Enhancement of a Short-Term Forecasting Method Based on Clustering and kNN: Application to an Industrial Facility Powered by a Cogenerator



Abstract
:1. Introduction
2. Method
2.1. Forecast Method Introduction
- Model training: A dataset of observations is used to train the model. Observations define the average demand curves and train the classification model;
- Classification: Observations are used to classify which is the most similar average curve;
- Forecast: Average curve forecast is used to define forecast of the observations.
2.2. Introduction to Clustering
2.3. Introduction to kNN
2.4. Model Training
- Define dataset: Firstly, it is necessary to define and to normalize the dataset. Successively, it is randomly divided into three subgroups, namely, the validation, training, and test datasets. These subgroups represent 25%, 50% and 25% of the total observations, respectively. The validation dataset is used to define the hyperparameters of the model, whereas the training dataset is used to train both the cluster and kNN models. Finally, the test dataset is useful to verify the performance of the trained model.
- Define hyperparameters: As previously mentioned, the proposed model defines both the cluster and kNN models. Both methods require the definition at least the distance function and the number of clusters (cluster model), or the number of observations for classification (kNN model). The Euclidean distance function is proposed for the cluster model, meanwhile, the number of clusters and number of observations for classification are defined using the validation dataset.
- Train cluster model: When all the hyperparameters are set, the training dataset is used to train the cluster model and to define the average forecast curves.
- Train kNN model: When both the cluster model and the consequently average forecast curves are defined, kNN is defined. kNN is used to forecast the observations.
- Test model: The test dataset is used to test the trained model and to check its performance by using the mean absolute percentage error (MAPE) and root mean square error (RMSE) criteria.
2.5. Data Normalization
2.6. Error Estimation
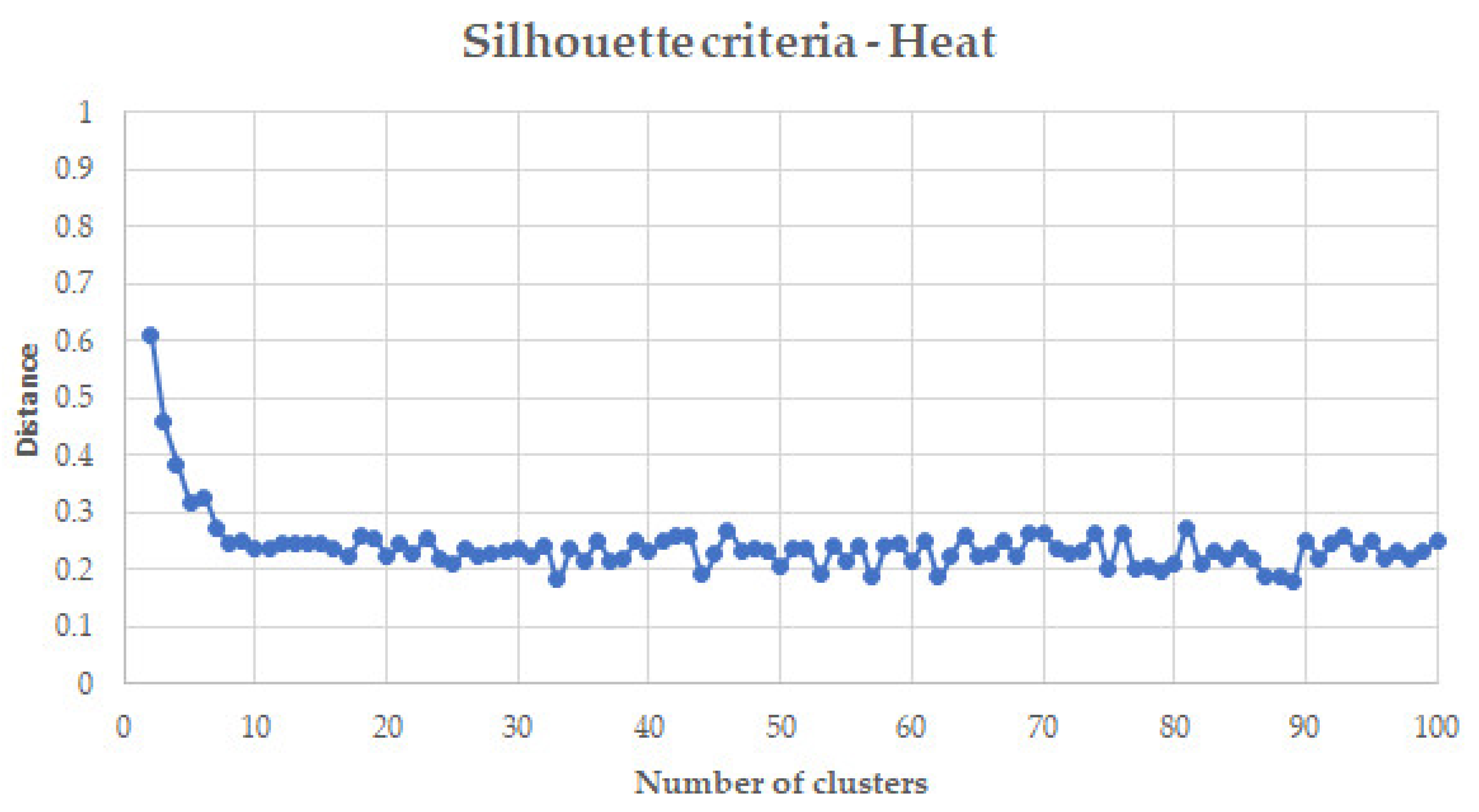
2.7. Hyperparameters Definition
3. Results
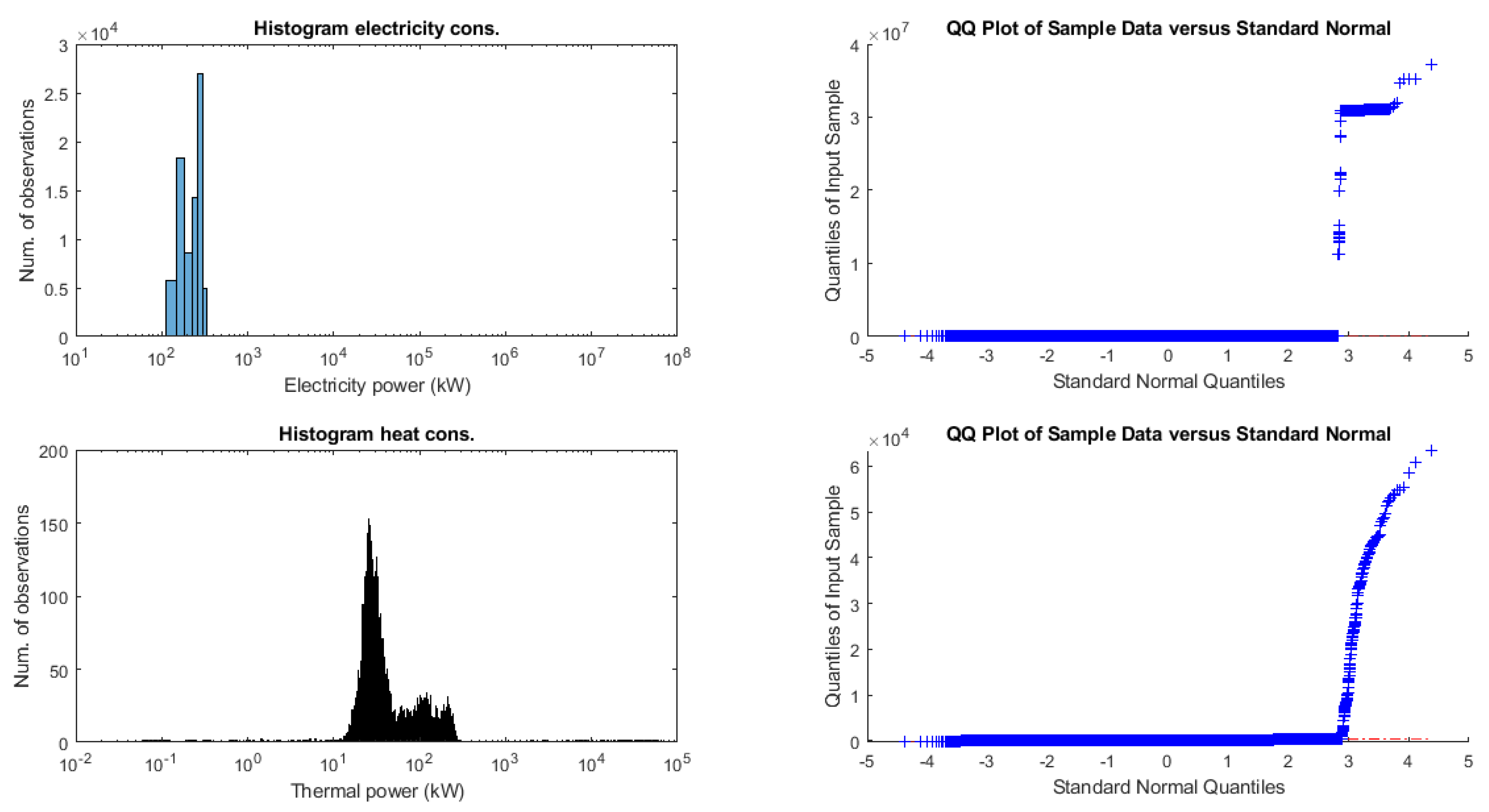
3.1. Case Study Description
3.2. Model Training and Test
4. Discussion
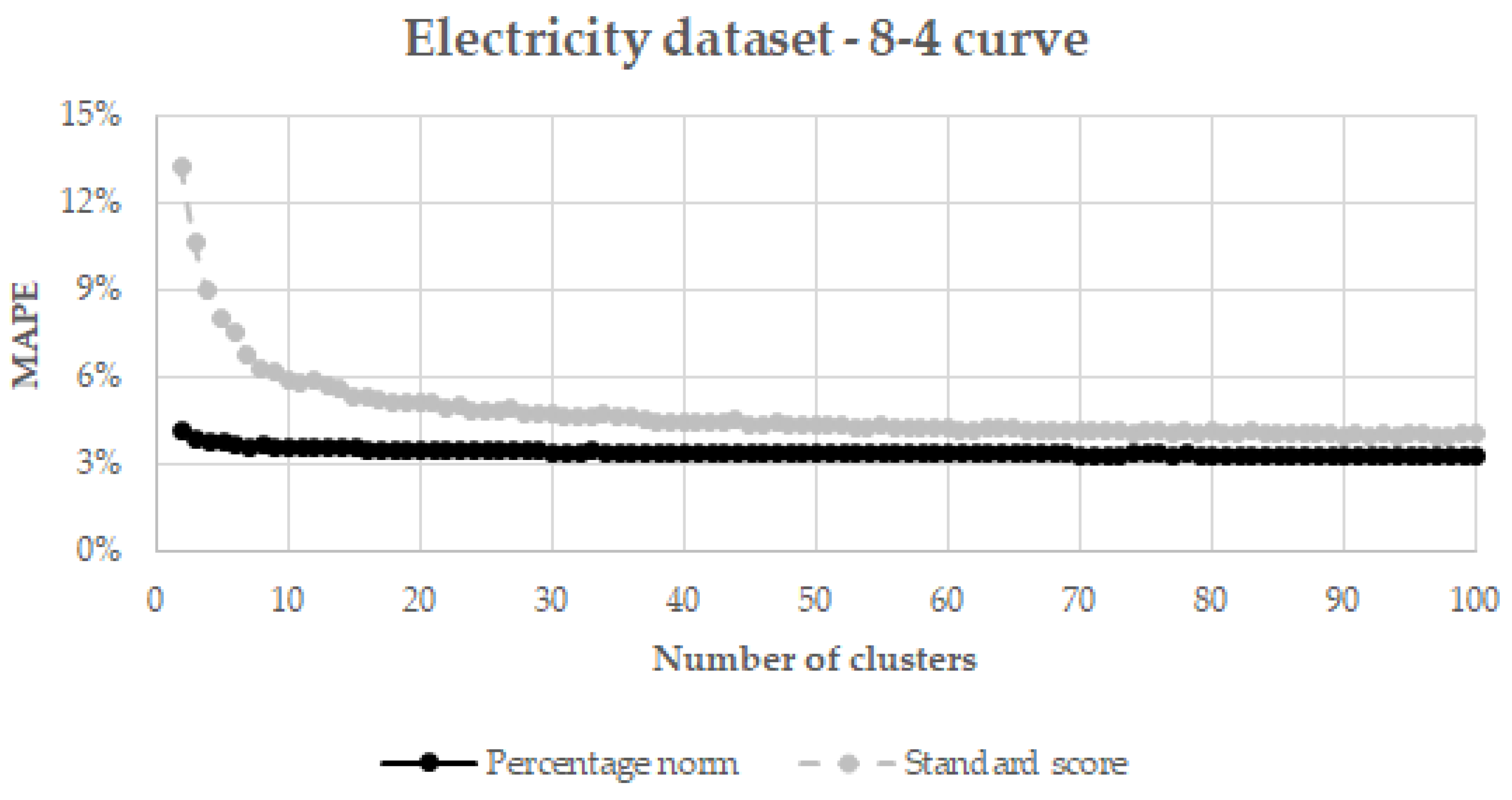
4.1. Influence of the Curve Size
4.2. Influence of the Normalization
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Noussan, M.; Nastasi, B. Data Analysis of Heating Systems for Buildings—A Tool for Energy Planning, Policies and Systems Simulation. Energies 2018, 11, 233. [Google Scholar] [CrossRef]
- Tronchin, L.; Manfren, M.; Nastasi, B. Energy analytics for supporting built environment decarbonisation. Energy Procedia 2019, 157, 1486–1493. [Google Scholar] [CrossRef]
