Multi-Pattern Data Mining and Recognition of Primary Electric Appliances from Single Non-Intrusive Load Monitoring Data




Abstract
1. Introduction
2. Data Preprocessing
- (1)
- During idle time: there is no electrical work, the monitoring power value is close to 0 (<10 W), so it is set to 0.
- (2)
- During stable operation: due to the interference of external factors, there were random abrupt data. These mutation data was replaced by the average value of the time monitoring data. If the difference between three or more continuous monitoring values did not exceed 5% of their average value, we considered that this time was in a stable operation stage. In the study, the data in the stable stage were used for calculation.
- (3)
- The daily data was divided into three parts according to the family’s daily habits: morning (06:00–14:00), afternoon (14:00–22:00), and night (22:00–06:00).
3. Methodology
3.1. Standard AP Clustering Algorithm
3.2. Improved AP Clustering Algorithm
3.2.1. Challenges with Standard AP Clustering Algorithm
3.2.2. Improvement Measures
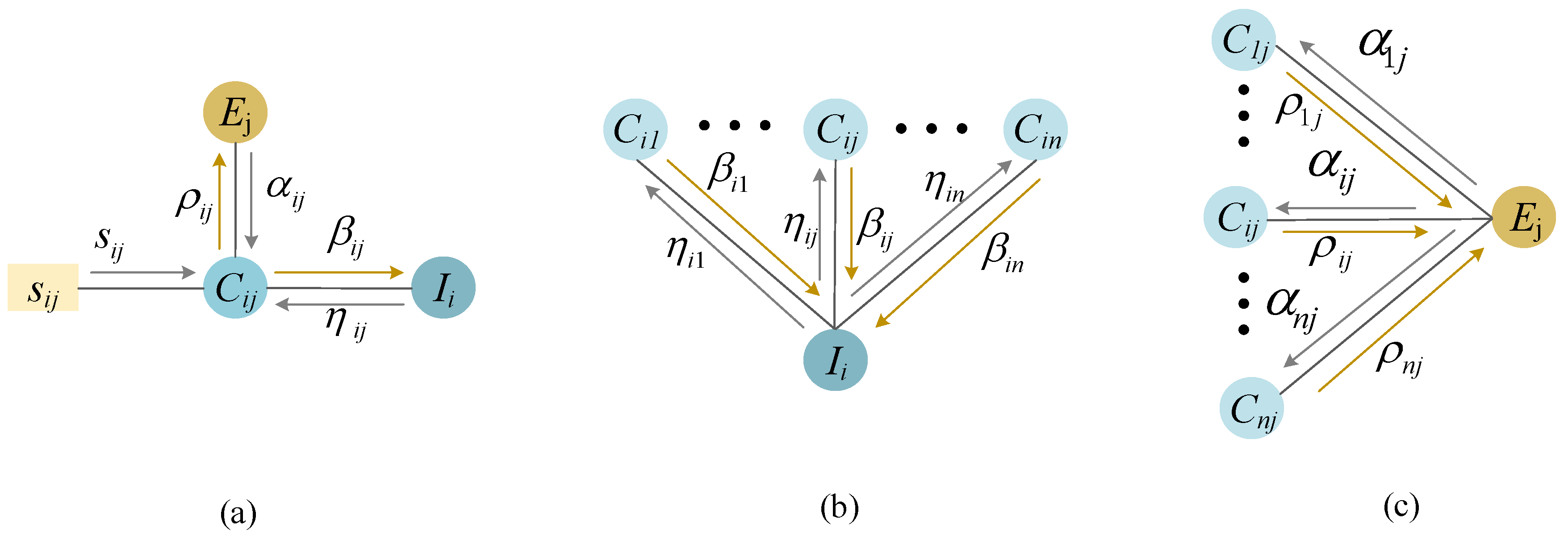
3.3. Electrical Appliances Pattern Recognition Process
- (1)
- The dataset was inputted with N points {xi, i = 1, 2, ..., N}, then divided into three periods of time.
