1. Introduction
Lithology identification is a fundamental process in reservoir characterization and formation evaluation. Usually, lithofacies are determined by either direct visualization of core samples or manual interpretation of well logs, by correlating similar physical characteristics of reservoir formations. These conventional methods for determining the lithology of the heterogeneous reservoir are time-consuming, labor intensive, and unreliable, since it is as a consequence of the intuition of geologists and log analysts [
1,
2,
3,
4].
To overcome these challenges, researchers have tried to introduce cross-plotting as a statistical method on well logs [
5,
6,
7,
8]. However, cross-plotting was found to be unable to fully expose the relationship that may exist within well log data [
9]. Interpretation from the cross-plot is similarly reliant on the experience of log analysts [
10,
11]. With the current computational power and the increasing number of well log tools, it has become necessary to automate the process of lithology determination, by minimizing the impact of human interference that can lead to biased and multiple interpretations [
12,
13,
14].
To achieve this, the application of machine-learning algorithms has proven to be a reliable and adaptive approach in identifying lithofacies in the subsurface [
15]. To date, the notably common algorithms employed in classifying lithology include the artificial neural network (ANN) and the support vector machine (SVM). The capability of the ANN and the SVM have been evidently portrayed by Al-Anazi and Gates [
16,
17], Deng et al. [
18], Sebtosheikh et al. [
19], and, Xie et al. [
15]. In addition, an attempt was made by 20. Konaté et al. [