- Fowdur, T.P.; Beeharry, Y.; Hurbungs, V.; Bassoo, V.; Ramnarain-Seetohul, V. Big Data Analytics with Machine Learning Tools. In Internet of Things and Big Data Analytics toward Next-Generation Intelligence; Springer: Berlin, Germany, 2018; pp. 49–97. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning; Springer: New York, NY, USA, 2009. [Google Scholar]
- Biswas, M.A.R.; Robinson, M.D.; Fumo, N. Prediction of residential building energy consumption: A neural network approach. Energy 2016, 117, 84–92. [Google Scholar] [CrossRef]
- Koschwitz, D.; Frisch, J.; van Treeck, C. Data-driven heating and cooling load predictions for non-residential buildings based on support vector machine regression and NARX Recurrent Neural Network: A comparative study on district scale. Energy 2018, 165, 134–142. [Google Scholar] [CrossRef]
- Cheng, K.; Guo, L.M.; Wang, Y.K.; Zafar, M.T. Application of clustering analysis in the prediction of photovoltaic power generation based on neural network. IOP Conf. Ser. Earth Environ. Sci. 2017, 93, 012024. [Google Scholar] [CrossRef]
- Yang, D.; Dong, Z.; Lim, L.H.I.; Liu, L. Analyzing big time series data in solar engineering using features and PCA. Sol. Energy 2017, 153, 317–328. [Google Scholar] [CrossRef]
- Malvoni, M.; De Giorgi, M.G.; Congedo, P.M. Photovoltaic forecast based on hybrid PCA–LSSVM using dimensionality reducted data. Neurocomputing 2016, 211, 72–83. [Google Scholar] [CrossRef]
- Malvoni, M.; De Giorgi, M.G.; Congedo, P.M. Data on Support Vector Machines (SVM) model to forecast photovoltaic power. Data Br. 2019, 9, 13–16. [Google Scholar] [CrossRef]
