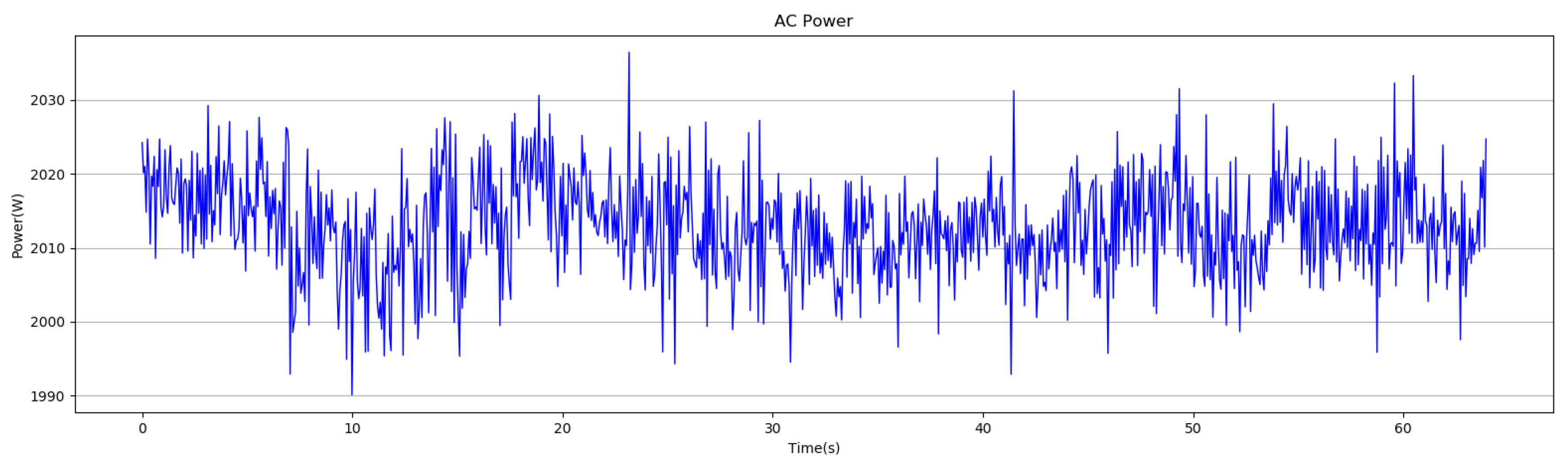
Figure 1.
An example of alternating current (AC) power pattern.
Figure 1.
An example of alternating current (AC) power pattern.
Figure 2.
Daily power consumption patterns of home appliances in general households.
Figure 2.
Daily power consumption patterns of home appliances in general households.
Figure 3.
The architecture of a typical RNN model.
Figure 3.
The architecture of a typical RNN model.
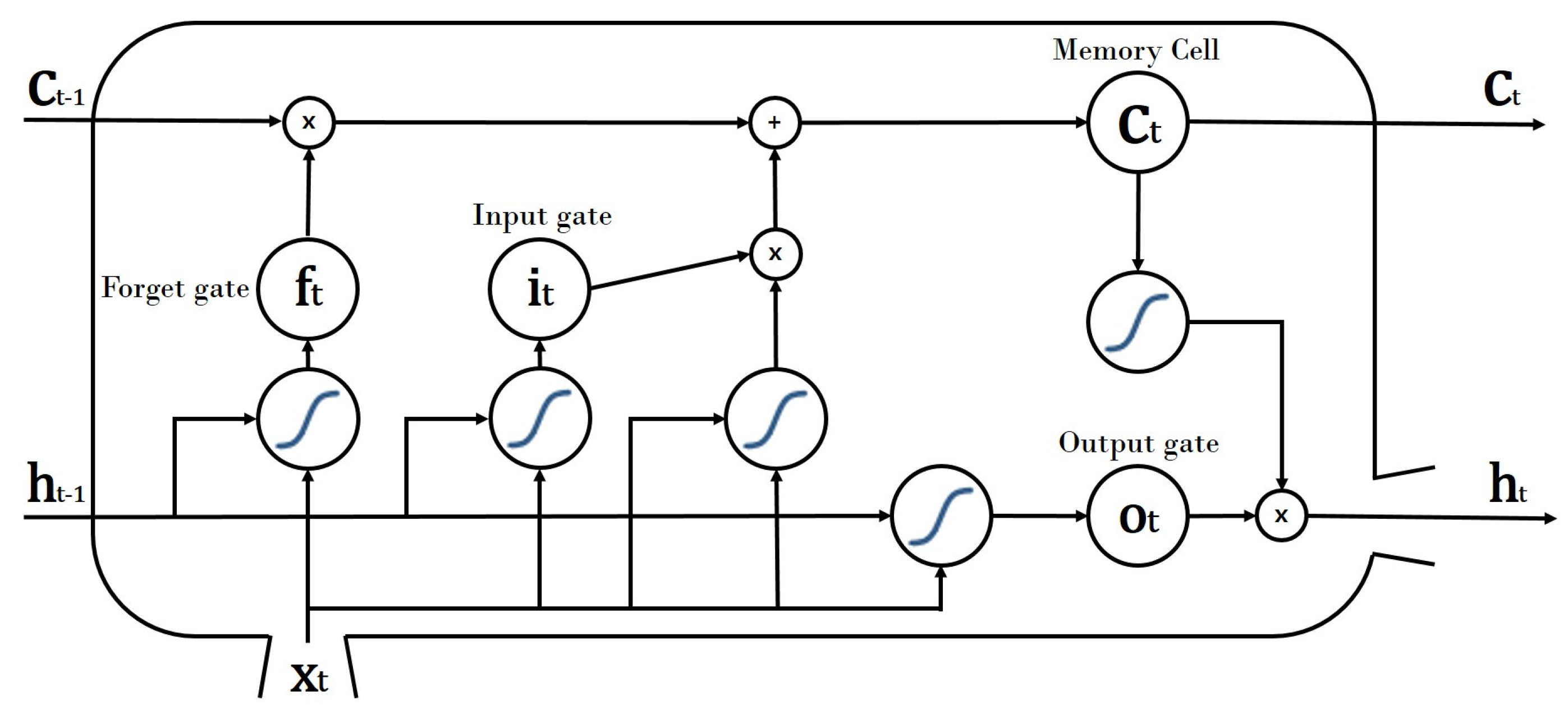
Figure 4.
The architecture of LSTM.
Figure 4.
The architecture of LSTM.
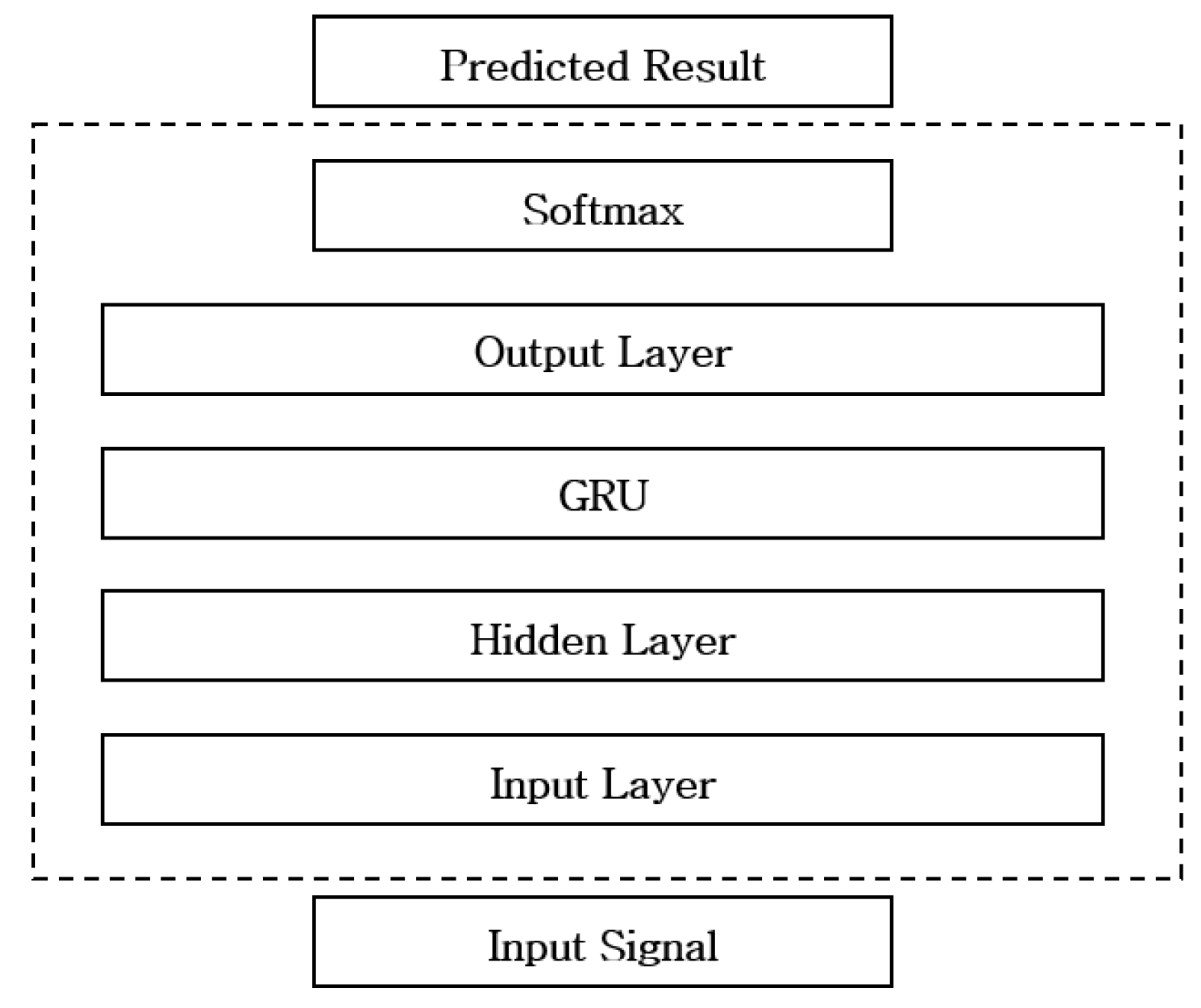
Figure 5.
Network structure of GRU.
Figure 5.
Network structure of GRU.
Figure 6.
Network structure of the FESL-LSTM.
Figure 6.
Network structure of the FESL-LSTM.
Figure 7.