- (2)
- During idle time, the monitored power data was close to 0. It was set to 0. In a stable time, the abrupt value is replaced by the mean value in this period.
- (3)
- The initial parameters were set as follows: the value of the reference degree p of the similarity matrix S was the opposite number of the maximum value of the dataset, the damping factor λ equaled 0.9, and the number of iterations was set to 200. The initial value of the attraction message matrix R and the ownership message matrix A was set to 0.
- (4)
- The values of the attraction message matrix R and the ownership message matrix A were calculated according to Equation (16).
- (5)
- The convergence of matrices A and R was determined. If they did not converge, we advanced to step (6); otherwise we advanced to step (7).
- (6)
- It was judged whether to reach the number of iterations. If so, we returned to step (3) and reset the initial parameters; if not, we went back to step (4).
- (7)
- The value of the diagonal of matrix A + R was determined to be higher than or less than 0. If it was greater, the point was a class-representative data point; if it was less, the point was a common data point.
- (8)
- The category of the measure was determined according to the similarity (Euclidean distance) between the common point and the class-representative point.
4. Analysis and Discussion
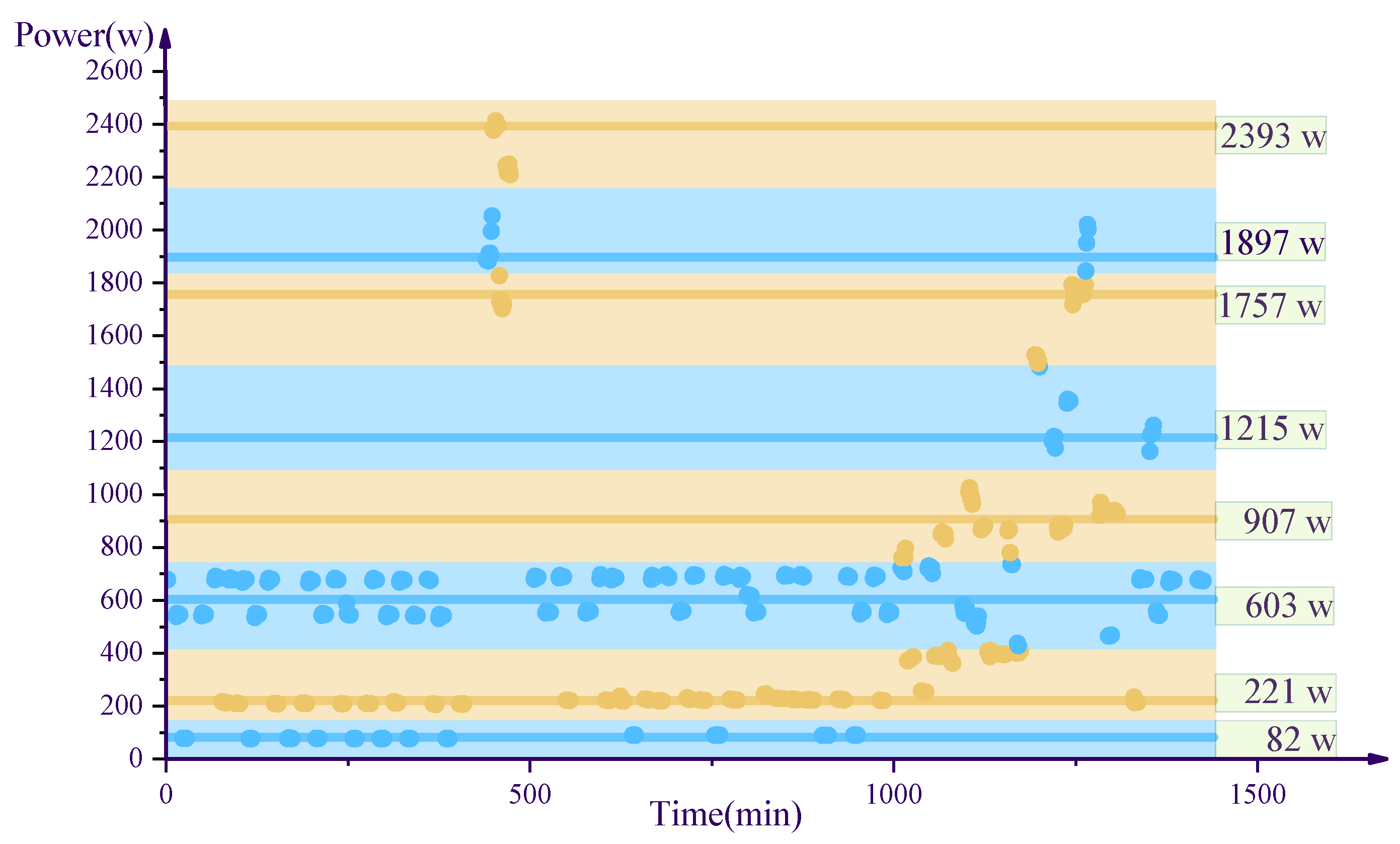
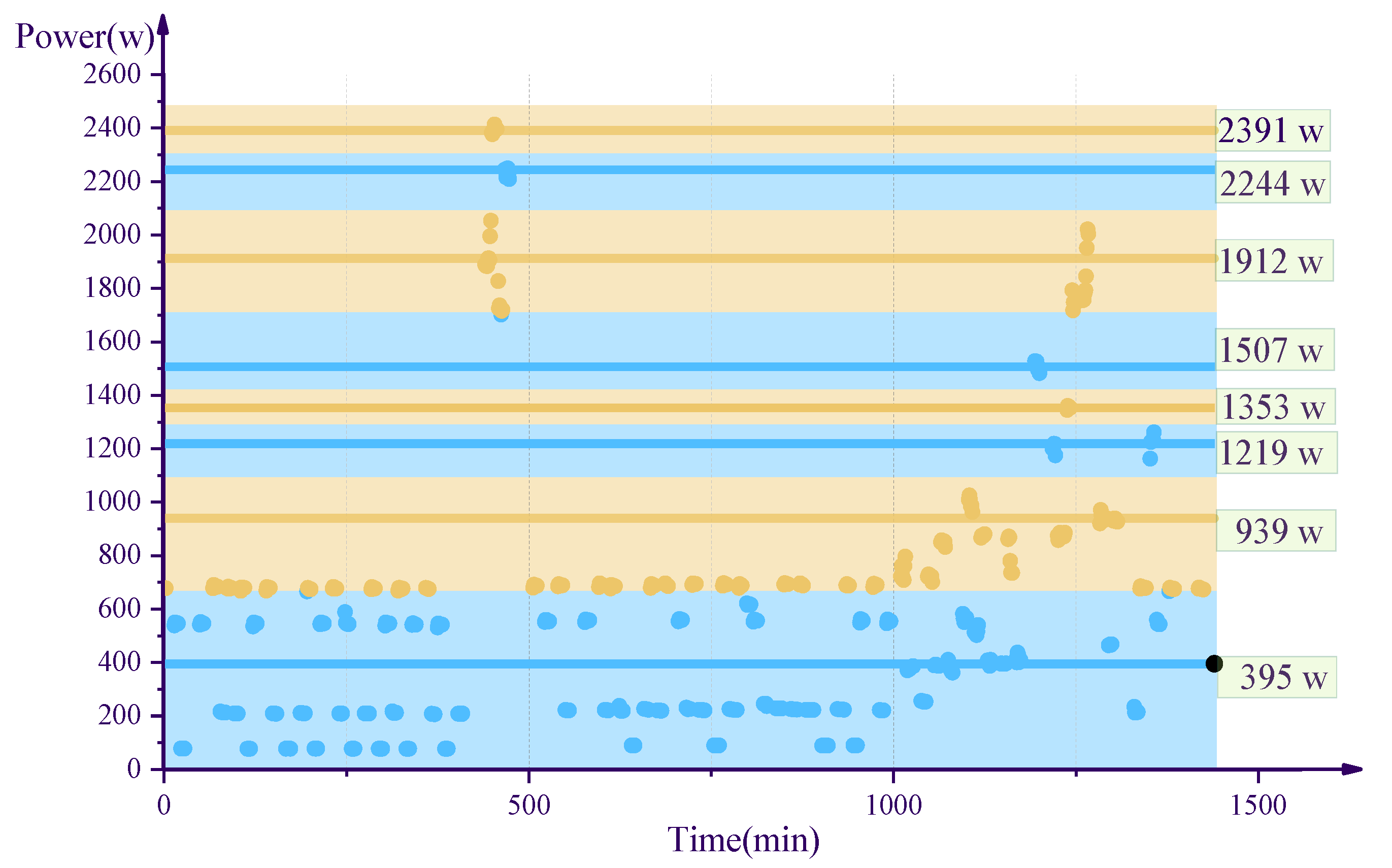
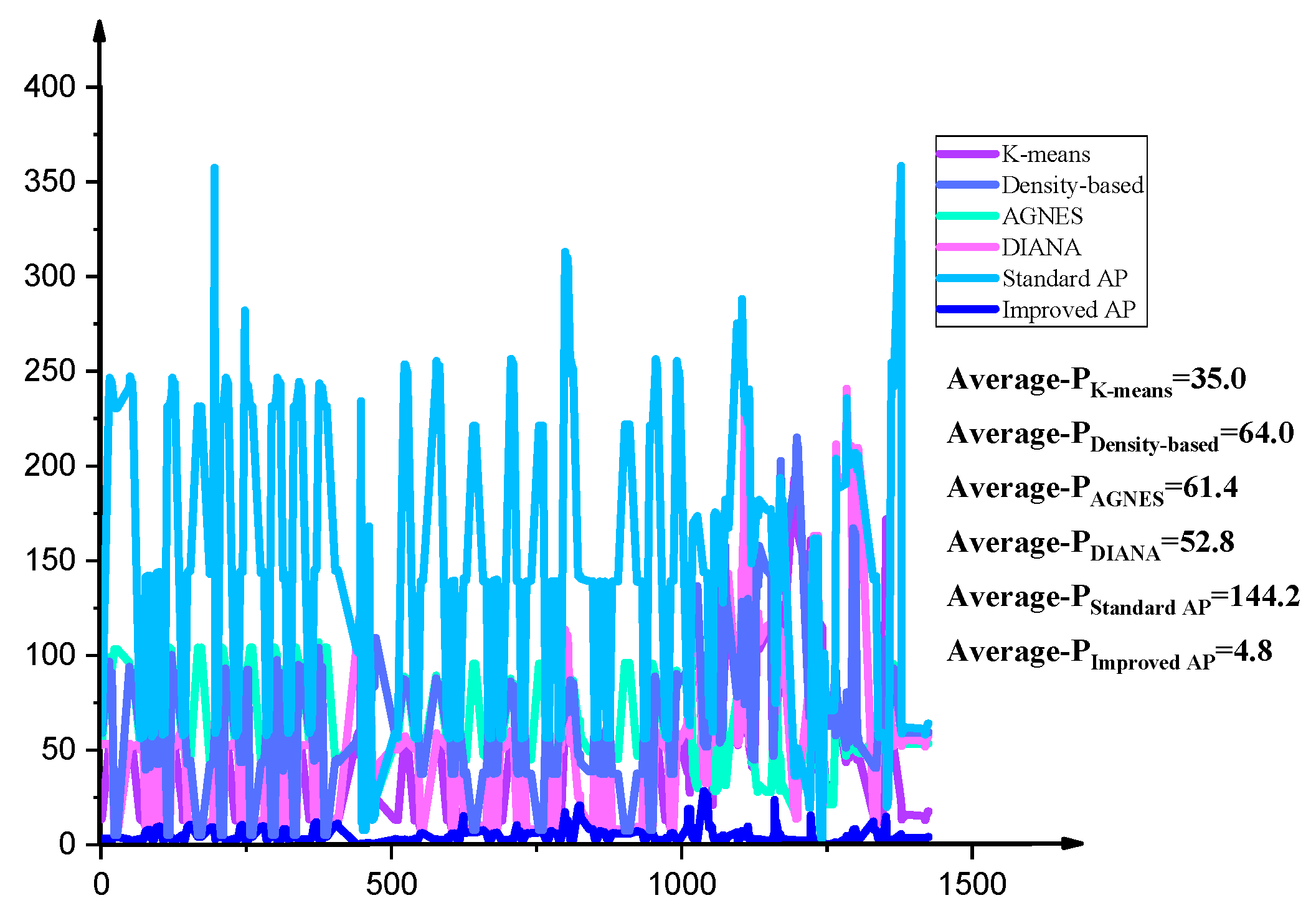
4.1. Comparison of Different Algorithms
4.2. Experimental Result
4.3. Power Load Decomposition
4.4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Wang, D.; Yuan, X.M.; Zhang, M.Q. Power-balancing based induction machine model for power system dynamic analysis in electromechanical timescale. Energies 2018, 11, 438. [Google Scholar] [CrossRef]
