1. Introduction
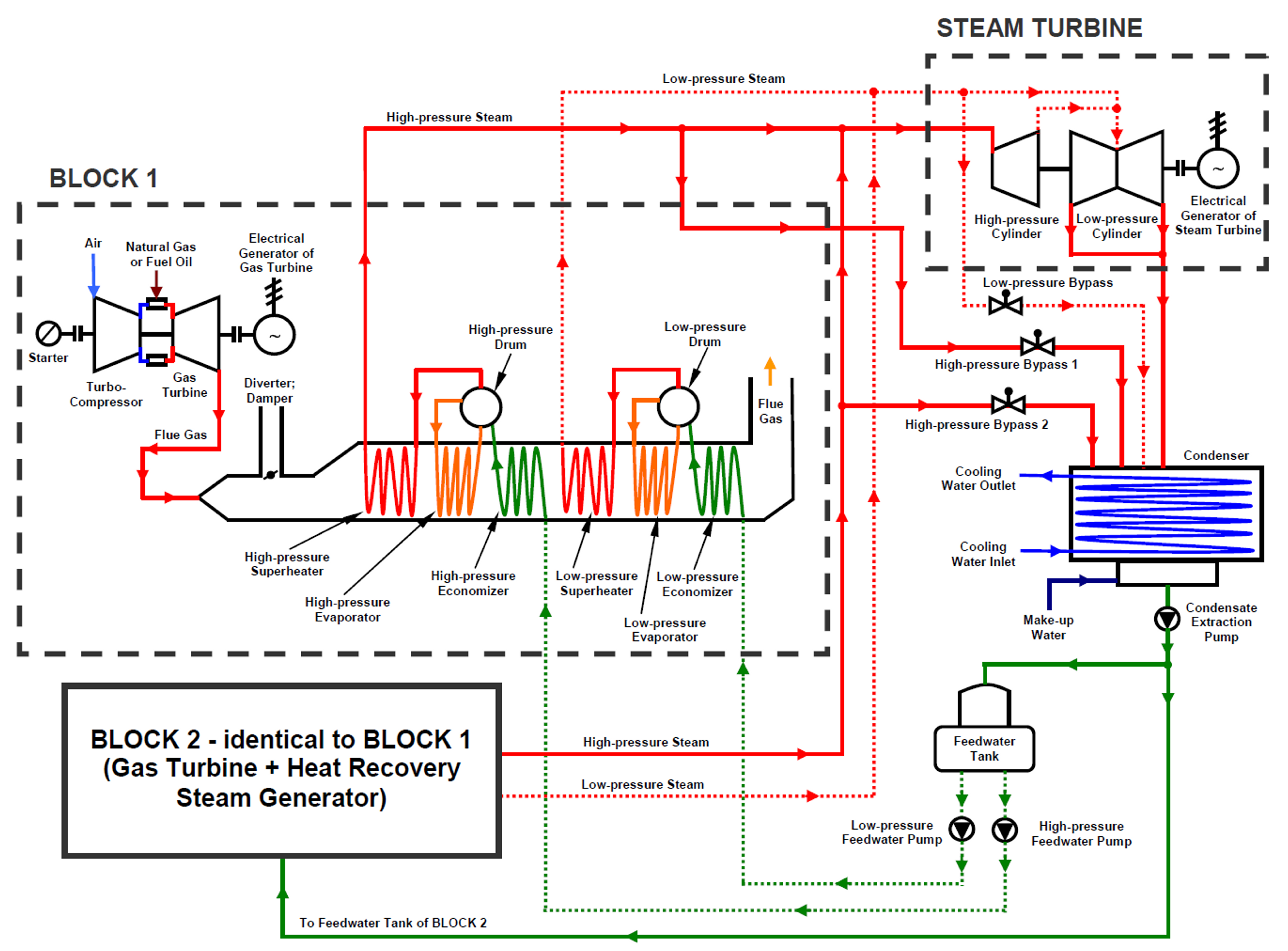
A Combined Cycle Power Plant (CCPP) is a power system composed of at least one gas turbine cycle, at least one steam turbine cycle and connection between these cycles – Heat Recovery Steam Generator (HRSG) [
1]. Today, engineers and researchers intensively investigate operation and made improvements of such power plants (for CCPPs which are currently in operation), while a new CCPPs are built in many countries worldwide. When CCPPs are compared with other power plants, it can be noticed that the CCPPs are achieving significantly higher efficiencies (usually higher than
) [
2], with lower specific emmisions [
3], and quick start capability (gas turbine cycle) while requiering lower operation and maintenance cost [
4]. Due to high complexity of CCPPs, in its investigation and analysis during operation, it is common to use various dynamic numerical simulations for predicting the changes in measured, as well as for calculating non-measured, operating parameters [
5].
