Forecasting in Blockchain-Based Local Energy Markets


Abstract
1. Introduction
1.1. Related Research
1.2. Present Research
- (a)
- forecasting net energy consumption and production of private consumers and prosumers one time-step ahead;
- (b)
- evaluating and quantifying the effects of forecasting errors; and
- (c)
- evaluating the implications of low forecasting quality for a market mechanism.
- Which prediction technique yields the best 15-min ahead forecast for smart meter time series measured in 3-min intervals using only input features generated from the historical values of the time series and calendar-based features?
- Assuming a forecasting error settlement structure, what is the quantified loss of households participating in the LEM due to forecasting errors by the prediction technique identified in Question (a)?
- Depending on Question (b), what implications and potential adjustments for an LEM market mechanism can be identified?
2. Method
- The forecasting technique has to produce deterministic (i.e., point) forecasts.
- The forecasting technique had—for comparison—to be used in previous studies.
- The previous study or studies using the forecasting technique had to use comparable data, i.e., recorded by smart meters in 60-min intervals or higher resolution, recorded in multiple households, and not recorded in small and medium enterprises (SMEs) or other business or public buildings.
- The forecasting task had to be comparable to the forecasting task of the present research, i.e., single consumer household (in contrast to the prediction of aggregated energy time series) and very short forecasting horizon ( h).