- Mahmood, D.; Javaid, N.; Alrajeh, N.; Khan, Z.A.; Qasim, U.; Ahmed, I.; Ilahi, M. Realistic scheduling mechanism for smart homes. Energies 2016, 9, 202. [Google Scholar] [CrossRef]
- Ahmed, I.S.; Asmaa, H.R.; Khalled, M.A. A data mining-based load forecasting strategy for smart electrical grids. Adv. Eng. Inform. 2016, 3, 422–448. [Google Scholar]
- Bonfigl, R.; Principi, E.; Fagiani, M.; Severini, M.; Squartini, S.; Piazza, F. Non-intrusive load monitoring by using active and reactive power in additive Factorial Hidden Markov Models. Appl. Energy 2017, 208, 1590–1607. [Google Scholar] [CrossRef]
- Suman, G.; Mario, B. An error correction framework for sequences resulting from known state-transition models in Non-Intrusive Load Monitoring. Adv. Eng. Inform. 2017, 32, 152–162. [Google Scholar]
- Bonfigli, R.; Felicetti, A.; Principi, E.; Fagiani, M.; Squartini, S.; Piazza, F. Denoising autoencoders for Non-intrusive load monitoring: Improvements and comparative evaluation. Energy Build. 2018, 158, 1461–1474. [Google Scholar] [CrossRef]
- Hart, G.W. Nonintrusive appliance load monitoring. Sr. Memb. 1992, 80, 1870–1879. [Google Scholar] [CrossRef]
- Chui, K.; Tsang, K.; Chung, S.H.; Yeung, L.F. Appliance signature identification solution using k-means clustering. In Proceedings of the 39th Annual Conference of the IEEE Industrial Electronics Society, Vienna, Austria, 10–13 November 2013; pp. 8420–8425. [Google Scholar]
- Kim, Y.; Kong, S.; Ko, R.; Joo, S.K. Electrical event identification technique for monitoring home appliance load using load signatures. In Proceedings of the IEEE International Conference on Consumer Electronics, Las Vegas, NV, USA, 10–13 January 2014; pp. 296–297. [Google Scholar]