20] to improve the accuracy of the ANN and the SVM classifiers using the dimensionality reduction techniques of principal component analysis (PCA) and linear discriminant analysis (LDA). Tian et al. [
21] presented a lithology recognition approach using extreme learning machine (ELM).
It is important to mention that, in order to achieve the desired outcome for the ANN, SVM, and ELM machine-learning algorithms, both constant model parameter adjustments and a form of human interference are required. Therefore, there is a high possibility of the model to converge at local minima. Authors, such as Saporetti et al. [
22], have avoided this limitation by combining differential evolution search algorithms with ELM to select the optimal learning parameters of ELM lithology classification.
The group method of data handling (GMDH) algorithm has been identified in the literature to be a promising alternative to address this shortcoming. The reason is that the GMDH algorithm does not rely on a constant adjustment of training parameters, before generating an optimal result. That is, there is little manual tasking in the GMDH modelling process. This is because the iterative tuning of the network parameters, optimum model structure, and number of layers and neurons in the hidden layers, are determined automatically due to its self-organizing nature. In effect, the GMDH model generates a polynomial functional structure using a selection of influential input variables [
23,
24]. Therefore, it must be acknowledged that the outcome from the GMDH model is significantly dependent on the nature of the inputs.
Generally, input variables of well logs can exhibit relationships between each other. This leads to the presence of multiple collinearities, which must be removed from the model development to improve the accuracy of the model. In this regard, dimensionality reduction methods are capable of reducing the set