- The forecasting technique had to take historical and calendar features only as input for the prediction.
- The forecasting technique had to produce absolutely and relative to other studies promisingly accurate predictions.
2.1. Baseline Model
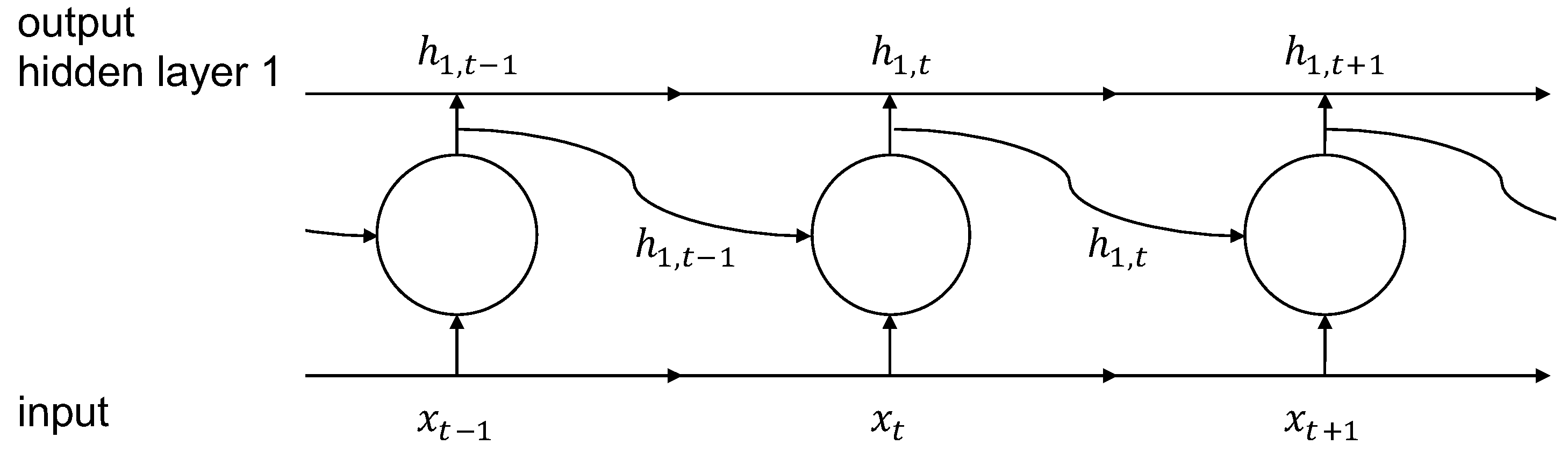
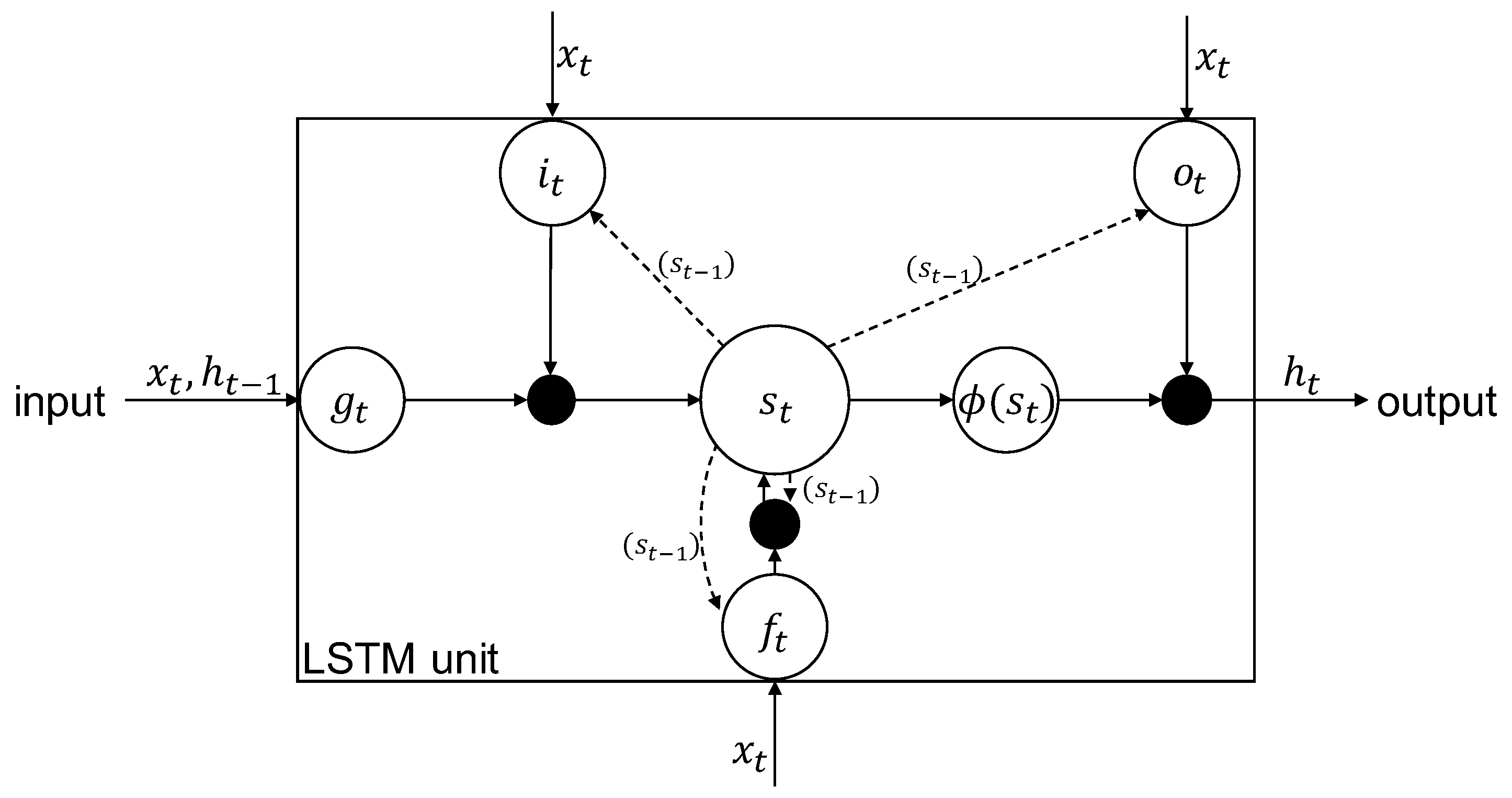
2.2. Machine Learning-Based Forecasting Approach
| Procedure 1 Supervised training of and prediction with LSTM RNN. |
|
2.3. Statistical Method-Based Forecasting Approach
| Procedure 2 Cross-validated selection of for LASSO and prediction. |
|
2.4. Error Measures
2.5. Market Simulation
3. Data
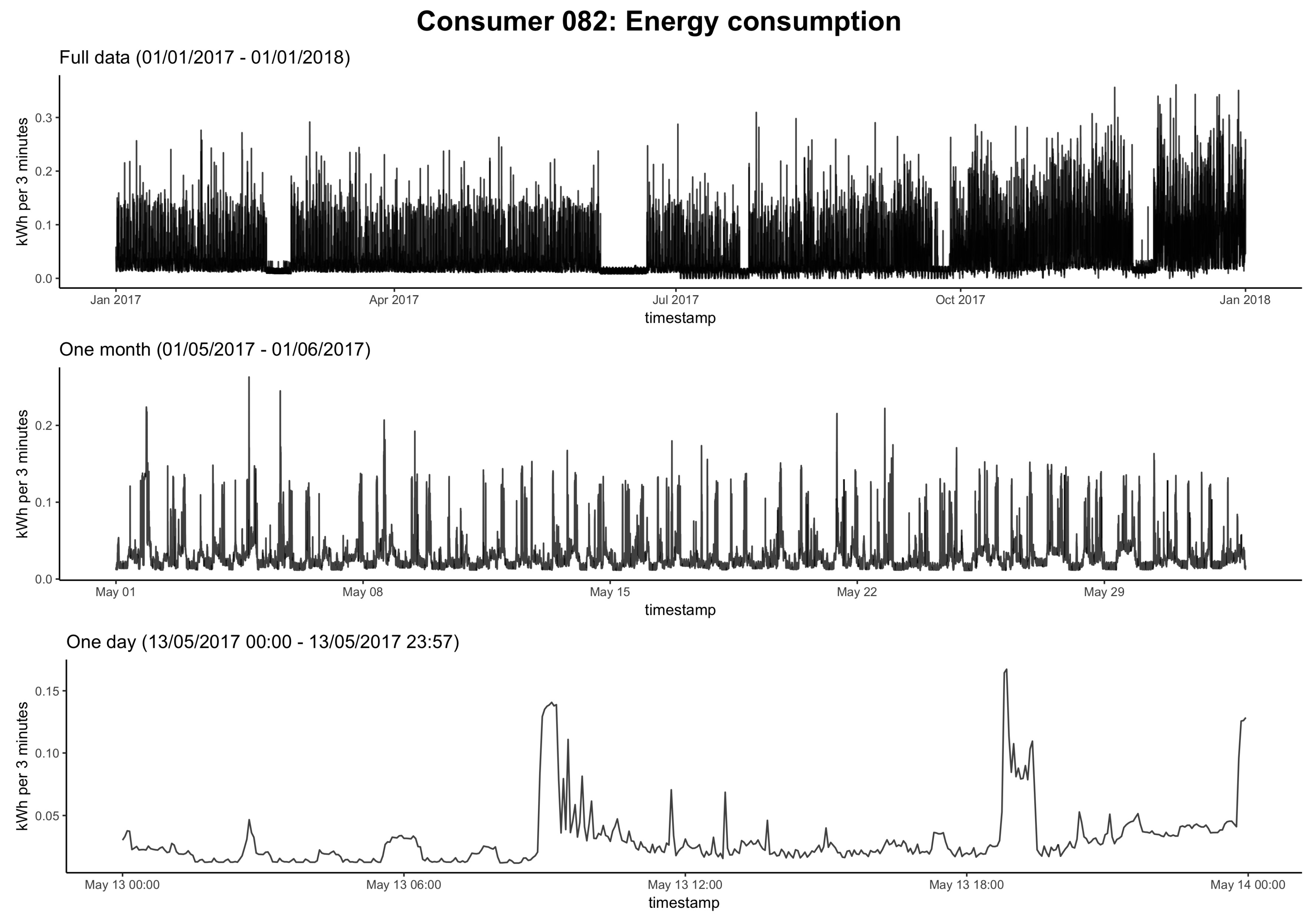
 BLEMdata (github.com/QuantLet/BLEM/tree/master/data), hosted at GitHub. Discovergy describes itself as a full-range supplier of smart metering solutions offering transparent energy consumption and production data for private and commercial clients [45]. To be able to offer such data-driven services, Discovergy smart meters record energy consumption and production near real-time—i.e., in 2-s intervals—and send the readings to Discovergy’s servers for storage and analysis. Therefore, Discovergy has extremely high resolution energy data of their customers at their disposal. This high resolution is in stark contrast to the half-hourly or even hourly recorded data used in previous studies on household energy forecasting (e.g., [21,23,46,47]). To our knowledge, there is no previous research using Discovergy smart meter data, apart from Teixeira et al. [48], who used the data as simulation input but not for analysis or prediction.