- Li, M.C.; Han, S.; Shi, J. An enhanced ISODATA algorithm for recognizing multiple electric appliances from the aggregated power consumption dataset. Energy Build. 2017, 140, 305–316. [Google Scholar] [CrossRef]
- Srinivasan, D.; Ng, W.S.; Liew, A.C. Neural-network-based signature recognition for harmonic source identification. IEEE Trans. Power Deliv. 2006, 21, 398–405. [Google Scholar] [CrossRef]
- Frey, B.J.; Dueck, D. Clustering by passing messages between data points. Science 2007, 315, 972–976. [Google Scholar] [CrossRef]
- Givoni, I.E.; Frey, B.J. A binary variable model for affinity propagation. Neural Comput. 2009, 21, 1589–1600. [Google Scholar] [CrossRef]
- Kschischang, F.R.; Frey, B.J.; Loeliger, H.A. Factor graphs and the Sum-Product algorithm. IEEE Trans. Inf. Theory 2001, 47, 498–519. [Google Scholar] [CrossRef]
- Pearl, J. Probabilistic reasoning in intelligent systems: Networks of plausible inference. J. Philos. 1991, 88, 434–437. [Google Scholar]
- Wang, L.; Zhang, Y.; Zhong, S. Typical process discovery based on affinity propagation. J. Adv. Mech. Des. Syst. Manuf. 2016, 10, 1–13. [Google Scholar] [CrossRef]
- Dueck, D. Affinity Propagation: Clustering Data by Passing Messages; University of Toronto: Toronto, ON, Canada, 2009. [Google Scholar]
- Leone, M.; Sumedha; Weigt, M. Clustering by soft-constraint affinity propagation: Applications to gene-expression data. Bioinformatics 2007, 23, 1–11. [Google Scholar] [CrossRef]
- Leone, M.; Sumedha; Weigt, M. Unsupervised and semi-supervised clustering by message passing: Soft-constraint affinity propagation. Phys. Condens. Matter 2008, 66, 1–11. [Google Scholar]
- Givoni, I.; Frey, B.J. Semi-supervised affinity propagation with Instance-level constraints. In Proceedings of the 12th International Conference on Artificial Intelligence and Statistics, New York, NY, USA, 8–12 June 2009; pp. 161–168. [Google Scholar]
