholar] [CrossRef]
- Bokde, N.D.; Andersen, G.B. ForecastTB: Test Bench for the Comparison of Forecast Methods; R Package Version 1.0.1; R Foundation for Statistical Computing: Vienna, Austria, 2020. [Google Scholar]
- Beck, M.W.; Bokde, N.; Asencio-Cortés, G.; Kulat, K. R package imputetestbench to compare imputation methods for univariate time series. R J. 2018, 10, 218. [Google Scholar] [CrossRef] [PubMed]
- Bokde, N.; Beck, M. imputeTestbench: Test Bench for Missing Data Imputing Models/Methods Comparison; R Package Version 3.0.3; R Foundation for Statistical Computing: Vienna, Austria, 2016. [Google Scholar]
- Bokde, N.; Beck, M.W.; Álvarez, F.M.; Kulat, K. A novel imputation methodology for time series based on pattern sequence forecasting. Pattern Recognit. Lett. 2018, 116, 88–96. [Google Scholar] [CrossRef] [PubMed]
- Shaadan, N.; Rahim, N. Imputation Analysis for Time Series Air Quality (PM10) Data Set: A Comparison of Several Methods. J. Phys. Conf. Ser. Iop Publ. 2019, 1366, 012107. [Google Scholar] [CrossRef]
- Arowolo, O.A. Foreign Investment Dependence and Infant Mortality Outcomes in the Sub-Sahara: A Bayesian P-Spline Approach to Processing Missing Sub-Regional Data. Ph.D. Thesis, University of Texas, Dallas, TX, USA, 2019. [Google Scholar]
- Bokde, N.; Feijóo, A.; Villanueva, D. Wind Turbine Power Curves Based on the Weibull Cumulative Distribution Function. Appl. Sci. 2018, 8, 1757. [Google Scholar] [CrossRef]
- Wickham, H. Reshaping Data with the reshape Package. J. Stat. Softw. 2007, 21, 1–20. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2019. [Google Scholar]
- Wickham, H. ggplot2: Elegant Graphics for Data Analysis; Springer: New York, NY, USA, 2016. [Google Scholar]
- Gu, Z.; Gu, L.; Eils, R.; Schlesner, M.; Brors, B. circlize implements and enhances circular visualization in R. Bioinformatics 2014, 30, 2811–2812. [Google Scholar] [CrossRef]
- Auguie, B. gridExtra: Miscellaneous Functions for “Grid” Graphics; R Package Version 2.3; R Foundation for Statistical Computing: Vienna, Austria, 2017. [Google Scholar]
- Neuwirth, E. RColorBrewer: ColorBrewer Palettes; R Package Version 1.1-2; R Foundation for Statistical Computing: Vienna, Austria , 2014. [Google Scholar]
- Hyndman, R.J.; Khandakar, Y. Automatic time series forecasting: The forecast package for R. J. Stat. Softw. 2008, 26, 1–22. [Google Scholar]
- Bokde, N.; Asencio-Cortes, G.; Martinez-Alvarez, F. PSF: Forecasting of Univariate Time Series Using the Pattern Sequence-Based Forecasting (PSF) Algorithm; R Package Version 0.4; R Foundation for Statistical Computing: Vienna, Austria, 2017. [Google Scholar]
- Bokde, N.; Asencio-Cortés, G.; Martínez-Álvarez, F.; Kulat, K. PSF: Introduction to R Package for Pattern Sequence Based Forecasting Algorithm. R J. 2017, 9, 324–333. [Google Scholar] [CrossRef]
- Alvarez, F.M.; Troncoso, A.; Riquelme, J.C.; Ruiz, J.S.A. Energy time series forecasting based on pattern sequence similarity. IEEE Trans. Knowl. Data Eng. 2010, 23, 1230–1243. [Google Scholar] [CrossRef]
- Bokde, N. decomposedPSF: Time Series Prediction with PSF and Decomposition Methods (EMD and EEMD); R Package Version 0.1.3; R Foundation for Statistical Computing: Vienna, Austria, 2017. [Google Scholar]
- Vico Moreno, A.; Rivera Rivas, A.J.; Perez Godoy, M.D. PredtoolsTS: Time Series Prediction Tools; R Package Version 0.1.1; R Foundation for Statistical Computing: Vienna, Austria, 2018. [Google Scholar]