BLEMdata (github.com/QuantLet/BLEM/tree/master/data), hosted at GitHub. Discovergy describes itself as a full-range supplier of smart metering solutions offering transparent energy consumption and production data for private and commercial clients [45]. To be able to offer such data-driven services, Discovergy smart meters record energy consumption and production near real-time—i.e., in 2-s intervals—and send the readings to Discovergy’s servers for storage and analysis. Therefore, Discovergy has extremely high resolution energy data of their customers at their disposal. This high resolution is in stark contrast to the half-hourly or even hourly recorded data used in previous studies on household energy forecasting (e.g., [21,23,46,47]). To our knowledge, there is no previous research using Discovergy smart meter data, apart from Teixeira et al. [48], who used the data as simulation input but not for analysis or prediction.4. Results
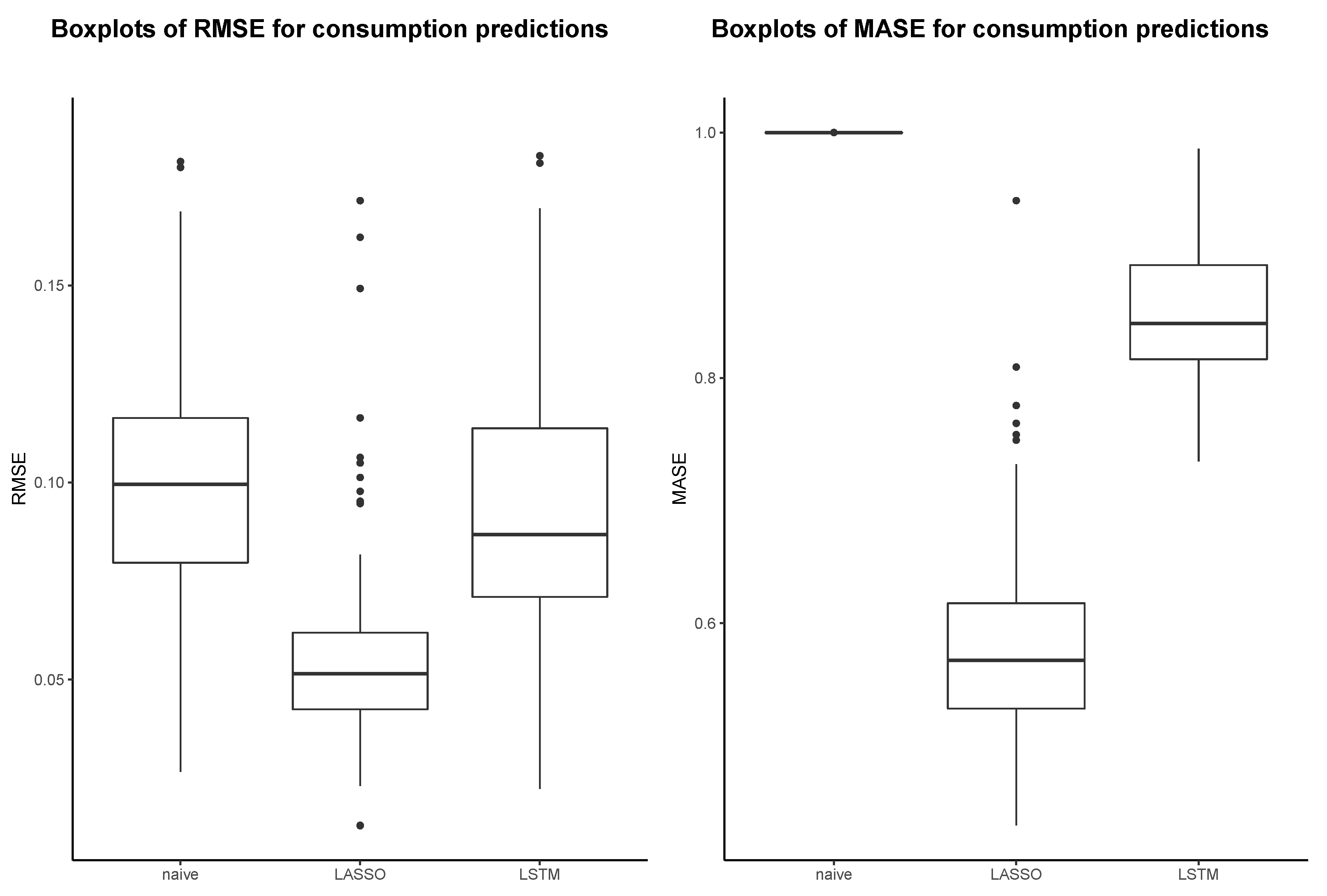