of well logs and the complexity of the model by transforming well logs into relevant or principal components, and discriminant factors. Here, all redundant well logs are removed when the dimensionality reduction technique is employed. Furthermore, the time-frequency information can be extracted from well log signals, using wavelet analysis by decomposing the signals into a series of wavelets having a different scale and position to improve the learning capacity of the model.
In this paper, we initially developed a GMDH model that can detect the various lithofacies of the southern basin of the South Yellow Sea, using well logs. In addition, the well log data pre-processing techniques of wavelet analysis, principal component analysis (PCA), and linear discriminant analysis (LDA), as dimensionality reduction methods, were presented with the aim of improving the accuracy of GMDH classification.
2. Data Description
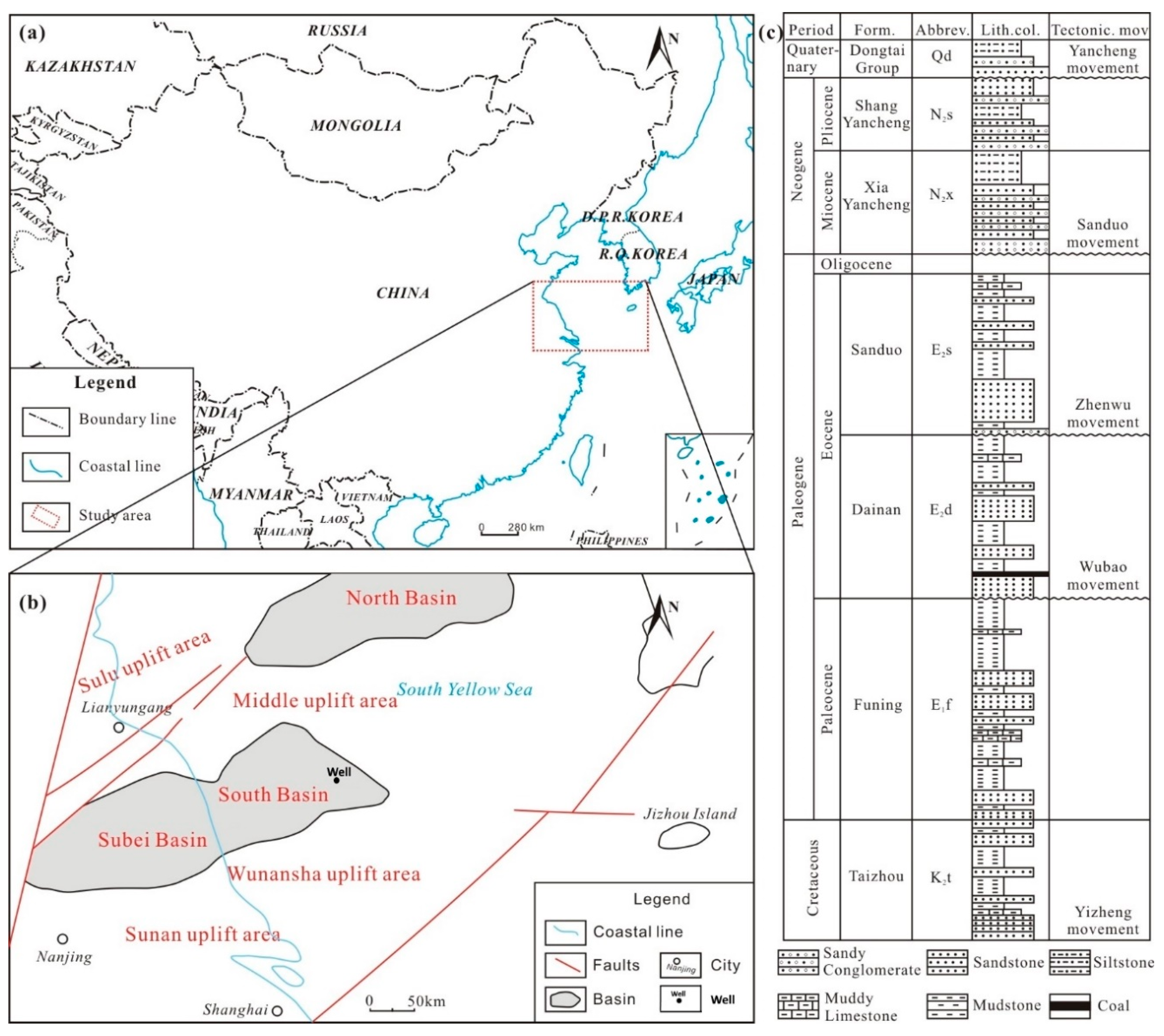
The South Yellow Sea basin is a south-west oriented rift depression basin, located between the Subei basin and Korea peninsular [
25,
26,
27], as shown in
Figure 1a. The Southern basin was created from a central uplift, dividing the South Yellow Sea basin into two (
Figure 1b). A 1350–2750 m exploratory well having a suite of five well logs and 10,127 core lithology data elements of the southern basin of the South Yellow Sea were considered for this research (
Figure 1b). The lithology of the southern basin is composed of sandy conglomerate, siltstone, muddy limestone, mudstone, and coal [
28,
29], as represented in
Figure 1c.
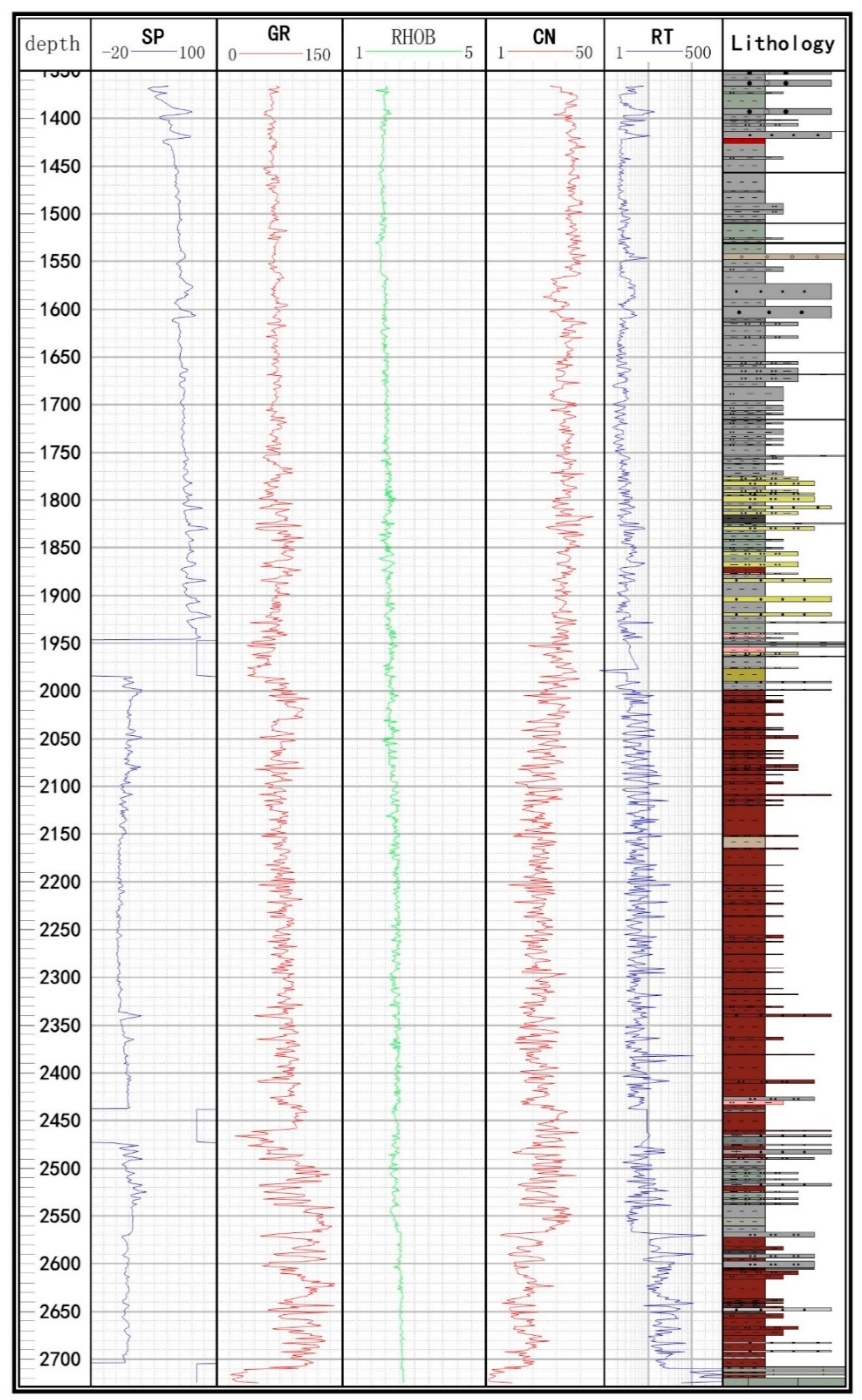
Table 1 summarizes the details of the core lithofacies identified, and considered as the output variable. The log suite that served as the input variables—consisting of bulk density (RHOB), gamma ray (GR), spontaneous potential (SP), compensated neutron (CN), and resistivity (RT)—were used in the development of the GMDH classifiers (