Network structure of MFC-ML-LSTM.
Figure 7.
Network structure of MFC-ML-LSTM.
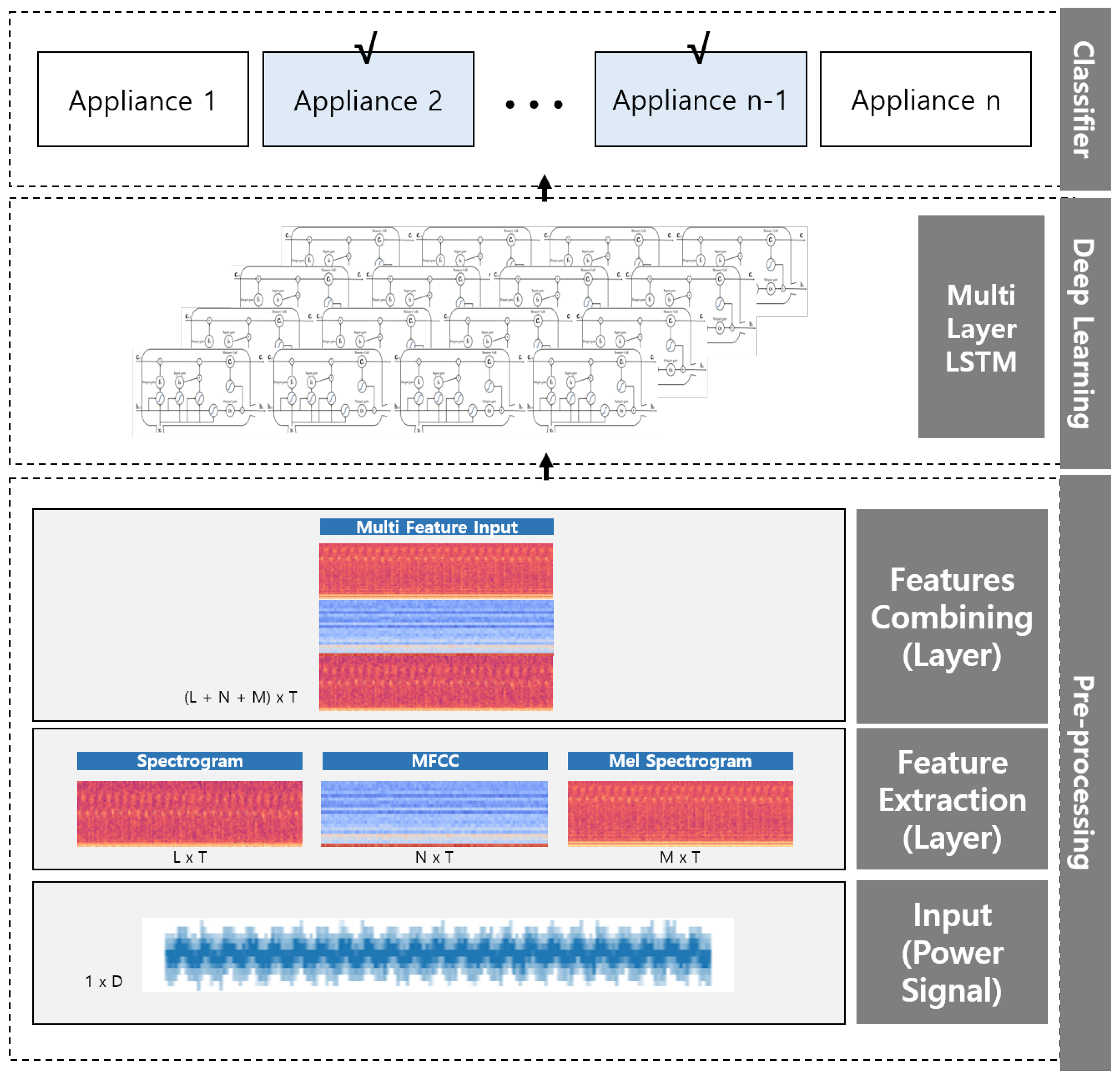
Figure 8.
A block diagram of the proposed appliance classification network.
Figure 8.
A block diagram of the proposed appliance classification network.
Figure 9.
The block diagram of the spectrogram based on STFT.
Figure 9.
The block diagram of the spectrogram based on STFT.
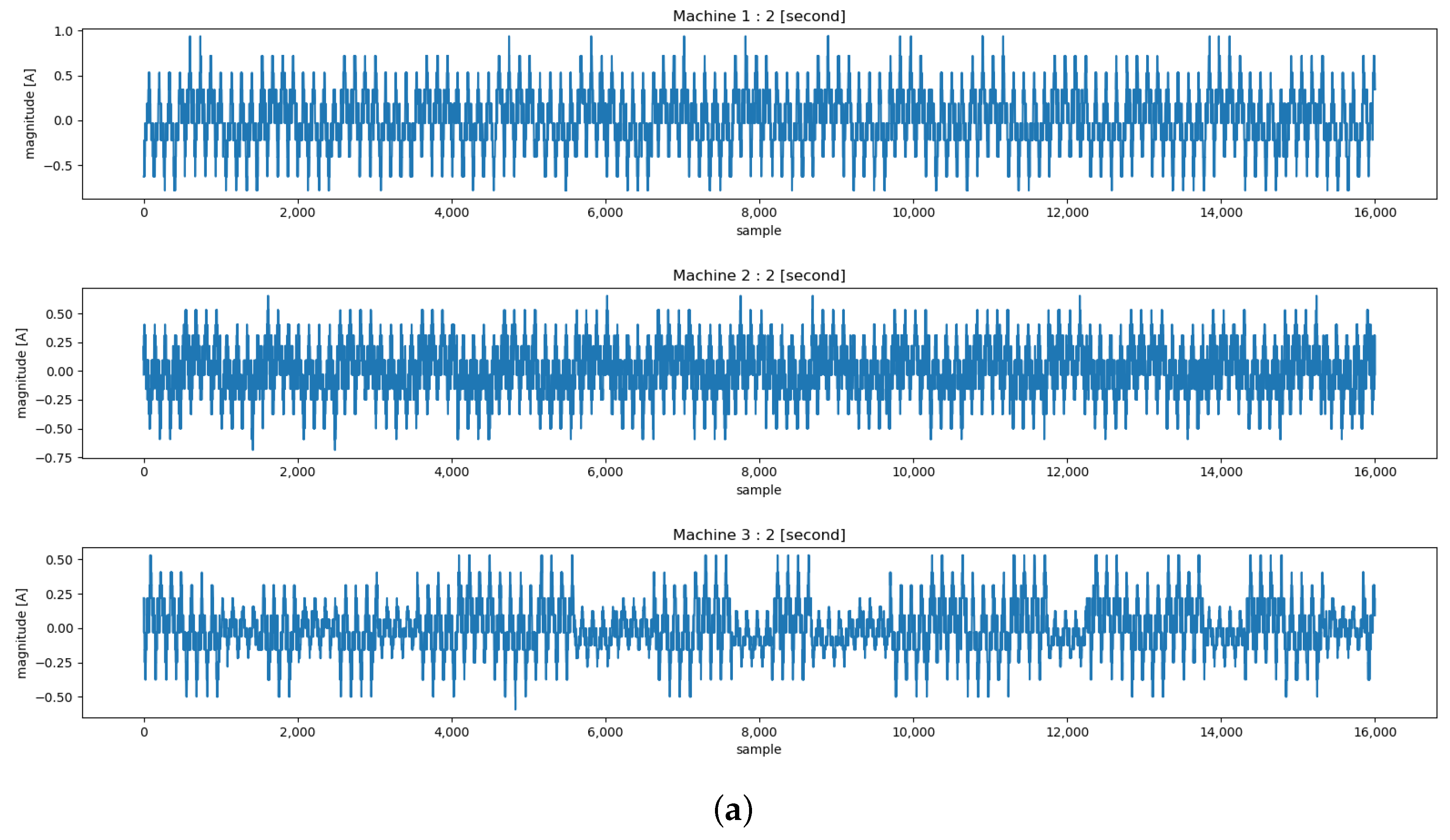
Figure 10.
The waveform and spectrogram of input time series data which is part of the self-configured dataset used in the experiment section. (a) The waveform of Machine 1–3’s current for 2 s (16,000 samples). (b) The spectrogram of Machine 1–3’s current for 60 s.
Figure 10.
