Solar Power Interval Prediction via Lower and Upper Bound Estimation with a New Model Initialization Approach



Abstract
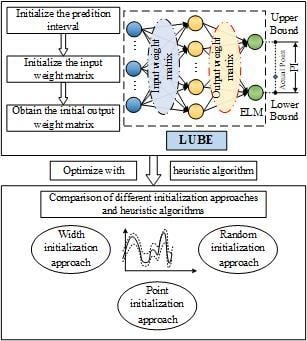
1. Introduction
2. Lower and Upper Bound Estimation
2.1. ELM
2.2. The Evaluation and Training of LUBE
3. Proposed Model Initialization Approach
3.1. Prediction Interval Initialization
| Algorithm 1 Prediction Interval Width Initialization |
| Input: |
| Training data {X,T} = ; |
| Nominal confidence α; |
| Number of data subsets m; |
| Expected prediction interval coverage probability φ. |
| Output: |
| Initial Prediction Interval {TU, TL}0. |
| (a) Calculate initial interval width B0 of {X, T}. (a-1) Divide the training dataset {X, T} into m subsets; (a-2) Sequentially select one subset as the testing data and other subsets are regarded as the training data; (a-3) Separately estimate the prediction error distribution and prediction interval of each test data according to α based on the corresponding training data. (a-4) Calculate PImean by (4), denoted as B0. (a-5) Calculate {TU, TL}0 by (10), where B = B0. |
| (b) Calculate the PICP of the ELM trained through {TU, TL}0 for the training set. If PICP < φ, go to (c). If PICP ≥ φ, output {TU, TL}0. |
| (c) Update B by the binary search algorithm |
| (c-1)Bnew = B× (1 + ϕ); |
| (c-2) Update {TU, TL}0 by (10) and go to (b), where B = Bnew; |
3.2. Input Weight Matrix Initialization
| Algorithm 2 Input Weight Initialization of LUBE |
| Input: |
| Training dataset ; |
| The number of hidden layer nodes of ELM-AE L. |
| Output: |
| Input weight matrix of LUBE |
| (a) Randomly generate the input weight matrix a and bias vector b of the ELM-AE hidden nodes. |
| (b) Orthogonalize a and b: |
| (c) Calculate the output of ELM-AE hidden nodes H |
| H = [g(al,bl, xi)]i = 1, … n, l = 1, …, L |
| (d) Calculate output weight β of ELM-AE, and the input matrix of LUBE is βT |
4. Experiment and Results
4.1. Parameter Settings
4.2. Computational Results
4.2.1. Result Analysis 1—Initialization Approach
4.2.2. Result Analysis 2—ELM-AE
4.2.3. Result Analysis 3—Heuristic Algorithm
5. Conclusions
Acronyms
| CWC | Coverage width-based criterion |
| DE | Differential evolution |
| ELM-AE | ELM auto encoder |
| HS | Harmony search |
| LRIE | linear regression interval estimation |
| LUBE | Lower and upper bound estimation |
| NN | Neural network |
| PI | Point initialization approach |
| PV | Photovoltaic |
| PICP | Prediction interval coverage probability |
| PINRW | PI normalized root-mean-square width |
| PSO | Particle swarm optimization |
| RI | Random initialization approach |
| SA | Simulated annealing |
| WI | Width initialization approach |
| w/ ELM-AE | Initialization approach with ELM-AE |
| w/o ELM-AE | Initialization approach without ELM-AE |
| ELM | Extreme learning Machine |
Author Contributions
Funding
Conflicts of Interest
References
- Khosravi, A.; Mazloumi, E.; Nahavandi, S.; Creighton, D.; Lint, J.W.C.V. Prediction intervals to account for uncertainties in travel time prediction. IEEE Trans. Intell. Transp. Syst. 2011, 12, 537–547. [Google Scholar] [CrossRef]
- Saez, D.; Avila, F.; Olivares, D.; Canizares, C.; Marin, L. Fuzzy prediction interval models for forecasting renewable resources and loads in microgrids. IEEE Trans. Smart Grid 2015, 6, 548–556. [Google Scholar] [CrossRef]
- He, Y.; Liu, R.; Li, H.; Wang, S.; Lu, X. Short-term power load probability density forecasting method using kernel-based support vector quantile regression and copula theory. Appl. Energy 2017, 185 Pt 1, 254–266. [Google Scholar] [CrossRef]