Figure 2). In this study, the well log data were sampled at an approximate interval of 0.14 m.
4. Results and Discussion
4.1. Principal Component Analysis
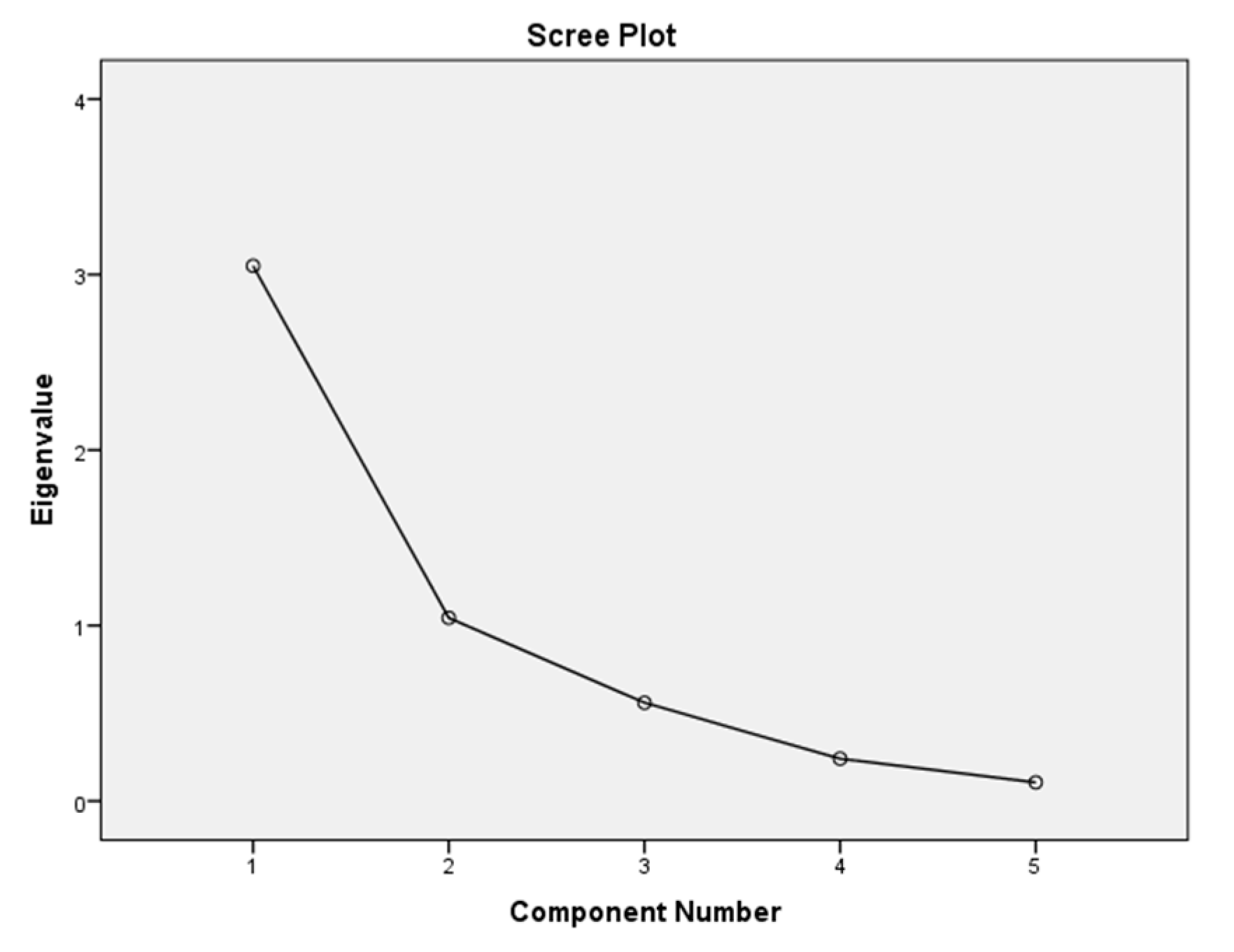
The results from the PCA as shown in
Table 2 indicate that component 1 and component 2 can retain and interpret a greater portion of the total variance of the entire well logs considered in this study. This assertion is based on the Kaiser criterion [
36], which reveals that components having eigenvalues of more than 1 can preserve and represent the total information of the data being reduced. Therefore, components 1 and 2 were selected since their eigenvalues are more than 1. From
Table 2, component 1 and component 2 observed an eigenvalue of 81.858% of the total variance of the well log suite. Component 1 accounted for 60.99%, while component 2 represented 20.87% of the total variance. An observation made from the scree plot in
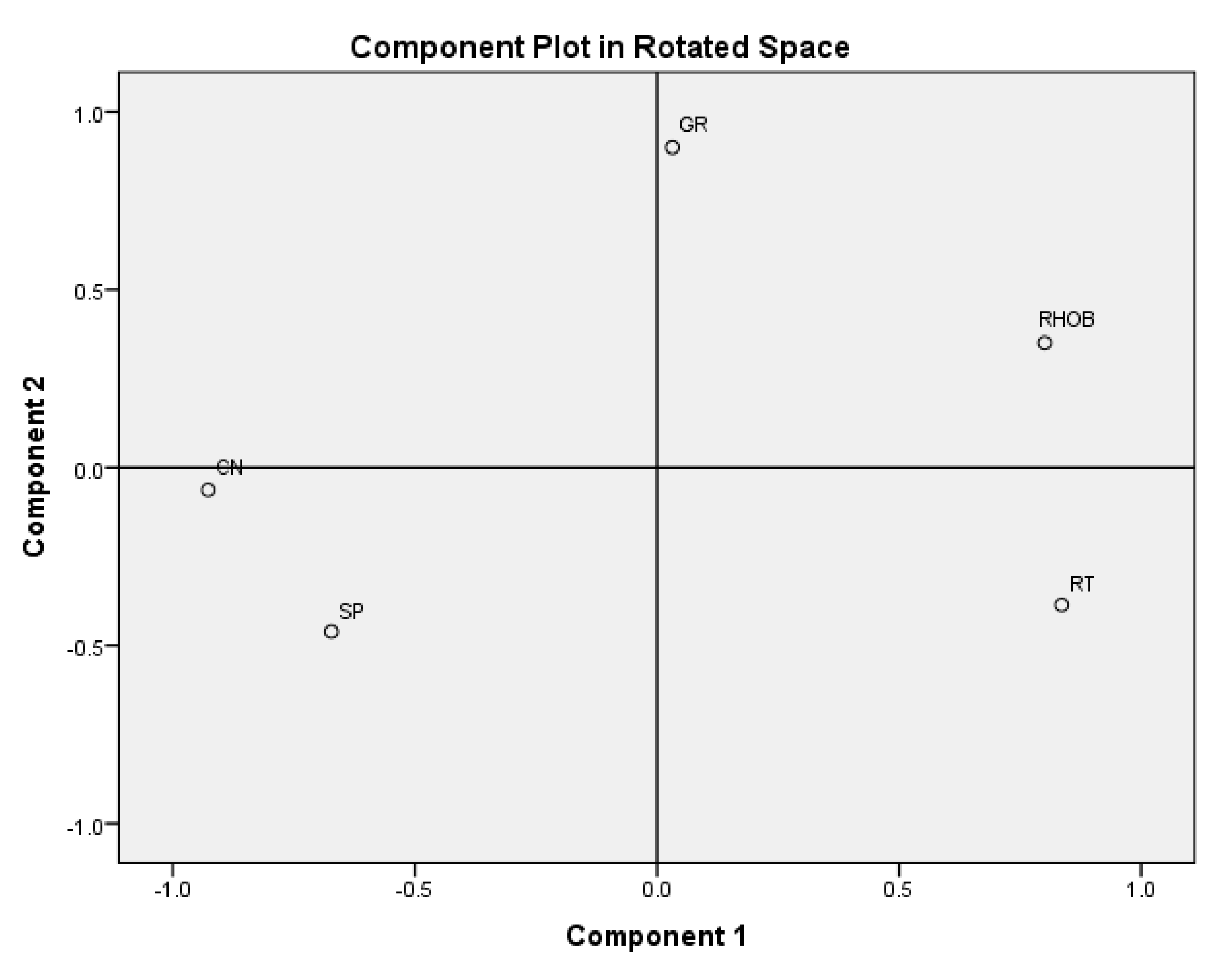
Figure 3 revealed a change in the direction of the line after component 2. This confirms the fact that only component 1 and component 2 are the meaningful variance from the suite of considered well logs. The selected PCs were further rotated to assess their correlation to each well log parameter in
Figure 4. Details of the linear relationship between the well logs and the principal components extracted are listed in
Table 3. RHOB, CN, and SP had high correlation values with component 1, while GR observed a high correlation value of 0.768 with component 2 (
Table 3). Therefore, components 1 and 2 replaced the well log parameters as inputs for the hybrid PCA-GMDH lithology classifier.