A literature review offers many analyses of current operating CCPPs. Exergo-economic and environmental analyses of solar integrated CCPP which operates in Poland is presented in [
6]. Integration of the solar system into CCPP operation only slightly increases power plant capital cost, but at the same time significantly decreases CO
emission and therefore CO
penalties. The investment return rate is only marginally affected after inclusion of the solar system into CCPP operation. In [
7] another exergo-economic analysis of CCPP and investigated three possible scenarios for power plant operation is performed. It is concluded that the optimum size and configuration of the CCPP differ for each observed scenario. Third exergo-economic analysis can be found in [
8] where two different CCPP configurations from the same manufacturer were analyzed. Analysis enables selection of better configuration and after selection, the authors performed its optimization and present possibilities of further improvements.
In energy and exergy analyses of CCPPs and its components, several researchers obtained the same conclusions about elements which have the highest losses from both (energy and exergy) aspect. The highest energy losses in CCPP of any kind can be found in steam condenser [
9,
10], while the highest exergy losses occur in gas turbine combustion chambers [
9,
10,
11]. These conclusions are confirmed by several researchers and for CCPPs of different size, power output and configuration, so it can be concluded that they are valid in general.
Exergy analysis of any power plant or of any control volume which operate in a power plant is dependable on the ambient pressure and temperature (unlike energy analysis for which the parameters of the ambient are irrelevant) [
12,
13]. The change in the ambient pressure is usually small and it does not have a major influence on the exergy analysis of power plant or control volume [
14], but the change in the ambient temperature can have a major influence on the exergy efficiency and exergy losses of any power plant or control volume. In [
15] the ambient temperature change influence on the selected CCPP overall exergy efficiency is investigated. The authors concluded that an increase in the ambient temperature reduces overall CCPP exergy efficiency (increase in the ambient temperature from 8
C to 23
C reduces overall exergy efficiency of the analyzed CCPP from
to
).
Techniques and recommendations for improving of CCPPs or for improving some components from such power plants can be found in several researches. In [
16] an analysis of the modern CCPP in which gas turbine uses steam cooling is presented. Proposed cooling technique increases CCPP overall efficiency, while simultaneously, such technique reduces plant flexibility and increases power plant start-up time. In [
17] various gas turbine improvements in a modern CCPP are analyzed and is concluded that industry - known solutions such as sequential combustion can significantly increase overall plant efficiency.
The authors in [
18,
19] investigate the benefits of steam injection into the combustion chambers of gas turbine which is a constituent component of CCPP. The main conclusions are that such improvement increases power output of CCPP, decreases plant NO
emission (due to decreasing of the maximum combustion temperature) and provide acceptable economic performance.
In [
20] a new operating strategy for improving part-load performance of analyzed CCPP is presented. Proposed strategy resulted with an increase in CCPP overall efficiency up to
at partial loads. The possibility of a wind farm integration into an offshore CCPP is investigated in [
21]. The authors found many difficulties in such integration because many, possibly conflicting requirements have to be satisfied simultaneously.
Analysis of the water amount reduction in CCPP cooling systems was performed in [
22]. Three different cooling systems were analyzed—wet, dry, and hybrid (the wet system uses water, and the dry system uses air circulated by a fan, while the hybrid system is an alternative which combines wet and dry techniques). The hybrid cooling system has the highest investment costs, but it also provides many benefits in comparison to other observed cooling systems.
In recent research papers, it can be noticed that the authors prefer two improvements of CCPPs which today bring the largest benefits into such power plants operation. The first is integration of solar systems and the second is integration of CO
post-combustion capture systems into CCPP operation. A computational analysis of small solar field integration in CCPP operation is presented in [
23]. When compared to base CCPP, small solar field integration increases plant overall efficiency for about
in the morning and afternoon periods and for about
in the midday periods. Another mathematical model of a typical solar integrated CCPP is developed in [
24] and applied on Al - Abdaliya’s solar integrated CCPP in Kuwait. Mathematical model results show that the observed solar integrated CCPP can reach an overall efficiency of more than
.
A post-combustion CO
capture system which use activated carbon and its comparison with commercial systems applied in CCPPs operation is investigated in [
25]. After performing comparisons, it was concluded that a system which uses activated carbon can be a good alternative for CO
capture and such a system can be more efficient and cost beneficial in comparison with other commercial systems. Another alternative to commercial systems for CO
capture in CCPPs, named the Moving Bed Temperature Swing Adsorption (MBTSA) system, was presented and analyzed in [
26]. As well as for activated carbon system, for MBTSA system is also concluded to represent a newer, more proper alternative for CO
capture in CCPPs, and it brings several advantages in comparison with other CO
capture systems.
Post-combustion CO
capture system along with methanation system and its implementation into CCPP operation in India was analyzed in [
27]. Captured CO
in this combination is used in methanation system to produce methane – produced methane is used as a fuel in a gas turbine. In comparison with base CCPP, implementation of these two systems resulted with a significant increase in plant power output.
Unlike other research papers which investigated CCPPs and its components, in [
28] a comparison analysis of different machine learning (ML) techniques for prediction of CCPP full load electrical power output is presented. This article, as well as the resulting dataset, was used as a starting point for research performed in this paper. The dataset presented in [
28] was published online as part of the UCI Machine Learning Repository. Overview of the methods presented in aforementioned article and achieved
is given in
Table 1.