- Tahmasebifar, R.; Sheikh-El-Eslami, M.K.; Kheirollahi, R. Point and interval forecasting of real-time and day-ahead electricity prices by a novel hybrid approach. IET Gener. Transm. Distrib. 2017, 11, 2173–2183. [Google Scholar] [CrossRef]
- Yang, X.; Ma, X.; Kang, N.; Maihemuti, M. Probability interval prediction of wind power based on kde method with rough sets and weighted markov chain. IEEE Access 2018, 6, 51556–51565. [Google Scholar] [CrossRef]
- Yun, S.L.; Scholtes, S. Empirical prediction intervals revisited. Int. J. Forecast. 2014, 30, 217–234. [Google Scholar]
- Sheng, C.; Zhao, J.; Wang, W.; Leung, H. Prediction intervals for a noisy nonlinear time series based on a bootstrapping reservoir computing network ensemble. IEEE Trans. Neural Netw. Learn. Syst. 2013, 24, 1036–1048. [Google Scholar] [CrossRef]
- MacKay, D.J.C. The evidence framework applied to classification networks. Neural Comput. 1992, 4, 720–736. [Google Scholar] [CrossRef]
- Veaux, R.D.D.; Schumi, J.; Ungar, S.L.H. Prediction intervals for neural networks via nonlinear regression. Technometrics 1998, 40, 273–282. [Google Scholar] [CrossRef]
- Kothari, S.C.; Oh, H. Neural Networks for Pattern Recognition. Adv Comput. 1993. Available online: https://books.google.com.hk/books?id=vL-bB7GALAwC&pg=PA165&lpg=PA165&dq=Kothari,+S.C.;+Oh,H.+Neural+Networks+for+Pattern+Recognition.&source=bl&ots=9dkbD_qwsK&sig=ACfU3U16HyCBDuZ2wEYkBNXD5MnuaqQ58Q&hl=zh-TW&sa=X&ved=2ahUKEwiY5rXG0MPlAhXLc94KHWtkAnMQ6AEwAHoECAoQAQ#v=onepage&q=Kothari%2C%20S.C.%3B%20Oh%2CH.%20Neural%20Networks%20for%20Pattern%20Recognition.&f=false (accessed on 30 October 2019).
- Trapero, J.R. Calculation of solar irradiation prediction intervals combining volatility and kernel density estimates. Energy 2016, 114, 266–274. [Google Scholar] [CrossRef]
- Taylor, J.W.; Mcsharry, P.E.; Buizza, R. Wind power density forecasting using ensemble predictions and time series models. IEEE Trans. Energy Convers. 2009, 24, 775–782. [Google Scholar] [CrossRef]
- Khosravi, A.; Nahavandi, S.; Creighton, D.; Atiya, A.F. Lower upper bound estimation method for construction of neural network-based prediction intervals. IEEE Trans. Neural Netw. 2011, 22, 337–346. [Google Scholar] [CrossRef] [PubMed]
- Quan, H.; Srinivasan, D.; Khosravi, A. Short-term load and wind power forecasting using neural network-based prediction intervals. IEEE Trans. Neural Netw. Learn. Syst. 2017, 25, 303–315. [Google Scholar] [CrossRef] [PubMed]
- Wan, C.; Niu, M.; Song, Y.; Xu, Z. Pareto optimal prediction intervals of electricity price. IEEE Trans. Power Syst. 2017, 32, 817–819. [Google Scholar] [CrossRef]
- Shi, Z.; Liang, H.; Dinavahi, V. Wavelet neural network based multiobjective interval prediction for short-term wind speed. IEEE Access 2018, 6, 63352–63365. [Google Scholar] [CrossRef]
- Yadav, A.K.; Chandel, S.S. Solar radiation prediction using artificial neural network techniques: A review. Renew. Sustain. Energy Rev. 2014, 33, 772–781. [Google Scholar] [CrossRef]
- Li, Z.; Liu, X.; Chen, L. Load interval forecasting methods based on an ensemble of Extreme Learning Machines. In Proceedings of the IEEE Power and Energy Society General Meeting, Denver, CO, USA, 26–30 July 2015. [Google Scholar]
- Kavousi-Fard, A.; Khosravi, A.; Nahavandi, S. A new fuzzy-based combined prediction interval for wind power forecasting. IEEE Trans. Power Syst. 2015, 31, 18–26. [Google Scholar] [CrossRef]
- Jiang, P.; Li, R.; Li, H. Multi-objective algorithm for the design of prediction intervals for wind power forecasting model. Appl. Math. Model. 2019, 67, 101–122. [Google Scholar] [CrossRef]