- Wang, C.D.; Lai, J.H.; Suen, C.Y.; Zhu, J.Y. Multi-Exemplar affinity propagation. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2223–2237. [Google Scholar] [CrossRef]
- Rostaminia, R.; Saniei, M.; Vakilian, M.; Mortazavi, S.S. An efficient partial discharge pattern recognition method using texture analysis for transformer defect models. Int. Trans. Electr. Energy Syst. 2018, 28, 1–14. [Google Scholar] [CrossRef]
- Faria, P.; Spinola, J.; Vale, Z. Reschedule of distributed energy resources by an aggregator for market participation. Energies 2018, 11, 713. [Google Scholar] [CrossRef]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X.W. A density-based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the 2nd International Conference on Knowledge Discovery and data Mining, Portland, OR, USA, 2–4 August 1996; pp. 226–231. [Google Scholar]
- Leuven, K.U.; Zvrich, E.T.H. Application of clustering for the development of retrofit strategies for large building stocks. Adv. Eng. Inform. 2017, 31, 32–47. [Google Scholar]
- Kolter, J.Z.; Batra, S.; Ng, A.Y. Energy disaggregation via discriminative sparse coding. Adv. Neural Inf. Process. Syst. 2010, 23, 1153–1161. [Google Scholar]
- Arberet, S.; Hutter, A. Non-intrusive load curve disaggregation using sparse decomposition with a translation-invariant boxcar dictionary. In Proceedings of the IEEE PES Innovative Smart Grid Technologies, Europe, Istanbul, Turkey, 12–15 October 2014; pp. 1–6. [Google Scholar]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| k-Means Algorithm (W) | Density-Based Algorithm (W) | AGNES (W) | DIANA(W) | Standard AP Algorithm (W) | Improved AP Algorithm (W) |
|---|---|---|---|---|---|
| 82 | 82 | 181 | 82 | 395 | 89 |
| 222 | 221 | 400 | 221 | 939 | 223 |