4.1. Evaluation of the Prediction Models
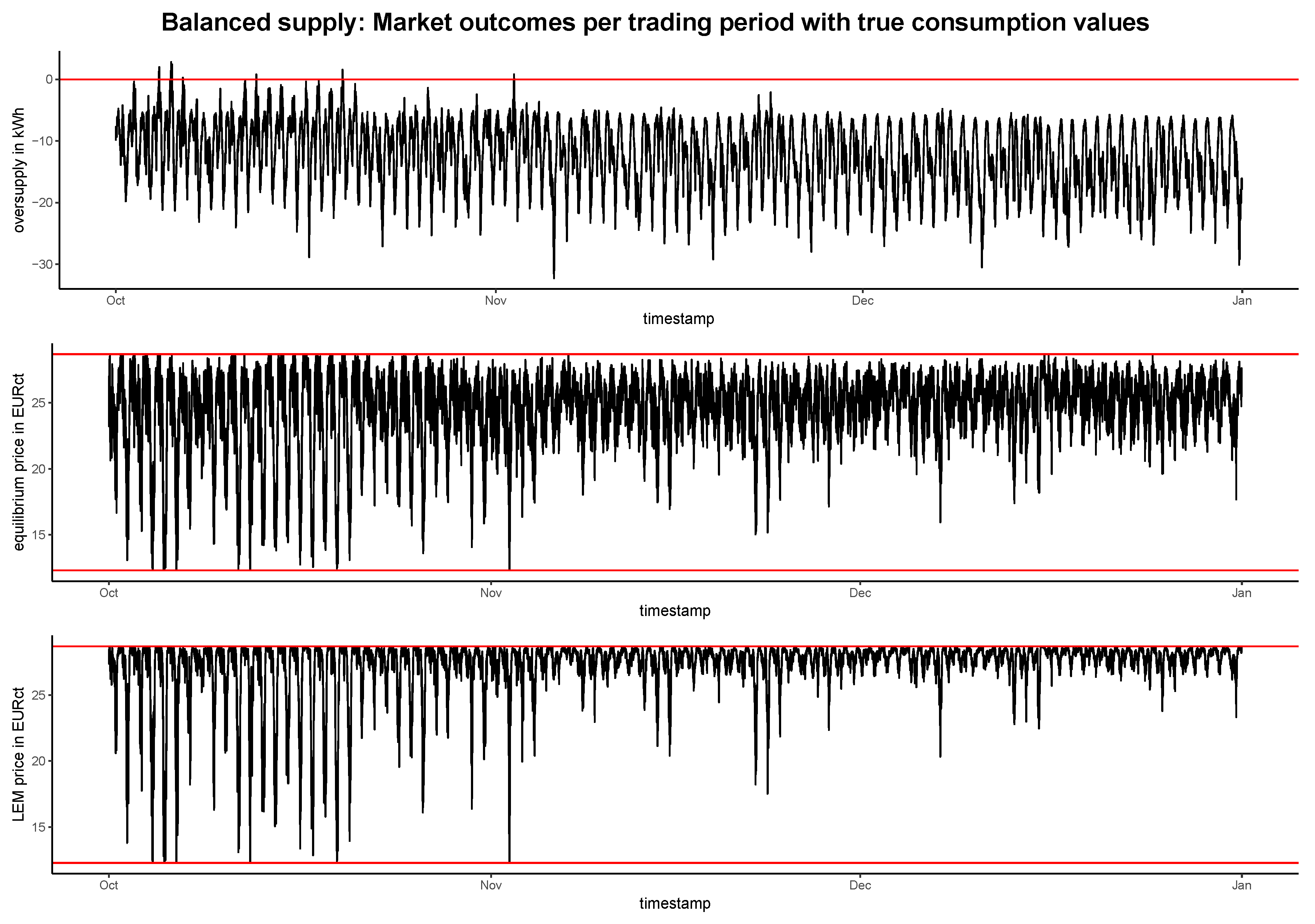
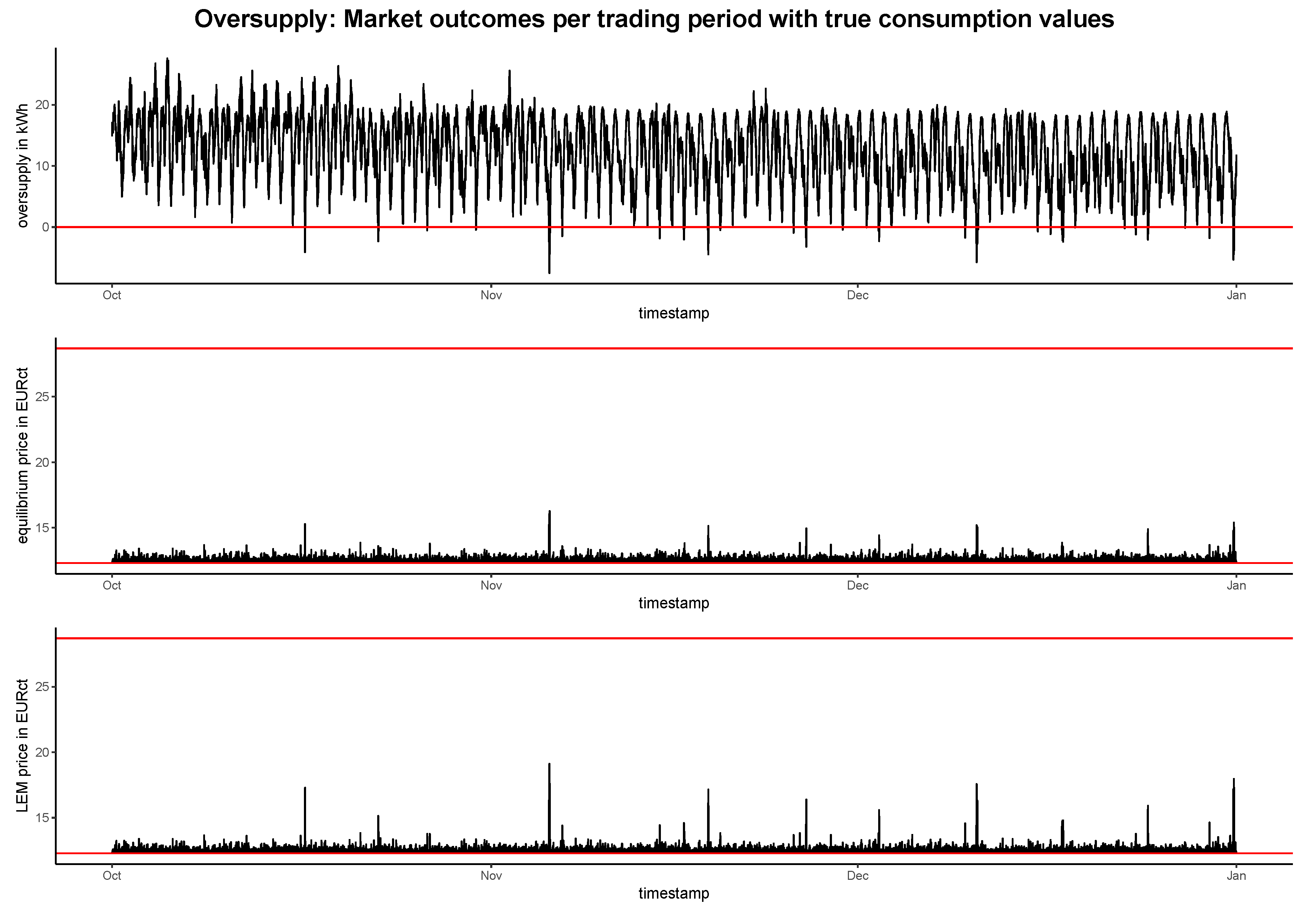
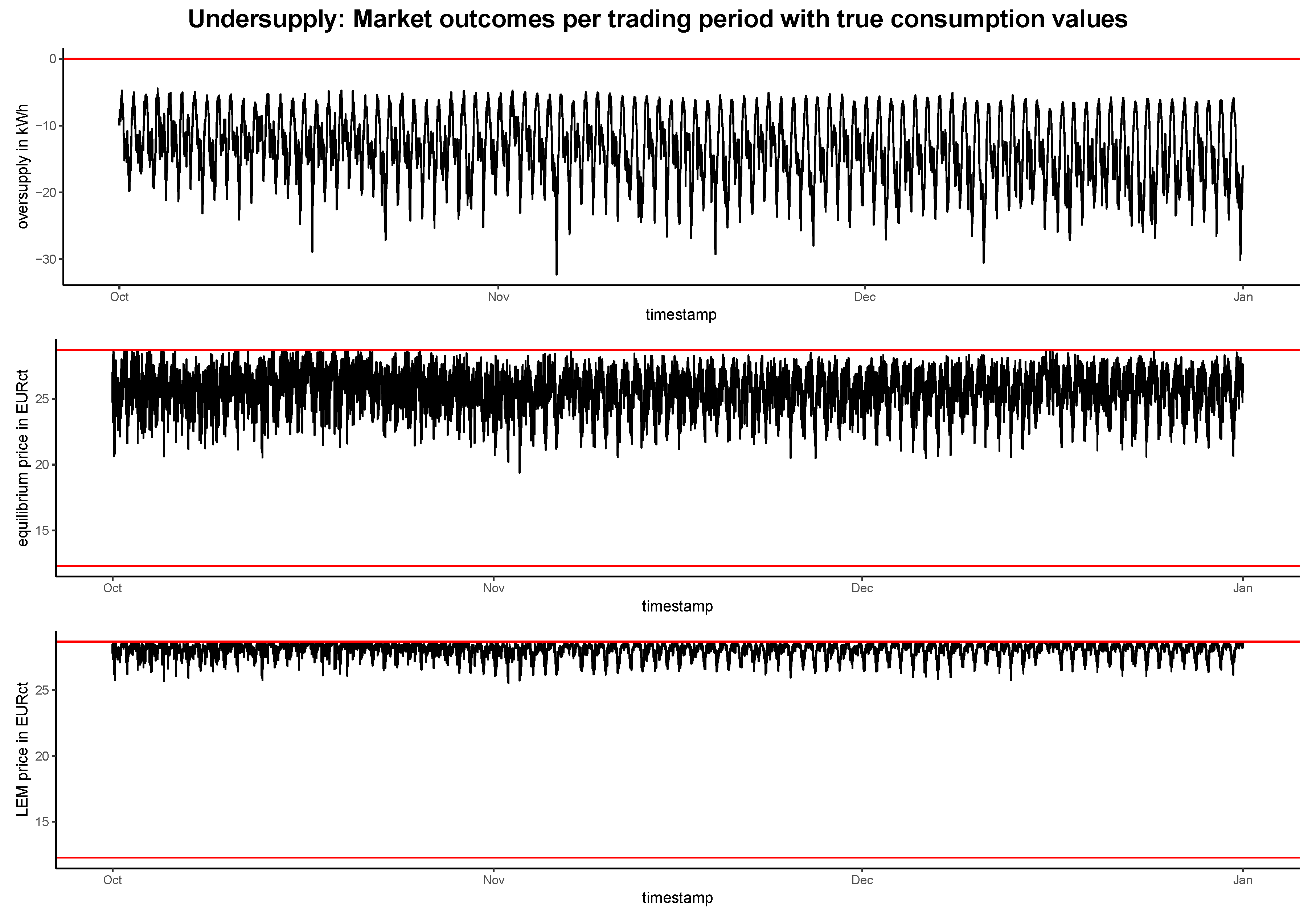
4.2. Evaluation of the Market Simulation
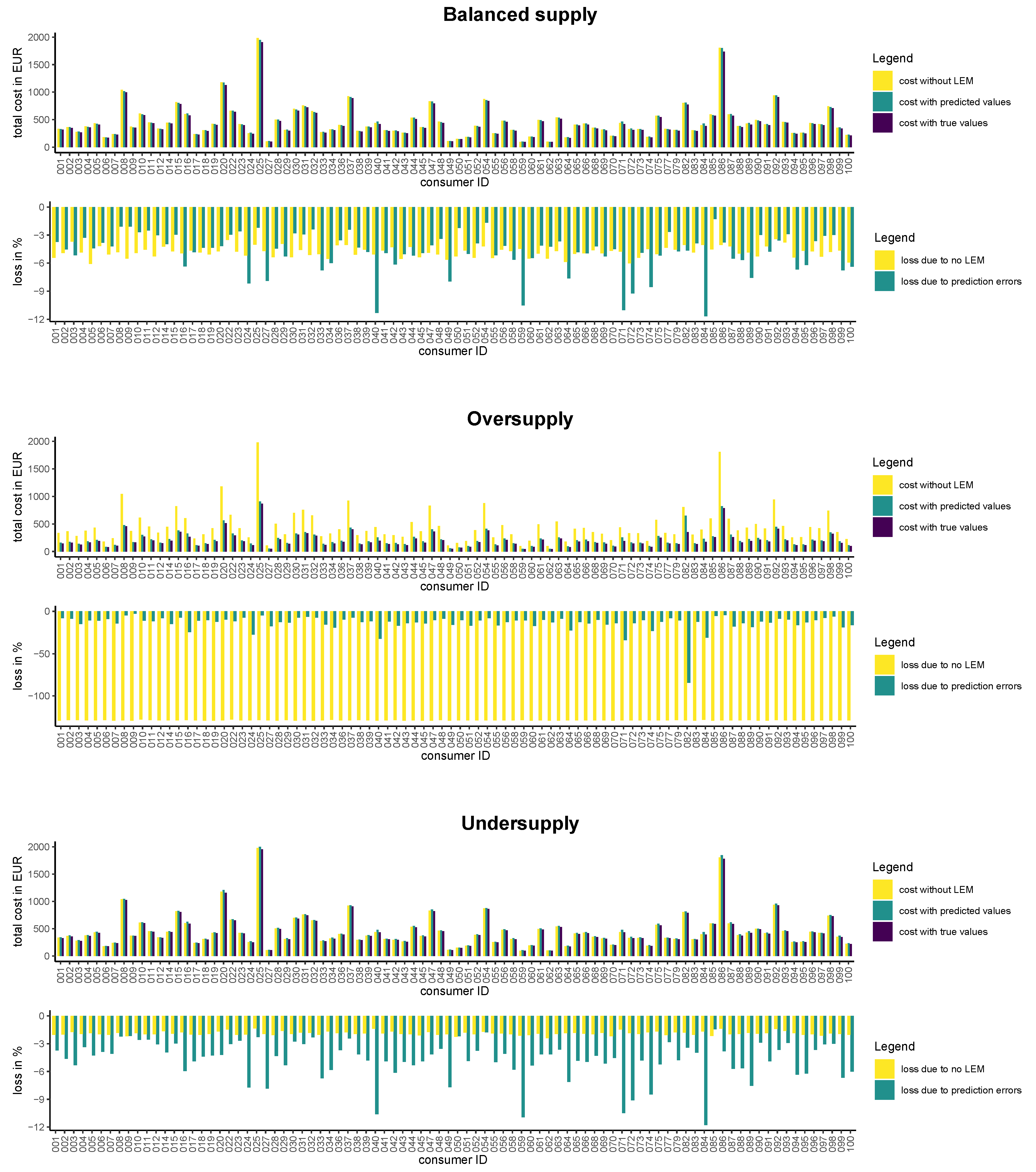
4.2.1. Market Outcomes in Different Supply Scenarios
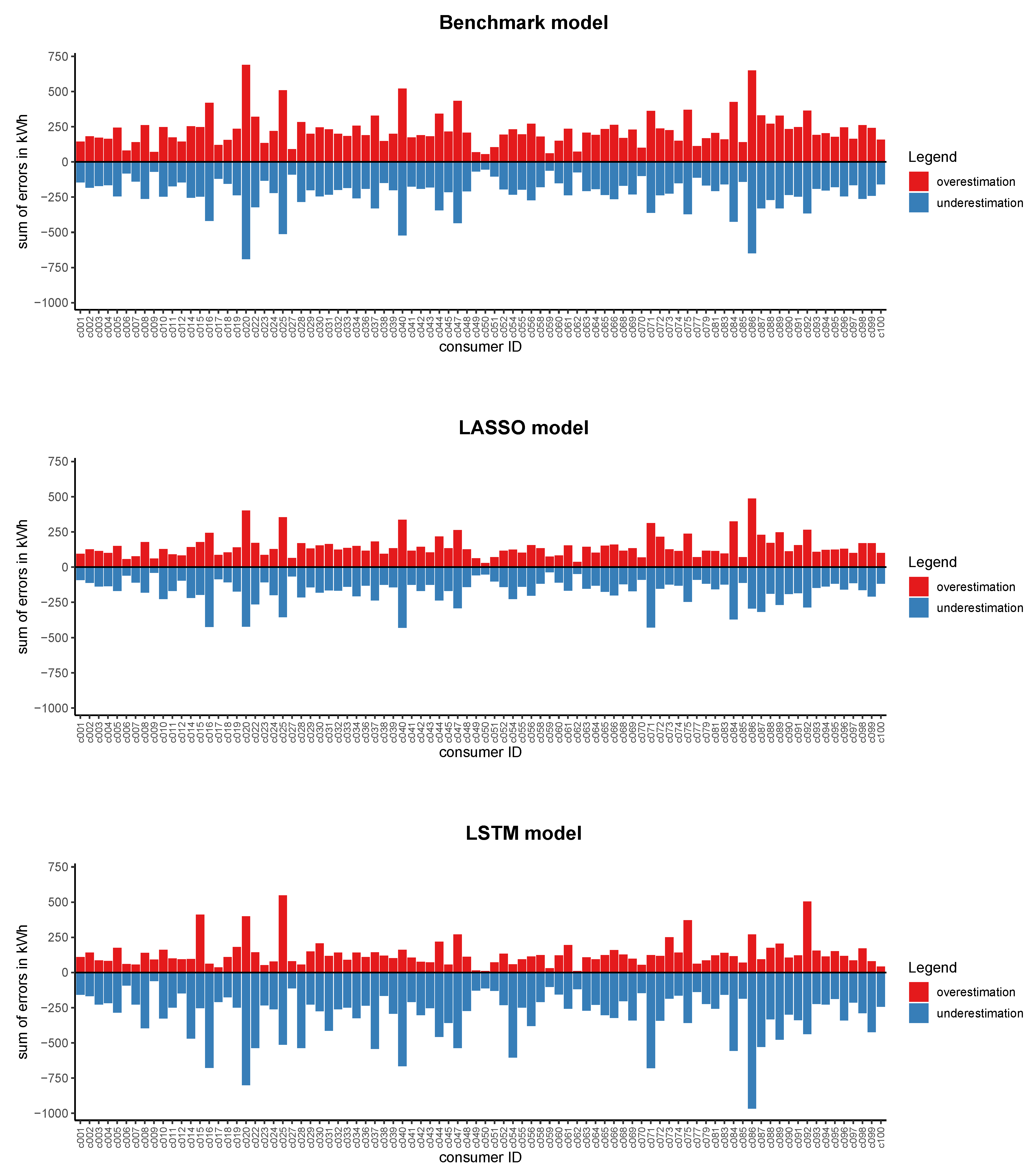
4.2.2. Loss to Consumers due to Prediction Errors
4.3. Implications for Blockchain-Based Local Energy Markets
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Data Availability
www.quantlet.de with the keyword BLEM and at GitHub: github.com/QuantLet/BLEM.Abbreviations
| LEM | Local energy market |
| LASSO | Least absolute shrinkage and selection operator |
| RNN | Recurrent neural network |
| LSTM | Long short-term memory |
| ML | Machine learning |
| GPU | Graphical processing unit |
| CPU | Central processing unit |
| CV | Cross-validation |
| SD | Standard deviation |
| MAE | Mean absolute error |
| RMSE | Root mean square error |
| MAPE | Mean absolute percentage error |
| NRMSE | Normalized root mean square error |
| MASE | Mean absolute scaled error |
References
- Sinn, H.W. Buffering volatility: A study on the limits of Germany’s energy revolution. Eur. Econ. Rev. 2017, 99, 130–150. [Google Scholar] [CrossRef]
- Bayer, B.; Matschoss, P.; Thomas, H.; Marian, A. The German experience with integrating photovoltaic systems into the low-voltage grids. Renew. Energy 2018, 119, 129–141. [Google Scholar] [CrossRef]
- BSW-Solar. Statistische Zahlen der deutschen Solarstrombranche (Photovoltaik); Bundesverband Solarwirtschaft e.V.: Berlin, Germany, 2018. [Google Scholar]
- Weron, R. Modeling and forecasting electricity loads and prices: A statistical approach; John Wiley & Sons: Chichester, UK, 2006. [Google Scholar]
- Rutkin, A. Blockchain-Based Microgrid Gives Power to Consumers in New York. Available online: newscientist.com/article/2079334-blockchain-based-microgrid-gives-power-to-consumers-in-new-york/ (accessed on 13 July 2019).