- Ak, R.; Li, Y.F.; Vitelli, V.; Zio, E.; Jacintod, C.M.C. NSGA-II-trained neural network approach to the estimation of prediction intervals of scale deposition rate in oil & gas equipment. Expert Syst. Appl. 2013, 40, 1205–1212. [Google Scholar]
- Huang, G.B.; Zhu, Q.Y.; Siew, C.K. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Kasun, L.L.C.; Zhou, H.; Huang, G.; Vong, C. Representational Learning with Extreme Learning Machine for Big Data. IEEE Intell. Syst. 2013, 28, 31–34. [Google Scholar]
- Xiong, L.; Jiankun, S.; Long, W.; Weiping, W.; Wenbing, Z.; Jinsong, W. Short-term wind speed forecasting via stacked extreme learning machine with generalized correntropy. IEEE Trans. Ind. Inform. 2018, 14, 4963–4971. [Google Scholar]
- Eberhart, R.; Kennedy, J. Particle swarm optimization. In Proceedings of the IEEE International Conference on Neural Networks, Perth, Australia, 27 November–1 December 1995; Volume 4, pp. 1942–1948. [Google Scholar]
- Storn, R.; Price, K. Differential evolution—A simple and efficient heuristic for global optimization over continuous spaces. J. Glob. Optim. 1997, 11, 341–359. [Google Scholar] [CrossRef]
- Kirkpatrick, S.; Gelatt, C.D.; Vecchi, M.P. Optimization by simulated annealing. Science 1983, 220, 671–680. [Google Scholar] [CrossRef] [PubMed]
- Geem, Z.W.; Kim, J.H.; Loganathan, G.V. A New Heuristic Optimization Algorithm: Harmony Search. Simulation 2001, 76, 60–68. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithms | Parameter | Value |
|---|---|---|
| PSO | Particle size | 100 |
| Inertia weight | (0.1, 0.7) | |
| Cognitive acceleration constant | 1.5 | |
| Social acceleration constant | 2.5 | |
| DE | Population size | 100 |
| Scaling factor F | 0.005 | |
| Crossover parameter CR | (0.1, 0.3) | |
| SA | Initial temperature | 5 |
| Re-annealing interval | 50 | |
| Cooling factor | 0.9 | |
| HS | Harmony memory size | 25 |
| Harmony memory considering rate | 0.98 | |
| Pitch adjusting rate | (0.05, 0.1) | |
| Bandwidth | (1, 50) |
| AVERAGE | WI w/ELM-AE | PI w/ELM-AE | RI w/ELM-AE | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| CWC | PICP | PINRW | CWC | PICP | PINRW | CWC | PICP | PINRW | ||
| PSO | Training | 26.64% | 93.01% | 26.64% | 26.47% | 93.01% | 26.47% | 117.57% | 93.01% | 117.57% |
| Test | 25.89% | 91.30% | 25.89% | 35.70% | 90.90% | 25.95% | 114.58% | 94.14% | 114.58% | |
| SA | Training | 27.91% | 93.06% | 27.91% | 28.31% | 93.07% | 28.31% | 269.35% | 93.03% | 269.35% |
| Test | 35.99% | 91.15% | 26.78% | 28.68% | 91.91% | 28.68% | 272.57% | 93.86% | 272.57% | |
| HS | Training | 32.75% | 94.68% | 32.75% | 48.46% | 95.64% | 48.46% | 476.17% | 96.26% | 476.17% |
| Test | 32.75% | 93.47% | 32.75% | 49.36% | 94.89% | 49.36% | 615.22% | 95.36% | 462.11% | |
| DE | Training | 32.75% | 94.68% | 32.75% | 37.22% | 94.68% | 37.22% | 350.1% | 98.11% | 350.10% |
| Test | 32.75% | 93.47% | 32.75% | 37.47% | 93.37% | 37.47% | 330.66% | 98.03% | 330.66% | |
| WORST | WI w/ ELM-AE | PI w/ ELM-AE | RI w/ ELM-AE | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| CWC | PICP | PINRW | CWC | PICP | PINRW | CWC | PICP | PINRW | ||
| PSO | Training | 28.19% | 93.01% | 28.19% | 25.94% | 93.01% | 25.94% | 66.04% | 91.08% | 66.04% |
| Test | 28.28% | 92.50% | 28.28% | 50.35% | 89.97% | 24.98% | 206.21% | 93.01% | 206.21% | |
| SA | Training | 28.11% | 93.03% | 28.11% | 28.88% | 93.16% | 28.88% | 328.42% | 93.03% | 328.42% |
| Test | 27.54% | 91.88% | 27.54% | 29.91% | 92.32% | 29.91% | 337.88% | 94.32% | 337.88% | |