| 503 | 603 | 637 | 506 | 939 | 391 |
| 687 | 907 | 907 | 736 | 1219 | 551 |
| 907 | 1215 | 1258 | 1215 | 1353 | 688 |
| 1335 | 1757 | 1510 | 1353 | 1353 | 878 |
| 1760 | 1897 | 1754 | 1510 | 1507 | 1504 |
| 1942 | 2393 | 1927 | 1816 | 1912 | 1757 |
| 2233 | - | 2233 | 2233 | 2244 | 1951 |
| 2393 | - | 2393 | 2392 | 2391 | 2224 |
| Electric Appliances (Rated Power) | K-Means Algorithm | Density Based Algorithm | AGNES | DIANA | Standard AP Algorithm | Improved AP Algorithm |
|---|---|---|---|---|---|---|
| Plasma TV (220 W) | √ (0.9%) | √ (0.5%) | × (17.7%) | √ (0.5%) | / | √ (1.4%) |
| Frig (400 W) | / | / | √ (0.0%) | / | √ (1.3%) | √ (2.25%) |
| Furnace (550 W) | × (8.5%) | × (9.6%) | × (15.8%) | × (8.0%) | / | √ (0.2%) |
| Oven (900 W) | √ (0.8%) | √ (0.8%) | √ (0.8%) | × (18.2%) | √ (4.3%) | √ (2.4%) |
| Bath (1500 W) | × (11.0%) | × (19.0%) | √ (0.7%) | √ (0.7%) | √ (0.5%) | √ (0.3%) |
| Dryer-p1 (1800 W) | √ (2.2%) | √ (2.4%) | √ (2.6%) | √ (0.9%) | / | √ (2.3%) |
| Microwave (2000 W) | √ (2.9%) | × (5.2%) | √ (3.7%) | / | √ (4.4%) | √ (2.5%) |
| Dryer-p2 (2200 W) | √ (1.5%) | × (8.8%) | √ (1.5%) | √ (1.5%) | √ (2.0%) | √ (1.1%) |
| Class | Morning (W) | Afternoon (W) | Night (W) | Average (W) |
|---|---|---|---|---|
| C1 | 75 | 76 | 77 | 76 |
| C2 | 94 | - | - | 94 |
| C3 | 122 | 129 | 129 | 127 |
| C4 | 141 | 150 | - | 146 |
| C5 | 186 | - | - | 186 |
| C6 | 213 | 201 | 206 | 207 |
| C7 | - | 223 | 230 | 226 |
| C8 | 251 | 252 | 262 | 255 |
| C9 | 306 | 288 | 293 | 296 |
| C10 | - | 326 | - | 326 |
| C11 | 360 | 380 | 356 | 365 |
| C12 | 433 | 427 | 428 | 429 |
| C13 | 479 | 479 | - | 479 |
| C14 | 538 | 554 | 532 | 541 |
| C15 | 615 | 622 | 614 | 617 |
| C16 | 719 | 688 | 716 | 708 |
| C17 | - | 762 | 795 | 778 |
| C18 | 842 | - | - | 842 |
| C19 | - | 900 | 901 | 900 |
| C20 | 978 | 1008 | - | 993 |