When presented results are compared, it can be observed that Artificial Neural Networks (ANNs) have significantly higher compared to other methods, even when compared to simple regression functions. This feature is also noticeable when using an MLP.
In the energy sector, Artificial Neural Networks (ANNs) are widely applied for resolving many problems and for optimization purposes. In [
29] ANN-based reinforcement learning algorithm is used to manage the optimal energy routing path in energy internet (EI) concept. In order to effectively analyze the quality of power signals, research [
30] proposes a method of signal feature capture and fault identification based on the ANN combined with discrete wavelet transform and Parseval’s theorem. ANN for air-temperature predictions in smart buildings was developed in [
31] in order to obtain better energy control. Short term forecasting prediction of the photovoltaic plant power output by using ANNs can be found in [
32,
33]. Analysis of heating expenses in a large social housing stock using artificial neural networks is presented in [
34]. Energy supply solution for sensor nodes in buildings based on ANNs was investigated and analyzed in [
35]. ANNs can be also used for fast and precise detection of garbage patches, oil spills or pollutions of any kind inside each energy plant or in the entire geographical area with several energy plants by using aerial imagery [
36].
It is shown that ANNs are, in general, performing better in comparison with other regression methods [
37] and it can be considered as a more flexible method [
38] that is acceptable from time standpoint. MLP can be considered as the most used type of ANN [
39] due to high performance from the standpoint of regression [
40,
41] and classification [
42,
43]. Because of these reasons, the aim of this research is to find a suitable solution to MLP model selection problem, that is applicable to prediction of CCPP electrical power output. Furthermore, the aim of this research is to find MLP model that performs with lower
, in comparison to ANNs presented in [
28].
There are many approaches to solving ANN model selection problem such as: grid search [
44,
45], Bayesian model selection [
46], etc. Another method for solving MLP model selection problem is a heuristic approach [
47,
48,
49]. This approach offers high performances in regard of regression [
50,
51] and classification [
52] problems. For these reasons a utilization possibility of heuristic algorithms in design of MLP for CCPP electrical power output estimation is investigated.
During analysis and optimization of energy systems, various heuristic algorithms can be used. However, the guidelines which will lead researchers to selection of optimal optimization algorithms for investigated (or similar) problem cannot be found in the literature. Therefore, the best selection procedure is to use an optimization algorithm which is used by other researchers during investigation of similar problems, or during analysis of similar systems. In this paper, the authors selected Genetic Algorithm (GA) for optimization of MLP neural network architecture for Combined Cycle Power Plant (CCPP) electrical power output estimation. Similar research of energy management optimization at building and district levels is performed in [
53] where the authors used ANN and GA. However, the authors in [
53] used GA for optimization of ANN predictions, not for optimization of ANN architecture. Literature review offers many examples of using GA in analysis and optimization of various elements from many energy systems or its parts. In [
54] as well as in [
55] GA is utilized for optimization of energy systems which uses solar energy sources. Optimal energy management of a stand-alone hybrid energy system by using GA strategies is presented in [
56], while energy quality management for a micro-energy network integrated with renewables in a tourist area was analyzed in [
57] where the authors used GA optimization in order to obtain optimal energy distribution. Reducing of water pumps electricity usage and pollution emissions by using sorting GA can be found in [
58]. From presented literature, it can be concluded that the various researchers often used GA in investigation, analysis and optimization of energy systems.
In the analysis and optimization of energy systems or its parts besides GA, other optimization algorithms can be utilized. Gravitational Search Algorithm (GSA) is one of such optimization algorithms used in optimization of pumped storage hydro unit [
59], in the forecasting of coal demand [
60] or in forecasting of monthly electricity demands [
48] as well as in other energy and engineering problems [
61]. Particle Swarm Optimization (PSO) algorithm is used so far for developing of power loss reduction method in power industry sector [
62], in optimization of power supply system [
63] as well as in the analysis and optimization of smart power grids [
64]. Ant Colony Optimization (ACO) can be used in optimization of biodiesel production [
65], in AC/DC distribution network planning problem [
66], etc. Cuckoo Search Algorithm (CSA) usage is found in the analysis and optimization of magnetic levitation system [
67], in route optimization of heating engineering [
68] as well as in research and application of hybrid wind-energy forecasting models [
69]. Hybrid Genetic Algorithm (HGA) is improved version of classic GA, which also can be used in resolving many problems of energy systems. For example, HGA can be used in developing of control schemes for small power systems with high-penetration wind farms [
70] or in the thermal fatigue failure prediction of microelectronic chips [
71]. In addition to the aforementioned research papers, in the literature, several other optimization algorithms used in energy and other practical applications can be found [
72,
73].