The waveform and spectrogram of input time series data which is part of the self-configured dataset used in the experiment section. (a) The waveform of Machine 1–3’s current for 2 s (16,000 samples). (b) The spectrogram of Machine 1–3’s current for 60 s.
Figure 11.
The Block diagram of MFCC.
Figure 11.
The Block diagram of MFCC.
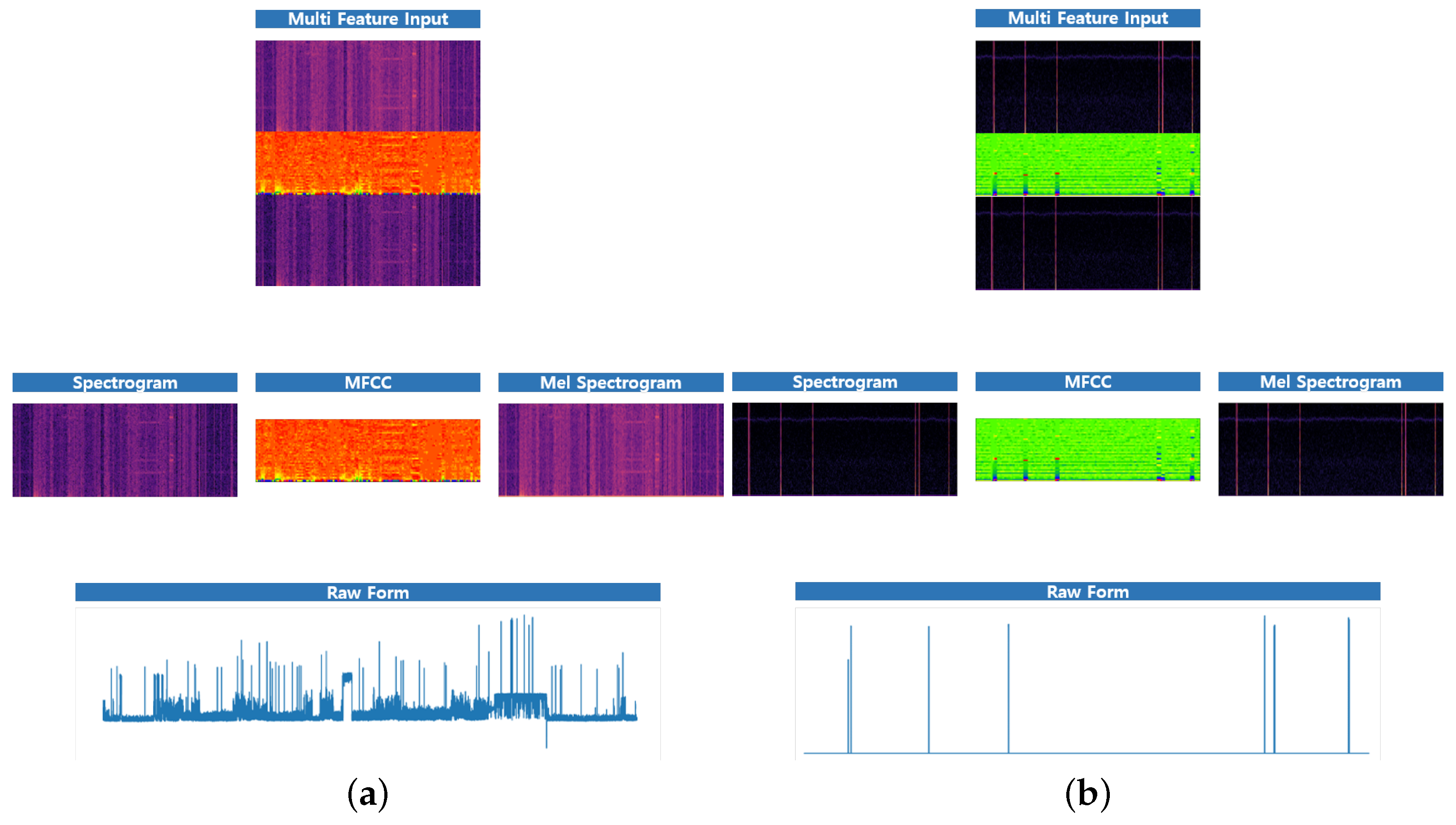
Figure 12.
The feature combination of some appliances with original signal. (a) i7_desktop (b) hairdryer (c) primary_tv (d) toaster (e) fridge_freezer (f) oven.
Figure 12.
The feature combination of some appliances with original signal. (a) i7_desktop (b) hairdryer (c) primary_tv (d) toaster (e) fridge_freezer (f) oven.
Figure 13.
The diagram of the data mixing process.
Figure 13.
The diagram of the data mixing process.
Figure 14.
Some mixed data plots.
Figure 14.