4.2. Linear Discriminant Analysis
Table 4 summarizes the results from LDA on the five well logs and the core lithology data. It was found that three discriminant factors had eigenvalues greater than 1. Specifically, factor 1, 2, and 3 obtained eigenvalues of 4.5939, 2.2632, and 1.5648 respectively (
Table 4). The three discriminant factors explained 97.6% variance of the entire well logs considered. Factor 1 accounted for 75.4%, factor 2 explained 15.2%, and factor 3 explained 7% of the total variance of the well logs. The coefficient of the well logs in each discriminant function is listed in
Table 5. It is important to note that the larger the coefficient in the discriminant function, the more that well log parameter will contribute to discriminating between the various classes. Therefore, it can be seen from
Table 5 that the CN well log contributed significantly to all of the three discriminant functions. The joint LDA-GMDH classification model was generated from discriminant function 1, 2, and 3 input variables.
4.3. Discrete Wavelet Transform
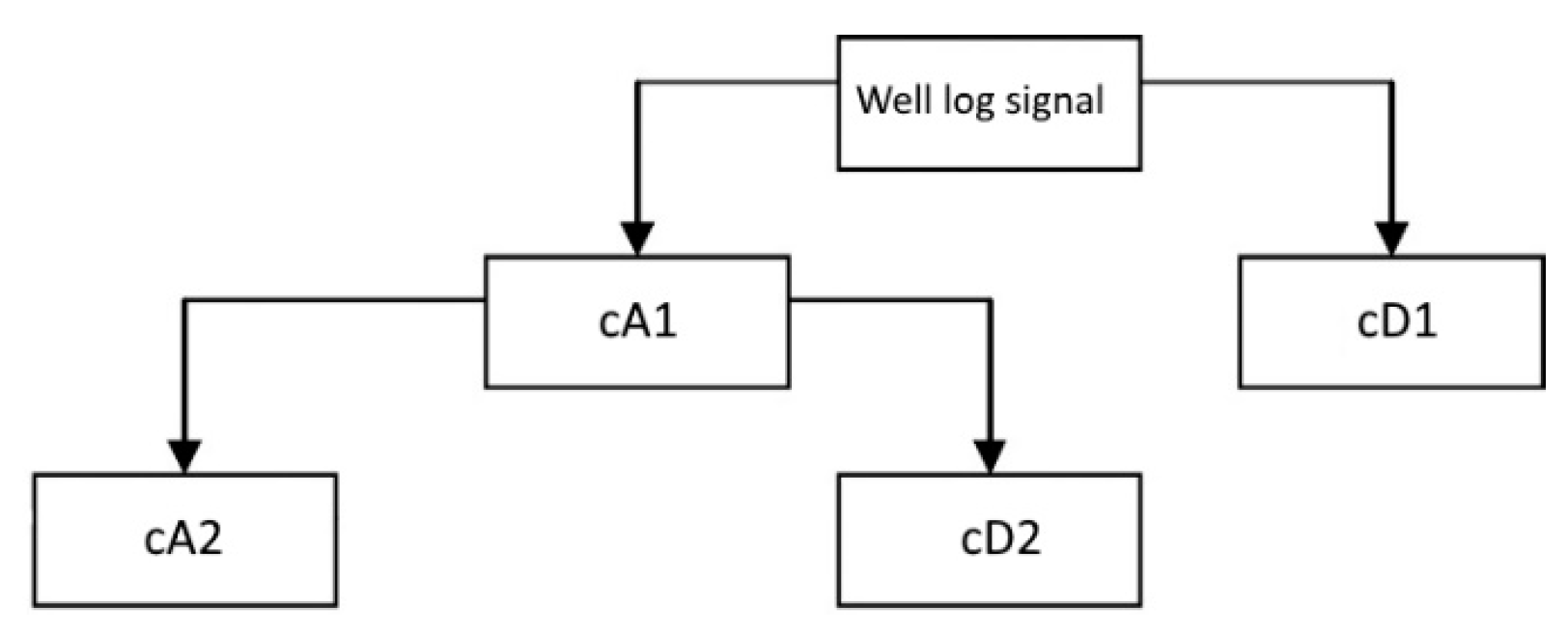
This study performed DWT using wavelet functions of Daubechies (db), ReverseBior (rbio), and Symlets (sym) to decompose the well log signals [
34,
35] in the wavelet toolbox in Matlab R2016a. A two-level decomposition using the db-2, rbio-2.2, and sym-2 wavelet function generated an approximation wavelet (cA2) and two detailed wavelets (cD1 and cD2). The well log signals were initially decomposed into low- and high-frequency components. The approximation value from the initial decomposition (cA1) is the low-frequency component, while the detail value of the signal (cD1) is the high-frequency component. From
Figure 5, the two-level decomposition is a further breakdown of the low-frequency component. The low-frequency component of most signals is the most important; however, the high-frequency component plays the role of an “additive” [
37].