The direct performance comparison of several optimization algorithms can be found in a few research papers. In [
74] were compared performances of several optimization algorithms (PSO, ACO, CSA, GA and HGA) while performing optimization of real-time task scheduling in multiprocessor systems. For this problem the authors concluded that the best performance shows HGA, following by GA and other algorithms. In [
75] the authors compared four algorithms (Simulated Annealing, GA, HGA and Variable Search Environment Descending) while solving problem of electric power grids distribution for optimal location and sizing. It is concluded that HGA (followed by GA) provides solutions of the best quality, with a note that HGA uses significantly higher computational time in comparison with other methods. Therefore, for solving the same problem, it is impossible to conclude which algorithm is absolutely dominant. A performance comparison of several optimization algorithms while solving residential load scheduling problem is presented in [
76]. This research also confirmed that GA in comparison to all other algorithms have advantages and disadvantages, but that it always give satisfying results along with using a reasonable amount of computational resources.
Presented literature review shows that GA can be used for optimization of many elements and problems in various energy systems, therefore it is also chosen for the research performed in this paper as a reliable and fast optimization solution for which can be expected to give satisfactorily accurate and precise results.
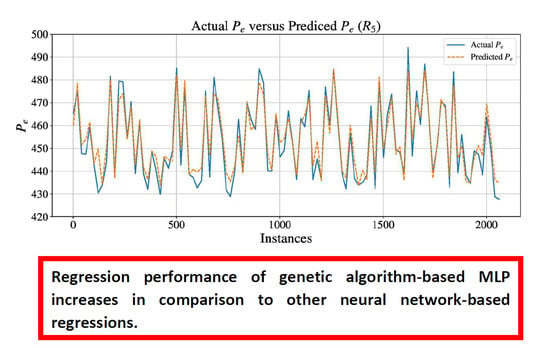
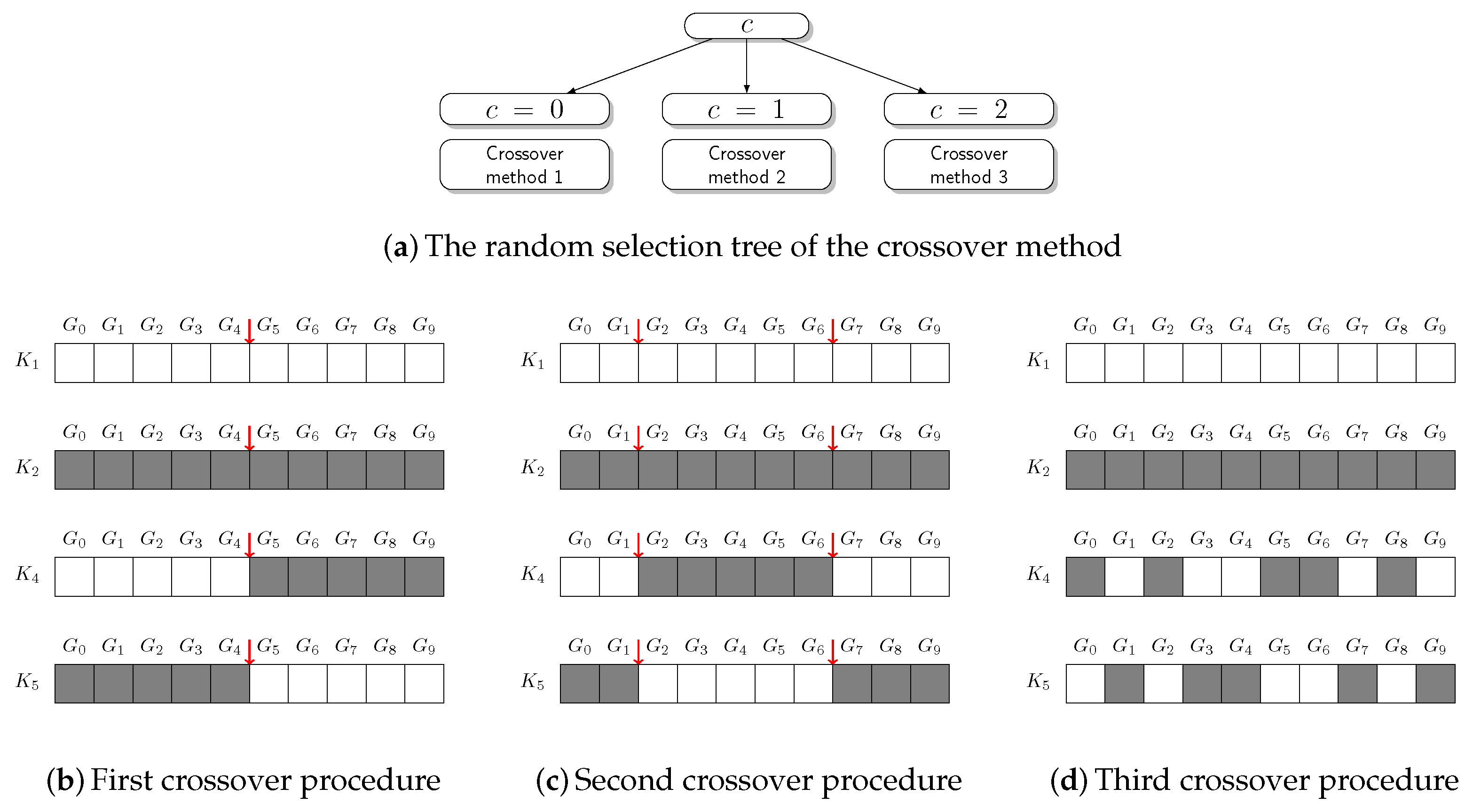
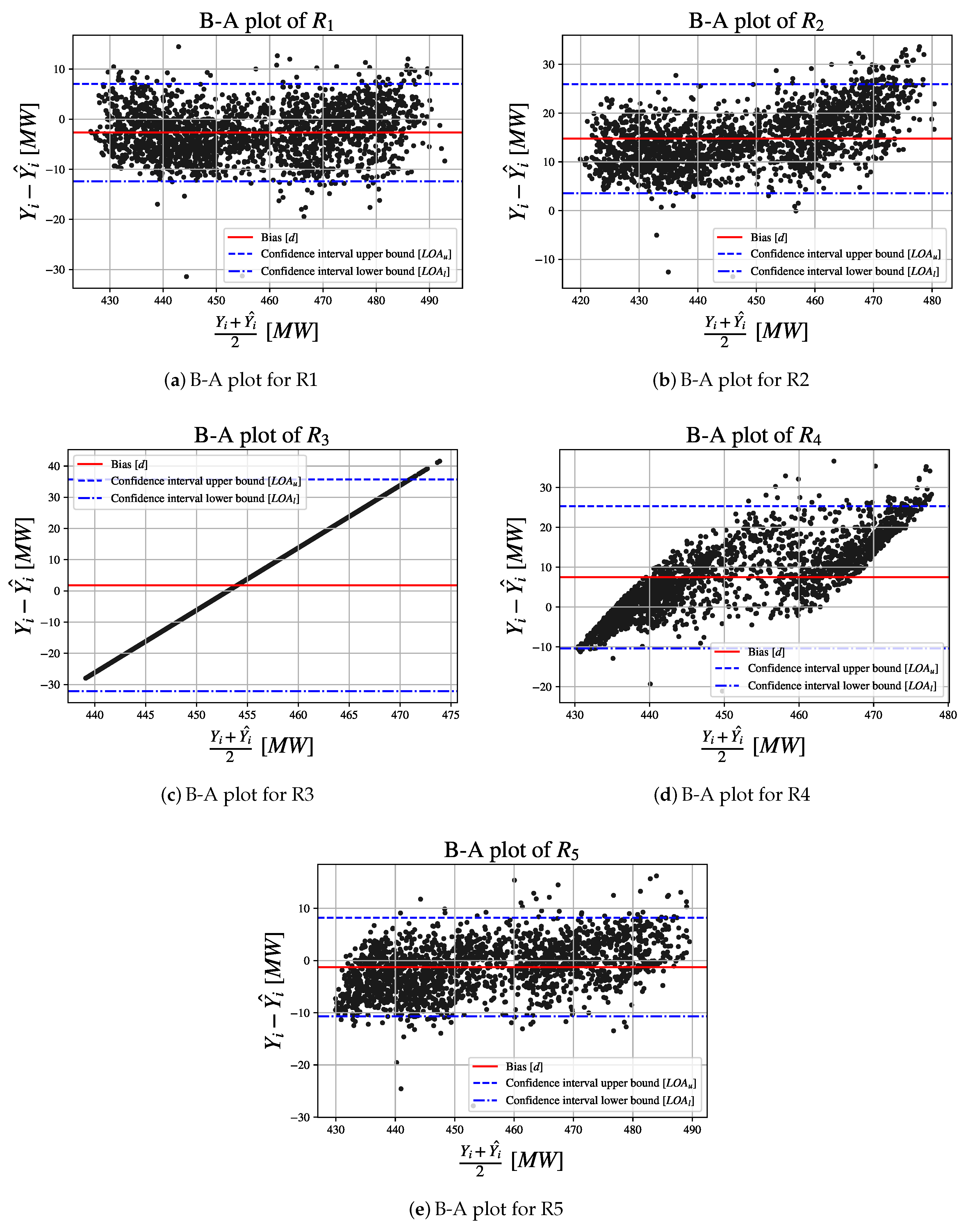
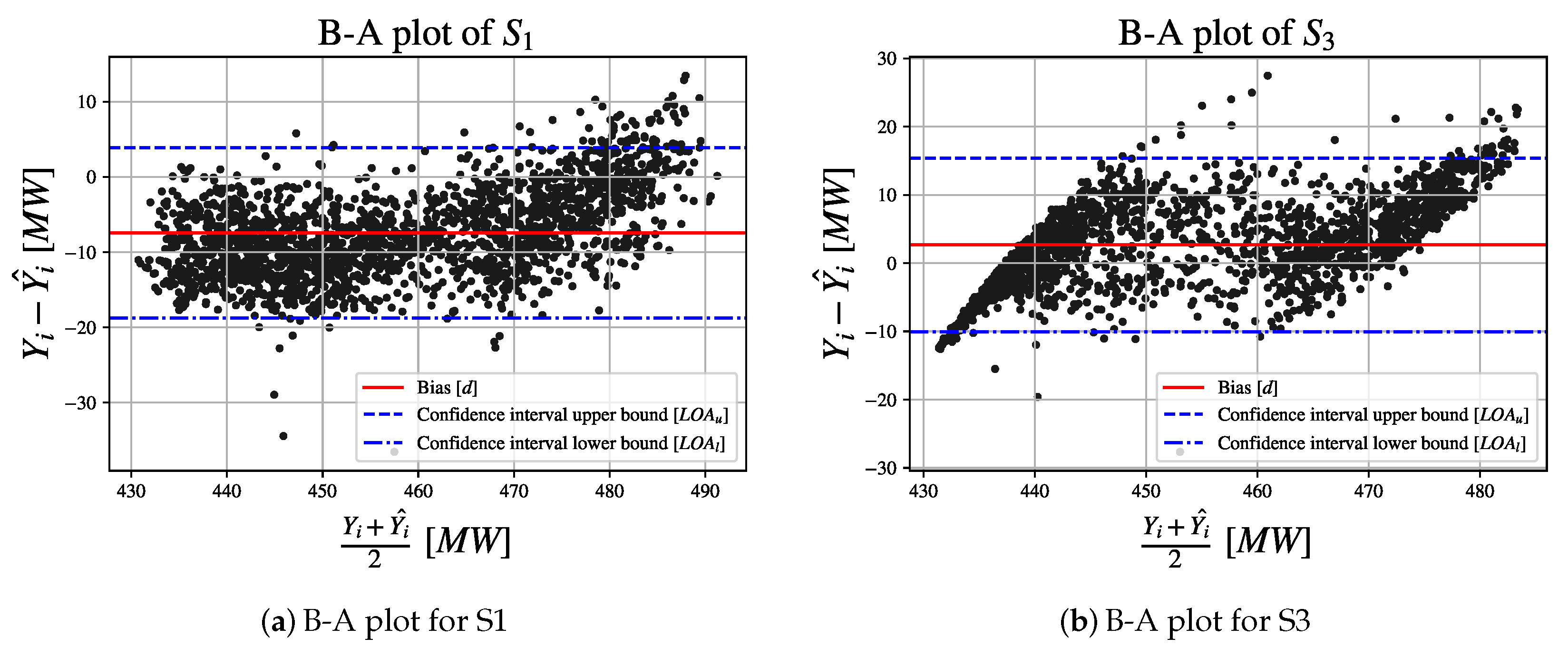
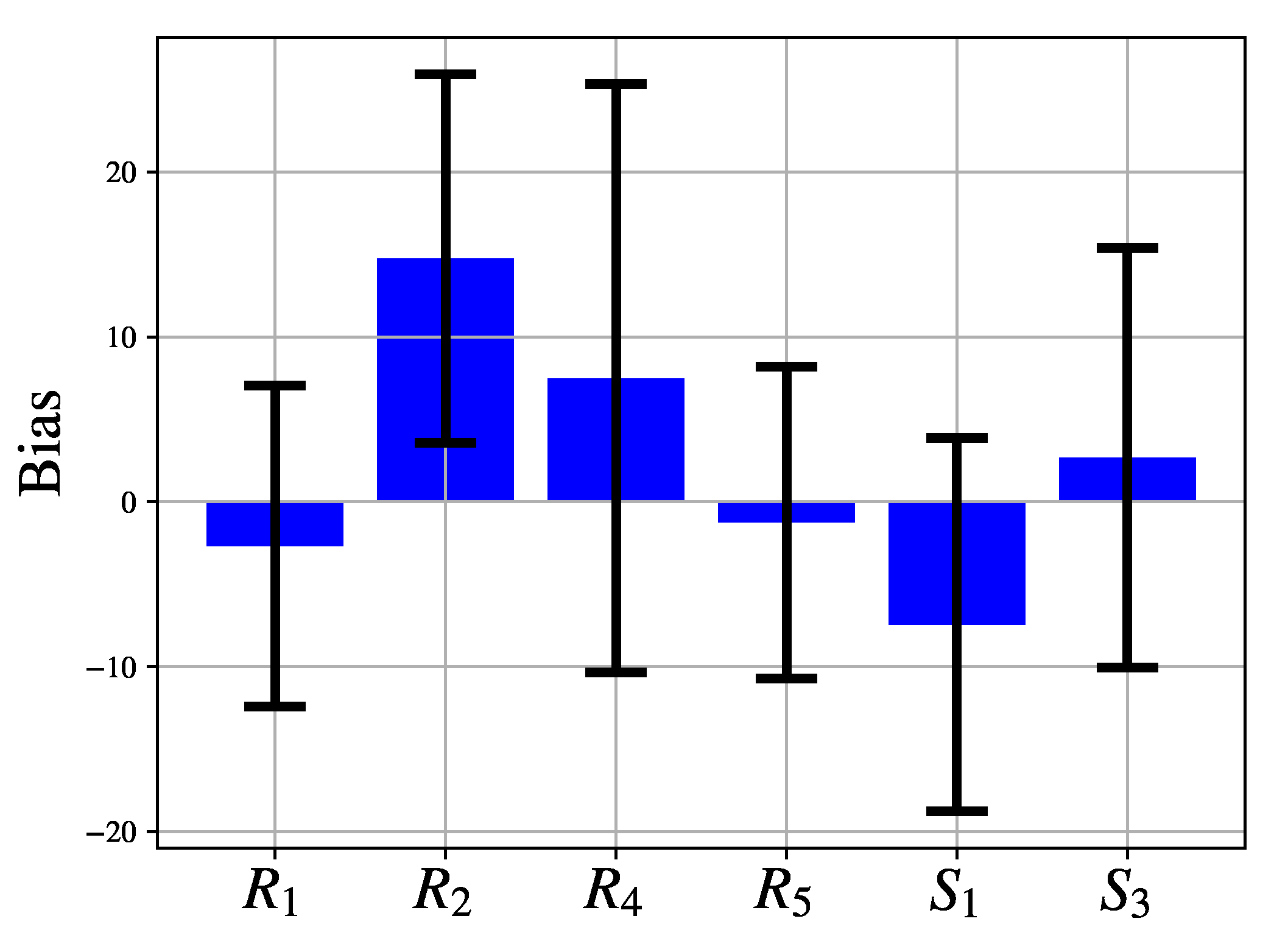
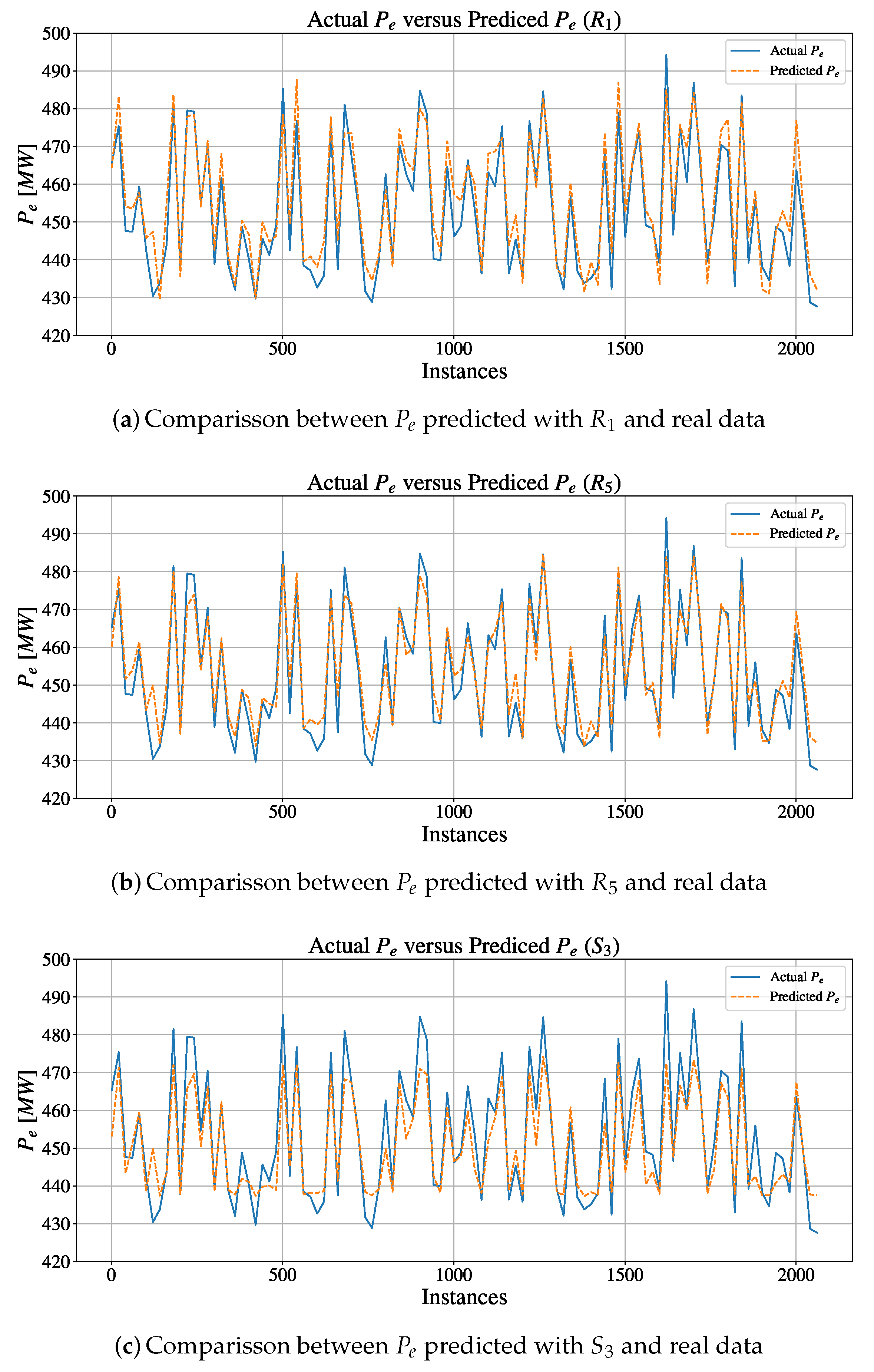
In this research, a GA approach to design of MLP for CCPP electrical power output estimation is presented. GA - based MLP model selection is performed for MLP with one, two, three, four and five hidden layers using one mutation procedure, three different crossover procedures and two different fitness functions. For obtained results, Bland-Altman (B-A) analysis is performed and three MLP configurations are chosen. Regression results achieved with aforementioned MLP configurations are than compared to real data. At the end,
values of MLPs designed with GA are compared to results presented in [
28].