Some mixed data plots.
Figure 15.
The training and test results for raw data and spectrogram of self-configured dataset as the input to an ML-LSTM model. (a) The training result in terms of the accuracy with respect to the number of epochs. (b) The test result in accuracy.
Figure 15.
The training and test results for raw data and spectrogram of self-configured dataset as the input to an ML-LSTM model. (a) The training result in terms of the accuracy with respect to the number of epochs. (b) The test result in accuracy.
Figure 16.
The training and test results for CNN and RNN using spectrogram of self-configured dataset. (a) The training result in terms of the accuracy with respect to the number of epochs. (b) The test result in accuracy.
Figure 16.
The training and test results for CNN and RNN using spectrogram of self-configured dataset. (a) The training result in terms of the accuracy with respect to the number of epochs. (b) The test result in accuracy.
Figure 17.
The results of the performance based on the input settings of the UK-DALE-2017 dataset. (a) Result of performance in terms of the accuracy when the input is only spectrogram. (b) Result of performance in terms of the accuracy when the input is the multiple feature combination of Spectrogram, MFCC, Mel-spectrogram.
Figure 17.
The results of the performance based on the input settings of the UK-DALE-2017 dataset. (a) Result of performance in terms of the accuracy when the input is only spectrogram. (b) Result of performance in terms of the accuracy when the input is the multiple feature combination of Spectrogram, MFCC, Mel-spectrogram.
Figure 18.
The multi-label classification results of the mixed data using UK-DALE-2017 dataset. The accuracy of (a) GRU, (b) FESL-LSTM, and (c) MFC-ML-LSTM.
Figure 18.
The multi-label classification results of the mixed data using UK-DALE-2017 dataset. The accuracy of (a) GRU, (b) FESL-LSTM, and (c) MFC-ML-LSTM.
Figure 19.
The multi-label classification results of the mixed data using UK-DALE-2017 dataset. The F1-score of (a) GRU, (b) FESL-LSTM, and (c) MFC-ML-LSTM.
Figure 19.
The multi-label classification results of the mixed data using UK-DALE-2017 dataset. The F1-score of (a) GRU, (b) FESL-LSTM, and (c) MFC-ML-LSTM.
Table 1.
Performance comparison between GRU and other existing algorithms [
23].