| C21 | 1092 | 1160 | 1092 | 1115 |
| C22 | 1223 | - | 1233 | 1228 |
| C23 | - | 1343 | - | 1343 |
| C24 | 1482 | 1515 | 1435 | 1477 |
| C25 | - | 1693 | - | 1693 |
| C26 | 1858 | 1990 | - | 1924 |
| C27 | - | - | 2108 | 2108 |
| C28 | 2259 | - | - | 2259 |
| C29 | - | 2349 | - | 2349 |
| C30 | - | 2712 | - | 2712 |
| Class | Morning (W) | Afternoon (W) | Night (W) | Average (W) |
|---|---|---|---|---|
| B0 | - | - | 1 | 1 |
| B1 | 18 | 14 | 13 | 15 |
| B2 | 46 | - | 46 | |
| B3 → C1 | 75 | 71 | 67 | 71 |
| B4 → C4 | 145 | 141 | 135 | 140 |
| B5 → C10 | 322 | 327 | 324 | 324 |
| B6 → C13 | 462 | 459 | 467 | 463 |
| B7 → C15 | 594 | 601 | 594 | 596 |
| B8 → C18 | - | - | 810 | 810 |
| B9 → C20 | 1003 | 1012 | - | 1008 |
| B10 → C21 | - | - | 1118 | 1118 |
| B11 | - | 1567 | - | 1567 |
| B12 → C25 | - | 1668 | - | 1668 |
| B13 → C28 | - | 2234 | - | 2234 |
| Combination Class Ci | Combination or Basic Class Cm | Basic Class Cn | Error (W) e = |Ci − Cm − Cn| | Decomposition Results |
|---|---|---|---|---|
| C2 | C1 | B1 | e2 = |94 − 76 − 15| = 3 | C2 = C1 + B1 + e2 |
| C3 | C1 | B2 | e3 = |127 − 76 − 46| = 5 | C3 = C1 + B2 + e3 |
| C5 | C4 | B2 | e5 = |186 − 146 − 46| = 6 | C5 = C4 + B2 − e5 |
| C6 | C1 | C4 | e6 = |207 − 76 − 146| = 15 | C6 = C1 + C4 − e6 |
| C7 | C6 | B1 | e7 = |226 − 207 − 15| = 4 | C7 = C1 + C4 + B1 + e7 |
| C8 | C3 | C4 | e8 = |255 − 127 − 146| = 18 | C8 = C1 + B2 + C4 − e8 |
| C9 | C8 | B2 | e9 = |296 − 255 − 46| = 5 | C9 = C1 + B2 + C4 + B2 − e9 |
| C11 | C9 | C1 | e11 = |365 − 296 − 76| = 7 | C11 = C1 + B2 + C4 + B2 + C1 − e11 |
| C12 | C11 | C1 | e12 = |429 − 365 − 76| = 12 | C12 = C1 + B2 + C4 + B2 + C1 + C1 − e12 |
| C14 | C13 | C1 | e14 = |541 − 479 − 76| = 14 | C14 = C13 + C1 − e14 |
| C16 | C6 | C13 | e16 = |708 − 207 − 479| = 22 | C16 = C1 + C4 + C13 + e16 |