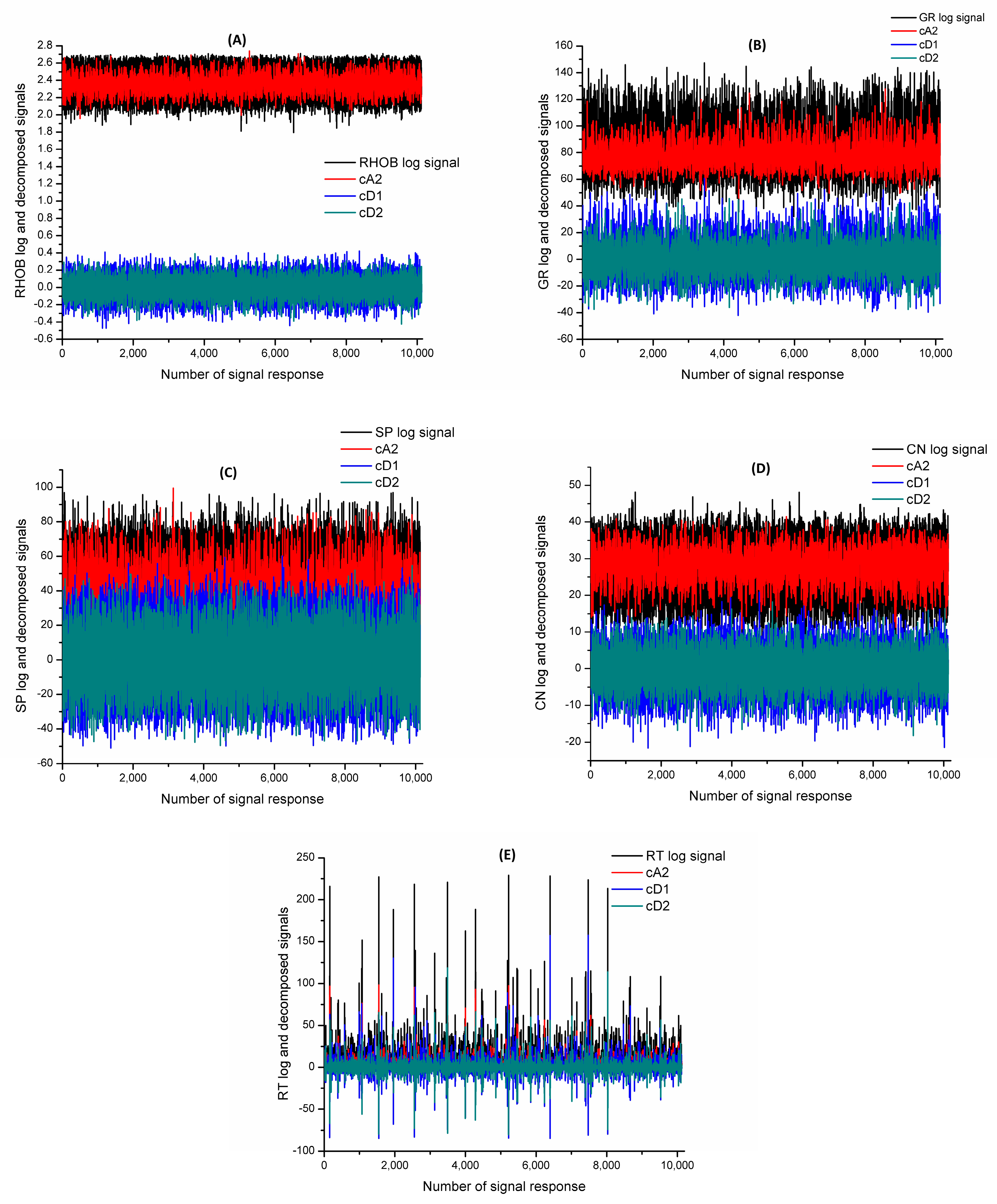
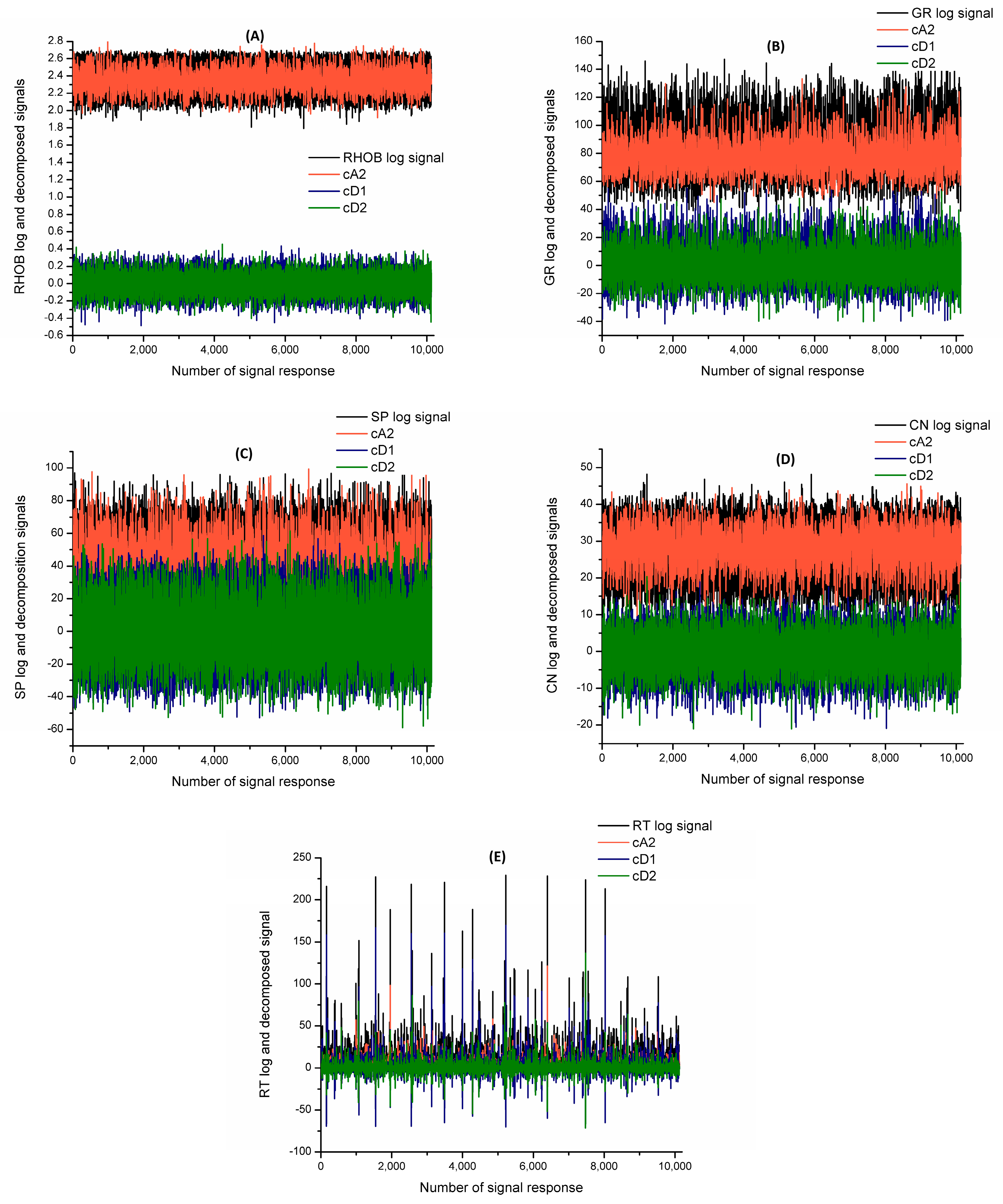
Figure 6 and
Figure 7 compare the various well log signals and their corresponding approximation (cA2) and detailed (cD1 and cD2) wavelet coefficients. Therefore, each well log was replaced by the generated three wavelet signals as inputs.
4.4. GMDH Classifiers
In this section, GMDH classifiers were developed by selecting 60% of the 10,127 lithology data elements and their corresponding well log signals, principal components, discriminant factors, and wavelet signals as training data. Forty percent (40%) of the data became the benchmark used to assess the trained classifiers, i.e., the testing dataset. The inputs of GMDH were the five well log sets (i.e., RHOB, GR, SP, CN, and RT) trained to identify the various lithofacies. Similarly, component 1 and component 2 were used as inputs to build the PCA-GMDH lithology classifier. For LDA-GMDH, discriminant factors 1, 2, and 3 were the input variables, while 15 wavelet signals comprised of the cA2, cD1, and cD2 for all five well log signals were the input variables for db2-GMDH, rbio2.2-GMDH, and sym2-GMDH. GMDH classification models were coded and implemented in MATLAB R2016a.
The performance of GMDH lithology classification models was assessed based on how accurate they were able to identify the various lithofacies. The optimal GMDH structure was made up of five input neurons, 15 hidden layers with a varying number of hidden neurons in each layer, and lithology as the output (
Table 6). The polynomial equations used to develop the optimal GMDH classification model are summarized in
Table 6. It was observed that GMDH using the suite of five well logs achieved a classification accuracy rate of 82.488% and 81.806% for training and testing, respectively.