- Mengelkamp, E.; Gärttner, J.; Rock, K.; Kessler, S.; Orsini, L.; Weinhardt, C. Designing microgrid energy markets—A case study: The Brooklyn Microgrid. Appl. Energy 2018, 210, 870–880. [Google Scholar] [CrossRef]
- Lamparter, S.; Becher, S.; Fischer, J.G. An Agent-based Market Platform for Smart Grids. In Proceedings of the 9th International Conference on Autonomous Agents and Multiagent Systems (AAMAS): Industry Track, Toronto, ON, Canada, 10–14 May 2010; pp. 1689–1696. [Google Scholar]
- Buchmann, E.; Kessler, S.; Jochem, P.; Böhm, K. The Costs of Privacy in Local Energy Markets. In Proceedings of the 2013 IEEE 15th Conference on Business Informatics, Vienna, Austria, 15–18 July 2013; pp. 198–207. [Google Scholar]
- Block, C.; Neumann, D.; Weinhardt, C. A Market Mechanism for Energy Allocation in Micro-CHP Grids. In Proceedings of the 41st Annual Hawaii International Conference on System Sciences (HICSS 2008), Waikoloa, HI, USA, 7–10 January 2008; pp. 172–183. [Google Scholar]
- Mengelkamp, E.; Notheisen, B.; Beer, C.; Dauer, D.; Weinhardt, C. A blockchain-based smart grid: Towards sustainable local energy markets. Comput. Sci. Res. Dev. 2018, 33, 207–214. [Google Scholar] [CrossRef]
- Stadler, M.; Cardoso, G.; Mashayekh, S.; Forget, T.; DeForest, N.; Agarwal, A.; Schönbein, A. Value streams in microgrids: A literature review. Appl. Energy 2016, 162, 980–989. [Google Scholar] [CrossRef]
- Mengelkamp, E.; Gärttner, J.; Weinhardt, C. Intelligent Agent Strategies for Residential Customers in Local Electricity Markets. In Proceedings of the Ninth International Conference on Future Energy Systems (e-Energy ’18), Karlsruhe, Germany, 12–15 June 2018; pp. 97–107. [Google Scholar]
- Koirala, B.P.; Koliou, E.; Friege, J.; Hakvoort, R.A.; Herder, P.M. Energetic communities for community energy: A review of key issues and trends shaping integrated community energy systems. Renew. Sustain. Energy Rev. 2016, 56, 722–744. [Google Scholar] [CrossRef]
- Hvelplund, F. Renewable energy and the need for local energy markets. Energy 2006, 31, 2293–2302. [Google Scholar] [CrossRef]
- Ilic, D.; Silva, P.G.D.; Karnouskos, S.; Griesemer, M. An energy market for trading electricity in smart grid neighbourhoods. In Proceedings of the 2012 6th IEEE International Conference on Digital Ecosystems and Technologies (DEST), Campione d’Italia, Italy, 18–20 June 2012; pp. 1–6. [Google Scholar]
- Rosen, C.; Madlener, R. An auction design for local reserve energy markets. Decis. Support System. 2013, 56, 168–179. [Google Scholar] [CrossRef]
- Mengelkamp, E.; Gärttner, J.; Weinhardt, C. Decentralizing Energy Systems Through Local Energy Markets: The LAMP-Project. In Proceedings of the Multikonferenz Wirtschaftsinformatik (MKWI), Lüneburg, Germany, 6–9 March 2018; pp. 924–930. [Google Scholar]
- Wang, Y.; Chen, Q.; Hong, T.; Kang, C. Review of smart meter data analytics: Applications, methodologies, and challenges. IEEE Trans. Smart Grid 2018, 10, 1–24. [Google Scholar] [CrossRef]
- Burger, C.; Kuhlmann, A.; Richard, P.; Weinmann, J. Blockchain in the Energy Transition. A Survey among Decision-Makers in the German Energy Endustry; Report; ESMT Berlin: Berlin, Germany, 2016. [Google Scholar]
- Münsing, E.; Mather, J.; Moura, S. Blockchains for decentralized optimization of energy resources in microgrid networks. In Proceedings of the 2017 IEEE Conference on Control Technology and Applications (CCTA), Mauna Lani, HI, USA, 27–30 August 2017; pp. 2164–2171. [Google Scholar]
- Arora, S.; Taylor, J.W. Forecasting electricity smart meter data using conditional kernel density estimation. Omega 2016, 59, 47–59. [Google Scholar] [CrossRef]
- Kong, W.; Dong, Z.Y.; Jia, Y.; Hill, D.J.; Xu, Y.; Zhang, Y. Short-Term Residential Load Forecasting Based on Resident Behaviour Learning. IEEE Trans. Power Syst. 2018, 33, 1087–1088. [Google Scholar] [CrossRef]
- Shi, H.; Xu, M.; Li, R. Deep learning for household load forecasting—A novel pooling deep RNN. IEEE Trans. Smart Grid 2018, 9, 5271–5280. [Google Scholar] [CrossRef]
- Li, P.; Zhang, B.; Weng, Y.; Rajagopal, R. A sparse linear model and significance test for individual consumption prediction. IEEE Trans. Power Syst. 2017, 32, 4489–4500. [Google Scholar] [CrossRef]
- Bansal, A.; Rompikuntla, S.K.; Gopinadhan, J.; Kaur, A.; Kazi, Z.A. Energy Consumption Forecasting for Smart Meters. In Proceedings of the third Internatial Conference on Business Analytics and Intelligence (BAI) 2015, Bangalore, India, 17–19 December 2015; pp. 1–20. [Google Scholar]
- Diagne, M.; David, M.; Lauret, P.; Boland, J.; Schmutz, N. Review of solar irradiance forecasting methods and a proposition for small-scale insular grids. Renew. Sustain. Energy Rev. 2013, 27, 65–76. [Google Scholar] [CrossRef]
- Gan, D.; Wang, Y.; Zhang, N.; Zhu, W. Enhancing short-term probabilistic residential load forecasting with quantile long–short-term memory. J. Eng. 2017, 2017, 2622–2627. [Google Scholar] [CrossRef]
- Chollet, F.; Allaire, J. Deep Learning with R; Manning Publications Co.: Shelter Island, NY, USA, 2018. [Google Scholar]