| C17 | C16 | C1 | e17 = |778 − 708 − 76| = 6 | C17 = C1 + C4 + C13 + C1 − e17 |
| C19 | C17 | C4 | e19 = |900 − 778 − 146| = 24 | C19 = C1 + C4 + C13 + C1 + C4 − e19 |
| C22 | C6 | C20 | e22 = |1228 − 207 − 993| = 28 | C22 = C1 + C4 + C20 + e22 |
| C23 | C21 | C4 | e23 = |1343 − 1115 − 146| = 82 | C23 = C21 + C4 + e23 |
| C24 | C23 | C4 | e24 = |1477 − 1343 − 146| = 12 | C24 = C21 + C4 + C4 − e24 |
| C26 | C19 | C20 | e26 = |1924 − 900 − 993| = 31 | C26 = C1 + C4 + C13 + C1 + C4 + C20 − e26 |
| C27 | C11 | C25 | e27 = |2108 − 365 − 1693| = 50 | C27 = C1 + B2 + C4 + B2 + C1 + C25 + e27 |
| C29 | C26 | C13 | e29 = |2349 − 1924 − 479| = 54 | C29 = C1 + C4 + C13 + C1 + C4 + C20 + C13 − e29 |
| C30 | C29 | C10 | e30 = |2712 − 2349 − 326| = 37 | C30 = C1 + C4 + C13 + C1 + C4 + C20 + C13 + C10 + e30 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Du, S.; Li, M.; Han, S.; Shi, J.; Li, H. Multi-Pattern Data Mining and Recognition of Primary Electric Appliances from Single Non-Intrusive Load Monitoring Data. Energies 2019, 12, 992. https://doi.org/10.3390/en12060992
Du S, Li M, Han S, Shi J, Li H. Multi-Pattern Data Mining and Recognition of Primary Electric Appliances from Single Non-Intrusive Load Monitoring Data. Energies. 2019; 12(6):992. https://doi.org/10.3390/en12060992
Chicago/Turabian StyleDu, Shengli, Mingchao Li, Shuai Han, Jonathan Shi, and Heng Li. 2019. "Multi-Pattern Data Mining and Recognition of Primary Electric Appliances from Single Non-Intrusive Load Monitoring Data" Energies 12, no. 6: 992. https://doi.org/10.3390/en12060992
APA StyleDu, S., Li, M., Han, S., Shi, J., & Li, H. (2019). Multi-Pattern Data Mining and Recognition of Primary Electric Appliances from Single Non-Intrusive Load Monitoring Data. Energies, 12(6), 992. https://doi.org/10.3390/en12060992