- Qijun, S.; Fen, L.; Jialin, Q.; Jinbin, Z.; Zhenghong, C. Photovoltaic power prediction based on principal component analysis and Support Vector Machine. In Proceedings of the 2016 IEEE Innovative Smart Grid Technologies-Asia (ISGT-Asia), Melbourne, VIC, Australia, 28 November–1 December 2016; pp. 815–820. [Google Scholar]
- Korkovelos, A.; Khavari, B.; Sahlberg, A.; Howells, M.; Arderne, C. The Role of Open Access Data in Geospatial Electrification Planning and the Achievement of SDG7. An OnSSET-Based Case Study for Malawi. Energies 2019, 12, 1395. [Google Scholar] [CrossRef]
- de Kok, R.; Mauri, A.; Bozzon, A. Automatic Processing of User-Generated Content for the Description of Energy-Consuming Activities at Individual and Group Level. Energies 2018, 12, 15. [Google Scholar] [CrossRef]
- Attanasio, A.; Piscitelli, M.; Chiusano, S.; Capozzoli, A.; Cerquitelli, T. Towards an Automated, Fast and Interpretable Estimation Model of Heating Energy Demand: A Data-Driven Approach Exploiting Building Energy Certificates. Energies 2019, 12, 1273. [Google Scholar] [CrossRef]
- Ganhadeiro, F.; Christo, E.; Meza, L.; Costa, K.; Souza, D. Evaluation of Energy Distribution Using Network Data Envelopment Analysis and Kohonen Self Organizing Maps. Energies 2018, 11, 2677. [Google Scholar] [CrossRef]
- MATLAB. Deep Learning Toolbox. Available online: https://www.mathworks.com/products/deep-learning.html (accessed on 14 July 2019).