- Van der Meer, D.W.; Widén, J.; Munkhammar, J. Review on probabilistic forecasting of photovoltaic power production and electricity consumption. Renew. Sustain. Energy Rev. 2018, 81, 1484–1512. [Google Scholar] [CrossRef]
- Chen, K.; Chen, K.; Wang, Q.; He, Z.; Hu, J.; He, J. Short-term Load Forecasting with Deep Residual Networks. IEEE Trans. Smart Grid 2018, 1–10. [Google Scholar] [CrossRef]
- Hornik, K.; Stinchcombe, M.; White, H. Multilayer feedforward networks are universal approximators. Neural Netw. 1989, 2, 359–366. [Google Scholar] [CrossRef]
- Bengio, Y.; Simard, P.; Frasconi, P. Learning long-term dependencies with gradient descent is difficult. IEEE Trans. Neural Netw. 1994, 5, 157–166. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Gers, F.A.; Schmidhuber, J.; Cummins, F. Learning to Forget: Continual Prediction with LSTM. Neural Comput. 2000, 12, 2451–2471. [Google Scholar] [CrossRef]
- Lipton, Z.C.; Berkowitz, J.; Elkan, C. A Critical Review of Recurrent Neural Networks for Sequence Learning. arXiv 2015, arXiv:1506.00019v4. [Google Scholar]
- Graves, A. Supervised Sequence Labelling. In Supervised Sequence Labelling with Recurrent Neural Networks; Springer: Berlin/Heidelberg, Germany, 2012; pp. 5–13. [Google Scholar]
- Chollet, F.; Allaire, J. R Interface to Keras. 2017. Available online: https://github.com/rstudio/keras (accessed on 30 September 2018).
- Tibshirani, R. Regression Shrinkage and Selection via the Lasso. J. R. Statist. Soc. Ser. B (Methodol.) 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Friedman, J.; Hastie, T.; Tibshirani, R. Regularization Paths for Generalized Linear Models via Coordinate Descent. J. Stat. Softw. 2010, 33, 1–22. [Google Scholar] [CrossRef]
- Hoff, T.; Perez, R.; Kleissl, J.; Renne, D.; Stein, J. Reporting of irradiance modeling relative prediction errors. Prog. Photovolt. Res. Appl. 2013, 21, 1514–1519. [Google Scholar] [CrossRef]
- Zhang, J.; Florita, A.; Hodge, B.M.; Lu, S.; Hamann, H.F.; Banunarayanan, V.; Brockway, A.M. A suite of metrics for assessing the performance of solar power forecasting. Sol. Energy 2015, 111, 157–175. [Google Scholar] [CrossRef]
- Hyndman, R.J.; Koehler, A.B. Another look at measures of forecast accuracy. Int. J. Forecast. 2006, 22, 679–688. [Google Scholar] [CrossRef]
- Heidjann, J. Strompreise in Deutschland - Vergleichende Analyse der Strompreise für 1437 Städte in Deutschland; StromAuskunft - Alles über Strom: Münster, Germany, 2017. [Google Scholar]
- Gode, D.K.; Sunder, S. Allocative Efficiency of Markets with Zero-Intelligence Traders: Market as a Partial Substitute for Individual Rationality. J. Political Econ. 1993, 101, 119–137. [Google Scholar] [CrossRef]
- Discovergy GmbH. Intelligente Stromzähler und Messsysteme; Discovergy GmbH: Heidelberg, Germany, 2018. [Google Scholar]
- Auder, B.; Cugliari, J.; Goude, Y.; Poggi, J.M. Scalable Clustering of Individual Electrical Curves for Profiling and Bottom-Up Forecasting. Energies 2018, 11, 1893. [Google Scholar] [CrossRef]
- Gerossier, A.; Girard, R.; Kariniotakis, G.; Michiorri, A. Probabilistic day-ahead forecasting of household electricity demand. CIRED - Open Access Proc. J. 2017, 2017, 2500–2504. [Google Scholar] [CrossRef]
- Teixeira, B.; Silva, F.; Pinto, T.; Santos, G.; Praça, I.; Vale, Z. TOOCC: Enabling heterogeneous systems interoperability in the study of energy systems. In Proceedings of the 2017 IEEE Power Energy Society General Meeting, Chicago, IL, USA, 16-20 July 2017; pp. 1–5. [Google Scholar]
- Chernozhukov, V.; Härdle, W.K.; Huang, C.; Wang, W. LASSO-Driven Inference in Time and Space. arXiv 2018, arXiv:1806.05081v3. [Google Scholar] [CrossRef]
- Maciejowska, K.; Nitka, W.; Weron, T. Day-Ahead vs. Intraday—Forecasting the Price Spread to Maximize Economic Benefits. Energies 2019, 12, 631. [Google Scholar] [CrossRef]
- Greveler, U.; Justus, B.; Loehr, D. Forensic content detection through power consumption. In Proceedings of the 2012 IEEE International Conference on Communications (ICC), Ottawa, ON, Canada, 10-15 June 2012; pp. 6759–6763. [Google Scholar]

 BLEMplotEnergyData (github.com/QuantLet/BLEM/tree/master/BLEMplotEnergyData)
BLEMplotEnergyData (github.com/QuantLet/BLEM/tree/master/BLEMplotEnergyData)
BLEMplotEnergyData (github.com/QuantLet/BLEM/tree/master/BLEMplotEnergyData)
BLEMplotEnergyData (github.com/QuantLet/BLEM/tree/master/BLEMplotEnergyData) BLEMplotPredErrors (github.com/QuantLet/BLEM/tree/master/BLEMplotPredErrors)
BLEMplotPredErrors (github.com/QuantLet/BLEM/tree/master/BLEMplotPredErrors)
BLEMplotPredErrors (github.com/QuantLet/BLEM/tree/master/BLEMplotPredErrors)
BLEMplotPredErrors (github.com/QuantLet/BLEM/tree/master/BLEMplotPredErrors) BLEMevaluateEnergyPreds (github.com/QuantLet/BLEM/tree/master/BLEMevaluateEnergyPreds)
BLEMevaluateEnergyPreds (github.com/QuantLet/BLEM/tree/master/BLEMevaluateEnergyPreds)
BLEMevaluateEnergyPreds (github.com/QuantLet/BLEM/tree/master/BLEMevaluateEnergyPreds)
BLEMevaluateEnergyPreds (github.com/QuantLet/BLEM/tree/master/BLEMevaluateEnergyPreds) BLEMevaluateEnergyPreds (github.com/QuantLet/BLEM/tree/master/BLEMevaluateEnergyPreds)