Table 1.
Performance comparison between GRU and other existing algorithms [
23].
| Classifier Algorithm | Accuracy (%) | F-measure (%) |
|---|
| Bayes | 80–92 | - |
| SVM [26] | 75–92 | - |
| HMM [14,15] | 75–87 | - |
| FHMM [17] | - | 80–90 |
| FHMM variants [15] | - | 69–98 |
| FHMM using MAP algorithm [14] | 71 | - |
| RNN [23] | 88–98 | 77–98 |
| GRU [23] | 89–98 | 81–98 |
Table 2.
The detailed description of UK-DALE-2017 dataset.
Table 2.
The detailed description of UK-DALE-2017 dataset.
| House | Building of Type | Duration of Recording (Days) | Number of Appliance | Number of Using Appliance | Sample Rate |
|---|
| 1 | End of terrace | 786 | 53 | 31 | 16 kHz, 1 Hz, 1/6 Hz |
| 2 | End of terrace | 234 | 20 | 12 | 16 kHz, 1 Hz, 1/6 Hz |
| 3 | - | 39 | 5 | 2 | 1/6 Hz |
| 4 | Mid-terrace | 205 | 6 | 2 | 16 kHz, 1 Hz, 1/6 Hz |
| 5 | flat | 137 | 26 | 15 | 1/6 Hz |
Table 3.
The list of appliances selected for learning in UK-DALE-2017 dataset.
Table 3.
The list of appliances selected for learning in UK-DALE-2017 dataset.
| House | Appliance |
|---|
| 1 | dishwasher, amp_livingroom, kitchen_dt_lamp, livingroom_lamp_tv, washing_machine, battery_charger, office_lamp3, livingroom_s_lamp, kitchen_lamp2, livingroom_s_lamp2, gigE_&_USBhub, solar_thermal_pump, fridge, samsung_charger, htpc, hifi_office, gas_oven, subwoofer_livingroom, tv, office_pc, bedroom_chargers, lighting_circuit, laptop, kitchen_lights, office_lamp1, lcd_office, adsl_router, kitchen_phone&stereo, childs_ds_lamp, data_logger_pc, office_lamp2 |
| 2 | server, dish_washer, laptop2, router, fridge, modem, washing_machine, monitor, running_machine, microwave, server_hdd, speakers |
| 3 | electric_heater, laptop |
| 4 | gas_boiler, freezer |
| 5 | core2_server, microwave, washer_dryer, i7_desktop, network_attached_storage, dishwasher, sky_hd_box, 24_inch_lcd_bedroom, fridge_freezer, oven, 24_inch_lcd, treadmill, atom_pc, home_theatre_amp, primary_tv |
Table 4.
The time L, M for each dataset setting.
Table 4.
The time L, M for each dataset setting.
| Dataset | L (One Data Duration) | M (Stride) | L-M (Overlapping) |
|---|
| UK-DALE-2017 | 24 h | 12 h | 12 h |
| Self-configured | 3 s | 2 s | 1 s |
Table 5.
The number of extracted data for each house of UK-DALE-2017 dataset.
Table 5.
The number of extracted data for each house of UK-DALE-2017 dataset.
| House | # of Train (+Validation) | # of Test |
|---|
| House 1 | 75,771 | 18,923 |
| House 2 | 3659 | 909 |
| House 3 | 112 | 28 |
| House 4 | 724 | 180 |
| House 5 | 3413 | 849 |
Table 6.
The number of extracted data for each feature of self-configured dataset.
Table 6.
The number of extracted data for each feature of self-configured dataset.
| # of Train | # of Validation | # of Test |
|---|
| 10,912 | 3632 | 3648 |
Table 7.
Hyper parameter settings for learning.
Table 7.
Hyper parameter settings for learning.
| Hyper Parameter | Value | Explanation |
|---|
| Learning rate | 0.0001 | The ratio to reach for the optimum set of parameters. It affects the optimization speed of deep learning model through the optimizer. |
| Hidden layer size | 256 | The number of the hidden layer’s nodes. It affects the learning depth of deep learning. |
| Optimizer | Adam | A parameter optimization model. Adam Optimizer is one of the most popular optimizers in deep learning as it adjusts the update level of learning rate by calculating the optimization speed of parameters while reducing learning rate during training. |
| ML-LSTM layer size | 6 | The number of stacked LSTM layers. As the more layers, the LSTM can store more information. |
| Batch size | 20 | The size of the batch which is a way of learning various information at the same time by grouping multiple inputs rather than one input. |
| Epochs | 600 | A unit for the process of learning with the whole data once in the training dataset. |
Table 8.