To summarize the novelty of this paper, the idea is to investigate the implementation possibility of heuristic algorithms, mainly GA, in order to increase regression performances of MLP for CCPP electrical power output estimation, in comparison to results presented in
Table 1. As an addition to classification performance measures, B-A analysis is introduced alongside
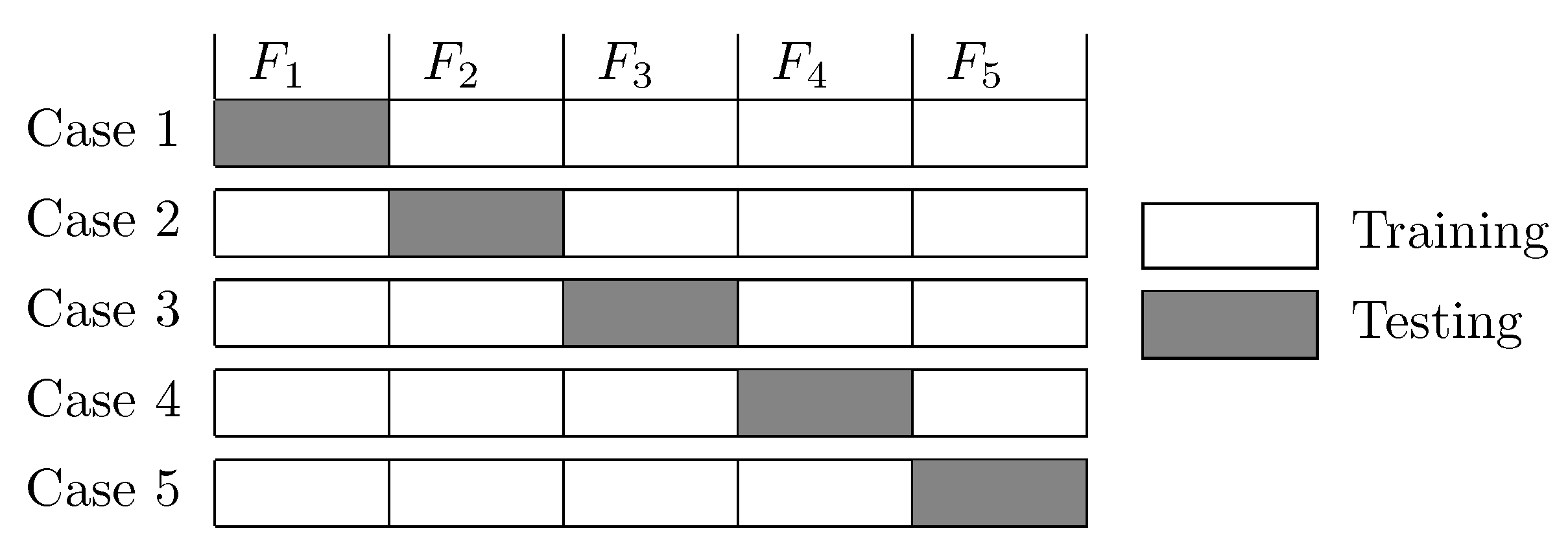
in order to examine standard derivation of errors produced by regression. For chosen configurations, cross-validation is performed in order to investigate generalization performances of aforementioned configurations. From previous statements, the following hypotheses can be imposed:
to investigate implementation possibility of GA in design of MLP for CCPP electrical power output estimation,
to compare regression performances of GA - designed MLP with results presented in available literature and
to determine MLP configuration with optimal performances in regard of regression errors.
Based on presented hypotheses, optimal MLP configuration will be presented and possibility of heuristic algorithms utilization in design of MLP for CCPP electrical power output estimation will be discussed.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}