- Paluszek, M.; Thomas, S. MATLAB Machine Learning; Apress: Berkeley, CA, USA, 2017. [Google Scholar]
- Kim, P. MATLAB Deep Learning; Apress: Berkeley, CA, USA, 2017. [Google Scholar]
- Ghatak, A. Machine Learning with R; Springer: Singapore, 2017. [Google Scholar]
- Ramasubramanian, K.; Singh, A. Machine Learning Using R; Apress: Berkeley, CA, USA, 2019. [Google Scholar]
- Amri, Y.; Fadhilah, A.L.; Setiani, N.; Rani, S. Analysis Clustering of Electricity Usage Profile Using K-Means Algorithm. IOP Conf. Ser. Mater. Sci. Eng. 2016, 105, 012020. [Google Scholar] [CrossRef]
- Müller, H. Classification of daily load curves by cluster analysis. In Proceedings of the Eighth Power Systems Computation Conference, Helsinki, Finland, 19–24 August 1984; pp. 381–388. [Google Scholar]
- Wahid, F.; Kim, D. A Prediction Approach for Demand Analysis of Energy Consumption Using K-Nearest Neighbor in Residential Buildings. Int. J. Smart Home 2016, 10, 97–108. [Google Scholar] [CrossRef]
- Wu, J.; Kong, D.; Li, W. A Novel Hybrid Model Based on Extreme Learning Machine, k-Nearest Neighbor Regression and Wavelet Denoising Applied to Short-Term Electric Load Forecasting. Energies 2017, 10, 694. [Google Scholar]
- Martinez Alvarez, F.; Troncoso, A.; Riquelme, J.C.; Aguilar Ruiz, J.S. Energy Time Series Forecasting Based on Pattern Sequence Similarity. IEEE Trans. Knowl. Data Eng. 2011, 23, 1230–1243. [Google Scholar] [CrossRef]
- Talavera-Llames, R.; Pérez-Chacón, R.; Troncoso, A.; Martínez-Álvarez, F. Big data time series forecasting based on nearest neighbours distributed computing with Spark. Knowl. Based Syst. 2018, 161, 12–25. [Google Scholar] [CrossRef]
- Talavera-Llames, R.; Pérez-Chacón, R.; Troncoso, A.; Martínez-Álvarez, F. MV-kWNN: A novel multivariate and multi-output weighted nearest neighbours algorithm for big data time series forecasting. Neurocomputing 2019, 353, 56–73. [Google Scholar] [CrossRef]
- Vialetto, G.; Rokni, M. Innovative household systems based on solid oxide fuel cells for a northern European climate. Renew. Energy 2015, 78, 146–156. [Google Scholar] [CrossRef]
- Vialetto, G.; Noro, M.; Rokni, M. Innovative household systems based on solid oxide fuel cells for the Mediterranean climate. Int. J. Hydrog. Energy 2015, 40, 14378–14391. [Google Scholar] [CrossRef]
- Vialetto, G.; Noro, M.; Rokni, M. Thermodynamic investigation of a shared cogeneration system with electrical cars for northern Europe climate. J. Sustain. Dev. Energy Water Environ. Syst. 2017, 5, 590–607. [Google Scholar] [CrossRef]
- Vialetto, G.; Noro, M.; Rokni, M. Combined micro-cogeneration and electric vehicle system for household application: An energy and economic analysis in a Northern European climate. Int. J. Hydrogen Energy 2017, 42, 10285–10297. [Google Scholar] [CrossRef]
- Vialetto, G.; Noro, M.; Colbertaldo, P.; Rokni, M. Enhancement of energy generation efficiency in industrial facilities by SOFC—SOEC systems with additional hydrogen production. Int. J. Hydrogen Energy 2019, 44, 9608–9620. [Google Scholar] [CrossRef]
- Lazzarin, R.M.; Noro, M. Energy efficiency opportunities in the production process of cast iron foundries: An experience in Italy. Appl. Therm. Eng. 2015, 90, 509–520. [Google Scholar] [CrossRef]
- Noro, M.; Lazzarin, R.M. Energy audit experiences in foundries. Int. J. Energy Environ. Eng. 2016, 7, 409–423. [Google Scholar] [CrossRef]
- MATLAB. K-Mean Function-MATLAB. Available online: https://it.mathworks.com/help/stats/kmeans.html (accessed on 19 January 2019).