The confusion matrix.
Table 8.
The confusion matrix.
| | Predicted | Yes | No |
|---|
| Label | |
|---|
| Yes | TP | FN |
| No | FP | TN |
Table 9.
The confusion matrix and F1-score of each appliance in House 2.
Table 9.
The confusion matrix and F1-score of each appliance in House 2.
| | Predicted | Monitor | Speakers | Server | Router | Server_Hdd | Kettle | Rice_Cooker | Running_Machine | Laptop2 | Washing_Machine | Dish_Washer | Fridge | Microwave | Toaster | Playstation | Modem | None | F1-Score |
|---|
| Label | |
|---|
| monitor | 62 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.939 |
| speakers | 0 | 70 | 2 | 2 | 0 | 0 | 0 | 3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.933 |
| server | 0 | 0 | 77 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.962 |
| router | 0 | 1 | 0 | 73 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 2 | 0 | 0.907 |
| server_hdd | 1 | 0 | 0 | 0 | 40 | 0 | 0 | 0 | 0 | 0 | 4 | 0 | 0 | 0 | 0 | 0 | 0 | 0.909 |
| kettle | 0 | 0 | 0 | 0 | 0 | 56 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.974 |
| rice_cooker | 0 | 0 | 0 | 0 | 0 | 2 | 53 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.955 |
| running_machine | 0 | 2 | 4 | 0 | 0 | 0 | 0 | 51 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.895 |
| laptop2 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 46 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0.920 |
| washing_machine | 0 | 0 | 0 | 8 | 0 | 0 | 0 | 0 | 0 | 38 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.884 |
| dish_washer | 0 | 0 | 0 | 0 | 2 | 0 | 0 | 0 | 0 | 0 | 44 | 0 | 0 | 0 | 0 | 0 | 0 | 0.936 |
| fridge | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 46 | 0 | 0 | 0 | 0 | 0 | 1.000 |
| microwave | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 0 | 0 | 0 | 7 | 0.222 |
| toaster | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 46 | 0 | 0 | 0 | 1.000 |
| playstation | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 45 | 0 | 0 | 0.989 |
| modem | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 45 | 0 | 0.968 |
| none | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 7 | 0 | 0 | 0 | 53 | 0.876 |
Table 10.
The multi-label classification result of each appliance in House 1.
Table 10.
The multi-label classification result of each appliance in House 1.
| Appliance | F1-Score | Accuracy | Appliance | F1-Score | Accuracy |
|---|
| dishwasher | 91.96% | 97.66% | subwoofer_livingroom | 99.74% | 99.89% |
| amp_livingroom | 97.93% | 99.10% | tv | 99.60% | 99.83% |
| kitchen_dt_lamp | 44.82% | 91.95% | office_pc | 50.45% | 94.26% |
| livingroom_lamp_tv | 87.78% | 95.04% | bedroom_chargers | 62.14% | 89.96% |
| battery_charger | 40.98% | 93.06% | lighting_circuit | 97.98% | 99.12% |
| office_lamp3 | 47.50% | 94.43% | laptop | 63.73% | 94.42% |
| livingroom_s_lamp | 84.32% | 93.97% | kitchen_lights | 98.17% | 99.21% |
| kitchen_lamp2 | 47.66% | 91.43% | office_lamp1 | 40.77% | 90.15% |
| livingroom_s_lamp2 | 73.84% | 91.21% | lcd_office | 49.30% | 93.10% |
| gigE_&_USBhub | 45.73% | 92.98% | adsl_router | 98.58% | 99.38% |
| solar_thermal_pump | 99.16% | 99.63% | kitchen_phone&stereo | 69.34% | 90.37% |
| fridge | 99.96% | 99.98% | childs_ds_lamp | 77.00% | 99.22% |
| samsung_charger | 77.45% | 92.33% | data_logger_pc | 99.86% | 99.94% |
| htpc | 98.92% | 99.53% | office_lamp2 | 52.97% | 88.29% |
| hifi_office | 48.82% | 93.58% | washing_machine | 93.28% | 97.54% |
| gas_oven | 99.04% | 99.58% | | | |
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}