BLEMevaluateEnergyPreds (github.com/QuantLet/BLEM/tree/master/BLEMevaluateEnergyPreds)
BLEMevaluateEnergyPreds (github.com/QuantLet/BLEM/tree/master/BLEMevaluateEnergyPreds)
BLEMevaluateEnergyPreds (github.com/QuantLet/BLEM/tree/master/BLEMevaluateEnergyPreds) BLEMmarketSimulation (github.com/QuantLet/BLEM/tree/master/BLEMmarketSimulation)
BLEMmarketSimulation (github.com/QuantLet/BLEM/tree/master/BLEMmarketSimulation)
BLEMmarketSimulation (github.com/QuantLet/BLEM/tree/master/BLEMmarketSimulation)
BLEMmarketSimulation (github.com/QuantLet/BLEM/tree/master/BLEMmarketSimulation) BLEMmarketSimulation (github.com/QuantLet/BLEM/tree/master/BLEMmarketSimulation)
BLEMmarketSimulation (github.com/QuantLet/BLEM/tree/master/BLEMmarketSimulation)
BLEMmarketSimulation (github.com/QuantLet/BLEM/tree/master/BLEMmarketSimulation)
BLEMmarketSimulation (github.com/QuantLet/BLEM/tree/master/BLEMmarketSimulation) BLEMmarketSimulation (github.com/QuantLet/BLEM/tree/master/BLEMmarketSimulation)
BLEMmarketSimulation (github.com/QuantLet/BLEM/tree/master/BLEMmarketSimulation)
BLEMmarketSimulation (github.com/QuantLet/BLEM/tree/master/BLEMmarketSimulation)
BLEMmarketSimulation (github.com/QuantLet/BLEM/tree/master/BLEMmarketSimulation) BLEMevaluateMarketSim (github.com/QuantLet/BLEM/tree/master/BLEMevaluateMarketSim)
BLEMevaluateMarketSim (github.com/QuantLet/BLEM/tree/master/BLEMevaluateMarketSim)
BLEMevaluateMarketSim (github.com/QuantLet/BLEM/tree/master/BLEMevaluateMarketSim)
BLEMevaluateMarketSim (github.com/QuantLet/BLEM/tree/master/BLEMevaluateMarketSim)

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameter | Possible Values | Possible Combinations | Sampling Rate | # of Assessed Combinations | |
|---|---|---|---|---|---|
| layer 1 | batch size | {128, 64, 32} | 81 | 0.2 | 16 |
| hidden units | {128, 64, 32} | ||||
| recurrent dropout | {0, 0.2, 0.4} | ||||
| dropout | {0, 0.2, 0.4} | ||||
| hidden units | {128, 64, 32} | ||||
| layer 2 | recurrent dropout | {0, 0.2, 0.4} | 26 | 0.5 | 13 |
| dropout | {0, 0.2, 0.4} | ||||
| hidden units | {128, 64, 32} | ||||
| layer 3 | recurrent dropout | {0, 0.2, 0.4} | 26 | 0.5 | 13 |
| dropout | {0, 0.2, 0.4} |
BLEMtuneLSTM (github.com/QuantLet/BLEM/tree/master/BLEMtuneLSTM)
BLEMtuneLSTM (github.com/QuantLet/BLEM/tree/master/BLEMtuneLSTM)| Hyperparameter | Tuned Value |
|---|---|
| layers | 1 |
| hidden units | 32 |
| dropout rate | 0 |
| recurrent dropout rate | 0 |
| batch size | 32 |
| number of input data points | 3360 |
| number of training samples | 700 |
| number of validation samples | 96 |
BLEMevaluateEnergyPreds (github.com/QuantLet/BLEM/tree/master/BLEMevaluateEnergyPreds)
BLEMevaluateEnergyPreds (github.com/QuantLet/BLEM/tree/master/BLEMevaluateEnergyPreds)| Model | MAE | RMSE | MAPE | NRMSE | MASE |
|---|---|---|---|---|---|
| LSTM | 0.04 | 0.09 | 22.22 | 3.30 | 0.85 |
| LASSO | 0.03 | 0.05 | 17.38 | 2.31 | 0.57 |
| Benchmark | 0.05 | 0.10 | 27.98 | 5.08 | 1.00 |
| Improvement LSTM (in %) | 16.21 | 12.61 | 20.57 | 34.98 | 14.78 |
| Improvement LASSO (in %) | 44.02 | 48.73 | 37.88 | 54.61 | 43.02 |
BLEMevaluateMarketSim (github.com/QuantLet/BLEM/tree/master/BLEMevaluateMarketSim)
BLEMevaluateMarketSim (github.com/QuantLet/BLEM/tree/master/BLEMevaluateMarketSim)| Model | Balanced Supply | Oversupply | Oversupply | |||
|---|---|---|---|---|---|---|
| True | Predicted | True | Predicted | True | Predicted | |
| Equilibrium price (in EURct) | 24.64 | 24.61 | 12.50 | 12.49 | 25.68 | 25.69 |
| LEM price (in EURct) | 27.31 | 27.28 | 12.51 | 12.49 | 28.08 | 28.10 |
| Revenue (in EUR) | 1113.84 | 1108.88 | 3454.62 | 3451.69 | 1035.90 | 1036.12 |
| Cost with LEM (in EUR) | 439.26 | 457.94 | 200.75 | 226.61 | 451.60 | 470.69 |
| Cost without LEM (in EUR) | 459.83 | 446.93 | 459.83 | 446.93 | 459.83 | 446.93 |
BLEMevaluateMarketSim (github.com/QuantLet/BLEM/tree/master/BLEMevaluateMarketSim)
BLEMevaluateMarketSim (github.com/QuantLet/BLEM/tree/master/BLEMevaluateMarketSim)| Mean | Balanced Supply | Oversupply | Undersupply |
|---|---|---|---|
| Cost without LEM (in EUR) | 459.83 | 459.83 | 459.83 |
| Cost predicted values (in EUR) | 457.94 | 226.61 | 470.69 |
| Cost true values (in EUR) | 439.26 | 200.75 | 451.60 |
| Savings due to LEM (in %) | 4.82 | 129.08 | 1.90 |
| Loss due to pred. errors (in %) | −4.80 | −13.75 | −4.76 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kostmann, M.; Härdle, W.K. Forecasting in Blockchain-Based Local Energy Markets. Energies 2019, 12, 2718. https://doi.org/10.3390/en12142718
Kostmann M, Härdle WK. Forecasting in Blockchain-Based Local Energy Markets. Energies. 2019; 12(14):2718. https://doi.org/10.3390/en12142718
Chicago/Turabian StyleKostmann, Michael, and Wolfgang K. Härdle. 2019. "Forecasting in Blockchain-Based Local Energy Markets" Energies 12, no. 14: 2718. https://doi.org/10.3390/en12142718
APA StyleKostmann, M., & Härdle, W. K. (2019). Forecasting in Blockchain-Based Local Energy Markets. Energies, 12(14), 2718. https://doi.org/10.3390/en12142718