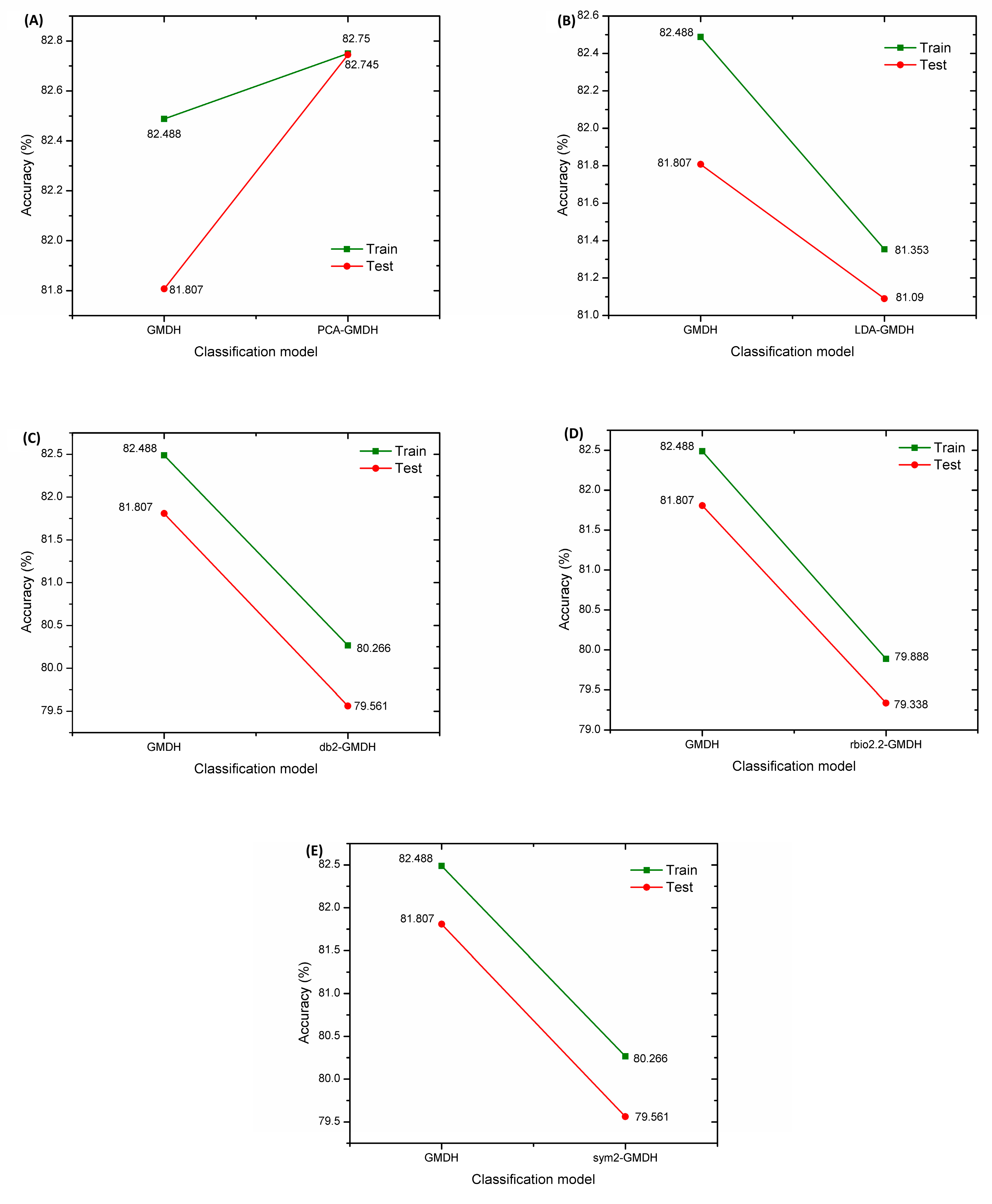
As explained earlier, we conducted a comparative study with PCA-GMDH, LDA-GMDH, db2-GMDH, rbio2.2-GMDH, and sym2-GMDH to see whether the results of the GMDH classification model can be improved. As illustrated in
Figure 8A, PCA-GMDH successfully improved the results of GMDH, as it produced classification results having an accuracy rate of 82.75% and 82.745% for training and testing, respectively. When analyzing the outcome from the LDA-GMDH, db2-GMDH, rbio2.2-GMDH, and sym2-GMDH classifiers, it was identified that, for the data used in this study, the LDA and DWT pre-processing techniques accounted for a decrease in the performance of GMDH. This means that LDA-GMDH, db2-GMDH, rbio2.2-GMDH, and sym2-GMDH could not perform better than GMDH. From
Figure 8B, LDA-GMDH obtained an accuracy rate of 81.353% and 81.09% for training and testing, respectively. According to
Figure 8C–E, db2-GMDH and sym2-GMDH had a similar accuracy output of 80.266% and 79.561%, while rbio2.2-GMDH achieved 79.888% and 79.338% for training and testing, respectively.
A detailed assessment of how each model misclassified the various lithofacies is summarized in
Table 7. According to
Table 7, all the GMDH models performed significantly well when identifying siltstone and mudstone facies. This is attributed to the large amount of siltstone and mudstone that were present in the study area. Lithofacies, such as sandy conglomerate, muddy limestone, and coal, were often misclassified by db2-GMDH, sym2-GMDH, and rbio2.2-GMDH. GMDH and LDA-GMDH failed to recognize coal facies. Furthermore, PCA-GMDH was able to distinguish between all the present classes of lithology, as shown in