- Rousseeuw, P.J. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. J. Comput. Appl. Math. 1987, 20, 53–65. [Google Scholar] [CrossRef]
- Tibshirani, R.; Walther, G.; Hastie, T. Estimating the number of clusters in a data set via the gap statistic. J. R. Stat. Soc. 2011, 63, 411–423. [Google Scholar] [CrossRef]
- Lantz, B. Machine Learning with R; Packt Publishing: Birmingham, UK, 2013. [Google Scholar]
- MATLAB. FitchkNN Function-MATLAB. Available online: https://it.mathworks.com/help/stats/fitcknn.html (accessed on 23 June 2019).















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Support | Forecast | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| i = 1 | i = 2 | … | i = s = 8 | j = 1 | … | j = f = 4 | |||||
| 10 | 11 | 10 | 13 | 12 | 14 | 16 | 12 | 11 | 12 | 18 | 13 |
| Curve | Type of Energy | Validation Dataset | Test Dataset | |||
|---|---|---|---|---|---|---|
| Mean Absolute Percentage Error (MAPE) | MAPE1 | MAPE | RMSE1 | Root Mean Square Error (RMSE) | ||
| 8-4 | Electricity | 3.60% | 2.75% | 3.58% | 5.15 kW | 3.82 kW |
| 8-4 | Heat power | 35.41% | 32.95% | 34.11% | 93.43 kW | 55.43 kW |
| 10-4 | Electricity | 3.71% | 2.74% | 3.57% | 5.15 kW | 3.82 kW |
| 10-4 | Heat power | 35.23% | 32.70% | 34.95% | 93.20 kW | 54.82 kW |
| 10-8 | Electricity | 4.79% | 2.90% | 4.47% | 5.47 kW | 3.53 kW |
| 10-8 | Heat power | 36.66% | 35.30% | 34.12% | 90.03 kW | 41.99 kW |
| 12-8 | Electricity | 4.69% | 2.80% | 4.47% | 5.31 kW | 3.53 kW |
| 12-8 | Heat power | 39.00 % | 32.10% | 37.21% | 95.14 kW | 43.05 kW |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vialetto, G.; Noro, M. Enhancement of a Short-Term Forecasting Method Based on Clustering and kNN: Application to an Industrial Facility Powered by a Cogenerator. Energies 2019, 12, 4407. https://doi.org/10.3390/en12234407
Vialetto G, Noro M. Enhancement of a Short-Term Forecasting Method Based on Clustering and kNN: Application to an Industrial Facility Powered by a Cogenerator. Energies. 2019; 12(23):4407. https://doi.org/10.3390/en12234407
Chicago/Turabian StyleVialetto, Giulio, and Marco Noro. 2019. "Enhancement of a Short-Term Forecasting Method Based on Clustering and kNN: Application to an Industrial Facility Powered by a Cogenerator" Energies 12, no. 23: 4407. https://doi.org/10.3390/en12234407
APA StyleVialetto, G., & Noro, M. (2019). Enhancement of a Short-Term Forecasting Method Based on Clustering and kNN: Application to an Industrial Facility Powered by a Cogenerator. Energies, 12(23), 4407. https://doi.org/10.3390/en12234407