- Charte, F.; Vico, A.; Pérez-Godoy, M.D.; Rivera, A.J. predtoolsTS: R package for streamlining time series forecasting. Prog. Artif. Intell. 2019, 8, 505–510. [Google Scholar] [CrossRef]
- Kuhn, M. Caret: Classification and Regression Training; R Package Version 6.0-85; R Foundation for Statistical Computing: Vienna, Austria, 2020. [Google Scholar]
- Sharafati, A.; Khosravi, K.; Khosravinia, P.; Ahmed, K.; Salman, S.A.; Yaseen, Z.M.; Shahid, S. The potential of novel data mining models for global solar radiation prediction. Int. J. Environ. Sci. Technol. 2019, 16, 7147–7164. [Google Scholar] [CrossRef]
- Tak, S.; Woo, S.; Yeo, H. Data-driven imputation method for traffic data in sectional units of road links. IEEE Trans. Intell. Transp. Syst. 2016, 17, 1762–1771. [Google Scholar] [CrossRef]
- Elsheikh, A.H.; Sharshir, S.W.; Elaziz, M.A.; Kabeel, A.; Guilan, W.; Haiou, Z. Modeling of solar energy systems using artificial neural network: A comprehensive review. Sol. Energy 2019, 180, 622–639. [Google Scholar] [CrossRef]
- Yaseen, Z.M.; Sulaiman, S.O.; Deo, R.C.; Chau, K.W. An enhanced extreme learning machine model for river flow forecasting: State-of-the-art, practical applications in water resource engineering area and future research direction. J. Hydrol. 2019, 569, 387–408. [Google Scholar] [CrossRef]
- Al-Musawi, A.A.; Alwanas, A.A.; Salih, S.Q.; Ali, Z.H.; Tran, M.T.; Yaseen, Z.M. Shear strength of SFRCB without stirrups simulation: Implementation of hybrid artificial intelligence model. Eng. Comput. 2020, 36, 1–11. [Google Scholar] [CrossRef]
- Tao, H.; Sulaiman, S.O.; Yaseen, Z.M.; Asadi, H.; Meshram, S.G.; Ghorbani, M. What is the potential of integrating phase space reconstruction with SVM-FFA data-intelligence model? Application of rainfall forecasting over regional scale. Water Resour. Manag. 2018, 32, 3935–3959. [Google Scholar] [CrossRef]
- Muschelli, J. Matlabr: An Interface for MATLAB using System Calls; R Package Version 1.5.2; R Foundation for Statistical Computing: Vienna, Austria, 2018. [Google Scholar]
- Eddelbuettel, D.; François, R.; Allaire, J.; Ushey, K.; Kou, Q.; Russel, N.; Chambers, J.; Bates, D. Rcpp: Seamless R and C++ integration. J. Stat. Softw. 2011, 40, 1–18. [Google Scholar] [CrossRef]
- Kisi, O.; Heddam, S.; Yaseen, Z.M. The implementation of univariable scheme-based air temperature for solar radiation prediction: New development of dynamic evolving neural-fuzzy inference system model. Appl. Energy 2019, 241, 184–195. [Google Scholar] [CrossRef]
- Tao, H.; Ebtehaj, I.; Bonakdari, H.; Heddam, S.; Voyant, C.; Al-Ansari, N.; Deo, R.; Yaseen, Z.M. Designing a new data intelligence model for global solar radiation prediction: Application of multivariate modeling scheme. Energies 2019, 12, 1365. [Google Scholar] [CrossRef]
- Bokde, N.; Feijóo, A.; Villanueva, D.; Kulat, K. A review on hybrid empirical mode decomposition models for wind speed and wind power prediction. Energies 2019, 12, 254. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Wind Speed | Solar Radiation | ||||||
|---|---|---|---|---|---|---|---|---|
| Daily Scale | ||||||||
| RMSE | MAE | MAPE | Execution Time | RMSE | MAE | MAPE | Execution Time | |
| LPSF | 7.57 | 5.34 | 35.84 | 0.55 | 71.60 | 61.52 | 28.22 | 0.49 |
| PSF | 8.47 | 7.00 | 57.69 | 0.42 | 74.74 | 63.65 | 26.93 | 1.06 |
| SVM | 54.28 | 49.02 | 472.57 | 0.43 | 279.86 | 237.87 | 93.45 | 0.30 |
| DPSF | 13.24 | 11.07 | 73.07 | 1.12 | 127.47 | 115.48 | 42.43 | 1.63 |