Table 7.
5. Conclusions
The self-organizing ability of the GMDH algorithm, whereby it does not rely on any human interference to adjust its model parameters, was successfully implemented to identify lithofacies present in the southern basin of the South Yellow Sea. This study explored the impact of the pre-processing techniques of PCA and LDA as dimensional-reduction methods, and wavelet analysis, regarding the performance of GMDH lithology classification.
The well log sets of five parameters were reduced to two principal components and three discriminant factors by PCA and LDA, respectively, while maintaining most of the total variance of the well log data. The discrete wavelet transform decomposed each well log signal into approximation (cA2) and detailed wavelet (cD1, cD2) signals.
Evaluating the GMDH lithology classification models revealed that PCA-GMDH achieved an improved accuracy rate, when compared with GMDH. For the purpose of this study, however, LDA-GMDH, db2-GMDH, sym2-GMDH, and rbio2.2-GMDH were unable to improve the results of GMDH.
Among the facies present in the southern basin of the South Yellow Sea, siltstone and mudstone were the accurately identified facies. Siltstone and mudstone were easily detected as a consequence of their large quantities. In the study area, PCA-GMDH presented the ability to differentiate between the various classes.
To conclude, based on the findings of this study, PCA is the well log data pre-processing technique that can improve the performance of GMDH, and can be adopted as the lithology classification model for the rest of the wells in the southern basin of the South Yellow Sea.


 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}