| HS | Training | 34.37% | 95.04% | 34.37% | 66.69% | 98.27% | 66.69% | 371.12% | 93.41% | 371.12% |
| Test | 34.37% | 94.05% | 34.37% | 66.40% | 98.76% | 66.40% | 908.87% | 88.55% | 296.42% | |
| DE | Training | 34.37% | 95.04% | 34.37% | 37.22% | 94.68% | 37.22% | 429.44% | 99.28% | 429.44% |
| Test | 34.37% | 94.05% | 34.37% | 37.47% | 93.37% | 37.47% | 417.74% | 98.09% | 417.74% | |
| AVERAGE | WI w/o ELM-AE | PI w/o ELM-AE | RI w/o ELM-AE | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| CWC | PICP | PINRW | CWC | PICP | PINRW | CWC | PICP | PINRW | ||
| PSO | Training | 22.66% | 93.01% | 22.36% | 24.55% | 93.01% | 24.55% | 199.31% | 93.01% | 199.31% |
| Test | 50.70% | 89.43% | 22.56% | 51.99% | 89.64% | 24.17% | 347.39% | 91.99% | 187.52% | |
| SA | Training | 26.36% | 93.07% | 26.36% | 27.07% | 93.16% | 27.07% | 697.12% | 93.04% | 697.12% |
| Test | 67.86% | 89.17% | 25.34% | 43.98% | 90.50% | 27.61% | 669.95% | 93.58% | 669.95% | |
| HS | Training | 30.48% | 94.65% | 30.48% | 102.92% | 92.75% | 33.21% | 994.26% | 96.43% | 994.26% |
| Test | 30.56% | 92.77% | 30.56% | 42.28% | 91.89% | 34.26% | 1037.78% | 97.38% | 1037.78% | |
| DE | Training | 26.30% | 93.30% | 26.30% | 24.86% | 93.38% | 24.86% | 688.64% | 96.36% | 688.64% |
| Test | 30.57% | 90.71% | 25.77% | 83.97% | 89.22% | 23.72% | 641.13% | 94.58% | 641.13% | |
| WORST | WI w/o ELM-AE | PI w/o ELM-AE | RI w/o ELM-AE | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| CWC | PICP | PINRW | CWC | PICP | PINRW | CWC | PICP | PINRW | ||
| PSO | Training | 21.79% | 93.01% | 21.79% | 23.48% | 93.01% | 23.48% | 195.77% | 93.01% | 195.77% |
| Test | 77.47% | 88.06% | 21.30% | 82.94% | 87.88% | 21.36% | 620.14% | 87.88% | 159.74% | |
| SA | Training | 25.25% | 93.04% | 25.25% | 26.08% | 93.06% | 26.08% | 845.49% | 93.06% | 845.49% |
| Test | 145.29% | 86.73% | 23.69% | 71.09% | 88.86% | 25.67% | 889.78% | 93.12% | 889.78% | |
| HS | Training | 31.25% | 95.02% | 31.25% | 29.88% | 93.27% | 29.88% | 1143.80% | 97.97% | 1143.80% |
| Test | 31.25% | 93.16% | 31.25% | 69.00% | 89.35% | 28.92% | 1273.26% | 99.64% | 1273.26% | |
| DE | Training | 22.45% | 93.12% | 22.45% | 30.29% | 93.04% | 30.29% | 825.84% | 97.04% | 825.84% |
| Test | 44.69% | 89.70% | 20.69% | 228.93% | 86.11% | 28.61% | 791.94% | 96.14% | 791.94% | |
| Algorithms | WI | PI | RI |
|---|---|---|---|
| PSO | 1374.22 | 1369.52 | 1360.97 |
| SA | 2235.66 | 2224.44 | 2223.50 |
| HS | 1670.62 | 1647.88 | 1647.88 |
| DE | 1398.42 | 1367.05 | 1366.08 |
| Algorithms | WI | PI | RI |
|---|---|---|---|
| PSO | 1533.88 | 1673.48 | 1484.03 |
| SA | 2327.96 | 2322.45 | 2330.64 |
| HS | 1647.88 | 1795.76 | 1788.86 |
| DE | 1474.17 | 1469.56 | 1465.95 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, P.; Zhang, C.; Long, H. Solar Power Interval Prediction via Lower and Upper Bound Estimation with a New Model Initialization Approach. Energies 2019, 12, 4146. https://doi.org/10.3390/en12214146
Li P, Zhang C, Long H. Solar Power Interval Prediction via Lower and Upper Bound Estimation with a New Model Initialization Approach. Energies. 2019; 12(21):4146. https://doi.org/10.3390/en12214146
Chicago/Turabian StyleLi, Peng, Chen Zhang, and Huan Long. 2019. "Solar Power Interval Prediction via Lower and Upper Bound Estimation with a New Model Initialization Approach" Energies 12, no. 21: 4146. https://doi.org/10.3390/en12214146
APA StyleLi, P., Zhang, C., & Long, H. (2019). Solar Power Interval Prediction via Lower and Upper Bound Estimation with a New Model Initialization Approach. Energies, 12(21), 4146. https://doi.org/10.3390/en12214146