| EEMD-ARIMA | 9.38 | 7.99 | 74.56 | 0.25 | 85.32 | 64.96 | 33.35 | 0.23 |
| Weekly Scale | ||||||||
| RMSE | MAE | MAPE | Execution Time | RMSE | MAE | MAPE | Execution Time | |
| LPSF | 3.75 | 3.20 | 32.82 | 0.19 | 66.17 | 47.36 | 23.72 | 0.30 |
| PSF | 3.30 | 2.57 | 24.50 | 0.50 | 59.33 | 49.72 | 21.88 | 0.78 |
| SVM | 13.51 | 10.73 | 117.89 | 0.30 | 548.47 | 438.63 | 250.93 | 0.24 |
| DPSF | 3.40 | 2.74 | 24.28 | 1.64 | 260.68 | 238.28 | 128.00 | 1.77 |
| EEMD-ARIMA | 2.73 | 2.33 | 24.60 | 0.44 | 147.88 | 124.65 | 67.65 | 0.39 |
| Monthly Scale | ||||||||
| RMSE | MAE | MAPE | Execution Time | RMSE | MAE | MAPE | Execution Time | |
| LPSF | 2.09 | 1.58 | 19.15 | 0.47 | 99.80 | 82.74 | 33.79 | 0.46 |
| PSF | 1.60 | 1.19 | 13.77 | 0.35 | 39.32 | 32.51 | 10.84 | 0.32 |
| SVM | 8.66 | 7.11 | 77.86 | 0.18 | 3881.20 | 3384.89 | 1632.05 | 0.19 |
| DPSF | 1.73 | 1.49 | 16.65 | 0.95 | 100.60 | 88.72 | 32.25 | 1.02 |
| EEMD-ARIMA | 1.93 | 1.63 | 19.55 | 0.19 | 50.00 | 36.94 | 13.90 | 3.62 |
| Methods | Wind Speed | Solar Radiation | ||||||
|---|---|---|---|---|---|---|---|---|
| Daily Scale | ||||||||
| RMSE | MAE | MAPE | Execution Time | RMSE | MAE | MAPE | Execution Time | |
| LPSF | 6.67 | 5.48 | 39.85 | 0.48 | 162.74 | 158.21 | 156.09 | 0.23 |
| PSF | 6.98 | 5.73 | 41.45 | 0.67 | 131.67 | 123.64 | 125.34 | 1.69 |
| SVM | 39.51 | 36.36 | 377.76 | 0.26 | 235.05 | 198.34 | 192.34 | 0.26 |
| DPSF | 10.48 | 9.02 | 64.90 | 1.77 | 44.29 | 36.30 | 30.20 | 1.18 |
| EEMD-ARIMA | 9.20 | 8.20 | 64.60 | 0.27 | 33.86 | 29.13 | 29.67 | 0.54 |
| Weekly Scale | ||||||||
| RMSE | MAE | MAPE | Execution Time | RMSE | MAE | MAPE | Execution Time | |
| LPSF | 2.95 | 2.04 | 23.68 | 0.79 | 70.21 | 55.65 | 26.74 | 0.22 |
| PSF | 2.18 | 1.79 | 21.33 | 0.44 | 80.83 | 68.79 | 32.76 | 0.96 |
| SVM | 11.05 | 8.60 | 94.95 | 0.26 | 117.46 | 89.32 | 53.93 | 0.53 |
| DPSF | 2.28 | 1.61 | 17.26 | 2.16 | 134.15 | 124.54 | 61.43 | 1.21 |
| EEMD-ARIMA | 1.87 | 1.55 | 17.56 | 0.38 | 147.10 | 126.24 | 71.94 | 0.23 |
| Monthly Scale | ||||||||
| RMSE | MAE | MAPE | Execution Time | RMSE | MAE | MAPE | Execution Time | |
| LPSF | 1.98 | 1.70 | 20.16 | 1.30 | 115.18 | 90.65 | 42.48 | 1.05 |
| PSF | 1.43 | 1.17 | 13.84 | 0.71 | 32.09 | 25.23 | 8.77 | 0.49 |
| SVM | 3.34 | 2.74 | 31.63 | 0.37 | 3739.78 | 3231.79 | 1719.36 | 0.52 |
| DPSF | 1.90 | 1.67 | 19.46 | 1.79 | 102.93 | 92,20 | 35.60 | 1.76 |
| EEMD-ARIMA | 1.30 | 1.02 | 11.29 | 0.73 | 65.96 | 58.27 | 26.29 | 0.39 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bokde, N.D.; Yaseen, Z.M.; Andersen, G.B. ForecastTB—An R Package as a Test-Bench for Time Series Forecasting—Application of Wind Speed and Solar Radiation Modeling. Energies 2020, 13, 2578. https://doi.org/10.3390/en13102578
Bokde ND, Yaseen ZM, Andersen GB. ForecastTB—An R Package as a Test-Bench for Time Series Forecasting—Application of Wind Speed and Solar Radiation Modeling. Energies. 2020; 13(10):2578. https://doi.org/10.3390/en13102578
Chicago/Turabian StyleBokde, Neeraj Dhanraj, Zaher Mundher Yaseen, and Gorm Bruun Andersen. 2020. "ForecastTB—An R Package as a Test-Bench for Time Series Forecasting—Application of Wind Speed and Solar Radiation Modeling" Energies 13, no. 10: 2578. https://doi.org/10.3390/en13102578
APA StyleBokde, N. D., Yaseen, Z. M., & Andersen, G. B. (2020). ForecastTB—An R Package as a Test-Bench for Time Series Forecasting—Application of Wind Speed and Solar Radiation Modeling. Energies, 13(10), 2578. https://doi.org/10.3390/en13102578